the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 13 Jul 2023
| 13 Jul 2023
A dynamical core based on a discontinuous Galerkin method for higher-order finite-element sea ice modeling
Véronique Dansereau
Christian Lessig
Piotr Minakowski
The ability of numerical sea ice models to reproduce localized deformation features associated with fracture processes is key for an accurate representation of the ice dynamics and of dynamically coupled physical processes in the Arctic and Antarctic. Equally key is the capacity of these models to minimize the numerical diffusion stemming from the advection of these features to ensure that the associated strong gradients persist in time, without the need to unphysically re-inject energy for re-localization. To control diffusion and improve the approximation quality, we present a new numerical core for the dynamics of sea ice that is based on higher-order finite-element discretizations for the momentum equation and higher-order discontinuous Galerkin methods for the advection. The mathematical properties of this core are discussed, and a detailed description of an efficient shared-memory parallel implementation is given. In addition, we present different numerical tests and apply the new framework to a benchmark problem to quantify the advantages of the higher-order discretization. These tests are based on Hibler's viscous–plastic sea ice model, but the implementation of the developed framework in the context of other physical models reproducing a strong localization of the deformation is possible.
- Article
(7617 KB) - Full-text XML
- BibTeX
- EndNote





Sea ice plays a critical role for the development of the Earth system, with up to 15 % of the world's oceans being covered by it at some point during the year. It contributes importantly to the global energy budget, and its high albedo keeps Arctic and Antarctic oceans cool, affecting global oceanic circulation. An accurate simulation of sea ice is therefore of importance, in particular to describe the evolution and impact of climate change. The numerical modeling of sea ice is, however, very challenging since it is characterized by nonlinear and highly localized processes.
In the present work, we develop a numerical scheme for sea ice that uses higher-order finite elements for the sea ice momentum and the advection equations and specifically aims to provide a high-fidelity discretization with small numerical diffusion and good approximation properties. We choose discontinuous Galerkin methods for the advection because they allow a Eulerian treatment of the equations of motion that is compatible with the habits of the sea ice and climate modeling community while extending naturally to high order and exhibiting limited numerical diffusion. The momentum equation will be formulated in a variational finite-element way that also allows naturally for higher-order schemes and allows for a direct coupling to the discontinuous Galerkin advection discretization. The proposed numerical scheme will form the dynamical core in the next-generation sea ice model with discontinuous Galerkin (neXtSIM-DG) that is currently under development.
Since the first extended in situ observational campaigns of the 1970s in the Arctic, sea ice has been identified as a densely fractured material in which most of the deformation is taking place locally by relative motion at the cracks with the ice between the cracks being virtually rigid (Coon et al., 1974). This relative motion of ice plates, referred to in the sea ice community as floes, translates into three main deformation processes: opening of fractures; joining along larger features called leads; and the shearing along opened fractures and the closing of leads, resulting in the formation of pressure ridges. Although highly localized around cracks, the processes play a key role in the polar ocean systems by governing the location and intensity of bio-chemical processes and the exchange of heat, mass, and momentum between the ice, ocean, and atmosphere (e.g., Marcq and Weiss, 2012; Vihma, 2014; Goosse et al., 2018; Horvat and Tziperman, 2018; Taylor et al., 2018). Importantly, the three processes also determine to a significant extent the large-scale mechanical resistance of the ice cover and hence its mobility and the overall rates of ice export out of the Arctic (e.g., Rampal et al., 2009, 2011).
Satellite remote sensing data, such as the RADARSAT Geophysical Processor System sea ice motion products which became available in the late 1990s, have allowed for the observation of these localized processes at the global scale of the Arctic Ocean. The term linear kinematic features (LKFs) was then proposed to designate the associated near-linear zones of discontinuities in the drift velocity fields. These LKFs correspond to areas with a high density of fractures in the ice cover, which strongly concentrates its deformation (Kwok, 2001). In recent years, a large number of observational analyses of sea ice deformation data, e.g., Lindsay and Stern (2003), Marsan et al. (2004), Rampal et al. (2008), Stern and Lindsay (2009), Hutchings et al. (2011), and Oikkonen et al. (2017), have fueled a race in the modeling community towards a better reproduction of LKFs in thermodynamical models, in particular with respect to their spatial and temporal statistics, e.g., Girard et al. (2011), Rampal et al. (2016), Hutter et al. (2018), Rampal et al. (2019), and Bouchat et al. (2022). Different approaches have been taken towards this goal: new mechanical (i.e., rheological) continuum models have been proposed for sea ice (Schreyer et al., 2006; Sulsky and Peterson, 2011; Girard et al., 2011; Dansereau et al., 2016; Ólason et al., 2022), the mechanical parameters of existing models have been tuned (Bouchat and Tremblay, 2017), and the spatial resolution of models has been increased (Hutter et al., 2018).
The ability to adequately reproduce LKFs in continuum sea ice models, however, raises an equally important challenge: that of keeping the very strong gradients in sea ice properties (e.g., velocity, thickness, concentration) that stem from the extreme localization of the deformation as the ice is advected by winds and ocean currents. This numerical discretization problem is, in fact, not unique to sea ice but encountered for all materials that are experiencing both highly localized deformations resulting from brittle fracturing processes and high post-fracture strains. Another important example from the geosciences is the Earth crust, where brittle processes leading to strain localization and slip coexist in faults, landslides, and volcanic edifices, e.g., Peng and Gomberg (2010) and Burov (2011). Sea ice, however, represents an extreme case as it is constantly moving and experiencing much larger relative deformations and drift velocities (about 5 and 10 cm s−1 as a daily average in the winter and summer, respectively).
Several numerical approaches have been studied, and dedicated advection schemes have been developed to limit numerical diffusion in models of the Earth crust (e.g., see Zhong et al., 2015, for a review). In the sea ice modeling community, however, the treatment and, in particular, the quantification of numerical diffusion of advected gradients has received relatively little attention. Notable exceptions are the works by Flato (1993) and Huang and Savage (1998), who applied particle-in-cell methods to treat the advection of strong gradients in ice concentration and thickness not associated with LKFs but with the migration of the edge of the Arctic sea ice cover (the so-called ice edge); by Lipscomb and Hunke (2005), who used an incremental remapping to limit diffusion; by Sulsky and Peterson (2011), who introduced the material point method and tested its robustness in the context of sea ice by performing idealized convection benchmark problems; and by Danilov et al. (2015), who employed a flux-corrected Taylor–Galerkin method. neXtSIM (Rampal et al., 2016) is based on a Lagrangian model and hence completely avoids diffusion during transport, although remeshing operations are required in this framework which themselves induce some diffusion. The implementation of discontinuous Galerkin methods to treat the advection of sea ice was first proposed by Dansereau et al. (2016, 2017) and used with higher orders, with a quantification of diffusion by Dansereau et al. (2021). Mehlmann et al. (2021b) compared sea ice simulations using different meshes, mesh resolutions, and advection schemes. However, the focus of their paper was the discretization of the momentum equation, and no specific discussion of numerical diffusion was given.
Outline. The following section will introduce the basic equations and the notation used throughout the paper. We limit ourselves to the most widely used dynamical framework, which is the so-called visco-plastic rheology (Hibler, 1979), to focus on the discretization and to aid comparison to other numerical schemes in the literature. We will extend the discretization to more recently developed elasto-brittle schemes (Maxwell elasto-brittle (MEB) and brittle Bingham–Maxwell (BBM), e.g., Dansereau et al., 2016; Ólason et al., 2022) elsewhere. Section 3 details the numerical discretization of the sea ice model, including the advection and the momentum equations. Section 4 focuses on the implementation as well as on the shared-memory parallelization of the numerical model. Finally, in Sect. 5 we consider basic tests to validate the method and apply it to established benchmark problems (Mehlmann and Korn, 2021). The paper concludes with an outlook.
We denote by Ω⊂ℝ2 the two-dimensional domain of the sea ice. The sea ice models we investigate consist of a momentum equation for the velocity field and further advection equations for tracer variables. In simple models, such as the one introduced by Hibler (1979), the tracers are usually the mean ice height and ice concentration . Here, we consider the following system of sea ice equations:
Here, ρice is the ice density, fcez×v is the Coriolis term with Coriolis parameter fc and vertical unit vector ez, g is the gravitational acceleration, and the sea surface height. We focus on a stand-alone dynamics model without coupling to an ocean and an atmospheric model. Following Coon (1980), we approximate the surface height by the Coriolis term
where vo is the ocean surface velocity. The forcing τ(v) is given by
The index “o” represents the ocean with the surface drag Co, the water density ρo, and again the ocean surface velocity vo, while “a” denotes the atmosphere with drag coefficient Ca, density ρa, and wind field va. We neglect turning angles and thermodynamic effects in Eq. (1). Therefore, the constraints and are not naturally enforced by the equations but must be ensured by projections. In the following, we will use the following notation of the momentum equation (with the approximation of the surface height):
Model (1) is closed by specifying a rheology, i.e., the relation between the (vertically integrated) stress σ and the strain rate ϵ,
as well as the ice tracer quantities H and A (and possibly further parameters). Different rheological models have been proposed in the literature. As this paper focuses on computational questions that are largely independent of the chosen rheology, we consider the most widely used one, i.e., the viscous–plastic (VP) model proposed by Hibler (1979). It prescribes
with viscosities η,ζ that, using the notation introduced in Mehlmann and Richter (2017), are given by
Here e=2 is the eccentricity of the elliptical yield curve, Δmin>0 is the threshold defining the transition to a viscous behavior for very small strain, P0 is the ice strength, and P is the replacement pressure:
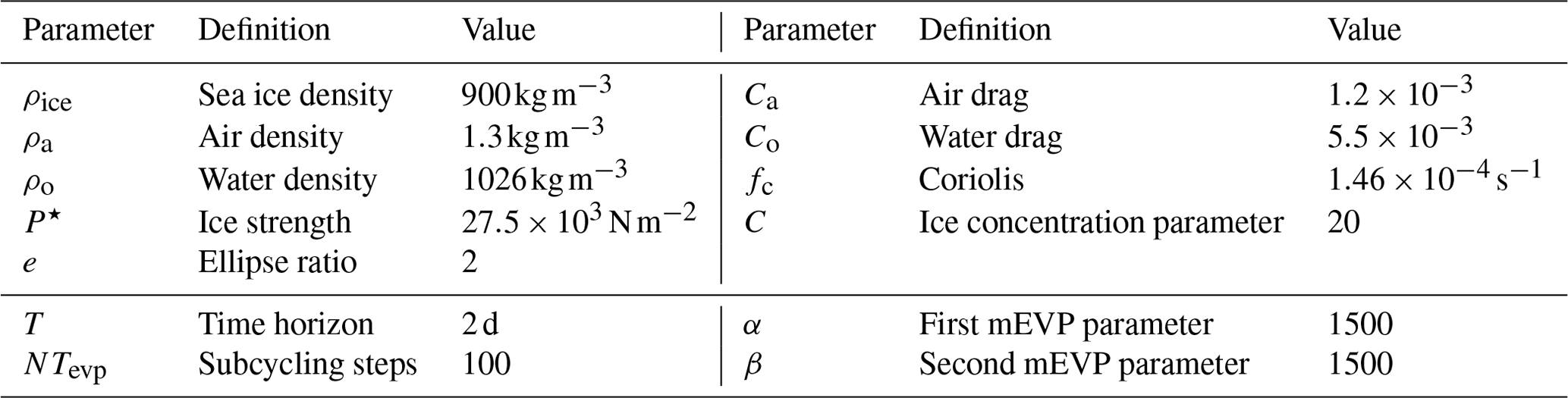
Common default values for the model parameters can be found in Table 1.
The VP model is highly nonlinear. Therefore, a solution with implicit methods is very challenging; see Losch et al. (2014), Mehlmann and Richter (2017), and Shih et al. (2023) for various approaches based on Newton's method. Picard iterations are also slow, and an explicit time stepping would require excessively small time steps (Ip et al., 1991). Hence, the so-called elastic–viscous–plastic (EVP) model is a widely used variant of the VP rheology (Hunke, 2001; Kimmritz et al., 2016). It adds a pseudo-elastic behavior to improve numerical performance. The constitutive law (3) is in this case given by
where σ(v) is the VP relation given by Eq. (3). The EVP model should, however, be considered as a model different from VP since its solutions do not converge to the VP ones. An alternative variant that can be considered as a pseudo-time-stepping scheme is the mEVP scheme (Bouillon et al., 2013); see Sect. 3.4. The mEVP scheme converges to the VP solution given a sufficiently large number of iterations.
In the following, we describe the discretization of the sea ice Eq. (1) in space and time using higher-order finite elements. All tracers and also the strain rate tensor ϵ and the stresses σ are discretized with a discontinuous Galerkin (dG) approach, whereas the ice velocity v is discretized using quadratic continuous finite elements.
3.1 Mesh domain
Discretizations of the sea ice equations are typically used within a coupled Earth system model. One consequence is that the time step of the numerical sea ice model is not only determined by the desired accuracy and stability considerations but also constrained by the atmospheric and oceanic components of the Earth system model.
By Δt we denote the time step of the sea ice equations. Although dynamic time discretizations with varying step sizes are possible, we will only consider uniform time steps with Δtn=Δt for all steps n. The time mesh is hence given by
Assuming, for example, the time step size Δt∈240 s and ice velocities , explicit time stepping will be stable for mesh sizes up to a resolution of
where Cr is a constant that depends on the degree r of the time-stepping scheme. The factor Cr scales like (Chalmers and Krivodonova, 2020). Hence, for a dG(2) method and time-stepping scheme of balanced order with r=2, the minimum mesh element size should be larger than 2 km if a time step of Δt=240 s is used. Usually, limitations due to the CFL condition are more relevant in the ocean model, where velocities are higher. For our higher-order sea ice model the CFL condition might become important due to its scaling with the polynomial degree.
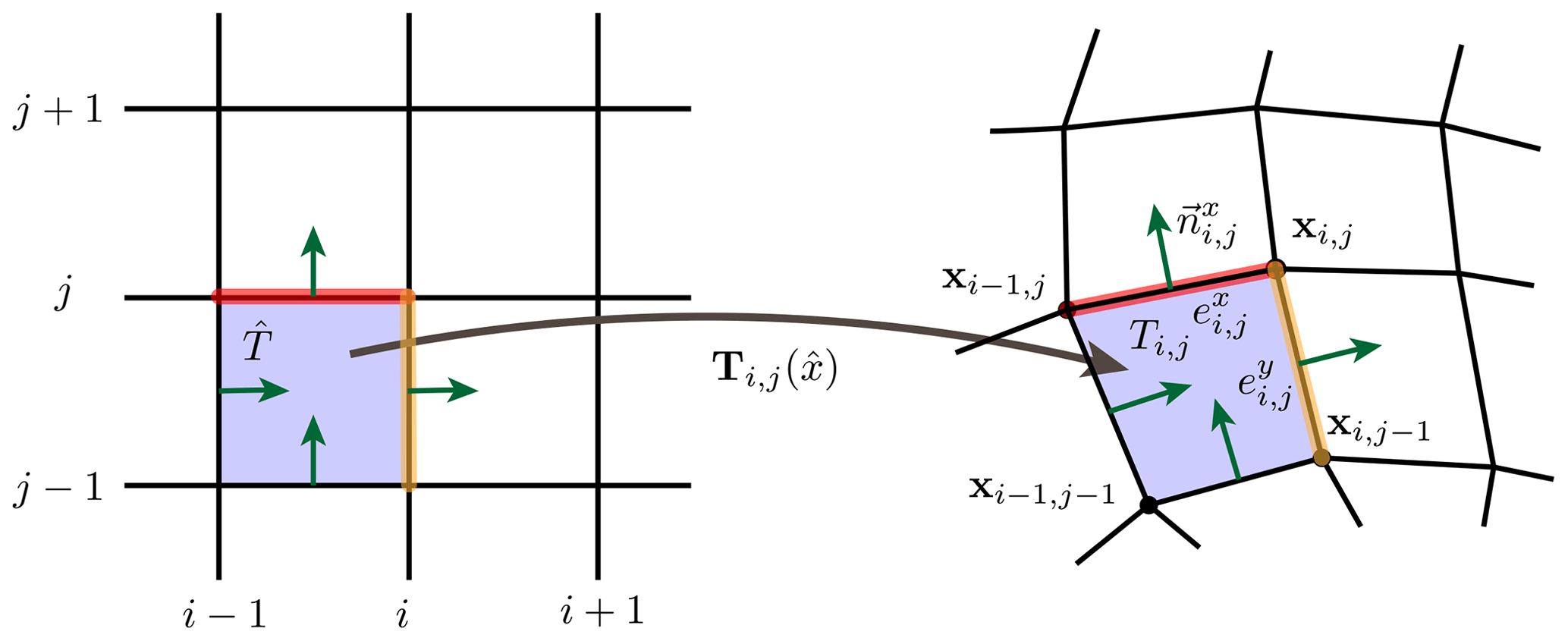
Figure 1Parametric mesh. Each element (on the right) arises from the a mapping from the reference element (on the left). The mesh elements Ti,j are general quadrilaterals such that the mappings T are bilinear polynomials. The edges and are straight lines.
For the spatial discretization, we employ a parametric finite-element mesh of the domain Ω. We base the discretization on quadrilateral meshes 𝒯h (as opposed to triangular ones). The meshes are topologically fully regular but geometrically distorted and consist of nodes xi,j for , and elements for , , horizontal edges for , and vertical edges ,
where denote the number of elements in the x and y direction. See Fig. 1 for an illustration. The nodes are lexicographically ordered; i.e., is the consecutive index. Each geometric mesh element Ti,j can be defined via a mapping
from a unique reference element using the bilinear polynomial
see again Fig. 1. On each edge and , we consider one unit normal vector. Its orientation arises from mapping the unit normal vectors and of the reference element to the edges of 𝒯h.
3.2 Finite-element spaces and degrees of freedom
We use continuous (cG) and discontinuous (dG) finite elements for the discretization of the momentum equation as well as the constitutive equations and advection problems, respectively. On the reference element , we define two sets of basis functions. The dG basis functions that we employ are given by
These basis functions are orthogonal, i.e., . Second, we use the degree r tensor product Lagrange finite-element basis functions
The one-dimensional basis functions (for r=1 and r=2) are given by
All basis functions are mapped from the reference element onto the mesh elements of 𝒯h.
We define continuous finite-element spaces , where is the degree, and spaces are associated with the discontinuous finite elements, where is the number of local basis functions,
where Ψ and Φ(r) are linear combinations of reference basis functions according to Eqs. (11) and (12), respectively. Locally on each mesh element T∈𝒯h, the tracer and velocity are therefore described by the linear combinations of the basis functions:
where is the local number of unknowns in each element. An analogous representation holds for the second tracer. Finally, by and we denote L2 scalar products,
on the elements Ti,j and the edges , respectively.
3.3 Discontinuous Galerkin advection scheme
We begin by describing the discretization of the advection equation
for the tracer . We follow the notation of Di Pietro and Ern (2012, Chap. 3).
The temporal discretization will be by explicit Runge–Kutta schemes of order 1, 2, or 3, and in space we choose ; see Eqs. (14) and (15). The discretization is based on the standard upwind formulation:
By {{Hh}}|e we denote the average of the dG function Hh on an edge between the two elements T1,T2 and by [[Hh]]|e the jump over this edge, i.e.,
The upwind scheme can be written in matrix-vector notation as
where M is the dG mass matrix in , which is block diagonal with blocks of size s×s, and where A(vh) gathers all remaining terms of Eq. (16) which are all linear in Hh. The equation is discretized in time by standard explicit Runge–Kutta methods on the advection time mesh in Eq. (7).
For dG(0) with space , the discretization is equivalent to the usual finite-volume upwind scheme since the per element term (Hhv,∇ψ) vanishes for all as ψ|T is constant on T. The advantage of using higher-order methods will become clear in Sect. 5.3.3.
3.4 Discretizing the momentum equation
The coupled advection and momentum equation system in Eq. (1) is decoupled in a partitioned iteration by performing the advection step and then solving the momentum equation. The momentum equation is approximated with an mEVP solver, which can be considered as a pseudo time-stepping scheme for the implicit backward Euler discretization of the VP formulation (e.g., see Lemieux et al., 2012; Bouillon et al., 2013). We introduce the iterates and for with and , in which case the update can be written as
The forcing term in Eq. (2) is split into explicit and implicit parts. The ocean forcing term is considered implicitly, which helps the stability of the scheme, and the remaining explicit terms on the right-hand side are
The parameters α and β in Eq. (17) control the stability but also the speed of convergence of the mEVP iteration to the VP solution, whereas the number of steps NmEVP controls the accuracy. We refer the reader to Kimmritz et al. (2016) for a discussion on this.
A mixed finite-element approach is used for the spatial discretization of Eqs. (17)–(18) with continuous finite elements for the momentum equation and discontinuous ones for the stress update. This yields
for test functions
Compatibility of the velocity and stress spaces is important for the stability of the coupled iteration; see Sect. 5.2.3 for an example of possible instabilities. Stress spaces that are too small do not provide sufficient control of the term (σ(v),Ψ) in Eq. (19) and lead to oscillatory stresses; see the upper right plot in Fig. 13. The problem is related to the control of the energy, and in a mixed formulation the spaces Vh and Wh must in particular satisfy the Babuška–Brezzi condition; see, e.g., Ern and Guermond (2021, see, e.g., Theorem 49.13) for well posedness. For a simplified linear equation, this condition would mean that there exists a constant γ>0 such that
This condition can easily be satisfied if for every vh∈Vh from the cG velocity space it holds that
Then, for any Φ=vh we choose Ψ as Eq. (22) and get, using the symmetry of the inner product,
where cK>0 is the constant of Korn's inequality (Ern and Guermond, 2021, Theorem 42.9 and 42.10). We therefore require that the spaces Wh and Vh always allow for choosing the stress test function Ψ∈Wh as the symmetric velocity gradient, Eq. (22). To be precise, the degree s has to be chosen such that the symmetric gradient of the discrete velocity is part of the stress space. On quadrilateral elements, the continuous finite-element basis is not the pure polynomial basis P(r), but it includes the additional mixed terms xy for r=1 and for r=2. Hence, the gradient space must also be enriched. For linear elements with r=1 the condition in Eq. (22) requires s=3, and for quadratic velocities with r=2 we must take s=8 in Eqs. (19)–(20). This update involves the inversion of the mass matrix of . The matrix is block diagonal with block size s×s so that in the cG(2) case with s=8 the costs for the inversion are substantial. Section 4.2 describes our approach for an efficient implementation.
The momentum equation is discretized with continuous finite elements in the discrete space Vh. All zero-order terms in the momentum equation, Eq. (19), are evaluated node-wise and no integration is required. Adding the stress, however, requires integration and inversion of the mass matrix of Vh. To avoid the inversion, we use mass lumping. The evaluation of the momentum equation's right-hand side in Eq. (19) then becomes
where Ml is the lumped mass matrix in the cG velocity space. The implicit terms are handled analogously. The integration of the stresses against the gradient of the test function is a non-local operation coupling adjacent degrees of freedom. All other operations, like computing , are fully decoupled and can be processed node-wise in parallel.
Remark 1 (optimality of velocity–stress discretization).
On triangular meshes, would be the spaces of piecewise polynomials of degree r. In this case, the optimal dG stress space would be the space of piecewise constants, i.e., in our notation in the case r=1 and the space of piecewise linear for r=2. The choice given in Eqs. (19)–(20) appears highly inefficient as the local basis has 3 instead of 1 unknowns for r=1 and 8 instead of 3 for r=2. However, a triangular mesh with the same number of velocity unknowns has twice the number of elements as a quadrilateral mesh. Hence, r=1 has 2 unknowns on triangles and r=2 brings 6 unknowns compared to s=3 and s=8 in the case of quadrilateral meshes. This means that the difference in effort is less dramatic than it appears on first sight.
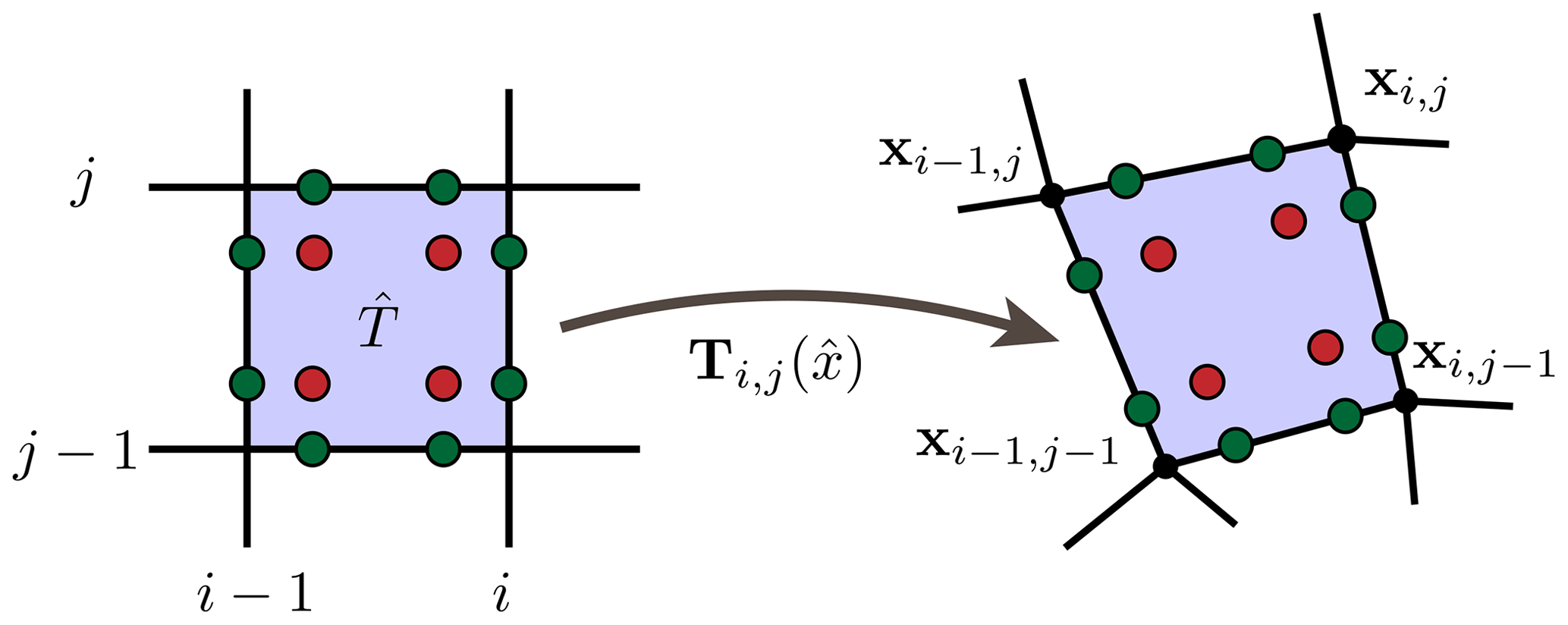
Figure 2The numerical quadrature nodes are defined on the reference element and mapped to the real mesh elements T∈𝒯h via . We show a 2-point Gauss rule (of degree 4) with 2 points on each edge and 4 points in the element.
3.5 Numerical quadrature
In the parametric finite-element setup, all integrals appearing in the advection scheme in Eq. (16) and the weak formulation of the mEVP iteration in Eq. (17) must be evaluated on the reference element and, in case of the upwind scheme, also on the reference edge since the basis functions are defined on . For the different terms of Eq. (16) it holds
where and are the functions on the reference element that by Eq. (15) are associated with Hh and v on the element T and analogously for the edge terms. The reference element map TT-dependent terms in Eq. (24) are the Jacobian and its determinant . Since TT is bilinear (and not linear), the Jacobian and its determinant are not element-wise constant. However, on the reference edges , TT is linear such that e∈𝒯h values are straight and hence as the reference element has an edge length of 1.
The integrals in Eq. (24) are approximated by Gaussian quadrature. For dG(r) () we use r+1 quadrature points on the edge and (r+1)2 quadrature points within the elements; see Fig. 2 for an example with 2 points on the edges and 2×2 points within the element.
Implementation details are described in Sect. 3.1. Evaluation of the terms in Eq. (24) is numerically costly, mostly due to the evaluation of the map TT, the Jacobian , its inverse, and the determinant of the Jacobian.
In the following paragraphs, we will describe the C++ implementation of the higher-order discretization. A hybrid parallelization approach consisting of distributed memory MPI splitting and local shared-memory OpenMP realization is considered. The data are structured such that the implementation also allows us to run modules on a GPU.
MPI parallelization builds on a domain decomposition that splits the complete mesh into a balanced number of rectangular subdomains such that the average number of ice-covered elements for each domain is comparable. Each parallel task then operates on a subdomain that is topologically structured into elements such as described in Sect. 3.1.
4.1 Implementation of continuous and discontinuous finite elements
We start by describing the handling of the data, i.e., the cG and dG vectors for each MPI task that is responsible for one topologically rectangular mesh 𝒯h consisting of Nx×Ny elements. A dG vector has s unknowns on each of the elements, and we store such a vector as a matrix. The implementation is based on Eigen (Guennebaud et al., 2010), a C++ library for linear algebra that heavily relies on C++ templates. In the code, the vector is represented as
Matrix<FloatType, Dynamic, s,
RowMajor> DGVector<s> A;
The first dimension of A (number of elements) is dynamic and determined at runtime, which allows us to flexibly handle different subdomain sizes.
The second dimension, i.e., the number of components, has degree s and is determined at compile time. This allows for vectorized SIMD processing of computations; see Sect. 5.3.2 for a numerical demonstration.
To provide one example of a frequently used operation, we explain the restriction of a dG(1) function (with three local unknowns on T) from an element T to one of its edges . Let T have the element index and let be the lower edge in the notation of Eq. (9). Then the restriction to the lower edge is realized as
Vector<FloatType, 2> l_edge (const DGVector<3>& A, size_t i)
{ return Vector<FloatType, 2> a_e( {A(i,0)-0.5 * A(i,2), A(i,1)}); }
Since the restriction does not depend on the specific element T∈𝒯h, the relations are implemented for the four edges and the different choices of dG spaces, i.e., for the number of local basis functions, using template specializations.
With this, both Eigen and the compiler can optimize the computations.
The parametric setup also allows for an efficient restriction of a dG or cG function to the Gauss points. Let and let T∈𝒯h be again any mesh element with element index . Assume that we want to evaluate Ah in the 3×3 Gauss points ; see Sect. 3.5. It holds and hence
That is, by working with the pulled-back function on the reference element, only needs to be evaluated on the fixed points . Furthermore, by the linearity of the basis representation, the mapping of the local coefficients of the dG vector to the values of in the 9 Gauss points on the element T can be written as a matrix-vector product,
with a fixed matrix . The matrices for possible dG degrees with s local unknowns and for supported choices of the Gauss quadrature rule with q points are precomputed and directly inlined into the code to allow for an optimization by Eigen and the compiler. The matrices and similar code are auto-generated by Python scripts to allow for easy extension.
Algorithm 1Evaluation of the viscosities in the 9 Gauss points in the case of biquadratic velocities.
Another challenge for an efficient implementation is the evaluation of the integrals that are required to determine the viscosity within the VP model (Eq. 4) in the mEVP iteration (see Eq. 19),
With again denoting the element index, the example in Algorithm 1 illustrates the evaluation of the viscosities in the 9 Gauss points in the case of biquadratic velocities, a strain tensor with 8 local unknowns, i.e., , and tracers discretized as dG(1) functions in . The above implementation is close to the mathematical notation which simplifies the implementation of model variations. Long expressions such as those in the last line also allow Eigen to vectorize operations efficiently.
4.2 Evaluation of the weak formulations on parametric meshes
A substantial part of the computational effort is due to the mapping of the reference element onto the mesh elements T∈𝒯h; compare Sect. 3.1 and 3.5. We discuss the details of an efficient implementation for one specific term in the mEVP momentum Eq. (19), namely the evaluation of , whose discretization has already been given in Eq. (23). In the following, we will omit all indices referring to the time step and the mEVP iteration count.
At the heart of is the integration of the symmetric stress tensor multiplied with the gradient of the (vector-valued) test function . Pulling this term back from an element T∈𝒯h onto the reference element , we obtain
Here, is the local number of cG degrees of freedom and is the full contraction of rank-2 tensors. Locally on the element T∈𝒯h, symmetric stresses and the element map's gradient are given in the dG and cG basis as
with the being the four corner nodes of the element T. Approximating Eqs. (27) and (28) by Gauss quadrature with nQ points and weights yields
The computational effort of the above equation is substantial. The Jacobian needs to be assembled times (cf. Eq. 29), and its inverse and determinant need to be computed. For the second-order case cG(2) with nQ=9, , and s=8, more than 15 000 floating point operations are required on each element.
The entries of the 2×2 matrices Xi,j, however, do not depend on the solution but only on the mesh elements T∈𝒯h. A closer analysis further reveals that and . Hereby, the complete scalar product with Gauss approximation is evaluated as
with matrices . The computational effort shrinks then to operations, which in the case of cG(2) amounts to about 2300 operations. The matrices and can be precomputed and stored for each mesh element. Their small size makes them, furthermore, amenable for efficient caching although additional storage is needed. Section 5.3.3 presents a numerical study on the effective performance of the alternatives, i.e., using precomputed matrices or computation of all terms on the fly.
The same technique can be applied to all further terms of Eq. (17). For some of them the computational savings of precomputing per element terms are even more substantial. This is in particular true if the inverse of the block-diagonal dG mass matrix is required, such as in the mEVP iteration (19).

Figure 3Parallel processing of the vectors on a small mesh with 12 elements, Nx=4 and Ny=3. All blocks of one color can be processed in parallel without memory conflicts. From left to right: node-wise operations, local element-wise operations, edge-wise operations on ex edges (blue) and ey edges (green), and operations writing on biquadratic cG(2) vectors.
4.3 OpenMP parallelization
In each MPI task, only topologically regular rectangular meshes are considered that consist of elements. As the complete numerical workflow is based on explicit integrators, OpenMP parallelization is easily realized. Depending on the specific task, a different coloring of the mesh elements (or mesh edges) is utilized to avoid any memory conflicts.
- Node-wise.
-
Vector operations (such as sums and entry-wise products) are parallel with respect to the major index referring to the node.
- Element-wise.
-
Operations such as the stress update in Eq. (19) within the mEVP iteration in Eq. (17) are parallel with respect to the mesh element. This also includes the element-wise terms (Hhv,∇ψ)T of the transport scheme in Eq. (16) where no communication is involved and also the projection of the strain rate tensor from the cG to the dG space:
- Edge-wise.
-
The edge integrals in Eq. (16) are assembled in two sweeps. First, all horizontal edges ex∈𝒯h are computed,
and the outer (in the x direction) is run in parallel as the integral on an edge will affect the two elements atop and below it. Then, a second sweep, parallelized in the y direction, performs the computation for the ey edges.
When updating cG vectors, e.g., in the stress update (cf. Eq. 23), more care is required. We use a row-wise coloring of the elements and perform the update in two sweeps. Figure 3 summarizes the parallel processing of the mesh.
Remark 2 (towards GPU acceleration).
Our finite-element discretization requires a large number of per element computations with a substantial amount of computations for each one. Furthermore, the computational costs increase substantially with the order; see Sect. 4.2. Only local coupling between adjacent elements thereby exists since an explicit time stepping and mEVP iterations are used. This makes the problem well suited for a GPU parallelization where thousands of independent computations are required to fully utilize a state-of-the-art GPU and even more when multiple GPUs are combined in a node. The current implementation has already been designed with a GPU implementation in mind. Its realization is planned as a next step.
In this section we will present a set of experiments to validate our discretization. We will thereby first only study the accuracy of the advection before considering the full mEVP scheme.
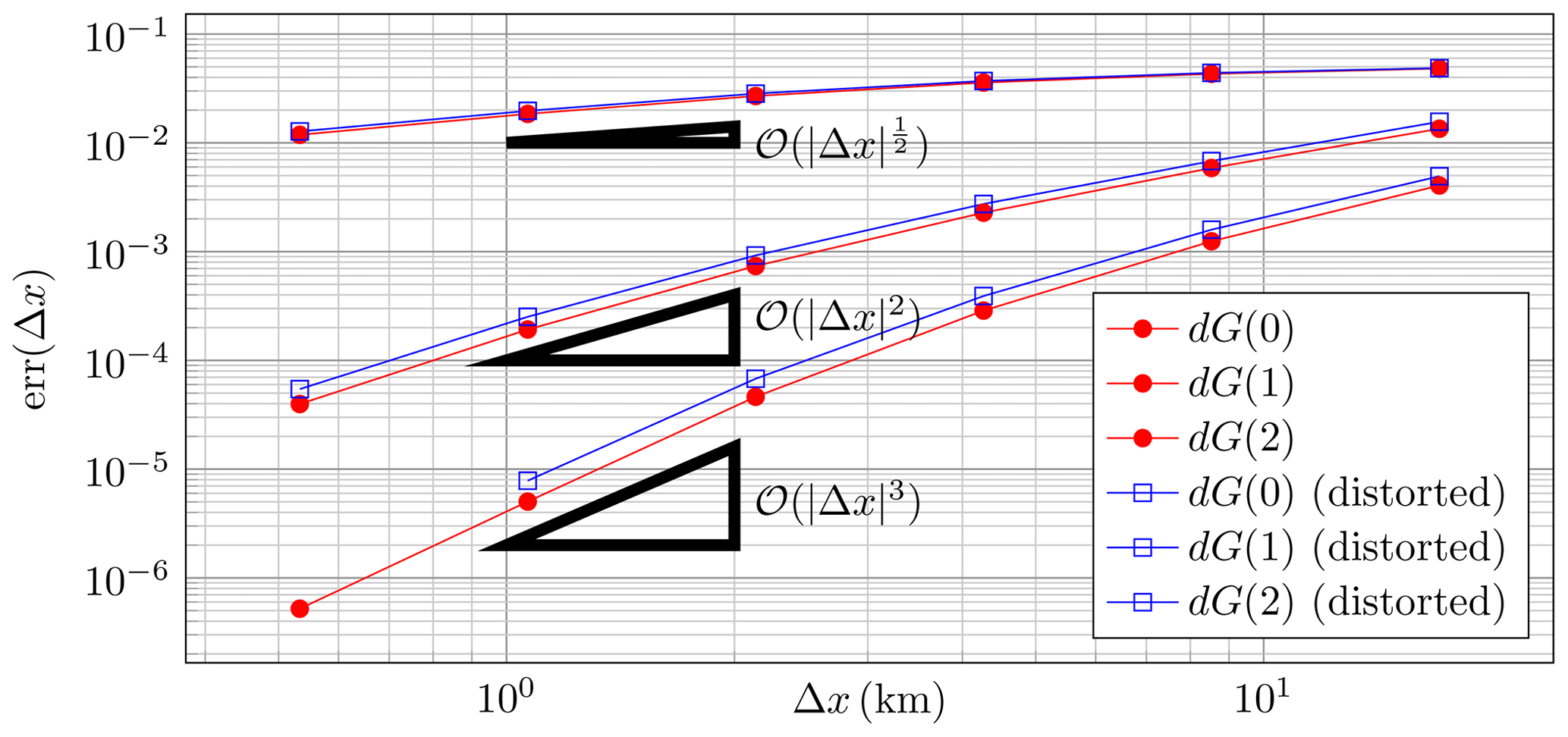
Figure 4Advection test case I: convergence rates on uniform (red) and distorted (blue) meshes.
5.1 Validating the higher-order transport scheme
5.1.1 Advection test case I: transport of an initially smooth bump
On the domain with Lx=409 600 and Ly=512 000 we advect the initially smooth bump,
with the stationary, rotational velocity field,
The problem is run in the time interval such that one complete revolution of the bump is performed. We compute the test case on a sequence of meshes consisting of elements and time steps using
where is the degree of the dG(r) approach. The coarsest discretization consists of elements of approximate size 17 km×19.6 km each and a time step Δt=512 s. This results in a CFL constant lower than , which is sufficient for a robust discretization. Next to these uniform rectangular meshes, we use a sequence of distorted meshes to model the effect one encounters in a mesh parametrization of the sphere; see Fig. 5. The nodes xi,j are in this case given by
Through the periodicity of the domain, the exact solution at time T=Lx equals the initial condition. We measure the scaled L2 error by
The scaling factor accounts for the drift-error accumulation that is expected to be dependent on the length of the advection in space.
Figure 4 shows the convergence behavior for the different meshes and degrees r. We observe the expected convergence rate of for dG(0) (cf. Di Pietro and Ern, 2012, Theorem 3.7) and even super-convergent second order instead of for dG(1) and super-convergent third order instead of for dG(2) (see Di Pietro and Ern, 2012, Theorem 3.13). Distortion of the meshes slightly increases the error constant, but the convergence order is not affected, as expected.
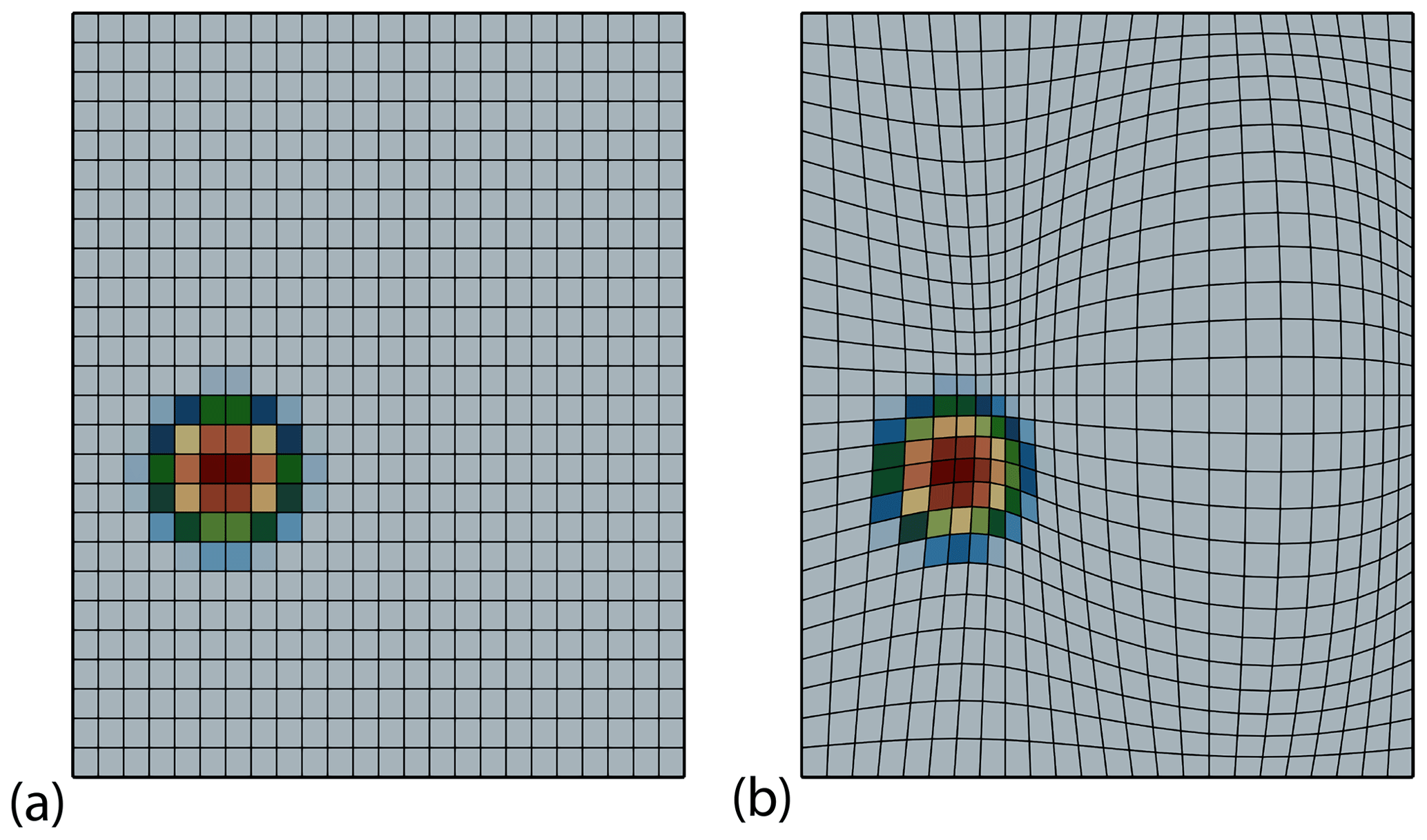
Figure 5Advection test case I: visualization of the coarse meshes and the initial dG(0) solution. (a) Regular rectangular mesh. (b) Distorted parametric mesh.
5.1.2 Advection test case II: transport in a circular annulus
The domain of the second test case is a circular annulus with inner radius r0=100 km and outer radius r1=250 km; see Fig. 6. The parametric mesh is constructed by mapping a uniform rectangular mesh onto the ring using the map
The divergence free stationary velocity field for the transport is given by
and it moves the initial conditions uniformly along the domain.
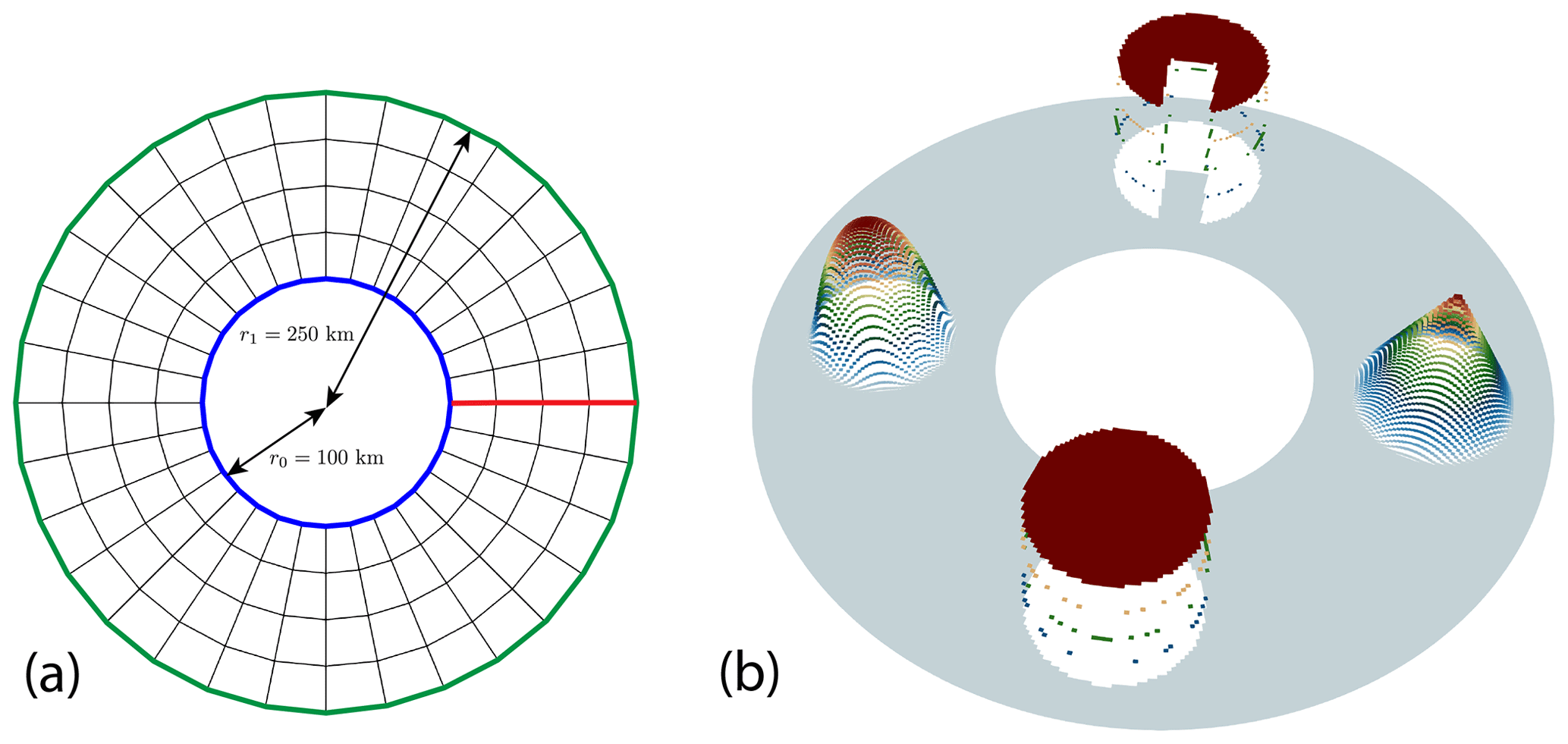
Figure 6Advection test case II: computational domain and mesh (a) for the transport in a ring. The boundary lines marked in red are the periodic boundaries of the regular reference mesh. On panel (b) we show the initial solution.
One complete revolution around the annulus is achieved in T=250 000 s. The initial field consists of four objects with different regularity: a smooth C∞ bump centered at of radius 50 km (on the left), a continuous C0 pyramid centered at (175 km,0 km) with radius 50 km (on the right), and two discontinuous discs with radius 50 km at (on the bottom) and (0 km,175 km) (on the top). The last one has a Pac-Man-shaped omission.
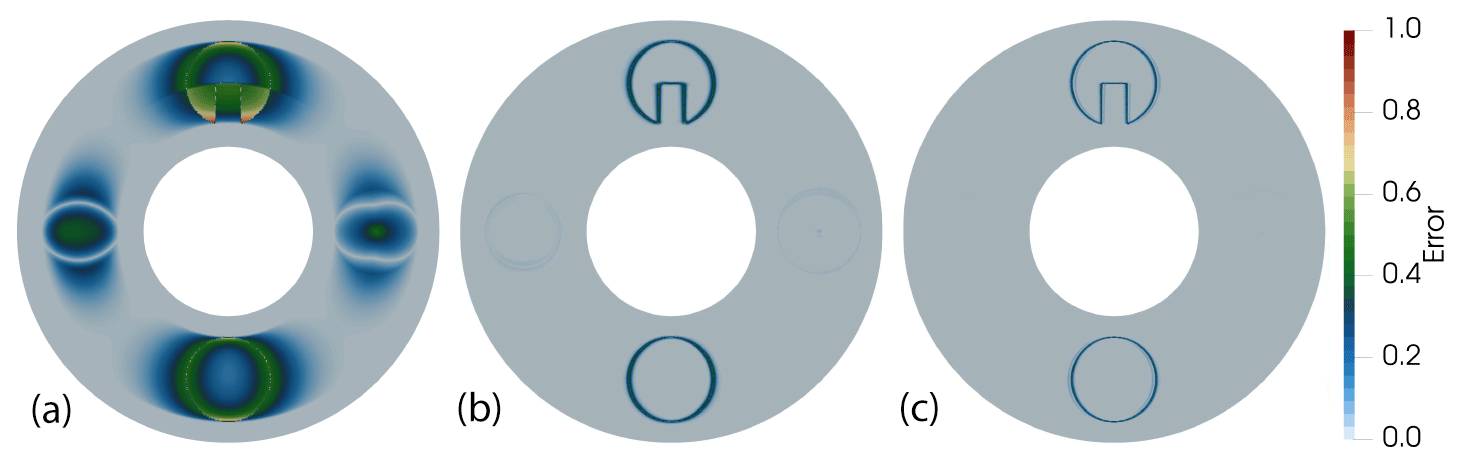
Figure 7Difference (absolute value) between the initial condition and the solution after one revolution for dG(0) (a), dG(1) (b), and dG(2) (c).
Figure 7 shows the absolute error between the initial condition and the solution at time T. The results verify the superiority of higher-order methods with respect to numerical diffusion. While the finite-volume dG(0) discretization is highly diffusive and inaccurate, both dG(1) and dG(2) preserve all shapes well with very small errors for the smooth ones and small but sharp interface errors for the disc and the Pac-Man-like shape.
5.2 Validating the mEVP framework
To validate the complete dynamical mEVP framework and to assess the higher-order discretization, we study the VP benchmark problem that has been introduced in Mehlmann and Richter (2017) and investigated in Mehlmann et al. (2021b) to compare different sea ice realizations with respect to their ability to depict linear kinematic features.
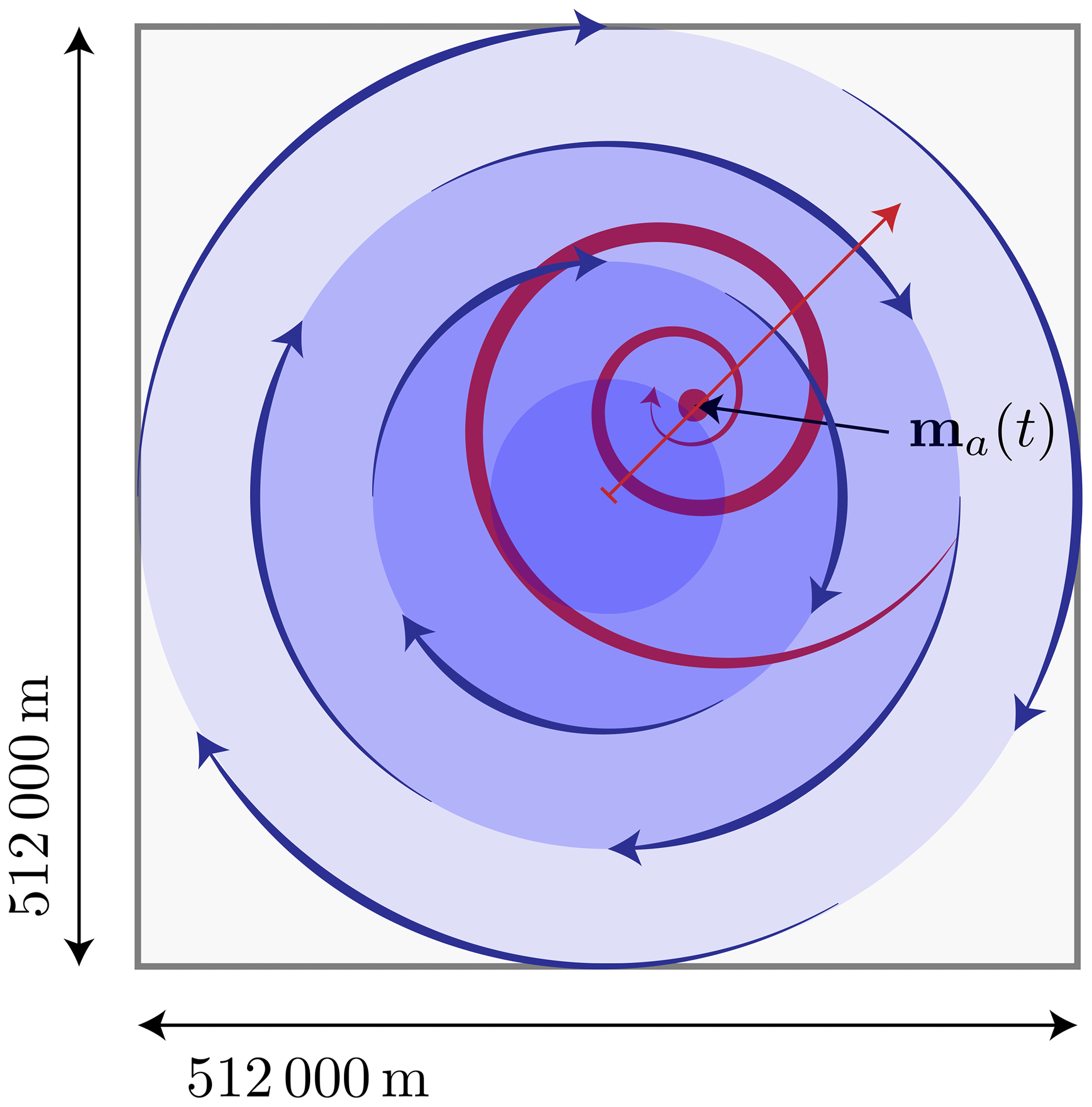
Figure 8Setup of the benchmark problem. Forcing by means of a steady circular ocean current (in blue) and a divergent wind field (in red) that is moving diagonally across the domain (with side length 512 km). Initially the ice has an average height of 0.3 m (with a periodic variation) and concentration A=1. The simulation is run for a period of 2 d, where the wind's center travels from the midpoint to the upper right (red arrow).
Table 1Default values of the VP model used to define the benchmark (Mehlmann and Richter, 2017) as well as default mEVP parameters used in all numerical test cases.
The setup of the benchmark is described in Fig. 8. On the domain of size 512 km×512 km, the ice has an initial concentration of one and an average height of 0.3 m with small amplitude oscillations of 0.005 m and with a wavelength of 105 km in the x direction and 210 km in the y direction; i.e., we have
The forcing in the benchmark problem consists of a rotational ocean forcing,
and a rotational divergent wind field with a center m(t) that is moving along the diagonal of the domain:
The different parameters of the VP model and the mEVP iteration are given in Table 1.

Figure 9Shear deformation (log 10) for the benchmark at time T=2 d. We compare different combinations of cG velocity discretizations (linear and quadratic) with dG advection discretization (constant, linear, and quadratic). All computations are run on meshes with the grid spacing h=2 km.
Figure 9 shows the shear at final time T=2 d on a mesh with h=2 km spacing. Results are presented for all combinations of the velocity discretization (low-order cG(1) and high-order cG(2)) and advection schemes dG(0), dG(1), and dG(2). The results are in very good agreement with earlier results for the benchmark (Mehlmann and Richter, 2017) and also with recent numerical studies that consider some of the most widely used sea ice models (Mehlmann et al., 2021b).
For all combinations of velocity and dG degrees, linear kinematic features are well resolved and the deformation field is stable (for a detailed discussion, we refer to Sect. 5.2.1). The results of Fig. 9 suggest that the role of the advection scheme is minor in comparison to the discretization of the velocities. This will be discussed in Sect. 5.2.2. While the cG(1) results in the top row of Fig. 9 are comparable to the B-grid staggerings (cG(1) is the finite-element equivalent of this) given in Mehlmann et al. (2021b, Fig. 6), the high-order cG(2) results show patterns that are at least as resolved as the CD-grid results in Mehlmann et al. (2021b, Figs. 6 and 7).
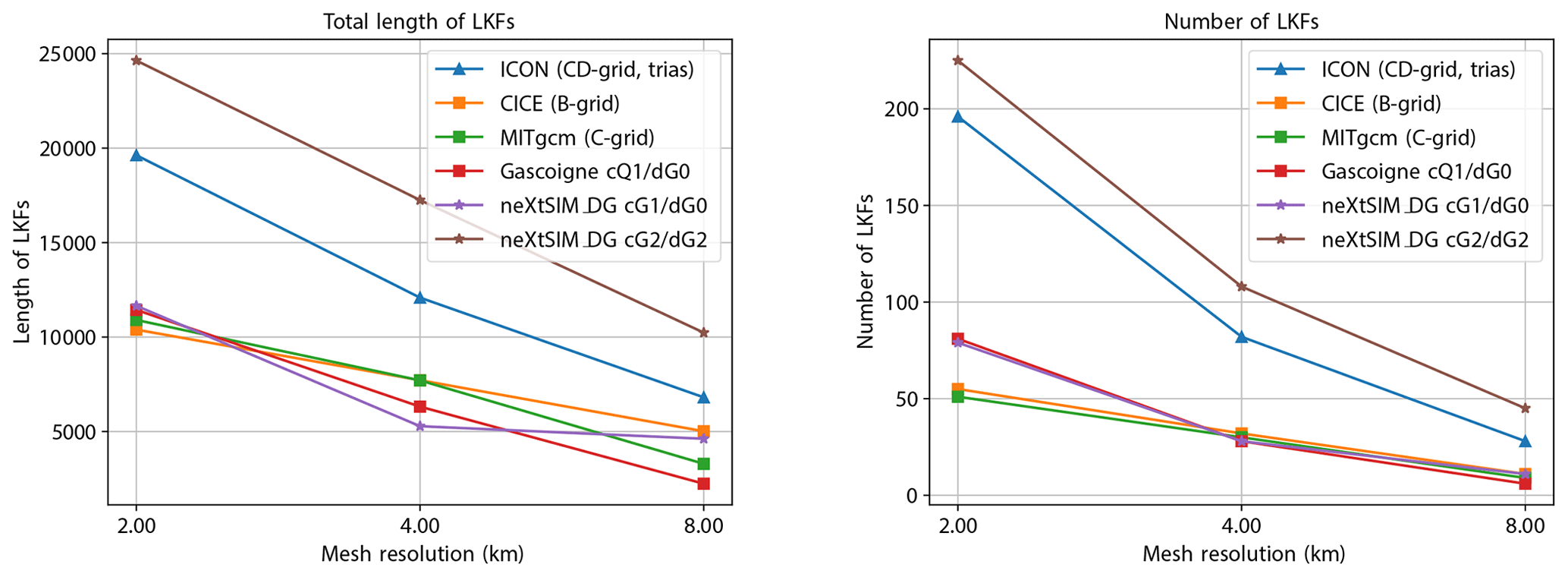
Figure 10Total length and number of linear kinematic features detected for the low-order cG(1)-dG(0) and high-order cG(2)-dG(2) schemes. For comparison, we show selected simulation results on quadrilateral meshes from various models taken from Mehlmann et al. (2021b).
5.2.1 Resolution of LKFs
To further investigate the ability of the cG-dG framework to resolve linear kinematic features, we use code provided by Hutter et al. (2019)1 that identifies LKFs from the shear deformation rate field. The original scripts have been slightly modified in the following manner: the resolution of the uniform quadrilateral mesh onto which the outputs are initially projected has been increased from 256×256 to 512×512 to account for the fact that the higher-order dG discretizations carry subgrid information that would otherwise be lost. The length of LKFs, which the scripts measure in pixels, was adjusted accordingly. Figure 10 shows the results for a selection of the originally published data sets (Mehlmann et al., 2021b, a) together with the results of the low-order cG(1)-dG(0) and high-order cG(2)-dG(2) simulations performed with the proposed discretization. The low-order results are consistent with the data published by Mehlmann et al. (2021b). In particular, the results agree with those obtained with Gascoigne (B-grid) (Braack et al., 2021), which is based on the same discretization. The high-order cG(2) scheme of our discretization can resolve substantially more (and longer) features on coarser meshes, demonstrating the advantage of higher-order schemes.
We note that the exact number and length of features is affected by the chosen mEVP parameters. We have not applied any fine-tuning here but use the values given in Table 1 for all meshes and all discretizations. Moreover, a direct comparison of results obtained on quadrilaterals and triangles is difficult, so we refrain from a more detailed analysis. We refer to Mehlmann et al. (2021b, Sect. 6) for an in-depth discussion of these aspects.
Table 2Computational time for the benchmark test case using the 4 km mesh. The specified times include the advection and the momentum equation for the complete simulation spanning from t=0 to t=2 d. Times for input/output are not included. Thirty-two parallel threads are used.
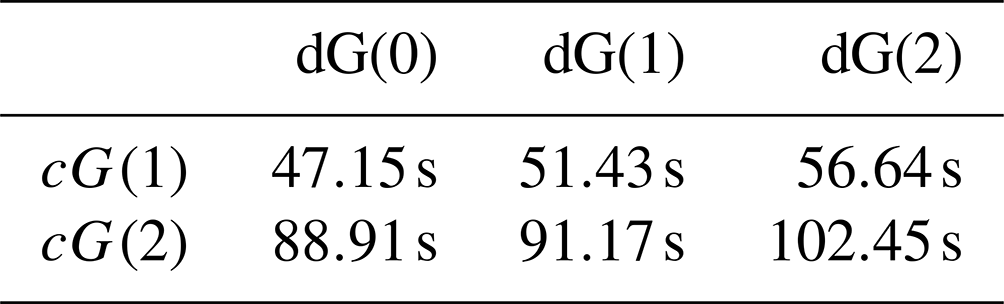
Table 2 indicates computational times for simulating the benchmark problem on the 4 km mesh for all different cG/dG combinations for velocity and tracers. The simulations are run on an AMD EPYC 7662 64-core processor at 3.20 GHz using 32 cores. The given times are the total times for the complete benchmark run, and they include everything apart from the input/output operations. The impact of the degree of the tracers is negligible as the advection scheme only takes a little fraction of the overall runtime. Scaling from linear to quadratic velocities is less severe than expected. This is due to the larger fraction of local work at high order and associated with this a better possibility of vectorization by Eigen as well as better efficiency of parallelization.
5.2.2 The role of the advection scheme
In the literature, the role of the advection scheme in the VP model and in particular for the LKF resolution is not entirely clear (again, see Mehlmann et al., 2021b, Sect. 6). We therefore compare for the above benchmark results for a high-order momentum discretization (biquadratic velocities) and dG(0), dG(1), and dG(2) advection to shed further light on the effect of the advection.

Figure 11Visualization of the ice concentration on meshes with a spacing of h=8 km for dG(0) (finite volumes), dG(1), and dG(2).
Figure 11 shows the ice concentration at time T=2 d for the benchmark problem run on a mesh with spacing h=8 km. The velocity is discretized bi-quadratically with cG(2), and the tracers are represented as discontinuous dG(0), dG(1), and dG(2) functions. The elevated surfaces in the middle and on the right in Fig. 11 show the additional information that is gained by higher-order approaches. The finite-volume dG(0) discretization only gives average values in each element, while the dG(1) discretization includes the slope of the tracers, and starting with dG(2) further information on the subgrid-scale, e.g., on the curvature, is also represented. The effect of the dG degree on the representation of the sea ice drift (and derived values like the shear deformation) is less drastic, as shown in Fig. 9. In comparison to the choice of the velocity discretization, the effect of the tracer discretization on the representation of LKFs is small. This is also the conclusion of Mehlmann et al. (2021b). Figure 12 shows the results of the LKF detection code by Hutter et al. (2019) for different advection schemes. While the low-order discretization with cG(1) velocities is hardly affected by the advection discretization, the impact on the cG(2) high-order scheme is larger. Here, the lowest-order upwind scheme dG(0) yields the most and longest LKFs.
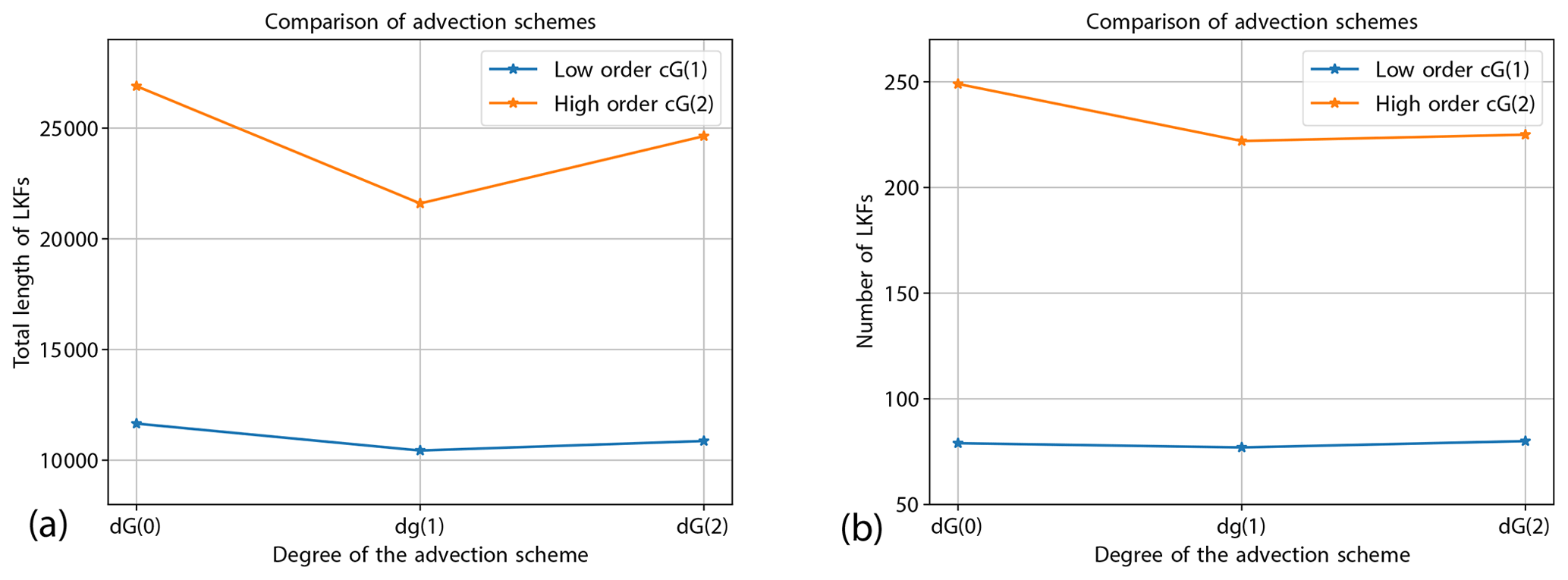
Figure 12Effect of the advection scheme on resolving linear kinematic features. (a) Total length of detected LKFs. (b) Number of LKFs.
5.2.3 Stability of the mixed finite-element formulation
Section 3.4 introduced the mEVP iteration as a mixed finite-element formulation, and in particular Remark 3.4 discussed the optimal choice of the velocity and stress spaces. In this section, we demonstrate the effect of this choice on the results. We again consider the benchmark problem of Sect. 5.2 using a mesh with h=2 km. The tracers are discretized with dG(1); all parameter values are as given in Table 1.

Figure 13Shear at final time T=2 for different choices of the velocity space and stress space (detail from the simulation domain). (a, b) Unstable finite-element pair with stresses one degree below the velocity space. (c, d) Stable combinations.
Figure 13 shows a snapshot of the shear deformation rate at time T=2 d for all different combinations of velocity and stress spaces. The plots clearly show the need to use large-enough stress spaces. For the low-order velocity the results based on piece-wise constant stresses (upper left) appears to give reasonable results, in particular when compared to the highly diffusive combination (lower left). , however, is unstable and does not satisfy Eq. (22). It shows oscillations on the level of the mesh elements, while the combination is stable. Stress spaces that are too small do not provide sufficient control of the term (σ(v),Ψ) in Eq. (19) and lead to oscillatory stresses; see the upper right plot in Fig. 13. We refer to the discussion in Sect. 3.4.
5.3 Computational efficiency
5.3.1 Shared-memory node-level parallelization
The complete code is parallelized using OpenMP to benefit from shared-memory parallelism available on individual nodes. To evaluate the parallel performance of the code, we run a strong scalability test. The benchmark problem described in Sect. 5.2.1 is run for T=1 h on a mesh with h=2 km spacing which amounts to elements. Using a time step size of Δt=60 s a total of 60 advection time steps and mEVP subiterations with 100 steps each are computed. We discretize the velocity with quadratic cG(2) elements and use dG(2) with 6 local unknowns for ice height and sea ice concentration.
The simulation is run on an AMD EPYC 7662 64-core processor at 3.20 GHz. Figure 14 shows the strong scalability results. The overall runtime drops from 245 s on 1 core to 6.5 s on 64 cores. The parallel efficiency stays very high at about 0.9 when run on up to 16 cores and then slightly drops. The parallel efficiency of the advection scheme is not as good as the efficiency of the mEVP iteration. In this benchmark problem, this is not significant since only two tracers are advected and since there are 100 substeps of the mEVP solver in each advection step. For more complex thermodynamics, the situation will be different and further optimizations appear to be necessary. However, the parallelization effort so far has been restricted to enabling OpenMP. A GPU implementation also provides significant opportunities for better parallel scaling.
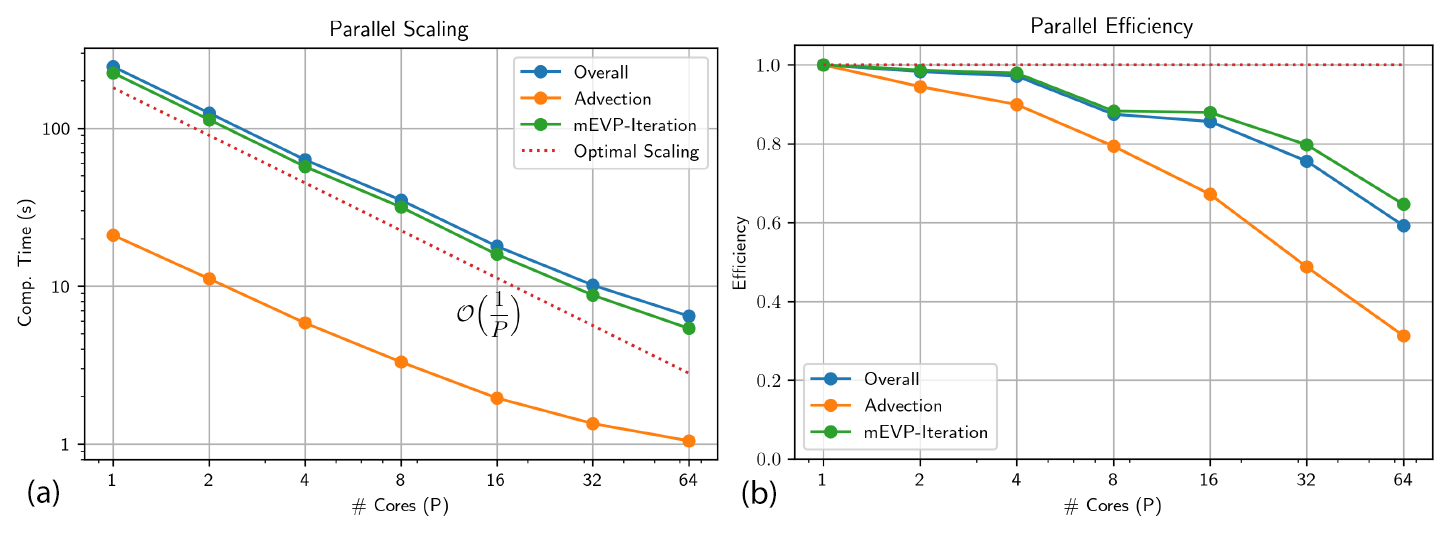
Figure 14Scaling (a) and parallel efficiency (b) of the OpenMP parallelization for the benchmark test case on the 2 km mesh. The mesh has 65 536 elements, and a total of 60 advection steps with 100 momentum substeps within the mEVP iteration are covered by the total time.
5.3.2 Vectorization
Our implementation described in Sect. 4 benefits from the vectorization capabilities of Eigen (Guennebaud et al., 2010). Eigen can in particular exploit the additional computations that arise in higher-order discontinuous Galerkin methods as the dG space naturally leads to many s×s matrices. Furthermore, the use of parametric meshes makes numerical quadrature with Gauss rules necessary and leads to operations involving nq×ncG matrices, where nq is the number of Gauss points in an element (usually 9) and ncG is the local number of cG basis functions (4 for cG(1) and 9 for cG(2)). Table 3 shows the effect of CPU-level vectorization.2
Table 3The effect of vectorization on the computational times for different discretizations of the momentum and the advection equations.
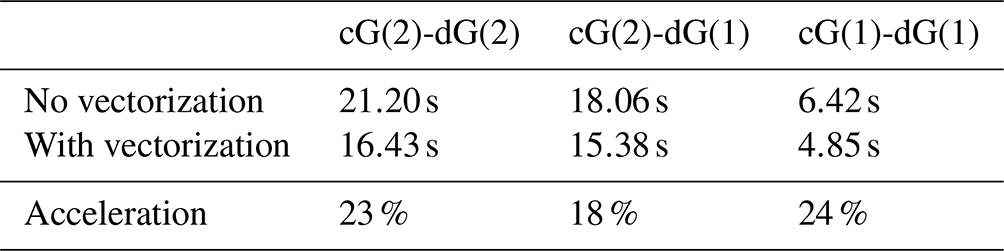
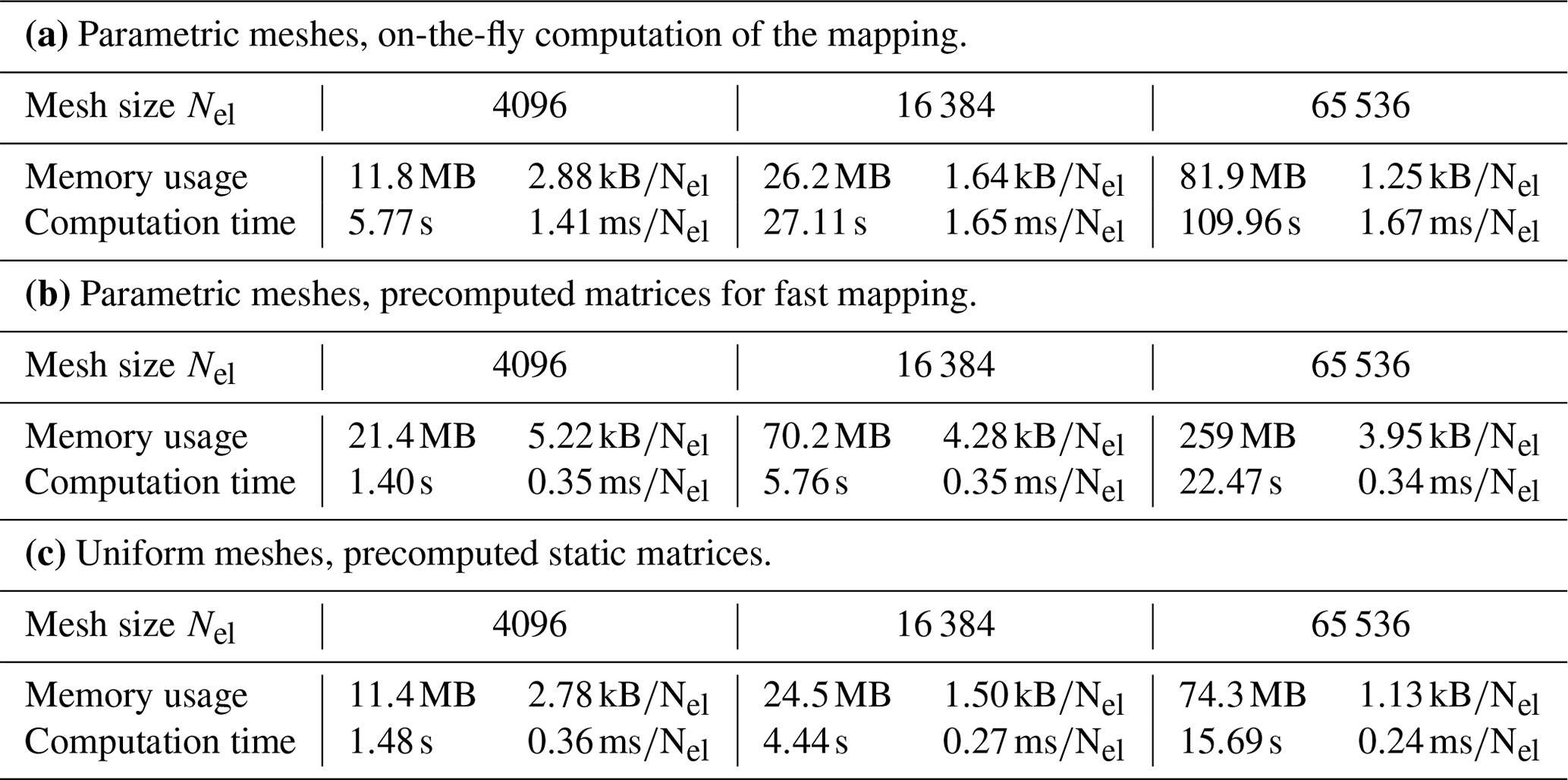
Table 4Comparison of different mesh structures. Evaluation of the benchmark problem with cG(2)-dG(2) discretization on meshes of size h=8 km, h=4 km, and h=2 km. The benchmark is simulated for T=1 h. Parts (a) and (b) refer to the parametric meshes, where the variational formulation must be evaluated using Gauss quadrature; part (c) corresponds to the uniform mesh, where the exact evaluation of the variational form is hard-coded. Part (b) in comparison to part (a) precomputes and stores the matrices required for the parametric mapping.
The effect is significant and purely based on the design principle in our implementation to use Eigen as much as possible. Computations are run using 16 cores of the AMD EPYC 7662 64-core CPU running at 3.20 GHz, and reported is the average of three consecutive calls.
5.3.3 Computational overhead of parametric meshes
As detailed in Sect. 4, with a parametric mesh the variational formulation needs to be mapped back onto the reference element for numerical quadrature. This has substantial computational overhead compared to fully uniform grids where all essential quantities can be precomputed. However, we described in Sect. 4 that also in the parametric case substantial precomputations are possible.
Table 4 shows memory usage and computation times as a function of the mesh type and for three successively refined meshes. We also provide computational time and memory consumption per element of the mesh. We again solve the benchmark problem of Sect. 5.2.1 but only in the short interval [0,1 h] using 16 CPU cores and a high-order discretization, i.e., cG(2) with dG(2) advection. The results in Table 4 clearly show the superiority of the uniform mesh approach both in terms of computational time and memory consumption. It shows, however, that parametric meshes can be realized either with a comparable memory footprint but with substantial computational overhead or with comparable computational efficiency but with increased memory requirements.
The trade-off that is chosen in an implementation will likely depend on the hardware that is targeted. On common multi-core CPUs with a moderate number of cores, the parametric approach with precomputed matrices seems to be superior. When using many-core systems or moving to GPUs or TPUs, the balance between compute-memory performance may differ. This remains a task for further research in the future.
We presented the numerics and implementation of the neXtSIM-DG dynamical core, a new discretization of sea ice dynamics aimed at Earth system models. A key feature is the use of a higher order in terms of local discretization and the consistent use of efficient data structures and modern programming paradigms.
The new framework has been validated in the context of Hibler's established viscous–plastic sea ice model, but the dynamical core is flexible and can accommodate different rheology models.
All advection equations are discretized using discontinuous Galerkin methods. Currently, the methods dG(0), dG(1), and dG(2) have been implemented and validated, but the flexible software concept based on code-generation and pre-assembled matrices for efficient implementation of the variational formulations easily allows an extension to even higher orders. This could become relevant in connection with alternative sea ice rheologies; see, e.g., Dansereau et al. (2016) and Rampal et al. (2016). The momentum equation is discretized using second-order continuous finite elements.
We validated the advection discretization and showed that the theoretically expected orders of convergence are realized in practice. Thereby, by using parametric grids, we achieve great flexibility on the spatial discretization. On the other hand, the underlying structured grid topology allows for an efficient numerical implementation. The momentum equation with an mEVP approximation of the visco-plastic model and was tested using an established benchmark problem (Mehlmann and Richter, 2017). In particular, we showed that the high-order discretization can resolve more LKFs than the established models (Mehlmann et al., 2021b), albeit with a larger number of degrees of freedom.
We also described the implementation of the dynamical core on a shared-memory compute node and parallelization using OpenMP. In our future work, we will add coarser parallelization on distributed clusters with MPI and also parallelization on GPUs.
While MPI parallelization is standard and can be easily accomplished by using topologically simple, structured rectangular grids, we enter new territory with GPU parallelization. However, this is already prepared by using a structured memory design. Moreover, the current implementation of neXtSIM-DG allows an easy choice between a pre-assembly of matrices and an on-the-fly computation of all sizes, which could be beneficial on GPUs to reduce memory bandwidth; see Sect. 5.3.3.
The software project neXtSIM-DG is under active development and hosted on GitHub, https://github.com/nextsimdg (last access: 22 June 2023). A snapshot including the scripts to reproduce the examples of this paper is published as a Zenodo repository (Richter et al., 2023, https://doi.org/10.5281/zenodo.7688635).
No data sets were used in this article.
All authors have worked on the concepts for the design of neXtSIM-DG. TR, CL, and PM designed and implemented the software framework. All authors worked on the draft of the paper and jointly contributed to the validation, discussion, and presentation of the results as well as the final editing of the manuscript.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We acknowledge support by the Open Access Publication Fund of Magdeburg University.
This research has been supported by the project SASIP funded by SChmidt Futures – a philanthropic initiative that seeks to improve societal outcomes through the development of emerging science and technologies (grant no. 353).
This paper was edited by James Kelly and reviewed by Sergey Danilov and one anonymous referee.
Bouchat, A. and Tremblay, B. L.: Using sea-ice deformation fields to constrain the mechanical strength parameters of geophysical sea ice, J. Geophys. Res.-Oceans, 122, 5802–5825, 2017. a
Bouchat, A., Hutter, N., Chanut, J., Dupont, F., Dukhovskoy, D., Garric, G., Lee, Y. J., Lemieux, J.-F., Lique, C., Losch, M., Maslowski, W., Myers, P. G., Ólason, E., Rampal, P., Rasmussen, T., Talandier, C., Tremblay, B., and Wang, Q.: Sea Ice Rheology Experiment (SIREx): 1. Scaling and Statistical Properties of Sea-Ice Deformation Fields, J. Geophysical Res.-Oceans, 127, e2021JC017667, https://doi.org/10.1029/2021JC017667, 2022. a
Bouillon, S., Fichefet, T., Legat, V., and Madec, G.: The elastic–viscous–plastic method revisited, Ocean Model., 71, 2–12, https://doi.org/10.1016/j.ocemod.2013.05.013, 2013. a, b
Braack, M., Becker, R., Meidner, D., Richter, T., and Vexler, B.: The Finite Element Toolkit Gascoigne, Zenodo [code], https://doi.org/10.5281/ZENODO.5574969, 2021. a
Burov, E. B.: Rheology and strength of the lithosphere, Marine Petrol. Geol., 28, 1402–1443, https://doi.org/10.1016/j.marpetgeo.2011.05.008, 2011. a
Chalmers, N. and Krivodonova, L.: A robust CFL condition for the discontinuous Galerkin method on triangular meshes, J. Comput. Phys., 403, 109095, https://doi.org/10.1016/j.jcp.2019.109095, 2020. a
Coon, M.: A review of AIDJEX modeling, in: Sea Ice Processes and Models: Symposium Proceedings, 12–27, Univ. of Wash. Press, Seattle, 1980. a
Coon, M. D., Maykut, G. A., Pritchard, R. S., Rothrock, D. A., and Thorndike, A. S.: Modeling the pack ice as an elastic plastic material, AIDJEX Bull., 24, 1–105, 1974. a
Danilov, S., Wang, Q., Timmermann, R., Iakovlev, N., Sidorenko, D., Kimmritz, M., Jung, T., and Schröter, J.: Finite-Element Sea Ice Model (FESIM), version 2, Geosci. Model Dev., 8, 1747–1761, https://doi.org/10.5194/gmd-8-1747-2015, 2015. a
Dansereau, V., Weiss, J., Saramito, P., and Lattes, P.: A Maxwell elasto-brittle rheology for sea ice modelling, The Cryosphere, 10, 1339–1359, https://doi.org/10.5194/tc-10-1339-2016, 2016. a, b, c, d
Dansereau, V., Weiss, J., Saramito, P., Lattes, P., and Coche, E.: Ice bridges and ridges in the Maxwell-EB sea ice rheology, The Cryosphere, 11, 2033–2058, https://doi.org/10.5194/tc-11-2033-2017, 2017. a
Dansereau, V., Weiss, J., and Saramito, P.: A Continuum Viscous-Elastic-Brittle, Finite Element DG Model for the Fracture and Drift of Sea Ice, in: Challenges and Innovations in Geomechanics, edited by: Barla, M., Di Donna, A., and Sterpi, D., 125–139, Springer International Publishing, https://doi.org/10.1007/978-3-030-64514-4_8, 2021. a
Di Pietro, D. and Ern, A.: Mathematical Aspects of Discontinuous Galerkin Methods, Springer Berlin Heidelberg, https://doi.org/10.1007/978-3-642-22980-0, 2012. a, b, c
Ern, A. and Guermond, J.-L.: Finite Elements II, Springer International Publishing, https://doi.org/10.1007/978-3-030-56923-5, 2021. a, b
Flato, G.: A particle-in-cell sea-ice model, Atmosphere-Ocean, 31, 339–358, https://doi.org/10.1080/07055900.1993.9649475, 1993. a
Girard, L., Bouillon, S., Weiss, J., Amitrano, D., Fichefet, T., and Legat, V.: A new modelling framework for sea ice mechanics based on elasto-brittle rheology, Ann. Glaciol., 52, 123–132, 2011. a, b
Goosse, H., Kay, J. E., Armour, K. C., Bodas-Salcedo, A., Chepfer, H., Docquier, D., Jonko, A., Kushner, P. J., Lecomte, O., Massonnet, F., Park, H.-S., Pithan, F., Svensson, G., and Vancoppenolle, M.: Quantifying climate feedbacks in polar regions, Nat. Commun., 9, 1–13, 2018. a
Avery, P., Bachrach, A., Barthelemy, S., et al.: Eigen v3, http://eigen.tuxfamily.org (last access: 22 June 2023), 2010. a, b
Hibler, W. D.: A Dynamic Thermodynamic Sea Ice Model, J. Phys. Oceanogr., 9, 815–846, https://doi.org/10.1175/1520-0485(1979)009<0815:adtsim>2.0.co;2, 1979. a, b, c
Horvat, C. and Tziperman, E.: Understanding Melting due to Ocean Eddy Heat Fluxes at the Edge of Sea-Ice Floes, Geophys. Res. Lett., 45, 9721–9730, https://doi.org/10.1029/2018GL079363, 2018. a
Huang, Z. J. and Savage, S. B.: Particle-in-cell and finite difference approaches for the study of marginal ice zone problems, Cold Reg. Sci. Technol., 28, 1–28, https://doi.org/10.1016/S0165-232X(98)00008-1, 1998. a
Hunke, E.: Viscous–Plastic Sea Ice Dynamics with the EVP Model: Linearization Issues, J. Comput. Phys., 170, 18–38, https://doi.org/10.1006/jcph.2001.6710, 2001. a
Hutchings, J. K., Roberts, A., Geiger, C. A., and Richter-Menge, J.: Spatial and temporal characterization of sea-ice deformation, Ann. Glaciol., 52, 360–368, 2011. a
Hutter, N., Losch, M., and Menemenlis, D.: Scaling Properties of Arctic Sea Ice Deformation in a High-Resolution Viscous-Plastic Sea Ice Model and in Satellite Observations, J. Geophys. Res.-Oceans, 117, 672–687, https://doi.org/10.1002/2017JC013119, 2018. a, b
Hutter, N., Zampieri, L., and Losch, M.: Leads and ridges in Arctic sea ice from RGPS data and a new tracking algorithm, The Cryosphere, 13, 627–645, https://doi.org/10.5194/tc-13-627-2019, 2019. a, b
Ip, C., Hibler, W., and Flato, G.: On the effect of rheology on seasonal sea-ice simulations, Ann. Glaciol., 15, 17–25, https://doi.org/10.3189/1991aog15-1-17-25, 1991. a
Kimmritz, M., Danilov, S., and Losch, M.: The adaptive EVP method for solving the sea ice momentum equation, Ocean Model., 101, 59–67, https://doi.org/10.1016/j.ocemod.2016.03.004, 2016. a, b
Kwok, R.: Deformation of the Arctic Ocean sea ice cover between November 1996 and April 1997: a qualitative survey, Solid Mech. Appl., 94, 315–322, 2001. a
Lemieux, J.-F., Knoll, D., Tremblay, B., Holland, D., and Losch, M.: A comparison of the Jacobian-free Newton–Krylov method and the EVP model for solving the sea ice momentum equation with a viscous-plastic formulation: A serial algorithm study, J. Comput. Phys., 231, 5926–5944, https://doi.org/10.1016/j.jcp.2012.05.024, 2012. a
Lindsay, R. W. and Stern, H. L.: The RADARSAT geophysical processor system: Quality of sea ice trajectory and deformation estimates, J. Atmos. Ocean. Tech., 20, 1333–1347, 2003. a
Lipscomb, W. and Hunke, E.: Modeling Sea Ice Transport Using Incremental Remapping, Mon. Weather Rev., 132, 1341–1354, https://doi.org/10.1175/1520-0493(2004)132<1341:MSITUI>2.0.CO;2, 2005. a
Losch, M., Fuchs, A., Lemieux, J.-F., and Vanselow, A.: A parallel Jacobian-free Newton–Krylov solver for a coupled sea ice-ocean model, J. Comput. Phys., 257, 901–911, https://doi.org/10.1016/j.jcp.2013.09.026, 2014. a
Marcq, S. and Weiss, J.: Influence of sea ice lead-width distribution on turbulent heat transfer between the ocean and the atmosphere, The Cryosphere, 6, 143–156, https://doi.org/10.5194/tc-6-143-2012, 2012. a
Marsan, D., Stern, H. L., Lindsay, R. W., and Weiss, J.: Scale Dependence and Localization of the Deformation of Arctic Sea Ice, Phys. Rev. Lett., 93, 178501, https://doi.org/10.1103/PhysRevLett.93.178501, 2004. a
Mehlmann, C. and Korn, P.: Sea-ice dynamics on triangular grids, J. Comput. Phys., 428, 110086, https://doi.org/10.1016/j.jcp.2020.110086, 2021. a
Mehlmann, C. and Richter, T.: A modified global Newton solver for viscous-plastic sea ice models, Ocean Model., 116, 96–107, https://doi.org/10.1016/j.ocemod.2017.06.001, 2017. a, b, c, d, e, f
Mehlmann, C., Danilov, S., Losch, M., Lemieux, J.-F., Hutter, N., Richter, T., Blain, P., Hunke, E., and Korn, P.: Sea Ice Numerical VP-Comparison Benchmark, Mendeley Repository, https://doi.org/10.17632/KJ58Y3SDTK.1, 2021a. a, b
Mehlmann, C., Danilov, S., Losch, M., Lemieux, J. F., Hutter, N., Richter, T., Blain, P., Hunke, E. C., and Korn, P.: Simulating Linear Kinematic Features in Viscous-Plastic Sea Ice Models on Quadrilateral and Triangular Grids With Different Variable Staggering, J. Adv. Model. Earth Sy., 13, e2021MS002523, https://doi.org/10.1029/2021ms002523, 2021b. a, b, c, d, e, f, g, h, i, j, k, l
Oikkonen, A., Haapala, J., Lensu, M., Karvonen, J., and Itkin, P.: Small-scale sea ice deformation during N-ICE2015: From compact pack ice to marginal ice zone, J. Geophys. Res.-Oceans, 122, 5105–5120, https://doi.org/10.1002/2016JC012387, 2017. a
Ólason, E., Boutin, G., Korosov, A., Rampal, P., Williams, T., Kimmritz, M., Dansereau, V., and Samaké, A.: A New Brittle Rheology and Numerical Framework for Large-Scale Sea-Ice Models, J. Adv. Model. Earth Sy., 14, e2021MS002685, https://doi.org/10.1029/2021MS002685, 2022. a, b
Peng, Z. and Gomberg, J.: An integrated perspective of the continuum between earthquakes and slow-slip phenomena, Nat. Geosci., 3, 599–607, https://doi.org/10.1038/ngeo940, 2010. a
Rampal, P., Weiss, J., Marsan, D., Lindsay, R., and Stern, H.: Scaling properties of sea ice deformation from buoy dispersion analysis, J. Geophys. Res.-Oceans, 113, c03002, https://doi.org/10.1029/2007JC004143, 2008. a
Rampal, P., Weiss, J., and Marsan, D.: Positive trend in the mean speed and deformation rate of Arctic sea ice, 1979-2007, J. Geophys. Res.-Oceans, 114, c05013, https://doi.org/10.1029/2008JC005066, 2009. a
Rampal, P., Weiss, J., Dubois, C., and Campin, J.-M.: IPCC climate models do not capture Arctic sea ice drift acceleration: Consequences in terms of projected sea ice thinning and decline, J. Geophys. Res.-Oceans, 116, c00D07, https://doi.org/10.1029/2011JC007110, 2011. a
Rampal, P., Bouillon, S., Ólason, E., and Morlighem, M.: neXtSIM: a new Lagrangian sea ice model, The Cryosphere, 10, 1055–1073, https://doi.org/10.5194/tc-10-1055-2016, 2016. a, b, c
Rampal, P., Dansereau, V., Olason, E., Bouillon, S., Williams, T., Korosov, A., and Samaké, A.: On the multi-fractal scaling properties of sea ice deformation, The Cryosphere, 13, 2457–2474, https://doi.org/10.5194/tc-13-2457-2019, 2019. a
Richter, T., Dansereau, V., Lessig, C., and Minakowski, P.: A snippet from neXtSIM_DG : next generation sea-ice model with DG, Zenodo [code], https://doi.org/10.5281/zenodo.7688635, 2023. a
Schreyer, H. L., Sulsky, D. L., Munday, L. B., Coon, M. D., and Kwok, R.: Elastic-decohesive constitutive model for sea ice, J. Geophys. Res.-Oceans, 111, C11S26, https://doi.org/10.1029/2005JC003334, 2006. a
Shih, Y., Mehlmann, C., Losch, M., and Stadler, G.: Robust and efficient primal-dual Newton-Krylov solvers for viscous-plastic sea-ice models, J. Comput. Phys., 474, 111802, https://doi.org/10.1016/j.jcp.2022.111802, 2023. a
Stern, H. L. and Lindsay, R. W.: Spatial scaling of Arctic sea ice deformation, J. Geophys. Res.-Oceans, 114, c10017, https://doi.org/10.1029/2009JC005380, 2009. a
Sulsky, D. and Peterson, K.: Toward a new elastic–decohesive model of Arctic sea ice, Physica D, 240, 1674–1683, https://doi.org/10.1016/j.physd.2011.07.005, 2011. a, b
Taylor, P., Hegyi, B., Boeke, R., and Boisvert, L.: On the Increasing Importance of Air-Sea Exchanges in a Thawing Arctic: A Review, Atmosphere, 9, 41–39, 2018. a
Vihma, T.: Effects of Arctic Sea Ice Decline on Weather and Climate: A Review, Surv. Geophys., 35, 1175–1214, 2014. a
Zhong, S., Yuen, D., Moresi, L., and Knepley, M.: Numerical Methods for Mantle Convection, in: Treatise on Geophysics (Second Edition), edited by: Schubert, G., Elsevier, Oxford, 2nd edn., 197–222, https://doi.org/10.1016/B978-0-444-53802-4.00130-5, 2015. a
The scripts are available in the repository (Mehlmann et al., 2021a).
Vectorization can be activated or deactivated by a simple compiler flag, for instance -march=native, which turns on all hardware-specific optimization and in particular vectorization support.
- Abstract
- Introduction
- Governing equations
- Higher-order finite-element discretization of the sea ice equations
- Efficient parallelizable implementation
- Numerical experiments
- Conclusion
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Governing equations
- Higher-order finite-element discretization of the sea ice equations
- Efficient parallelizable implementation
- Numerical experiments
- Conclusion
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References