the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 20 Oct 2022
| 20 Oct 2022
A fast, single-iteration ensemble Kalman smoother for sequential data assimilation
Marc Bocquet
Ensemble variational methods form the basis of the state of the art for nonlinear, scalable data assimilation, yet current designs may not be cost-effective for real-time, short-range forecast systems. We propose a novel estimator in this formalism that is designed for applications in which forecast error dynamics is weakly nonlinear, such as synoptic-scale meteorology. Our method combines the 3D sequential filter analysis and retrospective reanalysis of the classic ensemble Kalman smoother with an iterative ensemble simulation of 4D smoothers. To rigorously derive and contextualize our method, we review related ensemble smoothers in a Bayesian maximum a posteriori narrative. We then develop and intercompare these schemes in the open-source Julia package DataAssimilationBenchmarks.jl, with pseudo-code provided for their implementations. This numerical framework, supporting our mathematical results, produces extensive benchmarks demonstrating the significant performance advantages of our proposed technique. Particularly, our single-iteration ensemble Kalman smoother (SIEnKS) is shown to improve prediction/analysis accuracy and to simultaneously reduce the leading-order computational cost of iterative smoothing in a variety of test cases relevant for short-range forecasting. This long work presents our novel SIEnKS and provides a theoretical and computational framework for the further development of ensemble variational Kalman filters and smoothers.
- Article
(11037 KB) - Full-text XML
- BibTeX
- EndNote





1.1 Context
Ensemble variational methods form the basis of the state of the art for nonlinear, scalable data assimilation (DA; Asch et al., 2016; Bannister, 2017). Estimators following an ensemble Kalman filter (EnKF) analysis include the seminal maximum likelihood filter and 4DEnVAR (Zupanski, 2005; Liu et al., 2008), the ensemble randomized maximum likelihood method (EnRML; Gu and Oliver, 2007; Chen and Oliver, 2012; Raanes et al., 2019b), the iterative ensemble Kalman smoother (IEnKS; Sakov et al., 2012; Bocquet and Sakov, 2013, 2014), and the ensemble Kalman inversion (EKI; Iglesias et al., 2013; Schillings and Stuart, 2018; Kovachki and Stuart, 2019). Unlike traditional 3D-Var and 4D-Var, which use the adjoint-based approximation for the gradient of the Bayesian maximum a posteriori (MAP) cost function, these EnKF-based approaches utilize an ensemble of nonlinear forecast model simulations to approximate the tangent linear model. The gradient can then be approximated by, e.g., finite differences from the ensemble mean as in the bundle variant of the IEnKS (Bocquet and Sakov, 2014). The ensemble approximation can thus obviate constructing tangent linear and adjoint code for nonlinear forecast and observation models, which comes at a major cost in development time for operational DA systems.
These EnKF-based, ensemble variational methods combine the high accuracy of the iterative solution to the Bayesian MAP formulation of the nonlinear DA problem (Sakov et al., 2012; Bocquet and Sakov, 2014), the relative simplicity of model development and maintenance in ensemble-based DA (Kalnay et al., 2007), the ensemble analysis of time-dependent errors (Corazza et al., 2003), and a variational optimization of hyperparameters for, e.g., inflation (Bocquet et al., 2015), localization (Lorenc, 2003), and surrogate models (Bocquet et al., 2020) to augment the estimation scheme. However, while the above schemes are promising for moderately nonlinear and non-Gaussian DA, an obstacle to their use in real-time, short-range forecast systems lies in the computational barrier of simulating the nonlinear forecast model in the ensemble sampling procedure. In order to produce forecast, filter, and reanalyzed smoother statistics, these estimators may require multiple runs of the ensemble simulation over the data assimilation window (DAW), consisting of lagged past and current times.
When nonlinearity in the DA cycle is not dominated by the forecast error dynamics, as in synoptic-scale meteorology, an iterative optimization over the forecast simulation may not produce a cost-effective reduction in the forecast error. Particularly, when the linear Gaussian approximation for the forecast error dynamics is adequate, nonlinearity in the DA cycle may instead be dominated by the nonlinearity in the observation model, the nonlinearity in the hyperparameter optimization, or the nonlinearity in temporally interpolating a reanalyzed, smoothed solution over the DAW. In this setting, our formulation of iterative, ensemble variational smoothing has substantial advantages in balancing the computational cost/prediction accuracy tradeoff.
1.2 Objectives and outline
This long paper achieves three connected objectives. First, we review and update a variety of already published smoother algorithms in a narrative of Bayesian MAP estimation. Second, we use this framework to derive and contextualize our estimation technique. Third, we develop all our algorithms and test cases in the open-source Julia package DataAssimilationBenchmarks.jl (Bezanson et al., 2017; Grudzien et al., 2021). This numerical framework, supporting our mathematical results, produces extensive simulation benchmarks, validating the performance advantages of our proposed technique. These simulations likewise establish fundamental performance metrics for all estimators and the Julia package DataAssimilationBenchmarks.jl.
Our proposed technique combines the 3D sequential filter analysis and retrospective reanalysis of the classic ensemble Kalman smoother (EnKS; Evensen and Van Leeuwen, 2000) with an iterative ensemble simulation of 4D smoothers. Following a 3D filter analysis and retrospective reanalysis of lagged states, we reinitialize each subsequent smoothing cycle with a reanalyzed, lagged ensemble state. The resulting scheme is a single-iteration ensemble Kalman smoother, denoted as such as it produces its forecast, filter, and reanalyzed smoother statistics with a single iteration of the ensemble simulation over the DAW. By doing so, we seek to minimize the leading-order cost of ensemble variational smoothing in real-time, geophysical forecast models, i.e., the ensemble simulation. However, the scheme can iteratively optimize the sequential filter cost functions in the DAW without computing additional iterations of the ensemble simulation.
We denote our framework single-iteration smoothing, while the specific implementation presented here is denoted as the single-iteration ensemble Kalman smoother (SIEnKS). For linear Gaussian systems, with the perfect model hypothesis, the SIEnKS is a consistent Bayesian estimator, albeit one that uses redundant model simulations. When the forecast error dynamics is weakly nonlinear, yet other aspects of the DA cycle are moderately to strongly nonlinear, we demonstrate that the SIEnKS has a prediction and analysis accuracy that is comparable to, and often better than, some traditional 4D iterative smoothers. However, the SIEnKS has a numerical cost that scales in iteratively optimizing the sequential filter cost functions for the DAW, i.e., the cost of the SIEnKS scales in matrix inversions in the ensemble dimension rather than in the cost of ensemble simulations, making our methodology suitable for operational short-range forecasting.
Over long DAWs, the performance of iterative smoothers can degrade significantly due to the increasing nonlinearity in temporally interpolating the posterior estimate over the window of lagged states. Furthermore, with a standard, single data assimilation (SDA) smoother, each observation is only assimilated once, meaning that new observations are only distantly connected to the initial conditions of the ensemble simulation; this can introduce many local minima to a smoother analysis, strongly affecting an optimization (Fillion et al., 2018, and references therein). To handle the increasing nonlinearity of the DA cycle in long DAWs, we derive a novel form of the method of multiple data assimilation (MDA), previously derived in a 4D stationary and sequential DAW analysis (Emerick and Reynolds, 2013; Bocquet and Sakov, 2014, respectively). Our new MDA technique exploits the single-iteration formalism to partially assimilate each observation within the DAW with a sequential 3D filter analysis and retrospective reanalysis. Particularly, the sequential filter analysis constrains the ensemble simulation to the observations while temporally interpolating the posterior estimate over the DAW – this constraint is shown to improve the filter and forecast accuracy at the end of long DAWs and the stability of the joint posterior estimate versus the 4D approach. This key result is at the core of how the SIEnKS is able to outperform the predictive and analysis accuracy of 4D smoothing schemes while, at the same time, maintaining a lower leading-order computational cost.
This work is organized as follows. Section 2 introduces our notations. Section 3 reviews the mathematical formalism for the ensemble transform Kalman filter (ETKF) based on the LETKF formalism of Hunt et al. (2007), Sakov and Oke (2008b), and Sakov and Bertino (2011). Subsequently, we discuss the extension of the ETKF to fixed-lag smoothing in terms of (i) the right-transform EnKS, (ii) the IEnKS, and (iii) the SIEnKS, with each being different approximate solutions to the Bayesian MAP problem. Section 4 discusses several applications that distinguish the performance of these estimators. Section 5 provides an algorithmic cost analysis for these estimators and demonstrates forecast, filter, and smoother benchmarks for the EnKS, the IEnKS, and the SIEnKS in a variety of DA configurations. Section 6 summarizes these results and discusses future opportunities for the single-iteration smoother framework. Appendix A contains the pseudo-code for the algorithms presented in this work, which are implemented in the open-source Julia package DataAssimilationBenchmarks.jl (Grudzien et al., 2021). Note that, due to the challenges in formulating localization/hybridization for the IEnKS (Bocquet, 2016), we neglect a treatment of these techniques in this initial study of the SIEnKS, though this will be treated in a future work.
Matrices are denoted with upper-case bold and vectors with lower-case bold and italics. The standard Euclidean vector norm is denoted . For a symmetric, positive definite matrix , we define the Mahalanobis vector norm with respect to A (Sankhya, 2018) as follows:
For a generic matrix , with full-column rank M, we denote the pseudo-inverse as follows:
When A has a full-column rank as above, we define the Mahalanobis vector “norm”, with respect to , as follows:
Note that when G does not have full-column rank, i.e., N>M, this is not a true norm on ℝN as it is degenerate in the null space of A†. Instead, this is a lift of a non-degenerate norm in the column span of A to RN. For v in the column span of A,
for a vector of weights w∈RM.
Let x denote a random vector of physics-based model states. Assume that an initial, prior probability density function (density henceforth) on the model state p(x0) is given, with a hidden Markov model of the following form:
which determines the distribution of future states, with the dependence on the time tk denoted by the subscript k. For simplicity, assume that is fixed for all k, though this is not a required restriction in any of the following arguments. The dimensions of the above system are denoted as follows: (i) Nx is the model state dimension , (ii) Ny is the observation vector dimension , and (iii) Ne is the ensemble size, where an ensemble matrix is given as . State model and observation variables are related via the (possibly) nonlinear observation operator . Observation noise ϵk is assumed to be an unbiased white sequence such that, in the following:
where 𝔼 is the expectation, is the observation error covariance matrix at time tk, and δk,l denotes the Kronecker delta function on the indices k and l. The error covariance matrix Rk is assumed to be invertible without losing generality.
The above configuration refers to a perfect model hypothesis (Grudzien and Bocquet, 2021) in which the transition probability for is written as follows:
with δv referring to the Dirac measure at . Similarly, we say that the transition density is proportional, as follows:
where δ represents the Dirac distribution. The Dirac measure is singular with respect to Lebesgue measure, so this is simply a convenient abuse of the notation that can be made rigorous with the generalized function theory of distributions (Taylor, 1996, see chap. 3 Sect. 4). The perfect model assumption is utilized throughout this work to frame the studied assimilation schemes in a unified manner, although this is a highly simplified framework for a realistic geophysical DA problem. Extending the single-iteration formalism to the case of model errors will be studied in a future work.
Define the multivariate Gaussian density as follows:
In the case where (i) ℳk:=Mk and ℋk:=Hk are both linear transformations, (ii) the observation likelihood is
and (iii) the first prior is given as follows:
Then, the DA configuration is of a perfect linear Gaussian model. This is a further restriction of the perfect model assumption from which many classical filtering results are derived, though it is only a heuristic for nonlinear and erroneous geophysical DA.
For a time series of model or observation states with l>k, we define the notations as follows:
To distinguish between the various conditional probabilities under consideration, we make the following definitions. Let l>k; then, the forecast density is denoted as follows:
Next, the filter density is denoted as follows:
A smoother density for xk, given observations yl:1, is denoted as follows:
In the above, the filter and smoother densities are marginals of the joint posterior density, denoted as follows:
The Markov hypothesis implies that the forecast density can, furthermore, be written as follows:
For a fixed-lag smoother, define a shift in length S≥1 analysis times and a lag of length L≥S analysis times, where time tL denotes the present time. We use an algorithmically stationary DAW throughout the work, referring to the time indices . Smoother schemes estimate the joint posterior density or one of its marginals in a DA cycle. After each estimate is produced, the DAW is subsequently shifted in time by S×Δt, and all states are reindexed by to begin the next DA cycle. For a lag of L and a shift of S, the observation vectors at times correspond to the observations newly entering the DAW at time tL. When S=L, the DAWs are disconnected and adjacent in time, whereas, for S<L, there is an overlap between the estimated states in sequential DAWs. Figure 1 provides a schematic of how the DAW is shifted for a lag of L=5 and shift of S=2. Following the convention in DA that there is no observation at time zero, in addition to the DAW , states at time t0 are estimated or utilized to connect estimates between adjacent/overlapping DAWs.
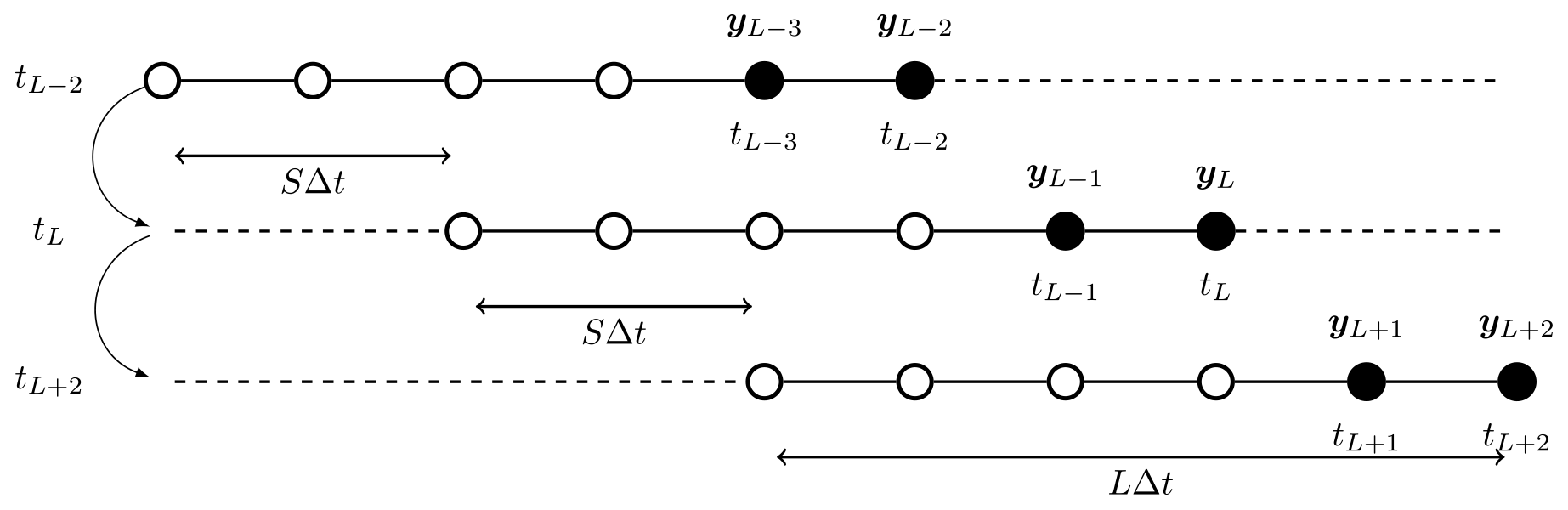
Figure 1Three cycles of a smoother with a shift S=2 and a lag L=5. The cycle number increases from top to bottom. Time indices in the left-hand margin indicate the current time for the associated cycle of the algorithm. New observations entering the current DAW are shaded black. The initial DAW ranges from . In the next cycle, this is shifted to and is shifted thereafter to . States at the zero-time indices are tL−7 in the first cycle, tL−5 in the second cycle, and tL−3 in the third cycle. These are estimated in addition to states in the DAW to connect the cycles in the sequential DAWs.
Define the background mean and covariance as follows:
where the label i refers to the density with respect to which the expectation is taken. The ensemble matrix is likewise given a label i, denoting the conditional density according to which the ensemble is approximately distributed. The ensemble is assumed to have columns sampled that are independent and identically distributed (iid), according to the forecast density. The ensemble is assumed to have columns iid, according to the filter density. The ensemble is assumed to have columns iid according to a smoother density for the state at time tk, given observations up to time tL. Multiple data assimilation schemes will also utilize a balancing ensemble and an MDA ensemble , which will be defined in Sect. 4.3. Time indices and labels may be suppressed when the meaning is still clear in the context. Note that, in realistic geophysical DA, the iid assumption rarely holds in practice, and even in the perfect linear Gaussian model, the above identifications are approximations due to the sampling error in estimating the background mean and covariance.
The forecast model is given by , referring to the action of the map being applied column-wise, and where the type of ensemble input and output (forecast/filter/smoother/balancing/MDA) is specified according to the estimation scheme. Define the composition of the forecast model as . Let 1 denote the vector with all entries equal to one, such that the ensemble-based empirical mean, the ensemble perturbation matrix, and the ensemble-based empirical covariance are each defined by linear operations with conformal dimensions as follows:
which is distinguished from the background mean and background covariance .
The ETKF analysis (Hunt et al., 2007) is utilized in the following for its popularity and efficiency and in order to emphasize the commonality and differences between other well-known smoothing schemes. However, the single-iteration framework is not restricted to any particular filter analysis, and other types of filter analysis, such as the deterministic EnKF (DEnKF) of Sakov and Oke (2008a), are compatible with the formalism and may be considered in future studies.
3.1 The ETKF
The filter problem is expressed recursively in the Bayesian MAP formalism with an algorithmically stationary DAW as follows. Suppose that there is a known filter density p(x0|y0) from a previous DA cycle. Using the Markov hypothesis and the independence of observation errors, we write the filter density up to proportionality, via Bayes' law, as follows:
which is the product of the (i) likelihood of the observation, given the forecast, and (ii) the forecast prior. The forecast prior (ii) is generated by the model propagation of the last filter density p(x0|y0), with the transition density p(x1|x0), marginalizing out x0. Given a first prior, the above recursion inductively defines the forecast and filter densities, up to proportionality, at all times.
In the perfect linear Gaussian model, the forecast prior and filter densities,
are Gaussian. The Kalman filter equations recursively compute the mean and covariance of the random model state x1, parameterizing its distribution (Jazwinski, 1970). In this case, the filter problem can also be written in terms of the Bayesian MAP cost function, as follows:
To render the above cost function into the right-transform analysis, define the matrix factor as follows:
where the choice of can be arbitrary but is typically given in terms of a singular value decomposition (SVD; Sakov and Oke, 2008b). Instead of optimizing the cost function in Eq. (22) over the state vector x1, the optimization is equivalently written in terms of weights w, where, in the following:
Thus, by rewriting Eq. (22) in terms of the weight vector w, we obtain the following:
Furthermore, for the sake of compactness, we define the following notations:
The vector is the innovation vector, weighted inverse proportionally to the observation uncertainty. The matrix Γ1, in one dimension with H1:=1, is equal to the standard deviation of the model forecast relative to the standard deviation of the observation error.
The cost function Eq. (25) is hence further reduced to the following:
This cost function is quadratic in w and can be globally minimized where ∇w𝒥=0. Notice that, in the following:
By setting the gradient equal to zero for , we find the following expression for the optimal weights:
From Eq. (28), notice that
Similarly, taking the gradient of Eq. (28), we find that the Hessian, , is equal to the following:
Therefore, with w=0 corresponding to as the initialization of the algorithm, the MAP weights are determined by a single iteration of Newton's descent method (Nocedal and Wright, 2006). For iterate i, this has the general form of the following:
The MAP weights define the maximum a posteriori model state as follows:
Under the perfect linear Gaussian model assumption, 𝒥 can then be rewritten in terms of the filter MAP estimate as follows:
Define the matrix decomposition and the change in variables as follows:
Then, Eq. (34b) can be rewritten as follows:
Computing the Hessian from each of Eqs. (27) and (36), we find, by their equivalence, the following:
If we define the covariance transform as
then this derivation above describes the square root Kalman filter recursion (Tippett et al., 2003) when written for the exact mean and covariance, which is recursively computed in the perfect linear Gaussian model. The covariance update is then as follows:
It is written entirely in terms of the matrix factor and the covariance transform T, such that the background covariance need not be explicitly computed in order to produce recursive estimates. Likewise, the Kalman gain update to the mean state is reduced to Eq. (33) in terms of the weights and the matrix factor. This reduction is at the core of the efficiency of the ETKF in which one typically makes a reduced-rank approximation to the background covariances .
Using the ensemble-based empirical estimates for the background, as in Eq. (19), a modification of the above argument must be used to solve the cost function 𝒥 in the ensemble span, without a direct inversion of when this is of a reduced rank. We replace the background covariance norm square with one defined by the ensemble-based covariance, as follows:
We then define the ensemble-based estimates as follows:
where w is now a weight vector in . The ensemble-based cost function is then written as follows:
Define to be the minimizer of the cost function in Eq. (42). Hunt et al. (2007) demonstrate that, up to a gauge transformation, yields the minimizer of the state space cost function, Eq. (22), when the estimate is restricted to the ensemble span. Let denote the Hessian of the ensemble-based cost function in Eq. (42). This equation is quadratic in w and can be solved similarly to Eq. (27) to render the following:
The ensemble transform Kalman filter (ETKF) equations are then given by the following:
where can be any mean-preserving, orthogonal transformation, i.e., U1=1. The simple choice of is sufficient, but it has been demonstrated that choosing a random, mean-preserving orthogonal transformation at each analysis, as above, can improve the stability of the ETKF, preventing the collapse of the variances to a few modes in the empirical covariance estimate (Sakov and Oke, 2008b). We remark that Eq. (44) can be written equivalently as a single linear transformation as follows:
The compact update notation in Eq. (45) is used to simplify the analysis.
If the observation operator ℋ1 is actually nonlinear, then the ETKF typically uses the following approximation to the quadratic cost function:
where term (46a) refers to the action of the observation operator being applied column-wise. Substituting the definitions in Eq. (46) for the definitions in Eq. (41) gives the standard nonlinear analysis in the ETKF. Note that this framework extends to a fully iterative analysis of nonlinear observation operators, as discussed in Sect. 4.1. Multiplicative covariance inflation is often used in the ETKF to handle the systematic underestimation of the forecast and filter covariance due to the sample error implied by a finite size ensemble and nonlinearity of the forecast model ℳ1 (Raanes et al., 2019a).
The standard ETKF cycle is summarized in Algorithm A5. This algorithm is broken into the subroutines, in Algorithms A1–A4, which are reused throughout our analysis to emphasize the commonality and the differences in the studied smoother schemes. The filter analysis described above can be extended in several different ways when producing a smoother analysis on a DAW, including lagged past states, depending in part on whether it is formulated as a marginal or a joint smoother (Cosme et al., 2012). The way in which this analysis is extended, utilizing a retrospective reanalysis or a 4D cost function, differentiates the EnKS from the IEnKS and highlights the ways in which the SIEnKS differs from these other schemes.
3.2 The fixed-lag EnKS
The (right-transform) fixed-lag EnKS extends the ETKF over the smoothing DAW by sequentially reanalyzing past states with future observations. This analysis is performed retrospectively in the sense that the filter cycle of the ETKF is left unchanged, while an additional smoother loop of the DA cycle performs an update on the lagged state ensembles stored in memory. Assume , then the EnKS estimates the joint posterior density recursively, given the joint posterior estimate over the last DAW . We begin by considering the filter problem as in Eq. (20).
Given , we write the filter density up to proportionality as follows:
with the product of (i) the likelihood of the observation yL, given xL, and (ii) the forecast for xL, using the transition kernel on the last joint posterior estimate and marginalizing out . Recalling that , this provides a means to sample the filter marginal of the desired joint posterior. The usual ETKF filter analysis is performed to sample the filter distribution at time tL; yet, to complete the smoothing cycle, the scheme must sample the joint posterior density .
Consider that the marginal smoother density is proportional to the following:
where (i) is the likelihood of the observation yL, given the past state xL−1, and (ii) is the marginal density for xL−1 from the last joint posterior.
Assume now the perfect linear Gaussian model; then, the corresponding Bayesian MAP cost function is given as follows:
where and are the mean and covariance of the marginal smoother density . Take the following matrix decomposition:
Then, write , rendering the cost function as follows:
Let now denote the minimizer of Eq. (51). It is important to recognize that
such that the optimal weight vector for the smoothing problem is also the optimal weight vector for the filter problem.
The ensemble-based approximation,
to the exact smoother cost function in Eq. (51) yields the retrospective analysis of the EnKS as follows:
The above equations generalize for arbitrary indices k|L, completely describing the smoother loop between each filter cycle of the EnKS. After a new observation is assimilated with the ETKF analysis step, a smoother loop makes a backwards pass over the DAW, applying the transform and the weights of the ETKF filter update to each past state ensemble stored in memory. This generalizes to the case where there is a shift in the DAW with S>1, though the EnKS does not process observations asynchronously by default, i.e., the ETKF filter steps, and the subsequent retrospective reanalysis, are performed in sequence over the observations and ordered in time rather than making a global analysis over . A standard form of the EnKS is summarized in Algorithm A6, utilizing the subroutines in Algorithms A1–A4.
A schematic of the EnKS cycle for a lag of L=4 and a shift of S=1 is pictured in Fig. 2. Time moves forwards, from left to right, on the horizontal axis, with a step size of Δt. At each analysis time, the ensemble forecast from the last filter density is combined with the observation to produce the ensemble update transform ΨL. This transform is then utilized to produce the posterior estimate for all lagged state ensembles conditioned on the new observation. The information in the posterior estimate thus flows in reverse time to the lagged states stored in memory, but the information flow is unidirectional in this scheme. It is understood then that reinitializing the improved posterior estimate for the lagged states in the dynamical model does not improve the filter estimate in the perfect linear Gaussian configuration. Indeed, define the product of the ensemble transforms as follows:
Then, for arbitrary ,
This demonstrates that conditioning on the information from the observation is covariant with the dynamics. Raanes (2016) demonstrates the equivalence of the EnKS and the Rauch–Tung–Striebel (RTS) smoother, where this property of perfect linear Gaussian models is well understood. In the RTS formulation of the retrospective reanalysis, the conditional estimate reduces to the map of the current filter estimate under the reverse time model (Jazwinski, 1970; see example 7.8, chap. 7). Note, however, that both of the EnKS and ensemble RTS smoothers produce their retrospective reanalyses via a recursive ensemble transform without the need to make backwards model simulations.
The covariance of conditioning on observations and the model dynamics does not hold, however, either in the case of nonlinear dynamics or of model error. Reinitializing the DA cycle in a perfect nonlinear model with the conditional ensemble estimate can dramatically improve the accuracy of the subsequent forecast and filter statistics. Particularly, this exploits the mismatch in perfect nonlinear dynamics between Chaotic dynamics generate additional information about the initial value problem in the sense that initial conditions nearby to each other are distinguished by their subsequent evolution and divergence due to dynamical instability. Reinitializing the model forecast with the smoothed prior estimate brings new information into the forecast for states in the next DAW. This improvement in the accuracy of the ensemble statistics has been exploited to a great extent by utilizing the 4D ensemble cost function (Hunt et al., 2004). Particularly, the filter cost function can be extended over multiple observations simultaneously and in terms of lagged states directly. This alternative approach to extending the filter analysis to the smoother analysis is discussed in the following.
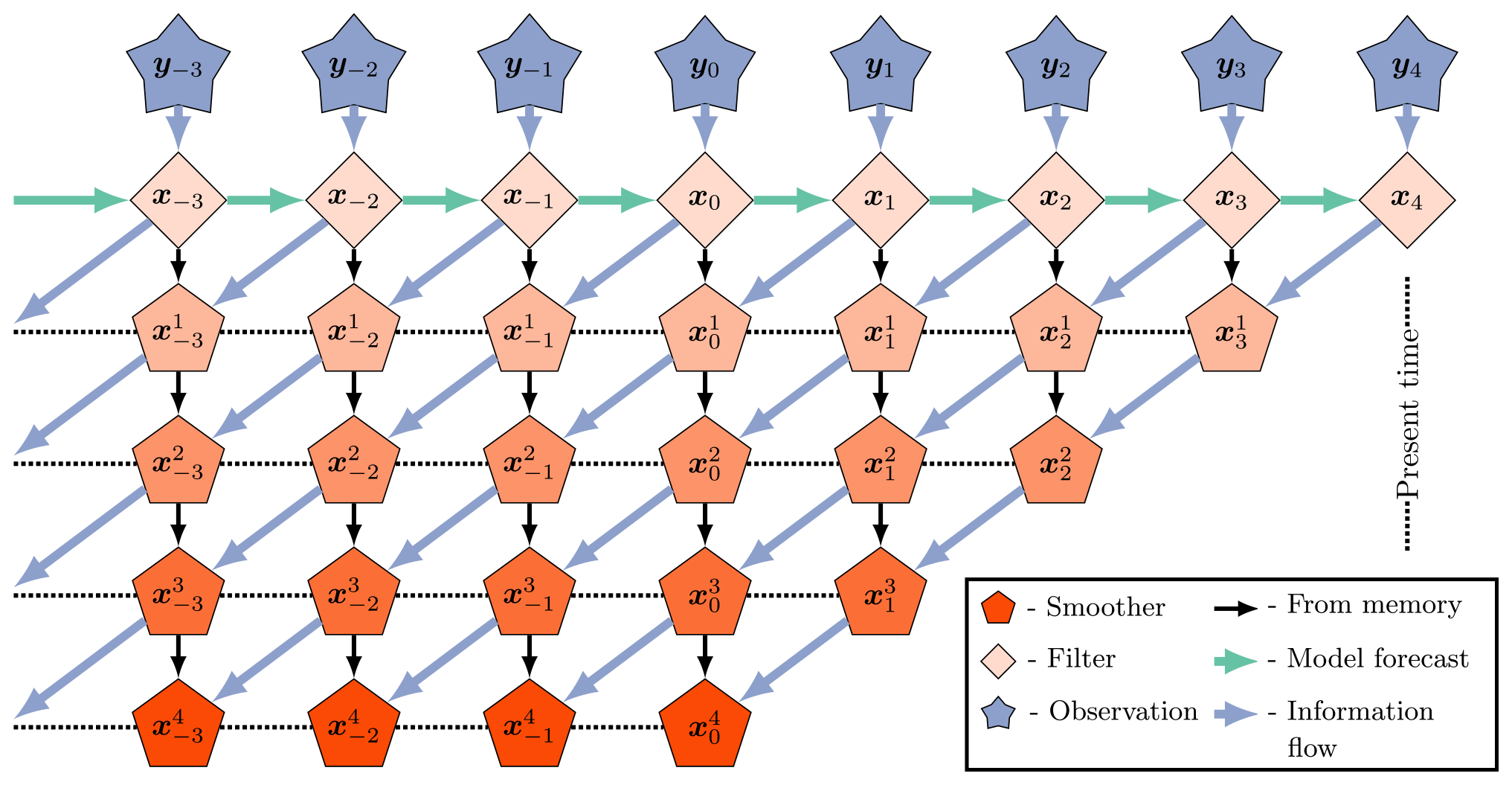
Figure 2The EnKS with a lag =4 and a shift =1. The observations are assimilated sequentially via the filter cost function, and a retrospective reanalysis is applied to all ensemble states within the lag window stored in memory. This figure is adapted from Asch et al. (2016).
3.3 The Gauss–Newton fixed-lag IEnKS
The following is an up-to-date formulation of the Gauss–Newton IEnKS of Bocquet and Sakov (2013, 2014) and its derivations. Instead of considering the marginal smoother problem, now consider the joint posterior density directly and for a general shift S. The last posterior density is written as . Using the independence of observation errors and the Markov assumption recursively,
Additionally, using the perfect model assumption,
for every k. Therefore,
where term (i) in Eq. (60) represents the marginal smoother density for over the last DAW, term (ii) represents the joint likelihood of the observations given the model state, and term (iii) represents the free forecast of the smoother estimate for . Noting that , this provides a recursive form to sample the joint posterior density.
Under the perfect linear Gaussian model assumption, the above derivation leads to the following exact 4D cost function:
The ensemble-based approximation, using notations as in Eq. (41), yields the following:
Notice that Eq. (62b) is quadratic in w; therefore, for the perfect linear Gaussian model, one can perform a global analysis over all new observations in the DAW at once.
The gradient and the Hessian of the ensemble-based 4D cost function are given as follows:
so that, evaluating at w=0, the minimizer is again given by a single iteration of Newton's descent
Define the covariance transform again as . We denote the right ensemble transform corresponding to the 4D analysis to distinguish from the product of the sequential filter transforms . The global analyses are defined as follows:
where U is any mean-preserving orthogonal matrix.
In the perfect linear Gaussian model, this formulation of the IEnKS is actually equivalent to the 4D-EnKF of Hunt et al. (2004), Fertig et al. (2007), and Harlim and Hunt (2007). The above scheme produces a global analysis of all observations within the DAW, even asynchronously from the standard filter cycle (Sakov et al., 2010). One generates a free ensemble forecast with the initial conditions drawn iid as , and all data available within the DAW are used to estimate the update to the initial ensemble. The perfect model assumption means that the updated initial ensemble can then be used to temporally interpolate the joint posterior estimate over the entire DAW from the marginal sample, i.e., for any , a smoothing solution is defined as follows:
When ℳk and ℋk are nonlinear, the IEnKS formulation is extended with additional iterations of Newton's descent, as in Eq. (32), in order to iteratively optimize the update weights. Specifically, the gradient is given by the following:
where represents a directional derivative of the observation and state models with respect to the ensemble perturbations at the ensemble mean, as follows:
This describes the sensitivities of the cost function, with respect to the ensemble perturbations, mapped to the observation space. When the dynamics is weakly nonlinear, the ensemble perturbations of the EnKS and IEnKS are known to closely align with the span of the backward Lyapunov vectors of the nonlinear model along the true state trajectory (Bocquet and Carrassi, 2017). Under these conditions, Eq. (68) can be interpreted as a directional derivative with respect to the forecast error growth along the dynamical instabilities of the nonlinear model (see Carrassi et al., 2022, and references therein).
In order to avoid an explicit computation of the tangent linear model and the adjoint as in 4D-Var, Sakov et al. (2012) and Bocquet and Sakov (2012) proposed two formulations to approximate the tangent linear propagation of the ensemble perturbations. The bundle scheme makes an explicit approximation of finite differences in the observation space where, for an arbitrary ensemble, they define the approximate linearization as follows:
for a small constant ϵ. Alternatively, the transform version provides a different approximation to the variational analysis, using the covariance transform T and its inverse as a pre-/post-conditioning of the perturbations used in the sensitivities approximation. The transform variant of the IEnKS is in some cases more numerically efficient than the bundle version, requiring fewer ensemble simulations, and it is explicitly related to the ETKF/EnKS/4D-EnKF formalism presented thus far. For these reasons, the transform approximation is used as a basis of comparison with the other schemes in this work.
For the IEnKS transform variant, the ensemble-based approximations are redefined in each Newton iteration as follows:
where the first covariance transform is defined as , the gradient and Hessian are computed as in Eq. (63) from the above, and where the covariance transform is redefined in terms of the Hessian, , at the end of each iteration. With these definitions, the first iteration of the IEnKS transform variant corresponds to the solution of the nonlinear 4D-EnKF, but subsequent iterates are initialized by pre-conditioning the initial ensemble perturbations via the update T and post-conditioning the sensitivities by the inverse transform T−1.
An updated form of the Gauss–Newton IEnKS transform variant is presented in Algorithm A7. Note that, while Algorithm A7 does not explicitly reference the sub-routine in Algorithm A1, many of the same steps are used in the IEnKS when computing the sensitivities. It is important to notice that, for S>1, the IEnKS only requires a single computation of the square root inverse of the Hessian of the 4D cost function, per iteration of the optimization, to process all observations in the DAW. On the other hand, the EnKS processes these observations sequentially, requiring S total square root inverse calculations of the Hessian, corresponding to each of the sequential filter cost functions.
The IEnKS is computationally constrained by the fact that each iteration of the descent requires L total ensemble simulations in the dynamical state model ℳk. One can minimize this expense by using a single iteration of the IEnKS equations, which is denoted the linearized IEnKS (Lin-IEnKS) by Bocquet and Sakov (2014). When the overall DA cycle is nonlinear, but only weakly nonlinear, this single iteration of the IEnKS algorithm can produce a dramatic improvement in the forecast accuracy versus the forecast/filter cycle of the EnKS. However, the overall nonlinearity of the DA cycle may be strongly influenced by factors other than the model forecast ℳk itself. As a simple example, consider the case in which ℋk is nonlinear yet ℳk≡Mk for all k. In this setting, it may be more numerically efficient to iterate upon the 3D filter cost function rather than the full 4D cost function which requires simulations of the state model. Combining (i) the filter step and retrospective reanalysis of the EnKS and (ii) the single iteration of the ensemble simulation over the DAW as in Lin-IEnKS, we obtain an estimation scheme that sequentially solves the nonlinear filter cost functions in the current DAW, while making an improved forecast in the next by transmitting the retrospective analyses through the dynamics via the updated initial ensemble.
3.4 The fixed-lag SIEnKS
3.4.1 Algorithm
Recall that, from Eq. (57), conditioning the ensemble with the right transform Ψk is covariant with the dynamics. In a perfect linear Gaussian model, we can therefore estimate the joint posterior over the DAW via model propagation of the marginal for , as in the IEnKS but by using the EnKS retrospective reanalysis to generate the initial condition. For arbitrary , define each of the right transforms as in the sequential filter analysis of the ETKF with Eq. (45). Rather than storing the ensemble matrix in memory for each time tk in the DAW, we instead store and to begin a DA cycle. Observations within the DAW are sequentially assimilated via the 3D filter cycle initialized with and a marginal, retrospective, smoother analysis is performed sequentially on with these filter transforms. The joint posterior estimate is then interpolated over the DAW for any via the model dynamics as follows:
Notice that, for S=1, the product of the 3D filter ensemble transforms reduces to the 4D transform, i.e.,
so that, in the perfect linear Gaussian model with S=1, the SIEnKS and the Lin-IEnKS coincide. The SIEnKS and the Lin-IEnKS have different treatments of nonlinearity in the DA cycle, but even in the perfect linear Gaussian model, a shift S>1 distinguishes the 4D approach of the Lin-IEnKS and the hybrid 3D/4D approach of the SIEnKS. For comparison, a schematic of the SIEnKS cycle is pictured in Fig. 3, while a schematic of the (Lin-)IEnKS cycle is shown in Fig. 4, and each is configured for a lag of L=4 and a shift of S=2. This comparison demonstrates how the sequential 3D filter analysis and retrospective smoother reanalysis for each observation differ from the global 4D analysis of all observations at once in the (Lin-)IEnKS. A generic form of the SIEnKS is summarized in Algorithm A8, utilizing the sub-routines in Algorithms A1–A4. Note that the version presented in Algorithm A8 is used to emphasize the commonality with the EnKS. However, an equivalent implementation initializes each cycle with alone, similar to the IEnKS. Such a design is utilized when we derive the SIEnKS MDA scheme in Algorithm A12 from the IEnKS MDA scheme in Algorithm A13.
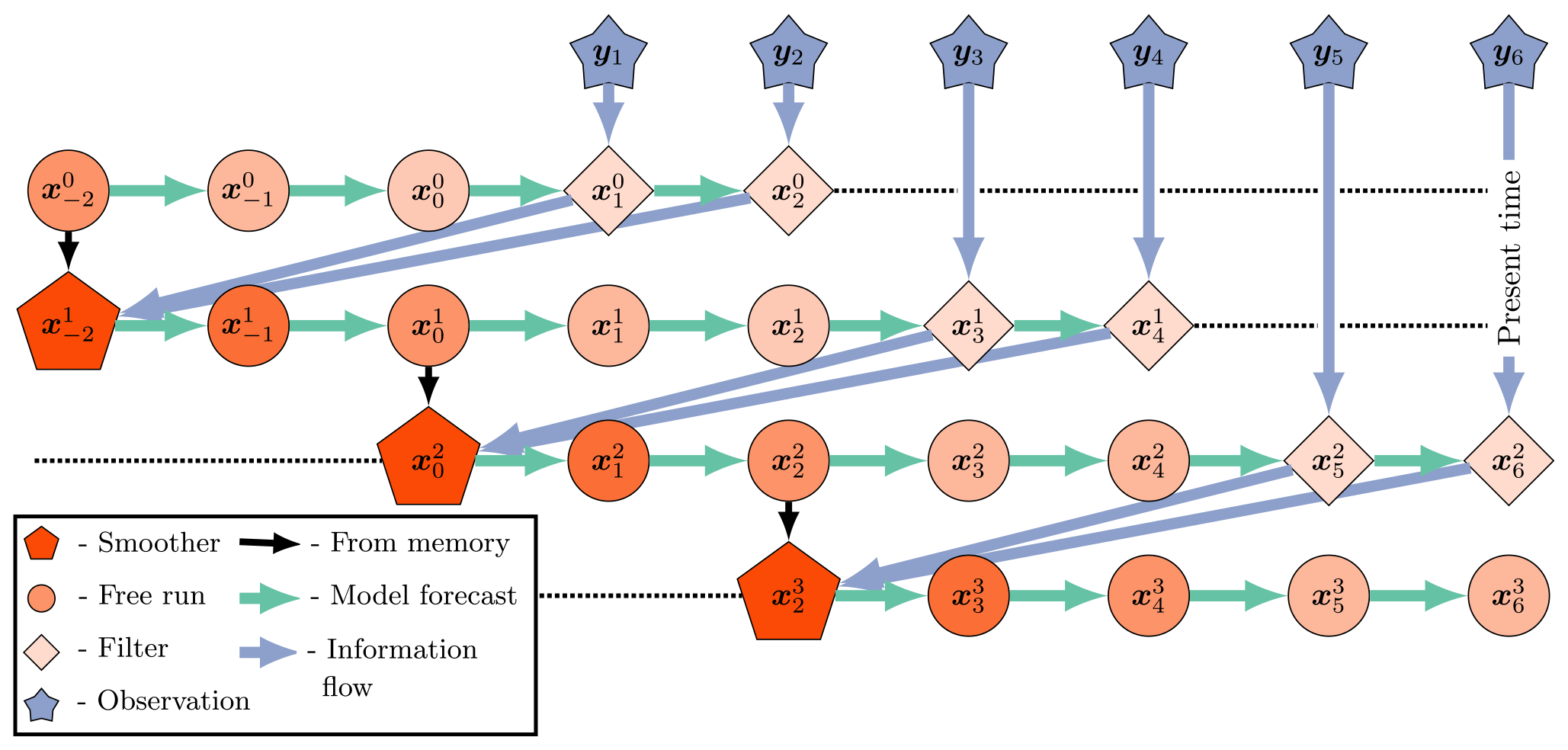
Figure 3The SIEnKS with a lag =4 and a shift =2. An initial condition from the last smoothing cycle initializes a forecast simulation over the current DAW of the L=4 states. New observations entering the DAW are assimilated sequentially via the 3D filter cost function. After each filter analysis, a retrospective reanalysis is applied to the initial ensemble. At the end of the DAW, after sequentially processing all observations, the reanalyzed initial condition is evolved, via the model S analysis times, forward to begin the next cycle.
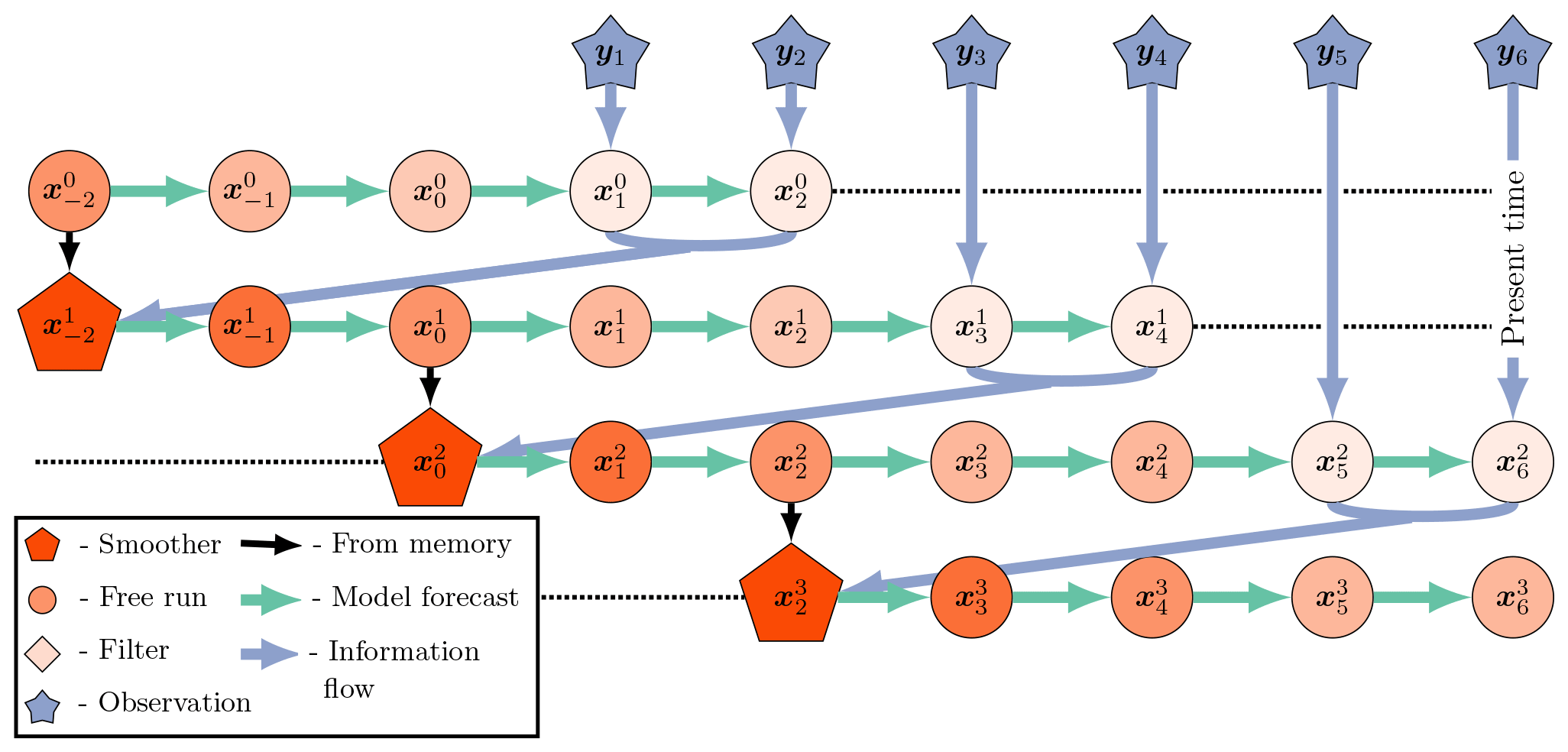
Figure 4The (Lin-)IEnKS with a lag =4 and a shift =2. An initial condition from the last smoothing cycle initializes a forecast simulation over the current DAW of the L=4 states. Unlike the SIEnKS, all new observations entering the DAW are assimilated globally at once via the 4D cost function. The innovations of the free forecast over all of the observation times are used to produce a retrospective reanalysis of the initial ensemble. Finally, the reanalyzed initial condition is evolved, via the model, S analysis times forward to begin the next cycle. Unlike the SIEnKS and the EnKS, the filter analysis of the (Lin-)IEnKS is performed by dynamically interpolating the smoothing estimate over new observation times with a free forecast in the subsequent cycle. The Lin-IEnKS is differentiated from the IEnKS by using only a single free ensemble forecast to produce the 4D optimization of the initial ensemble in each cycle.
3.4.2 Comparison with other schemes
Other well-known DA schemes combining a retrospective reanalysis and reinitialization of the ensemble forecast include the running-in-place (RIP) smoother of Kalnay and Yang (2010) and the one-step-ahead (OSA) smoother of Desbouvries et al. (2011) and Ait-El-Fquih and Hoteit (2022). The RIP smoother iterates over both the ensemble simulation and filter cost function, in order to apply a retrospective reanalysis to the first prior with a lag and shift of . The RIP smoother is designed to spin up the LETKF from a cold start of a forecast model and DA cycle (Yang et al., 2013). However, the RIP optimizes a different style cost function than the S/Lin-/IEnKS family of smoothers. The stopping criterion for RIP is formulated in terms of the mean square distance between the ensemble forecast and the observation, potentially leading to an overfitting of the observation. The OSA smoother is also proposed as an optimization of the DA cycle and integrates an EnKF framework, including for a two-stage, iterative optimization of dynamical forecast model parameters within the DA cycle (Gharamti et al., 2015; Ait-El-Fquih et al., 2016; Raboudi et al., 2018). The OSA smoother uses a single iteration and a lag and shift of , making a filter analysis of the incoming observation and a retrospective reanalysis of the prior. However, the OSA smoother differs from the SIEnKS in using an additional filter analysis while interpolating the joint posterior estimate over the DAW, accounting for model error in the simulation of . Without model error, the second filter analysis in the OSA smoother simulation is eliminated from the estimation scheme. Therefore, with an ETKF-style filter analysis, a perfect linear Gaussian model and a lag of , the SIEnKS, and RIP and OSA smoothers all coincide.
The rationale for the SIEnKS is to focus computational resources on optimizing the sequence of 3D filter cost functions for the DAW when the forecast error dynamics is weakly nonlinear, rather than computing the iterative ensemble simulations needed to optimize a 4D cost function. The SIEnKS generalizes some of the ideas used in these other DA schemes, particularly for perfect models with weakly nonlinear forecast error dynamics, including for (i) arbitrary lags and shifts , (ii) an iterative optimization of hyperparameters for the filter cost function, (iii) multiple data assimilation, and (iv) asynchronous observations in the DA cycle. In order to illustrate the novelty of the SIEnKS, and to motivate its computational cost/prediction accuracy tradeoff advantages, we discuss each of these topics in the following.
4.1 Nonlinear observation operators
Just as the IEnKS extends the linear 4D cost function, the filter cost function in Eq. (42) can be extended with Newton iterates in the presence of a nonlinear observation operator. The maximum likelihood ensemble filter (MLEF) of Zupanski (2005) and Zupanski et al. (2008) is an estimator designed to process nonlinear observation operators and can be derived in the common ETKF formalism. Particularly, the algorithm can be granted bundle and transform variants like the IEnKS (Asch et al., 2016; see Sect. 6.7.2.1), which are designed to approximate the directional derivative of the nonlinear observation operator with respect to the forecast ensemble perturbations at the forecast mean,
which is used in the nonlinear filter cost function gradient as follows:
When the forecast error dynamics is weakly nonlinear, the MLEF-style nonlinear filter cost function optimization provides a direct extension to the SIEnKS. The transform, as defined in the sub-routine in Algorithm A9, is interchangeable with the usual ensemble transform in Algorithm A1. In this way, the EnKS and the SIEnKS can each process nonlinear observation operators with an iterative optimization in the filter cost function alone and, subsequently, apply their retrospective analyses as usual. We refer to the EnKS analysis with MLEF transform as the maximum likelihood ensemble smoother (MLES), though we refer to the SIEnKS as usual, whether it uses a single iteration or multiple iterations of the solution to the filter cost function. Note that only the transform step needs to be interchanged in Algorithms A6 and A8, so we do not provide additional pseudo-code.
Consider that, for the MLES and the SIEnKS, the number of Hessian square root inverse calculations expands in the number of iterations used in Algorithm A9 to compute the transform for each of the S observations in the DAW. For each iteration of the IEnKS, this again requires only a single square root inverse calculation of the 4D cost function Hessian. However, even if the forecast error dynamics is weakly nonlinear, optimizing versus the nonlinear observation operator requires L ensemble simulations for each iteration used to optimize the cost function.
4.2 Adaptive inflation and the finite size formalism
Due to the bias of Kalman-like estimators in nonlinear dynamics, covariance inflation, as in Algorithm A4, is widely used to regularize these schemes. In particular, this can ameliorate the systematic underestimation of the prediction/posterior uncertainty due to sample error and bias. Empirically tuning the multiplicative inflation coefficient λ≥1 can be effective in stationary dynamics. However, empirically tuning this parameter can be costly, potentially requiring many model simulations, and the tuned value may not be optimal across timescales in which the dynamical system becomes non-stationary. A variety of techniques is used in practice for adaptive covariance estimation, inflation, or augmentation, accounting for these deficiencies of the Kalman-like estimators (Tandeo et al., 2020, and references therein).
One alternative to empirically tuning λ is to derive an adaptive multiplicative covariance inflation factor via a hierarchical Bayesian model by including a prior on the background mean and covariance , as in the finite size formalism of Bocquet (2011), Bocquet and Sakov (2012), and Bocquet et al. (2015). This formalism seeks to marginalize out over the first 2 moments of the background, yielding a Gaussian mixture model for the forecast prior as follows:
Using Jeffreys' hyperprior for and , the ensemble-based filter MAP cost function can be derived as proportional to the following:
where . Notice that Eq. (76) is non-quadratic in w, regardless of whether ℋ1 is linear or nonlinear, such that one can iteratively optimize the solution to the nonlinear filter cost function with a Gauss–Newton approximation of the descent. When accounting for the nonlinearity in the ensemble evolution and the sample error due to small ensemble sizes in perfect models, optimizing the extended cost function in Eq. (76) can be an effective means to regularize the EnKF. In the presence of significant model error, one may need to extend the finite size formalism to the variant developed by Raanes et al. (2019a).
Algorithm A10 presents an updated version of the finite size ensemble Kalman filter (EnKF-N) transform calculation of Bocquet et al. (2015), explicitly based on the IEnKS transform approximation of the gradient of the observation operator. The hyperprior for the background mean and covariance is similarly introduced to the IEnKS and optimized over an extended 4D cost function. Note that, in the case when ℋk≡Hk is linear, a dual, scalar optimization can be performed for the filter cost function with less numerical expense. However, there is no similar reduction to the extended 4D cost function, and in order to emphasize the structural difference between the 4D approach and the sequential approach, we focus on the transform variant analogous to the IEnKS optimization.
Extending the adaptive covariance inflation in the finite size formalism to either the EnKS or the SIEnKS is simple, requiring that the ensemble transform calculation is interchanged with Algorithm A10 and that the tuned multiplicative inflation step is eliminated. The finite size iterative ensemble Kalman smoother (IEnKS-N) transform variant, including adaptive inflation as above, is described in Algorithm A11. Notice that iteratively optimizing the inflation hyperparameter comes at the additional expense of square root inverse Hessian calculations for the EnKS and the SIEnKS, while the IEnKS also requires L additional ensemble simulations for each iteration.
4.3 Multiple data assimilation
When the lag L>1 is long, temporally interpolating the posterior estimate in the DAW via the nonlinear model solution, as in Eq. (71), becomes increasingly nonlinear. In chaotic dynamics, the small simulation errors introduced this way eventually degrade the posterior estimate, and this interpolation becomes unstable when L is taken to be sufficiently large. Furthermore, for the 4D cost function, observations only distantly connected with the initial condition at the beginning of the DAW render the cost function with more local minima that may strongly affect the performance of the optimization. Multiple data assimilation is a commonly used technique, based on statistical tempering (Neal, 1996), designed to relax the nonlinearity of performing the MAP estimate by artificially inflating the variances of the observation errors with weights and assimilating these observations multiple times. Multiple data assimilation is made consistent with the Bayesian posterior in perfect linear Gaussian models by appropriately choosing weights so that, over all times that an observation vector is assimilated, all of its associated weights sum to one (Emerick and Reynolds, 2013). Given Gaussian likelihood functions, this implies that the sum of the precision matrices over the multiple assimilation steps equals R−1, as with the usual Kalman filter update.
Multiple data assimilation is integrated into the EnRML for static DAWs in reservoir modeling (Evensen, 2018, and references therein). With the fixed-lag, sequential EnKS, there is no reason to perform MDA as the assimilation occurs in a single pass over each observation with the filter step as in the ETKF. Sequential MDA, with DAWs shifting in time, was first derived with the IEnKS by Bocquet and Sakov (2014). In order to sample the appropriate density, the IEnKS MDA estimation is broken over two stages. First, in the balancing stage, the IEnKS fully assimilates all partially assimilated observations, targeting the joint posterior statistics. Second, the window of the partially assimilated observations is shifted in time with the MDA stage. The SIEnKS is similarly broken over these two stages, using the same weights as the IEnKS above. However, there is an important difference in the way MDA is formulated for the SIEnKS versus the IEnKS. For the SIEnKS, each observation in the DAW is assimilated with the sequential 3D filter cost function instead of the global 4D analysis in the IEnKS. The sequential filter analysis constrains the posterior's interpolation estimate to the observations in the balancing stage, as observations are assimilated sequentially in the SIEnKS, whereas the posterior estimate is performed by interpolating with a free forecast from the marginal posterior estimate in the IEnKS. Our novel SIEnKS MDA scheme is derived as follows.
Recall our algorithmically stationary DAW, , and suppose, at the moment, that there is a shift of S=1 and an arbitrary lag L. We take the notation that the covariance matrices for the likelihood functions are inflated to be as follows:
where the observation weights are assumed . We index the weight for observation yk at the present time tL as βk|L. For consistency with the perfect linear Gaussian model, we require that
This implies that, as we assimilate an observation vector for L total times, shifting the algorithmically stationary DAW, the sum of the weights used to assimilate the observation equals one.
We denote
as the fraction of the observation yk that has been assimilated after the analysis step at the time tL. Note that, under the Gaussian likelihood assumption, and assuming the independence of the fractional observations, this implies that
Let and denote the length vectors as follows:
We then define the sequences,
as the observations yl:k in the current DAW , with Eq. (82a), the corresponding MDA weights for this DAW, and, with Eq. (82b), the total portion of each observation assimilated in the MDA conditional density for this DAW after the analysis step. Similar definitions apply with the indices but are relative to the previous DAW.
For the current DAW, the balancing stage is designed to sample the joint posterior density,
where the current cycle is initialized with a sample of the MDA conditional density,
That is, from the previous cycle, we have a marginal estimate for x0, given the sequence of observations , where the portion of observation yk that has been assimilated already is given by . Notice that so that y0 has already been fully assimilated. To fully assimilate y1, we note that , and therefore,
The above corresponds to a single simulation/analysis step in an EnKS cycle, where the observation is assimilated, and a retrospective reanalysis is applied to the ensemble at t0.
More generally, to fully assimilate observation yk, we assimilate the remaining portion left unassimilated from the last DAW and given as . We define an inductive step describing the density for xk:0, which has fully assimilated yk:0, though it has yet to assimilate the remaining portions of observations , as follows:
For , this describes a subsequent simulation/analysis step of an EnKS cycle but where the observation is assimilated and a retrospective analysis is applied to the ensemble at times . A subsequent EnKS analysis gives the following:
i.e., this samples the joint posterior for the last DAW. A final EnKS analysis is used to assimilate yL, for which no portion was already assimilated in the previous DAW, as follows:
We thus define an initial ensemble, distributed approximately as follows:
In the balancing stage, the observation error covariance weights are defined by the following:
where . When for all k, we obtain the balancing weights as for all . An EnKS cycle initialized as in Eq. (89), using the balancing weights in Eq. (90), will approximately, sequentially, and recursively sample
from the inductive relationship in Eq. (86), where the final analysis gives from Eq. (88).
To subsequently shift the DAW and initialize the next cycle, we target the density . Given , the target density is sampled by assimilating each observation , so that the portion of each observation assimilated becomes . Notice that, for ,
The above recursion corresponds to an EnKS step in which the observation is assimilated and a retrospective analysis is applied to ensembles at times . Subsequent EnKS analyses using the MDA weights then give the following:
We therefore perform a second EnKS cycle using the MDA observation error covariance weights βk|L to sample the target density. Given that , the first analysis of the balancing stage in Eq. (85) is identical to the first analysis in the MDA stage, corresponding to k=1 in Eq. (92). Therefore, this first EnKS analysis step can be reused between the two stages.
Define an initial ensemble for the MDA stage, reusing the first analysis in the balancing stage, as follows:
An EnKS cycle initialized as in Eq. (95), using the MDA weights βk, approximately, sequentially, and recursively samples
from the relationship in Eq. (92). The final analysis samples the density , as in Eq. (94), which is used to initialize the next cycle. To make the scheme more efficient, we note that we need only sample the marginal to reinitialize the next cycle of the algorithm. This means that the smoother loop of the EnKS in the second stage needs to only store and sequentially condition the ensemble with the retrospective filter analyses in this stage. Combining the two stages together into a single cycle that produces forecast, filter, and smoother statistics over the DAW , as well as the ensemble initialization for the next cycle, requires 2L ensemble simulations. Due to the convoluted nature of the indexing over multiple DAWs above, a schematic of the two stages of the SIEnKS MDA cycle is presented in Fig. 5.
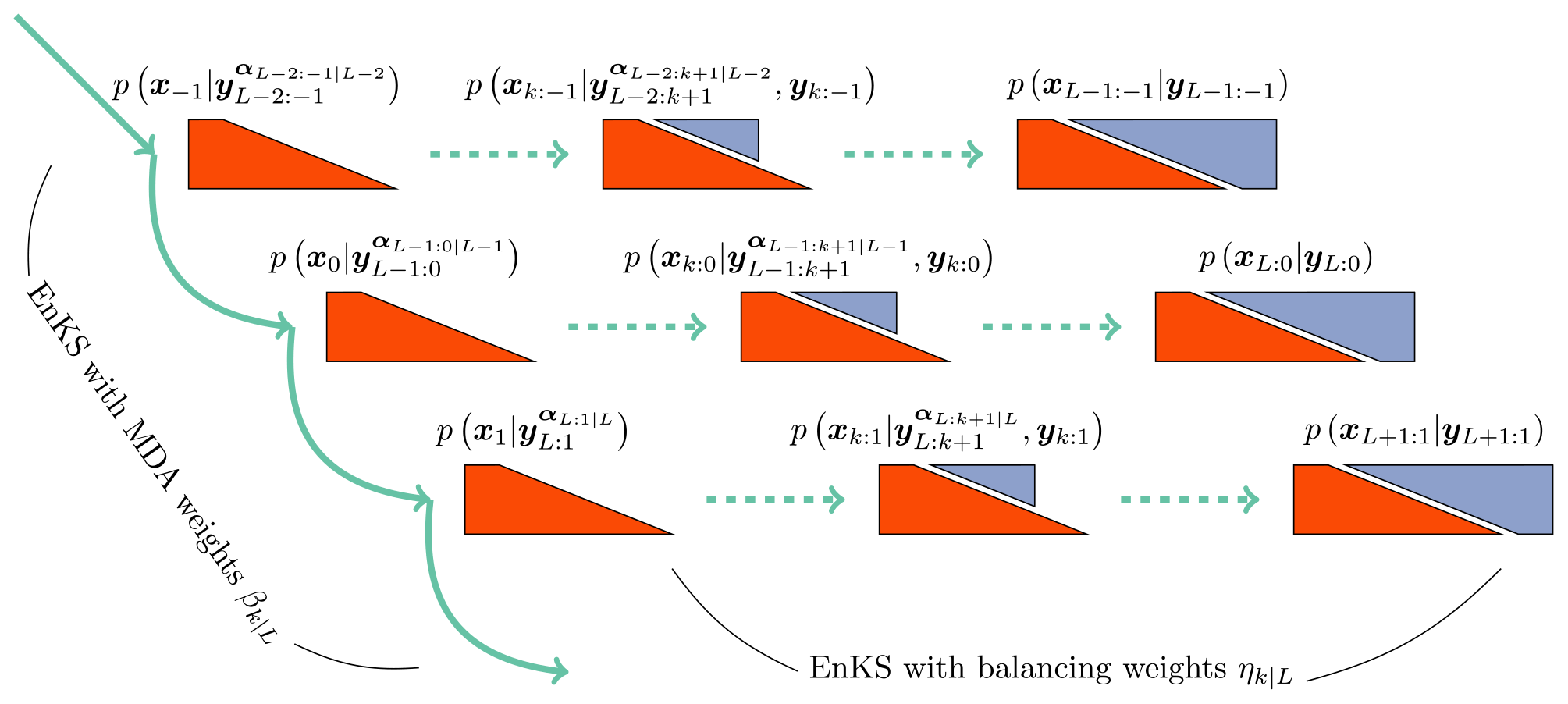
Figure 5A schematic of the two stages of the SIEnKS MDA cycle. The DAW of the SIEnKS moves forward in time, from top to bottom, where the EnKS stage using MDA weights pushes the MDA conditional density, on the far left, forward in time. The middle layer represents the indexing of the stationary DAW, while the top layer represents a DAW one cycle back in time, and the bottom layer represents a DAW one cycle forward in time. The balancing density is sampled sequentially and recursively with an EnKS stage, using the balancing weights and moving from left to right in each cycle. For the current DAW, the middle balancing density has fully assimilated observations yk:0 and has partially assimilated observations . The EnKS stage with balancing weights completes when sampling the joint posterior, and the EnKS stage with MDA weights begins again.
The MDA algorithm is generalized to shift windows of S>1 with the number of ensemble forecasts remaining invariant at 2L when using blocks of uniform MDA weights in the DAW. Assume that L=SQ for some positive integer Q, so that we partition yL:1 into Q total blocks of observations each of length S. In this case, the perfect linear Gaussian model consistency constraint is revised as follows:
where the above brackets represent rounding up to the nearest integer. This ensures, again, that the weights corresponding to the Q total times to which yk is assimilated sum to one. With this weighting scheme, the equivalence between the balancing and MDA stages' first EnKS filter analysis extends to the first S total EnKS filter analyses, and therefore, initializes the MDA stage. Memory usage is further reduced by only performing the retrospective conditioning in the balancing stage on the states . This samples the density in the final cycle before the estimates for these states are discarded from all subsequent DAWs. MDA variants of the SIEnKS and the (Lin-)IEnKS are presented in Algorithms A12 and A13.
The primary difference between the SIEnKS and IEnKS MDA schemes lies in the 3D filter balancing analysis versus the global 4D balancing analysis. The IEnKS MDA scheme is not always robust in its 4D balancing estimation because the MDA conditional prior estimate that initializes the scheme may lie far away from the solution for the balanced, joint posterior. As a consequence, the optimization may require many iterations of the balancing stage. On the other hand, the sequential SIEnKS MDA approach uses the partially unassimilated observations in the DAW directly as a boundary condition to the interpolation of the joint posterior estimate over the DAW with the sequential EnKS filter cycle. For long DAWs, this means that the SIEnKS controls error growth in the ensemble simulation that accumulates over the long free forecast in the 4D analysis of the IEnKS.
Note how the cost of assimilation scales differently between the SIEnKS and the IEnKS when performing MDA. Both the IEnKS and the SIEnKS use the same weights ηk|L and βk|L for their balancing and MDA stages. However, each stage of the IEnKS separately performs an iterative optimization of the 4D cost function. While each iteration therein requires only a single square root inverse calculation of the cost function Hessian, the iterative solution requires at least 2L total ensemble simulations in order to optimize and interpolate the estimates over the DAW. An efficient version of the scheme can be performed as such by using the same free ensemble simulation initialized, as in Eq. (89), in order to assimilate each of the observation sequences and . However, the IEnKS additionally requires S total ensemble simulations in order to shift the DAW thereafter. This differs from the SIEnKS, which requires fixed 2L ensemble simulations over the DAW. However, the computational barrier to the SIEnKS MDA scheme lies in the fact that it requires 2L−S square root inverse calculations, corresponding to each unique filter cost function solution over the two stages; in the case that MDA is combined with, e.g., the ensemble transform in the MLEF, this further grows to the sum of the number of iterations , where ij iterations are used in the jth optimization of a filter cost function. However, when the cost of an ensemble simulation is sufficiently greater than the cost of the square root inverse in the ensemble dimension, the SIEnKS MDA scheme can substantially reduce the leading-order computational cost of the ensemble variational smoothing with MDA, especially when S>1.
4.4 Asynchronous data assimilation
In real-time prediction, fixed-lag smoothers with shifts in S>1 are computationally more efficient in terms of reducing the number of smoother cycles necessary to traverse a time series of observations with sequential DAWs – versus a shift of one, the number of cycles necessary is reduced by the factor of S. A barrier to using the SIEnKS with S>1 lies in the fact that the sequential filter analysis of the EnKS does not in and of itself provide a means to asynchronously assimilate observations. However, the SIEnKS differs from the EnKS in numerically simulating lagged states in the DAW. When one interpolates the posterior estimate with the dynamical model over lagged states, one can easily revise the algorithm to assimilate any newly available data corresponding to a time within the past simulation window, though the weights in MDA need to be adjusted accordingly. There are many ways in which one may even design methods of excluding observations and reintroducing them in a later DAW with a shift S>1. In the current work, the SIEnKS assimilates all observations synchronously, even with S>1. A systematic investigation of algorithms that would optimize this asynchronous assimilation in single-iteration smoothers goes beyond the scope of the current work. However, this key difference between the EnKS and the SIEnKS will be considered later.
5.1 Algorithm cost analysis
Fix the ensemble size Ne in the following, and let us suppose that the cost of the nonlinear ensemble simulation is fixed in Δt, equal to Cℳ floating-point operations (flops). In order to compute the ensemble transform in any of the methods, we assume that the inversion of the approximate Hessian , and its square root, is performed with an SVD-based approach with the cost of the order of flops. This assures stability and efficiency in the sense that the computation of all of , and combined is dominated by the cost of the SVD of the symmetric, which is Ne×Ne matrix . If a method is iterative, we denote the number of iterations used in the scheme with ij, where the sub-index j distinguishes distinct iterative optimizations.
A summary of how each of the S/I/EnKS scale in their numerical cost is presented in Tables 1 and 2. This analysis is easily derived based on the pseudo-code in Appendix A and with the discussions in Sect. 4. Table 1 presents schemes that are used in the SDA configuration, while Table 2 presents schemes that are used in the MDA configurations. Note that, while adaptive inflation in the finite size formalism can be used heuristically to estimate a power of the joint posterior, this has not been found to be fully compatible with MDA (Bocquet and Sakov, 2014), and this combination of techniques is not considered here.
Table 1Order of the SDA cycle flops for lag=L, shift=S, tuned inflation (TI), or adaptive inflation (AI)/nonlinear observation operator (NO).
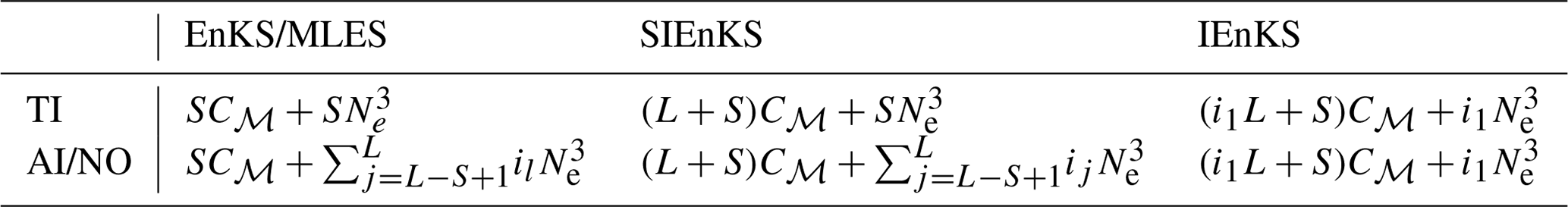
For realistic geophysical models, note that the maximal ensemble size Ne is typically of the order of 𝒪(102), while the state dimension Nx can be of the order of 𝒪(109) (Carrassi et al., 2018); therefore, the cost of all algorithms is reduced to terms of at leading-order in target applications. It is easy to see then that the EnKS/MLES has a cost that is of the order of the regular ETKF/MLEF filter cycle, representing the least expensive of the estimation schemes. Consider now, in row one of Table 1, that the i1 in the IEnKS represents the number of iterations utilized to minimize the 4D cost function. If we set i1=1, then this represents the cost of the Lin-IEnKS. Particularly, we see that, for S=1 and a linear filter cost function, the Lin-IEnKS has the same cost as the SIEnKS. However, even in the case of a linear filter cost function, when S>1, then the SIEnKS is more expensive than the Lin-IEnKS. Setting i1 in Table 1 to terminate with a maximum possible value the cost of the IEnKS is bounded at the leading order; yet, we demonstrate shortly how the number of iterations tends to be small in stable filter regimes.
Consider the case when the filter cost function is nonlinear, as when adaptive inflation is used (as defined in Sect. 4.2), or when there is a nonlinear observation operator. Row two of Table 1 shows how the cost of these estimators is differentiated when nonlinearity is introduced – particularly, the cost of the MLES and the SIEnKS requires one SVD calculation for each iteration used to process each new observation. This renders the SIEnKS notably more expensive than the Lin-IEnKS, which uses a single Hessian SVD calculation to process all observations globally. However, for target applications, such as synoptic-scale meteorology, the additional expense of iteratively optimizing filter cost functions with the SIEnKS versus the single iteration of the Lin-IEnKS in the 4D cost function is insignificant.
Table 2 describes the cost of the SIEnKS and the IEnKS using MDA when there is a linear observation operator and when there is a nonlinear observation operator. Recall that, at leading-order Cℳ, the cost of the SIEnKS is invariant in S. This again comes with the caveat that observations are assumed to be assimilated synchronously in this work, while the IEnKS assimilates observations asynchronously by default. Nonetheless, the equivalence between the first S-filter cycles in the balancing stage and the MDA stage in the SIEnKS allows the scheme to fix the leading-order cost at the expense of two passes over the DAW with the ensemble simulation.
Table 2Order of the MDA cycle flops for lag , shift =S, tuned inflation, linear observation operator (LO), or nonlinear observation operator (NO).
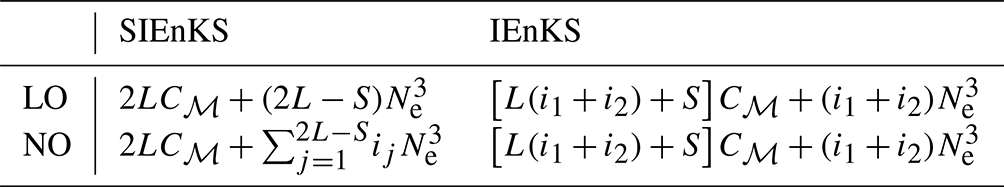
5.2 Data assimilation benchmark configurations
To demonstrate the performance advantages and limitations of the SIEnKS, we produce statistics of its forecast/filter/smoother root mean square error (RMSE) versus the EnKS/Lin-IEnKS/IEnKS in a variety of DA benchmark configurations. Synthetic data are generated in a twin experiment setting, with a simulated truth twin generating the observation process. Define the truth twin realization at time tk as ; we define the ensemble RMSE as follows:
where i refers to an ensemble label , j refers to the state dimension index , and k refers to time tk as usual.
A common diagnostic for the accuracy of the linear Gaussian approximation in the DA cycle is verifying that the ensemble RMSE has approximately the same order as the ensemble spread (Whitaker and Loughe, 1998), which is known as the spread–skill relationship; overdispersion and underdispersion of the ensemble both indicate the inadequacy of the approximation. Define the ensemble spread as follows:
where i again refers to an ensemble matrix label, j in this case refers to the ensemble matrix column index, and k again refers to time. The spread is then given by the square root of the mean square deviation of the ensemble from its mean. Performance of these estimators will be assessed in terms of having low RMSE scores with the spread close to the value of the RMSE. Estimators are said to be divergent when either the filter or smoother RMSE is greater than the standard deviation of the observation errors, indicating that initializing a forecast with noisy observations is preferable to the posterior estimate. The perfect hidden Markov model in this study is defined by the single-layer form of the Lorenz 96 equations (Lorenz, 1996). The state dimension is fixed at Nx=40, with the components of the vector x given by the variables xj with periodic boundary conditions, x0=x40, , and x41=x1. The time derivatives , also known as the model tendencies, are given for each state component by the following:
Each state variable heuristically represents the atmospheric temperature at one of the 40 longitudinal sectors discretizing a latitudinal circle of the Earth. The Lorenz 96 equations are not a physics-based model, but they mimic the fundamental features of geophysical fluid dynamics, including conservative convection, external forcing, and linear dissipation of energy (Lorenz and Emanuel, 1998). The term F is the forcing parameter that injects energy into the model, and the quadratic terms correspond to energy-preserving convection, while the linear term −xj corresponds to dissipation. With F≥8, the system exhibits chaotic, dissipative dynamics; we fix F=8 in the following simulations, with the corresponding number of unstable and neutral Lyapunov exponents being equal to N0=14.
For a fixed Δt, the dynamical model ℳk is defined by the flow map generated by the dynamical system in Eq. (100). Both the truth twin simulation, generating the observation process, and ensemble simulation, used to sample the appropriate conditional density, are performed with a standard four-stage Runge–Kutta scheme with the step size h=0.01. This high-precision simulation is used for generating a ground truth for these methods, validating the Julia package DataAssimilationBenchmarks.jl (Grudzien et al., 2021) and testing its scalability; however, in general, h=0.05 should be of sufficient accuracy and is recommended for future use. The nonlinearity of the forecast error evolution is controlled by the length of the forecast window, Δt. A forecast length Δt=0.05 corresponds to a 6 h atmospheric forecast, while for Δt>0.05, the level of nonlinearity in the ensemble simulation can be considered to be greater than that which is typical of synoptic-scale meteorology.
Localization, hybridization, and other standard forms of ensemble-based gain augmentation are not considered in this work for the sake of simplicity. Therefore, in order to control the growth of forecast errors under weakly nonlinear evolution, the rank of the ensemble-based gain must be equal to or greater than the number of unstable and neutral Lyapunov exponents N0=14, corresponding to Ne≥15 (see Grudzien et al., 2018, and references therein). In the following experiments, we range the ensemble size as , from the minimal rank needed without gain augmentation to a full-rank ensemble-based gain. When the number of experimental parameters expands, we restrict to the case where Ne=21 for an ensemble-based gain of actual rank 20, making a reduced-rank approximation of the covariance in analogy to DA in geophysical models.
Observations are full dimensional, such that , and observation errors are distributed according to the Gaussian density , i.e., with mean zero, uncorrelated across state indices and with homogeneous variances equal to one. When the observation map is linear, it is defined as ; when the observation map is taken to be nonlinear, define the following:
where ∘ above refers to the Schur product. This observation operator is drawn from Sect. 6.7.2.2 of Asch et al. (2016), where the parameter γ controls the nonlinearity of the map. In particular, for γ=1, this corresponds to the linear observation operator Hk, while γ>1 increases the nonlinearity of the map. When we vary the nonlinearity of the observation operator, we take corresponding to 10 different nonlinear settings and the linear setting for reference.
When tuned inflation is used to regularize the smoothers, as in Algorithm A4, we take a discretization range of , corresponding to the usual Kalman update with λ=1.0 and to up to 10 % inflation of the empirical variances with λ=1.1. Using tuned inflation, estimator performance is selected for the minimum average forecast RMSE over the experiment for all choices of λ, unless this is explicitly stated otherwise. When adaptive inflation is used, no additional tuned inflation is utilized. Simulations using the finite size formalism will be denoted with -N, following the convention of the EnKF-N. Multiple data assimilation will always be performed with uniform weights as for all estimators.
For the IEnKS, we limit the maximum number of iterations per stage at ij=10 for . Therefore the IEnKS can take a maximum of iterations in the MDA configuration to complete a cycle. Iteratively optimizing the filter cost function in the MLES(-N)/SIEnKS(-N), the maximum number of iterations is capped at ij=40 per analysis. The tolerance for the stopping condition in the filter cost functions is set to 10−4, while the tolerance for the 4D estimates is set to 10−3. However, the scores of the algorithms are, to a large extent, insensitive to these particular hyperparameters.
In order to capture the asymptotically stationary statistics of the filter/forecast/smoother processes, we take a long time-average of the RMSE and spread over the time indices k. The long experiment average ensures that, for an ergodic dynamical system, we average over the spatial variation in the attractor, and we account for variations in the observation noise realizations that may affect the estimator performance. So that the truth twin simulates observations on the attractor, it is simulated for an initial spinup of 5×103 analysis times before observations are given. Let the time be given as t0 after this initial spinup. Observations are generated identically for all estimators using the same Gaussian error realizations at a given time to perturb the observation map of the truth twin. At time t0, the ensemble is initialized identically for all estimators (depending on the ensemble size) with the same iid sample drawn from the multivariate Gaussian with mean at the truth twin and covariance equal to the identity . All estimation schemes are subsequently run over observation times indexed as . As the initial warmup of the estimators' statistics from this cold start tends to differ from the asymptotically stationary statistics, we discard the forecast/filter/smoother RMSE and spread corresponding to the observations times , taking the time average of these statistics for the remaining 2×104 analysis time indices. Particularly, this configuration is sufficient to represent estimator divergence which may have a delayed onset.
Forecast statistics are computed for each estimator whenever the ensemble simulates a time index tk for the first time, before yk has been assimilated into the estimate. Filter statistics are computed in the first analysis at which the observation yk is assimilated into the simulation. For the (Lin-)IEnKS, with S>1, this filter estimate includes the information from all observations when making a filter estimate for the state at . Smoother statistics are computed for the time indices in each cycle, corresponding to the final analysis for these states before they are discarded from subsequent DAWs. Empty white blocks in heat plots correspond to Inf (non-finite) values in the simulation data. Missing data occur due to numerical overflow when attempting to invert a close-to-singular cost function Hessian , which is a consequence of the collapse of the ensemble spread. When an estimator suffers this catastrophic filter divergence, the experiment output is replaced with Inf values to indicate the failure. Other benchmarks for the EnKS/Lin-IEnKS/IEnKS in the Lorenz 96 model above can be found in, e.g., Bocquet and Sakov (2014), Asch et al. (2016), and Raanes et al. (2018), which are corroborated here with similar but slightly different configurations.
5.3 Weakly nonlinear forecast error dynamics – linear observations
We fix Δt=0.05 in this section, set S=1, and use the linear observation operator in order to demonstrate the baseline performance of the estimators in a simple setting. On the other hand, we vary the lag length, the ensemble size, and the use of tuned/adaptive inflation or MDA. The lag in this section is varied on a discretization of . As a first reference simulation, consider the simple case where all schemes use tuned covariance inflation, so that the SIEnKS and the Lin-IEnKS here are formally equivalent. Likewise, with S=1, there is no distinction between asynchronous or synchronous DA. Figure 6 makes a heat plot of the forecast/filter/smoother RMSE and spread as the lag length L is varied along with the ensemble size Ne.
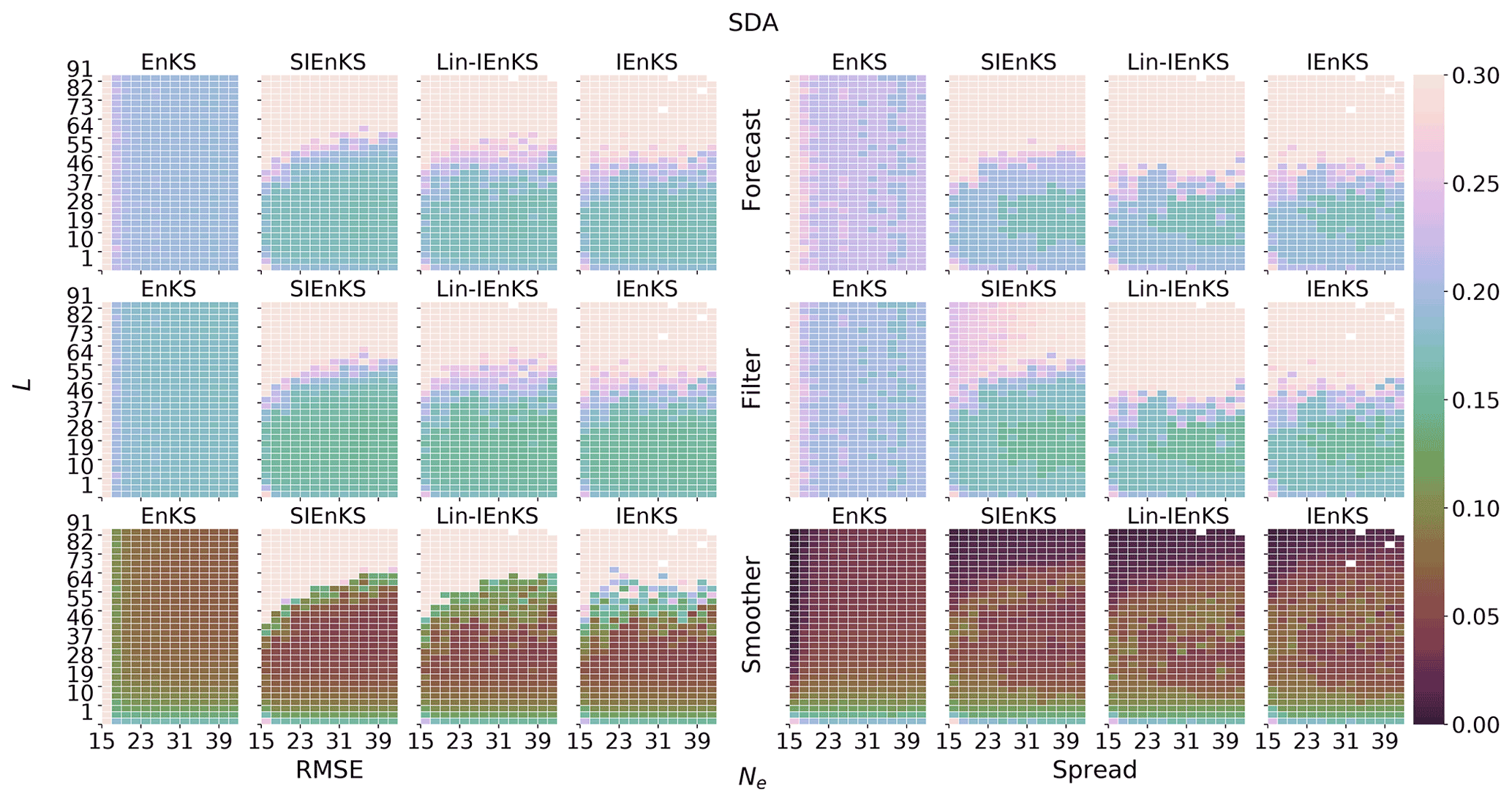
Figure 6The lag length L is shown on the vertical axis, and the ensemble size Ne is shown on the horizontal axis. SDA, tuned inflation, shift S=1, linear observations, and Δt=0.05 are also indicated.
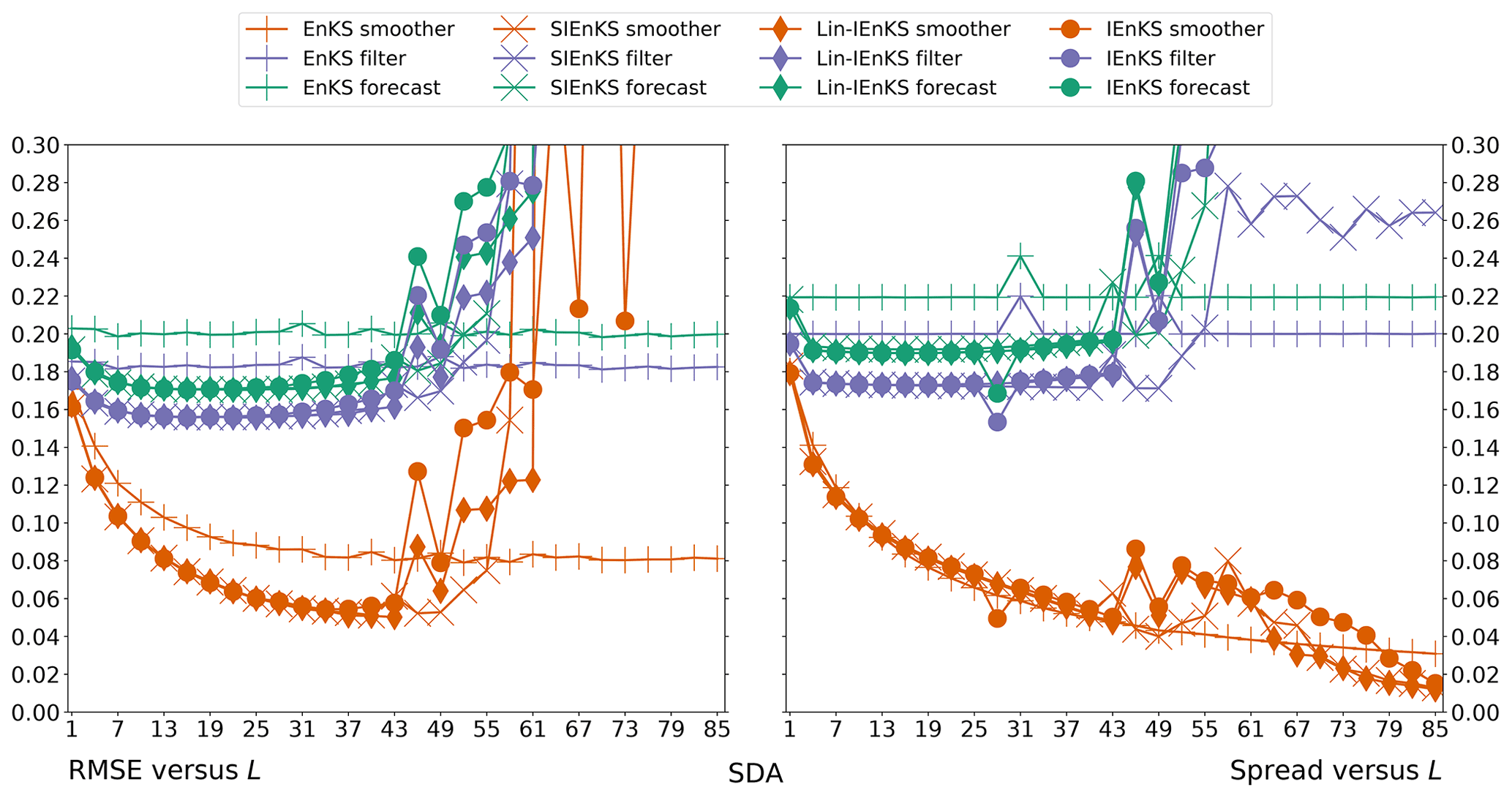
It is easy to see the difference in the performance between the EnKS and the iterative S/Lin-/IEnKS schemes. Particularly, the forecast and filter RMSE does not change with respect to the lag length in the EnKS, as these statistics are generated independently of the lag with a standard ETKF filter cycle. However, the smoother performance of the EnKS does improve with longer lags, without sacrificing stability over a long lag as in the iterative schemes. In particular, all of the iterative schemes use the dynamical model to interpolate the posterior estimate over the DAW. For sufficiently large L, this becomes unstable due to the small simulation errors that are amplified by the chaotic dynamics. The scale of the color map is capped at 0.30, as a more accurate forecast/filter performance can be attained in this setting with the ETKF alone, as demonstrated by the EnKS.
On the other hand, the iterative estimate of the posterior, as in the S/Lin-/IEnKS in this weakly nonlinear setting, shows a dramatic improvement in the predictive and analysis accuracy for a tuned lag length. Unlike the standard ETKF observation/analysis/forecast cycle, these iterative smoothers are able to control the error growth in the neutral Lyapunov subspace corresponding to the N0=14th Lyapunov exponent. With the ensemble size Ne=15 corresponding to a rank 14 ensemble-based gain, the iterative smoothers maintain stable prediction and posterior estimates over a wide range of lags while the EnKS diverges for all lag settings. We notice that the stability regions of the S/Lin-/IEnKS are otherwise largely the same in this simple benchmark configuration, though the IEnKS has a slightly longer stability over long lags with low sample sizes.
In order to illustrate the difference in accuracy between the iterative schemes and the non-iterative EnKS, Fig. 7 plots a cross section of Fig. 6 for Ne=21. The iterative schemes have almost identical performance until approximately a lag of L≈37, at which point all schemes become increasingly unstable. The differences shown between the iterative schemes here are insignificant and may vary between different implementations of these algorithms or pseudo-random seeds. We note that all estimators are also slightly overdispersive due to selecting a tuned inflation value based on the minimum forecast RMSE rather than balancing the RMSE and spread simultaneously. Nonetheless, we clearly demonstrate how all iterative estimators reduce the prediction and analysis error over the noniterative EnKS approach. Tuning the lag L, the forecast error for the iterative schemes is actually lower than the filter error in the EnKS.

Figure 8The lag length L is shown on the vertical axis, and the ensemble size Ne is shown on the horizontal axis. SDA, adaptive inflation, shift S=1, linear observations, and Δt=0.05 are also indicated.
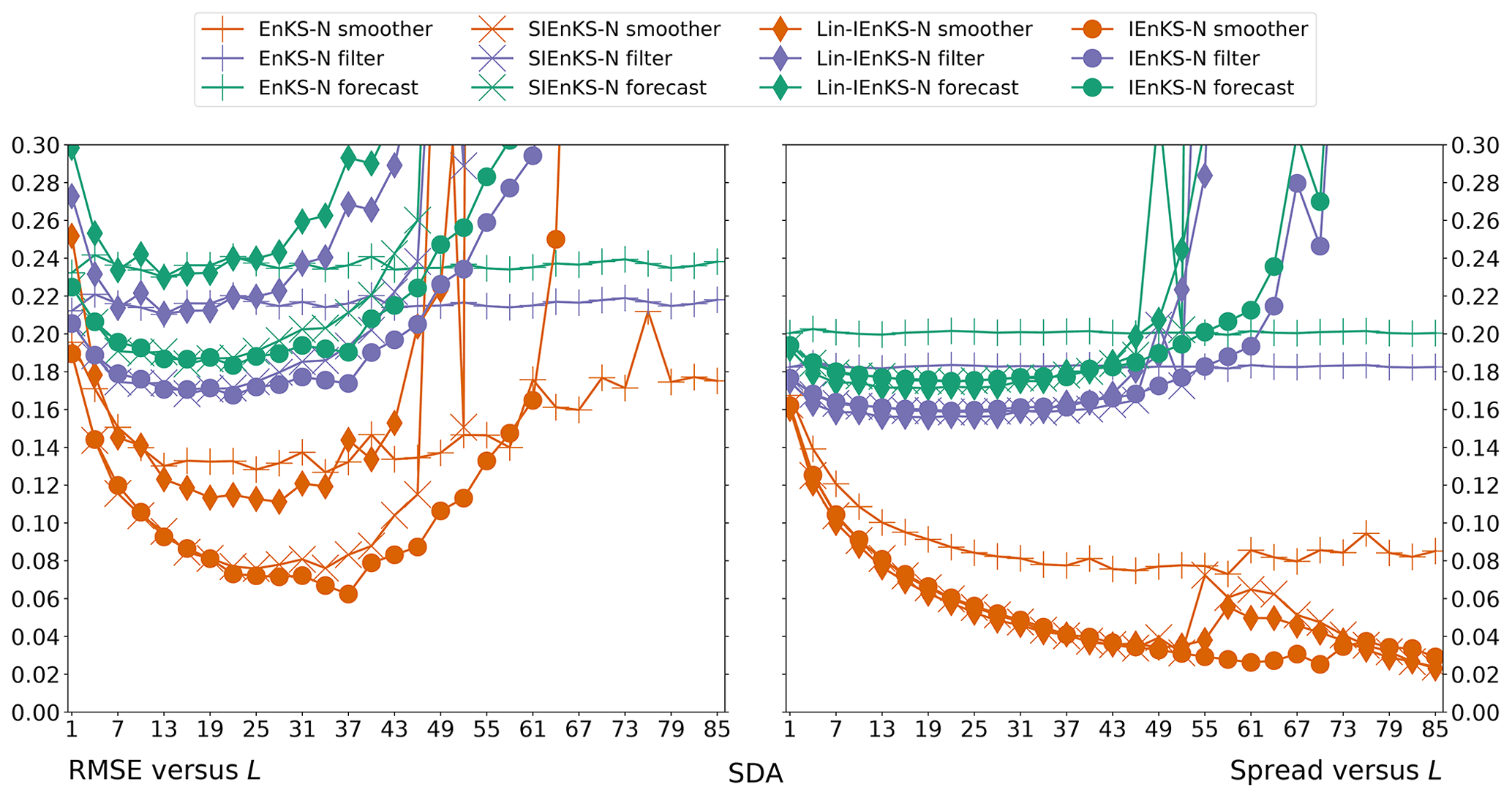
Consider the case where the filter cost function is nonlinear due to the adaptive inflation scheme. Figure 8 makes the same heat plot as in Fig. 6 but where the finite size formalism is used instead of tuned inflation. All schemes tend to have slightly weaker performance in this setting, except for the IEnKS-N in the low-ensemble-size regime. The design of the adaptive inflation scheme is to account for sample error due to the low ensemble size and nonlinearity in the forecast error dynamics, which is typical of mid-range forecasts. The efficacy of the design is illustrated, as the scheme is most effective when the low ensemble size and nonlinear forecast error dynamics conditions are present. Note that the Lin-IEnKS-N uses a single iteration of the extended 4D cost function, optimizing both the weights for the initial condition and the hyperparameter simultaneously. On the other hand, while the SIEnKS-N makes a single iteration of the ensemble simulation over the DAW, it iteratively optimizes the adaptive inflation hyperparameter in the filter cost function. This allows the SIEnKS-N to make substantial improvements over the Lin-IEnKS-N in terms of the stability region while remaining at the same leading-order cost.
Figure 9 plots a cross section of Fig. 8 at Ne=21 in order to further demonstrate the improved accuracy of the forecast/filter/smoother statistics of the SIEnKS-N versus the Lin-IEnKS-N. For a tuned lag L, the Lin-IEnKS-N fails to achieve distinctly better forecast and filter accuracy than the EnKS-N. While the smoother RMSE for the Lin-IEnKS-N does make an improvement over the EnKS-N, this improvement is not comparable to the smoother accuracy of the SIEnKS-N, which has the same leading-order cost. The performance of the SIEnKS-N is almost indistinguishable from the 4D IEnKS-N up to a lag of L≈25. At this point, the stability of the SIEnKS-N begins to suffer, while, on the other hand, the IEnKS-N is able to improve smoother RMSE for slightly longer lags. Nonetheless, both the SIEnKS-N and the IEnKS-N become increasingly underdispersive for lags L≥25, demonstrating the systematic underestimation of the estimator's uncertainty that leads to divergence for sufficiently large L.
We now demonstrate how MDA relaxes the nonlinearity of the MAP estimation and the interpolation of the posterior estimate over the DAW. Recall that MDA is handled differently in the SIEnKS from the 4D schemes because the 4D approach interpolates the DAW with the balancing estimate from a free forecast, while the SIEnKS interpolates the posterior estimate via a sequence of filter analyses steps using the balancing weights. Recall that, for target applications, the SIEnKS is the least expensive MDA estimator, requiring only 2L ensemble simulations in this configuration, while the (Lin-)IEnKS uses at least 2L+1. Figure 10 presents the same experiment configuration as in Figs. 6 and 8 but where MDA is used with tuned inflation. The EnKS does not use MDA, but the results from Fig. 6 are presented here for reference.
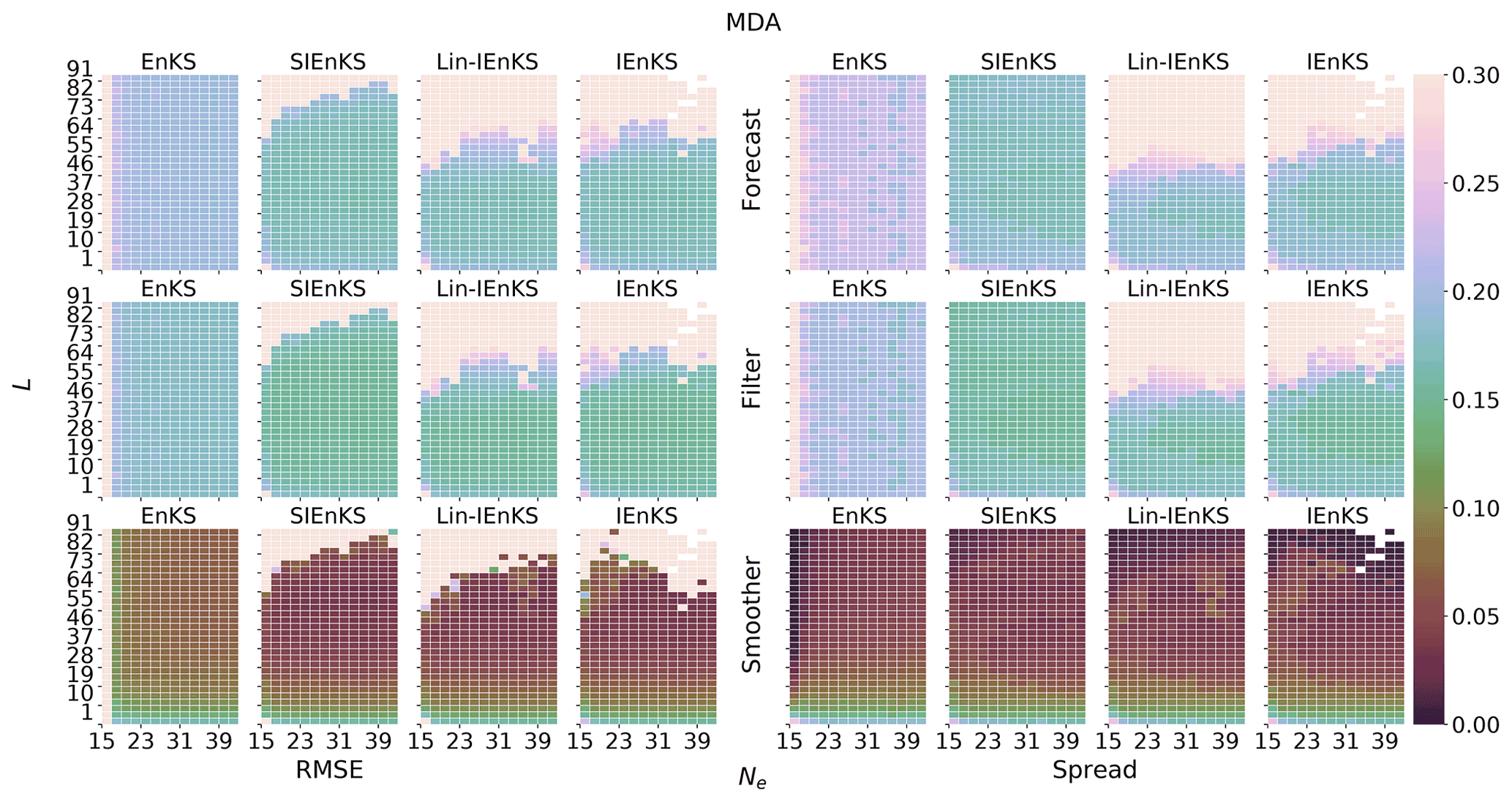
Figure 10The lag length L is shown on the vertical axis, and the ensemble size Ne is shown on the horizontal axis. MDA, tuned inflation, shift S=1, linear observations, and Δt=0.05 are indicated. The EnKS SDA results are presented here for reference.

It is easy to see that MDA improves all of the iterative smoothing schemes in Fig. 10, with greatly expanded stability regions from Fig. 6. Moreover, a key new pattern emerges that differentiates the traditional 4D MDA approach and the new MDA scheme in the SIEnKS. In particular, while the stability regions for the SIEnKS/(Lin-)IEnKS are similar for their smoother statistics in this configuration, the forecast/filter statistics are strongly differentiated. Unlike the free forecast solution used to interpolate the posterior estimate over the DAW in the 4D approach, the filter step within the SIEnKS MDA controls the simulation errors that accumulate when L is large.
In order to examine the effect more precisely, consider the cross section of Fig. 10 for Ne=21 presented in Fig. 11. Notice that all iterative MDA estimators have almost indistinguishable performance until lag L≈31. From this point, although the smoother accuracy increases with longer lags for the (Lin-)IEnKS, this comes at a sacrifice in the forecast/filter accuracy. Particularly, for lags L≥31, the forecast/filter accuracy of the (Lin-)IEnKS begins to degrade; at a lag of L≈61, the IEnKS performs worse than the EnKS, while the Lin-IEnKS has diverged. This is in stark contrast to the SIEnKS because not only does the forecast/filter accuracy remain stable for lags L≥40, but each of these also improve along with the smoother accuracy until a lag L≈61. Furthermore, the spread of the SIEnKS indicates that the SIEnKS MDA and perfect linear Gaussian approximation is well satisfied, with the ensemble dispersion very close to the RMSE within the stability region.
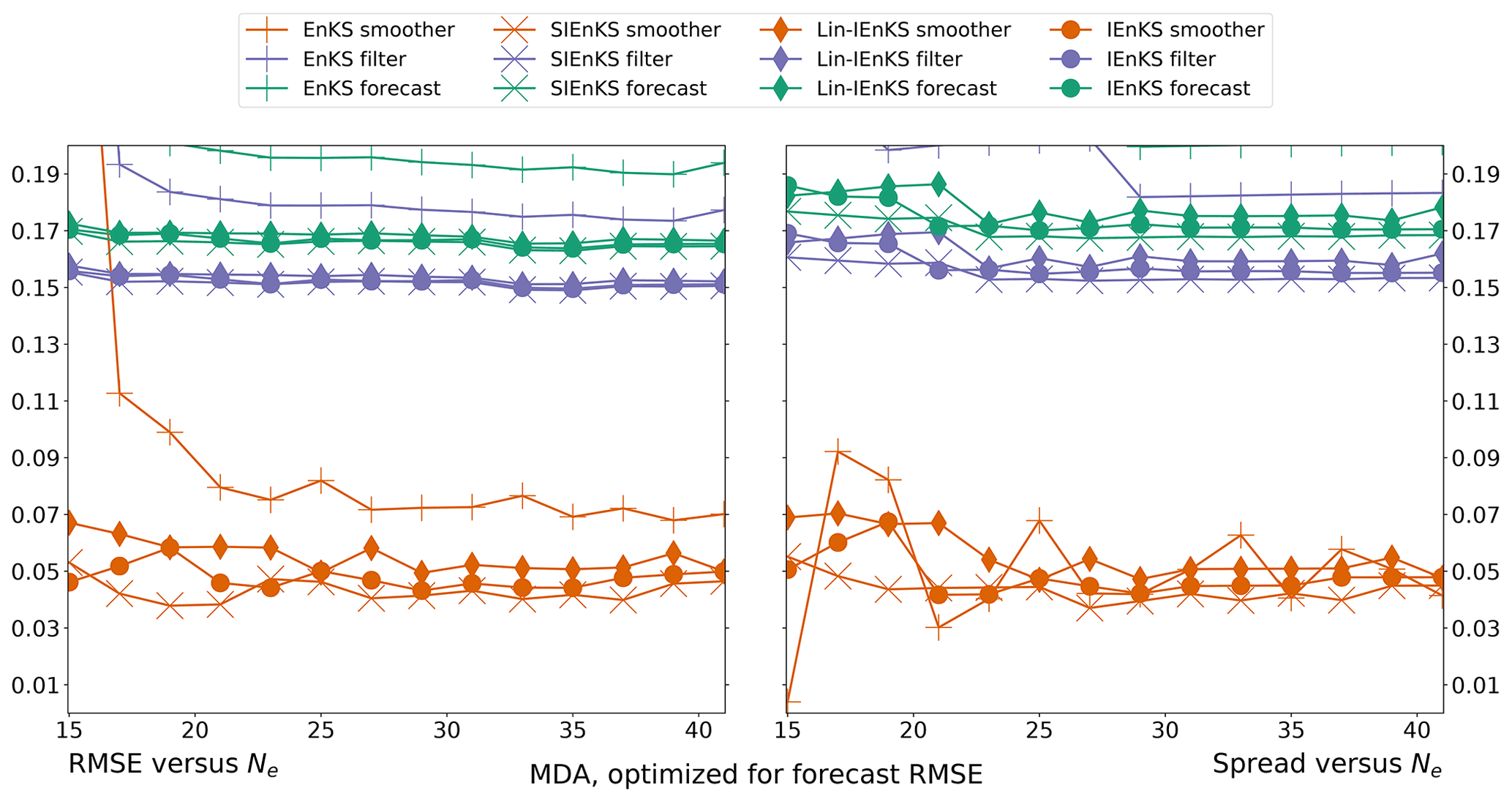
Figure 12MDA configuration. RMSE and spread versus the ensemble size Ne. Lag and inflation are optimized for a minimum forecast RMSE in Fig. 10.
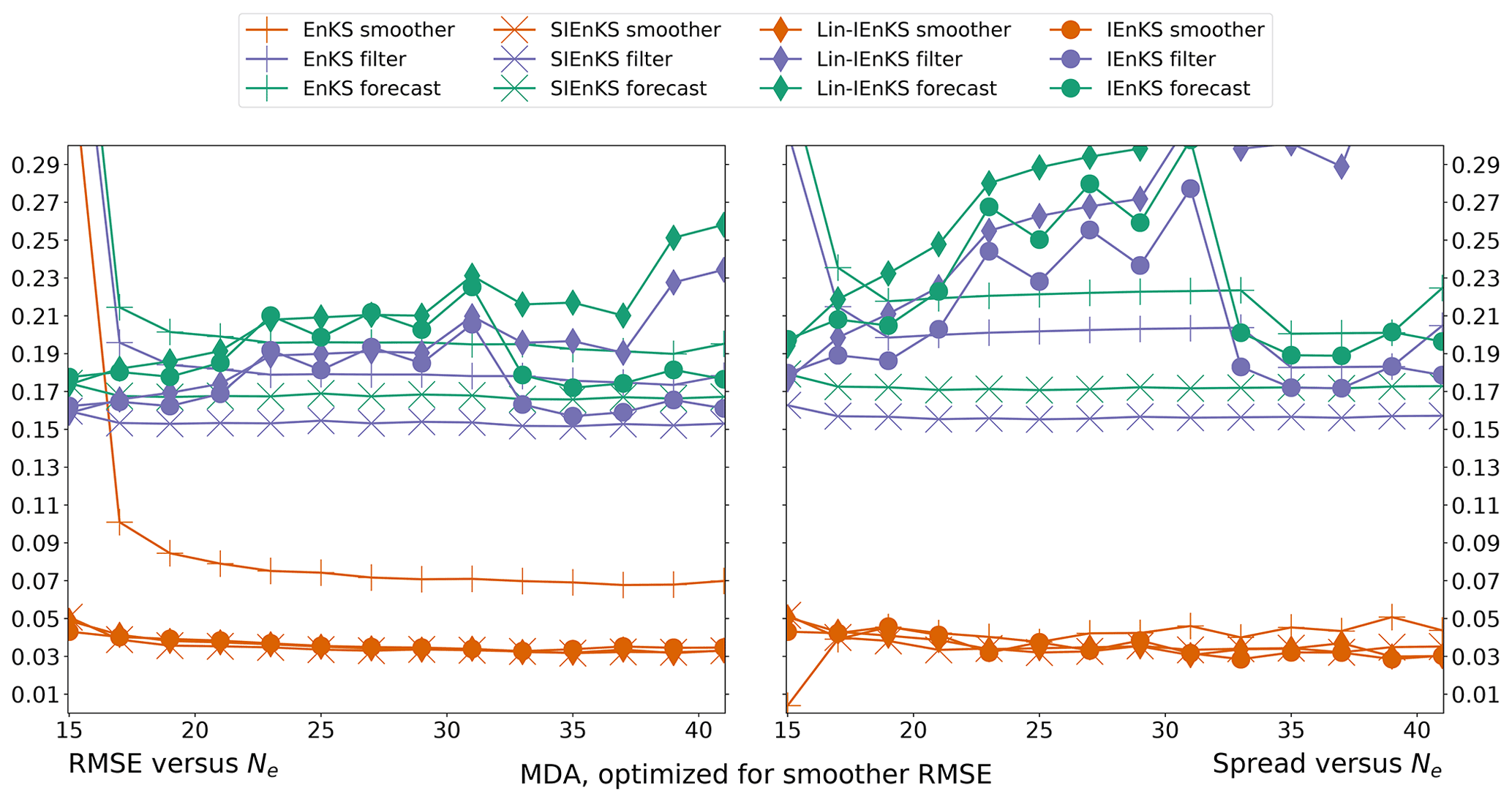
Figure 13MDA configuration. RMSE and spread versus the ensemble size Ne. Lag and inflation are optimized for a minimum forecast RMSE in Fig. 10.
The SIEnKS thus highlights a performance tradeoff of the 4D MDA schemes that it does not suffer from itself. In particular, suppose that the lag L in Fig. 10 is selected in order to optimize each estimator's accuracy, in terms of RMSE, for each fixed ensemble size Ne. One can optimize the lag L using the forecast RMSE or the smoother RMSE as the criterion. However, Fig. 11 indicates that L may be quite different for the forecast accuracy versus the smoother accuracy in the 4D schemes. Figures 12 and 13 demonstrate this tradeoff precisely, where the former plots the RMSE and spread, with lag and inflation simultaneously optimized for forecast accuracy, and the latter is optimized for smoother accuracy.
Tuning for optimum forecast RMSE, as in Fig. 12, the performance of the SIEnKS/(Lin-)IEnKS for any fixed Ne is indistinguishable with respect to this metric. On the other hand, the SIEnKS strongly outperforms the Lin-IEnKS and even exhibits a slightly better overall stability and accuracy than the IEnKS across the range of ensemble sizes. The difference in performance is more pronounced when tuning for the minimal smoother RMSE in Fig. 13. Again, the three estimators are indistinguishable in their smoother estimates, but the SIEnKS forms high-precision smoother estimates without sacrificing its predictive accuracy while interpolating the solution over long lags.
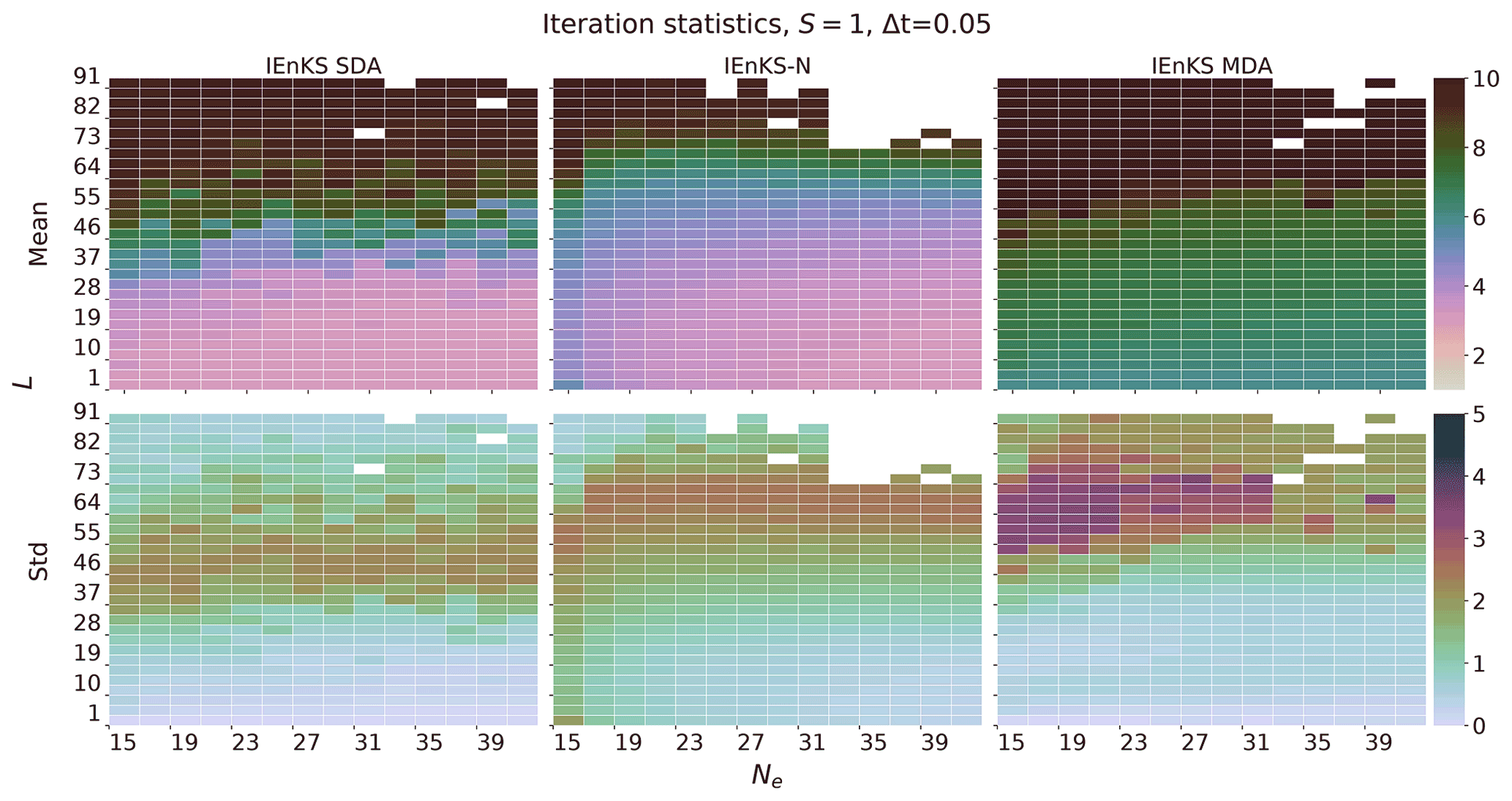
Using MDA or adaptive inflation in DA cycles with weakly nonlinear forecast error dynamics, we demonstrate how the SIEnKS greatly outperforms the Lin-IEnKS with the same, or lower, leading-order cost. The SIEnKS MDA scheme also outperforms the IEnKS MDA scheme with less cost, but the 4D IEnKS-N is able to extract additional accuracy over the SIEnKS-N at the cost of L additional ensemble simulations per iteration. Therefore, it is worth considering the statistics on the number of iterations that the IEnKS uses in each of the above-studied configurations. Figure 14 shows a heat plot for the mean and the standard deviation of the number of iterations used per cycle for each of the IEnKS with SDA, IEnKS-N, and IEnKS with MDA to optimize the 4D cost function. Notice that, in the MDA configuration, the mean and the standard deviation is computed over the two stages of the IEnKS, accounting for both the balancing and MDA 4D cost functions.
Although the number of possible iterations is bounded below by one in the case of SDA and two in the case of MDA, the frequency distribution for the total iterations is not especially skewed within the stability region of the IEnKS. This is evidenced by the small standard deviation, less than or equal to one, that defines the stability region for the scheme. Particularly, the IEnKS typically stabilizes around (i) three iterations in the SDA, with tuned inflation configuration, (ii) three to four iterations in the SDA, with adaptive inflation configuration, and (iii) six to eight iterations in the MDA, with tuned inflation configuration. Therefore, the SIEnKS is shown to make a reduction ranging between (i) 2L, (ii) 2L to 3L, or (iii) 4L to 6L ensemble simulations of the estimator's cycle, on average, versus the IEnKS. While this is unremarkable for the SDA, a tuned inflation configuration where the Lin-IEnKS performs similarly, this demonstrates a strong performance advantage of the SIEnKS in its target application, i.e., in settings with weakly nonlinear forecast error dynamics and other sources of nonlinearity dominating the DA cycle. This an especially profound reduction for the MDA configuration, where the SIEnKS MDA scheme proves to be both the least expensive and the most stable/accurate estimator by far.
5.4 Weakly nonlinear forecast error dynamics – nonlinear observations
A primary motivating application for the SIEnKS is the scenario where the forecast error dynamics is weakly nonlinear but where the observation operator is weakly to strongly nonlinear. There are infinite possible ways for how nonlinearity in the observation operator can be expressed, and the results are expected to strongly depend on the particular operator. In the following, we consider the operator in Eq. (101) for the ability to tune the strength of this effect with the parameter γ. In order to avoid conflating the effect of the nonlinearity in the hyperparameter optimization and the nonlinearity in the observation operator, we suppress adaptive inflation in this section. In this case, SDA and MDA schemes are considered to compare how MDA can be used to temper the effects of local minima in the MAP estimation versus a nonlinear observation operator. We again choose Δt=0.05 to maintain weakly nonlinear forecast error dynamics. We restrict to Ne=21, as we expand the experimental parameters to include γ. The lag is varied as .
Figure 15 demonstrates the effect of varying the nonlinearity in the observation operator, where strong differences once again emerge between the retrospective analysis of the MLES and the iterative schemes. The scale of the color map is raised to a maximum of 0.5, as a better performance can be achieved with the MLEF alone, as demonstrated by the MLES. In the MLES, the forecast and analysis error increases almost uniformly in γ, but a very different picture emerges for the iterative smoothers. While the stability regions of the iterative schemes tend to shrink for larger γ, the accuracy of the estimators changes non-monotonically. Moreover, iteratively optimizing the filter cost function in the SIEnKS or the 4D cost function in the IEnKS does not in and of itself guarantee a better performance than the Lin-IEnKS, due to the increasing presence of local minima. Particularly for the SIEnKS and the IEnKS with highly nonlinear observations, this optimization can also become deleterious to the estimator performance, with evidence of instability and catastrophic divergence in these regimes.
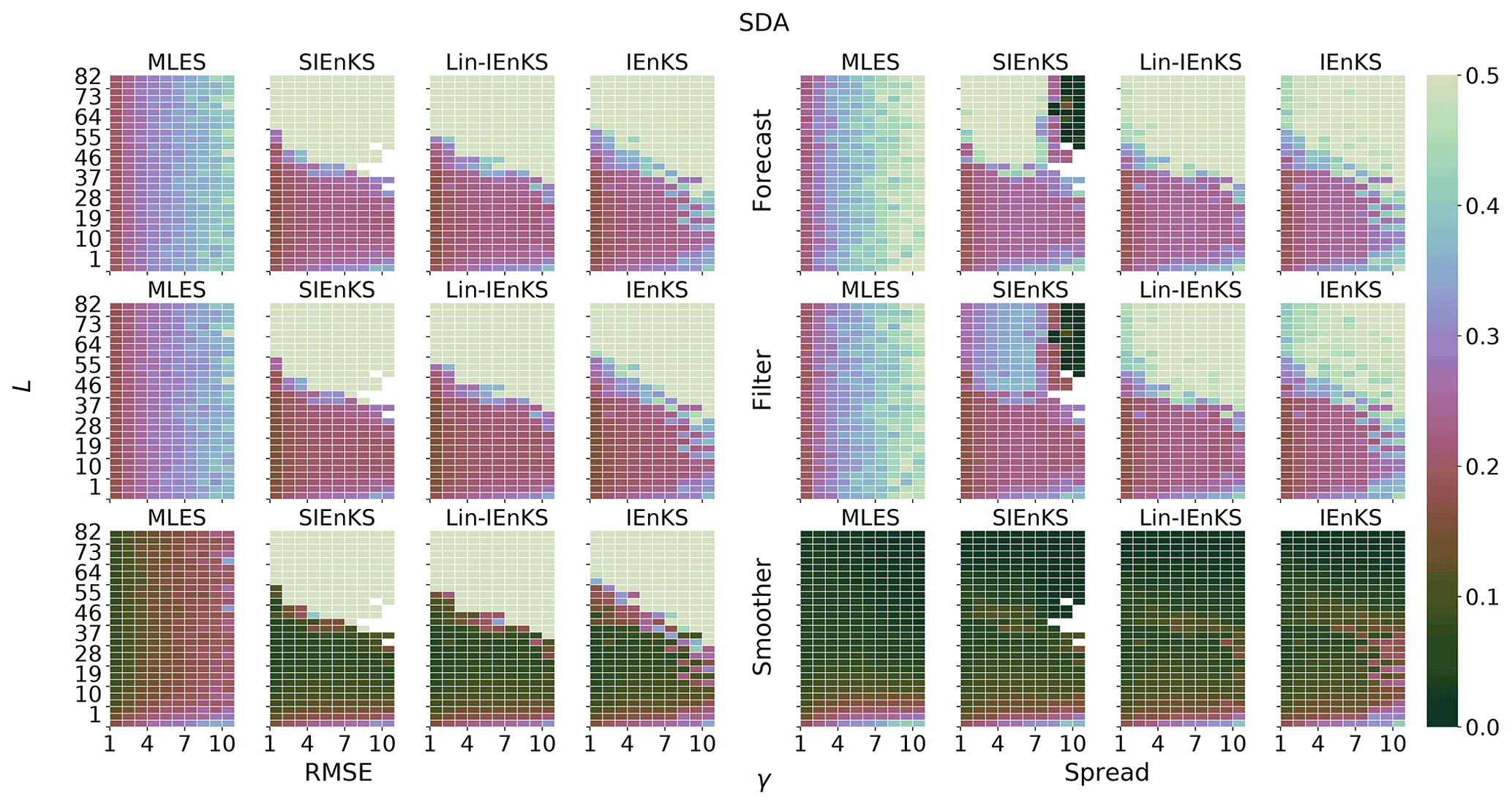
Figure 15Lag length L on the vertical axis and nonlinearity parameter γ on the horizontal axis. SDA, tuned inflation, shift S=1, Ne=21, and Δt=0.05 are indicated.
In Fig. 16, we repeat the experimental configuration of Fig. 15, with the exception of using the MDA configuration. As seen in Fig. 10, MDA greatly extends the forecast/filter accuracy of the SIEnKS over the 4D schemes. Multiple data assimilation in this context additionally weakens the effect of the assimilation update step, smoothing the cost function contours and expanding the stability regions of all estimators.
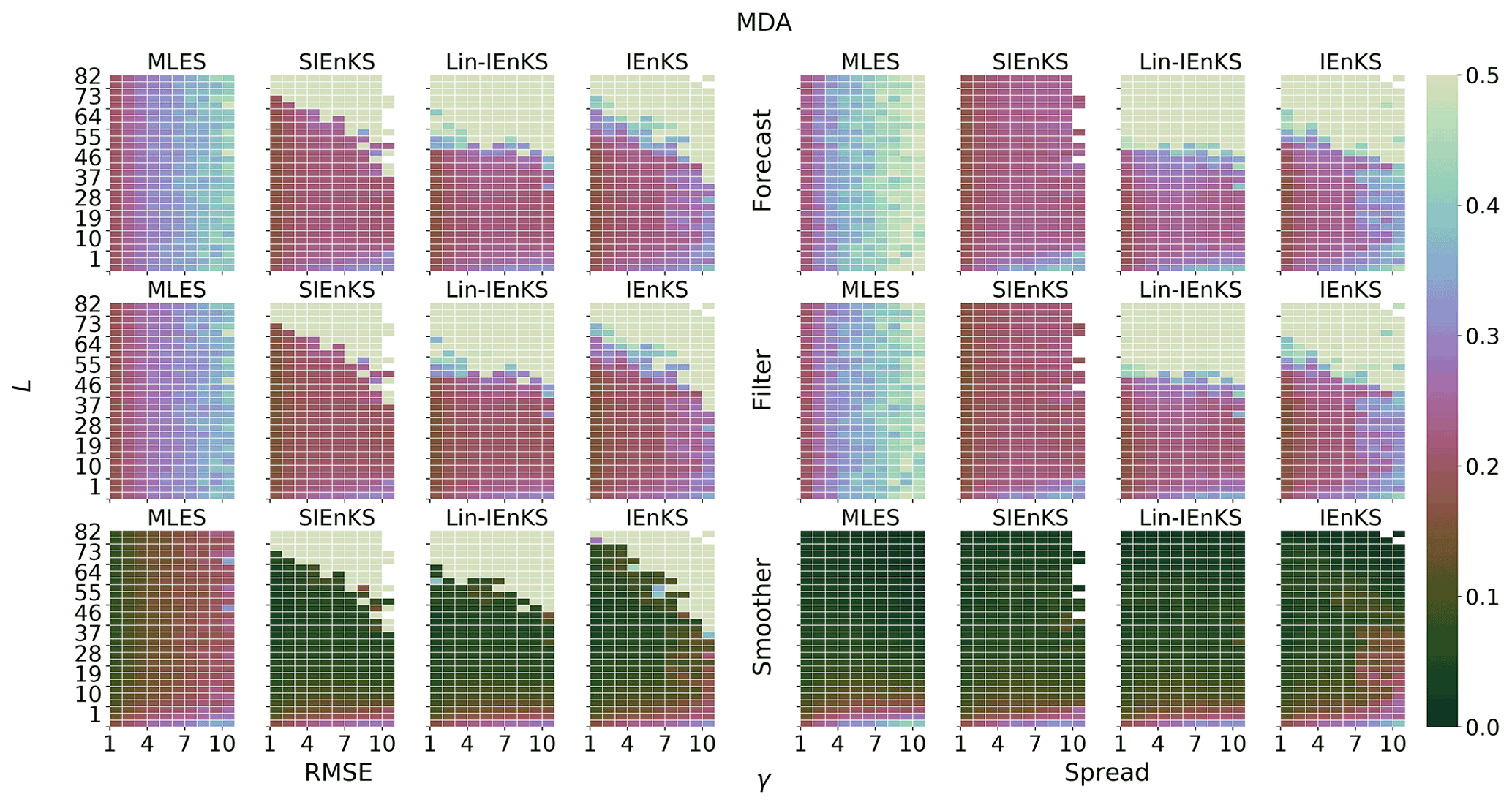
Figure 16Lag length L is shown on the vertical axis, and the nonlinearity parameter γ is shown on the horizontal axis. MDA, tuned inflation, shift S=1, Ne=21, and Δt=0.05 are indicated. The MLES SDA results are presented here for reference.
Figure 17 presents tuned results from Fig. 16, where the lag and inflation are simultaneously optimized for the minimal forecast RMSE. In this context, we clearly see how the effect of varying γ is non-monotonic on the estimator accuracy for the iterative schemes. However, important differences also emerge in this configuration between the SIEnKS and the (Lin-)IEnKS. While the forecast and filter accuracy of these schemes remains indistinguishable for γ≤7, the smoother RMSE of the SIEnKS is almost uniformly lower than these other schemes for all γ. Interestingly, the degradation of the performance of the IEnKS for highly nonlinear observations, γ≥8, does not extend to either of the Lin-IEnKS or the SIEnKS in the MDA configuration. Whereas the iterative optimization of the 4D cost function becomes susceptible to the effects of the local minima with large γ, the Lin-IEnKS remains stable for the full window of the γ presented here. Moreover, the SIEnKS demonstrates significantly improved smoother accuracy over the Lin-IEnKS while remaining at a lower leading-order cost. This suggests that the sequential MDA scheme of the SIEnKS is better equipped to handle highly nonlinear observation operators than the 4D formalism, which appears to suffer from a greater number of local minima.
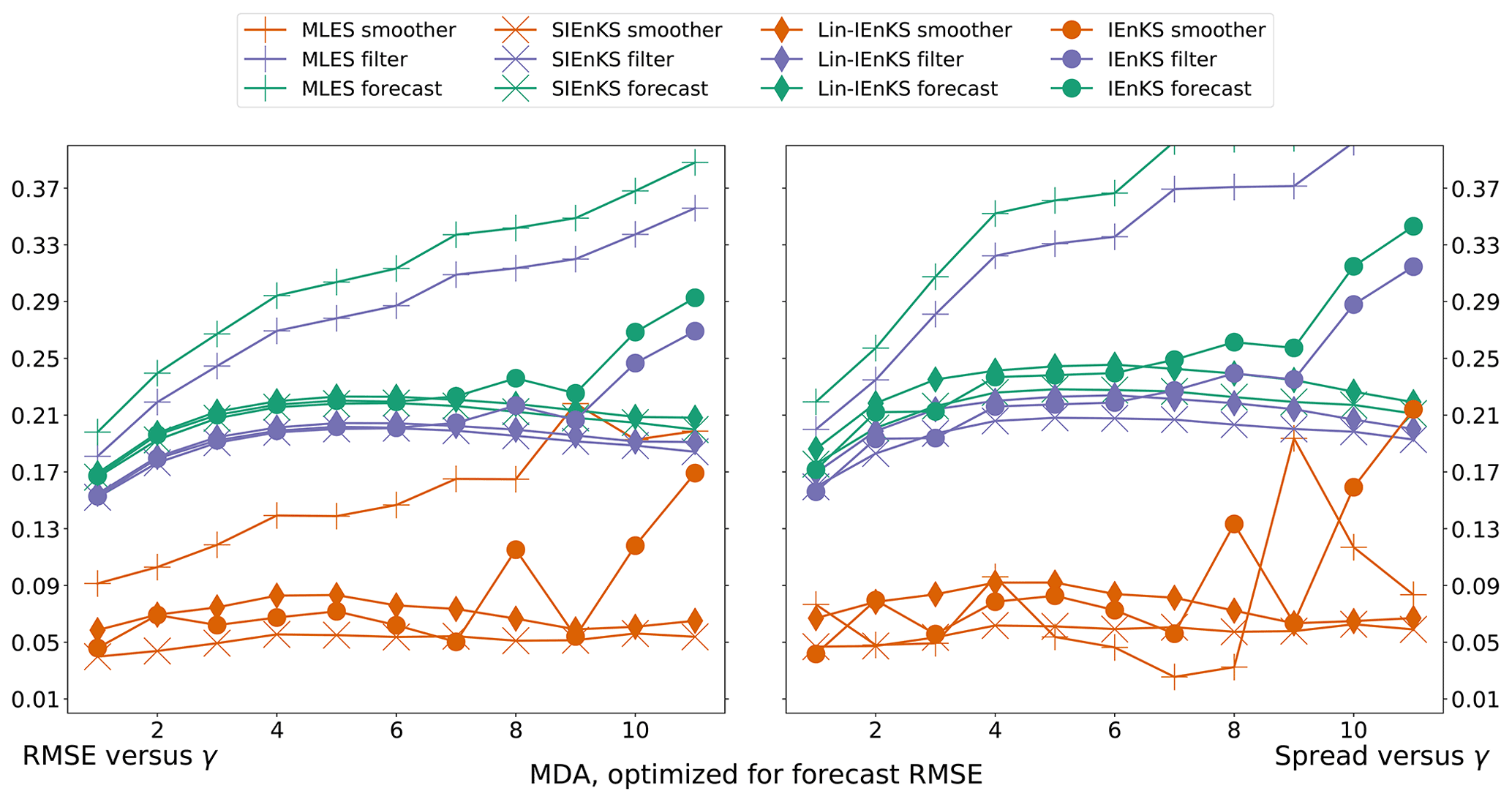
Figure 17MDA configuration. RMSE and spread versus γ. Lag and inflation are optimized for a minimum forecast RMSE.
5.5 Weakly nonlinear forecast error dynamics – lag versus shift
Even for a linear observation operator and tuned inflation, a shift S>1 distinguishes the performance of each of the studied estimators. In this section, we fix Δt=0.05, corresponding to weakly nonlinear forecast error dynamics, and we vary to demonstrate these differences. For the iterative schemes, we only consider combinations of L divisible by S for compatibility with the MDA schemes. The EnKS is defined for arbitrary S<L, and all such configurations are presented for reference.
Recall the qualification that the EnKS and SIEnKS are designed to assimilate observations sequentially and synchronously in this work, whereas the (Lin-)IEnKS assimilates observations asynchronously by default. When S=1, there is no distinction between asynchronous and synchronous assimilation, but in this section this distinction is borne in mind. Likewise, it is recalled that, for the (Lin-)IEnKS with a shift S>1, filter statistics are computed, including the information from all observations when making a filter estimate for states at times . This arises from the asynchronous design of the IEnKS, whereas filter statistics are computed sequentially without future information in the SIEnKS.
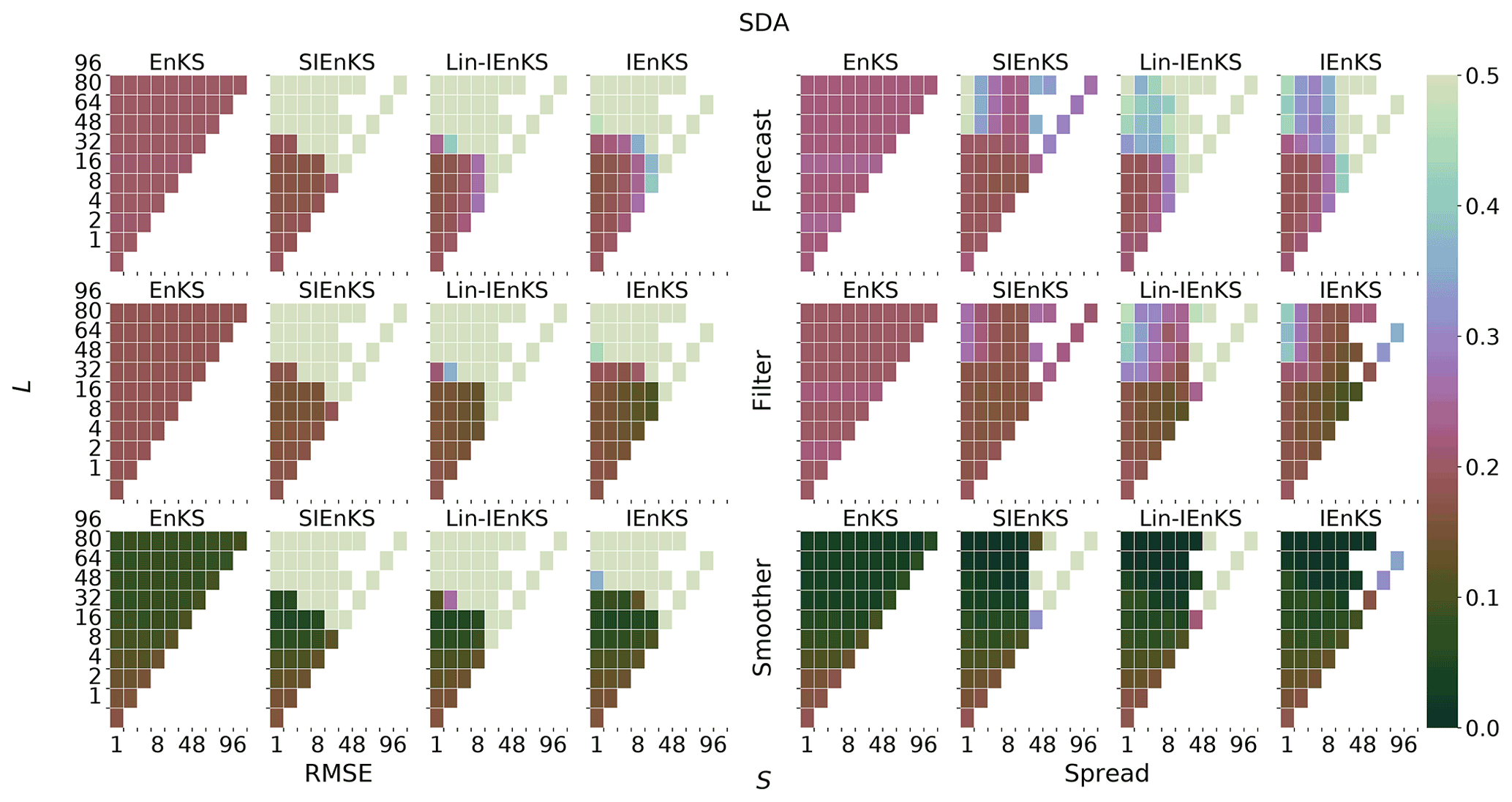
Figure 18Lag length L on the vertical axis and shift S on the horizontal axis. SDA, tuned inflation, linear observations, ensemble size Ne=21, and Δt=0.05 are indicated.
Figure 18 presents the heat plot of RMSE and spread for each estimator in the SDA configuration. We note that the EnKS for a fixed L has a performance that is largely invariant with respect to changes in S, except for the special case where S=L. In this case, the non-overlapping DAWs impose that posterior estimates are constructed with fewer observations conditioning the final estimate than in overlapping DAWs. Otherwise, the stability regions of the iterative schemes are largely the same, with the SIEnKS only achieving a slight improvement over the Lin-IEnKS and the IEnKS only slightly improving on the SIEnKS.
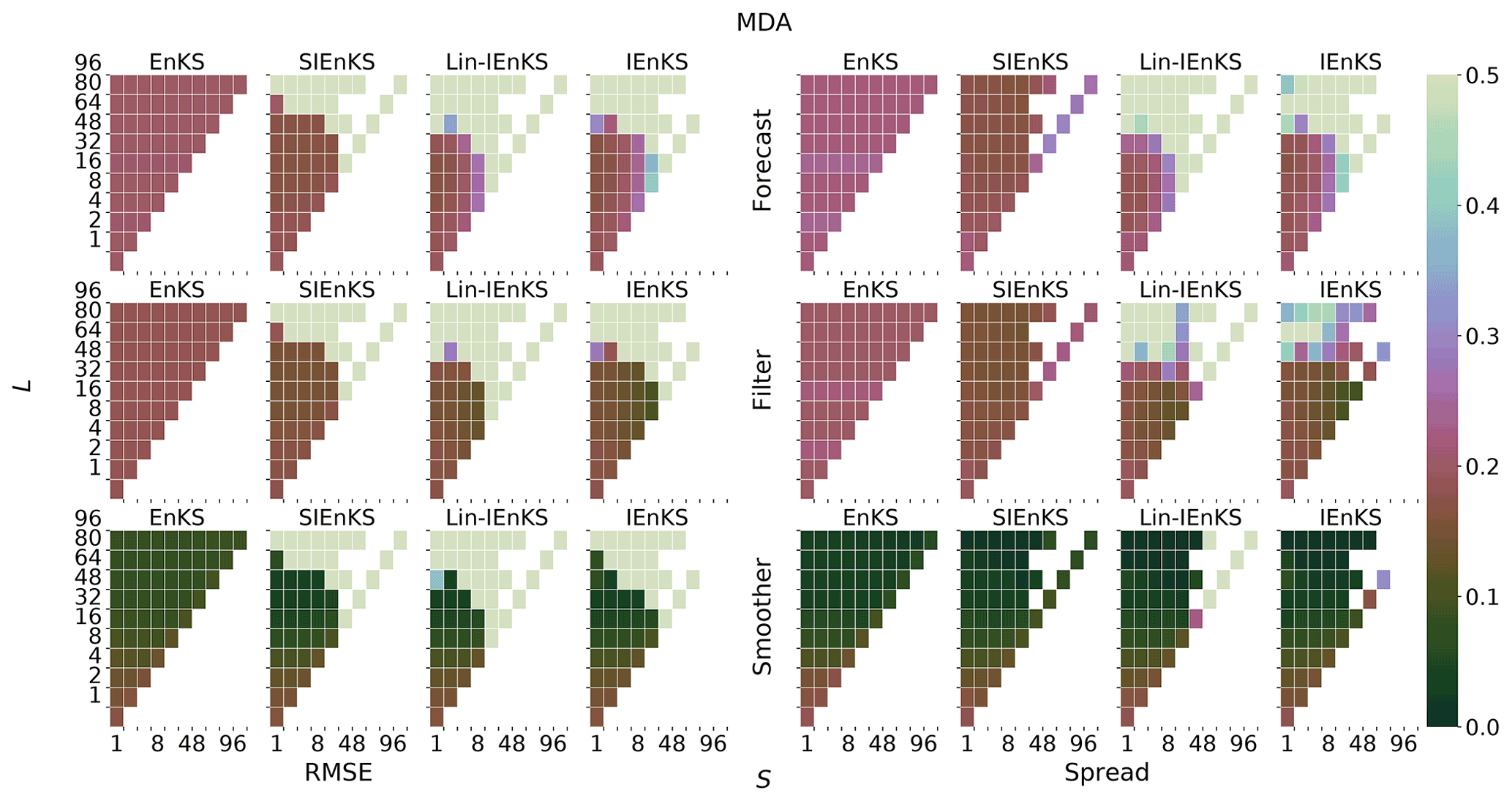
Figure 19Lag length L on the vertical axis and shift S on the horizontal axis. MDA, tuned inflation, linear observations, ensemble size Ne=21, and Δt=0.05 are indicated. The EnKS SDA results are presented here for reference.
The SDA configuration is contrasted with Fig. 19, where we again see the apparent strengths of the SIEnKS MDA scheme. When MDA is introduced, all iterative schemes increase their respective stability regions to include longer lags and larger shifts in the DAW simultaneously. However, the SIEnKS has the largest stability region of all iterative estimators, extending to shifts at least as large as the other schemes for every lag setting. Likewise, the earlier distinction between the forecast and filter statistics of the SIEnKS and the 4D schemes is readily apparent. Not only does the stability region of the SIEnKS improve over the other schemes, but it is also generally more accurate in its predictive statistics at the end of long lag windows.
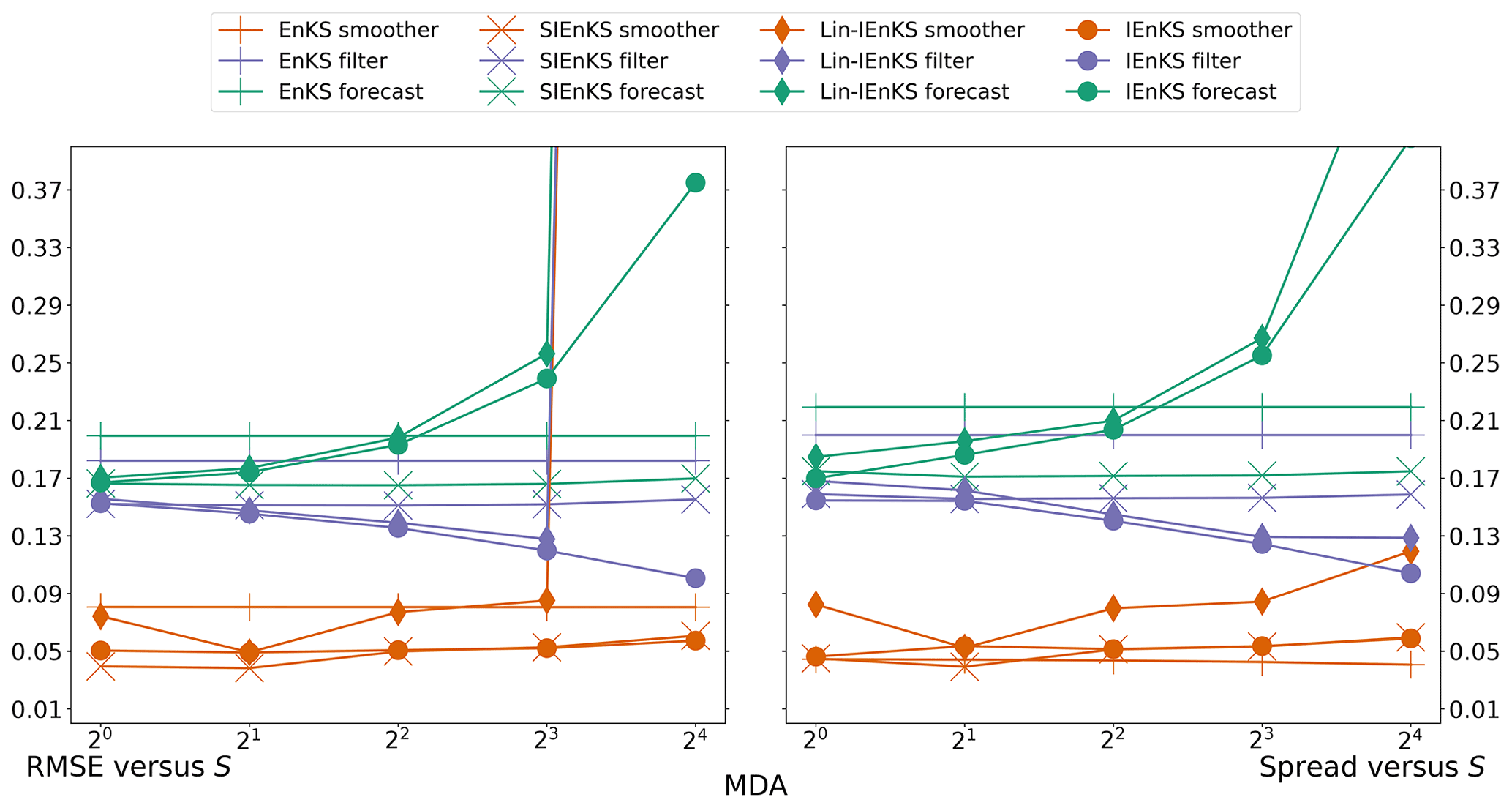
Figure 20MDA configuration. RMSE and spread versus shift S. Lag L optimized for a minimum forecast RMSE in Fig. 19.
In order to obtain a finer picture of the effect of varying the shift S, we tune the lag and inflation simultaneously for each estimator for their minimal forecast RMSE when given a fixed shift; we plot the results of this tuning in Fig. 20. Given that all iterative estimators uniformly diverge for a shift S≥32, we only plot results for shifts in the range . Several important features stand out in this plot. First, note that, while optimizing the lag, the performance of the SIEnKS is almost invariant in the shift, similar to the performance of the EnKS. This is because the sequential filter analysis of the SIEnKS constrains the growth of the filter and forecast errors as the DAW shifts. Indeed, the prediction of states at times arises from a filter ensemble at the previous time point. In the MDA scheme, the balancing weights for the observations of these newly introduced states in the DAW are, furthermore, all equal to one and equivalent to a standard ETKF filter analysis.
Second, note that the filter estimates of the (Lin-)IEnKS actually improve with larger shifts; however, this is an artifact of computing the filter statistics over all times and using the observations simultaneously. This means that the filter estimates for all times except tL actually contain future information. This is contrasted with the sequential analyses of the EnKS and the SIEnKS, which only produce filter statistics with observations from past and current times.
Third, note that the Lin-IEnKS, while maintaining a similar prediction and filtering error to the IEnKS, is less stable and performs almost uniformly less accurately than the IEnKS in its smoothing estimates. The SIEnKS, moreover, tends to exhibit a slight improvement in stability and accuracy over the IEnKS therein.
Finally, it is immediately apparent how S>1 strongly increases the prediction error for the 4D estimators. The longer free forecasts for S>1, used to shift the DAW, accumulate errors such that, for S≥16, the Lin-IEnKS actually experiences filter divergence. The difference in the estimators' performances is once again a consequence of how observations are assimilated synchronously as in the EnKS/SIEnKS or asynchronously by default in the (Lin-)IEnKS.
Bearing all the above qualifications in mind, we analyze the performance of the estimators while varying the shift S. First, for all experimental settings, the leading-order cost of the SIEnKS MDA scheme is fixed at 2L ensemble simulations, whereas for the other schemes the minimal cost is at 2L+S ensemble simulations. For configurations where S>1, the SIEnKS thus makes a dramatic cost reduction versus the other schemes in this aspect alone, requiring fewer ensemble simulations per cycle. We consider that the leading-order cost for the Lin-IEnKS is similar to the SIEnKS for S=1, requiring only one more ensemble simulation per cycle. However, the SIEnKS with a shift S=16 maintains a prediction and smoother error that is comparable to the Lin-/IEnKS for a shift of S=1. This implies that the SIEnKS can maintain a performance similar to the S=1 IEnKS MDA scheme, while using of the total cycles needed by the IEnKS to pass over the same observations in real time. If we assume that the observations can be assimilated synchronously, then the above SIEnKS MDA scheme is thus able to run in its EnKS cycle over a long time series of observations while needing infrequent reinitialization with its smoothed estimates. For a real-time forecast cycle, where the computational cost/prediction accuracy tradeoff is the most important consideration, this once again demonstrates how the SIEnKS can balance this tradeoff, performing as well as, and often better than, 4D estimators with a substantially lower leading-order cost. Not only is each cycle less expensive in the SIEnKS than in the (Lin-)IEnKS, but the SIEnKS reduces the number of required cycles by an order of magnitude.
5.6 Strongly nonlinear forecast error dynamics – lag versus Δt
In all other numerical benchmarks, we focus on the scenario that the SIEnKS is designed for, i.e., DA cycles in which the forecast error evolution is weakly nonlinear. In this section, we demonstrate the limits of the SIEnKS when the forecast error dynamics dominate the nonlinearity of the DA cycle. We vary , while the ensemble size Ne=21 and the shift S=1 are fixed. The lag is varied as . We neglect the nonlinear observation operators in this section, though we include the finite size adaptive inflation formalism, which is itself designed to ameliorate the increasing nonlinearity in the forecast error dynamics. Single data assimilation and MDA configurations are considered for the iterative schemes as usual.
Figure 21 demonstrates the effect of the increasing nonlinearity of the forecast error evolution with tuned inflation. Due to the extreme nonlinearity for large Δt, we raise the heat map scale for the RMSE and spread to 1.0. Several features become apparent with the increasing forecast nonlinearity. First, the EnKS, which has a performance dependent on the standard ETKF cycle, is fully divergent for Δt≥0.2. This is in contrast with all iterative schemes which maintain adequate performance for Δt≤0.25. We note that the performance of the SIEnKS and the Lin-IEnKS, in this first scenario, is nearly identical; this corresponds to the fact that they are formally equivalent in this setting. However, appropriately, it is the 4D IEnKS that maintains the most stable and accurate performance over the range of forecast lengths. Indeed, this demonstrates the precise benefit of the iterative solution to 4D cost function for moderately nonlinear, non-Gaussian DA.
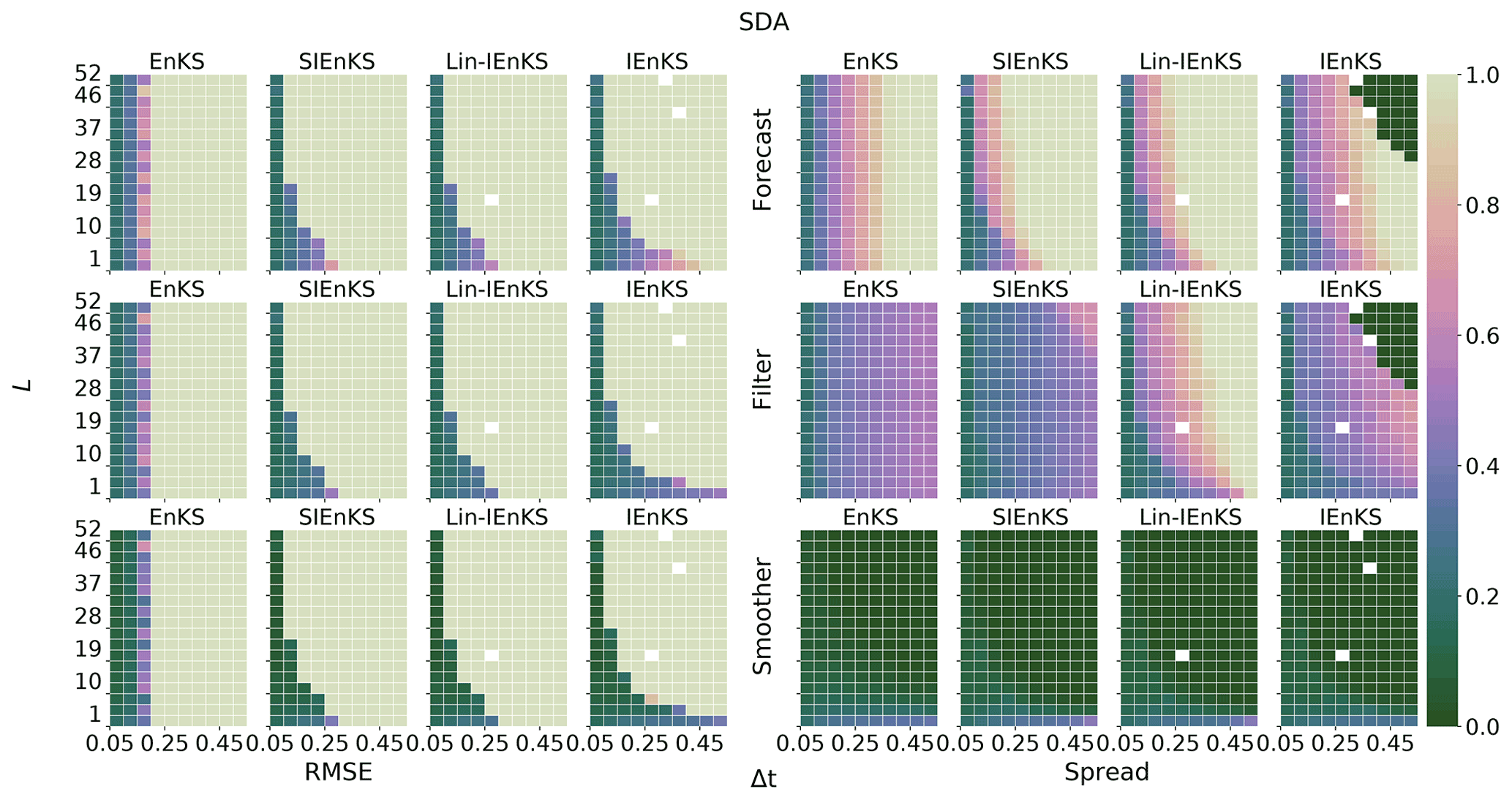
Figure 21Lag length L on the vertical axis and Δt on the horizontal axis. SDA, tuned inflation, and ensemble size Ne=21 are indicated.
In Fig. 22, we repeat the same experiments as in Fig. 21 but using the finite size adaptive inflation, rather than tuned inflation, for each estimator. Once again, the efficacy of the finite size formalism in ameliorating the nonlinearity of the forecast error dynamics is demonstrated. In particular, all schemes except the SIEnKS see an overall improvement in their stability region and often in their overall accuracy. The EnKS-N actually strongly outperforms the tuned inflation EnKS, extending an adequate filter performance as far as Δt≤0.35. Likewise, the IEnKS-N has a strongly enhanced stability region, though it increasingly suffers from catastrophic filter divergence outside of this zone. Notably, whereas the SIEnKS-N outperformed the Lin-IEnKS-N for Δt=0.05, the Lin-IEnKS-N generally yields a better performance for moderately to strongly nonlinear forecast error dynamics. Indeed, the finite size formalism appears to become incompatible with the design of the SIEnKS for strongly nonlinear forecast error dynamics, as suggested by the widespread ensemble collapse and catastrophic divergence.
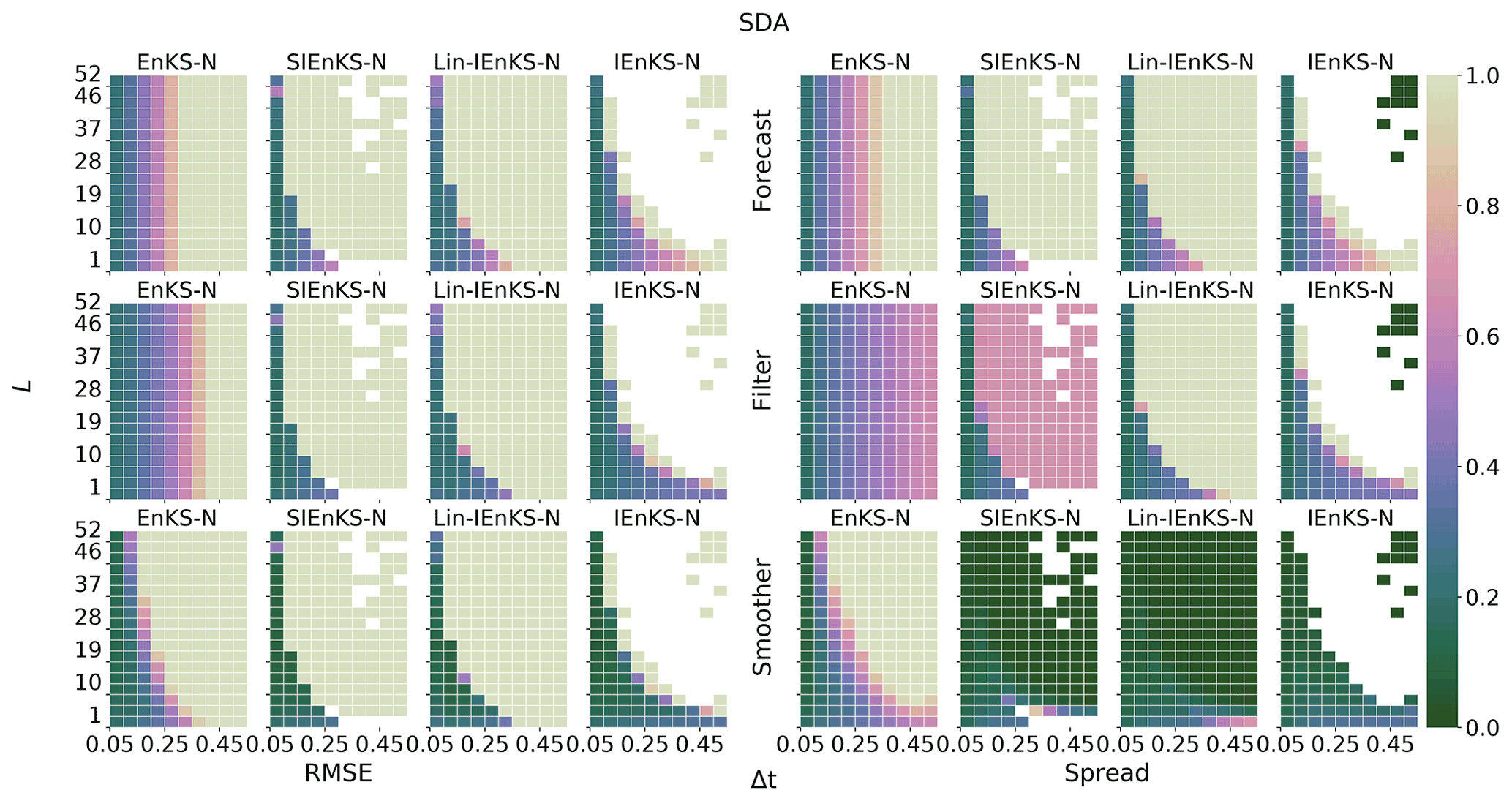
Figure 22Lag length L on the vertical axis and Δt on the horizontal axis. SDA, adaptive inflation, and ensemble size Ne=21 are indicated.
As a final experimental configuration, we consider how MDA affects the increasing nonlinearity of the forecast error dynamics. Figure 23 demonstrates the performance of these estimators in the MDA configuration with tuned inflation, where the SDA results of the EnKS are pictured for reference. In particular, we see the usual increase in the estimators' stability regions over the SDA configuration. However, the improvement in the SIEnKS over the Lin-IEnKS is marginal to nonexistent for moderately to strongly nonlinear forecast error dynamics. The 4D IEnKS, furthermore, is again the estimator with the largest stability region and greatest accuracy over a wide range of Δt.

Figure 23Lag length L on the vertical axis and Δt on the horizontal axis. MDA, tuned inflation, and ensemble size Ne=21 are indicated.
The results in this section indicate that, while the SIEnKS is very successful in weakly nonlinear forecast error dynamics, the approximations used in this estimator strongly depend on the source of nonlinearity in the DA cycle. Particularly, when the nonlinearity of the forecast error dynamics dominates the DA cycle, the approximations of the SIEnKS break down. It is thus favorable to consider the Lin-IEnKS, or to set a low threshold for the iterations in the IEnKS, instead of applying the SIEnKS in this regime. Notably, as the finite size inflation formalism is designed for a scenario different to that of the SIEnKS, one may instead consider designing adaptive covariance inflation in such a way that it exploits the design principles of the SIEnKS. Such a study goes beyond the scope of this work and will be considered later.
In this work, we achieve three primary objectives. First, we provide a review of sequential, ensemble variational Kalman filters and smoothers with perfect model assumptions within the Bayesian MAP formalism of the IEnKS. Second, we rigorously derive our single-iteration formalism as a novel approximation of the Bayesian MAP estimation, explaining how this relates to other well-known smoothing schemes and how its design is differentiated in a variety of contexts. Third, using the numerical framework of DataAssimilationBenchmarks.jl (Grudzien et al., 2021), we extensively demonstrate how the SIEnKS has a unique advantage in balancing the computational cost/prediction accuracy tradeoff in short-range forecast applications. Pursuant to this, we provide a cost analysis and pseudo-code for all of the schemes studied in this work, in addition to the open-source implementations available in the supporting Julia package. Together, this work provides a practical reference for a variety of topics at the state of the art in ensemble variational Kalman smoothing.
The rationale of the SIEnKS is, once again, to efficiently perform a Bayesian MAP estimation in real-time, short-range forecast applications where the forecast error dynamics is weakly nonlinear. Our central result is the novel SIEnKS MDA scheme, which not only improves the forecast accuracy and analysis stability in this regime but also simultaneously reduces the leading-order cost versus the traditional 4D MDA approach. This MDA scheme is demonstrated to produce significant performance advantages in the simple setting where there is a linear observation operator and especially when the shift S can be taken greater than one. Not only is each cycle of the SIEnKS MDA scheme significantly less expensive than the other estimators for S>1, but the estimator performance while varying S tends to be invariant. This crucial aspect also means that one can, in principle, reduce the number of cycles actually needed by the estimator to produce forecasts in real time. Our scheme also appears better equipped than the 4D MDA estimation to handle highly nonlinear observation operators, as it maintains greater accuracy and is more robust to the effects of local minima. Separately, we find that, in our target regime, the single-iteration formalism is cost-effective for optimizing hyperparameters of the estimation scheme, as with the SIEnKS-N.
The above successes of the SIEnKS come with the following three important qualifications: (i) we have focused on synchronous DA, assuming that we can sequentially assimilate observations before producing a prediction step, (ii) we have not studied localization or hybridization, which are widely used in ensemble-based estimators to overcome the curse of dimensionality for realistic geophysical models, and (iii) we have relied upon the perfect model assumption, whereas realistic forecast settings include significant modeling errors. These restrictions come by necessity, to limit the scope of an already lengthy study. However, we note that the SIEnKS is capable of asynchronous DA, as already discussed in Sect. 4.4. Likewise, it is possible that some of the issues faced by the IEnKS in integrating localization/hybridization (Bocquet, 2016) may actually be ameliorated by the design principles of the SIEnKS. Domain localization, as in the LETKF (Hunt et al., 2007; Sakov and Bertino, 2011), is likely to have a satisfactory extension to the SIEnKS, where this may be applied directly in the filter step as usual. Assuming that the ensemble forecast dynamics is not highly nonlinear, the spatial correlations defining the observation domain truncation for the initial ensemble at t0 may, furthermore, be well approximated by the domains from the filter step but mapped by a linear, reverse-time evolution over the DAW via an explicit or implicit adjoint model. Experiments suggest that a tuned radius for a smoother domain localization can be implemented successfully in an EnKS analysis (Nerger et al., 2014). However, there are also rich opportunities to iteratively optimize a localization hyperparameter as with, e.g., the α trick (Lorenc, 2003) within the SIEnKS framework. Similarly, it is possible that an extension of the single-iteration formalism could provide a novel alternative to other iterative ensemble smoothers designed for model error, such as the IEnKS-Q (Sakov et al., 2018; Fillion et al., 2020), EnKS expectation maximization schemes (Pulido et al., 2018), or the family of OSA smoothers (Ait-El-Fquih and Hoteit, 2022).
For the reasons above, this initial study provides a number of directions in which our single-iteration formalism can be extended. Localization and hybridization are both prime targets to translate the benefits of the SIEnKS to an operational short-range forecasting setting. Likewise, an asynchronous DA design is an important operational topic for this estimator. Noting that the finite size adaptive inflation formalism is designed to perform in a different regime than the SIEnKS and is not fully compatible with MDA schemes, developing an adaptive inflation and/or model error estimation based on the design principles of the SIEnKS is an important direction for a future study. Having currently demonstrated the initial success of this single-iteration formalism, each of these above directions can be considered in a devoted work. We hope that the framework provided in this paper will guide these future studies and will provide a robust basis of comparison for further development of ensemble variational Kalman filters and smoothers.
Algorithm A1Ensemble transform (ET).
Algorithm A2Random mean-preserving orthogonal matrix (RO).
Algorithm A3Ensemble update (EU).
Algorithm A4Covariance inflation (CI).
Algorithm A5ETKF.
Algorithm A6EnKS.
Algorithm A7Gauss–Newton IEnKS in the SDA transform version.
Algorithm A8SIEnKS in the SDA version.
Algorithm A9Maximum likelihood ensemble transform (MLET).
Algorithm A10Finite size ensemble transform (FSET).
Algorithm A11Gauss–Newton IEnKS-N in the SDA transform version.

Algorithm A12SIEnKS in the MDA version.
Algorithm A13Gauss–Newton IEnKS in the MDA transform version.
The current version of DataAssimilationBenchmarks.jl is available at https://github.com/cgrudz/DataAssimilationBenchmarks.jl (last access: 10 October 2022) and is in the Julia General Registries under the Apache 2.0 License. The exact version of the package used to produce the results used in this paper is archived on Zenodo (https://doi.org/10.5281/zenodo.5430619; Grudzien et al., 2021), as are scripts to process data and produce the plots for all the simulations presented in this paper.
All data in this study were generated synthetically by the package DataAssimilationBenchmarks.jl, with the specific version in the code availability statement above. Settings for generating equivalent synthetic data experiments are described in Sect. 5.2.
CG mathematically derived the original SDA and MDA SIEnKS schemes. CG and MB together refined and improved upon these mathematical results for their final form. All numerical simulation and plotting codes were developed by CG, and MB shared the original Python code for the IEnKS and the finite size formalism schemes, which contributed to the development of the Julia code supporting this work. CG and MB worked together on all conceptual diagrams. All numerical experiments and benchmark configurations for the SIEnKS were devised together between CG and MB. The paper was written by CG, with contributions from MB to refine the narrative and presentation of results in their final form.
The contact author has declared that neither of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Special thanks go to Eric Olson, Grant Schissler, and Mihye Ahn, for high-performance computing support and logistics at the University of Nevada, Reno. Thanks go to Patrick Raanes, for the open-source DAPPER Python package, which was referenced at times for the development of DA schemes in Julia. Thanks go to Amit N. Subrahmanya and Pavel Sakov, who reviewed this paper and provided important suggestions and clarifications to improve this work. CEREA is a member of Institut Pierre-Simon Laplace.
This paper was edited by Adrian Sandu and reviewed by Pavel Sakov and Amit N. Subrahmanya.
Ait-El-Fquih, B. and Hoteit, I.: Filtering with One-Step-Ahead Smoothing for Efficient Data Assimilation, in: Data Assimilation for Atmospheric, Oceanic and Hydrologic Applications (Vol. IV), edited by: Park, S. K. and Xu, L., Springer, Cham, 69–96, https://doi.org/10.1007/978-3-030-77722-7_1, 2022. a, b
Ait-El-Fquih, B., El Gharamti, M., and Hoteit, I.: A Bayesian consistent dual ensemble Kalman filter for state-parameter estimation in subsurface hydrology, Hydrol. Earth Syst. Sci., 20, 3289–3307, https://doi.org/10.5194/hess-20-3289-2016, 2016. a
Asch, M., Bocquet, M., and Nodet, M.: Data Assimilation: Methods, Algorithms, and Applications, SIAM, ISBN 978-1-61197-453-9, https://doi.org/10.1137/1.9781611974546, 2016. a, b, c, d, e
Bannister, R. N.: A review of operational methods of variational and ensemble-variational data assimilation, Q. J. Roy. Meteor. Soc., 143, 607–633, https://doi.org/10.1002/qj.2982, 2017. a
Bezanson, J., Edelman, A., Karpinski, S., and Shah, V.: Julia: A fresh approach to numerical computing, SIAM Rev., 59, 65–98, https://doi.org/10.1137/141000671, 2017. a
Bocquet, M.: Ensemble Kalman filtering without the intrinsic need for inflation, Nonlin. Processes Geophys., 18, 735–750, https://doi.org/10.5194/npg-18-735-2011, 2011. a
Bocquet, M.: Localization and the iterative ensemble Kalman smoother, Q. J. Roy. Meteor. Soc., 142, 1075–1089, https://doi.org/10.1002/qj.2711, 2016. a, b
Bocquet, M. and Carrassi, A.: Four-dimensional ensemble variational data assimilation and the unstable subspace, Tellus A, 69, 1304504, https://doi.org/10.1080/16000870.2017.1304504, 2017. a
Bocquet, M. and Sakov, P.: Combining inflation-free and iterative ensemble Kalman filters for strongly nonlinear systems, Nonlin. Processes Geophys., 19, 383–399, https://doi.org/10.5194/npg-19-383-2012, 2012. a, b
Bocquet, M. and Sakov, P.: Joint state and parameter estimation with an iterative ensemble Kalman smoother, Nonlin. Processes Geophys., 20, 803–818, https://doi.org/10.5194/npg-20-803-2013, 2013. a, b
Bocquet, M. and Sakov, P.: An iterative ensemble Kalman smoother, Q. J. Roy. Meteor. Soc., 140, 1521–1535, https://doi.org/10.1002/qj.2236, 2014. a, b, c, d, e, f, g, h, i
Bocquet, M., Raanes, P. N., and Hannart, A.: Expanding the validity of the ensemble Kalman filter without the intrinsic need for inflation, Nonlin. Processes Geophys., 22, 645–662, https://doi.org/10.5194/npg-22-645-2015, 2015. a, b, c
Bocquet, M., Brajard, J., Carrassi, A., and Bertino, L.: Bayesian inference of chaotic dynamics by merging data assimilation, machine learning and expectation-maximization, Foundations of Data Science, 2, 55–80, https://doi.org/10.3934/fods.2020004, 2020. a
Carrassi, A., Bocquet, M., Bertino, L., and Evensen, G.: Data Assimilation in the Geosciences-An overview on methods, issues and perspectives, WIREs Clim. Change, 9, e535, https://doi.org/10.1002/wcc.535, 2018. a
Carrassi, A., Bocquet, M., Demaeyer, J., Grudzien, C., Raanes, P., and Vannitsem, S.: Data Assimilation for Chaotic Dynamics, in: Data Assimilation for Atmospheric, Oceanic and Hydrologic Applications (Vol. IV), edited by: Park, S. K. and Xu, L., Springer, Cham, 1–42, https://doi.org/10.1007/978-3-030-77722-7_1, 2022. a
Chen, Y. and Oliver, D. S.: Ensemble randomized maximum likelihood method as an iterative ensemble smoother, Math. Geosci., 44, 1–26, https://doi.org/10.1007/s11004-011-9376-z, 2012. a
Corazza, M., Kalnay, E., Patil, D. J., Yang, S.-C., Morss, R., Cai, M., Szunyogh, I., Hunt, B. R., and Yorke, J. A.: Use of the breeding technique to estimate the structure of the analysis “errors of the day”, Nonlin. Processes Geophys., 10, 233–243, https://doi.org/10.5194/npg-10-233-2003, 2003. a
Cosme, E., Verron, J., Brasseur, P., Blum, J., and Auroux, D.: Smoothing problems in a Bayesian framework and their linear Gaussian solutions, Mon. Weather Rev., 140, 683–695, https://doi.org/10.1175/MWR-D-10-05025.1, 2012. a
Desbouvries, F., Petetin, Y., and Ait-El-Fquih, B.: Direct, prediction-and smoothing-based Kalman and particle filter algorithms, Signal Process., 91, 2064–2077, https://doi.org/10.1016/j.sigpro.2011.03.013, 2011. a
Emerick, A. A. and Reynolds, A. C.: Ensemble smoother with multiple data assimilation, Comput. Geosci., 55, 3–15, https://doi.org/10.1016/j.cageo.2012.03.011, 2013. a, b
Evensen, G.: Analysis of iterative ensemble smoothers for solving inverse problems, Comput. Geosci., 22, 885–908, https://doi.org/10.1007/s10596-018-9731-y, 2018. a
Evensen, G. and Van Leeuwen, P. J.: An ensemble Kalman smoother for nonlinear dynamics, Mon. Weather Rev., 128, 1852–1867, https://doi.org/10.1175/1520-0493(2000)128<1852:AEKSFN>2.0.CO;2, 2000. a
Fertig, E. J., Harlim, J., and Hunt, B. R.: A comparative study of 4D-VAR and a 4D ensemble Kalman filter: Perfect model simulations with Lorenz-96, Tellus A, 59, 96–100, https://doi.org/10.1111/j.1600-0870.2006.00205.x, 2007. a
Fillion, A., Bocquet, M., and Gratton, S.: Quasi-static ensemble variational data assimilation: a theoretical and numerical study with the iterative ensemble Kalman smoother, Nonlin. Processes Geophys., 25, 315–334, https://doi.org/10.5194/npg-25-315-2018, 2018. a
Fillion, A., Bocquet, M., Gratton, S., Görol, S., and Sakov, P.: An iterative ensemble Kalman smoother in presence of additive model error, SIAM/ASA J. Uncertainty Quantification, 8, 198–228, 2020. a
Gharamti, M. E., Ait-El-Fquih, B., and Hoteit, I.: An iterative ensemble Kalman filter with one-step-ahead smoothing for state-parameters estimation of contaminant transport models, J. Hydrol., 527, 442–457, https://doi.org/10.1016/j.jhydrol.2015.05.004, 2015. a
Grudzien, C. and Bocquet, M.: A Tutorial on Bayesian Data Assimilation, arXiv [preprint], https://doi.org/10.48550/arXiv.2112.07704, 2021. a
Grudzien, C., Carrassi, A., and Bocquet, M.: Asymptotic forecast uncertainty and the unstable subspace in the presence of additive model error, SIAM/ASA J. Uncertainty Quantification, 6, 1335–1363, https://doi.org/10.1137/17M114073X, 2018. a
Grudzien, C., Sandhu, S., and Jridi, A.: cgrudz/DataAssimilationBenchmarks.jl:, Zenodo [code], https://doi.org/10.5281/zenodo.5430619, 2021. a, b, c, d, e
Gu, Y. and Oliver, D. S.: An iterative ensemble Kalman filter for multiphase fluid flow data assimilation, SPE J., 12, 438–446, https://doi.org/10.2118/108438-PA, 2007. a
Harlim, J. and Hunt, B. R.: Four-dimensional local ensemble transform Kalman filter: numerical experiments with a global circulation model, Tellus A, 59, 731–748, https://doi.org/10.1111/j.1600-0870.2007.00255.x, 2007. a
Hunt, B. R., Kalnay, E., Kostelich, E. J., Ott, E., Patil, D. J., Sauer, T., Szunyogh, I., Yorke, J. A., and Zimin, A. V.: Four-dimensional ensemble Kalman filtering, Tellus A, 56, 273–277, https://doi.org/10.3402/tellusa.v56i4.14424, 2004. a, b
Hunt, B. R., Kostelich, E. J., and Szunyogh, I.: Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter, Phys. D, 230, 112–126, https://doi.org/10.1016/j.physd.2006.11.008, 2007. a, b, c, d
Iglesias, M. A., Law, K. J. H., and Stuart, A. M.: Ensemble Kalman methods for inverse problems, Inverse Problems, 29, 045001, https://doi.org/10.1088/0266-5611/29/4/045001, 2013. a
Jazwinski, A. H.: Stochastic Processes and Filtering Theory, Academic Press, New-York, IBSN 9780486462745, 1970. a, b
Kalnay, E. and Yang, S. C.: Accelerating the spin-up of ensemble Kalman filtering, Q. J. Roy. Meteor. Soc., 136, 1644–1651, https://doi.org/10.1002/qj.652, 2010. a
Kalnay, E., Li, H., Miyoshi, T., Yang, S.-C., and Ballabrera-Poy, J.: 4-D-Var or ensemble Kalman filter?, Tellus A, 59, 758–773, https://doi.org/10.1111/j.1600-0870.2007.00261.x, 2007. a
Kovachki, N. B. and Stuart, A. M.: Ensemble Kalman inversion: a derivative-free technique for machine learning tasks, Inverse Problems, 35, 095005, https://doi.org/10.1088/1361-6420/ab1c3a, 2019. a
Liu, C., Xiao, Q., and Wang, B.: An Ensemble-Based Four-Dimensional Variational Data Assimilation Scheme. Part I: Technical Formulation and Preliminary Test, Mon. Weather Rev., 136, 3363–3373, https://doi.org/10.1175/2008MWR2312.1, 2008. a
Lorenc, A. C.: The potential of the ensemble Kalman filter for NWP – A comparison with 4D-Var, Q. J. Roy. Meteor. Soc., 129, 3183–3203, https://doi.org/10.1256/qj.02.132, 2003. a, b
Lorenz, E. N.: Predictability: A problem partly solved, in: Proc. Seminar on predictability, vol. 1, https://www.ecmwf.int/node/10829 (last access: 10 October 2022), 1996. a
Lorenz, E. N. and Emanuel, K. A.: Optimal sites for supplementary weather observations: Simulation with a small model, J. Atmos. Sci., 55, 399–414, https://doi.org/10.1175/1520-0469(1998)055<0399:OSFSWO>2.0.CO;2, 1998. a
Neal, R. M.: Sampling from multimodal distributions using tempered transitions, Stat. Comput., 6, 353–366, https://doi.org/10.1007/BF00143556, 1996. a
Nerger, L., Schulte, S., and Bunse-Gerstner, A.: On the influence of model nonlinearity and localization on ensemble Kalman smoothing, Q. J. Roy. Meteor. Soc., 140, 2249–2259, https://doi.org/10.1002/qj.2293, 2014. a
Nocedal, J. and Wright, S.: Numerical optimization, Springer Science & Business Media, https://doi.org/10.1007/978-0-387-40065-5, 2006. a
Pulido, M., Tandeo, P., Bocquet, M., Carrassi, A., and Lucini, M.: Stochastic parameterization identification using ensemble Kalman filtering combined with maximum likelihood methods, Tellus A, 70, 1442099, https://doi.org/10.1080/16000870.2018.1442099, 2018. a
Raanes, P. N.: On the ensemble Rauch-Tung-Striebel smoother and its equivalence to the ensemble Kalman smoother, Q. J. Roy. Meteor. Soc., 142, 1259–1264, https://doi.org/10.1002/qj.2728, 2016. a
Raanes, P. N., Bocquet, M., and Carrassi, A.: Adaptive covariance inflation in the ensemble Kalman filter by Gaussian scale mixtures, Q. J. Roy. Meteor. Soc., 145, 53–75, https://doi.org/10.1002/qj.3386, 2019a. a, b
Raanes, P. N., Stordal, A. S., and Evensen, G.: Revising the stochastic iterative ensemble smoother, Nonlin. Processes Geophys., 26, 325–338, https://doi.org/10.5194/npg-26-325-2019, 2019b. a
Raanes, P. N., Grudzien, C., and14tondeu: nansencenter/DAPPER: Version 0.8, Zenodo [code], https://doi.org/10.5281/zenodo.2029296, 2018. a
Raboudi, N. F., Ait-El-Fquih, B., and Hoteit, I.: Ensemble Kalman filtering with one-step-ahead smoothing, Mon. Weather Rev., 146, 561–581, https://doi.org/10.1175/MWR-D-17-0175.1, 2018. a
Sakov, P. and Bertino, L.: Relation between two common localisation methods for the EnKF, Comput. Geosci., 15, 225–237, https://doi.org/10.1007/s10596-010-9202-6, 2011. a, b
Sakov, P. and Oke, P. R.: A deterministic formulation of the ensemble Kalman filter: an alternative to ensemble square root filters, Tellus A, 60, 361–371, https://doi.org/10.1111/j.1600-0870.2007.00299.x, 2008a. a
Sakov, P. and Oke, P. R.: Implications of the form of the ensemble transformation in the ensemble square root filters, Mon. Weather Rev., 136, 1042–1053, https://doi.org/10.1175/2007MWR2021.1, 2008b. a, b, c
Sakov, P., Evensen, G., and Bertino, L.: Asynchronous data assimilation with the EnKF, Tellus A, 62, 24–29, https://doi.org/10.1111/j.1600-0870.2009.00417.x, 2010. a
Sakov, P., Oliver, D. S., and Bertino, L.: An iterative EnKF for strongly nonlinear systems, Mon. Weather Rev., 140, 1988–2004, https://doi.org/10.1175/MWR-D-11-00176.1, 2012. a, b, c
Sakov, P., Haussaire, J. M., and Bocquet, M.: An iterative ensemble Kalman filter in presence of additive model error, Q. J. Roy. Meteor. Soc., 144, 1297–1309, https://doi.org/10.1002/qj.3213, 2018. a
Sankhya, A.: Reprint of: Mahalanobis, P.C. (1936) “On the Generalised Distance in Statistics”, 80 (Suppl 1), 1–7, https://doi.org/10.1007/s13171-019-00164-5, 2018. a
Schillings, C. and Stuart, A. M.: Convergence analysis of ensemble Kalman inversion: the linear, noisy case, Appl. Anal., 97, 107–123, https://doi.org/10.1080/00036811.2017.1386784, 2018. a
Tandeo, P., Ailliot, P., Bocquet, M., Carrassi, A., Miyoshi, T., Pulido, M., and Zhen, Y.: A review of innovation-based methods to jointly estimate model and observation error covariance matrices in ensemble data assimilation, Mon. Weather Rev., 148, 3973–3994, https://doi.org/10.1175/MWR-D-19-0240.1, 2020. a
Taylor, M. E.: Partial differential equations. 1, Basic theory, Springer, https://doi.org/10.1007/978-1-4419-7055-8, 1996. a
Tippett, M. K., Anderson, J. L., Bishop, C. H., Hamill, T. M., and Whitaker, J. S.: Ensemble square root filters, Mon. Weather Rev., 131, 1485–1490, https://doi.org/10.1175/1520-0493(2003)131<1485:ESRF>2.0.CO;2, 2003. a
Whitaker, J. S. and Loughe, A. F.: The relationship between ensemble spread and ensemble mean skill, Mon. Weather Rev., 126, 3292–3302, https://doi.org/10.1175/1520-0493(1998)126<3292:TRBESA>2.0.CO;2, 1998. a
Yang, S.-C., Lin, K. J., Miyoshi, T., and Kalnay, E.: Improving the spin-up of regional EnKF for typhoon assimilation and forecasting with Typhoon Sinlaku (2008), Tellus A, 65, 20804, https://doi.org/10.3402/tellusa.v65i0.20804, 2013. a
Zupanski, M.: Maximum likelihood ensemble filter: Theoretical aspects, Mon. Weather Rev., 133, 1710–1726, https://doi.org/10.1175/MWR2946.1, 2005. a, b
Zupanski, M., Navon, I. M., and Zupanski, D.: The Maximum Likelihood Ensemble Filter as a non-differentiable minimization algorithm, Q. J. Roy. Meteor. Soc., 134, 1039–1050, https://doi.org/10.1002/qj.251, 2008. a