the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 11 Dec 2019
| 11 Dec 2019
Algorithmic differentiation for cloud schemes (IFS Cy43r3) using CoDiPack (v1.8.1)
Manuel Baumgartner
Max Sagebaum
Nicolas R. Gauger
Peter Spichtinger
André Brinkmann
Numerical models in atmospheric sciences not only need to approximate the flow equations on a suitable computational grid, they also need to include subgrid effects of many non-resolved physical processes. Among others, the formation and evolution of cloud particles is an example of such subgrid processes. Moreover, to date there is no universal mathematical description of a cloud, hence many cloud schemes have been proposed and these schemes typically contain several uncertain parameters. In this study, we propose the use of algorithmic differentiation (AD) as a method to identify parameters within the cloud scheme, to which the output of the cloud scheme is most sensitive. We illustrate the methodology by analyzing a scheme for liquid clouds, incorporated into a parcel model framework. Since the occurrence of uncertain parameters is not limited to cloud schemes, the AD methodology may help to identify the most sensitive uncertain parameters in any subgrid scheme and therefore help limiting the application of uncertainty quantification to the most crucial parameters.
- Article
(1413 KB) - Full-text XML
- BibTeX
- EndNote





Modeling the atmosphere is a highly non-trivial task due to the multiscale and multicomponent nature of the atmospheric flow, where multiple physical processes on different length and timescales interact simultaneously (Orlanski, 1975). One particular result of the interaction of such processes is regularly observed in the sky: clouds appear and disappear. The evolution of a cloud (see, e.g., Lamb and Verlinde, 2011, for an in-depth treatment of cloud evolution) starts on the length scale of a few nanometers, where aerosol particles get wetted by ambient water vapor leading to the formation of haze particles. If thermodynamic conditions are fulfilled, i.e., the (relative) humidity is large enough, the haze particles grow further to become cloud droplets with typical diameters of about 10–30 µm. This growth process is described by combining Maxwell and Köhler theories (Rogers and Yau, 1989; Devenish et al., 2012; Köhler, 1936; Maxwell, 1877). Collisions of the cloud droplets eventually lead to rain drops with sizes up to larger than 100 µm (see, e.g., Devenish et al., 2012; Grabowski and Wang, 2013, for a discussion including turbulence effects). Due to their weight, rain drops fall out of the cloud and form precipitation. Since all phase transitions are connected with the release or consumption of latent heat, the formation and evaporation of a cloud can affect the ambient atmospheric flow by modifying local buoyancy (see, e.g., Cotton et al., 2010). However, all aforementioned cloud processes are microphysical processes and not resolved in numerical models, in particular not in the operational models used for weather forecasts. In these models, the cloud itself is not resolved and instead considered as a subgrid process, calling for a representation of the impact of the cloud by using so-called “parameterizations” or “cloud schemes” (see, e.g., Khain et al., 2000). These schemes take the values of the resolved fields as input and compute the feedback of the unresolved process as an output.
In the literature, many cloud schemes are formulated as one- or two-moment schemes, predicting the mass mixing ratio and, in the case of a two-moment scheme, also the number concentration of the cloud species considered in the scheme (Khain et al., 2015), e.g., the number of cloud droplets per unit mass of dry air. However, at the moment no universal governing equation is available to describe the evolution of a cloud across all involved scales, explaining the existence of different formulations of the cloud processes. In addition, cloud schemes typically contain parameters with uncertain values, which may be introduced by artificial parameters or limited observational evidence of the precise value. A typical example for an uncertain parameter is the autoconversion rate, encoding the efficiency of colliding cloud droplets to form large and falling rain drops (Khain et al., 2015). Historically, the autoconversion rate was introduced by Kessler, who advocated the partitioning of the whole size spectrum of droplets into small cloud droplets, with negligible sedimentation velocity, and falling rain drops (Kessler, 1969). Most cloud schemes adopt the partitioning of the size spectrum, especially all schemes of the Kessler type. The cloud scheme to be described in Sect. 3 below is also of the Kessler type. More examples of processes with uncertainties in their description and of how uncertainties enter the description of clouds are discussed in Khain et al. (2015).
In any case, uncertain parameters introduce uncertainty in the cloud scheme at hand, and ultimately into the numerical model as a whole. To assess the uncertainty of the parameters, one usually performs sensitivity studies, e.g., by running ensemble simulations, where each ensemble member employs slightly different values for the parameters. However, usually the number of ensemble members is limited to small values posing an additional challenge to extract the desired signal from the simulations.
In this study, we propose the use of “algorithmic differentiation” (AD) as another way of identifying the parameters with largest sensitivity. Although this method is well known in computer science and engineering, its potential in meteorological contexts, and cloud physics in particular, has not yet been fully exploited. Most applications of AD in meteorology are limited to individual studies investigating model sensitivities (usually with respect to initial values) by using adjoint models (e.g., Bischof et al., 1996b; van Oldenborgh et al., 1999; Kaminski et al., 1999; Xiao et al., 2008; Rauser et al., 2010; Zhang et al., 2013; Belikov et al., 2016) or studies targeting applications in data assimilation (e.g., Le Dimet et al., 2002; Blessing et al., 2014). We will introduce the technique in Sect. 2, but, in a nutshell, it provides the derivative of a given computer code with respect to selected parameters. A cloud scheme may be described as a function f, taking the flow characteristics y from the given grid box together with parameters η as an input, and computing the feedback z of the cloud, i.e., , as an output. Assessing the sensitivity of the output z with respect to the parameters η amounts to computing the derivative . AD helps in evaluating this derivative by computing the derivative of the function with respect to the parameters, where the hat notation indicates the implemented version of the mathematical function f in some computer code. Using this technique can help in the development of cloud schemes by providing the respective derivatives to machine accuracy in an automated fashion, i.e., without implementing finite difference approximations of .
Recently, a field called uncertainty quantification has emerged in mathematics as a more systematic combination of (numerical) analysis and statistics in order to study the propagation of uncertainties (e.g., Sullivan, 2015; Le Maître and Knio, 2010). Although powerful methods for the investigation of uncertainties already exist, their practical use often limits the number of the considered uncertain parameters due to the curse of dimensionality; see Chertock et al. (2019) for an application in the context of cloud physics. Therefore, it is valuable to first identify the parameters with the highest sensitivity using AD in order to limit more rigorous or extensive investigation to these parameters.
We emphasize that AD is not related to a specific application (as a cloud scheme) nor to a specific programming language. Although we use an implementation in C++ together with an AD tool suited for this language, AD tools for other languages like Fortran are available (e.g., Bischof et al., 1996a). A list can be found on http://www.autodiff.org (last access: 23 October 2019).
In this study, we will first explain the concept of algorithmic differentiation in Sect. 2, introduce the warm cloud scheme used for illustration purposes within an air parcel framework in Sect. 3, and show results in Sect. 4. Some concluding remarks are given in Sect. 5.
Algorithmic differentiation (AD) is a mathematical theory that describes how the computation of derivatives in a computer program can be automatized. It was developed in the early 1980s and rediscovered several times since then. The most well-known resource is the book of Griewank and Walther (2008). A useful first introduction is given by Neidinger (2010).
For the purpose of computing the derivative of a program, it is considered as a sequence of simple elemental (or intrinsic) functions including the sine, cosine, multiplication, division, and addition. The approach of AD considers the given program as a composition of elemental functions and, by applying the chain rule, computes its directional derivative by accumulating the derivatives of each elemental function within the program code. It is important to stress that AD does not generate a generalized representation of the derivative of the computer program. Instead, AD computes the derivatives alongside the execution path. The path might change due to conditional instructions within the code.
As an example, assume the computer program to be differentiated is given by
where are the input variables and w is the output. This program can now be split into elemental functions which yield the intermediate steps t1, t2 required by AD as follows:
For the application of the chain rule the Jacobian matrix has to be computed for each of these intermediate steps with respect to all input variables, which is quite simple; e.g., for the matrix is since and . However, for notational convenience it is common to drop the indication of the formal dependence of the elemental function t1 and its derivatives on the input parameters c, d since they are unchanged in t1. In order to compute the directional derivative, the Jacobian matrix is multiplied with the desired direction , where the dot notation is used in the AD theory to describe the corresponding derivative direction of a variable. Applying this process to the full procedure Eq. (2), the result is
since, e.g.,
where we again neglected the formal dependency of t1 on c and d. By computing the corresponding directional derivative statements in procedure Eq. (3) alongside the original statements in procedure Eq. (2), the directional derivative is computed for the whole computer program Eq. (1). Note that the choices and for the input directions for the AD computation results in the computation of the partial derivatives and .
The example shows the application of the forward AD mode on a simple computer
program. The general theory of AD assumes that the elemental functions are
evaluated at argument values where they are differentiable in a neighborhood
of the argument value. Actually, many common elemental functions are
differentiable everywhere as, e.g., addition or multiplication, but there are
elemental functions which are differentiable except at some critical points. Examples for elemental functions with a
critical point are square root, absolute value, and division, which are not
differentiable at the origin. How these difficulties are treated mainly
depends on the AD tool. The AD tool CoDiPack used in this study provides the
preprocessor option CODI_CheckExpressionArguments to throw an
exception if such a critical point is encountered. In any case, the exact
derivative of each elemental function, at least apart from the critical
points, may be written down explicitly. Note that conditional instructions
(e.g., if-else switches) do not pose problems, since they only alter the
program path, i.e., the specific sequence of the elemental instructions that
are executed. Since the whole computer program is a composition of the
differentiable elemental operations, the chain rule states that also the
whole program is differentiable (apart from the critical points). Moreover,
if the program is represented by the function , the so-called forward mode of AD
computes
In Eq. (5), is the Jacobian of the full program at state x, vector is the direction for which the program derivative is desired along the computational path and the variable x subsumes all input variables. In the notation of Sect. 1, we have , i.e., x contains the cloud model and thermodynamic variables y together with the inherent parameters η. In this terminology, an inherent parameter of the (cloud) model is also now considered as a parameter if this parameter is to be investigated.
Equation (5) just states which result is computed by the forward mode of AD and not how it is computed. The evaluation of the derivative is done alongside the primal computation of by applying Eq. (5) to each elemental operation as in the above example, i.e., the full Jacobian is never computed explicitly but accumulated by considering each code statement individually.
The second operation mode of AD is called the reverse AD mode. As will become clear, the reverse mode can be introduced by multiplying an adjoint direction from the left side to the derivative representation of the computer program, instead of multiplying a derivative direction from the right as in Eq. (5). This yields the general equation . The standard AD notation for the adjoint of a variable v is the bar notation and may be thought of as containing the immediate derivative of the current statement with respect to the particular variable.
As an example, for the statement , the AD reverse mode evaluation is
The information flow in Eq. (6) is reversed for the adjoint variables: the input variable is , while and are output variables. Because of this reversal of the information flow, all reverse AD statements need to be evaluated in reverse order. The reverse of the last statement of the program code will be evaluated first, the second to last statement as second, and so on. The reverse AD procedure for the example procedure Eq. (2) is then
As discussed above, the statements from procedure Eq. (2) are now handled in reverse order. The values , , , and contain the derivatives of w with respect to themselves. Taking as an example, according to the chain rule this is
and the value of t1 is taken from the primal evaluation of the program. By choosing as input for the reverse AD mode, the adjoint variable contains the derivative of procedure Eq. (2) with respect to the input d.
The example, Eq. (7), shows the application of the reverse AD mode on a simple computer program. According to the general theory of AD, given a computer program which can be represented by the function , the reverse AD mode computes
where, again, denotes the Jacobian of and its transpose, while represents the desired direction for the derivative. Eq. (9) again just states the result that is computed by the reverse mode of AD and not how it is computed. The actual evaluation of the derivative is done without forming the Jacobian and instead by storing information during the primal computation of . Afterwards, a reverse sweep over the stored information is performed. This reverse sweep applies a slightly modified version of Eq. (9) to each elemental function as in the above example.
Both operation modes of AD are connected via the discrete adjoint operator. Let and denote the Euclidian scalar products in ℝn and ℝm, respectively. We now select an arbitrary direction , which we apply to the result of the forward mode. This yields the equality
by shifting the Jacobian matrix of to the left side of the scalar product. This shows that the reverse mode is the discrete adjoint of the forward mode (see, e.g., Kalnay, 2003, for the use of adjoint models in atmospheric data assimilation).
The advantage of the reverse mode becomes clear if we assume that we want to compute the full gradient of a function . In the case of m=1, i.e., a computer program with n input and a single output variable, the full gradient is a matrix with n columns and one row; hence its transpose is a matrix with n rows and a single column. Since m=1, the direction is a vector with a single entry. Consequently, we obtain the result by computing Eq. (9) exactly once with the single input . Using the forward mode of AD, we infer from Eq. (5) that the computation of the full gradient requires n subsequent computations with the choices , and ei∈ℝn denotes the ith unit vector. If n is large, these n subsequent computations require much more computational effort than a single (but slightly more costly) computation using the reverse mode of AD.
In contrast, if n=1, i.e., the computer program has a single input and m output variables, the forward mode of AD computes the full derivative with a single computation by choosing the 1×1 matrix as the input direction, whereas the reverse mode needs m computations, being costly for large values of m.
An alternative approach to compute the derivative of in the direction d∈ℝn is to apply the finite difference approach
with a (small) step size t>0, requiring two evaluations of the program . Instead of the approximation Eq. (11), one could alternatively choose a finite difference approximation of a higher order (e.g., Grossmann and Roos, 2007), but these typically need even more program evaluations. In contrast to AD, the finite difference approach requires the choice and tuning of the step size t>0 to achieve the desired accuracy of the derivative. Moreover, the optimal value of the step size will in general depend on the selected direction d and the state x (see Elizondo et al., 2002, for a comparison with AD). These issues render the finite difference approach as quite unattractive but due to its simplicity it is often used, accepting all drawbacks of the method.
If is a linear function, then an arbitrary step size t can be chosen for all directions. For non-linear functions, t should be as small as possible to achieve the desired accuracy but large enough to avoid cancellation errors due to the difference in Eq. (11). AD has the advantage of not having to choose and tune a step size. Since the derivative of each elemental function is known exactly and AD applies the chain rule, the computed derivatives are accurate up to machine precision (Griewank et al., 2012).
Moreover, using the reverse mode for computing the full gradient in the case of only a small number of output variables, AD has the potential of being several times faster compared to using finite difference approximations.
AD is introduced into computer programs mostly in two ways: either through operator overloading or through source transformation. For C++, the majority of tools (as listed at http://www.autodiff.org, last access: 23 October 2019) use the operator overloading approach which is also used by the AD tool CoDiPack (Sagebaum et al., 2017a) developed by the authors from the Scientific Computing group in Kaiserslautern and employed in this study. CoDiPack uses expression templates to reduce the amount of required information for the reverse AD mode. The data layout of the information is such that a minimal memory footprint is required and caching strategies of the processors can be applied. The general focus of CoDiPack is its application in high performance computing environments which was successfully demonstrated in Sagebaum et al. (2017b) and Albring et al. (2016).
The source transformation approach is mostly used in Fortran source codes. Here, the code is parsed and new code is generated which adds the additional statements for the forward or reverse AD mode. Tapenade (e.g., Hascoët and Pascual, 2013) is the most widespread tool for source transformations in Fortran. It is written in Java and supports nearly all features of older Fortran standards. Support for more modern features in newer Fortran versions is an ongoing development.
In general AD can be applied to any computer program. After an initial effort, the derivative computations can be automatized in the sense that every change in the code will immediately affect the primal computation and also the derivative evaluation. How much time the initial effort requires depends strongly on the code and which AD tool is applied. A general effort at analyzing software and detecting problematic code constructs is done in Hück et al. (2015). In general, operator overloading tools are usually quite easy to introduce into a code if it is well written and there is a distinct place where the computation type of the program can be defined. Source transformation usually requires much greater effort. In both cases an early introduction of AD into the code reveals incorrect implementation assumptions and yields a cleaner code.
As an application for AD, we consider a slightly generalized one-moment scheme for warm cloud microphysics, i.e., liquid clouds without ice, within a zero-dimensional air parcel framework. One-moment schemes are designed to predict the temporal evolution of the mass of non-sedimenting cloud droplets, rain drops, and water vapor, i.e., the mixing ratios , , and where Mc is the mass of cloud droplets, Mr the mass of rain drops, Mv the mass of water vapor, and Ma the mass of dry air. One-moment schemes have a long history and are governed by the classical partitioning of the droplet spectrum into non-sedimenting cloud droplets and larger rain drops, which fall due to the gravitational acceleration (Kessler, 1969). Although these schemes remain the default choice in many computational models, for example, the operational numerical weather forecast models IFS (ECMWF, 2017), run by the European Center for Medium Range Weather Forecast (ECMWF), and COSMO (Doms et al., 2011), run by the German Weather Service (DWD), much consensus exists that two-moment schemes are in general more accurate (Igel et al., 2015). The difference between a one-moment and a two-moment scheme is that the two-moment scheme not only predicts the evolution of the mass mixing ratios but also the corresponding number concentrations.
The one-moment warm cloud schemes of the IFS and the COSMO model may be written in generic form as (see Rosemeier et al., 2018; Porz et al., 2018)
with the coefficients , the exponents and the saturation ratio , comparing the partial pressure pv of water vapor to the saturation vapor pressure psat over a flat surface of water. The scheme includes the following processes:
- i.
condensational growth of cloud droplets;
- ii.
autoconversion, describing the formation of rain drops by colliding cloud droplets;
- iii.
accretion, describing the collection of cloud droplets by falling rain drops;
- iv.
evaporation of rain drops;
- v.
sedimentation of rain drops out of the grid box.
The term B subsumes the flux of rain drops falling from above into the considered grid box. The splitting of the evaporation term in Eq. (12d) is due to the appearance of the ventilation factor in the diffusional growth equation for the rain drops, taking a non-uniform distribution of water vapor around the falling rain drop into account.
The major differences of Eq. (12) from the actual scheme in the operational model are the formulations of the sedimentation process as a sum of the incoming and outgoing fluxes B and , and the use of an explicit condensation term, which is usually circumvented by employing a saturation adjustment scheme (Asai, 1965; McDonald, 1963; Langlois, 1973; Soong and Ogura, 1973; Kogan and Martin, 1994). Note that the values of the coefficients may also depend on the environmental conditions. Also note that the formulation in Eq. (12) does not contain a term for the activation of new cloud droplets. Within the operational models, the activation of cloud droplets is done with the help of the saturation adjustment, where the excess water vapor is converted into mass of cloud droplets, thus always activating the maximal number if not restricted otherwise.
After choosing an appropriate set of coefficients and exponents, Eq. (12) represent a cloud scheme for a warm cloud in the spirit of Kessler, although not every choice of parameters yields a physically meaningful scheme. Apart from the condensation term, the parameterizations of the other processes are not based on purely physical reasoning. Rather the structure of the terms represent in some sense ad hoc formulations and approximations, but may also be motivated in the sense of population dynamics. The values of the coefficients and the exponents are usually obtained by fitting to observational data or results of detailed models (e.g., Khairoutdinov and Kogan, 2000). In any case, the precise values of the coefficients and the exponents are uncertain to some degree.
For simplicity, we consider the cloud scheme Eq. (12) within an adiabatic air parcel, providing a natural framework to start with in the development of cloud schemes. The closure of Eq. (12) is given by the evolution equations for pressure p and temperature T:
where g denotes the gravitational acceleration, the gas constant for moist air, Ra the gas constant for dry air, Rv the gas constant for water vapor, and the quotient of the gas constants of dry air and water vapor, w the vertical velocity and L the latent heat of vaporization. The coefficient c of the condensation is given by
with ρl the density of water, Nc an assumed constant number concentration of the cloud droplets, and the thermodynamic correction (Howell factor)
for the condensational growth of a cloud droplet. In Eq. (15), K denotes the thermal conductivity of dry air and D the diffusivity of water vapor in air. Note that the choice of a fixed constant cloud droplet number Nc in Eq. (14) is motivated by the default Kessler-type warm cloud scheme of the IFS model (ECMWF, 2017).
Using the notation introduced in Sect. 1, the combined discretization of the governing Eqs. (12) and (13) represents the (mathematical) function , taking the values of the foregoing time step
together with the parameters
to compute the state of the system at the new time level, i.e., computing . Implementing f yields the function , from which AD can compute the derivatives with respect to the parameters η.
We implemented the air parcel model in C++ and discretized the ordinary differential equations using the classical explicit Runge–Kutta method of order 4 (Hairer et al., 1993), although any other method could be used as well. We chose the values of the parameters according to the warm rain scheme used in the operational forecast model IFS (ECMWF, 2017). In this case, all exponents are independent of the environmental conditions and only the coefficients e1, e2 of the evaporation depend on the environmental conditions. Table 1 collects the values of the constant coefficients and exponents together with the values of e1, e2 at pressure 850 hPa and temperature 270 K. Note that e1, e2 vary only weakly with pressure and temperature. Prior to each time step, we compute the values of the parameters e1, e2 for the cloud model using the environmental values of pressure and temperature from the old time step. This fixes the values of the parameters for the call to the function , computing numerically a single time step of the governing Eqs. (12) and (13). Using AD, we compute the derivative of the implemented code with respect to the parameters Eq. (17) at the current time step.
Table 1Values of the coefficients and exponents used for the cloud scheme. All coefficients except for e1, e2 are independent of environmental pressure and temperature. The values for the exponents are exact; the values for the coefficients are rounded to three digits. The coefficient values displayed for e1, e2 are for environmental pressure 850 hPa and temperature 270 K.

In the following, we always assume a constant vertical velocity w, the initial environmental conditions 270 K and 850 hPa, the constant cloud droplet number density ρNc=50 cm−3 (as suggested in ECMWF, 2017 over ocean), no fall of rain drops from above B=0 s−1, and the constant time step Δt=0.01 s. To arrive at a meaningful sedimentation rate, we adopt the assumption of constant terminal velocity of the rain drops from ECMWF (2017) and assume an air parcel with height h=1000 m.
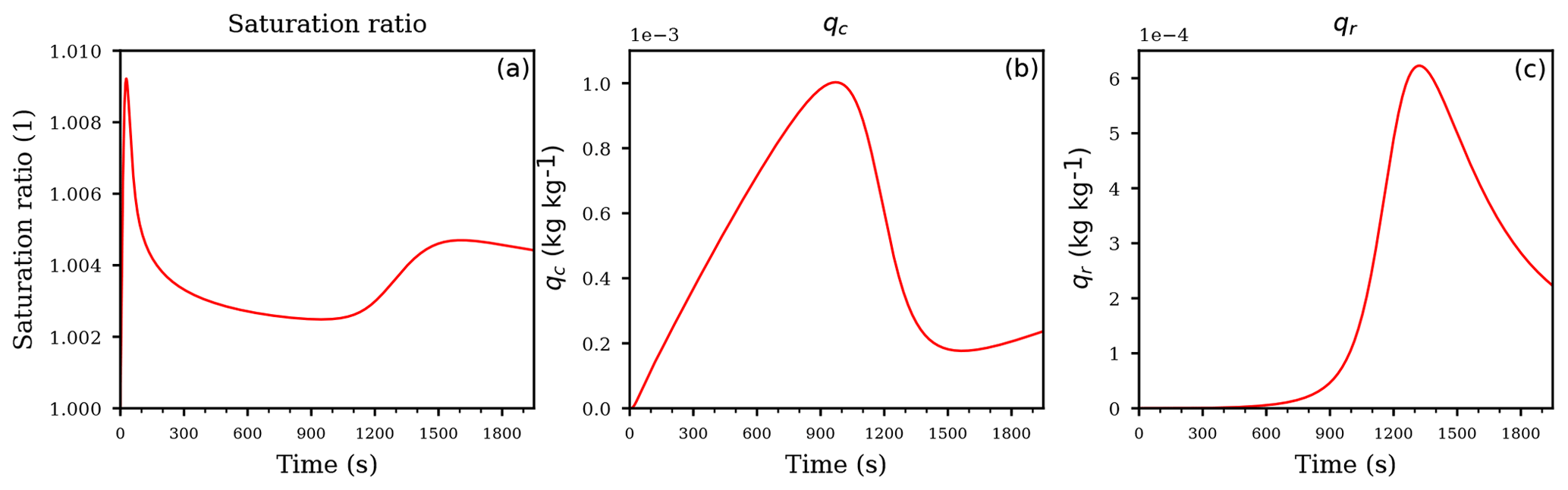
Figure 1Temporal evolution of the saturation ratio S (a), the cloud droplet mixing ratio qc (b), and the rain drop mixing ratio qr (c) for the ascending air parcel with no pre-existing clouds.
4.1 Cloud formation in updraft
As the first example we consider an updraft velocity w=1 m s−1, the initial conditions
for the mixing ratios, and S(0)=1 for the saturation ratio and integrate the governing equations for 1950 s. The reason of not choosing qc(0)=0 kg kg−1 is that Eq. (12a) needs a non-zero initial value to allow for a non-constant and non-zero solution. Physically, this reflects the fact that the cloud scheme Eq. (12) does not include a precise activation mechanism which predicts the number of activated cloud droplets as a function of saturation ratio. Such a mechanism is not included in the operational model due to its usage of a saturation adjustment scheme (e.g., Kogan and Martin, 1994).
Figure 1a, b, and c show, respectively, the temporal evolution of the saturation ratio S, the cloud droplet mixing ratio qc, and the rain drop mixing ratio qr. Apparently, the saturation ratio increases initially due to adiabatic cooling, until cloud droplet mass increased enough to balance the source for the saturation ratio from the adiabatic cooling by the diffusional growth of the cloud droplets. Since autoconversion is the only process for forming rain, its formation starts after enough cloud droplet mass is available. The time interval between 900 and 1200 s is a transition region, where the influence of autoconversion decreases while the influence of accretion increases, i.e., falling rain drops start to effectively collect cloud droplets and consequently increase the rain drop mass mixing ratio qr. This may also be seen directly from the model Eq. (12): accretion is modeled as , hence an increase of rain drop mass directly increases the influence of this process and the further decrease in cloud droplet mass may be attributed to accretion. At about 1200 s the saturation ratio starts to increase again, since the decreasing cloud droplet mass diminishes the sink for water vapor due to its condensational growth. Note that, according to Eq. (12c), the evaporation term is inactive for supersaturated conditions with S≥1.
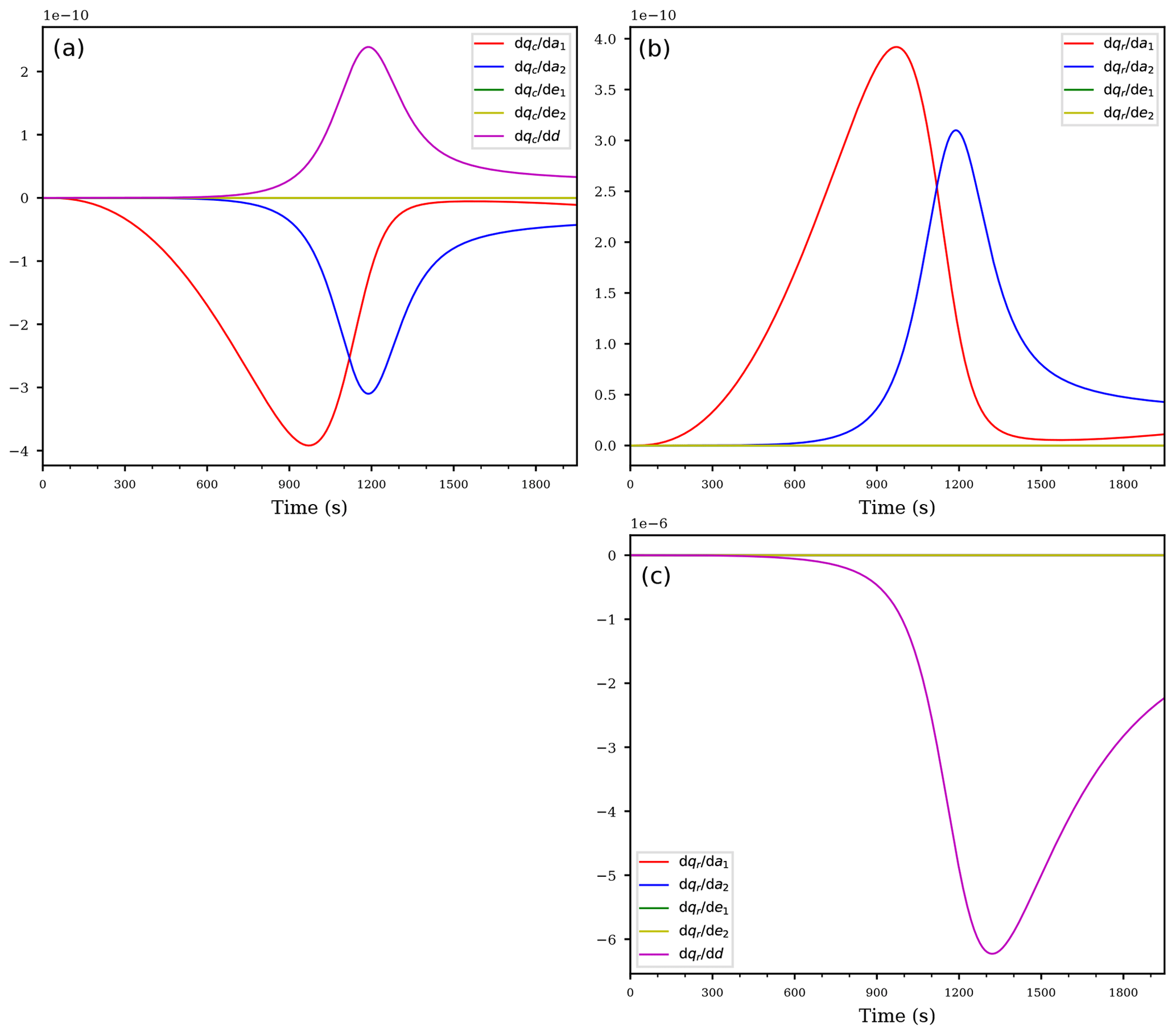
Figure 2Temporal evolution of the derivatives of the cloud droplet mixing ratio qc (a) and the derivatives of the rain drop mixing ratio qr (b) and (c) with respect to the coefficients. Panel (b) shows the derivatives of the rain drop mixing ratio qr with respect to the coefficients but without the derivative with respect to the sedimentation coefficient; the panel (c) shows the derivatives of qr including the derivative with respect to the sedimentation coefficient d (purple curve). All panels correspond to the first case of an ascending air parcel with no pre-existing clouds.
The derivatives of the mixing ratios with respect to the coefficients are shown in Fig. 2, whereas Fig. 3 shows the derivatives with respect to the exponents. As Fig. 2a shows, the coefficient with the largest sensitivity to the cloud droplet mass qc up to about 1000 s is the coefficient a1 for autoconversion (red curve). The large sensitivity during the initial stage of the cloud evolution implies that the main loss of cloud droplet mass can be attributed to the autoconversion process, rendering the autoconversion rate a critical parameter. Given that autoconversion is the only process for producing rain drops out of the cloud droplets, this result may be anticipated. The negative value of the derivative indicates a decrease in qc if the value of a1 is increased by a small amount, i.e., a larger autoconversion rate results in a faster decrease of the cloud droplet mass. The transition region between 900 and 1200 s, where the influence of autoconversion decreases and accretion increases, is also clearly visible as a decreasing magnitude of and an increasing magnitude of the derivative of cloud droplet mass mixing ratio with respect to the accretion parameter a2 (blue curve).
Inspecting Fig. 2b, we observe a positive derivative of the rain mixing ratio with respect to the autoconversion coefficient with the same magnitude as . This simply resembles the mass continuity, since a faster autoconversion implies a faster decrease in the cloud droplet mass qc and an equally fast increase in the rain drop mass qr. The same is true for the accretion, i.e., the derivatives (blue curves in Fig. 2a and b).
The derivatives of the cloud droplet mixing ratio with respect to the rain evaporation rate coefficients e1, e2 and the derivatives of the rain mixing ratio with respect to the same coefficients are identically zero, consistent with the fact that the evaporation term is inactive within a supersaturated cloud parcel; see Eq. (12c). However, the purple curve Fig. 2a, representing the derivative of the cloud droplet mixing ratio with respect to the sedimentation coefficient, is not identically zero although the sedimentation term is absent in Eq. (12a) for the cloud droplet mixing ratio qc. This is an example of an indirect sensitivity of qc to this coefficient: altering the sedimentation coefficient modifies the sedimentation rate which obviously directly affects the rain mixing ratio qr. This in turn feeds back to the cloud droplet mixing ratio qc since the rain mixing ratio qr enters Eq. (12a) through the accretion term. We conclude that the AD methodology is able to detect such indirect effects. Moreover, as may be concluded from Fig. 2a, this indirect sensitivity could easily be masked due to the comparable magnitude of the positive sensitivity (purple curve) and the negative sensitivity (blue curve).
Figure 2c shows the derivatives of qr with respect to all coefficients, in particular with respect to the sedimentation parameter d (purple curve; this curve was not included in Fig. 2b). From this figure it is evident that qr is most sensitive to the sedimentation coefficient. Comparing the different scalings of the ordinate in Figs. 2b and c corroborates this result. To summarize, at the beginning of this simulation, the most sensitive parameter is the autoconversion rate at creating rain drop mass. Towards the end of the simulation, enough rain drop mass is formed and the sedimentation becomes more important, actually much more important than the autoconversion or the accretion since the derivatives , and differ by almost 4 orders of magnitude.
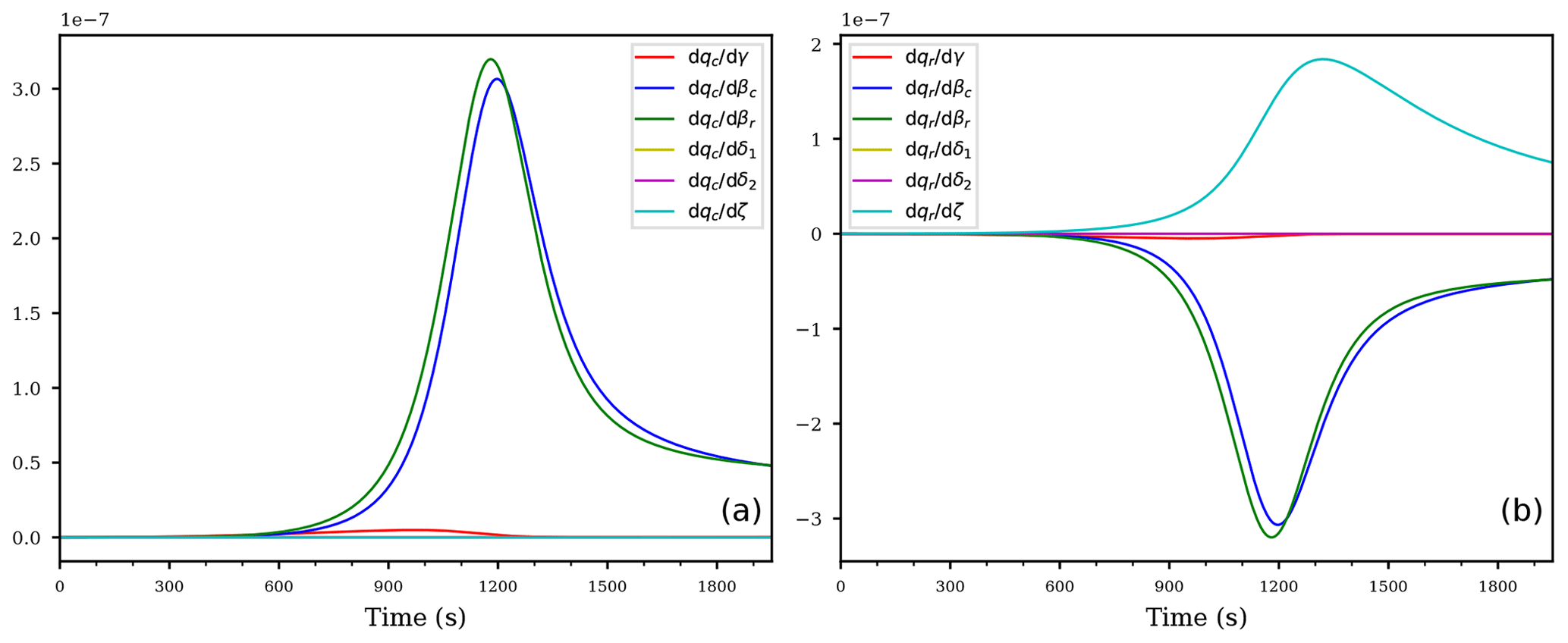
Figure 3As in Fig. 2, but for the derivatives of qc (a) and qr (b) with respect to the exponents.
Figure 3 shows the derivatives of the mixing ratios qc, qr with respect to the exponents. For both mixing ratios, obviously the exponents βc, βr from the accretion process are most sensitive (blue and green curves).
Note that the sign of the curves is counter intuitive, because, e.g., positive values of the blue and green curves imply slower accretion after increasing the values of those exponents by a small amount. This behavior is easily explained with the values of both mixing ratios being smaller than unity: increasing the exponent in the expression with leads to decreased values of the expression and consequently to a slower accretion process. It is important to keep such a behavior in mind in interpreting the derivatives.
The second most sensitive exponent for the rain mixing ratio is given by exponent ζ from the sedimentation process, but only after enough rain drop mass has formed after about 1000 s. The magnitude of the derivatives with respect to ζ and the accretion exponents βc, βr are comparable and of opposite sign. Therefore, the influence of increasing these exponents simultaneously may cancel out.
Observe that the derivatives of both mixing ratios with respect to the exponents δ1, δ2 in Fig. 3 are exactly zero, again resembling the in-activeness of the evaporation term in Eq. (12c) within the supersaturated cloud parcel.
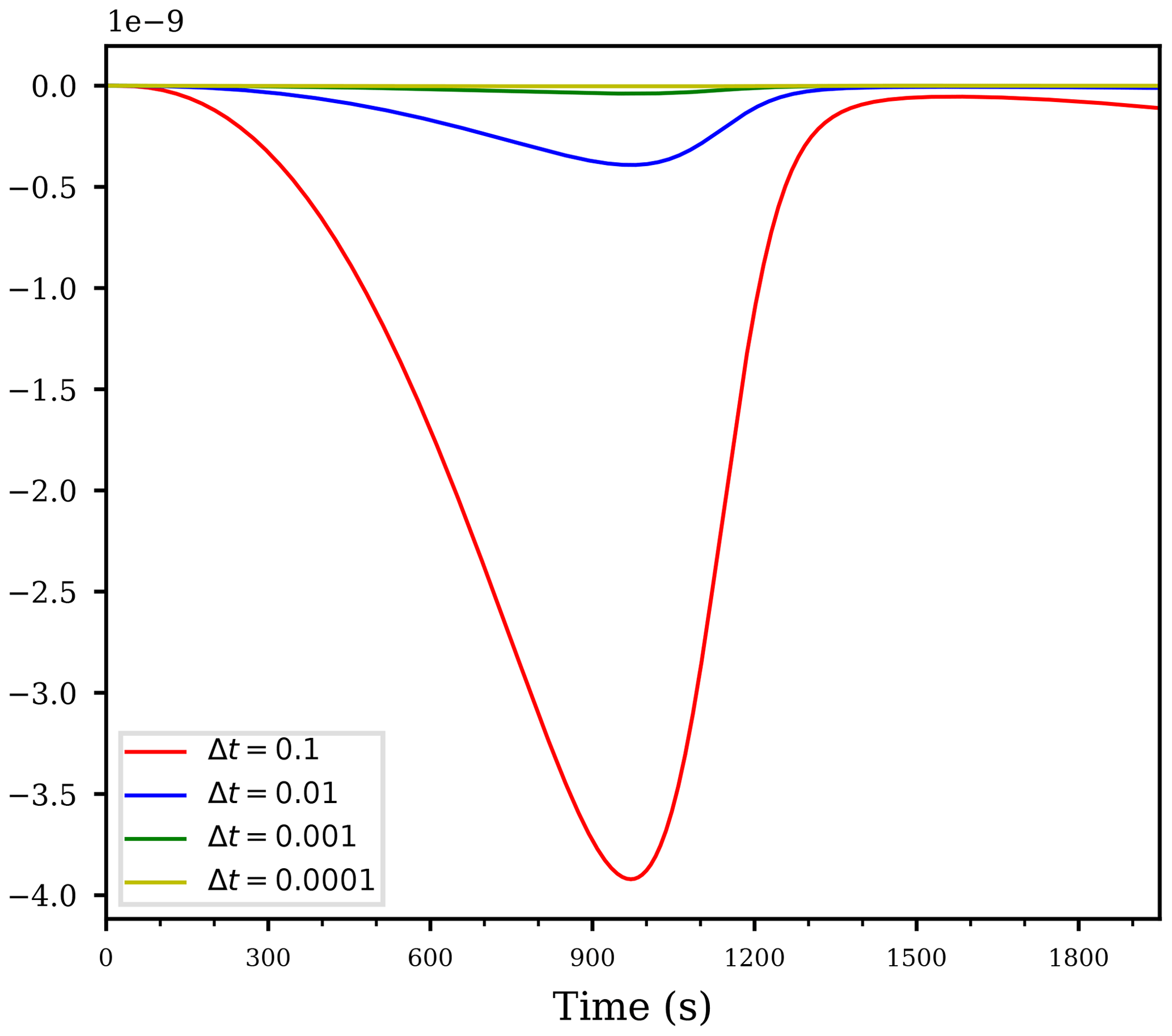
Figure 4Temporal evolution of the derivative using the time steps for the computation of the same case as in Fig. 2.
As indicated, AD computes the derivatives of the implemented code, which in our case involves a numerical method, rather than derivatives of the (unknown) continuous solution of the governing differential equation. This distinction is important for the interpretation of the computed sensitivities and we are now going to discuss the subtleties connected with them.
First of all, we outline the fact that since the numerical discretization of the governing differential equation depends on the time step Δt, the magnitude of all computed derivatives also depend on the time step. Figure 4 illustrates this fact by showing the derivative of the cloud droplet mass on the parameter a1 for autoconversion for several time steps. In this figure, the dependency on Δt becomes obvious, however, the shape of the curve does actually not change. Rescaling the curves in Fig. 4 by multiplying the values of the blue curve by , the values of the green curve by , and the values of the yellow curve by , all rescaled curves coincide with the red curve (not shown), representing the derivative computed with time step Δt=0.1. Although this scaling with the time step is quite intuitive due to the fact that if the time step is larger, the simulation is done for a larger time interval and the sensitivities are expected to increase, one should be aware of this scaling when trying to interpret the magnitudes of the derivatives.
A second issue regarding the meaning of the computed sensitivities is addressed in Bischof and Eberhard (1999). There are two possibilities of computing sensitivities:
-
apply AD on the implemented code, which numerically approximates the unknown solution of the governing differential equation, or
-
derive an analytical differential equation (called the sensitivity or variational equation as an analogue of the forward AD mode or the adjoint equation as an analogue of the reverse AD mode), describing how the sensitivities evolve with time (see, e.g., Sandu et al., 2003, or Walther, 2007, for details). In this approach, AD may enter the computation of the derivatives of the right-hand side of the governing equation.
The essential difference between the possibilities is that the first approach explicitly includes the numerical method in the computation of the sensitivities, while the second approach excludes any numerical method in the first place and instead creates an analytical differential equation, e.g., the sensitivity equation, for the description of the sensitivities and only in a second step approximates the exact solution of this equation using a numerical method.
In our study we choose the first option and include the numerical method in the differentiation, since this seems more appropriate if one is interested in how the sensitivities propagate through a given, already implemented, numerical model. We use a one-step numerical method with constant time step Δt to approximate the ordinary differential equation, hence the numerical solution ynew at the new time level is connected to the old solution yold at the old time level by , where η represents the parameter vector as in Eq. (17) and Φ is the numerical method. Moreover, we compute the derivatives at each time step separately, i.e., the approximation yold is considered as independent of the parameters at the current time level, hence . Consequently, in our case the AD methodology factually computes the derivative
showing once again the observed dependency of the computed sensitivities on the time step. In addition, Eq. (19) shows explicitly that the numerical method Φ is included in the differentiation, and thus the computed sensitivities depend on the numerical method. Note that we employed a constant time step that, according to the results in Bischof and Eberhard (1999), ensures that the computed sensitivities are indeed approximations of the sensitivities of the unknown, exact solution. If we had used a numerical method with adaptive time-stepping, this would not necessarily be true, since in this case the current time step depends on the solution which in turn depends on the parameters η, implying in general. Again, if one is interested in an approximate computation of the sensitivities of the exact solution, a correction is needed for this non-zero contribution of ; see Bischof and Eberhard (1999). However, if one is interested in the sensitivities of the implemented code, no correction is needed.
Finally, it is not obvious that the computed sensitivities, which depend on the time step, converge to the sensitivities of the exact but unknown solution in the limit Δt→0. In our case, since we rely on an explicit Runge–Kutta method of order 4, the desired convergence is established in Walther (2007). An extension to a more general Runge–Kutta method for the adjoint equation is presented in Sandu (2006).
Although the magnitude of the computed derivatives depend on the time step of the numerical method, the relative magnitudes of the individual derivatives are independent of the time step. Table 2 highlights this observation by comparing the ratios of some derivatives of the mixing ratios at t=1000 s, computed with several time steps Δt. The ratios of the derivatives shown in Table 2 are indeed approximately constant (except for the effects of a coarse time resolution), implying that these ratios are indeed independent of the time step. Therefore, the derivative with respect to the most sensitive parameter will show the largest magnitude compared to the derivatives with respect to the other parameters, regardless of the chosen time step of the numerical method involved. This allows the possibility of using the computed derivatives to identify the most sensitive parameters of the cloud scheme.
Table 2Ratios of the derivatives of the mixing ratios with respect to different parameters at t=1000 s, computed for several time steps Δt. All numbers are taken from the computations of the first case of an ascending air parcel with no pre-existing cloud. The numbers are rounded to four digits.

4.2 Cloud evaporation in a downdraft
As the second example, we consider a downdraft with velocity , the initial conditions
for the mixing ratios and S(0)=1.01 for the saturation ratio, representing an initial supersaturation of 1 %.
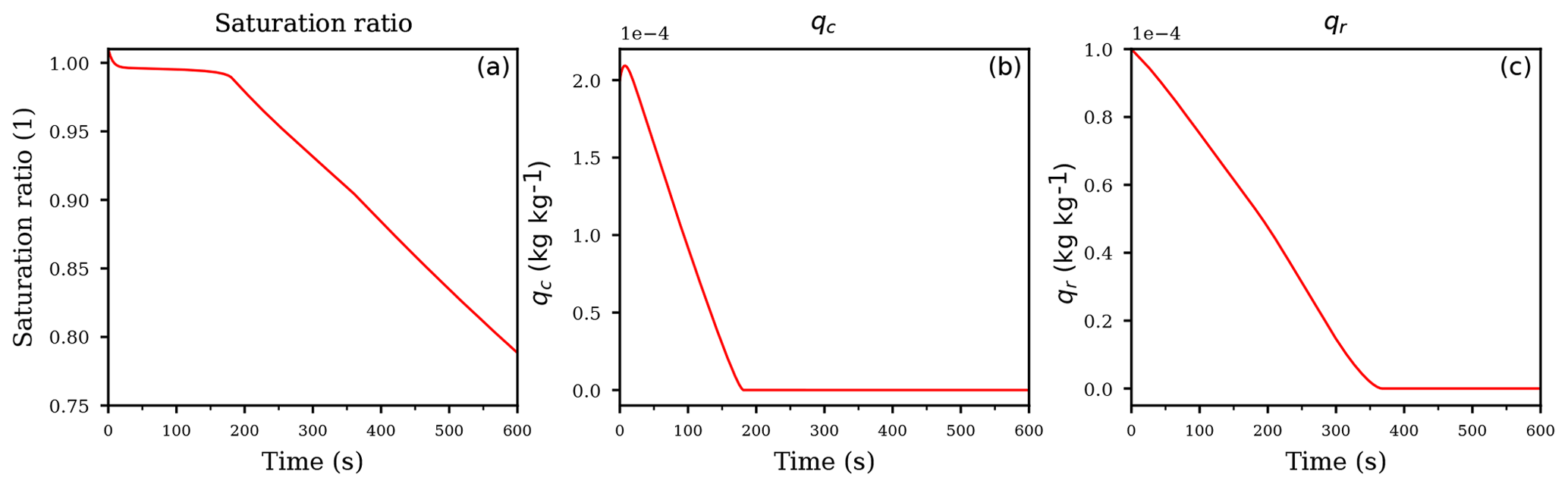
Figure 5Temporal evolution of the saturation ratio S (a), the cloud droplet mixing ratio qc (b), and the rain drop mixing ratio qr (c) for the descending air parcel with evaporating cloud.
The temporal evolution of the saturation ratio and the mixing ratios are shown in Fig. 5. The downward vertical motion of the air parcel causes the saturation ratio to decrease due to adiabatic heating. However, until the complete evaporation of the cloud droplets at about 175 s (see Fig. 5b), the release of water vapor of the evaporating cloud droplets counteracts the decrease of the saturation ratio and keeps the air parcel only slightly subsaturated (Fig. 5a). After roughly 175 s, the saturation ratio decreases continuously, resulting in a substantially subsaturated air parcel. Consequently, the available rain drops not only sediment out of the air parcel but also evaporate due to the subsaturation (Fig. 5c). However, the release of water vapor of the evaporating rain drops is seemingly not able to counteract the decrease of the saturation ratio as was the case for the evaporating cloud droplets at the beginning of the simulation, but the precise sensitivities of rain drop evaporation and sedimentation cannot be deduced from the temporal evolution of the mass mixing ratio qr.
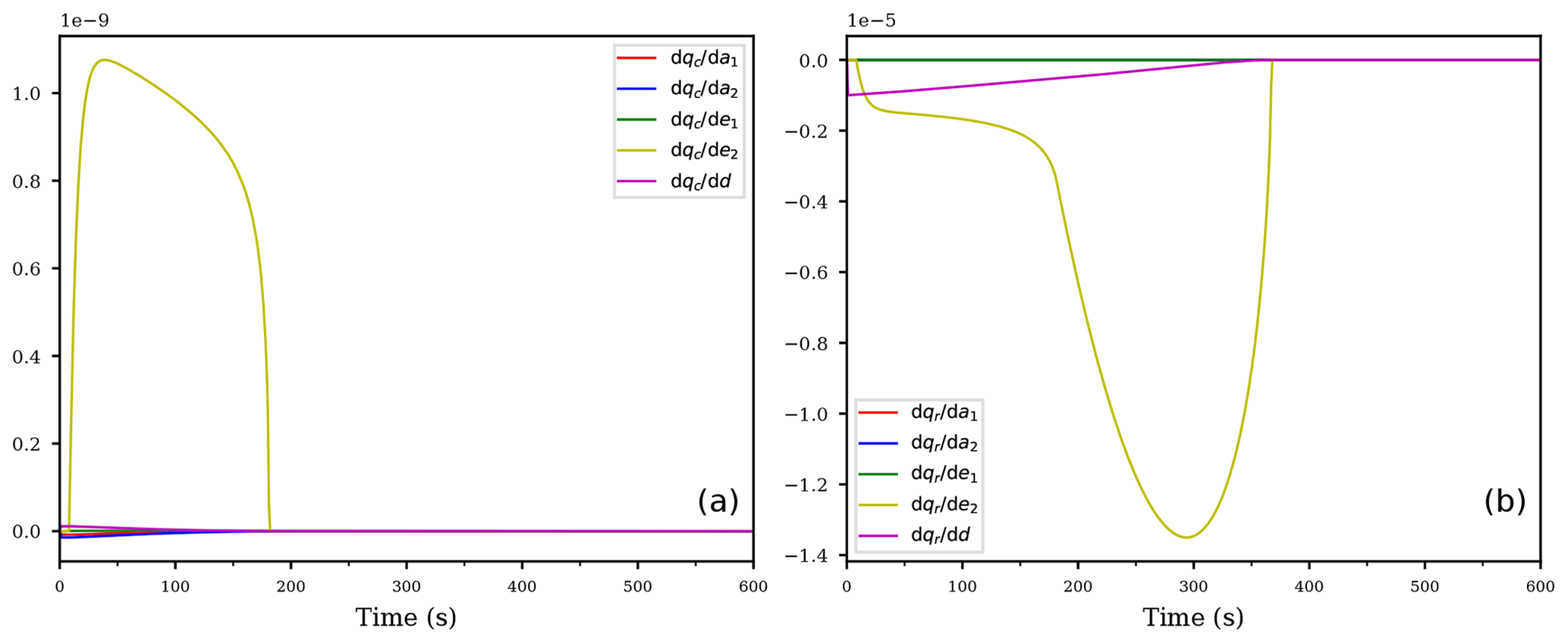
Figure 6Temporal evolution of the derivatives of the cloud droplet mixing ratio qc (a) and the rain drop mixing ratio qr (b) with respect to the coefficients for the descending air parcel with evaporating cloud.
The temporal evolutions of the derivatives of the mixing ratios with respect to the coefficients are shown in Fig. 6. Contrary to the first case from Sect. 4.1, the air parcel rapidly becomes subsaturated with S≤1 and the evaporation process in Eq. (12c) is now active, hence no derivative is identically zero. Inspecting Fig. 6, the most sensitive coefficient for both mixing ratios is e2 (yellow curve), corresponding to the ventilation coefficient within the formulation of the evaporation process of the rain drops; see Eq. (12c). This result may be anticipated regarding the rain drop mass mixing ratio qr, because the air parcel is subsaturated and the evaporation process directly affects the rain drop mixing ratio. However, we also observe a large sensitivity of the cloud droplet mixing ratio qc on the same parameter. This feedback is, again, an indirect sensitivity originating from the accretion process: if the rain drop mass decreases faster due to a slight increase of the coefficient e2, the accretion gets slower and therefore less cloud droplets get collected by the falling rain drops. Consequently, the decrease of cloud droplet mixing ratio is diminished.
Figure 6b also shows that the second most sensitive coefficient for qr is given by the sedimentation rate coefficient. This observation also answers the question which process is more sensitive to changes in its rate coefficient for the decrease of rain drop mass, seen in Fig. 5b. Due to the larger absolute values of compared to (yellow and purple curves in Fig. 6b), a slight change in the evaporation rate coefficient e2 will result in larger responses than a change in the sedimentation rate.
Although not visible in Fig. 6a, the derivatives with respect to the coefficients are all of about the same magnitude, while the sensitivity to the second evaporation coefficient e1 is significantly smaller.
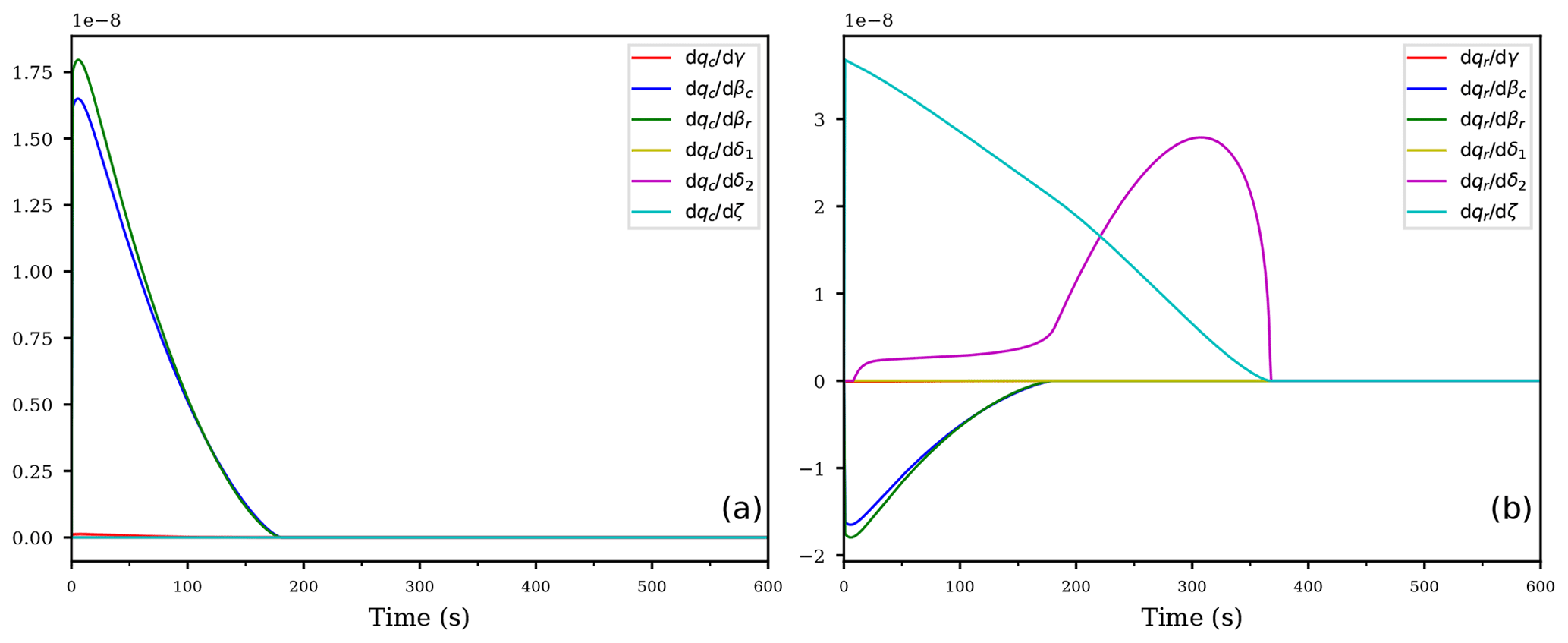
Figure 7As in Fig. 6, but for the derivatives of qc (a) and qr (b) with respect to the exponents.
Inspecting Fig. 7, illustrating the derivatives of both mixing ratios to the exponents, the most sensitive exponents for the cloud droplet mixing ratio qc are again the exponents βc, βr corresponding to the accretion process (blue and green curve in Fig. 7a). For the rain drop mixing ratio qr (Fig. 7b), the most sensitive exponent changes from the sedimentation exponent ζ (cyan curve) at the beginning to exponent δ2, occurring in the second term of the evaporation term, consistent with the large sensitivity of the corresponding rate coefficient e2; see the yellow curve in Fig. 6a.
To summarize the second example: the AD methodology pinpoints the second summand of the evaporation term together with the exponents βc, βr of the accretion process in introducing the largest sensitivity in the model results. Although one could find the same sensitivities using classical sensitivity studies instead of AD, the AD methodology provides an immediate suggestion on the large sensitivity of the coefficient e2 for both mixing ratios (see Fig. 6), without having to carry out multiple model runs, where one perturbs each coefficient of the cloud scheme separately, one after the other. Moreover, the sensitivity of the cloud droplet mixing ratio qc to e2 is indirect, rendering it difficult to identify this sensitivity directly using the ensemble approach, in particular because the governing Eq. (12a) provides no indication due to the absence of coefficient e2. Given that even the simple cloud scheme Eq. (12) already contains five rate coefficients, perturbing each coefficient within a separate model run results in a significant total number of runs.
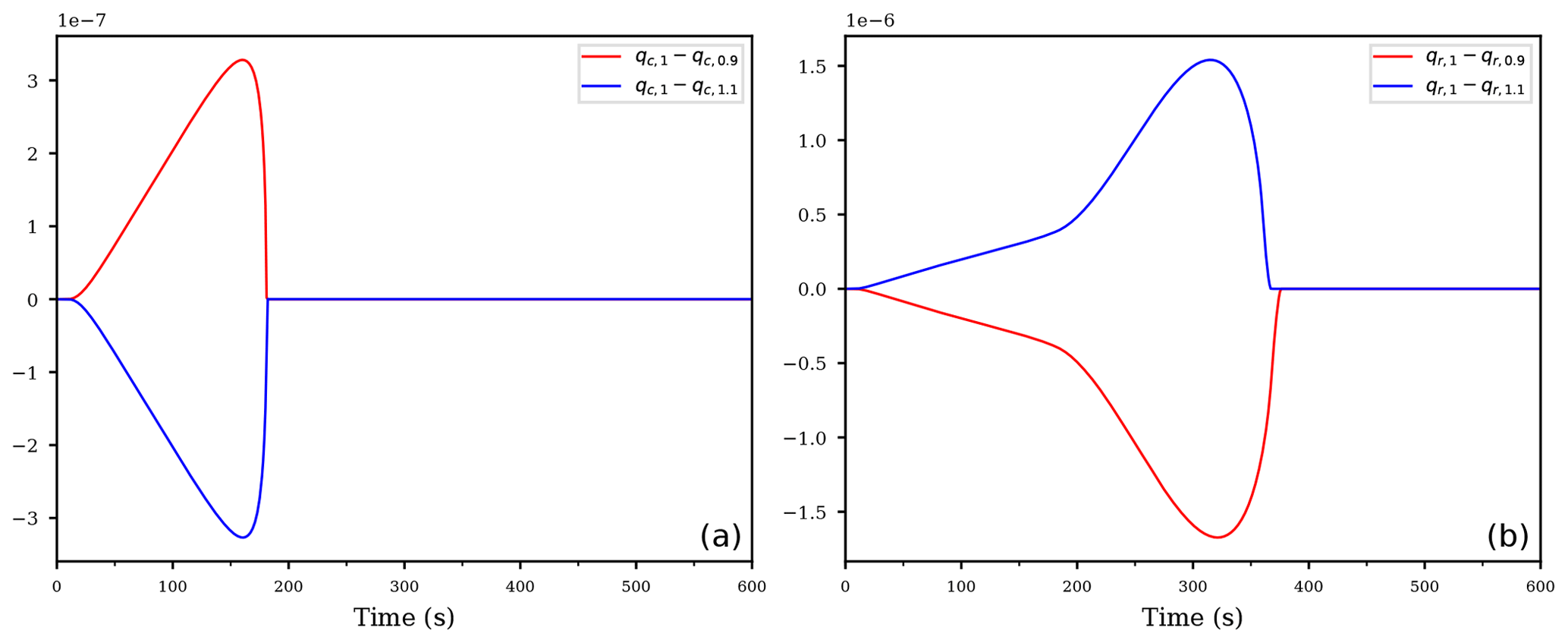
Figure 8Difference between the reference run with unperturbed coefficient e2, denoted as qx,1 for and using the perturbed second evaporation coefficient s⋅e2 with , denoted as qx,0.9 or qx,1.1, for the cloud droplet mixing ratio (a) and the rain mixing ratio (b), respectively.
After the identification of the most sensitive parameters using AD, one can carry out further model runs, targeted at the parameters which were identified beforehand. Figure 8 illustrates a possible further analysis step. It shows the difference between an unperturbed run, denoted by qx,1 with , and two further runs with perturbed rate coefficient s⋅e2 instead of e2, where is a scaling parameter. Observe that the signal is consistent with the derivative, computed by AD, in Fig. 6: the derivative is negative, hence a slight increase of the coefficient should result in a smaller rain mixing ratio qr and, consequently, the difference of should be positive. Similarly, the derivative is positive, and hence a slight increase of the coefficient should result in negative values for the difference . Figure 8 shows exactly these tendencies (blue curves). The red curves show the resulting differences using the scaling parameter s=0.9; note that the curves are asymmetric to each other.
4.3 Dependency on the model trajectory
After having discussed both exemplary cases individually, we now point to another important aspect of the AD methodology. Given that AD was applied to the exactly same computational code, a comparison between, e.g., the derivatives of the cloud droplet mixing ratio qc with respect to the rate coefficients (see Figs. 2a and 6a) reveals that the corresponding curves are not equal to each other, but show significantly different behavior. The only difference between the examples were the values of the initial conditions. Consequently, the model trajectories between the runs evolved differently despite the fact that the computational code was unchanged. This observation is a crucial aspect of the AD methodology since it underlines that AD computes the derivative of the model, i.e., the computational code, along the particular model trajectory, rather than providing the derivatives for each possible state of the model. Therefore, the AD approach can provide the desired sensitivities for the particular evolution of the model state, posing the same limitations as the computation of the derivatives using the aforementioned finite difference approach.
In this study, we presented and applied the technique of algorithmic differentiation (AD) in the context of cloud schemes, representing an important example of a subgrid parameterization of numerical models within the atmospheric sciences. In the literature, many different cloud schemes are suggested since at the moment, a universal governing equation for the full description of a cloud is not available (in contrast to the Navier–Stokes equation for the description of a non-reacting flow), making it impossible to derive cloud schemes from a common universal basis. As a consequence, many ad hoc assumptions are made within the formulations of the cloud processes typically leading to the introduction of uncertain parameters.
We propose the use of algorithmic differentiation in the development of cloud schemes in order to identify the most sensitive parameters in the adopted formulation along the simulated solution trajectory. The AD methodology is based on the observation that each computer code is a large composition of only a few differentiable elemental operations; hence, by the chain rule, the code itself is differentiable apart from critical points, where the elemental functions are not differentiable. Since the derivatives of the elemental operations are known, the full computational code can be differentiated in a (semi-)automatic fashion. Moreover, the resulting derivatives are accurate to machine precision because the AD approach merely evaluates the exact derivative.
In the context of sensitivity studies, the AD approach yields the desired sensitivities of the result of the computation on the parameters by requiring only a constant additional computational effort; see Griewank and Walther (2008). The forward mode of AD roughly doubles the number of code instructions since each statement is complemented with its derivative, and hence also roughly doubles the code execution time for each run. Note that the forward mode needs the specification of the desired direction for the directional derivative in advance, and thus it only computes a single directional derivative per run. This may rapidly become very computational intensive if there are many input parameters or if one is interested in the full gradient. In this case one should use the vector forward mode, which leads to a significant reduction in complexity. In contrast, the reverse mode introduces more overhead than the forward mode for a single run, but the amount is independent of the number of input variables, among which are also the parameters to be investigated. Therefore, the reverse AD mode has the ability to outperform the forward mode in the case of many input variables but only a small number of output variables because only a single run of the reverse mode is required to establish the derivatives with respect to each input variable, whereas the forward mode requires as many runs as the number of input variables. The fact that AD introduces only a constant computational overhead is especially useful if the number of parameters is comparably high, since establishing an ensemble to investigate the sensitivity of the parameters quickly results in a high number of model runs. Moreover, using an ensemble of model runs to study parameter sensitivities additionally involves a thorough post-processing of all model output. In contrast, the AD approach clearly identifies the parameters with high sensitivity, regardless of whether the sensitivity is direct or indirect, and allows one to focus further post-processing on only the relevant parameters.
AD helps in computing the derivatives, but one has to keep in mind the subtleties: using AD as advocated in this study implies that the computed derivatives involve the differentiation of the numerical method used to approximate the solution of the differential Eqs. (12), (13). Consequently, the derivatives depend on the time step and may change if the numerical method is replaced by another method. Nevertheless, the computed sensitivities resemble the actual sensitivities of the implemented code and comprise the correct result to tackle the question how uncertainties propagate through a given numerical model as, e.g., a weather forecasting model.
We emphasize that the technique of AD is not restricted to a specific programming language nor to the analysis of cloud schemes. It is a generic technique which may help in the development of any (subgrid) scheme for a (geophysical) numerical model by providing information about the sensitivities of the involved parameters.
In adopting a cloud scheme or any subgrid scheme, the question of how the inherent uncertainties of the scheme influence the (numerical) solution of the model arises. In the context of the topic of this study, an example of the influences of a single parameter within a typical cloud scheme on the overall cloud development is discussed in Igel and van den Heever (2017a, b, c). Answering the question of how uncertainties propagate within a given model is a highly non-trivial task. As indicated in Sect. 1, methods from uncertainty quantification allow to assess this propagation (e.g., Sullivan, 2015; Le Maître and Knio, 2010), but taking many parameters simultaneously into account is challenging and computationally expensive. Algorithmic differentiation allows one to first identify the parameters which influence the result of a given parameterization at most, e.g., a cloud scheme, and limit the more extensive investigation to only these parameters; see Chertock et al. (2019) for an example of such an investigation. However, as AD by design computes the derivatives along the numerical solution trajectory, one might not detect all possible sensitivities, but at least the most sensitive parameters in “typical” situations.
The code for the cloud model together with all scripts needed to reproduce the results in this study are available at https://doi.org/10.5281/zenodo.3461483 (Baumgartner, 2019). The algorithmic differentiation tool CoDiPack may be found online at https://github.com/scicompkl/codipack (last access: 6 December 2019) and the version 1.8.1, which is used in this study, is available at https://doi.org/10.5281/zenodo.3460682 (Sagebaum et al., 2019).
MB developed the cloud model code and carried out the numerical experiments under the supervision of AB and PS. MS developed the algorithmic differentiation tool CoDiPack under the supervision of NRG. MB and MS prepared the manuscript with reviews from NRG, AB, and PS.
The authors declare that they have no conflict of interest.
The authors thank the anonymous referees for their valuable comments and suggestions, which considerably helped in improving the manuscript. The authors acknowledge support of the Deutsche Forschungsgemeinschaft (DFG) within the project Enabling Performance Engineering in Hesse and Rhineland-Palatinate (grant number 320898076). Manuel Baumgartner, Peter Spichtinger and André Brinkmann acknowledge support by the DFG within the Transregional Collaborative Research Centre TRR165 Waves to Weather (http://www.wavestoweather.de, 6 December 2019), projects B7 and Z2.
This research has been supported by the Deutsche Forschungsgemeinschaft (grant nos. 320898076 and 257899354).
This paper was edited by David Topping and reviewed by two anonymous referees.
Albring, T., Sagebaum, M., and Gauger, N. R.: Efficient Aerodynamic Design using the Discrete Adjoint Method in SU2, AIAA 2016-3518, 2016. a
Asai, T.: A Numerical Study of the Air-Mass Transformation over the Japan Sea in Winter, J. Meteorol. Soc. Jpn. Ser. II, 43, 1–15, 1965. a
Baumgartner, M.: Algorithmic Differentiation for Cloud Schemes using CoDiPack (v1.8.1), Zenodo, https://doi.org/10.5281/zenodo.3461483, 2019. a
Belikov, D. A., Maksyutov, S., Yaremchuk, A., Ganshin, A., Kaminski, T., Blessing, S., Sasakawa, M., Gomez-Pelaez, A. J., and Starchenko, A.: Adjoint of the global Eulerian–Lagrangian coupled atmospheric transport model (A-GELCA v1.0): development and validation, Geosci. Model Dev., 9, 749–764, https://doi.org/10.5194/gmd-9-749-2016, 2016. a
Bischof, C. H. and Eberhard, P.: Automatic differentiation of numerical integration algorithms, Math. Comp., 68, 717–731, https://doi.org/10.1090/S0025-5718-99-01027-3, 1999. a, b, c
Bischof, C. H., Khademi, P., Mauer, A., and Carle, A.: Adifor 2.0: automatic differentiation of Fortran 77 programs, IEEE Comput. Sci. Eng., 3, 18–32, https://doi.org/10.1109/99.537089, 1996a. a
Bischof, C. H., Pusch, G. D., and Knoesel, R.: Sensitivity analysis of the MM5 weather model using automatic differentiation, Comput. Phys., 10, 605–612, https://doi.org/10.1063/1.168585, 1996b. a
Blessing, S., Kaminski, T., Lunkeit, F., Matei, I., Giering, R., Köhl, A., Scholze, M., Herrmann, P., Fraedrich, K., and Stammer, D.: Testing variational estimation of process parameters and initial conditions of an earth system model, Tellus A, 66, 22606, https://doi.org/10.3402/tellusa.v66.22606, 2014. a
Chertock, A., Kurganov, A., Lukáčová-Medvid'ová, M., Spichtinger, P., and Wiebe, B.: Stochastic Galerkin Method for Cloud Simulation, Mathematics of Climate and Weather Forecasting, 5, 65–106, https://doi.org/10.1515/mcwf-2019-0005, 2019. a, b
Cotton, W. R., Bryan, G. H., and van den Heever, S. C.: Storm and Cloud Dynamics, Academic Press, 2nd Edn., 2010. a
Devenish, B. J., Bartello, P., Brenguier, J.-L., Collins, L. R., Grabowski, W. W., IJzermans, R. H. A., Malinowski, S. P., Reeks, M. W., Vassilicos, J. C., Wang, L.-P., and Warhaft, Z.: Droplet growth in warm turbulent clouds, Q. J. Roy. Meteor. Soc., 138, 1401–1429, https://doi.org/10.1002/qj.1897, 2012. a, b
Doms, G., Förstner, J., Heise, E., Herzog, H.-J., Mironow, D., Raschendorfer, M., Reinhardt, T., Ritter, B., Schrodin, R., Schulz, J.-P., and Vogel, G.: A Description of the Nonhydrostatic Regional COSMO Model, Part II: Physical Parameterization, available at: http://www.cosmo-model.org/content/model/documentation/core/default.htm (last access: 23 October 2019), 2011. a
ECMWF: IFS DOCUMENTATION – Cy43r3, Part IV: Physical Processes, available at: https://www.ecmwf.int/en/elibrary/16648-part-iv-physical-processes (last access: 23 October 2019), 2017. a, b, c, d, e
Elizondo, D., Cappelaere, B., and Faure, C.: Automatic versus manual model differentiation to compute sensitivities and solve non-linear inverse problems, Comput. Geosci., 28, 309–326, https://doi.org/10.1016/S0098-3004(01)00048-6, 2002. a
Grabowski, W. W. and Wang, L.-P.: Growth of Cloud Droplets in a Turbulent Environment, Annu. Rev. Fluid Mech., 45, 293–324, https://doi.org/10.1146/annurev-fluid-011212-140750, 2013. a
Griewank, A. and Walther, A.: Evaluating Derivatives, 2nd Edn., ISBN 978-0-898716-59-7, SIAM, 2008. a, b
Griewank, A., Kulshreshtha, K., and Walther, A.: On the numerical stability of algorithmic differentiation, Computing, 94, 125–149, https://doi.org/10.1007/s00607-011-0162-z, 2012. a
Grossmann, C. and Roos, H.-G.: Numerical Treatment of Partial Differential Equations, Universitext, Springer-Verlag, Berlin Heidelberg, 2007. a
Hairer, E., Nørsett, S. P., and Wanner, G.: Solving Ordinary Differential Equations I, vol. 8 of Springer Series in Computational Mathematics, Springer-Verlag, Berlin Heidelberg, 2nd revised Edn., https://doi.org/10.1007/978-3-540-78862-1, 1993. a
Hascoët, L. and Pascual, V.: The Tapenade Automatic Differentiation tool: Principles, model, and specification, ACM T. Math. Software, 39, 20:1–20:43, https://doi.org/10.1145/2450153.2450158, 2013. a
Hück, A., Bischof, C. H., and Utke, J.: Checking C++ codes for compatibility with operator overloading, in: 2015 IEEE 15th International Working Conference on Source Code Analysis and Manipulation (SCAM), 91–100, https://doi.org/10.1109/SCAM.2015.7335405, 2015. a
Igel, A. L. and van den Heever, S. C.: The Importance of the Shape of Cloud Droplet Size Distributions in Shallow Cumulus Clouds. Part I: Bin Microphysics Simulations, J. Atmos. Sci., 74, 249–258, https://doi.org/10.1175/JAS-D-15-0382.1, 2017a. a
Igel, A. L. and van den Heever, S. C.: The Importance of the Shape of Cloud Droplet Size Distributions in Shallow Cumulus Clouds. Part II: Bulk Microphysics Simulations, J. Atmos. Sci., 74, 259–273, https://doi.org/10.1175/JAS-D-15-0383.1, 2017b. a
Igel, A. L. and van den Heever, S. C.: The role of the gamma function shape parameter in determining differences between condensation rates in bin and bulk microphysics schemes, Atmos. Chem. Phys., 17, 4599–4609, https://doi.org/10.5194/acp-17-4599-2017, 2017c. a
Igel, A. L., Igel, M. R., and van den Heever, S. C.: Make It a Double? Sobering Results from Simulations Using Single-Moment Microphysics Schemes, J. Atmos. Sci., 72, 910–925, https://doi.org/10.1175/JAS-D-14-0107.1, 2015. a
Kalnay, E.: Atmospheric modeling, data assimilation and predictability, Cambridge University Press, 2003. a
Kaminski, T., Heimann, M., and Giering, R.: A coarse grid three-dimensional global inverse model of the atmospheric transport: 1. Adjoint model and Jacobian matrix, J. Geophys. Res.-Atmos., 104, 18535–18553, https://doi.org/10.1029/1999JD900147, 1999. a
Kessler, E.: On the Distribution and Continuity of Water Substance in Atmospheric Circulations, American Meteorological Society, Boston, MA, 1–84, https://doi.org/10.1007/978-1-935704-36-2_1, 1969. a, b
Khain, A. P., Ovtchinnikov, M., Pinsky, M., Pokrovsky, A., and Krugliak, H.: Notes on the state-of-the-art numerical modeling of cloud microphysics, Atmos. Res., 55, 159–224, https://doi.org/10.1016/S0169-8095(00)00064-8, 2000. a
Khain, A. P., Beheng, K. D., Heymsfield, A. J., Korolev, A. V., Krichak, S. O., Levin, Z., Pinsky, M., Phillips, V., Prabhakaran, T., Teller, A., van den Heever, S. C., and Yano, J.-I.: Representation of microphysical processes in cloud-resolving models: Spectral (bin) microphysics versus bulk parameterization, Rev. Geophys., 53, 247–322, https://doi.org/10.1002/2014RG000468, 2015. a, b, c
Khairoutdinov, M. and Kogan, Y.: A New Cloud Physics Parameterization in a Large-Eddy Simulation Model of Marine Stratocumulus, Mon. Weather Rev., 128, 229–243, https://doi.org/10.1175/1520-0493(2000)128<0229:ANCPPI>2.0.CO;2, 2000. a
Kogan, Y. L. and Martin, W. J.: Parameterization of Bulk Condensation in Numerical Cloud Models, J. Atmos. Sci., 51, 1728–1739, https://doi.org/10.1175/1520-0469(1994)051<1728:POBCIN>2.0.CO;2, 1994. a, b
Köhler, H.: The nucleus in and the growth of hygroscopic droplets, T. Faraday Soc., 32, 1152–1161, https://doi.org/10.1039/TF9363201152, 1936. a
Lamb, D. and Verlinde, J.: Physics and Chemistry of Clouds, Cambridge University Press, Cambridge, 2011. a
Langlois, W. E.: A rapidly convergent procedure for computing large-scale condensation in a dynamical weather model, Tellus, 25, 86–87, https://doi.org/10.1111/j.2153-3490.1973.tb01598.x, 1973. a
Le Dimet, F.-X., Navon, I. M., and Daescu, D. N.: Second-Order Information in Data Assimilation, Mon. Weather Rev., 130, 629–648, https://doi.org/10.1175/1520-0493(2002)130<0629:SOIIDA>2.0.CO;2, 2002. a
Le Maître, O. and Knio, O. M.: Spectral Methods for Uncertainty Quantification: With Applications to Computational Fluid Dynamics, Scientific Computation, Springer Science & Business Media, https://doi.org/10.1007/978-90-481-3520-2, 2010. a, b
Maxwell, J. C.: Diffusion, reprinted in: The Scientific Papers of James Clerk Maxwell, edited by: Niven, W. D., 2, 625–645, 1877. a
McDonald, J. E.: The saturation adjustment in numerical modelling of fog, J. Atmos. Sci., 20, 476–478, 1963. a
Neidinger, R. D.: Introduction to Automatic Differentiation and MATLAB Object-Oriented Programming, SIAM Rev., 52, 545–563, https://doi.org/10.1137/080743627, 2010. a
Orlanski, I.: A Rational Subdivision of Scales for Atmospheric Processes, B. Am. Meteorol. Soc., 56, 527–530, 1975. a
Porz, N., Hanke, M., Baumgartner, M., and Spichtinger, P.: A model for warm clouds with implicit droplet activation, avoiding saturation adjustment, Mathematics of Climate and Weather Forecasting, 4, 50–78, https://doi.org/10.1515/mcwf-2018-0003, 2018. a
Rauser, F., Riehme, J., Leppkes, K., Korn, P., and Naumann, U.: On the use of discrete adjoints in goal error estimation for shallow water equations, Procedia Comput. Sci., 1, 107–115, https://doi.org/10.1016/j.procs.2010.04.013, 2010. a
Rogers, R. and Yau, M.: A Short Course in Cloud Physics, International Series in Natural Philosophy, Butterworth-Heinemann, 3rd Edn., 1989. a
Rosemeier, J., Baumgartner, M., and Spichtinger, P.: Intercomparison of Warm-Rain Bulk Microphysics Schemes using Asymptotics, Mathematics of Climate and Weather Forecasting, 4, 104–124, https://doi.org/10.1515/mcwf-2018-0005, 2018. a
Sagebaum, M., Albring, T., and Gauger, N. R.: High-Performance Derivative Computations using CoDiPack, arXiv preprint arXiv:1709.07229, 2017a. a
Sagebaum, M., Özkaya, E., Gauger, N. R., Backhaus, J., Frey, C., Mann, S., and Nagel, M.: Efficient Algorithmic Differentiation Techniques for Turbo-machinery Design, AIAA 2017-3998, https://doi.org/10.2514/6.2017-3998, 2017b. a
Sagebaum, M., Albring, T., Demidov, D., Möller, M., van der Weide, E., and Lam, M.: SciCompKL/CoDiPack: Version 1.8.1 (Version v1.8.1), Zenodo, https://doi.org/10.5281/zenodo.3460682, 2019. a
Sandu, A.: On the Properties of Runge-Kutta Discrete Adjoints, in: Computational Science – ICCS 2006, edited by: Alexandrov, V. N., van Albada, G. D., Sloot, P. M. A., and Dongarra, J., Springer Berlin Heidelberg, Berlin, Heidelberg, 550–557, 2006. a
Sandu, A., Daescu, D. N., and Carmichael, G. R.: Direct and adjoint sensitivity analysis of chemical kinetic systems with KPP: Part I – theory and software tools, Atmos. Environ., 37, 5083–5096, https://doi.org/10.1016/j.atmosenv.2003.08.019, 2003. a
Soong, S.-T. and Ogura, Y.: A Comparison Between Axisymmetric and Slab-Symmetric Cumulus Cloud Models, J. Atmos. Sci., 30, 879–893, https://doi.org/10.1175/1520-0469(1973)030<0879:ACBAAS>2.0.CO;2, 1973. a
Sullivan, T. J.: Introduction to Uncertainty Quantification, vol. 63 of Texts in Applied Mathematics, Springer-Verlag, Cham Heidelberg New York Dordrecht London, https://doi.org/10.1007/978-3-319-23395-6, 2015. a, b
van Oldenborgh, G. J., Burgers, G., Venzke, S., Eckert, C., and Giering, R.: Tracking Down the ENSO Delayed Oscillator with an Adjoint OGCM, Mon. Weather Rev., 127, 1477–1496, https://doi.org/10.1175/1520-0493(1999)127<1477:TDTEDO>2.0.CO;2, 1999. a
Walther, A.: Automatic differentiation of explicit Runge-Kutta methods for optimal control, Comput. Optim. Appl., 36, 83–108, https://doi.org/10.1007/s10589-006-0397-3, 2007. a, b
Xiao, Q., Kuo, Y.-H., Ma, Z., Huang, W., Huang, X.-Y., Zhang, X., Barker, D. M., Michalakes, J., and Dudhia, J.: Application of an Adiabatic WRF Adjoint to the Investigation of the May 2004 McMurdo, Antarctica, Severe Wind Event, Mon. Weather Rev., 136, 3696–3713, https://doi.org/10.1175/2008MWR2235.1, 2008. a
Zhang, X., Huang, X.-Y., and Pan, N.: Development of the Upgraded Tangent Linear and Adjoint of the Weather Research and Forecasting (WRF) Model, J. Atmos. Ocean. Tech., 30, 1180–1188, https://doi.org/10.1175/JTECH-D-12-00213.1, 2013. a