the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 01 Dec 2020
| 01 Dec 2020
On the tuning of atmospheric inverse methods: comparisons with the European Tracer Experiment (ETEX) and Chernobyl datasets using the atmospheric transport model FLEXPART
Lukáš Ulrych
Václav Šmídl
Nikolaos Evangeliou
Andreas Stohl
Estimation of the temporal profile of an atmospheric release, also called the source term, is an important problem in environmental sciences. The problem can be formalized as a linear inverse problem wherein the unknown source term is optimized to minimize the difference between the measurements and the corresponding model predictions. The problem is typically ill-posed due to low sensor coverage of a release and due to uncertainties, e.g., in measurements or atmospheric transport modeling; hence, all state-of-the-art methods are based on some form of regularization of the problem using additional information. We consider two kinds of additional information: the prior source term, also known as the first guess, and regularization parameters for the shape of the source term. While the first guess is based on information independent of the measurements, such as the physics of the potential release or previous estimations, the regularization parameters are often selected by the designers of the optimization procedure. In this paper, we provide a sensitivity study of two inverse methodologies on the choice of the prior source term and regularization parameters of the methods. The sensitivity is studied in two cases: data from the European Tracer Experiment (ETEX) using FLEXPART v8.1 and the caesium-134 and caesium-137 dataset from the Chernobyl accident using FLEXPART v10.3.
- Article
(2978 KB) - Full-text XML
- BibTeX
- EndNote





The source term describes the spatiotemporal distribution of an atmospheric release, and it is of great interest in the case of an accidental atmospheric release. The aim of inverse modeling is to reconstruct the source term by maximization of agreement between the ambient measurements and prediction of an atmospheric transport model in a so-called top-down approach (Nisbet and Weiss, 2010). Since information provided by the measurements is often insufficient in both spatial and temporal domains (Mekhaimr and Wahab, 2019), additional information and regularization of the problem are crucial for a reasonable estimation of the source term (Seibert et al., 2011). Otherwise, the top-down determination of the source term can produce artifacts, often resulting in some completely implausible values of the source term. One common regularization is the knowledge of the prior source term, also known as the first guess, considered within the optimization procedure (Eckhardt et al., 2008; Liu et al., 2017; Chai et al., 2018). However, this knowledge could dominate the resulting estimate and even outweigh the information present in the measured data. The aim of this study is to discuss drawbacks that may arise in setting the prior source term and to study the sensitivity of inversion methods to the choice of the prior source term. We utilize the ETEX (European Tracer Experiment) and Chernobyl datasets for demonstration.
We assume that the measurements can be explained by a linear model using the concept of the source–receptor sensitivity (SRS) matrix calculated from an atmospheric transport model (e.g., Seibert and Frank, 2004). The problem can be approached by a constrained optimization with selected penalization term on the source term (Davoine and Bocquet, 2007; Ray et al., 2015; Henne et al., 2016) and further with an additional smoothness constraint (Eckhardt et al., 2008) used for both spatial (Stohl et al., 2011) and temporal (Seibert et al., 2011; Stohl et al., 2012; Evangeliou et al., 2017) profile smoothing. The optimization terms are typically weighted by covariance matrices whose forms and estimation have been studied in the literature. Diagonal covariance matrices have been considered by Michalak et al. (2005) and its entries estimated using the maximum likelihood method. Since the estimation of full covariance matrices tends to diverge (Berchet et al., 2013), approaches using a fixed common autocorrelation timescale parameter for non-diagonal entries has been introduced (Ganesan et al., 2014; Henne et al., 2016) for atmospheric gas inversion. Uncertainties can be also reduced with the use of ensemble techniques (see, e.g., Evensen, 2018; Carrassi et al., 2018, and references therein) when such an ensemble is available in the form of several meteorological input datasets and/or variations in atmospheric model parameters. Even with only one SRS matrix, the problem can be formulated as a probabilistic hierarchical model with unknown parameters estimated together with the source term with constraints such as positivity, sparsity, and smoothness (Tichý et al., 2016). The drawback of these methods is the necessity of selection and tuning of various model parameters, with the selection of the prior source term and its uncertainty being the most important.
There are various assumptions on the level of knowledge of the prior source term used in the inversion procedure. Assumption of the zero prior source term (Bocquet, 2007; Tichý et al., 2016) is common in the literature with a preference for a zero solution on elements whereby no sufficient information from data is available. This assumption is typically formalized as the Tikhonov (Golub et al., 1999) or LASSO (Tibshirani, 1996) regularizations or their variants. Soft assumptions in the form of the scale of the prior source term (Davoine and Bocquet, 2007), bounds on emissions (Miller et al., 2014), or even knowledge of total released amount as discussed, e.g., in Bocquet (2005) can be considered. One can also assume the ratios between species in multispecies source term scenarios (Saunier et al., 2013; Tichý et al., 2018). However, the majority of inversion methods explicitly assume knowledge of the prior source term (Connor et al., 2008; Eckhardt et al., 2008; Liu et al., 2017). This is more or less justified by appropriate construction of the prior source term based, for example, on a detailed analysis of an inventory and accident (Stohl et al., 2012), on previous estimates when available (Evangeliou et al., 2017), or on measured or observed data (Stohl et al., 2011). While in well-documented cases this approach could be well-justified, in cases with very limited available information or even complete absence of information on the source term, such as the iodine occurrence over Europe in 2017 (Masson et al., 2018) and the unexpected detection of ruthenium in Europe in 2017 (Bossew et al., 2019; Saunier et al., 2019), the use of strong prior source term assumptions could lead to prior-dominated results with limited validity. Although the choice of the prior source term is crucial, few studies have discussed the choice of the prior source term in detail and provided sensitivity studies on this selection as in Seibert et al. (2011) for the temporal profile of sulfur dioxide emissions and in Stohl et al. (2009) for the spatial distribution of greenhouse gas emissions.
The aim of this paper is to explore the sensitivity of linear inversion methods to the prior source term selection coupled with tuning of the covariance matrix representing modeling error. We considered the optimization method proposed by Eckhardt et al. (2008), as well as its probabilistic counterpart formulated as the hierarchical Bayesian model, extended here by a nonzero prior source term with variational Bayes' inference (Tichý et al., 2016) and with Monte Carlo inference using a Gibbs sampler (Ulrych and Šmídl, 2017). Two real cases will be examined: the ETEX (Nodop et al., 1998) and Chernobyl (Evangeliou et al., 2016) datasets. ETEX provides ideal data for a prior source term sensitivity study since the emission profile is exactly known. We propose various modifications of the known prior source term and study their influence on the results of the selected inversion methods. The Chernobyl dataset, on the other hand, provides a very demanding case in which only consensus on the release is available and the source term is more speculative.
We are concerned with linear models of atmospheric dispersion using an SRS matrix (Seibert, 2001; Wotawa et al., 2003; Seibert and Frank, 2004), which has been used in inverse modeling (Evangeliou et al., 2017; Liu et al., 2017). Here, the atmospheric transport model calculates the linear relationship between potential sources and atmospheric concentrations. The source–receptor sensitivity is calculated as , where xj is the assumed release from the release site at time j and ci is the calculated concentration at a receptor ci at the respective time period. The measurement yi at a given time and location can be explained as a sum of contributions from all elements of the source term weighted by mij. In matrix notation,
where y∈ℜp is a vector aggregating measurements from all locations and times (in arbitrary order), and x∈ℜn is a vector of all possible releases from a given time period and all possible source–receptor sensitivities form the SRS matrix . The residual model, e∈ℜp, is a sum of model and measurement errors. While the model looks trivial, its use in practical applications poses significant challenges. The key reason is that all elements of the model are subject to uncertainty (Winiarek et al., 2012; Liu et al., 2017) and the problem is ill-posed.
In the rest of this section, we will discuss an influence of the modeling error and show how existing methods approach compensation of such error. We will analyze in detail two methods for the source term estimation: (i) the optimization model proposed by Eckhardt et al. (2008) with a prior source term already considered and (ii) a Bayesian model (Tichý et al., 2016) extended here by prior source term information and solved using both the variational Bayes' method and the Gibbs sampling method.
2.1 Influence of atmospheric model error
It is generally assumed that the SRS matrix M is correct and the true source term minimizes error of y=Mx. However, M is prone to errors due to a number of approximations in the formulation of the atmospheric transport model and use of uncertain weather analysis data as input to the atmospheric transport model. Therefore, one should rather consider a hypothetical model,
where M is the available estimate of the sensitivity matrix from a numerical model, and the term ΔM is the deviation of the estimate from the true generating matrix, . Exact estimation of ΔM is not possible due to a lack of data; however, many existing regularization techniques can be interpreted as various simplified parameterizations of ΔM.
The L2 norm1 of the residuum between measurement and reconstruction for Eq. (3) would become
The ideal optimization problem (right-hand side of Eq. 3) can be decomposed into the norm of residues of the estimated model , with both linear (i.e., −2yTΔMx) and quadratic terms in x (i.e., xTΦx). Both of the additional terms contribute to incorrect estimation of x when ΔM is significant.
An common attempt to minimize the influence of the linear term is to define the prior source term xa and subtract Mxa from both sides of Eq. (2). This yields a new decomposition derived in Appendix A (with substitutions and ) as
where Φ is the same term as in Eq. (3).
In the ideal situation, we would like to optimize the left-hand side of Eqs. (3) and (4). However, due to unavailability of ΔM the linear term is typically ignored (assumed to be negligible) and the quadratic term is approximated using a parametric form of Φ≈Ξ. The optimization criterion is then
The estimation error caused by approximation (5) can be influenced by two choices of the user: (i) first guess xa and (ii) regularization matrix Ξ. The purpose of choosing xa is minimization of the linear term in Eq. (4). The choice of the parametric form of Ξ corresponds to choosing a model of the SRS matrix error ΔM, since Ξ is an approximation of Φ, which is determined by ΔM.
In the following sections, we will discuss methods that estimate Ξ from the data using parameterization of Ξ by tri-diagonal matrices with a limited number of parameters. Specifically, we will investigate if the choice of xa has an impact on better estimation of Ξ.
2.2 Optimization approach

In Eckhardt et al. (2008), the source term inversion problem is formulated as in Eq. (5) with choices
where matrix B is the selected or estimated precision matrix, the matrix D a discrete representation of the second derivative with diagonal elements equal to −2 and equal to 1 on the first sub-diagonals, and the scalar ϵ is the parameter weighting the smoothness of the solution x.
Minimization of Eq. (5) does not guarantee the non-negativity of the estimated source term x. To solve this issue, an iterative procedure is adopted (Eckhardt et al., 2008) whereby minimization of Eq. (5) is done repetitively with reduced diagonal elements of B related to the negative parts of the solution, thus tightening the solution to the prior source term, which is assumed to be non-negative. The diagonal elements of B related to the positive parts of the solution can, on the other hand, be enlarged up to a selected constant. This can be iterated until the absolute value of the sum of negative source term elements is lower than 0.01 % of the sum of positive source term elements. Formally, Bj,j in the ith iteration is calculated as
We observed very low sensitivity to the choice of the recommended values of 0.5 and in Eq. (7). In most cases, varying these values does not lead to any serious differences in the resulting estimate. However, the selection of parameters xa, errx, and ϵ is crucial and will be discussed in Sect. 2.4.
The method is summarized as Algorithm 1 and will be denoted as the optimization method in this study. The maximum number of iterations is set to 50, which was enough for convergence in all our experiments. To solve the minimization problem (5), we use the CVX toolbox (Grant and Boyd, 2008, 2018) for MATLAB.
2.3 Bayesian approach

In Tichý et al. (2016), the problem was addressed using a Bayesian approach. The difference from the optimization approach is twofold. First, it has a different approximation of the covariance matrix Ξ:
where matrix L models smoothness and matrix Υ models closeness to the prior source term xa. Matrix is a diagonal matrix with positive entries, while matrix L is a lower bi-diagonal matrix:
Second, the Bayesian approach allows us to estimate the hyper-parameters Υ and L from the data.
Specifically, it formulates a hierarchical probabilistic model:
Here, 𝒩(μ,Σ) denotes a multivariate normal distribution with a given mean vector and covariance matrix, denotes a multivariate normal distribution truncated to given support [a,b] (for details, see Appendix in Tichý et al., 2016), and 𝒢(α,β) denotes a gamma distribution with given scalar parameters. Prior constants α0 and β0 are selected similarly to ϑ0 and ρ0 as 10−10, yielding a noninformative prior, and prior constants ζ0 and η0 are selected as 10−2 to favor a smooth solution (equivalent to lj prior value −1); see the discussion in Tichý et al. (2016). To consider the prior vector xa is novel in the LS-APC model.
To estimate the parameters of the prior model (10), (11), and (10)–(15), we will use two inference methods, variational Bayes' approximation and Gibbs sampling.
2.3.1 Variational Bayes' solution
The variational Bayes' solution (Šmídl and Quinn, 2006) seeks the posterior in the specific form of conditional independence such as
The best possible approximation minimizes Kullback–Leibler divergence (Kullback and Leibler, 1951) between the estimated solution and hypothetical true posterior. This minimization uniquely determines the form of the posterior distribution:
for which the shaping parameters , and ρ are derived in Appendix B. The shaping parameters are functions of standard moments of posterior distribution, which are denoted here as and indicate the expected value with respect to the distribution on the variable in the argument. The standard moments together with shaping parameters form a set of implicit equations solved iteratively; see Algorithm 2. Note that only convergence to a local optimum is guaranteed; hence, a good initialization and iteration strategy are beneficial (see Algorithm 2 and the discussion in Tichý et al., 2016). The algorithm is denoted as the LS-APC-VB algorithm.
2.3.2 Gibbs sampling solution

The Gibbs sampler is a Markov chain Monte Carlo method for obtaining sequences of samples from distributions for which direct sampling is difficult or intractable (Casella and George, 1992). It is a special case of the Metropolis–Hastings algorithm with the proposal distribution derived directly from the model (Chib and Greenberg, 1995). Given a joint probability density , a full conditional distribution needs to be derived for each variable or a block of variables; i.e., for x, distribution has to be found. These full conditionals then serve as proposal generators and have the same form as Eqs. (17)–(21). We use the original Gibbs sampler from George and McCulloch (1993). Having samples from the last iteration, or a random initialization for the first iteration, the algorithm sweeps through all variables and draws samples from their respective full conditional distributions. It can be shown that samples generated in such a manner form a Markov chain whose stationary distribution, the distribution to which the chain converges, is the original joint probability density. Since the convergence of the algorithm can be very slow, it is common practice to discard the first few obtained samples. This is known as a burn-in period. The advantage of this algorithm is its indifference to the initial state from which sampling starts.
2.4 Tuning parameters and prior source term
All mentioned methods are sensitive to a certain extent to the selection of their parameters. Here, we will identify these tuning parameters and discuss their settings in the following experiments. Moreover, we will discuss the selection of the prior source term.
The optimization approach is summarized in Algorithm 1 wherein two key tuning parameters are needed: parameter errx, which affects the closeness of a solution to the prior source term through the matrix B, and parameter ϵ, which affects the smoothness of a solution. In the following experiments, we select the parameter ϵ by experience, while it can be seen that the solution is similar for a relatively wide range of values (a few orders of magnitude). The parameter errx seems to be crucial for the optimization method and sensitivity to the choice of this parameter will be studied, while errx will be referred to as the tuning parameter. Note that heuristic techniques such as the L-curve method (Hansen and O'Leary, 1993) cannot be used here because of the modification of the matrix B within the algorithm. This will be demonstrated in Sect. 3 (Fig. 2). The LS-APC-VB method, summarized in Algorithm 2, also needs the selection of initial errx; however, relatively low sensitivity to this choice was reported (Tichý et al., 2016). The LS-APC-G method, summarized in Algorithm 3, is also initialized using errx, while its sensitivity to this choice is negligible due to the Gibbs sampling mechanism.
To select the prior source term seems to be an even more difficult problem, especially in cases of releases with limited available information. Therefore, we will investigate various errors in the prior source term, which can be considered thanks to controlled experiments in which the true source term is available. We consider the time shift of the prior source term in contrast with the true source term, different scales, and a blurred version of the true source term. These errors can be examined alone or combined, which will probably be more realistic.
2.5 Tuning by cross-validation
While the tuning parameters selected in the previous section are often selected manually, statistical methods for their selection are also available. One of the most popular is cross-validation (Efron and Tibshirani, 1997), which we will investigate in the context of source term determination. The method is really simple: all available data are split into training and testing datasets ytrain, Mtrain, ytest, and Mtest. The training dataset is then used for source term estimation, while the test dataset is used for computation of the norm of the residue of the estimated source term, . Such an estimate is known to be almost unbiased but with large variance. Therefore, the procedure is repeated several times and the tuning parameters are selected based on statistical evaluation of the results. In this experiment, we repeat the random selection of 80 % of the measurements as the training set and using the remaining 20 % as the test set. For each tuning parameter errx, this is repeated 100 times in order to reach statistical significance of the selected tuning parameter.
The European Tracer Experiment (ETEX) is one of a few large controlled tracer experiments (see https://rem.jrc.ec.europa.eu/etex/, last access: 26 April 2020). We use data from the first release in which a total amount of 340 kg of nearly inert perfluoromethylcyclohexane (PMCH) was released at a constant rate for nearly 12 h at Monterfil in Brittany, France, on 23 October 1994 (Nodop et al., 1998). Atmospheric concentrations of PMCH were monitored at 168 measurement stations across Europe with a sampling interval of 3 h and a total number of measurements of 3102. The ETEX dataset has been used as a validation scenario for inverse modeling (see, e.g., Bocquet, 2007; Martinez-Camara et al., 2014; Tichý et al., 2016). The great benefit of this dataset is that the estimated source terms can be directly compared with the true release given in Fig. 1 (first row) using dashed red lines.
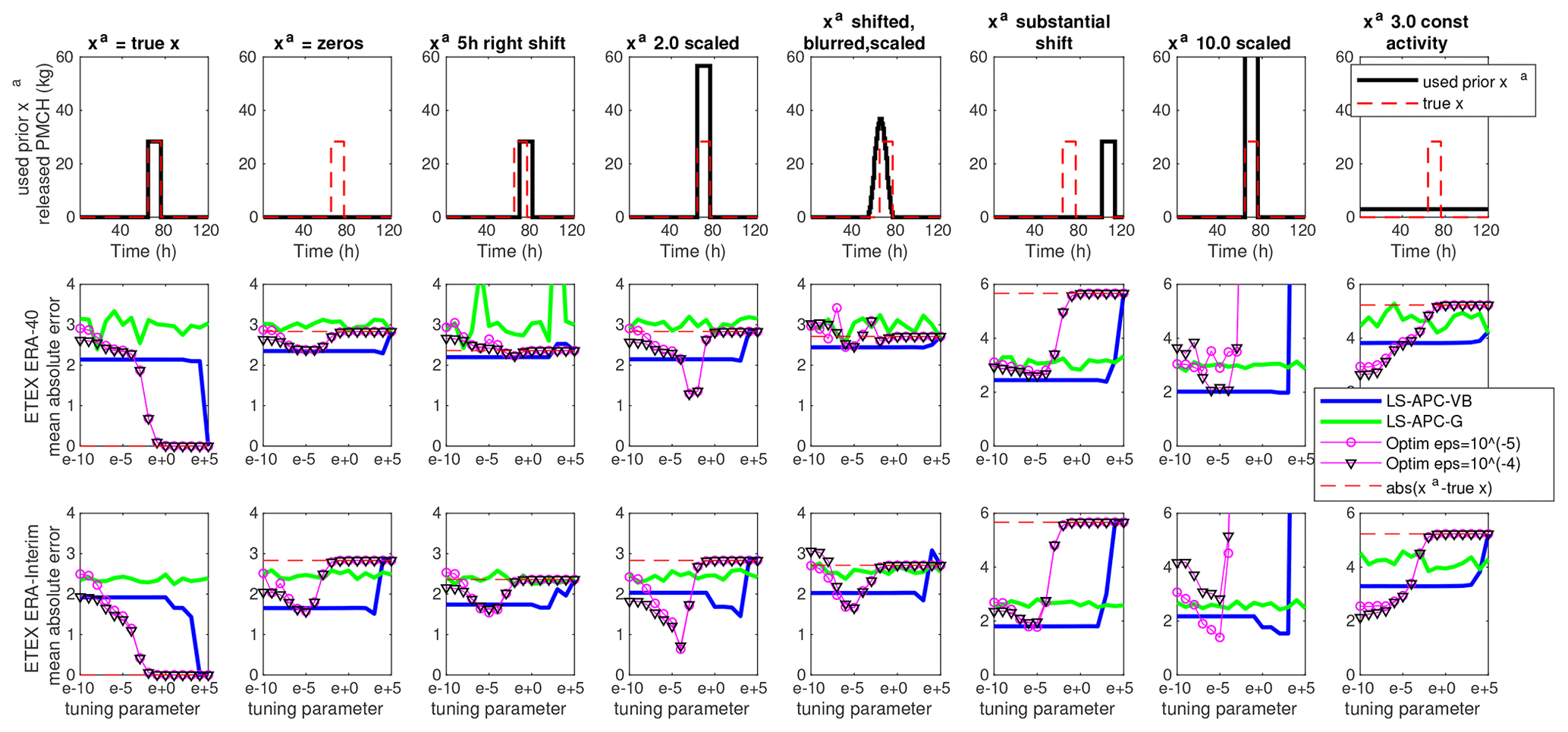
Figure 1The uppermost row of panels shows eight different prior source terms xa (black lines) used for the ETEX source term estimation. The true ETEX source term is repeated in every panel (red dashed line). The middle and the lowermost rows display the mean absolute error between estimated and true source terms for the ETEX ERA-40 and ETEX ERA-Interim datasets, respectively.
To calculate the SRS matrices, we used the Lagrangian particle dispersion model FLEXPART (Stohl et al., 1998, 2005) version 8.1. We assume that the release period occurred during 120 h period; thus, 120 forward calculations of a 1 h hypothetical unit release were performed and SRS coefficients were calculated from simulated concentrations corresponding to the 3102 measurements. As a result, we obtained the SRS matrix . FLEXPART is driven by meteorological input data from the European Center for Medium-Range Weather Forecasts (ECMWF) from which different datasets are available. We used two: (i) data from the 40-year reanalysis (ERA-40) and (ii) data from the continuously updated ERA-Interim reanalysis. The computed matrices for ETEX are given in Appendix C together with their associated singular values to demonstrate conditioning of the problem.
The tested method will be compared in terms of the mean absolute error (MAE) between the estimated and the true source term for different tuning parameters errx. We select two representative values of the smoothing parameter ϵ for the optimization method. Specifically, we selected and , while higher values lead to overly smooth and lower values to non-smooth solutions. We tested eight different prior source terms xa; see Fig. 1, top row, black lines. These included the following: xa equal to (i) the true source term; (ii) zeros for all elements; (iii) true source term right-shifted by five time steps; (iv) true source term scaled by a factor of 2.0; (v) true source term blurred using a convolution kernel of five time steps, left-shifted by five time steps, and scaled by a factor of 1.3; (vi) true source term substantially right-shifted; (vii) true source term scaled by a factor of 10; and (viii) source term with constant activity. The resulting MAEs for all tested methods and for all eight prior source terms are displayed in Fig. 1 for ETEX with the ERA-40 dataset in the second column and for ETEX with ERA-Interim in the third row. The figures in the second and third rows are accompanied by the MAE between the true source term and the prior source term used, displayed with dashed red lines.
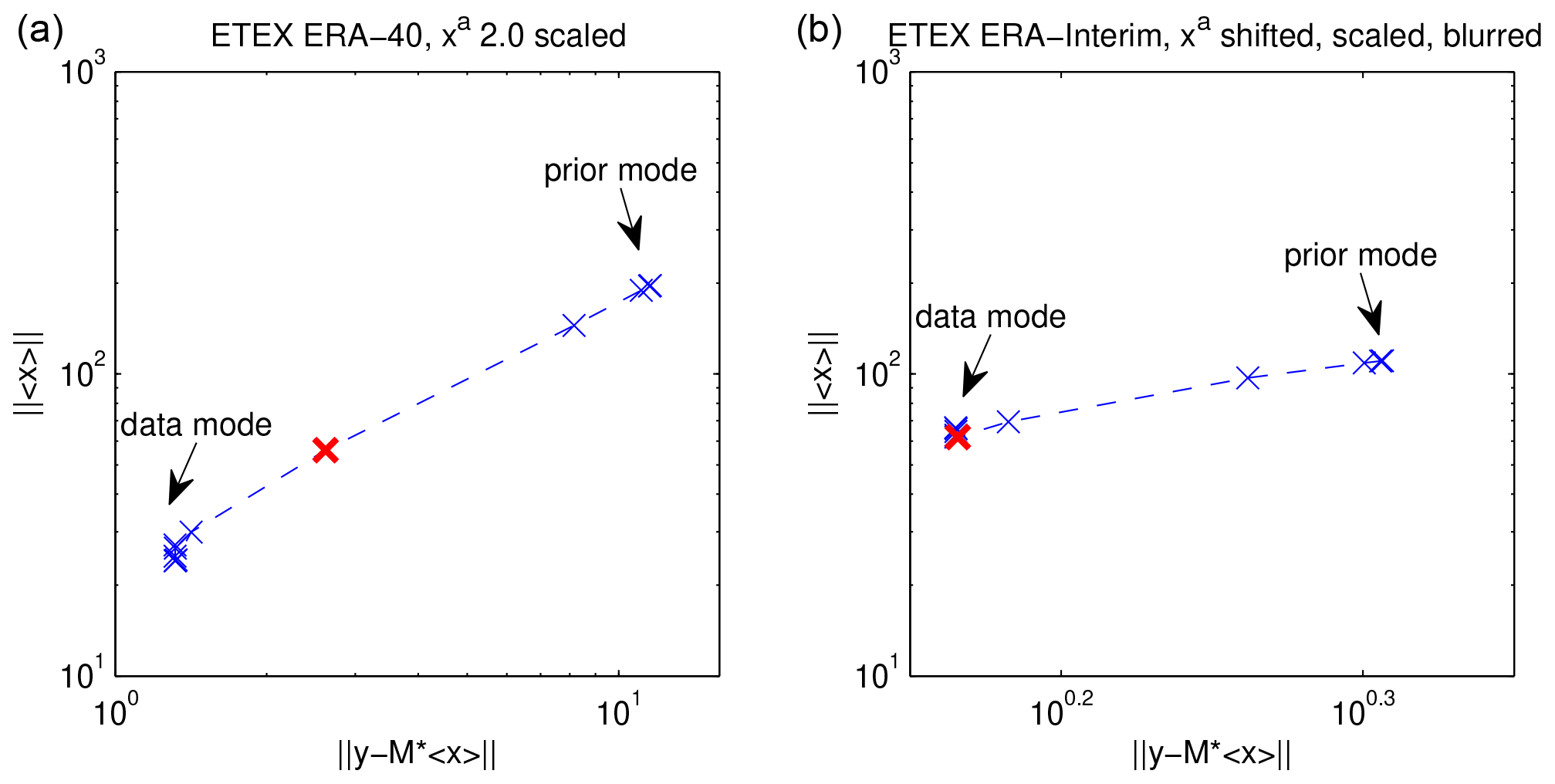
Figure 2L-curve-type plots using the optimization algorithm with from ETEX ERA-40 with xa 2.0 scaled (a) and from ETEX ERA-Interim with xa shifted, scaled, and blurred (b). The red crosses denote “sweet spots”.
3.1 Results
We observe that for all choices of the optimization method, the results exhibit two notable modes of solution: the data mode for tuning parameters with minimum impact on the loss function and the prior mode for tuning parameter values that cause the prior to dominate the loss function. This is notable for the results in the range of errx in Fig. 1. For the data term dominates the loss function, and all methods converge to a similar answer (note that the data mode is different for different smoothing parameters in the optimization method).
For errx=105, the loss function is dominated by the prior and all estimates converge to xa. Although there are typically only two visibly stable modes of all the solutions (the data and prior mode), we also observe a third mode in the optimization solution, best seen, e.g., in Fig. 1 in the second row and the fourth column or in the third row and the fifth column, where the error significantly drops. These “sweet spots” are the desired locations that we hope to find by tuning of the hyper-parameters. While they are obvious when we know the ground truth, the challenge is to find them without this knowledge.
An attempt to find the optimal tuning via the L-curve method (i.e., dependence between the norm of the solution and the norm of the residuum between measurement and reconstruction) is displayed and demonstrated in two cases: ETEX ERA-40 with xa 2.0 scaled (Fig. 2, left) and ETEX ERA-Interim with xa shifted, scaled, and blurred (Fig. 2, right) for the optimization method with . In these cases (and all others), L-curve shapes were not reached at all and thus an optimum regularization parameter cannot be chosen from these plots. The red crosses denote the value corresponding to minima of MAEs. One can see that the sweet spots are on the transition between the data mode and the prior mode of solutions with no specific feature in these measures. More detailed analysis is presented in the next section.
The LS-APC-VB method also exhibits modes of solution; however, the transition between the data mode and the prior source term mode seems to be rather fast. Notably, no such transitions are observed in the case of the LS-APC-G method. This is caused by the fact that the Gibbs sampling is not sensitive to the selection of the initial state, as discussed in Sect. 2.3.2. With the exception of xa as a constant activity (Fig. 1, eighth column), the LS-APC-VB method performs better than the optimization method when approaching the data mode of a solution. The LS-APC-G method suffers from overestimating the source term in time steps when the true source term is zero and not enough evidence is available in the data. This can clearly be seen in Figs. 3 and 4 where estimates from the LS-APC-G method are displayed using green lines; see especially the time steps between 15 and 45 h. This is closely related to the low sensitivities in SRS matrices between the 15th and 45th columns; see Fig. C1 for an illustration.
3.2 Desired optima of the estimated source term
Here, we will discuss the behavior of the methods around the regions of the tuning parameter with minimum MAE (sweet spots) observed in the case of the optimization method. Note that no such regions are observed in the case of the LS-APC-VB and LS-APC-G methods. The temporal profiles of the estimated source term at different penalization coefficients selected around two different sweet spots are displayed in Figs. 3 and 4.
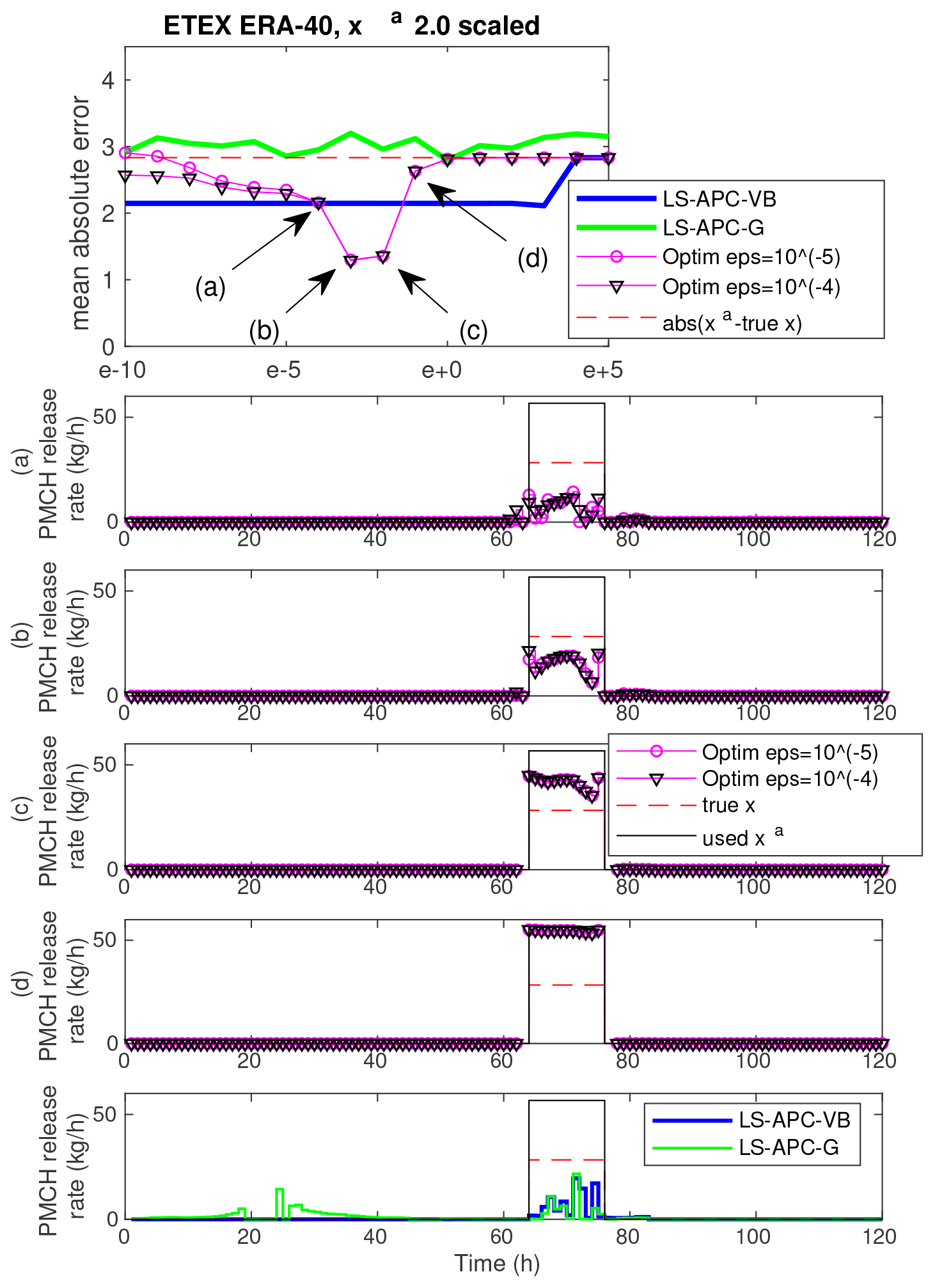
Figure 3The uppermost panel shows mean absolute errors between estimated and true source terms for the ETEX ERA-40 dataset with xa 2.0 scaled for all methods. Certain settings of the tuning parameter are highlighted and labeled with (a), (b), (c), and (d). Estimated source terms for these tuning parameter choices are given in the panels below. The lowermost panel displays the estimated source terms from the LS-APC-VB and LS-APC-G algorithms for comparison.
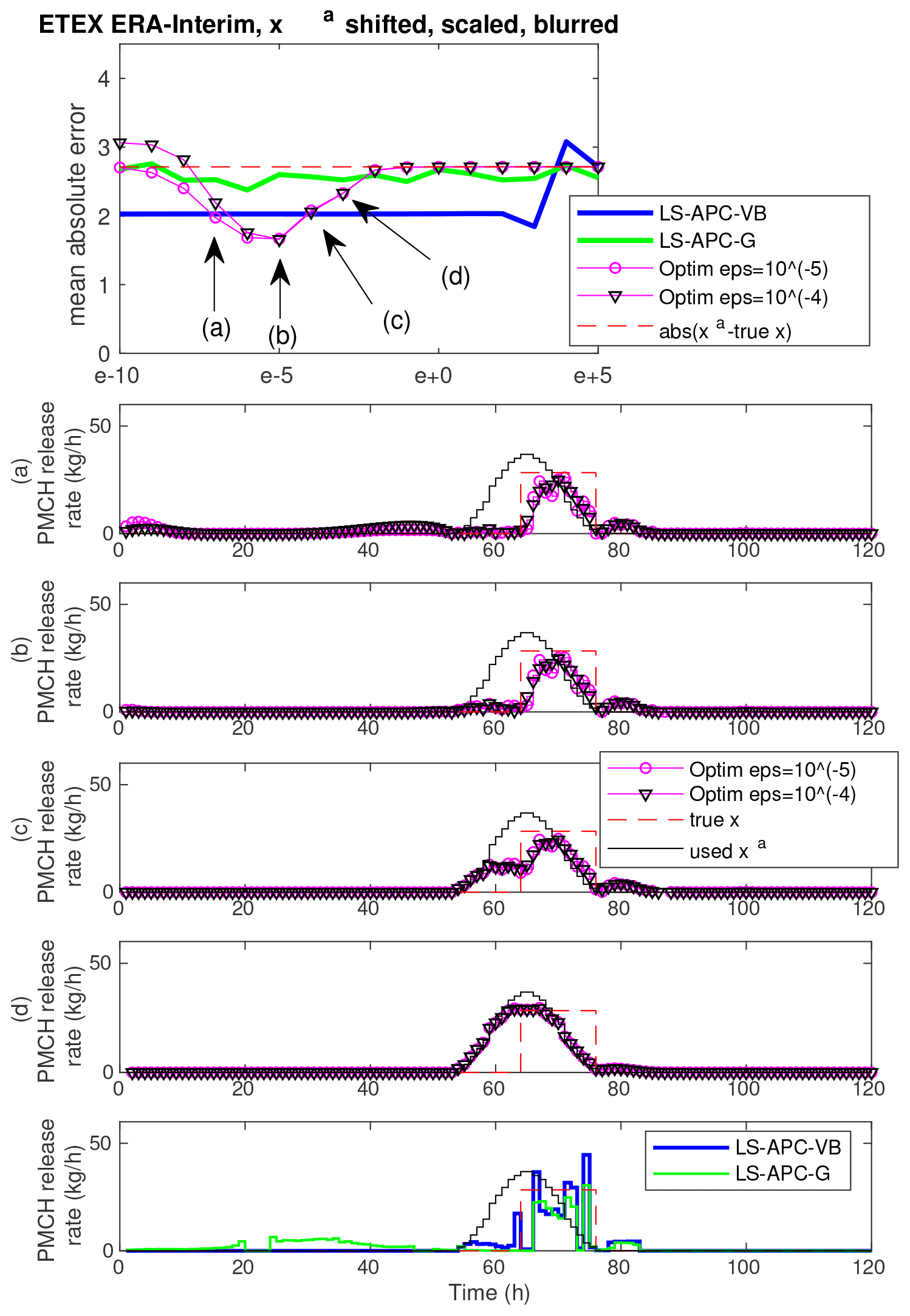
Figure 4Same as Fig. 3 for the ETEX ERA-Interim dataset with xa shifted, scaled, and blurred.
Figure 3 displays results for the ETEX ERA-40 dataset with the prior source term selected as the 2.0 times scaled true source term. The top graph is a copy of sensitivity to tuning in terms of MAE from Fig. 1 (second row, fourth column), and labels (a), (b), (c), and (d) indicate selected values of tuning parameters for which the resulting estimated source terms are shown in Fig. 3. The four estimates illustrate the transition from the data mode of solution (a) to the prior mode of solution (d). The data mode underestimates the true release, while the prior mode overestimates it. As displayed in Fig. 3b and c, the slow transition between these two modes allows us to approach the true source term closely, since the chosen prior term is only a scaled version of the true release and the sweet spot lies exactly between the two modes. Both the LS-APC-VB and the LS-APC-G methods diverge from the “good” solution since they consider it to be very unlikely with respect to the observed data. Since no heuristics such as the L-curve can identify this tuning as providing good results (see Fig. 2, left), we argue that choosing the optimal setting of the tuning parameter is not possible without knowledge of the true source term and the occurrence of the sweet spot is only a coincidence.
Figure 4 displays results for the ETEX ERA-Interim dataset with the prior source term shifted, scaled, and blurred in the same way as in the third row and fifth column of Fig. 3. Here, the transition is not so sharp as in the previous case since the true source term does not lie exactly on the transition between the data mode (panel a) and the prior mode (panel d). The data mode (a) also contains nonzero elements, mainly in the first half of the source term. The transition can be seen in Fig. 4b and c where the nonzero activity at the beginning of the data mode is eliminated by using prior source term information, while the nonzero elements are relatively close to the true release (b). In (c), the zero activity in the first half remains due to the prior source term; however, the estimated activity within the true release period moves toward the assumed prior source term. In (d), the estimation is already very close to the chosen prior source term. Once again, the improvement appears to be coincidental rather than systematic.
We note that the two discussed sweet spots are selected as representative cases and other observed sweet spots (see, e.g., Fig. 3, the second or eighth column) are very similar in nature. By analyzing the sweet spots, we conclude that they represent a transition from the data mode to the prior mode of solution. In some cases, the transition is very close to the true release (see, e.g., Fig. 3), while in some cases, no point on the transition path approaches the true solution (see, e.g., Fig. 4), and the data or prior mode is the closest.
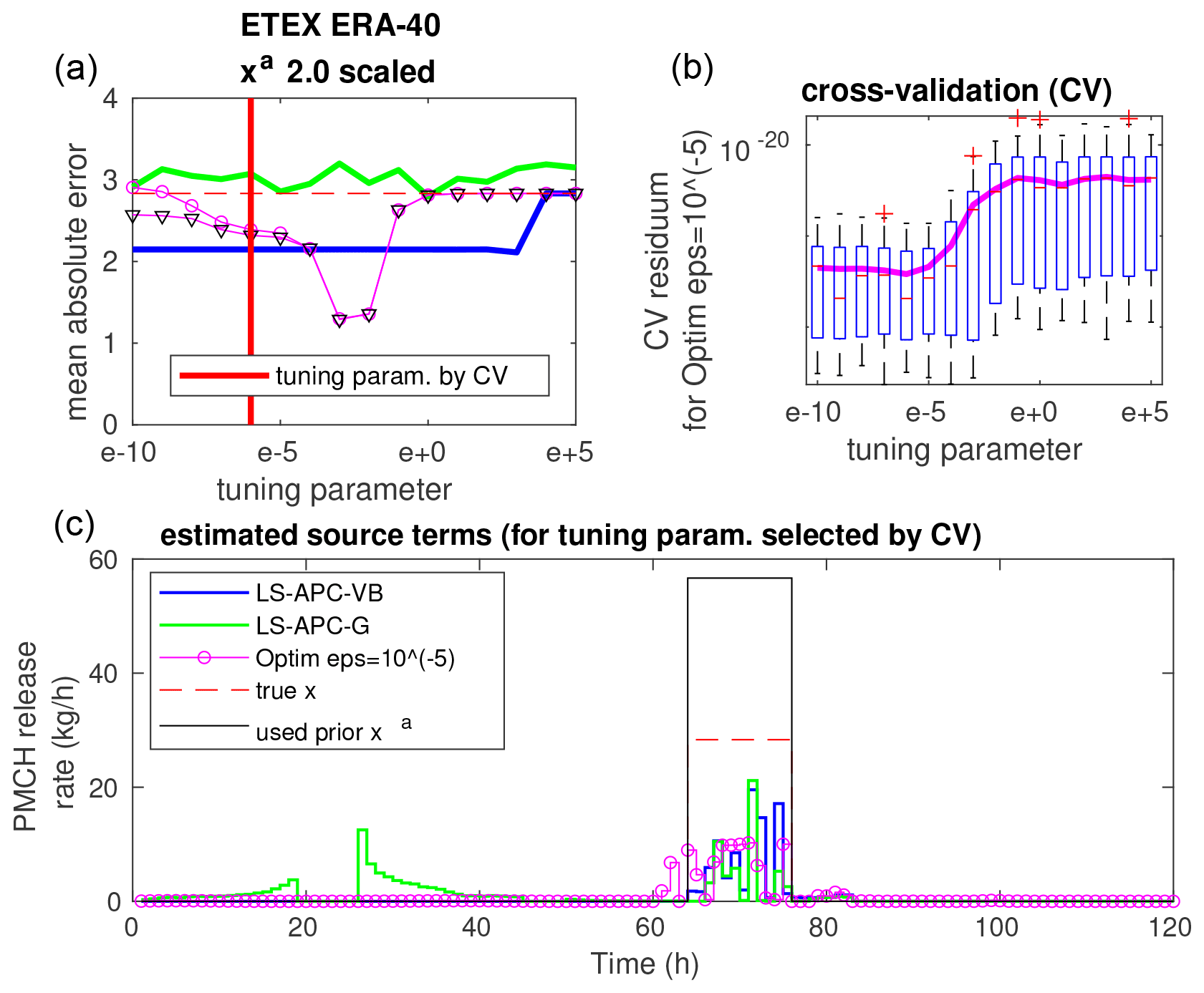
Figure 5The top left panel (a) shows the sensitivity of MAE to the tuning parameter for the ETEX ERA-40 dataset with xa 2.0 scaled. This is a repetition from Fig. 1. The chosen optimal setting based on CV is shown with a thick red vertical line. The top right panel (b) shows the error residuals of the CV experiments as a function of the tuning parameter. Residuals are shown as box-and-whisker plots, where the boxes extend between the 25th and 75th percentiles (whiskers between 2.7 sigmas) and medians are marked with red lines, while mean values are displayed using a solid magenta line. The lowermost panel (c) shows the source term obtained with the tuning parameter setting chosen via CV.
3.3 Tuning by cross-validation
Since the LS-APC-VB and LS-APC-G methods provide rather stable estimates of the source term, we will investigate the use of cross-validation (CV) in optimization-based approaches. The results of CV for the optimization method with for selected combinations are displayed in Figs. 5, 6, and 7 in the top right panels: (i) ERA-40 with xa 2.0 scaled; (ii) ERA-Interim with xa shifted, blurred, and scaled; and (iii) ERA-40 with xa equal to the true source term. The results are displayed using box plots where medians are displayed using red lines inside boxes, while the boxes cover the 25th and 75th quantiles. The mean values of the residuals for each tuning parameter are displayed using magenta lines. The value of the tuning parameter that minimizes the CV error is also visualized in the top left panels using solid vertical red lines inside the graphs of MAE sensitivity from Fig. 1. Bottom panels of figures display the estimated source terms using the tested methods for the tuning parameter selected by cross-validation together with the true source term (dashed red line) and the prior source term used (full black line).

Figure 6Same as Fig. 5 for the ETEX ERA-Interim dataset with xa shifted, scaled, and blurred.
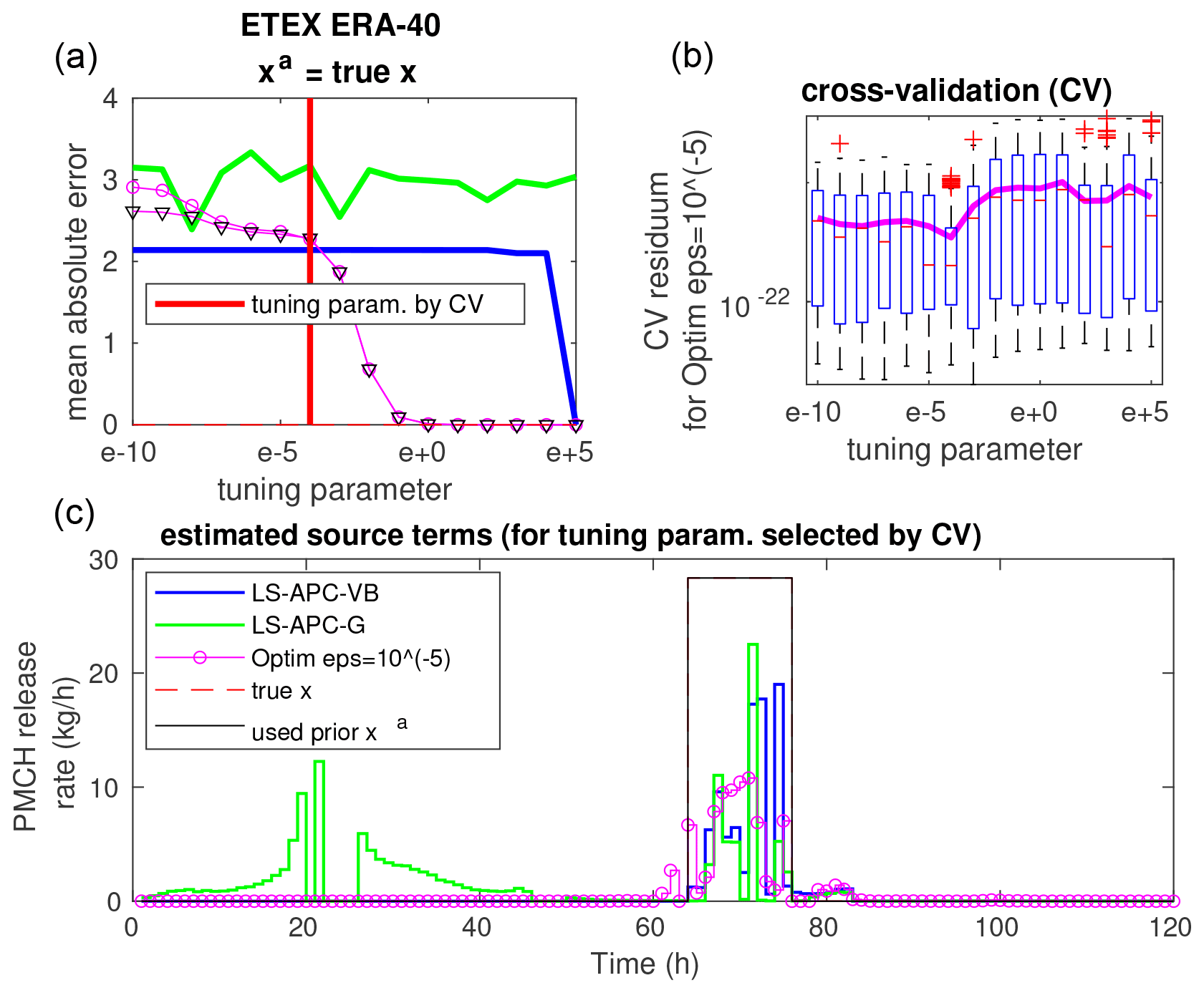
The results demonstrate significant differences between the prior mode and the data mode of the solution, which can be seen in all cross-validation box plots. This is also the case for xa, which is not displayed here. Notably, the minima of cross-validation are not reached in the positions of the sweet spots, indicating that the observed MAE minima are coincidental. In all tested cases, the minima of cross-validation are reached closer to the data mode than to the prior mode. This is demonstrated for the extreme case of xa equal to the true source term in Fig. 7. Even for this case, the minimum of cross-validation is associated with the data mode rather than the prior mode.
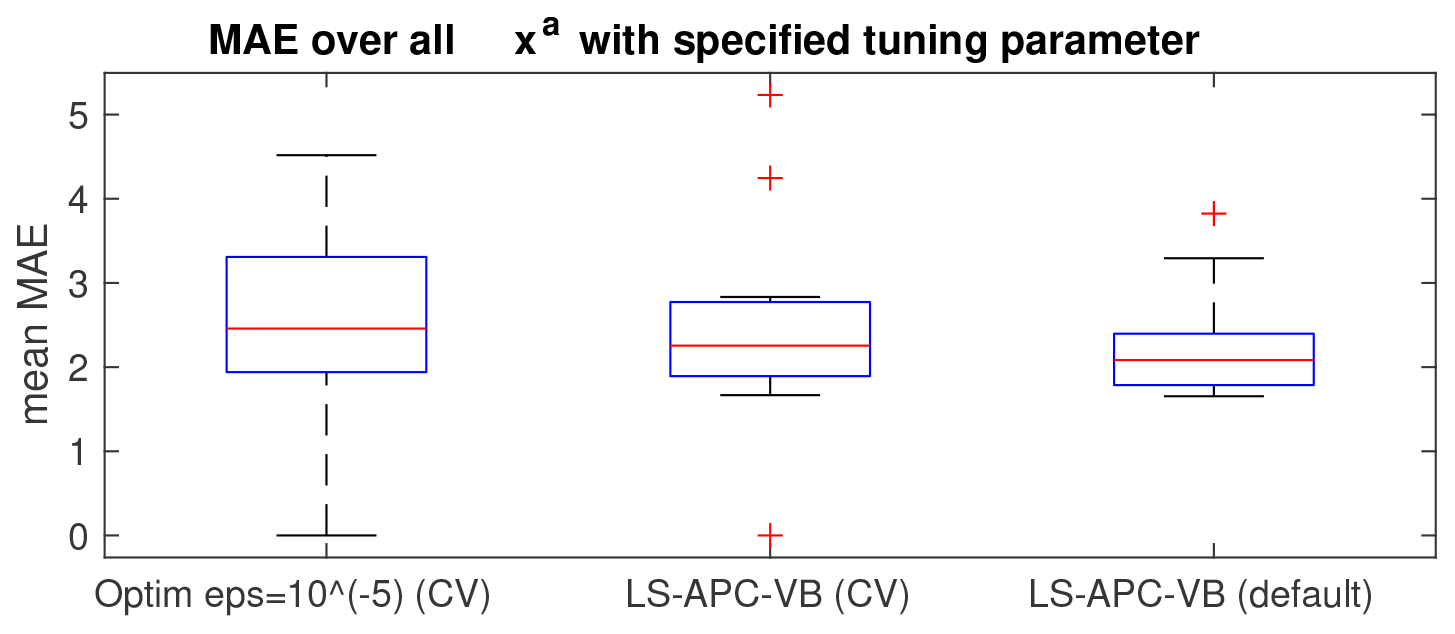
Figure 8Box-and-whisker plots of the MAE averaged over all explored prior source terms, with the tuning parameter settings determined by CV for the optimization method (left) and the LS-APC-VB method (middle), as well as for the LS-APC-VB method using a default errx setting of 100.
To evaluate the overall results, we compute the mean MAE over all estimated source terms using the optimization method with and the tuning parameter errx selected using cross-validation (CV) for each prior source term xa. This result is given in Fig. 8 using a box-and-whisker plot. The same box-and-whisker plots are also computed for the LS-APC-VB method with the same scheme of selection of tuning parameters errx using the cross-validation method (denoted CV in Fig. 8) and for the LS-APC-VB algorithm with the tuning parameter errx set to 100 as recommended in Tichý et al. (2016) (denoted default in Fig. 8). These results suggest that the LS-APC-VB method with fixed start (but weighted to data using selection of ω(0)) slightly outperforms other methods in terms of the mean MAE for ETEX data with various assumed prior source terms without the necessity of exhaustive tuning.
We demonstrate the sensitivity of the tuning methods to estimation of the source term for the Chernobyl accident, which became, together with the Fukushima accident, a widely discussed case in the inverse modeling literature. Specifically, we study caesium-134 (Cs-134) and caesium-137 (Cs-137) releases from the Chernobyl nuclear power plant (ChNPP). For this purpose, we use a recently published dataset (Evangeliou et al., 2016) consisting of 4891 observations of Cs-134 and 12 281 observations of Cs-137. We use the same experimental setup as in Evangeliou et al. (2017), which will now briefly be described.
4.1 Atmospheric modeling
The Lagrangian particle dispersion model FLEXPART version 10.3 (Stohl et al., 1998, 2005; Pisso et al., 2019) was used to simulate the transport of radiocesium and to calculate the SRS matrices. FLEXPART was driven by two meteorological reanalyses so that these can be compared. First, ERA-Interim (Dee et al., 2011), a European Center for Medium-Range Weather Forecast (ECMWF) reanalysis, was used with a temporal resolution of 3 h and spatial resolution of circa 80 km on 60 vertical levels from the surface up to 0.1 hPa. Second, the ERA-40 (Uppala et al., 2005) ECMWF reanalysis was used at a 125 km spatial resolution. The emissions from the ChNPP are discretized into six 0.5 km high vertical layers from 0 to 3 km. The assumed temporal resolution is 3 h from 00:00 UTC on 26 April to 21:00 UTC on 5 May 1986, for which the forward runs of FLEXPART are done. This period is selected according to the consensus that the activity declined by approximately 6 orders of magnitude after 5 May (De Cort et al., 1998). This discretized the temporal–spatial domain to 480 assumed releases (80 temporal elements times 6 vertical layers) for each nuclide. For each spatiotemporal element, concentration and deposition sensitivities are computed using 300 000 particles. Following Evangeliou et al. (2017), the aerosol tracers Cs-134 and Cs-137 are subject to wet (Grythe et al., 2017) and dry (Stohl et al., 2005) deposition depending on different particle sizes with aerodynamic mean diameters of 0.4, 1.2, 1.8, and 5.0 µm. The distribution of mass is assumed as 15 %, 30 %, 40 %, and 15 % for 0.4, 1.2, 1.8, and 5.0 µm particle sizes, respectively, following measurements of Malá et al. (2013) and computation results of Tichý et al. (2018).
4.2 Prior source term and measurement uncertainties
The exact temporal profile of the Chernobyl release is uncertain, although certain features are commonly accepted (De Cort et al., 1998). The first 3 d correspond to higher release with an initial explosion and release of part of the fuel. The next 4 d correspond to lower releases, and the last 3 d correspond to higher releases again due to fires and core meltdown. After these 10 d, the released activity dropped by several orders of magnitude (De Cort et al., 1998).
We follow the setup of Evangeliou et al. (2017) and consider six previously estimated Chernobyl source terms of Cs-134 and Cs-137 for which the criteria of consideration were their sufficient temporal resolution and emission height information. The source terms are taken from Brandt et al. (2002) (two cases with the same amount of release but slightly different release heights), Persson et al. (1987), Izrael et al. (1990), Abagyan et al. (1986), and Talerko (2005). See Evangeliou et al. (2017) for detailed descriptions and profiles. The prior source term in our experiment is computed as their average emissions at a given time and height. In sum, the total prior releases of Cs-134 and Cs-137 are 54 and 74 PBq, respectively.
The uncertainties associated with measurements are relatively high since both concentration and deposition measurements are used from the dataset (Evangeliou et al., 2016). As was pointed out by Gudiksen et al. (1989) and Winiarek et al. (2014), deposition measurements may be biased by an unknown mass of radiocesium already deposited over Europe from, e.g., nuclear weapons tests. This mass has, however, been reported (De Cort et al., 1998) and already subtracted from the dataset. Still, similarly to Evangeliou et al. (2017), we consider relative measurement errors of 30 % for concentration measurements and 60 % for deposition measurements, while the absolute measurement errors are handled in the same way as in Stohl et al. (2012). Here, the measurement vector and SRS matrix are preconditioned (scaled) using the matrix R, which is a diagonal matrix with on its diagonal, where σabs is assumed absolute error, σrel is assumed relative error, and ∘ denotes the Hadamard product (element-wise multiplication). The scaling is then yscaled=Ry and Mscaled=RM.
4.3 Results
In this case, direct comparison of the estimates with the true emission profile is not possible since this remains unknown. Therefore, we will provide results of the tested methods as the sensitivity of the total estimated release activity to tuning parameters in the same way as in Sect. 3. Note that the total release activity is a sum of releases from all six vertical layers and all four aerosol size fractions. Due to this composition of the problem, the selection of the smoothness parameter ϵ in the case of the optimization approach is relatively difficult since specific selection may fit better for one vertical layer than for another. We will provide results for two settings of this parameter, and , leading to two different behaviors of the optimization method.

Figure 9Estimated total released activities for both meteorological reanalyses (ERA-40 and ERA-Interim) and both nuclides (Cs-134 and Cs-137) using all tested methods; see the label bar on the right for a line description.
The resulting estimates of the total released activity are displayed in Fig. 9 where the total of the prior source term used xa is displayed with a dashed red line (same for all tested settings of the tuning parameter errx). The estimated total release activity with the use of the prior source term xa is displayed using full lines with colors given in the legend in Fig. 9, while estimations without the use of this prior source term, i.e., with xa=0, are given using dashed lines and respective colors.
Similarly to the ETEX results, the results in Fig. 9 suggest the occurrence of two main modes of solution, the data mode and the prior mode, with a smooth transition between them in the case of the LS-APC-VB and optimization methods. The LS-APC-G method (evaluated only at four points denoted by green squares due to high computational costs) has, again, low sensitivity to the initialization of the tuning parameter. However, the results of the LS-APC-G method are close to the data mode of the remaining method, or higher than those. Contrary to the previous results, the LS-APC-VB algorithm does not provide a stable solution and suffers from the need to select the tuning parameter. This signifies that the problem is ill-conditioned even with the proposed regularization term; thus, VB converges to various local minima. The optimization method with both settings of the smoothness parameter also has two modes of solution. In the prior mode of solution (higher values of the tuning parameter), both settings approach the same total release activity for both nonzero (full lines) and zero (dashed lines) prior source terms. The prior mode is dominated by the prior source term used for an arbitrary smoothness parameter ϵ. The difference can be seen in the data mode whereby about one-third higher total released activity was estimated for smoothness parameter than for smoothness parameter on the same level of tuning parameter errx. This is caused by the penalization of high peaks of activity in the case of . Thus, in the data mode of solution, the smoothness parameter is much more important than the prior source term used, which plays almost no role here.
Notice that the estimated mass is higher in the data mode than in the prior mode. This means that the model constrained by the measurement data alone would support a higher total release amount than the a priori source term. The true source term is not known; however, it is likely that the data mode overestimates the true total release. This can happen when the SRS matrix is biased. For instance, removal of radiocesium that is too rapid would lead to estimated air concentrations with the correct source term that are too low, and the inversion would compensate for the bias by increasing the posterior source term (notice, though, that deposition values would in this case be overestimated at least close to the source, leading to the contrary effect for the deposition data). Regardless, this effect shows that in the data mode, the resulting source term is heavily influenced by possible biases in the transport model.

Figure 10Cross-validation for Chernobyl Cs-134 (top panels) and Cs-137 (bottom panels) source terms using FLEXPART driven with ERA-40 meteorological reanalyses. Optima in the sense of cross-validation are denoted using red circles with total estimated releases reported in the legends.
4.4 Tuning by cross-validation
The same cross-validation scheme as in the case of ETEX (Sect. 3.3) was used here for the Chernobyl datasets. The train–test split was once again 80 %–20 %, and the CV was performed 50 times for each tuning parameter errx. The cross-validation errors are displayed in Fig. 10 using box plots and associated mean values of the residue errors . Here, the results are given for the datasets of Cs-134 (top row) and Cs-137 (bottom row) with FLEXPART driven with ERA-40 meteorological fields. We will investigate CV for the tuning of parameters for the optimization and the LS-APC-VB method. The results are presented for two xa configurations in Fig. 10: LS-APC-VB with xa, LS-APC-VB with xa=0, the optimization method with xa and with smoothness parameter , and the optimization method with xa=0 and with smoothness parameter . For these, box plots are displayed together with mean residuals using the same types of lines as in Fig. 9. Moreover, minimal mean residuals are identified and denoted using red circles in Fig. 10 for each graph, and their associated total activities are displayed in the legend of each graph.
In the case of Cs-134 (top row), the cross-validation was able to determine optimal values of tuning parameters in the case of all tested methods. The total estimated releases associated with these tuning parameters are 87.1 PBq (LS-APC-VB with xa), 56 PBq (LS-APC-VB with xa=0), 69.7 PBq (the optimization method with xa), and 43 PBq (the optimization method with xa=0), which are in accordance with the mean of previously reported total activity of 54 PBq used as a prior. Note that the prior-dominated modes have lower residuals than the data-dominated modes in all cases. This suggests that the prior source term used and applied to the FLEXPART/ERA-40 simulation matches the measurements well. On the other hand, this is not the case for Cs-137 for which the prior-dominated modes have, with the exception of LS-APC-VB with xa=0, significantly higher residuals than the data-dominated modes. This may be caused by two factors. First, the prior source term is less adequate for interpretation of measurements of Cs-137 than those of Cs-134. Second, all methods assume a quadratic loss function, which may be less appropriate for this dataset and could cause overestimation of the source term with the tuning parameter selected using cross-validation in comparison with the previously reported 74 PBq used as a prior. We note that similar results were also observed with the ERA-Interim dataset.
The results suggest that a well-selected prior source term can bind the solution to acceptable values and prevent the occurrence of extreme outliers. On the other hand, we observed that the regularization terms commonly used to compensate for errors of the SRS matrices are not able to compensate for the error caused by inaccurate SRS matrices. Further research is clearly needed to develop a more relevant method of regularization.
Methods for the determination of the source term of an atmospheric release have to cope with inaccurate prediction models often represented by the source–receptor sensitivity (SRS) matrix. Relying solely on the SRS matrix using a best estimate of weather and dispersion parameters may lead to highly inaccurate results. We have shown that various regularization terms introduced by different inversion methods are essentially coarse approximations of the error of the SRS matrix, and thus we can evaluate their suitability using methods of statistical model validation. We have performed sensitivity tests of inverse modeling methods to the selection of the prior source term (first guess) and other tuning parameters for two selected inversion methods: the optimization method (Eckhardt et al., 2008) and the LS-APC method (Tichý et al., 2016). These were preformed on datasets from the ETEX controlled release and the Chernobyl releases of caesium-134 and caesium-137.
We have observed that the results have two strong modes of solution: the data mode for minimal influence of the prior on the loss and the prior mode for the loss function with significant influence of the prior. The prior mode is naturally significantly influenced by the choice of the prior source term. However, the dominant impact on the resulting estimate has the choice of the regularization. In the case of the ETEX dataset, good estimates were obtained for every choice of the prior source term; however, the regularization has to be carefully tuned. For some choices of the prior source term, the error of the estimated source term was exceptionally low for good selection of the tuning parameters. After analyzing these minima, we conjecture that they are caused by coincidence. These minima are visible only in comparison with the ground truth; they have no visible impact on the common validation metrics such as the L-curve or cross-validation and thus cannot be objectively identified.
We have tested the suitability of the cross-validation approach for selection of the tuning parameters for both methods. In the case of the ETEX release, we have observed that this approach tends to select modes closer to the data mode than the prior mode of solution. However, this is not the case of the Chernobyl Cs-134 release for which cross-validation selects solutions close to the prior-dominated mode. This may be caused by the fact that the prior source term used here fits the measurements well, and only small corrections by the inversion are needed. An interesting question is whether it is beneficial to use a nonzero prior source term at all. Considering ETEX, for which the true release is known, one can see that the estimates in data modes are often even better than the considered prior source terms. On the other hand, when the prior source term used is close to the true release, which is probably the case for the Chernobyl Cs-134 release, its use seems beneficial. Also, the prior source term could be valuable in cases when the release is not fully seen by the measurement network and thus the measurements do not provide a good constraint for the source term estimation. However, determining the reliability of the prior source term is difficult and even impossible in real-world scenarios, and the prior source term would probably be shifted, scaled, and/or blurred. We recommend tackling this task using the cross-validation approach, providing a reasonable although computationally expensive tool for determination at least between a prior-dominated mode or a data-dominated mode of solution. A more sophisticated approach is to design a different regularization of the error term ΔM exploiting, e.g., sensitivities to local changes in concentrations around the measuring sites. The information about sensitivity is already available from an atmospheric transport model but it is not fully exploited with current source term determination methods.
From Eq. (2), can be rewritten using the subtraction of Mxa and ΔMxa from both sides, yielding
which can be read as
for commonly used substitutions and . This means that the minimization of Eq. (A2) is equivalent to the minimization of the former Eq. (2). Thus,
where terms independent of are omitted.
SRS matrices for ETEX are displayed in Fig. C1 for illustration. The SRS matrix computed using ERA-40 reanalyses is in the left column, while the SRS matrix computed using ERA-Interim is in the right column. The matrices are associated with their singular values displayed in the bottom row. These illustrate properties of the matrices and, importantly, their ill conditionality.
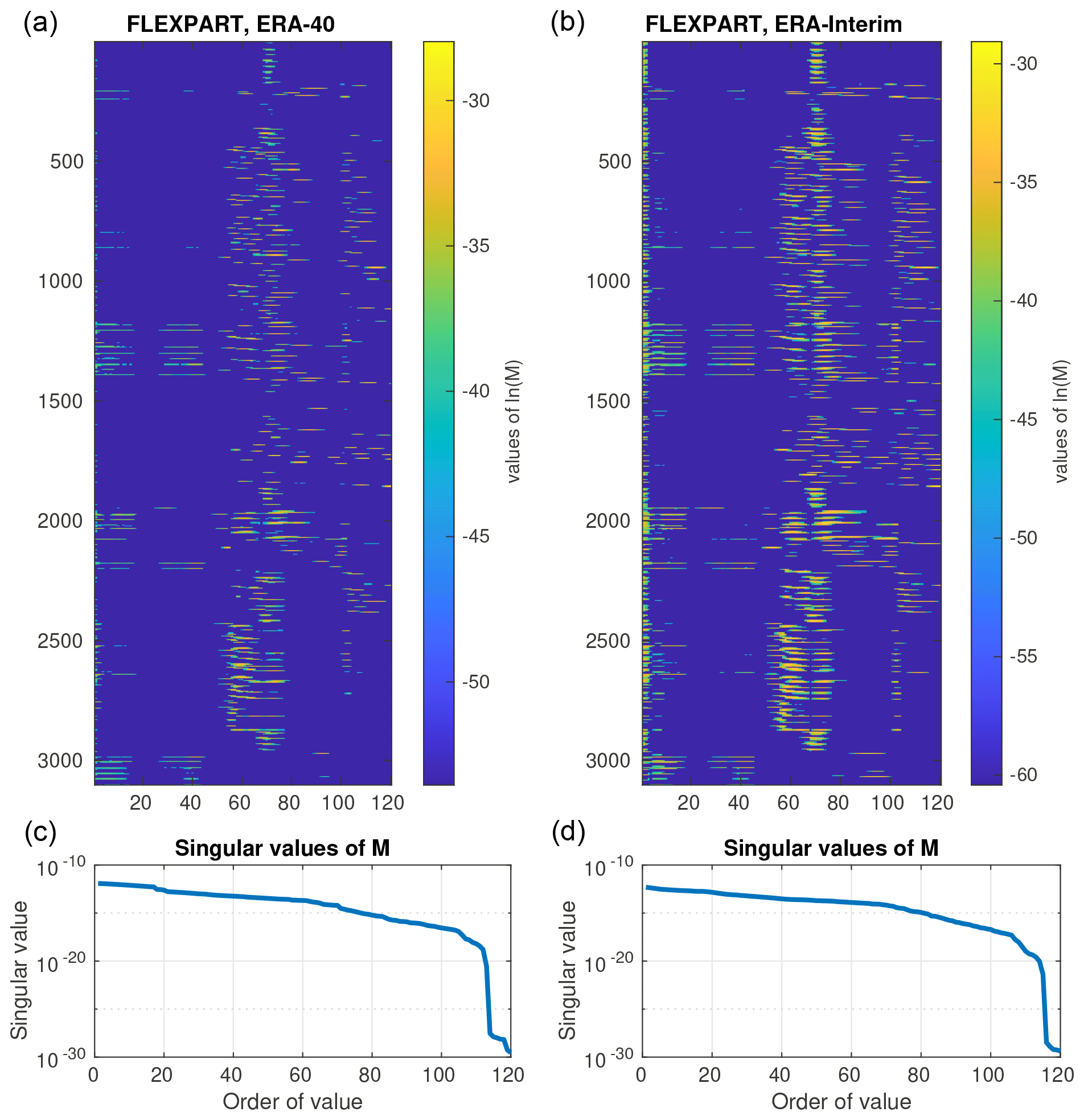
Figure C1ETEX SRS matrices computed using FLEXPART driven by meteorological input data from the European Center for Medium-Range Weather Forecasts (ECMWF). (a, c) Data from the 40-year reanalysis (ERA-40) and (b, d) data from the continuously updated ERA-Interim reanalysis. The matrices are associated with their singular values (bottom row).
All data used for the present publication can be freely downloaded from https://rem.jrc.ec.europa.eu/etex/ (last access: 26 April 2020, Nodop et al., 1998) and from the Supplement of Evangeliou et al. (2016). The FLEXPART model versions 8.1 and 10.3 are open-source and freely available from their developers at https://www.flexpart.eu/ (last access: 26 April 2020, Pisso et al., 2019). Reference MATLAB implementations of algorithms can be downloaded from http://www.utia.cas.cz/linear_inversion_methods/ (last access: 26 April 2020, Tichý et al., 2016).
OT designed and performed the experiments and wrote the paper. LU performed Gibbs sampling experiments and wrote parts of the paper. VŠ designed and supervised the study and wrote parts of the paper. NE prepared the Chernobyl dataset and commented on the paper. AS commented on the paper and wrote parts of the final version.
The authors declare that they have no conflict of interest.
This research has been supported by the Czech Science Foundation (grant no. GA20-27939S).
This paper was edited by Slimane Bekki and reviewed by two anonymous referees.
Abagyan, A., Ilyin, L., Izrael, Y., Legasov, V., and Petrov, V.: The information on the Chernobyl accident and its consequences, prepared for IAEA, Sov. At. Energy, 61, 301–320, https://doi.org/10.1007/BF01122262, 1986. a
Berchet, A., Pison, I., Chevallier, F., Bousquet, P., Conil, S., Geever, M., Laurila, T., Lavrič, J., Lopez, M., Moncrieff, J., Necki, J., Ramonet, M., Schmidt, M., Steinbacher, M., and Tarniewicz, J.: Towards better error statistics for atmospheric inversions of methane surface fluxes, Atmos. Chem. Phys., 13, 7115–7132, https://doi.org/10.5194/acp-13-7115-2013, 2013. a
Bocquet, M.: Reconstruction of an atmospheric tracer source using the principle of maximum entropy. II: Applications, Q. J. Roy. Meteor. Soc., 131, 2209–2223, 2005. a
Bocquet, M.: High-resolution reconstruction of a tracer dispersion event: application to ETEX, Q. J. Roy. Meteor. Soc., 133, 1013–1026, 2007. a, b
Bossew, P., Gering, F., Petermann, E., Hamburger, T., Katzlberger, C., Hernandez-Ceballos, M., De Cort, M., Gorzkiewicz, K., Kierepko, R., and Mietelski, J.: An episode of Ru-106 in air over Europe, September–October 2017–Geographical distribution of inhalation dose over Europe, J. Environ. Radioactiv., 205, 79–92, 2019. a
Brandt, J., Christensen, J. H., and Frohn, L. M.: Modelling transport and deposition of caesium and iodine from the Chernobyl accident using the DREAM model, Atmos. Chem. Phys., 2, 397–417, https://doi.org/10.5194/acp-2-397-2002, 2002. a
Carrassi, A., Bocquet, M., Bertino, L., and Evensen, G.: Data assimilation in the geosciences: An overview of methods, issues, and perspectives, Wires. Climate Change, 9, 9:e535, https://doi.org/10.1002/wcc.535, 2018. a
Casella, G. and George, E. I.: Explaining the Gibbs Sampler, Am. Stat., 46, 167–174, 1992. a
Chai, T., Stein, A., and Ngan, F.: Weak-constraint inverse modeling using HYSPLIT-4 Lagrangian dispersion model and Cross-Appalachian Tracer Experiment (CAPTEX) observations – effect of including model uncertainties on source term estimation, Geosci. Model Dev., 11, 5135–5148, https://doi.org/10.5194/gmd-11-5135-2018, 2018. a
Chib, S. and Greenberg, E.: Understanding the Metropolis-Hastings Algorithm, Am. Stat., 49, 327–335, 1995. a
Connor, B., Boesch, H., Toon, G., Sen, B., Miller, C., and Crisp, D.: Orbiting Carbon Observatory: Inverse method and prospective error analysis, J. Geophys. Res.-Atmos., 113, D05305, https://doi.org/10.1029/2006JD008336, 2008. a
Davoine, X. and Bocquet, M.: Inverse modelling-based reconstruction of the Chernobyl source term available for long-range transport, Atmos. Chem. Phys., 7, 1549–1564, https://doi.org/10.5194/acp-7-1549-2007, 2007. a, b
De Cort, M., Dubois, G., Fridman, S., Germenchuk, M., Izrael, Y., Janssens, A., Jones, A., Kelly, G., Kvasnikova, E., Matveenko, I., Nazarov, I., Pokumeiko, Y., Sitak, V., Stukin, E., Tabachny, L., Tsaturov, Y., and Avdyushin, S.: Atlas of caesium deposition on Europe after the Chernobyl accident, Catalogue number CG-NA-16-733-29-C, EUR 16733, eU – Office for Official Publications of the European Communities, 1–63, 1998. a, b, c, d
Dee, D., Uppala, S., Simmons, A., Berrisford, P., Poli, P., Kobayashi, S., Andrae, U., Balmaseda, M., Balsamo, G., Bauer, P., Bechtold, P., Beljaars, A., van de Berg, L., Bidlot, J., Bormann, N., Delsol, C., Dragani, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hersbach, H., Hólm, E., Isaksen, L., Kallberg, P., Kohler, M., Matricardi, M., Mcnally, A., Monge-Sanz, B., Morcrette, J., Park, B., Peubey, C., de Rosnay, P., Tavolato, C., Thepaut, J., and Vitart, F.: The ERA-Interim reanalysis: Configuration and performance of the data assimilation system, Q. J. Roy. Meteor. Soc., 137, 553–597, 2011. a
Eckhardt, S., Prata, A. J., Seibert, P., Stebel, K., and Stohl, A.: Estimation of the vertical profile of sulfur dioxide injection into the atmosphere by a volcanic eruption using satellite column measurements and inverse transport modeling, Atmos. Chem. Phys., 8, 3881–3897, https://doi.org/10.5194/acp-8-3881-2008, 2008. a, b, c, d, e, f, g, h
Efron, B. and Tibshirani, R.: Improvements on cross-validation: the 632+ bootstrap method, J. Am. Stat. Assoc., 92, 548–560, 1997. a
Evangeliou, N., Hamburger, T., Talerko, N., Zibtsev, S., Bondar, Y., Stohl, A., Balkanski, Y., Mousseau, T., and Møller, A.: Reconstructing the Chernobyl Nuclear Power Plant (CNPP) accident 30 years after. A unique database of air concentration and deposition measurements over Europe, Environ. Pollut., 216, 408–418, 2016. a, b, c, d
Evangeliou, N., Hamburger, T., Cozic, A., Balkanski, Y., and Stohl, A.: Inverse modeling of the Chernobyl source term using atmospheric concentration and deposition measurements, Atmos. Chem. Phys., 17, 8805–8824, https://doi.org/10.5194/acp-17-8805-2017, 2017. a, b, c, d, e, f, g, h
Evensen, G.: Analysis of iterative ensemble smoothers for solving inverse problems, Comput. Geosci., 22, 885–908, 2018. a
Ganesan, A. L., Rigby, M., Zammit-Mangion, A., Manning, A. J., Prinn, R. G., Fraser, P. J., Harth, C. M., Kim, K.-R., Krummel, P. B., Li, S., Mühle, J., O'Doherty, S. J., Park, S., Salameh, P. K., Steele, L. P., and Weiss, R. F.: Characterization of uncertainties in atmospheric trace gas inversions using hierarchical Bayesian methods, Atmos. Chem. Phys., 14, 3855–3864, https://doi.org/10.5194/acp-14-3855-2014, 2014. a
George, E. I. and McCulloch, R. E.: Variable selecetion via Gibbs sampling, J. Am. Stat. Assoc., 88, 881–889, 1993. a
Golub, G., Hansen, P., and O'Leary, D.: Tikhonov regularization and total least squares, SIAM J. Matrix Anal. A., 21, 185–194, 1999. a
Grant, M. and Boyd, S.: Graph implementations for nonsmooth convex programs, in: Recent Advances in Learning and Control, edited by: Blondel, V., Boyd, S., and Kimura, H., Lecture Notes in Control and Information Sciences, Springer-Verlag Limited, 95–110, 2008. a
Grant, M. and Boyd, S.: CVX: Matlab Software for Disciplined Convex Programming, version 2.1, available at: http://cvxr.com/cvx (last access: 26 April 2020), 2018. a
Grythe, H., Kristiansen, N. I., Groot Zwaaftink, C. D., Eckhardt, S., Ström, J., Tunved, P., Krejci, R., and Stohl, A.: A new aerosol wet removal scheme for the Lagrangian particle model FLEXPART v10, Geosci. Model Dev., 10, 1447–1466, https://doi.org/10.5194/gmd-10-1447-2017, 2017. a
Gudiksen, P. H., Harvey, T. F., and Lange, R.: Chernobyl Source Term, Atmospheric Dispersion, and Dose Estimation, Health Physics, 57, 697–706, 1989. a
Hansen, P. C. and O'Leary, D. P.: The use of the L-curve in the regularization of discrete ill-posed problems, SIAM J. Sci. Comput., 14, 1487–1503, 1993. a
Henne, S., Brunner, D., Oney, B., Leuenberger, M., Eugster, W., Bamberger, I., Meinhardt, F., Steinbacher, M., and Emmenegger, L.: Validation of the Swiss methane emission inventory by atmospheric observations and inverse modelling, Atmos. Chem. Phys., 16, 3683–3710, https://doi.org/10.5194/acp-16-3683-2016, 2016. a, b
Izrael, Y. A., Vakulovsky, S. M., Vetrov, V. A., Petrov, V. N., Rovinsky, F. Y., and Stukin, E. D.: Chernobyl: Radioactive Contamination of the Environment, Leningrad, Hydrometereological Publishing, 1990 (in Russian). a
Kullback, S. and Leibler, R.: On information and sufficiency, Ann. Math. Stat., 22, 79–86, 1951. a
Liu, Y., Haussaire, J.-M., Bocquet, M., Roustan, Y., Saunier, O., and Mathieu, A.: Uncertainty quantification of pollutant source retrieval: comparison of Bayesian methods with application to the Chernobyl and Fukushima Daiichi accidental releases of radionuclides, Q. J. Roy. Meteor. Soc., 143, 2886–2901, 2017. a, b, c, d
Malá, H., Rulík, P., Bečková, V., Mihalík, J., and Slezáková, M.: Particle size distribution of radioactive aerosols after the Fukushima and the Chernobyl accidents, J. Environ. Radioactiv., 126, 92–98, 2013. a
Martinez-Camara, M., Béjar Haro, B., Stohl, A., and Vetterli, M.: A robust method for inverse transport modeling of atmospheric emissions using blind outlier detection, Geosci. Model Dev., 7, 2303–2311, https://doi.org/10.5194/gmd-7-2303-2014, 2014. a
Masson, O., Steinhauser, G., Wershofen, H., Mietelski, J. W., Fischer, H. W., Pourcelot, L., Saunier, O., Bieringer, J., Steinkopff, T., Hýža, M., Moller, B., Bowyer, T. W., Dalaka, E., Dalheimer, A., de Vismes-Ott, A., Eleftheriadis, K., Forte, M., Gasco Leonarte, C., Gorzkiewicz, K., Homoki, Z., Isajenko, K., Karhunen, T., Katzlberger, C., Kierepko, R., Kovendiné Kónyi, J., Malá, H., Nikolic, J., Povinec, P. P., Rajacic, M., Ringer, W., Rulík, P., Rusconi, R., Sáfrány, G., Sykora, I., Todorovic, D., Tschiersch, J., Ungar, K., and Zorko, B.: Potential Source Apportionment and Meteorological Conditions Involved in Airborne 131I Detections in January/February 2017 in Europe, Environ. Sci. Technol., 52, 8488–8500, 2018. a
Mekhaimr, S. and Wahab, M. A.: Sources of uncertainty in atmospheric dispersion modeling in support of Comprehensive Nuclear–Test–Ban Treaty monitoring and verification system, Atmos. Pollut. Res., 10, 1383–1395, https://doi.org/10.1016/j.apr.2019.03.008, 2019. a
Michalak, A., Hirsch, A., Bruhwiler, L., Gurney, K., Peters, W., and Tans, P.: Maximum likelihood estimation of covariance parameters for Bayesian atmospheric trace gas surface flux inversions, J. Geophys. Res.-Atmos., 110, D24107, https://doi.org/10.1029/2005JD005970, 2005. a
Miller, S. M., Michalak, A. M., and Levi, P. J.: Atmospheric inverse modeling with known physical bounds: an example from trace gas emissions, Geosci. Model Dev., 7, 303–315, https://doi.org/10.5194/gmd-7-303-2014, 2014. a
Nisbet, E. and Weiss, R.: Top-down versus bottom-up, Science, 328, 1241–1243, 2010. a
Nodop, K., Connolly, R., and Girardi, F.: The field campaigns of the European Tracer Experiment (ETEX): Overview and results, Atmos. Environ., 32, 4095–4108, 1998. a, b, c
Persson, C., Rodhe, H., and De Geer, L.-E.: The Chernobyl accident: A meteorological analysis of how radionuclides reached and were deposited in Sweden, Ambio, 16, 20–31, 1987. a
Pisso, I., Sollum, E., Grythe, H., Kristiansen, N. I., Cassiani, M., Eckhardt, S., Arnold, D., Morton, D., Thompson, R. L., Groot Zwaaftink, C. D., Evangeliou, N., Sodemann, H., Haimberger, L., Henne, S., Brunner, D., Burkhart, J. F., Fouilloux, A., Brioude, J., Philipp, A., Seibert, P., and Stohl, A.: The Lagrangian particle dispersion model FLEXPART version 10.4, Geosci. Model Dev., 12, 4955–4997, https://doi.org/10.5194/gmd-12-4955-2019, 2019. a, b
Ray, J., Lee, J., Yadav, V., Lefantzi, S., Michalak, A. M., and van Bloemen Waanders, B.: A sparse reconstruction method for the estimation of multi-resolution emission fields via atmospheric inversion, Geosci. Model Dev., 8, 1259–1273, https://doi.org/10.5194/gmd-8-1259-2015, 2015. a
Saunier, O., Mathieu, A., Didier, D., Tombette, M., Quélo, D., Winiarek, V., and Bocquet, M.: An inverse modeling method to assess the source term of the Fukushima Nuclear Power Plant accident using gamma dose rate observations, Atmos. Chem. Phys., 13, 11403–11421, https://doi.org/10.5194/acp-13-11403-2013, 2013. a
Saunier, O., Didier, D., Mathieu, A., Masson, O., and Le Brazidec, J.: Atmospheric modeling and source reconstruction of radioactive ruthenium from an undeclared major release in 2017, P. Natl. Acad. Sci. USA, 116, 24991–25000, 2019. a
Seibert, P.: Iverse modelling with a Lagrangian particle disperion model: application to point releases over limited time intervals, in: Air Pollution Modeling and its Application XIV, Springer, 381–389, 2001. a
Seibert, P. and Frank, A.: Source-receptor matrix calculation with a Lagrangian particle dispersion model in backward mode, Atmos. Chem. Phys., 4, 51–63, https://doi.org/10.5194/acp-4-51-2004, 2004. a, b
Seibert, P., Kristiansen, N., Richter, A., Eckhardt, S., Prata, A., and Stohl, A.: Uncertainties in the inverse modelling of sulphur dioxide eruption profiles, Geomatics, Natural Hazards and Risk, 2, 201–216, 2011. a, b, c
Šmídl, V. and Quinn, A.: The Variational Bayes Method in Signal Processing, Springer, https://doi.org/10.1007/3-540-28820-1, 2006. a
Stohl, A., Hittenberger, M., and Wotawa, G.: Validation of the Lagrangian particle dispersion model FLEXPART against large-scale tracer experiment data, Atmos. Environ., 32, 4245–4264, 1998. a, b
Stohl, A., Forster, C., Frank, A., Seibert, P., and Wotawa, G.: Technical note: The Lagrangian particle dispersion model FLEXPART version 6.2, Atmos. Chem. Phys., 5, 2461–2474, https://doi.org/10.5194/acp-5-2461-2005, 2005. a, b, c
Stohl, A., Seibert, P., Arduini, J., Eckhardt, S., Fraser, P., Greally, B. R., Lunder, C., Maione, M., Mühle, J., O'Doherty, S., Prinn, R. G., Reimann, S., Saito, T., Schmidbauer, N., Simmonds, P. G., Vollmer, M. K., Weiss, R. F., and Yokouchi, Y.: An analytical inversion method for determining regional and global emissions of greenhouse gases: Sensitivity studies and application to halocarbons, Atmos. Chem. Phys., 9, 1597–1620, https://doi.org/10.5194/acp-9-1597-2009, 2009. a
Stohl, A., Prata, A. J., Eckhardt, S., Clarisse, L., Durant, A., Henne, S., Kristiansen, N. I., Minikin, A., Schumann, U., Seibert, P., Stebel, K., Thomas, H. E., Thorsteinsson, T., Tørseth, K., and Weinzierl, B.: Determination of time- and height-resolved volcanic ash emissions and their use for quantitative ash dispersion modeling: the 2010 Eyjafjallajökull eruption, Atmos. Chem. Phys., 11, 4333–4351, https://doi.org/10.5194/acp-11-4333-2011, 2011. a, b
Stohl, A., Seibert, P., Wotawa, G., Arnold, D., Burkhart, J. F., Eckhardt, S., Tapia, C., Vargas, A., and Yasunari, T. J.: Xenon-133 and caesium-137 releases into the atmosphere from the Fukushima Dai-ichi nuclear power plant: determination of the source term, atmospheric dispersion, and deposition, Atmos. Chem. Phys., 12, 2313–2343, https://doi.org/10.5194/acp-12-2313-2012, 2012. a, b, c
Talerko, N.: Mesoscale modelling of radioactive contamination formation in Ukraine caused by the Chernobyl accident, J. Environ. Radioactiv., 78, 311–329, 2005. a
Tibshirani, R.: Regression shrinkage and selection via the lasso, J. Roy. Stat. Soc., 58, 267–288, 1996. a
Tichý, O., Šmídl, V., Hofman, R., and Stohl, A.: LS-APC v1.0: a tuning-free method for the linear inverse problem and its application to source-term determination, Geosci. Model Dev., 9, 4297–4311, https://doi.org/10.5194/gmd-9-4297-2016, 2016. a, b, c, d, e, f, g, h, i, j, k, l, m
Tichý, O., Šmídl, V., Hofman, R., and Evangeliou, N.: Source term estimation of multi-specie atmospheric release of radiation from gamma dose rates, Q. J. Roy. Meteor. Soc., 144, 2781–2797, https://doi.org/10.1002/qj.3403, 2018. a, b
Ulrych, L. and Šmídl, V.: Sparse and Smooth Prior for Bayesian Linear Regression with Application to ETEX Data, arXiv preprint, arXiv:1706.06908, 2017. a
Uppala, S. M., Kallberg, P. W., Simmons, A. J., Andrae, U., Bechtold, V. D. C., Fiorino, M., Gibson, J. K., Haseler, J., Hernandez, A., Kelly, G. A., Li, X., Onogi, K., Saarinen, S., Sokka, N., Allan, R. P., Andersson, E., Arpe, K., Balmaseda, M. A., Beljaars, A. C. M., Berg, L. V. D., Bidlot, J., Bormann, N., Caires, S., Chevallier, F., Dethof, A., Dragosavac, M., Fisher, M., Fuentes, M., Hagemann, S., Holm, E., Hoskins, B. J., Isaksen, L., Janssen, P. A. E. M., Jenne, R., Mcnally, A. P., Mahfouf, J.-F., Morcrette, J.-J., Rayner, N. A., Saunders, R. W., Simon, P., Sterl, A., Trenberth, K. E., Untch, A., Vasiljevic, D., Viterbo, P., and Woollen, J.: The ERA-40 re-analysis, Q. J. Roy. Meteor. Soc., 131, 2961–3012, 2005. a
Winiarek, V., Bocquet, M., Saunier, O., and Mathieu, A.: Estimation of errors in the inverse modeling of accidental release of atmospheric pollutant: Application to the reconstruction of the cesium-137 and iodine-131 source terms from the Fukushima Daiichi power plant, J. Geophys. Res.-Atmos., 117, D05122, https://doi.org/10.1029/2011JD016932, 2012. a
Winiarek, V., Bocquet, M., Duhanyan, N., Roustan, Y., Saunier, O., and Mathieu, A.: Estimation of the caesium-137 source term from the Fukushima Daiichi nuclear power plant using a consistent joint assimilation of air concentration and deposition observations, Atmos. Environ., 82, 268–279, 2014. a
Wotawa, G., De Geer, L.-E., Denier, P., Kalinowski, M., Toivonen, H., D’Amours, R., Desiato, F., Issartel, J.-P., Langer, M., Seibert, P., Frank, A., Sloan, C., and Yamazawa, H.: Atmospheric transport modelling in support of CTBT verification – Overview and basic concepts, Atmos. Environ., 37, 2529–2537, 2003. a
The analysis can be generalized to a quadratic norm with arbitrary kernel R; however, we will discuss its simpler version for clarity.
- Abstract
- Introduction
- Inverse modeling using the prior source term
- Sensitivity study on the ETEX dataset
- Sensitivity study on the Chernobyl dataset
- Conclusions
- Appendix A: Derivation of residuum between measurement and reconstruction
- Appendix B: Shaping parameters of LS-APC-VB posteriors
- Appendix C: SRS matrices used for the ETEX and Chernobyl experiments
- Code and data availability
- Author contributions
- Competing interests
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Inverse modeling using the prior source term
- Sensitivity study on the ETEX dataset
- Sensitivity study on the Chernobyl dataset
- Conclusions
- Appendix A: Derivation of residuum between measurement and reconstruction
- Appendix B: Shaping parameters of LS-APC-VB posteriors
- Appendix C: SRS matrices used for the ETEX and Chernobyl experiments
- Code and data availability
- Author contributions
- Competing interests
- Financial support
- Review statement
- References