the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 25 Jan 2018
| 25 Jan 2018
Parametric decadal climate forecast recalibration (DeFoReSt 1.0)
Alexander Pasternack
Jonas Bhend
Mark A. Liniger
Henning W. Rust
Wolfgang A. Müller
Uwe Ulbrich
Near-term climate predictions such as decadal climate forecasts are increasingly being used to guide adaptation measures. For near-term probabilistic predictions to be useful, systematic errors of the forecasting systems have to be corrected. While methods for the calibration of probabilistic forecasts are readily available, these have to be adapted to the specifics of decadal climate forecasts including the long time horizon of decadal climate forecasts, lead-time-dependent systematic errors (drift) and the errors in the representation of long-term changes and variability. These features are compounded by small ensemble sizes to describe forecast uncertainty and a relatively short period for which typically pairs of reforecasts and observations are available to estimate calibration parameters. We introduce the Decadal Climate Forecast Recalibration Strategy (DeFoReSt), a parametric approach to recalibrate decadal ensemble forecasts that takes the above specifics into account. DeFoReSt optimizes forecast quality as measured by the continuous ranked probability score (CRPS). Using a toy model to generate synthetic forecast observation pairs, we demonstrate the positive effect on forecast quality in situations with pronounced and limited predictability. Finally, we apply DeFoReSt to decadal surface temperature forecasts from the MiKlip prototype system and find consistent, and sometimes considerable, improvements in forecast quality compared with a simple calibration of the lead-time-dependent systematic errors.
- Article
(4129 KB) - Full-text XML
- BibTeX
- EndNote





Decadal climate predictions aim to characterize climatic conditions over the coming years. Recent advances in model development, data assimilation and climate-observing systems together with the need for up-to-date and reliable information on near-term climate for adaptation planning have led to considerable progress in decadal climate predictions. In this context, international and national projects like the German initiative Mittelfristige Klimaprognosen (MiKlip) have developed model systems to produce a skillful decadal climate prediction (Pohlmann et al., 2013a; Marotzke et al., 2016).
Despite the progress being made in decadal climate forecasting, such forecasts still suffer from considerable systematic biases. In particular, decadal climate forecasts are affected by lead-time-dependent biases (drift) and exhibit long-term trends that differ from the observed changes. To correct these biases in the expected mean climate, bias correction methods tailored to the specifics of decadal climate forecasts have been developed (Kharin et al., 2012; Fučkar et al., 2014; Kruschke et al., 2015).
Given the inherent uncertainties due to imperfectly known initial conditions and model errors, weather and climate predictions are framed probabilistically (Palmer et al., 2006). Such probabilistic forecasts are often affected by biases in forecast uncertainty (ensemble spread); i.e., they are not reliable. Forecasts are reliable if the forecast probability of a specific event equals the observed occurrence frequency on average (Palmer et al., 2008). Briefly said, if some event is declared with a certain probability, say 80 %, it should also occur on average 80 % of all times such a forecast is issued. Probabilistic forecasts, however, are often found to be underdispersive/overconfident (Hamill and Colucci, 1997; Eckel and Walters, 1998); i.e., the ensemble spread underestimates forecast uncertainty, and events with a forecast probability of 80 % occur on average less often.
Statistical postprocessing (Gneiting and Raftery, 2005) can be used to optimize – or recalibrate – the forecast, e.g., reducing systematic errors, such as bias and conditional bias, as well as adjusting ensemble spread. The goal of recalibrating probabilistic forecasts is to maximize sharpness without sacrificing reliability (Gneiting et al., 2003). A forecast is sharp if its distribution differs from the climatological distribution. For example, a constant climatological probability forecast is perfectly reliable but exhibits small sharpness. Recalibration methods have been developed for medium-range to seasonal forecasting; it is unclear to what extent lead-time-dependent biases (also called drift) and long-term trends of decadal climate forecasts can effectively be corrected. Here, we aim at adapting existing recalibration methods to deal with the specific problems found in decadal climate forecasting: lead-time- and start-time-dependent biases, conditional biases and inadequate ensemble spread.
The most prominent recalibration methods proposed in the context of medium-range weather forecasting are Bayesian model averaging (BMA; Raftery et al., 2005; Sloughter et al., 2007) and nonhomogeneous Gaussian regression (NGR; Gneiting et al., 2005). In seasonal forecasting, the climate conserving recalibration (CCR; Doblas-Reyes et al., 2005; Weigel et al., 2009) is often applied, which is based on a scalar conditional adjustment of ensemble mean and ensemble spread. Here, Eade et al. (2014) applied this concept also to decadal predictions. BMA assigns a probability density function (PDF) to every individual ensemble member and generates a weighted average of these densities where the weights represent the forecasting skill of the corresponding ensemble member. NGR extends traditional model output statistics (MOS, Glahn and Lowry, 1972) by allowing the predictive uncertainty to depend on the ensemble spread. A further extension, proposed by Sansom et al. (2016), also accounts for a linear time dependency of the mean bias. However, CCR is closely related to NGR in that the forecast mean error and forecast spread are jointly corrected to satisfy the necessary criterion for reliability that the time mean ensemble spread equals the forecast root mean square error.
We expand on NGR and CCR by introducing a parametric dependence of the forecast errors on forecast lead time and long-term time trends hereafter named Decadal Climate Forecast Recalibration Strategy (DeFoReSt). To better understand the properties of DeFoReSt, we conduct experiments using a toy model to produce synthetic forecast observation pairs with known properties. We compare the decadal recalibration with the drift correction proposed by Kruschke et al. (2015) to illustrate its benefits and limitations.
The remainder of the paper is organized as follows. In Sect. 2, we introduce the MiKlip decadal climate prediction system and the corresponding reference data used. Moreover, we discuss how forecast quality of probabilistic forecasts is assessed. In Sect. 3, we motivate the extension of the NGR method named DeFoReSt and illustrate how verification and calibration can be linked by the way the calibration parameters are estimated. The toy model used to study DeFoReSt is introduced and assessed in Sect. 4.2. In the following section, we apply the drift correction and DeFoReSt to decadal surface temperature predictions from the MiKlip system (Sect. 5). We assess global mean surface temperature and temperature over the North Atlantic subpolar gyre region (50–65∘ N, 60–10∘ W). The investigated North Atlantic region has been identified as a key region for decadal climate predictions with forecast skill for different parameters (e.g., Pohlmann et al., 2009; van Oldenborgh et al., 2010; Matei et al., 2012; Mueller et al., 2012). The paper closes with a discussion in Sec. 6.
2.1 Decadal climate forecasts
In this study, we use retrospective forecasts (hereafter called hindcasts) of surface temperature performed with the Max Planck Institute Earth System Model in a low-resolution configuration (MPI-ESM-LR). The atmospheric component of the coupled model is ECHAM6 run at a horizontal resolution of T63 with 47 vertical levels up to 0.1 hPa (Stevens et al., 2013). The ocean component is the Max Planck Institute Ocean Model (MPIOM) with a nominal resolution of 1.58 and 40 vertical levels (Jungclaus et al., 2013).
We investigate one set of decadal hindcasts, namely from the MiKlip prototype system, which consists 41 hindcasts, each with 15 ensemble members, yearly initialized at 1 January between 1961 and 2000 and then integrated for 10 years. The initialization of the atmospheric part was realized by full field initialization from fields of ERA-40 (Uppala et al., 2005) and ERA-Interim (Dee et al., 2011), while the oceanic part was initialized with full fields from GECCO2 reanalysis (Köhl, 2015). Here, the full field initialization nudges the atmospheric or oceanic fields from the corresponding reanalysis to the MPI-ESM as full fields and not as anomalies. A detailed description of the prototype system is given in Kröger et al. (2017).
2.2 Validation data
This study uses the 20th Century Reanalysis (20CR; Compo et al., 2011) for evaluation of the hindcasts. The reanalysis has been built by solely assimilating surface pressure observations, whereas the lower boundary forcing is given from HadISST1.1 sea surface temperatures and sea ice (Rayner et al., 2003). Moreover, 20CR is based on ensemble Kalman filtering with 56 members and therefore also addresses observation and assimilation uncertainties. Additionally, 20CR covers the whole period of the investigated decadal hindcasts, which is a major benefit over other common reanalysis data sets.
2.3 Assessing reliability and sharpness
Calibration or reliability refers to the statistical consistency between the forecast PDFs and the verifying observations. Hence, it is a joint property of the predictions and the observations. A forecast is reliable if forecast probabilities correspond to observed frequencies on average. Alternatively, a necessary condition for forecasts to be reliable is given if the time mean intra-ensemble variance equals the mean squared error (MSE) between ensemble mean and observation (Palmer et al., 2006).
A common tool to evaluate the reliability and therefore the effect of a recalibration is the rank histogram or “Talagrand diagram” which was separately proposed by Anderson (1996), Talagrand et al. (1997) and Hamill and Colucci (1997). For a detailed understanding, the rank histogram has to be evaluated by visual inspection. Here, we have chosen to use the ensemble spread score (ESS) as a summarizing measure. The ESS is the ratio between the time mean intra-ensemble variance and the mean squared error between ensemble mean and observation, MSE(μ,y) (Palmer et al., 2006; Keller and Hense, 2011):
with
and
Here, and yj are the ensemble variance, the ensemble mean and the corresponding observation at time step j, with , where k is the number of time steps.
Following Palmer et al. (2006), ESS of 1 indicates perfect reliability. The forecast is overconfident when ESS < 1; i.e., the ensemble spread underestimates forecast error. If the ensemble spread is greater than the model error (ESS > 1), the forecast is overdispersive and the forecast spread overestimates forecast error. To better understand the components of the ESS, we also analyze the MSE of the forecast separately.
Sharpness, on the other hand, refers to the concentration or spread of a probabilistic forecast and is a property of the forecast only. A forecast is sharp when it is taking a risk, i.e., when it is frequently different from the climatology. The smaller the forecast spread, the sharper the forecast. Sharpness is indicative of forecast performance for calibrated and thus reliable forecasts, as forecast uncertainty reduces with increasing sharpness (subject to calibration). To assess sharpness, we use properties of the width of prediction intervals as in Gneiting and Raftery (2007). In this study, the time mean intra-ensemble variance is used to asses the prediction width.
Scoring rules, finally, assign numerical scores to probabilistic forecasts and form attractive summary measures of predictive performance, since they address reliability and sharpness simultaneously (Gneiting et al., 2005; Gneiting and Raftery, 2007; Gneiting and Katzfusss, 2014). These scores are generally taken as penalties; thus, the forecasters seek to minimize them. A scoring rule is called proper if its expected value is minimized when the observation is drawn from the same distribution as the predictive distribution. If a scoring rule is not proper, it is possible to minimize its expected value by predicting an unrealistic probability of occurrence. In simple terms, a forecaster would be rewarded for not being honest. Moreover, a proper scoring rule is called strictly proper if the minimum is unique. In this regard, the continuous ranked probability score (CRPS) is a suitable, strictly proper scoring rule for ensemble forecasts.
Given that F is the predictive cumulative distribution function (CDF) and o is the verifying observation, the CRPS is defined as
where F0(y) is the Heaviside function and takes the value 0 if y is less than the observed value o and the value 1 otherwise. Under the assumption that the predictive CDF is a normal distribution with mean μ and variance σ2, Gneiting et al. (2005) showed that Eq. (4) can be written as
where Φ(⋅) and φ(⋅) denote the CDF and the PDF, respectively, of the standard normal distribution.
The CRPS is negatively oriented. A lower CRPS indicates more accurate forecasts; a CRPS of zero denotes a perfect (deterministic) forecast. Moreover, the average score over k pairs of forecasts Fj and observations yj,
reduces to the mean absolute error for deterministic forecasts (Gneiting and Raftery, 2004); i.e., Fi in Eq. (6) would also be a step function. The CRPS can therefore be interpreted as a distance measure between the probabilistic forecast and the verifying observation (Siegert et al., 2015).
The continuous ranked probability skill score (CRPSS) is, as the name implies, the corresponding skill score. A skill score relates the accuracy of the prediction system to the accuracy of a reference prediction (e.g., climatology). Thus, with a given CRPSF for the hindcast distribution and a given CRPSR for the reference distribution, the CRPSS can be defined as
Positive values of the CRPSS imply that the prediction system outperforms the reference prediction. Furthermore, this skill score is unbounded for negative values (because hindcasts can be arbitrarily bad) but bounded by 1 for a perfect forecast.
In the following paragraphs, we discuss DeFoReSt and illustrate how forecast quality is used to estimate the parameters of the recalibration method.
We assume that the recalibrated predictive PDF for random variable X is a normal PDF with mean and variance being functions of ensemble mean μ(t,τ) and variance σ2(t,τ), as well as start time t and lead year τ:
The term α(t,τ) accounts for the mean or unconditional bias depending on lead year (i.e., the drift). Analogously, β(t,τ) accounts for the conditional bias. Thus, the expectation could be a conditional- and unconditional-biased and drift-adjusted deterministic forecast (we call a deterministic forecast a forecast without specifying uncertainty). For now, we assume that the ensemble spread σ(t,τ) is sufficiently well related to forecast uncertainty such that it can be adjusted simply by a multiplicative term γ(t,τ)2. We thus refrain from using the additive term suggested for NGR by Gneiting et al. (2005) to not end up with a too-complex model, as the additive term should consequently be also a function of start time t and lead time τ; this term might be included in a future variant.
In the following, we motivate and develop linear parametric functions for α(t,τ), β(t,τ) and γ(t,τ).
3.1 Addressing bias and drift: α(t,τ)
For bias and drift correction, we start with a parametric approach based on the studies of Kharin et al. (2012) and Kruschke et al. (2015). In their study, a third-order polynomial captures the drift along lead time τ (Gangstø et al., 2013; Kruschke et al., 2015). Here, Gangstø et al. (2013) suggested that a third-order polynomial is a good compromise between flexibility and parameter uncertainty. The drift-corrected forecasts is approximated with a linear function of the forecast as
Here, , is the raw, i.e., uncorrected, hindcast for the start time t, ensemble member i and lead year τ. In the case that the observations and model climatology have different climate trends, the bias between model and observations is nonstationary. Thus, the second term in Eq. (9) also accounts for the dependency of the bias on the start year and therefore corrects errors in time trends. Here, as suggested by Kharin et al. (2012) the dependency on start time is only linear to avoid a too-complex model. The parameters a0–a7 are estimated by standard least squares using the differences between the ensemble mean of all available hindcasts and the reanalysis corresponding to the given start and lead time (Kruschke et al., 2015).
This motivates the following functional form for α(t,τ) analogously to Eq. (9):
In principle, arbitrary orders are possible for t and τ as long as there are sufficient data to estimate the parameters.
3.2 Addressing conditional bias and ensemble spread: β(t,τ) and γ(t,τ)
In addition to adjusting the unconditional lead-year-dependent bias, DeFoReSt aims at simultaneously adjusting conditional bias and ensemble spread. As a first approach, we take the same functional form for β(t,τ) and γ(t,τ):
The ensemble inflation γ(t,τ) is, however, assumed to be quadratic at most and constrained to be greater zero by using a static logarithmic link function. We assumed that a higher flexibility may not be necessary, because the MSE – which influences the dispersion – is already addressed by a third-order polynomial of unconditional and conditional biases.
These assumptions on model complexity are supported only by our experience; however, they remain subjective. A more transparent order selection will be a topic of future work.
3.3 Parameter estimation
The coefficients and γ(t,τ) are now expressed as parametric functions of t and τ. The parameters are estimated by minimizing the average CRPS over the training period (Gneiting et al., 2005). The associated score function is
where
is the standardized forecast error for the jth forecast in the training data set. In the present study, optimization is carried out using the algorithm of Nelder and Mead (1965) as implemented in R (R Core Team, 2016).
The initial guesses for optimization need to be carefully chosen to avoid local minima. Here, we obtain the ai and bj from linearly modeling the observations o with the forecast ensemble mean μ, t and τ,
using the notation for linear models from McCullagh and Nelder (1989); are set to zero which yields unity inflation (). However, convergence to a global minimum cannot be guaranteed.
In this section, we apply DeFoReSt to a stochastic toy model, which is motivated from Weigel et al. (2009) but has been significantly altered to suit the needs of this study. Here, a detailed description of the toy models construction is given in the following subsection. Subsequently, we assess DeFoReSt for two exemplary toy model setups.
4.1 Toy model construction
The toy model consists of two parts which are detailed in the following two subsections: (a) pseudo-observations, the part generating a substitute x(t+τ) for the observations, and (b) pseudo-forecasts, the second part deriving an associated ensemble prediction f(t,τ) from these observations. The third subsection motivates the choice of parameters for the toy model.
4.1.1 Pseudo-observations
We construct a toy model setup simulating ensemble predictions for the decadal timescale and associated pseudo-observations. Both are based on an arbitrary but predictable signal μx. The pseudo-observations x (e.g., annual means of surface temperature over a given area) are the sum of this predictable signal μx and an unpredictable noise term ϵx:
Following Kharin et al. (2012) μx can be interpreted as the atmospheric response to slowly varying and predictable boundary conditions, while ϵx represents the unpredictable chaotic components of the observed dynamical system. The processes μx and ϵx are assumed to be stochastic Gaussian processes:
and
The variation of μx around a slowly varying climate signal can be interpreted as the predictable part of decadal variability, its amplitude is given by the variance . The total variance of the pseudo-observations is thus . Here, the relation of the latter two is uniquely controlled by the parameter , which can be interpreted as potential predictability ().
In this toy model setup, the specific form of the variability of μx and ϵx is not considered and thus taken as random. A potential climate trend could be superimposed as a time-varying mean μ(t)=E(x(t)). For recalibration, only a difference in trends is important. Here, we use α(t,τ), addressing this difference in trends of forecast and observations.
4.1.2 Pseudo-forecasts
We now specify a model giving a potential ensemble forecast with ensemble members fi(t,τ) for observations x(t+τ):
where μens(t,τ) is the ensemble mean and
is the deviation of ensemble member i from the ensemble mean; is the ensemble variance. In general, ensemble mean and ensemble variance can both depend on lead time τ and start time t. We relate the ensemble mean μens(t,τ) to the predictable signal in the observations μx(t,τ) by assuming (a) a systematic deviation characterized by an unconditional bias χ(t,τ) (accounting also for a drift and difference in climate trends), a conditional bias ψ(t,τ) and (b) a random deviation ϵ(t,τ):
with being a random forecast error with variance in order to avoid negative values of the ensemble variance . Although the variance of the random forecast error can in principle be dependent on lead time τ and start time t, we assume for simplicity a constant variance .
We further assume an ensemble dispersion related to the variability of the unpredictable noise term ϵx with an inflation factor ω(t,τ):
According to Eq. (21), the forecast ensemble mean μens is simply a function of the predictable signal μx. In this toy model formulation, an explicit formulation of μx is not required; hence, a random signal might be used for simplicity and it would be legitimate to assume without restricting generality. Here, we propose a linear trend in time to the pseudo-forecasts to emphasize a typical problem encountered in decadal climate prediction: different trends in observations and predictions (Kruschke et al., 2015).
4.1.3 Choosing the toy models' parameters
This toy model setup is controlled by four parameters. The first parameter (η) determines the ratio between the variances of the predictable signal and the unpredictable noise term (and thus characterizes potential predictability; see Sec. 4.1.2). Here, we investigate two cases: one with low (η=0.2) and one with high potential predictability (η=0.8).
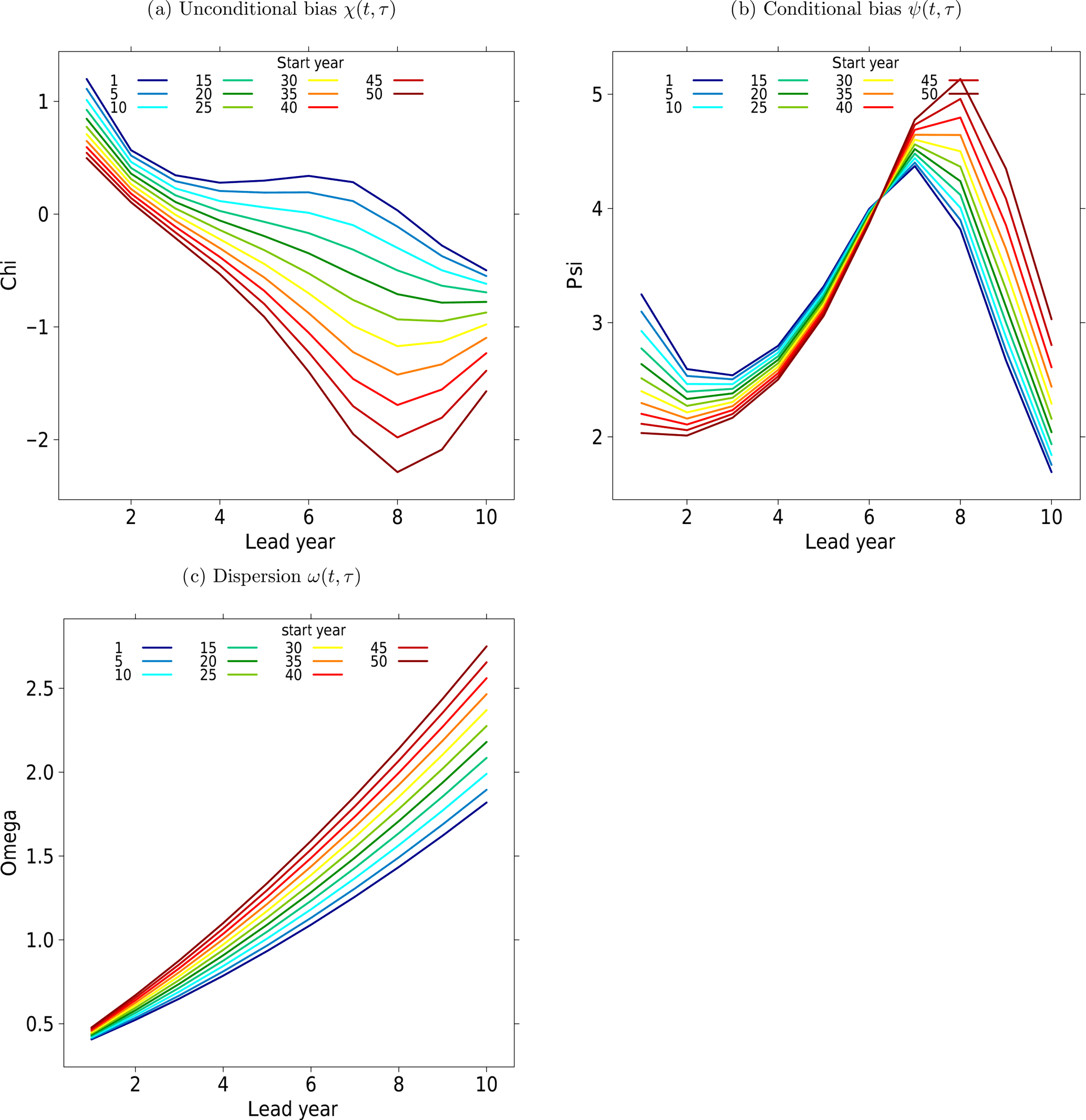
Figure 1Unconditional bias (a, χ(t,τ)), conditional bias (b, ψ(t,τ)) and dispersion of the ensemble spread (c, ω(t,τ)) as a function of lead year τ with respect to different start years t.
The remaining three parameters are χ(t,τ), ψ(t,τ) and ω(t,τ), which control the unconditional and conditional biases and the dispersion of the ensemble spread. To have a toy model experiment related to observations, χ(t,τ) and ψ(t,τ) are based on the correction parameters obtained from calibrating the MiKlip prototype ensemble surface temperature over the North Atlantic against NCEP 20CR reanalyses; χ(t,τ) and ψ(t,τ) are based on ratios of polynomials up to third order (in lead years), Eqs. (A1) and (A2) with coefficients varying with start years (see Fig. 1a and b).
The ensemble inflation factor ω(t,τ) is chosen such that the forecast is overconfident for the first lead years and becomes underconfident later; this effect intensifies with start years; see Fig. 1c. A more detailed explanation and numerical values used for the construction of χ(t,τ), ψ(t,τ) and ω(t,τ) are given in Appendix A.
Given this setup, a choice of , and would yield a perfectly calibrated ensemble forecast:
The ensemble mean μx(t,τ) of fperf(t,τ) is equal to the predictable signal of the pseudo-observations. The ensemble variance is equal to the variance of the unpredictable noise term representing the error between the ensemble mean of fperf(t,τ) and the pseudo-observations. Hence, fperf(t,τ) is perfectly reliable.
Analogous to the MiKlip experiment, the toy model uses 50 start years (), each with 10 lead years () and 15 ensemble members (). The corresponding pseudo-observations x(t+τ) run over a period of 59 years in order to cover lead year 10 of start year 50.
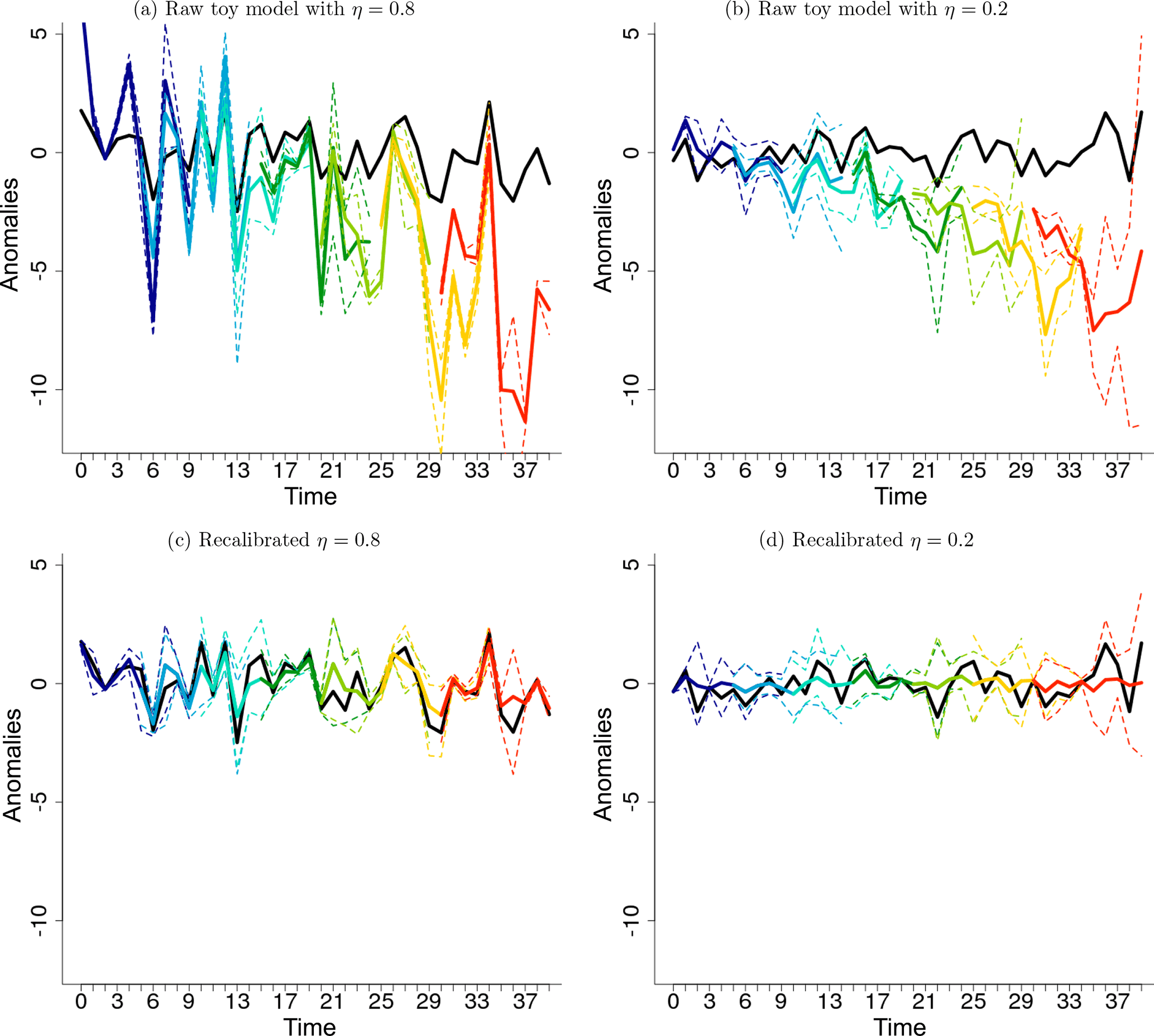
Figure 2Temporal evolution of the raw (a, b) and DeFoReSt recalibrated (c, d) pseudo-forecasts for different start years (colored lines) with potential predictability η=0.8 (a, c) and η=0.2 (b, d). Each pseudo-forecast runs over 10 lead years. The black line represents the associated pseudo-observation.
4.2 Toy model verification
To assess DeFoReSt, we consider two extreme toy model setups. The two setups are designed such that the predictable signal is stronger than the unpredictable noise for higher potential predictability (setup 1), and vice versa (setup 2; see Sect. 4.1). For each toy model setup, we calculated the ESS, the MSE, time mean intra-ensemble variance and the CRPSS with respect to climatology for the corresponding recalibrated toy model.
In addition to the recalibrated pseudo-forecast, we compare
-
a “raw” pseudo-forecast (no correction of unconditional, conditional bias and spread),
-
a “drift-corrected” pseudo-forecast (no correction of conditional bias and spread) and
-
a “perfect” pseudo-forecast (Eq. 23, available only in this toy model setup).
All scores have been calculated using cross validation with a yearly moving calibration window with a width of 10 years. A detailed description of this procedure is given in Appendix B.
The CRPSS and reliability values of the perfect forecast could be interpreted as optimum performance within the associated toy model setup, due to the missing bias and ensemble dispersion. For instance, the perfect model's CRPSS with respect to climatology would be 1 for a toy model setup with perfect potential predictability (η=1) and 0 for a setup with no potential predictability (η=0). Hence, the climatology could not be outperformed by any prediction model when no predictable signal exists.
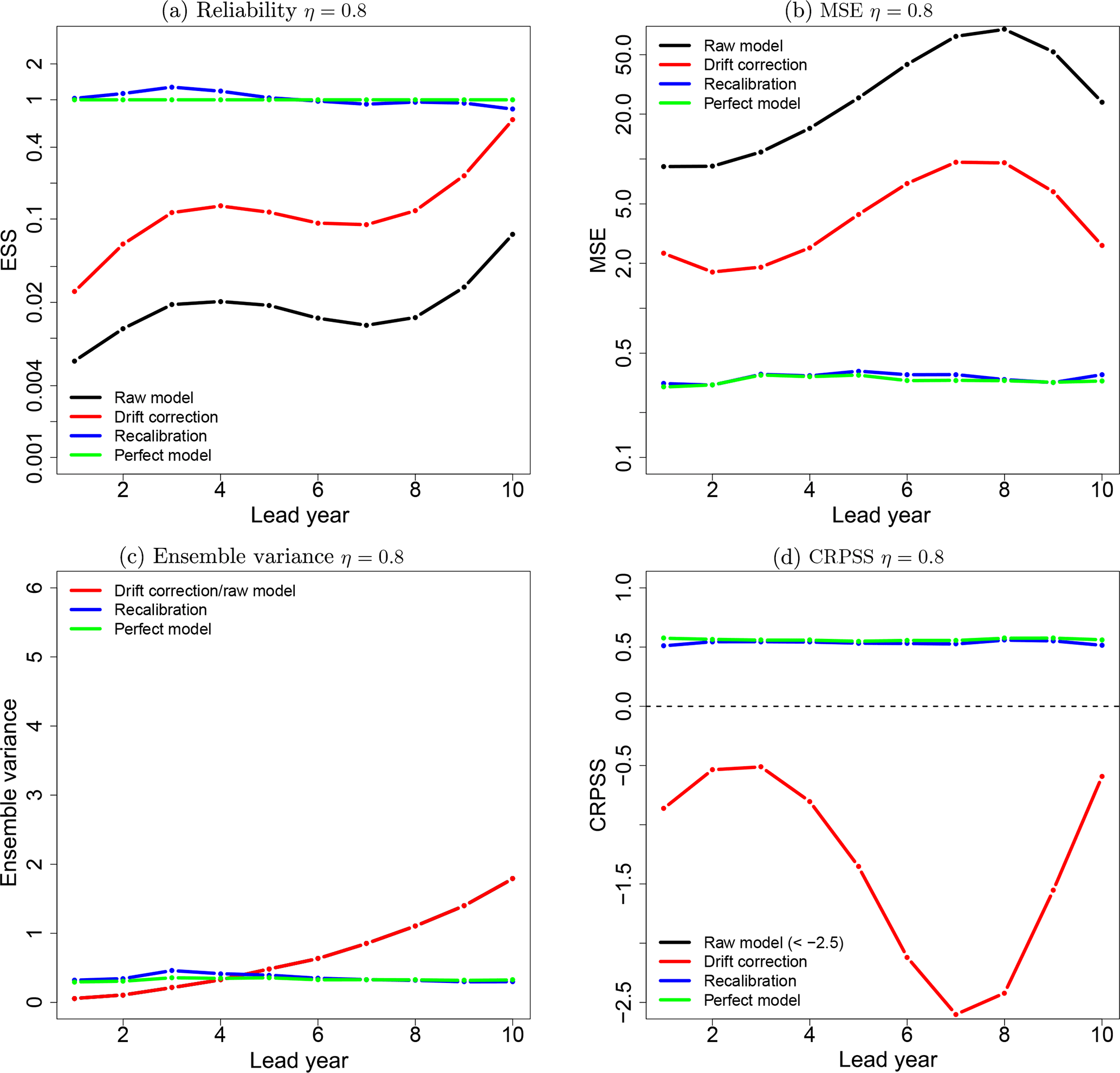
Figure 3Reliability (a), MSE (b), ensemble variance (c) and CRPSS (d) of the raw toy model (black line), the drift-corrected toy model forecast (red line), recalibrated (DeFoReSt) toy model forecast (blue line) and the perfect toy model (green line) for η=0.8. The drift correction method does not account for the ensemble spread; thus, the ensemble variance of the raw model and the drift-corrected forecast is equal. For reasons of clarity, the raw models' CRPSS with values between −5 and −9 is not shown here.
4.2.1 A toy model setup with high potential predictability
Figure 2a and c show the temporal evolution of the toy model data before and after recalibration with DeFoReSt together with the corresponding pseudo-observations. Before recalibration, the pseudo-forecast apparently exhibits the characteristic problems of a decadal ensemble prediction: unconditional bias (drift), conditional bias and underdispersion, which are lead- and start-time-dependent. Additionally, the pseudo-observations and the pseudo-forecast have different trends. After recalibration, the lead- and start-time-dependent biases are corrected, such that the temporal evolution of the pseudo-observations is mostly represented by the pseudo-forecast.
Moreover, the pseudo-forecast is almost perfectly reliable after recalibration (not underdispersive), which could be shown with the ESS (Fig. 3a). Here, the recalibrated model is nearly identical to the perfect model for all lead years with reliability values close to 1.
The recalibrated forecast outperforms the raw model output and the drift-corrected forecast, whose ESS values are lower than 1 and thus underdispersive. The lower performance of the raw models and the drift correction is a result of the toy model design, leading to a higher ensemble mean variance combined with a decreased ensemble spread. In addition, the increased variance of the ensemble mean also results in an increased influence of the conditional bias. The problem is that the raw model forecast and the drift correction could not account for that conditional bias, because neither the ensemble mean nor the ensemble spread were corrected by these forecasts. Therefore, the influence of the conditional bias also becomes noticeable for the reliability of the raw model and the drift-corrected forecast; one can see that the minimum and maximum of the conditional bias (see Fig. 1) are reproduced by the reliability values of these forecasts.
Regarding the differences between the raw model and the drift-corrected forecast, it is visible that the latter outperforms the raw model. The explanation is that the drift correction accounts for the unconditional bias, while the raw model does not correct this type of error. Here, one can see the impact of the unconditional bias on the raw model. Nonetheless, the influence of the unconditional bias is rather small compared to the conditional bias.
The effect of unconditional and conditional biases is illustrated in Fig. 3b, which shows the MSE of the different forecasts to the pseudo-observations. Here, the drift-corrected forecast outperforms the raw model. These forecasts are outperformed by the recalibrated forecast, which simultaneously corrects the unconditional and conditional biases. In this regard, both biases are corrected properly because the MSE of the recalibrated forecast is almost equal to the perfect models' MSE.
The sharpness of the different forecasts is compared by calculating the time mean intra-ensemble variance (see Fig. 3c). For all lead years, the raw model and the drift-corrected forecast exhibit the same sharpness, because the ensemble spread is unmodified for both forecasts.
Another notable aspect is that the raw and drift-corrected forecasts have a higher sharpness (i.e., lower ensemble variance) than the perfect model for lead years 1 to 4, and vice versa for lead years 5 to 10. This is because the toy models incorporated underdispersion for the first lead years and an overdispersion for later lead years. Therefore, the sharpness of the perfect model could be interpreted as the maximum sharpness of the model without being unreliable.
The sharpness of the recalibrated forecast is very similar to the sharpness of the perfect model for all lead years. The recalibration therefore performs well in correcting under- and overdispersion in the toy model forecasts.
A joint measure for sharpness and reliability is the CRPS and consequently the CRPSS with respect to climatology, where the latter is shown in Fig. 3d. The relatively low CRPSS values of the raw and drift-corrected forecasts are mainly affected by their reliability; i.e., the unconditional and conditional bias influences are also noticeable for this skill score. Thus, both models exhibit a maximum at lead year 2 and a minimum at lead year 7, where the drift-corrected forecast performs better. However, the raw model and the drift-corrected forecast are inferior to climatology (the CRPSS is below zero) for all lead years.
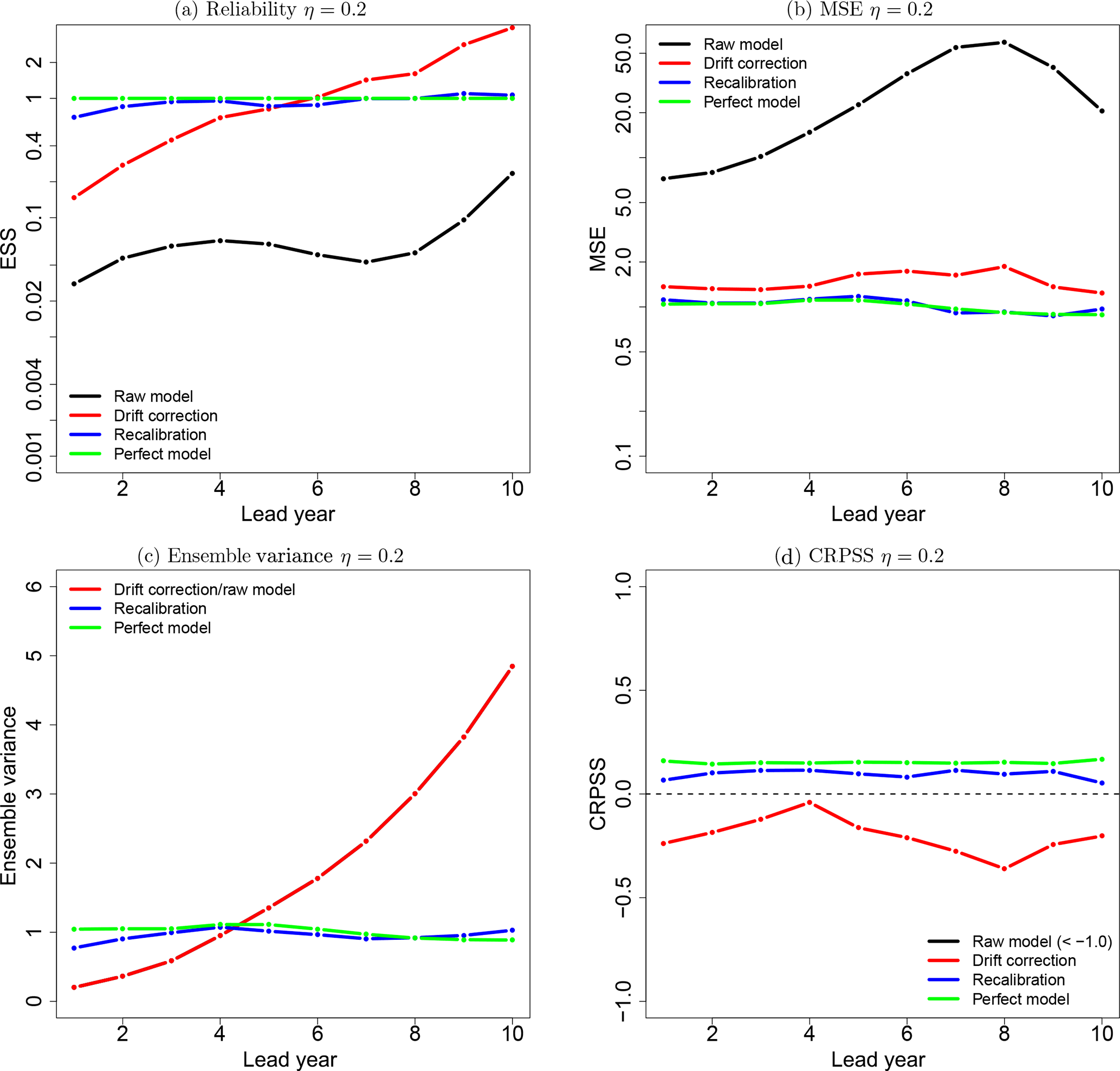
Figure 4Reliability (a), MSE (b), ensemble variance (c) and CRPSS (d) of the raw toy model (black line), the drift-corrected toy model (red line), recalibrated (DeFoReSt) toy model (blue line) and the perfect toy model (green line) for η=0.2. The drift correction method does not account for the ensemble spread; thus, the ensemble variance of the raw model and the drift-corrected forecast is equal. For reasons of clarity, the raw models' CRPSS with values between −3 and −9 is not shown here.
In contrast, the recalibrated forecast approaches CRPSS values around 0.5 for all lead years and performs nearly identical to the perfect model. This illustrates that the unconditional bias, conditional bias and ensemble dispersion can be corrected with this method.
4.2.2 A toy model setup with low potential predictability
Figure 2b and d show the temporal evolution of the toy model data with low potential predictability before and after recalibration with DeFoReSt together with the corresponding pseudo-observations. Before recalibration, the pseudo-forecast is underdispersive for the first lead years, whereas the ensemble spread increases for later lead years. Moreover, the pseudo-forecast exhibits lead- and start-time-dependent (unconditional) bias (drift) and conditional bias.
After recalibration, the lead- and start-time-dependent biases are corrected, such that the recalibrated forecast mostly describes the trend of the pseudo-observations.
The recalibrated forecast is also reliable (Fig. 4a); it performs as well as the perfect model. Here, the value of the ESS is close to 1 for both forecasts. Thus, comparing the reliability of the setups with low and high potential predictability, no differences are recognizable. The reason is that the ratio between MSE and ensemble variance, characterizing the ESS, does not change much; the lower MSE performance of the recalibrated forecast (Fig. 4b) is compensated with a higher ensemble variance (Fig. 4c).
In contrast, one can see a general improvement of the raw and drift-corrected forecasts' reliability compared to the model setup with high potential predictability. The reason is that the low potential predictability η of this toy model setup leads to smaller variance of the ensemble mean; i.e., the conditional bias has a minor effect. Another aspect for the comparatively good performance of the raw model, is the increased ensemble spread, leading to an enhanced representation of the unconditional bias.
The minor effect of the conditional bias in the low potential predictability setup is also represented by the MSE (Fig. 4b). Here, the difference between drift-corrected and recalibrated forecasts has decreased compared to the high potential predictability setup. Comparing both toy model setups, it is also apparent that, for a setup with η=0.2, the MSE generally has increased for all forecasts. The reason is that the predictable signal decreases for a lower η. Therefore, even the perfect models' MSE has increased.
Figure 4c shows the time mean intra-ensemble variance for the toy model setup with low potential predictability. It is notable that the ensemble variance for this low potential predictability setup is generally greater than for a high η (Fig. 3c). This is due to the fact that the total variance in the toy model is constrained to 1, and a lower η therefore leads to a greater ensemble spread.
Nonetheless, the raw model and drift-corrected forecast also still have a higher sharpness (i.e., lower ensemble variance) than the perfect model for lead years 1 to 4, and vice versa for lead years 5 to 10. Here, the reason for this is again the construction of the toy model, with an underdispersion for the first lead years and an overdispersion for later lead years.
The recalibrated forecast reproduces the perfect models' sharpness also quite well for the potential predictability setup.
Figure 4d shows the CRPSS with respect to climatology. Firstly, it is apparent that the weak predictable signal of this toy model setup shifted the CRPSS of all models closer to zero or the climatological skill. Nevertheless, please note that the recalibrated forecast is almost as good as the perfect model and that it is slightly superior to the drift-corrected forecast. We conclude that the recalibration works well also in situations with limited predictability.
While in Sect. 4.2 DeFoReSt was applied to toy model data, in this section, DeFoReSt will be applied to surface temperature of MiKlip prototype runs with MPI-ESM-LR. Here, global mean and spatial mean values over the North Atlantic subpolar gyre (50–65∘ N, 60–10∘ W) region will be analyzed.
Analogous to the previous section, we compute the ESS, the MSE, the intra-ensemble variance and the CRPSS with respect to climatology. The scores have been calculated for a period from 1961 to 2005. In this section, a 95 % confidence interval was additionally calculated for these metrics using a bootstrapping approach with 1000 replicates. For bootstrapping, we draw a new pair of dummy time series with replacement from the original validation period and calculate these scores again. This procedure has been repeated 1000 times. Furthermore, all scores have been calculated using cross validation with a yearly moving calibration window with a width of 10 years (see Appendix B).
5.1 North Atlantic mean surface temperature
Figure 5a and b show the temporal evolution of North Atlantic mean surface temperature before and after recalibration with the corresponding NCEP 20CR reference. Before recalibration, the MiKlip prototype hindcasts exhibit a lead-time-dependent bias (drift) and a lead-time-dependent ensemble spread. Here, lead-time-dependent bias of the prototype is a consequence of an initialization shock due to a full-field initialization (Meehl et al., 2014; Kruschke et al., 2015; Kröger et al., 2017). After recalibration with DeFoReSt, the drift of the MiKlip prototype was corrected and the ensemble spread is also modified.
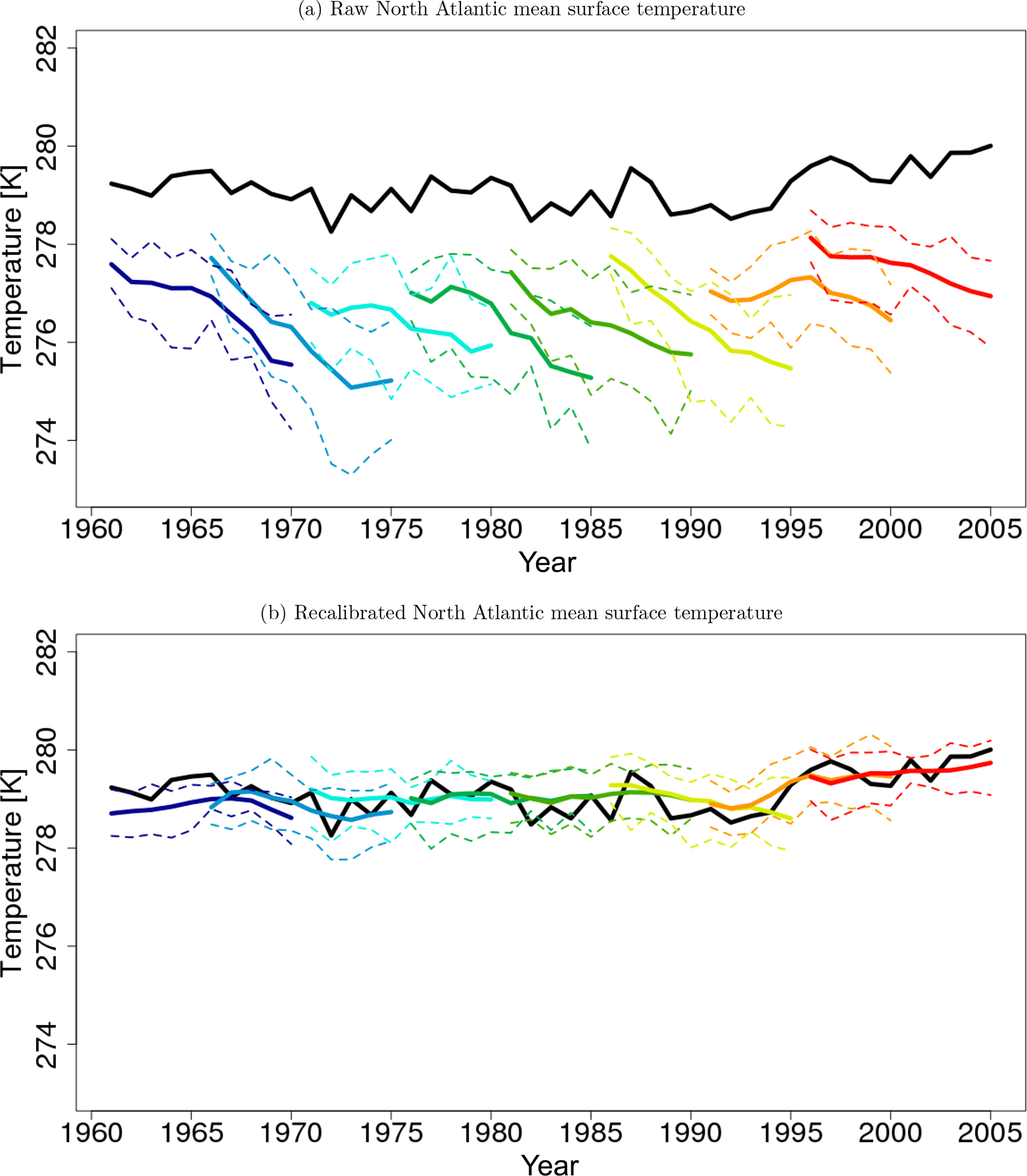
Figure 5Temporal evolution of North Atlantic yearly mean surface temperature from the MiKlip prototype (a) before and (b) after recalibration with DeFoReSt. Shown are different start years with 5-year intervals (colored lines). The black line represents the surface temperature of NCEP 20CR. Units are in Kelvin (K).

Figure 6Reliability (a), MSE (b), ensemble variance (c) and CRPSS (d) of surface temperature over the North Atlantic without any correction (black line), after drift correction (red line) and recalibration with DeFoReSt (blue line). The CRPSS for the raw forecasts (black line) is smaller than −1 and therefore not shown. As the drift correction method does not account for the ensemble spread, the ensemble variance of the raw model and the drift-corrected forecast is equal. The vertical bars show the 95 % confidence interval due to 1000-wise bootstrapping.
Regarding the reliability, Fig. 6a shows the ESS. The recalibrated forecast is almost perfectly reliable for all lead years because all ESS values of this model are close to 1. Moreover, the recalibrated forecast is more skillful than the drift-corrected forecast for years 3 to 10, where the improvement is only significant for lead years 4 to 8. It is also apparent that the drift-corrected forecast is significantly overdispersive for lead years 3 to 10. For lead years 1 and 2, both postprocessing methods perform equally well. The raw model's reliability is obviously inferior to the postprocessed models and significantly underdispersive for all lead years. This implies that the unconditional bias induces most of the systematic error of the MiKlip prototype runs.
Regarding the MSE, one can see that the recalibrated forecast outperforms the drift-corrected forecast for lead years 1 and 2 and 8 to 10 (Fig. 6b). Although this improvement of the recalibrated forecast is not significant, it may be still attributed to its correction of the conditional bias. Here, the raw model performs obviously worse compared to the postprocessed models, because neither the unconditional nor the conditional bias were corrected.
Figure 6c shows the spread as measured by the time mean intra-ensemble variance for the North Atlantic mean surface temperature. The ensemble variance of the raw model and the drift-corrected forecast is equal, since the ensemble spread of the drift-corrected forecast was not corrected. Here, the ensemble variance of both models is increasing with lead times. The ensemble variance of the recalibrated forecast is lower than the variance of the raw and drift-corrected forecasts for the first lead years (2 to 10); i.e., the recalibrated forecast has a higher sharpness than the other two forecasts. The combination of increasing ensemble variance and almost constant MSE leads to the identified increasing lack of confidence (see Fig. 6a) of the drift-corrected forecast for that period.
Figure 6d shows that in terms of CRPSS both the drift-corrected forecast and the recalibrated forecast outperform the raw model. Here, the CRPSS of the raw model is less than −1 for all lead years; thus, the corresponding graph lies below the plotted range. DeFoReSt performs slightly better (but not significantly better) than the drift-corrected forecast for almost all lead years, except lead years 3 and 4. Additionally, the CRPSS with respect to climatology shows that the recalibrated forecast outperforms a constant climatological forecast for all lead times and is significantly better for lead years 1 and 3 to 10.
5.2 Global mean surface temperature
Figure 7a and b show the temporal evolution of global mean surface temperature before (see Eq. 19) and after recalibration and the corresponding NCEP 20CR reference. Before recalibration with DeFoReSt, the MiKlip prototype hindcasts exhibit a lead-time-dependent bias (drift) and a lead-time-dependent ensemble spread. The drift of the global mean surface temperature is even stronger than the North Atlantic counterpart. After applying DeFoReSt, the drift of the MiKlip prototype was corrected and the ensemble spread is basically constant for all lead times.
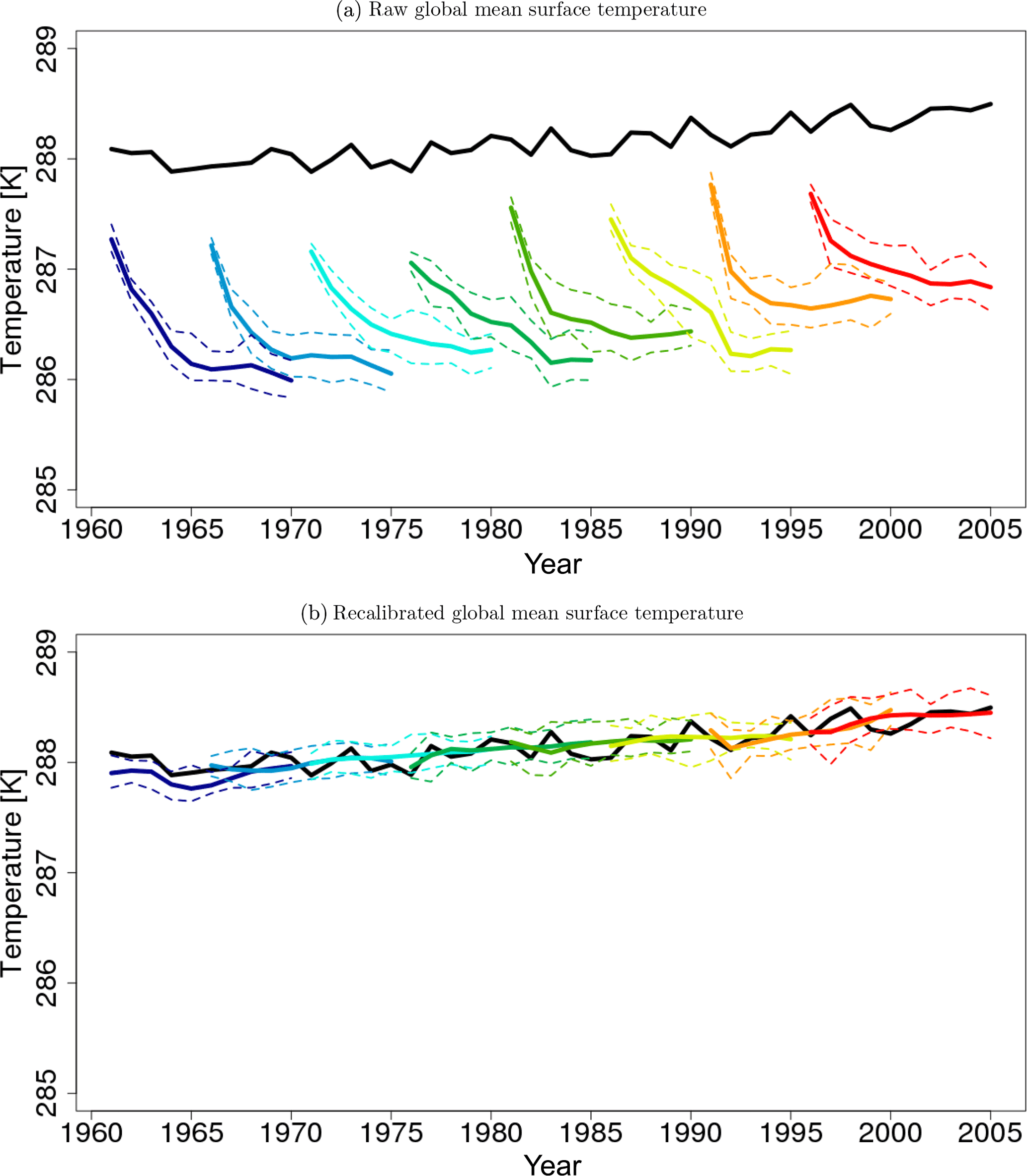
Figure 7Temporal evolution of global yearly mean surface temperature from MiKlip prototype (a) before and (b) after recalibration with DeFoReSt. Shown are different start years with 5-year intervals (colored lines). The black line represents the surface temperature of NCEP 20CR. Units are in Kelvin (K).
The ESS for a global mean surface temperature is shown in Fig. 8a. It can be seen that the recalibrated forecast is also perfectly reliable for the global mean surface temperature. Here, all ESS values are near 1. Additionally, the recalibrated forecast is more skillful than the drift-corrected forecast for all lead years. Here, only lead years 1 and 10 are significant. The reliability values of the drift-corrected forecast indicate a significant overconfidence for almost every lead year. As for the North Atlantic mean, the raw model's reliability for a global mean temperature is inferior to the postprocessed models.
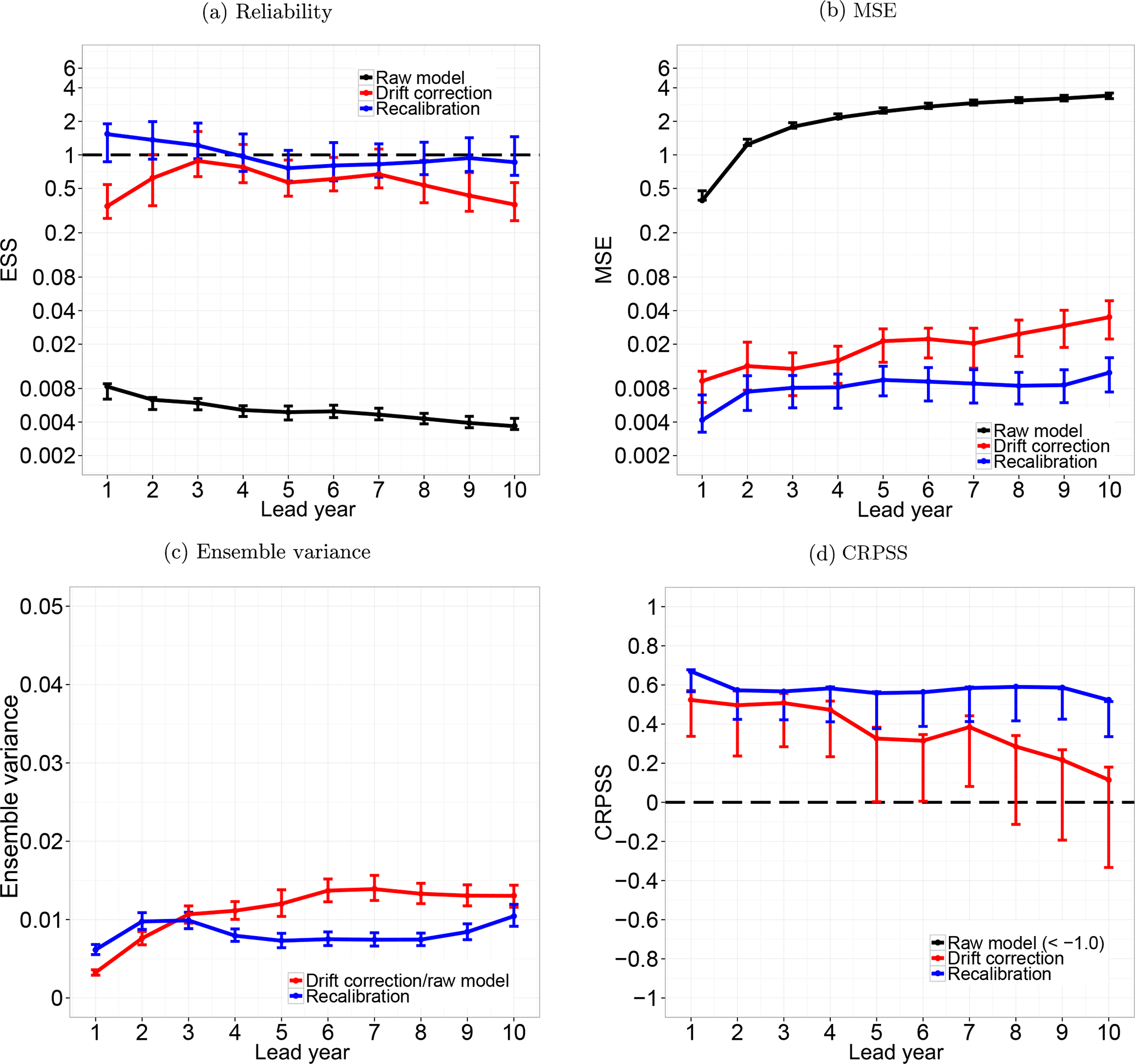
Figure 8Reliability (a), MSE (b), ensemble variance (c) and CRPSS (d) of global mean surface temperature without any correction (black line), after drift correction (red line) and recalibration with DeFoReSt (blue line). The CRPSS for the raw forecasts (black line) is smaller than −1 and therefore not shown. As the drift correction method does not account for the ensemble spread, the ensemble variance of the raw model and the drift-corrected forecast is equal. The vertical bars show the 95 % confidence interval due to 1000-wise bootstrapping.
Figure 8b shows the MSE. It is apparent that the recalibrated forecast outperforms the drift-corrected forecast for all lead years, where the improvement for lead years 5 to 6 and 8 to 10 is significant. Moreover, the MSE of the drift-corrected forecast increases with lead years, while the MSE of the recalibrated forecast is almost constant. Thus, this increasing difference between these forecasts is an effect of a lead year dependency of the conditional bias.
Figure 8c shows the time mean intra-ensemble variance for the global mean surface temperature. Regarding sharpness, the drift-corrected and the recalibrated forecasts perform similarly for lead years 2 and 3. Hence, the improved reliability of the recalibrated forecast could not attributed to a modified ensemble spread. The explanation is that the recalibration method also accounts for conditional and unconditional biases, while the drift correction method only addresses to the unconditional bias. Thus, the error between observation and ensemble mean of the recalibrated forecast is lower than the error of the drift-corrected forecast (see Fig. 8b). Consequently, the drift-corrected forecast is overconfident for this period (see Fig. 8a), due to a greater error combined with an equal sharpness.
Regarding the CRPSS, Fig. 8d shows that DeFoReSt performs significantly better than the drift-corrected forecast for lead years 1 and 8 to 10. Furthermore, the CRPSS shows that these forecasts also outperform the climatology, where the improvement of the drift-corrected forecast against climatology is not significant for lead years 8 to 9. The CRPSS of the raw model is smaller than −1 for all lead years and therefore out of the shown range.
All in all, the better CRPSS performance of DeFoReSt model could be explained due to a superior reliability for all lead years (see Fig. 8a).
There are many studies describing recalibration methods for weather and seasonal forecasts (e.g., Gneiting et al., 2005; Weigel et al., 2009). Regarding decadal climate forecasts, those methods cannot be applied easily, because decadal climate prediction systems on that timescale exhibit characteristic problems including model drift (lead-time-dependent unconditional bias) and climate trends which could differ from observations. In this regard, Kruschke et al. (2015) and Kharin et al. (2012) proposed methods to account for lead- and start-time-dependent unconditional biases of decadal climate predictions.
In addition to unconditional biases, probabilistic forecasts could show lead- and start-year-dependent conditional biases and under- or overdispersion. Therefore, we proposed the postprocessing method DeFoReSt which accounts for the three abovementioned issues. Following the suggestion for the unconditional bias (Kruschke et al., 2015), we allow for the conditional bias and the ensemble dispersion to change with lead time and linearly with start time. Two advantages of a polynomial fit over the common exponential fit (e.g., as proposed by Kharin et al., 2012) are stated by Gangstø et al. (2013). First, for a small sample size (this is given for decadal climate predictions), the fit of an exponent with offset is relatively difficult and unreliable. Second, a polynomial approach can capture a local maximum/minimum of the abovementioned errors at a specific lead time; the evolution of these errors may be nonmonotonous. Following Kruschke et al. (2015), we chose a third-order polynomial approach for the correction parameter of the unconditional bias and the conditional bias. A second-order polynomial approach is chosen for the correction parameter of the ensemble dispersion. Note that these choices might influence the resulting forecast skill. It might be worth using a transparent model selection strategy; this is the topic of future research. The associated DeFoReSt parameters are estimated by minimization of the CRPS (Gneiting et al., 2005). The CRPSS, the ESS, the time mean intra-ensemble variance (as measure for sharpness) and the MSE assess the performance of DeFoReSt. All scores were calculated with 10-year block-wise cross validation.
We investigated DeFoReSt using toy model simulations with high (η=0.8) and low potential predictability (η=0.2). Errors based on the same polynomial structure as used for the recalibration method were imposed. DeFoReSt is compared to a conventional drift correction and a perfect toy model without unconditional bias, conditional bias or ensemble spread was used as a benchmark. Here, the recalibration and drift correction benefits from the fact that the structure of errors imposed is known. Although the model for the error structure is flexible, the gain in skill is an upper limit to other applications where the structure of errors is unknown. Conclusions on the relative advantage of DeFoReSt over the drift correction for different potential predictability setups, however, should be largely unaffected by the choice of toy model errors.
A recalibrated forecast shows (almost) perfect reliability (ESS of 1). Sharpness can be improved due to the correction of conditional and unconditional biases. Thus, given a high potential predictability (η=0.8), recalibration leads to major improvements in skill (CRPSS) over a climatological forecast. Forecasts with low potential predictability (η=0.2) improve also but the gain in skill (CRPSS) over a climatological forecast is limited. In both cases, reliability, sharpness and thus CRPSS of the recalibrated model are almost equal to the perfect model. DeFoReSt outperforms the drift-corrected forecast with respect to CRPSS, reliability and MSE, due to additional correction of the conditional bias and the ensemble dispersion. The differences between these two postprocessed forecasts are, however, smaller for the low potential predictability setup.
We also applied DeFoReSt to surface temperature data of the MiKlip prototype decadal climate forecasts, spatially averaged over the North Atlantic subpolar gyre region and a global mean. Pronounced predictability for these cases has been identified by previous studies (e.g., Pohlmann et al., 2009; van Oldenborgh et al., 2010; Matei et al., 2012; Mueller et al., 2012). Nonetheless, both regions are also affected by model drift (Kröger et al., 2017). The North Atlantic region shows overconfident forecasts for all lead years for the raw model output. The drift-corrected forecast is underconfident for lead years 8 to 10. The recalibrated forecast is almost perfectly reliable for all lead years (ESS of 1) and outperforms the drift correction method with respect to CRPSS for lead years 1 and 2 and 5 to 10. For the global mean surface temperature, DeFoReSt significantly outperforms the drift-corrected forecast for several lead years with respect to CRPSS. The CRPSS for the global case is generally higher than that for the North Atlantic region. The recalibrated global forecast is perfectly reliable; the drift-corrected forecast, however, tends to be overconfident for all lead years. This is in accordance to other studies suggesting that ensemble forecasts typically underestimate the true uncertainty and tend to be overconfident (Weigel et al., 2009; Hamill and Colucci, 1997; Eckel and Walters, 1998). DeFoReSt thus accounts for both underdispersive and overdispersive forecasts.
DeFoReSt with third-/second-order polynomials is quite successful. However, it is worthwhile investigating the use of order selection strategies, such as LASSO (Tibshirani, 1996) or information criteria. Furthermore, parameter uncertainty due to a small training size may result in forecasts that are still underdispersive after recalibration. For the seasonal scale, this has been discussed by Siegert et al. (2015). However, for decadal climate forecasts, this aspect should be further considered in future studies. Recalibration based on CRPS minimization is computationally expensive, which might become problematic if not regional means but individual grid points are considered. As an alternative to the CRPS minimization, the Vector Generalized Linear Model (VGLM; Yee, 2008), which has been implemented in an efficient way, might be considered. We proposed DeFoReSt to recalibrate ensemble predictions of a single model. However, DeFoReSt needs to be modified if it should be applied to a multimodel prediction. This is necessary because single ensemble members of a multimodel prediction may differ in their systematic errors (Tebaldi et al., 2005; Arisido et al., 2017).
Based on simulations from a toy model and the MiKlip decadal climate forecast system, we could show that DeFoReSt is a consistent recalibration strategy for decadal forecast leading to reliable forecast with increased sharpness due to simultaneous adjustment of conditional and unconditional biases depending on lead time.
The NCEP 20CR reanalysis used in this study is freely accessible through NCAR (National Centers for Atmospheric Research) after a simple registration process. The MiKlip prototype data used for this paper are from the BMBF-funded project MiKlip and are available on request. The postprocessing, toy model and cross-validation algorithms are implemented using GNU-licensed free software from the R Project for Statistical Computing (http://www.r-project.org). Our implementations are available on request.
For this toy model setup, χ(t,τ) and ψ(t,τ) are obtained from α(t,τ) and β(t,τ) as follows:
The parameters χ(t,τ), ψ(t,τ) and ω(t,τ) are defined such that a perfectly recalibrated toy model forecast fCal would have the following form:
where ϵi is the deviation of each ensemble member i from the ensemble mean μens(t,τ). Here, is the ensemble variance. Writing Eq. (A4) as a Gaussian distribution and applying the definitions of μens (Eq. 21) and σens (Eq. 22), leads to
and applying the definitions of χ(t,τ), ψ(t,τ) and ω(t,τ) (Eqs. A1–A3) to Eq. (A5) would further lead to
This shows that fCal is equal to the perfect toy model fPerf(t,τ) (Eq. 23):

This setting has the advantage that the perfect estimation of α(t,τ), β(t,τ) and γ(t,τ) is already known prior to calibration with CRPS minimization.
Following the suggestion of Kruschke et al. (2015), a third-order polynomial approach was chosen for unconditional α(t,τ) and conditional biases β(t,τ) as well as for the inflation factor ω(t,τ), yielding
For the current toy model experiment, we exemplarily specify values for ui and vi as obtained from calibrating the ensemble mean of MiKlip prototype GECCO2 () surface temperature over the North Atlantic against NCEP 20CR reanalyses (Tobs):
The values of the coefficients are given in Table A1 (upper and middle rows). The last row of Table A1 gives the values of wi, i.e., the series expansion of the inflation factor ω(t,τ). These are chosen such that the forecast is overconfident for the first lead years and becomes underconfident for later lead years (see Fig. 1c).
We propose a cross-validation setting for decadal climate predictions to ensure fair conditions for assessing the benefit of a postprocessing method over a raw model without any postprocessing. All scores are calculated with a yearly moving validation period with a length of 10 years. This means that 1 start year including 10 lead years was left out for validation. The remaining start years and the corresponding lead years were used for estimating the correction parameters for the prediction within the validation period; start years within the validation period were not taken into account. This procedure was repeated for a start-year-wise shifted validation period.
This setting is illustrated in Fig. B1 for an exemplary validation period from 1964 to 1973; i.e., the correction parameters are estimated for all hindcasts which are initialized outside the validation period (1962; 1963; 1974; 1975, …).
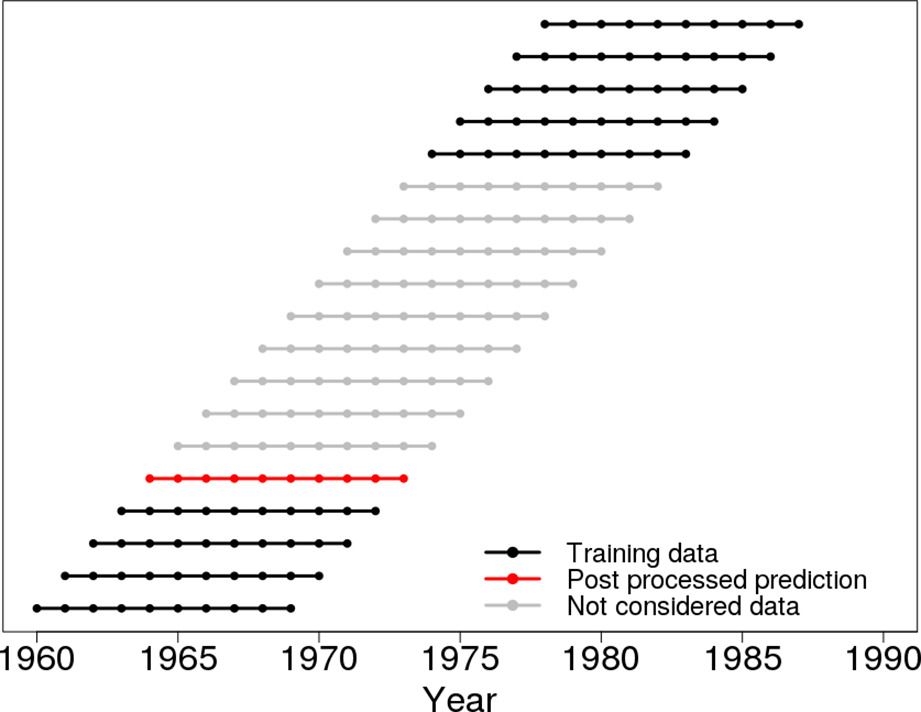
Figure B1Schematic overview of the applied cross-validation procedure for a decadal climate prediction, initialized in 1964 (red dotted line). All hindcasts which are initialized outside the prediction period are used as training data (black dotted lines). A hindcast which is initialized inside the prediction period is not used for training (gray dotted lines).
The authors declare that they have no conflict of interest.
This study was funded by the German Federal Ministry for Education and
Research (BMBF) project MiKlip (subprojects CALIBRATION
Förderkennzeichen FKZ 01LP1520A and FLEXFORDEC Förderkennzeichen: FKZ
01LP1519A). Mark Liniger and Jonas Bend have received funding from the
European Union's Seventh Framework Programme (FP7/2007–2013) under grant
agreement no. 308291.
Edited by: James
Annan
Reviewed by: two anonymous referees
Anderson, J. L.: A method for producing and evaluating probabilistic forecasts from ensemble model integrations, J. Climate, 9, 1518–1530, 1996. a
Arisido, M. W., Gaetan, C., Zanchettin, D., and Rubino, A.: A Bayesian hierarchical approach for spatial analysis of climate model bias in multi-model ensembles, Stoch. Env. Res. Risk A., 31, 1–13, 2017. a
Compo, G. P., Whitaker, J. S., Sardeshmukh, P. D., Matsui, N., Allan, R. J., Yin, X., Gleason, B. E., Vose, R. S., Rutledge, G., Bessemoulin, P., Brönnimann, S., Brunet, M., Crouthamel, R. I., Grant, A. N., Groisman, P. Y., Jones, P. D., Kruk, M. C., Kruger, A. C., Marshall, G. J., Maugeri, M., Mok, H. Y., Nordli, Ø., Ross, T. F., Trigo, R. M., Wang, X. L., Woodruff, S. D., and Worley, S. J.: The twentieth century reanalysis project, Q. J. Roy. Meteor. Soc., 137, 1–28, 2011. a
Dee, D. P., Uppala, S. M., Simmons, A. J., Berrisford, P., Poli, P., Kobayashi, S., Andrae, U., Balmaseda, M. A., Balsamo, G., Bauer, P., Bechtold, P., Beljaars, A. C. M., van de Berg, L., Bidlot, J., Bormann, N., Delsol, C., Dragani, R., Fuentes, M., Geer, A. J., Haimberger, L., Healy, S. B., Hersbach, H., Hólm, E. V., Isaksen, L., Kållberg, P., Köhler, M., Matricardi, M., McNally, A. P., Monge-Sanz, B. M., Morcrette, J.-J., Park, B.-K., Peubey, C., de Rosnay, P., Tavolato, C., Thépaut, J.-N., and Vitart, F.: The ERA-Interim reanalysis: configuration and performance of the data assimilation system, Q. J. Roy. Meteor. Soc., 137, 553–597, https://doi.org/10.1002/qj.828, 2011. a
Doblas-Reyes, F. J., Hagedorn, R., and Palmer, T. N.: The rationale behind the success of multi-model ensembles in seasonal forecasting – II. Calibration and combination, Tellus A, 57, 234–252, 2005. a
Eade, R., Smith, D., Scaife, A., Wallace, E., Dunstone, N., Hermanson, L., and Robinson, N.: Do seasonal-to-decadal climate predictions underestimate the predictability of the real world?, Geophys. Res. Lett., 41, 5620–5628, 2014. a
Eckel, F. A. and Walters, M. K.: Calibrated probabilistic quantitative precipitation forecasts based on the MRF ensemble, Weather Forecast., 13, 1132–1147, 1998. a, b
Fučkar, N. S., Volpi, D., Guemas, V., and Doblas-Reyes, F. J.: A posteriori adjustment of near-term climate predictions: Accounting for the drift dependence on the initial conditions, Geophys. Res. Lett., 41, 5200–5207, 2014. a
Gangstø, R., Weigel, A. P., Liniger, M. A., and Appenzeller, C.: Methodological aspects of the validation of decadal predictions, Clim. Res., 55, 181–200, https://doi.org/10.3354/cr01135, 2013. a, b, c
Glahn, H. R. and Lowry, D. A.: The use of model output statistics (MOS) in objective weather forecasting, J. Appl. Meteorol., 11, 1203–1211, 1972. a
Gneiting, T. and Katzfusss, M.: Probabilistic forecasting, Annu. Rev. Stat. Appl., 1, 125–151, 2014. a
Gneiting, T. and Raftery, A. E.: Strictly proper scoring rules, prediction, and estimation, Tech. Rep. 463, Department of Statistics, University of Washington, 29 pp., available at: http://www.stat.washington.edu/tech.reports (last access: 22 January 2018), 2004. a
Gneiting, T. and Raftery, A. E.: Weather forecasting with ensemble methods, Science, 310, 248–249, 2005. a
Gneiting, T. and Raftery, A. E.: Strictly proper scoring rules, prediction, and estimation, J. Am. Stat. Assoc., 102, 359–378, 2007. a, b
Gneiting, T., Raftery, A. E., Balabdaoui, F., and Westveld, A. H.: Verifying probabilistic forecasts: Calibration and sharpness, Proc. Workshop on Ensemble Weather Forecasting in the Short to Medium Range, Val-Morin, QC, Canada, 2003. a
Gneiting, T., Raftery, A. E., Westveld, A. H., and Goldman, T.: Calibrated probabilistic forecasting using ensemble model output statistics and minimum CRPS estimation, Mon. Weather Rev., 133, 1098–1118, 2005. a, b, c, d, e, f, g
Hamill, T. M. and Colucci, S. J.: Verification of Eta-RSM short-range ensemble forecasts, Mon. Weather Rev., 125, 1312–1327, 1997. a, b, c
Jungclaus, J. H., Fischer, N., Haak, H., Lohmann, K., Marotzke, J., Mikolajewicz, D. M. U., Notz, D., and von Storch, J. S.: Characteristics of the ocean simulations in the Max Planck Institute Ocean Model (MPIOM) the ocean component of the MPI-Earth system model, J. Adv. Model. Earth Syst., 5, 422–446, 2013. a
Keller, J. D. and Hense, A.: A new non-Gaussian evaluation method for ensemble forecasts based on analysis rank histograms, Meteorol. Z., 20, 107–117, 2011. a
Kharin, V. V., Boer, G. J., Merryfield, W. J., Scinocca, J. F., and Lee, W.-S.: Statistical adjustment of decadal predictions in a changing climate, Geophys. Res. Lett., 39, L19705, https://doi.org/10.1029/2012GL052647, 2012. a, b, c, d, e, f
Köhl, A.: Evaluation of the GECCO2 ocean synthesis: transports of volume, heat and freshwater in the Atlantic, Q. J. Roy. Meteor. Soc., 141, 166–181, 2015. a
Kröger, J., Pohlmann, H., Sienz, F., Marotzke, J., Baehr, J., Köhl, A., Modali, K., Polkova, I., Stammer, D., Vamborg, F., and Müller, W. A.: Full-Field initialized decadal predictions with the MPI Earth System Model: An initial shock in the North Atlantic, Clim. Dynam., https://doi.org/10.1007/s00382-017-4030-1, 2017. a, b, c
Kruschke, T., Rust, H. W., Kadow, C., Müller, W. A., Pohlmann, H., Leckebusch, G. C., and Ulbrich, U.: Probabilistic evaluation of decadal prediction skill regarding Northern Hemisphere winter storms, Meteorol. Z, 1, 721–738, https://doi.org/10.1127/metz/2015/0641, 2015. a, b, c, d, e, f, g, h, i, j, k
Marotzke, J., Müller, W. A., Vamborg, F. S. E., Becker, P., Cubasch, U., Feldmann, H., Kaspar, F., Kottmeier, C., Marini, C., Polkova, I., Prömmel, K., Rust, H. W., Stammer, D., Ulbrich, U., Kadow, C., Köhl, A., Kröger, J., and Kruschke, T., Pinto, J. G., Pohlmann, H., Reyers, M., Schröder, M., Sienz, F., Timmreck, C., and Ziese, M.: Miklip – a national research project on decadal climate prediction, B. Am. Meteorol. Soc., 97, 2379–2394, 2016. a
Matei, D., Baehr, J., Jungclaus, J. H., Haak, H., Müller, W. A., and Marotzke, J.: Multiyear prediction of monthly mean Atlantic meridional overturning circulation at 26.5∘ N, Science, 335, 76–79, 2012. a, b
McCullagh, P. and Nelder, J.: Generalized Linear Models, 2nd Edn, CRC Press, Boca Raton, Fla., 1989. a
Meehl, G. A., Goddard, L., Boer, G., Burgman, R., Branstator, G., Cassou, C., Corti, S., Danabasoglu, G., Doblas-Reyes, F., Hawkins, E., Karspeck, A., Kimoto, M., Kumar, A., Matei, D., Mignot, J., Msadek, R., Navarra, A., Pohlmann, H., Rienecker, M., Rosati, T., Schneider, E., Smith, D., Sutton, R., Teng, H., van Oldenborgh, G. J., Vecchi, G., and Yeager, S.: Decadal Climate Prediction: An Update from the Trenches, B. Am. Meteorol. Soc., 95, 243–267, https://doi.org/10.1175/BAMS-D-12-00241.1, 2014. a
Mueller, W. A., Baehr, J., Haak, H., Jungclaus, J. H., Kröger, J., Matei, D., Notz, D., Pohlmann, H., Storch, J., and Marotzke, J.: Forecast skill of multi-year seasonal means in the decadal prediction system of the Max Planck Institute for Meteorology, Geophys. Res. Lett., 39, 22, https://doi.org/10.1029/2012GL053326, 2012. a, b
Nelder, J. A. and Mead, R.: A simplex method for function minimization, Comput. J., 7, 308–313, 1965. a
Palmer, T., Buizza, R., Hagedorn, R., Lawrence, A., Leutbecher, M., and Smith, L.: Ensemble prediction: a pedagogical perspective, ECMWF newsletter, 106, 10–17, 2006. a, b, c, d
Palmer, T. N., Doblas-Reyes, F. J., Weisheimer, A., and Rodwell, M. J.: Toward seamless prediction: Calibration of climate change projections using seasonal forecasts, B. Am. Meteorol. Soc., 89, 459–470, 2008. a
Pohlmann, H., Jungclaus, J. H., Köhl, A., Stammer, D., and Marotzke, J.: Initializing decadal climate predictions with the GECCO oceanic synthesis: effects on the North Atlantic, J. Climate, 22, 3926–3938, 2009. a, b
Pohlmann, H., Mueller, W. A., Kulkarni, K., Kameswarrao, M., Matei, D., Vamborg, F., Kadow, C., Illing, S., and Marotzke, J.: Improved forecast skill in the tropics in the new MiKlip decadal climate predictions, Geophys. Res. Lett., 40, 5798–5802, 2013a. a
R Core Team: R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria, available at: https://www.R-project.org/ (last access: 22 January 2018), 2016. a
Raftery, A. E., Gneiting, T., Balabdaoui, F., and Polakowski, M.: Using Bayesian model averaging to calibrate forecast ensembles, Mon. Weather Rev., 133, 1155–1174, 2005. a
Rayner, N. A., Parker, D. E., Horton, E. B., Folland, C. K., Alexander, L. V., Rowell, D. P., Kent, E. C., and Kaplan, A.: Global analyses of sea surface temperature, sea ice, and night marine air temperature since the late nineteenth century, J. Geophys. Res.-Atmos., 108, 4407, https://doi.org/10.1029/2002JD002670, 2003. a
Sansom, P. G., Ferro, C. A., Stephenson, D. B., Goddard, L., and Mason, S. J.: Best Practices for Postprocessing Ensemble Climate Forecasts. Part I: Selecting Appropriate Recalibration Methods, J. Climate, 29, 7247–7264, 2016. a
Siegert, S., Sansom, P. G., and Williams, R.: Parameter uncertainty in forecast recalibration, Q. J. Roy. Meteor. Soc., 142, 696, https://doi.org/10.1002/qj.2716, 2015. a, b
Sloughter, J. M., Raftery, A. E., Gneiting, T., and Fraley, C.: Probabilistic quantitative precipitation forecasting using Bayesian model averaging, Mon. Weather Rev., 135, 3209–3220, 2007. a
Stevens, B., Giorgetta, M., Esch, M., Mauritsen, T., Crueger, T., Rast, S., Salzmann, M., Schmidt, H., Bader, J., Block, K., Brokopf, R., Fast, I., Kinne, S., Kornblueh, L., Lohmann, U., Pincus, R., Reichler, T., and Roeckner, E.: Atmospheric component of the MPI-M Earth System Model: ECHAM6, J. Adv. Model. Earth Syst, 5, 146–172, https://doi.org/10.1002/jame.20015, 2013. a
Talagrand, O., Vautard, R., and Strauss, B.: Evaluation of probabilistic prediction systems, Proc. Workshop on Predictability, Reading, UK, European Centre for Medium-Range Weather Forecasts, 1–25, 1997. a
Tebaldi, C., Smith, R. L., Nychka, D., and Mearns, L. O.: Quantifying uncertainty in projections of regional climate change: A Bayesian approach to the analysis of multimodel ensembles, J. Climate, 18, 1524–1540, 2005. a
Tibshirani, R.: Regression shrinkage and selection via the lasso, J. Roy. Stat. Soc. B Met., 58, 267–288, 1996. a
Uppala, S. M., Kållberg, P. W., Simmons, A. J., Andrae, U., Da Costa Bechtold, V., Fiorino, M., Gibson, J. K., Haseler, J., Hernandez, A., Kelly, G. A., Li, X., Onogi, K., Saarinen, S., Sokka, N., Allan, R. P., Andersson, E., Arpe, K., Balmaseda, M. A., Beljaars, A. C. M., Van De Berg, L., Bidlot, J., Bormann, N., Caires, S., Chevallier, F., Dethof, A., Dragosavac, M., Fisher, M., Fuentes, M., Hagemann, S., Hólm, E., Hoskins, B. J., Isaksen, L., Janssen, P. A. E. M., Jenne, R., Mcnally, A. P., Mahfouf, J.-F., Morcrette, J.-J., Rayner, N. A., Saunders, R. W., Simon, P., Sterl, A., Trenberth, K. E., Untch, A., Vasiljevic, D., Viterbo, P., and Woollen, J.: The ERA-40 re-analysis, Q. J. Roy. Meteor. Soc., 131, 2961–3012, 2005. a
van Oldenborgh, G. J., Doblas Reyes, F., Wouters, B., and Hazeleger, W.: Skill in the trend and internal variability in a multi-model decadal prediction ensemble, Geophys. Res. Abstr., EGU2010-9946, EGU General Assembly 2010, Vienna, Austria, 2010. a, b
Weigel, A. P., Liniger, M. A., and Appenzeller, C.: Seasonal ensemble forecasts: Are recalibrated single models better than multimodels?, Mon. Weather Rev., 137, 1460–1479, 2009. a, b, c, d
Yee, T. W.: VGAM: Vector generalized linear and additive models, R package version 0.7-7, available at: http://CRAN.R-project.org/package=VGAM (last access: 22 January 2018), 2008. a
- Abstract
- Introduction
- Data and methods
- DeFoReSt: Decadal Climate Forecast Recalibration Strategy
- Calibrating a toy model for decadal climate predictions
- Calibrating decadal climate surface temperature forecasts
- Summary and conclusions
- Code and data availability
- Appendix A: Construction of the toy model's free parameters
- Appendix B: Cross-validation procedure for decadal climate predictions
- Competing interests
- Acknowledgements
- References
- Abstract
- Introduction
- Data and methods
- DeFoReSt: Decadal Climate Forecast Recalibration Strategy
- Calibrating a toy model for decadal climate predictions
- Calibrating decadal climate surface temperature forecasts
- Summary and conclusions
- Code and data availability
- Appendix A: Construction of the toy model's free parameters
- Appendix B: Cross-validation procedure for decadal climate predictions
- Competing interests
- Acknowledgements
- References