the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Aug 2024
| 30 Aug 2024
Analysis of model error in forecast errors of extended atmospheric Lorenz 05 systems and the ECMWF system
Holger Kantz
Forecast error growth as a function of lead time of atmospheric phenomena is caused by initial and model errors. When studying the initial error growth, it may turn out that small-scale phenomena, which contribute little to the forecast product, significantly affect the ability to predict this product. The question under investigation is whether omitting these atmospheric phenomena will improve the predictability of the resulting value. The topic is studied in the extended Lorenz (2005) system. This system shows that omitting small spatiotemporal scales that significantly affect prediction ability will reduce predictability more than modeling it. In other words, a system with model error (omitting phenomena) will not improve predictability. A hypothesis explaining and describing this behavior is developed, with the difference between systems (model error) produced at each time step seen as the error of the initial conditions. The resulting model error is then defined as the sum of the increments of the time evolution of the initial conditions so defined. The hypothesis is compared to the fit parameters that define the model error in certain approximations of the average forecast error growth. Parameters are interpreted in this context, and the approximations are used to estimate the errors described in the hypothesis. A method is proposed to distinguish increments of prediction error growth from small-spatiotemporal-scale phenomena and model errors. Results are presented for the error growth of the ECMWF system, where a 40 % reduction in model error between 1987 and 2011 is calculated based on the developed hypothesis, while over the same period the instability (error growth rate) of the system with respect to initial condition errors has grown.
- Article
(2423 KB) - Full-text XML
- BibTeX
- EndNote





Forecast errors in numerical weather prediction systems grow over time due to the inaccuracy of the initial state (initial error), which is amplified by the chaotic nature of the system itself and model imperfections (model error). In the setting of classical low-dimensional chaos, one would observe an exponential error growth of any tiny initial error whose exponent is given by the largest Lyapunov exponent of the system, with some saturation when the error reaches the magnitude of the standard deviation of the quantity to be predicted. In contrast to this, several authors have observed in the past (Toth and Kalnay, 1993; Lorenz, 1969; Aurell et al., 1996, 1997; Boffetta et al., 1998) that the proper Lyapunov exponent of a dynamical system might not be a relevant description of the initial error growth. Brisch and Kantz (2019) and Zhang et al. (2019) associated initial error growth with scale-dependent error growth, where tiny errors grow much faster than larger ones. Lorenz (1996) gave a sketch of such error growth: a typical quantity to be predicted is a superposition of the dynamics on different scales. After fast growth of small-scale errors with saturation at these very same small scales, the large-scale errors continue to grow at a slower rate until even these saturate. Therefore, Lyapunov exponents of structures of various spatiotemporal scales are taken as the previously mentioned scale-dependent quantity, and they determine the error growth on their respective scales. It is also evident that in practice initial errors are not infinitesimal in the mathematical sense, and therefore the exponential growth of infinitesimal errors might be irrelevant for the growth of forecast errors in operational weather forecasts.
In numerical weather predictions, the average forecast error as function of lead time is influenced by many deviations from a simple exponential growth: there is the saturation effect of larger errors, the potential scale dependence of the instability, and also the fact that real initial errors are not infinitesimal and might not point into the locally most unstable direction. Moreover, if the model error is due to neglecting small-scale and fast phenomena, it is highly fluctuating along the model trajectory. In order to describe such effects, the literature contains different phenomenological approximations for the time derivative of the average error magnitude (error growth rate or tendency) as a function of the error magnitude in numerical weather predictions. We will briefly recall these here since we will use suitable fits to the observed error growth as function of error magnitude for our atmospheric model simulations later. We will show that initial errors of magnitudes that are comparable to real weather forecasts do not play a dominant role in our studied model systems, while model errors do play such a role. Moreover, we will present an explanation of the observed error growth in terms of an averaged model error called the “drift”.
In low-dimensional-bounded chaotic systems with at least one positive Lyapunov exponent, the growth of infinitesimal errors is exponential for a finite time interval, given by a linear time derivative:
where E(t) is the error magnitude, t is time, and λ is the largest Lyapunov exponent of the system. Since Eexp(t) in Eq. (1) grows unboundedly, this can be true only as long as E(t) is small since every error has to saturate at the latest when it has grown to the order of magnitude of the diameter of the attractor (the invariant set). This saturation effect was considered by Lorenz (1982), who introduced the “quadratic hypothesis” Eqv(t):
where Elim is the limit (saturation) value of the error magnitude. As a function of time, the error Eqv(t) shows a sigmoidal shape; see Fig. 5b.
For a scale-dependent error growth in the spirit of Lorenz (1969), Brisch and Kantz (2019) proposed using a power law divergence of the effective, scale-dependent Lyapunov exponent , which gives the following time evolution:
where the exponent b connects Lyapunov exponents and limit errors of the different scales (Brisch and Kantz, 2019), while the coefficient a determines the degree of the scales' coupling (Bednář and Kantz, 2022). The forecast error then grows as a power law in time, Ep(t), with a very fast growth rate when it is still small and a slow growth rate when it is large. Since Ep(t) (see Eq. 3) again grows unboundedly, Bednář and Kantz (2022) introduced the extended power law Eep(t) that allows saturation using the same trick as Lorenz (1982):
Zhang et al. (2019) described scale-dependent error growth differently. They took a two-parametric hypothesis:
where λr is a synoptic-scale error growth rate and βr is an upscale error growth rate from small-scale processes. If is large, this leads to a super-exponential growth of small errors and to the classical exponential error growth when Er(t) is large. We can and should again include saturation of the error by the factor :
The two-parametric model dEr Eq. (5) was originally designed to describe initial and model error growth (Leith, 1978). In this interpretation, λr is the largest Lyapunov exponent of the system (similar to λexp in Eq. 1), while βr is the model error source term due to the imperfect representation of the atmosphere. In addition, dEq, Eq. (6) is called the quadratic hypothesis with model error for the same reason as for dEr (Savijarvi, 1995; Dalcher and Kalnay, 1987), although in contrast to Eq. (2) it includes a constant term and therefore allows for some skewness in as a function of E.
When we present the results of our error growth numerical analysis, we particularly present the error growth rate as a function of error magnitude. This allows us to better distinguish between these different error growth models than studying the error magnitude as a function of time, even though error magnitude as function of time is relevant in predictions.
While the above-listed error growth approximations are supposed to approximate the effectively observed average error growth in operational forecasts, let us now focus on the model error. The model is given as a set of the first order in time differential equations of the form , where X is a (high-dimensional) phase space vector that describes the current state of the atmosphere and G(X) is a vector-valued function that defines the rate of change of this vector at every possible state. In operational weather forecasts, the core of such a system in given by wind speed, pressure, density, and temperature, and the minimal setting for G is then called the “primitive equations” (Phillips, 1973). Following (part of) the meteorological literature, we will call the right-hand side G(X) the “model tendency”, while in the context of dynamical systems it is called the “vector field”.
Following, e.g., Orrell et al. (2001), the model error Ge at a model space point is described as the difference between the model vector field (tendency) and the observed time derivative (tendency) of the projection of the “reality” into the model space:
Let us stress that in operational forecasts, since we do not know the perfect model, the true time derivative is only known by observation, while in our later model studies, we have a mathematical expression for the vector field of reality as well. In a very strong simplification, one could assume that the absolute value of Ge is, on average, the constant β in Eq. (5), which irrespective of initial condition errors will lead to a deviation of the model solution from reality. While it is evident how to define the model error in a single time step, we will later discuss how model errors propagate in time and how model errors at different positions along a trajectory accumulate, and we will also introduce the notion of drift for that purpose.
The main issue about forecasts is how far into the future they might be useful. The “prediction horizon” quantifies this as the time when the forecast error has grown to a certain percentage of the climatological uncertainty of the forecast target, where the latter is approximated by Elim in the above error growth assumptions.
For exponential growth and for an initial error E0 going to zero, the time tlim at which the error reaches a limiting value Elim goes to infinity:
However, a strict predictability limit tlim exists for scale-dependent error growth even when the initial error E0 vanishes (Palmer et al., 2014; Brisch and Kantz, 2019). For a description by a power law dEp (see Eq. 3) the predictability limit tlim is as follows:
For an exponential growth with a non-zero βr parameter dEr (see Eq. 5), the prediction horizon tlim is as follows:
Scale-dependent error growth implies that both model assumptions Ep and Er grow faster than exponentially when errors are small, thereby limiting the prediction horizon because further and further improvements of the precision of the initial condition are compensated by a faster initial error growth. In the context of weather prediction, this means that the influence of small-scale atmospheric phenomena, which contribute little to the final value, significantly affect the ability to predict this value. Figures 1–3 show such behavior simulated in the extended Lorenz (2005) system with one (L05-1), two (L05-2), and three (L05-3) spatiotemporal scales (see Appendix A for more information on these systems). Figure 1a shows the values of the L05-1 system variables at a given time. Because this is a single spatiotemporal scaled system, the average growth of the initially small error is exponential. The two initially nearby trajectories begin to diverge significantly in this setting after about 30 d (Fig. 1b). Adding a considerably smaller scale (L05-2 system) that does not significantly affect the overall value in sum (Fig. 2a) reduces the closeness of the two initially nearby trajectories of an overall variable by 10 d (Fig. 2b). By adding a third medium scale (Fig. 3a, L05-3 system), the two initially nearby trajectories of an overall variable start to diverge significantly after about 10 d (Fig. 3b), which is about 3 times earlier than for the L05-1 system. This is a consequence of the much faster growth of the small-scale errors.
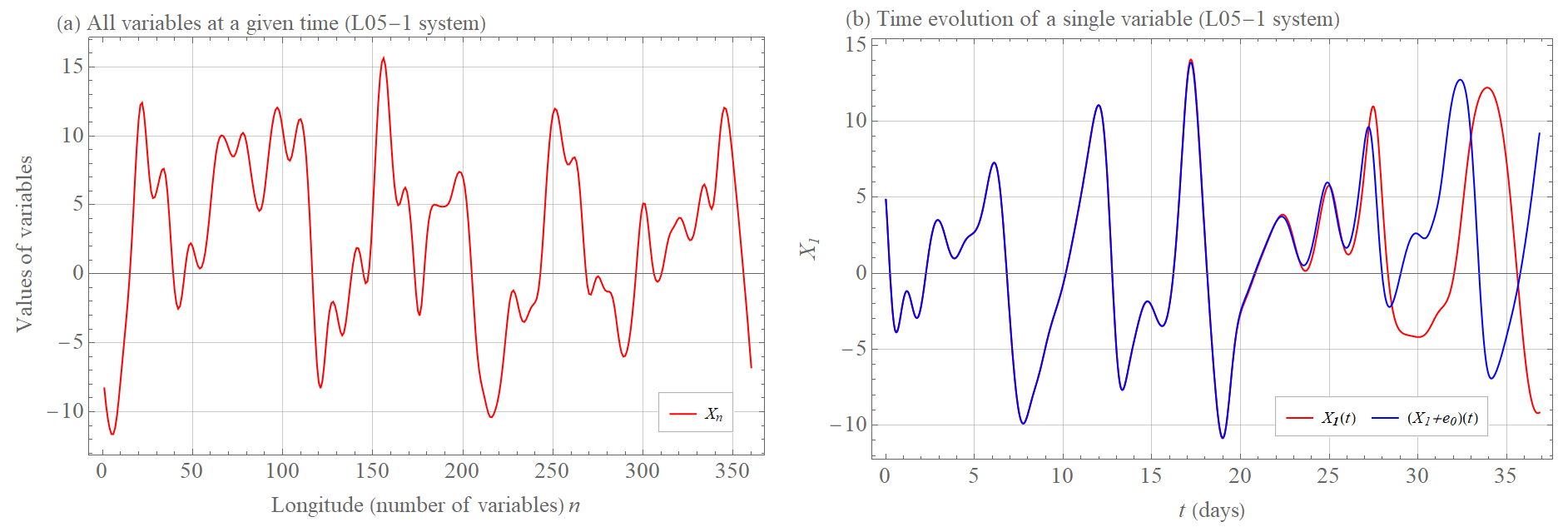
Figure 1(a) Values of Xn, variables (red curve) of the L05-1 system at a given time (see Appendix A for more information on the system and its settings). (b) The time evolution t of the variable X1(t) (red curve) and the time evolution of the initially nearby trajectory (X1(0)+e0)(t) (blue curve) of the system L05-1, where e0=0.01.
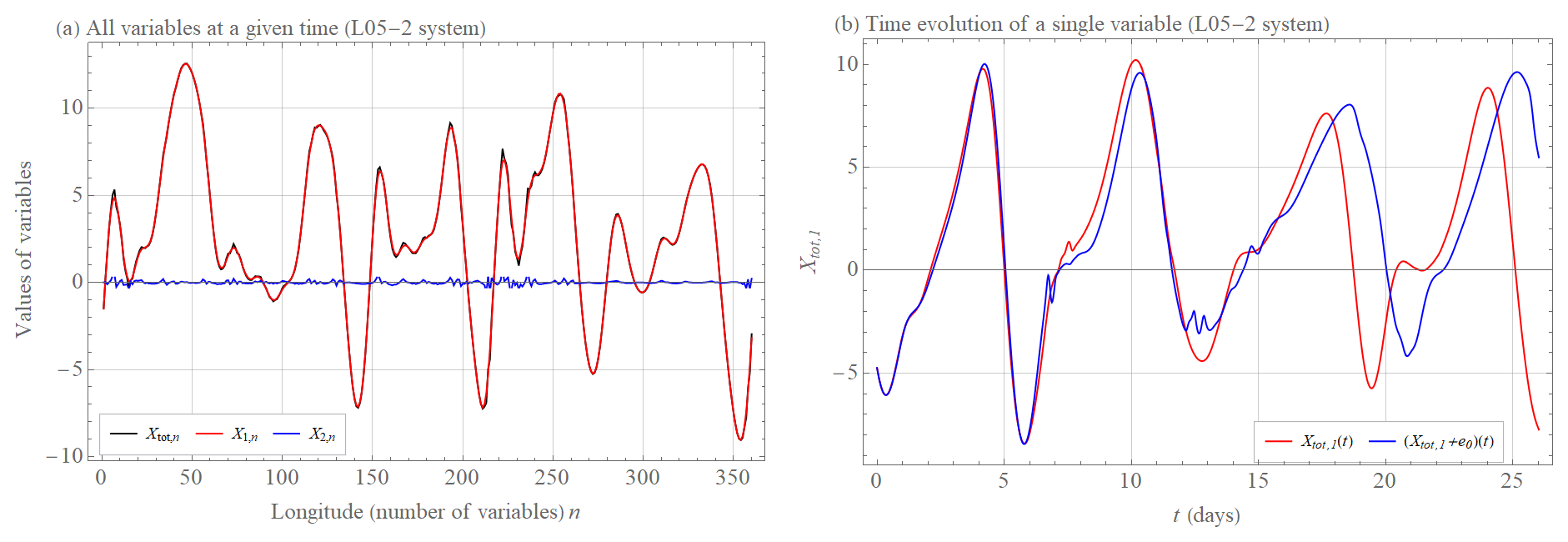
Figure 2(a) Values of X1,n (large scale, red curve), X2,n (small scale, blue curve), and Xtot,n (overall curve, black curve) variables of the L05-2 system at a given time (see Appendix A for more information on the system and its settings). (b) The time evolution t of the variable Xtot,1(t) (red curve) and the time evolution of the initially nearby trajectory (blue curve) of the system L05-2, where e0=0.01.
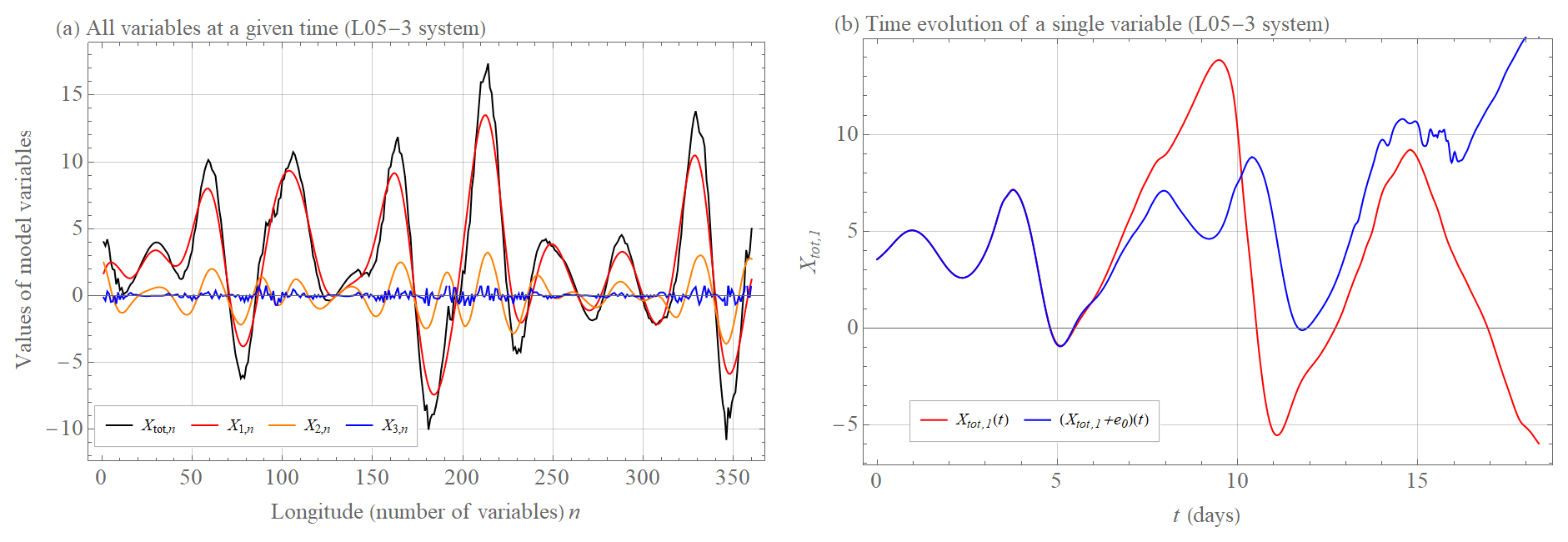
Figure 3(a) Values of X1,n (large scale, red curve), X2,n (medium scale, yellow curve), X3,n (small scale, blue curve), and Xtot,n (overall curve, black curve) variables of the L05-3 system at a given time (see Appendix A for more information on the system and its settings). (b) The time evolution t of the variable Xtot,1(t) (red curve) and the time evolution of the initially nearby trajectory (blue curve) of the system L05-2, where e0=0.01.
Including small spatiotemporal scales, i.e., improving the model's spatial and temporal resolution, therefore enhances the instability (error growth rate) with respect to initial condition errors. The question under investigation in this paper is whether omitting small-scale atmospheric phenomena, which contribute little to the final value, will improve the predictability of the resulting value. In other words, how does the average forecast error growth change in a model where small-scale phenomena are omitted but where model errors are therefore introduced, compared to a model where all phenomena are present but the average forecast error growth is scale-dependent.
Buizza (2010), Magnusson and Kallen (2013), or Jacobson (2001) show that improving the model's spatial and temporal resolution will improve the prediction ability, especially for short forecast ranges (Buizza, 2010). However, the cited studies work with models that do not model small spatiotemporal phenomena (they are parameterized) and whose initial condition error magnitude is larger than the magnitude of these phenomena. We have verified the fact that the high-resolution model (that models small scales) is less stable than the low-resolution model (that does not model small scales) against initial condition errors (Bednář and Kantz, 2022; Budanur and Kantz, 2022) and that therefore the issue of omitting small scales has another facet. Our new approach models and omits small spatiotemporal scales using the one- and two-scale Lorenz (2005) system (L05-1 and L05-2) and its three-scale extension (L05-3) introduced before in Bednář and Kantz (2022). The omitted scale is the small scale for the L05-2 system, and the small and medium scale are for the L05-3 system. L05 system definition and further details can be found in Appendix A.
The protocol for how to measure the initial error growth for the L05 systems is defined in Sect. 2.1, and the results are presented and compared in Sect. 3.1. The model error scenario, where the L05-1 system is the model and the L05-2 and L05-3 systems are reality, is defined in Sect. 2.2, and the results are presented and compared in Sect. 3.2. The variant with initial and model error is defined in Sect. 2.3, and the results are presented and compared in Sect. 3.3. The results of different error growth scenarios are compared and discussed in Sect. 3.4. Section 4.1 includes the calculation of the model error (drift) defined in Sect. 2.4 and a hypothesis linking the error so defined with the growth of the average model error determined by the difference between model and reality. The meaning of the model error source β in dEr of Eq. (5) and dEq Eq. (6) and how to link the value of β with the value of the model error (drift) is discussed and explained in Sect. 4.2. Section 5 presents a similar analysis for the ECMWF forecast system data. Conclusions and discussions are then presented in the final section.
The average error magnitude for L05 systems is calculated numerically using the method introduced by Lorenz (1996, 2005). Generally, we define an “error” as the distance between two trajectories where one, the reference trajectory, is supposed to be the “truth”, while a second trajectory is generated under perturbation of the initial condition, under perturbation of the dynamical equations, or both. We measure the error magnitude e(t) after fixed time intervals. We then calculate the mean error magnitude E(t) after fixed times, calculate the average growth tendency during the last time interval, and report the mean error magnitudes vs. time and the mean growth tendencies (rates) vs. mean error magnitudes.
An alternative method for calculating scale-dependent error growth is called the “finite-size Lyapunov exponent” (Aurell et al., 1996, 1997; Boffetta et al., 1998; Cencini and Vulpiani, 2013). In brief, a finite-size Lyapunov exponent or finite-size error growth tendency can be defined as the ergodic average over phase space of the growth rate of perturbations of a given magnitude E, where the growth rate is defined as the inverse of the time tf needed for the error magnitude to increase by a pre-defined factor f, hence . We choose the former method because it is closer to the process of calculating the average forecast error magnitude of numerical weather prediction systems (Lorenz, 1982; Savijarvi, 1995; Froude et al., 2013; Zhang et al., 2019) and because it is more consistent with the performance of forecasts.
For numerical weather prediction systems, errors in initial conditions and model errors (inaccurate representation of atmospheric processes by the model) are sources of prediction inaccuracy. For the L05 systems, we simulate the initial error growth (perfect model assumption), the model error growth (perfect initial conditions assumption), a combination of both (initial and model error assumption), and the model error growth as defined by Orrell et al. (2001) (drift assumption). To calculate the average error magnitude, a reference trajectory (considered the truth or verification) and a trajectory that is the numerical solution of the systems with a given error are repeatedly generated. For this scheme to be meaningful, we have to ensure that the reference trajectory is on the system's attractor and that the repetition of this scheme samples the whole attractor with correct weights (the invariant measure). We solve this issue in the following way: we first integrate the system over 10 years (175 200 steps), starting from arbitrary initial conditions, and assume that after discarding this transient that the trajectory is on the attractor. We continue to integrate this single trajectory and consider segments of it as reference trajectories for error growth, i.e., the many reference trajectories are simply segments of one very long trajectory, which ensures not only that all these segments are located on the attractor but also that they sample the attractor according to the invariant measure.
2.1 Initial error growth
When we use the term “initial error growth”, we denote the growth of errors in the initial conditions, which limit predictability if a system is chaotic. In order to numerically determine the largest Lyapunov exponent, we have to ensure that initial perturbations already point into the locally most unstable direction since otherwise errors might even shrink over short time periods (this is also a relevant issue in ensemble forecasts, and there its solution is found using bred vectors; see Toth and Kalnay, 1997). We solve these issues in the following way: we start with a random perturbation of the reference trajectory of very small amplitude and let this trajectory evolve over time before determining its distance toward the reference trajectory. In other words, we discard some initial time interval of error growth since this is affected by some transient behavior before it starts to grow with the maximum Lyapunov exponent.
We calculate the initial error growth in systems with one (L05-1), two (L05-2), and three (L05-3) scales to illustrate the behavior in systems with a different number of spatiotemporal scales. The three spatial scales X1, X2, and X3 for the L05-3 system and two spatial scales X1 and X2 for the L05-2 system cannot be separated in terms of a coordinate transform but are intrinsically coupled and superimposed in the variables Xtot of the system. The initial conditions of the reality for L05-3 and L05-2 systems are called , from which one finds , , and through Eqs. (A10), (A11), and (A12), respectively, for the L05-3 system and and through Eqs. (A4) and (A5), respectively, for the L05-2 system. The initial conditions of the reality for the L05-1 system are called X0,n. The initial values of the “prediction” are then for the L05-1 system , where en(0) are the initial errors randomly selected from the normal distribution . Since the system's state Xtot is the sum over all spatiotemporal components, for L05-3 and L05-2 systems any arbitrary but small error with spatially uncorrelated components affects only the smallest-scale component. Only a spatially correlated initial error would appear in another component. However, since this error would immediately propagate into the small-scale variables and then grow fastest in these, a perturbation with initial errors in the smallest-scale component is the only practical choice. The initial values of the prediction for the L05-3 system are then , where e3,n(0) is the initial error randomly selected from the normal distribution . The initial error e2,n(0) of the L05-2 system is also randomly selected from the same normal distribution, where the initial value of the prediction is .
From the initial values of reality and prediction, we integrate the L05 system equations (Eqs. A1, A8, and A9) for 41.7 d (K=2000 steps). In each time step, k of the numerical integration and are obtained. The size of the error at a given time kΔt is , where , (N=360 variables for all used systems). τ defines a scale or sum of scales ( (L05-3 system), (L05-2 system)) and is therefore omitted for the L05-1 system. We perform M=400 runs to calculate the average error growth. In each new run, the initial values are the last values of the previous run. The average initial error growth E(t) is calculated as the geometric mean of the runs of the Euclidean distances between reality and prediction:
The geometric mean is chosen because of its suitability for comparison with growth governed by the largest Lyapunov exponent. For further information, see Bednář et al. (2014) or Ding and Li (2011). As a result, we have numerical averages for the error growth as a function of time steps after perturbing the reference trajectories in the full phase space and for each scale. We can convert these results into the error growth tendency (rate) as a function of the error magnitude.
2.2 Model error growth
By “model error growth”, we denote the growth of errors caused by the inaccurate description of reality by the “model”. This inaccuracy involves small-scale atmospheric processes unresolved by the model, which for numerical weather prediction systems are approximated to the resolved scale by a procedure called parameterization. It also denotes model biases that are either unknown or have not yet been addressed (Allen et al., 2006). It is a common expectation that model errors in numerical weather forecasts can be reduced by improving the spatial and temporal resolution of the forecast system.
To simulate this in the L05 systems environment (Appendix A), we use the L05-2 and L05-3 systems as the reality and the L05-1 system as the model. Thus, the unresolved or unknown scale is the small scale for the L05-2 system and the small and medium scale for the L05-3 system. This approach is justified by the fact that the L05-2 and L05-3 systems can be viewed as a variant of the L05-1 system:
where for the L05-2 system and for the L05-3 system are treated as a forcing, which varies in a complicated manner with time. We parameterize these small-scale phenomena contained in by the average value of these phenomena, which is close to zero, and therefore we can write:
where 〈…〉 represents the mean calculated over a long orbit on the L05-2 and L05-3 system attractors.
To calculate the average model error growth, we first define initial conditions that are the same for model and reality (perfect initial conditions assumption) and are determined from the values of reality (L05-2 or L05-3 systems) at the end of the initial transient. Let us stress that we can use of our high-resolution L05-3 or L05-2 system without any projection as the initial state of the L05-1 system and that the lack of smaller scales is only expressed by the lack of feedback from the smaller scales in the equation of motion.
From these initial values, we integrate the L05-2 or L05-3 system equations (reality) and the L05-1 system equations (model) forward for 41.7 d (K=2000 steps). In each time step k of the numerical integration, (reality) and Xk,n (model) are obtained. The size of the error at a given time kΔt is , where , (N=360 variables for all used systems). We perform L=400 runs to calculate the average error growth. In each new run, the initial values are the last values of the previous run. The average model error growth EM(t) is calculated as the geometric mean of the runs of the Euclidean distances between reality and model:
As a result, we have numerical averages for the model error growth as a function of time steps. Note that in this framework, only (L05-2 and L05-3 systems) values compared to Xk,n (the L05-1 system) and not the individual scales. We can convert these results into the error growth tendency (rate) as a function of the error magnitude.
2.3 Initial and model error growth
By “initial and model error growth”, we denote the combination of the initial error growth defined in Sect. 2.1 and the model error growth defined in Sect. 2.2. We describe the L05-2 and L05-3 systems as reality and the L05-1 system with perturbations in the initial conditions of reality as “model prediction”.
In this setting, we do not discard the initial time interval of initial error growth because this transition period is negligible compared to the model error growth. The initial conditions of the reality for L05-3 and L05-2 systems are called and determined in the same way described above. The initial values of the model prediction for the L05-1 system are then , where en(0) values are the initial errors randomly selected from the normal distributions and . From initial values, we integrate the L05-2 or L05-3 system equations (reality) and the L05-1 system equations (model prediction) forward for 41.7 d (K=2000 steps). In each time step k of the numerical integration, (reality) and (model prediction) are obtained. The size of the error at a given time kΔt is , where , (N=360 variables for all used systems). We perform L=400 runs to calculate the average error growth. In each new run, the initial values are the last values of the previous run. The average initial and model error growth EM+ie(t) is calculated as the geometric mean of the runs of the Euclidean distances between reality and model prediction:
As a result, we have numerical averages for the initial and model error growth as a function of time steps. Note that in this framework only (L05-2 and L05-3 systems) values are compared to Xk,n (the L05-1 system) and not the individual scales. We can convert these results into the error growth tendency (rate) as a function of the error magnitude.
2.4 Drift
Section 2.2 describes how we can numerically measure the effects of the model error on forecast accuracy. However, if we want to understand how the model error drives the model trajectory away from reality, we need an additional concept. The reason is that model errors at different positions along the trajectory are only weakly correlated. This is a consequence of the fact that the lack of small scales and fast degrees of freedom in the model equations dominates model errors. However, if model errors at different positions along a trajectory are uncorrelated, then they can partially compensate each other, and their effect is not the same as if we assume that model errors along a trajectory are about the same everywhere. Therefore, We will recall the concept of drift as discussed by Orrell et al. (2001). For these purposes, let us first generally define the model (L05-1 system in our case) as , where X∈ℝn is the model state space vector (n=360 in our case) and the reality state space vector is . In general, , and it is necessary to project from the state space of reality to the state space of model (Data Assimilation for Numerical Prediction Models). In our case, , , and we use either the L05-2 system or the L05-3 system as reality. The model error Ge at the point Xtot(t) is then the difference between the model vector field (tendency) and the tendency of the projection of reality into the model space. In our case, we can write the following equation:
The drift vector d(τ) was introduced by Orrell et al. (2001) as
This is an accumulation of model errors along a piece of the model trajectory. As we will see in numerical simulations (Fig. 11), the absolute value of drift |d(τ)| will not grow approximately linearly in time, i.e., it is not the same as accumulating the absolute value of the model error |Ge| along the same piece of the trajectory.
This is a consequence of the here-considered case of neglected small-scale motion: since the ignored scales fluctuate quickly, the model errors at successive positions on the trajectory lose their correlations. We checked this for our L05 models explicitly by calculating the auto-correlation function of the drift vectors as a function of their time lag and found a very fast decay within a few time steps. Therefore, different from model errors in low-dimensional systems, which can be assumed to be spatially highly correlated, one here accumulates random vectors, and the drift therefore follows a path that resembles a Brownian path, as already suggested in Orrel et al. (2001). There and in Orrell (2002) it is also shown how to approximate the integral by summing a series of short-time model errors over finite time steps Δt. The absolute value of drift |d(τ)| as a function of τ grows sublinearly, as will be demonstrated later, which gives a more realistic estimate of the role of model errors. What, however, is ignored here is that a model error in the first time step creates a kind of initial condition error for the second time step, which would then grow as an initial condition error. We will discuss this later.
To calculate the average drift D comparable to previous cases, we first calculate the time evolution of reality (L05-2 or L05-3 systems), calculated from the initial conditions after the transient period. From each time step k of the time evolution of reality (up to K=2000 steps), we calculate the one-step Δt time evolution of the model. values are therefore viewed as initial conditions for the one-step Δt time evolution of the model. The size of the drift at a given time kΔt is the sum of all previous and current error vectors: , where , (N=360 variables for all used systems). Notice that it is not the absolute values of the Δt errors that are accumulated but the vectors (see Fig. 4), meaning that in the summation there can be cancellation effects and hence a slower-than-linear growth of the drift with time.
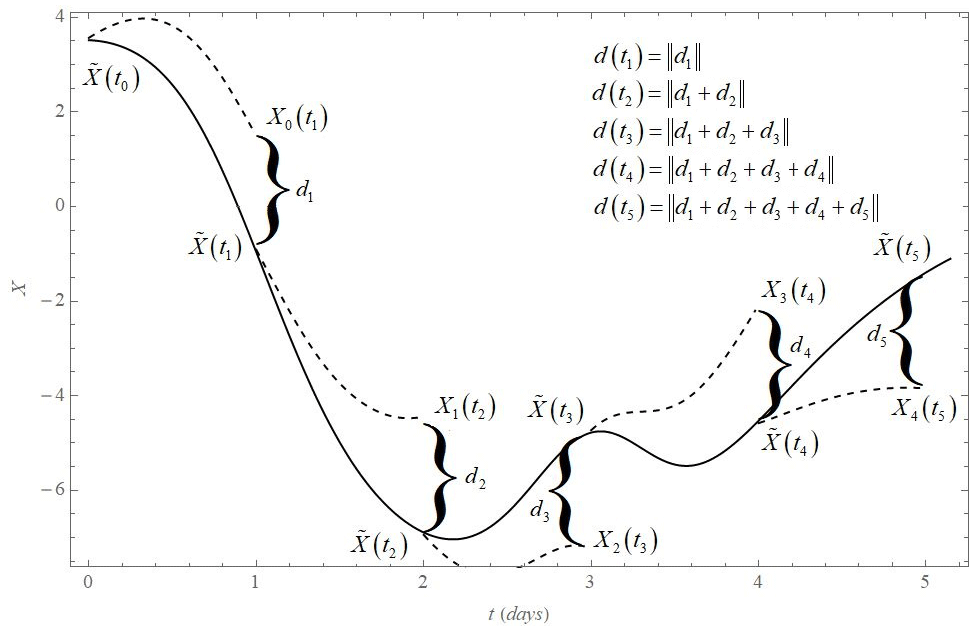
Figure 4Schematic description of drift d calculation. The solid curve shows the time evolution of the reality projected into the model space at the time for . The dashed curves show the short (Δt) time evolutions of the model Xj(t) for t≥tj initiated at the points . Drift d(t) is then the sum of the difference at each time step.
We perform L=400 runs in order to calculate the average error growth. In each new run, the initial values are the last values of the previous run. The average drift D(t) is defined as the geometric mean of the runs of the Euclidean distances between reality and model:
As a result, we have numerical averages for the drift as a function of time step. We can convert these results into the drift growth tendency as a function of the drift magnitude.
Based on the described methods, we calculate the average prediction error growth for L05 systems. We approximate the numerical error growth curves using the hypotheses Eqs. (1)–(6) and try to identify the most appropriate description. We use these results to determine how the average forecast error growth changes in a model where small-scale phenomena are omitted, but the model error is therefore created (perfect initial conditions assumption or initial and model error assumption) compared to a model where all phenomena are present, whereas the average forecast error growth is scale-dependent (perfect model assumption). The resulting behavior will be explained using the drift.
3.1 Initial error growth
Figure 5a shows the initial error growth rate (tendency) as a function of the error magnitude E for the L05-1 system, while Fig. 5b shows the error magnitude as a function of time. We also show the best-fit results of the error growth models represented by Eqs. (1)–(6). It turns out that the initial part of the growth rate is linear without any significant offset, i.e., we see a linear increase with a beginning at (). Therefore, constants in the error growth models that were included to represent the model error are consequently close to zero. In addition, the power law fit yields a power close to 1. Because of the saturation of the error after some time, the error growth rate decays to zero when the error is large, which can be represented well by the factor () in the error growth models. Hence, all models with this saturation term allow good fits to the error growth rate and the error magnitude as a function of time in the whole range and confirm that the L05-1 system is a classical chaotic system with the largest Lyapunov exponent of about λ≈0.33 d−1.
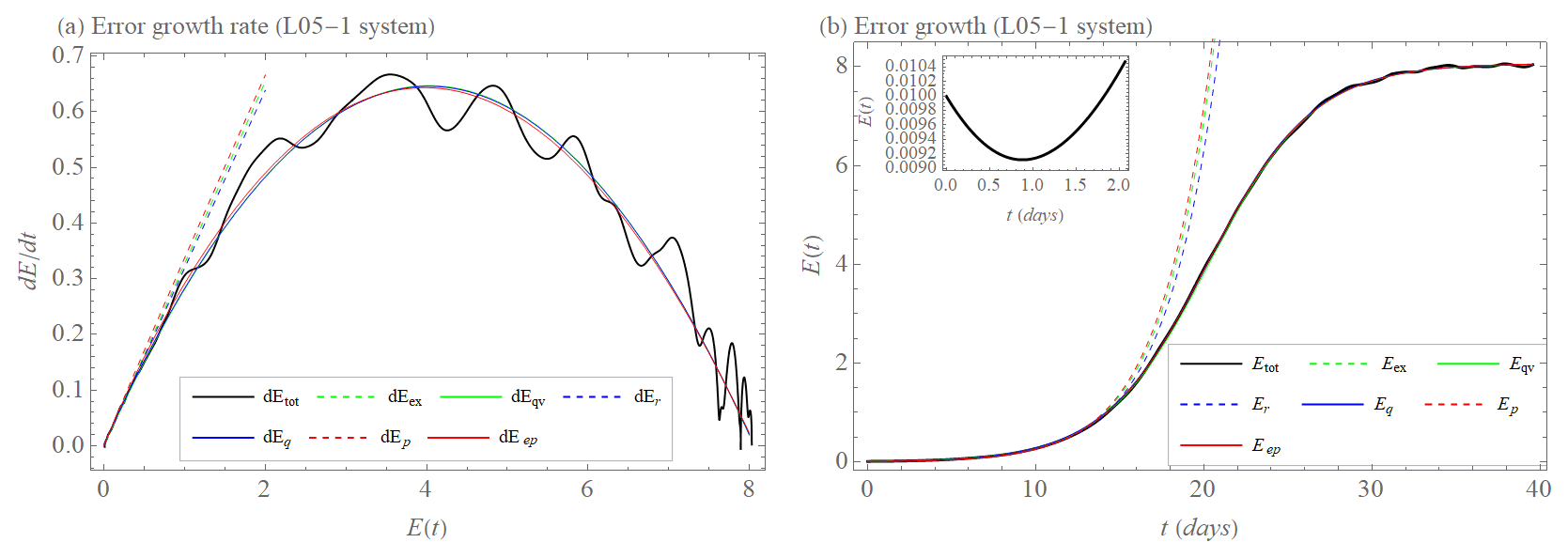
Figure 5(a) Initial error growth tendency (rate) as a function of the error magnitude E (dEtot, black). Approximation of the early part of the growth by exponential growth rate dEex (Eq. 1, dashed green); exponential growth rate with model error dEr (Eq. 5, dashed blue) and power law dEp (Eq. 3, dashed red). Approximation of the full curve by growth rate of quadratic hypothesis dEqv (Eq. 2, green); growth rate of quadratic hypothesis with model error dEq (Eq. 6, blue); and extended power law dEep (Eq. 4, red) for the L05-1 system. (b) Initial error growth E as a function of time t (Etot, Eq. 11, black). Approximation of the early part of the growth by integration of dEex (Eex, dashed green) with λex=0.33 d−1; integration of dEr (Er, dashed blue) with λr=0.32 d−1 and βr=0.00006 unit d−1; integrations of dEp (Ep, dashed red) with a=0.34 unit0.02 d−1 and b=0.02. Approximation of the full curve by integration of dEqv (Eqv, green) with λqv=0.32 d−1 and Elim=8.1 unit; integration of dEq (Eq, blue) with λq=0.32 d−1, βq=0.003 unit d−1 and Elim=8.1 unit; and integration of dEep (Eep, red) with a=0.33 unit0.03 d−1, b=0.03, and Elim=8.1 unit for the L05-1 system. The inset shows transient behavior before the error magnitude grows (for more details, see Sect. 2.1).
The behavior is obviously different for the L05-2 system, which contains additional small-scale degrees of freedom, as shown in Fig. 6. The initial part of the error growth rate (for small E) is already curved, and hence the exponential growth model does not provide a good fit anymore. Introducing a non-vanishing error growth rate right from the beginning, i.e., starting from (), which is the description by dEr, the approximation moves closer to the data, but this is in clear contradiction to the initial error growth idea. Due to the lack of model errors, the growth rate starts from 0. In addition, the quadratic hypothesis is unable to reproduce this curvature well enough. Therefore, the data are best approximated by the power law in the initial part and by the extended power law with saturation on the whole range.
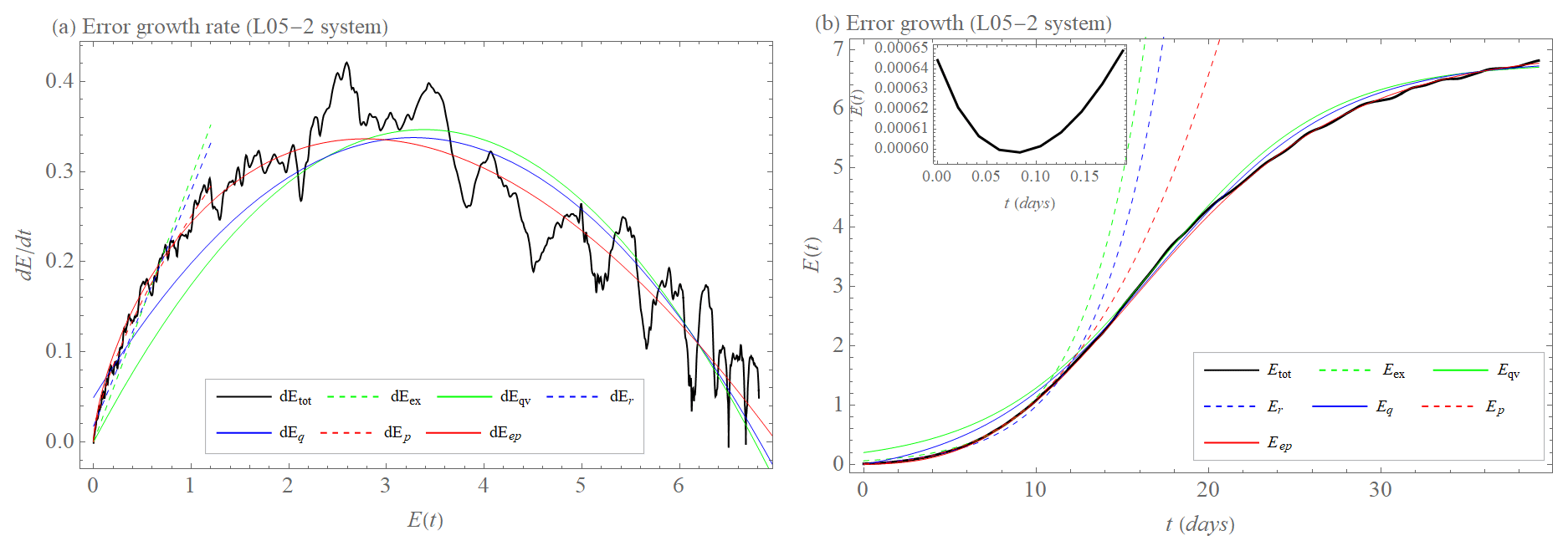
Figure 6(a) Initial error growth tendency (rate) as a function of the error magnitude E (dEtot, black). Approximation of the early part of the growth by exponential growth rate dEex (Eq. 1, dashed green); exponential growth rate with model error dEr (Eq. 5, dashed blue); and power law dEp (Eq. 3, dashed red). Approximation of the full curve by growth rate of quadratic hypothesis dEqv (Eq. 2, green); and growth rate of hypothesis with model error dEq (Eq. 6, blue) and extended power law dEep (Eq. 4, red) for the L05-2 system. (b) Initial error growth E as a function of time t (Etot, Eq. 11, black). Approximation of the early part of the growth by integration of dEex (Eex, dashed green) with λex=0.29 d−1; integration of dEr (Er, dashed blue) with λr=0.26 d−1 and βr=0.02 unit d−1; integrations of dEp (Ep, dashed red) with a=0.25 unit0.32 d−1 and b=0.32. Approximation of the full curve by integration of dEqv (Eqv, green) with λqv=0.2 d−1 and Elim=6.8 unit; integration of dEq (Eq, blue) with λq=0.18 d−1, βq=0.05 unit d−1, and Elim=6.8 unit and integration of dEep (Eep, red) with a=0.28 unit0.34 d−1, b=0.34 and Elim=7 unit for the L05-2 system. The inset shows transient behavior before the error magnitude grows (for more details, see Sect. 2.1).
What we found for the initial error growth of the L05-2 system is even more pronounced in the L05-3 system with three spatiotemporal scales. The superiority of approximations dEp and dEep over the other approximations is enhanced by the even faster growth of Etot(t) compared to the exponential growth and Etot(t) for the L05-2 system (Fig. 7). The reason for this behavior is described in Brisch and Kantz (2019) or in Bednář and Kantz (2022). Lorenz's (1969) statement can summarize it: a typical quantity to be predicted is a superposition of the dynamics on different scales. After a fast growth of the small-scale errors with saturation at these very same small scales, the large-scale errors continue to grow at a slower rate until even these saturate. This is the phenomenon of scale-dependent error growth. We also see that if we interpret the three systems L05-1 to L05-3 as low- and high-resolution models, the high-resolution model has larger instability and hence a shorter time until an ensemble of initial conditions has spread out on the attractor. If this were of relevance for the prediction horizon, then the high-resolution model would be less useful for forecasting than the low-resolution model.
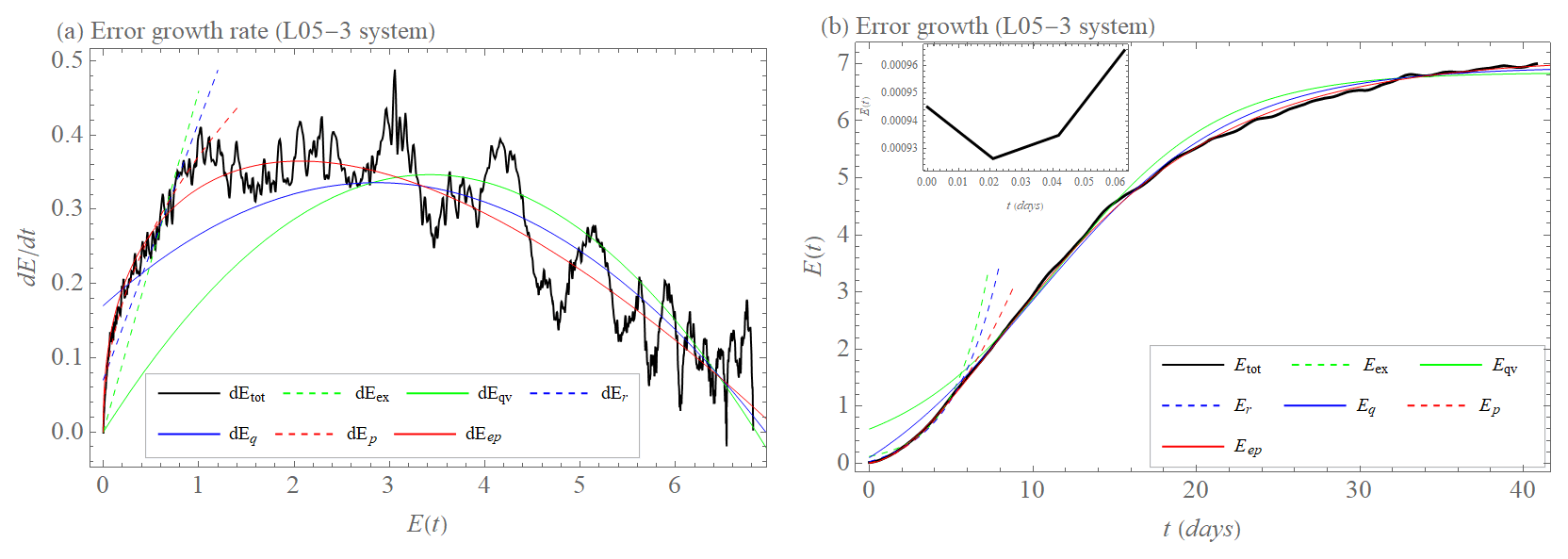
Figure 7(a) Initial error growth tendency (rate) as a function of the error magnitude E (dEtot, black). Approximation of the early part of the growth by exponential growth rate dEex (Eq. 1, dashed green); exponential growth rate with model error dEr (Eq. 5, dashed blue); and power law dEp (Eq. 3, dashed red). Approximation of the full curve by growth rate of quadratic hypothesis dEqv (Eq. 2, green); and growth rate of quadratic hypothesis with model error dEq (Eq. 6, blue) and extended power law dEep (Eq. 4, red) for the L05-3 system. (b) Initial error growth E as a function of time t (Etot, Eq. 11, black). Approximation of the early part of the growth by integration of dEex (Eex, dashed green) with λex=0.46 d−1; integration of dEr (Er, dashed blue) with λr=0.35 d−1 and βr=0.07 unit d−1; integrations of dEp (Ep, dashed red) with a=0.37 unit0.63 d−1 and b=0.63. Approximation of the full curve by integration of dEqv (Eqv, green) with λqv=0.2 d−1 and Elim=6.9 unit; integration of dEq (Eq, blue) with λq=0.14 d−1, βq=0.17 unit d−1, and Elim=6.9 unit; and integration of dEep (Eep, red) with a=0.38 unit0.59 d−1, b=0.59, and Elim=7.1 unit for the L05-3 system. The inset shows transient behavior before the error magnitude grows (for more details, see Sect. 2.1).
3.2 Model error growth
We use the L05-2 system as reality and make forecasts using the L05-1 system. Their suitably averaged differences give rise to the model error as a function of lead time. Figure 8a (solid black curve) shows the model error growth rate as a function of the error magnitude E, while Fig. 8b shows the time evolution of this error. We see an initially very fast error growth caused by the differences in the equations of motion of reality and the model. After a short transient, we see in both panels of Fig. 8a behavior compatible with our error growth models. Those models with a constant term (i.e., the quadratic hypothesis with model error and the exponential growth with model error) provide the best fits, where to be good in the whole range the factor of the quadratic hypothesis with model error is needed. In view of what will follow, we stress that based on the data both Er and Eq provide good fits up to error magnitudes of about three units, with different values λq≈0.27 d−1 and λr≈0.17 d−1 of the largest Lyapunov exponent.
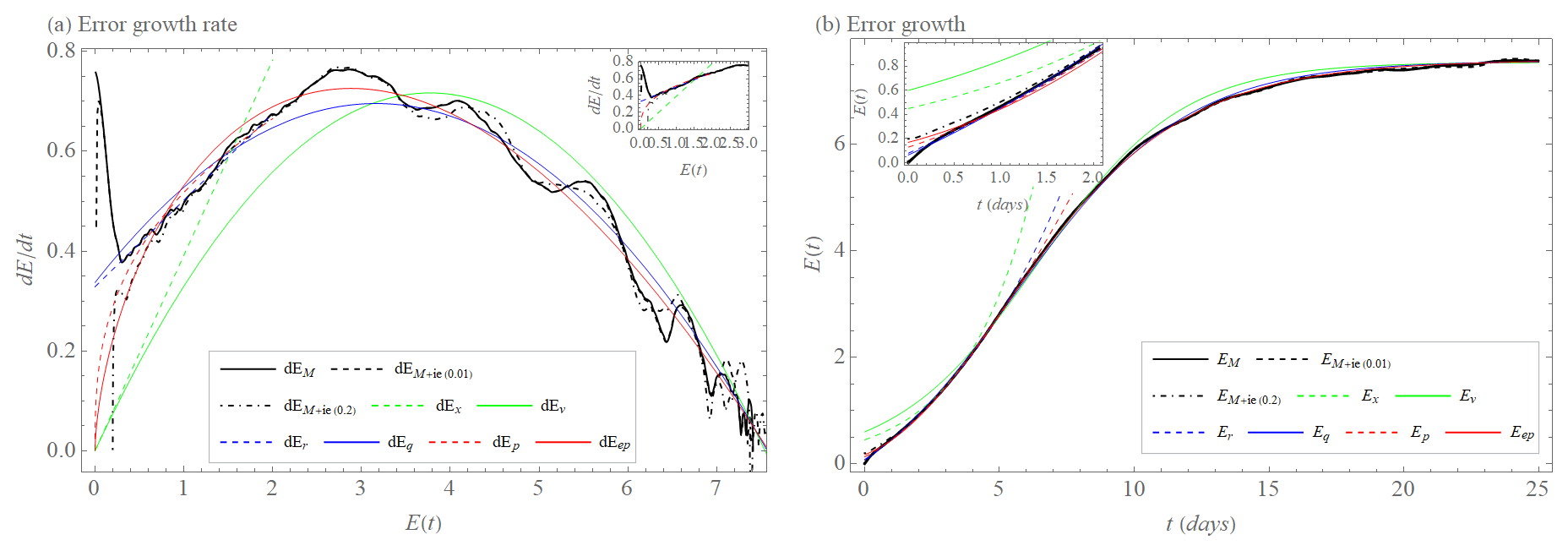
Figure 8(a) Model error growth tendency (rate) as a function of the error magnitude E (dEM, black); initial and model error growth tendency as a function of the error magnitude E (dEM+ie(0.01) (dashed black) for E(0)=0.01 and dEM+ie(0.2) (dashed–dotted black) for E(0)=0.2). Approximation of the early part of the model growth by exponential growth rate dEex (Eq. 1, dashed green); exponential growth rate with model error dEr (Eq. 5, dashed blue) and power law dEp (Eq. 3, dashed red). Approximation of the full curve by growth rate of quadratic hypothesis dEqv (Eq. 2, green), growth rate of quadratic hypothesis with model error dEq (Eq. 6, blue), and extended power law dEep (Eq. 4, red) for the L05-2 system as the reality and the L05-1 system as the model. The inset shows the early phase. (b) Model error growth E as a function of time t (EM, Eq. 14, black); initial and model error growth E as a function of time t (EM+ie(0.01) (Eq. 15, dashed black), for E(0)=0.01 and EM+ie(0.2) (Eq. 15, dashed–dotted black) for E(0)=0.2). Approximation of the early part of the growth by integration of dEex (Eex, dashed green) with λex=0.39 d−1; integration of dEr (Er, dashed blue) with λr=0.17 d−1 and βr=0.33 unit d−1; integrations of dEp (Ep, dashed red) with a=0.52 unit0.64 d−1 and b=0.64. Approximation of the full curve by integration of dEqv (Eqv, green) with λqv=0.38 d−1 and Elim=7.5 unit, integration of dEq (Eq, blue) with λq=0.27 d−1, βq=0.34 unit d−1 and Elim=7.6 unit, and integration of dEep (Eep, red) with a=0.61 unit0.39 d−1, b=0.39, and Elim=7.6 unit for the L05-2 system as the reality and the L05-1 system as the model. The inset shows the early phase of the time evolution.
When we use L05-3 as reality and L05-1 as the model, the same conclusions are valid for the model error growth rate as a function of the error magnitude E (Fig. 9a) and EM(t) (Fig. 9b). Note, however, that the rates have much larger maximal values and that EM(t) grows faster than when taking L05-2 as reality. However, if we ignore the very initial part of the error growth rate for small values E, which the error growth models cannot reproduce, we see that Er and Eq provide the best fits.
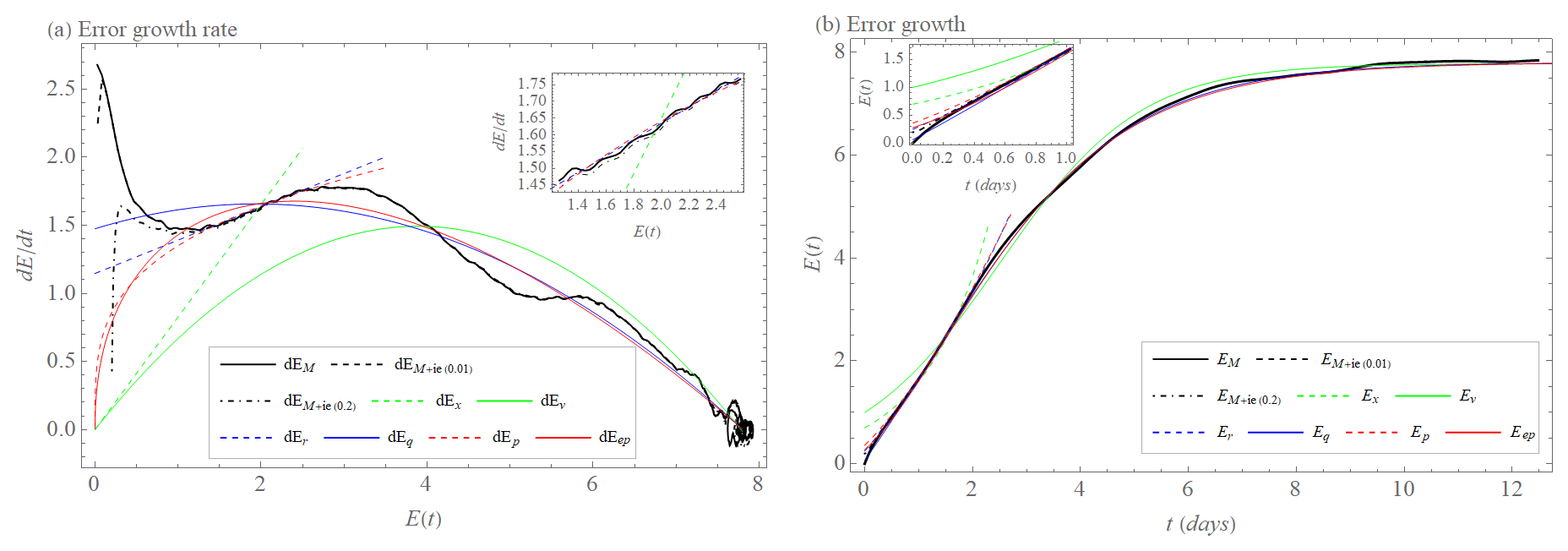
Figure 9(a) Model error growth tendency (rate) as a function of the error magnitude E (dEM, black); initial and model error growth tendency as a function of the error magnitude E (dEM+ie(0.01) (dashed black) for E(0)=0.01 and dEM+ie(0.2) (dashed–dotted black) for E(0)=0.2). Approximation of the early part of the model growth by exponential growth rate dEex (Eq. 1, dashed green); exponential growth rate with model error dEr (Eq. 5, dashed blue), power law dEp (Eq. 3, dashed red). Approximation of the full curve by growth rate of quadratic hypothesis dEqv (Eq. 2, green); and growth rate of quadratic hypothesis with model error dEq (Eq. 6, blue) and extended power law dEep (Eq. 4, red) for the L05-3 system as the reality and the L05-1 system as the model. The inset shows the early phase. (b) Model error growth E as a function of time t (EM, Eq. 14, black); initial and model error growth E as a function of time t (EM+ie(0.01) (Eq. 15, dashed black) for E(0)=0.01 and EM+ie(0.2) (Eq. 15, dashed–dotted black) for E(0)=0.2). Approximation of the early part of the growth by integration of dEex (Eex, dashed green) with λex=0.83 d−1, integration of dEr (Er, dashed blue) with λr=0.25 d−1 and βr=1.15 unit d−1, integrations of dEp (Ep, dashed red) with a=1.35 unit0.72 d−1 and b=0.72. Approximation of the full curve by integration of dEqv (Eqv, green) with λqv=0.77 d−1 and Elim=7.8 unit, integration of dEq (Eq, blue) with λq=0.38 d−1, βq=1.47 unit d−1, and Elim=7.8 unit, and integration of dEep (Eep, red) with a=1.64 unit0.55 d−1, b=0.55, and Elim=7.8 unit for the L05-3 system as the reality and the L05-1 system as the model. The inset shows the early phase of the time evolution.
3.3 Initial and model error growth
In both settings, we also show the results when we include a small initial condition error in addition to the model error. This initial condition error implies that the forecast error as a function of time starts with a non-zero value and correspondingly with a much lower growth rate than the model error alone, but apart from that there are no strong effects. Figures 8 and 9 show that it is not the net sum of the initial error growth Etot(t) and the model error growth EM(t). EM+ie(t) goes from the initial value EM+ie(0) through some transition period to the model error growth curve EM(t). EM(t) is therefore the limiting value to which EM+ie(t) is attracted. Indeed, solid and dashed black curves in the insets of Figs. 8b and 9b show that already after time t=0.2 the model error alone has grown so much that there is no effect of even of the larger initial condition error of magnitude E(0)=0.2 anymore. The larger the initial error and the smaller the model error, the longer the transition period, but it is still short for realistic values of the initial condition error. For these reasons, it can be seen that the appropriate approximation for describing the variant with initial and model error remains the same as for describing the variant with model error only, which is the exponential growth with model error, dEr Eq. (5), for the early growth phase and the quadratic hypothesis with model error dEq, Eq. (6), for the entire length of the evolution (Figs. 8 and 9).
3.4 Comparison of initial and model error growth
We want to use the approximation formulae to construct the error curves for Etot(0)=0, =0.1, and =0.2. The initial error magnitudes of 0.1 and 0.2 correspond to the relative values of the initial errors of current numerical weather prediction models for the L05 models. For the initial error growth Etot(t) (for simplicity, let us redefine Etot(t) to Eie(t)), we use the extended power law solution and find the parameter values for the L05-2 system and for the L05-3 system, with initial values Eie(0)(0)→0 (Fig. 10, solid red curve), Eie(0.1)(0)=0.1 (Fig. 10a, dashed red curve), and Eie(0.2)(0)=0.2 (Fig. 10b, dashed red curve).
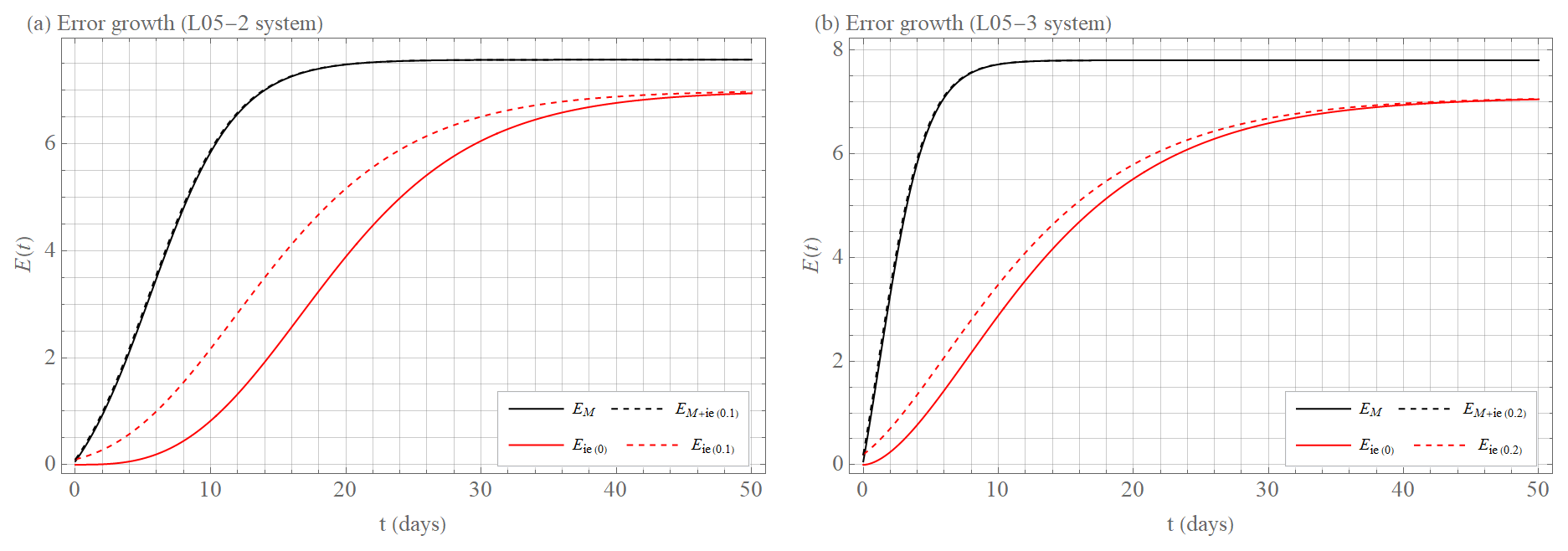
Figure 10Error growth E as a function of time t. The solid black curve shows model error growth EM (Eq. 14), the dashed black curve shows initial and model error growth EM+ie (Eq. 15), the solid red curve displays initial error growth Eie for E(0)→0 (Eq. 11), and the dashed red curve displays initial error growth Eie for (a) E(0)≈0.1 and (b) E(0)≈0.2 (Eq. 11). Shown are calculations of the best-fit approximations for given types of error growth (see Sect. 3 for more details). The initial error growth Eie is calculated for (a) the L05-2 system and (b) the L05-3 system. The model error growth EM and initial plus the model error growth EM+ie is calculated as the difference (a) between the L05-1 system and the L05-2 system and (b) between the L05-1 system and the L05-3 system.
For the model error growth EM(t), we use the quadratic hypothesis with model error with the following best-fit parameters: and EM(0)≈0.1 for the L05-2 system and with EM(0)≈0.1 for the L05-3 system.
The reason why E0 is non-zero when using the approximation can be found in Sect. 4.2. We can use the same approximations for the initial and model error growth EM+ie(t) as for the model error growth alone, EM(t) with for the L05-2 system, and for the L05-3 system. The justification can be found in Sect. 4.3.
In addition to the graphical representation (Fig. 10), we compare the variants by expressing the times t95 %, t71 %, t50 %, and t25 % when the error magnitude E reaches 95 %, 71 %, 50 %, and 25 %, respectively, of its limiting (saturated) value Elim. In the literature, t95 % is understood as a practical predictability limit, while t71 % corresponds to climatic variability, according to Savijarvi (1995). For Fig. 10, let us first comment on the difference between the limiting (saturation) values Elim of the initial error curves Eie(t) and the model error curves EM(t) or EM+ie(t). The pure initial error curves are produced in the perfect model scenario, meaning that forecast and reality are obtained with the same system. When model error is present, the variability of forecast and reality is different, and hence the limiting error is larger, in agreement with Simmons et al. (1995) or Li et al. (2018).
Figure 10 also provides insight into our question of whether high-resolution or low-resolution models will produce better forecasts. We recall that high-resolution models suffer from much faster initial condition error growth due to the stronger instability of small-scale motion. However, the small scales usually do not contribute to the forecast target. Figure 10 shows that predictability is significantly worsened by the model error rather than by the initial error growth. This means that the average forecast error in a model where small-scale phenomena are omitted but the model error is therefore present (black curves EM(t) and EM+ie(t)) grows significantly faster compared to a model where all scales are resolved (no model error) but the average forecast error growth is scale-dependent (red curves Eie(t)). However, this phenomenon depends on the relative magnitudes of the model error term β, the (effective) Lyapunov exponent λ, and the initial condition error. If the growth rate λ were larger and the model error smaller, then the exponential error growth would overwhelm the contribution of model error in every time step. In our numerical experiments using the L05 models, the magnitude of the initial condition error is tuned to values corresponding to initial condition errors in real weather forecasts, so we are tempted to believe that in weather forecasts high-resolution models should also be superior.
Specifically, for the L05-2 system (Fig. 10a), the forecast with model error (i.e., using L05-1 for the forecast), the time t25 is more than 3 times shorter than the limit without model and initial condition error (Eie(0)(0)→0), being d and d, respectively. With increasing error magnitude, the ratio of forecast times decreases ( d vs. d and d vs. d) until d, which is approximately half as large as d. Adding the error of the initial condition does not significantly change the error growth for the model error variant (; see Sect. 4.3 for details). The error growth naturally increases for the variant with the initial error, and the ratio is reduced to twice the growth rate over the entire growth period ( d vs. d, d vs. d, d vs. d, and d vs. d).
For the L05-3 system (Fig. 10b) taken as truth, the effect is even more dramatic. Without initial error (respectively for Eie(0)(0)→0), d is 7 times smaller than d. Gradually, the ratio decreases ( d vs. d and d vs. d) until d, which is approximately 4 times smaller than d. Adding the error of the initial condition does not significantly change the error growth for the model error variant (; see Sect. 4.3 for details). The growth changes for the variant with the initial error, and the ratio is reduced to 5 times the growth rate in the first half of growth ( d vs. d, d vs. d, d vs. d, and d vs. d).
In the numerical error growth study described so far, we used L05-1 as a model and compared its performance to two types of reality with different spatiotemporal resolutions. We complemented this study using as a single reality the L05-3 system and comparing the performance of the L05-1 and L05-2 models when using them for forecasts as two forecasts with different spatiotemporal resolutions. These findings (not shown) confirm the dominance of the model error over the initial condition error growth, i.e., the model with the higher resolution again provides better forecasts even for larger errors and therefore has a better prediction horizon. However, the effect in this setting is not as dramatic as in the results presented above .
In this section, we present considerations that explain the dominance of the model error in our forecast studies, where the notion of the drift (Sect. 2.4) plays a relevant role. We will consider the feedback of the drift as an initial error, which modifies the interpretation of the parameters in the exponential growth with model error dEr (Eq. 5) and the quadratic hypothesis with model error dEq (Eq. 6) and its relationship with the drift.
4.1 Drift and its role in explaining the model error growth
Figure 11 compares the model error growth EM(t) (Eq. 14), the drift D(t) (Eq. 18), and the exponential growth approximation with model error Er(t) (Eq. 5). The curves are determined from the difference between the L05-2 and the L05-1 systems (Fig. 11a) and between the L05-3 and the L05-1 systems (Fig. 11b) for error magnitudes where the saturation effect is not yet present (up to 2 and 3 d). We intend to understand the behavior of the model error since this is the issue in real forecasts. The drift D(t) (Fig. 11, blue curve) describes the early part of the model error evolution EM(t) (Fig. 11, black curve) very well, while at longer lead times it is the exponential growth with model error contribution (Fig. 11, dashed black line) which can be fitted well to the model error curve. Notice, however, that the drift is calculated numerically from the simulation data, like the model error curve, and hence does not contain any free parameters, while the exponential growth with model error has two free parameters, which allow us to optimally achieve the agreement between the solid and dashed black curves.
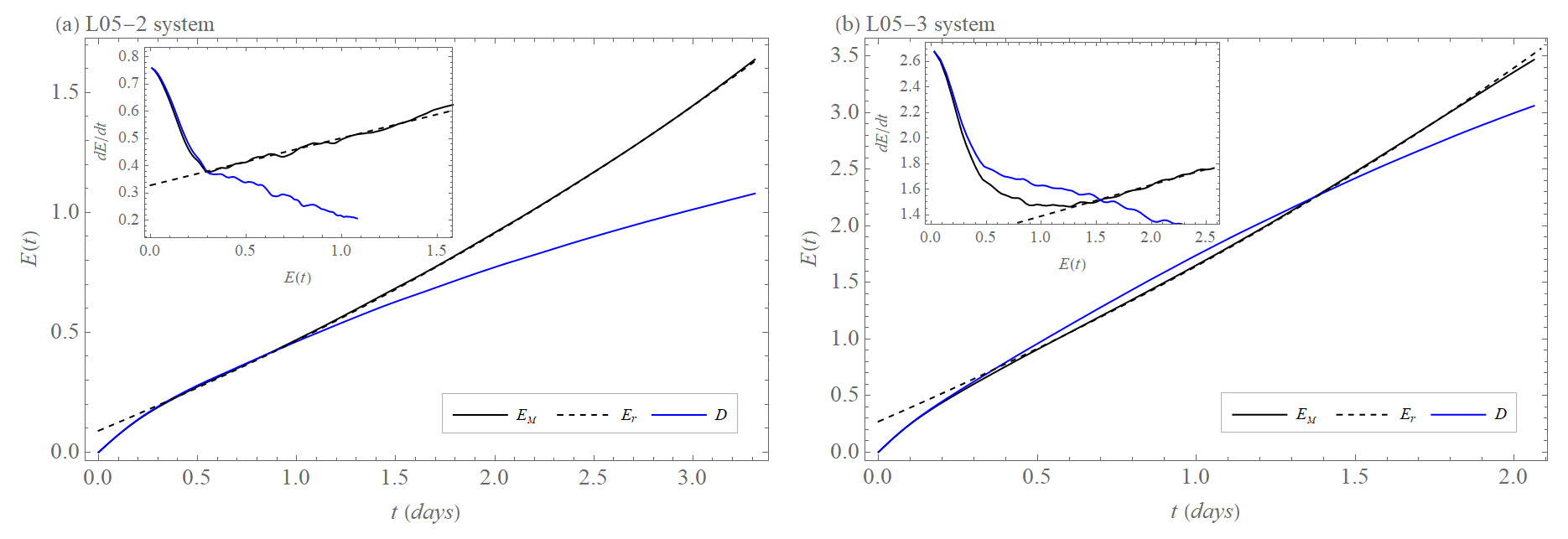
Figure 11Time evolution of drift D (blue), model error EM (black), and approximation by exponential growth with model error Er (dashed black). The inset shows the tendency (rate) of drift (blue), model error (black), and dEr (dashed black) as a function of D(t), EM(t), and Er(t). The difference (a) between the L05-1 system and the L05-2 system and (b) between the L05-1 system and the L05-3 system.
In particular, in the L05-3 model, for the times where the model error growth EM(t) can be fitted by Er(t), the drift D(t) first overestimates the model error growth EM. Following this, a significantly slower growth of the drift D relative to the model error growth EM is observed, corresponding to a decrease in the growth rate (tendency) of the drift compared to the increase in the model error growth rate (tendency) (insets in Fig. 11).
As already mentioned in Sect. 2.4, the drift can be viewed as the sum of the displacements from reality, created at each time step of the model, similar to how an error in the initial conditions will create an initial displacement at the initial time. If we interpret the drift increment at each time step , as a new initial error at time tk, then (similar to Orrell et al., 2001) we can model the model error growth EM by applying the same time evolution assumption to as the initial error growth, i.e., the exponential growth driven by the largest Lyapunov exponent λD of the model (L05-1 system). However, this growth should set in only at some time in the future since does not point into the locally most unstable direction (see Sects. 2.1 and 3.1 for a description of the initial error growth for the L05-1 system). We approximate this behavior in two different ways and will explore which one gives better results. (Fig. 12). In the first, evolves with time ti in a constant approximation as follows:
while in a linearly decaying approximation it evolves as follows:
M and σ are parameters that we fix empirically. We propose the hypothesis ED(t) as a description of the model error growth EM(t) based on the sum of the individual increments of the drift:
where ap is the symbol for the constant (con) or linear (lin) approximation.
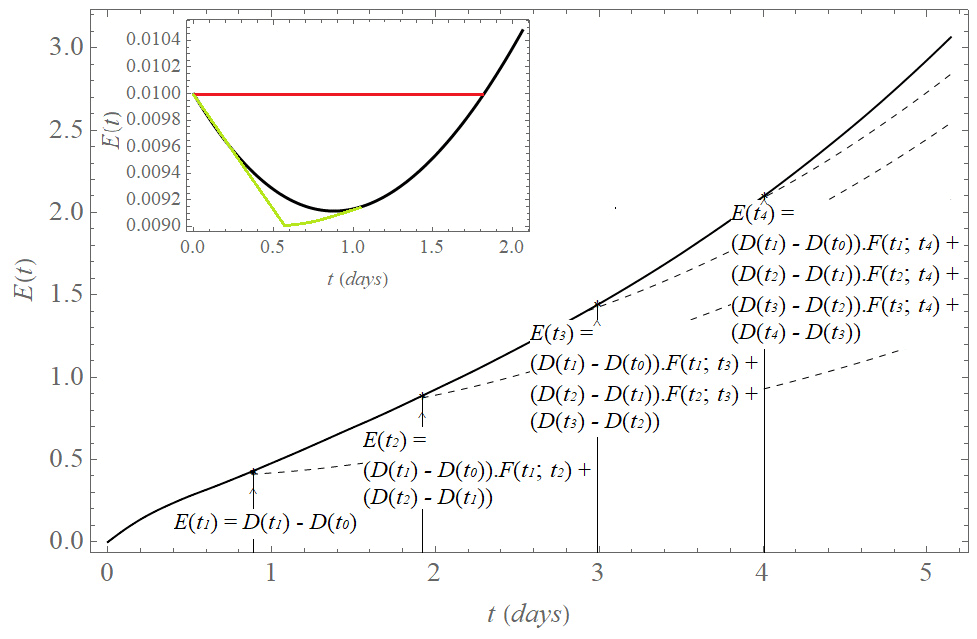
Figure 12Hypothesis ED(t) explaining the model error growth EM(t) (black curve). The drift increment at each time step , is taken as the error of the initial conditions with an exponential growth eλt driven by the largest Lyapunov exponent λ of the model (L05-1 system). Since d(t) does not point into the locally most unstable direction, time evolution of decreases in early time (black curve in the inset). A constant (red curve in the inset) or linear decrease (green curve in the inset) approximates this initial decrease. evolves with time ti (dashed curves) in the constant approximation as for and for , and in the linear approximation as for and for . M and σ are found experimentally. The resulting hypothesis ED(t) describing the model error growth EM(t) (black curve) is the sum of the individual increments: , where ap is the symbol for the constant (con) or linear (lin) approximation.
In comparison to the exponential error growth with model error (with or without saturation), this is a modification in two relevant details. First, the model error is not the same at all time steps into the future like the constant βr or βq, but it is the time-into-the-future-dependent increment of the drift D(t). Second, the new contribution in a given time step is not amplified exponentially in the next step, but because it does not point into the locally most unstable direction we let it either remain constant or even decay for a few time steps.
Figure 13 demonstrates how well the model error growth can be approximated by ED(t), particularly by the approximation with an initial linear decay ED,lin(t). As the numerical value of the Lyapunov exponent λD in the hypothesis ED(t) we use the one determined as λq in the quadratic hypothesis with model error dEq (Eq. 6), which is λq,L05-2=0.27 d−1 from the difference between the L05-1 and L05-2 systems (Fig. 8) and λq,L05-3=0.38 d−1 from the difference between the L05-1 and L05-3 systems (Fig. 9). The justification for using the parameter λq as λD can be found in Bednář et al. (2021). In short, we argue that λq is a better estimate of the Lyapunov exponent of the model system than, e.g., λr. The parameters M and σ of the hypotheses ED(t) are determined empirically. It is, however, a bit puzzling that when using the value λq in ED,lin(t), we can approximate that part of the model error growth curve EM(t), which can also be well approximated by the exponential growth with model error dEr (Fig. 13), leads to a value of the exponent that is different from λq. Therefore, in the next section, we discuss the relationship between the drift D and parameters λ and β in dEq (Eq. 6) and dEr (Eq. 5).
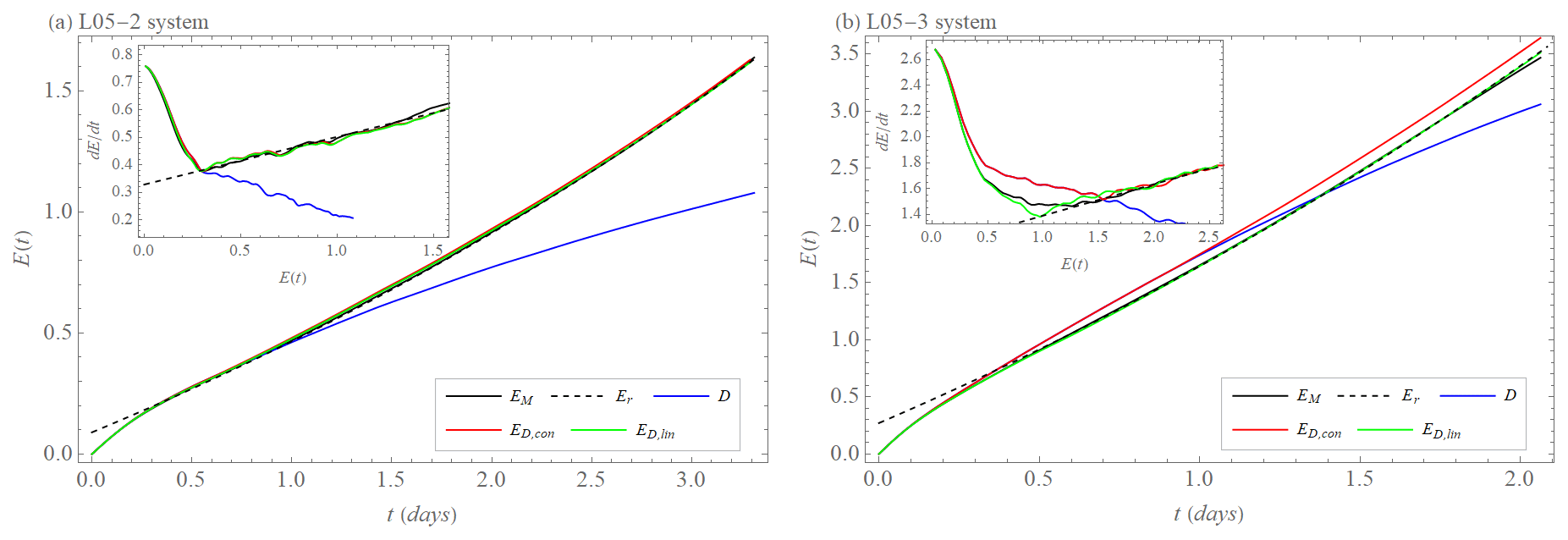
Figure 13Approximation of model error growth EM(t) (black curve) by exponential growth with model error Er (dashed black curve) and by hypotheses ED,con (Eqs. 19 and 21, red curve) and ED,lin (Eqs. 20 and 21, green curve) based on drift D (blue curve). (a) Calculation of model error EM and drift D from the difference between the L05-1 and L05-2 systems. The approximation ED,con is with M=28 and λ=0.27 d−1, and approximation ED,lin is with M=24, σ=0.001, and λ=0.27 d−1. (b) Calculation of model error EM and drift D from the difference between the L05-1 and L05-3 systems. The approximation ED,con is with M=43 and λ=0.38 d−1, and the approximation ED,lin is with M=27, σ=0.005, and λ=0.38 d−1. The insets show the time differences (rates) of the quantities as a function of the quantities presented in the main figures.
4.2 Understanding the drift through parameters of the quadratic hypothesis and exponential growth both with model error
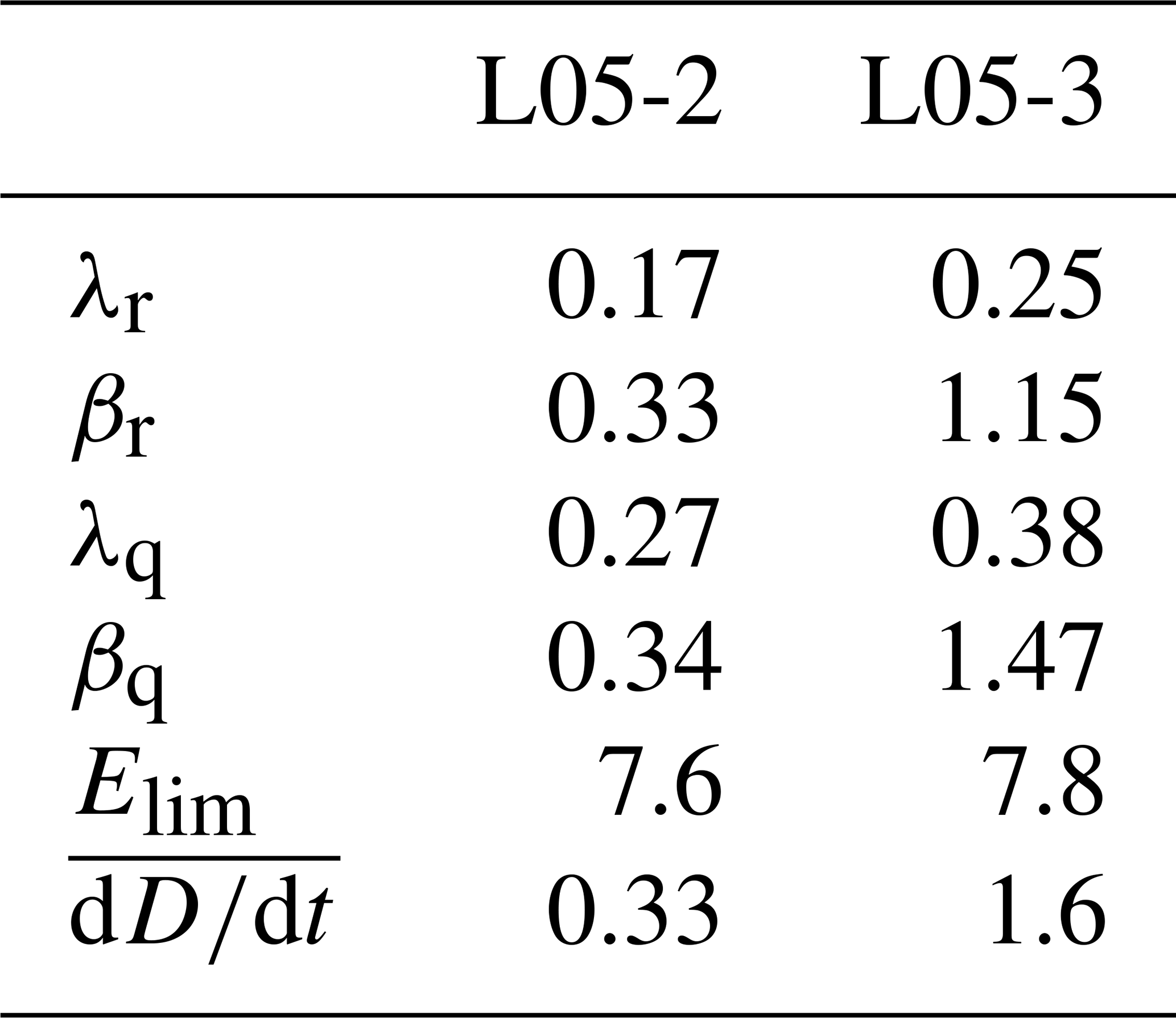
We saw two meaningful approximations to the model error growth curve over lead time: the quadratic hypothesis with model error and the exponential growth with model error. The best-fit parameter values of these two approximations are listed in Table 1. This table shows that , but the most evident is the difference of the exponential growth exponent λ, where for both realities L05-2 and L05-3 the exponent λq of the quadratic hypothesis is larger than λr of the best-fit exponential error growth.
Table 1Table of fitted constants of the different error growth approximations for the L05-2 model and the L05-3 model. All values except Elim are given as units d−1 or d−1.
To understand the meaning of the parameters of the exponential growth with model error dEr (Figs. 8 and 9), let us first define the model error growth ED,0(t) based on the drift D, ignoring the initial decrease caused by D(t) not pointing into the locally most unstable direction:
where λD is the largest Lyapunov exponent of the model (L05-1 system). The time derivative (calculated from the difference at successive time steps) of ED,0(t) is
where , meaning that due to the monotonicity of ED,0(t) in time, we can exchange the dependence on t by the dependence on ED,0(t) (see Fig. 14). Equation (23) now claims that the dashed red curve, which is λDE, plus the values of the blue curve taken at corresponding times tk, sum up to yield the red curve ED(E(t)), where we approximate the slope of the linear increase of the red curve by the slope of the black curve, which describes the observed total error.
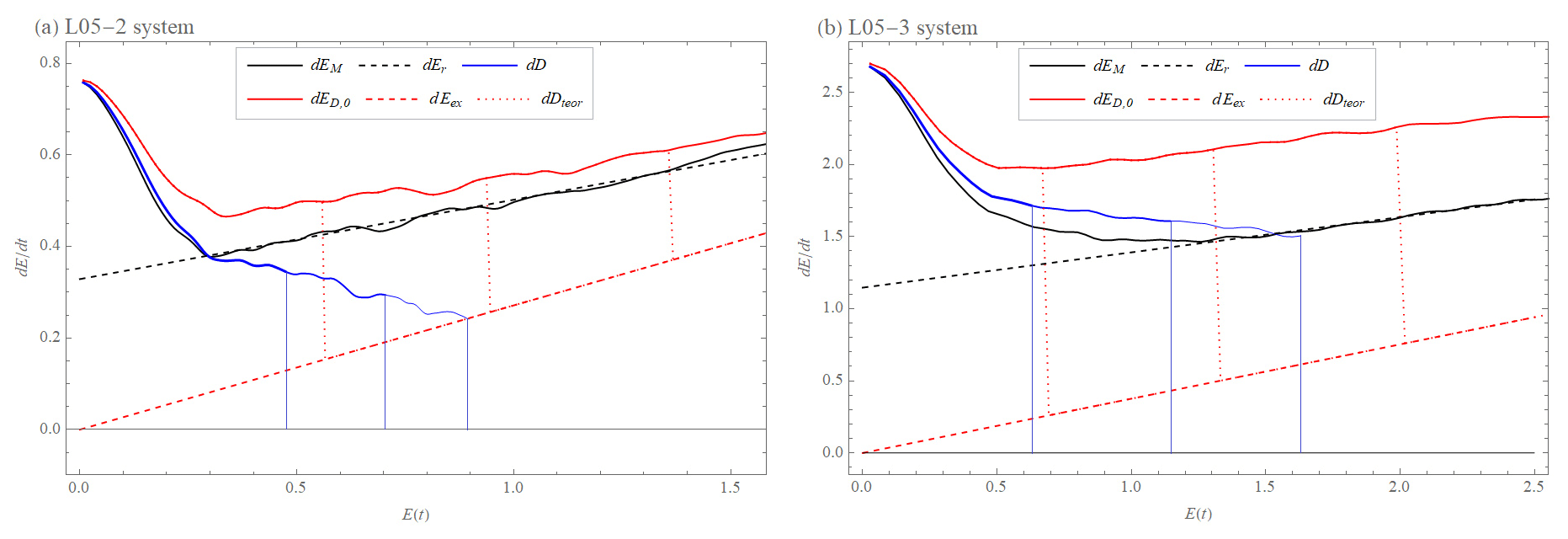
Figure 14The validity of Eq. (23) () is shown by vertical lines, where the length of the blue lines is the same as the length of the dotted red dDteor lines at times t1=1, t2=1.75, and t3=2.5 d (from left to right) for (a) the difference between the L05-1 and L05-2 systems and at times t1=0.3, t2=0.6, and t3=0.9 d (from left to right) for (b) difference between L05-1 and L05-3 systems, where (Eq. 18, blue curve) is time difference of drift, (Eq. 14, black curve) is model error growth, is a hypothesis Eq. (23) (red curve), dEr (Eq. 5, dashed black curve) is exponential growth with model error (, ), and dEex (Eq. 1, dashed red line) is exponential growth with the value of λ determined from the quadratic hypothesis with model error dEq (Eq. 6) ( and ).
We focus now on those parts of the three curves E>0.3 for L02-5 or for E>0.5 for L05-3. As has been said above, we observe that in this range of E, (Fig. 14, red curve) has the same growth rate (tendency) as (Fig. 14, black curve), which is expressed by λr, fitting the Er(t) behavior of Eq. (5) to the data (Fig. 14, dashed black curve, λr,L05-2=0.17 d−1, λr,L05-3=0.25 d−1) If we compare these parameter values to the fit using the quadratic hypothesis with model error, we see that λr is smaller than λq of dEq (λq,L05-2=0.27 d−1, λq,L05-3=0.38 d−1). In our interpretation of the model errors involving the drift, this is due to the decrease in the drift growth rate over time (Fig. 14, blue curve). Hence, βr of the dEr approximation of is then an extrapolation of the linear decline of to . Therefore, if we solve Eq. (23) for and define , then βr=βD. Equation (23) can be used to determine the drift decrease rate αD: . However, βr=βD is not the same as βr in (Fig. 14, black curve) because it is reduced by the transition term expressed by Eqs. (20) and (21) and αD is valid for and not for . In general, because tends to decrease, λq>λr. Since is almost identical to and differs only in the early stage of development, the approximations of dEq and dEr are only marginally affected (Figs. 8a and 9a). Therefore, information about the drift D can be derived from these hypotheses also for the variant with initial and model error.
For the sole initial condition error, we found that λq≤λr, but this describes a setting very different from model error. In the initial condition error, we compare the forecast and reality of a given high-resolution model, which indeed has much larger error growth exponents for short times and small errors due to small-scale degrees of freedom. As soon as we talk about model errors (with or without initial error), we use the low-resolution L05-1 model for forecasts, and hence its parameters are relevant for the propagation of errors.
In summary, we propose a new interpretation of the growth of forecast errors due to model errors: model errors in successive time steps of the forecasts are only weakly correlated. Therefore, modeling them by a constant term in the error growth dE is inappropriate. The observed model forecast error growth can be modeled much more accurately if we use the accumulated model errors called drift, interpret the drift increments as additional initial condition errors, and propagate these forward in time. The decrease of the drift growth rate over forecast time can then explain the growth rate of the model errors. Depending on what data are observed, one can either use the drift to predict the forecast errors or use the forecast errors to infer the drift due to model error.
For the ECMWF forecasting system, we cannot perform error growth experiments, but we can check average forecast errors as a function of lead time. We therefore apply the new way of assessing the model error to the error growth EEFS(t) of the 500 hPa geopotential height values (Bednář, 2023) calculated (Magnusson and Kallen, 2013) as 25 annual averages over the Northern Hemisphere (20–90°) obtained daily from 1 January 1987 to 31 December 2011. Over this period, we determine the decline in the average initial displacements of the model from reality per unit of time using the parameter βq of the quadratic hypothesis with model error. Since the parameter β is also used to describe an upscale error growth rate from small-scale processes (Zhang et al., 2019), we check whether λq>λr, as defined in Sect. 5.2, for βq determined by model error and λq≤λr for βq determined from small-scale processes (see Sect. 4).
5.1 Methods of calculation
To eliminate the effects of model errors, the initial error growth curve EEFS,ie(t) is calculated as the differences between two operational forecasts issued with 1 d lag for the same day. Specifically, we evaluate these for 27 different lead times and used the following pairs of lead times in hours: 0–24, 6–30, ..., 96–120, with 6 h shift, and from 108–132, 120–144, ..., 216–240 with 12 h shift. Detailed information about calculating the error growth of the ECMWF forecasting system can be found in Lorenz (1982). The error growth rate (tendency) is with Δt=6 h for the first 17 time steps and Δt=12 h for the rest. It is evident that this data analysis solely used data produced by the very same model. One can understand this 1 d offset between two forecasts in the following way. At day 0, we use some initial condition and propagate it forward in time. At day 1, when a new forecast starts with new initial conditions, these can be interpreted as perturbations to the day 1 forecast started at day 0. Therefore, comparing these two forecasts for the very same day as a function of lead time gives us the initial condition error growth. The only disadvantage of this procedure is that we cannot control the magnitude of the perturbation. What we interpret as perturbation is the deviation of the true forecast at day 1 from the new analysis, which is used to initialize the new forecast.
The initial and model error growth curve is calculated as differences between operational forecasts and analyses from ERA-Interim for a given day. Forecasts range from 0.5 d ago relative to the given day to 10 d ago, with time step Δt=12 h. The difference between operational analysis and analysis from ERA-Interim is taken as the initial error. The error growth rate (tendency) is with Δt=12 h.
5.2 Results and comparisons
From the data, we calculate 25 annual averages of the initial error growth curve EEFS,ie(t) and 25 annual averages of the initial and model error growth curve and their growth rates (tendencies) and . We approximate the growth rates by the exponential growth with model error dEr and by the quadratic hypothesis with model error dEq. Because the data are only up to 10 d and therefore do not cover the entire growth curve and because dEq is a three-parameter approximation, we first discuss the error in parameter estimation. Magnusson and Kallen (2013) showed that the error saturation parameter Elim estimated from the dEq hypothesis underestimates the true limiting value. Bednář et al. (2021) showed that the deviations of the values of λq and βq of dEq from the true values are anti-correlated, meaning that when one is overestimated, the other is underestimated. The average value of λq over 25 annual averages of EEFS,ie(t) and has been determined by Bednář et al. (2021) to be d−1, and to approximate the data, we fix λq to this value. Therefore, we decrease the oscillation of βq and bring Elim of dEq closer to the values determined by Magnusson and Kallen (2013). The fact that Elim is closer to the theoretical limit values estimated by Magnusson and Kallen (2013) justifies this approach.
The resulting values are shown in Fig. 15. We find that λr,ie≥λq,ie and , which satisfies the hypothesis presented in Sect. 4.2. Here, (Fig. 15a, solid red curve) has an approximately constant value, showing approximately the same decrease in αD = the drift rate over the years because it is shown in Sect. 4.2 that .
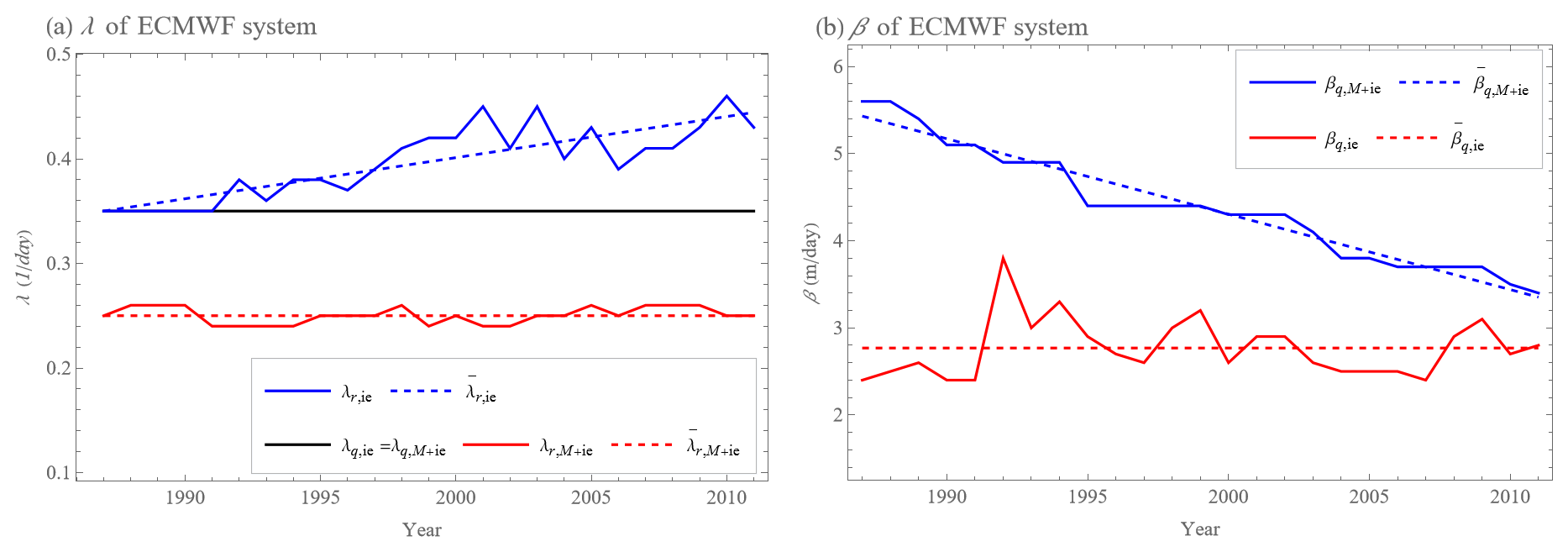
Figure 15Values of parameters λ (a) and β (b) of exponential growth with model error dEr and quadratic hypothesis with model error dEq approximated from annual averages (1987–2011) of the error growth tendencies (rates) and of the ECMWF forecasting system's 500 hPa geopotential height values over the Northern Hemisphere (for more details, see Sect. 5.1). (a) The black curve is d−1 determined as the average of the approximated λq of dEq hypothesis over 25 annual averages of EEFS,ie(t) and . The solid red curve shows the values λr of the dEr approximation of the 25 annual averages of . The dashed red curve shows that the best approximation of is a constant function with d−1. The solid blue curve shows the values λr of the dEr approximation of the 25 annual averages of . The dashed blue curve shows that the best-fitting approximation of λr is a linear function that increases with time. (b) Values of βq of dEq hypothesis approximating 25 annual averages of (solid red curve) and (solid blue curve). The dashed red curve shows that the best approximation of βq,ie is a constant function with m d−1. The dashed blue curve shows that the best-fitting approximation of is a linear function decreasing with time.
For λr,ie (Fig. 15a, solid blue curve), an increase over time is observed, indicating an increase in the resolution of the ECMWF system with smaller spatiotemporal-scale phenomena with a larger error growth rate. The parameter (Fig. 15b, solid blue curve) of the quadratic hypothesis with model error (Eq. 6) shows an approximately linear decrease over the years. These values indicate that the average displacement value per unit of time decreased by 40 % from 1987 to 2011, from 5.6 to 3.4 m d−1. The parameter βq,ie (Fig. 15b, solid red curve) for the variant with an initial error shows an approximately constant value. Together with a constant value of λq,ie (Fig. 15a, black curve), this means that the shape of the error growth rate (tendency) changes over the years only by adding a part for smaller Eie as the model better describes smaller spatiotemporal-scale phenomena, but this does not change the overall approximation of dEq, as can be seen in Fig. 16. These figures also show the similarity to the error growth rates of the L05-2 and L05-3 systems (Figs. 6–9) and the relevance of fixing λq to approximate the data using dEq.
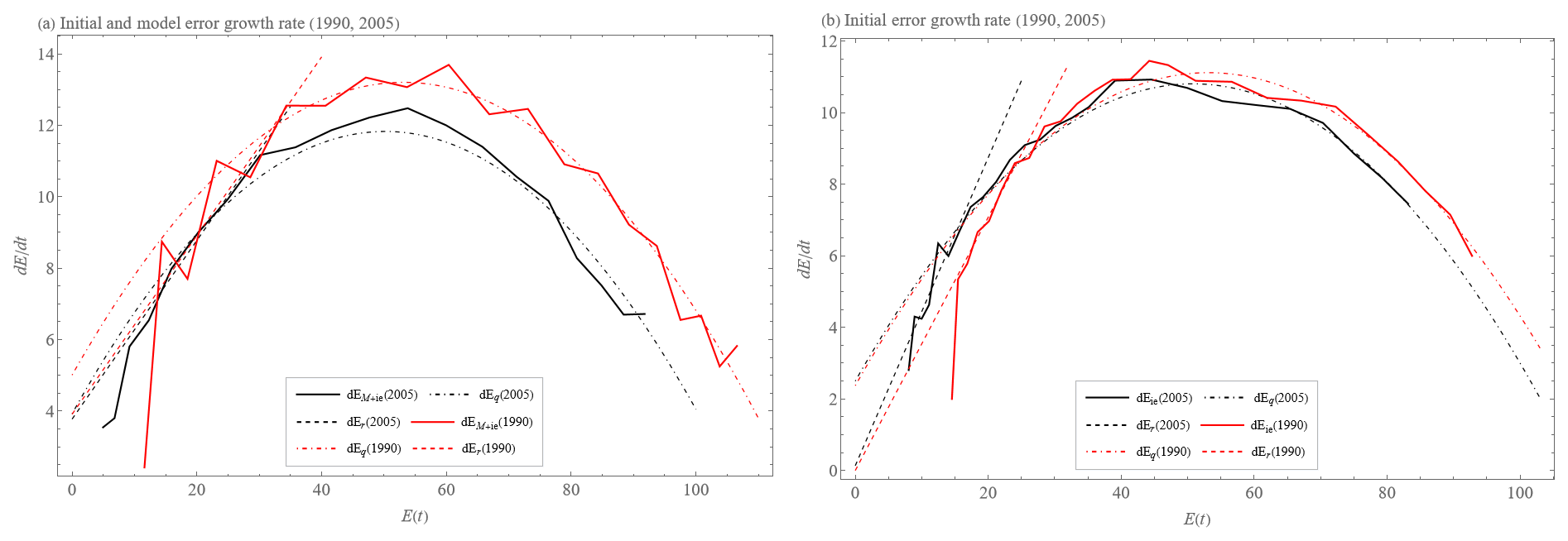
Figure 16Annual average from 2005 data of the error growth tendencies (rates) (a) and (b) of the ECMWF forecasting system's 500 hPa geopotential height values over the Northern Hemisphere (solid curves), approximation by the quadratic hypothesis with model error dEq (Eq. 6) with a constant value of the parameter λq=0.35 d−1 (dashed–dotted curves), and approximation by the exponential growth with model error dEr (Eq. 5, dashed curves). We compare the data from the year 1990 (red) to those of 2005 (black).
Based on the fact that scale-dependent error growth implies an intrinsic predictability limit, we examined whether omitting atmospheric phenomena, which contribute little to the final value, will improve the predictability of the resulting value. In other words, how does the average forecast error growth change in a model where small-scale phenomena are omitted, but the model error is therefore larger compared to a model where all phenomena are present and the average forecast error growth is scale-dependent. For this, we used the L05 systems defined by Lorenz (2005) and Bednář and Kantz (2022) and the ECMWF systems with data from Magnusson and Kallen (2013) stored in Bednář (2023).
We confirmed that for the multi-scale systems L05-2 and L05-3, the initial error growth Eie(t) can be described well by the power law dEp Eq. (3) or the extended power law dEw Eq. (4), respectively, while a simple exponential growth with model error dEr (Eq. 5) or the quadratic hypothesis with model error dEq (Eq. 6) are less appropriate. However, the non-zero parameter β in dEr and dEq describing the model error also generally relates the multi-scale nature of the system. We showed that in the L05 and ECMWF data (in contrast to the model error scenario) λq≤λr, meaning that the approximation of in the early stage grows faster than the approximation of the whole curve due to the presence of only smaller spatiotemporal scales in this part.
For the scenarios of model error growth EM(t) and both initial and model error growth EM+ie(t), we showed the appropriateness of the description using exponential growth with model error dEr and a quadratic hypothesis with model error dEq (Figs. 8 and 5). For , we explained the initial decline and subsequent growth described by dEr using the drift D (Fig. 11) defined by Orrell et al. (2001), which we extended using a hypothesis that views the drift D as a succession of initial errors followed by an exponential time evolution driven by the largest Lyapunov exponent λ of the model after a transition period (Fig. 12). We identified that λ≈λq, and the validity of λq>λr based on the drift evolution was verified in the L05 and ECMWF systems (Fig. 14 and Eq. 21). For the L05 systems, we have demonstrated that , i.e., that from the βq value of the quadratic hypothesis with model error dEq the average displacement per unit time (average drift rate) can be determined.
For ECMWF systems (forecast of 500 hPa geopotential height), this means that from 1987 to 2011 we observe a decrease in the model error by approximately 40 % from an average displacement value of 5.6 to 3.4 m d−1. Note that while in 1987 the error in initial displacement (initial error) was approximately 16 m (Magnusson and Kallen, 2013; Bednář et al., 2021), for the variant with initial and model error, a displacement of 5.6 m is produced every day in addition to this value. In 2011, the initial displacement was 6 m; for the variant with initial and model error, an average displacement of 3.4 m is produced daily. Thus, we observe a significant contribution of the model error to the error growth. This is also why the findings from the model error growth scenario can be applied to the initial and model error growth scenario, where the initial and model error growth goes asymptotically to the model error growth.
It is also why omitting atmospheric phenomena, which contribute little to the final value, will not improve the predictability of the resulting value. The average prediction error grows faster in a model where small-scale phenomena are omitted, but the model error is therefore created, compared to a model where all phenomena are present, but the average forecast error growth is scale-dependent (Fig. 10).
We now discuss the possibility that the growth of the displacement produced by the model error may also be scale-dependent. In our case, the model was an L05-1 system, i.e., a system with one scale and exponential error growth (ED(t) hypothesis). A variant where the L05-2 system was used as the model and the L05-3 system as the reality was also tested. The resulting model error growth is approximately identical to the previous variant (L05-1 system as the model and L05-3 system as the reality), i.e., adding a small scale did not affect the exponential growth of the drift D increment. However, it should be noted that the magnitude of the average drift per unit of time is much greater than the limit (saturation) value of small-scale error magnitude E2,lim, and thus we are already in the region of exponential error growth of large-scale variables. For the ECMWF system, it can be seen (Fig. 15) that over the years that the values of a parameter βq of the dEq approximation of average initial error growth Eie(t) and initial and model error growth Eie+M(t) converge, and the growth curves of the two variants are similar for the later analyzed years, as also confirmed by Froude et al. (2013). This means that, in contrast to the presented results of the L05 system, the drift rate of these years is low, and the issue of scale-dependent growth of the drift D increment is relevant and should be further investigated.
Another topic for further research is extending the ED(t) hypothesis (Eq. 21) to describe the model error growth EM(t) over the entire range up to saturation rather than just the early part where exponential growth is valid. For the part of the time evolution of the model error where the growth slows down and reaches saturation, it can be seen that the drift must reach its limiting value and then no longer contributes to the model error growth and that the exponential growth of the drift increment must slow down and reach its limiting value. However, the specific form needs to be investigated.
The L05-1 system was introduced by Lorenz (2005) as a spatial continuity modification of the Lorenz (1996) system with N variables connected by governing equations:
where
. Xn are unspecified (i.e., unrelated to actual physical variables) scalar meteorological quantities (units), F is a constant representing external forcing, and t is time. The index is cyclic so that and variables can be viewed as existing around a latitude circle. If L is even, denotes a modified summation in which the first and last terms are to be divided by 2. If L is odd, denotes an ordinary summation. Generally, L is much smaller than N and if L is even and if L is odd. To a certain extent, the model quantitatively describes weather systems, but unlike the well-known Lorenz model of atmospheric convection (Lorenz, 1963), it cannot be derived from any atmospheric dynamic equations. The motivation was to formulate the simplest possible set of dissipative chaotically behaving differential equations that share some properties with the “real” atmosphere. Although mechanisms such as potential vorticity generation are lacking in the equations, the model generates five to seven main highs and lows corresponding to planetary waves (Rossby waves). To keep five to seven main highs and lows, Lorenz (2005) suggested a ratio and F=15. The choice of parameters F and the setting of time unit=5 d is also made to obtain a similar value of the largest Lyapunov exponent to that of the ECMWF forecasting system (Lorenz, 2005).
The L05-2 system (extension to two spatiotemporal scales) was also introduced by Lorenz (2005) as a modification of the two-scale Lorenz (1996) system, where scales were coupled by linear terms that together do not alter the large-scale plus small-scale energy and where small-scale variables were driven entirely by the coupling. Rewriting the equations of the L05-1 system, we would get
where c sets the rapidness of small scale compared to large scale and b sets the small-scale amplitude size compared to large scale. Equations (A2) and (A3) have an unrealistic property compared to the numerical weather prediction systems. The large-scale and small-scale features are represented by separate sets of variables X1 and X2 instead of appearing as superimposed features of a single set Xtot. Lorenz (2005) wanted to keep the system as simple as possible, so instead of, for example, Fourier analysis, a procedure for expressing variables Xtot,n as sums of X1,n and X2,n was introduced:
Parameters α, ω, and I are chosen so that X1 is a low-pass-filtered version of Xtot, and X2 represents the difference between the full signal Xtot and the filtered signal. By this procedure, X2 has a much smaller amplitude than X1, and also its time evolution should be faster since the temporal derivative is related to the spatial derivative via the difference , which for the low-pass-filtered signal X1 is typically smaller than for the signal X2.
More precisely, Lorenz's (2005) idea is that the parameters α and ω are chosen so that X1 equals Xtot whenever Xtot changes quadratically over the longitudes (variables) n−I through n+I. It is when and . By solving these equations, we get
The procedures (Eqs. A4 and A5) are functions of the interval length .
When creating a system as the sum of and (sum of Eqs. A2 and A3), the coupling term cX1,n in Eq. (A3), which enables short waves to develop, is combined with the dissipation term in Eq. (A2). Therefore, the coupling term can be canceled entirely, or it can appear in X1 rather than X2 when Xtot is analyzed, and there might be nothing to enable the short waves in X2 to grow. Lorenz (2005) reformulated the coupling process by adding a small fraction of X1 to X2 so small waves in X2 can amplify. It is done by replacing by in Eq. (A3), and the L05-2 system would be
where .
Based on the L05-2 system (Eqs. A4–A8), Bednář and Kantz (2022) designed a three-level (scales) system (L05-3):
where c1, c2, b1, and b2 are parameters, and the procedures for expressing the variables are
where I1 and I2 set the length of the intervals .
The parameters of L05 systems (L05-1, L05-2, L05-3) should be set so that all scales behave chaotically (the largest Lyapunov exponent of each scale is positive) and that all scales have a significant difference in amplitudes and fluctuation rates. For the L05-1 system (Eq. A1), the chaotic behavior is determined by the value of F and the number of variables N. For Eqs. (A2) and (A3), where the forcing F acts only on a large scale, the chaotic behavior of the small scale is created by coupling. The coupling size is cascaded from a large scale to a small one. Because the values of large-scale variables are determined by the forcing F, the F value indirectly affects the small-scale chaotic behavior and must be chosen large enough to ensure chaotic behavior through coupling for all scales (levels). This fact must also apply to L05-2 and L05-3 systems, but procedures (A4) and (A5) for the L05-2 system and (A10)–(A12) for the L05-3 system also affect the scales' chaotic behavior, amplitude, and fluctuation rate through the choice of I (Lorenz, 2005).
To maintain the required properties F=15, N=360, L=12, and J=6 is chosen for the L05-1 system (Fig. 1a). To have the small scale 100 times smaller than the large scale, F=15, N=360, L=12, J=6, b=10, c=1, and I=10 are selected for the L05-2 system (Fig. 2a). For the L05-3 system, with requirements for the medium-scale amplitude to be about 10 times smaller than the large-scale amplitude, the small-scale amplitude to be about 10 times smaller than the medium-scale amplitude, and for the scales to have different oscillation rates (Fig. 3a), F=15, N=360, L=12, J=6, b1=1, b2=10, c1=1, c2=1, I1=20, and I2=10. The calculation is done using a fourth-order Runge–Kutta method with a time step or 0.5 h.
The ECMWF forecasting system dataset was obtained from the personal repository of Linus Magnusson (Bednář, 2023). The L05-3 system dataset and products from the ECMWF forecasting system dataset, codes, and figures were conducted in Wolfram Mathematica, and they are permanently stored at https://doi.org/10.17605/OSF.IO/2EWXB (Bednář, 2023).
HB proposed the idea, carried out the experiments, and wrote the paper. HK supervised the study and co-authored the paper.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The authors are grateful to Linus Magnusson for offering the use of the ECMWF forecasting system dataset from his personal repository.
This research has been supported by the Grantová Agentura České Republiky (grant no. 19-16066S).
This paper was edited by Chanh Kieu and reviewed by Quan Wang and three anonymous referees.
Allen, M., Frame, D., Kettleborough, J., and Stainforth, D.: Model error in weather and climate forecasting, in: Predictability of Weather and Climate, edited by: Palmer, T. and Hagedorn, R., Cambridge University Press, Cambridge, UK, 391–427, https://doi.org/10.1017/CBO9780511617652.004, 2006.
Aurell, E., Boffetta, G., Crisanti, A., Paladin, G., and Vulpiani, A.: Growth of noninfinitesimal perturbations in turbulence, Phys. Rev. Lett., 77, 1262, https://doi.org/10.1103/PhysRevLett.77.1262, 1996.
Aurell, E., Boffetta, G., Crisanti, A., Paladin, G., and Vulpiani, A.: Predictability in the large: an extension of the concept of Lyapunov exponent, J. Phys. A-Math. Gen., 30, 1–26, https://doi.org/10.1088/0305-4470/30/1/003, 1997.
Bednář, H.: Analysis of model error in forecast errors of Extended Atmospheric Lorenz' 05 Systems and the ECMWF system, OSF [code and data set], https://doi.org/10.17605/OSF.IO/2EWXB, 2023.
Bednář, H. and Kantz, H.: Prediction error growth in a more realistic atmospheric toy model with three spatiotemporal scales, Geosci. Model Dev., 15, 4147–4161, https://doi.org/10.5194/gmd-15-4147-2022, 2022.
Bednář, H., Raidl, A., and Mikšovský, J.: Initial Error Growth and Predictability of Chaotic Low-dimensional Atmospheric Model, International Journal of Automation and Computing, 11, 256–264, https://doi.org/10.1007/s11633-014-0788-3, 2014.
Bednář, H., Raidl, A., and Mikšovský, J.: Recalculation of error growth models' parameters for the ECMWF forecast system, Geosci. Model Dev., 14, 7377–7389, https://doi.org/10.5194/gmd-14-7377-2021, 2021.
Boffetta, G., Giuliani, P., Paladin, G., and Vulpiani, A.: An Extension of the Lyapunov Analysis for the Predictability Problem, J. Atmos. Sci., 23, 3409–3416, https://doi.org/10.1175/1520-0469(1998)055<3409:AEOTLA>2.0.CO;2, 1998.
Brisch, J. and Kantz, H.: Power law error growth in multi-hierarchical chaotic system-a dynamical mechanism for finite prediction horizon, New J. Phys., 21, 1–7, https://doi.org/10.1088/1367-2630/ab3b4c, 2019.
Budanur, N. R. and Kantz, H.: Scale-dependent error growth in Navier-Stokes simulations, Phys. Rev. E, 106, 1–7, https://doi.org/10.1103/PhysRevE.106.045102, 2022.
Buizza, R.: Horizontal resolution impact on short- and long-range forecast error, Q. J. Roy. Meteor. Soc., 136, 1020–1035, https://doi.org/10.1002/qj.613, 2010.
Cencini, M. and Vulpiani, A.: Finite Size Lyapunov Exponent: Review on Applications, J. Phys. A-Math. Theor., 46, 254019, https://doi.org/10.1088/1751-8113/46/25/254019, 2013.
Dalcher, A. and Kalnay, E.: Error growth and predictability in operational ECMWF analyses, Tellus A, 39, 474–491, https://doi.org/10.1111/j.1600-0870.1987.tb00322.x, 1987.
Ding, R. and Li, J.: Comparisons of two ensemble mean methods in measuring the average error growth and the predictability, Acta Meteorol. Sin., 25, 395–404, https://doi.org/10.1007/s13351-011-0401-4, 2011.
Froude, L. S., Bengtsson, L., and Hodges, K. I.: Atmospheric Predictability Revised, Tellus A, 63, 1–13, https://doi.org/10.3402/tellusa.v65i0.19022, 2013.
Jacobson, M. Z.: GATOR-GCMM: 2. A study of day- and nighttime ozone layers aloft, ozone in national parks, and weather during the SARMAP field campaign, J. Geophys. Res., 106, 5403–5420, https://doi.org/10.1029/2000JD900559, 2001.
Leith, C. E.: Objective methods for weather prediction, Annu. Rev. Fluid Mech., 10, 107–128, https://doi.org/10.1146/annurev.fl.10.010178.000543, 1978.
Li, J., Feng, J., and Ding, R.: Attractor radius and global attractor radius and their application to the quantification of predictability limits, Clim. Dynam., 51, 2359–2374, https://doi.org/10.1007/s00382-017-4017-y, 2018.
Lorenz, E. N.: Deterministic nonperiodic flow, J. Atmos. Sci., 20, 130–141, https://doi.org/10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2, 1963.
Lorenz, E. N.: The predictability of a flow which possesses many scales of motion, Tellus, 21, 289–307, https://doi.org/10.1111/j.2153-3490.1969.tb00444.x, 1969.
Lorenz, E. N.: Atmospheric predictability experiments with a large numerical model, Tellus, 34, 505–513, https://doi.org/10.1111/j.2153-3490.1982.tb01839.x, 1982.
Lorenz, E. N.: Predictability: a problem partly solved, in: Predictability of Weather and Climate, edited by: Palmer, T. and Hagedorn, R., Cambridge University Press, Cambridge, UK, 1–18, https://doi.org/10.1017/CBO9780511617652.004, 1996.
Lorenz, E. N.: Designing chaotic models, J. Atmos. Sci., 62, 1574–1587, https://doi.org/10.1175/JAS3430.1, 2005.
Magnusson, L. and Kallen, E.: Factors Influencing Skill Improvements in the ECMWF Forecasting System, Mon. Weather Rev., 141, 3142–3153, https://doi.org/10.1175/MWR-D-12-00318.1, 2013.
Orrell, D.: Role of the metric in forecast error growth: how chaotic is the weather?, Tellus, 54, 350–362, https://doi.org/10.1034/j.1600-0870.2002.01389.x, 2002.
Orrell, D., Smith, L., Barkmeijer, J., and Palmer, T. N.: Model error in weather forecasting, Nonlin. Processes Geophys., 8, 357–371, https://doi.org/10.5194/npg-8-357-2001, 2001.
Palmer, T. N., Döring, A., and Seregin, G.: The real butterfly effect, Nonlinearity, 27, 9, https://doi.org/10.1088/0951-7715/27/9/R123, 2014.
Phillips, N. A.: Principles of Large Scale Numerical Weather Prediction, in: Dynamic Meteorology, edited by: Morel, P., Springer, Dordrecht, https://doi.org/10.1007/978-94-010-2599-7_1, 1973.
Savijarvi, H.: Error Growth in a Large Numerical Forecast System, Mon. Weather Rev., 123, 212–221, https://doi.org/10.1175/1520-0493(1995)123<0212:EGIALN>2.0.CO;2, 1995.
Simmons, A. J., Mureau, R., and Petroliagis, T.: Error growth and estimates of predictability from the ECMWF forecasting system, Q. J. Roy. Meteor. Soc., 121, 1739–1771, https://doi.org/10.1002/qj.49712152711, 1995.
Toth, Z. and Kalnay, E.: Ensemble forecasting at NMC: The generation of perturbations, B. Am. Meteorol. Soc., 74, 2317–2330, https://doi.org/10.1175/1520-0477(1993)074<2317:EFANTG>2.0.CO;2, 1993.
Toth, Z. and Kalnay, E.: Ensemble forecasting at NCEP and the breeding method, Mon. Weather Rev., 12, 3297–3319, https://doi.org/10.1175/1520-0493(1997)125<3297:EFANAT>2.0.CO;2, 1997.
Zhang, F., Sun, Q., Magnusson, L., Buizza, R., Lin, S. H., Chen J. H., and Emanuel, K.: What is the Predictability Limit of Multilatitude Weather, J. Atmos. Sci., 76, 1077–1091, https://doi.org/10.1175/JAS-D-18-0269.1, 2019.
- Abstract
- Introduction
- Error growth in the L05 systems – types and methods of calculation
- Error growth in the L05 systems – results and comparisons
- Error growth in the L05 systems – discussion and explanation of results
- Error growth in the ECMWF systems
- Conclusion and discussion
- Appendix A: Lorenz's L05 systems
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Error growth in the L05 systems – types and methods of calculation
- Error growth in the L05 systems – results and comparisons
- Error growth in the L05 systems – discussion and explanation of results
- Error growth in the ECMWF systems
- Conclusion and discussion
- Appendix A: Lorenz's L05 systems
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References