the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Jul 2021
| 30 Jul 2021
Ocean Plastic Assimilator v0.2: assimilation of plastic concentration data into Lagrangian dispersion models
Axel Peytavin
Bruno Sainte-Rose
Gael Forget
Jean-Michel Campin
A numerical scheme to perform data assimilation of concentration measurements in Lagrangian models is presented, along with its first implementation called Ocean Plastic Assimilator, which aims to improve predictions of the distributions of plastics over the oceans. This scheme uses an ensemble method over a set of particle dispersion simulations. At each step, concentration observations are assimilated across the ensemble members by switching back and forth between Eulerian and Lagrangian representations. We design two experiments to assess the scheme efficacy and efficiency when assimilating simulated data in a simple double-gyre model. Analysis convergence is observed with higher accuracy when lowering observation variance or using a circulation model closer to the real circulation. Results show that the distribution of the mass of plastics in an area can effectively be improved with this simple assimilation scheme. Direct application to a real ocean dispersion model of the Great Pacific Garbage Patch is presented with simulated observations, which gives similarly encouraging results. Thus, this method is considered a suitable candidate for creating a tool to assimilate plastic concentration observations in real-world applications to estimate and forecast plastic distributions in the oceans. Finally, several improvements that could further enhance the method efficiency are identified.
- Article
(1429 KB) - Full-text XML
- BibTeX
- EndNote





Plastic pollution reveals itself to be an urgent matter if humans are to preserve their oceans. Previous publications such as Lebreton et al. (2018) reviewed how plastics are rapidly accumulating in the oceans and concentrating in oceanic gyres. As public and private ventures set out cleanup goals, accurate and regular forecasts of the state of plastics in the oceans are becoming necessary.
A modeling framework is currently undergoing development at The Ocean Cleanup towards this goal, as the company set itself out to clean 90 % of the oceans' floating macroplastics by 2040. It is used to assess and improve our ability to perform the largest cleanup in history.
This framework, the results of which are presented in Lebreton et al. (2018), is built upon the Pol3DD Lagrangian dispersion model and presented in Lebreton et al. (2012). In this model, virtual particles representing plastics are generated and let drift over time using current data extracted from the oceanic circulation modeling system HYCOM (HYbrid Coordinate Ocean Model; see Bleck, 2002). Results from this model are compared with two other plastic forecast models in van Sebille et al. (2015).
While the Lebreton et al. (2012) modeling framework has already produced valuable results, it is not able to assimilate observations and update forecasts accordingly yet. However, as the company prepares to release a number of systems to clean the ocean, it will soon have numerous sources of data-collecting devices measuring the concentration of plastics in the oceans. Therefore, we believe it is timely to develop a method to assimilate incoming real-time observations.
Methods to assimilate plastic concentration observations over a Lagrangian dispersion model are in the early development stage (Lermusiaux et al., 2019). However, earlier studies dealing with data assimilation applied to the atmospheric dispersion of particles around polluting facilities, such as Zheng et al. (2007), have been published.
This paper introduces Ocean Plastic Assimilator v0.2, a numerical scheme developed to assimilate plastic concentration data into 2D Lagrangian dispersion models. Section 2 formulates the method, and Sect. 3 then describes its initial implementation and application. For this proof-of-concept paper, we use a dispersion simulation generated with the OpenDrift framework in a controlled environment based on a double-gyre analytical flow field. The assimilation results are presented in Sect. 4. Real-world application perspectives and future developments that could further improve the method are discussed in Sect. 5. Finally, in Sect. 6, we present a direct application of the method to a dispersion model of the actual Great Pacific Garbage Patch, with simulated observations sampled from another simulation.
This section formulates our methodology to perform data assimilation of plastic concentration (or density) observations in any 2D Lagrangian dispersion model using an ensemble Kalman filter (EnKF). It includes the two representations of data (Eulerian and Lagrangian) being used for this process, the transformation between Eulerian and Lagrangian space, the ensemble assimilation method itself, and model ensemble initialization.
2.1 Representations of data
The distribution of the mass of plastics in a Lagrangian dispersion model is represented by weighted particles drifting according to a flow field in a 2D domain. Each virtual particle represents a drifting concentration of plastics. In turn, virtual concentration measurements are collected at fixed locations (grid points) within the studied 2D domain, i.e., an Eulerian representation of the plastic mass distribution.
Our method aims to assimilate concentration observations collected in the Eulerian representation and update the Lagrangian representation accordingly. One cycle of this process consists of projecting particle weights on the concentration grid, assimilating observation data into the concentration grid, projecting grid cell concentration updates on particle weights, and finally letting particles drift until the next assimilation time step. This procedure is summarized in Fig. 1.
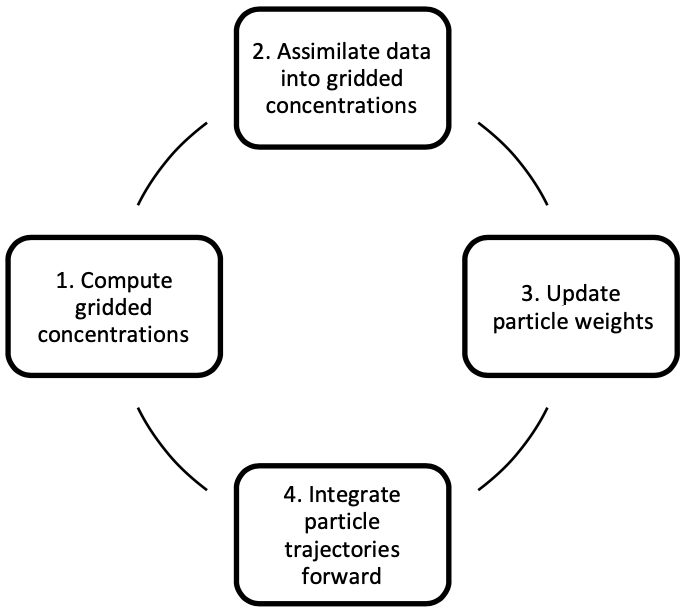
The complete workflow requires the following:
-
an assimilation method,
-
a dispersion model along with the flow field used,
-
projection methods to go back and forth between Eulerian and Lagrangian representations, and
-
prior estimates for model parameters and uncertainties.
2.2 Procedure
This section presents our procedure for a set of Np particles drifting in a gridded domain, with a grid size (m,n) and indices i and j to designate a grid cell. An ensemble Kalman filter works by running different simulations, or ensemble members, simultaneously with variations in model parameters (e.g., initial conditions). We use Ne members in the following.
2.2.1 Projecting weights on densities
At each step t, we define the following:
-
the forecast weights vector of size Np (kg);
-
the forecast density vector computed after projecting on the density grid (kg m−2);
-
yt the density observation vector (kg m−2), with its error covariance matrix R;
-
the analyzed density vector computed by assimilating observations yt in via the ensemble Kalman filter (kg m−2);
-
the analysis weight vector computed by projecting on the corrections computed on (in kg); and
-
the set of particles present at step t in grid cell i,j.
To start, for grid cell i,j with area Ai,j, is computed with the formula
In the following, we omit sub-index t when all the operations are performed at the same time step t.
2.2.2 Assimilating with the ensemble Kalman filter (EnKF)
Our assimilation step relies on the use of ensemble Kalman filtering, as described in Evensen (2003). This method is derived from Kalman filtering and is notably suitable for situations in which the model is not an easily invertible matrix (used in standard Kalman filtering) and one cannot efficiently compute an adjoint (used in extended Kalman filtering).
Standard Kalman filtering allows computing the analysis state using a single equation. In standard Kalman filtering, the forecast state vector xf (in this case, the densities) and the analysis vector xa are linked with
H is the observation matrix that maps the state xf to the observation space of y.
The Kalman gain matrix K is defined by the following equation.
R is the observation error covariance matrix. Pf is the forecast error covariance matrix. When using a Kalman filter, Pf is in principle meant to be computed from the previous state by application of the forward integration matrix operator, but this is generally too computationally expensive and impractical. Here, we use ensemble Kalman filtering, whereby the Pf matrix computation is approximated by relying on an ensemble of simulations.
Ensemble members are different instances of our simulation with different initializations. For ensemble member , we write the forecast state vector and the ensemble average:
Accordingly, the computation of Pf can be accomplished using the formula
Each ensemble member k is then updated using Eq. (2) with xk instead of x.
2.2.3 Projecting the density updates on particles
Several ways of projecting the density updates (step 3 in Fig. 1) can be thought of. In the Ocean Plastic Assimilator v0.2, we simply choose to update the weights by uniformly distributing the density correction ratio of a grid cell i,j among the particles in the same box using this formula:
In this equation, (xf)i,j cannot be null when a grid cell i,j contains particles (see Eq. 1) unless all particles have null weights. While extremely unlikely (we did not encounter this phenomenon during our numerous tests), particles with exactly null weights have to be taken out of the simulation.
This heuristic was chosen primarily for its simplicity and its computational efficiency. The multiplicative approach also tends to prevent computing negative weights if the density analysis is lower than the density forecast.
Finally, for step 4 in Fig. 1, since the dispersion model changes particles' positions but not their weights when integrating, the forecast weights at time t+1 are
2.2.4 Initialization
As stated by Evensen (2003) the ensemble Kalman filter requires the initial ensemble to sample the uncertainty in variables that we want to update with data assimilation. In this article, we focus on our method's ability to compute the correct total mass of particles drifting. For this reason, we normally distribute the members' initial total masses with a mean μe and standard deviation σe. If we write Mk the initial total mass for ensemble member k, we thus have
Finally, we attribute an initial weight of to each particle.
This section presents the Python implementation of the aforementioned method, called Ocean Plastic Assimilator (v0.2). We then describe the Lagrangian dispersion model (OceanDrift) used to generate double-gyre dispersion simulations and the experiments created with it to observe how our method performs in a controlled environment.
3.1 Python implementation of the Ocean Plastic Assimilator
This first implementation is coded in Python (see Peytavin, 2021a, for the repository). It is meant as a stand-alone program using dispersal model output data as input, formatted as a NetCDF4 dataset containing particle coordinates in a given space and time domain, along with their weights. It is assumed that the advection in the dispersion model does not depend on particle masses. In the more general case, one would have to run the model again after each assimilation time step, as a change of a particle mass could change its future trajectory.
Once loaded, the input weights are duplicated in Ne arrays, and the program runs the assimilation scheme presented in the previous section in a time loop, taking observations from an input data frame at each time step. The assimilator can also take one additional dispersion simulation output from which it samples observations to assimilate at each time step. This is the approach used in the following test case.
This implementation leverages the use of arrays and the fact that we only use one simulation for all ensemble members to perform vectorized computations for the computation of Pf in Eqs. (1) and (6). It also allows computing only once for all ensemble members. Some parts of the algorithm are also executed with the just-in-time compiler Numba (see Lam et al., 2015) in order to run faster.
This implementation allows our algorithm to perform each following test case with repeated assimilation of two observation points during 2000 time steps in a (60,40) gridded domain in less than 30 min on a modern laptop using about 3 GB of storage and 2 GB of RAM.
Running the assimilator on a dispersion output and not inside a dispersion model allows it to work on outputs from different models, as long as the data are appropriately formatted. Future implementations could also offer the option of running online (i.e., embedded inside a dispersion model), which could allow more flexibility and possibilities, as discussed in Sect. 6.2.3.
3.2 Double-gyre plastic dispersion using the OceanDrift model
In order to create our test cases, we first need a dispersion model and a flow field. We chose the OceanDrift model from the Norwegian Lagrangian trajectory modeling framework OpenDrift (see Dagestad et al., 2018). It was chosen mainly for its simplicity and the fact that OpenDrift embeds a module to generate a dispersion based on a 2D double-gyre flow field.

Figure 2Generated particles (a) in a double-gyre flow field with OpenDrift and the corresponding plastic concentration field in particles per grid area (b). The domain grid size is 60×40.
This field consists of two gyres periodically moving closer then farther away in an enclosed area. It is a simple field but complex enough to stir and disseminate particles and is regularly used as a standard case to study time-varying flows, for example in Guo et al. (2018). The evolving currents are generated using an analytical field1. The equations generating this 2D, time-varying, deterministic field are as follows.
The dimensionless domain size for these equations is .
Parameter A is the circulation amplitude, ω is the frequency of oscillation of the gyres, and ϵ is the amplitude of the gyre oscillation relative to the steady state.
Particles are then generated and advected using the OceanDrift Lagrangian model from the Norwegian trajectory modeling framework OpenDrift (Dagestad et al., 2018). Figure 2 shows such a dispersion and the associated concentration field.
Thus, we can generate different dispersion simulations by changing the initial particle position seed, which changes the distribution of particle trajectories and the initial masses of the particles. We can also change the flow field parameters A, ω, and ϵ.
In the following section, we modify the flow field parameters and the particle position seeds to create assimilation test cases that use two simulations: a reference and a forecast. We then sample observations from the reference simulation and assimilate them inside the forecast simulation. By doing so, we mimic assimilating real concentration data into an uncertain flow field in the presence of model error.
3.3 Assimilation experiment setup
In order to assess and quantify the efficacy of the assimilator in different cases, we designed two experiments.
The first one aims to verify that, when the forecast flow field reproduces the reference flow field accurately, our implemented scheme can correct an incorrect total mass guess. It also intends to check that the estimate gets better when the observation error gets lower, as one would generally expect.
The second experiment aims to assess the assimilator's behavior and efficacy when the forecast flow field is slightly different from the reference by changing the double-gyre parameters A and ϵ.
In both experiments, we run several test cases to assimilate observations taken from a reference simulation into a forecast simulation using the assimilator. Then, we compute the total plastic mass estimation error and the concentration field root mean square error (RMSE) to assess how close the assimilated forecast gets to the reference situation. This procedure is depicted in Fig. 3.
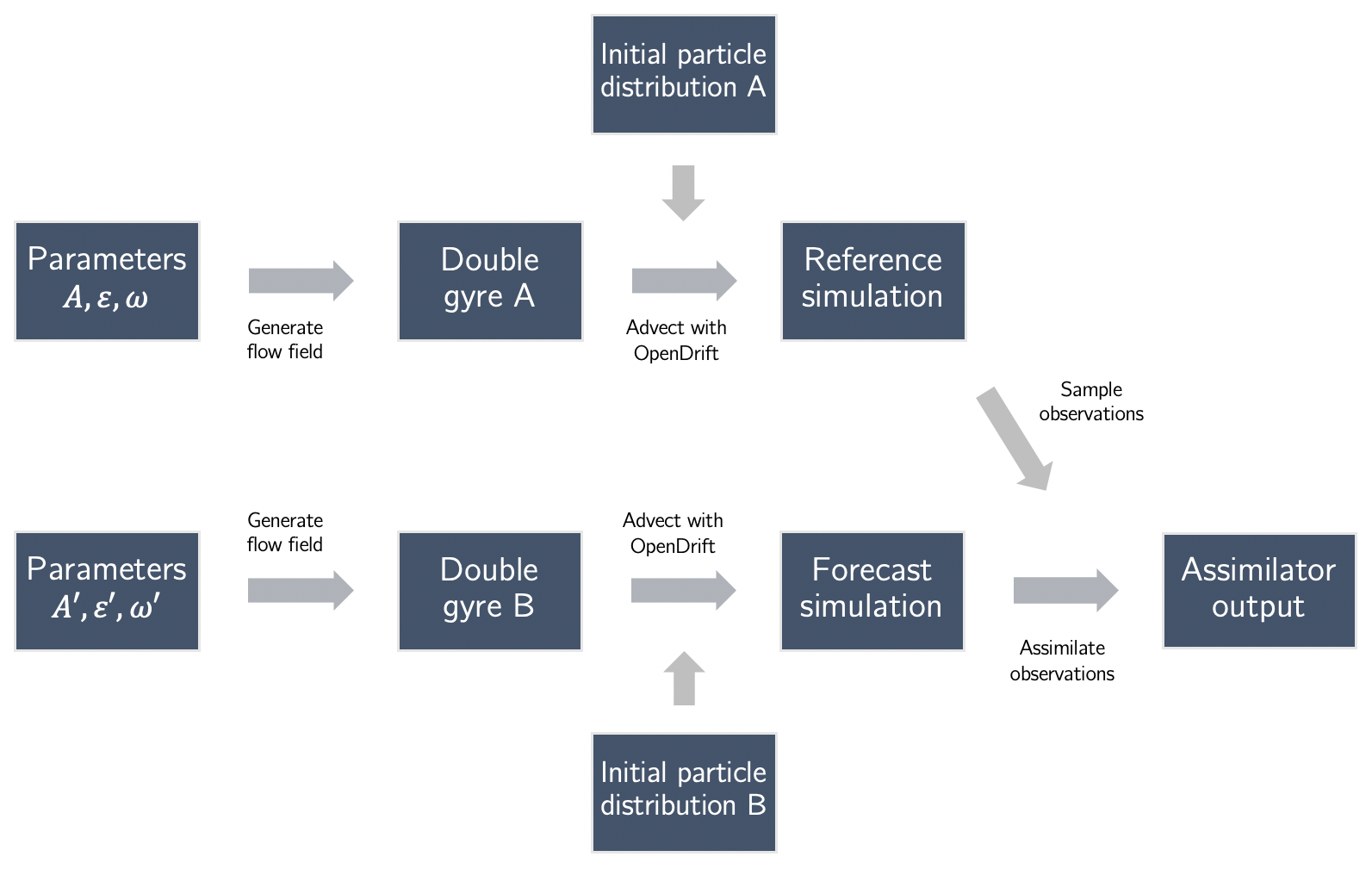
In each test case, the Ocean Plastic Assimilator is executed over the course of 2000 time steps. The double-gyre size, which is , is dimensionless; this means that the time step is dimensionless too. However, if the flow field was the size of the Great Pacific Garbage Patch, then with A=0.1 the time step would be of the order of a day.
Over the double gyre, we define a gridded domain of size (60,40) and select two fixed observation points to run each assimilation test case. This sampling pattern can be thought of as representing a set of moorings that one may deploy in the real ocean. H is defined as a matrix that subsets (x)i,j to two points of observations.
For the ith point, the measurement is simulated by adding a random error to xi such as
To compute matrix R, we choose to model the observation error as a sum of an additive error σ0 and a multiplicative relative error σrel. As such, with yi the value measured at the ith observation point is
In the following, unless specified otherwise, we use Ne=10, σe=0.05, Np=25 000, σ0=0.1, and σrel=1 %. The coordinates of the two observation points are the following pairs: .
4.1 Estimating the total plastic mass in the forecast
In this first experiment, we want to assess the ability of our newly implemented scheme to estimate the total mass of plastics in the reference simulation correctly.
First, we generate a reference situation using ϵ=0.25, A=0.1, and . We input the same parameters to integrate the particle trajectories in the forecast simulation. By doing so, we are in a position where we understand the flow of the reference situation correctly, but we do not know the total mass of plastics drifting. In the following, Mref=25 000 is the constant total mass of the reference situation.
We initiate five different forecasts with μe=0.25Mref, 0.5Mref, Mref, 2Mref, and 5Mref. Observations are collected (and later assimilated) at each time step on two observation points that could, for example, represent a pair of moored instruments.

Figure 4Evolution of total mass over time for five different forecast simulations with five different initial total masses (Table 1) over 100 assimilation iterations (a) and 2000 iterations (b). The total mass evolution of the reference simulation is indicated by a solid line.
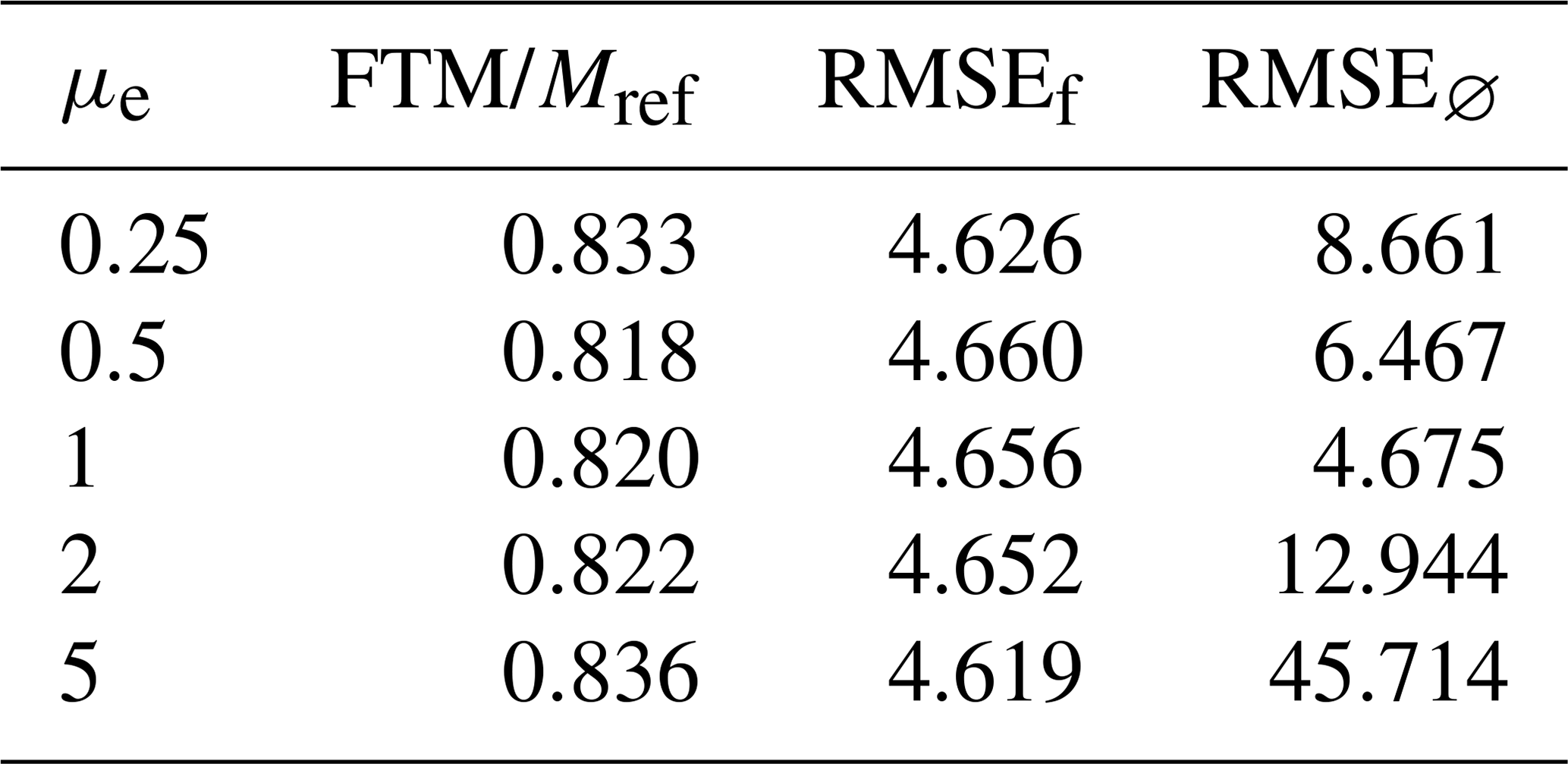
Figure 4 shows the evolution of the forecast total mass for each simulation. Forecasts starting with an initial total mass lower than approximately 0.82Mref have their total mass rise, while those starting with higher total mass have their total mass fall. Final total plastic masses in the forecast after 1900 steps of assimilation for each simulation are presented in Table 1. Overall, the forecast total masses seem to converge towards a similar value of approximately 0.82Mref, from which we can conclude that in this situation the method makes an 18 % error.
Table 1Final total mass (FTM) relative to Mref and the concentration field RMSE for five different forecast simulations with five different initial total masses μe. RMSEf and RMSE∅ are the concentration field RMSE at the end of simulations with and without assimilation of observations.
Another indicator of the correctness of a simulation can be computed from the concentration field at each step. For one of the forecasts (with μe=2), we analyze the distribution of concentration errors over the gridded domain and through time (Fig. 5). We observe a decrease in the mean absolute percentage error and a decrease in the absolute percentage error standard deviation. We also observe that this distribution does not contain overly large values.
We also compute the concentration field root mean square error (RMSEf) at the end of the simulation after assimilating and RMSE∅ at the end of a simulation with no assimilation. Values in Table 1 indicate a clear improvement of the RMSE when the initial total mass was erroneous and a stable one compared to no assimilation when the initial total mass was correct.
Overall, this points to an improvement in the forecast concentration field over time, thanks to data assimilation.
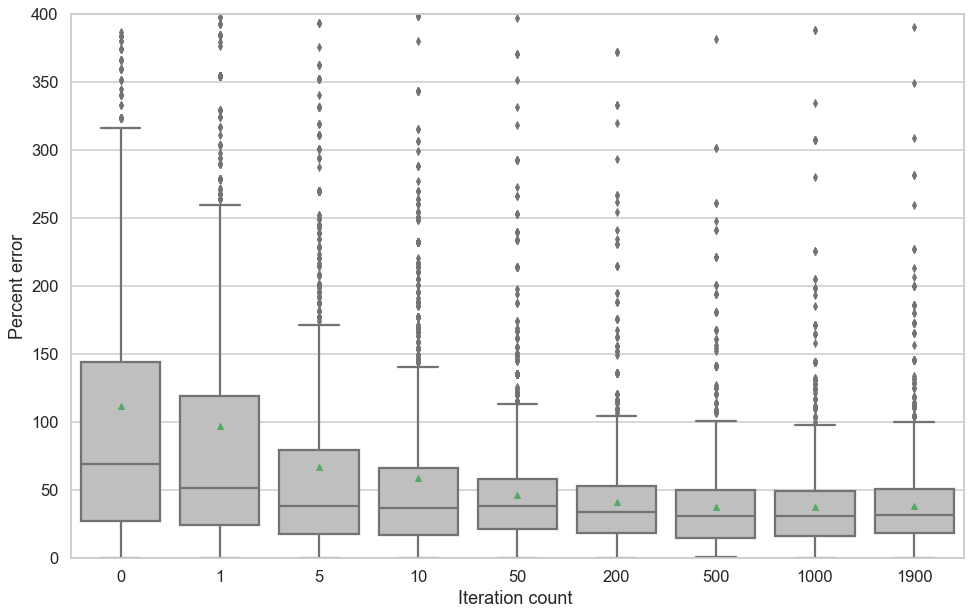
Figure 5Evolution of the error field between the reference concentration field and the forecast concentration field, in percent, for μe=2. At each time step, the error field is computed and the distribution of the absolute errors in each cell, in percent of the cell reference concentration, is depicted in the box plots. Dots outside whiskers represent outliers, and the triangle is the mean.
Finally, in order to assess the method accuracy depending on observation errors, we set μe=2 and run simulations with different values of σrel. FTM and RMSE are then computed and presented in Table 2.
Table 2Parameters and metrics for assimilation simulations with different values of σrel, with μe=2. FTM is the final total mass, and RMSEf and RMSE∅ are the concentration field RMSE at the end of simulations with and without assimilating.
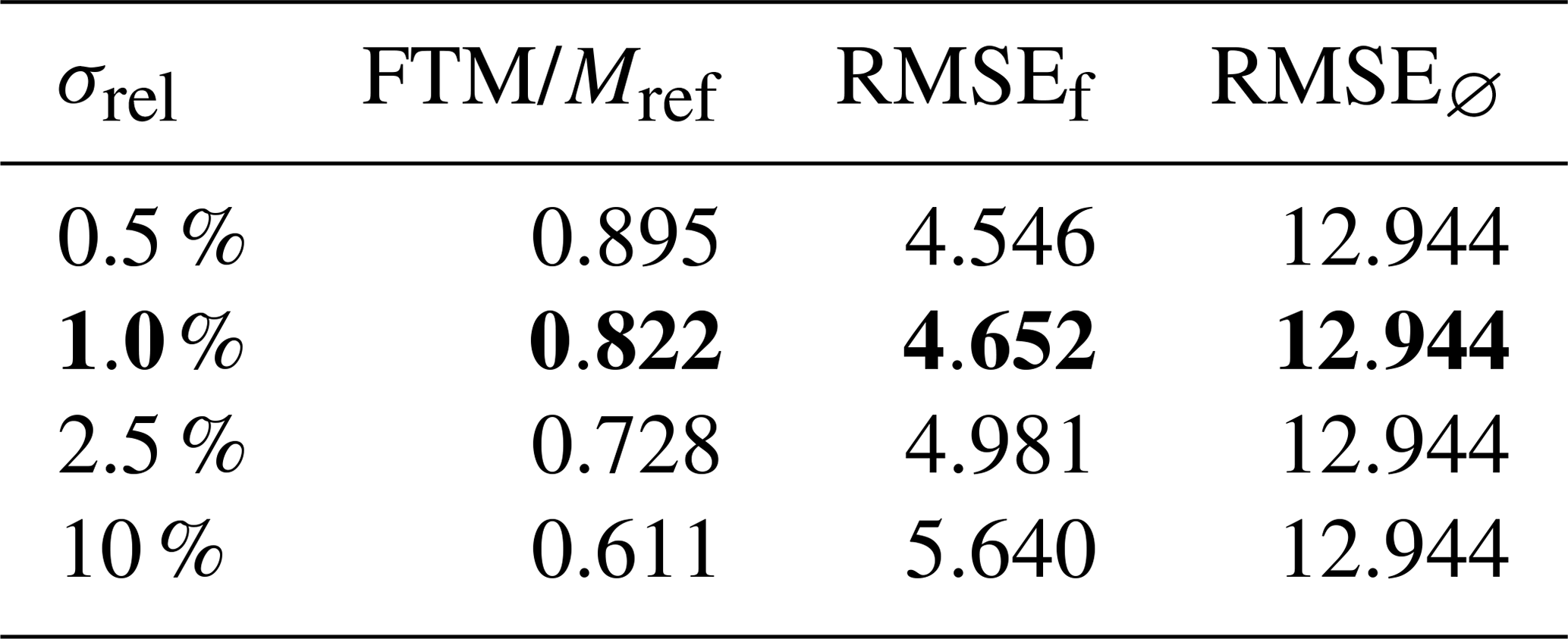
We find that decreasing σrel increases the final total mass of the forecast, getting it closer to 1, while the RMSE decreases. This demonstrates that the forecast bias can be reduced by decreasing the observation error, as one would usually expect of a data assimilation method.
4.2 Impact of physical model errors
In this second experiment, we change the parameters used to generate the currents of the reference simulation double gyre. For example, the impact of a modification of ϵ on the generated flow field is illustrated in Fig. 6. By assimilating observations from reference situations with different double-gyre parameters, we can observe the effects of having an erroneous physical dispersion model when assimilating data.
We initiate the forecast with an erroneous initial total mass of 2Mref and expect that the best total mass predictions will arise from assimilation simulations with the closest flow field.

Figure 6Flow fields at t=2.5 s for two double-gyre simulations with (a) ϵ=0.1 and (b) ϵ=0.5.
The forecast simulation is generated using ϵref=0.25, Aref=0.1, and .
We then generate different reference simulations with different values of A and ϵ, and we try assimilating observations sampled from each of them into the forecast.
We find that data assimilation remains effective and that simulations run with values of ϵ and A closer to ϵref and Aref lead to better estimations of the total mass and concentration field after some time as one might expect (Fig. 7 and Table 3).
Table 3Parameters and metrics for simulations with different values of A and ϵ for the reference simulation. FTM is the final total mass, and RMSEf and RMSE∅ are the concentration field RMSE at the end of simulations with and without assimilating.
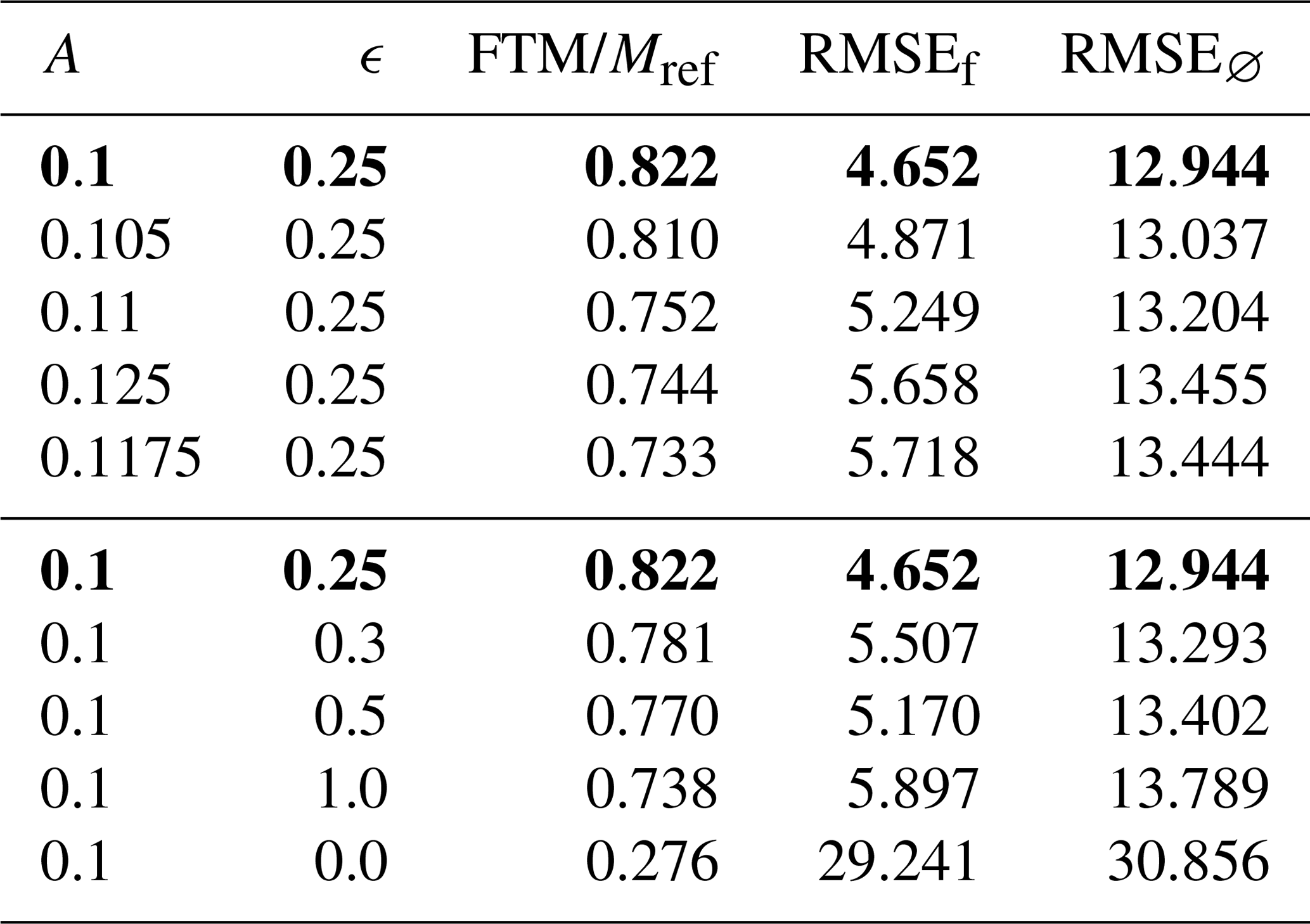
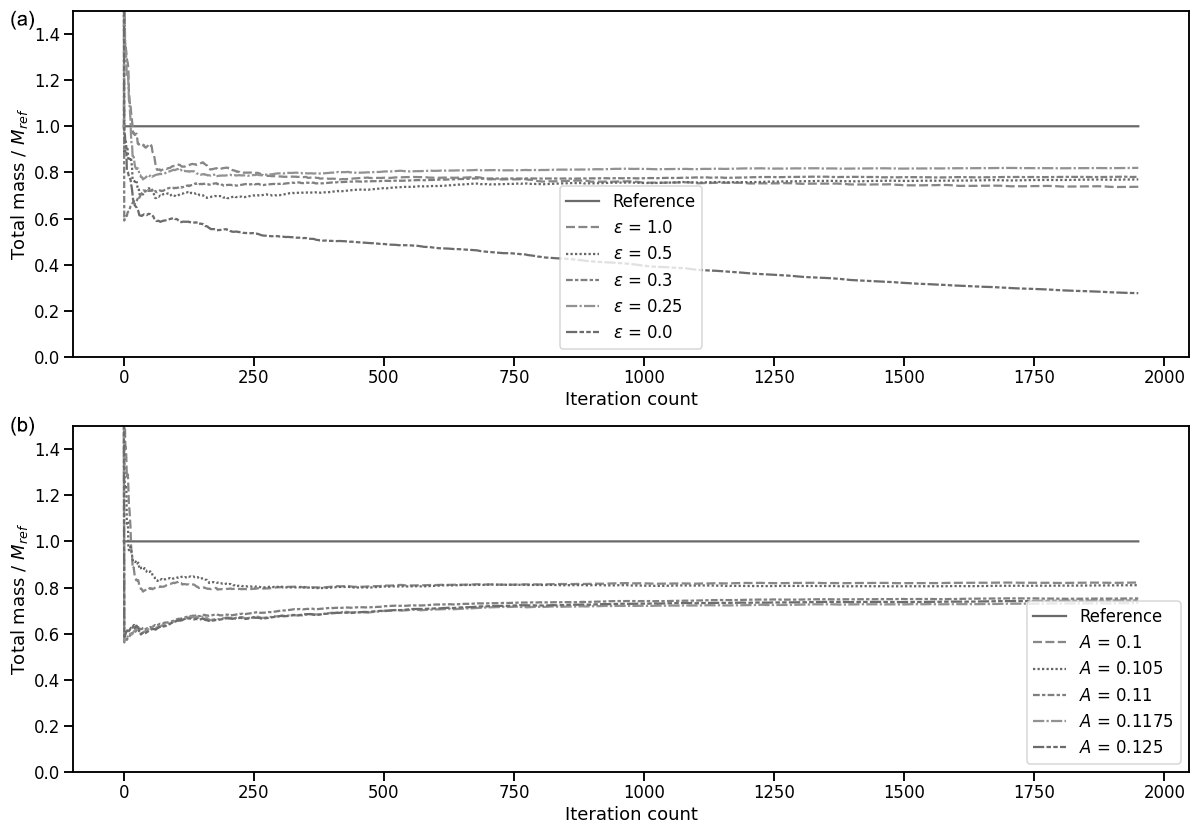
Figure 7Evolution of the total plastic mass in the forecast simulation for five different runs with varying values of double-gyre parameters A and ϵ, along with the total plastic mass in the reference simulation.
This result illustrates that the assimilation method can be robust to unknown model errors.
In this section, we present an application to real-world global dispersion models. As before, we sample observations from one simulation and assimilate them into another in order to mimic the assimilation of observations that could be collected daily by a pair of moorings deployed in the real ocean. We just use an estimate of real ocean currents in place of the simplified double gyre defined in Eq. (9).
We generate two global dispersion simulations with the Lagrangian dispersion model presented by Lebreton et al. (2012). In both cases, the circulation model uses output from the HYbrid Coordinate Ocean Model (see Bleck, 2002), available every 6 h at 0.08∘. This estimate includes Ekman transport and convergence, as well as mesoscale eddies. The first simulation has particles seeded along the coasts of 192 countries depending on reported garbage input estimates. The second simulation has particles seeded at river mouths only based on estimates of their outflow of plastics. Both generation models are described in the Supplement of Lebreton et al. (2018). A model spin-up was done from 1993 to the end of 2011.
We initialize plastic particle masses generated in the coastal-seeded model depending on their release year. If x is the time spent (in fraction of years) since the beginning of the simulation, then is the mass of particles, in tonnes, seeded at time x. This formula increments particle masses by 1 t each new release year, with some periodic variability. The particle masses in the river-seeded simulation are initialized to 1 t regardless of their release date. By doing so, we mimic a situation in which we underestimate the yearly increase in plastic mass input to the ocean.
The gridded domain has a resolution of 0.5∘, with 80 by 44 points, going from 165 to 125∘ W and from 23 to 45∘ N. Throughout 2012, we sample two observations per day at positions 152.5∘ W, 29∘ N and 140∘ W, 35∘ N from the coastal-seeded dispersion simulation and assimilate them in the river-seeded dispersion model. We use Ne=10, σe=50, Np=25 000, σ0=0.1, and σrel=1 %.
Our method is able to predict the total mass of floating plastics with a 17 % error and to divide the concentration field RMSE by 4 (Fig. 8). The computations take about an hour to run on a standard laptop.
The updates to the concentration field are presented in Fig. 9, which shows that, as expected, the assimilated forecast has increased concentrations.
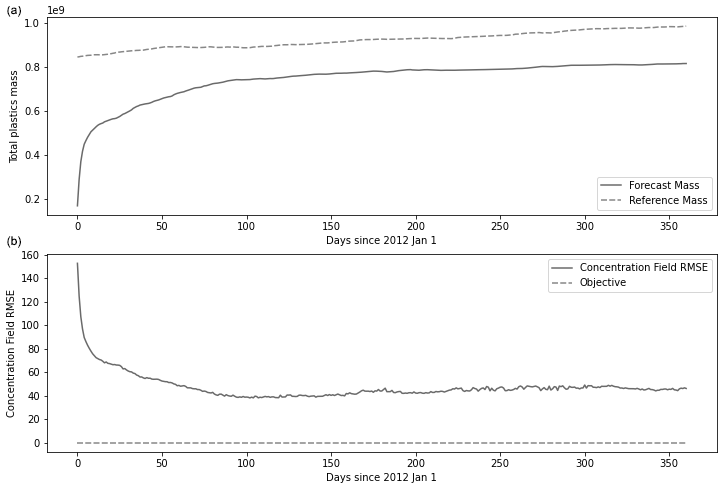
Figure 8(a) Evolution of total plastic mass in the domain through 2012 for the reference simulation and the forecast simulation. (b) Evolution of the concentration field RMSE in the assimilation domain through the year 2012.
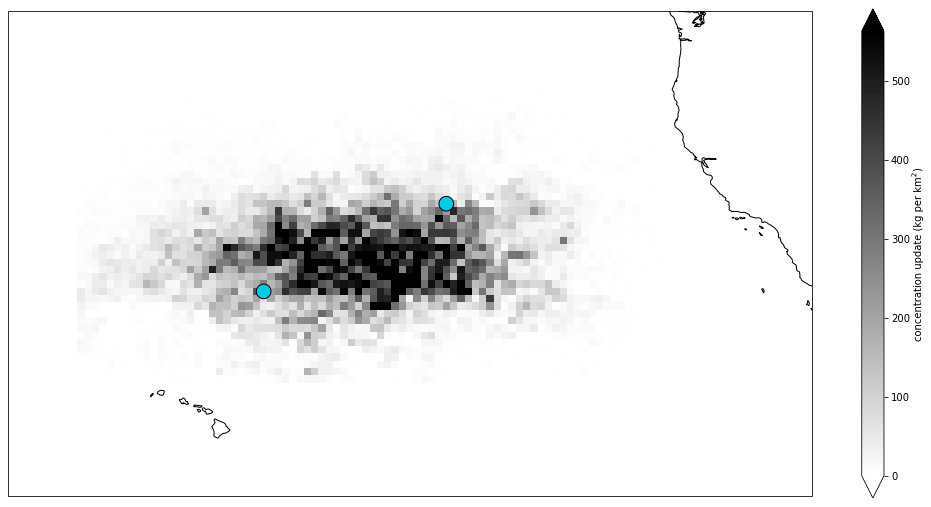
Figure 9Concentration field updates at the end of the assimilation cycle, with the two observation locations in blue. This field is the difference between the forecast concentration field at the end of the year 2012 with assimilation and the same without assimilation.
Further experimentation will be required to assess the benefits of using this method in real-world use cases with real data. However, these results confirm the potential skill of our method, even in the presence of sizable model error.
6.1 Towards an application to real-world data
In this proof-of-concept paper, we placed ourselves in a controlled environment to assess the efficacy of the method. In the future, our goal will be to eventually apply the method to real data by replacing the simulated reference situation observations with real-world observations, and the previous results can help in understanding what might happen in assimilating real-world data. The fact that replacing the analytic circulation field by a real-world one (in Sect. 5) did not prevent the method from improving the forecast is viewed as an encouraging first step in that direction.
In Fig. 7a and b we observed that the more accurate the underlying dispersion model is, the more accurate the assimilation result is. For our method to be applied successfully to a real global plastic assessment model, its dispersion prediction would have to be accurate enough. Ongoing work, which is focused on identifying model error sources and refining statistical priors, should benefit the planned application to real data (e.g., Maximenko et al., 2012; van Sebille et al., 2020; Meijer et al., 2021).
Conveniently, we observed that the forecast total mass gets higher when the dispersion model is more accurate, thus acting, in a way, like a score. As a result, we might discriminate between dispersion models based on this method's output by selecting the ones that output the highest total mass.
6.2 Future developments
Amongst the potential applications of the presented method, one might highlight the evaluation and design of real observational strategies. Here we considered one hypothetical, albeit plausible, scenario which might represent the deployment of a few relatively accurate moorings. In future studies it would be interesting to investigate how data coverage in space and time may affect forecast skill in more detail, for example, or use this data assimilation system as a benchmark for proposed field campaigns. Several directions to further develop the method and make it more accurate also seem worth considering, as outlined below.
6.2.1 Improving the filter
Throughout the last 2 decades, the ensemble Kalman filter has been extensively developed and improved, with numerous variants published in the scientific literature. Using different ensemble sampling strategies or a square root algorithm was described as a way to improve accuracy in Evensen (2004). Other solutions include inflating the ensemble before assimilating (see Anderson, 2007), resampling the ensemble, or using a method to assimilate observations locally by adding a Schur product with a so-called correlation matrix in the computation of the Kalman gain in Eq. (3) (see Houtekamer and Mitchell, 2002). Assimilating locally around observation locations could also have the advantage of further improving the geography of the concentration field, which would translate in reduced values of RMSEf.
6.2.2 Decoupling the positions of the particles for all ensemble members
The method presented here uses the same dispersion simulation as a base for the trajectories of the particles for all ensemble members. In all members, the particle positions through time are the same; the only variables that differ are the particle masses. In particular, the particle trajectories are the same in each member. This approach greatly reduces the storage cost and increases computation speed.
However, it significantly lowers the diversity of the ensemble, so in future work one might want to decouple the ensemble member trajectories, i.e., have a unique set of trajectories for each member. We anticipate that extending the method to use an ensemble with diverse particle simulations should help the forecast converge towards a concentration field closer to the reference one. We regard this possibility as a leading candidate to make the method even more accurate.
6.2.3 Studying other projection operators
In Sect. 2.2.3, we presented a simple way to update particle weights after assimilating density observations through Eq. (6). Different possibilities for performing this step have been thought of, some of which we think may be worth investigating further. Another simple approach would be to apply an additive correction instead of the multiplicative correction used in Eq. (6):
This approach was not favored in this first study, as it seemed more likely to generate negative weights more often.
Another alternative would be to generate new particles so that their weights sum up to the updated density, possibly fewer or more particles. This could be more technically challenging to implement and requires implementing the assimilation scheme directly inside the dispersion model loop. However, it could also have the advantage of conveniently increasing resolution where there are high concentrations of plastics.
This paper presents a simple yet readily effective method to assimilate observations of plastic concentration data into a Lagrangian dispersion model and its first implementation called the Ocean Plastic Assimilator (v0.2). We apply it in a controlled environment to assess its efficacy. We study the impact of observation errors on the prediction accuracy and changed some of the dispersion parameters (A and ϵ) to evaluate the impacts of model errors. Finally, we apply the method to a more realistic case with a real-world circulation field and find that the method still performs well. The encouraging results indicate that it is an excellent candidate to perform data assimilation with real-world data over ocean gyres.
Thus, the Ocean Plastic Assimilator will be further developed at The Ocean Cleanup to assimilate plastic concentration data from the oceans and improve our cleanup operations in oceanic gyres. This method will undergo more research to develop its features and assess its efficacy when using real-world observations. We expect it to be used to assess the cleanup operations of The Ocean Cleanup in real time.
The simplicity of the developed data assimilation method means that it should be easy to generalize to various other popular open-source Lagrangian frameworks such as OceanParcels (Delandmeter and van Sebille, 2019) or MITgcm (Campin et al., 2020). Porting the data assimilation procedure to the Julia language is also being envisioned whereby one could leverage the newly developed IndividualDisplacements.jl package to carry out Lagrangian simulations of plastic concentrations (Forget, 2021).
The current version of Ocean Plastic Assimilator is available from the github repository: https://github.com/TheOceanCleanup/OceanPlasticAssimilator (last access: 28 July 2021) under the GNU General Public Licence v3.0. The version of the model used to produce the results presented in this paper is archived on Zenodo (Peytavin, 2021a, https://doi.org/10.5281/zenodo.4740408), as are the input data to run the model and the raw data presented in this paper (Peytavin, 2021b, https://doi.org/10.5281/zenodo.4740138). The code repository contains a Python notebook that allows for the download of necessary data to reproduce the presented experiments.
BSR conceived and presented to AP the idea of applying data assimilation to a dispersal model. AP studied the data assimilation literature and suggested using an ensemble Kalman filter. AP wrote and maintained the code and applied it initially to real oceanic data. JMC introduced AP to GF, and GF with BSR recommended applying the method to an analytical flow field to assess its performance. AP structured the paper, wrote the initial draft and the next versions, and prepared figures. GF and AP met every 2 weeks or so to discuss the paper as AP was writing it. GF provided advice on tweaking the method and improving the paper. BSR and JMC were sometimes also present to provide advice during these meetings.
The authors declare that they have no conflict of interest.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Axel Peytavin and Bruno Sainte-Rose would like to thank The Ocean Cleanup and all its funders for supporting them. The authors acknowledge the reviewers for their careful reading of our paper and their comments.
This research has been supported by The Ocean Cleanup, NASA-IDS (award no. 80NSSC20K0796), NASA-PO (award no. 80NSSC17K0561), and the Simons Foundation (award no. 549931).
This paper was edited by Volker Grewe and reviewed by Erik van Sebille and one anonymous referee.
Anderson, J.: An adaptive covariance inflation error correction algorithm for ensemble filters, Tellus A, 59, 210–224, https://doi.org/10.1111/j.1600-0870.2006.00216.x, 2007. a
Bleck, R.: An oceanic general circulation model framed in hybrid isopycnic-Cartesian coordinates, Ocean Model., 37, 55–88, https://doi.org/10.1016/S1463-5003(01)00012-9, 2002. a, b
Campin, J.-M., Heimbach, P., Losch, M., Forget, G., edhill3, Adcroft, A., amolod, Menemenlis, D., dfer22, Hill, C., Jahn, O., Scott, K., stephdut, Mazloff, M., Fox-Kemper, B., antnguyen13, E., D., Fenty, I., Bates, M., AndrewEichmann-NOAA, Smith, T., Martin, T., Lauderdale, J., Abernathey, R., samarkhatiwala, hongandyan, Deremble, B., dngoldberg, Bourgault, P., and Dussin, R.: MITgcm/MITgcm: mid 2020 version (Version checkpoint67s), Zenodo, https://doi.org/10.5281/zenodo.3967889, 2020. a
Dagestad, K.-F., Röhrs, J., Breivik, Ø., and Ådlandsvik, B.: OpenDrift v1.0: a generic framework for trajectory modelling, Geosci. Model Dev., 11, 1405–1420, https://doi.org/10.5194/gmd-11-1405-2018, 2018. a, b
Delandmeter, P. and van Sebille, E.: The Parcels v2.0 Lagrangian framework: new field interpolation schemes, Geosci. Model Dev., 12, 3571–3584, https://doi.org/10.5194/gmd-12-3571-2019, 2019. a
Evensen, G.: The Ensemble Kalman Filter: theoretical formulation and practical implementation, Ocean Dynam., 53, 343–367, https://doi.org/10.1007/s10236-003-0036-9, 2003. a, b
Evensen, G.: Sampling strategies and square root analysis schemes for the EnKF, Ocean Dynam., 54, 539–560, https://doi.org/10.1007/s10236-004-0099-2, 2004. a
Forget, G.: IndividualDisplacements.jl: a Julia package to simulate and study particle displacements within the climate system, J. Open Source Softw., 6, 2813, https://doi.org/10.21105/joss.02813, 2021. a
Guo, H., He, W., and Seo, S.: Extreme-Scale Stochastic Particle Tracing for Uncertain Unsteady Flow Visualization and Analysis, IEEE T. Vis. Comput. Gr., 25, 2710–2724, https://doi.org/10.1109/TVCG.2018.2856772, 2018. a
Houtekamer, P. and Mitchell, H.: A Sequential Ensemble Kalman Filter for Atmospheric Data Assimilation, Mon. Weather Rev., 129, 123–137, https://doi.org/10.1175/1520-0493(2001)129<0123:ASEKFF>2.0.CO;2, 2002. a
Lam, S., Pitrou, A., and Seibert, S.: Numba: a LLVM-based Python JIT compiler, Association for Computing Machinery, New York, NY, United States, 1–6, https://doi.org/10.1145/2833157.2833162, 2015. a
Lebreton, L.-M., Greer, S., and Borrero, J.: Numerical modelling of floating debris in the world’s oceans, Mar. Pollut. Bul., 64, 653–661, https://doi.org/10.1016/j.marpolbul.2011.10.027, 2012. a, b, c
Lebreton, L.-M., Slat, B., Ferrari, F., Sainte-Rose, B., Aitken, J., Marthouse, R., Hajbane, S., Cunsolo, S., Schwarz, A., Levivier, A., Noble, K., Debeljak, P., Maral, H., Schoeneich-Argent, R., Brambini, R., and Reisser, J.: Evidence that the Great Pacific Garbage Patch is rapidly accumulating plastic, Sci. Rep.-UK, 8, 4666, https://doi.org/10.1038/s41598-018-22939-w, 2018. a, b, c
Lermusiaux, P. F. J., Flier, G. R., and Marshall, J.: Plastic Pollution in the Coastal Oceans: Characterization and Modeling, in: OCEANS 2019, 1–10, MTS/IEEE, Seattle, USA, 2019. a
Maximenko, N., Hafner, J., and Niiler, P.: Pathways of marine debris derived from trajectories of Lagrangian drifters, Mar. Pollut. Bull., 65, 51–62, https://doi.org/10.1016/j.marpolbul.2011.04.016, 2012. a
Meijer, L. J. J., van Emmerik, T., van der Ent, R., Schmidt, C., and Lebreton, L.: More than 1000 rivers account for 80 % of global riverine plastic emissions into the ocean, Sci. Adv., 7, 18, https://doi.org/10.1126/sciadv.aaz5803, 2021. a
Peytavin, A.: TheOceanCleanup/OceanPlasticAssimilator: Version 0.2: Improved usability, additional plots, bugfixes, added license [code], Zenodo, https://doi.org/10.5281/zenodo.4740408, 2021a. a, b
Peytavin, A.: Assimilation of Plastics Concentration Data into Lagrangian Dispersion Models: Data Archive [data set], Zenodo, https://doi.org/10.5281/zenodo.4740138, 2021b. a
van Sebille, E., Wilcox, C., and Lebreton, L.-M.: A global inventory of small floating plastic debris, Environ. Res. Lett., 10, 12, https://doi.org/10.1088/1748-9326/10/12/124006, 2015. a
van Sebille, E., Aliani, S., Law, K. L., Maximenko, N., Alsina, J. M., Bagaev, A., Bergmann, M., Chapron, B., Chubarenko, I., Cózar, A., Delandmeter, P., Egger, M., Fox-Kemper, B., Garaba, S. P., Goddijn-Murphy, L., Hardesty, B. D., Hoffman, M. J., Isobe, A., Jongedijk, C. E., Kaandorp, M. L. A., Khatmullina, L., Koelmans, A. A., Kukulka, T., Laufkötter, C., Lebreton, L., Lobelle, D., Maes, C., Martinez-Vicente, V., Maqueda, M. A. M., Poulain-Zarcos, M., Rodríguez, E., Ryan, P. G., Shanks, A. L., Shim, W. J., Suaria, G., Thiel, M., van den Bremer, T. S., and Wichmann, D.: The physical oceanography of the transport of floating marine debris, Environ. Res. Lett., 15, 023003, https://doi.org/10.1088/1748-9326/ab6d7d, 2020. a
Zheng, D., Leung, J., and Lee, B.: Data assimilation in the atmospheric dispersion model for nuclear accident assessments, Atmos. Environ., 41, 2438–2446, https://doi.org/10.1016/j.atmosenv.2006.05.076, 2007. a
https://shaddenlab.berkeley.edu/uploads/LCS-tutorial/examples.html#Sec7.1 (last access: 26 July 2021).
- Abstract
- Introduction
- Method
- Implementation and test-case setup
- Results
- Application to the Great Pacific Garbage Patch
- Discussion and perspectives
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Method
- Implementation and test-case setup
- Results
- Application to the Great Pacific Garbage Patch
- Discussion and perspectives
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References