the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 10 Aug 2023
| 10 Aug 2023
Automatic snow type classification of snow micropenetrometer profiles with machine learning algorithms
Julia Kaltenborn
Amy R. Macfarlane
Viviane Clay
Snow-layer segmentation and classification are essential diagnostic tasks for various cryospheric applications. The SnowMicroPen (SMP) measures the snowpack's penetration force at submillimeter intervals in snow depth. The resulting depth–force profile can be parameterized for density and specific surface area. However, no information on traditional snow types is currently extracted automatically. The labeling of snow types is a time-intensive task that requires practice and becomes infeasible for large datasets. Previous work showed that automated segmentation and classification is, in theory, possible but cannot be applied to data straight from the field or needs additional time-costly information, such as from classified snow pits. We evaluate how well machine learning models can automatically segment and classify SMP profiles to address this gap. We trained 14 models, among them semi-supervised models and artificial neural networks (ANNs), on the MOSAiC SMP dataset, an extensive collection of snow profiles on Arctic sea ice. SMP profiles can be successfully segmented and classified into snow classes based solely on the SMP's signal. The model comparison provided in this study enables SMP users to choose a suitable model for their task and dataset. The findings presented will facilitate and accelerate snow type identification through SMP profiles. Anyone can access the tools and models needed to automate snow type identification via the software repository “snowdragon”. Overall, snowdragon creates a link between traditional snow classification and high-resolution force–depth profiles. Traditional snow profile observations can be compared to SMP profiles with such a tool.
- Article
(9312 KB) - Full-text XML
- BibTeX
- EndNote





The cryosphere covers around 10 % of our Earth and plays a significant role in stabilizing the Earth's climate (IPCC, 2022). Snow cover plays a role in optics, heat, and mass balance and is one of the most significant uncertainties in global climate models (Sturm and Massom, 2017; Steger et al., 2013; Douville et al., 1995). Snow layer segmentation and classification put forth knowledge about the atmospheric conditions a snowpack has experienced (Colbeck, 1987; Fierz et al., 2009). This knowledge helps to discern fundamental snow and climate mechanisms in the Arctic and to analyze polar tipping points. Classification of snow types (also referred to as “snow grain type” or “grain type” in the community) is essential to assess the state of our cryosphere. It is thus of interest for polar, cryospheric, and climate change research (Domine et al., 2019; King et al., 2015; Sturm and Liston, 2021). Snow type is often better reproduced in detailed snow cover models (Vionnet et al., 2012) than their effective physical properties, especially indirectly structural anisotropy (King et al., 2015). This is especially relevant for active and passive microwave sensing, essential to map the Arctic snowpack during polar night (Sandells et al., 2023).
Traditionally, snow stratigraphy measurements are made in snow pits. These pits are dug manually into snowpacks, requiring trained operators and a substantial time commitment. To accelerate these measurements, the SnowMicroPen (SMP), a portable high-resolution snow penetrometer, can be used (Johnson and Schneebeli, 1998). It has been demonstrated that the SMP is a capable tool for rapid snow type classification and layer segmentation. The measurement results are stored in an SMP profile that consists of the penetration force signal of the measurement tip in newtons and the depth signal indicating how far the tip moved. Afterwards, the SMP profiles must be manually labeled by an expert, which requires time and practice.
To address these shortcomings, machine learning (ML) algorithms could be used to automate the labeling process. Instead of manually labeling each SMP profile, an ML model can be trained on a few labeled profiles and subsequently reproduce the labeling patterns on other profiles. As a consequence, this would (1) immensely accelerate the SMP analysis, (2) enable the analysis of large datasets, and (3) support interdisciplinary scientists that are unfamiliar with snow type categorization.
Such an automatic classification of SMP profiles helps to find layers with shared properties within a large SMP dataset. By reproducing a trained labeling pattern on new profiles with ML, SMP classification is upscaled. While it is impossible to manually label and analyze a dataset of thousands of SMP profiles, an ML-assisted classification enables us to conduct completely new analyses. Questions like “How does a typical snow layer in the Arctic look?” suddenly move within reach. Statistical analyses of signal and layer types rely on consistent, large, and fully labeled SMP datasets.
Several previous works have addressed automatically classifying snow types with machine learning algorithms. The nearest-neighbor method of Satyawali et al. (2009) was the first model that automated the segmentation and classification of SMP profiles without needing additional snow pit information. To assign a snow type to an unlabeled data point, the method chooses the most frequent class occurring in the neighborhood of this data point. The neighborhood contains the most similar points to the unlabeled data point. Their algorithm predicts five different snow types (“new snow”, “faceted snow”, “depth hoar”, “rounded grains”, “melt–freeze”), with an accuracy ranging from 0.68 to 0.94. However, this high performance is only achieved by integrating specific and inflexible expert rules. For example, one rule ensures that no faceted snow, depth hoar, or rounded grains occur between layers of new snow, but precisely this happens under certain circumstances, as they point out. Hard-coded rules might improve the performance of one dataset, but they cannot capture all phenomena and will not generalize well to other datasets. The performance results are also limited by the fact that their testing set consists of only three SMP profiles; i.e., it is not clear how representative their results are. In addition, their results can hardly transfer to the real-world setting because they explicitly exclude any mixed snow type layers. Suppose an automatic segmentation and classification algorithm will work with profiles straight from the field. In that case, this algorithm should be able to handle mixed classes and diverse snow phenomena and be thoroughly tested.
Havens et al. (2013) worked with random forests and support vector machines (SVMs) to classify SMP profiles. They used previously segmented SMP profiles and classified the snow type of each layer with the help of a random forest model. They build upon their previous work with single decision trees (Havens et al., 2010). They trained the model on three different snow types (new snow, rounded grains, faceted grains), achieving error rates between 16.4 % and 44.4 % (depending on the dataset). Notably, Havens et al. (2013) requires profiles that have been manually segmented beforehand. Since this is done manually, this takes a considerable amount of time, raising the question as to what extent the task has been “automated”. Only layers larger than 100 mm (sometimes 20 mm) could be considered due to manual segmentation. In the field, particularly for avalanche risk assessment (Lutz et al., 2007), it is important to detect layers only a few millimeters thick. Improving on the work of Havens et al. (2010) would thus include more snow types, thinner layers, and no need for manual segmentation.
More recently, King et al. (2020a) trained SVMs on SMP force signals and manual density cutter measurement. Both segmentation and classification are conducted automatically. They distinguish three types of snow grains (“rounded”, “faceted”, and “hoar”) and achieve classification accuracies between 0.76 and 0.83. The profiles were collected on Arctic ice in the same region, which means that the profiles might be more homogeneous than in other datasets. In theory, the model's generalizability could be enhanced by training it on additional, broader datasets. Most importantly, the SVM method by King et al. (2020a) relies on additional manual density cutter measurements and time-intensive snow pit measurements that are not always available. Thus, similarly to Havens et al. (2013), more snow types would make the work more applicable in the field and eliminate the necessity of additional manual density cutter measurements. In summary, previous work showed that supervised machine learning algorithms are a promising pathway to automatic snow grain categorization.
While all these works put forward the task of automated SMP analysis, SMP users still lack a method that can be used in practice. Users need a model that fully automates their SMP analysis (1) without the need of digging a snow pit, (2) picking layers manually, or (3) constructing specific knowledge rules. Furthermore, SMP users need models to deal with SMP profiles from the field. This implies that (4) the profiles have multiple snow types (more than three) and that (5) no layers are excluded. This study aims to provide models that fully automate SMP analysis and can directly be used, addressing all five mentioned needs.
To this end, we implemented 14 different machine learning (ML) models and compared their performance on the MOSAiC SMP dataset, consisting of 164 labeled profiles (see Fig. 1) (Kaltenborn et al., 2021). We provide the first comparable performance overview of different models classifying and segmenting SMP profiles. Moreover, we used semi-supervised methods and artificial neural networks (ANNs) for SMP classification.
Results show that especially artificial neural networks (ANNs), such as the long short-term memory (LSTM) and encoder–decoder, can produce predictions similar to profiles labeled by experts and achieve the best results among all models. However, the choice of the model depends mostly on the individual needs of an SMP user because factors such as explainability, desired sensitivity to rare classes, available time, and computational resources must be considered.
The work presented here is a methodological contribution. We provide insights into which ML algorithms can be used to automatically and consistently classify large SMP datasets. Our findings can be applied to different SMP datasets or similar data. The more fine-grained contributions of this study are as follows:
-
demonstration that SMP profiles straight from the field can be automatically segmented and classified without manual preparation of the profiles or additional snow-pit data after training on a smaller set of SMP profiles,
-
evaluation of semi-supervised models and ANNs for SMP classification,
-
detailed comparison of different ML models for SMP classification,
-
use of the snowdragon repository that provides the tools to automate SMP labeling.
In the following section (Sect. 2) the data, the classification task, and the 14 different models used in this study are described. In Sect. 3, the models' performances are presented. Subsequently, the results, their limitations, and future work are discussed in Sect. 4. The impact of this work is addressed in Sect. 5. The code and data availability is outlined directly after the conclusion, and a detailed guide on how to use snowdragon with your SMP dataset can be found in Appendix A.
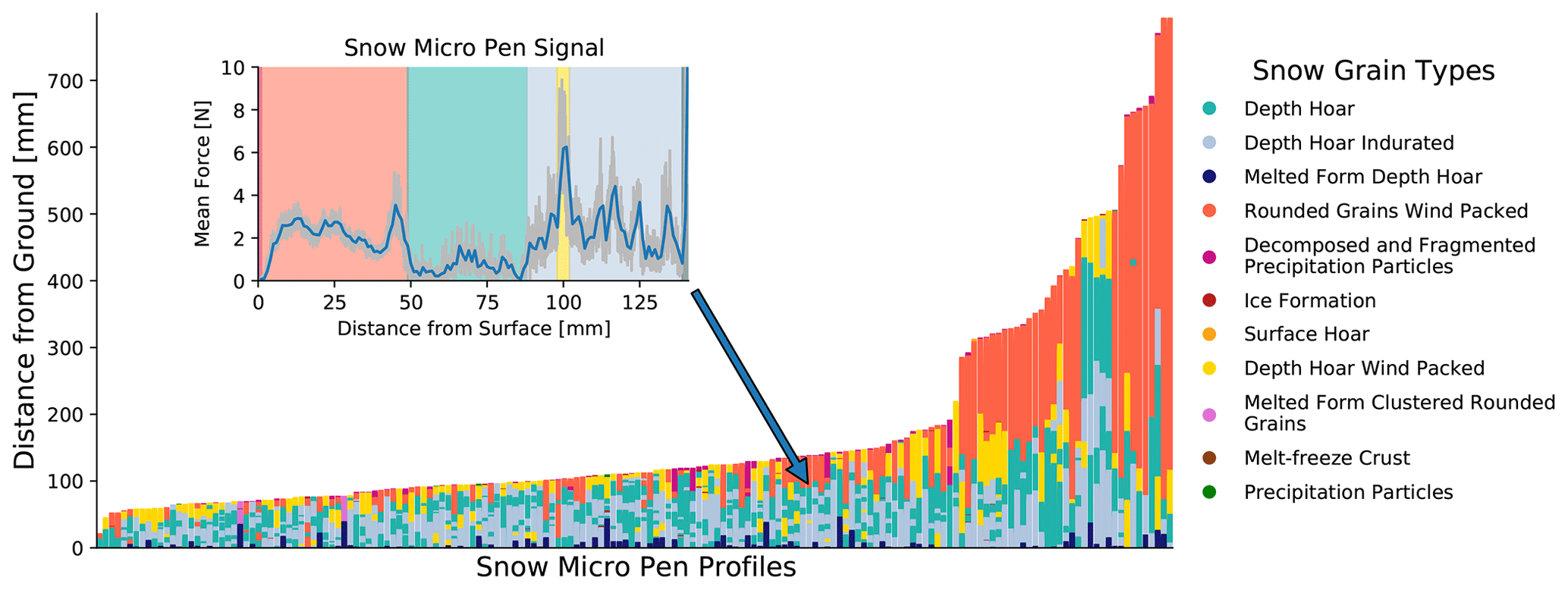
Figure 1All 164 labeled SnowMicroPen (SMP) profiles used for training, validation (80 %), and testing (20 %). Each bar represents one SMP profile. The colors encode the different snow types. The top of each bar is the air–snow interface, while the bottom is the profile's snow–ground interface. The inset image illustrates the force signal (grey) and the mean force signal (blue) of a single SMP profile (S31H0368). The snow–air interface is on the left, and the bottom of the profile is on the right. The background shading in the inset panel and the colors in the main panel represent the labeling of the profiles.
2.1 Data
All experiments throughout this study use snow data collected during the MOSAiC expedition (October 2019–September 2020) (Nicolaus et al., 2022). The snow pit measurements conducted include SMP profiles, micro-computer tomography (Micro-CT) (Coléou et al., 2001), and near-infrared (NIR) photographs (Matzl and Schneebeli, 2006). Collecting snow profiles on Arctic sea ice is especially challenging because (i) only a few hours were available to perform all measurements within one snow pit and (B) the measurements must be conducted with wind velocities up to 25 m s−1 and temperatures of C. Changing personnel, i.e., different operators, were conducting the snow pit measurements. As a result, traditional stratigraphy analysis and in situ snow grain classification from snow pits carry operator biases. Merkouriadi et al. (2017) could measure only 27 snow pits with stratigraphy under similar conditions.
In contrast, during the MOSAiC expedition, several thousand (3680) SMP profiles were collected. Out of the 269 snow pit events that included SMP measurements, 102 had NIR measurements and 103 had micro-CT profiles collected simultaneously. A total of 71 snow pit events had all three measurements (SMP, NIR, and micro-CT). We encountered 8 different snow types. Refer to Fierz et al. (2009) for descriptions of the different snow types referenced here and a classification guideline for snow particles that were visually observed.1
The main measurements collected were signal profiles from the snow micropenetrometer since it provides profiles quickly with little physical labor and independent of the person that measures them. Of the 3680, 164 profiles from the cold season (January–May 2020) were labeled and evaluated here (see Fig. 1). The labels expressed by color in Fig. 1 indicate which snow type is found at the respective position of the profile. In this study, we focus only on profiles of cold snow that is not experiencing melt, as no standardized interpretation of SMP force profiles exists for wet snow. All profiles collected in the cold season are referred to as “MOSAiC winter data” in the following. Micro-CT and NIR data were recorded whenever possible to validate the subsequent labeling of the SMP profiles. More details on the collection methods can be found in Macfarlane et al. (2023). A comparison of these instruments can be seen in Appendix B in Fig. B2.
The labeling of the SMP profiles was conducted by two snow experts and is based on the properties of the force signal (magnitude, frequency, and gradient) and the signature of the SMP signal. The labeling procedure is described in detail in Appendix B, building upon the notion and observations of (Schneebeli et al., 1999). The first labeling phase was conducted by one expert, and in the second phase, two experts revisited the profiles to ensure consistent labeling. The labeling process involves using Micro-CT samples and NIR photography to validate the snow types identified from the force signal where possible. When assigning the labels to the SMP profiles, we lean to the abovementioned international classification guideline of seasonal snow on the ground Fierz et al. (2009). However, we regard the labels assigned to the SMP signals as mere approximators. During the labeling process, signal types are grouped together, and we infer from Micro-CTs which snow type matches each group best. Since we seek a language that is common to the snow community, we are using the labels provided by Fierz et al. (2009) where possible. Since Fierz et al. (2009) focuses on Alpine snow and does not cover all snow types on Arctic sea ice, such as different forms of depth hoar (further details are given in Appendix B), we extend those labels where necessary. The resulting labeled profiles were used during training, testing, and validation, while some unlabeled profiles were used for semi-supervised models and out-of-distribution tests. Upscaling consistent labeling of SMP profiles is exactly the type of task that ML algorithms can tackle.
We preprocessed each SMP profile and the complete labeled dataset. The surface and the ground of the profiles were detected automatically by the snowmicropyn package (https://snowmicropyn.readthedocs.io/en/latest/, last access: 3 August 2023). For each SMP profile, we replaced negative force values with 0; summarized the signal into bins (1 mm); and added mean, variance, maximum, and minimum force values for those bins. Those values were also determined for a 4 mm and 12 mm moving window. Moreover, the Poisson shot noise model of Löwe and Van Herwijnen (2012) was used to extract δ, f, L, and the median force value for a 4 and 12 mm window. We added further depth-dependent information, including the distance from the ground and position within the snowpack for each data point. Refer to Table C1 in Appendix C for an overview of all features used for each SMP profile and to Fig. C1 to see the feature importance for each snow type.
We preprocessed the complete labeled dataset by normalizing it, removing profiles from the melting season, and merging snow classes. For example, “decomposed and fragmented precipitation particles” are merged with the class “precipitation particles” since they represent a similar type of snow. The few occurring ice formations and surface hoar instances in the MOSAiC dataset are summarized in the class “rare”. While a high classification performance cannot be expected for the rare classes, we still include them to show how the models perform on a “real-world dataset” that in most cases will also include classes with few occurrences. The data preprocessing ensures that the dataset is clean and that all necessary information, such as depth-dependent information, is available during classification.
The resulting dataset has the following properties. (1) There are multiple noisy and overlapping classes. (2) There is a between-class imbalance; i.e., some snow types occur much more frequently than others. (3) There is a within-class imbalance; i.e., some grain classes contain different sub-grain-classes, but some of them are more frequent than others. (4) The labeling of classes is afflicted with uncertainty; i.e., snow experts themselves are not sure to which class exactly some data points belong. The complexity of the dataset complicates classification and lowers the maximum achievable accuracy.
2.2 Task description
We compare the capabilities of different models to classify and segment the profiles of the MOSAiC winter SMP dataset. To this end, the models first classify each data point of the signal and then summarize the classified points into distinct snow layers (“first-classify-then-segment”). This task can be solved with different learning and classification techniques.
The task can be addressed via independent classification or sequence labeling. In independent classification, each individual point is classified independently, without looking at other data points. The underlying assumption is that each individual data point carries enough information to be classified solely on that basis. In contrast, sequence labeling assumes that the data are an intra-dependent sequence, where the label of each data point also depends on the preceding labels (Nguyen and Guo, 2007).
The models can follow either the supervised, unsupervised, or semi-supervised learning regime. In supervised learning, labels are provided to learn an input–output mapping function (Russell and Norvig, 2021). In unsupervised learning, patterns and structure are found in unlabeled data (Ghahramani, 2004); however, no classification is possible, which is why no unsupervised models are employed here. Instead, semi-supervised models are used, which are able to find structures in sparsely labeled data and leverage this information during classification. In the following, all models employed in this work are shortly presented and put in the context of their learning and task type.
2.3 Models
The majority vote classifier is used as the baseline for the performance comparison and simply predicts always the majority class (“rounded grains wind packed”). It satisfies the criteria that a baseline should not require much expertise, be easy to build, and be quick to evaluate (Li et al., 2020).
The cluster-then-predict models employed in this study can be separated into three different semi-supervised and independent classification models. Unsupervised methods are used to find clusters in the dataset, and a supervised model is subsequently used to assign labels to the cluster (Soni and Mathai, 2015; Trivedi et al., 2015). As an unsupervised model, k-means clustering (Forgy, 1965; Lloyd, 1982), mixture model clustering (GMM) (Bishop, 2006), and Bayesian Gaussian mixture models (BGMM) (Bishop, 2006) were used. The supervised part of the model is a simple majority vote within the clusters in order to see if the unsupervised model adds enough information to beat the majority vote baseline.
Label propagation is a graph-based, semi-supervised, and independent classification algorithm. It propagates the labels of labeled data points to unlabeled ones (Zhu and Ghahramani, 2002). Here, a modified version of this algorithm by Zhou et al. (2003) is used (also known as “label spreading”) (Yoshua et al., 2006; Pedregosa et al., 2011).
Self-trained classifiers turn a given supervised classifier into a semi-supervised independent classifier. It follows an iterative approach of training a supervised model on labeled data, predicting more data with the model, and retraining the model with the most confident predictions (Yarowsky, 1995).
Random forests (RFs) are ensembles of diversified decision trees (supervised and independent classification). The diversification happens via tree and feature bagging, where only subsets of data or features are used during training (Ho, 1995; Breiman, 2001). Decision trees are simple-to-build, explainable, white-box classifiers, and for these reasons they are among the most popular machine learning algorithms (Wu et al., 2008). Additionally, a balanced random forest was used with random undersampling to balance the data (Chao et al., 2004).
Support vector machines (SVMs) construct a hyperplane in a high-dimensional space to solve binary classification tasks (Cortes and Vapnik, 1995; Han et al., 2012) (supervised and independently). When a problem is nonlinearly separable, the input data can be projected into a higher-dimensional space until the problem becomes linearly separable. The kernel trick can be used to circumvent the computationally expensive data transformation involved here. It directly extracts a nonlinear optimal hyperplane (Schölkopf and Smola, 2002).
K-nearest neighbors (KNN) is a local, non-parametric classification method that compares samples and classifies new samples based on their k-nearest training data points (supervised and independently). The class of the prediction sample is determined via a majority vote (Fix and Hodges, 1952; Cover and Hart, 1967).
Easy ensemble classifiers are ensembles of balanced adaptive boosting classifiers (supervised and independent). The method is especially helpful for imbalanced datasets since the learners are trained on different bootstrap samples, which are balanced via random undersampling (Liu et al., 2008).
Long short-term memories (LSTMs) are a form of artificial neural networks (ANNs) and can perform supervised sequence labeling tasks. ANNs incrementally update their decision function that describes the decision boundary between classes. ANNs have different nodes, which can be seen as representing different parts of the functions that are weighted differently. During training, the weights of the ANN are optimized by minimizing a loss function via gradient descent. A long short-term memory can handle time series data. It consists of different memory cells so the LSTM can forget information that is no longer needed, remember information that is required for future decisions, and retrieve information that is required for current decisions (Hochreiter and Schmidhuber, 1997; Jurafsky and Martin, 2021).
Bidirectional LSTMs (BLSTMs) connect two independent LSTMs, where the first LSTM processes the inputs forward, and the second one processes the inputs backwards. The outputs of both LSTMs are connected to one output. This architecture is helpful when the dependencies of a time series go in both time directions, which is the case for snow profiles (Schuster and Paliwal, 1997; Jurafsky and Martin, 2021).
Encoder–decoder networks consist of an ANN encoder that compresses the time-dependent information into a vector and a decoder that uses this information to solve a supervised sequence labeling task. Additionally, the attention mechanism can be used to strengthen the ability to learn long-term dependencies by focusing only on the parts of the input sequence that are relevant for the current time step (Bahdanau et al., 2014; Jurafsky and Martin, 2021).
2.4 Evaluation
In this work, (1) the performance of different models is compared, (2) differences in the classification of different snow types are analyzed, and (3) the generalization capability of the best-performing model is examined. (1) The performance comparison is done by looking at the metrics of each model and the specific predictions on the test dataset. The metrics used here are accuracy, balanced accuracy, weighted precision, F1 score, area-under-the-receiver operating characteristic (AUROC), log loss, fitting, and scoring time (see Appendix D for further explanations). (2) The label-wise performance is analyzed with the help of label-wise accuracy plots and receiver operating characteristic (ROC) curves. ROC curves plot the true-positive rate versus the false-positive rate. The higher the area under the ROC curve, the clearer the model can separate between positive and negative samples. (3) The generalization capability is tested by running the best-performing model on 100 random profiles from different parts of MOSAiC winter data. These profiles are outside of the distribution of the training, validation, and testing data, and we refer to them as “out-of-distribution profiles”. Here, the out-of-distribution profiles contain the same classes as the training data, so the model still has a chance to predict the correct labels. Evaluating these three aspects ensures that users can choose a model and know (1) how it performs compared to other models, (2) what to expect from the snow-type-specific predictions, and (3) how robust a chosen model will be.
2.5 Experimental setup
The experimental setup includes a training, validation, and testing framework: roughly 80 % of the labeled dataset is used for training and validation, while the other 20 % is set aside for testing. Validation is realized as 5-fold cross validation (Stone, 1974). The hyperparameters were tuned on the validation data and the best hyperparameters found were used during testing.
Hyperparameter tuning is the process of searching the optimal internal learning settings of an ML model. Hyperparameters control the learning process of the models, whereas parameters are learned by the model. The tuning is performed on the validation data and the hyperparameters that achieve the highest performance for their model chosen for subsequent model evaluation. Here, tuning was applied moderately and with a simple grid search. All tuning results can be found in the GitHub repository. Specifications of the machine on which the experiments were run can be found in Appendix E and descriptions of the model setup can be found in Appendix F.
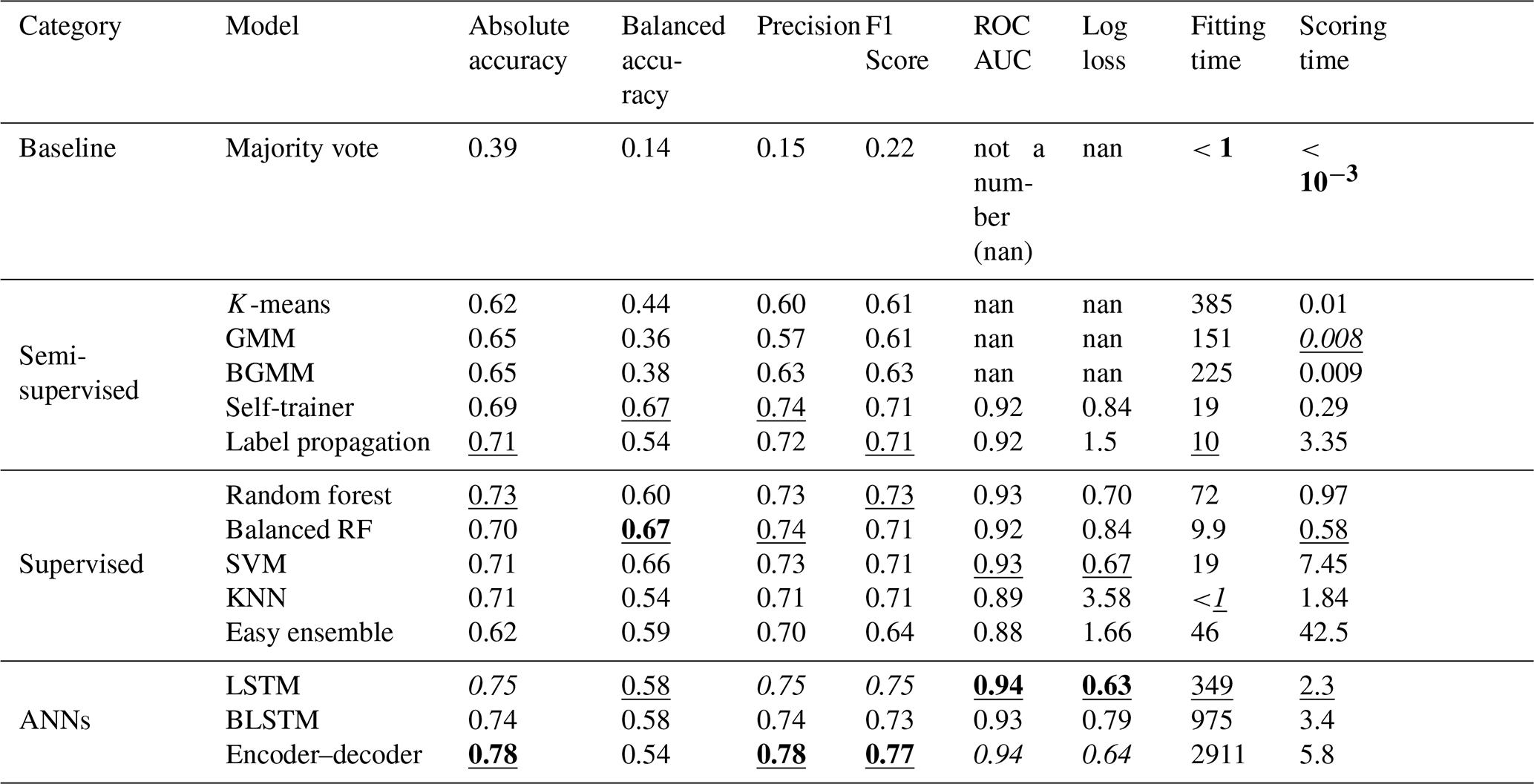
Table 1Results of different models from the categories baseline, semi-supervised, supervised, and ANN. The best values among all models are given in bold. The second-best values among all models are given in italics. The best values among one category are underlined. The area under the curve (AUC) of the receiver operating characteristic (ROC) and logistic loss (log loss) could not be determined for the baseline and some of the semi-supervised models due to the design of these models.
3.1 Classification performance of models
Overall, the results show that an automatic classification and segmentation of SMP profiles with ML algorithms is possible, even if no further information such as snow pit data or manual segmentation is provided. Category wise, all semi-supervised models were not performing particularly well (see Table 1). Only the self-trainer could compete with models from other categories, but this might be the case because the self-trainer is based on a balanced random forest. The supervised models achieved mixed performances. Some models such as the random forests and the SVM are clearly performing well, whereas other models such as the KNN and the easy ensemble are underperforming. Overall, the random forest was the best model in the supervised category since it achieves the highest absolute accuracy (0.73) and F1 score (0.73). However, considering rare classes, the balanced random forest outperformed the plain random forest. All three ANNs did exceptionally well, and their category was clearly the most successful among all three categories. The encoder–decoder showed the best scores among all models in terms of absolute accuracy, precision, and F1 score, closely followed by the LSTM. We consider the LSTM to be the best model within that category since the encoder–decoder only reached its high performance after extensive hyperparameter tuning and underperformed significantly when not tuned well. In contrast, the LSTM achieved its performance more consistently, even under moderate hyperparameter tuning, and it is thus more suitable for users. The subsequent analyses compare the three models that performed best within their category: the LSTM performed best among the ANNs, the random forest among the supervised models, and the self-trainer among the semi-supervised models.
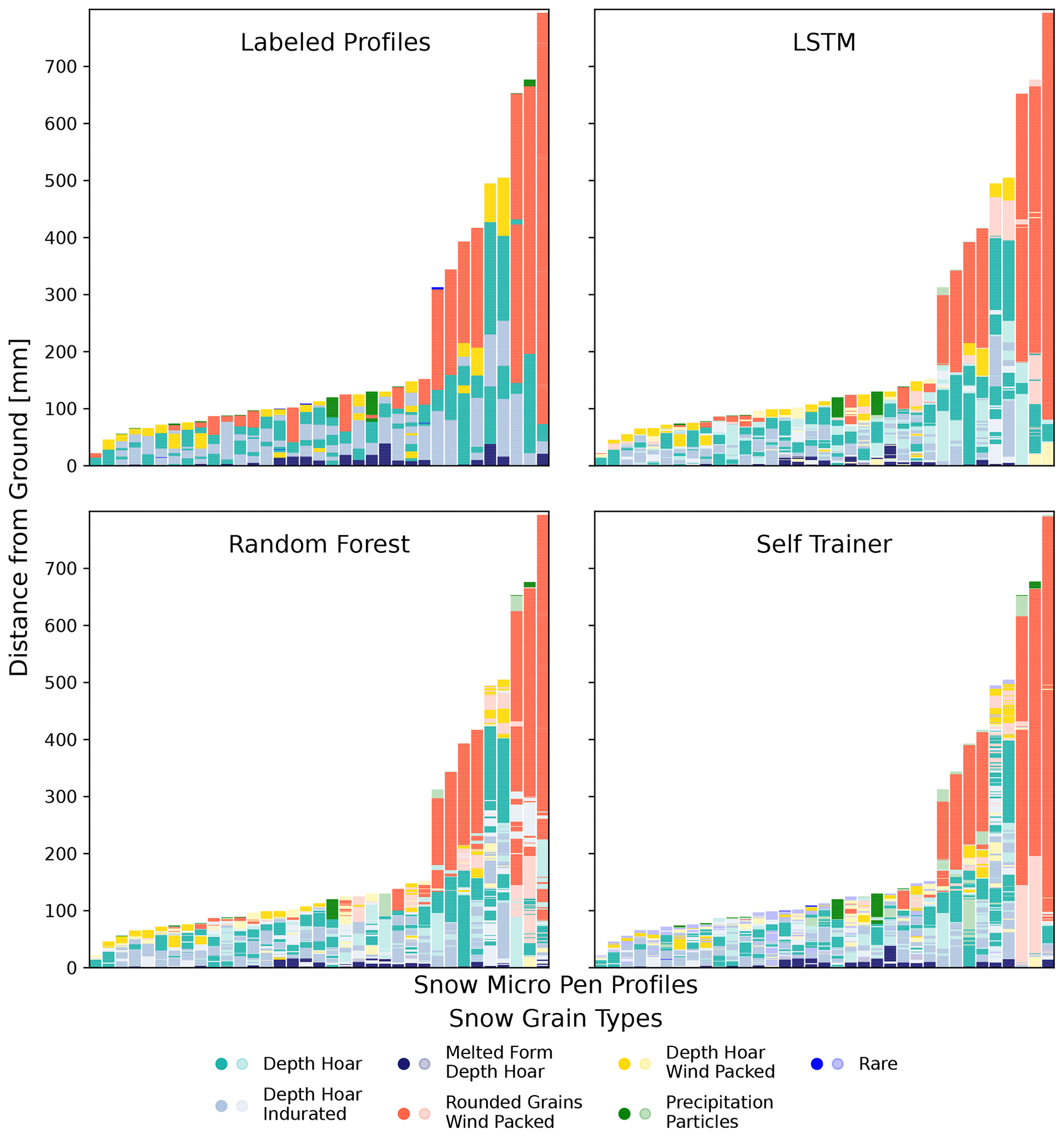
Figure 2Predictions on the test dataset of the LSTM, random forest, and self-trainer. The upper-left panel shows the labeled data. In the other panels, the correct predictions are shown with more intense colors and the wrong predictions with less intense colors. The LSTM has the highest rate of correct predictions and imitates the smoothness of the labeled data very well. The random forest does well but provides more segmented predictions. The self-trainer immensely overestimates rare classes.
Different ML models exhibited different prediction styles in terms of smoothness and ability to predict rare classes. In Fig. 2 it becomes visible that the models' predictions are not far off from the labels. In general, the predictions are somewhat similar to the labeled profiles, but the models often had difficulties in determining the precise start and end of a segment. Looking at three random exemplary profiles of the test data in Fig. 3, one can see that the three main models seem to not only generate similar predictions but also make similar mistakes. In the medium-depth profile (middle column), all three models predicted a longer segment of depth hoar that was not present in the labeled profile. In the shallow profile, all three models predicted some intermediate “depth hoar wind packed” layers in the first third that did not exist. In the deep profile, all three models miss the narrow intermediate depth hoar layer. In summary, it becomes apparent that the different models are producing consistent predictions to a certain degree. There are of course also significant differences among the models. First, the LSTM is closest to the labeled profiles (see Fig. 3). Second, the LSTM provided much smoother and less fragmented predictions than the other two models. Third, the self-trainer clearly overestimates rare classes, which hurts the overall performance. To summarize, the LSTM, random forest, and self-trainer show certain prediction similarities among each other; however, the LSTM imitates expert labeling best.
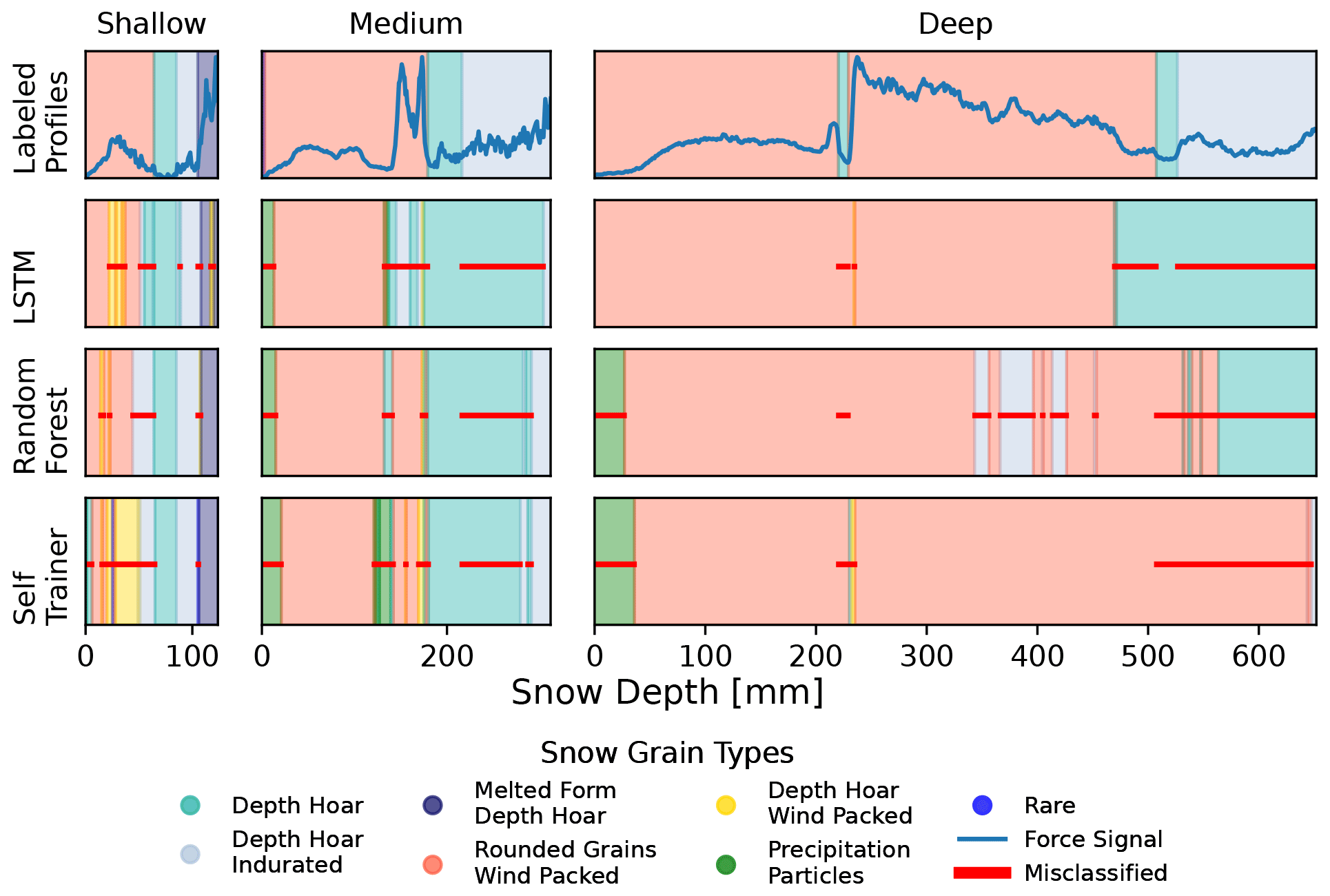
Figure 3Model predictions for three randomly chosen SMP profiles. The first row represents the labeled profiles (with force signal). The subsequent rows represent the LSTM, random forest, and self-trainer predictions, with the red bar indicating wrong predictions. Each column shows a different profile randomly chosen from the test data (shallow profile: S31H0276; medium profile: S31H0206; deep profile: S49M1918). All three models seem to make similar mistakes, e.g., they predict a larger portion of depth hoar at the end of the medium SMP profile. The predictions of the LSTM are closest to the labeled profiles.
3.2 Classification difficulty of snow types
Figure 4 shows that some snow types are easier and others are harder to classify. The label-wise accuracy seems to be influenced by the following factors: (1) choice of model, (2) the frequency of snow type in the dataset, and (3) the snow type itself. Within one snow type category, the models perform differently; however, some snow types seem to be easier, while others are more difficult to classify for all models. For example, rounded grains wind packed achieved a high accuracy among all models, whereas depth hoar wind packed achieved a low accuracy among all models. This could be partially attributed to the fact that there are fewer samples available for depth hoar wind packed. However, the snow types themselves seem to influence the classification difficulty as well: the precipitation particles class achieves high accuracy values among some models, despite the fact that it is the rarest class in the dataset. For some snow types, some models are able to access certain information, enabling a high performance for that particular snow type that is independent of its frequency. This means that the classification difficulty does not solely depend on the number of available samples. Instead, several other underlying characteristics determine the classification of difficulty of each snow type as well, most notably (1) the initial classification, which is not always consistent; (2) the underlying micro-mechanical properties, i.e., some snow types have characteristic force signals that separate them more clearly from others; and (3) the training dataset, since it does not cover all types of force signals.
Depending on the model, a higher accuracy score could lead to a lower precision score for a label (accuracy–precision trade-off). The ROC curve in Fig. 5 illustrates this relationship between the true-positive and false-positive rates for the different snow types and their averaged performances. It becomes apparent that both the snow type and the choice of model influence the accuracy–precision trade-off. For example, the rare class seems to be difficult to classify both accurately and precisely for all models, whereas precipitation particles show an almost perfect ROC curve. If one is interested in choosing a model that performs well for a particular snow type, these ROC curves can reveal which model is most suitable. To get even more detailed label- and model-wise insights, refer to the confusion matrices in Appendix H. Both the LSTM and the random forest achieve an area under the ROC curve of 0.96. However, on average (see Fig. 5, dotted pink line), the LSTM outperforms the self-trainer and random forest and is thus most suitable for general classification tasks.
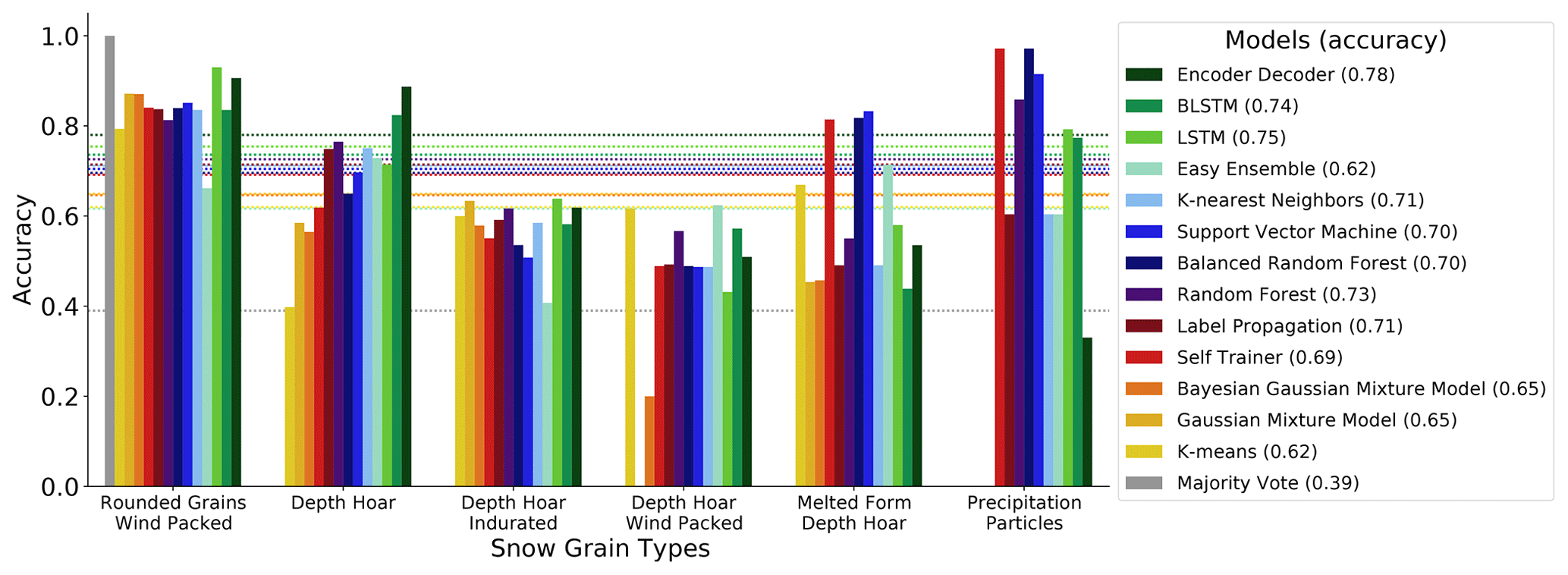
Figure 4Label-wise accuracy of all models. Each model is encoded with a different color. The most frequent label is on the left of the x axis (rounded grains wind packed), and the least frequent is on the right (precipitation particles). The rare class was dropped. Each bar represents the accuracy for a single snow type. The dotted lines show the overall accuracy performance of each model. The encoder–decoder, the BLSTM, and the LSTM achieved the highest accuracy values. For all models, some classes are more difficult to classify than others, e.g., depth hoar indurated and depth hoar wind packed. Some classes are easier to classify than others, such as rounded grains wind packed. Some classes can only be classified well by a subset of the models, such as precipitation particles and melted form depth hoar.
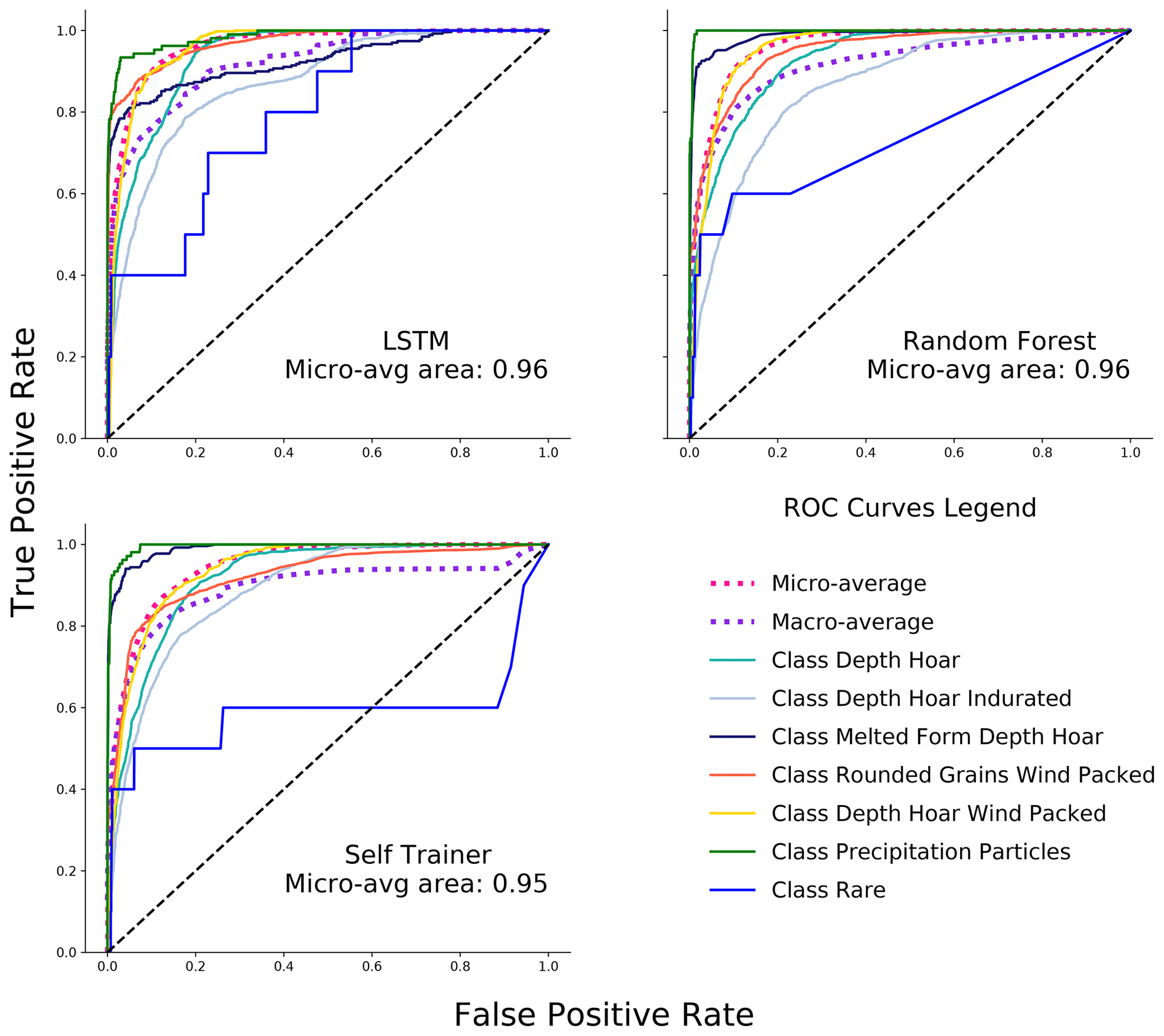
Figure 5ROC curves of the LSTM, random forest, and self-trainer for each class. The dotted lines are the micro- and macro-averaged ROC curves. The macro-average calculates the ROC for each class and averages the performances afterwards. The micro-average weights the performance according to class contribution (balanced performance results). The LSTM achieves the highest ROC performance overall. The order of the best-performing snow types is similar among all models. The rare and depth hoar indurated classes have the lowest ROC areas, whereas the precipitation particles class has the highest ROC area for all models.
3.3 Generalizability
The prediction of the LSTM for 100 random profiles outside of the training and testing distribution is shown in Fig. 6. Since the labeled profiles are not yet available for these predictions, the generalization capabilities can only be evaluated on the basis of what seems “reasonable”. Melted form depth hoar appears only at the ground of the profiles, precipitation particles appears only at the top, and rounded grains wind packed appears mostly at the top and rather deep – these are all reasonable predictions. However, there are also some predictions that are not reasonable or at least unexpected: the left profile consists almost entirely of depth hoar wind packed, sometimes depth hoar wind packed appears right before melted form depth hoar, and rounded grains wind packed sometimes appears briefly in the “middle” of a profile (and not at the top). Overall, the LSTM seems to make mostly reasonable predictions; however, an in-depth expert analysis of the predictions is necessary to validate that further.
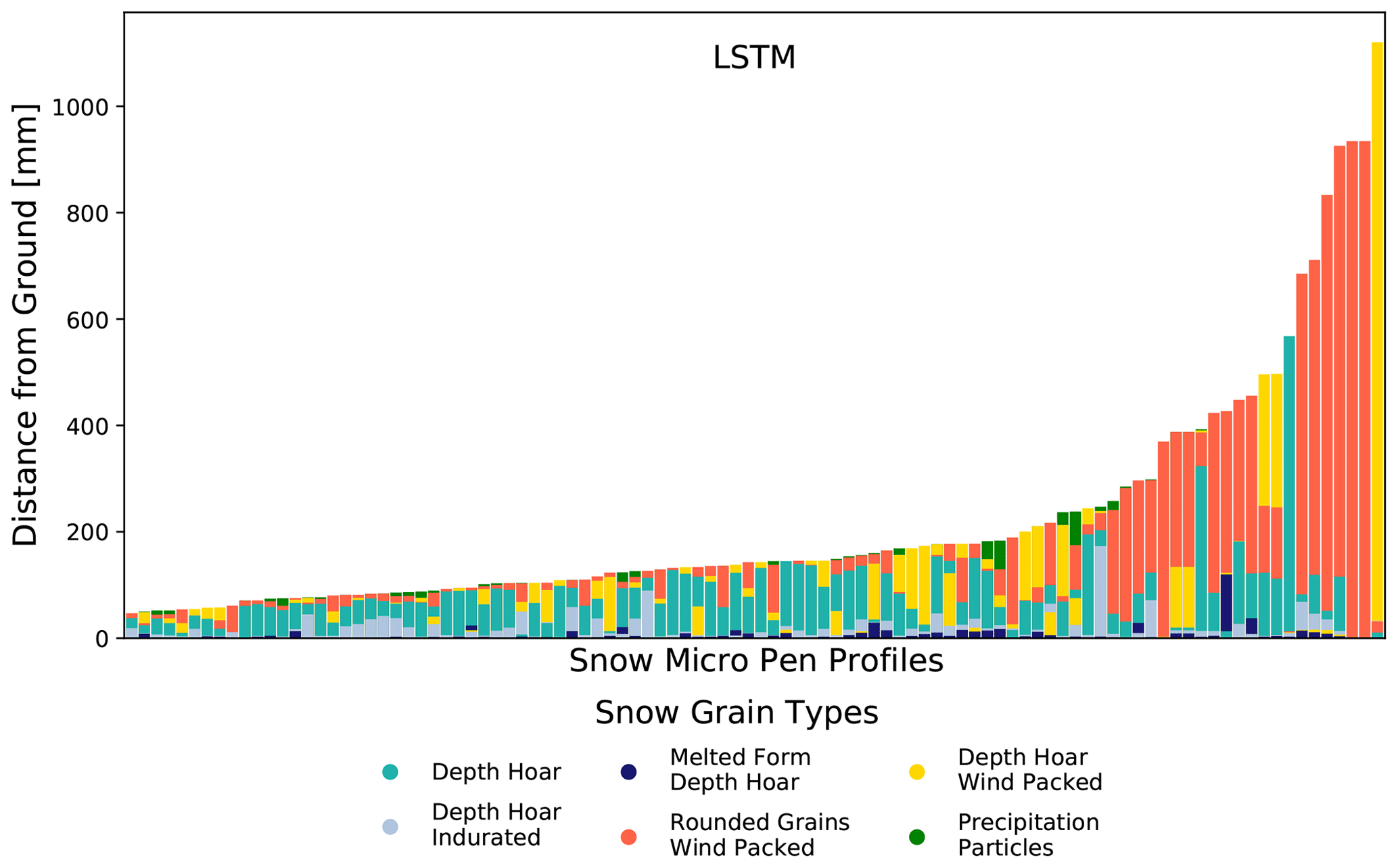
Figure 6LSTM SMP profile predictions on out-of-distribution data. The SMP profiles used here come from different legs of the MOSAiC expedition than the training, validation, and test data. The profiles used here still stem from the winter season to ensure that the same set of snow types can be used as in the training dataset. The distribution of the predicted profiles looks convincing, with only a few profiles standing out as certainly wrong predictions (e.g., the rightmost profile with ∼90 % depth hoar wind packed).
The results showed that the automatic classification of SMP profiles is possible with up to 78 % accuracy. In the following, the nature, impact, and limits of these results are discussed.
The metrical results presented are in line with previous findings. King et al. (2020a) reported an overall accuracy score of 0.76 when using SVMs and additional snow pit information to classify three snow types. Satyawali et al. (2009) achieved an average accuracy of 0.81 when using the nearest-neighbor approach and knowledge rules to classify five snow types. However, these results stem from only three profiles and are not representative. Havens et al. (2013) achieved an accuracy of maximal 0.76 (global dataset) when using random forests and time-intensive manual layer segmentation to classify three snow types. The major difference from these previous results is that the accuracy results of this study were achieved for seven snow types, without time-intensive layer picking, snow pit digging, or additional knowledge rules. This means that in contrast to previous work, the models here can be directly employed by users for their own SMP datasets in the field: simply retrain and predict. For this, they only need to provide a set of training samples for their specific dataset and classification style. The work presented here enables scientists for the first time to rely on fully automated ML SMP profile classification and segmentation.
The results were also satisfying to domain experts since the predictions were consistent within themselves and followed the patterns of the training data. In general, the snowpack on sea ice is extremely variable, and the traditional snow types are often a mixture of different features. This becomes visible when comparing the SMP profiles to the micro-CT samples. In the view of the authors, a temporally consistent classification is more relevant to the interpretation of the development of the snowpack, even if there is a certain, but unknown, bias to an expert interpretation. Hence, the models were in practice also helpful when analyzing Arctic snowpack development.
4.1 Classification performance of models
Each model category performs differently because each model takes different aspects of the data into account. Semi-supervised models try to take unlabeled data into account to improve their predictions; however, this did not work well in our context. The most likely reason for the overall underperformance of this category is that the unlabeled data contained out-of-distribution data, i.e., the unlabeled data had different underlying mechanisms than the labeled data (different parts of the winter season). Another reason might be that only a small subset of unlabeled data were included in order to limit running times. Moreover, the poor performance of the cluster-then-predict models is most likely also a result of the classifier used after clustering: a more sophisticated method than a majority vote classifier is needed here.
The simple supervised models take one data point after the other into account and do not consider time series structures within the data. The algorithms used in all previous SMP automation studies fall into this category. In contrast, ANNs are supervised models that take the underlying time sequence of the data into account. While the supervised model in general performed well, they were still clearly outperformed by the ANNs. A likely reason why the ANNs outperformed all the other models is precisely the ANNs' ability to process time-dependent – or in the case of snow profiles depth-dependent – information. ANNs are tackling the classification task as a sequence labeling task, which enables them to include information from the order and position of snow layers. The supervised models still have access to time-relevant information (time window features; see Appendix C1); however, they do not have any ability to learn time-based information (what should be remembered and forgotten). Besides, the ANNs learn to imitate the training set, leading to smooth and expert-like predictions. In comparison, taking the time component of SMP signals into account has not been done in previous methods, and we argue that it adds a major information piece and boosts the overall prediction performance significantly.
Each model exhibits a different prediction style due to the models' intrinsic differences and thus might be suitable for specific tasks. The following aspects are listed for consideration (user's guide).
- A.
Time and resources for hyperparameter tuning. The LSTM and the encoder–decoder network are recommended when plenty of tuning time is available. The encoder–decoder network performs especially badly if not tuned well. The SVM and the balanced random forest need little tuning time, whereas the random forest is the go-to model in cases where (almost) no tuning time can be provided.
- B.
Need for a simple to handle, off-the-shelf algorithm. Among the high-performing models, the random forest and the SVM are the easiest to handle off-the-shelf algorithms with. The self-supervised algorithms and especially the ANNs require a somewhat deeper understanding of the models and the ability to implement them.
- C.
Desired level of explainability. The random forests are most explainable since the decision trees can be directly visualized (Appendix G). The ANNs are the least explainable models (without further modifications).
- D.
Importance of minority classes. When deciding on a model, the underlying task must be examined as well. In the case of avalanche prediction, it might be essential to predict a buried layer of surface hoar, a very uncommon class, which needs to be detected no matter the costs. In such a case of “minority class prediction,” the balanced RF or the SVM should be employed. The ANNs and the random forest, in contrast, are more suitable to achieve an overall good classification.
- E.
Availability of unlabeled data that are from the same distribution as the labeled data. In cases where a lot of unlabeled data from the same distribution and time are available, the self-trained classifier can be considered. The weak learner of the self-trained classifier can be chosen according to the criteria listed above. Since in this work we only had a small subset of unlabeled data stemming from the same distribution as the labeled data, further evaluations of the self-trained classifier and label propagation remain open.
This highlights that there is not a single best model and that users can instead deliberately choose a model that suits their needs, such as overall accuracy, ability to predict rare classes, explainability, training, and deployment time.
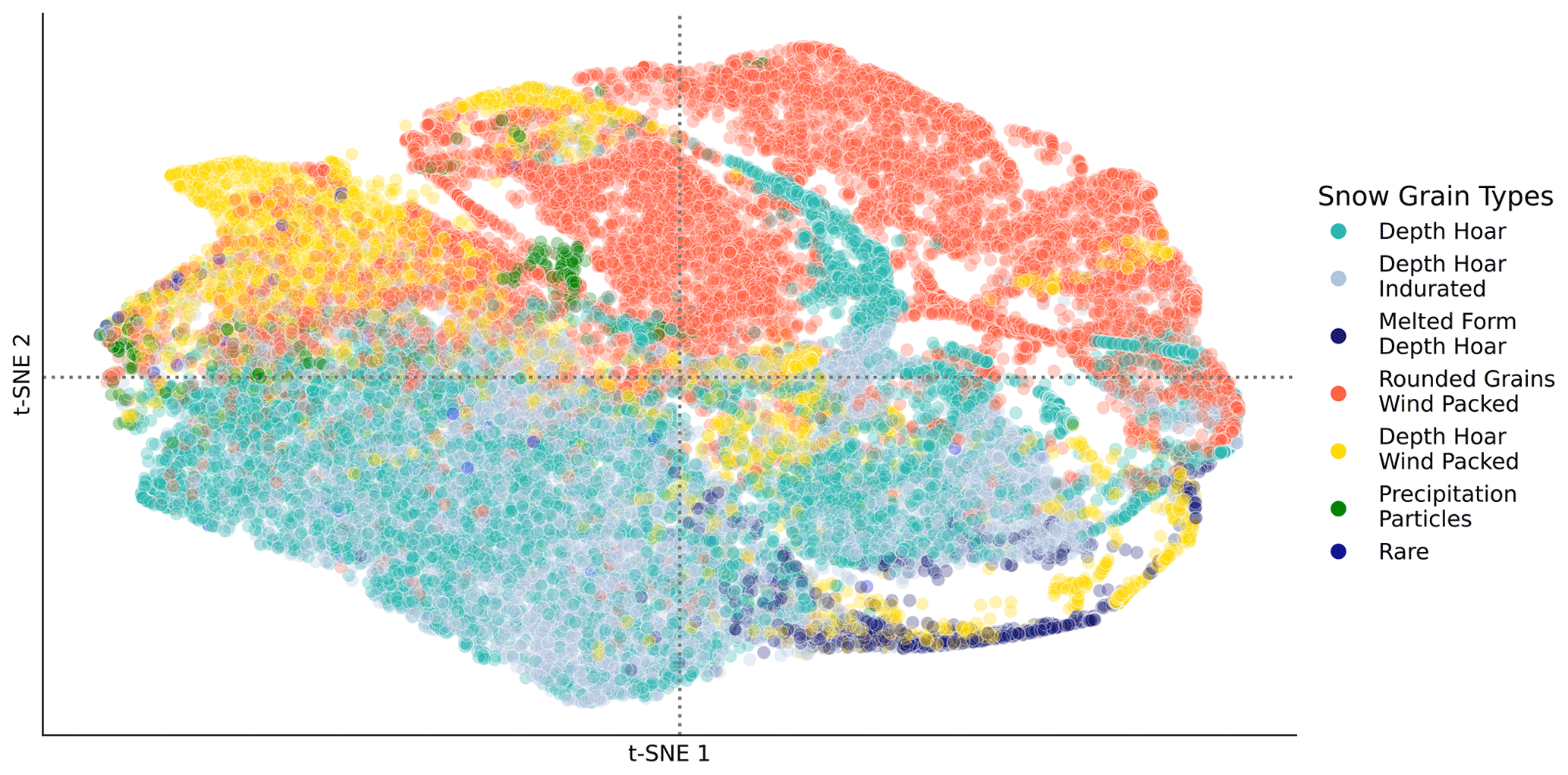
Figure 7Two-dimensional t-distributed stochastic neighbor embedding (t-SNE) of SnowMicroPen (SMP) dataset. The colors encode the snow types. The figure shows that (1) depth hoar and depth hoar indurated are hardly separable; (2) depth hoar wind packed is similar to several other snow types; and (3) precipitation particles, melted form of depth hoar, and rounded grains wind packed can each be separated more clearly from the other snow types.
4.2 Classification difficulty of snow types
Snow types are difficult to classify since their categories are continuous rather than discrete. This was also observed in previous work, and in all previous work performances were reported label-wise to account for those differences (Satyawali et al., 2009; Havens et al., 2013; King et al., 2020a). We performed t-distributed stochastic neighbor embedding (t-SNE) on the SMP dataset to visualize how separable the different classes are (see Fig. 7). The precipitation particles class, for example, appears as a singled-out green grouping, which is in line with our (and previous) findings (Satyawali et al., 2009) that it is easier to classify than other snow types. We conclude that some classes have features distinguishing them more strongly from other snow types. The rounded grain wind packed class behaves in a similar way (Satyawali et al., 2009). However, some classes, such as depth hoar and depth hoar indurated are completely overlapping in Fig. 7, and indeed our models had problems with differentiating between those two classes. Similarly, depth hoar wind packed seems to overlap largely with rounded grains wind packed and melted form of depth hoar. We theorize that the reason for their non-separability is that those snow types transform into each other during snow metamorphosis. This means many data points can not be discretized into one single category since they are on a continuous spectrum. Satyawali et al. (2009) also pointed out that they often found data points that were in transition between snow classes and attributed this to the fact that the snow is changing continuously. In conclusion, it is currently impossible to reach 100 % classification accuracy on every snow type since some snow types will always lie between categories.
Despite these difficulties, the underlying SMP signals are still characteristic enough for specific snow types to be classified successfully. The different micro-mechanical properties of the snow types are reflected in the SMP signal and are thus the driver for the classification. Some classes, such as precipitation particles, can be clearly separated from others since the bonding between the grains is so weak that the force signal is very low. As long as precipitation particles do not share this characteristic with other snow types, they can be easily classified. Refer to Appendix B to learn more about the relation between snow types and SMP signal, and refer to Appendix G to see which classes have unique signal characteristics and which classes have shared signal characteristics.
The classification difficulties also extend to the expert labeling process itself. The continuous nature of the snow types makes it particularly difficult for domain experts to agree on labeling, i.e., two different snow experts will produce two different labeled and segmented profiles for the same SMP measurement (Herla et al., 2021). This is another reason why a classification accuracy of 100 % cannot be reached. One might suggest supplementing the classification process with additional observational data to make the process more “objective” (as we also do here). However, each classification and segmentation of a snowpack is “subjective” in nature right now, no matter which observational data are used as the basis for the classification. When requesting a segmentation and classification of a snowpack, one is always requesting the classification of a specific expert. While the operator bias can be mitigated by using NIR, Micro-CTs, or the SMP, the classification of those measurements remains subjective. It is neither this study's goal nor its task to provide an objective classification; instead, we aim for a consistent classification.
However, difficulties in reaching 100 % accuracy do not preclude overall good performance. While experts may end up with different segmentations and classifications, they can still agree that two different analyses are both valid analyses of the same profile. Similarly, the algorithms provided here output predictions that may not always align with the expert labeling but are sensible and directly usable. Hence, we cannot evaluate the models solely based on numerical metrics, such as accuracy, but must also evaluate the performance from a qualitative perspective. This is the reason why we evaluated if an SMP user, who also labeled the training data, would (1) accept the predictions of the ML algorithms on an out-of-distribution dataset, (2) find them consistent with their own labeling, (3) and subsequently work with those predictions. In the case of the MOSAiC dataset, all those aspects were fulfilled. We find such a qualitative assessment important since these questions decide whether or not the tools provided will be used in practice.
We also want to point out that the algorithms themselves are entirely agnostic to the question of “subjectivity”. The algorithms are merely reproducing what they have been trained on. If we can provide the algorithms with a dataset that can be considered “fully objective”, and the community agrees on that as ground truth data, the algorithms could reproduce those hypothetical objective labels. Alternatively, signals could also be grouped first, and some abstract classes could be assigned to them. Nevertheless, even this would rely on human expertise since the parameters to separate those groups would be subject to discussion (see Fig. 7; the groups are not simply separable from each other, and the clustering would depend on parameter choices). In general, we provide a methodological framework here to classify and segment SMP profiles. Which classification patterns are reproduced depends on the user's choice.
The benefits of using an automatic classification are that the SMP user can (1) save valuable time, (2) receive consistent labeling, and (3) perform statistical analysis on their SMP dataset. In the case of the MOSAiC dataset, manual labeling would have meant labeling over 3000 profiles, which can easily take up to a year to classify (next to other obligations of domain experts). In terms of consistency, we already experienced how some of the models' predictions helped us – to our surprise – to detect human mistakes and inconsistencies during the first labeling round. Furthermore, such an upscaled classification enables, for the first time, the statistical analysis of an SMP dataset. One of the initial research questions for MOSAiC was “Is depth hoar in Arctic snowpacks mostly present at the bottom and rounded grains wind packed at the top?”. With the help of snowdragon, the MOSAiC dataset could be consistent and accurately labeled enough to answer such a question with “Yes, this is indeed the case.”.
4.3 Generalizability
The LSTM can generalize to other winter profiles with the same snow types since the underlying classification and segmentation rules stay the same. However, the LSTM's generalization capability does not extend to other seasons or regions when and where other snow types are found, such as melted forms or regional snow types. As mentioned before, the models do not generalize regarding the different classification styles of experts. The models used in this work are still generalizable in that they can be used on any desired dataset as long as they are retrained on the chosen dataset. This would not have been possible in previous works, such as Satyawali et al. (2009), since knowledge rules for one snow region and season do not transfer to other regions or seasons. For greater generalization capability, the LSTM – or any other model – must be either trained with a more general dataset or specifically retrained for an individual dataset.
4.4 Limitations and future work
As previously discussed, the uncertainty in expert labeling is a general limitation of this particular study. While this uncertainty might be partially mitigated further by using a dataset for which many additional in situ observations exist, it would still remain an issue. One approach for future work would be to quantify the uncertainty that is inflicted upon the labeled profiles. Subsequently, a machine learning model could be trained to not only classify snow types but also provide a probabilistic classification.
This work does not address the task setting of a first-segment-then-classify algorithm because this would require a completely different set of methods. In a first-segment-then-classify setting, the SMP signal could first be segmented with techniques used in audio segmentation (Theodorou et al., 2014). The resulting time series pieces could subsequently be classified as a whole (Ismail Fawaz et al., 2019). Future work could experiment with this problem formulation and analyze if performance further increases in this setting.
The ANNs used here are off-the-shelf networks and are not adapted to the specific underlying task in order to ensure a fair comparison between the different models. However, one could look into adapting the loss functions to include similarity measurements between snow samples. Results from clustering, performed on t-SNE data, could then be leveraged during classification to increase classification performance. Adapting the loss function of the ANNs could increase prediction performance greatly; however, such a loss function must be carefully constructed and evaluated on different datasets.
As mentioned in Sect. 4.3, the models cannot generalize to completely different settings in terms of seasons and regions. To ensure generalization capability one could train a large model on a dataset that includes snow types from different regions and seasons. Such a dataset would need to be newly compiled because common SMP datasets are usually limited to one region (Ménard et al., 2019; Calonne et al., 2020). In theory, a large enough model trained on a large enough dataset could be able to produce direct predictions for any SMP users. Thus, it would be interesting to train an ML model on a generalized dataset and validate its performance on the specialized MOSAiC SMP dataset. This would shed new light on the spatiotemporal transferability of the ML models presented here.
Alternatively, SMP users can simply retrain a chosen model for their particular dataset. They need to provide a set of SMP profiles for their region, season, and classification style, but the overall time savings are still immense. To summarize, the generalization capabilities may be enhanced by using a more general dataset, or one can bypass this problem by retraining to specific datasets. The snowdragon repository addresses the needs of the latter.
An immediate consequence of this study is the further analysis of the unlabeled part of the MOSAiC dataset. Domain experts can use the LSTM or other models to create predictions for the remaining 3516 profiles. A previously almost impossible task to classify and segment those thousands of profiles became feasible by providing just a set of 164 labeled profiles. The results of these predictions and their impacts on the cryospheric analysis of snow coverage in the Arctic will become apparent in future publications.
Snowdragon provides SMP users with a way to upscale manual SMP labeling and provide large statistically consistent datasets. We showed for the first time that SMP profiles straight from the field can be automatically segmented and classified (up to 0.78 accuracy). A total of 14 different models were trained here to classify seven snow types without providing any additional manual information. It also showed for the first time how ANNs and semi-supervised models can be used for the task of SMP classification and segmentation. Among all models, the LSTM and the encoder–decoder models perform the best. The resulting predicted profiles show smooth segmentations and expert-like classification patterns that were satisfying to domain experts.
These findings will enable SMP users to automatically analyze their SMP measurements. To that end, an SMP user must simply decide on 1 of the 14 models provided by the snowdragon repository given the considerations listed in this paper and retrain the model for their particular dataset. Afterwards, the SMP user can simply predict SMP classifications for the remaining unlabeled profiles.
The models presented here, in particular the LSTM model, could be trained on a broad dataset from different regions and seasons so that automatic SMP classification becomes even more accessible. Such a model could even be integrated into the snowmicropyn package. The resulting tool would make knowledge about snowpacks easier and faster to access for all scientists. This is of particular interest (1) for interdisciplinary scientists that rely on snow type information but do not have the tools to classify them themselves (remote sensing); (2) for scientists that require fast analysis of SMP profiles, such as in avalanche prediction; and (3) for SMP users facing large datasets.
Snowdragon enables the analysis of the SMP MOSAiC dataset, a dataset containing detailed information about snow on Arctic sea ice. In times of climate change, this information is crucial. We need to understand the state of the sea ice in order to understand which state the Arctic system is in. For the first time, MOSAiC enables the scientific community to have access to such a detailed and large dataset. Snowdragon is one example of how ML can help us to actually access the knowledge behind all the data.
Here, we provide a walk-through of how to use snowdragon with SMP profiles collected in the field.
-
Data collection.
-
Collect the desired SMP profiles.
-
If you are familiar with snow stratigraphy measurements, you should consider collecting additional in situ observations such as Micro-CTs, NIR photography, or similar to inform your labeling procedure (see also points listed under “labeling”).
-
If you are not familiar with snow stratigraphy measurements, you should ask experts if a labeled dataset for your snow conditions exists (Macfarlane et al., 2021; Wever et al., 2022; King et al., 2020b) or if you need to onboard an expert to conduct a few in situ observations and label some of your profiles.
-
-
Labeling.
-
Evaluate the following questions before you start the data collection.
-
If you conduct your own labeling proceed through the following steps:
-
use additional in situ observations to fine-tune your labeling where possible;
-
ask a fellow researcher for their opinion on a few profiles (before you label all of them);
-
note down your labeling criteria – this way you can ensure consistency in your labeling;
-
revisit your labeled profiles (all of them!) at least a second time because you can catch mistakes and ensure once more that there is consistency in your labeling.
-
-
If a labeled dataset exists for a specific location, proceed through the following questions and analyze carefully if the labeled data do transfer to your snow conditions. Can you expect the same snow types? Was the data collected in the same location or a similar location? Is it the same season? Might changing climatic conditions have also changed the nature of the snowpacks? Has the environment of the location gone through other types of changes?
-
If labeled datasets exist capturing SMP profiles in general, proceed through the following questions and analyze carefully if you can work with a general dataset or need a specialized labeled dataset. Does the general dataset reflect the profiles you have collected well? Do you have snow types dominating your dataset that are a minority in the general dataset? Do you have a particular season dominating your dataset that is underrepresented in the general dataset? Does the general dataset contain all snow types that you have encountered in your dataset?
-
-
Setup.
-
Raw preprocess your SMP profiles and labels if necessary; data must be provided in
.pntformat. -
Establish a consistent naming convention for your profiles. The labeling files (in
.iniformat) should have the same file name as the SMP profile that belongs to that labeling file. For example, you can have aS31H0370.inicontaining the label markers for the force fileS31H0370.pnt. -
Clone or fork the snowdragon repository (https://github.com/liellnima/snowdragon).
-
Follow the setup guide in the GitHub repository.
-
Tell the repository where your raw data lives. Change the
SMP_LOCindata_handling/data_parameters.pyto the right path as described online. -
Preprocess all the SMP profiles (follow online guidelines).
-
-
Model selection.
-
Select the right model for your use case. Refer to Sect. 4.1 for further information.
-
-
Training and evaluation.
-
Refer to the online guide of the repository.
-
-
Tuning.
-
Refer to the online guide of the repository.
-
-
Inference.
-
Use the
predict_profile()orpredict_all()functions from thepredict.pyfile (provide path to data again). The functions can either be directly used or further adapted to your particular needs. The model you choose for inference must be stored somewhere, meaning you either need to train it beforehand or download the pre-trained models we provide.
-
-
Analysis.
-
Conduct your specific analysis on the labeled profiles. Run visualizations if desired, as explained in the online guide.
-
A snow micro penetrometer (SMP) is a device used to determine bond strength between internal snow grains in a snowpack. The micro-structural and micro-mechanical properties of the snow, for example, density and specific surface area (SSA), are directly influencing the bond strength. When a snow micropenetrometer penetrates the snowpack and breaks these bonds between the snow grains, we are able to directly infer these micro-structural properties, as shown in the existing method by Proksch et al. (2015). For example, snow with high density has a higher bond strength and therefore a higher penetration resistance force (measurable with the SMP) in comparison to low-density snow.
Different types of snow (Fierz et al., 2009) are known to have different densities and SSAs, so the extraction of this data from the SMP force signal already allows us to draw pivotal conclusions about the snow type. However, the characteristics (using magnitude, frequency, and gradient) and the signature of the penetration force signal can provide more information about the internal snow type. This document outlines the process of classification of a snow type found on sea ice in the High Arctic using the SMP penetration resistance force signal.
Typical grains observed as part of the MOSAiC expedition on sea ice in the High Arctic are listed below:
-
precipitation particles (PP) or decomposing and fragmented precipitation particles (DF);
-
ice formations (IF);
-
surface hoar (SH);
-
rounded grains wind packed (RGwp);
-
depth hoar (DH);
-
depth hoar indurated (DHid);
-
depth hoar wind packed (DHwp);
-
melt form depth hoar (MFdh).
It is important to mention that the melt season is not included in this study due to liquid water influencing the interpretation of the SMP signal. For more information on the environmental and meteorological conditions under which the dataset has been collected refer to Rinke et al. (2021).
For the majority of snow types, we follow the classification of Fierz et al. (2009). However, Fierz et al. (2009) was adapted for Alpine snow, meaning some of the snow types listed above are either not included in the classification or differ from the ones encountered in Alpine snow.
Melt form, depth hoar. When working on sea ice we identified one alternative snow grain class (melt form, depth hoar, MFdh) that does not exist in the Fierz et al. (2009) classification. This snow type is known in the sea ice community as a surface scattering layer (Light et al., 2015). It is typically found in the summer season when sea ice melts; however, we identified this as a persistent layer when transitioning into winter. In the field, this was an extremely dense layer at the snow–sea ice interface, and the penetration resistance force of this layer varied throughout the season. The melt form depth hoar label was chosen as this is a feature of melting sea ice that has persisted into the winter and has undergone metamorphism when buried under snow.
Depth hoar, wind packed. Grains initially classified as rounded grains wind packed (RGwp) metamorphose into a very hard, dense depth hoar under the large temperature gradients, which we call depth hoar wind packed (DHwp) (Pfeffer and Mrugala, 2002).
All other classifications are listed in Fierz et al. (2009).
B1 Classification details
Table B1Features used to identify snow types visually from the SMP signal.
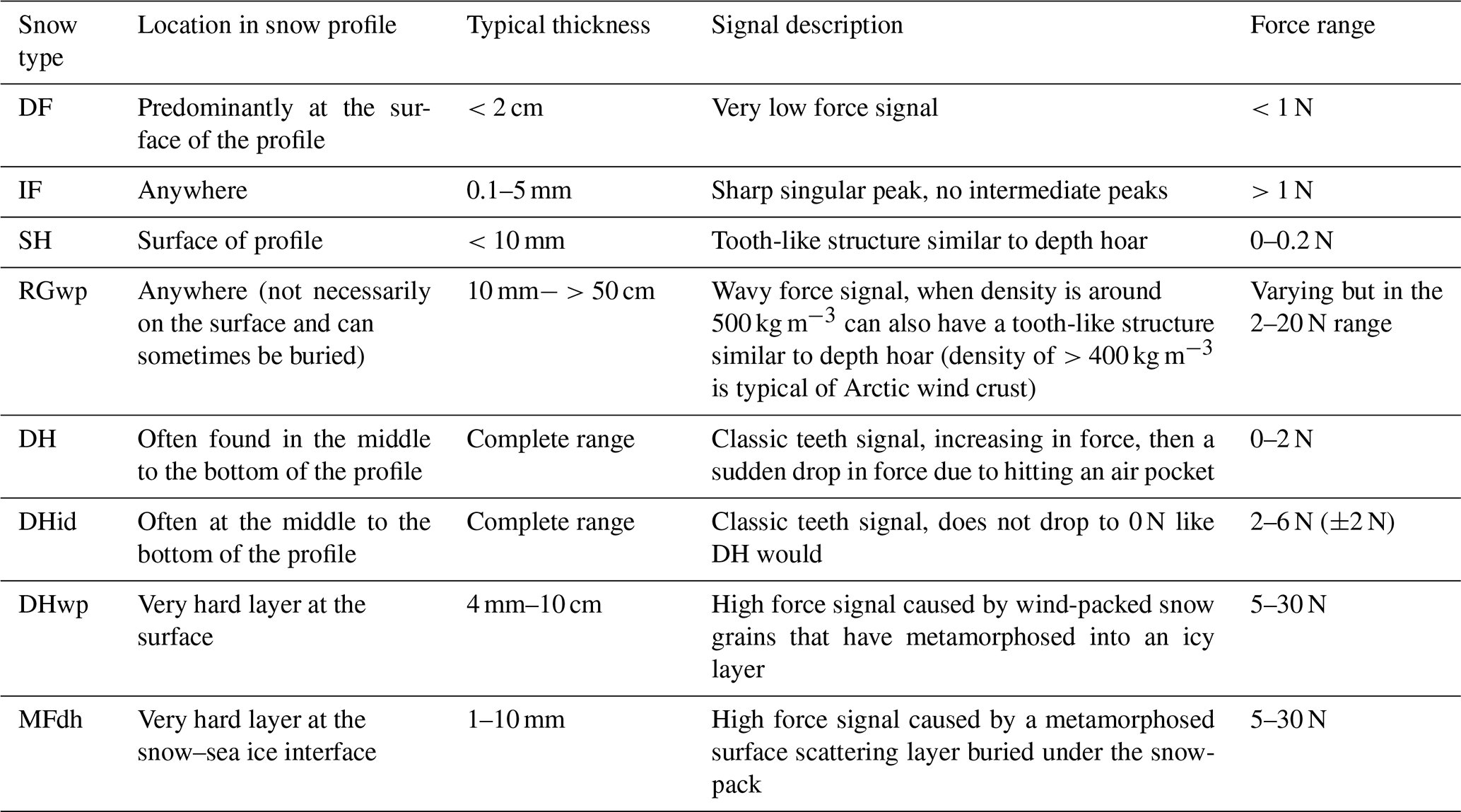
B2 Examples of snow types' SMP signals
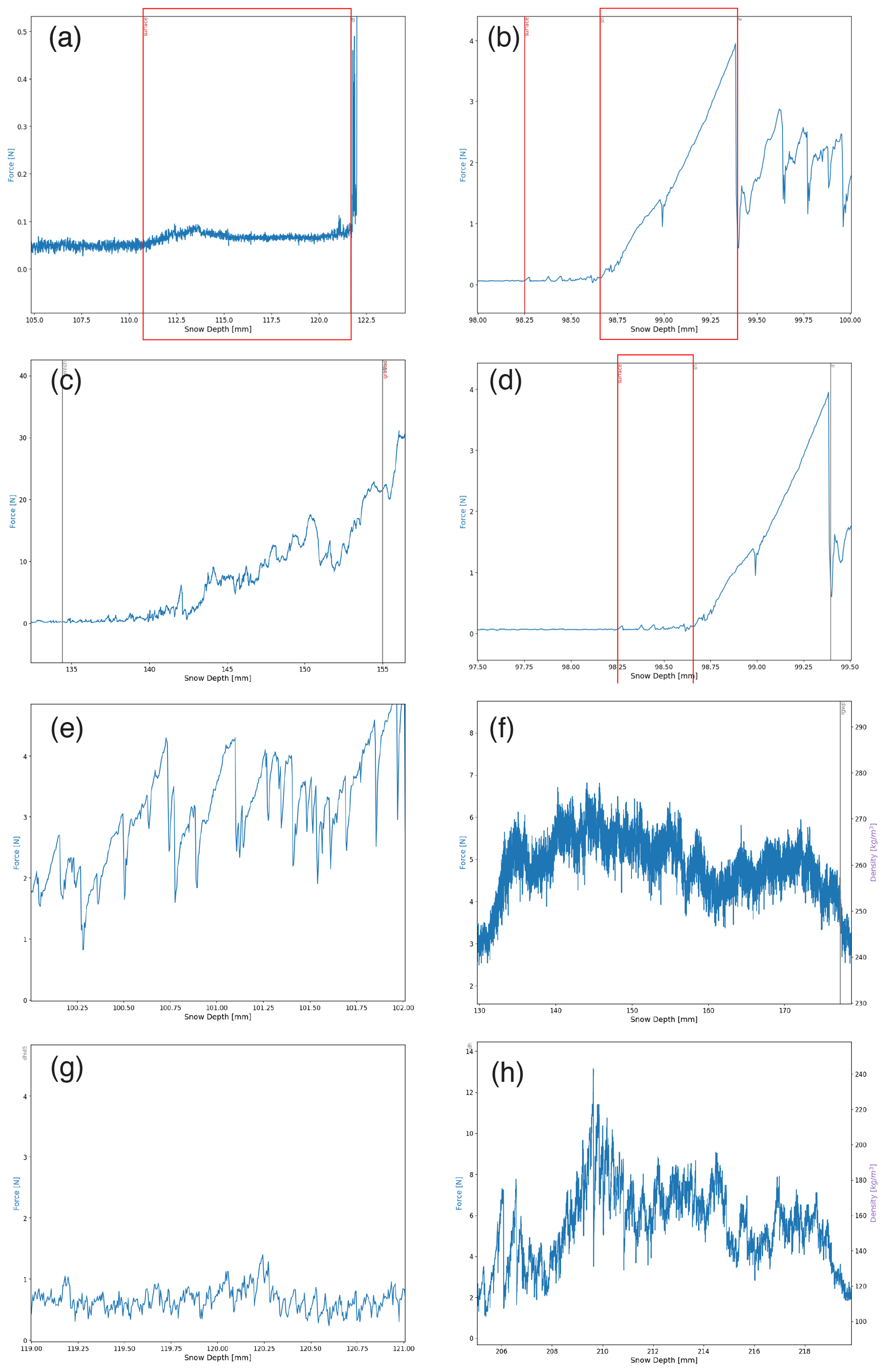
Figure B1SMP profiles with typical SMP signals for the following snow types: (a) a typical signal for decomposing and fragmented precipitation particles (DF) with a force remaining under 0.1 N between approximately 111 and 121 mm, (b) a typical signal for ice formations (IF) with a sharp singular peak at a maximum of 4 N between approximately 98.6 and 99.3 mm, and (c) a typical increase in force at the snow–sea ice interface. This signal is typical of a remnant surface scattering layer, named melt form, depth hoar (MFdh) in this study. This signal typically has a force range of 5–30 N showing (d) a typical signal for surface hoar (SH) at the surface of the profile with a tooth-like structure with a low force signal; (e) a typical tooth-like signal for indurated depth hoar (DHid) with a force between 2–6 N, (f) a typical wavy force signal for rounded grains, wind packed snow (RGwp); (g) a typical tooth-like signal for depth hoar (DH), and (h) a typical wavy and tooth-like signal for depth hoar, wind packed (DHwp) with a force between 5–30 N at snow depths 208 to 215 mm.
B3 Complementary parallel measurements
When measuring the snow properties, we had access to numerous instruments, with each proving beneficial when interpreting the snow grain type. For example, the near-infrared camera provided overview images of the cross section of the snow pit wall (see examples in Fig. B2a and c), and micro-computer tomography measured the snow's micro-structure in high resolution (Fig. B2d). The metadata section in the dataset by Macfarlane et al. (2021) gives additional information about how many micro-CTs and NIR images are used in parallel.
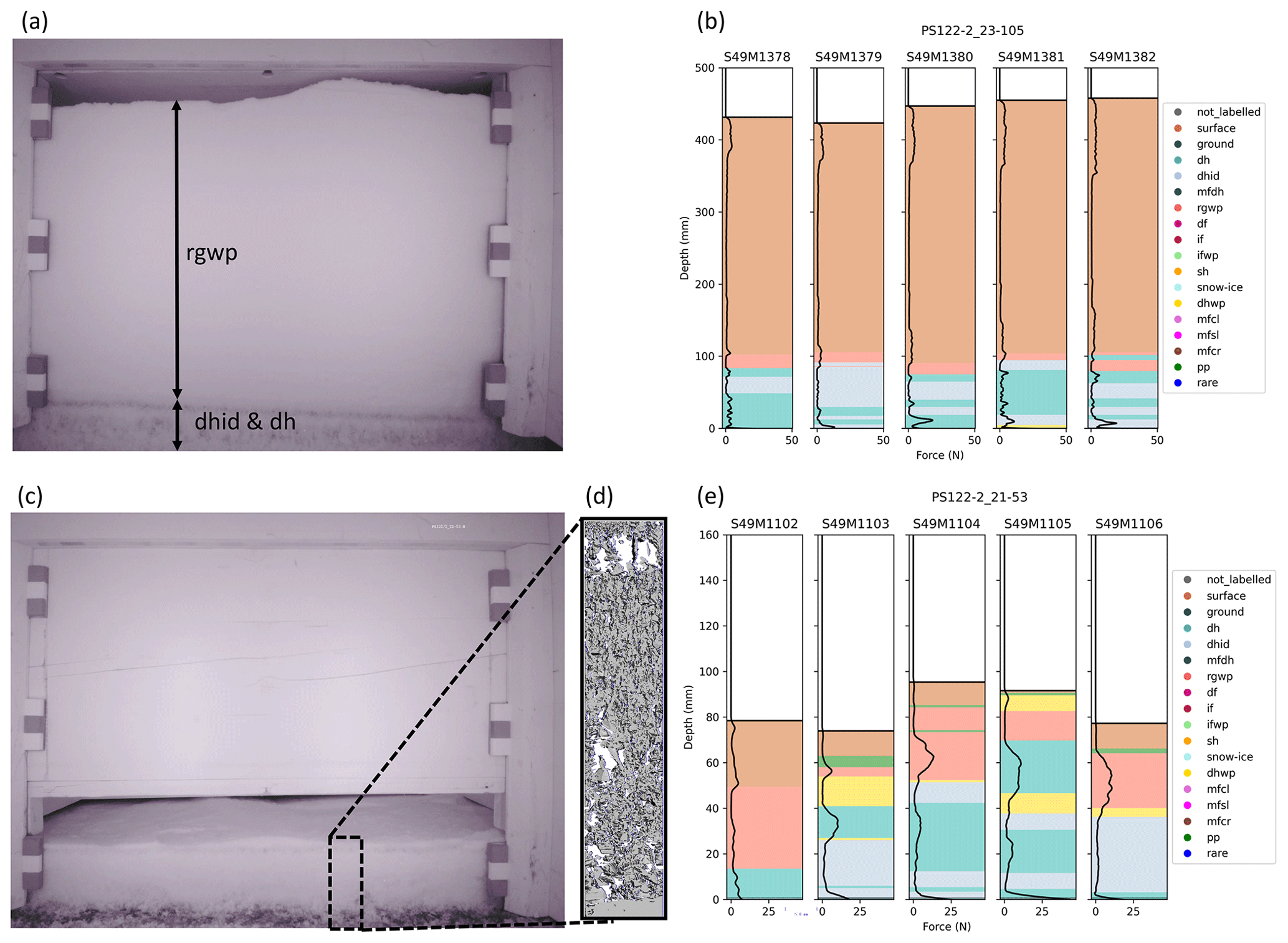
Figure B2A holistic figure showing the use of a library of datasets to assist in labeling the SMP signal. (a) An NIR image from the event PS122-2_23-105 giving a horizontal cross section of the snowpack where the five SMP measurements in (b) were taken. The rounded grain, wind packed (rgwp); indurated depth hoar (dhid); and depth hoar (dh) regions are identified. (b) Five SMP profiles measured approximately 20 cm apart in the same snow pit during event PS122-2_23-105. (c) An NIR image from event PS122-2_21-53 giving a horizontal cross section of the snowpack where the five SMP measurements in (e) were taken. (d) A 3-D reconstruction of the snow microstructure measured using micro-computer tomography. (e) Five SMP profiles measured approximately 20 cm apart in the same snow pit during event PS122-2_21-53.
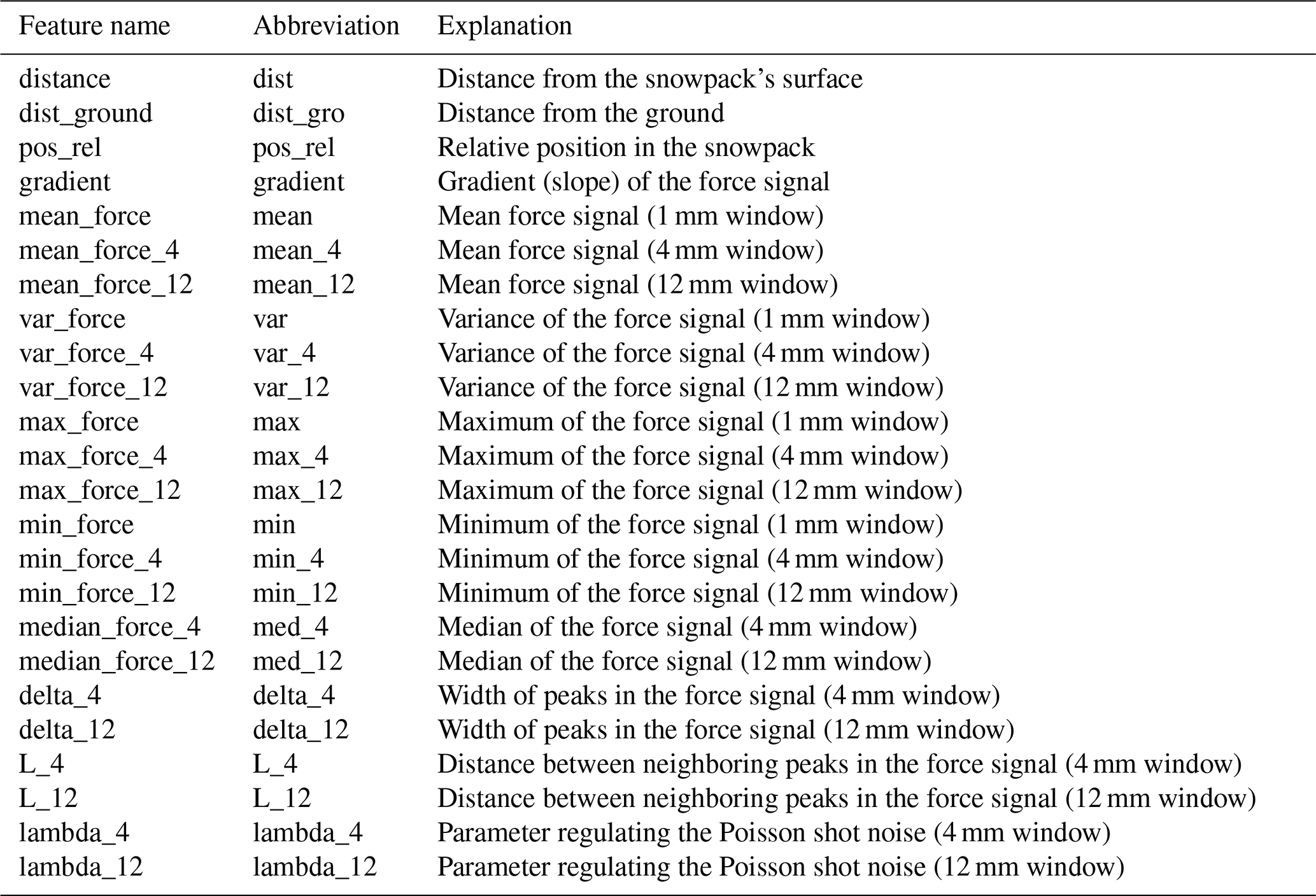
C1 Features included in data
Table C1 lists all features that were included in the training, validation, and testing data of this study. The importance of those features depends on the specific snow type that should be classified (see Fig. C1). For example, rounded grains wind packed shows a high correlation with micro-mechanical features such as L (4 mm window), whereas melted form depth hoar is mainly correlated with the force values of the SMP profile. Further feature importance analysis (ANOVA and decision tree importance) can be found online in the snowdragon GitHub repository.
Table C1Names and description of the features included in the training, validation, and testing data.
C2 Label-wise feature correlation
Figure C1 shows why classification for this dataset is so hard. Some labels have lower correlations among all features, making it unclear how the right predictions can be achieved on this basis. Other more predictive features are missing; i.e., if a feature is discovered that shows a high correlation within this plot, it might boost the overall classification capabilities of the models. The figure also shows that there might be interaction effects arising since some snow types show very similar correlations (for example melted form depth hoar and depth hoar wind packed). In summary, the label-wise feature correlation reveals the classification difficulty of the dataset and can be used to discover new predictive features.
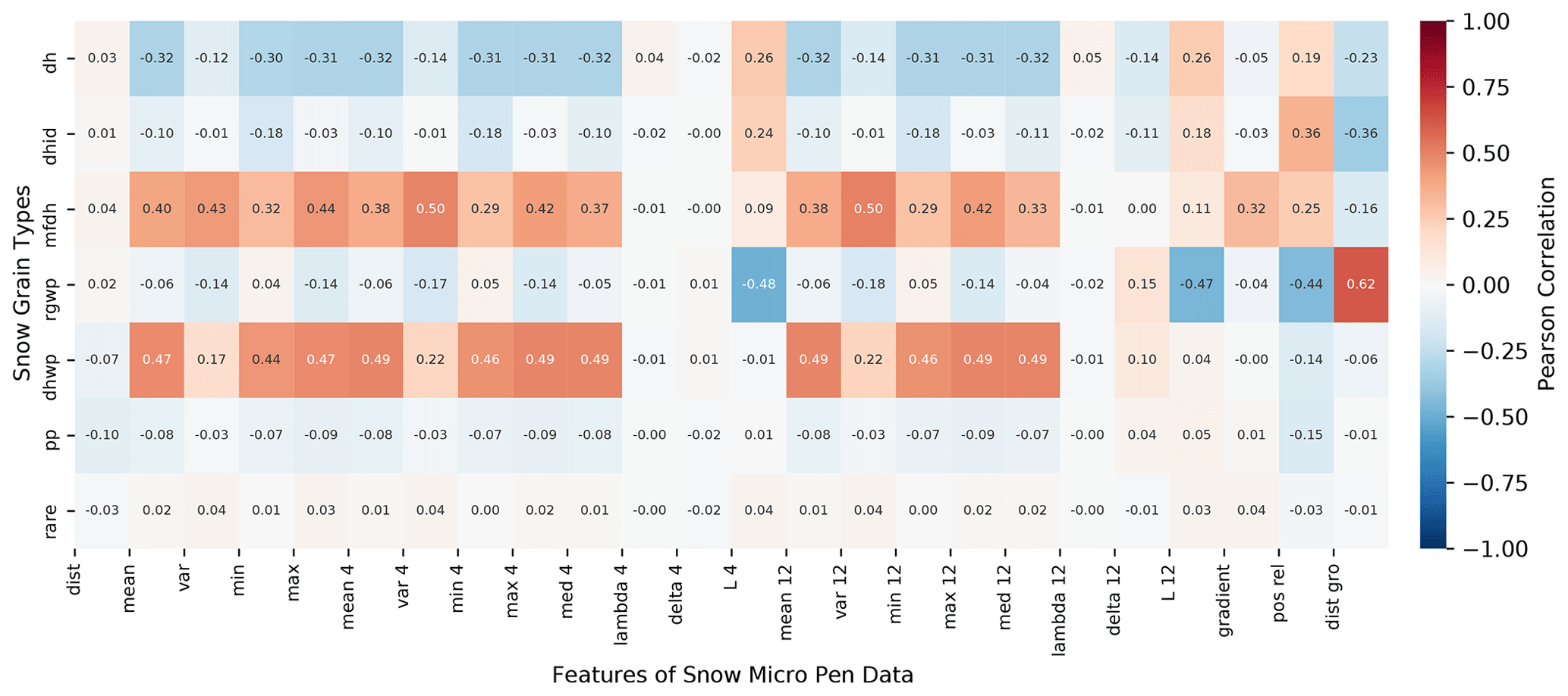
Figure C1Label–feature correlation between snow types and aggregated features of the SMP profiles. The numbers in the feature names stand for the window size used during aggregation. Depth hoar (dh), depth hoar indurated (dhid), and rounded grains wind packed (rgwp) show some negative correlations with a subset of the features. Melted form depth hoar (mfdh), depth hoar wind packed (dhwp), and rounded grains wind packed (rgwp) show a strong positive correlation with at least one feature. Precipitation particles (pp) does not show strong correlations with any feature; however, a correlation with distance (dist), variance, and force features was expected by experts. The low correlations could be caused by the data-preprocessing step when decomposed and fragmented precipitation particles were categorized as precipitation particles as well. The rare class shows no correlations with the features since it consists of very different sub-classes (ice formation and surface hoar).
The metrics used for validation and testing are listed and explained in Table D1. It might be helpful to familiarize oneself with a binary confusion matrix beforehand.
Table D1List of metrics employed during validation and testing. The given formulas are only simplified versions for a binary classification case where no weighting takes place. The formula for the AUROC is not given here, since it is not a one-line formula and actually involves calculating an area under the ROC curve. Implementation and explanations of the metrics are from Pedregosa et al. (2011).
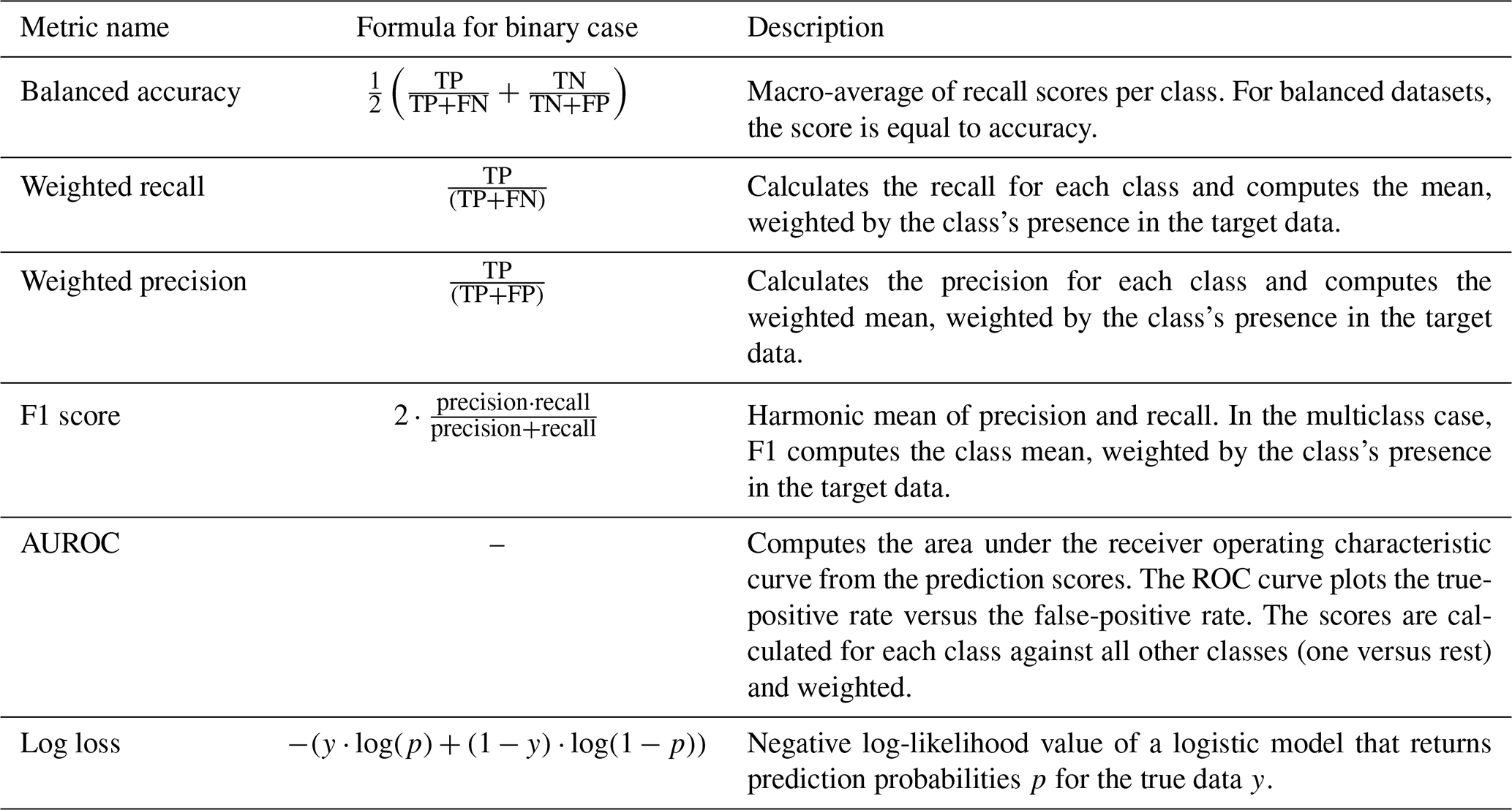
Intuitively speaking, accuracy expresses how many samples were predicted correctly relative to all predictions; recall expresses how many positive samples were predicted correctly relative to all positive samples; precision expresses how many positive samples were predicted correctly relative to all positive predictions; F1 score can be used to measure both recall and precision in one score; ROC is the receiver operating characteristics and plots the true-positive rate versus the false-positive rate; AUROC expresses that the higher the area under the ROC curve, the clearer can the model separate between positive and negative samples; and log loss expresses how good or bad the prediction probabilities of each sample are compared to the target predictions. All these values are better the larger they are (except for log loss, which is kept as low as possible). Some of the metrics from Table D1 cannot be computed for all models. This is the case because the AUROC and the log loss metric operate on prediction probabilities for the different classes, which not every model can provide. In these cases, the missing metric is marked with “–” in the result tables.
The evaluation and hyperparameter tuning experiments were run on two different machines. The complete evaluation was conducted on a 64 bit system with an Ubuntu 18.04.5 (Bionic Beaver) operating system. The machine has 16 GB RAM and an Intel® Core™ i7-6700HQ CPU @ 2.60GHz×8 (and the GPU was not used). The machine on which the first hyperparameter tuning, training, and validation experiments have been run has the following specifications: 64 bit system with an Ubuntu 20.04.1 (Focal Fossal) operating system, an Intel® Core™ i7-4510U CPU @ 2.00GHz×4 CPU, and 12 GB RAM (and the GPU was not used). Final hyperparameter tuning, training, and validation (results presented here) were run on an Azure virtual machine of the Dsv3-series, namely on a Standard_D4s_v3 (https://docs.microsoft.com/en-us/azure/virtual-machines/dv3-dsv3-series, last access: 3 August 2023) machine with Ubuntu 18.04 (Bionic Beaver) as an operating system, 16 GB RAM, and four vCPUs.
The project was executed in Python 3.6, and all used packages can be found on GitHub in the “requirements.txt” file. Principal component analysis, t-SNE, k-means clustering, Gaussian mixture models, Bayesian Gaussian mixture models, random forests, SVMs, and the k-nearest-neighbor algorithm were used as made available through scikit-learn by Pedregosa et al. (2011). (https://scikit-learn.org/stable/, last access: 3 August 2023) The easy ensemble for imbalanced datasets and a balanced variant of the random forest are imported from imbalanced-learn by Lemaître et al. (2017) (https://imbalanced-learn.org/stable/, last access: 3 August 2023). All ANN architecture was created with the help of TensorFlow (Abadi et al., 2016) (https://www.tensorflow.org/, last access: 3 August 2023) and Keras (Chollet et al., 2015) (https://keras.io/, last access: 3 August 2023). The attention model within the encoder–decoder network was used as provided in the keras-attention-mechanism package by CyberZHG (2020).
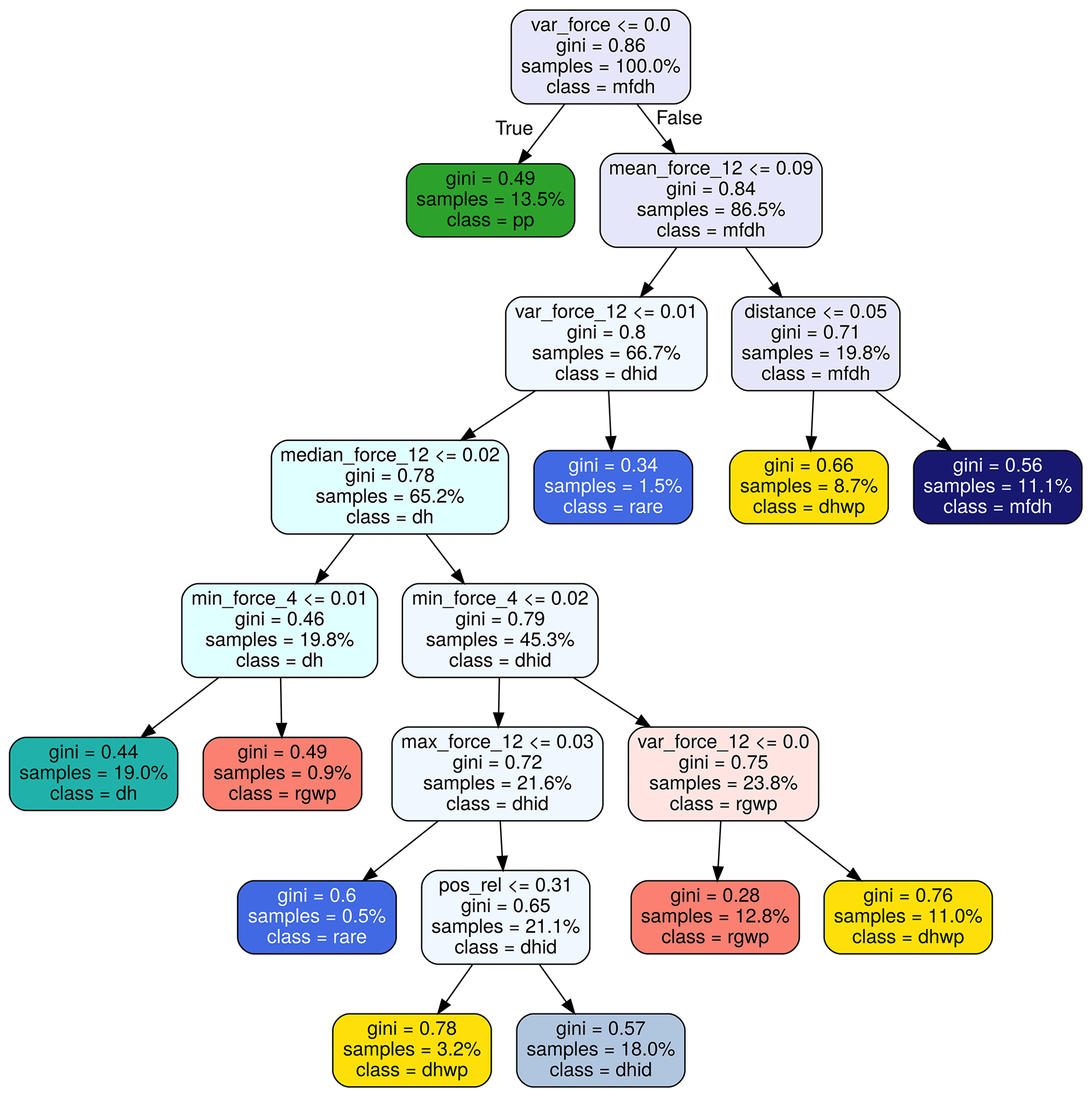
Figure G1Pruned decision tree extracted from the random forest. See Appendix C1 for an explanation of the features that the nodes represent. Decision trees encode the decision rules for predicting snow type labels. This approach helps explain the model's decisions, a property often asked for by domain experts. At each leaf node, a labeling decision is made. All the other nodes encode the labeling rules used to classify each point. Take the root node as an example. If the variance of the force is smaller or equal to zero, the point is labeled as precipitation particles. In all other cases, it has to be one of the other labels. The Gini index encodes how separable the subsets of data points are (the bigger the number the better), and the sample's number shows what percent of the complete data can be found in this subset.
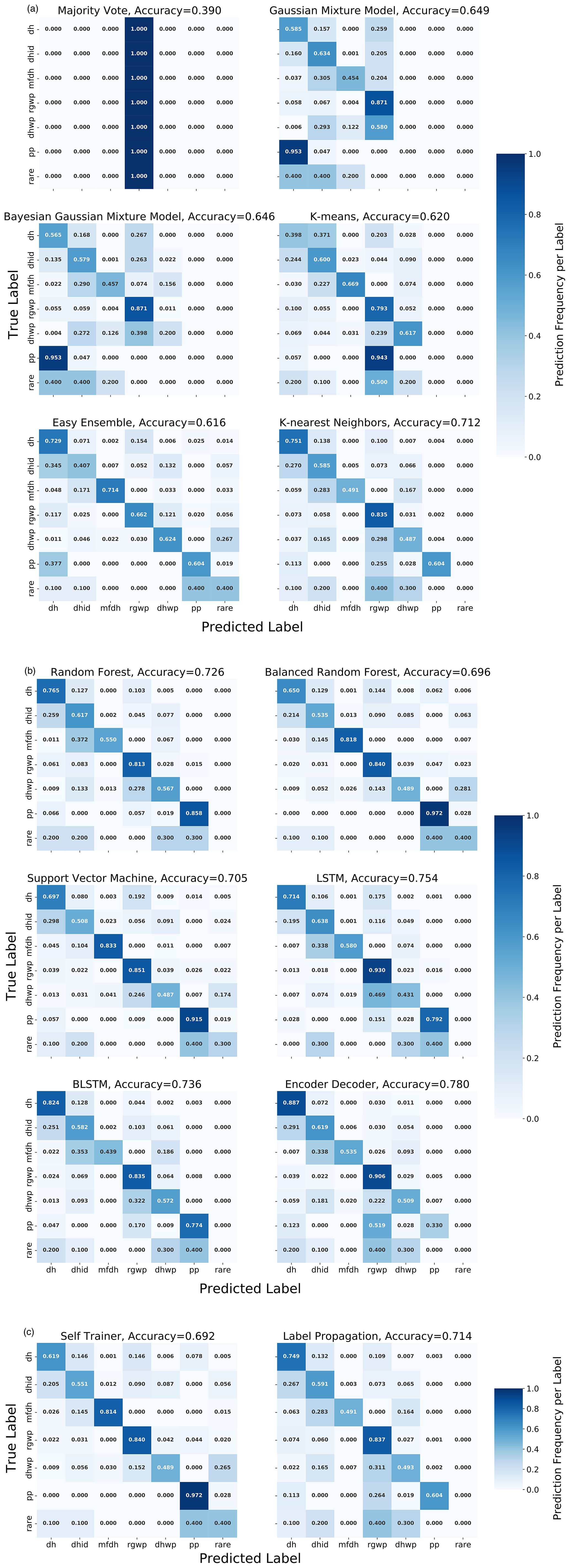
Figure H1Confusion matrices of all models displaying the predicted and the observed snow types. The number in each cell is the relative prediction frequency of a label within the observed class. The numbers of the diagonal (upper left to lower right) represent the prediction accuracy of each label. The more pronounced the diagonal and less pronounced the upper and the lower triangles are, the better the predictions become. The confusion matrices help for an in-depth analysis of the label-specific performances. This is useful when users want to choose a model that is suitable for a specific snow classification task. (a) Confusion matrices of majority vote, Gaussian mixture model, k-mean, easy ensemble, and k-nearest neighbor approaches. (b) Confusion matrices of random forest, support vector machine, LSTM, BLSTM, and encoder approaches. (c) Confusion matrices of self-trainer and label propagation approaches.
The current version of snowdragon is available on GitHub under the MIT License: https://github.com/liellnima/snowdragon (last access: 3 August 2023). To run the code version used in this paper, please refer to v1.0.0 on GitHub or Zenodo: https://doi.org/10.5281/zenodo.7335813 (Kaltenborn and vclay, 2022). The exact versions of the models used to produce the results used in this paper are also archived on Zenodo: https://doi.org/10.5281/zenodo.7063520 (Kaltenborn et al., 2022). The MOSAiC SMP data used as input and training data are available on PANGAEA: https://doi.org/10.1594/PANGAEA.935554 (Macfarlane et al., 2021).
ARM and MS collected and curated the data. ARM and MS labeled the data. ARM and JK preprocessed the data. JK developed the methodological framework. JK implemented, compared, tuned, and validated the models. JK and VC visualized the results. JK wrote the manuscript draft. VC, ARM, and MS reviewed and edited the manuscript. VC supervised the ML part of the study. MS supervised the cryospheric part of the study.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Data used in this paper were produced as part of the international Multidisciplinary drifting Observatory for the Study of the Arctic Climate (MOSAiC) with the tag MOSAiC20192020. The data were collected during the Polarstern expedition AWI_PS122_00. We acknowledge the contribution of the MOSAiC expedition (Nixdorf et al., 2021). We especially thank the crew of RV Polarstern (Knust, 2017) and participants of leg one to three for their help in the field. We would especially like to thank the late Joshua M. L. King for insightful discussions and comments.
This research has been supported by the Swiss Polar Institute (grant no. DIRCR-2018-003), the European Union's Horizon 2020 research and innovation programme project ARICE (grant no. 730965) for berth fees associated with the participation of the DEARice project, the WSL-Institut für Schnee- und Lawinenforschung (grant no. WSL201812N1678), the Deutsche Forschungsgemeinschaft (grant no. GRK2340), and the Alfred Wegener Institute Helmholtz Centre for Polar and Marine Research (grant no. AWI_PS122_00). Additional funding was provided for the research training group by the Deutsche Forschungsgemeinschaft (DFG) (grant no. GRK2340).
This paper was edited by Fabien Maussion and reviewed by Pascal Hagenmuller and two anonymous referees.
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G. S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A., Irving, G., Isard, M., Jia, Y., Jozefowicz, R., Kaiser, L., Kudlur, M., Levenberg, J., Mane, D., Monga, R., Moore, S., Murray, D., Olah, C., Schuster, M., Shlens, J., Steiner, B., Sutskever, I., Talwar, K., Tucker, P., Vanhoucke, V., Vasudevan, V., Viegas, F., Vinyals, O., Warden, P., Wattenberg, M., Wicke, M., Yu, Y., and Zheng, X.: TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems, arXiv [preprint], https://doi.org/10.48550/arXiv.1603.04467, 2016. a
Bahdanau, D., Cho, K., and Bengio, Y.: Neural Machine Translation by Jointly Learning to Align and Translate, arXiv [preprint], https://doi.org/10.48550/ARXIV.1409.0473, 2014. a
Bishop, C. M.: Pattern recognition and machine learning, Information science and statistics, Springer, New York, 738 pp., ISBN 978-0-387-31073-2, 2006. a, b
Breiman, L.: Random forests, Mach. Learn., 45, 5–32, https://doi.org/10.1023/A:1010933404324, 2001. a
Calonne, N., Richter, B., Löwe, H., Cetti, C., ter Schure, J., Van Herwijnen, A., Fierz, C., Jaggi, M., and Schneebeli, M.: The RHOSSA campaign: multi-resolution monitoring of the seasonal evolution of the structure and mechanical stability of an alpine snowpack, The Cryosphere, 14, 1829–1848, https://doi.org/10.5194/tc-14-1829-2020, 2020. a
Chao, C., Liaw, A., and Breiman, L.: Using random forest to learn imbalanced data, Tech. Reports 666, University of California, Dep. Statistics, Berkeley, https://statistics.berkeley.edu/tech-reports/666 (last access: 3 August 2023), 2004. a
Chollet, F. et al.: Keras, GitHub, https://github.com/fchollet/keras (last access: 3 August 2023), 2015. a
Colbeck, S.: A review of the metamorphism and classification of seasonal snow cover crystals, IAHS Publication, 162, 3–24, https://iahs.info/uploads/dms/6807.3-34-162-Colbeck.pdf, 1987. a
Coléou, C., Lesaffre, B., Brzoska, J.-B., Ludwig, W., and Boller, E.: Three-dimensional snow images by X-ray microtomography, Ann. Glaciol., 32, 75–81, https://doi.org/10.3189/172756401781819418, 2001. a
Cortes, C. and Vapnik, V.: Support-vector networks, Mach. Learn., 20, 273–297, https://doi.org/10.1007/BF00994018, 1995. a
Cover, T. and Hart, P.: Nearest neighbor pattern classification, IEEE Transactions on Information Theory, 13, 21–27, https://doi.org/10.1109/TIT.1967.1053964, 1967. a
CyberZHG: Keras Self-Attention, GitHub, https://github.com/CyberZHG/keras-self-attention (last access: 3 August 2023), 2020. a
Domine, F., Picard, G., Morin, S., Barrere, M., Madore, J.-B., and Langlois, A.: Major Issues in Simulating Some Arctic Snowpack Properties Using Current Detailed Snow Physics Models: Consequences for the Thermal Regime and Water Budget of Permafrost, J. Adv. Model. Earth Syst., 11, 34–44, https://doi.org/10.1029/2018MS001445, 2019. a
Douville, H., Royer, J. F., and Mahfouf, J. F.: A new snow parameterization for the Météo-France climate model, Clim. Dynam., 12, 21–35, https://doi.org/10.1007/BF00208760, 1995. a
Fierz, C., Armstrong, R., Durand, Y., Etchevers, P., Greene, E., Mcclung, D. M., Nishimura, K., Satyawali, P., and Sokratov, S.: The international classification for seasonal snow on the ground, Tech. rep., UNESCO-IHP, Paris, Paris, publication Title: IHP-VII Technical Documents in Hydrology No. 83, IACS Contribution No. 1, 2009. a, b, c, d, e, f, g, h, i, j, k
Fix, E. and Hodges, J. L.: Discriminatory Analysis - Nonparametric Discrimination: Small Sample Performance, Tech. rep., California University Berkeley, https://apps.dtic.mil/sti/citations/ADA800391 (last access: 3 August 2023), section: Technical Reports, 1952. a
Forgy, E. W.: Cluster analysis of multivariate data: efficiency versus interpretability of classifications, Biometrics, 21, 768–769, 1965. a
Ghahramani, Z.: Unsupervised Learning, pp. 72–112, Springer Berlin Heidelberg, Berlin, Heidelberg, https://doi.org/10.1007/978-3-540-28650-9_5, 2004. a
Han, J., Kamber, M., and Pei, J.: 9 – Classification: Advanced Methods, in: Data Mining (Third Edition), edited by: Han, J., Kamber, M., and Pei, J., The Morgan Kaufmann Series in Data Management Systems, pp. 393–442, Morgan Kaufmann, Boston, third edition edn., https://doi.org/10.1016/B978-0-12-381479-1.00009-5, 2012. a
Havens, S., Marshall, H.-P., Steiner, N., and Tedesco, M.: Snow micro penetrometer and near infrared photography for grain type classification, in: 2010 International Snow Science Workshop, pp. 465–469, https://arc.lib.montana.edu/snow-science/objects/ISSW_P-029.pdf (last access: 3 August 2023), 2010. a, b
Havens, S., Marshall, H.-P., Pielmeier, C., and Elder, K.: Automatic Grain Type Classification of Snow Micro Penetrometer Signals With Random Forests, IEEE Transactions on Geoscience and Remote Sensing, 51, 3328–3335, https://doi.org/10.1109/TGRS.2012.2220549, 2013. a, b, c, d, e
Herla, F., Horton, S., Mair, P., and Haegeli, P.: Snow profile alignment and similarity assessment for aggregating, clustering, and evaluating snowpack model output for avalanche forecasting, Geosci. Model Dev., 14, 239–258, https://doi.org/10.5194/gmd-14-239-2021, 2021. a
Ho, T. K.: Random decision forests, in: Proceedings of 3rd international conference on document analysis and recognition, vol. 1, pp. 278–282, IEEE, 1995. a
Hochreiter, S. and Schmidhuber, J.: Long short-term memory, Neural Computat., 9, 1735–1780, 1997. a
Ismail Fawaz, H., Forestier, G., Weber, J., Idoumghar, L., and Muller, P.-A.: Deep learning for time series classification: a review, Data Min. Knowl. Disc., 33, 917–963, https://doi.org/10.1007/s10618-019-00619-1, 2019. a
Johnson, J. B. and Schneebeli, M.: Snow strength penetrometer, https://patents.google.com/patent/US5831161/en (last access: 3 August 2023), 1998. a
Jurafsky, D. and Martin, J. H.: Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 3rd ed. draft, in progress, https://web.stanford.edu/~jurafsky/slp3/ (last access: 3 August 2023), 2021. a, b, c
Kaltenborn, J. and vclay: liellnima/snowdragon: Snowdragon Release 1.0.0 (v1.0.0), Zenodo [code], https://doi.org/10.5281/zenodo.7335813, 2022. a
Kaltenborn, J., Clay, V., Macfarlane, A. R., and Schneebeli, M.: Machine Learning for Snow Stratigraphy Classification, in: NeurIPS 2021 Workshop on Tackling Climate Change with Machine Learning, https://www.climatechange.ai/papers/neurips2021/48 (last access: 3 August 2023), 2021. a
Kaltenborn, J., Macfarlane, A. R., Clay, V., and Schneebeli, M.: Pre-trained Models for SMP Classification and Segmentation, Zenodo [code], https://doi.org/10.5281/zenodo.7063521, 2022. a
King, J., Kelly, R., Kasurak, A., Duguay, C., Gunn, G., Rutter, N., Watts, T., and Derksen, C.: Spatio-temporal influence of tundra snow properties on Ku-band (17.2 GHz) backscatter, J. Glaciol., 61, 267–279, https://doi.org/10.3189/2015JoG14J020, 2015. a, b
King, J., Howell, S., Brady, M., Toose, P., Derksen, C., Haas, C., and Beckers, J.: Local-scale variability of snow density on Arctic sea ice, The Cryosphere, 14, 4323–4339, https://doi.org/10.5194/tc-14-4323-2020, 2020a. a, b, c, d
King, J., Howell, S., Brady, M., Toose, P., Derksen, C., Haas, C., and Beckers, J.: SnowMicroPen Measurements on Sea Ice 2016–2017, Zenodo, https://doi.org/10.5281/zenodo.4068349, 2020b. a
Knust, R.: Polar Research and Supply Vessel POLARSTERN Operated by the Alfred-Wegener-Institute, Journal of Large-Scale Research Facilities, 3, A119–A119, https://doi.org/10.17815/jlsrf-3-163, 2017. a
Lemaître, G., Nogueira, F., and Aridas, C. K.: Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning, J. Mach. Learn. Res., 18, 559–563, https://www.jmlr.org/papers/volume18/16-365/16-365.pdf (last access: 3 August 2023), 2017. a
Li, D., Hasanaj, E., and Li, S.: 3 – Baselines, https://blog.ml.cmu.edu/2020/08/31/3-baselines/ (last access: 4 March 2021), 2020. a
Light, B., Perovich, D. K., Webster, M. A., Polashenski, C., and Dadic, R.: Optical properties of melting first-year Arctic sea ice, J. Geophys. Res.-Oceans, 120, 7657–7675, https://doi.org/10.1002/2015JC011163, 2015. a
Liu, X.-Y., Wu, J., and Zhou, Z.-H.: Exploratory undersampling for class-imbalance learning, IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 39, 539–550, https://doi.org/10.1109/TSMCB.2008.2007853, 2008. a
Lloyd, S.: Least squares quantization in PCM, IEEE Transactions on Information Theory, 28, 129–137, https://doi.org/10.1109/TIT.1982.1056489, 1982. a
Löwe, H. and Van Herwijnen, A.: A Poisson shot noise model for micro-penetration of snow, Cold Reg. Sci. Technol., 70, 62–70, https://doi.org/10.1016/j.coldregions.2011.09.001, 2012. a
Lutz, E., Birkeland, K. W., Kronholm, K., Hansen, K., and Aspinall, R.: Surface hoar characteristics derived from a snow micropenetrometer using moving window statistical operations, Cold Reg. Sci. Technol., 47, 118–133, https://doi.org/10.1016/j.coldregions.2006.08.021, 2007. a
Macfarlane, A., Schneebeli, M., Dadic, R., Tavri, A., Immerz, A., Polashenski, C., Krampe, D., Clemens-Sewall, D., Wagner, D., Perovich, D., Henna-Reetta, H., Raphael, I., Matero, I., Regnery, J., Smith, M., Nicolaus, M., Jaggi, M., Oggier, M., Webster, M., Lehning, M., Kolabutin, N., Itkin, P., Naderpour, R., Pirazzini, R., Hammerle, S., Arndt, S., and Fons, S.: A Database of Snow on Sea Ice in the Central Arctic Collected during the MOSAiC expedition, Scientific Data, 10, 398, https://doi.org/10.1038/s41597-023-02273-1, 2023. a
Macfarlane, A. R., Schneebeli, M., Dadic, R., Wagner, D. N., Arndt, S., Clemens-Sewall, D., Hämmerle, S., Hannula, H.-R., Jaggi, M., Kolabutin, N., Krampe, D., Lehning, M., Matero, I., Nicolaus, M., Oggier, M., Pirazzini, R., Polashenski, C., Raphael, I., Regnery, J., Shimanchuck, E., Smith, M. M., and Tavri, A.: Snowpit SnowMicroPen (SMP) force profiles collected during the MOSAiC expedition, PANGAEA [data set], https://doi.org/10.1594/PANGAEA.935554, 2021. a, b, c
Matzl, M. and Schneebeli, M.: Measuring specific surface area of snow by near-infrared photography, J. Glaciol., 52, 558–564, https://doi.org/10.3189/172756506781828412, 2006. a
Ménard, C. B., Essery, R., Barr, A., Bartlett, P., Derry, J., Dumont, M., Fierz, C., Kim, H., Kontu, A., Lejeune, Y., Marks, D., Niwano, M., Raleigh, M., Wang, L., and Wever, N.: Meteorological and evaluation datasets for snow modelling at 10 reference sites: description of in situ and bias-corrected reanalysis data, Earth Syst. Sci. Data, 11, 865–880, https://doi.org/10.5194/essd-11-865-2019, 2019. a
Merkouriadi, I., Gallet, J.-C., Graham, R. M., Liston, G. E., Polashenski, C., Rösel, A., and Gerland, S.: Winter snow conditions on Arctic sea ice north of Svalbard during the Norwegian young sea ICE (N-ICE2015) expedition, J. Geophys. Res.-Atmos., 122, 10–837, https://doi.org/10.1002/2016JD026035, 2017. a
Nguyen, N. and Guo, Y.: Comparisons of sequence labeling algorithms and extensions, in: Proceedings of the 24th International Conference on Machine Learning, pp. 681–688, https://doi.org/10.1145/1273496.1273582, 2007. a
Nicolaus, M., Perovich, D. K., Spreen, G., Granskog, M. A., von Albedyll, L., Angelopoulos, M., Anhaus, P., Arndt, S., Belter, H. J., Bessonov, V., Birnbaum, G., Brauchle, J., Calmer, R., Cardellach, E., Cheng, B., Clemens-Sewall, D., Dadic, R., Damm, E., de Boer, G., Demir, O., Dethloff, K., Divine, D. V., Fong, A. A., Fons, S., Frey, M. M., Fuchs, N., Gabarró, C., Gerland, S., Goessling, H. F., Gradinger, R., Haapala, J., Haas, C., Hamilton, J., Hannula, H.-R., Hendricks, S., Herber, A., Heuzé, C., Hoppmann, M., Høyland, K. V., Huntemann, M., Hutchings, J. K., Hwang, B., Itkin, P., Jacobi, H.-W., Jaggi, M., Jutila, A., Kaleschke, L., Katlein, C., Kolabutin, N., Krampe, D., Kristensen, S. S., Krumpen, T., Kurtz, N., Lampert, A., Lange, B. A., Lei, R., Light, B., Linhardt, F., Liston, G. E., Loose, B., Macfarlane, A. R., Mahmud, M., Matero, I. O., Maus, S., Morgenstern, A., Naderpour, R., Nandan, V., Niubom, A., Oggier, M., Oppelt, N., Pätzold, F., Perron, C., Petrovsky, T., Pirazzini, R., Polashenski, C., Rabe, B., Raphael, I. A., Regnery, J., Rex, M., Ricker, R., Riemann-Campe, K., Rinke, A., Rohde, J., Salganik, E., Scharien, R. K., Schiller, M., Schneebeli, M., Semmling, M., Shimanchuk, E., Shupe, M. D., Smith, M. M., Smolyanitsky, V., Sokolov, V., Stanton, T., Stroeve, J., Thielke, L., Timofeeva, A., Tonboe, R. T., Tavri, A., Tsamados, M., Wagner, D. N., Watkins, D., Webster, M., and Wendisch, M.: Overview of the MOSAiC expedition: Snow and sea ice, Elementa: Science of the Anthropocene, 10, https://doi.org/10.1525/elementa.2021.000046, 2022. a
Nixdorf, U., Dethloff, K., Rex, M., Shupe, M., Sommerfeld, A., Perovich, D. K., Nicolaus, M., Heuzé, C., Rabe, B., Loose, B., Damm, E., Gradinger, R., Fong, A., Maslowski, W., Rinke, A., Kwok, R., Spreen, G., Wendisch, M., Herber, A., Hirsekorn, M., Mohaupt, V., Frickenhaus, S., Immerz, A., Weiss-Tuider, K., König, B., Mengedoht, D., Regnery, J., Gerchow, P., Ransby, D., Krumpen, T., Morgenstern, A., Haas, C., Kanzow, T., Rack, F. R., Saitzev, V., Sokolov, V., Makarov, A., Schwarze, S., Wunderlich, T., Wurr, K., and Boetius, A.: MOSAiC Extended Acknowledgement, Zenodo, https://doi.org/10.5281/zenodo.5541624, 2021. a
IPCC: The Ocean and Cryosphere in a Changing Climate: Special Report of the Intergovernmental Panel on Climate Change, Cambridge University Press, Cambridge, https://doi.org/10.1017/9781009157964, 2022. a
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Édouard Duchesnay: Scikit-learn: Machine Learning in Python, J. Mach. Learn. Res., 12, 2825–2830, http://jmlr.org/papers/v12/pedregosa11a.html (last access: 3 August 2023), 2011. a, b, c
Pfeffer, W. T. and Mrugala, R.: Temperature gradient and initial snow density as controlling factors in the formation and structure of hard depth hoar, J. Glaciol., 48, 485–494, https://doi.org/10.3189/172756502781831098, 2002. a
Proksch, M., Löwe, H., and Schneebeli, M.: Density, specific surface area, and correlation length of snow measured by high-resolution penetrometry, J. Geophys. Res.-Ea. Surf., 120, 346–362, https://doi.org/10.1002/2014JF003266, 2015. a
Rinke, A., Cassano, J. J., Cassano, E. N., Jaiser, R., and Handorf, D.: Meteorological conditions during the MOSAiC expedition: Normal or anomalous?, Elementa: Science of the Anthropocene, 9, 00023, https://doi.org/10.1525/elementa.2021.00023, 2021. a
Russell, S. J. and Norvig, P.: Artificial intelligence: a modern approach, Pearson series in artificial intelligence, Pearson, Hoboken, fourth edition edn., 1136 pp., ISBN 978-0-13-461099-3, 2021. a
Sandells, M., Rutter, N., Wivell, K., Essery, R., Fox, S., Harlow, C., Picard, G., Roy, A., Royer, A., and Toose, P.: Simulation of Arctic snow microwave emission in surface-sensitive atmosphere channels, EGUsphere [preprint], https://doi.org/10.5194/egusphere-2023-696, 2023. a
Satyawali, P., Schneebeli, M., Pielmeier, C., Stucki, T., and Singh, A.: Preliminary characterization of Alpine snow using SnowMicroPen, Cold Reg. Sci. Technol., 55, 311–320, https://doi.org/10.1016/j.coldregions.2008.09.003, 2009. a, b, c, d, e, f, g
Schneebeli, M., Pielmeier, C., and Johnson, J. B.: Measuring snow microstructure and hardness using a high resolution penetrometer, Cold Reg. Sci. Technol., 30, 101–114, https://doi.org/10.1016/S0165-232X(99)00030-0, 1999. a
Schölkopf, B. and Smola, A. J.: Learning with kernels: support vector machines, regularization, optimization, and beyond, MIT press, 626 pp., ISBN 0-262-19475-9, 2002. a
Schuster, M. and Paliwal, K. K.: Bidirectional recurrent neural networks, IEEE transactions on Signal Processing, 45, 2673–2681, https://doi.org/10.1109/78.650093, 1997. a
Soni, R. and Mathai, K. J.: Improved Twitter Sentiment Prediction through Cluster-then-Predict Model, arXiv [preprint], https://doi.org/10.48550/arXiv.1509.02437, 2015. a
Steger, C., Kotlarski, S., Jonas, T., and Schär, C.: Alpine snow cover in a changing climate: a regional climate model perspective, Clim. Dynam., 41, 735–754, https://doi.org/10.1007/s00382-012-1545-3, 2013. a
Stone, M.: Cross-validatory choice and assessment of statistical predictions, J. R. Stat. Soc. B, 36, 111–133, https://doi.org/10.1111/j.2517-6161.1974.tb00994.x, 1974. a
Sturm, M. and Liston, G. E.: Revisiting the Global Seasonal Snow Classification: An Updated Dataset for Earth System Applications, J. Hydrometeorol., 22, 2917–2938, https://doi.org/10.1175/JHM-D-21-0070.1, 2021. a
Sturm, M. and Massom, R. A.: Snow in the sea ice system: friend or foe?, in: Sea Ice, John Wiley & Sons, Ltd, pp. 65–109, section: 3, https://doi.org/10.1002/9781118778371.ch3, 2017. a
Theodorou, T., Mporas, I., and Fakotakis, N.: An Overview of Automatic Audio Segmentation, International Journal of Information Technology and Computer Science, 6, 1–9, https://doi.org/10.5815/ijitcs.2014.11.01, 2014. a
Trivedi, S., Pardos, Z. A., and Heffernan, N. T.: The Utility of Clustering in Prediction Tasks, arXiv [preprint], https://doi.org/10.48550/arXiv.1509.06163, 2015. a
Vionnet, V., Brun, E., Morin, S., Boone, A., Faroux, S., Le Moigne, P., Martin, E., and Willemet, J.-M.: The detailed snowpack scheme Crocus and its implementation in SURFEX v7.2, Geosci. Model Dev., 5, 773–791, https://doi.org/10.5194/gmd-5-773-2012, 2012. a
Wever, N., Keenan, E., Kausch, T., and Lehning, M.: SnowMicroPen measurements and manual snowpits from Dronning Maud Land, East Antarctica, EnviDat, https://doi.org/10.16904/envidat.331, 2022. a
Wu, X., Kumar, V., Ross Quinlan, J., Ghosh, J., Yang, Q., Motoda, H., McLachlan, G. J., Ng, A., Liu, B., Yu, P. S., Zhou, Z.-H., Steinbach, M., Hand, D. J., and Steinberg, D.: Top 10 algorithms in data mining, Knowl. Inf. Syst., 14, 1–37, https://doi.org/10.1007/s10115-007-0114-2, 2008. a
Yarowsky, D.: Unsupervised word sense disambiguation rivaling supervised methods, in: 33rd annual meeting of the association for computational linguistics, pp. 189–196, https://doi.org/10.3115/981658.981684, 1995. a
Yoshua, B., Olivier, D., and Nicolas Le, R.: 192193Label Propagation and Quadratic Criterion, in: Semi-Supervised Learning, The MIT Press, https://doi.org/10.7551/mitpress/9780262033589.003.0011, 2006. a
Zhou, D., Bousquet, O., Lal, T., Weston, J., and Schölkopf, B.: Learning with Local and Global Consistency, in: Advances in Neural Information Processing Systems, edited by: Thrun, S., Saul, L., and Schölkopf, B., vol. 16, pp. 321–328, MIT Press, https://proceedings.neurips.cc/paper_files/paper/2003/file/87682805257e619d49b8e0dfdc14affa-Paper.pdf (last access: 3 August 2023), 2003. a
Zhu, X. and Ghahramani, Z.: Learning from labeled and unlabeled data with label propagation, Tech. rep., Carnegie Mellon University, https://mlg.eng.cam.ac.uk/zoubin/papers/CMU-CALD-02-107.pdf (last access: 3 August 2023), 2002. a
Fierz et al. (2009) refer only to visually observed snow grains and not to SMP signals.
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: User's guide
- Appendix B: Labeling
- Appendix C: Features
- Appendix D: Metrics
- Appendix E: Machine specifications
- Appendix F: Model setup
- Appendix G: Pruned decision tree
- Appendix H: Confusion matrices
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: User's guide
- Appendix B: Labeling
- Appendix C: Features
- Appendix D: Metrics
- Appendix E: Machine specifications
- Appendix F: Model setup
- Appendix G: Pruned decision tree
- Appendix H: Confusion matrices
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References