the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Jun 2026
| 30 Jun 2026
Improvement of the Rnnmm-type climate index approach with a spatio-temporal model based on the Hawkes process
Fidel Ernesto Castro Morales
Antonio Marcos Batista do Nascimento
Marina Silva Paez
Daniele Torres Rodrigues
Carla de Moraes Apolinário
This paper proposes an innovative geostatistical model based on self-exciting Hawkes processes for modeling the Rnnmm-type extreme climate index, representing a novel contribution to the literature on climate extremes. The proposed approach generalizes non-homogeneous spatio-temporal Poisson models by incorporating temporal dependence between events through excitation functions, enabling the capture of clustering patterns commonly observed in precipitation time series. The model is formulated within a Bayesian framework, with parameter estimation performed via Markov Chain Monte Carlo (MCMC) methods. Spatial dependence is introduced through hierarchical Gaussian processes, allowing for interpolation in locations without observed data. The model is applied to the R20mm index (annual number of days with precipitation exceeding 20 mm) using data from northern Maranhão (Brazil) for the period 2013–2022. Cross-validation results demonstrate that the proposed model outperforms non-homogeneous Poisson models with and without seasonality in terms of predictive accuracy. Furthermore, the excitation parameters provide additional insights into the persistence and intensity of extreme events, revealing patterns not captured by conventional models. These findings highlight the model's potential to enhance the analysis of climate extremes in regions with high spatio-temporal variability in precipitation.
- Article
(2223 KB) - Full-text XML
- BibTeX
- EndNote




The occurrence of extreme climate events, such as intense and prolonged rainfall, poses significant challenges in vulnerable regions, particularly in areas characterized by high climate variability. In the state of Maranhão, Brazil, for instance, the rainfall regime exhibits pronounced seasonality. During the rainy season, precipitation events exceeding 20 mm tend to occur frequently, with short intervals between them. As the dry season approaches, these intervals gradually increase until such events cease to be recorded. Capturing this dynamic and irregular behavior is essential for a more accurate understanding of climate extremes and for supporting mitigation and adaptation strategies in local contexts.
In this regard, climate indices developed by the Expert Team on Climate Change Detection and Indices (ETCCDI), such as the Rnnmm index, have proven to be valuable tools for measuring and monitoring climate extremes. The Rnnmm index is defined as the annual number of days in which daily precipitation exceeds nn mm, where nn is a user-defined threshold. Despite its usefulness, the statistical modeling of these indices still faces limitations, especially in regions affected by large-scale phenomena such as El Niño and La Niña, which irregularly influence seasonal precipitation cycles.
Recent studies, such as Morales and Vicini (2020) and Morales and Rodrigues (2023), have investigated the behavior of extreme rainfall frequencies using the Rnnmm index. Morales and Vicini (2020) incorporated anisotropy into the spatial covariance structure of a spatiotemporal model based on inhomogeneous Poisson processes, originally proposed by Morales et al. (2017), thereby enhancing the model's ability to represent complex spatial patterns. Subsequently, Morales and Rodrigues (2023) developed a more comprehensive model that accounts for the high spatial and temporal variability of precipitation and captures regular seasonal rainfall cycles by incorporating a cyclic function into the intensity function. However, despite these advances, the approach proposed by Morales and Rodrigues (2023) has limitations in capturing temporal factors that influence the index, particularly in regions such as northeastern Brazil, where precipitation cycles are strongly affected by irregular large-scale climate phenomena, such as El Niño and La Niña, leading to significant deviations from expected seasonal patterns.
To address these limitations, Morales (2023) proposed an alternative approach based on partitioning the analysis period, allowing different intensity functions to be defined for each partition of the inhomogeneous Poisson process. This method employs a priori specification of the intensity function parameters using state-space models (West and Harrison, 1997), providing greater flexibility in the modeling process. Additionally, the proposed approach incorporates anisotropy in the spatial covariance structure, further improving the representation of complex spatial patterns. By explicitly considering temporal variability, this strategy enhances the model's ability to capture fluctuations driven by global climate phenomena, resulting in a more refined understanding of extreme precipitation events over time.
Moreover, one of the major challenges in developing studies in this field is the limited spatial and temporal coverage of historical data, particularly in developing countries such as Brazil, where the density of rain gauges is below the threshold recommended by the World Meteorological Organization (Curtarelli et al., 2014). To overcome this limitation, researchers have increasingly relied on remote sensing estimates, such as those provided by satellite products. However, studies indicate that these estimates often underestimate extreme precipitation events. For example, Rodrigues et al. (2020) found that the 3B42V7 product from the Tropical Rainfall Measuring Mission satellite underestimated extreme events between 2000 and 2015 in northeastern Brazil. Similarly, dos Santos et al. (2022) analyzed the Integrated Multi-satellite Retrievals for GPM (IMERG) product from the Global Precipitation Measurement (GPM) mission and demonstrated that the quality of climate index estimates, including Rnnmm, depends on factors such as location and time period. Comparable findings were reported by Batista et al. (2024), who evaluated eight extreme precipitation indices estimated by IMERG in the Parnaíba basin.
Although the models proposed by Morales and Vicini (2020); Morales and Rodrigues (2023) and Morales (2023) have advanced the modeling of the Rnnmm index, several aspects remain unexplored. For instance, the specific seasonal patterns of the rainfall regime in Maranhão have not yet been thoroughly examined. To bridge this gap, this study proposes an innovative geostatistical model based on self-exciting Hawkes processes (Hawkes, 1971), which enables a more accurate representation of the temporal and spatial dynamics of climate extremes, particularly in regional contexts such as Maranhão. Self-exciting Hawkes processes are a useful class of stochastic processes which can model point patterns exhibiting temporal clustering features, in which the occurrence of an event of interest increases the likelihood of observing new occurrences in the near future. This approach is crucial for improving the understanding of the frequency and intensity of extreme events, thereby contributing to the development of effective mitigation and adaptation strategies for climate change. Originally introduced by Hawkes in 1971, Hawkes processes and extensions have been extensively used in real-world applications in several different fields such as earthquakes (Ogata, 1988), violence (Holbrook et al., 2021) and social interactions (Miscouridou et al., 2018). We also refer to (Reinhart, 2018; Laub et al., 2025) for reviews on the subject.
We now formally define the geostatistical model considered in this article. Let 𝒜⊂ℝd denote the spatial domain of interest, with n fixed observation sites located at . These sites represent the locations where data are collected over time. The data are assumed to originate from an underlying stochastic process, evolving as follows.
At each site sj, for , we observe a continuous-time counting process Nj(t), which keeps track of the number of events that have occurred at location sj up to time t. The history of each process is denoted by , and it depends on a set of unknown parameters , where φj and ϱj are vectors whose specific roles will be defined later. The collection of all such parameters across sites is denoted by .
Conditional on a realization of Φ, we assume that the counting processes evolve independently according to self-exciting point processes, meaning that the occurrence of an event at any given time increases the likelihood of subsequent events occurring in the near future. This characteristic makes the model particularly suitable for representing extreme weather events, where an intense occurrence at a given location tends to trigger additional events within a short period. Specifically, each Nj(t) follows a Hawkes process, a model designed to capture clustering patterns in the event occurrences.
The likelihood of an event occurring at site sj at time t is governed by the conditional intensity function λj(t∣Φ), which is defined as:
Here, the function gj(t∣Φ) represents a baseline rate of events, independent of past occurrences. This can be interpreted as the background intensity, describing how frequently events would occur if there were no interactions between them. The second term, , accounts for the influence of past events.
The quantity tj,k denotes the occurrence time of the k-th event observed at site sj, with all such events forming the ordered sequence . Each past event at time tj,k contributes an additional increase to the intensity at time t, according to the function . This function, often called the excitation kernel, controls how strongly and for how long past events influence the likelihood of future occurrences.
To precisely characterize this excitation mechanism, we assume that the function μj(τ∣Φ) follows an exponential decay:
where , with αj>0, βj>0, and αj<βj. This formulation ensures that the influence of past events diminishes over time, capturing the natural decay in their impact on future occurrences.
Simultaneously, the background intensity function gj(t∣Φ) is assumed to follow the parametric form:
where are site-specific parameters that control the baseline occurrence of events independently of past observations. This parametric form provides flexibility in capturing different temporal patterns of extreme events.
The model specified by the excitation function in Eq. (2) and the background rate in Eq. (3) will be referred to as the Weibull-Hawkes model, reflecting the Weibull-distributed baseline hazard function and the Hawkes process governing self-exciting dynamics.
2.1 Model's Prior Distributions
To fully specify the Weibull-Hawkes model in a Bayesian framework, we must assign prior distributions to its parameters. These priors reflect our initial beliefs about the parameter values before incorporating observed data and play a fundamental role in the inference process. A well-chosen prior structure not only provides regularization, but also ensures that the model remains flexible enough to capture the underlying patterns in the data.
In this work, we assign prior distributions to the parameters βj, αj, γj, and ηj for . The choice of these priors is guided by both computational considerations and prior knowledge about their plausible values.
The excitation parameter βj is particularly relevant, as it controls the decay rate of the self-excitation function and influences the temporal clustering of events. The selection of its prior is crucial for the stability and convergence of the estimation algorithm. Some studies suggest using a uniform prior U(0,a) for a suitable choice of constant a>0. However, in this work, we opt for a hierarchical formulation that introduces additional flexibility while preserving interpretability. Specifically, we assume that βj follows the hierarchical structure:
where denotes the Beta distribution, and a, ν, aτ, and bτ are known constants. This hierarchical formulation allows for variability across locations while maintaining control over the range of βj values.
For the background rate γj and the excitation parameter αj, we assign priors to their logarithmic transformations to ensure positivity and improve numerical stability. Specifically, we define:
for each . Instead of assuming independent priors for these transformed parameters, we introduce a spatial dependency structure by modeling them as realizations of Gaussian processes:
where xk represents a vector of covariates, Ψk is a vector of unknown regression coefficients, is a scale parameter, and is a spatial correlation function depending on the parameter ϕk, for . This formulation ensures that sites closer to each other exhibit more similar parameter values, allowing spatial smoothing.
By standard properties of Gaussian processes, the prior distributions of the transformed parameters are given by:
where Xk is a matrix of covariates, and Σk is the covariance matrix with entries:
To model spatial dependencies, we assume an exponential correlation function for all processes W, U, and M, such that:
where denotes the Euclidean distance between locations si and sj. This choice ensures that correlation decays smoothly as the distance between sites increases.
To complete the prior specification, we assign hyperpriors to the unknown parameters governing the Gaussian process structure. Specifically, for each , we assume:
where mk, Ck, , , , and are known hyperparameters that control the mean, variance, and spatial correlation range of each Gaussian process.
To formally describe the full prior distribution of the Weibull-Hawkes model, let:
The joint prior distribution factorizes as:
This factorization assumes that the priors for the excitation parameter vector β, the transformed background and excitation parameters W, U, and M, and the hyperparameters governing the Gaussian processes are mutually independent. That is, we assume that knowledge about one group of parameters does not inform or constrain the prior distribution of another.
Although the assumption of prior independence simplifies computations and facilitates inference, it may not always be strictly valid in practical applications. In some cases, incorporating dependencies between priors through hierarchical structures or copula models could improve the model's flexibility. However, for the purposes of this work, we adopt the independence assumption to maintain tractability while still allowing for spatial dependencies to be captured through the Gaussian process priors on W, U, and M.
This completes the prior specification for the Weibull-Hawkes model, establishing a structured Bayesian framework that integrates parameter uncertainty while accounting for spatial dependencies.
In this section, we outline the Bayesian inference procedure used to estimate the parameters of the Weibull-Hawkes model. Our objective is to derive the posterior distribution of the parameter set Θ, given the observed event times t.
Let L(Θ∣t) denote the likelihood function of Θ, conditional on the observed data t. Due to the model's construction, the likelihood factorizes across the n observation sites as:
where Lj(Θ∣tj) represents the likelihood contribution from site sj. The likelihood at each site is given by:
where λj(t∣Θ) denotes the conditional intensity function of the process at site sj, evaluated at time t, and Λj(T∣Θ) represents the integrated intensity over the observation window [0,T], corresponding to the expected number of events up to time T.
For the Weibull-Hawkes model, the conditional intensity function is given by:
where the first term corresponds to the background Weibull rate, while the second term captures the influence of past events at site sj. The integrated intensity is expressed as:
where nj(Tj) denotes the number of observed events at site sj up to time Tj.
Bayesian inference is conducted by combining the likelihood function with the prior distribution to obtain the posterior distribution of the parameters. Using Bayes' theorem, the posterior is proportional to:
where p(Θ) is the prior distribution specified in the previous section.
Given the complexity of the likelihood function and the hierarchical structure of the model, exact analytical inference is intractable. Therefore, we employ Markov chain Monte Carlo (MCMC) methods to sample from the posterior distribution. Specifically, a Metropolis-Hastings algorithm or a Gibbs sampler can be used to efficiently explore the high-dimensional posterior space. These methods not only provide point estimates for the parameters but also allow for uncertainty quantification, yielding credible intervals for key parameters such as βj, αj, γj, and ηj in the Weibull-Hawkes model.
3.1 Estimation Scheme
We employ a Markov Chain Monte Carlo (MCMC) algorithm to estimate the model parameters. The estimation process iteratively updates the parameters by sampling from their respective full conditional distributions. To ensure reliable posterior inference, we discard the initial samples (burn-in period) and retain only the post-convergence samples for posterior estimation.
The full estimation scheme is detailed in Algorithm 1.
Algorithm 1MCMC Sampling Scheme for Parameter Estimation.

In this section, we address the problem of estimating the conditional intensity function, λ*(t), at a new location s*, where no events have been previously recorded. Since the model assumes that event occurrences are spatially correlated, we can leverage information from the observed locations to make predictions at unobserved sites. This is achieved by applying spatial interpolation techniques to the components of the intensity function.
Specifically, we consider interpolation for the background intensity function g(τ|φ) and the excitation function μ(τ∣ϱ). In Sect. 4.1, we outline the procedure for interpolating g(τ|φ) at the new location; in Sect. 4.2, we extend the interpolation framework to μ(τ∣ϱ), ensuring that excitation dynamics are spatially consistent; finally, in Sect. 4.3, we describe how these interpolated components are combined to estimate the full conditional intensity function λ*(t) over continuous time.
4.1 Interpolation of the function g(τ|φ)
At the new location s*, the background intensity function is given by , where the parameter vector must be inferred from the observed locations .
Recall that we defined Wj=log (γj) and Mj=log (ηj) as the logarithmic transformations of γj and ηj. Since these transformed parameters follow Gaussian process priors, the joint distribution of the observed values and the unobserved value W* at s* is Gaussian. The same holds for M*.
The posterior predictive distribution for W* is given by:
A similar expression holds for M*, where ΣM and xM replace ΣW and xW, respectively.
At each iteration of the MCMC algorithm, after drawing samples of W* and M*, we obtain the interpolated parameters and at the new location s*, conditioned on the observed values W and M. Consequently, in each iteration, we compute the estimated background intensity function at s*, allowing us to extend the model to locations where no events have been previously recorded.
4.2 Interpolation of the function μ(τ∣ϱ)
Interpolating the excitation function μ(τ∣ϱ) presents a unique challenge compared to the background intensity function g(τ∣φ). Unlike g(τ∣φ), which depends on continuous parameters that can be directly interpolated using Gaussian processes, μ(τ∣ϱ) is event-driven. It depends on the discrete event times at each location, making it more sensitive to local temporal clustering patterns. As a result, standard interpolation techniques are not directly applicable, since neighboring locations may exhibit different past event histories, affecting the excitation dynamics.
To address this issue, we introduce a spatially weighted sampling method that probabilistically selects nearby locations, ensuring that the interpolated excitation function at an unobserved site reflects the rainfall dynamics of its surroundings. The key idea is that locations close to each other tend to share similar excitation structures. Therefore, by borrowing information from neighboring sites while incorporating spatial variability, we can construct a reasonable estimate of μ(τ∣ϱ) at unobserved locations.
The method consists of two main steps, which are detailed in Algorithm 2:
-
Spatially weighted selection of reference locations. A location is chosen from the set of observed sites, with a probability that decreases with distance from the interpolation site s*. This ensures that closer locations contribute more to the estimate of μ(τ∣ϱ) at s*, while more distant locations have a lower influence.
-
Reconstruction of the excitation function. Once a reference location is selected, its event times are used to reconstruct the excitation function at s*, incorporating the sampled parameters from the MCMC iterations.
To formalize the procedure, let S be an n×2 matrix representing the spatial coordinates of the n monitoring stations, and let be the set of indices corresponding to the rows of S. Given a new location s* where we wish to interpolate , we proceed as follows at each iteration of the MCMC algorithm:
Algorithm 2Sampling from at an interpolation location s*.

As outlined in Algorithm 2, this approach ensures that the interpolated excitation function preserves both spatial and temporal structure in rainfall events. The weighting scheme favors closer locations, capturing local variability while preventing excessive influence from distant sites. Additionally, the exponential decay function naturally reflects the temporal influence of past events, maintaining consistency in excitation dynamics across space.
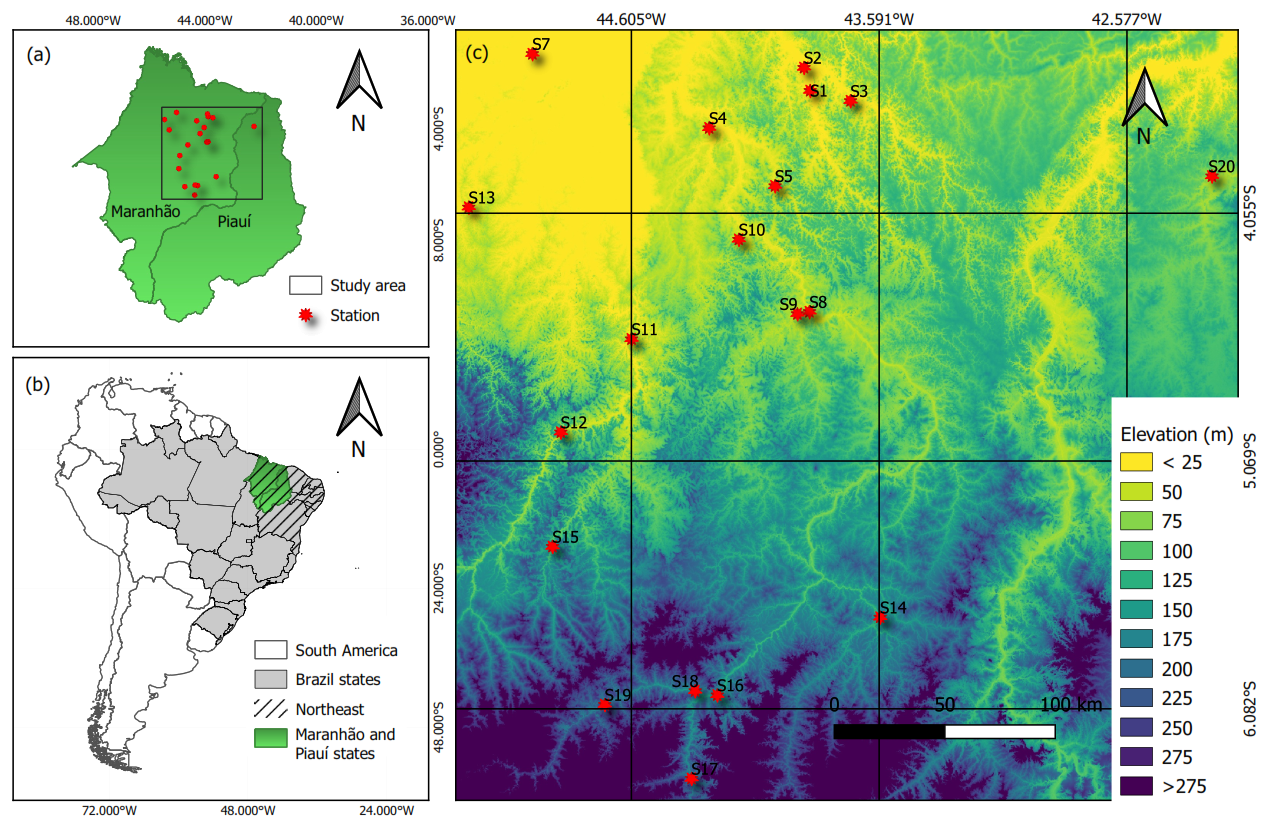
Figure 1 Study area and location of rainfall stations.
4.3 Interpolation of the function λ*(t)
With the interpolated background intensity function and excitation function at the new location s*, we now estimate the full conditional intensity function λ*(t). Since λ*(t) governs the occurrence rate of events at s* over time, its interpolation must reflect both the spatial structure of the background intensity and the temporal clustering effects captured by the excitation function.
Following the model specification, the conditional intensity function at s* is given by:
where:
-
is the interpolated background intensity function at s*.
-
represents the set of inferred past event times at s*.
-
is the interpolated excitation function, incorporating the influence of past events at s*.
Since no direct event observations exist at s*, we must infer the event history . A natural approach is to simulate event times from the interpolated intensity function itself. At each iteration of the MCMC algorithm, we follow these steps:
-
Draw samples of the background and excitation parameters: Using the previously computed interpolations, obtain φ* and ϱ* for the new location s*.
-
Simulate event times at s*. Generate a set of candidate event times from a Poisson process with intensity .
-
Compute λ*(t) at each sampled time. Using Eq. (22), evaluate the interpolated conditional intensity function at each time step.
By iterating over this procedure during the MCMC sampling process, we obtain a probabilistic estimate of λ*(t) at the unobserved location, allowing us to characterize the expected occurrence rate of extreme events in regions without direct observations.
This framework ensures that λ*(t) maintains consistency with the spatiotemporal structure of the observed data. The background intensity function preserves large-scale spatial patterns, while the excitation function captures local clustering behavior, ensuring that interpolated event dynamics remain realistic.
Understanding the occurrence and intensity of extreme precipitation events is crucial for hydrological planning and disaster mitigation. In this study, we model the frequency and spatial distribution of extreme daily precipitation events, defined as days with rainfall exceeding 20 mm (R20mm), in the northern region of Maranhão State, Brazil.
To achieve this, we analyze daily accumulated precipitation data (mm) over a 10-year period, from 1 January 2013 to 31 December 2022. These data were obtained from 20 rain gauges located at national meteorological stations, managed by the National Institute of Meteorology (INMET) and the National Water and Basic Sanitation Agency (ANA). The datasets are publicly available through the INMET meteorological database (https://bdmep.inmet.gov.br, last access: 25 June 2026) and the ANA open data portal (https://dadosabertos.ana.gov.br, last access: 25 June 2026).
Table 1 MAD and MSE values obtained in the cross-validation study for each excluded station (sj, with ), along with the station-wide median of each metric, generated by Model A with radius R1 and different weight vectors (P1, P2, P3).
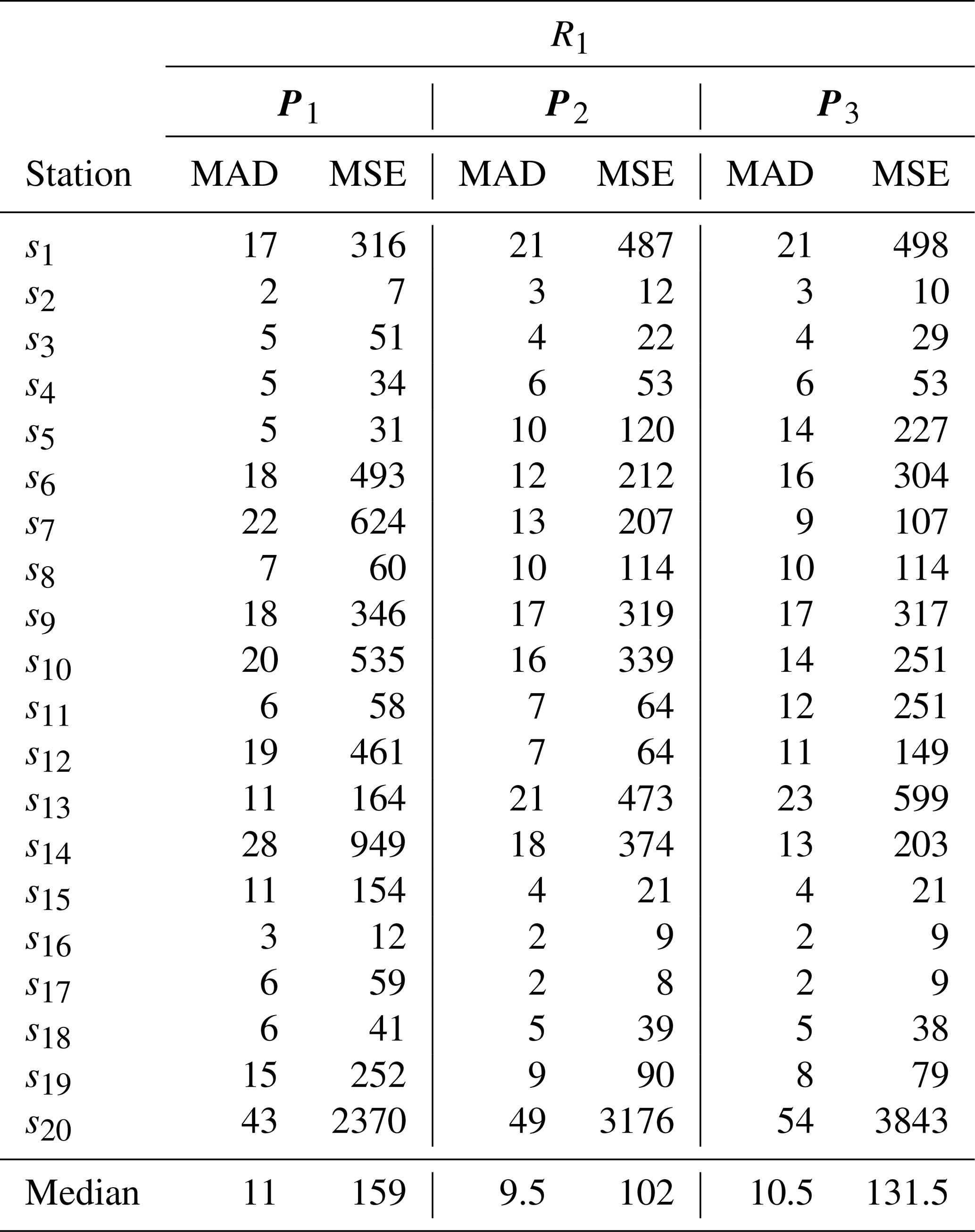
Table 2 MAD and MSE values obtained in the cross-validation study for each excluded station (sj, with ), along with the station-wide median of each metric, generated by Model A with radius R2 and different weight vectors (P1, P2, P3).
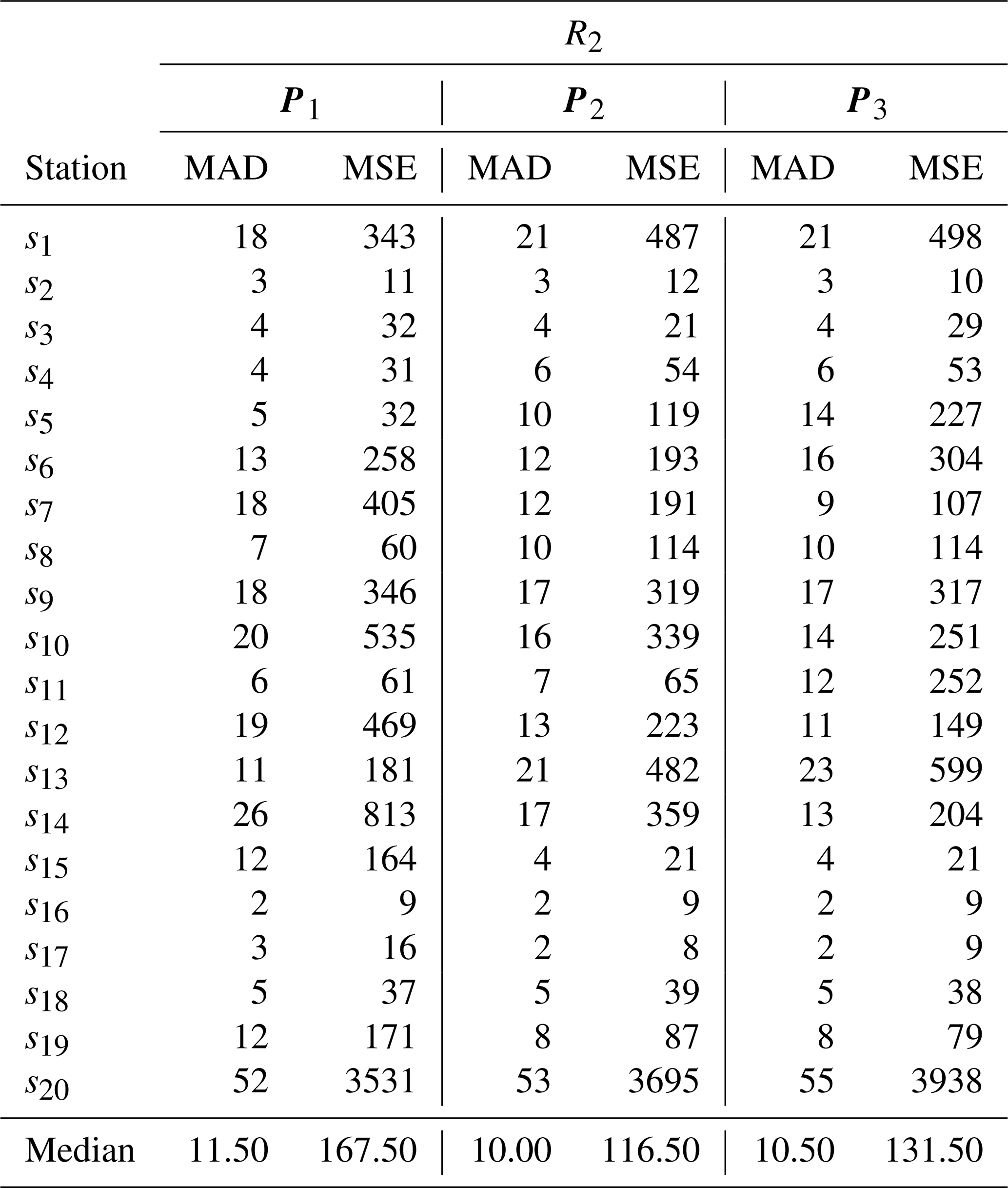
Figure 1 presents the spatial distribution of the rain gauges (P) used in this study. The study area spans parts of the states of Maranhão and Piauí, in northeastern Brazil, a region marked by significant climatic and geographical diversity (Moura and Shukla, 1981; Vale et al., 2024) and persistent socio-economic challenges (IBGE, 2024). Covering approximately 145 611 km2, it extends between latitudes 3.2 and 6.5° S and longitudes 41.9 and 45.5° W. The region's topography varies considerably, with elevations ranging from below 25 m to over 275 m, influencing local precipitation patterns. According to the National Institute of Meteorology, annual rainfall in this area ranges from 1000 to 1800 mm (INMET, 2025), with extreme daily events occasionally exceeding 100 mm (Rodrigues et al., 2020).
Precipitation in the region is governed by multiple atmospheric systems throughout the year. The primary driver of rainfall is the Intertropical Convergence Zone (ITCZ), which migrates towards northern and northeastern Brazil during summer and autumn, generating intense precipitation between February and May (Uvo, 1989; Utida et al., 2019). Additionally, the Upper Tropospheric Cyclonic Vortex (UTCV) plays a significant role, particularly during the summer months from December to February, further shaping the regional precipitation regime (Kousky and Alonso Gan, 1981; Lyra et al., 2020).
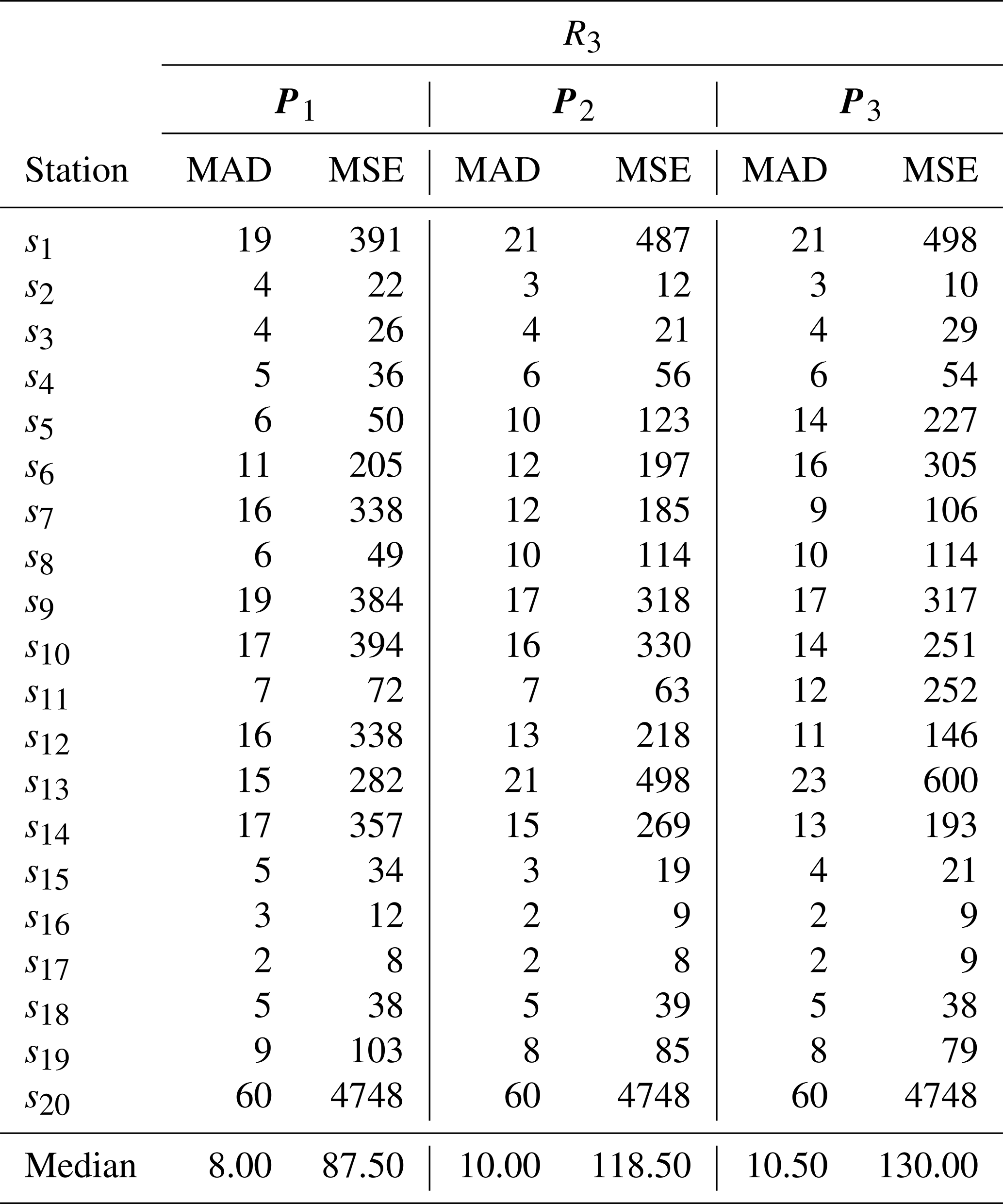
Table 3 MAD and MSE values obtained in the cross-validation study for each excluded station (sj, with ), along with the station-wide median of each metric, generated by Model A with radius R3 and different weight vectors (P1, P2, P3).
5.1 Application and Predictive Performance Analysis
The proposed model is applied to analyze the spatiotemporal dynamics of extreme precipitation events in the northern region of Maranhão. By estimating its parameters, we aim to characterize the frequency, intensity, and clustering patterns of these events, providing insights into their underlying drivers. This analysis allows us to better understand the precipitation regime in the region and assess how extreme rainfall events are distributed over time and space. To ensure the robustness of our approach, we compare its performance with alternative models commonly used in the literature, evaluating their ability to capture the observed precipitation dynamics.
The following models are considered for comparison:
-
Model A: The proposed Hawkes process model.
-
Model B: A Poisson model with a seasonal component.
-
Model C: A standard Poisson model without seasonality.
All three models employ a Weibull intensity function. The processes W, M, and U incorporate the covariates , with . The variance parameters , , and follow an Inverse-Gamma prior distribution, IG(0.001,0.001), while the scale parameters ϕW, ϕM, and ϕU follow a Gamma prior distribution, Gamma(0.001,0.001).
In the case of the Hawkes process model, the excitation decay parameter β is defined as β=aZ, where a=2 and , allowing for flexibility in capturing self-excitation effects.
Finally, for models incorporating seasonal effects, the prior distributions for the seasonal component parameters δ and f are given by:
This comparative analysis enables us to evaluate how well the proposed model represents precipitation extremes in Maranhão and how it performs relative to other modeling strategies. By contrasting its predictive capabilities with existing methodologies, we assess its effectiveness in capturing the temporal and spatial structure of extreme rainfall events, ensuring a comprehensive understanding of the region's precipitation patterns.
5.1.1 Sensitivity Analysis of the Interpolation Method
Before comparing the predictive performance of the models, we conduct a sensitivity analysis to evaluate the impact of key parameters in the interpolation process for the function Λ. Specifically, we assess the influence of the radius R used to define neighboring stations and the weight vector P assigned to each neighbor.
To analyze the effect of R, we consider three different definitions:
-
R1: The maximum distance between the observed stations.
-
R2: The midpoint between the maximum and average distances.
-
R3: The average distance between stations.
Similarly, we test three different weight functions for the neighboring stations:
where si represents the location where the function Λ(si,t) is being predicted, and sk are the neighboring stations within the selected radius Rj, for .
To evaluate interpolation accuracy, we compute the mean absolute deviation (MAD) and mean squared error (MSE) at each excluded station sj in a cross-validation procedure. These metrics are defined as
where nj,t is the observed number of extreme precipitation events in the interval (0,t] at location sj, and is the set of observed event times at that location.
Tables 1, 2, and 3 present the MAD and MSE values obtained in the cross-validation study for each excluded station (sj, with ), considering Model A applied to each radius (R1, R2, and R3) and the different weight vectors (P1, P2, P3), as well as the median MAD and MSE across all stations for each radius–weight combination. The results indicate that the combination of R3 with P1 yielded the lowest MAD and MSE values in most cases, both at the station level and in terms of the reported medians, leading to its selection for use in the interpolation method of Model A.
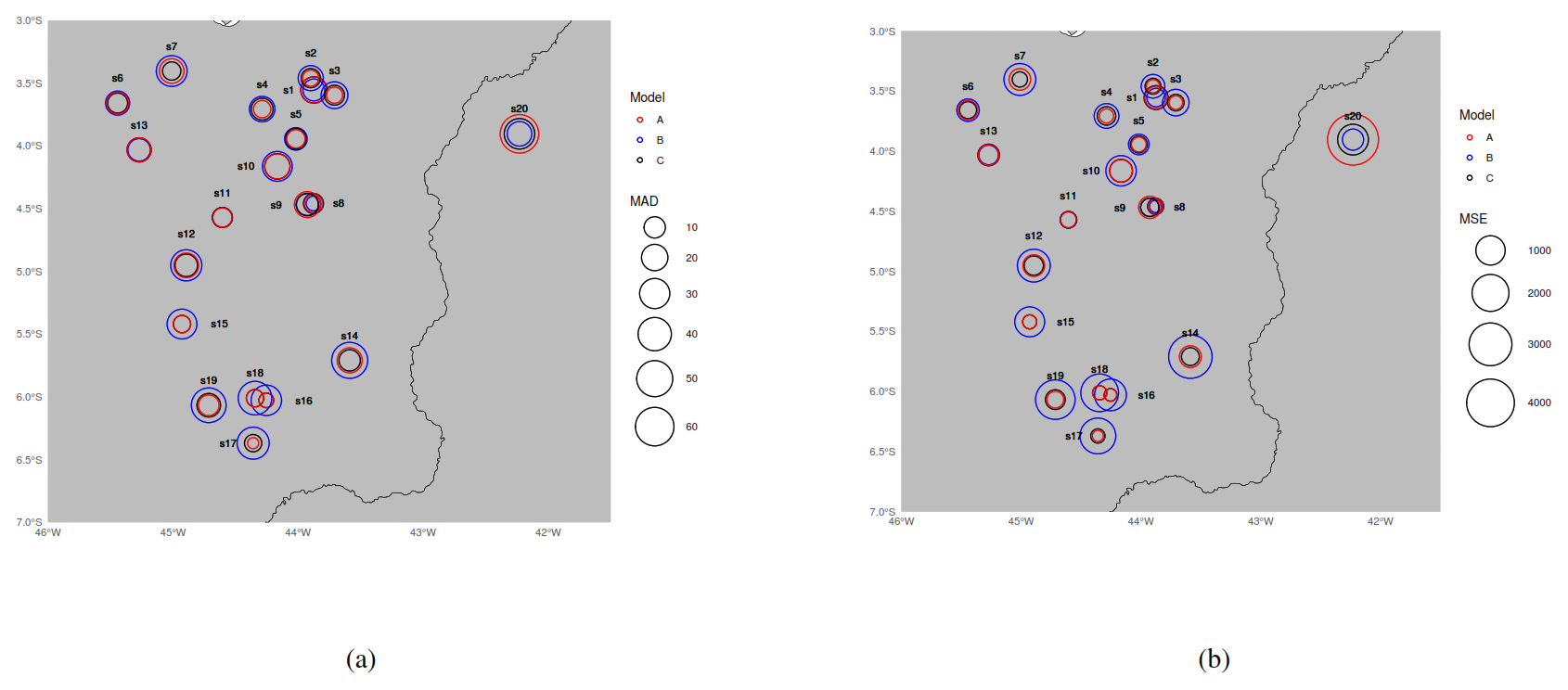
Figure 2MDA (a) and MSE (b) results in the cross-validation study for each excluded station , generated by the competing models. In each subplot, the colored circles represent the models on the study-area map with a radius length scale representing MAD/MSE measurement.
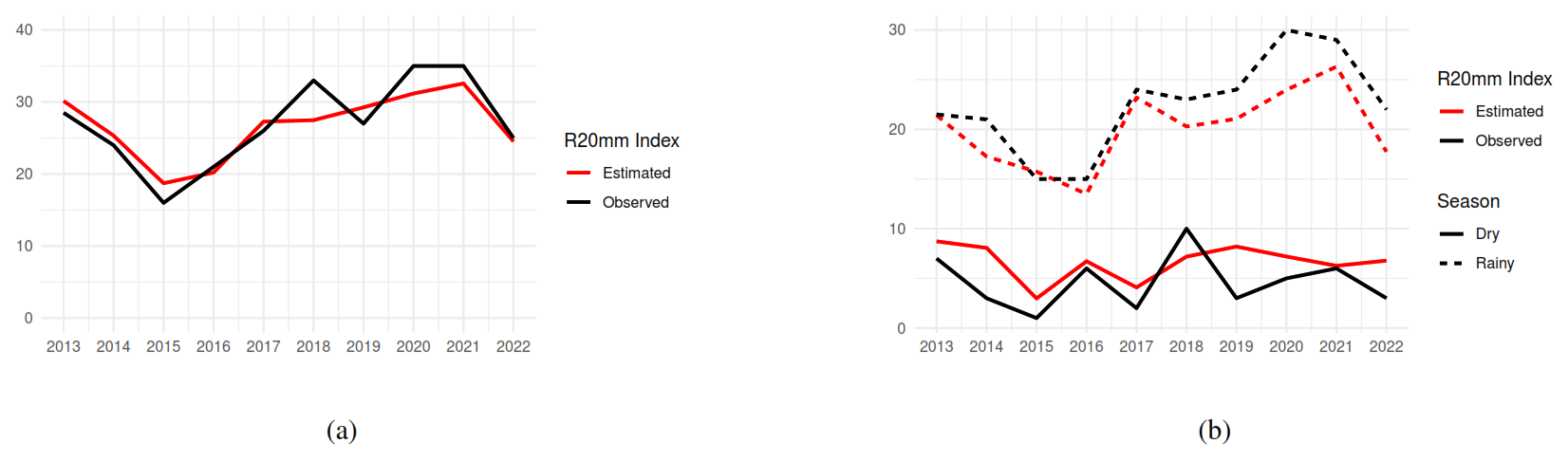
Figure 3The estimated and the observed R20mm index by year (a) and season (b) at station s3.
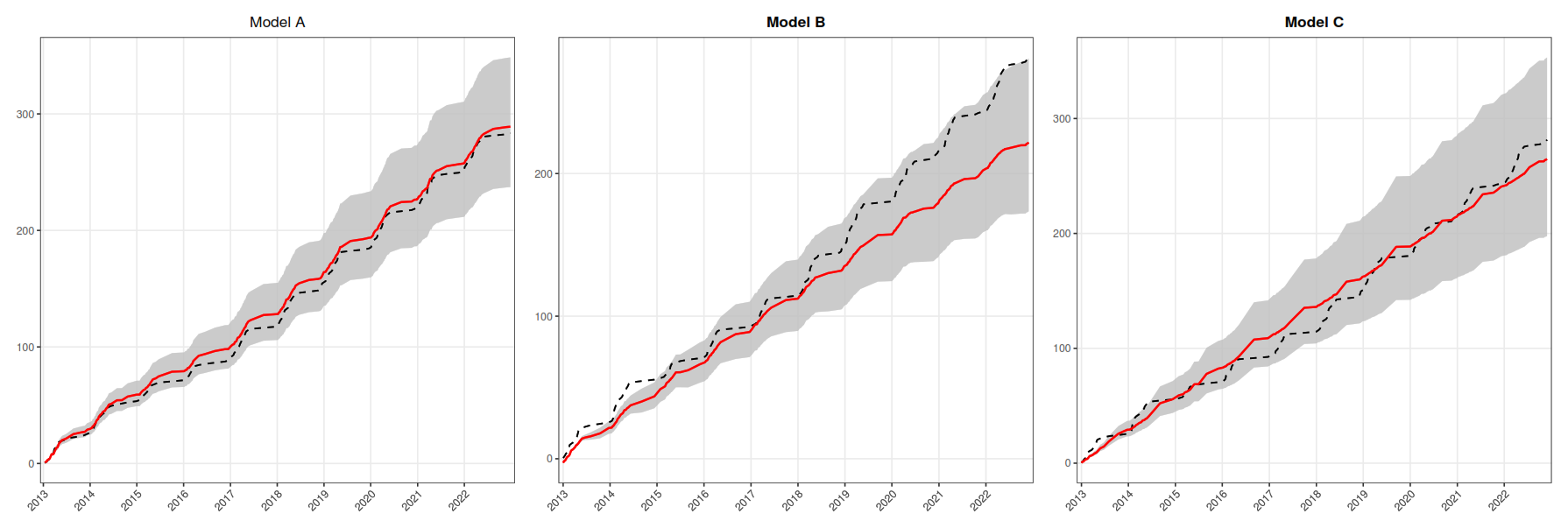
Figure 4 Estimated function Λ3(t) (solid red line) with a 95 % credibility interval (shaded area) and the observed number of event occurrences in the interval (0,t], nj,t (black dashed line), for each of the analyzed models.
5.1.2 Cross-Validation for Predictive Performance
To assess the predictive performance of the models in interpolating the R20mm index, we conduct a leave-one-out cross-validation study. The procedure consists of systematically removing data from one station si at a time and fitting the models using the remaining stations. This process is repeated for all 20 stations in the dataset.
After fitting each model under these 20 different configurations, we apply interpolation methods to estimate the integrated intensity function Λj(t) at the removed station sj. The quality of these predictions is then evaluated using the MAD and MSE metrics defined in Eqs. (23) and (24).
By combining the sensitivity analysis and the cross-validation study, we aim to ensure that the proposed model not only accurately captures the spatiotemporal structure of extreme precipitation events but also demonstrates superior predictive performance compared to alternative approaches.
In Fig. 2, we observe that Model A generally exhibited the lowest MAD and MSE values compared to the other models, indicating its superior predictive performance. These results suggest that Model A is the most suitable for capturing the observed data patterns, providing more accurate forecasts. Figure 4 displays the predictions of the function Λ3(t) generated by each model, along with their respective 95 % credibility intervals. It is evident from this figure that Model A yields the most consistent predictions, with lower uncertainty and a better fit to the observed data, confirming its superior predictive performance. In Fig. 3, we present time series plots comparing the estimated and observed R20mm index at station s3 by year and season (dry/rainy); in Maranhão, the rainy season occurs from January to June, while the dry season occurs from July to December. These plots demonstrate the high accuracy of Model A in predicting the R20mm index and effectively capturing its temporal dynamics.
Figure 2 also shows that Model A outperforms Model B in terms of predictive accuracy. Model A achieved lower MAD and MSE values in 85 % of cases compared to Model B. Additionally, Model A also demonstrated superior performance compared to Model C, achieving lower MAD values in 50 % of cases, tying in 20 %, and showing higher values in only 30 % of instances. These results indicate that, overall, Model A provides better predictive performance than Model C.
Table 4 summarizes the estimated values of the parameters ϕ, σ2, ΨW, ΨM, ΨU, δ, θ, and f for Models A, B, and C. The results indicate notable differences in parameter estimates across models, particularly in the spatial dependence parameters (ϕW, ϕM, ϕU) and the variance components (, , ). Table 5 presents the estimates of the shape parameter ηj of the Weibull intensity function for each station, showing that Model C generally yields higher mean estimates compared to Models A and B, with relatively narrow credibility intervals across all stations. Table 6 presents the estimates of the scale parameter γj of the Weibull intensity function for each station, showing that Model B generally yields higher mean estimates compared to Models A and C, with relatively narrow credibility intervals across all stations. Finally, Table 7 reports the estimates of the parameters αj and βj governing the excitation function μ in the Hawkes process, specifically for Model A. In our application context, the parameter αj reflects the instantaneous increase in the intensity function following the occurrence of a new event, while the parameter βj describes the rate at which the intensity decays back to its baseline level. That is, the occurrence of a precipitation event exceeding 20 mm in a single day increases the probability of a subsequent similar event by an increment of 0.049 in the intensity, as observed at location s1 (Table 7). This influence decays at a rate of 0.064 (Table 7).
The results suggest some variability in the excitation intensity (αj) and decay rate (βj) across different stations, reflecting the spatial heterogeneity in extreme precipitation events. Higher values of αj and βj are concentrated in the northern part of the study area, whereas the lowest values are observed at the southernmost stations (s15, s16, s17, s18, and s19), where αj ranges from 0.035 to 0.037, and βj from 0.053 to 0.058 (Table 7). These variations in αj and βj between the northern and southern regions may be partly attributed to differences in elevation and rainfall regimes influenced by proximity to the coast and the activity of the Intertropical Convergence Zone (ITCZ). Northern regions, characterized by lower elevation and higher atmospheric humidity, tend to exhibit greater intensity and persistence of extreme rainfall events, while southern, more elevated and inland areas experience lower frequency and weaker clustering of such events.
Table 4 Summary of parameter estimates for ϕ, σ2, ΨW, ΨM, ΨU, δ, θ, and f for Models A, B, and C.
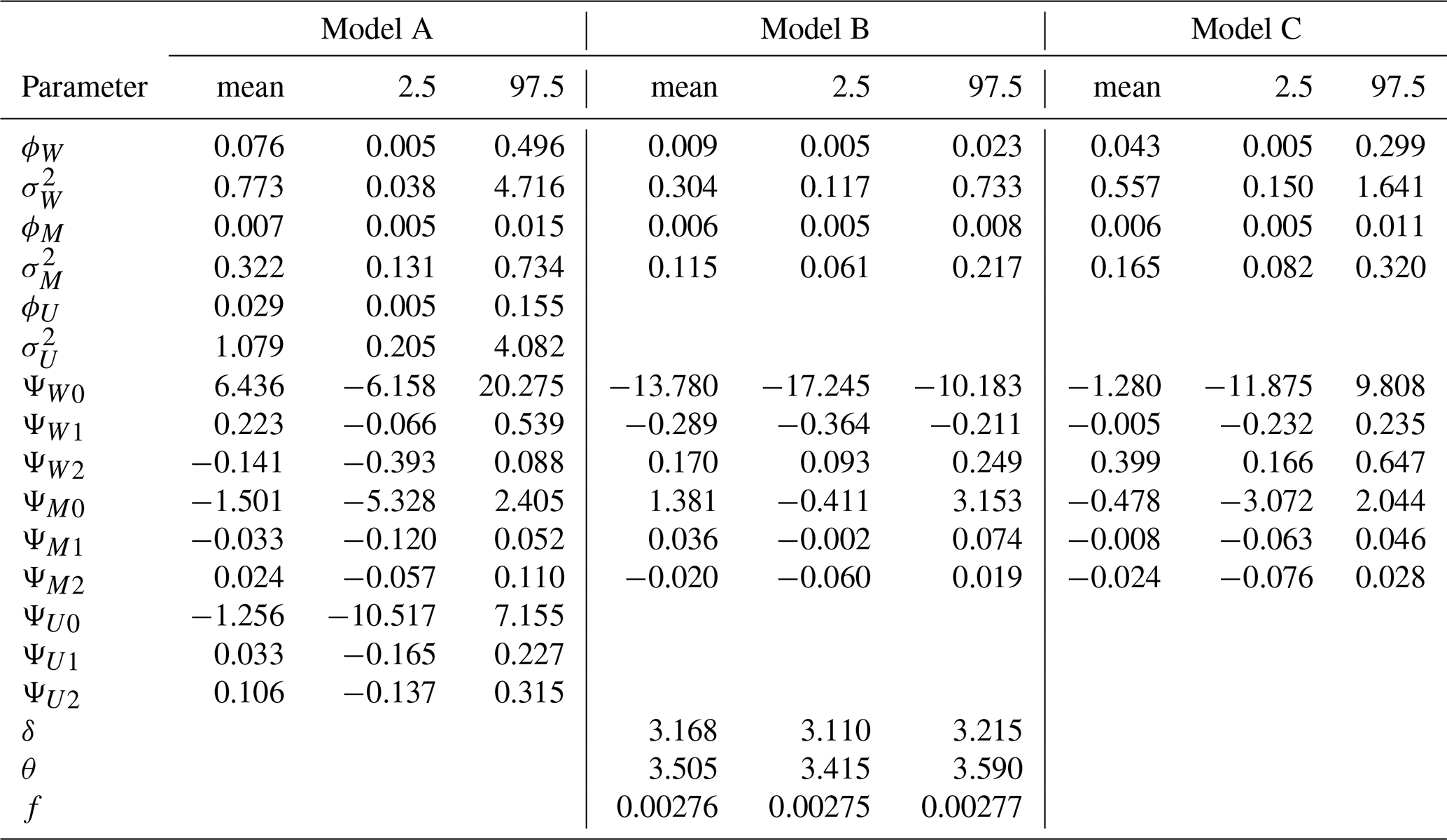
Table 5 Summary of the shape parameter estimates ηj of the Weibull intensity function, for , obtained by Models A, B, and C.
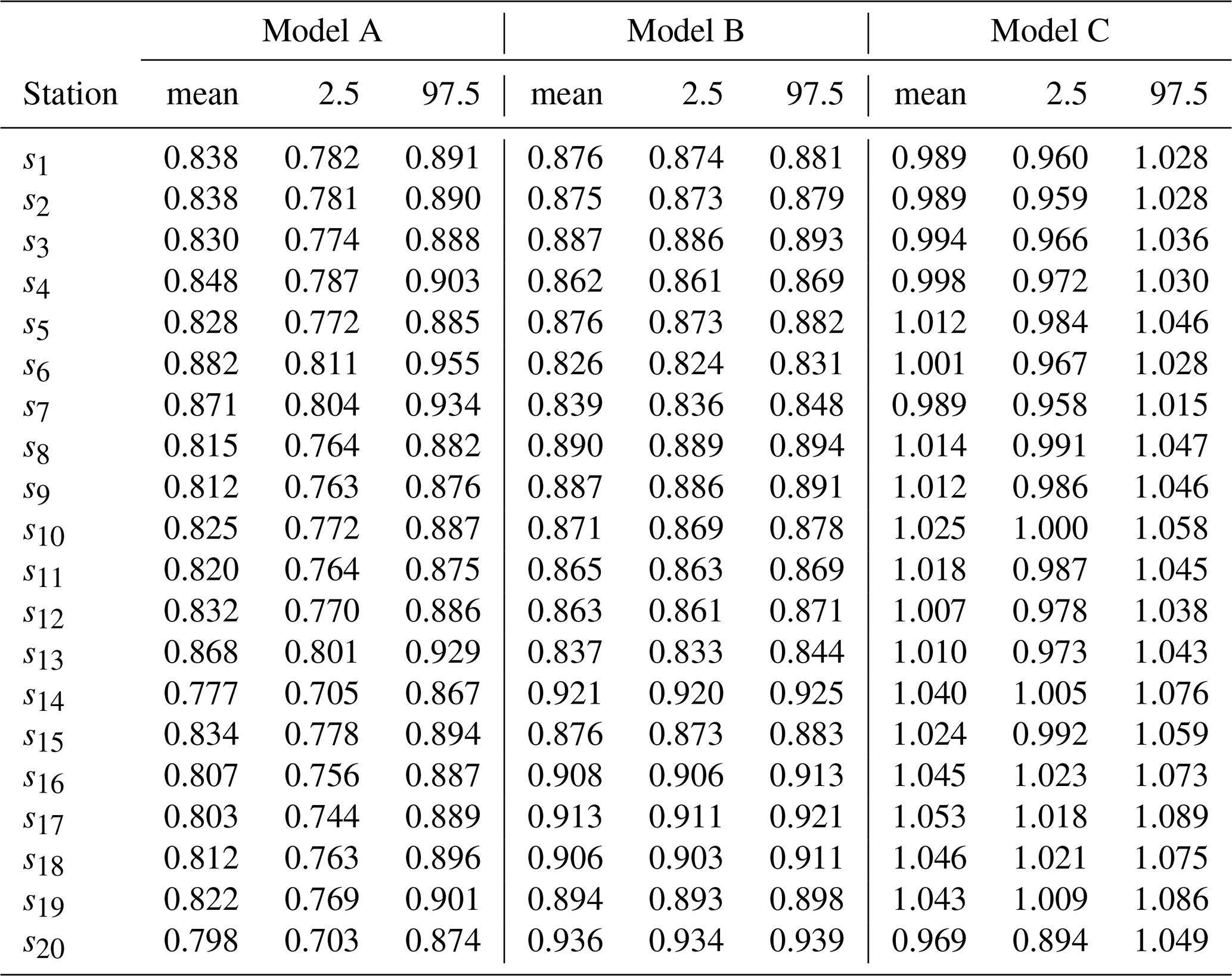
Table 6 Summary of the scale parameter estimates γj of the Weibull intensity function, for , obtained by Models A, B, and C.
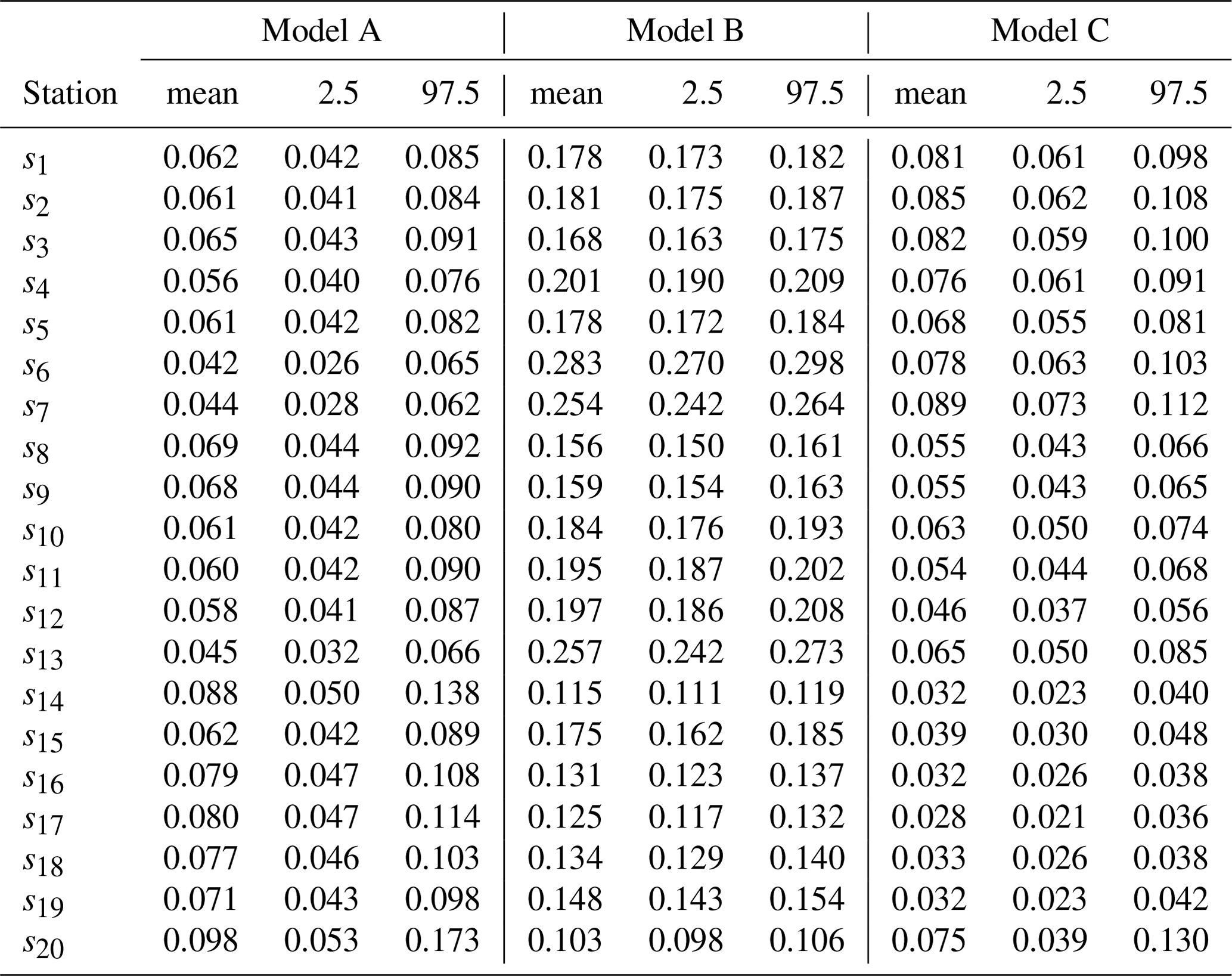
Table 7 Summary of the estimates for the parameters αj and βj of the function μ in the Hawkes process, for , obtained for Model A.
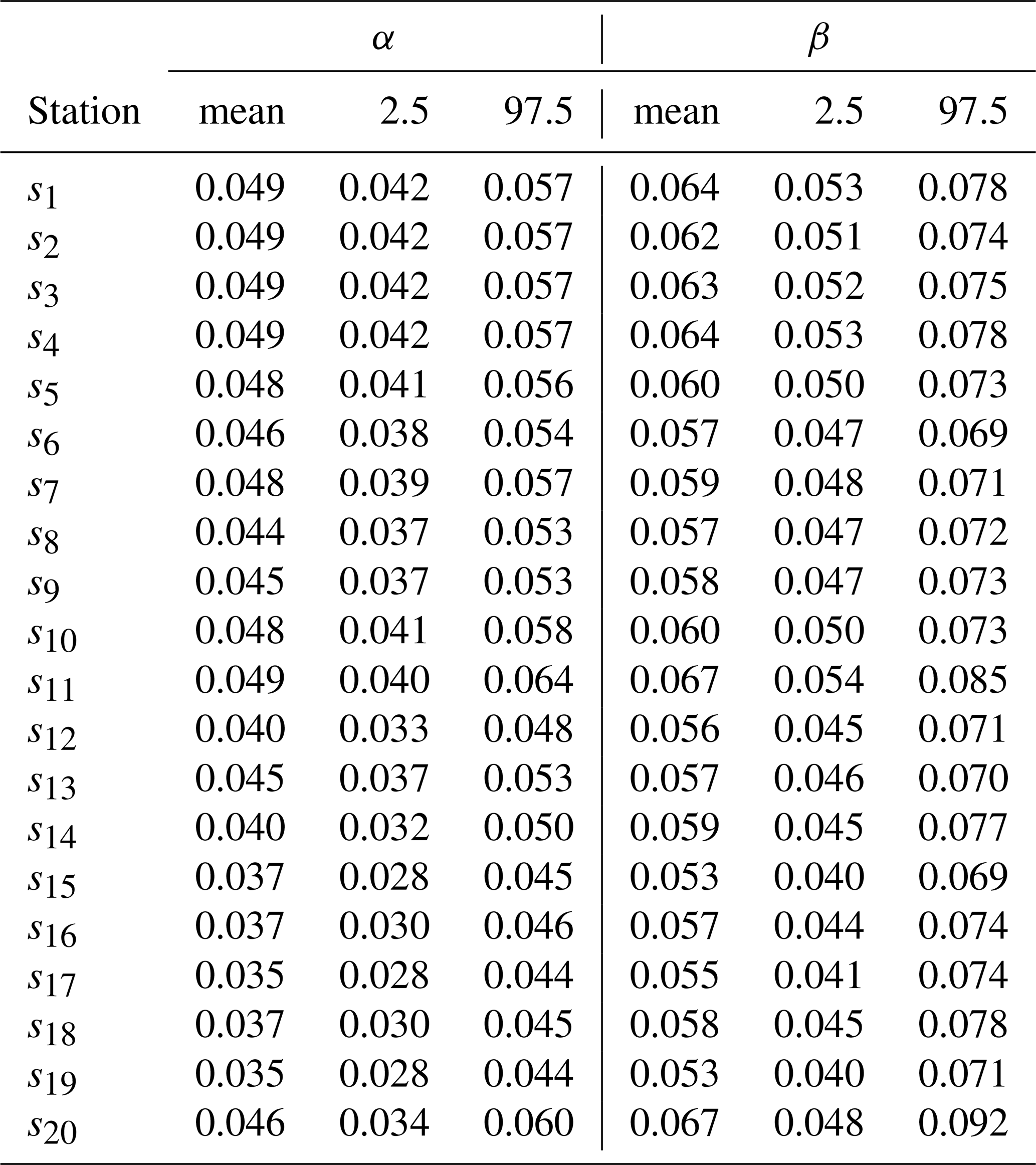
This study proposed a novel geostatistical model based on self-exciting Hawkes processes for modeling the R20mm climate index, representing an innovative extension of the class of non-homogeneous spatio-temporal Poisson models. The main motivation for developing the model stems from the empirical observation that extreme rainfall events in northern Maranhão tend to occur in clusters, especially during the rainy season, suggesting temporal dependence between events.
The proposed model incorporates temporal dependence through an excitation function and spatial dependence via hierarchical Gaussian processes, allowing for interpolation at locations with no observed data. Parameter estimation was conducted under a Bayesian framework using Markov Chain Monte Carlo (MCMC) methods. The model's predictive performance was assessed through a leave-one-out cross-validation, comparing the results to those obtained from Poisson models with and without seasonality.
The results indicate that the Hawkes-based model outperformed the competing models in terms of predictive accuracy, particularly in regions with pronounced rainfall seasonality. Additionally, the excitation function parameters provided further insights into the intensity and persistence of extreme events, revealing spatio-temporal patterns not adequately captured by conventional models.
We conclude that the proposed model is promising for applications in climatology, especially in regions with high spatio-temporal rainfall variability. It contributes to the improvement of climate extremes analysis and forecasting, with potential applications in the planning of climate change adaptation strategies and natural disaster mitigation.
The study area considered corresponds to the square spatial domain , while the temporal interval is defined as (0,1000]. The proposed model is simulated over a regular spatial grid of 8×8 points, as illustrated in Fig. A1a.

Figure A1 Regular 8×8 spatial grid over the domain , with locations denoted by si, for . Panels illustrate different sampling configurations: (a) full set of 64 locations; (b) random subsample of 25 locations; (c) random subsample of 36 locations; and (d) random subsample of 49 locations. Circled points indicate the selected locations in each subsample.
The parameters used in the simulation process are specified as:
and we assume η=1 throughout the spatial domain.
For the inference stage, weakly informative prior distributions (diffuse priors) are considered for all model parameters, given by:
The objective of this simulation study is to evaluate the performance of the parameter estimation procedure of the spatial process, with emphasis on its stability and convergence properties as the number of observed locations varies. To this end, subsets of different sizes are randomly selected from the full set of locations, considering samples with 25, 36, and 49 spatial points. These configurations correspond to the subsampling scenarios presented in Fig. A1b, c, and d, respectively.
For each configuration, the model is fitted and the parameter estimates are analyzed in terms of bias, variability, and convergence behavior. Additionally, the model is estimated using the full set of locations, allowing for a direct comparison with the subsampling scenarios.
This experimental design makes it possible to systematically investigate the impact of spatial sampling density on the inferential quality of the model, providing evidence on the robustness of the proposed method under different levels of available spatial information.
For each configuration, four independent MCMC chains were run from distinct initial values in order to assess parameter convergence. The number of iterations was adjusted according to the spatial sample size to ensure stability of the estimates. Specifically, for N=25, it was used 300 000 iterations, with a burn-in period of 200 000 and thinning of 100; for N=36 and N=49, we used 500 000 iterations, with burn-in of 300 000 and thinning of 100; and for N=64, it was used 600 000 iterations, with burn-in of 400 000 and thinning of 100. This scheme was adopted to ensure adequate exploration of the parameter space and to allow for a robust assessment of convergence across chains.
The results of the simulation study indicate an overall satisfactory performance of the proposed estimation procedure across all sampling configurations considered. For the smallest sample size (N=25), most parameters exhibit good convergence behavior, as indicated by the potential scale reduction factor (PSRF), with the majority of the upper bounds of the 95 % credible intervals below 1.2 (Table A1). Small deviations from full convergence are observed for the parameters ϕu and , although their PSRF values remain close to the acceptable threshold, suggesting near convergence.
As the sample size increases to N=36 and N=49, an overall improvement in convergence diagnostics is observed, with most parameters showing stable estimates; however, the parameter ϕu still exhibits relatively slower convergence compared to the others (Tables A1 and A2). For the full dataset (N=64), all parameters show clear convergence, with PSRF values essentially equal to 1.
In terms of accuracy, the 95 % credible intervals for most parameters include the true values used in the simulation, indicating the reliability of the inferential procedure. This behavior is further supported by the posterior distributions presented in Fig. A2, where an increasing concentration of the densities around the true values is observed as the number of spatial locations increases. Overall, the results highlight the positive effect of increasing spatial sampling density on both convergence and estimation accuracy, indicating that the proposed model provides robust inference even under moderate levels of spatial subsampling.
Table A1Posterior summaries and convergence diagnostics for the simulated study with subsamples of N=25 and N=36 spatial locations. The posterior summaries include the median, 2.5 % and 97.5 % posterior quantiles, and posterior standard deviation (SD). Convergence is assessed using the potential scale reduction factor, reported as point estimate and upper confidence interval (upper C.I.).
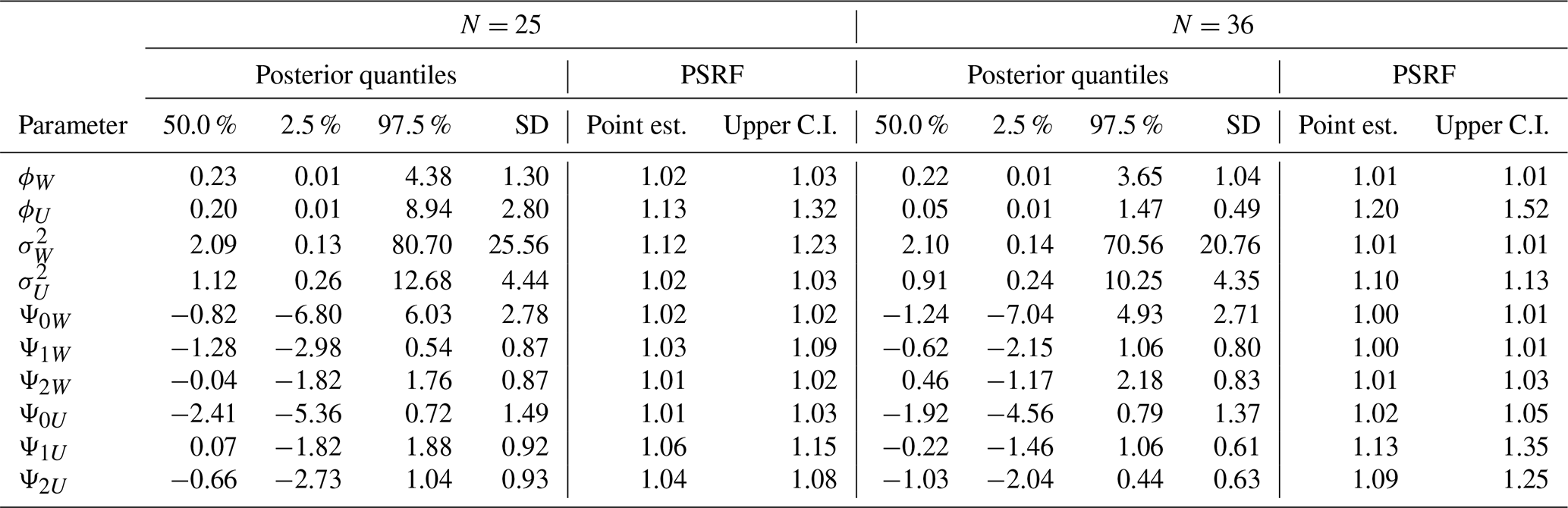
Table A2Posterior summaries and convergence diagnostics for the simulated study with subsamples of N=49 spatial locations and the full grid with N=64 locations. The posterior summaries include the median, 2.5 % and 97.5 % posterior quantiles, and posterior standard deviation (SD). Convergence is assessed using the potential scale reduction factor, reported as point estimate and upper confidence interval (upper C.I.).
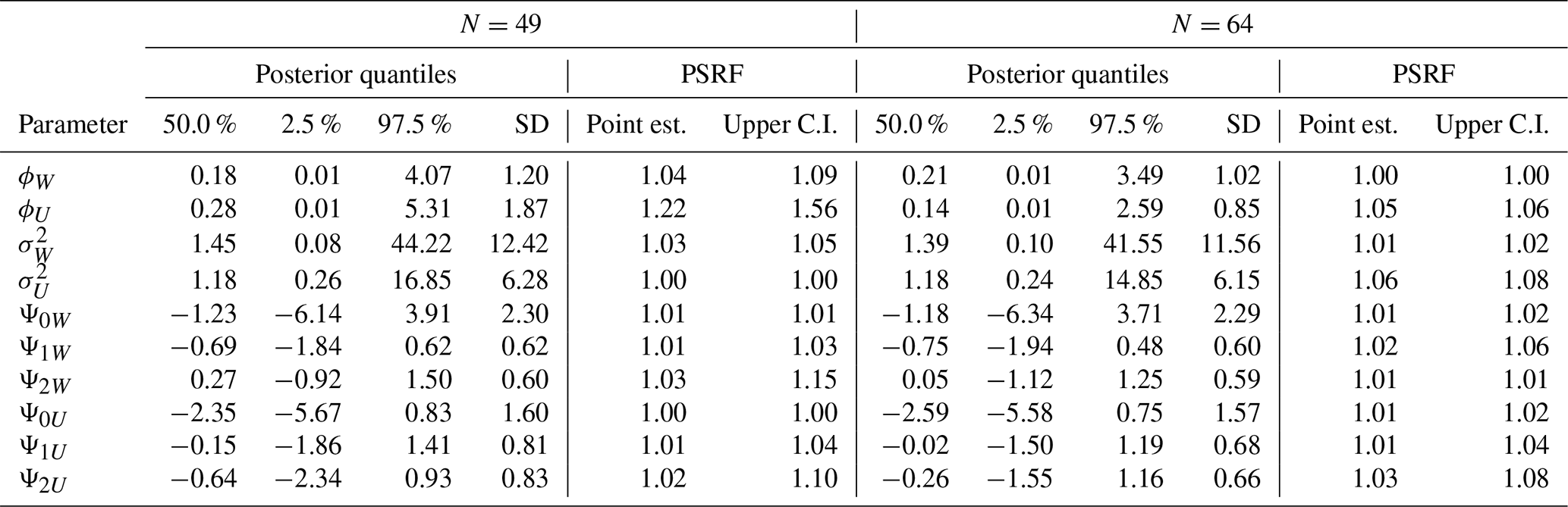
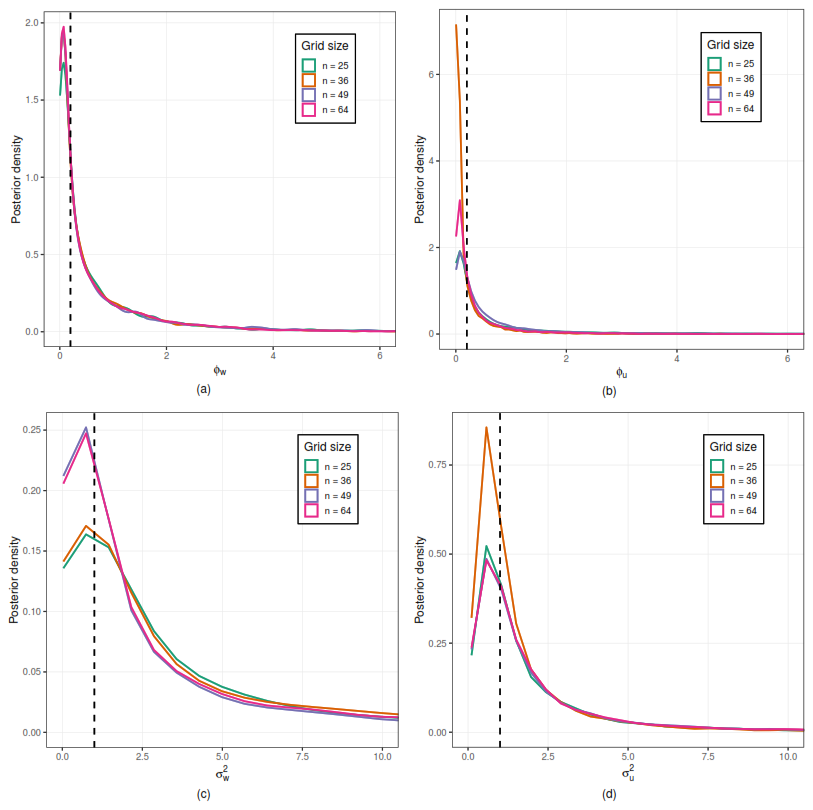
Figure A2Posterior distributions of the model parameters under different spatial sampling configurations. Panels (a) and (b) display the posterior densities of the spatial decay parameters ϕw and ϕu, respectively, while panels (c) and (d) correspond to the variance parameters and . Results are shown for grid sizes and 64. The dashed vertical lines indicate the true parameter values used in the simulation. The figure illustrates the impact of increasing spatial sample size on the concentration and stability of the posterior distributions.
The spatio-temporal non-homogeneous Poisson models are implemented in the STprocpoisson R package (https://doi.org/10.5281/zenodo.15651335, Projeto-CNPq-Clima, 2024b), while the proposed Hawkes-based models are implemented in the STprocHawkes R package (https://doi.org/10.5281/zenodo.15652279, Projeto-CNPq-Clima, 2024a).
The data utilized in this article are freely accessible. Specifically, we analysed data collected from the SISDAGRO (Agricultural Decision Support System) platform, developed by INMET (the National Institute of Meteorology, Brazil) and the National Water and Basic Sanitation Agency (ANA). To ensure full reproducibility, the dataset is provided in both the STprocHawkes R package (https://doi.org/10.5281/zenodo.15652279, Projeto-CNPq-Clima, 2024a) and the STprocpoisson R package (https://doi.org/10.5281/zenodo.15651335, Projeto-CNPq-Clima, 2024b).
FECM conceptualized the proposed model and coordinated the team in developing and implementing it in the R software environment. AMBN and MSP developed the statistical properties of the model and assisted in constructing the interpolation method, as well as conducting the literature review on statistical models relevant to the study. DTR contributed to the preprocessing of precipitation data for the state of Maranhão, Brazil, supported the conceptual development of the model by advising on appropriate assumptions for extreme event analysis based on her expertise in climate extremes, and helped interpret the results from a climate science perspective. CMA implemented the model code in R and organized it into an R package format.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
We deeply thank the National Council for Scientific and Technological Development (CNPq) and the Ministry of Science, Technology and Innovation (MCTI) for the generous funding granted to the project, identified by process number 405750/2022-6, included in the so-called Call 59/2022 – Line 1 – Modelling the Global Climate System, Impacts, Vulnerability and Adaptation to Climate Change and Monitoring and Forecasting Natural Disasters. The trust and investment of these agencies were fundamental to the success of this work.
We express our gratitude to the LABEST and BME laboratories of the Statistics Department of the Federal University of Rio Grande do Norte. We thank you for generously granting access to and for permission to use your computer laboratories to implement the computational part of this project. The collaboration and support of these laboratories were essential for the successful completion of this research.
This research has been supported by the Conselho Nacional de Desenvolvimento Científico e Tecnológico (grant no. 405750/2022-6).
This paper was edited by Rohitash Chandra and reviewed by two anonymous referees.
Batista, F. F., Rodrigues, D. T., and e Silva, C. M. S.: Analysis of climatic extremes in the Parnaíba River Basin, Northeast Brazil, using GPM IMERG-V6 products, Weather and Climate Extremes, 43, 100646, https://doi.org/10.1016/j.wace.2024.100646, 2024. a
Curtarelli, M. P., Rennó, C. D., and Alcântara, E. H.: Evaluation of the Tropical Rainfall Measuring Mission 3B43 product over an inland area in Brazil and the effects of satellite boost on rainfall estimates, J. Appl. Remote Sens., 8, 083589, https://doi.org/10.1117/1.JRS.8.083589, 2014. a
dos Santos, A. L. M., Gonçalves, W. A., Rodrigues, D. T., Andrade, L. D. M. B., and e Silva, C. M. S.: Evaluation of extreme precipitation indices in Brazil’s Semiarid region from Satellite Data, Atmosphere, 13, 1598, https://doi.org/10.3390/atmos13101598, 2022. a
Hawkes, A. G.: Spectra of some self-exciting and mutually exciting point processes, Biometrika, 58, 83–90, 1971. a, b
Holbrook, A. J., Loeffler, C. E., Flaxman, S. R., and Suchard, M. A.: Scalable Bayesian inference for self-excitatory stochastic processes applied to big American gunfire data, Stat. Comput., 31, 1–15, 2021. a
IBGE: Síntese de indicadores sociais: uma análise das condições de vida da população brasileira: 2024/IBGE, Coordenação de População e Indicadores Sociais, IBGE, ISBN 978-85-240-4641-4, 2024. a
INMET: Banco de dados meteorológicos para ensino e pesquisa, BDMEP, https://bdmep.inmet.gov.br (last access: 25 June 2026), 2025. a
Kousky, V. E. and Alonso Gan, M.: Upper tropospheric cyclonic vortices in the tropical South Atlantic, Tellus, 33, 538–551, 1981. a
Laub, P. J., Lee, Y., Pollett, P. K., and Taimre, T.: Hawkes models and their applications, Annu. Rev. Stat. Appl., 12, 233–258, 2025. a
Lyra, M. J. A., Fedorova, N., Levit, V., and Freitas, I. G. F. D.: Características dos complexos convectivos de mesoescala no Nordeste Brasileiro, Revista Brasileira de Meteorologia, 35, 727–734, 2020. a
Miscouridou, X., Caron, F., and Teh, Y. W.: Modelling sparsity, heterogeneity, reciprocity and community structure in temporal interaction data, Adv. Neur. In., 31, 2018. a
Morales, F. E. C.: State-space prior distribution for parameter of nonhomogeneous Poisson spatiotemporal models, Biometrical J., 65, 2200125, 2023. a, b
Morales, F. E. C. and Rodrigues, D. T.: Spatiotemporal nonhomogeneous poisson model with a seasonal component applied to the analysis of extreme rainfall, J. Appl. Stat., 50, 2108–2126, 2023. a, b, c, d
Morales, F. E. C. and Vicini, L.: A non-homogeneous Poisson process geostatistical model with spatial deformation, Adv. Stat. Anal., 104, 503–527, 2020. a, b, c
Morales, F. E. C., Vicini, L., Hotta, L. K., and Achcar, J. A.: A nonhomogeneous Poisson process geostatistical model, Stoch. Environ. Res. Risk A., 31, 493–507, 2017. a
Moura, A. D. and Shukla, J.: On the dynamics of droughts in northeast Brazil: Observations, theory and numerical experiments with a general circulation model, J. Atmos. Sci., 38, 2653–2675, 1981. a
Ogata, Y.: Statistical models for earthquake occurrences and residual analysis for point processes, J. Am. Stat. Assoc., 83, 9–27, 1988. a
Projeto-CNPq-Clima: STprocHawkes: Repository for Spatio-Temporal Hawkes Process Models, Zenodo [code], https://doi.org/10.5281/zenodo.15652279, 2024a. a, b
Projeto-CNPq-Clima: STprocPoisson: Spatio-Temporal Non-homogeneous Poisson Process Models, Zenodo [code], https://doi.org/10.5281/zenodo.15651335, 2024b. a, b
Reinhart, A.: A review of self-exciting spatio-temporal point processes and their applications, Stat. Sci., 33, 299–318, 2018. a
Rodrigues, D. T., Gonçalves, W. A., Spyrides, M. H. C., and Santos e Silva, C. M.: Spatial and temporal assessment of the extreme and daily precipitation of the Tropical Rainfall Measuring Mission satellite in Northeast Brazil, Int. J. Remote Sens., 41, 549–572, 2020. a, b
Utida, G., Cruz, F. W., Etourneau, J., Bouloubassi, I., Schefuß, E., Vuille, M., Novello, V. F., Prado, L. F., Sifeddine, A., Klein, V., Zular, A., Viana, J. C. C., and Turcq, B.: Tropical South Atlantic influence on Northeastern Brazil precipitation and ITCZ displacement during the past 2300 years, Sci. Rep., 9, 1698, https://doi.org/10.1038/s41598-018-38003-6, 2019. a
Uvo, C. R. B.: A Zona de Convergência Intertropical (ZCIT) e sua relação com a precipitação da região norte do Nordeste Brasileiro, M.Sc. Dissertation, Instituto Nacional de Pesquisas Espaciais (INPE), São José dos Campos, Brazil, INPE-4887-TDL/378, 1989. a
Vale, T. M. C. d., Spyrides, M. H. C., Cabral Júnior, J. B., Andrade, L. d. M. B., Bezerra, B. G., Rodrigues, D. T., and Mutti, P. R.: Climate and water balance influence on agricultural productivity over the Northeast Brazil, Theor. Appl. Climatol., 155, 879–900, 2024. a
West, M. and Harrison, J.: Bayesian Forecasting and Dynamic Models, Springer Series in Statistics, 2nd Edn., Springer Series in Statistics, Springer, New York, ISBN 0-387-94725-6, 1997. a
- Abstract
- Introduction
- The Model
- Bayesian Inference
- Interpolation
- Modeling Extreme Precipitation Events (R20mm) in the Northern Region of Maranhão State
- Conclusions
- Appendix A: Simulation Study
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- The Model
- Bayesian Inference
- Interpolation
- Modeling Extreme Precipitation Events (R20mm) in the Northern Region of Maranhão State
- Conclusions
- Appendix A: Simulation Study
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References