the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 12 Dec 2022
| 12 Dec 2022
A local data assimilation method (Local DA v1.0) and its application in a simulated typhoon case
Shizhang Wang
Xiaoshi Qiao
Integrating the hybrid and multiscale analyses and the parallel computation is necessary for current data assimilation schemes. A local data assimilation method, Local DA, is designed to fulfill these needs. This algorithm follows the grid-independent framework of the local ensemble transform Kalman filter (LETKF) and is more flexible in hybrid analysis than the LETKF. Local DA employs an explicitly computed background error correlation matrix of model variables mapped to observed grid points/columns. This matrix allows Local DA to calculate static covariance with a preset correlation function. It also allows the conjugate gradient (CG) method to be used to solve the cost function and allows localization to be performed in model space, observation space, or both spaces (double-space localization). The Local DA performance is evaluated with a simulated multiscale observation network that includes sounding, wind profiler, precipitable water vapor, and radar observations. In the presence of a small-size time-lagged ensemble, Local DA can produce a small analysis error by combining multiscale hybrid covariance and double-space localization. The multiscale covariance is computed using error samples decomposed into several scales and independently assigning the localization radius for each scale. Multiscale covariance is conducive to error reduction, especially at a small scale. The results further indicate that applying the CG method for each local analysis does not result in a discontinuity issue. The wall clock time of Local DA implemented in parallel is halved as the number of cores doubles, indicating a reasonable parallel computational efficiency of Local DA.
Please read the corrigendum first before continuing.
-
Notice on corrigendum
The requested paper has a corresponding corrigendum published. Please read the corrigendum first before downloading the article.
-
Article
(19803 KB)
-
The requested paper has a corresponding corrigendum published. Please read the corrigendum first before downloading the article.
- Article
(19803 KB) - Full-text XML
- Corrigendum
- BibTeX
- EndNote





Data assimilation (DA), which estimates the atmospheric state by ingesting information from model predictions, observations, and background error covariances, is crucial for the success of numerical weather prediction (Bonavita et al., 2017). Therefore, many previous studies on DA have focused primarily on how to utilize observations and how to estimate background error covariances (e.g., Huang et al., 2021; Wang et al., 2012, 2013a, 2021; Lei et al., 2021; Zhang et al., 2009; Brousseau et al., 2011, 2012; Kalnay and Yang, 2008; Buehner and Shlyaeva, 2015). At present, there are two prevailing research orientations of DA: hybrid analysis, which concerns the background error covariance, and multiscale analysis, which often addresses the difference in observation scales.
Hybrid analysis aims to utilize both the ensemble and static covariances to leverage the advantages of flow-dependent error information and prevents the analysis from degrading due to a limited ensemble size (Wang et al., 2009; Etherton and Bishop, 2004). A widely used hybrid approach is to add an ensemble-associated control variable to a variational DA framework (Lorenc, 2003; Wang et al., 2008). An alternative combines the ensemble and static covariances (Hamill and Snyder, 2000). These two approaches are equivalent (Wang et al., 2007). Another hybrid method averages the analyses yielded by the ensemble Kalman filter (EnKF) and the variational method (Bonavita et al., 2017; Penny, 2014). Recently, a hybrid scheme based on the EnKF framework was developed (Lei et al., 2021) that uses a large ensemble size (i.e., 800) to simulate the static error covariance. Nevertheless, given the variety of hybrid approaches available, how to conduct hybrid DA is still a matter of debate. In this study, a hybrid scheme is implemented following Hamill and Snyder (2000), although the proposed scheme differs regarding the details.
Multiscale DA is designed to utilize observations at different scales and performs multiscale localization in either the model or observation space. Localization is inevitable due to sampling errors (e.g., distant spurious correlations) in ensemble-based DA, including in hybrid DA (e.g., Huang et al., 2021; Wang et al., 2021). Varying the localization radius for observations according to the observation scale or density is a straightforward method; examples include the assimilation of synoptic-scale observations with a large localization radius and then performing radar DA with a small radius of influence (e.g., Zhang et al., 2009; Johnson et al., 2015). An alternative is to perform multiscale localization in model space, requiring the scale decomposition of the ensemble members (Buehner and Shlyaeva, 2015). The model space localization allows all observations to be ingested on different scales simultaneously. Recent studies have shown that multiscale DA outperforms DA with fixed localization (Caron and Buehner, 2018; Caron et al., 2019; Huang et al., 2021).
In addition to the analysis quality of DA, computational efficiency should also be considered (Bonavita et al., 2017). A highly parallelized DA scheme is preferable due to the continuously increasing model resolution and the number of available observations. One DA scheme that can be highly parallelized is the local ensemble transform Kalman filter (LETKF; Hunt et al., 2007), whose analysis is grid-independent.
In brief, both hybrid DA and multiscale DA are necessary, and the parallel computation efficiency of the LETKF is attractive. Thus, it is desirable to utilize all their advantages. A straightforward idea for achieving hybrid DA with the LETKF is to use a large-size static ensemble, similar to the EnKF-based hybrid scheme proposed by Lei et al. (2021). The large ensemble () is not always available in practice because of the limited computational and storage resources. However, it is inevitable to use such an ensemble to realize the hybrid analysis in the original LETKF framework because the LETKF works in the ensemble space. In this situation, it is desirable to design a flexible DA scheme that follows the grid-independent analysis of the LETKF and can perform both hybrid and multiscale analysis with or without static ensemble members, similar to other variational-based hybrid schemes. The scheme is named Local DA hereafter.
Compared with the LETKF, Local DA computes the linear combination of columns of a local background error correlation matrix rather than the combination of ensemble members. The local background error correlation matrix is in model space, but the model variables are interpolated to observed grid points/columns. In other words, Local DA works on unstructured grids. This framework is suitable for assimilating integrated observations, such as precipitation water vapor (PWV), because vertical localization can be performed in model grid space. Explicitly computing the error correlation matrix requires much more memory than the LETKF but allows Local DA to calculate the static background error correlation with a preset correlation function, such as the distant correlation function. Moreover, the computational cost of the matrix is acceptable if observations are appropriately thinned.
Since the error correlation matrix is explicitly constructed, it is straightforward to realize the hybrid DA according to the idea of Hamill and Snyder (2000). This approach is often utilized with a simple model (Kleist and Ide, 2015; Penny, 2014; Etherton and Bishop, 2004; Lei et al., 2021) because it explicitly computes and directly combines the background error covariance matrices. In this study, we attempt to evaluate the hybrid idea of Hamill and Snyder (2000) in a realistic complicated scenario.
Another feature of Local DA is the ability to perform multiscale analysis in model space, observation space, or both spaces (double-space localization). In the model space, Local DA adopts a scale-aware localization approach for multiscale analysis that applies a bandpass filter to decompose samples and individually performs localization at each scale; no cross-scale covariance is considered in current Local DA. A similar idea (i.e., lacking cross-scale covariance) is the scale-dependent localization technique proposed by Buehner (2012). Although cross-scale covariance is likely to improve multiscale analysis, the relative performance depends on ensemble size (Caron et al., 2019).
Local DA can perform observation-space localization similar to LETKF, which magnifies the observation error as the distance between the observation and model variables increases. For the multiscale analysis in the observation space, the localization radius increases as the scale of observation increases. Compared with radar data, the scale of sounding data is larger so that a larger radius is assigned.
Because model space localization and observation space localization are conducted for covariances in different spaces, it is possible to perform both localizations synchronously. Although double-space localization may result in a double penalty, it would be interesting to note the localization performance. Note that the LETKF of Wang et al. (2021) can also realize double-space localization, but this application has not yet been investigated.
As the first paper to report on Local DA, this study focuses on the following main issues: (i) how to locally conduct the hybrid and multiscale analysis, (ii) the spatial continuity of local analysis, (iii) the impact of the hybrid covariance, and multiscale localization on Local DA, and (iv) the performance of Local DA on cycling DA. Since Local DA is designed to be a more flexible hybrid scheme than LETKF, we do not expect Local DA to outperform LETKF in all scenarios. The comparison of both methods only focuses on (i) if they yield similar results in the case of using observation space localization and ensemble covariance only and (ii) if Local DA with hybrid covariance outperforms the LETKF with a poor ensemble.
Observing system simulation experiments (OSSEs) are adopted to avoid issues associated with the quality control of observations. The simulated multiscale observing system consists of sounding, wind profiler, PWV, and radar (radial velocity and reflectivity) observations; the scales of these observations vary from the synoptic scale to the convective scale. A simulated typhoon case is selected for the evaluation.
The remainder of this paper is organized as follows. In Sect. 2, Local DA and its associated multiscale localization technique are described, including the formula, workflow, and other details. Section 3 describes the numerical experiments, and Sect. 4 discusses the results. A summary and conclusions are given in Sect. 5.
2.1 The Local DA scheme
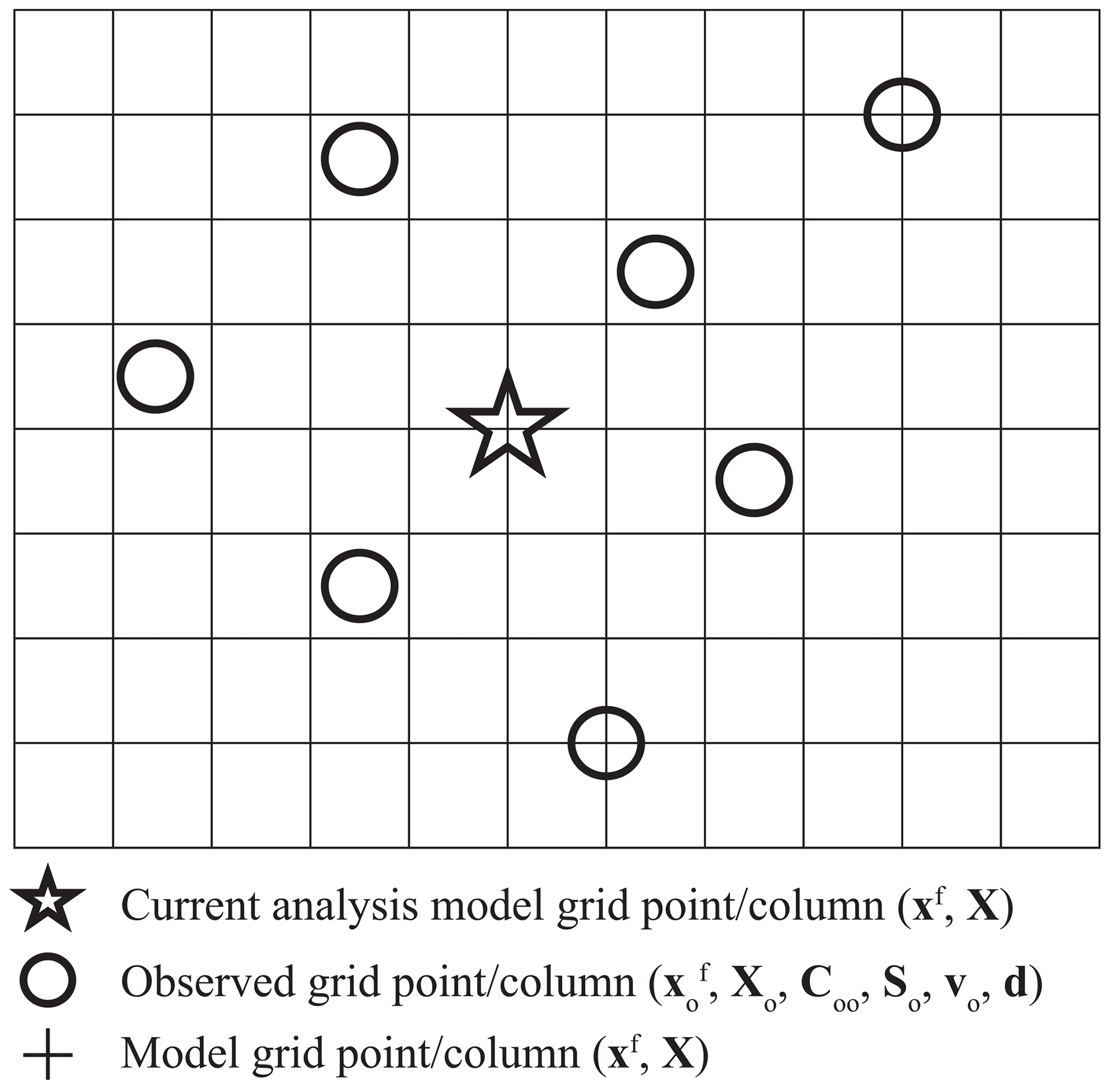
As mentioned above, Local DA performs analysis in model space, but it needs to map model variables onto observed grid points/columns before the analysis. All DA methods conduct the mapping, but Local DA updates the mapped model variables. Both the background model state (xf) and the ensemble perturbations (X) are mapped according to Hi, the vector of interpolation operators. The mapped model state and perturbations are denoted by and Xo, respectively, where the subscript “o” represents the observed grid points/columns. Note that Local DA only stores and Xo for a local analysis rather than the whole forecast domain. An example of the spatial distribution of variables involved in Local DA is shown in Fig. 1.
The cost function of Local DA is written as
where vo is the control variable (or a combination of error samples); the observation error covariance is denoted by R, which is a diagonal matrix in this study; Ho is the linear operator of that converts the model variables into observation variables; and d is the observation innovation vector. (=αSoCoo) represents a constructed error-sample matrix, where Coo is the local background error correlation matrix, So stores the standard deviations (SDs) of the model variables, and α is a parameter that adjusts the trace of Coo. The dimensions of vectors and matrices in Eq. (1) depend on the number of observations involved in a local analysis and the complexity of observation operators. We will give the dimensions and computations of the above variables in the following subsections.
Once vo is obtained, the model state increment xi on the model grids can be computed in terms of
where , Sm contains the SDs of the model variables on the model grids, and Cmo is a correlation matrix that contains the correlation coefficients between Xo and X. Details regarding Coo and Cmo will be given later. The analyzed model state xa is computed in accordance with .
To update ensemble perturbations, the current version of Local DA adopts the stochastic method (Houtekamer and Mitchell, 1998) that treats observations as random variables. This method adds random perturbations with zero mean to d in Eq. (1). For an M-member ensemble, Eqs. (1) and (2) are conducted M times to update members with perturbed observations, similar to the procedure of Li et al. (2012). These analyses share the same background error covariance but use different observations. The stochastic approach was reported to be less accurate than the deterministic approach (e.g., Whitaker and Hamill, 2002) because it introduces additional sampling error. At this stage, Local DA mainly concerns the deterministic analysis; further improvement of the analysis ensemble is left in future work.
Compared with the LETKF or the En4DVar of Liu et al. (2008), Local DA seeks the combination (v0) in model space or, more specifically, the combination of the columns of a local background error correlation matrix of model variables, rather than the combination in ensemble space. Thus how to construct Coo and Cmo is key for Local DA. Explicitly computing Coo raises the question of how to solve the cost function of Local DA in the case of large-size Coo. In addition, how to deal with nonlinear observation operators should be determined. The subsequent subsections present the answers to these questions.
2.1.1 The local background error correlation matrix
In Local DA, the actual correlation matrix is the square of Coo multiplied by a rescaling parameter α2:
Using the rescaling parameter, the trace of is equivalent to that of Coo. α is computed according to
where tr( ) denotes the calculation of the trace of a matrix. Notably, tr is equal to the sum of squares of all elements in Coo. There is no need to compute . and Coo are identical in terms of eigenvectors and the trace of the matrix (total variance). The eigenvalues of are the squares of the corresponding eigenvalues of Coo multiplied by α2. Therefore, is an approximation of Coo. Storto and Andriopoulos (2021) proposed a hybrid DA scheme that also used the rescaling parameter to tune the trace of a matrix (see their Eq. 15), but they constructed the background error covariance in a way differing from ours.
Coo is a K×K matrix, where K is the number of model variables associated with the observations to be assimilated. K is computed according to
where Nt is the number of observation types, such as the zonal wind from soundings and the radial velocity from radars; No(i) is the number of observations of the ith type; and Nop(i) is the number of model variables used by the observation operator of the ith type. For instance, if radar reflectivity is the only available observation type, and there are 100 observations, K is equal to 300 (100×3) in the case of using the observation operator of Gao and Stensrud (2012) because the operator requires three hydrometeors (qr, qs, and qg). Now we are going to give an example of Coo. Assuming there are three available observations (two zonal wind observations and a surface pressure observation), the background error correlation matrix is
where c is the correlation coefficient in the space of Xo, and the subscripts “u1”, “u2”, and “ps1” represent the two zonal wind observations and a surface pressure observation, respectively. Correspondingly, the SD matrix So can be written as
where s denotes the SDs of the model variables projected onto the observed grids. So is a K×K matrix, but a K×1 array is sufficient to store So. After Coo and So are formed,vo can be solved. In this example, vo is in the following form:
where subscripts “u1”, “u2”, and “ps1” have the same meaning in Eqs. (6) and (7).
To obtain the model state increment xi, it is necessary to form Cmo and the corresponding Sm. If the model variables to be updated are the zonal wind (v1), potential temperature (θ1), and water vapor mixing ratio (q1), Cmo is written as
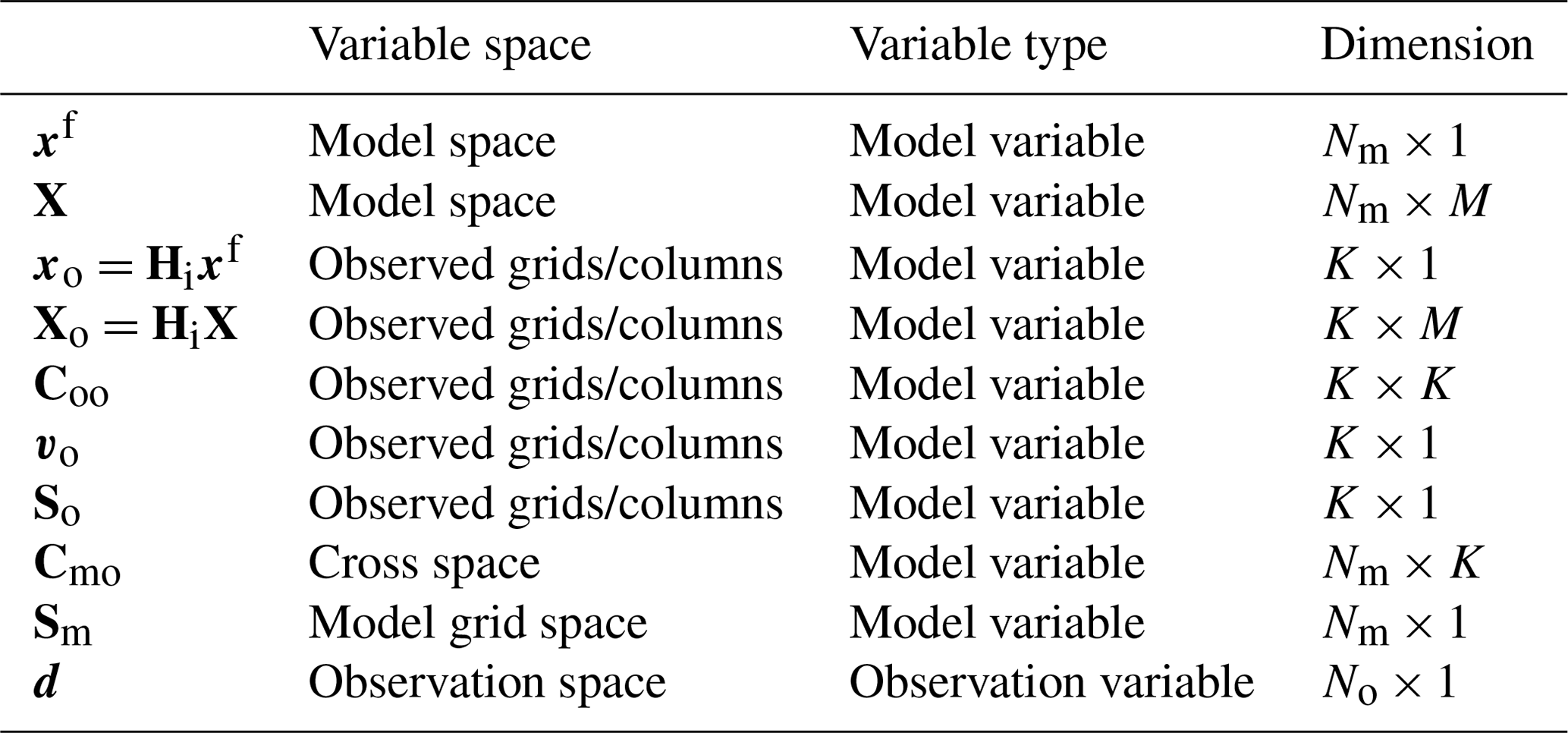
where subscripts “u1”, “u2”, and “ps1” are the same as those in Eqs. (6) and (7), while subscripts “v1”, “θ1”, and “q1” denote the model variables to be updated. Cmo comprises the error correlation coefficients between X and Xo. The size of Cmo is NmK which depends on the number (Nm) of model variables to be updated. However, there is no need to store full Cmo in practice because one row of Cmo is needed to update the corresponding model variable. Sm is the SD matrix of model variables, containing sv1, sθ1, and sq1 in this example. For convenience, a summary of the dimensions of variables involved in Local DA is listed in Table 1.
Table 1The dimensions of variables in Local DA. M denotes the ensemble size, Nm is the total number of analysis variables, and K is proportional to the number of observations (No).
Note that the variational DA methods and Local DA differ in the control variable transform viewpoint. The former uses the square root of the background error covariance matrix, while Local DA employs the error correlation matrix. It is based on the consideration of computational cost because it is expensive to obtain the square root of Coo if the size of Coo is large. Moreover, modeling the square root of the background error covariance matrix, as many variational DA methods do, is also difficult for Local DA because the irregular distribution of observations makes it infeasible to utilize a recursive filter.
Additionally, note that the size of Coo grows rapidly as K increases. However, the memory requirement is affordable since Coo is only used for local analysis. For high-resolution observations, thinning can help reduce the cost, which is also necessary to ensure that the observation errors are uncorrelated (e.g., Hoeflinger et al., 2001). We use the same model variables for the data observing the same grid point/column. For example, the same hydrometeor variables (qr, qs, and qg) are used to compute the radar reflectivity and differential reflectivity at the same observed grid point. In this situation, the size of Coo does not increase with the observations. This strategy is also valid for passive microwave observations at different frequencies obtained by a satellite because they observe the same column of the atmosphere. Therefore, the size of Coo is controllable. We use a simple thinning approach to control the matrix size in this study, as described in the Appendix.
2.1.2 The solution of Local DA
There are two methods to solve the gradient of Eq. (1): (i) matrix decomposition and (ii) an iterative algorithm. The first approach is straightforward but is time-consuming and sometimes infeasible if the Coo size is large. Therefore, Local DA adopts an iterative algorithm, namely, the conjugate gradient (CG) method (Shewchuk, 1994). Theoretically, the CG method requires the background error covariance matrix to be positive definite. However, with the control variable transform, a positive semidefinite covariance matrix is sufficient to obtain the best linear unbiased estimate (Ménétrier and Auligné, 2015). A strictly diagonally dominant matrix with nonnegative diagonal elements is positive semidefinite.
Although a positive semidefinite covariance matrix is sufficient, using a higher-rank background error covariance matrix helps obtain a lower analysis error (Huang et al., 2019). Compared with the rank of X, which is not higher than the ensemble size, that of is much higher after Coo is localized. Our early test (not shown) indicates that is a full rank matrix in most cases. For rank-deficient cases, the rank of is often greater than 97 % of the full rank value. The details of this localization will be given later.
Note that Local DA performs the CG step locally, unlike other variational-based DA methods that apply the CG method globally. Therefore, it is necessary to investigate whether the local application of the CG method causes a nonnegligible spatial discontinuity, which will be discussed in Sect. 4. For computational efficiency, the maximum number of iterations is 100. If the error tolerance ε2 defined in Shewchuk (1994) cannot reach by the 100th step, the CG method is stopped.
2.1.3 The observation operator
The EnKF algorithm often approximates the linear projection, H in Eq. (1), according to the departure of the observation priors from their ensemble mean. It is straightforward for Local DA to use the ensemble approximation approach. However, for nonlinear observation operators, there is an alternative, namely, the observation prior calculated using the ensemble mean of the model variables. Tang et al. (2014) demonstrated that this alternative could lead to better results. Furthermore, Yang et al. (2015) examined the application of this alternative in radar DA and showed that the alternative approach produced lower analysis errors for the model variables associated with radial velocity (three wind components) and reflectivity (mixing ratios of rain, snow, and graupel). Given that remote sensing observations such as those obtained by radars and satellites are important parts of a multiscale observation network, Local DA adopts the alternative approach proposed by Tang et al. (2014).
Local DA approximates the linear projection according to
where h is the nonlinear observation operator, xf is the background model state vector, and is the mean of . Note that Eq. (10) is written for a deterministic forecast in this study. Compared with the results using the ensemble mean of observation priors, Eq. (10) reduces the analysis error of reflectivity by approximately 2 dBZ in our early test (not shown). This result is consistent with that of Yang et al. (2015).
2.2 Multiscale localization
To realize multiscale localization in model space, Local DA first performs scale decomposition with a bandpass filter. The decomposed perturbation, , is
where the superscript “l” represents the lth scale, and Nb is the number of scales. After decomposition, the number of samples becomes Nb times as large as the original ensemble size. As a localization approach lacking cross-scale covariance (no term in , Local DA computes the SD of the perturbation, s, according to
where i and m denote the ith model variable and the mth sample, respectively, and N is the sample size. Compared with the raw SD, , the cross influence among different scales of is ignored in Eq. (12). Nevertheless, we acknowledge the importance of the cross influence of these perturbations and plan to investigate this issue with regard to Local DA in our future work.
The multiscale correlation coefficient c(i,j) is calculated according to
where i andj denote the ith and jth variables, respectively. For the case of i=j, Eq. (13) ensures .
We perform localization for each scale independently to construct the multiscale correlation matrix. In principle, our multiscale localization method trusts the correlation coefficient of each scale when the distance between two variables is smaller than the lower bound of the scale. For instance, for the scale of 50–100 km, Local DA starts the localization when the distance d is greater than 50 km. The decorrelation coefficient for the lth scale and c(i,j) is calculated according to
where dmin(l) and dmax(l) are the lower and upper bounds of the lth scale, respectively, and dr(l) is the localization radius for the lth scale. Note that how to optimally localize the background error covariance is still an open question; rather, Eq. (14) is simply a preliminary implementation of multiscale localization for Local DA.
Substituting Eqs. (13) and (14) into Eq. (6), an example of Coo in Eq. (6) is written as
where i and j in Eq. (13) are replaced by subscripts in Eq. (6). For brevity, only the first column of Coo is listed. Obviously, applying multiscale localization does not change the size of Coo. Correspondingly, an example of Cmo in Eq. (8) can be written as
Because the multiscale localization does not change the sizes of Coo and Cmo, there is no modification for vo, xi, xf, and xa. The only modification to realize multiscale localization in model space is to store the error sample of each scale and compute the corresponding correlation coefficient. Therefore, realizing multiscale analysis within the Local DA framework is easy.
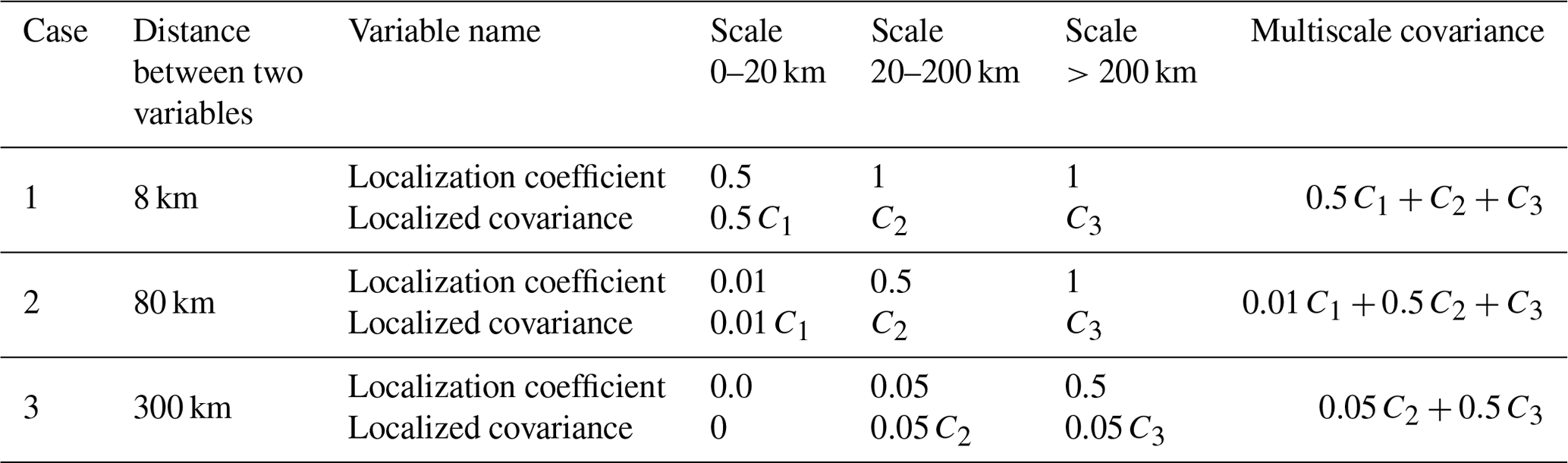
The multiscale localization proposed in this subsection gradually diminishes the contribution of small-scale covariance as the distance between two variables increases while retaining that of large-scale covariance until the distance is very large. Table 2 shows an example of multiscale localization. In this example, there are two arbitrary variables of which the error samples are decomposed into three scales. The values of covariance between the two variables are C1, C2, and C3 at three scales. When the two variables are close (8 km), the localization coefficients of C2 and C3 are 1.0, according to the first formula in Eq. (14). As the distance increases to 300 km, the localization coefficients of C1 and C2 become nearly zero, and the total covariance is mainly attributable to C3. Note that the multiscale covariance proposed in this section naturally excludes cross-scale covariance, and it is hard to incorporate cross-scale localization. How to determine the localization between two scales is also a question. The existing cross-scale localization (e.g., Huang et al., 2021; Wang et al., 2021) is implemented in spectral space and cannot be directly applied in Eqs. (15) and (16). We plan to deal with the cross-scale issue in future work.
Table 2Examples of applying the model-space multiscale localization. C1, C2, and C3 represent the covariance of the small scale (0–20 km), middle scale (20–200 km), and large scale (>200 km), respectively.
In addition to multiscale localization in the model space, Local DA can perform localization in the observation space, similar to LETKF. Observation space localization is conducted by enlarging the observation error as the distance between variables increases. The localization coefficient in the observation space is calculated according to the second formula of Eq. (14), but d−dmin(l) and dmin(l) are replaced by d and do, respectively, where do is the localization radius that varies among different observation types.
Because Coo and R are independently localized, Local DA can perform both localizations synchronously. Although performing localization in both spaces may result in a double penalty, it would be interesting to note the performance of the double-space localization approach, which has not yet been investigated. The related experiments and results are given in the following sections.
2.3 Hybrid covariance
The current version of Local DA calculates a simple “static” correlation matrix using the second formula of Eq. (14), except that d-dmin(l) and dmin(l) are replaced by d and ds, respectively, where ds is a preset radius. For the ith and jth variables, the hybrid correlation coefficient c(i,j) in Coo is computed according to
where γ is the weight of the dynamic correlation. The hybrid c(i,j) in Cmo is also computed according to Eq. (17), but and s(i) represent the variable at the model grid point. To prevent s(i) and s(j) in Eq. (17) from being forced to zero (which often occurs for convective-related variables such as the mixing ratios of rainwater, snow, and graupel), we add small, random perturbations with an SD of to the variables for which the SDs are smaller than .
Note that the static part of Eq. (17) represents merely a distant correlation. It is valid for the univariate correlation rather than the cross-variable scenario. Therefore, the static part of Eq. (17) is forced to zero if the ith and jth variables are different types of variables. In other words, the cross-variable correlation is contributed only by the ensemble part. The authors acknowledge that the cross-variable correlation is important for DA, but the static cross-variable correlation must be carefully modeled, such as the correlation between wind components and geopotential height or between the stream function and potential temperature. The modeling work is in progress.
2.4 The workflow of Local DA
Here, we present a step-by-step description of how the hybrid and multiscale analyses described in the previous sections are performed for all the model variables. There is a way for Local DA to perform analysis much faster; we will discuss this method later.
-
Apply a bandpass filter to decompose into Nb scales.
-
Store the background model state, decomposed samples, and observations in separate arrays denoted by xf, , and yo, respectively.
-
For each model variable to be updated, search its ambient observations according to their scales, and store these observations in array ; for example, search for sounding data within 300 km while searching for radar data within 15 km. In addition, according to the observation operators of , store the observation-associated model variables that have been projected onto observed grids/columns into arrays denoted by and , respectively.
-
Calculate the vector d in Eq. (1) with and .
-
Use to generate So, Coo, Sm, and Cmo according to Eqs. (12), (15), and (16).
-
Compute α for Coo using Eq. (4).
-
Compute .
-
Calculate using Eq. (9).
-
Use the CG method to solve and obtain vo.
-
Compute the model state increment xm according to Eq. (2).
In step 1, there are many ways to realize the bandpass filter. In this study, the difference between two low-pass analyses defines the bandpass field (Maddox, 1980), where the low-pass filter is the Gaussian filter. An example of a bandpass field is shown in Fig. 2. For convenience, the radius of the Gaussian filter is used to represent the scale in this study. For the scale of 0–20 km (Fig. 2a), the small-scale feature prevails and corresponds to convection in the simulated typhoon. As the radius increases (Fig. 2b), larger-scale information is extracted. A large-scale anticyclonic shear is observed when the radius is greater than 200 km (Fig. 2c). The results (Fig. 2d–f) also show that the contribution of the small-scale ensemble spread is often less than 10 % out of the convective area, while in most areas of the forecast domain, the contribution of the large-scale (>200 km) spread is greater than 20 %.
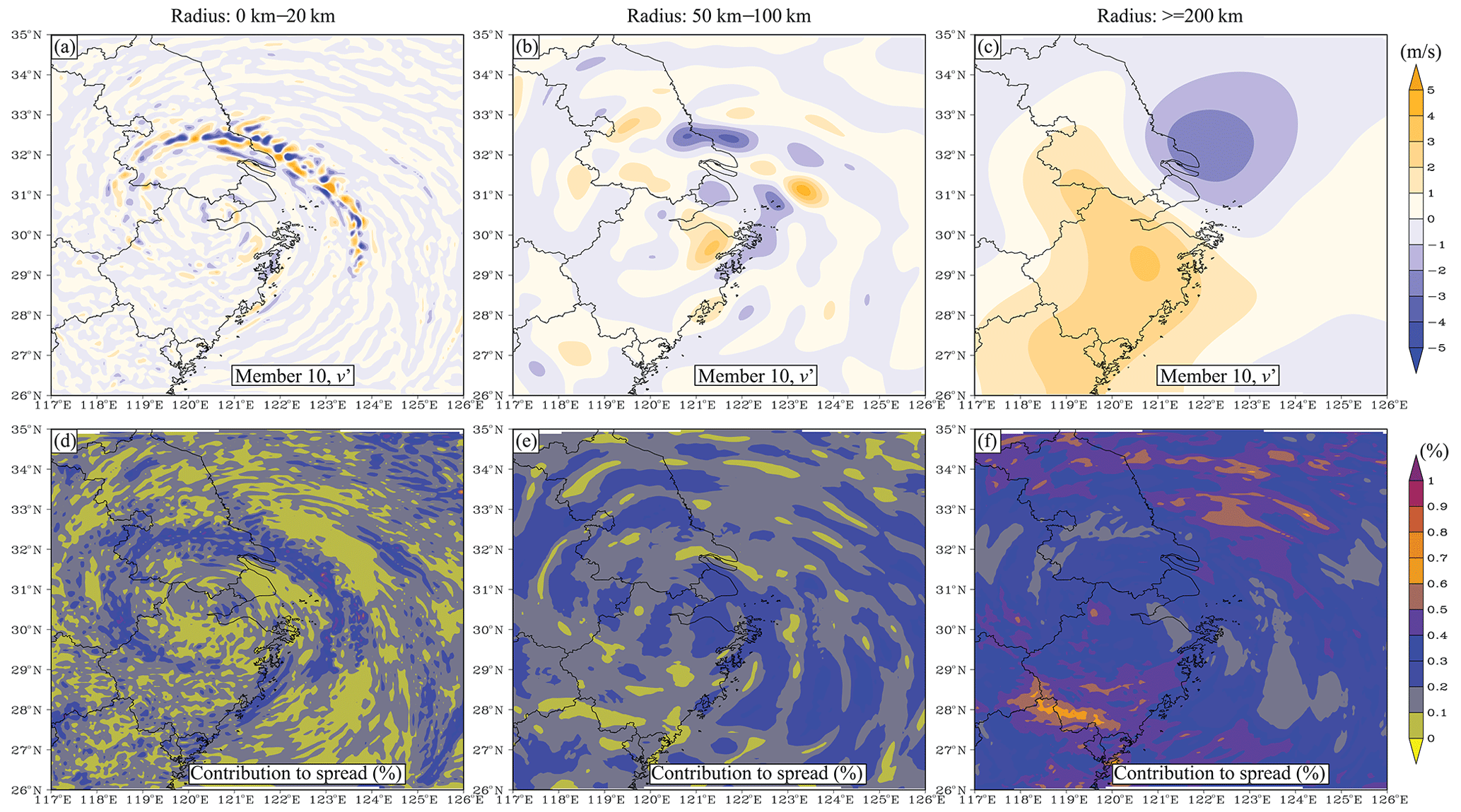
Figure 2An example of scale decomposition for scales of (a, d) 0–20 km, (b, e) 50–100 km, and (c, f) greater than 200 km. The upper panels show the decomposed v perturbation (m s−1), while the lower panels show the contribution of each scale to the ensemble spread in terms of percentage.
Steps 5–9 contribute the most to the computational cost of Local DA. Computing Coo requires MK2 operations, which is not less than , where M represents the size of the ensemble, and No denotes the number of observations to be assimilated. Step 7 requires two K2 operations. To calculate step 8, NoK2 operations are needed. For each iteration step of the CG method, the number of operations is slightly larger than 2NoK. Ni iteration steps require 2NiNoK operations.
As mentioned above, step 9 can also be solved through eigenvalue decomposition as the LETKF does. However, Y in Local DA has more columns than the LETKF. In the LETKF, Y has M columns, while the corresponding value is K in Local DA. Therefore, Local DA has to deal with a K by K matrix, while the LETKF only needs to solve an M by M matrix. M is often smaller than 102; thus, I + YTY can be handled efficiently by eigenvalue decomposition. In contrast, K could be 103 or higher; thus, the CG method is more suitable.
Despite the large number mentioned above, we do not have to do that many operations in practice. For example, step 8 requires just operations if only scalar observations are available. Notably, for a 3-D domain containing Ng grid points and Nv variables, the total number of operations will be NgNv times that of one local analysis. However, it is possible to reduce the cost.
Considering that Sm, Cmo, and xm can be applied to all variables influenced by , it is not necessary to compute Coo for each model variable. Moreover, Sm, Cmo, and xm may contain variables in more than one vertical column (N-column analysis). The total number of operations in an N-column analysis is reduced to times one local analysis, where Nz is the number of levels in one column. Due to using the same Coo for neighboring columns, the N-column analysis is slightly rasterized (not shown), leading to slightly higher errors than the one-column analysis. However, the extent of this degeneration is acceptable as long as N is not too large (<9). The wall clock time of the N-column analysis is close to of the one-column analysis. All Local DA results are generated using a five-column analysis in this study. A similar N-column analysis approach is the weighted interpolation technique in the LETKF (Yang et al., 2009), which performs LETKF analysis every 3 grid points in both the zonal and meridional directions.
3.1 The simulated typhoon
The third typhoon of the 2021 western Pacific season, In-fa, is selected for the OSSEs performed herein. The true simulation, starting at 00:00 UTC on 25 July 2021 and ending at 18:00 UTC on 26 July 2021, simulates the stage in which In-fa approaches China. The Weather Research and Forecasting (WRF; Skamarock et al., 2018) model V3.9.1 is used for the simulation. The central latitude and longitude of the forecast domain are 30.5 and 122.0∘, respectively. The domain size is 201 grids × 201 grids × 34 levels, with a horizontal resolution of 5 km and a model top pressure of 50 hPa. The physical parameterization schemes are as follows. The WRF Single-Moment 6-Class Microphysics Scheme (Hong and Lim, 2006) is adopted for microphysical processes. For longwave and shortwave radiation, the rapid radiative transfer model (RRTM) scheme (Mlawer et al., 1997) and the Dudhia scheme (Dudhia, 1989), respectively, are used. The Yonsei University (YSU) scheme (Hong et al., 2006) is employed for the planetary boundary layer simulation. For the cumulus parameterization, the Kain–Fritsch (new Eta) scheme (Kain, 2004) is enabled. The unified Noah land surface model is used to simulate the land surface. We adopt the global forecast system (GFS) analysis at 00:00 UTC on 25 July 2021 as the initial condition of the Truth simulation.
According to Hoffman and Atlas (2016), a criterion for reasonable OSSEs is that true simulation agrees with the real atmosphere. The typhoon central pressure in the Truth simulation gradually increases from 968 to 980 hPa by 18:00 UTC on 26 July 2021 (not shown), which is consistent with the real observation obtained from the China Meteorological Administration (CMA), except that the observed pressure increases more rapidly, reaching 985 hPa by 18:00 UTC on 26 July 2021. The simulated typhoon's central location also agrees with the CMA observation. Therefore, the Truth simulation is eligible for OSSEs.
3.2 Multiscale observation network
The simulated multiscale observation network (Fig. 3) comprises sounding, wind profiler, PWV, and radar observations. Soundings are available at 00:00 and 12:00 UTC on 26 July 2021, whereas the other types of observations are available hourly on 26 July 2021.
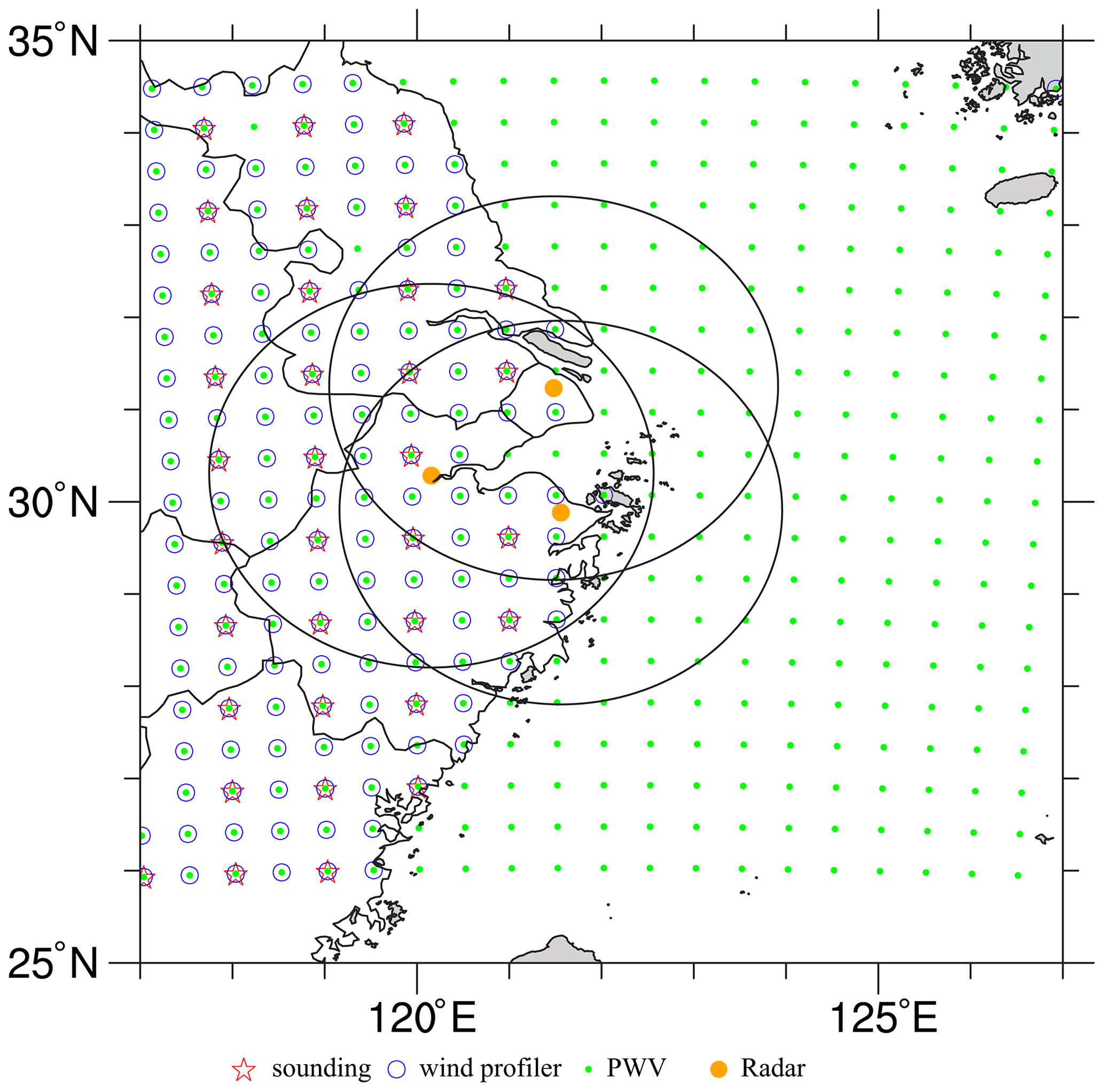
Figure 3The distribution of simulated observations, where the black rings denote the maximum observation ranges of radars.
For each sounding, we simply extract the perturbed model variables, u, v, θ, and qv, every two model levels as the observations. The simulated soundings also record the perturbed surface pressure, ps. The sounding perturbations follow a Gaussian distribution with zero mean. The perturbation SDs are 0.5, 5 m s−1, 0.5 K, kg kg−1, and 10 Pa for u, v, θ, qv, and ps, respectively. To better reflect reality, no simulated soundings are available over the ocean, and the horizontal resolution of each sounding is 100 km.
The simulated wind profiler provides data on horizontal wind components, u and v, at all model levels. The perturbations added to the wind profiler data follow a Gaussian distribution with zero mean and an SD of 0.5 m s−1. The wind profilers, the data from which have a horizontal resolution of 50 km, provide data only on land.
The PWV observations are computed according to
where g is the gravitational constant of acceleration, and p1 and p2 represent the bottom and top of a model column, respectively. Perturbations with zero mean and an SD of 0.5 kg m−2 are added to the PWV observations. Because the PWV is observed by satellites, this type of observation is available for the whole forecast domain, and the horizontal observation interval is 50 km in both the x and y directions.
The radar data to be assimilated are radial velocity and reflectivity. We adopt Eq. (3) of Xiao and Sun (2007) to compute the radial velocity, but we ignore the terminal velocity in OSSEs. For reflectivity, the operator proposed by Gao and Stensrud (2012) is employed. Three radars located at approximately Shanghai (31.23∘ N, 121.48∘ E), Hangzhou (30.28∘ N, 120.16∘ E), and Ningbo (29.88∘ N, 121.55∘ E) are simulated with a maximum observation range of 230 km. The simulated radars work on the volume coverage pattern (VCP) 11 mode, which has 14 elevation levels from 0.5 to 19.5∘. Radar data are created on volume-scan elevations, but they are on model grids in the horizontal direction, as shown in Xue et al. (2006). The radial velocity and reflectivity observation errors are 1.0 m s−1 and 2.0 dBZ, respectively. The horizontal resolution of the radar data is identical to the model grid spacing.
In total, 2795 simulated soundings, 400 PWV data points, 5332 wind profiler observations, and 391 618 radar observations (including radial velocity and reflectivity) are utilized in this study.
3.3 DA experiments
In this study, two sets of experiments are designed. The first set of experiments consists of single deterministic analyses and is used to examine the impact of the hybrid covariance, the multiscale localization in model space, and the double-space localization. The other set of experiments comprises several cycling analyses, mainly focusing on the analysis balance (in terms of surface pressure tendency) and the impact of Local DA on cycling analysis. To perform the analysis with ensemble covariance, it is necessary to generate the ensemble first. Therefore, in this subsection, we first describe the generation of the ensemble and then introduce the experimental design.
3.3.1 Ensemble perturbations
For the single deterministic analysis, the time-lagged approach (e.g., Branković et al., 1990) is employed to generate the ensemble perturbations, which are created by using deterministic forecasts with different initial times and varying GFS data. For example, the first sample at 00:00 UTC on 26 July 2021 stores the difference between two deterministic forecasts initialized at 06:00 UTC UTC on 25 July 2021 and 12:00 UTC on 25 July 2021. To distinguish these forecasts from the forecasts of the DA experiments, the forecasts used to produce ensemble members are referred to as sample forecasts. The sample forecasts used in this study are shown in Fig. 4a. Note that some sample forecasts are initialized by the 3 or 6 h GFS forecast data (highlighted by the thick tick marks in Fig. 4). A small-size ensemble is employed; it combines six sample forecasts according to and thus has 15 members.

Figure 4(a) The flowchart of the time-lagged ensemble generation, where the thick blue arrows represent the sample forecasts used by the 15-member ensemble. The sample forecasts initialized using the GFS forecast data are highlighted with orange tick marks. Sample forecasts used to form a member are denoted by thin colored arrows. (b) The flowchart of cycling DA. Each member assimilates the observations containing a different set of perturbations.
Focusing on the result of a small-size ensemble is based on two concerns. First, Local DA is designed as a flexible scheme for hybrid analysis; hybrid analysis is often beneficial in the presence of a small ensemble or a poor ensemble. In the case of using a well sampled ensemble, the pure ensemble DA is preferred. Second, the available computational resources are not always sufficient to support a large-size ensemble. The authors have tested a larger ensemble with 36 members and obtained lower analysis errors than the 15-member counterpart. For brevity, the results with the 36-member ensemble are not shown.
For the cycling analysis, the first analysis uses the time-lagged 15-member ensemble. In the remaining cycles, the ensemble forecast initialized from the previous analysis ensemble provides the ensemble perturbations. The analysis ensemble is created by performing Local DA 15 times with perturbed observations. The perturbations are added to Ctrl so that the ensemble center is on Ctrl. The Ctrl in the first cycle is obtained using GFS analysis at 00:00 UTC on 26 July 2021. Figure 4b shows the flowchart of the cycling DA.
3.3.2 The DA configurations
A total of 14 experiments for deterministic analyses at 00:00 UTC on 26 July 2021 are examined. The first three experiments investigate the influence of using the pure ensemble covariance (Ens_noFLTR), distant correlation covariance (Static_BE), and hybrid covariance (Hybrid_noFLTR) on the Local DA analysis. The model variables to be analyzed are the three wind components (u, v, w), potential temperature (θ), water vapor mixing ratio (qv), dry-air mass in column (mu), and hydrometeor mixing ratios (qc, qr, qi, qs, and qg). A fixed localization radius of 200 km is used for most variables. For ps and hydrometeor variables (qc, qr, qi, qs, and qg), the fixed influence radii are 1000 and 20 km, respectively. These values are tuned for the case in which Typhoon In-fa made landfall in this study and are only used for static correlation and experiments without multiscale localization (e.g., Ens_noFLTR). The background error covariance is empirically inflated by 50 %. For Hybrid_noFLTR, the weight between the dynamic and static covariances is 0.5.
Then, the impact of model-space multiscale localization is evaluated through six experiments with/without the hybrid covariance. Ens_2band, Ens_3band, and Ens_5band use the pure ensemble covariance, but the ensemble is decomposed into two, three, and five scales, respectively. The two-band experiment uses samples with a scale of 0–200 km and a scale greater than 200 km. In this experiment, the contribution of a scale greater than 200 km is amplified because the localization coefficient is 1.0 until the distance between two grid points is greater than 200 km. For the Ens_3band, the three scales are 0–50, 50–200, and >200 km. The corresponding values for Ens_5band are 0–20, 2–50, 50–100, 100–200, and >200 km, respectively. Through the above three experiments, we can examine the sensitivity of Local DA to the configuration of multiscale analysis. Hybrid_2band, Hybrid_3band, and Hybrid_5band use the same ensemble covariance as Ens_3band, and Ens_5band, respectively; the ensemble covariance and static covariance weight equally in the hybrid covariance.
The last five experiments are designed to discuss the impact of the localization space. Ens_noFLTR_OL performs localization in observation space. The horizontal radii are 360, 150, 120, and 15 km for sounding, wind profiler, PWV, and radar data, respectively. Notably, Ens_noFLTR_OL performs vertical localization in model space, identical to Ens_noFLTR. Ens_LETKF uses the LETKF algorithm and the same horizontal localization radii as Ens_noFLTR_OL. The vertical radius for all observations is 5 km in Ens_LETKF, where the PWV observations are treated as being located at 4000 m for LETKF localization. Ens_noFLTR_DSL performs localization in both the model and observation space. In the model space, a fixed localization radius is used, as in Ens_noFLTR, while the localization parameters of Ens_noFLTR_OL are adopted for observation-space localization. Using five-band samples, Ens_noFLTR_DSL becomes Ens_5band_DSL. Adding hybrid covariance to Ens_5band _DSL yields Hybrid_5band_DSL. For convenience, all single deterministic analysis experiments are listed in Table 3, where “M”, “O”, and “M + O” denote model-space, observation-space, and double-space localization, respectively. The vertical localization in the observation space is disabled for all Local DA experiments.
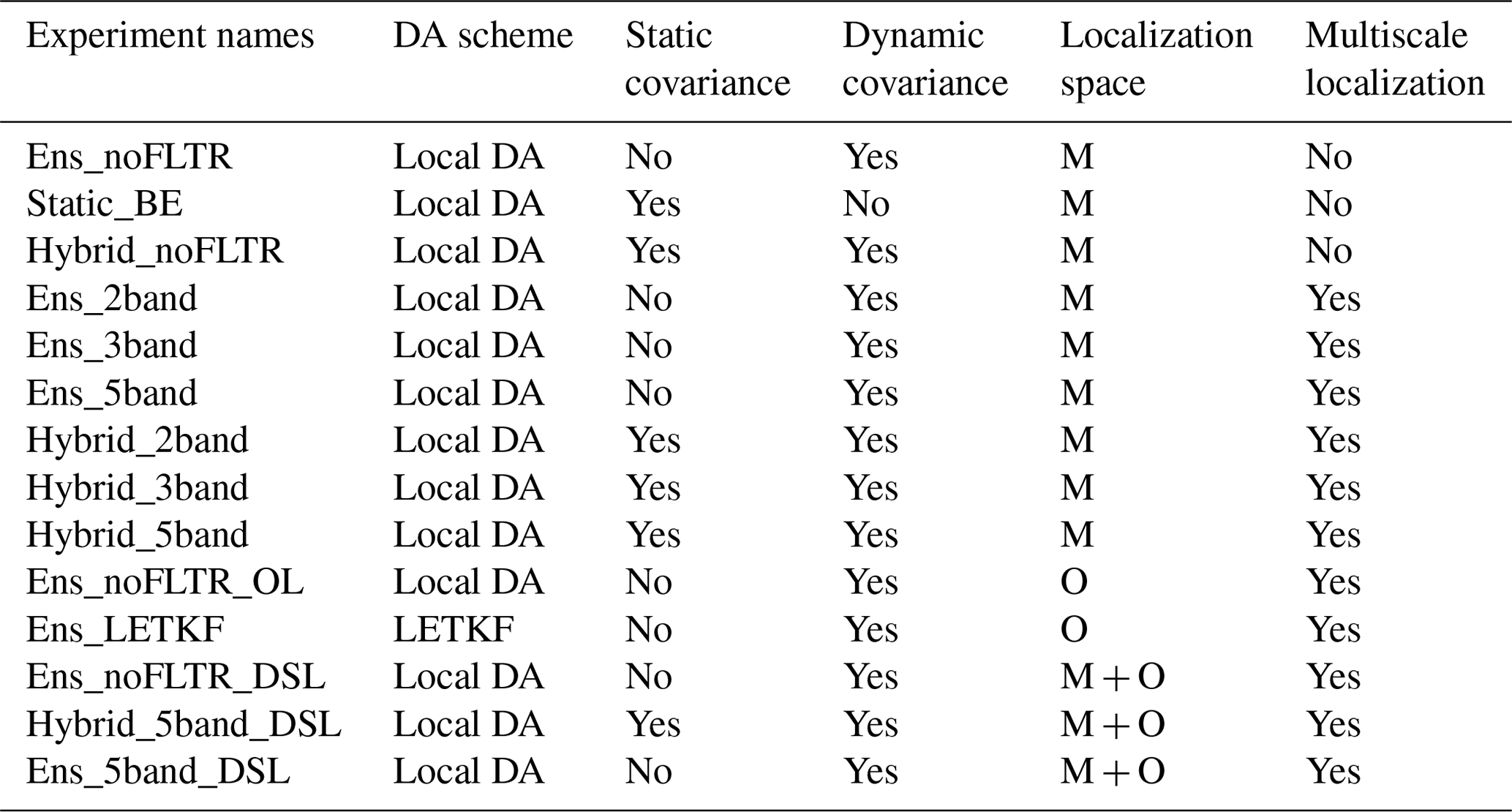
For experiments with cycling analysis, we examine Local DA in the cases of (i) using the ensemble covariance without multiscale localization and (ii) using hybrid covariance and multiscale localization. The DA configuration of Ens_noFLTR is employed for the first scenario, while that of Hybrid_5band_DSL is adopted for the second scenario. Cycling intervals of 3 and 6 h are examined, where we mainly focus on the experiments with the 6 h interval. The experiment with a 3 h cycle interval is used to show the impact of imbalance analysis to forecast. A total of three experiments are examined, namely, Ens_noFLTR_6h, Hybrid_5band_DSL_6h, and Hybrid_5band_DSL_3h, where the suffixes represent the cycling intervals. During cycling, sounding observations are available at 00:00 and 12:00 UTC, while other observation types are available hourly. A total of 15 sets of perturbed observations are created to update 15 members in cycling DA. The standard deviations of observation perturbations are identical to the observation errors mentioned in Sect. 3.2. The covariance inflation factor is also 1.5 for cycling analysis.
4.1 The convergence of minimization
We examine the minimization convergence using the data extracted from Hybrid_5band. Figure 5 shows the number of iterations and the ratio of the final value of the cost function (Jfinal) to the initial value (Jinitial). Fewer than 100 iterations indicate that the tolerance ε2 reaches within 100 steps. If the minimization does not converge within 100 steps, the CG iteration is stopped by the program. The number of iterations is large near the center of the forecast domain but decreases rapidly outward. According to the distribution of observations (Fig. 3), the results (Fig. 5a) indicate that the minimization converges more slowly as the number of observations to be assimilated increases.

Figure 5The spatial distributions of (a) the number of iterations and (b) the ratio of the final value of the cost function to the initial value.
Although the minimization fails to converge within 100 steps in the area where the observation density is high, the cost function is reduced by 70 % or 80 % (Fig. 5b). In contrast, near the northeastern and southeastern corners of the domain, where the minimization converges within 10 steps, the final value of the cost function is greater than 70 % of its initial value. However, in those areas, the initial cost function is small, implying no need for a large extent of correction. The results also indicate that no severe discontinuity occurs in Hybrid_5band, which is desired. Similar to the LETKF, using slightly different Coo between neighboring columns does not yield remarkably different analyses.
Further investigation (for data within the yellow rectangle plotted in Fig. 5a) indicates that approximately 25 % of minimizations fail to converge within 100 steps (Fig. 6a), all associated with the application of radar data. Therefore, we rerun Hybrid_5band using only radar data and observe that only 4 % of all minimizations require more than 100 steps to converge. In the case of setting the maximum number of iterations to 500 for Hybrid_5band, all minimizations converge within 300 iteration steps. The results also show that assimilating only radar data produces a smaller ratio of Jfinal to Jinitial than the case using all observations (Fig. 6b). According to previous studies (e.g., Wang and Wang, 2017), the inefficient minimization may be caused by the assimilation of radar reflectivity due to the use of the mixing ratios as state variables. Too small hydrometeor mixing ratio values can lead to an overestimated cost function gradient. Nevertheless, despite the slow convergence, Local DA reduces the cost function by more than 70 % within 100 iteration steps in most cases (Fig. 6b). Further suppressing the error may require a better background error covariance, which we plan to seek in future work.
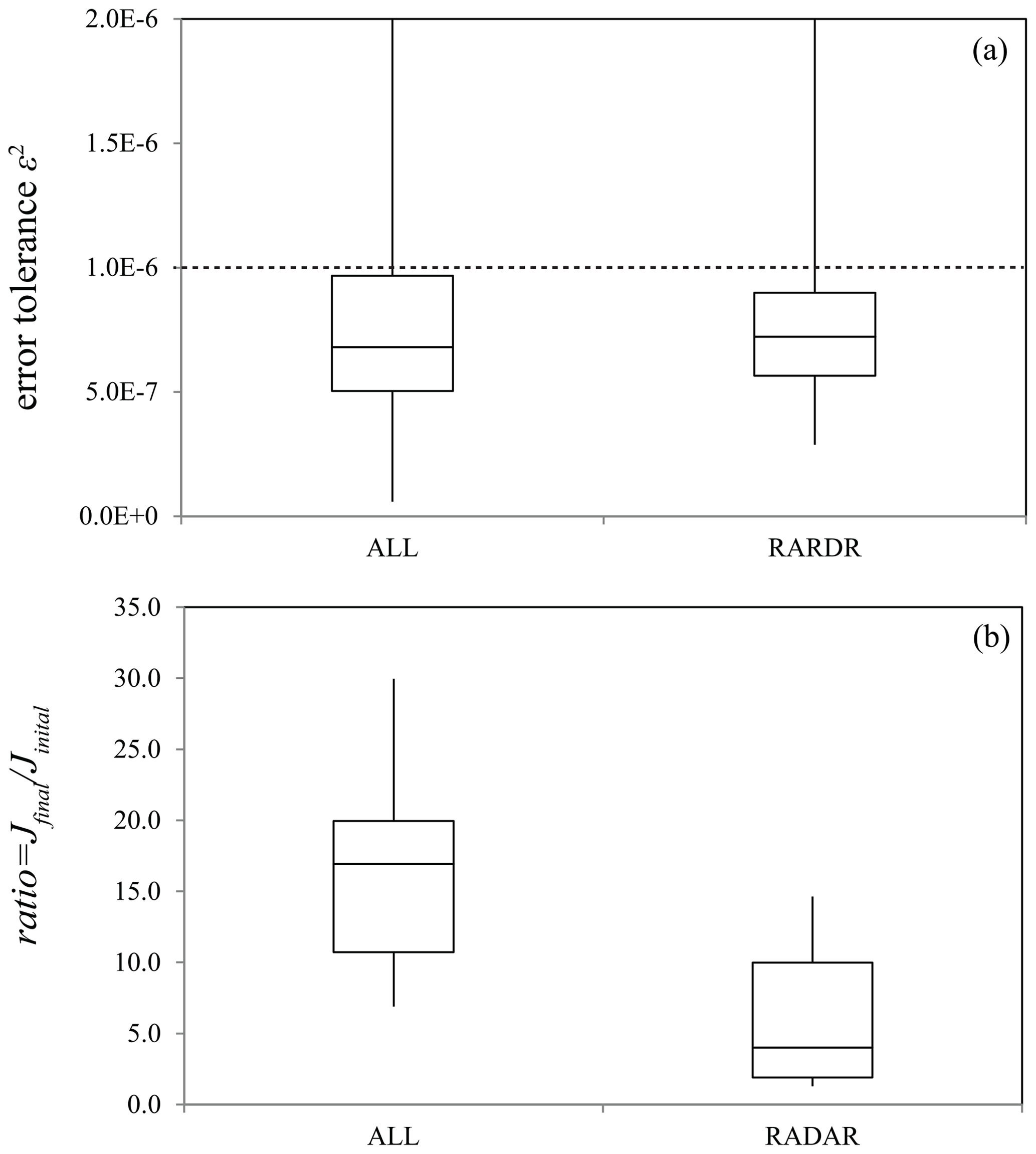
Figure 6Box plots of (a) ε2 and (b) the ratio of the final J to the initial J in the dashed rectangle area shown in Fig. 3, where “ALL” denotes the DA using all observations, and “RADAR” corresponds to the DA using radar data only. The upper and lower bounds of the boxes are the 75th and 25th percentiles, respectively. The middle line indicates the median.
4.2 The single deterministic analysis
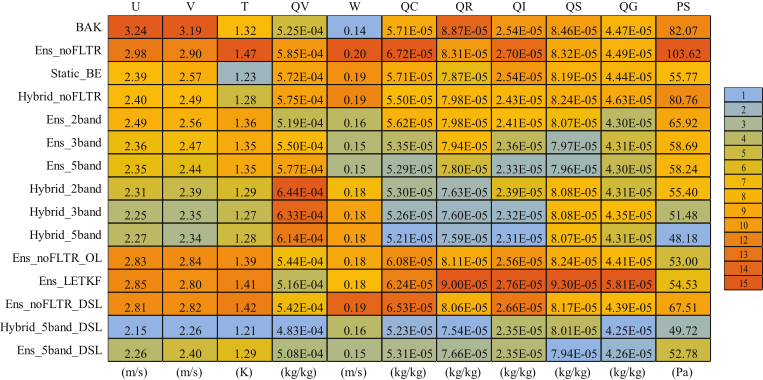
The domain-averaged root mean square root error (RMSE) is examined first. For convenience, the initial condition extracted from GFS analysis is referred to as BAK. All experiments reduce the errors in the observation space after DA, but their differences are significant (Table 4). The experiments (Ens_noFLTR, Ens_ noFLTR_OL, Ens_LETKF, and Ens_noFLTR_DSL) without the hybrid covariance and model-space multiscale localization produce relatively higher analysis errors than other experiments for wind components, temperature, radial velocity, and reflectivity. Using distance correlation (Static_BE) results in lower errors than Ens_noFLTR for most variables, while Hybrid_noFLTR further suppresses the errors except for reflectivity. The benefit of using hybrid covariance is consistent with many previous studies (e.g., Wang et al., 2009, 2013b; Tong et al., 2020).
Table 4The RMSEs in observation space for all single deterministic analyses, where BAK represents the background error, SND denotes the sounding observation, and PRO corresponds to profile observation. The values of 1 and 15 in the legend represent the smallest and the largest error among all experiments, respectively.
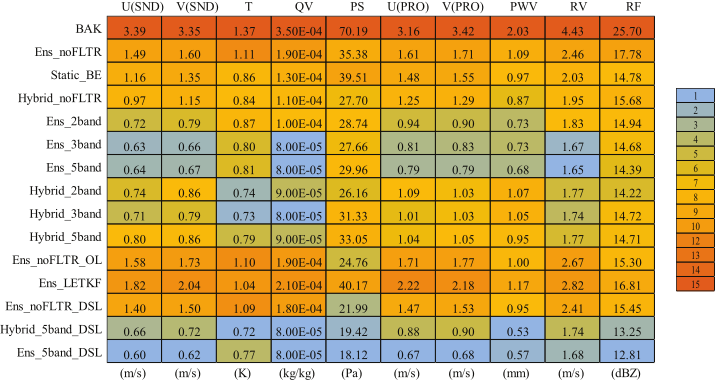
Model-space multiscale localization (Ens_2band, Ens_3band, and Ens_5band) is conducive to error reduction. Even with two-scale samples, Ens_2band dramatically reduces the errors of wind-related variables, compared with Ens_noFLTR. Involving more scales further improves the analysis, but the benefit is not as great as the case of comparing Ens_noFLTR with Ens_2band. Combining the hybrid covariance and model-space multiscale localization does not further narrow the gap between the analysis and observation.

Figure 7The analysis error decomposed into scales of 0–50, 50–200 km, and greater than 200 km (shown on the x axis), where BAK represents the initial condition before DA.
Double-space localization does not necessarily ensure small analysis errors (Ens_noFLTR_DSL). However, when the localization is combined with the hybrid covariance and model-space multiscale localization (Hybrid_5band_DSL and Ens_5band_DSL), the analysis error can be substantially reduced, especially for PWV and reflectivity.
In model space, similar results can be observed (Table 5). The hybrid covariance, model-space localization, and double-space localization are helpful for error reduction. Notably, unlike the result in the observation space, the analysis errors in some experiments are higher than those of BAK. Because the RMSE in model space counts for grid points that are not directly observed and are updated through error covariance, the error becoming higher after DA is likely due to the poor error covariance in model space.
In the following subsections, the background and analysis errors in model space are decomposed into three scales using a Gaussian filter with radii of 50–200 km, respectively, representing errors of the small scale (0–50 km), middle scale (50–200 km), and large scale (>200 km). Through this decomposition, we can investigate the results in detail. The vertical velocity (w) and hydrometeor variables (qc, qr, qi, qs, and qg) are not decomposed because their scales are often small. In addition, convective-scale DA usually computes the errors for grid points with reflectivity larger than a threshold, which is another way to investigate small-scale errors. The difference between errors in the convective area (reflectivity >10 dBZ) and the rest of the area is similar to that between small-scale and large-scale errors (not shown). Therefore, the errors in the convective area are not discussed in subsequent sections.
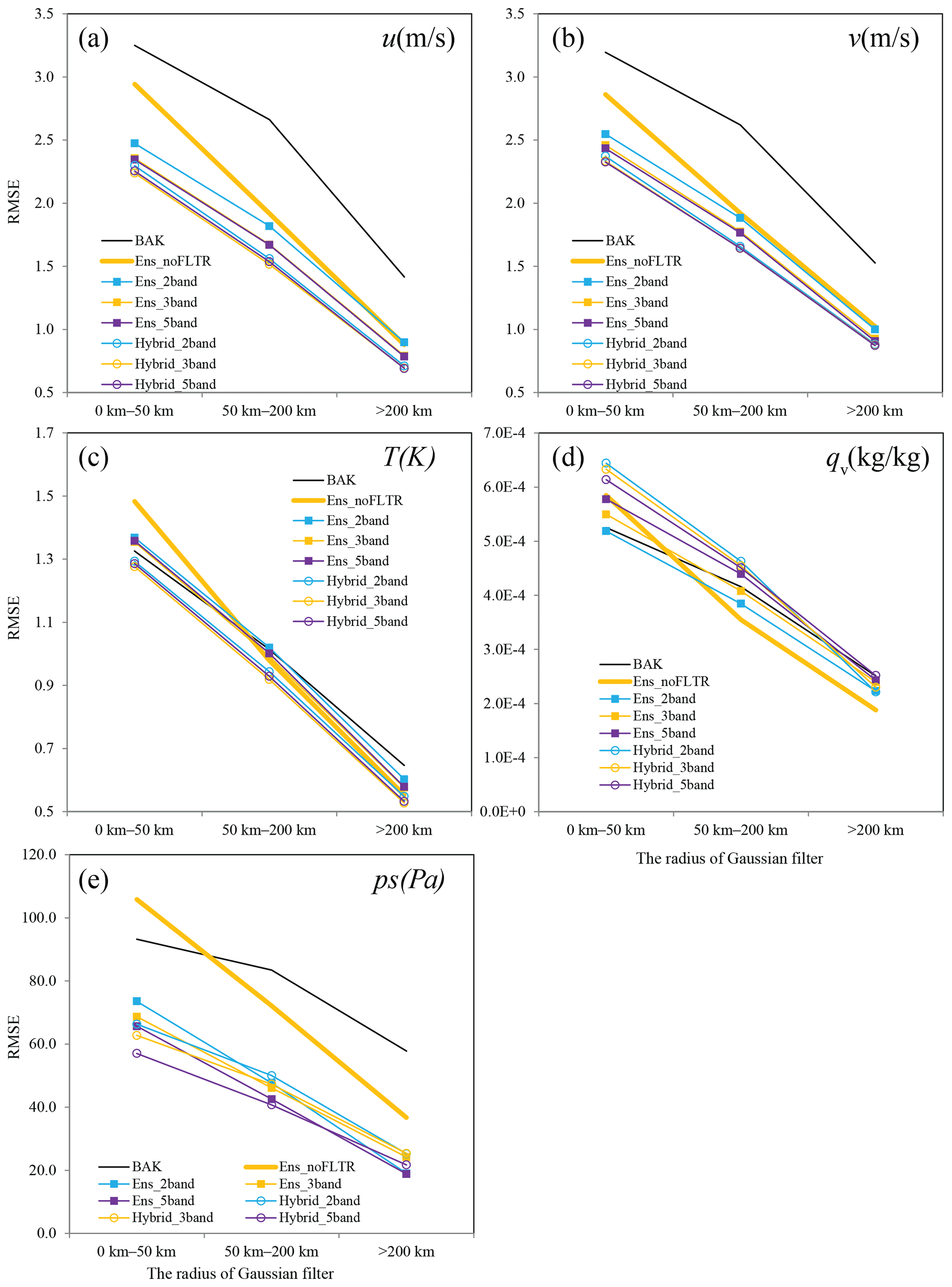
Figure 8As in Fig. 7 but for Ens_2band, Ens_3band, Ens_ 5band, Hybrid_2band, Hybrid_3band, and Hybrid_5band, where BAK and Ens_noFLTR are duplicated for comparison.
4.2.1 Hybrid analysis
Figure 7 shows that the smallest-scale error contributes most to the background and analysis error, while the quantities of large-scale errors are often half of their small-scale counterparts. Ens_noFLTR reduces errors at all scales for horizontal wind components, where the error reduction is relatively higher at a large scale. For T, qv, and ps, Ens_noFLTR suppresses the large-scale errors but amplifies the small-scale ones. This result implies that the large-scale error covariance is likely reliable, but the smaller one is not.
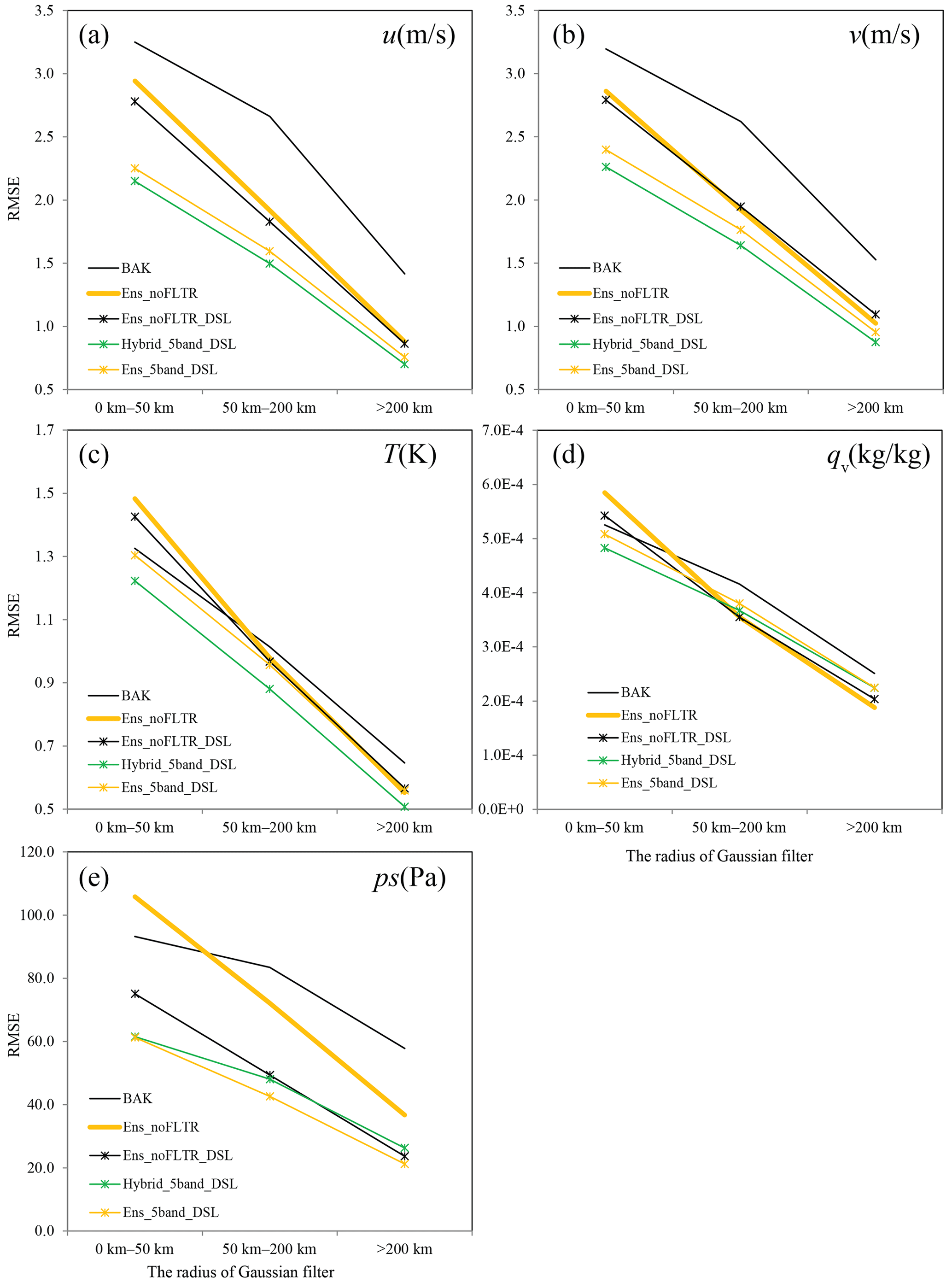
Figure 9As in Fig. 7 but for Ens_noFLTR_DSL, Hybrid_ 5band_DSL, and Ens_5band_DSL, where BAK and Ens_noFLTR are duplicated for comparison.
When the static correlation is enabled for Local DA (Static_BE and Hybrid_noFLTR), the small-scale and middle-scale errors are substantially decreased. This difference becomes much larger for ps when Ens_noFLTR is compared with Static_BE, even at a large scale. The analysis errors of Static_BE and Hybrid_noFLTR are nearly identical at all scales for u, v, T, and qv, but the reason for this phenomenon is still unknown. We plan to determine the cause in future work. Overall, the main contribution of employing static correlation to the lower analysis errors of Static_BE and Hybrid_noFLTR is at a small scale. The result implies that constraining the small-scale ensemble correlation in a small radius may be conducive to the small analysis error, which is what the model-space multiscale localization does.
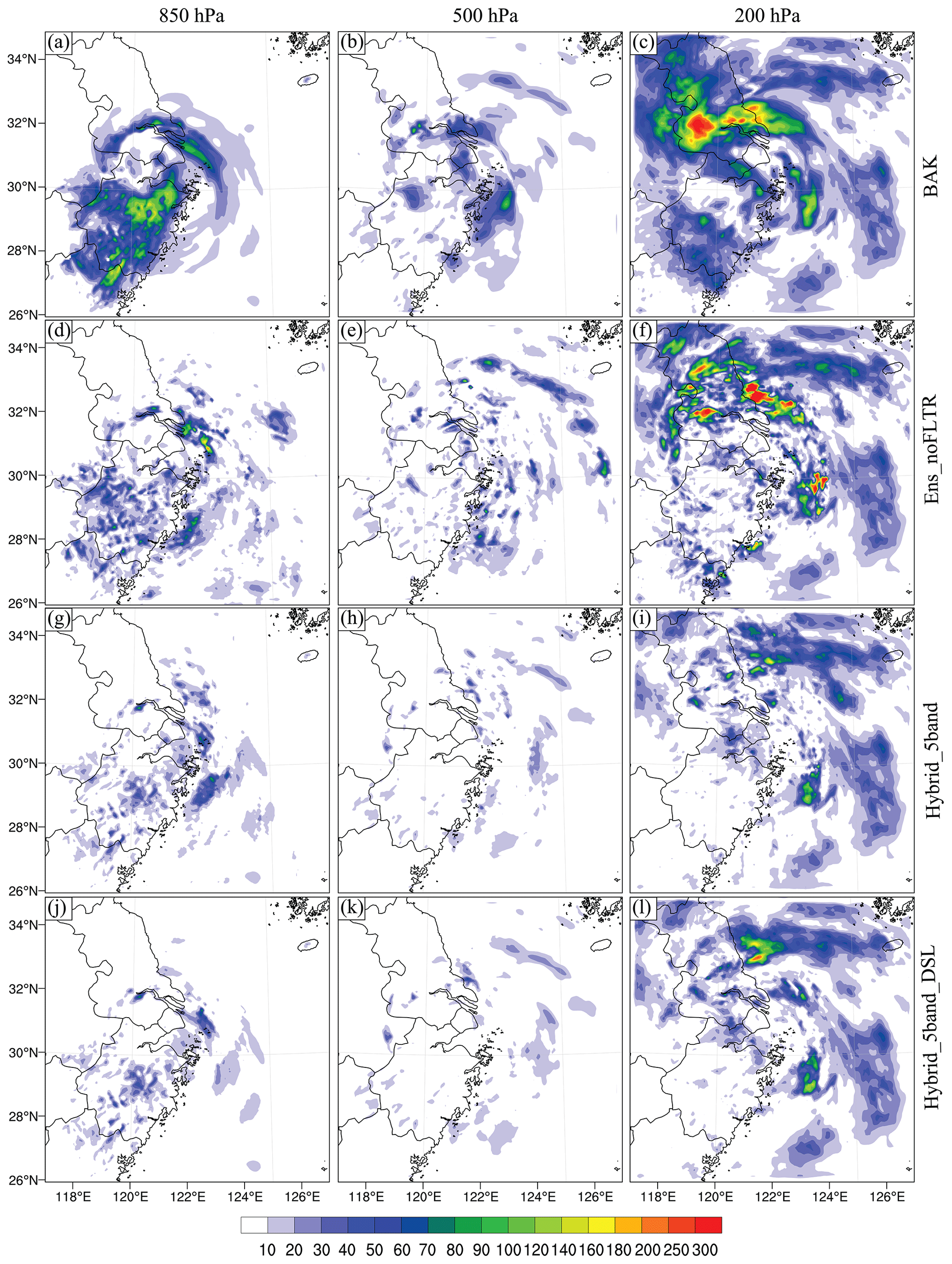
Figure 10The DTE at 850 hPa (left column), 500 hPa (middle column), and 200 hPa (right column) for (a–c) BAK, (d–f) Ens_noFLTR, (g–i) Hybrid_5band, and (j–l) Hybrid_5band_DSL.
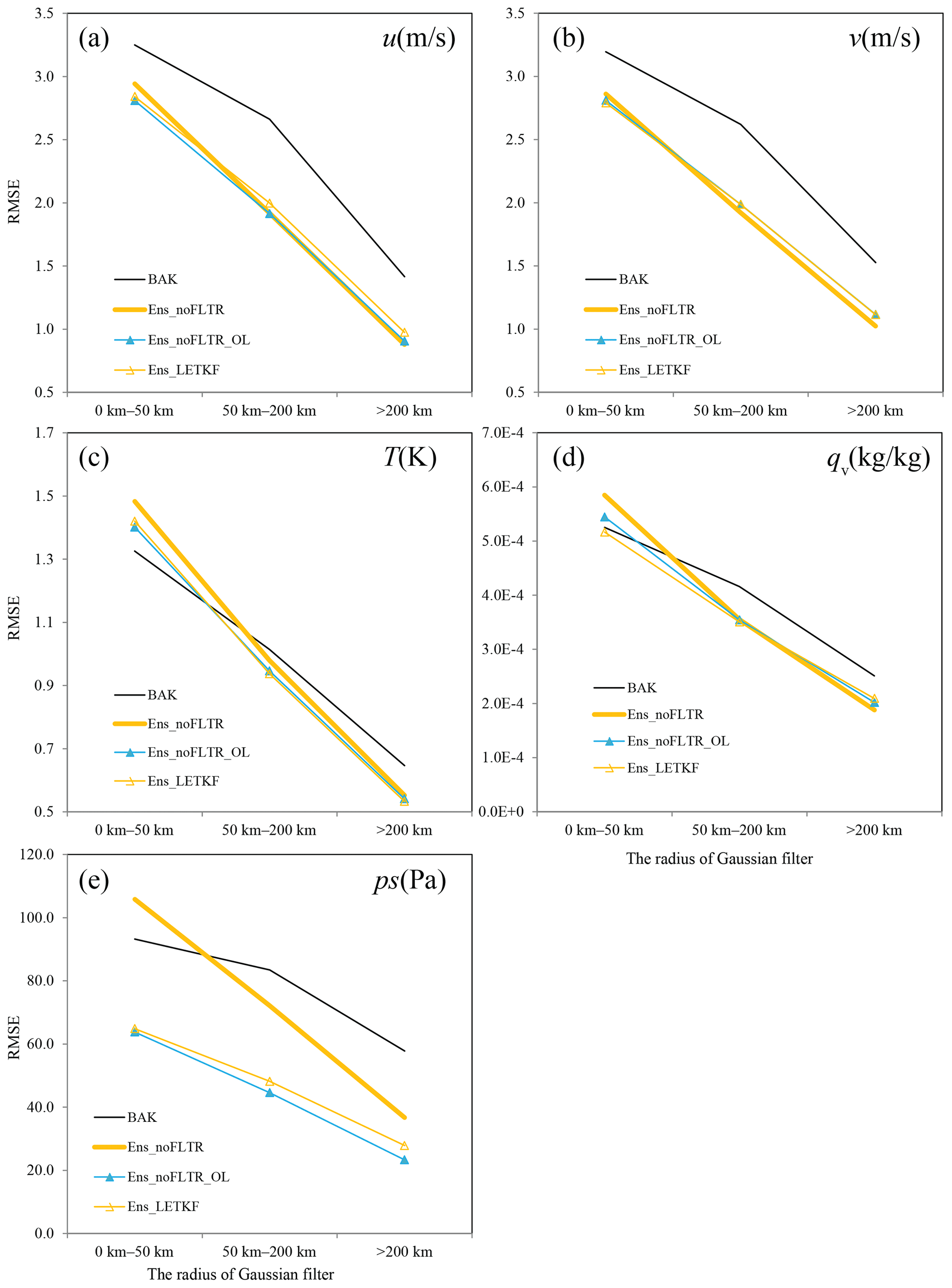
Figure 11As in Fig. 7 but for Ens_noFLTR_OL and Ens_LETKF, where BAK and Ens_noFLTR are duplicated for comparison.
4.2.2 Multiscale analysis
After decomposing the ensemble samples into two parts (Ens_2band) and independently applying the localization radius for each scale, the small-scale analysis error becomes lower than that of Ens_noFLTR for all examined variables (Fig. 8). Compared with Ens_2band, further decomposing the ensemble samples into more scales (Ens_3band and Ens_5band) and using smaller radii for small scales slightly reduces the analysis error for wind components and surface pressure but increases the error for qv. This result confirms the assumption that restricting the impact of small-scale correlation in a small region is beneficial. The difference between Ens_3band and Ens_5band is small, indicating that three or five scales should be sufficient for the model-space multiscale localization in Local DA.
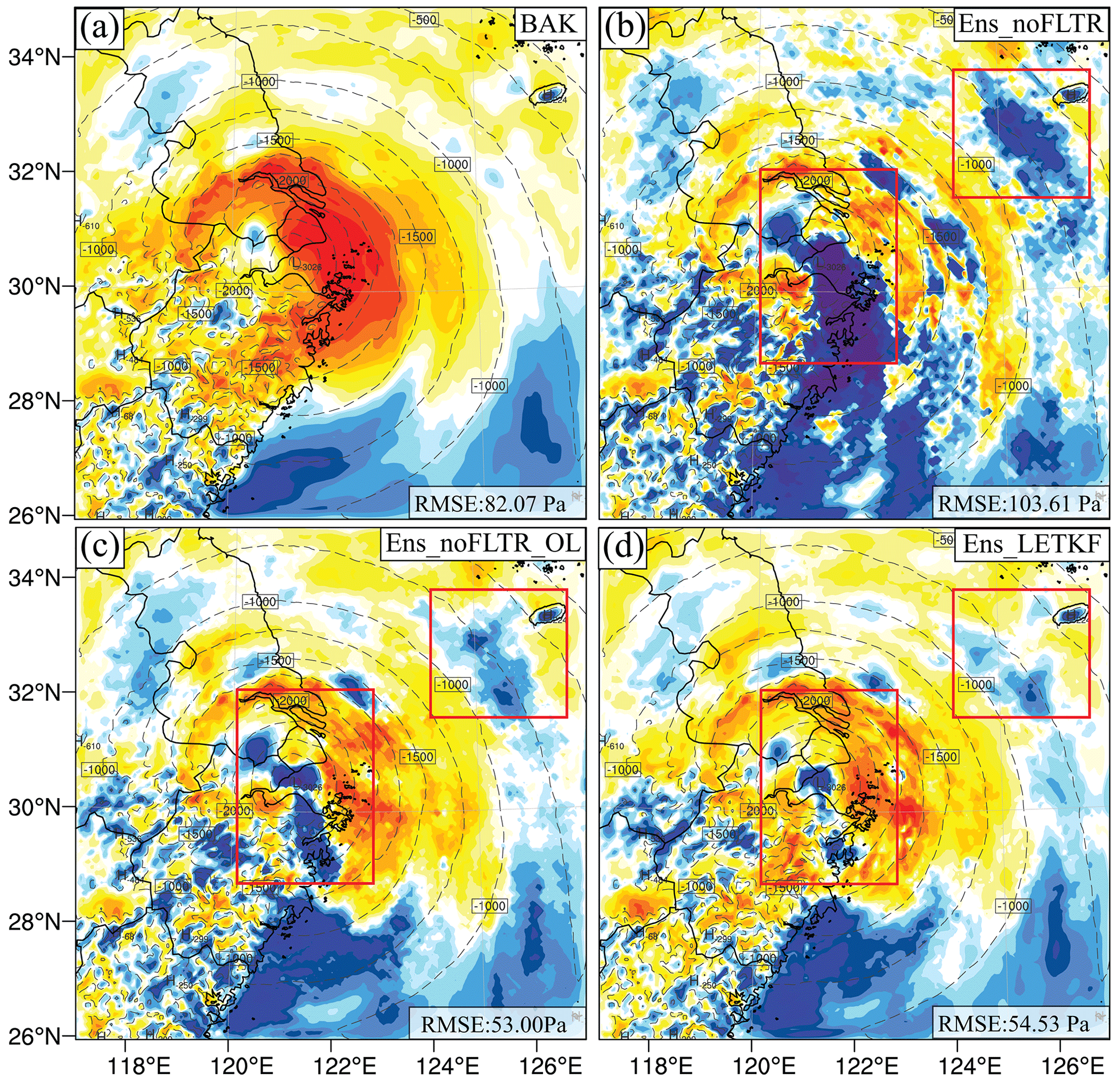
Figure 12The difference in the dry-air mass in column (mu) between the truth (contours) and analysis (shading) for (a) BAK, (b) Ens_noFLTR_ OL, and (c) Ens_LETKF, where rectangles highlight the areas where Ens_noFLTR_OL and Ens_LETKF analyses are similar.
Experiments combining multiscale localization with hybrid covariance (Hybrid_2band, Hybrid_3band, and Hybrid_5band) produce lower analysis errors for most variables, compared with Ens_2band, Ens_3band, and Ens_5band. However, the improvement is not substantial. The small difference implies that we need more approaches to make further improvements. Employing double-space localization is one of the approaches, according to the result shown in Table 5.
4.2.3 Double-space localization
Compared with Ens_noFLTR, Ens_noFLTR_DSL has a small but positive impact on the analysis of u, v, T, and qv at a small scale, while its influence on larger-scale errors is negligible (Fig. 9). In contrast, Ens_noFLTR_DSL substantially reduces the analysis error of ps at all scales. After combining the model-space localization (Ens_5band_DSL), the analysis errors further decline at a small scale. Adding a hybrid covariance to Ens_5band_DSL (Hybrid_5band_DSL) leads to lower analysis error for most variables. The large-scale analysis error of ps is increased after using hybrid covariance, implying that the large-scale error correlation related to ps and computed by using ensemble samples is better than the distant correlation with a fixed influence radius. It is encouraging to see that Hybrid_5band_DSL and Ens_5band_DSL produce the analysis error of qv lower than BAK at small and middle scales, while Ens_5band and Hybrid_5band yield a higher analysis error than BAK. The result indicates the benefit of double-space localization.
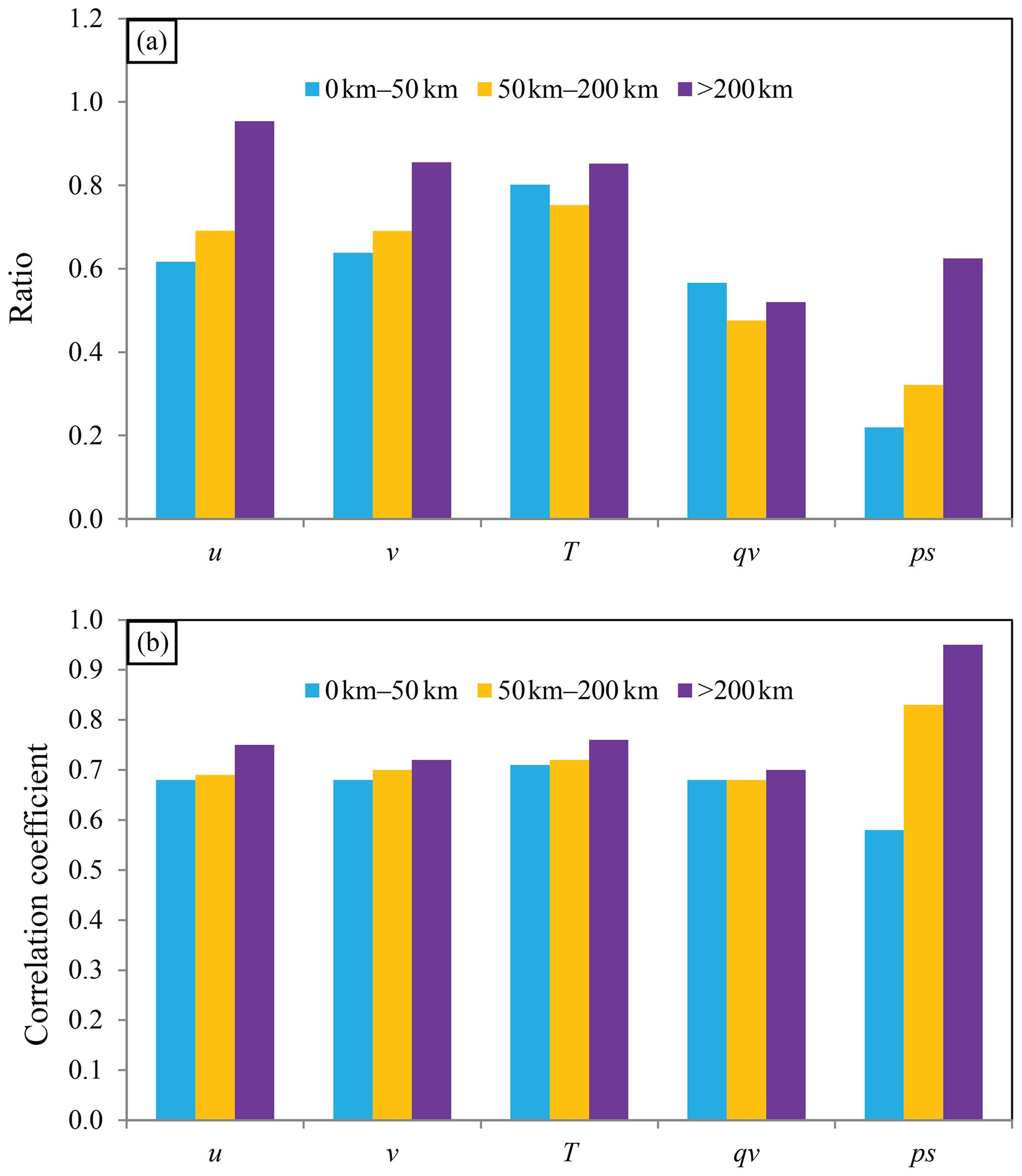
Figure 13(a) The ratio of ensemble spread to RMSE at 00:00 UTC on 26 July 2021 and (b) the spatial correlation coefficient between ensemble spread and RMSE for scales of 0–50, 50–200 km, and greater than 200 km.
To qualitatively assess the analysis error, we compute the difference in total energy (DTE; Meng and Zhang, 2007). Wang et al. (2012) used the square root of the mean DTE to evaluate the error of DA to simplify the presentation. The DTE is computed in the form of the difference between the analysis and truth. Ens_noFLTR (Fig. 10d–f) decreases the background errors (Fig. 10a–c) at 850 and 500 hPa but generates many spurious increments over the ocean, increasing the error there; this problem is more pronounced at 200 hPa. Accordingly, the error after Ens_noFLTR analysis is still high. The spurious increment corresponds to the large analysis error at a small scale. In contrast, utilizing the hybrid covariance and model-space multiscale localization suppresses the small-scale spurious errors (Hybrid_5band; Fig. 10g–i) from the lower to the upper levels. The spurious increment is further reduced in Hybrid_5band_DSL, especially at 850 and 500 hPa, indicating that the positive impact of double-space localization corresponds to less noise in the analysis. According to the above result, double-space localization may serve as a supplement to pure model-space localization, which determines the level of analysis error.
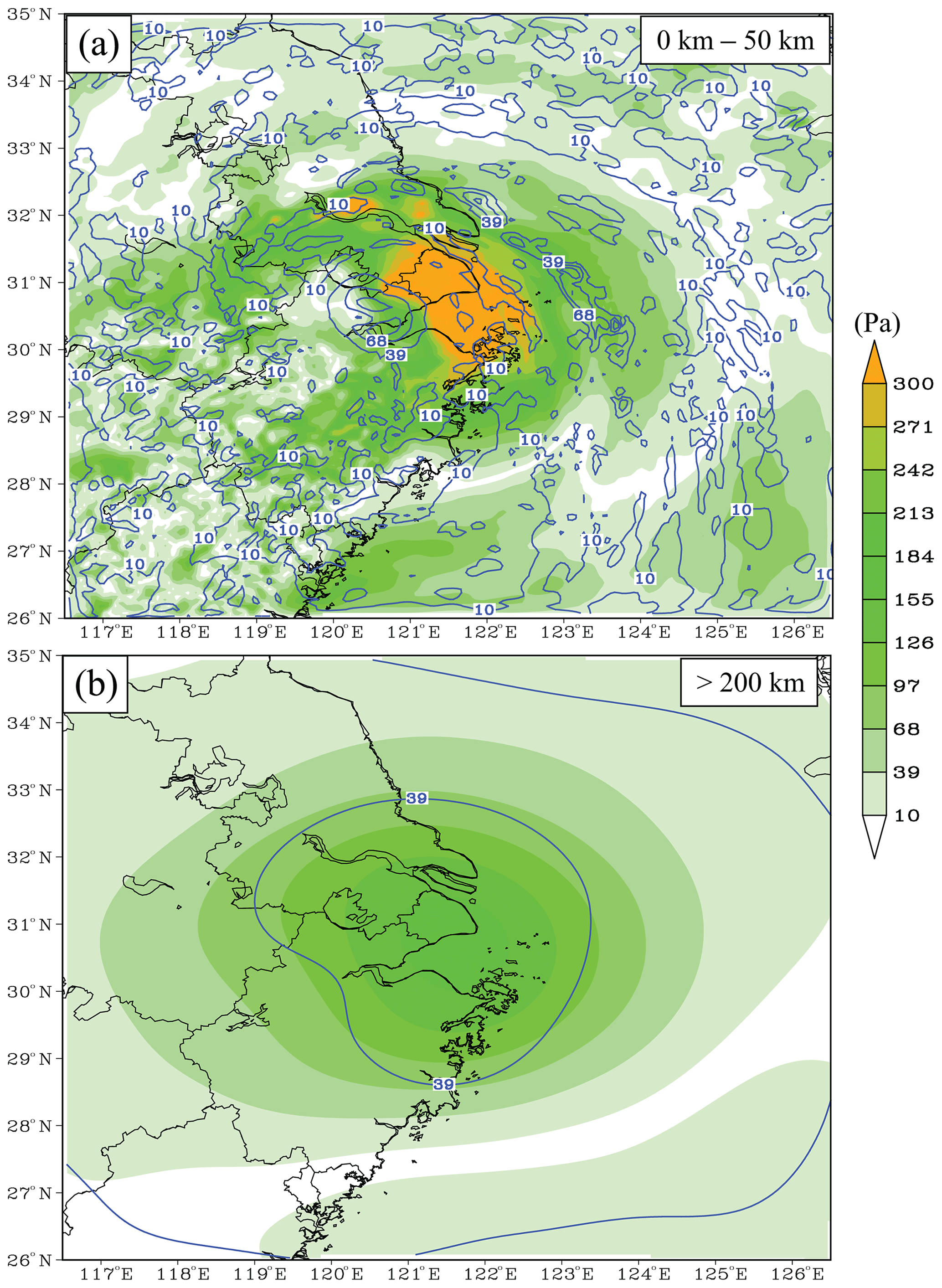
Figure 14The RMSE (shaded) and ensemble spread (contours) of ps decomposed into scales of (a) 0–50 km and (b) greater than 200 km.
4.2.4 The similarity between Local DA with observation space localization and the LETKF
Considering that Local DA can perform observation space localization only as in the LETKF, it is interesting to see if their analyses are similar. Note that Ens_noFLTR_OL and Ens_LETKF merely share the same horizontal localization configuration; they differ in vertical localization. Figure 11 shows that the difference in analysis error between Ens_noFLTR_OL and Ens_LETKF is small for all variables and at all scales. Figure 12 gives an intuitive comparison between the Ens_noFLTR_OL and Ens_LETKF analyses. The overlarge negative increment in both experiments is constrained in a much smaller area than Ens_noFLTR (marked by red rectangles in Fig. 12). They also suppress the small-scale noise in the Ens_noFLTR analysis, corresponding to the lower error in Fig. 11e. Overall, in the case of using observation-space localization, Local DA can produce an analysis similar to the LETKF.
In addition, the small-scale error of qv yielded by Ens_noFLTR_OL is lower than that of Ens_noFLTR (Fig. 11d). The result is similar to the difference between Ens_noFLTR_DSL and Ens_noFLTR, indicating that the improvement of Ens_noFLTR_DSL on qv analysis compared with Ens_noFLTR is mainly attributable to observation-space localization.
4.2.5 Error and ensemble spread
For a well-sampled ensemble, a criterion is that the spatial distribution of the ensemble spread is similar to that of RMSE. In addition, the amplitudes of the ensemble spread must be close to the RMSE. The relationship is shown in Fig. 13 for the time-lagged ensemble at 00:00 UTC on 26 July 2021. For u, v, and ps, the ratio of ensemble spread to RMSE ascends as the error scale increases, indicating that the quality of the time-lagged ensemble is rational at a large scale. This relationship is also valid for the spatial distribution (Fig. 13b), but the correlation coefficient does not vary from small scale to large scale too much for most variables, except for ps. The correlation coefficient for ps is nearly 1.0 at a large scale, while it is approximately 0.6 at a small scale. This large difference explains why the hybrid covariance and multiscale localization can substantially reduce the error at a small scale for ps. For qv, the small-scale spread is greater than the large-scale spread; the correlation coefficients at all scales are close. This result implies that suppressing the small-scale error covariance does not necessarily improve the analysis quality of qv. Therefore, it is not irrational for Ens_5band and Hybrid_5band to produce a higher analysis error for qv than Ens_2band.
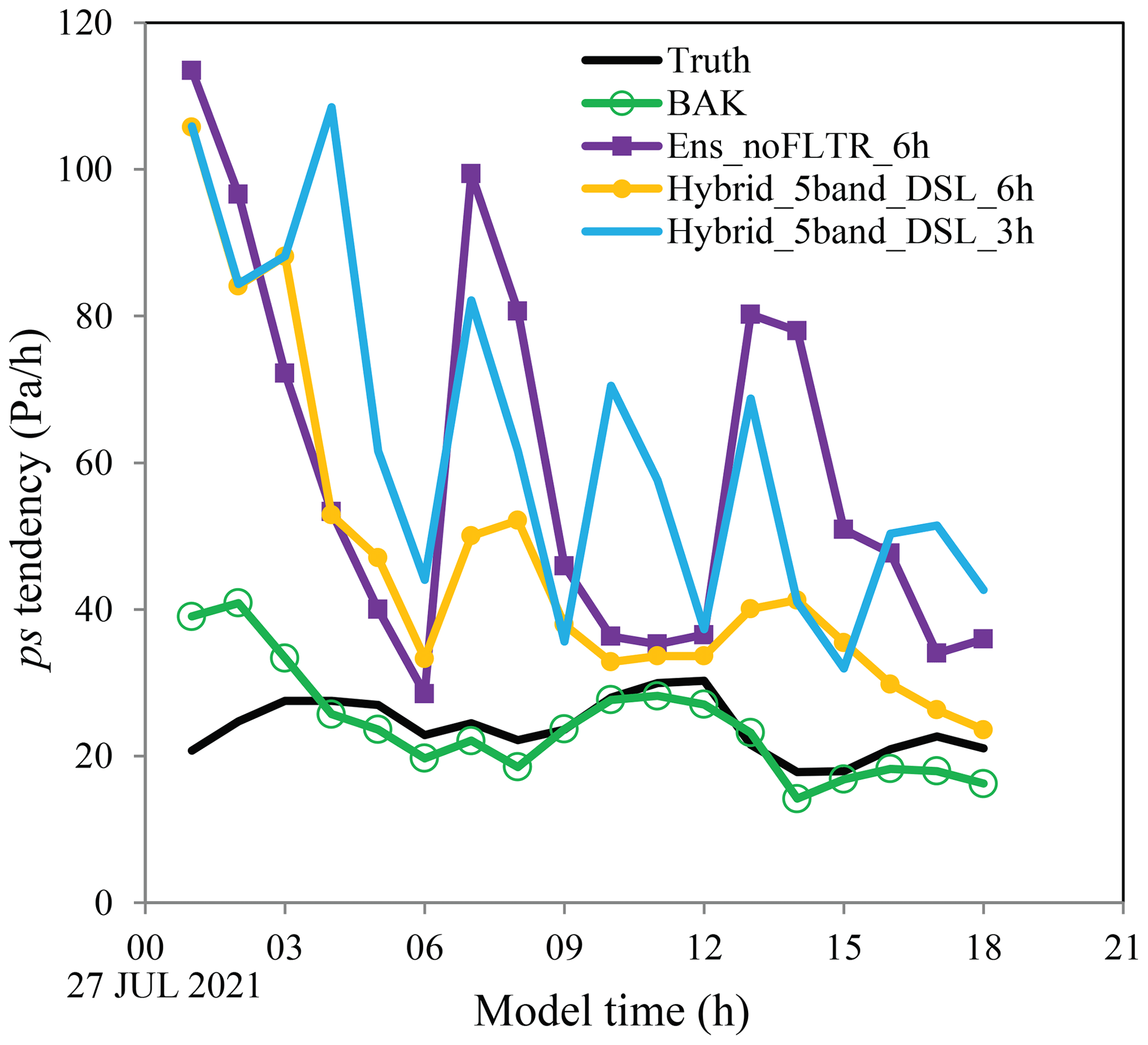
Figure 15The tendency of surface pressure (Pa h−1) for Truth (black), BAK (green), Ens_noFLTR (blue), Hybrid_5band_ DSL_6h (orange), and Hybrid_5band_DSL_3h (light blue).
An example related to the ensemble spread and RMSE of ps is shown in Fig. 14. The RMSE is smooth at a small scale, and there is a maximum near the typhoon center. Although the ensemble spread also has a maximum near the typhoon center, there is a large bias concerning the location. Moreover, the ensemble spread is much noisier than the RMSE, which is a cause of the noisy analysis shown in Fig. 12b. In contrast, the large-scale ensemble spread matches the error well, which is conducive to error reduction. Therefore, even with a large localization radius, the surface pressure analysis of Ens_noFLTR at a large scale is not much worse than that of the other experiments.
4.3 The cycling DA
Because ensemble DA approaches often take several cycles to obtain a reasonable analysis, it is worth seeing if Ens_noFLTR produces a better analysis after some cycles and if Hybrid_5band_DSL maintains the advantage in cycling DA. Before looking at the RMSE evolution during cycling, the ps tendency is examined as it is a metric of dynamic imbalance (Zeng et al., 2021). If the unphysical ps tendency is large, the analysis may be degenerated, and the forecast could be unstable. Although it is better to analyze the ps tendency at each time step, in this study, the hourly ps tendency is sufficient to demonstrate the impact of imbalance analysis. The forecast from GFS analysis is referred to as BAK in this subsection.

Figure 16The evolution of RMSE for BAK (black), Ens_noFLTR (blue), Hybrid_5band_DSL_6h (orange), and Hybrid_5band_DSL_3h (light blue), where the solid markers denote the forecast error, while the hollow markers represent the analysis error.
4.3.1 The tendency of ps
The ps tendency in the truth simulation is selected as a criterion as it is assumed to be in balance status after a 24 h forecast. The balanced tendency is approximately 20 Pa h−1 (Fig. 15), which is reached by BAK in 3 h. After the first DA cycle, the ps tendency becomes much larger than that of BAK, no matter the DA configuration. The large ps tendency after the first DA cycle is not surprising because the landing typhoon is not fully observed by the simulated observation network, especially for the wind field, causing an imbalance between the corrected part and the rest of the analyzed typhoon. A similar phenomenon was discussed by Wang et al. (2012) in a simulated supercell case. They concluded that such an imbalance shocks the model forecast and increases the forecast error.
After a 6 h forecast, the ps tendencies in Hybrid_5band_DSL_6h and Ens_noFLTR_6h are close to the balance status. As expected, the ps tendency increases again after the second DA cycle. However, Hybrid_5band_DSL_6h produces a much smaller ps tendency than Ens_ noFLTR_6h, indicating that Hybrid_5band_DSL_6h has a more balanced analysis. The peaks of ps tendency in Hybrid_5band_DSL_6h and Ens_noFLTR_6h gradually decline as the number of cycles increases. By 18:00 UTC, Hybrid_5band_DSL_6h reaches the balance status, while Ens_noFLTR_6h does not. The above result indicates that using the hybrid covariance and multiscale localization is beneficial for cycling DA.
Note that the advantage of Hybrid_5band_DSL_6h has a precondition that the cycling interval is sufficiently long for the model to spin up. When the cycling interval becomes shorter (Hybrid_5band_DSL_3h), the ps tendency cannot be effectively suppressed as Hybrid_5band_DSL_6h does.
4.3.2 The performance of cycling DA
We only discuss the results of u, v, qv, and ps in this subsection for brevity. For u and v, all experiments reduce the forecast error compared with BAK (Fig. 16a and b). However, the error evolution of these experiments substantially differs. Ens_noFLTR_6h fails to decrease the forecast error after the second cycle, while Hybrid_5band_DSL_6h successively reduces the forecast and analysis error as the number of cycles increases. For Hybrid_5band_ DSL_3h, an oscillation in error evolution is observed, which is likely associated with the imbalance analysis and the insufficient cycle interval for spinup. Despite the oscillation, the forecast and analysis errors of Hybrid_5band_ DSL_3h are comparable to those of Hybrid_5band_DSL_6h for wind components.
However, in regard to water vapor and surface pressure (Fig. 16c and d), Hybrid_5band_DSL_6h becomes better than Hybrid_5band_DSL_3h. Hybrid_5band_DSL_6h also outperforms Ens_noFLTR_6h; the latter fails to suppress the forecast error of qv and produces a higher ps error after analysis. Figure 17 shows the spatial distribution of forecast error at 18:00 UTC for Hybrid_5band_DSL_6h and Ens_noFLTR_6h. The area of large error in Hybrid_5band_DSL_6h is much lower than that of Ens_noFLTR_6h for both v and ps. The large error in Ens_noFLTR_6h corresponds to a weak cyclonic rotation and weak low pressure. The above result confirms the benefit of using the hybrid covariance and multiscale localization.
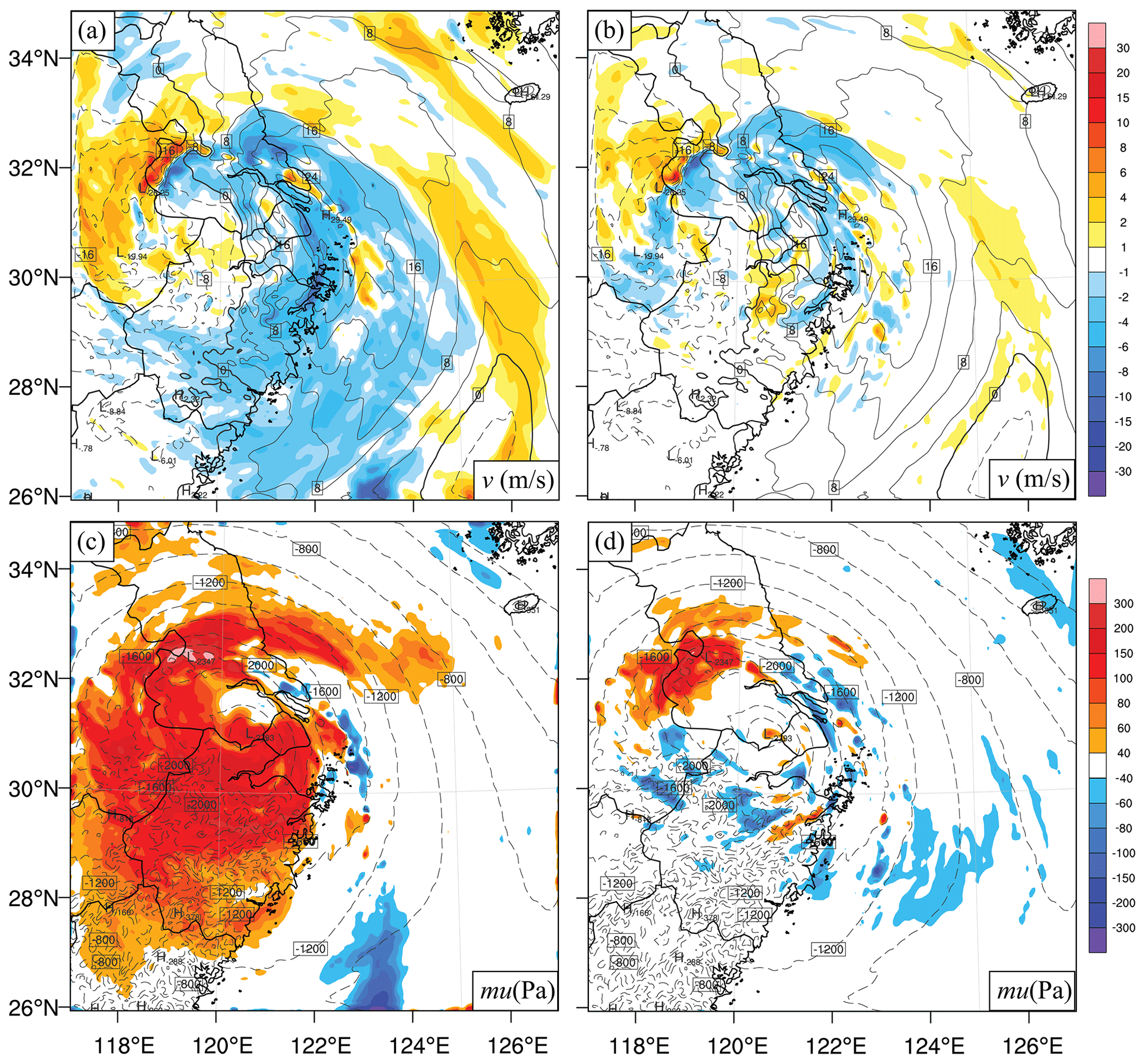
Figure 17The difference in (a, b) meridional wind and (c, d) the dry-air mass in column (mu between the truth (contours) and forecast (shading) at 18:00 UTC 26 July 2021 (the last analysis cycle) for (a, c) Ens_noFLTR_6h and (b, d) Hybrid_5band_DSL_6h.
4.3.3 The evolution of the relationship between ensemble spread and RMSE
For Hybrid_5band_DSL_6h, the initial ensemble spread is smaller than the RMSE at all scales (Fig. 18a) for both u and ps. As the number of cycles increases, the ratio of ensemble spread to RMSE increases. By 18:00 UTC, the ensemble spread is comparable to or greater than the corresponding RMSE at all scales for u. The underestimation of RMSE by the ensemble spread is alleviated for ps (Fig. 18b). For the spatial distribution, the relationship between the ensemble spread and RMSE does not vary much for u at all scales (Fig. 18c). In contrast, the relationship becomes better for ps at a small scale (Fig. 18d). Overall, the ensemble is improved in Hybrid_5band_DSL_6h.

Figure 18The ensemble spread (solid lines), RMSE (dotted lines), and correlation coefficient between spread and RMSE (dotted dashed lines) in three scales for Ens_noFLTR (rectangle markers) and Hybrid_5band_DSL_6h (circle markers), where scales of 0–50, 50–200, and >200 km are denoted by blue, orange, and light blue, respectively.
For Ens_noFLTR_6h, the ensemble spread of u and ps at the small-scale remains smaller than the corresponding RMSE during the cycling DA. In contrast, the ensemble spread at the large scale dramatically increases after the second cycle. The amplitude of the large-scale ensemble spread is even higher than that of the small-scale spread, leading to a severe overestimation of the large-scale error. Meanwhile, the correlation between ensemble spread and RMSE at the small scale is not improved during cycling. In general, the ensemble in Ens_noFLTR_6h does not become better after four cycles, which explains why Ens_noFLTR_6h produces a large analysis error.
4.4 The computational cost and efficiency
The computational cost and efficiency of Local DA are discussed in this subsection. All tests are conducted on a 36-core workstation with an Intel Xeon Gold 6139 CPU (the maximum frequency is set to 2.30 GHz) and 48 GB of available memory. Heretofore, we have implemented the parallel Local DA with OpenMP, which is not suitable for large-scale parallel computing; however, for this study, OpenMP is sufficient. The parallel efficiency is examined first. LDA_HBC_MSL is selected as an example. Figure 19 shows the wall clock time as a function of the number of cores. The wall clock time covers Local DA steps 3 through 9 (as described in Sect. 2.4). As expected, the wall clock time is reduced by approximately 50 % upon doubling the number of cores, which is valid if the number of cores is not greater than 16. In contrast, increasing the number of cores from 16 to 32 does not shorten the wall clock time; this is attributable to the fact that OpenMP is only suitable when the number of processors is small (<16; Hoeflinger et al., 2001). Given that no messages need to be passed between the cores for steps 3 through 9, the parallel efficiency of Local DA is likely insensitive to the number of cores. In general, the results demonstrate that Local DA can be highly parallelized.
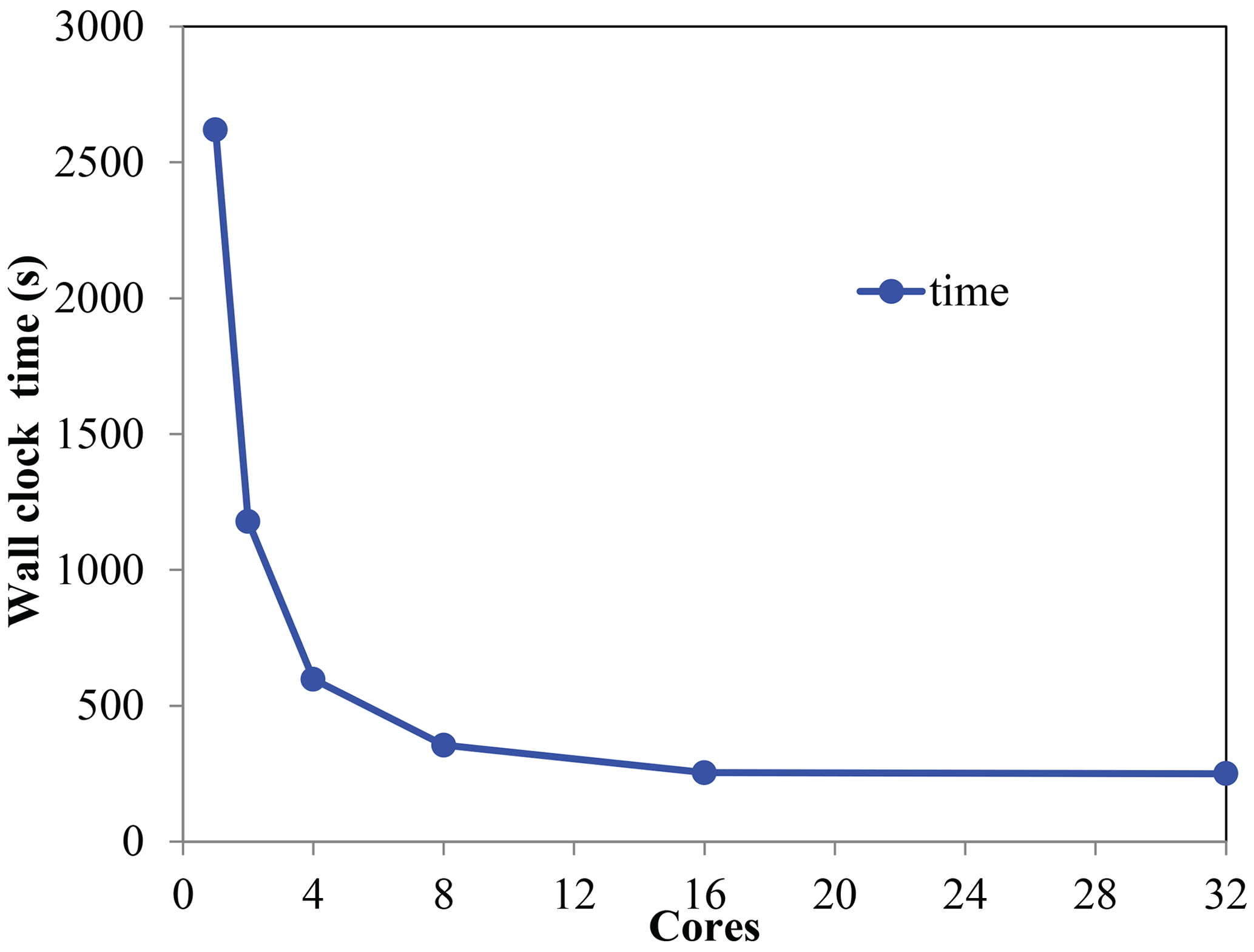
Figure 19The wall clock time as a function of the number of cores used in the parallel test.
In addition to its parallelization, the computational speed of Local DA is also investigated. Hybrid_5band takes 225 s to complete all local analyses when 16 cores are used. Note that the number of horizontal grid points within the forecast domain is 40 000, and more than 200 000 observations are assimilated. Given that the processors work at a frequency of 2.30 GHz, the computational speed of Local DA is acceptable. On average, nearly 70 % of the computational time is used to compute Coo and Cmo; for the minimization using the CG method, the corresponding percentage is approximately 18 %.
We also assess the memory consumption of Local DA. To complete Local DA steps 3 through 9, Hybrid_5band uses approximately 4 GB when 16 cores are engaged to store Coo and the associated matrices. In contrast, the LETKF uses only hundreds of megabytes. For each five-column analysis, the Coo size varies from 2000×2000 to 4500×4500, which is affordable. However, for a much larger size, such as 9000×9000, OpenMP is insufficient; under these circumstances, the MPI-OpenMP hybrid scheme is likely a viable solution for both the computational speed and the memory consumption, which is in progress. In addition to Coo, the model-space multiscale localization requires large memory. Memory consumption is proportional to the number of scales. For example, Ens_3band requires 3 times as much memory as Ens_noFLTR to store the decomposed perturbations. In general, the total computational cost of Local DA is high, but the cost of each local analysis is affordable.
This study proposed a local data assimilation scheme (Local DA) that can utilize hybrid covariance and multiscale localization. Local DA explicitly computes a local background error correlation matrix and uses the correlation matrix to construct a local error sample matrix. The error sample matrix with proper localization allows Local DA to adopt the conjugate gradient (CG) method to solve the cost function. The constructed matrix also renders Local DA a flexible hybrid analysis scheme. Local DA is evaluated in a perfect model scenario that includes a simulated multiscale observation network for a typhoon case. We examined the impacts of the hybrid covariance and multiscale localization on Local DA and evaluated the performance of cycling DA. Several conclusions can be drawn from the results of the DA experiments:
-
Applying the CG method independently for each column group does not result in a severe discontinuity in the Local DA analysis.
-
Explicitly computing the background correlation matrix projected onto observation-associated grids/columns is computationally affordable if the observations have been properly thinned.
-
Local DA can effectively utilize the hybrid covariance to produce a better analysis than the analysis using ensemble covariance with a fixed localization radius.
-
The model-space multiscale localization can reduce the analysis error at a small scale. Combining the hybrid covariance with the multiscale localization yields a small improvement, and adding double-space localization to the combination can further reduce the analysis error.
-
Local DA requires a large amount of memory, but its computational efficiency is acceptable.
Despite the encouraging results, whether to use double-space localization should be considered case by case. In this study, the background error covariance is noisy, so double-space localization has a positive impact. With a well-sampled ensemble and a well-designed multiscale localization, there is no need to use double-space localization. In the case of applying Local DA in the four-dimensional DA scenario, double-space localization should not be used because observation-space localization does not consider the advection of error covariance.
As the first study to present Local DA, this paper focuses on its idea and basic formulation. Future efforts to enhance the algorithm will include developing an MPI-OpenMP hybrid parallel scheme, a static covariance scheme that objectively determines the error variance and scales, and a better multiscale localization scheme. Furthermore, the current version of Local DA introduces a strong shock to the model, which limits the applicability of Local DA in cycling DA. Therefore, we plan to add a cross-variable balance procedure to improve the cycling DA performance. Moreover, many parameters of Local DA have yet to be tested; hence, the sensitivity of Local DA to each of these parameters will also be discussed in a future investigation.
This section provides an example of the procedure used to thin the observations (as mentioned in Sect. 2.1.1). The observations are thinned horizontally, whereas thinning does not occur in the vertical direction. First, we set several rings with different radii at the center point or column of the model variables to be updated. For the five-column analysis, the center coordinates of the variable-radius rings are the mean latitude and mean longitude of the five columns. The radius of the outer ring is the observation search radius mentioned in Sect. 2.4 (e.g., 300 km for sounding data and 15 km for radar data). From small to large, the radii of the rings are denoted rr1, rr2, … rr, where Nr is the number of rings. We successively search the observations from the inner ring to the outer ring. Within the smallest ring, all ambient observations are selected; this is equivalent to no thinning. For the observations located between two rings (between rri and rri−1), we select one observation for each quadrant of the space between the two rings. There are four quadrants: the upper-right, lower-right, lower-left, and upper-left quadrants (numbered I, II, III, and IV, respectively). A schematic plot is shown in Figure A1. If no observation is available in the smallest ring, the second ring is treated as the first ring.
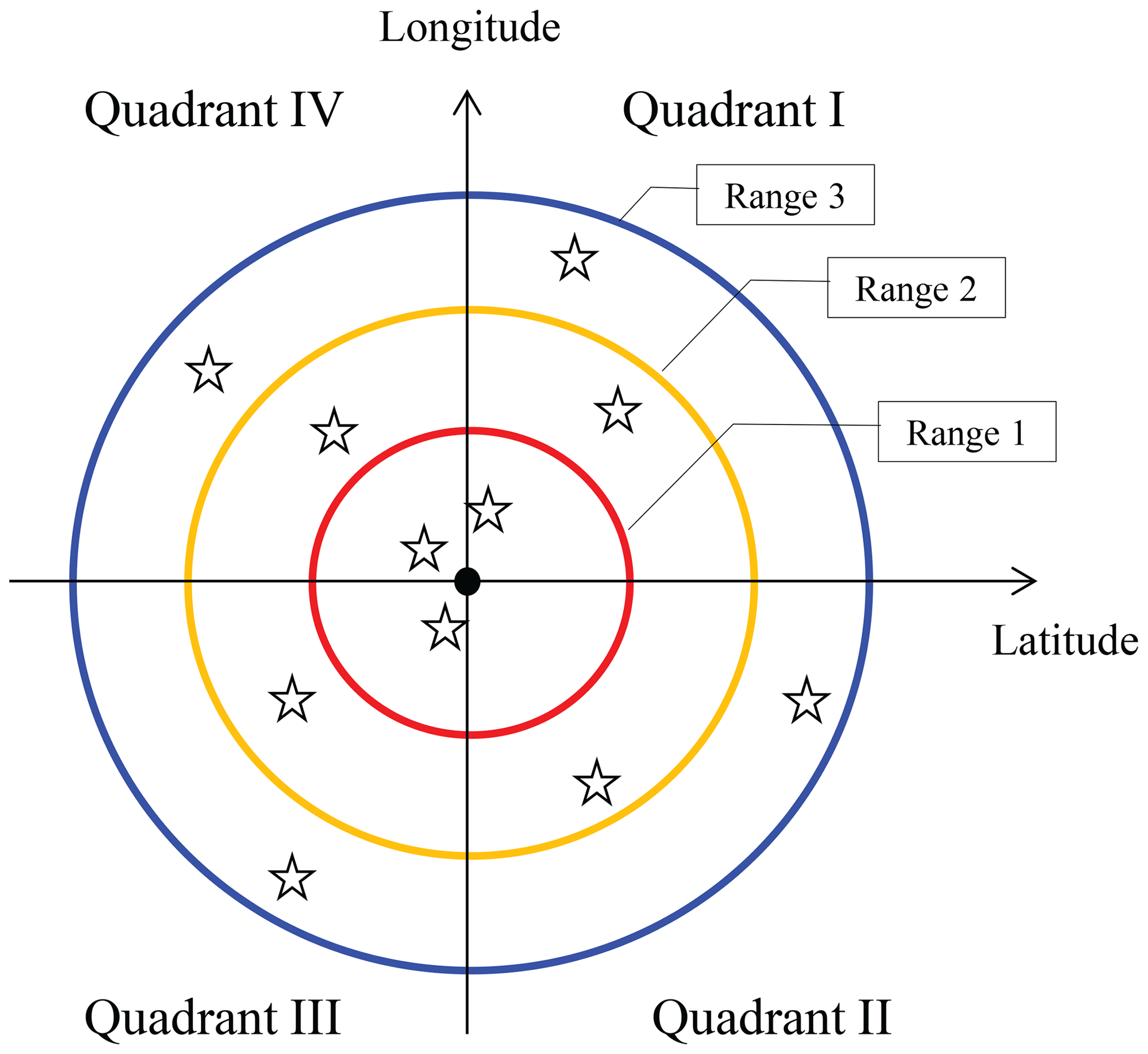
Figure A1A schematic of the observation searching approach used in Local DA, where stars represent the selected observations near the grid point (solid dark dot) to be analyzed.
Because no thinning occurs in the smallest ring, in a one-column analysis, we still utilize all observations throughout the forecast domain when Local DA is conducted at a single point. In the five-column analysis, the thinning approach discards some observations and slightly increases the analysis error relative to the one-column analysis. Our early test (not shown) indicates that Local DA becomes very time-consuming when the thinning process is disabled, as expected. Moreover, the resulting analysis error increases because the assumption of observation errors being uncorrelated is not valid, which is not desired.
The code of Local DA v1.0 and the scripts for running the experiments in this study are available at https://doi.org/10.5281/zenodo.6609906 (Wang, 2022) or by contacting the corresponding author via e-mail. The GFS data are available at https://www.ncdc.noaa.gov/data-access/model-data/model-datasets/global-forcast-system-gfs (NCEP, 2022).
SW performed the coding and designed the data assimilation experiments. XQ analyzed the experimental results. Both authors contributed to the writing of the paper.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We thank our colleagues at NJIAS and CAMS for their valuable suggestions that promoted the development of Local DA and improved the manuscript. We also thank two anonymous reviewers for valuable comments and suggestions.
This research has been supported by the National Science and Technology Major Project (grant no. 2021YFC3000901), the National Natural Science Foundation of China (grant nos. 41875129, 41505090, and 42105006), and the Basic Research Fund of CAMS (grant nos. 2021R001 and 2021Y006).
This paper was edited by Travis O'Brien and reviewed by two anonymous referees.
Bonavita, M., Trémolet, Y., Holm, E., Lang, S. T., Chrust, M., Janisková, M., Lopez, P., Laloyaux, P., de Rosnay, P., and Fisher, M.: A strategy for data assimilation, European Centre for Medium Range Weather Forecasts Reading, UK, https://doi.org/10.21957/tx1epjd2p, 2017.
Branković, Č., Palmer, T., Molteni, F., Tibaldi, S., and Cubasch, U.: Extended-range predictions with ECMWF models: Time-lagged ensemble forecasting, Q. J. Roy. Meteorol. Soc., 116, 867–912, 1990.
Brousseau, P., Berre, L., Bouttier, F., and Desroziers, G.: Background-error covariances for a convective-scale data-assimilation system: AROME–France 3D-Var, Q. J. Roy. Meteorol. Soc., 137, 409–422, 2011.
Brousseau, P., Berre, L., Bouttier, F., and Desroziers, G.: Flow-dependent background-error covariances for a convective-scale data assimilation system, Q. J. Roy. Meteorol. Soc., 138, 310–322, 2012.
Buehner, M.: Evaluation of a spatial/spectral covariance localization approach for atmospheric data assimilation, Mon. Weather Rev., 140, 617–636, 2012.
Buehner, M. and Shlyaeva, A.: Scale-dependent background-error covariance localisation, Tellus A, 67, 28027, https://doi.org/10.3402/tellusa.v67.2802, 2015.
Caron, J.-F. and Buehner, M.: Scale-dependent background error covariance localization: Evaluation in a global deterministic weather forecasting system, Mon. Weather Rev., 146, 1367–1381, 2018.
Caron, J.-F., Michel, Y., Montmerle, T., and Arbogast, É.: Improving background error covariances in a 3D ensemble–variational data assimilation system for regional NWP, Mon. Weather Rev., 147, 135–151, 2019.
Dudhia, J.: Numerical study of convection observed during the winter monsoon experiment using a mesoscale, two-dimensional model, J. Atmos. Sci., 46, 3077–3107, 1989.
Etherton, B. J. and Bishop, C. H.: Resilience of hybrid ensemble/3DVAR analysis schemes to model error and ensemble covariance error, Mon. Weather Rev., 132, 1065–1080, 2004.
Gao, J. and Stensrud, D. J.: Assimilation of reflectivity data in a convective-scale, cycled 3DVAR framework with hydrometeor classification, J. Atmos. Sci., 69, 1054–1065, 2012.
Hamill, T. M. and Snyder, C.: A hybrid ensemble Kalman filter–3D variational analysis scheme, Mon. Weather Rev., 128, 2905–2919, 2000.
Hoeflinger, J., Alavilli, P., Jackson, T., and Kuhn, B.: Producing scalable performance with OpenMP: Experiments with two CFD applications, Parallel Comput., 27, 391–413, 2001.
Hoffman, R. N. and Atlas, R.: Future Observing System Simulation Experiments, B. Am. Meteorol. Soc., 97, 1601–1616, https://doi.org/10.1175/bams-d-15-00200.1, 2016.
Hong, S.-Y. and Lim, J.-O. J.: The WRF single-moment 6-class microphysics scheme (WSM6), Asia-Pac. J. Atmos. Sci., 42, 129–151, 2006.
Hong, S.-Y., Noh, Y., and Dudhia, J.: A new vertical diffusion package with an explicit treatment of entrainment processes, Mon. Weather Rev., 134, 2318–2341, 2006.
Houtekamer, P. L. and Mitchell, H. L.: Data assimilation using an ensemble Kalman filter technique, Mon. Weather Rev., 126, 796–811, 1998.
Huang, B., Wang, X., and Bishop, C. H.: The High-Rank Ensemble Transform Kalman Filter, Mon. Weather Rev., 147, 3025–3043, https://doi.org/10.1175/mwr-d-18-0210.1, 2019.
Huang, B., Wang, X., Kleist, D. T., and Lei, T.: A simultaneous multiscale data assimilation using scale-dependent localization in GSI-based hybrid 4DEnVar for NCEP FV3-based GFS, Mon. Weather Rev., 149, 479–501, 2021.
Hunt, B. R., Kostelich, E. J., and Szunyogh, I.: Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter, Physica D, 230, 112–126, https://doi.org/10.1016/j.physd.2006.11.008, 2007.
Johnson, A., Wang, X., Carley, J. R., Wicker, L. J., and Karstens, C.: A comparison of multiscale GSI-based EnKF and 3DVar data assimilation using radar and conventional observations for midlatitude convective-scale precipitation forecasts, Mon. Weather Rev., 143, 3087–3108, 2015.
Kain, J. S.: The Kain–Fritsch convective parameterization: an update, J. Appl. Meteorol., 43, 170–181, 2004.
Kalnay, E. and Yang, S. C.: Accelerating the spin-up of Ensemble Kalman Filtering, Q. J. Roy. Meteorol. Soc., submitted, 2008.
Kleist, D. T. and Ide, K.: An OSSE-based evaluation of hybrid variational–ensemble data assimilation for the NCEP GFS. Part I: System description and 3D-hybrid results, Mon. Weather Rev., 143, 433–451, 2015.
Lei, L., Wang, Z., and Tan, Z.-M.: Integrated Hybrid Data Assimilation for an Ensemble Kalman Filter, Mon. Weather Rev., 149, 4091–4105, 2021.
Li, Y., Wang, X., and Xue, M.: Assimilation of radar radial velocity data with the WRF hybrid ensemble–3DVAR system for the prediction of Hurricane Ike (2008), Mon. Weather Rev., 140, 3507–3524, 2012.
Liu, C., Xiao, Q., and Wang, B.: An ensemble-based four-dimensional variational data assimilation scheme. Part I: Technical formulation and preliminary test, Mon. Weather Rev., 136, 3363–3373, 2008.
Lorenc, A.: The potential of the ensemble Kalman filter for NWP – a comparison with 4D-Var, Q. J. Roy. Meteor. Soc., 129, 3183–3204, 2003.
Maddox, R. A.: An Objective Technique for Separating Macroscale and Mesoscale Features in Meteorological Data, Mon. Weather Rev., 108, 1108–1121, https://doi.org/10.1175/1520-0493(1980)108<1108:aotfsm>2.0.co;2, 1980.
Ménétrier, B. and Auligné, T.: An Overlooked Issue of Variational Data Assimilation, Mon. Weather Rev., 143, 3925–3930, https://doi.org/10.1175/mwr-d-14-00404.1, 2015.
Meng, Z. Y. and Zhang, F. Q.: Tests of an ensemble Kalman filter for mesoscale and regional-scale data assimilation. Part II: Imperfect model experiments, Mon. Wea. Rev., 135, 1403–1423, https://doi.org/10.1175/Mwr3352.1, 2007.
Mlawer, E. J., Taubman, S. J., Brown, P. D., Iacono, M. J., and Clough, S. A.: Radiative transfer for inhomogeneous atmospheres: RRTM, a validated correlated-k model for the longwave, J. Geophys. Res.-Atmos., 102, 16663–16682, 1997.
NCEP (National Centers for Environmental Prediction): GFS Forecast (GFS Model), NCEI (National Centers for Environmental Information) [data set], https://www.ncdc.noaa.gov/data-access/model-data/model-datasets/global-forcast-system-gfs, last access: 7 December 2022.
Penny, S. G.: The hybrid local ensemble transform Kalman filter, Mon. Weather Rev., 142, 2139–2149, 2014.
Shewchuk, J. R.: An introduction to the conjugate gradient method without the agonizing, Edition 1 1/4, School of Computer Science, Carnegie Mellon University, https://www.cs.cmu.edu/~quake-papers/painless-conjugate-gradient.pdf (last access: 7 Decemeber 2022), 1994.
Skamarock, W. C., Klemp, J. B., Dudhia, J., Gill, D. O., Barker, D. M., Duda, M. G., Huang, X.-Y., Wang, W., and Powers, J. G.: A description of the advanced research WRF version 3, National Center For Atmospheric Research, Boulder, CO, NCAR/TN-475+STR, 91, 2018.
Storto, A. and Andriopoulos, P.: A new stochastic ocean physics package and its application to hybrid-covariance data assimilation, Q. J. Roy. Meteorol. Soc., 147, 1691–1725, 2021.
Tang, Y., Ambandan, J., and Chen, D.: Nonlinear measurement function in the ensemble Kalman filter, Adv. Atmos. Sci., 31, 551–558, 2014.
Tong, C. C., Jung, Y., Xue, M., and Liu, C.: Direct Assimilation of Radar Data With Ensemble Kalman Filter and Hybrid Ensemble-Variational Method in the National Weather Service Operational Data Assimilation System GSI for the Stand-Alone Regional FV3 Model at a Convection-Allowing Resolution, Geophys. Res. Lett., 47, e2020GL090179, https://doi.org/10.1029/2020GL090179, 2020.
Wang, S.: children1985/Local_DA_lib: Local DA v1.00 for GMD (v1.00), Zenodo [code], https://doi.org/10.5281/zenodo.6609906, 2022.
Wang, S., Xue, M., and Min, J.: A four-dimensional asynchronous ensemble square-root filter (4DEnSRF) algorithm and tests with simulated radar data, Q. J. Roy. Meteor. Soc., 139, 805–819, https://doi.org/10.1002/qj.1987, 2012.
Wang, S., Xue, M., Schenkman, A. D., and Min, J.: An iterative ensemble square root filter and tests with simulated radar data for storm-scale data assimilation, Q. J. Roy. Meteorol. Soc., 139, 1888–1903, 2013a.
Wang, X., Hamill, T. M., Whitaker, J. S., and Bishop, C. H.: On the theoretical equivalence of differently proposed ensemble – 3DVAR hybrid analysis scheme, Mon. Wea. Rev., 135, 1055–1076, 2007.
Wang, X., Barker, D. M., Snyder, C., and Hamill, T. M.: A hybrid ETKF–3DVAR data assimilation scheme for the WRF model. Part I: Observing system simulation experiment, Mon. Weather Rev., 136, 5116–5131, 2008.
Wang, X., Hamill, T. M., Whitaker, J. S., and Bishop, C. H.: A comparison of the hybrid and EnSRF analysis schemes in the presence of model errors due to unresolved scales, Mon. Weather Rev., 137, 3219–3232, 2009.
Wang, X., Parrish, D., Kleist, D., and Whitaker, J.: GSI 3DVar-based ensemble–variational hybrid data assimilation for NCEP Global Forecast System: Single-resolution experiments, Mon. Weather Rev., 141, 4098–4117, 2013b.
Wang, X., Chipilski, H. G., Bishop, C. H., Satterfield, E., Baker, N., and Whitaker, J. S.: A multiscale local gain form ensemble transform Kalman filter (MLGETKF), Mon. Weather Rev., 149, 605–622, 2021.
Wang, Y. and Wang, X.: Direct Assimilation of Radar Reflectivity without Tangent Linear and Adjoint of the Nonlinear Observation Operator in the GSI-Based EnVar System: Methodology and Experiment with the 8 May 2003 Oklahoma City Tornadic Supercell, Mon. Weather Rev., 145, 1447–1471, https://doi.org/10.1175/mwr-d-16-0231.1, 2017.
Whitaker, J. S. and Hamill, T. M.: Ensemble data assimilation without perturbed observations, Mon. Weather Rev., 130, 1913–1924, 2002.
Xiao, Q. and Sun, J.: Multiple-radar data assimilation and short-range quantitative precipitation forecasting of a squall line observed during IHOP_2002, Mon. Weather Rev., 135, 3381–3404, 2007.
Xue, M., Tong, M. J., and Droegemeier, K. K.: An OSSE framework based on the ensemble square root Kalman filter for evaluating the impact of data from radar networks on thunderstorm analysis and forecasting, J. Atmos. Oceanic Technol., 23, 46–66, 2006.
Yang, C., Min, J., and Tang, Y.: Evaluation of two modified Kalman gain algorithms for radar data assimilation in the WRF model, Tellus A, 67, 25950, https://doi.org/10.3402/tellusa.v67.25950, 2015.
Yang, S. C., Kalnay, E., Hunt, B., and E. Bowler, N.: Weight interpolation for efficient data assimilation with the local ensemble transform Kalman filter, Q. J. Roy. Meteor. Soc., 135, 251–262, 2009.
Zeng, Y., de Lozar, A., Janjic, T., and Seifert, A.: Applying a new integrated mass-flux adjustment filter in rapid update cycling of convective-scale data assimilation for the COSMO model (v5.07), Geosci. Model Dev., 14, 1295–1307, https://doi.org/10.5194/gmd-14-1295-2021, 2021.
Zhang, F., Weng, Y., Sippel, J. A., Meng, Z., and Bishop, C. H.: Cloud-resolving hurricane initialization and prediction through assimilation of Doppler radar observations with an ensemble Kalman filter, Mon. Weather Rev., 137, 2105–2125, 2009.
The requested paper has a corresponding corrigendum published. Please read the corrigendum first before downloading the article.
- Article
(19803 KB) - Full-text XML