the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 10 Aug 2023
| 10 Aug 2023
Using probabilistic machine learning to better model temporal patterns in parameterizations: a case study with the Lorenz 96 model
Hannah M. Christensen
J. Scott Hosking
Damon J. Wischik
The modelling of small-scale processes is a major source of error in weather and climate models, hindering the accuracy of low-cost models which must approximate such processes through parameterization. Red noise is essential to many operational parameterization schemes, helping model temporal correlations. We show how to build on the successes of red noise by combining the known benefits of stochasticity with machine learning. This is done using a recurrent neural network within a probabilistic framework (L96-RNN). Our model is competitive and often superior to both a bespoke baseline and an existing probabilistic machine learning approach (GAN, generative adversarial network) when applied to the Lorenz 96 atmospheric simulation. This is due to its superior ability to model temporal patterns compared to standard first-order autoregressive schemes. It also generalizes to unseen scenarios. We evaluate it across a number of metrics from the literature and also discuss the benefits of using the probabilistic metric of hold-out likelihood.
- Article
(5011 KB) - Full-text XML
- BibTeX
- EndNote





A major source of inaccuracies in climate models is due to “unresolved” processes. These occur at scales smaller than the resolution of the climate model (“sub-grid” scales) but still have key effects on the overall climate. In fact, most of the inter-model spread in how much global surface temperatures increase after CO2 concentrations double is due to the representation of clouds (Schneider et al., 2017; Zelinka et al., 2020). The typical approach to deal with the problem of unresolved processes has been to model the effects of these unresolved processes as a function of the resolved ones. This is known as “parameterization”.
Red noise is a key feature in many parameterization schemes (Christensen et al., 2015; Johnson et al., 2019; Molteni et al., 2011; Palmer et al., 2009; Skamarock et al., 2019; Walters et al., 2019). It is characterized by a power spectral density which is inversely proportional to the square of the frequency. It is the type of noise produced by a random walk, where independent offsets are added to each step to generate the next step. This leads to strong autocorrelations in the time series. It contrasts with a white noise process where each step is independent. Hasselmann (1976) developed the theory underpinning the importance of red noise for parameterization, showing that the coupling of processes with different timescales leads to red-noise signals in the longer timescale process, analogously to what takes place in Brownian motion. In parameterization, the resolved processes typically have far longer timescales than the unresolved ones, motivating the inclusion of red noise in these schemes. The usefulness of tracking the history of the system for parameterization follows from the importance of red noise.
We use probabilistic machine learning to propose a data-driven successor to red noise in parameterization. The theory explaining the prevalence of red noise in the climate was developed in an idealized model, within the framework of physics-based differential equations. Such approaches may be intractable outside the idealized case. Recently, there has been much work looking at uncovering relationships from data instead (Arcomano et al., 2022; Beucler et al., 2020, 2021; Bolton and Zanna, 2019; Brenowitz and Bretherton, 2018, 2019; Chattopadhyay et al., 2020a; Gagne et al., 2020; Gentine et al., 2018; Krasnopolsky et al., 2013; O'Gorman and Dwyer, 2018; Rasp et al., 2018; Vlachas et al., 2022; Yuval and O’Gorman, 2020; Yuval et al., 2021). We develop a recurrent neural network in a probabilistic framework, combining the benefits of stochasticity with the ability to learn temporal patterns in more flexible ways than permitted by red noise. We use the Lorenz 96 model (Lorenz, 1996), henceforth the L96, as a proof of concept. Our model is competitive with, and often outperforms, a bespoke baseline. It also generalizes to unseen scenarios as shown in Sect. 4.3.
1.1 Numerical models
Numerical models represent the state of the Earth system at time t by a state vector Xt. The components of Xt may include, for example, the mean temperature and humidity at time t in every cell of a grid that covers the Earth. The goal is to parameterize the effects of unresolved processes in such a way that the model can reproduce the evolution of this finite-dimensional representation of the state of the real Earth system. A simple way to model the evolution would be
where Xk,t is the value that the state variable X takes at the spatial coordinate k and time point t and , Xt∈ℝdK, and f is a function for the updating process.
1.2 Stochastic schemes
Stochasticity can be included using the following form:
where hidden variables (discussed below) created by the modeller are denoted and are tracked through time, β is a function for updating these, and is a source of stochasticity.
Introducing stochasticity through Eq. (2) represented an improvement on models of the form in Eq. (1). Results included better ensemble forecasts (Buizza et al., 1999; Leutbecher et al., 2017; Palmer, 2012) and improvements to climate variability (Christensen et al., 2017) and mean climate statistics (Berner et al., 2012). The motivation for using stochasticity comes from the understanding that the effects of the unresolved (sub-grid) processes cannot be effectively predicted as a deterministic function of the resolved ones due to a lack of scale separation between them. Stochasticity allows us to capture our uncertainty about those aspects of the unresolved processes which may affect the resolved outcomes.
1.3 Hidden variables and red noise
Hidden variables – Hk,t in Eqs. (2) and (3) – are defined here as being variables separate from the observed state, Xk,t, which, if tracked, help better model Xk,t. Using them is key to numerical weather and climate models using stochastic parameterizations, allowing temporal correlations to be better modelled. Red noise results when the hidden variables evolve with a first-order autoregressive (AR1) process such as
where ϕ is the lag-1 correlation and σ is the standard deviation.
One example is the stochastically perturbed parameterization tendency (SPPT) scheme (Buizza et al., 1999; Palmer et al., 2009), which is frequently employed in forecasting models (Leutbecher et al., 2017; Molteni et al., 2011; Palmer et al., 2009; Sanchez et al., 2016; Skamarock et al., 2019; Stockdale et al., 2011). Here, the AR1 process results in far better weather and climate forecasting skill than a simple white noise model, with good modelling of regime behaviour requiring correlated noise (Christensen et al., 2015; Dawson and Palmer, 2015).
There is no intrinsic reason why an AR1 process is the best way to deal with these correlations. It is simply a modelling choice.
1.4 Machine learning for parameterization
Learning the parameters of a climate model, either the simple form (1) or the general form (2)–(4), requires deciding on a parametric form for the functions f and β. For full-scale climate models, it is difficult to find appropriate functions. The machine learning (ML) approach is to learn these from data. Various researchers have proposed ML methods for learning the deterministic (meaning the same output is always returned for a given input) model of the form in Eq. (1) (Beucler et al., 2020, 2021; Bolton and Zanna, 2019; Brenowitz and Bretherton, 2018, 2019; Gentine et al., 2018; Krasnopolsky et al., 2013; O'Gorman and Dwyer, 2018; Rasp et al., 2018; Yuval and O’Gorman, 2020; Yuval et al., 2021).
Amongst ML-trained stochastic models (Gagne et al., 2020; Guillaumin and Zanna, 2021), various ones with red noise were proposed by Gagne et al. (2020), using generative adversarial networks (GANs) (Goodfellow et al., 2014). Full architectural details are in Gagne et al. (2020), and we will refer to one of their best-performing models (which they call X-sml-r) as the GAN, with italics indicating that X-sml-r is meant. A wider range of generative models can be trained using such an adversarial approach as opposed to maximum likelihood (the standard way to train models in ML, discussed in Sect. 3), but such methods are notoriously unstable due to the nature of the minimax loss in training (Goodfellow, 2016). Although they used ML to learn f in Eq. (2), it was not used to learn β, which they modelled with an AR1 process.
Recurrent neural networks (RNNs) are a popular ML tool for modelling temporally correlated data, eliminating the need for update functions (like that in Eq. 3) to be manually specified. RNNs have had great success in the ML literature in a variety of sequence modelling tasks, including text generation (Graves, 2013; Sutskever et al., 2011), machine translation (Sutskever et al., 2014), and music generation (Eck and Schmidhuber, 2002; Mogren, 2016). The state-of-the-art RNNs are long short-term memory (LSTM) networks (Hochreiter and Schmidhuber, 1997) and gated recurrent unit (GRU) networks (Cho et al., 2014). These use gating mechanisms to control information flow, providing major improvements to the vanilla RNN's issue of unstable gradients and therefore making it easier to capture long-range dependencies.
Current parameterization work using ML to model temporal correlations has predominantly used deterministic approaches, including deterministic RNNs and echo state networks (Arcomano et al., 2022; Chattopadhyay et al., 2020a, b; Vlachas et al., 2018, 2020, 2022), and found notable success. A stochastic RNN for ocean modelling was recently presented by Agarwal et al. (2021). Our work differs in how we provide a joint training approach for the deterministic and stochastic parts. All this work with RNNs suggests such ML approaches are effective ways of modelling temporal dynamics in physical systems. However, the investigation of how to implement these in probabilistic frameworks is limited.
Other off-the-shelf models are not obviously suited for the parameterization task. Transformers and attention-based models (Vaswani et al., 2017) perform well for sequences but require all the previous data to be tracked for each simulation step, providing a computational burden which may increase simulation cost. Random forests (RFs) have been used for parameterization (O'Gorman and Dwyer, 2018; Yuval and O’Gorman, 2020) and shown to be stable at run time (due to predicting averages from the training set), but it is not obvious how they would learn and track hidden variables.
We introduce the L96 model here and then present two L96 parameterization models from the literature which help clarify the above discussion and serve as our baselines.
2.1 Lorenz 96 model
We use the two-tier L96 model, a toy model for atmospheric circulation that is extensively used for stochastic parameterization studies (Arnold et al., 2013; Crommelin and Vanden-Eijnden, 2008; Gagne et al., 2020; Kwasniok, 2012; Rasp, 2020). We use the configuration described in Gagne et al. (2020). It comprises two types of variables: a large, low-frequency variable, Xk, interacting with small, high-frequency variables, Yj. These are dimensionless quantities, evolving as follows:
where the variables have cyclic boundary conditions: and . In our experiments, the number of X variables is K=8 and the number of Y variables per X is J=32. The value of the constants are set to , and c=10. These indicate that the fast variable evolves 10 times faster than the slow variable and has the amplitude. The chosen parameters follow those used in Arnold et al. (2013) and are such that 1 model time unit (MTU) is equivalent to 5 atmospheric days when comparing the error doubling time from the model to that seen in the atmosphere (Lorenz, 1996).
The L96 model is useful for parameterization work as we can consider the Xk to be coarse processes resolved in both low-resolution and high-resolution simulators, whilst the Yj can be regarded as those that can only be resolved in high-resolution, computationally expensive simulators. In this study the coupled set of L96 equations is treated as the “truth”, and the aim is to learn a good model for the evolution of X alone using this truth data. The effects of Yj must therefore be parameterized. Success would be if the modelled evolution of X matched that from the truth.
The L96 is also useful as it contains separate persistent dynamical regimes, which change with different values of F (Christensen et al., 2015; Lorenz, 2006). The dominant regime exhibits a wave-2 pattern around the ring of X variables, whilst the rarer regime exhibits a wave-1-type pattern. In the atmosphere, regimes include persistent circulation patterns like the Pacific–North American (PNA) pattern and the North Atlantic Oscillation (NAO).
It is easy to use models with no memory, which do well on standard loss metrics but fail to capture this interesting regime behaviour. This is seen in the L96, where including temporally correlated (red) noise improves the statistics describing regime persistence and frequency of occurrence (Christensen et al., 2015) and improves weather forecasting skill (Arnold et al., 2013; Palmer, 2012). Temporally correlated noise also improves regime behaviour (frequency of occurrence and persistence) in operational models (Dawson and Palmer, 2015) as well as forecasting skill (Palmer et al., 2009).
2.2 Parameterization models in the literature
The below models are stochastic. They use AR1 processes to model temporal correlations, but this need not be the case, as we show in Sect. 3.
2.2.1 Stochastic non-ML model with non-ML hidden variables
Arnold et al. (2013) propose a model which we refer to as the polynomial model (in light of the polynomial in Eq. 6), with italics indicating that we are referring specifically to the following model:
where Hk,t evolves as in Eq. (5) with and where
and
where Eq. (7) is the implementation of a second-order Runge–Kutta method and [λ(a)]k=λk(a). Hk,t only depends on .
3.1 Stochastic ML model with ML hidden variables
Our model, henceforth denoted as L96-RNN, follows the general form in Eqs. (2)–(4) but splits the hidden variable into two parts: . The model is
where g, b, and s are NNs with weights θ, is exogenous noise as defined in Eq. (4), ω is specified in Eq. (7) above (implements a second-order Runge–Kutta method and expresses physical quantities like advection), and θ and σ are parameters to be learnt. We set as is typically done with RNNs and . The dimensions of the variables are , and lt∈ℝ8K. The dimensions of the NNs are , and . The L96-RNN is structurally based on a recurrent neural network (RNN) as it has hidden variables, the same update procedure is used each step, and g, b and s are NNs. In this model, the sub-grid parameterization is split into a deterministic part (parameterized by gθ) and a stochastic part, R, which is parameterized by an RNN (bθ and sθ). The RNN is described by Eqs. (11)–(12) and models the stochastic term at the next time step given the past sequence of , where we use upper-case Rk,t to denote the random variable and use lower-case rk,t to denote the values which a random variable Rk,t may take. When the random variable being referred to is clear from the context, we drop it and just write , for example. The same notation is used for X. The notation is only important when talking about the probabilistic perspective of the model and the likelihood. Otherwise, the distinction between the upper- and lower-case variables can be ignored by the reader. The backbone of the L96-RNN is the sθ mapping, which takes as input rk,t and the hidden state lk,t (which summarizes the information in ) and updates the hidden state. The stochastic term is then modelled using a Gaussian distribution parameterized by the output layers of the L96-RNN, bθ, and σ. The sampled value, , is used in Eq. (10) to output and is fed back into the L96-RNN.
The key insight is that our model allows more flexibility than the standard AR1 processes for expressing temporal relationships. This is shown by how Eq. (10) is identical in form to Eq. (6), but the hidden variable is evolved in a more flexible manner than the AR1 process in Eq. (5).
Figure 1 shows the mechanism of generation and the NN architectures used to learn the functions. The main architectural details are that s in Eq. (12) is implemented using two GRU layers, each composed of four units, and b in Eq. (11) is represented by a dense layer of size 1. g in Eq. (10) is implemented using three fully connected layers.
Here, as well as in the baselines, the parameterization models are “spatially local”, meaning that the full Xt vector is not taken in as input when modelling anywhere apart from in ωk(Xt). This is done to mimic parameterizations in operational weather and climate models. For all forecast models, Δt=0.005 model time units (MTU).
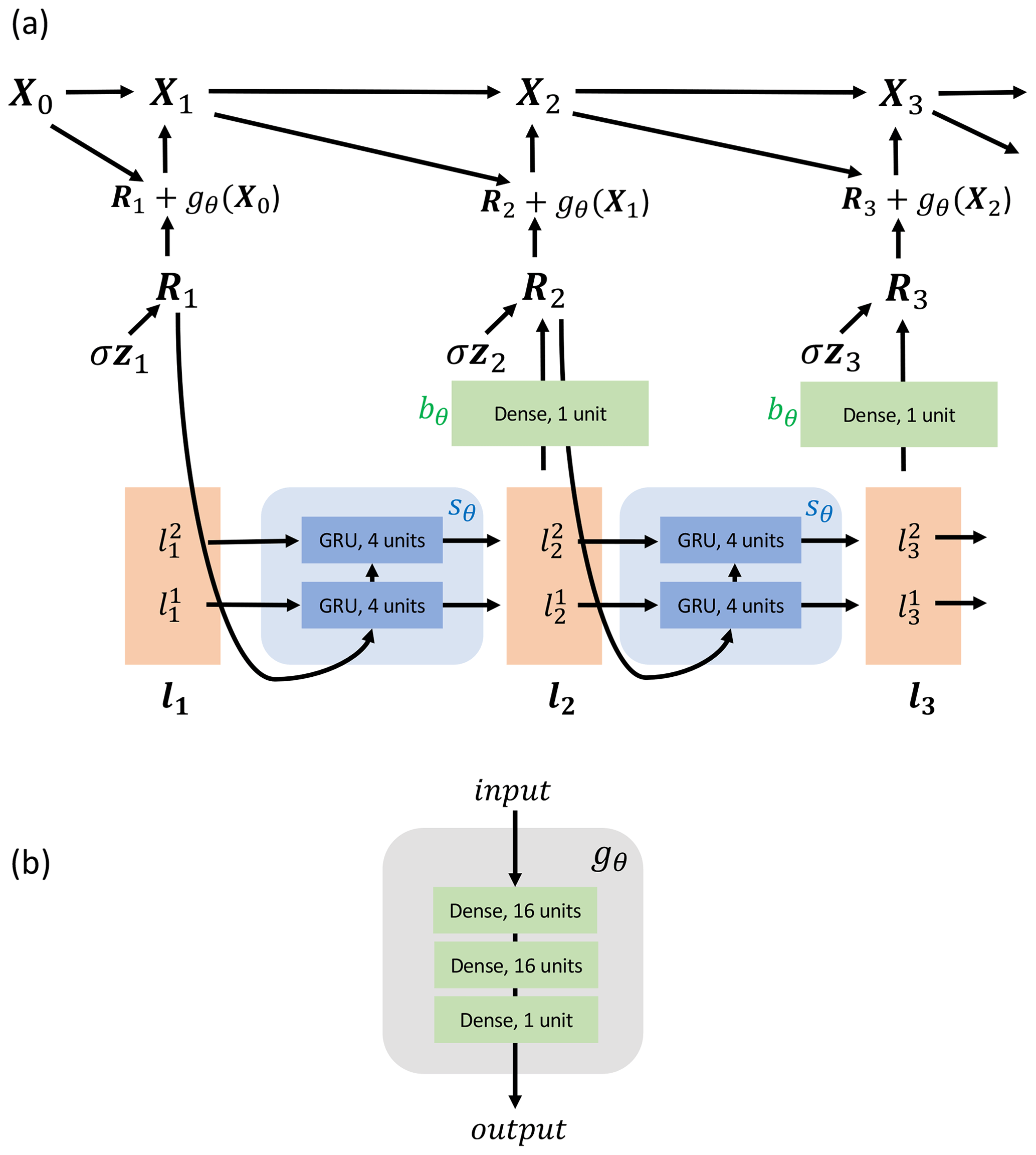
Figure 1(a) RNN graphical model showing how each Xt is generated. Xt+1 is a function of Xt and Rt+1, and Rt is a function of lt and zt. zt∈ℝK is the source of stochasticity. bθ, sθ and gθ are NNs. lt consists of a stack of and , each ∈ℝ4. The neural networks are stacked K times (not shown in the figure), with each section of the stack being applied to each of the K components of Xt. (b) The architecture of the gθ neural network.
3.2 Training probability models using likelihood
The L96-RNN is probabilistic and trained by maximizing the likelihood of sequences xt in the training data, as is commonly done in the ML literature for RNN models (Bahdanau et al., 2014; Cho et al., 2014; Goodfellow et al., 2016; Sutskever et al., 2011, 2014). The “likelihood of a sequence” is denoted and can be interpreted as the probability assigned to a given sequence of variables by a given model. For our L96-RNN, the log likelihood (the natural logarithm of the likelihood) of a sequence of xt is
where the semicolon denotes that x0 is given and r and l are deterministic functions of the training sequence , derived from Eqs. (10)–(12). Specifically, by rearranging Eq. (10) we get
and so we can calculate what values rk,t must take in order for the training sequence to be generated. Now, given the known sequence and the initial value l1=0, the sequence of l values, can be calculated from Eq. (12). For example, . To reduce clutter in the final equation which we show in this section, we will rewrite Eq. (14) as
where and can be understood as the true sub-grid forcing. Now, the explicit expression for the log likelihood is given by
The L96-RNN is trained by maximizing this likelihood with respect to the parameters θ and σ. The explicit form of the L96-RNN likelihood makes training by maximum likelihood relatively straightforward. The full derivation of the likelihood is in Appendix A.
From Eq. (16) we can see that both the deterministic part (gθ) and the stochastic model (bθ and sθ, which are involved via lk,t) are trained jointly to minimize the mean squared error in the sub-grid forcing prediction. This is unlike the polynomial and GAN models where the deterministic part is fitted first and then the stochastic part is modelled in a separate step.
3.3 RNN training
Truth data for training were created by running the full L96 model five separate times with the following values of F: . Henceforth, we use truth data to refer to data from the full L96 model. We gave our model data from different forcing scenarios so it could learn how perturbations in the forcing may affect the evolution of Xt. The GAN and polynomial were trained in a similar manner to allow for a fair comparison. The truth data were created by solving the two-level L96 equations using a fourth-order Runge–Kutta time stepping scheme and a fixed time step Δt=0.001 MTU, with the output saved at every 0.005 MTU. A training set of the length 2500 MTU was assembled from the truth data, consisting of three equal 500 MTU components with and one 1000 MTU component with F=20, with a F=21.5 set of the length 500 MTU kept as a validation hold-out set. This resulted in a 75:25 training : validation set split (3 999 992 samples : 800 008 samples).
The L96-RNN was trained using truncated back propagation through time on sequences of a length of 700 time steps for 100 epochs with a batch size of 32 using Adam (Kingma and Ba, 2014), with θ and σ being the learnable parameters. A variable learning rate was used, starting at 0.0001 for the first 70 epochs and decayed to 0.00003 for the remaining 30. A small grid search was conducted over the number of GRU layers (searching over 1 to 3) and the GRU unit sizes (searching between 4 to 16). The model parameters which gave the lowest loss on the validation set were saved.
This section analyses performance across a range of timescales. The first results are for F=20. Assessing the model in the training realm allows us to verify if it can replicate the L96 attractor. Later experiments are for F≥28. For F=20 and F=28, 50 000 MTU long simulations (≈685 “atmospheric years”) were created for analysis.
4.1 Weather evaluation
The models were evaluated in a weather forecast framework. A total of 745 initial conditions were randomly taken from the truth data, and an ensemble of 40 forecasts each lasting 3.5 MTU were generated from each initial condition. Figure 2 shows the spread and error terms for these experiments over time. The error is defined as
where there are M different initial conditions, is the observed state at time t for the mth initial condition and is the ensemble mean forecast at time t.
The spread is defined as
where N is the number of ensemble members and is the state of the nth member at time t for the mth initial condition.
As noted by Leutbecher and Palmer (2008), for a perfectly reliable forecast (defined as one where and are independent samples from the same distribution), for large N and M the error should be equal to the spread. A smaller error implies an ensemble forecast that better matches observations, and a spread / error ratio close to 1 implies a reliable forecast. Figure 2 shows that the polynomial and the L96-RNN have the smallest errors, but the L96-RNN has the better spread / error ratio until 1.0 MTU. After that, its spread is still slightly better matched to its error compared to the polynomial. The GAN is underdispersive, with the greatest error but smallest spread / error ratio, suggesting it is overconfident in its predictions.
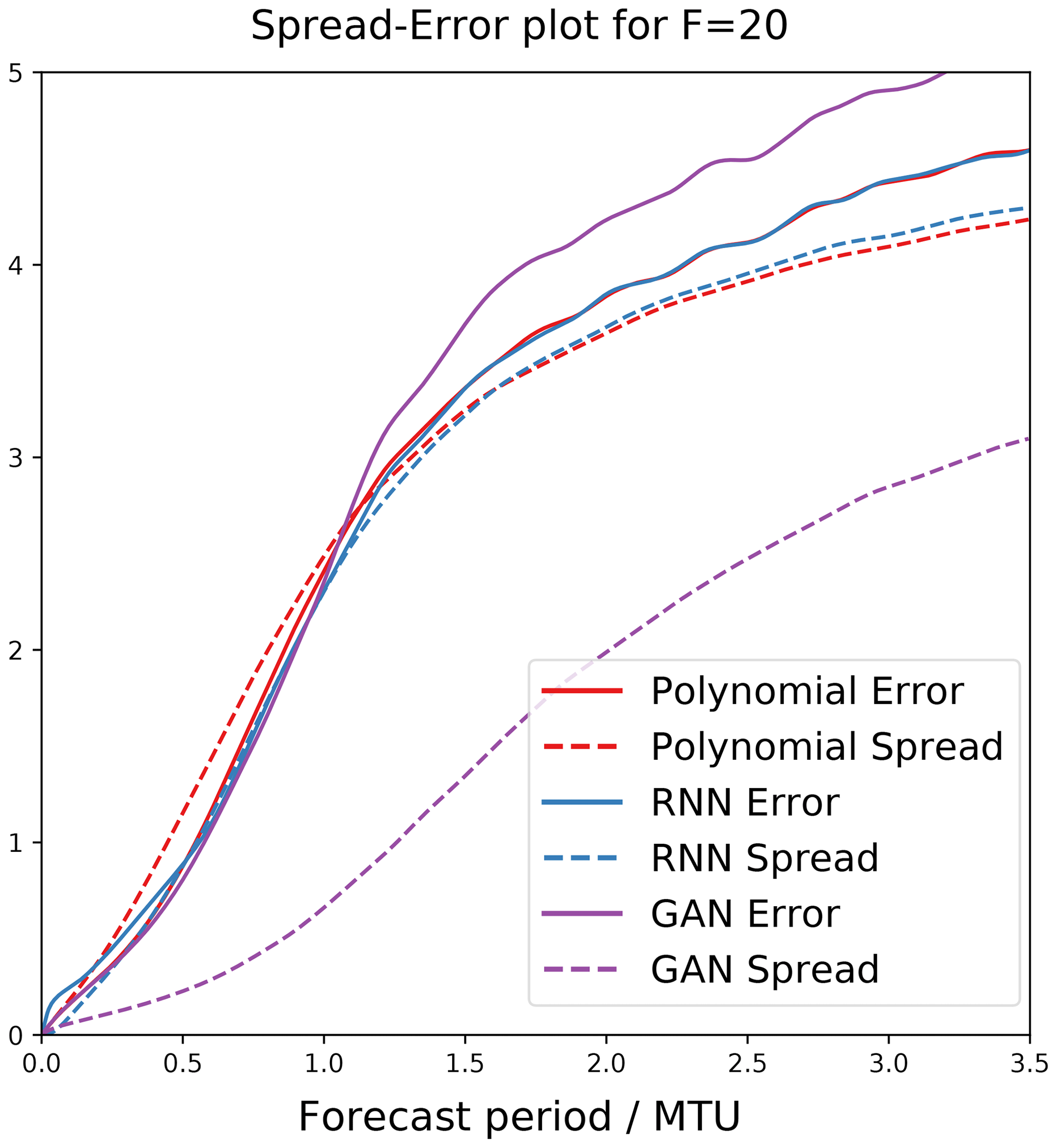
Figure 2Error and spread for weather experiments. We expect a smaller error for a more accurate forecast model. The spread / error ratio would be close to 1 in a “perfectly reliable” forecast.
4.2 Climate evaluation
The ability to simulate the climate of the L96 was evaluated using the 50 000 MTU simulations. We use histograms to represent various climate-related distributions. For example, Fig. 3a represents each model's marginal distribution of Xk,t. Since the true continuous distributions for this quantity are unavailable, we represent them using histograms (a discrete estimate). The idea of estimating an underlying continuous distribution's density with a discrete distribution based on a finite set of sampled points is commonplace and known as histogram density estimation (Silverman, 1986; Wilks, 2011). When plotting histograms, an appropriate bin width is necessary. Too few bins will lead to over-smoothing where the underlying distribution's shape is not captured, whilst too many bins will lead to under-smoothing. Both cases lead to poor representations of the underlying distribution. We use the Freedman–Diaconis rule (Freedman and Diaconis, 1981) to determine the bin widths (and therefore number of bins). The rule is based on minimizing the mean integrated squared error between the histogram's density estimate and the true density function. The number of bins used are noted in the relevant figure captions.
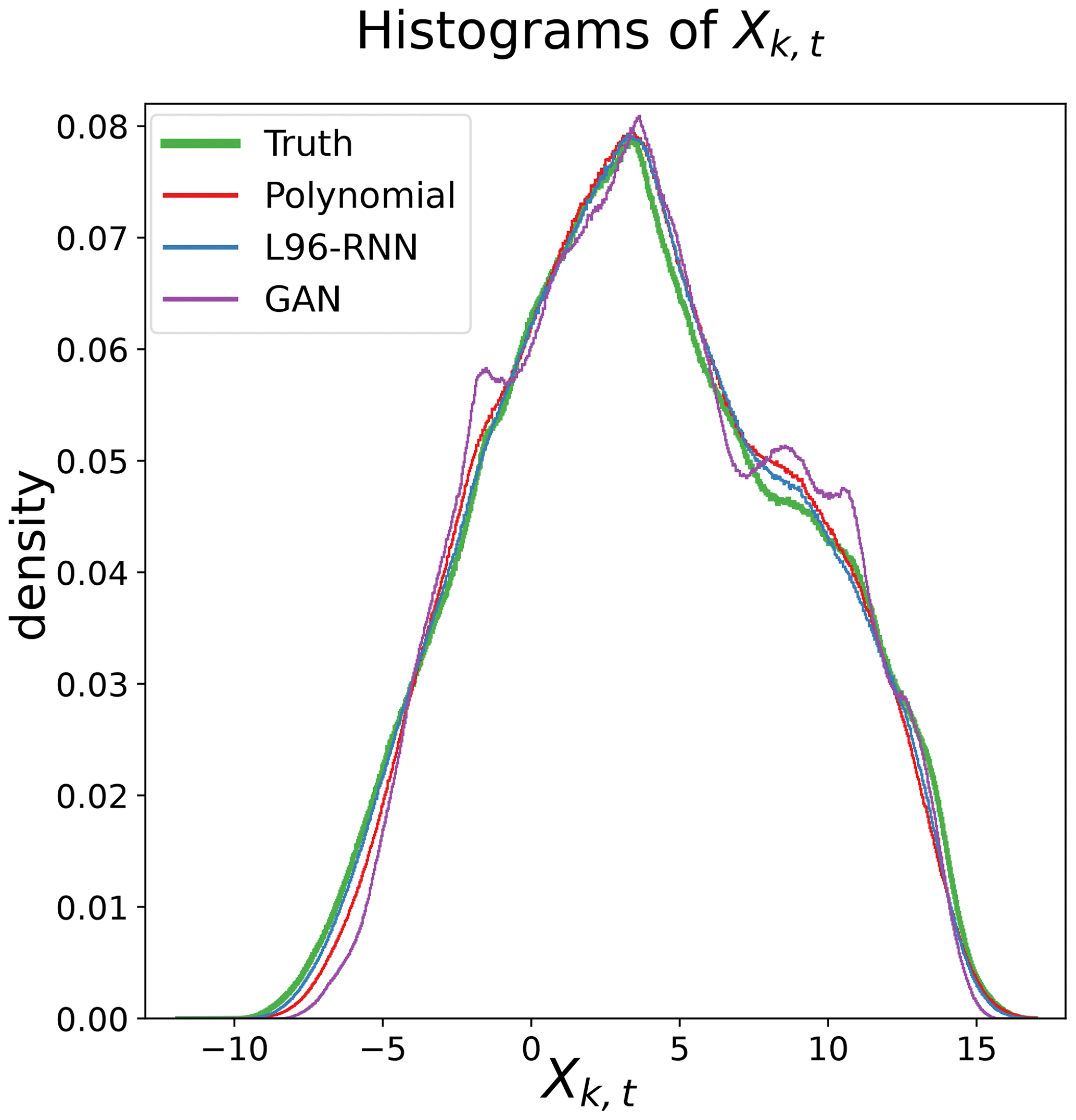
Figure 3Histograms of Xk,t. The truth histogram is shown in green and bold. The closer a model's histogram to the truth, the better it models the probability density of Xk,t. A total of 827 bins are used for all shown models.
We can quantitatively measure how well the histogram density estimates from each model match the histogram density estimate from the truth using KL (Kullback–Leibler divergence) divergence. The KL divergence has a direct equivalence to log likelihood: minimizing the KL divergence between a true distribution and a model's distribution is equivalent to maximizing the log likelihood of the true data under the model. We evaluate the KL divergence between q(a), the distribution described by the histogram of a variable A in the true L96 model, and p(a), the distribution described by the histogram of that variable in a parameterized model, using
where the sum is over all the discrete values which A takes. The smaller this measure, the better the goodness of fit. The calculated KL divergence is obviously dependent on the number of bins used in our histograms. Using a number of bins=1 would give a KL divergence of 0, whilst using a number of bins=n, where n is the number of data points, would give a KL divergence of ∞ in this case as the variables under consideration are continuous so their empirical probability density functions will not overlap. Therefore, a bin number which best represents the underlying distribution is important to use. As noted earlier, we use the Freedman–Diaconis rule for this. Nevertheless, we also provide results in Appendix B for the KL divergences for a range of bin numbers centred on the Freedman–Diaconis suggestions.
Successful reproduction of the L96 climate would result in a model's histogram matching the truth model's. Qualitatively, from Fig. 3, the polynomial and the L96-RNN are closest to the truth, with the L96-RNN doing slightly better around . Quantitatively, the KL divergence results (Table 1) confirm that the L96-RNN best matches the truth model here. Results from Appendix B confirm that the stronger L96-RNN performance is also seen over a range of bin numbers.
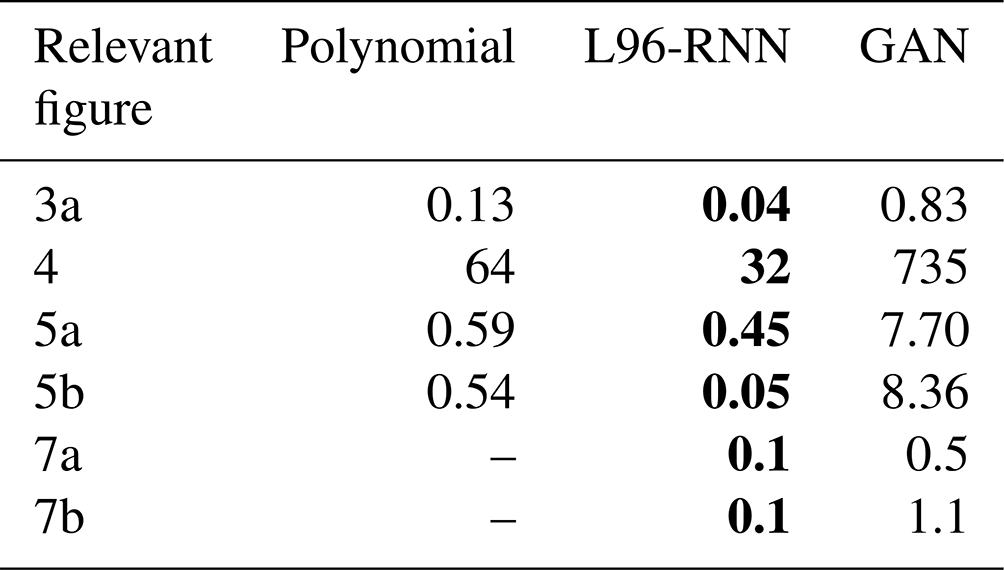
Table 1KL divergence (goodness of fit) between (1) the truth and (2) the parameterized models, for the distributions shown in the noted figures. The smaller the KL divergence, the better the match between the true and modelled distributions. The best model in each case is shown in bold.
The L96 model used here displays two distinct regimes with separate dynamics. We use the approach from Christensen et al. (2015) to examine the regimes. First, the time series are temporally smoothed with a running average over 0.4 MTU to help identify regimes (Stephenson et al., 2004; Straus et al., 2007). The dimensionality of the system is then reduced using principal component analysis, as is often done when studying atmospheric data (Selten and Branstator, 2004; Straus et al., 2007). For the truth time series, the components PC1 (principal component 1) and PC2 (principal component 2) are degenerate, offset in phase by radians, and represent wavenumber 2 oscillations. PC3 and PC4 are also degenerate, offset in phase by radians, and represent wavenumber 1 oscillations. All model runs are projected onto the truth model's components. Given the degeneracies, the magnitudes of the principal component vectors, [PC1, PC2] and [PC3, PC4], where [PC1, PC2], are computed and histograms of the system are plotted in this space.
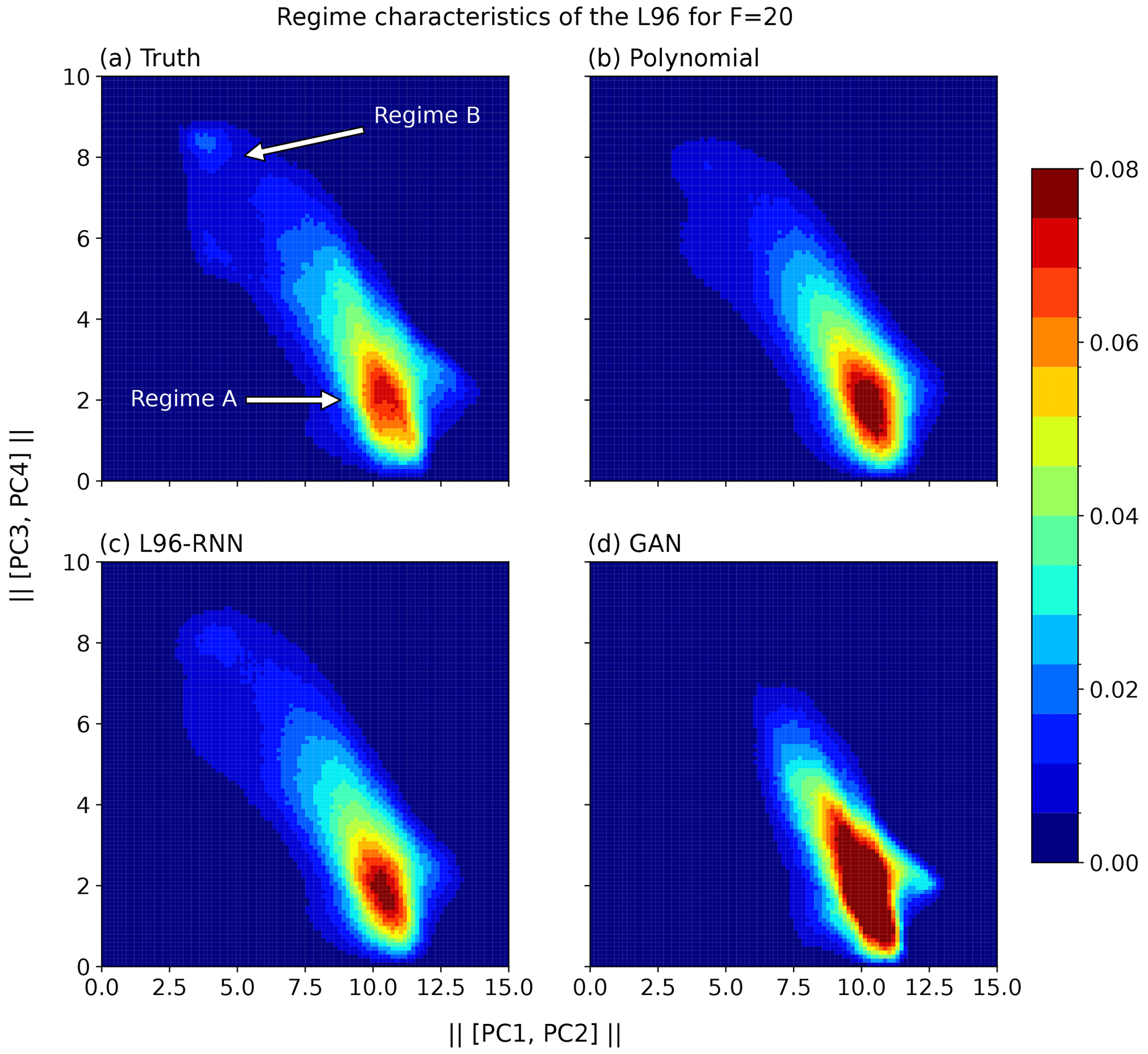
Figure 4Regime characteristics of the L96 for F=20. Two-dimensional histograms show the magnitudes of the projections of Xk,t onto the principle components from the truth series. A total of 100 bins are used for this visualization. When calculating the KL divergence in Table 1, 350 bins are used.
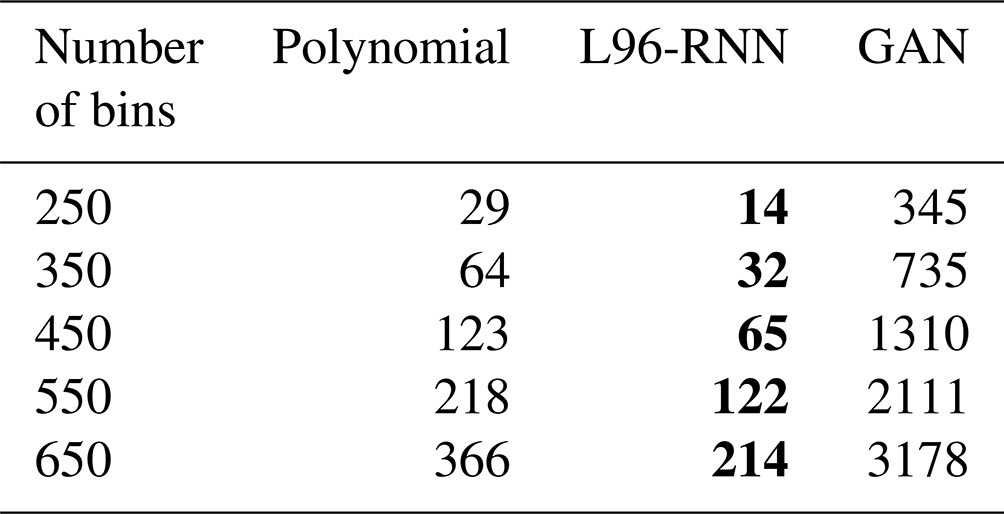
The presence of two regimes is apparent in Fig. 4a where there is a large maximum corresponding to the major regime, A, but also a smaller peak corresponding to the minor regime, B. The polynomial and GAN fail to capture the two regimes, whereas the L96-RNN is more successful. Comparison is made easier by decomposing the 2D Fig. 4 into two 1D density plots (Fig. 5). We can use the KL divergence to measure how well our models match the truth across all three histograms. Table 1 shows that the L96-RNN best matches the truth and so captures the regime characteristics best. There are still evidently deficiencies though as further density is required to be placed around Regime B.
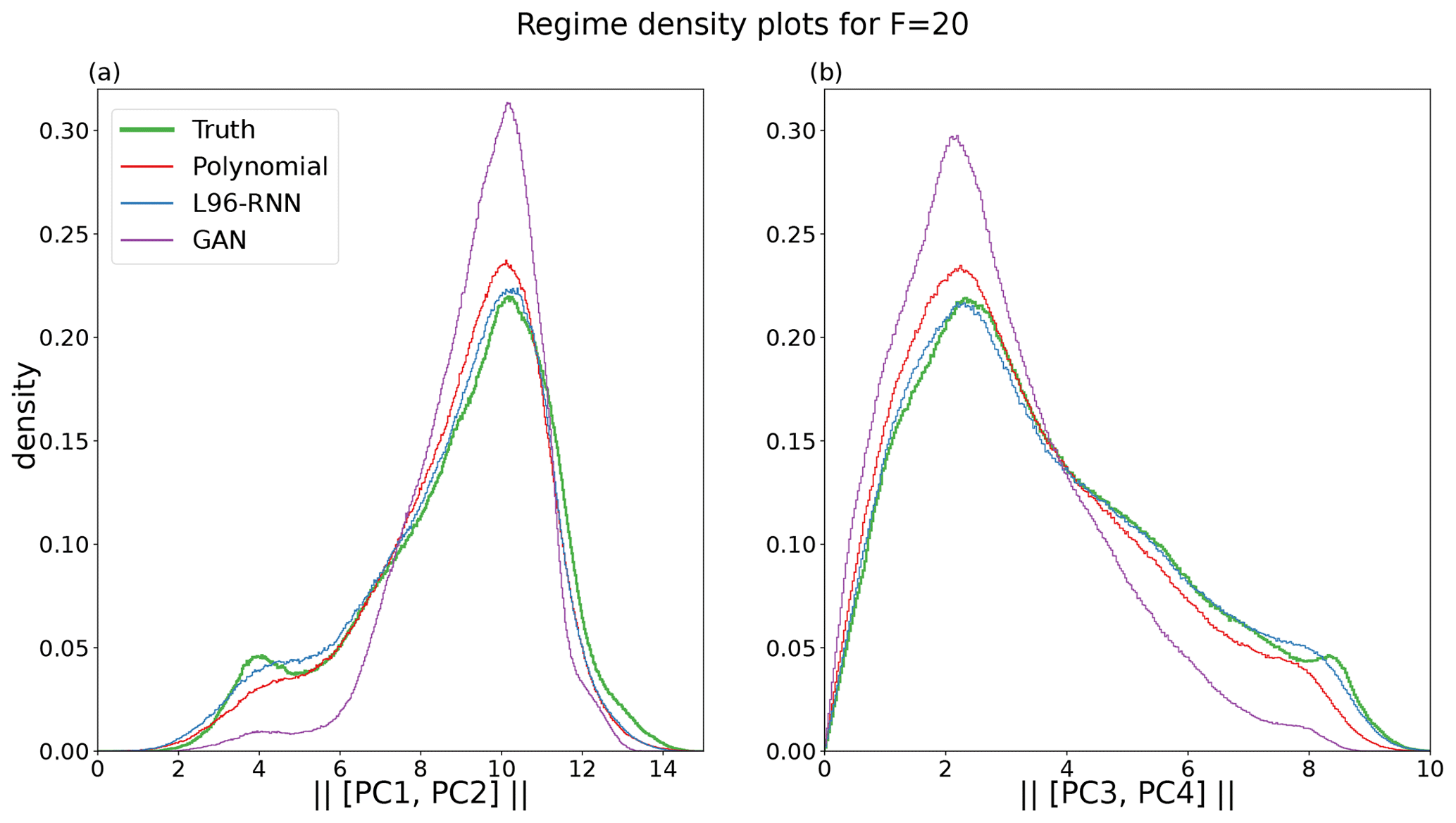
Figure 5Density plots for each regime for F=20. The truth is shown in green and bold. (a) Magnitude of [PC1, PC2]. A total of 534 bins are used for this. (b) Magnitude of [PC3, PC4]. A total of 350 bins are used for this.
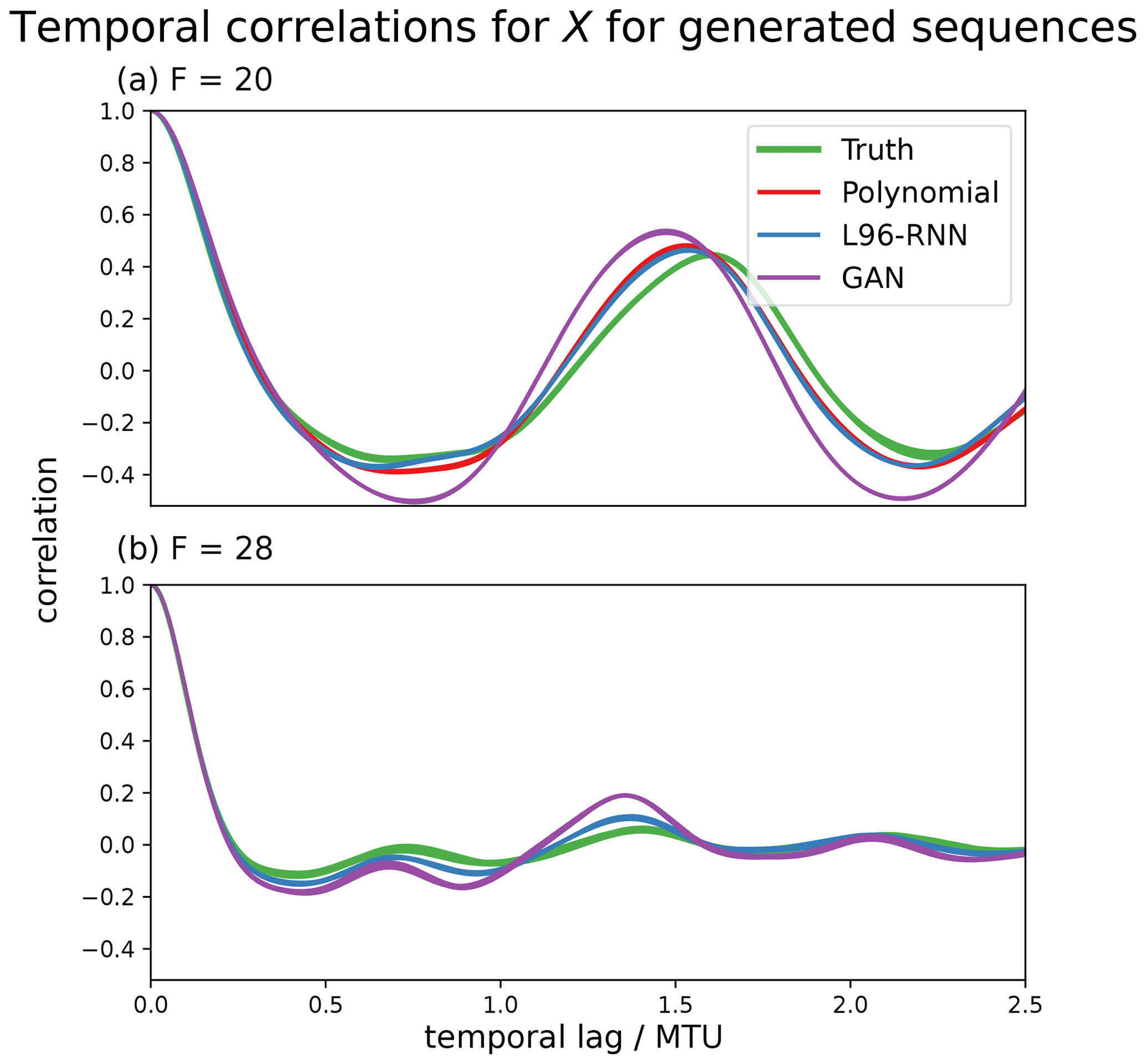
Figure 6The ability of the parameterized models to reproduce the “true” temporal correlations of the X variables in the L96 system (green). The correlations for each of the K components are plotted – the variability is indicated by the line width. Panel (a) is for the sequences generated with F=20, and (b) is for those with F=28. The polynomial is not shown for (b) as the simulations are unstable and go to infinity.
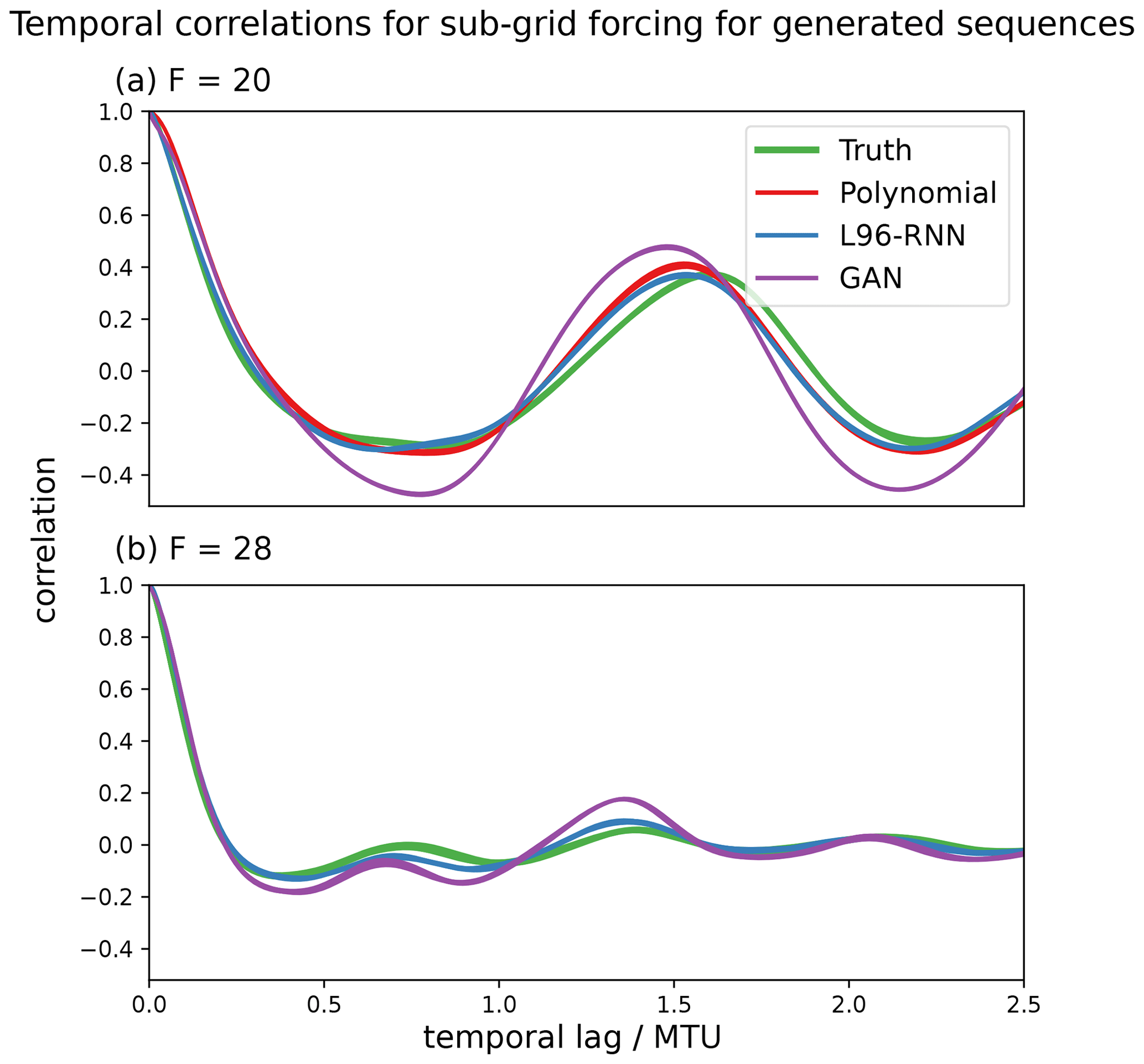
Figure 7The ability of the parameterized models to reproduce the “true” temporal correlations of the sub-grid forcing terms (U) in the L96 system (green). The correlations for each of the K components are plotted – the variability is indicated by the line width. Panel (a) is for the sequences generated with F=20, and (b) is for those with F=28. The polynomial is not shown for (b) as the simulations are unstable and go to infinity.
We desire our parameterized models to correctly capture the temporal behaviour of the L96 system. One way to assess this is by considering the temporal correlations (linear associations) using an autocorrelation plot. The autocorrelation plots of the generated X variables are shown in Fig. 6, and those of the corresponding sub-grid forcing terms, U, are shown in Fig. 7, where . In Fig. 6a we see that for F=20, all the parameterized models perform well, but the L96-RNN best captures the trough behaviour at the 0.7 temporal lag. In Fig. 7a, for F = 20, the L96-RNN and polynomial perform the best.
4.3 Generalization experiments
We set the L96 forcing to , and 40 and examine how the models can capture changes due to varying external forcings. These F values are notably different to those in the training data and so allow us to test generalization. For example, the change from F=21.5 (validation set) to F=28 results in the following changes to the regime structure: the centroid location of the rarer regime shifts to higher values of and (Fig. 8), and the proportion of time spent in the rarer regime increases from 38 % to 50 %. The range of Xk,t also increases from to . The differences in wave behaviour between regimes means the above changes result in different system dynamics.
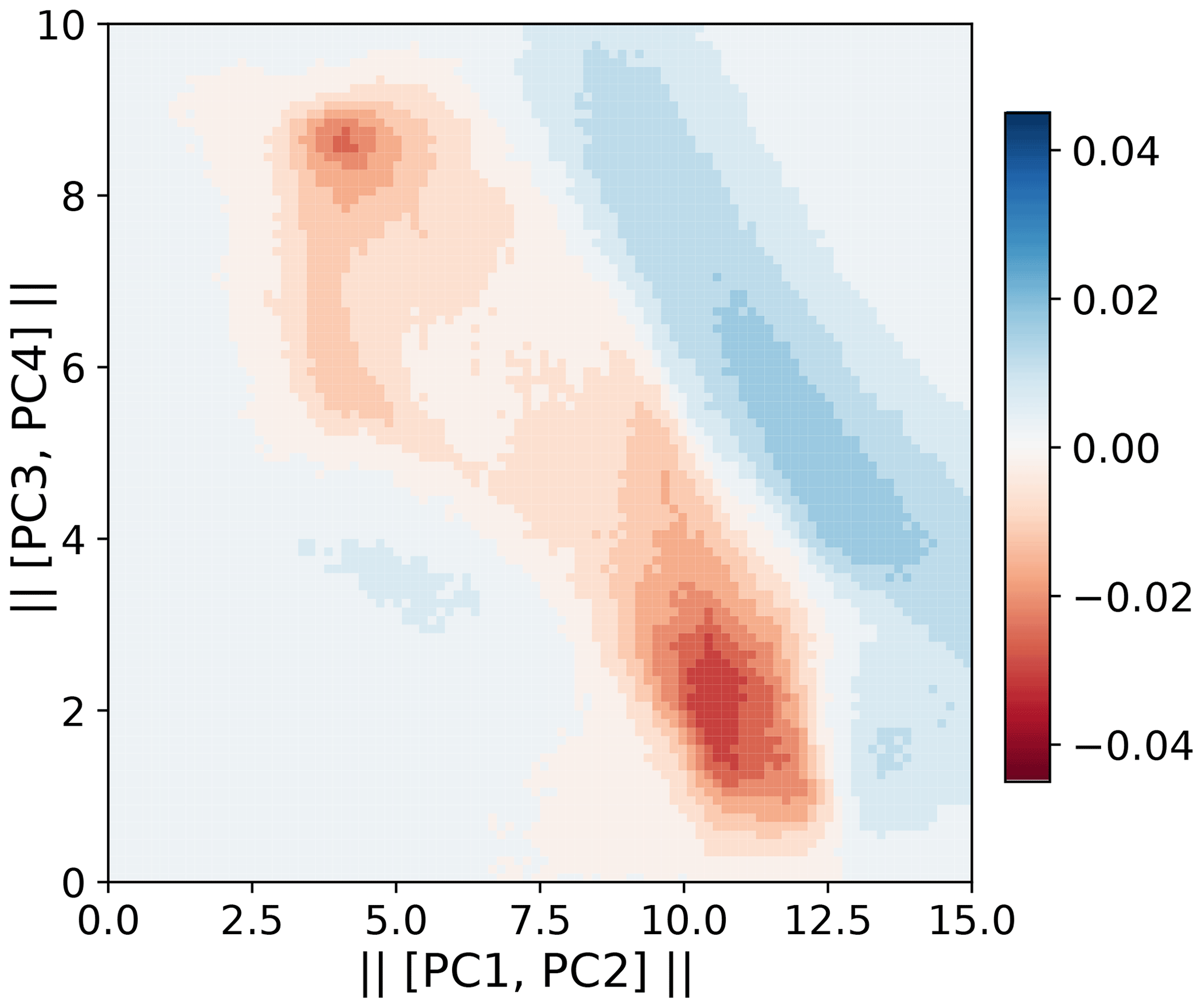
Figure 8Difference between the F=21.5 and F=28 densities in principal component space. The principal components are those from the F=20 truth series. A total of 100 bins are used for this visualization.
In all the below experiments the polynomial model's trajectories exploded (went to infinite values), so the polynomial is omitted. This is merely due to the specification of a third-order polynomial. It significantly deviates from its target values when Xk,t values notably different from those in training (such as ) are taken as inputs.
The F=28 climate was explored in a similar manner to the F=20 one. First, for the histograms of Xk,t (analogous to Fig. 3) the L96-RNN and GAN both had small KL divergences (0.02 vs. 0.14). Next, the principal component projections were examined (analogously to Fig. 4). The same components as determined from the F=20 truth data set are used. In this space, the L96-RNN has a smaller KL divergence (11) than the GAN (57). Figures for the above two plots are omitted due to it being hard to visually distinguish between the models. As before, further comparison can be made by examining the two, 1D density plots in Fig. 9 (analogously to Fig. 5). Both models perform well (KL divergence in Table 1), but neither put enough density in the right-hand side tails. In terms of temporal correlation, as seen in Figs. 6b and 7b, both models perform well, but the L96-RNN generally tracks the periodicity and the amplitude of the peaks and troughs better.
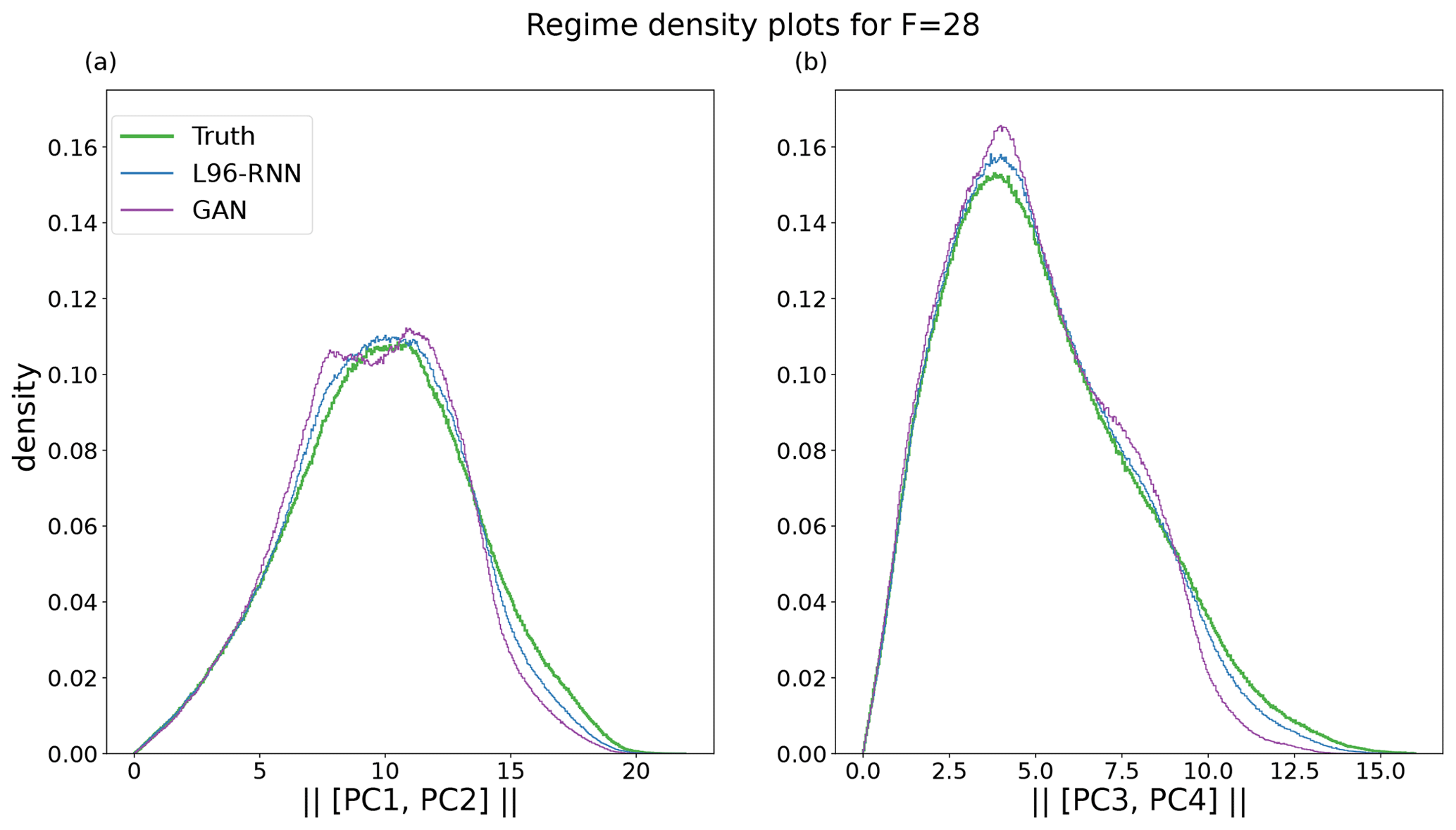
Figure 9Density plots for each regime for F=28. The truth is shown in green and bold. (a) Magnitude of [PC1, PC2]. A total of 479 bins are used. (b) Magnitude of [PC3, PC4]. A total of 444 bins are used. The right-hand side tails are not given sufficient density by the L96-RNN or the GAN.
The models were also evaluated in the weather forecasting framework for , and 40. A total of 750 initial conditions were randomly selected from the truth attractors, and an ensemble of 40 forecasts each lasting 2.5 MTU were produced. Figure 10 shows the L96-RNN generally has lower errors than the GAN, with a better matching spread. The GAN continues to be underdispersive.
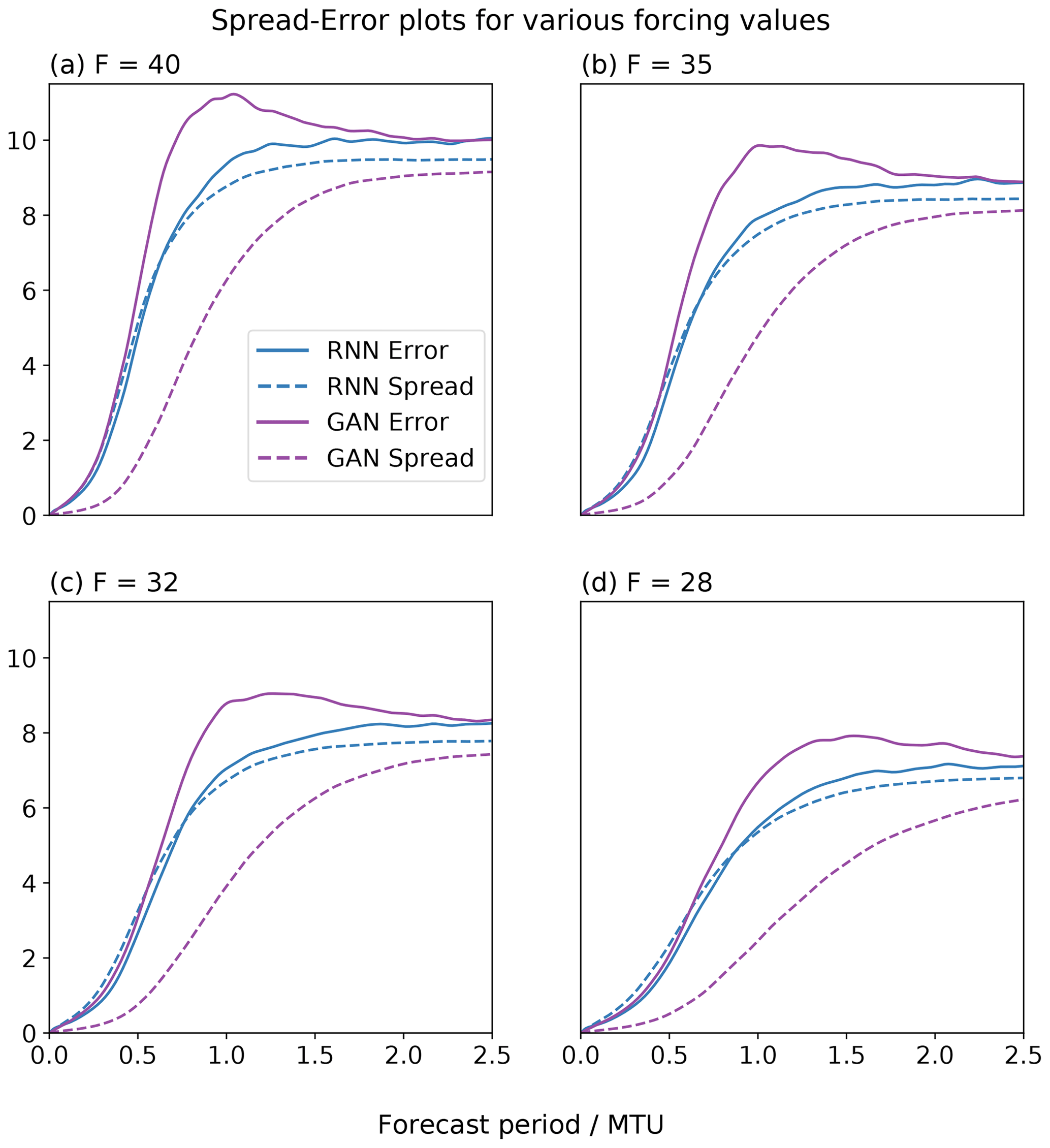
Figure 10Error and spread for weather experiments for varying forcing values. This is done to assess generalization performance. The L96-RNN's spread is best matched to its error, unlike the GAN.
4.4 Residual analysis
We can also compare the polynomial and the L96-RNN's ability to capture temporal patterns by assessing their residuals. The residuals are the differences between observed data and a model's predictions. It can be considered an offline metric. For the proposed models, the residuals should be uncorrelated and resemble white noise. In Fig. 11 we show the autocorrelation of the residuals. Ideally, there would be no significant autocorrelation. Neither of the models succeeds in this aspect, but the autocorrelation of the L96-RNN's residuals drops off far quicker than that of the polynomial. This is likely due to the L96-RNN's ability to capture longer temporal trends. The L96-RNN still has a decaying oscillation, suggesting further changes must be made to the model to account for this.
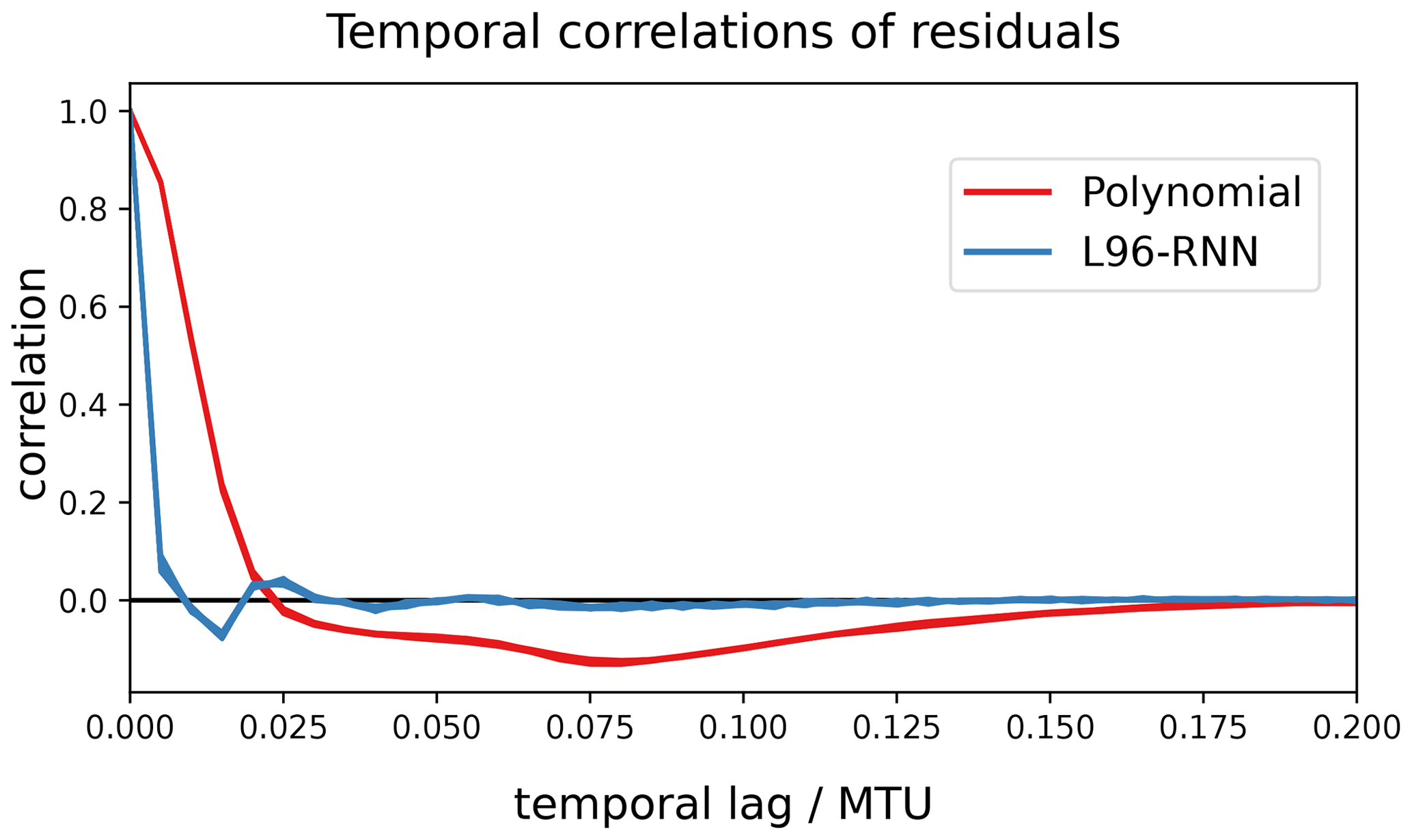
Figure 11Autocorrelation plot of the residuals for the polynomial and the L96-RNN. Ideally, these would show no correlations (and match the black line). The L96-RNN's residual correlations decay more quickly than the polynomial's.
4.5 Computational costs
We wish our models to have a lower simulation cost than the full L96. This is measured by considering the number of floating-point operations per simulated time step (Δt=0.005). The L96-RNN (8682) is notably cheaper than the truth model (88 000) and the GAN (14 074) and so meets the computational cost objective of parameterization work. The polynomial (334) is the cheapest.
In terms of training times, both ML models were trained using a 32 GB NVIDIA V100S GPU. The L96-RNN and GAN took 12 min and 30 h respectively.
5.1 Hold-out likelihood
We also evaluate using the likelihood (explained in Sect. 3.2) of hold-out data. This is a standard approach in the ML literature. Evaluation is done on hold-out sets to ensure that overly complex models which just overfit the training data are not selected.
Here, hold-out sets for F=20 and F=28 were created by taking a 10 000 MTU subset from the 50 000 MTU truth sets created in Sect. 4. The hold-out log likelihoods are shown in Table 2. The likelihood for the polynomial model and its derivation is in Appendix A. We also present an approach to approximate the GAN likelihood. This is despite its full form being intractable (involving integrals which cannot be efficiently approximated using Monte Carlo sampling), meaning it is not typically used to evaluate GANs. This is also detailed in Appendix A. The L96-RNN has a worse likelihood on F=28 than the polynomial, despite the polynomial simulations exploding, unlike the L96-RNN's. This is discussed below.
5.2 What is the use of likelihood?
5.2.1 For evaluation
The other metrics used above only capture snapshots of model performance. Likelihood is a composite measure which assesses a model's full joint distribution (Casella and Berger, 2002). For example, in the univariate case, the mean squared error and variance of a model show two separate things about its performance, with implicit assumptions being made about variables being normally distributed (as is the case whenever mean squared error is used). The likelihood captures both of these and without enforcing such assumptions.
Likelihood also captures information about more complex, joint distributions, saving the need for custom metrics to be invented to assess specific features. To illustrate this, consider that we wish to assess a model's temporal associations (not just the linear temporal correlations). The likelihood already contains this information. Although custom metrics could be invented to assess this, the likelihood is an off-the-shelf metric which is already available. We suggest it is wasteful not to use it.
Using a composite metric brings challenges though. Poor performance in certain aspects may be overshadowed by good performance elsewhere. This can result in cases where increased hold-out likelihoods do not correspond to better sample quality, as noted in the ML literature (Goodfellow et al., 2014; Grover et al., 2018; Theis et al., 2015; Zhao et al., 2020) and seen in our results: the L96-RNN has a worse F=28 hold-out likelihood than the polynomial (Table 2), yet the polynomial model explodes unlike the L96-RNN. In this case, the phenomenon of “explosion” does not significantly penalize the likelihood. This links to how likelihood is evaluated on trajectories of the true system, so is an “offline” metric. Just as with the offline metric of mean squared error, you would expect better “online” performance (the performance of generated simulations) as the likelihood improves, but there is no guarantee of a monotonic relationship between the two. Likelihood is therefore a complement to, not a replacement of, to other metrics which are important to the end user.
5.2.2 For diagnostics
Likelihood's composite nature makes it a helpful diagnostic tool. Just like KL divergence, the further away a model is – in any manner – from the data in the hold-out set, the worse the likelihood will be. If a model has a poor likelihood despite performing well on a range of standard metrics, this suggests there are still deficiencies in the model which need investigating. For example, with the L96-RNN at F=28, the poor average likelihood (Table 2) is caused by a tiny number of segments of the Xk,t sequences being extremely poorly modelled (and therefore having extremely poor likelihoods assigned). On inspection, the issue is due to the choice of a fixed σ in Eq. (11) – this is appropriate for most of the time series, but for parts which are difficult to model, it is too small, preventing the model from expressing sufficient uncertainty. This could be rectified by allowing σ to vary, and we suggest future work explore this.
Table 2Log likelihood on hold-out data for different forcing values. The best model in each case is shown in bold.

We present an approach to replace red noise with a more flexible stochastic machine-learnt model for temporal patterns. Even though we used ML to model the deterministic part gθ(Xk,t) in Eq. (10), the real benefit came from using ML to model the hidden variables. For example, on setting gθ(Xk,t) in our model equal to from the polynomial baseline, our model performance hardly suffered (and the cost halved) for F=20. This finding is supportive of physics-based ML approaches where conventional parameterizations are augmented with a stochastic term learnt using ML.
Using physical knowledge to structure ML models can help with learning. The L96-RNN includes “physically relevant” features for the L96, particularly advection, in Eq. (10). This gave better results than when we modelled the system without them (e.g. when we used an RNN to do the full updating step of Xt given ). Although in theory a NN can learn to create helpful features (such as advection), giving these useful features can make learning easier. The NN does not need to learn the known, useful physical relationships and instead can focus on learning other helpful ones.
There are more sophisticated models which can be used for the L96 system. We noticed that in some cases the L96-RNN struggled even to overfit the training data, regardless of the L96-RNN complexity. This could be due to difficulties in learning the evolution of the hidden variables. Creating architectures that permit better hidden variables to be learnt (ones which model long-term correlations better) would give better models. Despite our use of GRU cells, which along with the LSTM were great achievements in sequence modelling, we still faced issues with the modelling of long-term trends as evidenced in Fig. 11. Attention-based models such as the Transformer (Vaswani et al., 2017) may improve on this. Separately, certain models (mainly those which did not leverage physical structure) resulted in unstable simulations. Using hierarchical models which learn to model trends at different temporal resolutions (Chung et al., 2016; Liu et al., 2020) may provide improvement. Our particular model had specific limitations on how the hidden state, Rt, was not a function of Xt−1, unlike the GAN, and on how σ was not a function of other variables. We did this to make a clearer comparison between hidden variables modelled with AR1 processes versus those modelled with RNNs. Nevertheless, it is simple to include Xt−1 in the model for Rt and to make σ a neural network function of other variables (including the forcing) if desired. We believe the latter change would be particularly useful in better capturing uncertainty.
We trained the L96-RNN using the likelihood of the sequence and showed how, for an RNN-based model, there is an explicit form of the likelihood which makes likelihood calculations tractable. In the L96, these Xt sequences are K-dimensional and correlated. Their likelihood can be written in terms of the likelihood of the hidden variables , and as shown in Eq. (13), training to maximize the likelihood of a sequence of hidden variables is equivalent to maximizing the likelihood of an Xt sequence. However, in the general case of a general circulation model, it will often not be possible to analytically derive the relationship between the likelihood of an Xt sequence and that for a sequence of hidden variables, as explained in Sect. A4.1. Therefore, maximizing the likelihood of other variables (the approach typically taken), such as the hidden variables or sub-grid terms, may not correspond to maximizing the likelihood of Xt. This is unideal as our actual goal is to create a model which generates realistic sequences of Xt. And this may be a reason why online evaluations of such models often show error accumulation leading to simulation blow-ups (Brenowitz and Bretherton, 2018; Rasp, 2020). In future work, we plan to investigate how to better train parameterization models for cases where you cannot easily maximize a likelihood which is proportional to the likelihood of Xt.
Learning from all the high-resolution data whilst still being computationally efficient at simulation time is an interesting idea. Whilst we cannot keep all the high-resolution variables in our schemes (as otherwise we might as well run the high-resolution model outright – which is not possible as it is too slow for the desired timescales and is a reason why this field of work exists), only keeping the average (as in existing work which coarse-grains data) means many data are thrown away. Our preliminary investigations used the graphical model in Fig. 12. We designed this so that in training, lt is learnt such that it contains useful information about the high-resolution data, Yt, whereas during generation, Yt is not required to be simulated. For the L96, this showed no improvement over our L96-RNN though. Parthipan and Wischik (2022) show that such an approach may be useful as a regularizer when training data are limited.
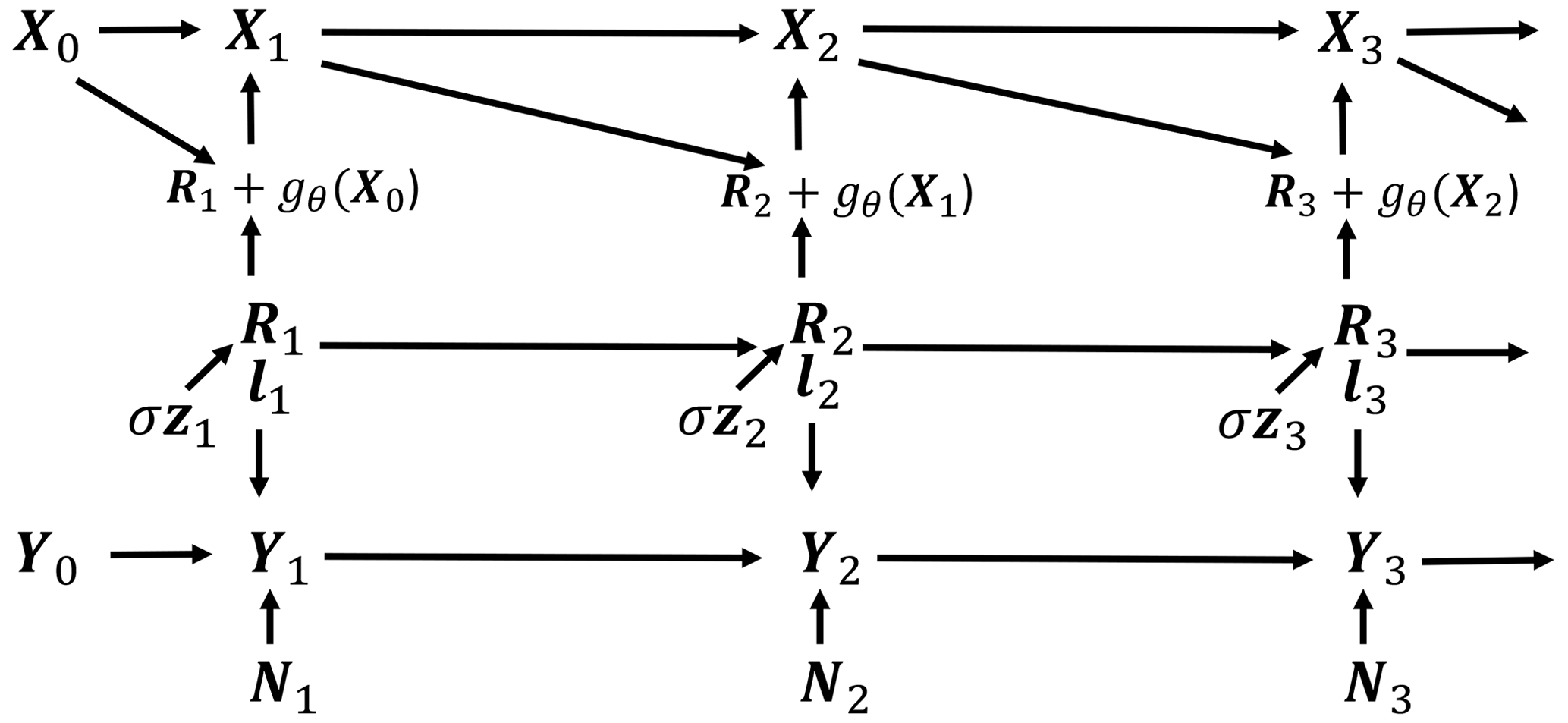
Figure 12Model which allows learning from high-resolution data without requiring it at simulation time, where . The model is trained to generate Y and so learns from these data, but at simulation time, Y is not required to generate X.
Further work with GANs could result in better models. There may be aspects of realism which we either may not be aware of or may not be able to quantify, so they are difficult to include explicitly in our probability models. The GAN discriminator could learn what features constitute “realism” and so the generator may learn to create sequences which contain these. However, we found that using the adversarial approaches from GANs and Wasserstein GANs (Arjovsky et al., 2017; Gulrajani et al., 2017) to train the L96-RNN (instead of by likelihood) did not show any benefit. This may be due to the difficulty of training GANs on longer sequences. They have been used to train RNNs on medical time series (Esteban et al., 2017) and to model music (Mogren, 2016), so applying this approach to climatic sequences may be something for future work to reconcile. The challenges of using GANs are seen by how we have not been able to reproduce the results shown in Gagne et al. (2020) despite the same set-up. This points to the instability of GAN training, as noted by them too. Mode collapse is a common issue encountered when training GANs, where the generator fails to produce samples that explore certain modes of the distribution, and could explain why density is only present for Regime A in Fig. 4 and not for Regime B.
We have shown how to build on the benefits of red-noise models (such as AR1 ones) in parameterizations by using a probabilistic ML approach based on a recurrent neural network (RNN). This can be seen as a natural generalization of the classical autoregressive approaches. This is done in the idealized case of the two-level Lorenz 96 system, where the unresolved variables must be parameterized. Our L96-RNN outperforms the red-noise baselines (a polynomial model and a GAN) in a weather forecasting framework and has lower KL divergence scores for the probability density functions arising from long-range simulations. The L96-RNN generalizes the best to new forcing scenarios. These strong empirical results, along with a less correlated residual pattern, supports the benefit of the L96-RNN being due to it better capturing temporal patterns.
This approach now needs testing on more complex systems – both to specifically improve on AR1 processes and to learn new, more flexible models of Xt. An interesting area for further work is to examine what information is tracked in the hidden variables of the L96-RNN and how this relates to the timescales of the required memory in the modelled system. The field is ripe for other probabilistic ML tools to be used, and we suspect that further customization of these will lead to many improved parameterization models.
Likelihood can often be fairly easily calculated, and where this is the case, we propose that the community also evaluate the hold-out likelihood for any devised probabilistic model (ML or otherwise). It is a useful debugging tool, assessing the full joint distribution of a model. It would also provide a consistent evaluation metric across the literature. Given the challenges relating to sample quality, likelihood should complement, not replace, existing metrics.
Finally, we have used demanding tests to show that ML models can generalize to unseen scenarios. We cannot hope for ML models to generalize to all settings. We do not expect this from our physics-based models either. But ML models can generalize outside their training realm. And it is by using challenging hold-out tests that we can assess their ability to do so and, if they fail, begin the diagnosis of why.
In all cases, the log likelihood of the sequence of Xt is given by
which follows from the laws of probability.
A1 L96-RNN
Now from Eq. (10), we can write
where for the L96-RNN
Xt denotes the random variable, and xt denotes the value which that random variable takes. Given this relationship between Xt and Rt, a change of variables (further details are in Appendix A4) for the likelihood gives
Eq. (A1) is therefore
where Eqs. (A6)–(A7) follow from the independencies in the graphical model (Fig. 1).
A2 Polynomial model
For the polynomial model, the log likelihood of the Xt sequence is
and the derivation follows below.
The graphical model is shown in Fig. A1a. From Eq. (6), we can write
and given this relationship between Xt and ht, a change of variables for the likelihood gives
Eq. (A1) is therefore
where Eqs. (A12)–(A13) follow from the independencies described in Eq. (5).
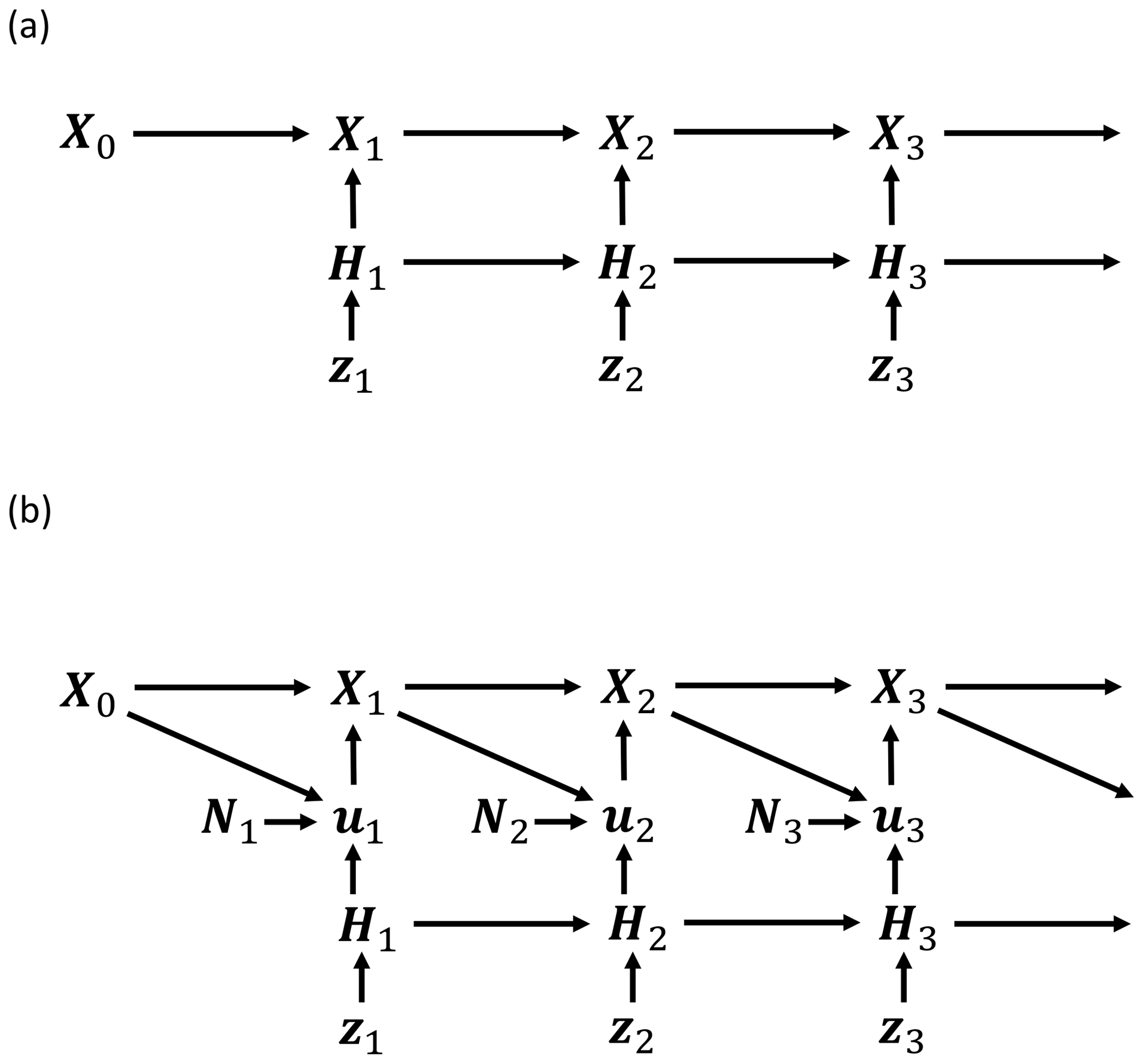
A3 GAN
We approximate the GAN's likelihood by calculating the likelihood of a model which functions and gives results almost identical to the GAN (one with a small amount of white noise added) using importance sampling and the reparameterization method as in the variational autoencoder Kingma and Welling (2013). Here, Eq. (9) is altered to
where and . The log likelihood is
where the expectation can now be approximated by a large sum if there is a suitable importance sampler . A total of 50 samples were used for the importance sampling, and this was repeated 50 times to give 95 % confidence intervals. We note that given the finite number of samples taken, it is of course possible that the GAN likelihood is larger, but a well-trained importance sampler should minimize the chance of this. The derivation and form of the importance sampler is detailed below.
The graphical model of the GAN with a small amount of white noise added is shown in Fig. A1b. Xt is related to ut as in Eq. (A14), so
and a change in variables for likelihood gives
Eq. (A1) is therefore
and just decomposing the first term below gives the following:
where Eq. (A18) can be approximated with a sufficiently large sum given a good enough encoder .
For training purposes, the lower bound is used:
The terms in the numerator decompose as follows, using the independencies from the graphical model and associated equations:
and
The perfect importance sampling distribution would be proportional to . Therefore we want to allow for the same dependencies. We choose it by carrying out the following steps:
where Eq. (A20) follows from using the laws of probability to decompose the term above, followed by applications of the independencies from the graphical model. Note that although the process is Markov, it is not necessarily time-homogeneous. To deal with this, an RNN is used to model as where the state st can in principle account for the non-homogeneous updating procedure of ht. The log likelihood is therefore
where the spatial independencies introduced in Eq. (A21) follow from the graphical model, and and . The only simplifying assumption used here is that the same update model for hk,t is used for each component k. Finally, the sequence of is summarized using a bidirectional RNN to give wk,t. Therefore, the final form of the log likelihood of our importance sampler is
The training of the importance sampler is done by maximizing Eq. (A19), with the learnable parameters being those of the model used to learn hk,1, the RNN used to model the update of hk,t, and the bidirectional RNN.
A4 Change of variables for probability density functions
For random variables, X∈ℝ1 and Y∈ℝ1, where X=η(Y), and , the probability density function for X, PrX(x), is
Now we will show how we arrive at Eq. (A4) for the RNN. A similar approach can be taken for the other two models. We can rewrite the equation (a single component of Eq. A2)
as
where
From this we see
and therefore
We can thus write
And from the conditional independencies in Eqs. (10)–(12),
and on taking logs and dropping the subscripts we get
which is Eq. (A4).
A4.1 Application to systems beyond the L96
It will sometimes not be possible to apply the approach based on changes of variables to more complex systems, for a few reasons. First, it requires the function η in X=η(Y) to be either a monotonically increasing or monotonically decreasing function (as the inverse must exist). This may not be the case in more sophisticated climate models. Second, the derivative of the inverse of η needs to be computable, which may not be feasible to do if the inverse is too challenging to calculate (for example, it may not be possible to run individual components of climate model functions in order to calculate η−1).
Further results for KL divergences are provided in order to see how results vary with differing bin sizes for the histograms.
Table B1 is for the distributions in Fig. 3, and Table B2 is for those in Fig. 4. Even for a range of bin sizes, the L96-RNN has the lowest KL divergences.
Table B1KL divergence (goodness of fit) between (1) the truth and (2) the parameterized models, for the distributions shown in Fig. 3. The smaller the KL divergence, the better the match between the true and modelled distributions. The best model in each case is shown in bold.
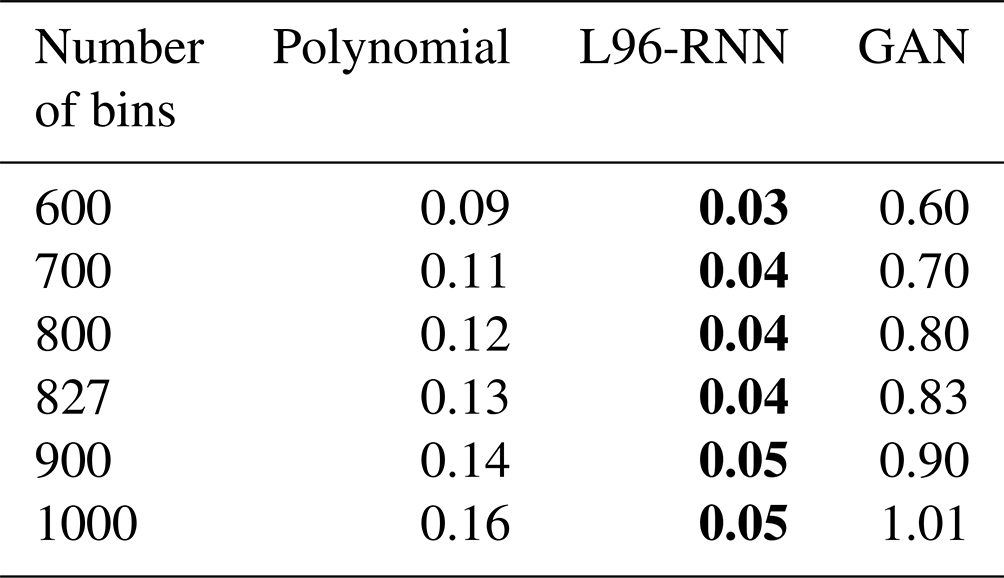
Table B2KL divergence (goodness of fit) between (1) the truth and (2) the parameterized models, for the distributions shown in Fig. 4. The smaller the KL divergence, the better the match between the true and modelled distributions. The best model in each case is shown in bold.
All code used in this study (including the code required to create the data) is publicly available at https://doi.org/10.5281/zenodo.7118667 (Parthipan, 2023).
All authors supported the design of the study. RP created the models and conducted research. RP prepared the paper with contributions from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We would like to thank Pavel Perezhogin and our other anonymous reviewer for their feedback, which has improved the paper.
Raghul Parthipan was funded by the Engineering and Physical Sciences Research Council (grant number EP/S022961/1). Hannah M. Christensen was supported by the Natural Environment Research Council (grant number NE/P018238/1). J. Scott Hosking was supported by the British Antarctic Survey, Natural Environment Research Council (NERC) National Capability funding. Damon J. Wischik was funded by the University of Cambridge.
This paper was edited by Travis O'Brien and reviewed by Pavel Perezhogin and one anonymous referee.
Agarwal, N., Kondrashov, D., Dueben, P., Ryzhov, E., and Berloff, P.: A Comparison of Data-Driven Approaches to Build Low-Dimensional Ocean Models, J. Adv. Model. Earth Sy., 13, e2021MS002537, https://doi.org/10.1029/2021MS002537, 2021. a
Arcomano, T., Szunyogh, I., Wikner, A., Pathak, J., Hunt, B. R., and Ott, E.: A Hybrid Approach to Atmospheric Modeling That Combines Machine Learning With a Physics-Based Numerical Model, J. Adv. Model. Earth Sy., 14, e2021MS002712, https://doi.org/10.1029/2021MS002712, 2022. a, b
Arjovsky, M., Chintala, S., and Bottou, L.: Wasserstein generative adversarial networks, in: International conference on machine learning, PMLR, 214–223, https://doi.org/10.48550/arXiv.1701.07875, 2017. a
Arnold, H. M., Moroz, I. M., and Palmer, T. N.: Stochastic parametrizations and model uncertainty in the Lorenz’96 system, Philosophical Transactions of the Royal Society A: Mathematical, Phys. Eng. Sci., 371, 20110479, https://doi.org/10.1098/rsta.2011.0479, 2013. a, b, c, d
Bahdanau, D., Cho, K., and Bengio, Y.: Neural machine translation by jointly learning to align and translate, arXiv [preprint], https://doi.org/10.48550/arXiv.1409.0473, 2014. a
Berner, J., Jung, T., and Palmer, T.: Systematic model error: The impact of increased horizontal resolution versus improved stochastic and deterministic parameterizations, J. Climate, 25, 4946–4962, 2012. a
Beucler, T., Pritchard, M., Gentine, P., and Rasp, S.: Towards physically-consistent, data-driven models of convection, in: IGARSS 2020-2020 IEEE International Geoscience and Remote Sensing Symposium, IEEE, 3987–3990, https://doi.org/10.48550/arXiv.2002.08525, 2020. a, b
Beucler, T., Pritchard, M., Rasp, S., Ott, J., Baldi, P., and Gentine, P.: Enforcing analytic constraints in neural networks emulating physical systems, Phys. Rev. Lett., 126, 098302, https://doi.org/10.1103/PhysRevLett.126.098302, 2021. a, b
Bolton, T. and Zanna, L.: Applications of deep learning to ocean data inference and subgrid parameterization, J. Adv. Model. Earth Sy., 11, 376–399, 2019. a, b
Brenowitz, N. D. and Bretherton, C. S.: Prognostic validation of a neural network unified physics parameterization, Geophys. Res. Lett., 45, 6289–6298, 2018. a, b, c
Brenowitz, N. D. and Bretherton, C. S.: Spatially extended tests of a neural network parametrization trained by coarse-graining, J. Adv. Model. Earth Sy., 11, 2728–2744, 2019. a, b
Buizza, R., Milleer, M., and Palmer, T. N.: Stochastic representation of model uncertainties in the ECMWF ensemble prediction system, Q. J. Roy. Meteorol. Soc., 125, 2887–2908, 1999. a, b
Casella, G. and Berger, R. L.: Chap. 6.3, The Likelihood Principle, in: Statistical inference, Duxbury Press, p. 290, ISBN 0-534-24312-6, 2002. a
Chattopadhyay, A., Hassanzadeh, P., and Subramanian, D.: Data-driven predictions of a multiscale Lorenz 96 chaotic system using machine-learning methods: reservoir computing, artificial neural network, and long short-term memory network, Nonlin. Processes Geophys., 27, 373–389, https://doi.org/10.5194/npg-27-373-2020, 2020a. a, b
Chattopadhyay, A., Subel, A., and Hassanzadeh, P.: Data-driven super-parameterization using deep learning: Experimentation with multiscale Lorenz 96 systems and transfer learning, Journal of Advances in Modeling Earth Systems, 12, e2020MS002084, https://doi.org/10.1029/2020MS002084, 2020b. a
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y.: Learning phrase representations using RNN encoder-decoder for statistical machine translation, arXiv [preprint], https://doi.org/10.48550/arXiv.1406.1078, 2014. a, b
Christensen, H. M., Moroz, I. M., and Palmer, T. N.: Simulating weather regimes: Impact of stochastic and perturbed parameter schemes in a simple atmospheric model, Clim. Dynam., 44, 2195–2214, 2015. a, b, c, d, e
Christensen, H. M., Berner, J., Coleman, D. R., and Palmer, T.: Stochastic parameterization and El Niño–Southern Oscillation, J. Climate, 30, 17–38, 2017. a
Chung, J., Ahn, S., and Bengio, Y.: Hierarchical multiscale recurrent neural networks, arXiv [preprint], https://doi.org/10.48550/arXiv.1609.01704, 2016. a
Crommelin, D. and Vanden-Eijnden, E.: Subgrid-scale parameterization with conditional Markov chains, J. Atmos. Sci., 65, 2661–2675, 2008. a
Dawson, A. and Palmer, T.: Simulating weather regimes: Impact of model resolution and stochastic parameterization, Clim. Dynam., 44, 2177–2193, 2015. a, b
Eck, D. and Schmidhuber, J.: A first look at music composition using lstm recurrent neural networks, Istituto Dalle Molle Di Studi Sull Intelligenza Artificiale, 103, 2002. a
Esteban, C., Hyland, S. L., and Rätsch, G.: Real-valued (medical) time series generation with recurrent conditional gans, arXiv [preprint] https://doi.org/10.48550/arXiv.1706.02633, 2017. a
Freedman, D. and Diaconis, P.: On the histogram as a density estimator: L 2 theory, Z. Wahrscheinlichkeit., 57, 453–476, 1981. a
Gagne, D. J., Christensen, H. M., Subramanian, A. C., and Monahan, A. H.: Machine learning for stochastic parameterization: Generative adversarial networks in the Lorenz'96 model, J. Adv. Model. Earth Sy., 12, e2019MS001896, https://doi.org/10.1029/2019MS001896, 2020. a, b, c, d, e, f, g, h
Gentine, P., Pritchard, M., Rasp, S., Reinaudi, G., and Yacalis, G.: Could machine learning break the convection parameterization deadlock?, Geophys. Res. Lett., 45, 5742–5751, 2018. a, b
Goodfellow, I.: Nips 2016 tutorial: Generative adversarial networks, arXiv [preprint], https://doi.org/10.48550/arXiv.1701.00160, 2016. a
Goodfellow, I., Bengio, Y., and Courville, A.: Deep Learning, chap. Sequence Modeling: Recurrent and Recursive Nets, MIT Press, 372–384, http://www.deeplearningbook.org (last access: 1 March 2023), 2016. a
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y.: Generative adversarial networks, arXiv [preprint], https://doi.org/10.48550/arXiv.1406.2661, 2014. a, b
Graves, A.: Generating sequences with recurrent neural networks, arXiv [preprint] https://doi.org/10.48550/arXiv:1308.0850, 2013. a
Grover, A., Dhar, M., and Ermon, S.: Flow-gan: Combining maximum likelihood and adversarial learning in generative models, in: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32, https://doi.org/10.48550/arXiv.1705.08868, 2018. a
Guillaumin, A. P. and Zanna, L.: Stochastic-deep learning parameterization of ocean momentum forcing, J. Adv. Model. Earth Sy., 13, e2021MS002534, https://doi.org/10.1029/2021MS002534, 2021. a
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and Courville, A.: Improved training of wasserstein gans, arXiv [preprint], https://doi.org/10.48550/arXiv:1704.00028, 2017. a
Hasselmann, K.: Stochastic climate models part I. Theory, Tellus, 28, 473–485, 1976. a
Hochreiter, S. and Schmidhuber, J.: Long short-term memory, Neural Comput., 9, 1735–1780, 1997. a
Johnson, S. J., Stockdale, T. N., Ferranti, L., Balmaseda, M. A., Molteni, F., Magnusson, L., Tietsche, S., Decremer, D., Weisheimer, A., Balsamo, G., Keeley, S. P. E., Mogensen, K., Zuo, H., and Monge-Sanz, B. M.: SEAS5: the new ECMWF seasonal forecast system, Geosci. Model Dev., 12, 1087–1117, https://doi.org/10.5194/gmd-12-1087-2019, 2019. a
Kingma, D. P. and Ba, J.: Adam: A method for stochastic optimization, arXiv [preprint], https://doi.org/10.48550/arXiv:1412.6980, 2014. a
Kingma, D. P. and Welling, M.: Auto-encoding variational bayes, arXiv [preprint], https://doi.org/10.48550/arXiv:1312.6114, 2013. a
Krasnopolsky, V. M., Fox-Rabinovitz, M. S., and Belochitski, A. A.: Using ensemble of neural networks to learn stochastic convection parameterizations for climate and numerical weather prediction models from data simulated by a cloud resolving model, Advances in Artificial Neural Systems, 2013, 5-5, https://doi.org/10.1155/2013/485913, 2013. a, b
Kwasniok, F.: Data-based stochastic subgrid-scale parametrization: an approach using cluster-weighted modelling, Philos. T. Roy. Soc. A, 370, 1061–1086, 2012. a
Leutbecher, M. and Palmer, T. N.: Ensemble forecasting, J. Comput. Phys., 227, 3515–3539, 2008. a
Leutbecher, M., Lock, S.-J., Ollinaho, P., Lang, S. T., Balsamo, G., Bechtold, P., Bonavita, M., Christensen, H. M., Diamantakis, M., Dutra, E., English, S., Fisher, M., Forbes, R. M., Goddard, J., Haiden, T., Hogan, R. J., Juricke, S., Lawrence, H., MacLeod, D., Magnusson, L., Malardel, S., Massart, S., Sandu, I., Smolarkiewicz, P. K., Subramanian, A., Vitart, F., Wedi, N., and Weisheimer, A.: Stochastic representations of model uncertainties at ECMWF: State of the art and future vision, Q. J. Roy. Meteorol. Soc., 143, 2315–2339, 2017. a, b
Liu, Y., Kutz, J. N., and Brunton, S. L.: Hierarchical deep learning of multiscale differential equation time-steppers, arXiv [preprint], https://doi.org/10.48550/arXiv:2008.09768, 2020. a
Lorenz, E. N.: Predictability: A problem partly solved, in: Proc. Seminar on Predictability, 4–8 September 1995, Vol. 1, 1–18, Shinfield Park, Reading, ECMWF, 1996. a, b
Lorenz, E. N.: Regimes in simple systems, J. Atmos. Sci, 63, 2056–2073, 2006. a
Mogren, O.: C-RNN-GAN: Continuous recurrent neural networks with adversarial training, arXiv [preprint], https://doi.org/10.48550/arXiv:1611.09904, 2016. a, b
Molteni, F., Stockdale, T., Balmaseda, M., Balsamo, G., Buizza, R., Ferranti, L., Magnusson, L., Mogensen, K., Palmer, T., and Vitart, F.: The new ECMWF seasonal forecast system (System 4), European Centre for medium-range weather forecasts Reading, vol. 49, https://doi.org/10.21957/4nery093i, 2011. a, b
O'Gorman, P. A. and Dwyer, J. G.: Using machine learning to parameterize moist convection: Potential for modeling of climate, climate change, and extreme events, J. Adv. Model. Earth Sy., 10, 2548–2563, 2018. a, b, c
Palmer, T. N.: Towards the probabilistic Earth-system simulator: A vision for the future of climate and weather prediction, Q. J. Roy. Meteorol. Soc., 138, 841–861, 2012. a, b
Palmer, T. N., Buizza, R., Doblas-Reyes, F., Jung, T., Leutbecher, M., Shutts, G. J., Steinheimer, M., and Weisheimer, A.: Stochastic parametrization and model uncertainty, https://doi.org/10.21957/ps8gbwbdv, 2009. a, b, c, d
Parthipan, R.: raghul-parthipan/l96_rnn: v1.1.0 (v1.1.0), Zenodo [code], https://doi.org/10.5281/zenodo.7837814, 2023. a
Parthipan, R. and Wischik, D. J.: Don't Waste Data: Transfer Learning to Leverage All Data for Machine-Learnt Climate Model Emulation, arXiv [preprint], https://doi.org/10.48550/arXiv:2210.04001, 2022. a
Rasp, S.: Coupled online learning as a way to tackle instabilities and biases in neural network parameterizations: general algorithms and Lorenz 96 case study (v1.0), Geosci. Model Dev., 13, 2185–2196, https://doi.org/10.5194/gmd-13-2185-2020, 2020. a, b
Rasp, S., Pritchard, M. S., and Gentine, P.: Deep learning to represent subgrid processes in climate models, P. Natl. Acad. Sci. USA, 115, 9684–9689, 2018. a, b
Sanchez, C., Williams, K. D., and Collins, M.: Improved stochastic physics schemes for global weather and climate models, Q. J. Roy. Meteorol. Soc., 142, 147–159, 2016. a
Schneider, T., Teixeira, J., Bretherton, C. S., Brient, F., Pressel, K. G., Schär, C., and Siebesma, A. P.: Climate goals and computing the future of clouds, Nat. Clim. Change, 7, 3–5, 2017. a
Selten, F. M. and Branstator, G.: Preferred regime transition routes and evidence for an unstable periodic orbit in a baroclinic model, J. Atmos. Sci., 61, 2267–2282, 2004. a
Silverman, B. W.: Density estimation for statistics and data analysis, CRC press, vol. 26, ISBN 978-0412246203, 1986. a
Skamarock, W. C., Klemp, J. B., Dudhia, J., Gill, D. O., Liu, Z., Berner, J., Wang, W., Powers, J. G., Duda, M. G., Barker, D. M., and Huang, X.-Y.: A description of the advanced research WRF model version 4, National Center for Atmospheric Research: Boulder, CO, USA, 145, https://doi.org/10.5065/1dfh-6p97, 2019. a, b
Stephenson, D., Hannachi, A., and O'Neill, A.: On the existence of multiple climate regimes, Q. J. Roy. Meteor. Soc., 130, 583–605, 2004. a
Stockdale, T. N., Anderson, D. L., Balmaseda, M. A., Doblas-Reyes, F., Ferranti, L., Mogensen, K., Palmer, T. N., Molteni, F., and Vitart, F.: ECMWF seasonal forecast system 3 and its prediction of sea surface temperature, Clim. Dynam., 37, 455–471, 2011. a
Straus, D. M., Corti, S., and Molteni, F.: Circulation regimes: Chaotic variability versus SST-forced predictability, J. Climate, 20, 2251–2272, 2007. a, b
Sutskever, I., Martens, J., and Hinton, G. E.: Generating text with recurrent neural networks, in: Proceedings of the 28th international conference on machine learning (ICML-11), 1017–1024, 2011. a, b
Sutskever, I., Vinyals, O., and Le, Q. V.: Sequence to sequence learning with neural networks, in: Advances in neural information processing systems, 3104–3112, https://doi.org/10.48550/arXiv.1409.3215, 2014. a, b
Theis, L., van den Oord, A., and Bethge, M.: A note on the evaluation of generative models, arXiv [preprint], https://doi.org/10.48550/arXiv:1511.01844, 2015. a
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I.: Attention is all you need, Adv. Neur. In., 30, 5998–6008, 2017. a, b
Vlachas, P. R., Byeon, W., Wan, Z. Y., Sapsis, T. P., and Koumoutsakos, P.: Data-driven forecasting of high-dimensional chaotic systems with long short-term memory networks, Proc. Roy. Soc. A:, 474, 20170844, https://doi.org/10.1098/rspa.2017.0844, 2018. a
Vlachas, P. R., Pathak, J., Hunt, B. R., Sapsis, T. P., Girvan, M., Ott, E., and Koumoutsakos, P.: Backpropagation algorithms and reservoir computing in recurrent neural networks for the forecasting of complex spatiotemporal dynamics, Neural Networks, 126, 191–217, 2020. a
Vlachas, P. R., Arampatzis, G., Uhler, C., and Koumoutsakos, P.: Multiscale simulations of complex systems by learning their effective dynamics, Nature Machine Intelligence, 4, 359–366, 2022. a, b
Walters, D., Baran, A. J., Boutle, I., Brooks, M., Earnshaw, P., Edwards, J., Furtado, K., Hill, P., Lock, A., Manners, J., Morcrette, C., Mulcahy, J., Sanchez, C., Smith, C., Stratton, R., Tennant, W., Tomassini, L., Van Weverberg, K., Vosper, S., Willett, M., Browse, J., Bushell, A., Carslaw, K., Dalvi, M., Essery, R., Gedney, N., Hardiman, S., Johnson, B., Johnson, C., Jones, A., Jones, C., Mann, G., Milton, S., Rumbold, H., Sellar, A., Ujiie, M., Whitall, M., Williams, K., and Zerroukat, M.: The Met Office Unified Model Global Atmosphere 7.0/7.1 and JULES Global Land 7.0 configurations, Geosci. Model Dev., 12, 1909–1963, https://doi.org/10.5194/gmd-12-1909-2019, 2019. a
Wilks, D. S.: Empirical Distributions and Exploratory Data Analysis, in: Statistical methods in the atmospheric sciences, Academic press, 100, 33–35, 2011. a
Yuval, J. and O’Gorman, P. A.: Stable machine-learning parameterization of subgrid processes for climate modeling at a range of resolutions, Nature Commun., 11, 1–10, 2020. a, b, c
Yuval, J., O'Gorman, P. A., and Hill, C. N.: Use of neural networks for stable, accurate and physically consistent parameterization of subgrid atmospheric processes with good performance at reduced precision, Geophys. Res. Lett., 48, e2020GL091363, https://doi.org/10.1029/2020GL091363, 2021. a, b
Zelinka, M. D., Myers, T. A., McCoy, D. T., Po-Chedley, S., Caldwell, P. M., Ceppi, P., Klein, S. A., and Taylor, K. E.: Causes of higher climate sensitivity in CMIP6 models, Geophys. Res. Lett., 47, e2019GL085782, https://doi.org/10.1029/2019GL085782, 2020. a
Zhao, M., Cong, Y., Dai, S., and Carin, L.: Bridging Maximum Likelihood and Adversarial Learning via α-Divergence, in: Proceedings of the AAAI Conference on Artificial Intelligence, 34, 6901–6908, https://doi.org/10.48550/arXiv.2007.06178, 2020. a
- Abstract
- Introduction
- Parameterization in the Lorenz 96
- Our L96-RNN model
- Results
- Evaluation and diagnostics using likelihood
- Discussion and conclusion
- Conclusions
- Appendix A: Likelihood derivations
- Appendix B: Further results
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Parameterization in the Lorenz 96
- Our L96-RNN model
- Results
- Evaluation and diagnostics using likelihood
- Discussion and conclusion
- Conclusions
- Appendix A: Likelihood derivations
- Appendix B: Further results
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References