the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 04 Aug 2022
| 04 Aug 2022
Climate Services Toolbox (CSTools) v4.0: from climate forecasts to climate forecast information
Louis-Philippe Caron
Silvia Terzago
Bert Van Schaeybroeck
Llorenç Lledó
Nicolau Manubens
Emmanuel Roulin
M. Carmen Alvarez-Castro
Lauriane Batté
Pierre-Antoine Bretonnière
Susana Corti
Carlos Delgado-Torres
Marta Domínguez
Federico Fabiano
Ignazio Giuntoli
Jost von Hardenberg
Eroteida Sánchez-García
Verónica Torralba
Deborah Verfaillie
Despite the wealth of existing climate forecast data, only a small part is effectively exploited for sectoral applications. A major cause of this is the lack of integrated tools that allow the translation of data into useful and skillful climate information. This barrier is addressed through the development of an R package. Climate Services Toolbox (CSTools) is an easy-to-use toolbox designed and built to assess and improve the quality of climate forecasts for seasonal to multi-annual scales. The package contains process-based, state-of-the-art methods for forecast calibration, bias correction, statistical and stochastic downscaling, optimal forecast combination, and multivariate verification, as well as basic and advanced tools to obtain tailored products. Due to the modular design of the toolbox in individual functions, the users can develop their own post-processing chain of functions, as shown in the use cases presented in this paper, including the analysis of an extreme wind speed event, the generation of seasonal forecasts of snow depth based on the SNOWPACK model, and the post-processing of temperature and precipitation data to be used as input in impact models.
- Article
(13609 KB) - Full-text XML
-
Supplement
(808 KB) - BibTeX
- EndNote





1.1 The need for climate information
Large multi-model seasonal forecasting systems have been developed in recent years, both from current international research projects and operational programs. These include, for instance, the C3S multimodel seasonal forecast system (successor to EUROSIP; Vitart et al., 2007; Mishra et al., 2019; Hemri et al., 2020), APEC (Wang et al., 2009; Min et al., 2014), the North-American Multi-Model Ensembles (Kirtman et al., 2014), and the Coupled Model Intercomparison Project Phase 6 – Decadal Climate Prediction Project (CMIP6-DCPP; Boer et al., 2016). In parallel, there has been an increasing demand for reliable climate information and tailored climate services, in particular at the seasonal timescale, as this period coincides with the planning horizon in several sectors of activities (Troccoli et al., 2008). However, a large availability of climate data does not automatically imply having access to useful climate information. Indeed, post-processing methods with different levels of sophistication are required to convert climate data into tailored climate information for each application, allowing users and decision-makers to develop and implement strategies of adaptation to climate variability and to guide well-informed decision-making. The generation of tailored climate information can be, for instance, the extraction of global data in a particular region of interest, the correction of the systematic errors that prevent the integration of the climate predictions in impact models, or the refinement of the coarse resolution of the climate datasets in order to be representative of the local climate variability. In fact, there is a strong need for and interest in reliable seasonal to decadal forecasts in a wide range of socioeconomic sectors such as energy, agriculture, tourism, health, insurance, or logistics, to name only a few (White et al., 2017). But the specific information needs for assisting decision-making vary strongly, even within the same sector. For instance, a wind farm owner might be interested in estimating the risk of low cash income due to low winds during a given season and plan a reduction in production accordingly. This requires local information of near-surface wind speed, combined with the specific performance specifications of the turbines (i.e., relevant wind thresholds vary across wind farms). On the other hand, a grid operator might require country aggregate information of temperature extremes as a proxy for anticipating electricity demand and ensuring the balance of supply and demand in the electricity grid. Similarly, for the agriculture sector, the required climate information may depend on the specific culture (e.g., olives, wine, or wheat) and even on the specific crop variety, since each of these crops may have different phenological evolution, which implies a climate sensitivity to different climate variables and different time periods. This diversity of user needs makes the generation of tailored products costly in time and resources, something that is sometimes known as the last mile problem of climate services (Celliers et al., 2021). Sharing software tools that provide state-of-the-art methods to solve common problems in the creation of specific climate services can alleviate this problem and facilitate the tailoring process with actors in the climate community and beyond (National Academies of Sciences, Engineering and Medicine, 2016).
In this context, a Climate Services Toolbox (CSTools) has been developed to address these needs. The toolbox was designed to include functions for each of the main seasonal forecast post-processing steps, but the methods are also suitable for sub-seasonal and decadal predictions. These forecasts are typically generated by running a forecast system several times using perturbations on the initial conditions and model physics (ECMWF, 2017). Each simulation is then considered a member of the ensemble. These similarities in the setups among forecasts of different time horizons generally lead to common requirements in their post-processing steps (Palmer et al., 2008). Such ensembles are generated to account for initial condition and model uncertainty, to make probabilistic statements about the most likely atmospheric state (ECMWF, 2017), and to inform sensitivity studies. However, additional post-processing steps are required to translate the simulations into climate information. First, this post-processing typically requires hindcasts (past forecasts), ideally generated using the same modeling and data assimilation system as is used to generate the real-time forecasts, to correct modeling system inadequacies, and to generate other forecast products (Hamill, 2011).
CSTools primarily targets applied climate scientists or climate services developers that require the use of high-quality climate data (e.g., high-resolution data obtained by applying downscaling methods). These users can handle the tool by themselves and understand each of the methodologies, given the provided documentation and with the support of scientific research publications. The tool is fully transparent since it is open source, allowing the user to control, understand, and even adapt every step of the analysis in depth. While simple examples are given in the package documentation, this paper aims to showcase the usefulness of CSTools in the context of advanced state-of-the-art use cases.
1.2 From climate data to climate information
There are different forecast post-processing steps necessary to translate climate data into climate information. These steps will vary, depending on the applications, but usually fall within the following categories (as illustrated in Fig. 1):
-
Data collection, curation, and homogenization. This includes collection of data from heterogeneous remote data sources, storage and indexing into local or organization-accessible file systems or servers, and homogenization in order for all data files to comply with common internal conventions. The complexity of this step can be high, particularly if the data sources do not follow community standards. While this step is out of the scope of this paper and the CSTools toolbox, we refer interested readers to the cds-data-downloader (https://earth.bsc.es/gitlab/es/cds-seasonal-downloader, last access: 22 June 2022) for this purpose (see Appendix A).
-
Data retrieval and formatting. This task refers to the loading of climate data from files stored in local or organization-accessible file systems or servers onto the main memory of the processing workstations and the required arrangement and transformations of the different datasets to be intercompared and analyzed. This can be a labor-intensive step when trying to combine multiple or diverse datasets such as observations and forecasts from multiple systems or sources. Slight differences in the internal conventions for storing the respective datasets need to be handled, and methods for spatial and temporal data manipulation, such as spatial interpolation methods, are often necessary.
-
Correction methods for forecast calibration. Calibration is necessary to correct systematic errors, uncover any predictive signal, and adjust forecasts to the observational statistical properties in order to be integrated into impact models. These biases originate from the approximate representation of unresolved climate processes in the forecast systems (Marcos, 2016; Van Schaeybroeck and Vannitsem, 2019; Manzanas et al., 2019).
-
Classification methods for multi-model forecast combination or scenario selection. Combining multiple forecasting systems allows us to substantially enlarge the diversity of potential weather situations (Hemri et al., 2020), errors are partially compensated, and there is an increase in consistency and reliability (Hagedorn et al., 2005). Scenario selection, on the other hand, may often be useful for communication and information synthesis for specific applications (Ferranti and Corti, 2011).
-
Downscaling. Climate forecast systems, due to computational limitations, typically provide global seasonal-to-decadal forecasts at a horizontal resolution of ∼100 km. Users, however, require information at a finer scale. As such, statistical and stochastic downscaling techniques are commonly used to perform realistic transformations from large to small scales (Maraun and Widmann, 2018; Ramon et al., 2021).
-
Skill assessment. Estimating the quality of the predictions is essential to understand the limitations of the simulations, to improve the current forecast systems, and to provide useful forecast products tailored to several sectors (Merryfield et al., 2020). Skill estimates should be provided together with the forecast products to allow a correct interpretation of the forecasts or the added value of a system with respect to a benchmark.
-
Visualization. From the climate services perspective, visualization tools are essential to illustrate different aspects of deterministic or probabilistic climate information.
The primary aim of CSTools is therefore to make post-processing methods (i.e., correction methods for forecast calibration, classification methods for multi-model forecast combination, or scenario selection, downscaling methods, and visualization tools) available in one coherent framework in order to facilitate analysis or the post-processing of data such that might be required by an impact model. Because additional steps are required, CSTools also includes functions for data retrieval and formatting and skill assessment in order to facilitate the use of the toolbox.
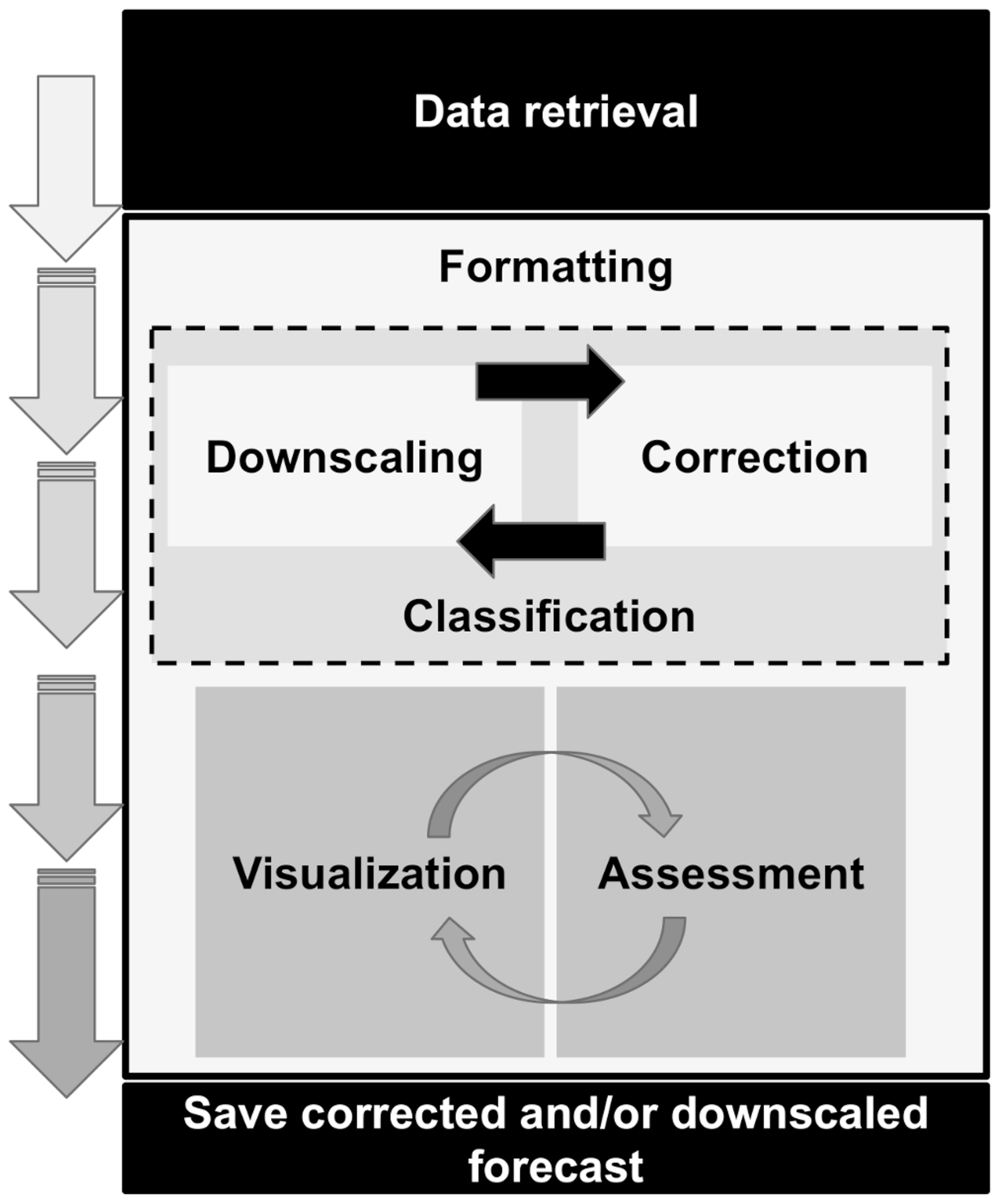
Figure 1Scheme of the flexible CSTools workflow (from top to bottom). Each box represents a category of functions that is part of CSTools.
Several software packages are already available to analyze different types of climate data. For instance, the Earth System Model Evaluation Tool (ESMValTool; Eyring et al., 2016b, 2020; Righi et al., 2020) was designed to facilitate the analysis of climate projections produced in the context of the Coupled Model Intercomparison Project (CMIP; Eyring et al., 2016a). The R packages s2dverification (Manubens et al., 2018), SpecsVerification (Siegert, 2017) and easyVerification (MeteoSwiss, 2017), or the Python package climpred (Brady and Spring, 2021) focus on a skill assessment of ensemble forecasts. climate4R (Iturbide et al., 2019) is an R-based framework for climate data post-processing including different methods. The main purpose of these different packages is the facilitation of research. CSTools, on the other hand, targets scientists interested in providing a climate product to some final users. This is done by allowing the creation of a complete post-processing chain from data retrieval to the obtention of high-quality datasets to feed impact models or tailored forecast visualization of forecast products. CSTools could, nonetheless, be useful to research scientists, as it has been designed to be compatible with some of the aforementioned R packages.
In this paper, an overview of the methods and documentation gathered in CSTools is presented in Sect. 2, while the creation of a tailored dataset is shown in Sect. 3. There are three case studies based on the analysis of an extreme wind speed event, the snow model SNOWPACK (Lehning et al., 2002a, b https://models.slf.ch/p/snowpack/, last access: 24 July 2022), and temperature and precipitation data preparation for models requiring evapotranspiration, or similar variables, that show the usefulness of the toolbox. Section 4 concludes this paper and discusses some future developments for the package. For a detailed description of CSTools functions and parameters, the reference manual is attached to the package and available at https://CRAN.R-project.org/package=CSTools (last access: 18 July 2022) in the standardized format of an R package documentation.
CSTools was created as part of a collaborative effort between six European institutions. Given the total number of contributors and collaborators (31 in version 4.0), compiling all methods into a software package using the R statistical programming language (R Core Team, 2017) was considered the most suitable and versatile option. Creating an R package allows the inclusion of multiple tools ranging from complex statistical and climatological methods to visualization tools in the same framework. Moreover, CSTools is open source, thus allowing users and developers alike to benefit from lower costs and software flexibility, quality, and reliability (Information Resources Management Association, 2013). At the same time, CSTools can be integrated into other software in order to take advantage of its functionalities, as does, for instance, the S2S4E Decision Support Tool (https://s2s4e-dst.bsc.es, last access: 20 May 2022).
CSTools was developed following common guidelines (see Supplement) agreed upon by all contributors, including conventions for adding new functionalities, and taking into account software development best practices such as the use of a version control system (i.e., Git; Chacon and Straub, 2014) and testing with continuous integration. The use of these development guidelines has resulted in a clean and homogeneous application programming interface (API).
Most functionalities exposed to the users can be invoked and applied to complex user datasets with a single function call. For example, in order to apply a given functionality named “Func”, the user would write:
CST_Func(dataset, ...).
The “CST_*” family of functions ingest and return objects of type “s2dv_cube” (see details in Sect. 2.1), thus allowing compatibility between each function and long post-processing chains to be created.
2.1 Software design aspects of CSTools
The CSTools development guidelines have been designed to maximize compatibility with other libraries such as s2dverification, s2dv, SpecsVerification, easyVerification and startR, as all of them are designed to operate fundamentally with the same array class. Furthermore, CSTools is also compatible with CSIndicators (Pérez-Zanón et al., 2021b), as the latter accepts s2dv_cube objects as inputs. In short, the class s2dv_cube is a list of named elements to keep data and metadata in a single object. One of its elements, “data”, is a multi-dimensional array with named dimensions containing the values of a variable. The rest of the elements are metadata such as spatial coordinates. Because of this design, the CSTools user is able to perform basic array inquiry on the data element of the s2dv_cube objects at any point in the workflow in order to check the dimensions of the data or to find the number of members, start dates, or forecast lead times analyzed. Internally, each of these high-level CST_* functions perform two nested calls to two other different but closely related functions in the package. For example, a given functionality named Func would involve the following function calls:
CST_Func(dataset, ...) {
...
Func(dataset$data, ...) {
...
.Func(data_array[i,], ...)
}
}.
At the most fundamental level of this nested call structure, there is a call to a basic function (e.g., “.Func”) that is designed to work with the least complex data structure possible (be it a single vector, a couple of vectors, an array and a vector, etc.). At the second level is a call to a wrapper function (e.g., Func) around the basic function, which leverages the multiApply package (BSC-CNS et al., 2019) to extend the computation of .Func to inputs with any number of dimensions. The top-level CST_* function is an additional wrapper function which adapts the second-level array-based function to work with s2dv_cube objects.
This nested structure has several benefits. Thanks to the array compatible, low-level functions, the R community can easily employ the CSTools methods in custom CSTools-agnostic workflows if necessary, multi-core parallelism is straightforward to exploit via middle-level functions and high-level CST_* functions, and, finally, in cases where the data to process is larger than the RAM memory in the workstation or the computation is very expensive, the low-level functions can be used together with the startR package (BSC-CNS and Manubens, 2020) to leverage high-performance computing (HPC) platforms and distribute workload in small chunks. An example on how to use a CSTools function in a startR workflow can be found in its GitLab repository (https://earth.bsc.es/gitlab/es/startR, last access: 20 July 2022). Last and foremost, the CSTools user code, using top-level CST_* functions, remains modular, concise, readable, and easy to maintain. This modular aspect of the CST_* functions makes it straightforward for users to create their own post-processing workflows, as shown in Sect. 3. Metadata are propagated and expanded all along the workflows. The development guidelines define conventions to ensure s2dv_cube objects are used in a coherent way throughout the package.
2.2 Methods in CSTools
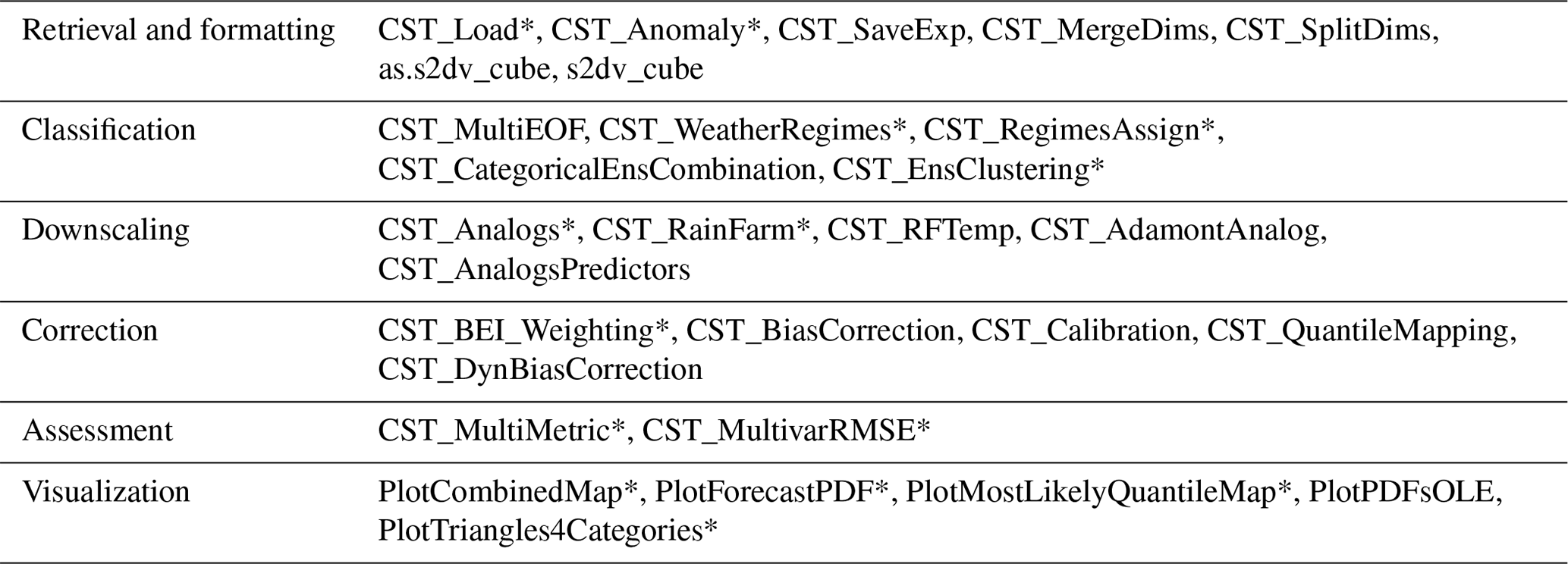
Given that the methods included in CSTools are made available as independent functions operating on a common data structure, the users can concatenate them to define their own post-processing workflow. This design provides flexibility, allowing the users to assess the impact of the various post-processing steps by modifying the chain of functions. The users can also select a single function and apply it outside of the CSTools workflow. The functions included in the package cover fundamental loading and transformation requirements, downscaling tools, methods for correcting and evaluating forecasts, and advanced visualization tools (see Table 1). All functions are documented in a standard reference manual on the CRAN website (https://CRAN.R-project.org/package=CSTools, last access: 18 July 2022). The documentation also include vignettes, which are self-contained pieces of documentation combining code, text, and images, describing some of the methodologies included in CSTools and information on how to use the package to conduct specific analysis.
Table 1Summary of the functions and methods by category included in CSTools. The prefix CST_ refers to functions working on a specific object class called s2dv_cube, while those without the prefix accept multi-dimensional arrays with named dimensions as input. Asterisks indicate functions that are used in vignettes (see Appendix B for a detailed table).
2.2.1 Retrieval and transformation function
CSTools includes a function to retrieve data from netCDF files called CST_Load. This function is a wrapper of the s2dverification Load function, which allows us to load monthly or daily forecast data together with date corresponding to the observations (Manubens et al., 2018). The function allows us to easily combine subsets of data stored in multiple files in POSIX (Portable Operating System Interface) file systems or OPeNDAP (Open-source Project for a Network Data Access Protocol) servers and is designed to support custom conventions for distribution of data across files, file naming, and NetCDF structure. Optionally, CSTools can automatically interpolate all the data onto a common grid if necessary, thus greatly removing complexity for the user. There are three samples of s2dv_cube objects created from using CST_Load provided along with the package, including area_average, with forecast and observational climate data averaged over a region, and lonlat_data and lonlat_prec, containing forecast and observational climate data for temperature and precipitation.
For users who retrieve data by other means (e.g., using the library ncdf4; Pierce, 2019), the CSTools package contains two functions to convert data to a s2dv_cube object. If the data and metadata have been loaded in separate objects, they can be merged into a s2dv_cube object with the function s2dv_cube. On the other hand, if the data and metadata have been loaded into a single object, then this object can be transformed into class s2dv_cube class with the as.s2dv_cube function.
One of the capabilities of CSTools is to create a new dataset after, for example, the data have been downscaled and/or calibrated. In that case, the user may need to save the new dataset into files to be shared among other users or its community. Therefore, the package comes with a saving function called CST_SaveExp, which creates netCDF files in a directory set by the user and which can be loaded again with the CST_Load function. Moreover, the climatological essential steps of computing anomalies can be done with CST_Anomaly, which is a wrapper function of s2dverification methods that also allows computing smoothed climatologies.
The functions CST_MergeDims and CST_SplitDims provide additional flexibility to manipulate s2dv_cube objects. For instance, it is commonly required to split the time dimension of annual data into two dimensions, with one identifying the season and the other the month of that season. On the contrary, some advanced classification methods may need to merge the latitudinal and longitudinal coordinates in a single dimension.
2.2.2 Classification methods
Classification methods are widely used in climatology to summarize the climatological conditions captured by observations or simulations. Sokal (1966) was already using sophisticated univariate and multivariate climatic classification systems generated from enormous databases (Balling, 1984). However, the functions included in CSTools for this purpose are modern methods adapted to observations, reanalyses, and climate model outputs with multiple ensemble members.
The CST_MultiEOF function allows conducting empirical orthogonal function (EOF) analysis simultaneously over multiple variables, either for each ensemble member or all the ensemble members concatenated altogether (i.e., it can be applied to each one of the ensemble members separately or to the whole ensemble). Based on singular value decomposition, the EOF analysis is applied over the region of interest (for example the Mediterranean region) in order to define, for each of the N variables chosen, a reduced phase space based on the leading modes of variability. A simultaneous analysis of these fields is then carried out with a (multivariate) EOF analysis in the subspace spanned by the leading EOFs of each field. This produces a N-variable EOF picture of the variability in the region. The associated principal components can represent multi-variable indices that can be used to verify the forecast.
CST_WeatherRegimes and CST_RegimesAssign are complementary functions to derive weather regimes (Cortesi et al., 2019; Torralba et al., 2021). The first function computes a set of weather regimes using a cluster analysis. The dimensionality of this object can also be reduced by using principal components (PCs) obtained from the application of the EOF analysis to filter the dataset, while the cluster analysis can be performed with the traditional k means or hierarchical clustering. On the other hand, CST_RegimesAssign matches anomalies to a set of reference maps obtained using CST_WeatherRegimes. The anomalies are assigned to the most similar reference map using either the minimum Euclidean distance or the highest spatial correlation, which can be particularly useful to classify the predictions according to the clusters identified in the observational reference.
CST_CategoricalEnsCombination converts a multi-model ensemble forecast into a categorical forecast by giving the probability for each category. Different methods are available to combine the different ensemble forecasting models into probabilistic categorical forecasts. The user can set up the total number of categories that will be used to define the observed climatological quantiles. The available methods are “pool”, for ensemble pooling where all ensemble members of all forecast systems are weighted equally, “comb”, for a model combination where each model system is weighted equally, and “mmw”, for model weighting. The model weighting method is described in Rajagopalan et al. (2002), Robertson et al. (2004), and Van Schaeybroeck and Vannitsem (2019). More specifically, this method uses different weights for the occurrence probability predicted by the available models and by a climatological model and optimizes the weights by minimizing the ignorance score, which is a measure of the information conveyed by a forecast (Tödter and Ahrens, 2012).
CST_EnsClustering is a cluster analysis tool, based on the k-means algorithm, for ensemble predictions. The aim is to group ensemble members according to similar characteristics and to select the most representative member for each cluster. The user chooses which feature of the data is used to group the ensemble members by clustering (e.g., temporal mean). The anomaly is computed with respect to the ensemble members and the EOF analysis is applied to these anomaly maps. After reducing the dimensionality via EOF analysis, k-means analysis is applied using the desired subset of PCs. The user can choose how many PCs to retain or how much of the percentage of explained variance to keep for the EOF analysis.
2.2.3 Downscaling methods
Downscaling is designed to increase the resolution of a dataset. In a climate service chain, downscaling is a fundamental step to transform the climate simulations from their coarse resolution to the finer resolution required by many final users studying regional environmental changes (Maraun et al., 2010; Rössler et al., 2019). CSTools contains five different downscaling methodologies based on analog techniques, stochastic simulations, or regression.
The CST_Analogs function can be used to downscale any gridded dataset using analogs. The function, based on the method of Yiou et al. (2013), searches for days, with similar large-scale conditions, to provide high-resolution fields over a specific region. Regions and variables can be defined by the user, and the following three different criteria to select the analogs are available: (1) minimum Euclidean distance in the large-scale pattern, (2) minimum Euclidean distance in a large-scale pattern and in a local-scale pattern, and (3) minimum Euclidean distance in a large-scale pattern and a local scale pattern and a maximum correlation in a local variable to be downscaled. Typically, criterion (1) is used to find the analog based on a large-scale variable (e.g., sea level pressure/geopotential in the North Atlantic or sea surface temperature over the tropics). Criterion (2) helps to confirm that both large-scale patterns and the large-scale variable in a local scale (e.g., sea level pressure in the Iberian Peninsula) are consistent. Criterion (3) also measures the similarities between the large-scale variable and a different variable (e.g., surface temperature in the Iberian Peninsula) in the local scale.
CST_RainFARM implements a stochastic downscaling technique and represents a so-called full-field weather generator. More specifically, this function generates synthetic fine-scale precipitation fields whose statistical properties are consistent with the small-scale statistics of observed precipitation, while preserving the properties of the large-scale precipitation field. The Rainfall Filtered Autoregressive Model (RainFARM; Rebora et al., 2006a, b) is based on the nonlinear transformation of a linearly correlated stochastic field generated by small-scale extrapolation of the Fourier spectrum of a large-scale precipitation field. Developed originally for downscaling data at weather timescales, the method has been adapted for downscaling at climate timescales by D'Onofrio et al. (2014) and recently improved for regions with complex orography, for which the fine-scale fields produced by RainFARM are corrected using weights derived from a fine-scale precipitation climatology (Terzago et al., 2018). This methodology relies on two distinct functions to compute weights from high-resolution climatologies (CST_RFWeights) and the spatial-spectral slope used to extrapolate the Fourier spectrum to the unresolved scales (CST_RFSlope).
CST_RFTemp implements a simple lapse rate correction to a near-surface temperature field to account for changes in orography between a low- and high-resolution gridded dataset.
ADAMONT (ADAptation of RCM outputs to MOuNTain regions; Verfaillie et al., 2017) is a downscaling method designed to adjust forecasts of daily variables. The method is based on the quantile mapping approach and originally relied on a regional reanalysis of hourly meteorological conditions. In total, two functions to implement ADAMONT have been included in CSTools. CST_AdamontQQcor computes a quantile mapping based on weather types for forecast data, while CST_AdamontAnalog uses these weather types to find analogous data in the reference dataset.
The CST_AnalogsPredictors function downscales precipitation or maximum/minimum temperature low-resolution forecast output data through the association with an observational high-resolution dataset (Peral García et al., 2017) and a collection of predictors and reference synoptic situations similar to the estimated day. As a first step, a partner function AnalogsPredictors_train must be run to compare the large-scale atmospheric circulation to each of the atmospheric configurations from a reference period. The most similar days, defined by the Euclidean distance of winds, are chosen as their analogs.
2.2.4 Correction methods
Correction methods can improve the quality of simulations by reducing the systematic errors that are present in the forecast due to model deficiencies. The periodicity of modes of variability (i.e., space–time patterns that tend to recur in the observed record) can also be exploited to improve the forecast skill.
Sánchez-García et al. (2019) used the North Atlantic Oscillation (NAO) to improve the skill of the seasonal precipitation forecast over the Iberian Peninsula. Given that this methodology could be explored to improve the skill of different climate variables that are led by other climate indices, the method has been generalized and named the best estimate index (BEI). The methodology consists of the following three functions: BEI_PDFBest combines the climate indices from the two forecast systems, BEI_Weights provides the weights to correct a forecast system, and CST_BEI_Weighting computes the ensemble mean or the tercile probabilities considering the weights returned by BEI_Weights.
Calibration can be considered as being a way of obtaining predictions with average statistical properties similar to those of a reference dataset. CST_Calibration performs the correction on the forecast systems' simulations using five different member-by-member methodologies, where each methodology can adjust one or more of the statistical properties of the predictions. The selection of the most appropriated method will thus depend on the user's needs. The “bias” method corrects the mean bias only, and the “evmos” method applies a variance inflation technique to ensure the correction of the mean and the correspondence of variance between forecasts and observations (Van Schaeybroeck and Vannitsem, 2011). The ensemble calibration methods “mse_min” and “crps_min” correct the bias, the overall forecast variance, and the ensemble spread as described in Doblas-Reyes et al. (2005) and Van Schaeybroeck and Vannitsem (2015), respectively. While the mse_min method minimizes a constrained mean squared error using three parameters, the crps_min method features four parameters and minimizes the continuous ranked probability score (CRPS). The “rpc-based” method adjusts the forecast variance to ensure that the ratio of predictable components (RPC) is equal to one (Eade et al., 2014). The function allows the five calibration methods to be performed in leave-one-out cross-validation mode, which means that the observed value of the year that is being corrected is not considered in the calibration, as it would be the case for real-time forecasts (Doblas-Reyes et al., 2005; Torralba et al., 2017). The use of cross-validation is particularly important in order to avoid overestimating the skill when the hindcasts are calibrated. CST_BiasCorrection performs the same analysis as CST_Calibration using the evmos method but allowing us to calibrate either a hindcast or forecast.
CST_QuantileMapping performs a quantile mapping adjustment by matching the probability distribution of a forecast with the probability distribution of a set of observations. The function in CSTools calculates the relation between a set of past forecasts (i.e., hindcasts) and observations and applies the correction to the hindcast itself or to a different forecast. This function relies on the R package qmap (Gudmundsson et al., 2012; Gudmundsson, 2016). The user can set several parameters to define the distance between quantiles when adjusting the distribution, or the sample length in cases when the user wants to split the temporal dimension to apply separate adjustments.
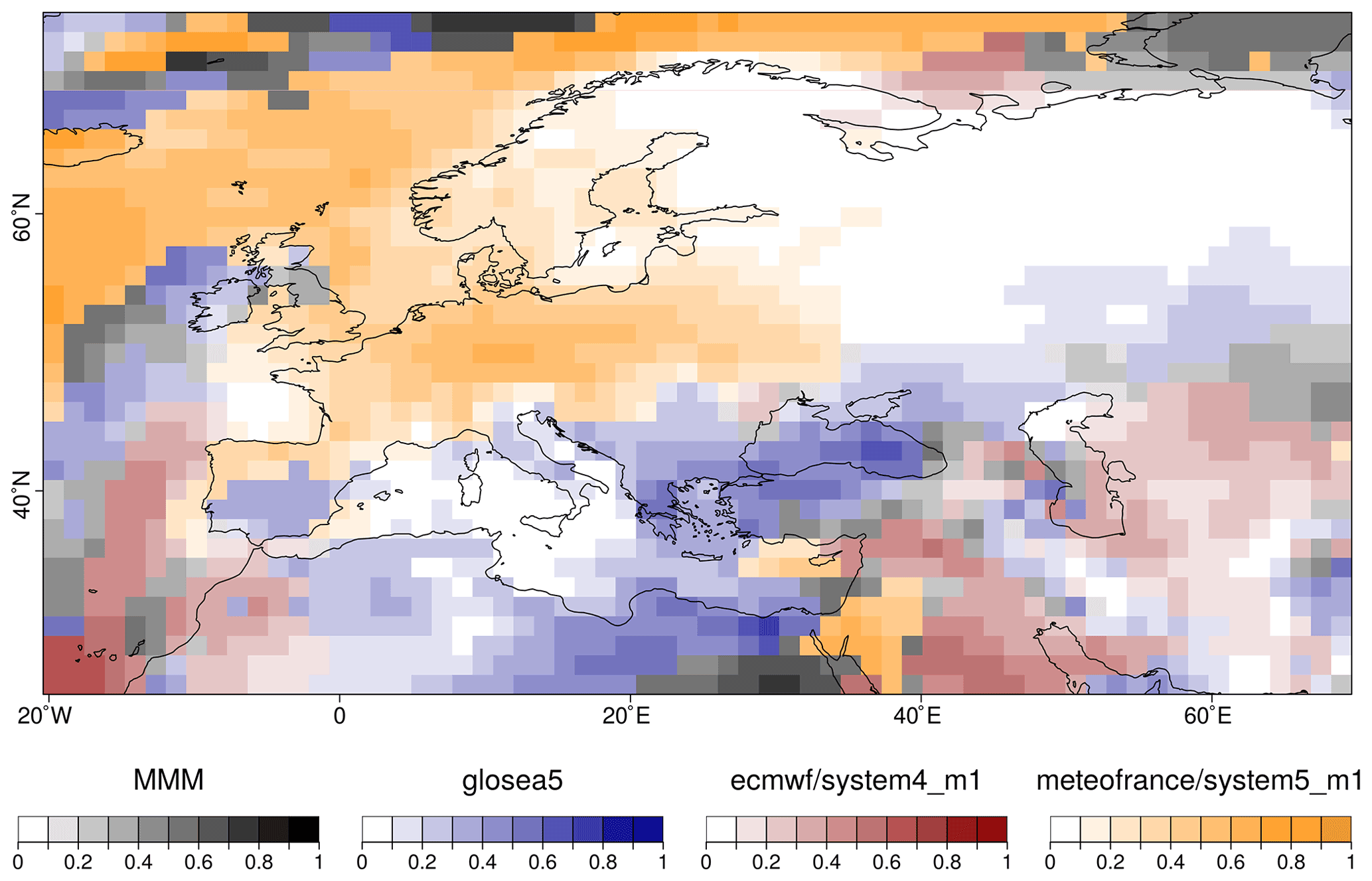
Figure 2Example of the PlotCombinedMap result over Europe comparing different forecasts systems and the multi-model mean by colors and the highest correlation value in each grid point by color intensity.
CST_DynBiasCorrection relies on the dynamical state of the system to correct the systematic errors rather than on its statistical properties. This method uses two dynamical system metrics to correct the bias of each ensemble member, i.e., the local (in phase space) dimension and the persistence. In simple terms, they describe the recurrences of a system around a state in phase space. The dimension provides information on how the system can reach a state and how it can evolve from it. Thus, dimension is a proxy for the system's active number of degrees of freedom. A very persistent state is typically highly predictable, while a very unstable state yields low persistence (Faranda et al., 2017, 2019). The functions CST_ProxiesAttractor (to compute local dimension, d, and inverse of persistence, theta) and Predictability (to compute scores of predictability based on the dynamical indicators resulting from CST_ProxiesAttractor) are internally used by CST_DynBiasCorrection, and they are also exposed for users interested in interpreting the method's intermediate results.
2.2.5 Verification functions
Verification is not the main objective of this package. For that purpose, we refer users to other R packages such as s2dverification, SpecsVerification, and easyVerification. However, in order to facilitate the evaluation of the forecasts, some basic metrics have been included.
CST_MultiMetric calculates correlation, root mean square error, and the root mean square error skill score, for individual models and the multi-model mean (if desired; Mishra et al., 2019), as well as the ranked probability skill score (RPSS) based on terciles.
CST_MultivarRMSE calculates the RMSE using multiple variables simultaneously. The output is the mean of each variable's RMSE scaled by its observed standard deviation. Variables can also be weighted based on their relative importance (as defined by the user).
2.2.6 Visualization
Some of the most requested functionalities in climate services are data visualization tools that allow the presentation of large quantities of information in an intuitive way. All the visualization functions in CSTools can be customized by modifying colors, titles, sizes, etc., and it is possible to save them to files in different formats (.ps, .eps, .png, .pdf, etc.) or to display the result in a pop-up window.
PlotCombinedMap combines multiple 2-dimensional datasets into a single map based on a decision function. In other words, several maps are provided as input, and for each map, the function creates a color legend. A decision function is used at each grid point to choose the value to be displayed, thus retaining the information of which map it belongs to in the process. For instance, multiple model skills could be compared in a region to visualize which is the best model in each region (Fig. 2; Mishra et al., 2019). Other applications, such as comparing multiple variables, are also possible.
PlotMostLikelyQuantileMap allows visualizing different probabilities easily. It receives as main input (via the parameter “probs”) a collection of longitude–latitude maps, each containing the probabilities (from 0 to 1) of the different grid cells belonging to a category, namely terciles, quantiles, or others (Fig. 3; Lledó et al., 2020; Torralba, 2019). The function plots the probability for the category with the maximum probability for each grid point.
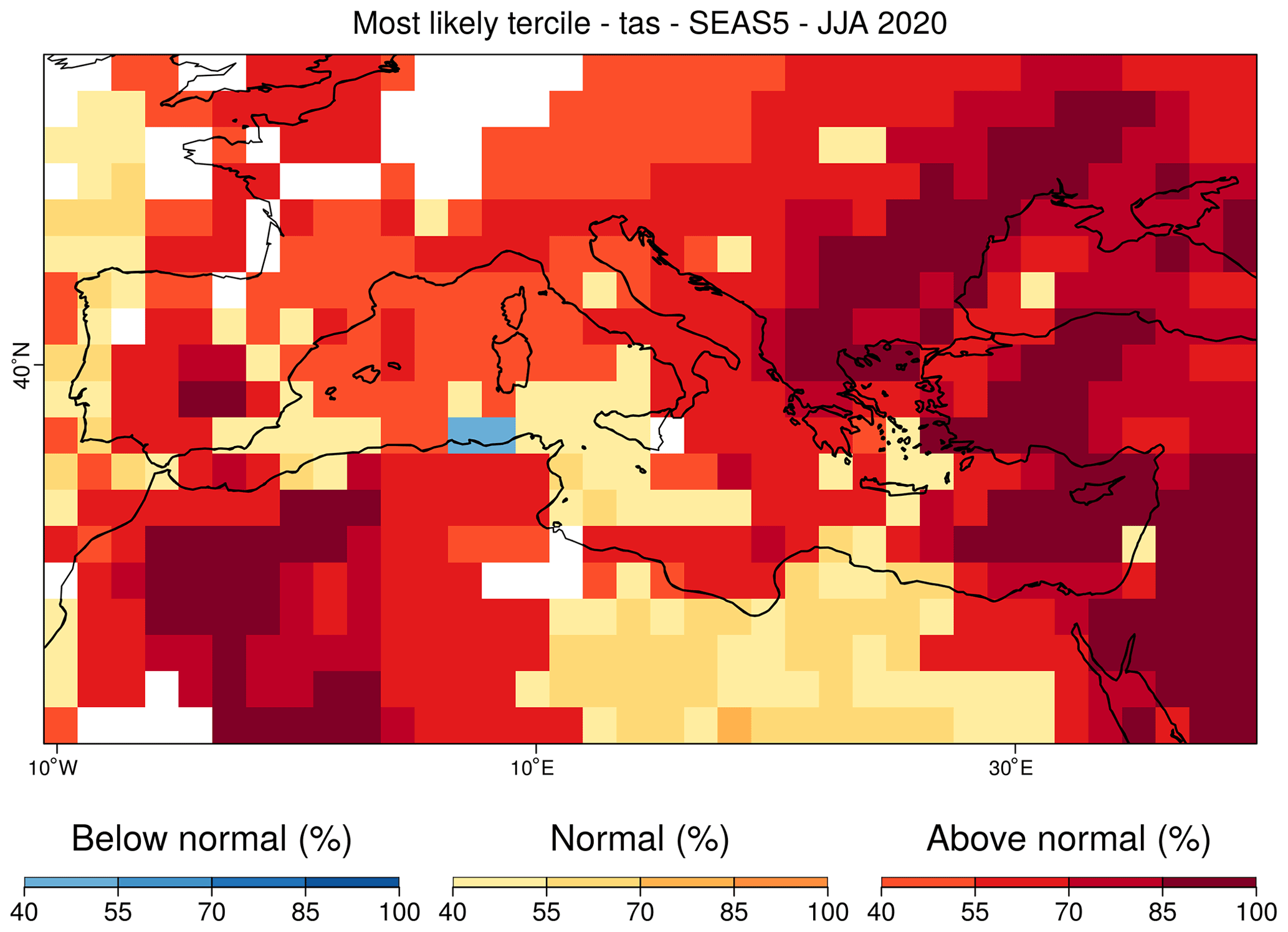
Figure 3Example of a PlotMostLikelyQuantileMap for which the tercile probabilities of the summer sea surface temperatures of 2020 in the Mediterranean region are compared. The function allows us to apply a mask (white grid points), which in this case correspond to areas where the system does not have sufficient skill for a given metric over the verification period.

Figure 4Example of a PlotForecastPDF result, using the lonlat_data sample provided along with CSTools, showing a possible comparison of two different lead times for a given forecast in a specific location. The individual ensembles (yellow dots), the corresponding observation (purple diamond), the probability of each tercile, i.e., above normal (pink), normal (green), and below normal (blue), are annotated, and the one with highest probability is marked with an asterisk and the extreme limits, i.e., above the 90th percentile (red) and below the 10th percentile (blue) correspond to the hatched areas and are also annotated.
PlotForecastPDF plots the probability distribution function of several ensemble forecasts in separate panels. By default, the function plots the ensemble members, the estimated density distributions, and the tercile probabilities (Fig. 4). The density functions are approximated by dressing the ensemble members with a kernel density estimate technique using a Gaussian kernel (Bröcker and Smith, 2008). Silverman's (1986) rule of thumb is used to select the spread of the kernel, which controls the degree of smoothing. Probabilities for extreme categories, above (below) the 90th (10th) percentile (from now on denoted as P90 (P10)), and observed values can also be included. This function is useful to compare changes in forecasts with different lead times (Soret et al., 2019). A comparison between forecasts from different models, different modes of variability (Lledó et al., 2020), or even forecasts at different locations is also possible.
PlotPDFsOLE plots two probability density Gaussian functions and their combination by the optimal linear estimation (OLE; Fig. 5). The mean and the standard deviation of the two probability functions must be provided (Sánchez-García et al., 2019).
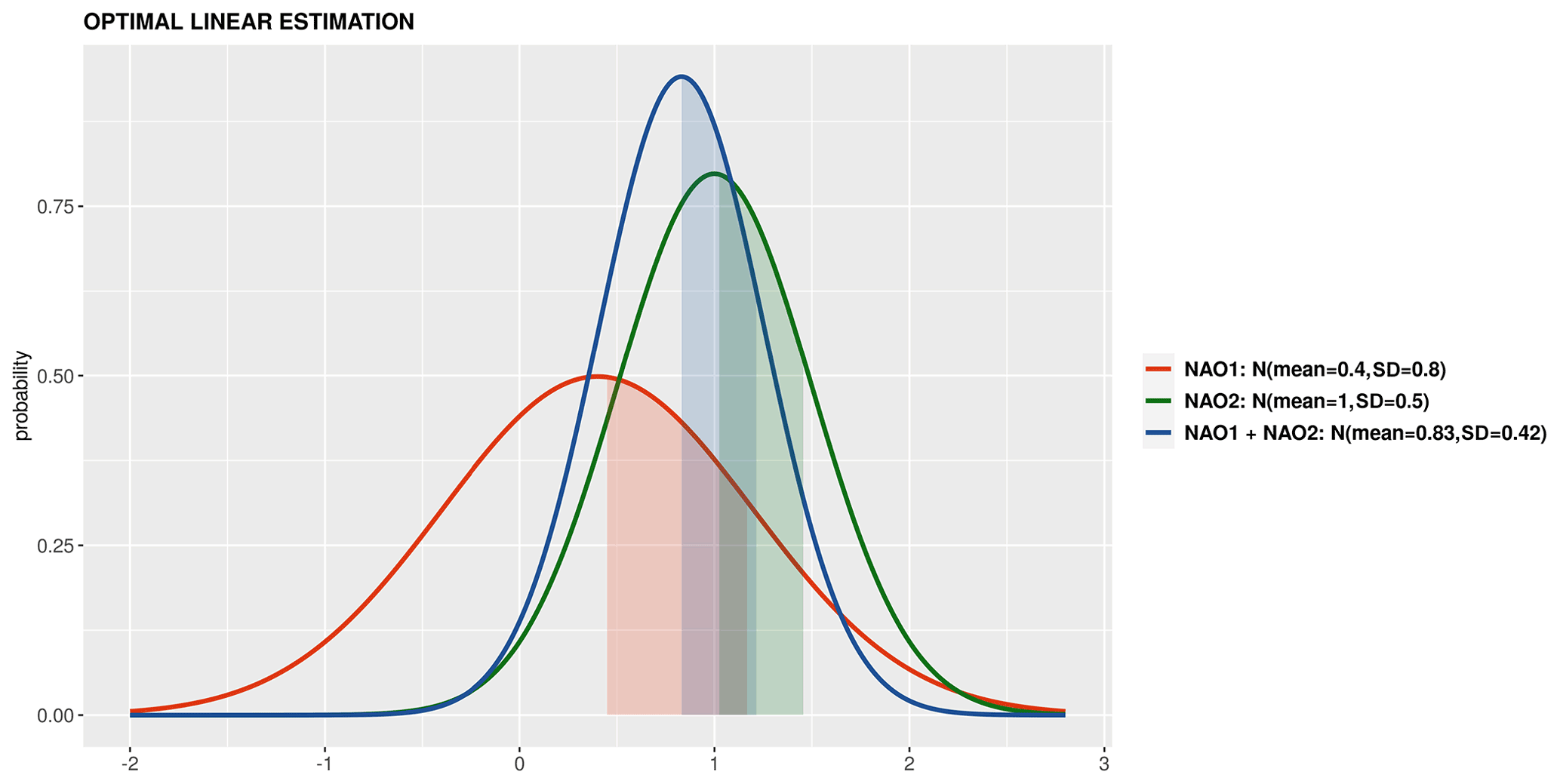
Figure 5A synthetic example of a PlotPDFsOLE in which two distribution functions are combined.
It can sometimes be useful to present tabular results as colors instead of numbers. For this purpose, PlotTriangles4Categories converts a 3-dimensional numerical data array into a colored grid with triangles (Fig. 6). This function can be used to quickly compare modes of variability, skill metrics, differences between methods, or forecast systems as a function of the lead times or seasons (Torralba, 2019; Verfaillie et al., 2021; Lledó and Doblas-Reyes, 2020).

Real examples of these visualization tools and other functions of the package are shown through the three example case studies provided in the next section.
In order to demonstrate how CSTools can be used to provide climate information to potential users, we present three case studies which rely on CSTools for data post-processing. The first case study assesses whether seasonal forecasts could anticipate the very strong near-surface winds over the Iberian Peninsula in March 2018 so as to provide useful information to the energy sector. In the second case, seasonal forecasts of precipitation are post-processed following the requirements to use them to drive model of snowpack depth in high mountain sites. Finally, we provide an example of how seasonal forecasts of rainfall and near-surface temperature can be post-processed.
3.1 Use case 1: assessing the odds of an extreme event
In March 2018, the Spanish Meteorological Agency activated its protocol of an early warning system for 47 regions of Spain due to the high-speed winds forecasted and possible coastal impact. Very high wind speeds were later recorded over large parts of the Iberian Peninsula due to the passing of four cyclones (AEMET, 2018). This type of event is of interest to the energy sector, given its impacts on wind power generation, energy demand, and electricity prices, and such an interest is likely to keep rising as we continue transitioning towards, and become more reliant on, renewable energy. For context, the renewable energy production had grown substantially in Spain over the course of 2017–2018, and renewable energy generation was 51.1 % higher in March 2018 compared to what it had been during the same month of the previous year. A historical maximum of monthly renewable generation was hit with 13 204 GWh (33.1 % of the share), of which wind energy contributed 7676 GWh, setting also a new record of monthly wind generation (Red Eléctrica de España, 2018). These high amounts of renewable generation in March 2018 resulted in an important drop in electricity prices. Because of its strong impact on the market, there is a lot of interest in the energy sector in anticipating this type of event.
The use case presented here shows whether the 2018 event had been anticipated a few months in advance by a seasonal forecast system. For both the hindcasts and the forecasts, we use monthly means of 10 m wind speed from the latest ECMWF long-range forecasting system SEAS5, obtained from the C3S data store (SEAS5; Johnson et al., 2019) at 1∘ spatial resolution. For the observational reference, we use monthly mean 100 m wind speeds from the ERA5 reanalysis (Hersbach et al., 2020) at 0.25∘ (around 30 km) spatial resolution. The seasonal forecasts initialized on December 2017, January 2018 and February 2018 are assessed. For each start date, three different data types are required, namely the hindcast, i.e., retrospective forecasts initialized in the past for start dates ranging from 1993 to 2016 for the December initialization and 2017 for the January and February initializations, the observational reference, which covers the same period as the hindcast, and the operational forecast, i.e., the latest simulations initialized just before the event (i.e., December 2017, January 2018, and February 2018).
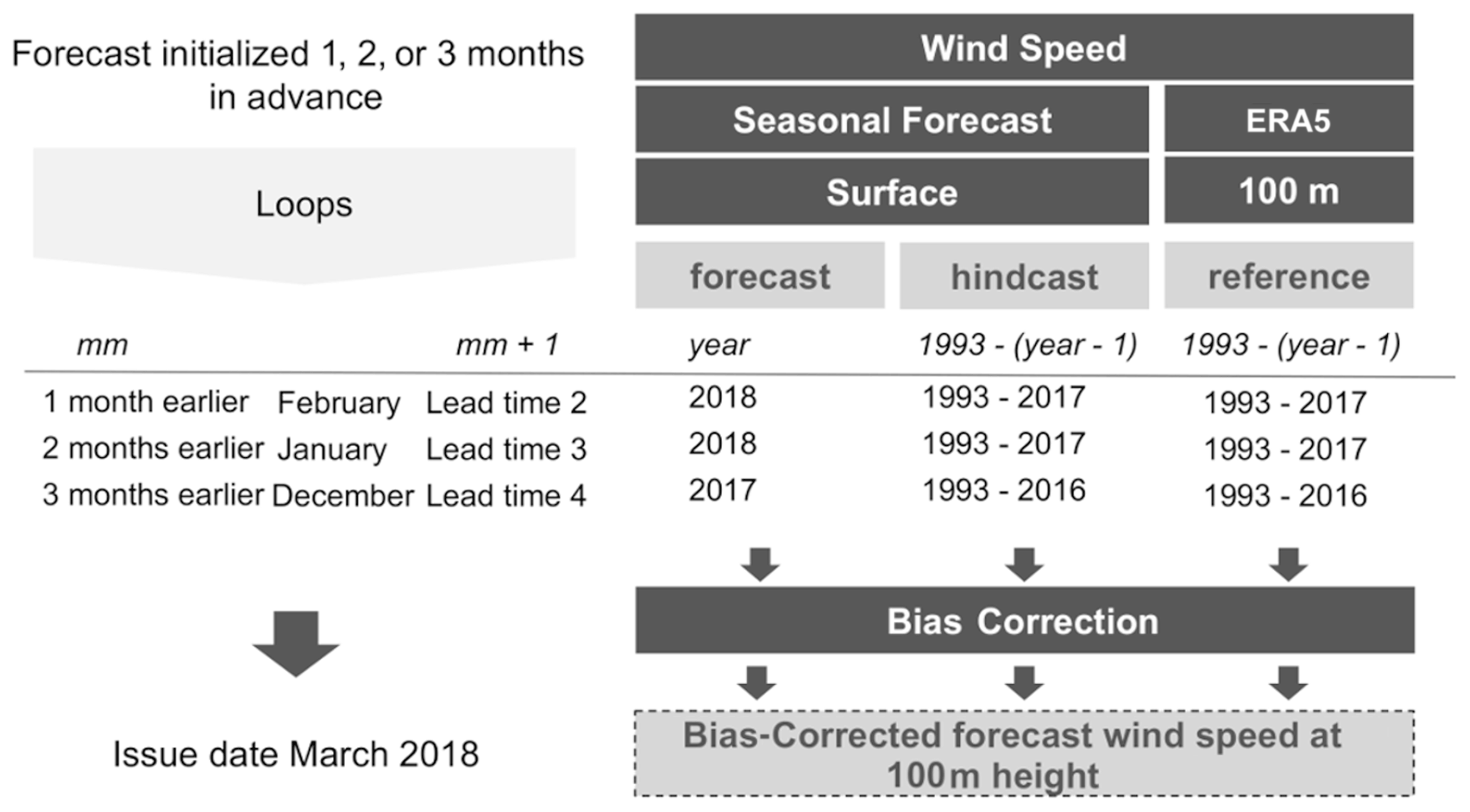
Figure 7Scheme of the methodology applied. Gray boxes indicate the data, methods, and results. The required parameters to analyze the March 2018 event are specified for the simulations initialized 1, 2, and 3 month(s) in advance on a white background.
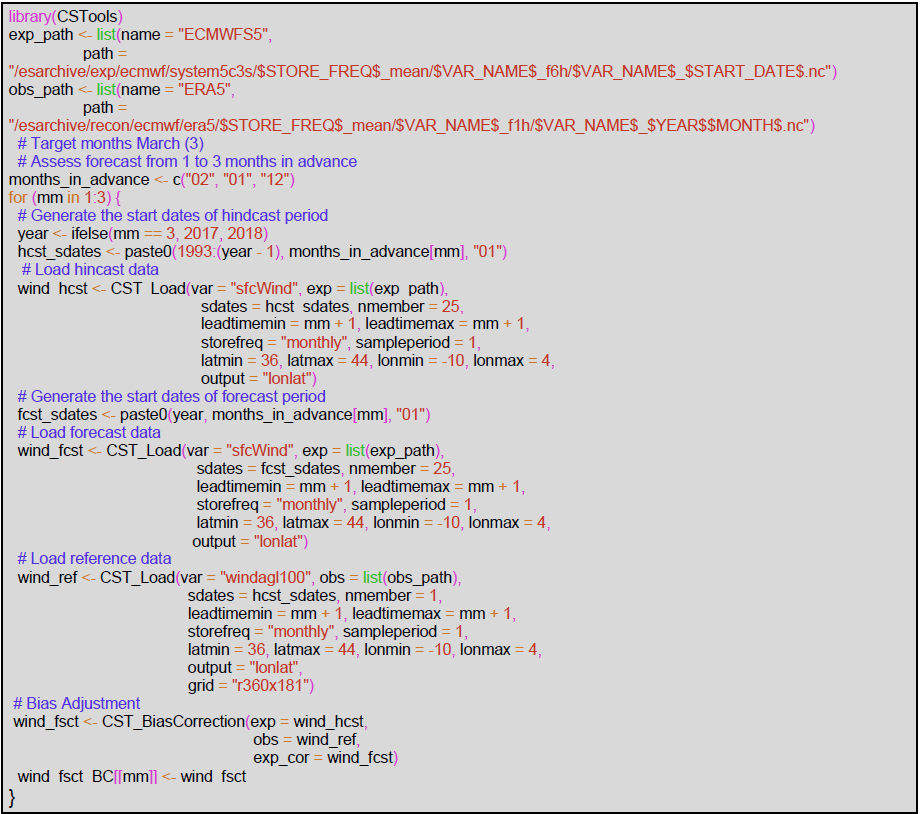
There are two functions from CSTools used to post-process the wind speed seasonal forecasts, i.e., CST_Load and CST_BiasCorrection. The key decisions are the parameters used to retrieve the data from files to achieve a coherent analysis of the March 2018 event (Fig. 7). The analysis is repeated for three different start dates (i.e., December, January, and February). In all the data loading calls, the same region must be requested through the parameters lonmin, lonmax, latmin, and latmax of the function CST_Load. The output type requested to be gridded data rather than area average by setting output parameter as “lonlat”. Note that the code could be adapted to other regions, time periods, and variables, and a detailed description of the code is provided below for users interested in modifying the necessary parameters.
The name of the different variables required must be specified in the CST_Load call through the parameter var, and the function will read the corresponding variables written in the NetCDF files in the data storage. Therefore, the var parameter is set to “sfcWind” when retrieving hindcasts and forecasts, while for the reference dataset it is set to “windagl100”. Given the difference in spatial resolution, a regridding of the reference dataset is also requested via the grid parameter. The path patterns expressing the set of files that comprise the simulations and the reference datasets are also passed to the CST_Load function through parameters exp and obs, respectively. Note that the labels $STORE_FREQ$, $VAR_NAME$, $START_DATE$, $YEAR$, and $MONTH$ are used when defining the patterns. These labels will be interpreted and replaced by the function following the information provided in the other parameters of CST_Load.
An index, mm, indicating the number of preceding months (mm) is introduced to loop over the three start dates in order to simplify the code. When mm is 1, the bias adjustment for March with the forecasts initialized 1 month in advance (i.e., the February start date) is computed. The target year is set in the year variable as 2018. The start dates of the simulations to be loaded are created and stored in the “hcst_sdates” and “fcst_sdates” variables, which correspond to a vector of dates for 1 February from 1993 to 2017 and 1 February 2018, respectively. For the February start date, the second lead time (i.e., mm + 1) corresponds to the forecast for March, which is selected through the leadtimemin and leadtimemax parameters.
Finally, a simple bias correction method (CST_BiasCorrection) is used to compute the biases between the hindcast and the reference datasets and then apply a correction to the mean and standard deviation of the forecast dataset. The results of each loop are stored in a list. Winds at 100 m height are of relevance for energy applications and, although this variable is not available directly from the seasonal prediction system, the bias adjustment procedure will convert 10 to 100 m winds by assuming a logarithmic wind profile (Drechsel et al., 2012).
Once the forecasts are post-processed, additional CSTools functions can be used to visualize the forecast distributions. The PlotForecastPDF function, for instance, compares the probability distribution function of the March 2018 100 m wind speed forecasts issued 1 to 3 month(s) in advance (Fig. 8). And, 3 months in advance, only one member out of 25 exceeds the P90. The simulations initialized 1 and 2 month(s) in advance suggest a weak shift towards above-normal conditions (∼40 % probability of the above-normal tercile) and towards extremely high values (12 % and 17 % exceeding P90). Moreover, the forecast's tercile probabilities do not indicate a shift towards above-normal winds as lead time decreases (the January start date suggests a slightly larger probability of above-normal winds than the February start date). Even though, for start dates in both January and February, three members exceed P90, the corresponding probabilities are different due to the ensemble dressing applied (see Sect. 2.2.6 for details). In February, the probability of observing extreme wind conditions was almost twice as large as in January. Individual ensemble members typically also suggest much weaker wind speed anomalies than observed, except for one member in the February initialization, indicating that in this case the prediction system anticipated this situation as a potential outcome.
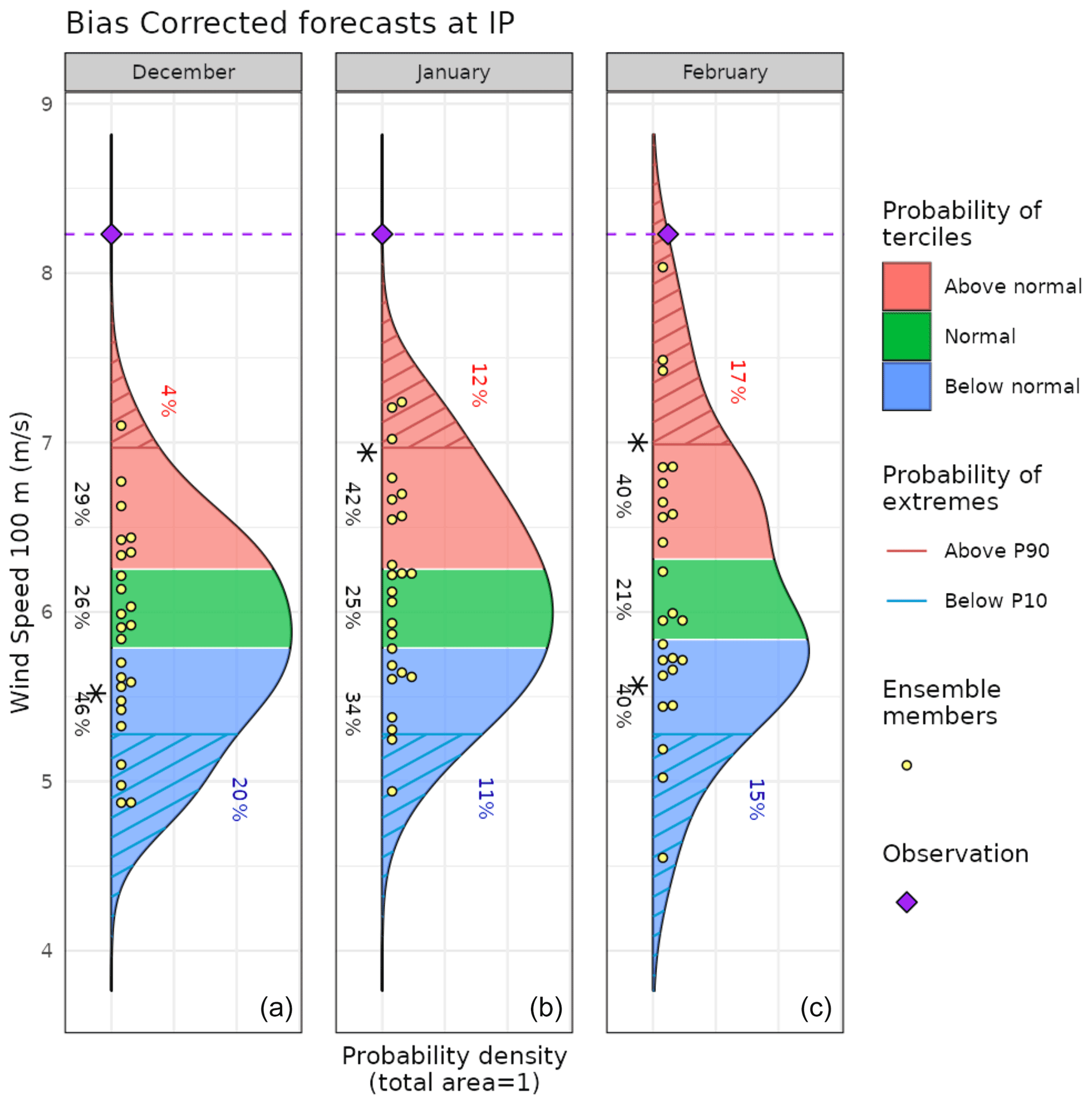
Figure 8Seasonal forecasts of wind speed at 100 m height, averaged over 10∘ W–4∘ E and 36–44∘ N for March 2018. Each panel corresponds to forecasts launched 3 to 1 month(s) ahead (from panels a to c). The methodology is a simple bias correction with ERA5 observations, based on previous hindcasts since 1993. An asterisk indicates the tercile with the highest probabilities.
The spatial distribution of the tercile probabilities can be displayed with the PlotMostLikelyQuantileMap function (Fig. 9). An extra layer has been included to mark, with crosses, the grid points where observations agree on the most likely tercile indicated by the forecast. And, 3 months in advance, most of the region shows that the tercile of highest probability is the below-normal category. At 1 and 2 month(s) in advance, the colors shift towards the normal and above-normal categories. In the January simulation, the eastern region presents more above-normal probability of high wind speed values than the western region. In the February simulation, the above-normal probability class is widespread on the whole Iberian Peninsula.

Figure 9Probabilities of the most likely tercile for the March 2018 100 m wind speeds, as indicated by the forecasts issued 3 to 1 month(s) ahead (top to bottom). The crosses indicate that the observations fell into the most likely tercile displayed by the forecast. White grid points indicate that no tercile category has more than 40 % of the probability.
Users that can benefit from climate information, such as stakeholders (e.g., energy system planners), are usually not familiar with probabilistic forecasts and the added value that it could potentially bring to their planning. In order to become more autonomous in their decision-making, a learning process could be started based on relevant showcase climate events such as the one provided here. Therefore, such a use case could be of interest for climate services developers who need to post-process a seasonal forecast variable and present the results in a concise, yet user-friendly, manner with a reduced number of images and tables.
The code of this use case could be reused to evaluate the seasonal forecast performance. The evaluation could consider whether other variables were better at capturing the situation in a specific event or if a different bias correction method would improve the skill of the seasonal forecast. Furthermore, it is possible to easily modify this code to compare the results provided by different models.
3.2 Use case 2: seasonal forecast of snow depth and snow water equivalent in high-elevation sites
The post-processing of the seasonal precipitation forecast in the Alps to be used as input for the SNOWPACK model is shown in this use case, in addition to the result of the SNOWPACK model snow depth. The relevance of this use case is that Alpine snowpack represents an essential water reservoir that is fed by snowfall during the cold season and then released in late spring and summer. Mountain meltwater is essential for several economic activities, including hydropower generation, agriculture, and industry, while meltwater shortage can induce strong economic losses. Therefore, reliable seasonal forecasts of snow resources that, at the beginning of the snow season (November), estimate the snow accumulation towards the end of spring (April–May), are highly pursued. These would allow water management authorities and hydropower companies to implement early water management plans several months ahead of a water demand peak and mitigate the effects of a possible water shortage. To support this need, a modeling chain driven by seasonal forecasts of essential climate variables from the C3S seasonal forecasting systems was developed, employing the physical 1-dimensional snow model SNOWPACK (Bartelt and Lehning, 2002), to estimate snow depth and snow water equivalent at selected high-elevation sites in the northwestern Italian Alps.
The SNOWPACK model requires a number of input variables, namely 2 m air temperature, atmospheric pressure, relative humidity, shortwave and longwave incoming radiation, wind speed, and ground temperature, at finer spatial and temporal resolutions (hourly; 1 km data) compared to the typical resolutions of the seasonal forecast system outputs (6 h or daily; about 100 km data). In order to provide the SNOWPACK model with the required climatological forcing, we apply bias adjustment and downscaling techniques depending on the specific variable.
-
Seasonal precipitation forecasts need to be downscaled and bias corrected.
-
Seasonal temperature forecasts need to be bias corrected using the daily annual climatology of station observations.
-
All other variables need to be bilinearly interpolated to the coordinates of the study sites.
After the spatial downscaling, seasonal forecast data are interpolated to 1 h temporal resolution with different methods depending on the variable (Terzago et al., 2022).
The post-processing of seasonal precipitation forecast is shown in this section. The target season is winter, so the 1 November start date simulations available for the period 1993–2018 for daily precipitation data of SEAS5 are being post-processed. The reference datasets employed are (i) ERA5 daily precipitation reanalysis at 0.25∘ (around 30 km) spatial resolution, for the bias correction and for the estimation of the spectral slopes employed in the downscaling procedure, and (ii) the WorldClim2 monthly climatology at 1 km spatial resolution (Fick and Hijmans, 2017), for generating the precipitation weights used to introduce the orographic effects in the downscaled fields. In this case, the region of study is the Alps mountain range in central Europe (42–49∘ N, 4–11∘ E), including the high-elevation stations for which the SNOWPACK model is run (although SEAS5 and ERA5 datasets are locally stored for the global domain).
The RainFARM downscaling method incorporated within CSTools is employed to downscale precipitation which is then used as input for the SNOWPACK model. This method allows taking into account the orographic effects on the precipitation distribution and generates a user-defined number of stochastic downscaling realizations for each member of the original seasonal forecast simulations. For each ensemble member of the seasonal forecast model, we generate 10 stochastic downscaling realizations. In the following subsection, we present the method applied to the SEAS5 model providing 25 ensemble members, such that, at the end of the downscaling procedure, we obtain a total of 250 fine-scale precipitation fields.
Since the RainFARM downscaling relies on the estimation of the spatial power spectrum of precipitation fields, a squared domain is required. Moreover, this domain has to be larger than the target study area to avoid artifacts/border effects within the target area.
Figure 10 shows the three steps that should be carried out before applying the RainFARM method. Steps 1 to 3 are dedicated to bias correct the precipitation forecast with the quantile mapping correction and compute the spectral slopes and the orographic weights required for the downscaling. In step 4, the downscaling procedure is applied.
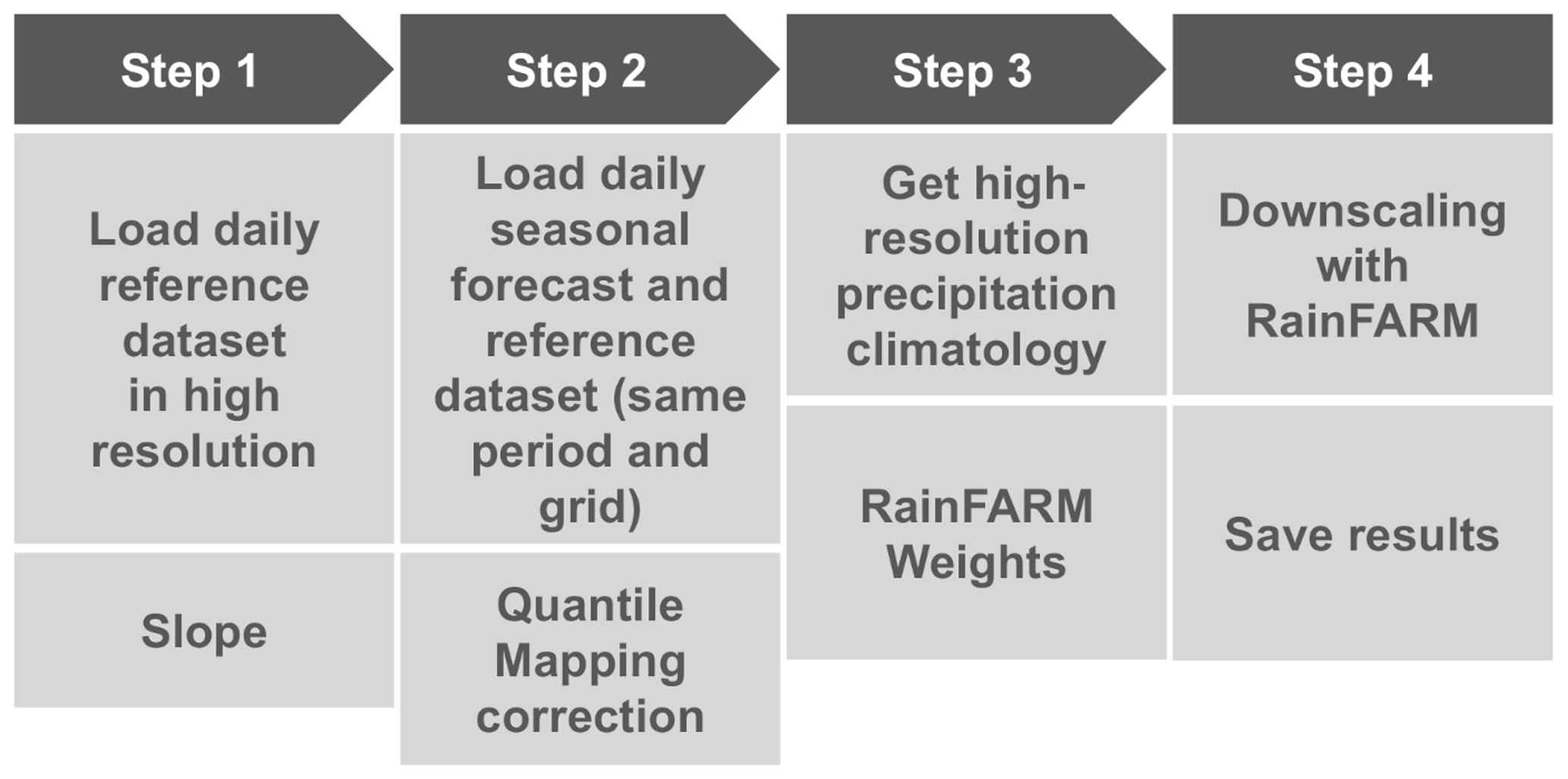
Figure 10Scheme of the steps that need to be carried out to obtain and save a downscaled precipitation dataset. These steps are explained in detail in the text of the paper.
All computations performed in the first step only require the CSTools package. As mentioned above, the spectral slope is calculated using ERA5 at its original resolution and over a larger domain than the target region (37.5–53.25∘ N, 2.5–18.25∘ E). The path pattern to the data is defined using the following labels: $STORE_FREQ$, $VAR_NAME$, $YEAR$, and $MONTH$. These labels will be interpreted by CST_Load. For instance, the $VAR_NAME$ will be substituted by the information passed by the parameter var, which in this case is “prlr” and stands for precipitation rate, and the $YEAR$ and $MONTH$ will be interpreted from the CST_Load sdates parameter which requires a vector of dates in the format “YYYYMM01”, where YYYY is the year and MM the month. Then, CST_Load retrieves the data from files and arranges it with the following dimensions: dataset of length 1, since only ERA5 is being requested, member = 1, since this reanalysis only provides one simulation, and the sdate dimension is of length 312, which corresponds to the 26 years of 12 months defined in object years with the ftime dimension up to 31, corresponding to each day of the month. The remaining dimensions, lat and lon correspond to the squared domain requested in CST_Load. Given that CST_Load splits the time series among sdates and ftime dimension when specifying a forecast dataset, our ERA5 path pattern has been requested through this option. On the other hand, specifying the ERA5 path pattern as an observational dataset (in the obs parameter), the function will return a continuous time series from 1993 to 2018, which is less convenient for our purposes here.
In this example over the Alpine domain, the slope of the spatial power spectrum of ERA5 daily precipitation at 0.25∘ exhibits temporal variability at the seasonal scale. In order to account for this, we calculate the spectral slopes at the monthly timescale, fitting wavenumbers 5 and higher (scales smaller than about 250 km) in order to better reproduce the slope of the spectrum at small scales (see Terzago et al., 2020, for details). The results of this code are the spectral slopes from January to December.
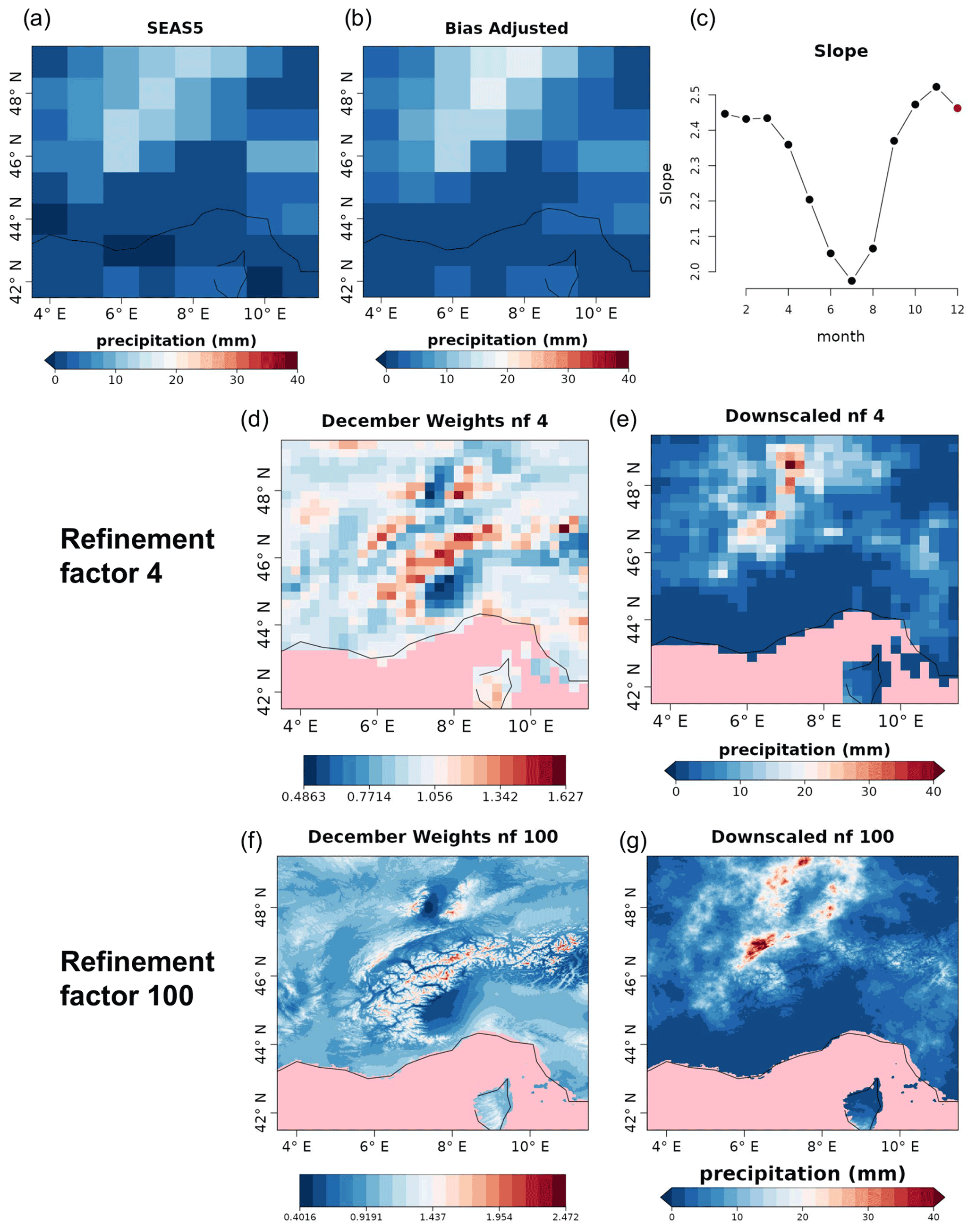
Figure 11One out of 25 ensemble members of the original ensemble (a) large-scale precipitation field for SEAS5 for 11 December 1993 to be downscaled, (b) a bias-corrected field, and (c) monthly slopes (the slope used for downscaling is highlighted in red). In the middle (refinement factor 4) and bottom (refinement factor 100) rows, the comparison of the weights (d, f) and the downscaled (e, g) precipitation fields for SEAS5 for 11 December 1993 are shown. Grid points for which no data are available are colored in pink.
In the second step, we load the data, taking advantage of library zeallot (Teetor, 2018) that allows us to simplify our code by using an advanced version of the assignment operator (% < − %). Again, the paths to the necessary data must be defined using labels; for the forecast data, the path points to the SEAS5 dataset, while for the reference data, the path points to the ERA5 reanalysis. Thanks to CST_Load, these datasets can be interpolated onto a common grid, which, by default, is the grid of the first dataset provided, i.e., the SEAS5 grid. The vector “StartDates”, which defines the period of study for the 1 November simulations, is then assigned to the sdates parameter. In order to apply the quantile mapping correction month by month, the function CST_SplitDim is used to divide the forecast time dimension in two, with one for identifying the days of the month and another to store each month separately.
Step 3 computes the orographic weights from a fine-scale precipitation climatology. In this case, the WorldClim2 dataset precipitation at 30 s resolution is used although other climatologies from a high-resolution dataset could be used. The WorldClim2 dataset is formatted in .tiff files that can be automatically downloaded in the R session thanks to the raster library (Hijmans, 2020). The piece of code for Step 3 shows how to compute the orographic weights for all individual months at once, i.e., obtaining the data from the remote dataset, subsetting for the Alps region with a small increment to correctly compute interpolation (3.5–11.5∘E, 41.5–49.5∘ N), and storing the data in an s2dv_cube object to be passed to CST_RFWeights.
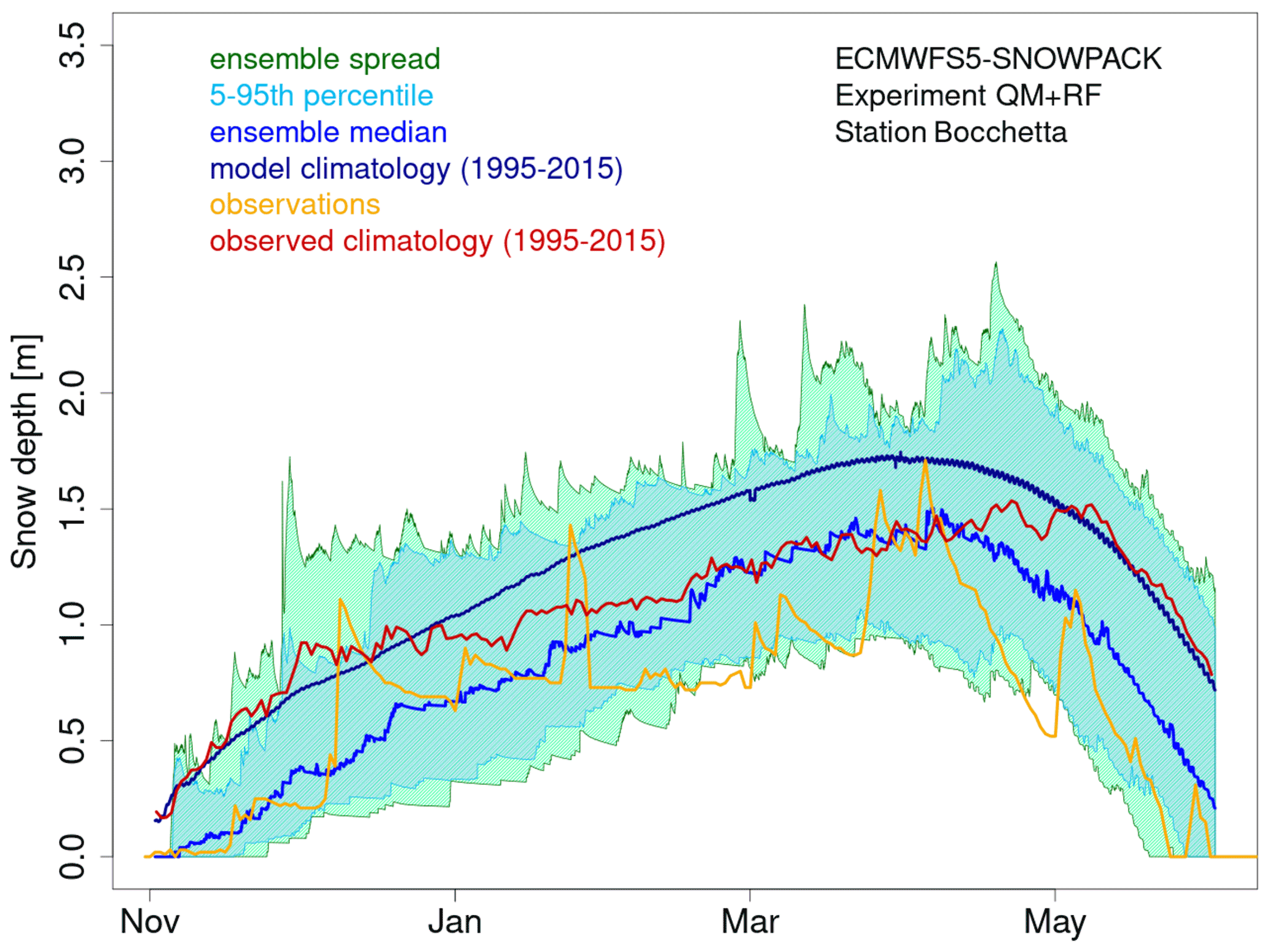
Figure 12Seasonal forecast of snow depth obtained from the SNOWPACK model driven by the SEAS5 seasonal forecast system data. The forecast, initialized on 1 November 2006 and covering the 7 following months, refers to the station of Bocchetta delle Pisse, 2410 m a.s.l. (above sea level) in the northwestern Italian Alps. The green shadow shows the spread of the 250 daily snow depth forecast ensemble members, the cyan shadow represents the 5th–95th percentile range of the forecast distribution, the blue line represents the ensemble median of the 250 ensemble members for the 2006/2007 season, the dark blue line represents the model climatology (mean over the seasons 1995–2015 and over all ensemble members), the red line represents the observed climatology, and the orange line represents the station observations for the 2006/2007 season.
The target resolution is the one most suitable for each specific application. To run the SNOWPACK model, we are interested in the local scale, and we choose a target resolution of 0.01∘, corresponding to about 1 km. Therefore, the weights and the RainFARM method (step 4) would be computed with a refinement factor (nf) of 100. However, such a high refinement factor implies a rather large computational load, and here we show the code using refinement factor 4. We recommend that the users to approximate the expected size of the final output, as follows: the original data input of the downscaling step has 25 members, 26 start dates, and 31 daily lead times in 8 months, covering a region of 8 by 8 grid points, which is 8 (bits/byte) times its product at ∼80 MB; this size will increase by a factor of 10, since the realizations and the refinement factor will be applied on both spatial dimensions. For a refinement factor of 100 (4), the expected output is ∼80 MB × (∼80 MB ), so around 8 TB (12.5 GB). The users need to consider that the data size also has implications for the computation time.
Finally, the downscaling method is run in step 4 using the corrected forecast, the slope, and the weights computed in the previous steps. Note that this code requires high memory resources, although the computation can be split by start date and realization if necessary.
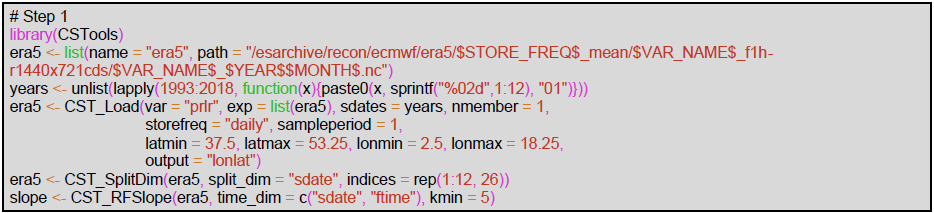
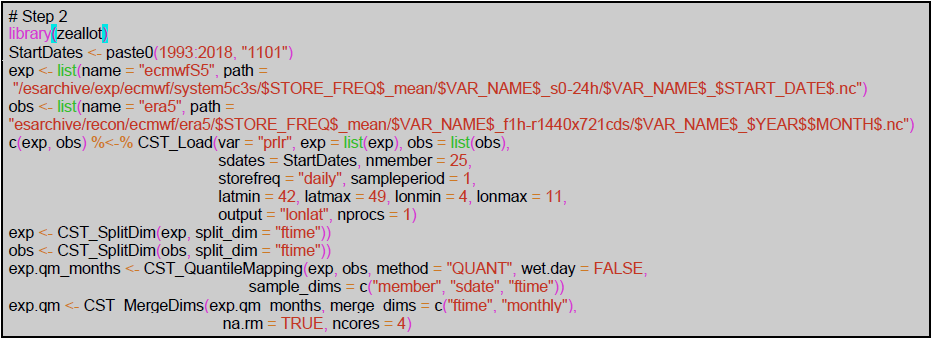
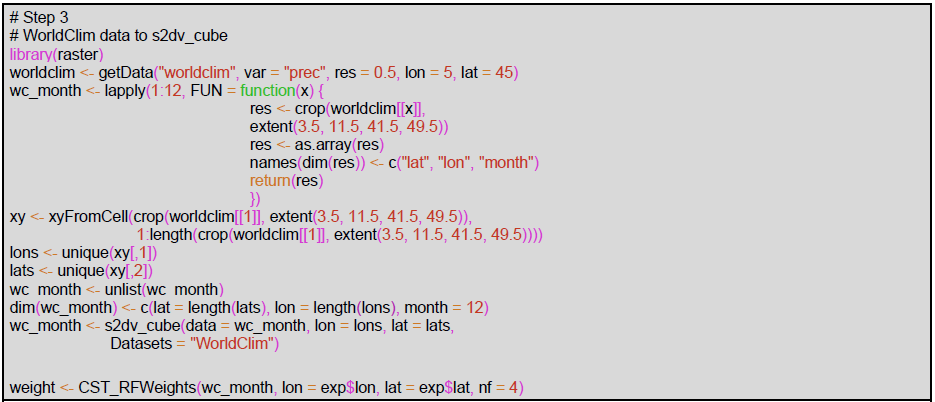
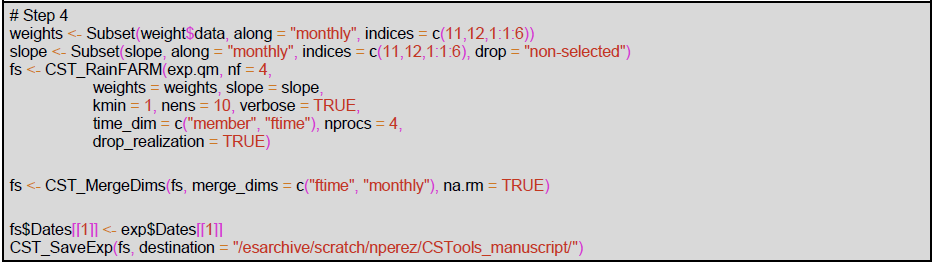
Figure 11 shows an example of the results for a random day (11 December 1993) of each post-processing step and the final result for one of the realizations. The monthly spectral slopes obtained in step 1 (Fig. 11c) show an annual cycle. The result of step 2 is a bias-corrected forecast consistent with the reference dataset in that the forecast probability density function matches the one for the references, resulting in the same climatology (Appendix C). A simple visual evaluation of the impact of the quantile mapping correction is available in Fig. 11a and b. The results of step 3 (Fig. 11d and f) are the monthly spectral slopes for which values greater (lower) than 1 amplify (reduce) the precipitation signal from the seasonal forecast. Finally, the spatial resolution improvement given by RainFARM for a specific date when applying a refinement factor 4 or 100 is shown in Fig. 11e and g.
The SNOWPACK model is run with each of the 21 seasonal forecasts using 7-month forecasts initialized on 1 November over the hindcast period 1996–2016 in order to simulate the most relevant period for the snow dynamics, i.e., November–May. Figure 7 shows an example of the SNOWPACK model output and, specifically, the snow depth forecasts obtained from the SEAS5 forecast initialized on the 1st of November 2006, for the area including the station of Bocchetta delle Pisse – 2410 m above sea level. For each forecast, we obtain an ensemble of 250 snow depth and snow water equivalent simulations, derived from 10 downscaling realizations for each of the 25 precipitation ensemble members of the SEAS5 forecast system. SEAS5-SNOWPACK forecasts are able to reproduce the variability of the observed snow depth (Fig. 12). For 2006/2007 in particular, the median forecast is lower than the model climatology, which is consistent with the low amount of snow that was observed that winter.
3.3 Use case 3: seasonal forecasts for a river flow
In this last use case, we provide downscaled and bias-adjusted seasonal forecasts of daily maximum, minimum, and mean temperature and precipitation. This use case can be relevant, for instance, to climate scientists, hydrologists, and developers of agriculture services because these variables are often used to calculate the evapotranspiration using the Hargreaves and Samani equation (e.g., Oudin et al., 2005). Indeed, while the typical seasonal forecasts are provided at a resolution of around 100 km, the spatial resolution required by some hydrological models is 5 km (Roulin and Vannitsem, 2005). Rather than giving detailed code instructions similar to the previous use cases, an extensive discussion on the data-generation process is provided, and the code is made available online. Note again that all steps are being executed using only CSTools functions.
The domain in this case covers the Aliakmon basin and a large part of Greece. Apart from the variables aimed to post-process, the sea level pressure (SLP) is used as a requirement for the downscaling method chosen. As seasonal forecast data, all the variables are taken for the 25 members of SEAS5 initialized on 1 May for the 1993–2019 period. For the reference rainfall dataset, the daily data from CHIRPS (Climate Hazards group Infrared Precipitation with Stations; https://data.chc.ucsb.edu/products/CHIRPS-2.0/, last access: 24 July 2022; Funk et al., 2015) are taken, and the available 0.05∘ resolution is used. Moreover, this dataset incorporates corrections for different mountain elevations and slopes, which is relevant in the orographically complex Aliakmon basin with elevations above 2000 m. For temperature and SLP, we use the ERA5-Land data (Muñoz-Sabater et al., 2021), available at around 0.1∘ and further downscaled to 0.05∘ resolution using a simple lapse rate correction.
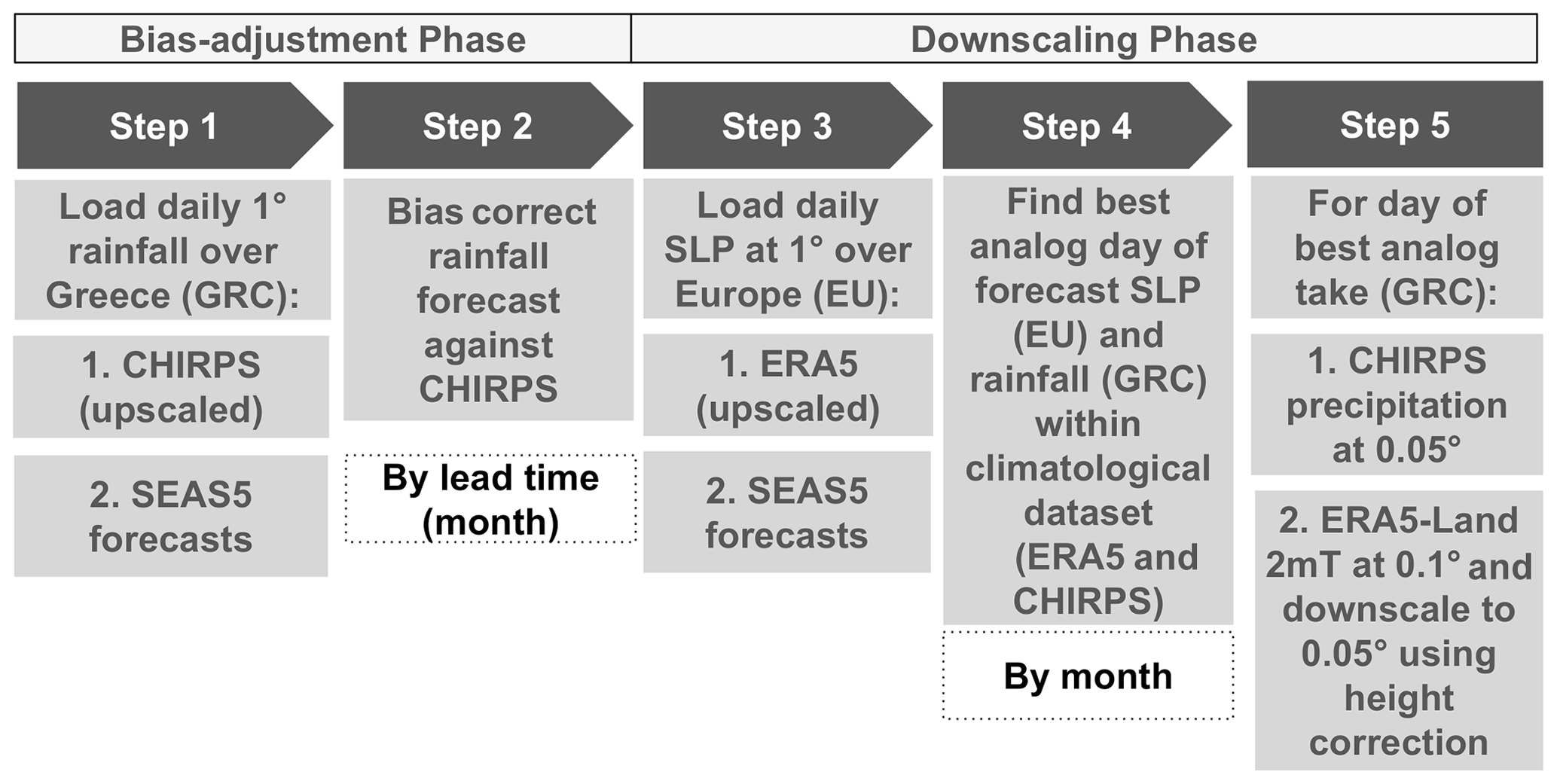
Figure 13Scheme of the necessary steps to obtain bias-adjusted and downscaled input. The abbreviations used are SLP, SEAS5, EU (Europe), and GRC (Greece).
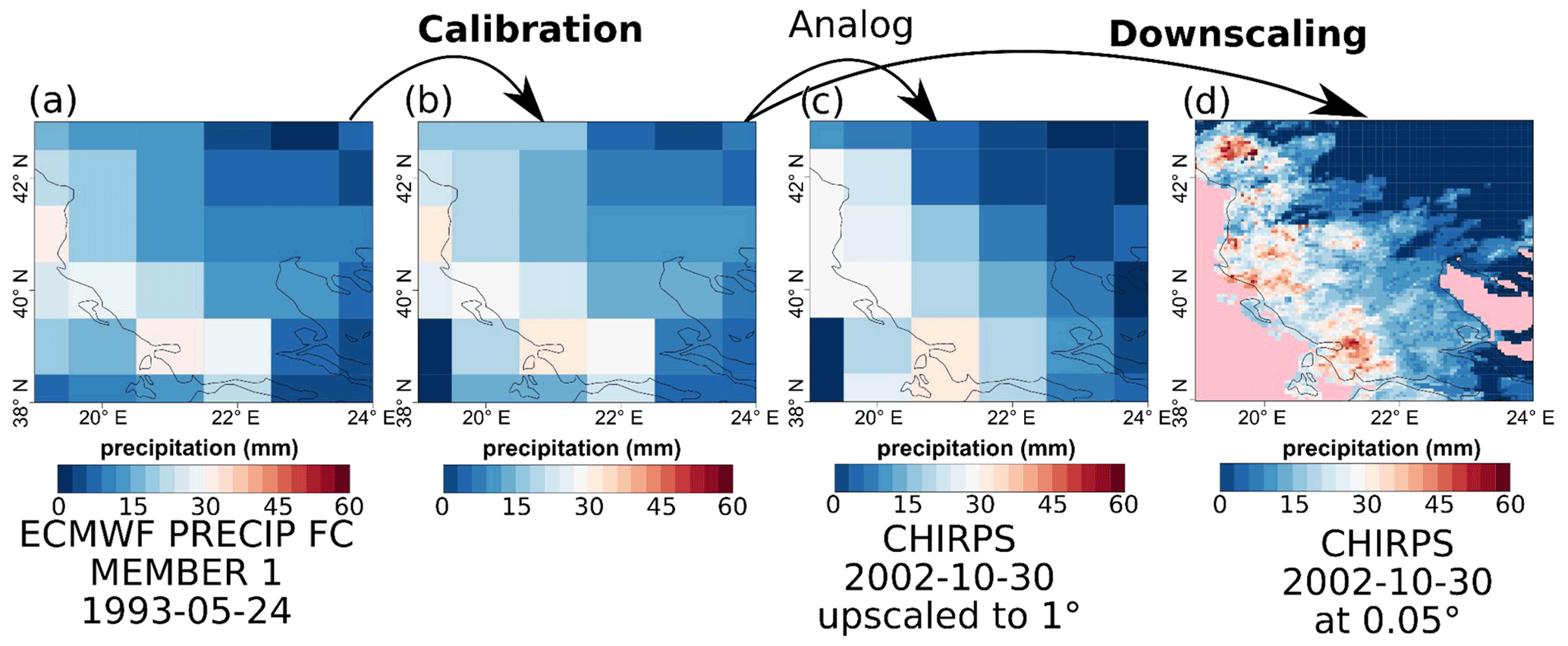
Figure 14Comparison of the original forecast (a), bias-adjusted forecast (b), the analog (c), and the downscaled (d) forecast over Greece for SEAS5 for 24 May 1993.
An analog approach is used, which combines both the synoptic-scale pressure (through the exploration of SLP) over Europe and the regional-scale rainfall over Greece. For the best analog day, the high-resolution fields of both temperature and rainfall over Greece are considered as the end product. This approach ensures the spatiotemporal consistency of both fields.
Figure 13 provides the step-by-step structure of the methodology used, while Fig. 14 provides a visual representation of the post-processing chain. As shown in Fig. 13, the overall methodology can be separated into a bias adjustment phase (steps 1–2) and a downscaling phase (steps 3–5) that uses an analog approach. The bias adjustment phase starts by loading (using CST_Load) the daily forecast and observational rainfall data over Greece upscaled at 1∘ resolution. In step 2, these daily rainfall forecasts are bias adjusted (using CST_Calibration with method bias) against the CHIRPS dataset. The bias adjustment is done per month of lead time using a leave-one-out or cross-validation approach. Breaking up the data per month was done using the CST_SplitDim function.
The downscaling phase starts in step 3 (see Fig. 13) by loading the sea level pressure (SLP) of the forecast and reference at 1∘ resolution over Europe. In step 4, both the bias-adjusted precipitation fields of a particular forecast day over Greece and the SLP anomaly fields over Europe of a particular forecast day are selected. These fields are then compared to all the fields of a large climatological reference dataset in order to find the best analog (using the Analogs function). This dataset covers the period 1993–2019 but includes only days with the same month as the selected day (and excludes the selected day). Separating the data per month was again done using the CST_SplitDim function. The criterion to find the best analog is called Local_dist and minimizes the Euclidean distances of the large-scale SLP and the local-scale rainfall patterns, both at 1∘ resolution. Finally, for the day corresponding to the best analog, the CHIRPS precipitation field at 0.05∘ resolution is then selected as the bias-adjusted and downscaled field of the selected day (see Fig. 14c and d). In order to obtain the temperature, the ERA5-Land dataset over Greece is considered for the day of the best analog. More specifically, the ERA5-Land daily minimum, maximum, and average temperature at 0.1∘ resolution are downscaled to a resolution of 0.05∘ using lapse rate height corrections. Finally, the downscaling procedure steps 4–5 are iterated over each day of every ensemble member of the seasonal forecast in order to obtain a fully bias-corrected and downscaled seasonal forecast over Greece.
CSTools contains state-of-the-art methods to post-process seasonal forecast datasets specially focusing on statistical correction and downscaling methods and classification methods. These methods are extremely valued in the community, given the need for correcting intrinsic systematic model errors and the need for many final applications to have these forecasts in higher resolution than the original resolution provided by the forecast systems. On the other hand, the visualization tools tailored for probabilistic forecasts are able to summarize the results in a concise, yet user-friendly, manner.
The three use cases showcased the ability of the CSTools R package to comprehensively post-process seasonal forecasts in the context of scientifically advanced impact modeling. The final users potentially interested in these three use cases represent a classical current-day sample of the users (and disciplines) that can benefit from CSTools. The energy sector can see the utility of seasonal forecast post-processed with CSTools in all the use cases presented. The first one showed the potential of seasonal forecasts to anticipate high wind speed events in the Iberian peninsula and the impact it had on energy production and prices; the second and third cases could be of high interest for the hydrological energy sector, since foreseeing the snow depths at high altitudes and the streamflow in catchments months in advance may allow hydropower managers to plan their activities. Similarly, these use cases are relevant for the risk management of high wind speed, coastal and flooding events, and agricultural issues implied by droughts, irrigation needs, or water resources management.
In addition to the climate post-processing methods, two aspects of the CSTools design are highly valuable, i.e., the data loading feature allows users to easily load and arrange the forecast and the reference datasets in a common structure (i.e., the s2dv_cube object), simplifying the subsequent data manipulation steps, and the internal use of the multiApply package in the data processing functions makes them flexible to work with any number of dimensions and allows parallel computation. Finally, its compatibility with the startR package allows us to process datasets larger than the available RAM memory.
The development guidelines are a fundamental piece of documentation for the future extension of the package when new state-of-the-art methods are required or become available. These guidelines are already being adopted by another R package called CSIndicators (that stands for Climate Services Indicators), which is dedicated to calculating the most suitable tailored indicator for each particular climate service application (agriculture, food security, energy, water management…). Other types of documentation, such as vignettes, provided along with the package, are intended to facilitate the users' learning process.
In order to use CST_Load, the storage needs to be homogenized. CST_Load accepts several parameters to configure the loading and interpolation of data. The CST_Load documentation in the reference manual is linked to the s2dverification (Manubens et al., 2018) reference manual where the description of all parameters is detailed.
Basically, CST_Load requires path patterns pointing to the NetCDF files or OPeNDAP URLs requested via the other parameters. A variable with a matching name must be present in the files. The path patterns, one for each experimental/observational dataset to be loaded, express the set of files comprising each dataset. Therefore, a path pattern is a string containing some specific wildcards that are recognized and replaced by the corresponding values by CST_Load. The most commonly used wildcards in a path pattern specification are “$START_DATE$”, “$STORE_FREQ$”, and “$VAR_NAME$”. For example, when given a dataset that consists of the following files:
-
/data/datasetA/monthly/tas_20180101.nc
-
/data/datasetA/monthly/tas_20180201.nc
-
/data/datasetA/monthly/tas_20180301.nc,
the path pattern to express the set of files would be as follows: /data/datasetA/$STORE_FREQ$/$VAR_NAME$_$ START_DATE$.nc.
Use case 1 (Sect. 3.1) directly loads wind speed (on the surface for the case of SEAS5 and at 100 m for the case of ERA5). However, this variable is not directly available in the Copernicus Climate Data Store (CDS) while u and v wind components are in 6 h and monthly frequencies. In order to obtain the monthly wind speed, the 6 h frequency components are used to calculate the 6 h wind speed and then to calculate the monthly average of the wind speed using Climate Data Operators (CDOs; Schulzweida, 2019). Notice that averaging the monthly wind components may lead to a different result. To automate this calculation on all the files in a folder, the following batch code could be adapted:
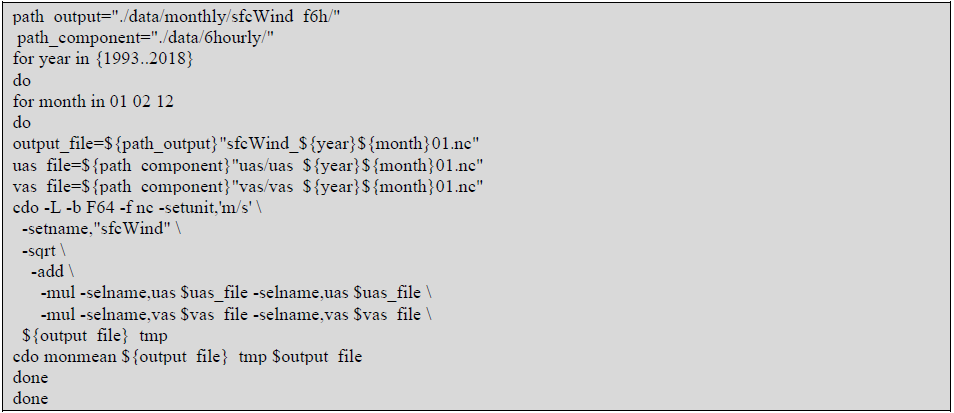
An equivalent script, using the CDO dailymean operator, can be used to convert the required variables in use cases 2 and 3 into daily mean values after the datasets are downloaded.
Table B1Summary of the functions and methods by category, including a description and the origin of the first known code and the references. The prefix CST_ refers to functions working on a specific object class called s2dv_cube, while those without the prefix accept multi-dimensional arrays with named dimensions as input. Asterisks indicate functions that are used in vignettes. Note: PCA is a principal component analysis.
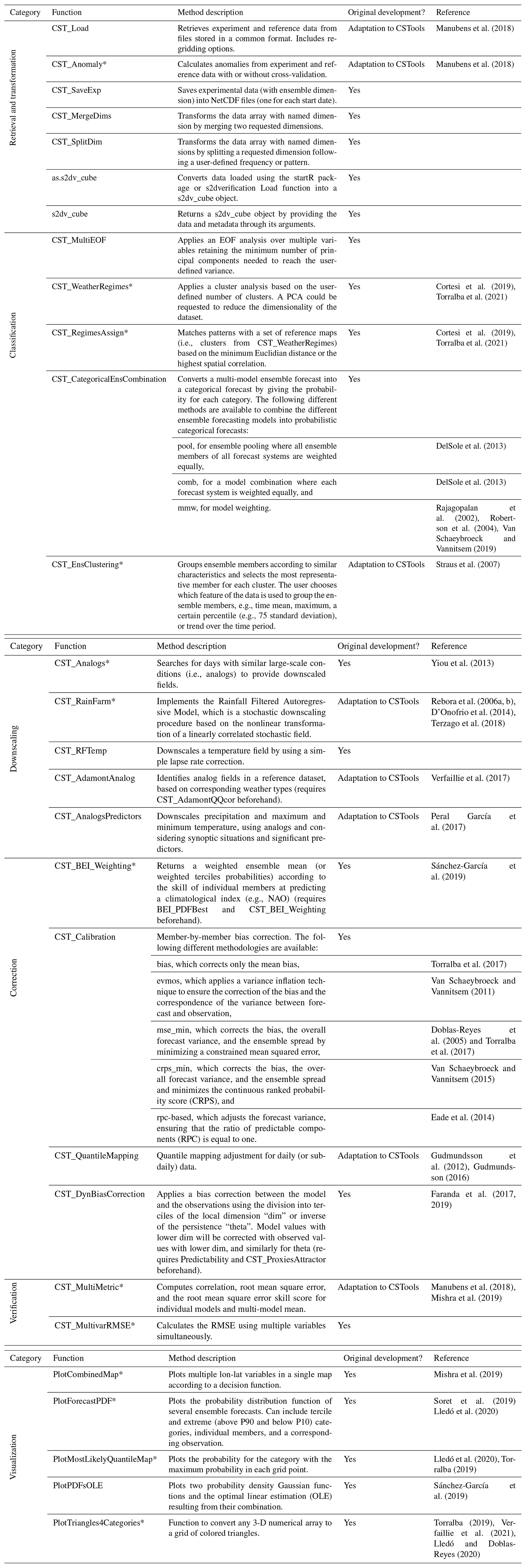
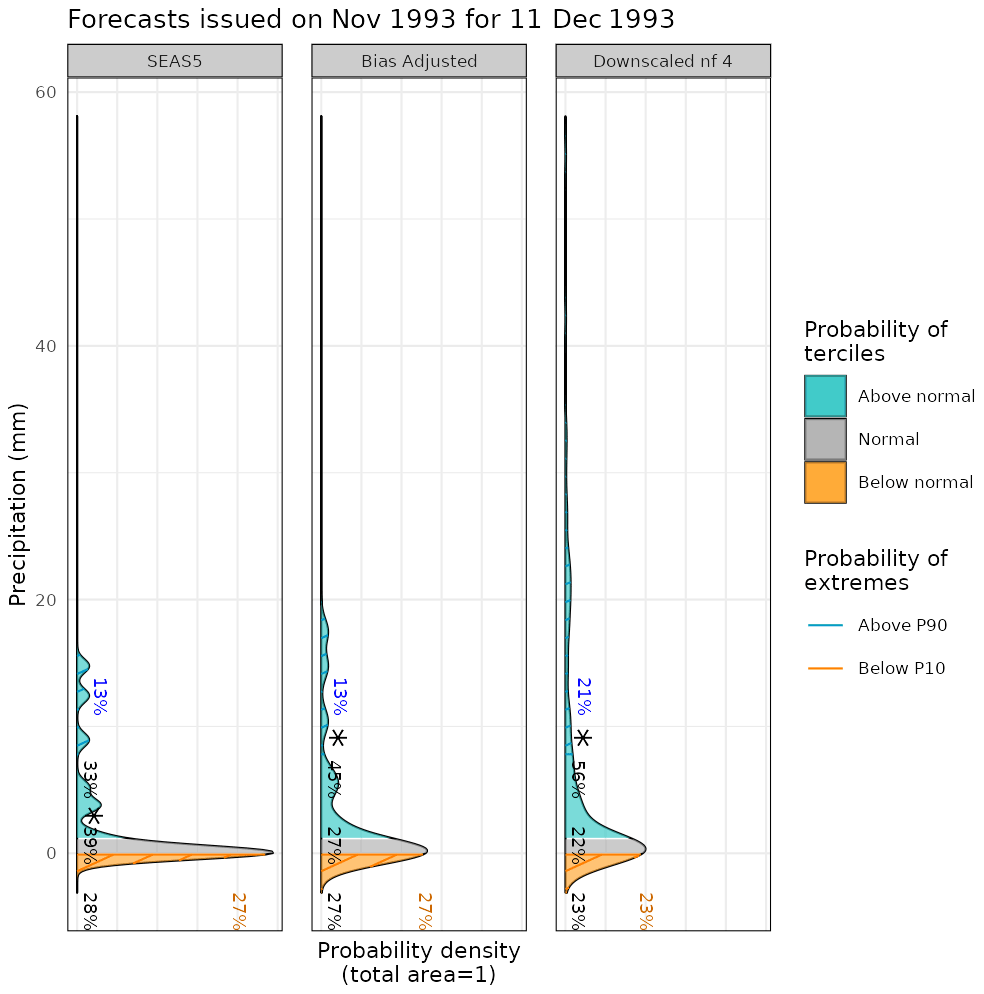
Figure C1From left to right, the PDF for the original, the bias corrected by quantile mapping, and the downscaled precipitation data (for refinement factor 4) SEAS5 for a grid point corresponding to a observational site in the Alps on 11 December 1993. For each PDF, three categories of equal size are shown, namely terciles above normal (blue), normal (gray), and below normal (orange), defined according to the area average of ERA5 reanalysis for the period 1993–2018. Percentages represent the forecast probabilities of each tercile, the most likely tercile is highlighted with a star, and the blue and orange percentages represent the probabilities for P10 and P90 (hatched areas), respectively.
The data sets used in this article are available from the CDS (https://cds.climate.copernicus.eu/ last access: 1 August 2022), which are the SEAS5 (Johnson et al., 2019; ECMWF long-range forecasting system SEAS5), the ERA5 (Hersbach et al., 2020) and the ERA5-Land data (Muñoz-Sabater et al., 2021), the CHIRPS (Funk et al., 2015; Climate Hazards group Infrared Precipitation with Stations; https://data.chc.ucsb.edu/products/CHIRPS-2.0/, last access: 24 July 2022), and in the WorldClim2 (Fick and Hijmans, 2017; http://www.worldclim.com/version2, last access: 1 August 2022).
CSTools is released under the Apache License version 2.0. The latest release of CSTools 4.0.1 is publicly available from a CRAN repository https://CRAN.R-project.org/package=CSTools (last access: 18 July 2022). It is being developed at BSC-CNS for a GitLab repository https://earth.bsc.es/gitlab/external/cstools/ (last access: 22 July 2022) and shared via Zenodo (https://doi.org/10.5281/zenodo.5549474; Pérez-Zanón et al., 2021a). The code to reproduce the use cases and plots shown in this work is shared on the three sites, and we recommend finding it in the GitLab repository https://earth.bsc.es/gitlab/external/cstools/-/tree/master/inst/doc (last access: 24 July 2022).
The supplement related to this article is available online at: https://doi.org/10.5194/gmd-15-6115-2022-supplement.
NPZ developed several functions in the package, namely CST_SaveExp, CST_SplitDims, CST_MergeDims, CST_QuantileMapping, CST_MultiMetric, s2dv_cube, and as.s2dv_cube. NPZ, as maintainer, also co-managed the package with LPC. ST and BVS, together with ER, designed the second and third use cases presented in the paper, respectively. LL created the function PlotForecastPDF and designed the first-use case presented in this work. NM provided advice on the design of the API and compatibility with other packages, drafted the CSTools development guidelines, developed the CST_Load and PlotCombinedMap functions and created the sample data provided along with the package. MCAC created the Analogs function and the dynamical bias correction methodology. LB adapted the ADAMONT downscaling methodology to CSTools. BVS also developed the CategoricalEnsCombination function and the methods of bias, evmos, and crps in the Calibration function. VT developed the mse_min method, while CDT added the rpc-based method to the Calibration function. PAB created the cds-seasonal-downloader code. SC developed the original code of EnsClustering. MD adapted the AnalogsPredictors downscaling methodology to be included in CSTools. FF and IG developed the code of MultiEOF and EnsClustering. JvH developed the RainFARM functionalities and RFTemp. ESG coded the BEI methodology and the PlotPDFsOLE visualization function. VT also coded the BiasCorrection, WeatherRegimes, RegimesAssign, PlotMostLikelyQuantileMap, and PlotTriangles4Categories functions. DV created the CST_MultivarRMSE function. NPZ prepared the paper, with contributions from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work has been performed in the framework of the MEDSCOPE (MEDiterranean Services Chain based On climate PrEdictions) ERA4CS project (grant no. 690462), with contributions from the Sub-seasonal to Seasonal climate forecasting for Energy (S2S4E; grant no. 776787) and the European Climate Prediction system (EUCP; grant no. 776613) from the European Union's Horizon 2020 research and innovation programme. CDT acknowledges the funding by the Spanish Ministry for Science and Innovation (grant no. FPI PRE2019-088646). We thank following contributors to the CSTools package: Filippo Calì Quaglia, Chihchung Chou, Nicola Cortesi, Paolo Davini, Raül Marcos, Niti Mishra, Jesus Peña, Francesc Roura-Adserias, and Danila Volpi. We also thank Margarida Samso, for the support on data formatting, An-Chi Ho for the work on s2dv, s2dverification and startR packages, and Kim Serradell and Francesco Benincasa, for the technical support. The R community and especially the developers of the packages rainfarmr, multiApply, ClimProjDiags, ncdf4, plyr, abind, data.table, reshape2, ggplot2, qmap, RColorBrewer, verification, zeallot, testthat, knitr, markdown, and rmarkdown are sincerely acknowledged, in addition to the CDO developers.
This research has been supported by the Horizon 2020 (S2S4E; grant no. 776787), EUCP (grant no. 776613), ERA4CS (grant no. 690462), and the Ministerio de Ciencia e Innovación (grant no. FPI PRE2019-088646).
This paper was edited by Jinkyu Hong and reviewed by Alfonso Senatore, Matteo De Felice, and one anonymous referee.
AEMET: Informe Mensual Climatológico Marzo de 2018, http://www.aemet.es/documentos/es/serviciosclimaticos/vigilancia_clima/resumenes_climat/mensuales/2018/res_mens_clim_2018_03.pdf (last access: 25 October 2021), 2018.
Balling, R. C.: Classification in Climatology, in: Spatial Statistics and Models, edited by: Gaile, G. L. and Willmott, C. J., Theory and Decision Library, vol. 40, Springer, Dordrecht, https://doi.org/10.1007/978-94-017-3048-8_5, 1984.
Bartelt, P. and Lehning, M.: A physical SNOWPACK model for the Swiss avalanche warning Part I: Numerical model, Cold Reg. Sci. Technol., 35, 123–145, https://doi.org/10.1016/S0165-232X(02)00074-5, 2002.
Boer, G. J., Smith, D. M., Cassou, C., Doblas-Reyes, F., Danabasoglu, G., Kirtman, B., Kushnir, Y., Kimoto, M., Meehl, G. A., Msadek, R., Mueller, W. A., Taylor, K. E., Zwiers, F., Rixen, M., Ruprich-Robert, Y., and Eade, R.: The Decadal Climate Prediction Project (DCPP) contribution to CMIP6, Geosci. Model Dev., 9, 3751–3777, https://doi.org/10.5194/gmd-9-3751-2016, 2016.
Brady, R. X. and Spring, A.: climpred: Verification of weather and climate forecasts, J. Open Source Softw., 6, 2781, https://doi.org/10.21105/JOSS.02781, 2021.
Bröcker, J. and Smith, L. A.: From ensemble forecasts to predictive distribution functions, Tellus A, 60, 663–678, https://doi.org/10.1111/j.1600-0870.2008.00333.x, 2008.
BSC-CNS and Manubens, N.: startR: Automatically Retrieve Multidimensional Distributed Data Sets, https://cran.r-project.org/package=startR (last access: 24 July 2022), 2020.
BSC-CNS, Manubens, N., and Hunter, A.: Apply Functions to Multiple Multidimensional Arrays or Vectors, https://cran.r-project.org/package=multiApply (last access: 24 July 2022), 2019.
Celliers, L., Costa, M., Williams, D., and Rosendo, S.: The `last mile' for climate data supporting local adaptation, Global Sustainability, 4, E14, https://doi.org/10.1017/sus.2021.12, 2021
Chacon, S. and Straub, B.: Pro git, Apress, Apress Berkeley, CA, https://doi.org/10.1007/978-1-4842-0076-6, 2014.
Cortesi, N., Torralba, V., González-Reviriego, N., Soret, A., and Doblas-Reyes, F. J.: Characterization of European wind speed variability using weather regimes, Clim. Dynam., 53, 4961–4976, https://doi.org/10.1007/s00382-019-04839-5, 2019.
DelSole, T., Yang, X., and Tippett, M. K.: Is unequal weighting significantly better than equal weighting for multi-model forecasting?, Q. J. Roy. Meteor. Soc., 139, 176–183, https://doi.org/10.1002/QJ.1961, 2013.
Doblas-Reyes, F. J., Hagedorn, R., and Palmer, T. N.: The rationale behind the success of multi-model ensembles in seasonal forecasting – II. Calibration and combination, Tellus A, 57, 234–252, https://doi.org/10.1111/j.1600-0870.2005.00104.x, 2005.
D'Onofrio, D., Palazzi, E., Von Hardenberg, J., Provenzale, A., and Calmanti, S.: Stochastic rainfall downscaling of climate models, J. Hydrometeorol., 15, 830–843, https://doi.org/10.1175/JHM-D-13-096.1, 2014.
Drechsel, S., Mayr, G. J., Messner, J. W., and Stauffer, R.: Wind speeds at heights crucial for wind energy: Measurements and verification of forecasts, J. Appl. Meteorol. Climatol., 51, 1602–1617, https://doi.org/10.1175/JAMC-D-11-0247.1, 2012.
Eade, R., Smith, D., Scaife, A., Wallace, E., Dunstone, N., Hermanson, L., and Robinson, N.: Do seasonal-to-decadal climate predictions underestimate the predictability of the real world?, Geophys. Res. Lett., 41, 5620–5628, https://doi.org/10.1002/2014GL061146, 2014.
ECMWF: SEAS5 user guide, 43 pp., https://www.ecmwf.int/sites/default/files/medialibrary/2017-10/System5_guide.pdf (last access: 22 October 2020), 2017.
Eyring, V., Bock, L., Lauer, A., Righi, M., Schlund, M., Andela, B., Arnone, E., Bellprat, O., Brötz, B., Caron, L.-P., Carvalhais, N., Cionni, I., Cortesi, N., Crezee, B., Davin, E. L., Davini, P., Debeire, K., de Mora, L., Deser, C., Docquier, D., Earnshaw, P., Ehbrecht, C., Gier, B. K., Gonzalez-Reviriego, N., Goodman, P., Hagemann, S., Hardiman, S., Hassler, B., Hunter, A., Kadow, C., Kindermann, S., Koirala, S., Koldunov, N., Lejeune, Q., Lembo, V., Lovato, T., Lucarini, V., Massonnet, F., Müller, B., Pandde, A., Pérez-Zanón, N., Phillips, A., Predoi, V., Russell, J., Sellar, A., Serva, F., Stacke, T., Swaminathan, R., Torralba, V., Vegas-Regidor, J., von Hardenberg, J., Weigel, K., and Zimmermann, K.: Earth System Model Evaluation Tool (ESMValTool) v2.0 – an extended set of large-scale diagnostics for quasi-operational and comprehensive evaluation of Earth system models in CMIP, Geosci. Model Dev., 13, 3383–3438, https://doi.org/10.5194/gmd-13-3383-2020, 2020.
Eyring, V., Bony, S., Meehl, G. A., Senior, C. A., Stevens, B., Stouffer, R. J., and Taylor, K. E.: Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization, Geosci. Model Dev., 9, 1937–1958, https://doi.org/10.5194/gmd-9-1937-2016, 2016a.
Eyring, V., Righi, M., Lauer, A., Evaldsson, M., Wenzel, S., Jones, C., Anav, A., Andrews, O., Cionni, I., Davin, E. L., Deser, C., Ehbrecht, C., Friedlingstein, P., Gleckler, P., Gottschaldt, K.-D., Hagemann, S., Juckes, M., Kindermann, S., Krasting, J., Kunert, D., Levine, R., Loew, A., Mäkelä, J., Martin, G., Mason, E., Phillips, A. S., Read, S., Rio, C., Roehrig, R., Senftleben, D., Sterl, A., van Ulft, L. H., Walton, J., Wang, S., and Williams, K. D.: ESMValTool (v1.0) – a community diagnostic and performance metrics tool for routine evaluation of Earth system models in CMIP, Geosci. Model Dev., 9, 1747–1802, https://doi.org/10.5194/gmd-9-1747-2016, 2016b.
Faranda, D., Messori, G., and Yiou, P.: Dynamical proxies of North Atlantic predictability and extremes, Sci. Rep.-UK, 7, 1–10, https://doi.org/10.1038/srep41278, 2017.
Faranda, D., Alvarez-Castro, M. C., Messori, G., Rodrigues, D., and Yiou, P.: The hammam effect or how a warm ocean enhances large scale atmospheric predictability, Nat. Commun., 10, 1–7, https://doi.org/10.1038/s41467-019-09305-8, 2019.
Ferranti, L. and Corti, S.: New clustering products, ECMWF Newsl., 127, 6–11, https://doi.org/10.21957/lr3bcise, 2011.
Fick, S. E. and Hijmans, R. J.: WorldClim 2: new 1-km spatial resolution climate surfaces for global land areas, Int. J. Climatol., 37, 4302–4315, https://doi.org/10.1002/joc.5086, 2017.
Funk, C., Peterson, P., Landsfeld, M., Pedreros, D., Verdin, J., Shukla, S., Husak, G., Rowland, J., Harrison, L., Hoell, A., and Michaelsen, J.: The climate hazards infrared precipitation with stations – A new environmental record for monitoring extremes, Sci. Data, 2, 1–21, https://doi.org/10.1038/sdata.2015.66, 2015.
Gudmundsson, L.: qmap: Statistical Transformations for Post-Processing Climate Model Output, CRAN, https://cran.r-project.org/package=qmap (last access: 22 July 2022), 2016.
Gudmundsson, L., Bremnes, J. B., Haugen, J. E., and Engen-Skaugen, T.: Technical Note: Downscaling RCM precipitation to the station scale using statistical transformations – a comparison of methods, Hydrol. Earth Syst. Sci., 16, 3383–3390, https://doi.org/10.5194/hess-16-3383-2012, 2012.
Hagedorn, R., Doblas-Reyes, F. J., and Palmer, T. N.: The rationale behind the success of multi-model ensembles in seasonal forecasting-I. Basic concept, Tellus A, 57, 219–233, https://doi.org/10.3402/tellusa.v57i3.14657, 2005.
Hamill, T. M.: Addressing model uncertainty through statistical post-processing using reforecasts, ECMWF Work. Model Uncertain., 20–24, https://www.ecmwf.int/sites/default/files/elibrary/2011/9753-addressing-model-uncertainty-through-statistical-post-processing-using-reforecasts.pdf (last access: 24 July 2022), 2011.
Hemri, S., Bhend, J., Liniger, M. A., Manzanas, R., Siegert, S., Stephenson, D. B., Gutiérrez, J. M., Brookshaw, A., and Doblas-Reyes, F. J.: How to create an operational multi-model of seasonal forecasts?, Clim. Dynam., 55, 1141–1157, https://doi.org/10.1007/s00382-020-05314-2, 2020.
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J. N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020.
Hijmans, R. J.: raster: Geographic Data Analysis and Modeling, CRAN, https://cran.r-project.org/package=raster (last access: 24 July 2022), 2020.
Information Resources Management Association: Software Design and Development: Concepts, Methodologies, Tools, and Applications, IGI Global, USA, edited by: Khosrow-Pour, M., DBA Contemporary Research in Information Science and Technology, Book Series, https://doi.org/10.4018/978-1-4666-4301-7, 2013.
Iturbide, M., Bedia, J., Herrera, S., Baño-Medina, J., Fernández, J., Frías, M. D., Manzanas, R., San-Martín, D., Cimadevilla, E., Cofiño, A. S., and Gutiérrez, J. M.: The R-based climate4R open framework for reproducible climate data access and post-processing, Environ. Model. Softw., 111, 42–54, https://doi.org/10.1016/J.ENVSOFT.2018.09.009, 2019.
Johnson, S. J., Stockdale, T. N., Ferranti, L., Balmaseda, M. A., Molteni, F., Magnusson, L., Tietsche, S., Decremer, D., Weisheimer, A., Balsamo, G., Keeley, S. P. E., Mogensen, K., Zuo, H., and Monge-Sanz, B. M.: SEAS5: the new ECMWF seasonal forecast system, Geosci. Model Dev., 12, 1087–1117, https://doi.org/10.5194/gmd-12-1087-2019, 2019.
Kirtman, B. P., Min, D., Infanti, J. M., Kinter, J. L., Paolino, D. A., Zhang, Q., Van Den Dool, H., Saha, S., Mendez, M. P., Becker, E., Peng, P., Tripp, P., Huang, J., Dewitt, D. G., Tippett, M. K., Barnston, A. G., Li, S., Rosati, A., Schubert, S. D., Rienecker, M., Suarez, M., Li, Z. E., Marshak, J., Lim, Y. K., Tribbia, J., Pegion, K., Merryfield, W. J., Denis, B., and Wood, E. F.: The North American multimodel ensemble: Phase-1 seasonal-to-interannual prediction; phase-2 toward developing intraseasonal prediction, B. Am. Meteorol. Soc., 95, 585–601, https://doi.org/10.1175/BAMS-D-12-00050.1, 2014.
Lehning, M., Bartelt, P., Brown, B., and Fierz, C.: A physical SNOWPACK model for the Swiss avalanche warning Part III: Meteorological forcing, thin layer formation and evaluation, Cold Reg. Sci. Technol., 35, 169–184, https://doi.org/10.1016/S0165-232X(02)00072-1, 2002a.
Lehning, M., Bartelt, P., Brown, B., Fierz, C., and Satyawali, P.: A physical SNOWPACK model for the Swiss avalanche warning Part II. Snow microstructure, Cold Reg. Sci. Technol., 35, 147–167, https://doi.org/10.1016/S0165-232X(02)00073-3, 2002b.
Lledó, L. and Doblas-Reyes, F. J.: Predicting daily mean wind speed in Europe weeks ahead from MJO status, Mon. Weather Rev., 148, 3413–3426, https://doi.org/10.1175/mwr-d-19-0328.1, 2020.
Lledó, L., Cionni, I., Torralba, V., Bretonnière, P. A., and Samsó, M.: Seasonal prediction of Euro-Atlantic teleconnections from multiple systems, Environ. Res. Lett., 15, 074009, https://doi.org/10.1088/1748-9326/ab87d2, 2020.
Manubens, N., Caron, L.-P., Hunter, A., Bellprat, O., Exarchou, E., Fuckar, N. S., Garcia-Serrano, J., Massonnet, F., En Egoz, M. M., Sicardi, V., Batt E C , Chlo E Prodhomme, L., Onica Torralba, V., Cortesi, N., Mula-Valls, O., Serradell, K., Guemas, V., and Doblas-Reyes, F. J.: An R package for climate forecast verification, Environ. Model. Softw., 103, 29–42, https://doi.org/10.1016/j.envsoft.2018.01.018, 2018.
Manzanas, R., Gutiérrez, J. M., Bhend, J., Hemri, S., Doblas-Reyes, F. J., Torralba, V., Penabad, E., and Brookshaw, A.: Bias adjustment and ensemble recalibration methods for seasonal forecasting: a comprehensive intercomparison using the C3S dataset, Clim. Dynam., 53, 1287–1305, https://doi.org/10.1007/s00382-019-04640-4, 2019.
Maraun, D. and Widmann, M.: Statistical Downscaling and Bias Correction for Climate Research, Cambridge University Press, https://doi.org/10.1017/9781107588783, 2018.
Maraun, D., Wetterhall, F., Ireson, A. M., Chandler, R. E., Kendon, E. J., Widmann, M., Brienen, S., Rust, H. W., Sauter, T., Themel, M., Venema, V. K. C., Chun, K. P., Goodess, C. M., Jones, R. G., Onof, C., Vrac, M., and Thiele-Eich, I.: Precipitation downscaling under climate change: Recent developments to bridge the gap between dynamical models and the end user, Rev. Geophys., 48, RG3003, https://doi.org/10.1029/2009RG000314, 2010.
Marcos, R.: Improvement of seasonal forecasting techniques applied to water resources and forest fires, Universitat de Barcelona, http://www.tdx.cat (last access: 1 October 2020), 2016.
Merryfield, W. J., Baehr, J., Batté, L., Becker, E. J., Butler, A. H., Coelho, C. A. S., Danabasoglu, G., Dirmeyer, P. A., Doblas-Reyes, F. J., Domeisen, D. I. V., Ferranti, L., Ilynia, T., Kumar, A., Müller, W. A., Rixen, M., Robertson, A. W., Smith, D. M., Takaya, Y., Tuma, M., Vitart, F., White, C. J., Alvarez, M. S., Ardilouze, C., Attard, H., Baggett, C., Balmaseda, M. A., Beraki, A. F., Bhattacharjee, P. S., Bilbao, R., De Andrade, F. M., DeFlorio, M. J., Díaz, L. B., Ehsan, M. A., Fragkoulidis, G., Grainger, S., Green, B. W., Hell, M. C., Infanti, J. M., Isensee, K., Kataoka, T., Kirtman, B. P., Klingaman, N. P., Lee, J. Y., Mayer, K., McKay, R., Mecking, J. V., Miller, D. E., Neddermann, N., Ng, C. H. J., Ossó, A., Pankatz, K., Peatman, S., Pegion, K., Perlwitz, J., Recalde-Coronel, G. C., Reintges, A., Renkl, C., Solaraju-Murali, B., Spring, A., Stan, C., Sun, Y. Q., Tozer, C. R., Vigaud, N., Woolnough, S., and Yeager, S.: Current and emerging developments in subseasonal to decadal prediction, B. Am. Meteorol. Soc., 101, E869–E896, https://doi.org/10.1175/BAMS-D-19-0037.1, 2020.
MeteoSwiss: easyVerification: Ensemble Forecast Verification for Large Data Sets, CRAN, https://cran.r-project.org/package=easyVerification (last access: 24 July 2022), 2017.
Min, Y. M., Kryjov, V. N., and Oh, S. M.: Assessment of APCC multimodel ensemble prediction in seasonal climate forecasting: Retrospective (1983–2003) and real-time forecasts (2008–2013), J. Geophys. Res., 119, 12132–12150, https://doi.org/10.1002/2014JD022230, 2014.
Mishra, N., Prodhomme, C., and Guemas, V.: Multi-Model Skill Assessment of Seasonal Temperature and Precipitation Forecasts over Europe, Clim. Dynam., 52, 4207–4225, https://doi.org/10.1007/s00382-018-4404-z, 2019.
Muñoz-Sabater, J., Dutra, E., Agustí-Panareda, A., Albergel, C., Arduini, G., Balsamo, G., Boussetta, S., Choulga, M., Harrigan, S., Hersbach, H., Martens, B., Miralles, D. G., Piles, M., Rodríguez-Fernández, N. J., Zsoter, E., Buontempo, C., and Thépaut, J.-N.: ERA5-Land: a state-of-the-art global reanalysis dataset for land applications, Earth Syst. Sci. Data, 13, 4349–4383, https://doi.org/10.5194/essd-13-4349-2021, 2021.
National Academies of Sciences, Engineering and Medicine: Next Generation Earth System Prediction: Strategies for Subseasonal to Seasonal Forecasts, Natl. Acad. Press, https://doi.org/10.17226/21873, 2016.
Oudin, L., Hervieu, F., Michel, C., Perrin, C., Andréassian, V., Anctil, F., and Loumagne, C.: Which potential evapotranspiration input for a lumped rainfall-runoff model? Part 2 – Towards a simple and efficient potential evapotranspiration model for rainfall-runoff modelling, J. Hydrol., 303, 290–306, https://doi.org/10.1016/j.jhydrol.2004.08.026, 2005.
Palmer, T. N., Doblas-Reyes, F. J., Weisheimer, A., and Rodwell, M. J.: Toward seamless prediction: Calibration of climate change projections using seasonal forecasts, B. Am. Meteorol. Soc., 89, 459–470, https://doi.org/10.1175/BAMS-89-4-459, 2008.
Peral García, C., Navascués Fernández-Victorio, B., and Ramos Calzado, P.: Serie de precipitación diaria en rejilla con fines climáticos, Nota Técnica 24 de AEMET, https://www.aemet.es/documentos/es/conocermas/recursos_en_linea/publicaciones_y_estudios/publicaciones/NT_24_AEMET/NT_24_AEMET.pdf (last access: 24 July 2022), 2017.
Pérez-Zanón, N., Caron, L.-P., Alvarez-Castro, C., Batte, L., Delgado, C., von Hardenberg, J., LLedó, L., Manubens, N., Palma, L., Sanchez-Garcia, E., van Schaeybroeck, B., Torralba, V., and Verfaillie, D.: CSTools (4.0.1), Zenodo [code], https://doi.org/10.5281/zenodo.5549474, 2021a.
Pérez-Zanón, N., Chihchung, C., and Lledó, L.: CSIndicators: Sectoral Indicators for Climate Services Based on Sub-Seasonal to Decadal Climate Predictions, CRAN, https://cran.r-project.org/package=CSIndicators (last access: 24 July 2022), 2021b.
Pierce, D.: ncdf4: Interface to Unidata netCDF (Version 4 or Earlier) Format Data Files, CRAN, https://CRAN.R-project.org/package=ncdf4 (last access: 24 July 2022), 2019
Rajagopalan, B., Lall, U., and Zebiak, S. E.: Categorical climate forecasts through regularization and optimal combination of multiple GCM ensembles, Mon. Weather Rev., 130, 1792–1811, https://doi.org/10.1175/1520-0493(2002)130<1792:CCFTRA>2.0.CO;2, 2002.
Ramon, J., Lledó, L., Bretonniere, P. A., Samsó, M., and Doblas-Reyes, F. J.: A perfect prognosis downscaling methodology for seasonal prediction of local-scale wind speeds, Environ. Res. Lett., 16, 54010, https://doi.org/10.1088/1748-9326/abe491, 2021.
R Core Team: R: A language and environment for statistical computing, R Found. Stat. Comput., https://www.R-project.org/ (last access: 24 July 2022), 2017.
Rebora, N., Ferraris, L., von Hardenberg, J., and Provenzale, A.: Rainfall downscaling and flood forecasting: a case study in the Mediterranean area, Nat. Hazards Earth Syst. Sci., 6, 611–619, https://doi.org/10.5194/nhess-6-611-2006, 2006a.
Rebora, N., Ferraris, L., von Hardenberg, J., and Provenzale, A.: RainFARM: Rainfall downscaling by a Filtered Autoregressive Model, J. Hydrometeorol., 7, 724–738, https://doi.org/10.1175/JHM517.1, 2006b.
Red Eléctrica de España: Informe del Sistema Eléctrico Español 2018, https://www.ree.es/sites/default/files/11_PUBLICACIONES/Documentos/InformesSistemaElectrico/2018/inf_sis_elec_ree_2018.pdf (last access: 7 June 2021), 2018.
Righi, M., Andela, B., Eyring, V., Lauer, A., Predoi, V., Schlund, M., Vegas-Regidor, J., Bock, L., Brötz, B., de Mora, L., Diblen, F., Dreyer, L., Drost, N., Earnshaw, P., Hassler, B., Koldunov, N., Little, B., Loosveldt Tomas, S., and Zimmermann, K.: Earth System Model Evaluation Tool (ESMValTool) v2.0 – technical overview, Geosci. Model Dev., 13, 1179–1199, https://doi.org/10.5194/gmd-13-1179-2020, 2020.
Robertson, A. W., Lall, U., Zebiak, S. E., and Goddard, L.: Improved combination of multiple atmospheric GCM ensembles for seasonal prediction, Mon. Weather Rev., 132, 2732–2744, https://doi.org/10.1175/MWR2818.1, 2004.
Rössler, O., Fischer, A. M., Huebener, H., Maraun, D., Benestad, R. E., Christodoulides, P., Soares, P. M. M., Cardoso, R. M., Pagé, C., Kanamaru, H., Kreienkamp, F., and Vlachogiannis, D.: Challenges to link climate change data provision and user needs: Perspective from the COST-action VALUE, Int. J. Climatol., 39, 3704–3716, https://doi.org/10.1002/joc.5060, 2019.
Roulin, E. and Vannitsem, S.: Skill of medium-range hydrological ensemble predictions, J. Hydrometeorol., 6, 729–744, https://doi.org/10.1175/JHM436.1, 2005.
Sánchez-García, E., Voces-Aboy, J., Navascués, B., and Rodríguez-Camino, E.: Regionally improved seasonal forecast of precipitation through Best estimation of winter NAO, Adv. Sci. Res., 16, 165–174, https://doi.org/10.5194/asr-16-165-2019, 2019.
Siegert, S.: SpecsVerification: Forecast Verification Routines for Ensemble Forecasts of Weather and Climate, CRAN, https://cran.r-project.org/package=SpecsVerification (last access: 24 July 2022), 2017.
Silverman, B. W.: Density Estimation for Statistics and Data Analysis 1st Edition, Chapman and Hall, London, 1986.
Sokal, R. R.: Numerical Taxonomy, Sci. Am., 215, 106–116, https://doi.org/10.1038/scientificamerican1266-106, 1966.
Soret, A., Torralba, V., Cortesi, N., Christel, I., Palma, L., Manrique-Suñén, A., Lledó, L., González-Reviriego, N., and Doblas-Reyes, F. J.: Sub-seasonal to seasonal climate predictions for wind energy forecasting, J. Phys. Conf. Ser., 1222, 012009, https://doi.org/10.1088/1742-6596/1222/1/012009, 2019.
Schulzweida, U.: CDO User Guide (Version 1.9.8), Zenodo, https://doi.org/10.5281/zenodo.3539275, 2019.
Straus, D. M., Corti, S., and Molteni, F.: Circulation Regimes: Chaotic Variability versus SST-Forced Predictability, J. Climate, 20, 2251–2272, https://doi.org/10.1175/JCLI4070.1, 2007.
Teetor, N.: Multiple, Unpacking, and Destructuring Assignment, CRAN, https://cran.r-project.org/package=zeallot (last access: 18 September 2020), 2018.
Terzago, S., Palazzi, E., and von Hardenberg, J.: Stochastic downscaling of precipitation in complex orography: a simple method to reproduce a realistic fine-scale climatology, Nat. Hazards Earth Syst. Sci., 18, 2825–2840, https://doi.org/10.5194/nhess-18-2825-2018, 2018.
Terzago, S., Bongiovanni, G., and von Hardenberg, J.: High quality climate prediction, Medcope Proj., 29 pp., https://drive.google.com/file/d/1qp2gbtKdBl4XmsyOeaEhFENwpeUuJwkf/view (last access: 23 November 2020), 2020.
Terzago, S., Bongiovanni, G., and von Hardenberg, J.: Seasonal forecasting of snow resources at Alpine sites, Hydrol. Earth Syst. Sci. Discuss. [preprint], https://doi.org/10.5194/hess-2022-32, in review, 2022.
Tödter, J. and Ahrens, B.: Generalization of the Ignorance Score: Continuous Ranked Version and Its Decomposition, Mon. Weather Rev., 140, 2005–2017, https://doi.org/10.1175/MWR-D-11-00266.1, 2012.
Torralba, V.: Seasonal climate prediction for the wind energy sector: methods and tools for the development of a climate service, Universidad Complutense de Madrid, https://eprints.ucm.es/56841 (last access: 24 July 2022), 2019.
Torralba, V., Doblas-Reyes, F. J., MacLeod, D., Christel, I., and Davis, M.: Seasonal climate prediction: A new source of information for the management of wind energy resources, J. Appl. Meteorol. Climatol., 56, 1231–1247, https://doi.org/10.1175/JAMC-D-16-0204.1, 2017.
Torralba, V., Gonzalez-Reviriego, N., Cortesi, N., Manrique-Suñén, A., Lledó, L., Marcos, R., Soret, A., and Doblas-Reyes, F. J.: Challenges in the selection of atmospheric circulation patterns for the wind energy sector, Int. J. Climatol., 41, 1525–1541, https://doi.org/10.1002/joc.6881, 2021.
Troccoli, A., Harrison, M., Coughlan, M., and Williams, J. B.: Seasonal Forecasts in Decision Making, Seas. Clim. Forecast. Manag. Risk, 82, 13–41, https://doi.org/10.1007/978-1-4020-6992-5_2, 2008.
Van Schaeybroeck, B. and Vannitsem, S.: Post-processing through linear regression, Nonlin. Processes Geophys., 18, 147–160, https://doi.org/10.5194/npg-18-147-2011, 2011.
Van Schaeybroeck, B. and Vannitsem, S.: Ensemble post-processing using member-by-member approaches: theoretical aspects, Q. J. Roy. Meteor. Soc., 141, 807–818, https://doi.org/10.1002/qj.2397, 2015.
Van Schaeybroeck, B. and Vannitsem, S.: Postprocessing of Long-Range Forecasts, in: Statistical Postprocessing of Ensemble Forecasts, Statistical Postprocessing of Ensemble Forecasts, edited by: Vannitsem, S., Wilks, D. S., and Messner, J. W., 267–290, https://doi.org/10.1016/B978-0-12-812372-0.00010-8, 2019.
Verfaillie, D., Déqué, M., Morin, S., and Lafaysse, M.: The method ADAMONT v1.0 for statistical adjustment of climate projections applicable to energy balance land surface models, Geosci. Model Dev., 10, 4257–4283, https://doi.org/10.5194/gmd-10-4257-2017, 2017.
Verfaillie, D., Doblas-Reyes, F. J., Donat, M. G., Pérez-Zanón, N., Solaraju-Murali, B., Torralba, V., and Wild, S.: How reliable are decadal climate predictions of near-surface air temperature?, J. Climate, 34, 697–713, https://doi.org/10.1175/JCLI-D-20-0138.1, 2021.
Vitart, F., Huddleston, M. R., Déqué, M., Peake, D., Palmer, T. N., Stockdale, T. N., Davey, M. K., Ineson, S., and Weisheimer, A.: Dynamically-based seasonal forecasts of Atlantic tropical storm activity issued in June by EUROSIP, Geophys. Res. Lett., 34, L16815, https://doi.org/10.1029/2007GL030740, 2007.
Wang, B., Lee, J. Y., Kang, I. S., Shukla, J., Park, C. K., Kumar, A., Schemm, J., Cocke, S., Kug, J. S., Luo, J. J., Zhou, T., Wang, B., Fu, X., Yun, W. T., Alves, O., Jin, E. K., Kinter, J., Kirtman, B., Krishnamurti, T., Lau, N. C., Lau, W., Liu, P., Pegion, P., Rosati, T., Schubert, S., Stern, W., Suarez, M., and Yamagata, T.: Advance and prospectus of seasonal prediction: Assessment of the APCC/ CliPAS 14-model ensemble retrospective seasonal prediction (1980-2004), Clim. Dynam., 33, 93–117, https://doi.org/10.1007/s00382-008-0460-0, 2009.
White, C. J., Carlsen, H., Robertson, A. W., Klein, R. J. T., Lazo, J. K., Kumar, A., Vitart, F., Coughlan de Perez, E., Ray, A. J., Murray, V., Bharwani, S., MacLeod, D., James, R., Fleming, L., Morse, A. P., Eggen, B., Graham, R., Kjellström, E., Becker, E., Pegion, K. V., Holbrook, N. J., McEvoy, D., Depledge, M., Perkins-Kirkpatrick, S., Brown, T. J., Street, R., Jones, L., Remenyi, T. A., Hodgson-Johnston, I., Buontempo, C., Lamb, R., Meinke, H., Arheimer, B., and Zebiak, S. E.: Potential applications of subseasonal-to-seasonal (S2S) predictions, Meteorol. Appl., 24, 315–325, https://doi.org/10.1002/met.1654, 2017.
Yiou, P., Salameh, T., Drobinski, P., Menut, L., Vautard, R., and Vrac, M.: Ensemble reconstruction of the atmospheric column from surface pressure using analogues, Clim. Dynam., 41, 1333–1344, https://doi.org/10.1007/s00382-012-1626-3, 2013.
- Abstract
- Introduction
- CSTools: overview
- Use cases
- Conclusions
- Appendix A: Details on data collection, curation, homogenization, and requirements for CST_Load
- Appendix B: CSTools functions synthetic description
- Appendix C: Probabilities distribution use case 2
- Data availability
- Code availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Introduction
- CSTools: overview
- Use cases
- Conclusions
- Appendix A: Details on data collection, curation, homogenization, and requirements for CST_Load
- Appendix B: CSTools functions synthetic description
- Appendix C: Probabilities distribution use case 2
- Data availability
- Code availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement