the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 21 Jan 2022
| 21 Jan 2022
Parameterization of the collision–coalescence process using series of basis functions: COLNETv1.0.0 model development using a machine learning approach
Camilo Fernando Rodríguez Genó
Léster Alfonso
A parameterization for the collision–coalescence process is presented based on the methodology of basis functions. The whole drop spectrum is depicted as a linear combination of two lognormal distribution functions, leaving no parameters fixed. This basis function parameterization avoids the classification of drops in artificial categories such as cloud water (cloud droplets) or rainwater (raindrops). The total moment tendencies are predicted using a machine learning approach, in which one deep neural network was trained for each of the total moment orders involved. The neural networks were trained and validated using randomly generated data over a wide range of parameters employed by the parameterization. An analysis of the predicted total moment errors was performed, aimed to establish the accuracy of the parameterization at reproducing the integrated distribution moments representative of physical variables. The applied machine learning approach shows a good accuracy level when compared to the output of an explicit collision–coalescence model.
- Article
(2716 KB) - Full-text XML
- BibTeX
- EndNote





Drop populations are represented using drop size distributions (DSDs). The first attempt at characterizing drop spectra in space as opposed to distributions over a surface was made by Marshall and Palmer (1948), who employed exponential distributions based on drop diameter to describe the DSDs. More recently, the use of a three-parameter gamma distribution has shown good agreement with observations (Ulbrich, 1983). However, lognormal distributions have shown a better squared-error fit to measurements of rain DSDs than gamma or exponential distributions (Feingold and Levin, 1986; Pruppacher and Klett, 2010). The analysis of several important characteristics of the Brownian coagulation process showed that the lognormal distribution adequately represents the particle distributions (Lee et al., 1984, 1997). In addition, some authors have employed this type of distribution function, which is lognormal, to parameterize cloud processes with promising results (Clark, 1976; Feingold et al., 1998; Huang, 2014).
There are two main approaches to modeling cloud processes: the explicit approach (bin microphysics) and the bulk approach (bulk microphysics). The bin microphysics approach is based on the discretization of a DSD into sections (bins) and calculates the evolution of the DSD due to the influence of different processes that could be dynamical and/or microphysical (Berry, 1967; Berry and Reinhardt, 1974; Bott, 1998a; Khain et al., 2004, 2010). The core of this method is the solution of the kinetic coagulation equation (KCE) (von Smoluchowski, 1916a, b) for the collision–coalescence of liquid drops (also known as the stochastic coalescence equation or kinetic collection equation within the cloud physics community) in a previously designed grid, which could be over mass or radius. Thus, previous knowledge of the characteristics or parameters of the distributions is not necessary. This way of solving the KCE is very accurate, but its operational utility is compromised because it is computationally very expensive due to the need to calculate a large number of equations, ranging from several dozen to hundreds, at each grid point and time step. Also, as the KCE has no analytical solution (with the exception of some simple cases), it has to be solved via numerical schemes, which are very diffusive by nature, depending on the grid choice and numerical method used to solve it. While diffusive schemes could be appropriate for certain microphysical processes such as sedimentation (Khain et al., 2015), it is a disadvantage that has to be dealt with. However, the numerical solutions of the KCE have evolved in such a way that today we can find models that are specifically designed to limit the diffusiveness of these numerical methods (Bott, 1998a).
In the case of bulk microphysics, the KCE is parameterized and the evolution of a chosen set of statistical moments related to physical variables is calculated, instead of the evolution of the DSD itself. A pioneering approach to this kind of parameterization can be found in Kessler (1969), where a simple but relatively accurate representation of the autoconversion process is introduced. One- or two-moment parameterizations are common (Cohard and Pinty, 2000; Lim and Hong, 2010; Milbrandt and McTaggart-Cowan, 2010; Morrison et al., 2009; Thompson et al., 2008). However, recently it has been extended to three-moment parameterizations (Huang, 2014; Milbrandt and Yau, 2005). This type of parameterization is computationally efficient, which makes it popular within the operational weather forecasting community. The main disadvantage of this approach is that the equations for solving the rates of the pth moment include moments of a higher order, so the system of equations employed to calculate the evolution of the moments is not closed (Seifert and Beheng, 2001). This could be avoided by using predefined parameters for the distributions that describe the DSD, which normally take the form of exponential (Marshall and Palmer, 1948), gamma (Milbrandt and McTaggart-Cowan, 2010; Milbrandt and Yau, 2005) or lognormal distributions (Huang, 2014). In addition, artificial categories are often used to separate hydrometeors (cloud and rainwater); depending on drop radius, values between 20 and 41 µm are examples of employed threshold values (Cohard and Pinty, 2000; Khairoutdinov and Kogan, 2000), with the moments for each category being calculated by means of partial integration of the KCE.
An additional approach to modeling microphysical processes is the particle-based one, which is based on the application of a stochastic model such as the Monte Carlo method to the coagulation (coalescence) of drop particles inside a cloud. This method has been approached from a number of perspectives. For example, Alfonso et al. (2008) analyzed the possible ways of solving the KCE by using a Monte Carlo algorithm and several collision kernels, with good correspondence between the analytical and numerical approaches for all the kernels, by estimating the KCE following Gillespie's Monte Carlo algorithm (Gillespie, 1972) and several analytical solutions. Also, the possible implications of this approach for cloud physics are discussed. Other variants of this approach are analyzed in Alfonso et al. (2011), and it has also been used to simulate the sub-processes of autoconversion and accretion by applying a Monte Carlo-based algorithm within the framework of Lagrangian cloud models (Noh et al., 2018). This approach is accurate and represents the stochastic nature of the collision–coalescence of drops well.
An alternative to these main approaches is a hybrid approach to parameterize the cloud microphysical processes. This approach simulates the explicit approach in the way that it describes the shape of the DSD through a linear combination of basis functions (Clark, 1976; Clark and Hall, 1983), and it could be considered a middle point between bulk and bin microphysics. This is done by having time-varying distribution parameters instead of fixed ones, as is common in conventional bulk approaches. A system of prognostic equations is solved to obtain the parameters' tendencies related to the statistical distribution functions based on the evolution of their total moments (the combination of the statistical moments with same order of all distribution functions involved), describing their tendencies due to condensation and collision–coalescence. Since the integration process covers the entire size spectrum, the artificial separation of the droplet spectrum is avoided, making the terms cloud droplet and raindrop meaningless (they are just drops), and it is possible to solve a fully closed system of equations without the need to keep any parameter of the distribution constant. Another advantage of this approach is its independence from a specific collision kernel type, as is common in the bulk approach; in order to obtain analytical expressions from the integrals of the KCE, a polynomial-type kernel such as the one derived by Long (1974) is frequently used. Having said that, a limitation of this approach is that the total moment tendencies have to be solved at each time step for the needed parameters. An alternative solution for this shortcoming is to first calculate the moment's rates by including a sufficiently wide range of parameters, and then to store the results in lookup tables that should be consulted several times at every time step.
Machine learning (ML) is the study of computer algorithms that improve automatically through experience and the use of data (training) (Mitchell, 1997). ML algorithms build a model based on sample data in order to make predictions or decisions without being explicitly programmed to do so (Koza et al., 1996). They are used in a wide variety of applications, such as in medicine, email filtering and computer vision, for which it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks. In particular, neural networks (NNs) are especially well suited for solving nonlinear fitting problems and for establishing relationships within complex data such as the outputs of the KCE. In the field of atmospheric sciences, the use of deep neural networks (DNNs) has been extended to the parameterization of sub-grid processes in climate models (Brenowitz and Bretherton, 2018; Rasp et al., 2018), while in cloud microphysics, the autoconversion process was parameterized using DNNs with a superior level of accuracy when compared with equivalent bulk models (Alfonso and Zamora, 2021; Loft et al., 2018). Also, a partial parameterization of collision–coalescence was tested in Seifert and Rasp (2020), who developed an ML parameterization that includes the processes of autoconversion and accretion, describing the droplet spectra as a gamma distribution and establishing a comparative study that exposed the advantages and disadvantages of the use of ML techniques in cloud microphysics.
In order to eliminate the need to solve the rate equations for the total moments of the KCE at every time step (Thompson, 1968) or resort to the use of lookup tables, we propose predicting the total moment tendencies using an ML approach within this parameterization. Thus, the objective of this study is to apply DNN to the parameterized formulation of the collision–coalescence process developed by Clark (1976) in order to replicate the rate equations for the total moments, eliminating the need for lookup tables or numerical solution of integrals. By doing this, a complete representation of collision–coalescence based on ML could be achieved (except drop breakup).
The research article is structured as follows: in Sect. 2, the parameterization framework is described, as is the reference model used for comparison purposes; in Sect. 3, the procedures of DNN methodology are explained, the network architecture is introduced, the training data set is generated, and the DNN is trained and validated; in Sect. 4, the experiment design is explained; in Sect. 5, the results of the experiment are discussed, an assessment of the results is made by contrasting them with the reference solution, and the predicted total moment errors are analyzed; and in Sect. 6 several conclusions are drawn.
2.1 Formulation of the total moment tendencies
Under the framework of the parameterization developed in this study, any given drop spectrum can be approximated by a series of basis functions. Therefore, the distribution that characterizes the evolution of the spectrum is given by a linear combination of probability density functions as shown below:
where fi〈r〉 represents the individual members of the set of distributions considered, I stands for the number of distribution functions that make up the set and r refers to the radius of drops. In the case at hand, a set of two statistical distributions is employed. At each time step, the rates of the parameters of each distribution will be calculated. It should be noted that, in any set of distributions considered, all the members have the same type of distribution. For the proposed parameterization, as described in Clark (1976), a distribution of lognormal type is used, as follows:
where μ and σ2 stand for the mean and variance of ln r, respectively, while N represents the number concentration of drops. Considering that moment of order of any distribution can be defined as (Straka, 2009)
the following analytical solution of Eq. (3) can be found for the moments of the lognormal distribution.
Combining Eqs. (1), (3) and (4), the pth total moment of a linear combination of lognormal distributions could be expressed as (Clark and Hall, 1983)
where the index i indicates each of the individual members of the set (I=2). Deriving Eq. (5) with respect to time, we obtain the tendencies of the total moments of a series of lognormal distributions.
Equation (6) can be expressed as a system of equations:
where X is a vector representing the tendencies of the distribution parameters.
The coefficient's matrix A is a squared matrix of order ν () defined as
with i=1, 2, …, ν and j=1, 2, …, I. The components of the independent vector F are the tendencies of the total moments of the distributions.
Both A and F are normalized in order to achieve better numerical stability in the solution of the system of equations. The evolution of the distribution functions' parameters is calculated by applying a simple forward finite-difference scheme (Clark and Hall, 1983).
Here, k is the time index in the finite-difference notation.
2.2 Description of the calculation of the total moment tendencies due to collision–coalescence
The KCE determines the evolution of a DSD due to collision–coalescence. This equation can be expressed in a continuous form as a function of mass as follows (Pruppacher and Klett, 2010)
where K(m|m′) is the collection kernel. Reformulating Eq. (12) in the form of Thompson (1968) and as a function of radius, we can calculate the total moment tendencies (vector F from the previous section) as follows:
where
Equation (15) represents the hydrodynamic kernel and E(r1r2) stands for the collection efficiencies taken from Hall (1980), which are based on a lookup table representing the effectiveness of drop collisions under given environmental conditions. A set of two lognormal distributions (Eq. 2) is used as members of the set in Eq. (1). Hence, the prognostic variables under the parameterization formulation will be the corresponding parameters of both distribution functions: N1, μ1, σ1, N2, μ2 and σ2. At this point in the parameterization the total moment tendencies should be calculated either by solving Eq. (13) at each time step for all the moments involved or by searching in a lookup table calculated a priori. Instead, the following chapter explains in detail the ML approach proposed and its implementation.
2.3 Description of the reference model
To obtain a reference solution (KCE from now onwards), the explicit model developed by Bott (1998a, b) was employed. This scheme is conservative with respect to mass and very efficient computationally speaking. It is based on the numerical integration of the KCE (Eq. 12), combined with the mass density function g(y,t) (Berry, 1967), in order to simplify the calculations:
where y=ln r and r is the radius of a drop of mass m. By substituting Eq. (17) in Eq. (12) we obtain the KCE for the mass density function (Bott, 1998a):
where . The first integral of the right-hand side of Eq. (18) represents the gain of drops of mass m due to collision–coalescence of two smaller droplets, while the second integral portrays the loss of drops of mass m being captured by bigger drops (Bott, 1998a). For the numerical solution of Eq. (18), a logarithmic equidistant mass grid is used and is generated as
where n is the total number of grid points.
ML methodology can be classified into three main categories according to the problem at hand: supervised, unsupervised and reinforced learning. In our case, supervised learning is used. Supervised learning algorithms build a mathematical model of a set of data that contains both the inputs and the desired outputs (Russell and Norvig, 2010). Under this classification, there is previous knowledge of the set of input values xk, and their corresponding outputs yk, with k=1, 2, …, n, where n is the number of input values. The objective is to obtain a function f(x), by means of which the new data xnew simulate the output values reasonably well. The set {xk, yk}; k=1, 2, …, n is called the training data set. To test the performance of f(x), the input and output data are separated into two different data sets: training and testing. As NNs are able to fit any nonlinear function (Schmidhuber, 2015), an ML parameterization should approximate the solution of the KCE in the form of Eq. (13) reasonably well given enough layers and neurons in the architecture of the network.
3.1 Neural network architecture
Deep neural networks are based on artificial neurons. Each neuron receives a set of input data, processes it and passes it to an activation function σ(z), which returns the activated output (Fig. 1). The activation value of neuron i in layer l is denoted by and is determined as follows.
In Eq. (21), is the bias, is the ponderation weight, ml−1 is the number of neurons in layer l−1, σ(z) is the activation function and z is the processing intermediate value of the variable. Hence, an NN could be defined as a set of input values (x), bias values (b) and weights (W) integrated in a functional form, i.e., , and its training procedure consists of minimizing an error function (known as loss function) by optimizing the weights and biases for the available training data. A commonly used loss function is the regression mean squared error (MSE). Hence, we need a minimization algorithm to process the following expression.

The selected algorithm for minimization of the loss function (Eq. 22) is the Bayesian regularization, which updates the weight and bias values according to the Levenberg–Marquardt optimization (Marquardt, 1963). Backpropagation is used to calculate the Jacobian of the performance with respect to the weight and bias variables (Dan Foresee and Hagan, 1997; MacKay, 1992).
The designed DNN is formed by one layer which receives the input data (input layer), three intermediate layers (hidden layers) with 20 neurons each and an output layer with a single neuron which returns the simulated target values (Fig. 2).
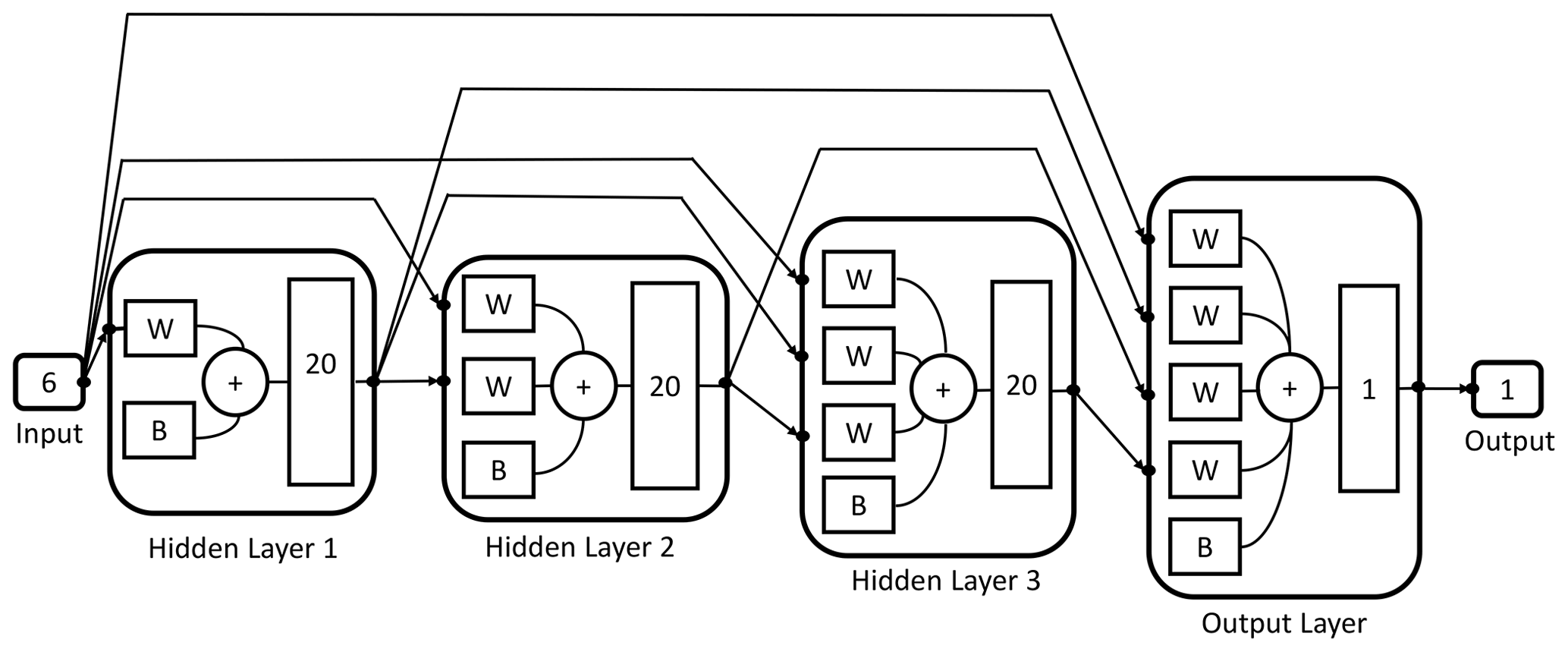
Figure 2Schematic representation of the architecture of the trained neural network used to calculate the total moment tendencies. The neural network receives six inputs and then processes them by means of three hidden layers of 20 neurons each and an output layer with a single neuron and one output value.
3.2 Generation of the training and validation data sets
The training procedure consists of feeding the DNN with six input values corresponding to the distribution parameters of each distribution and the total moment tendency for the pth order obtained from Eq. (13) as a target. The NN training algorithm then processes those values in order to establish the relationships between the data provided. This process is repeated until all input and target data are processed. The resulting trained DNN should be able to estimate the total moment tendencies from a given set of distribution parameters that falls within the ranges of the training variables. A schematic representation of the trained NN with the inputs and output is shown in Fig. 3.
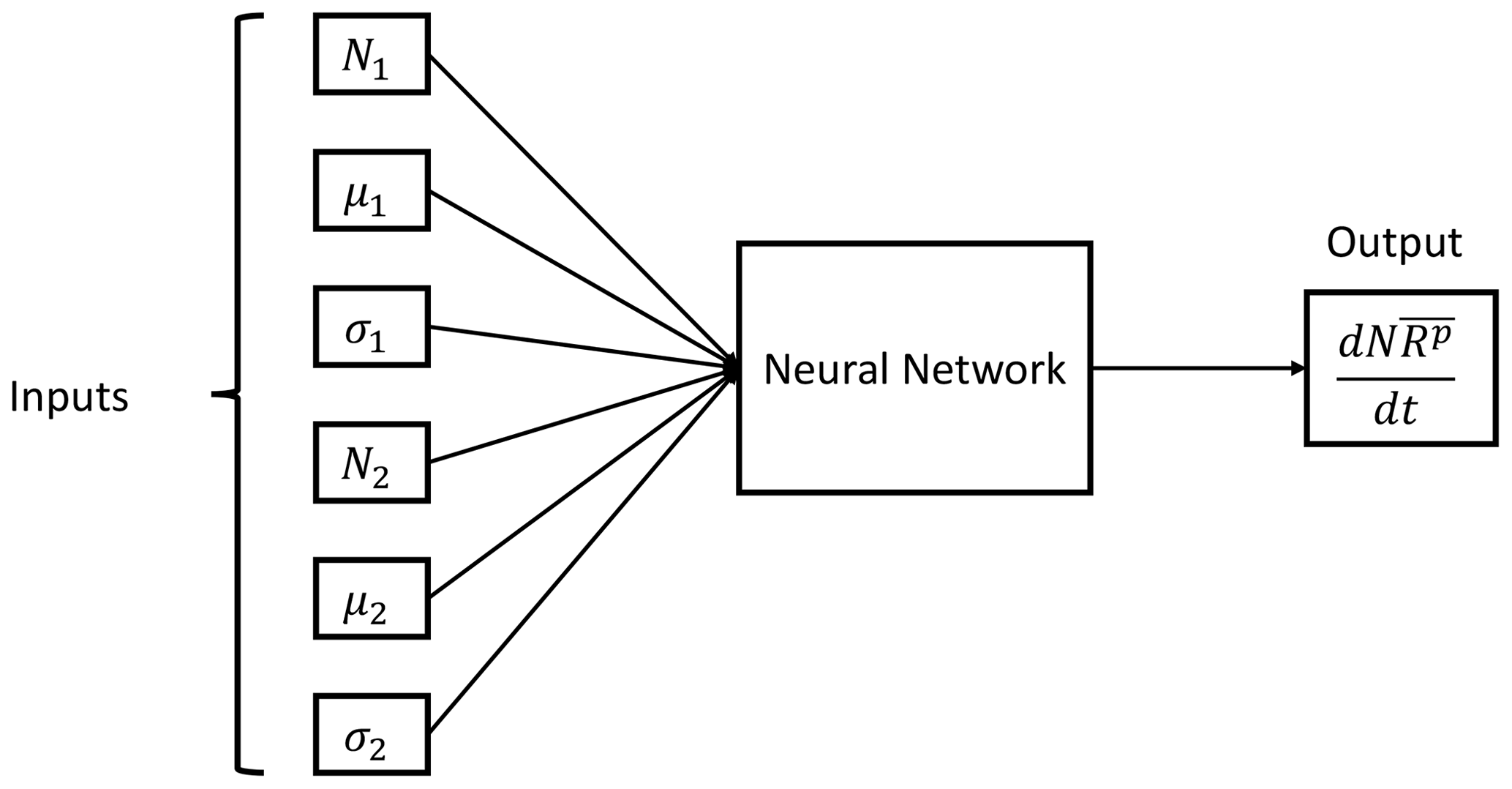
Figure 3Neural network parameterization inputs and output. The input data are the six distribution parameters (N1, μ1, σ1, N2, μ2 and σ2) needed to feed Eq. (13), while the output is the pth order total moment tendency .
In order to generate the training and test data sets, 100 000 drop spectra derived from the input variables are employed over a wide range of distribution parameters (N1, μ1, σ1, N2, μ2 and σ2). Those input parameters are used to calculate the total moment rates from Eq. (13) and train the DNN. Five DNNs are trained, one for each total moment tendency involved in the formulation of the parameterization (moment orders ranged from 0 to 5), with the exception of the total moment of order 3, as total mass is not affected by the collision–coalescence process. The same training input parameters are used to train all NNs, varying only the target values corresponding to the total moment tendencies of each order.
The physical variables related to the input parameters are shown in Fig. 4 for a better representation of the generated training clouds. The training and test data are created using a uniformly distributed random number generator, with means and standard deviations shown in Table 1, as well as the ranges (minimum and maximum values) of each predictor variable.
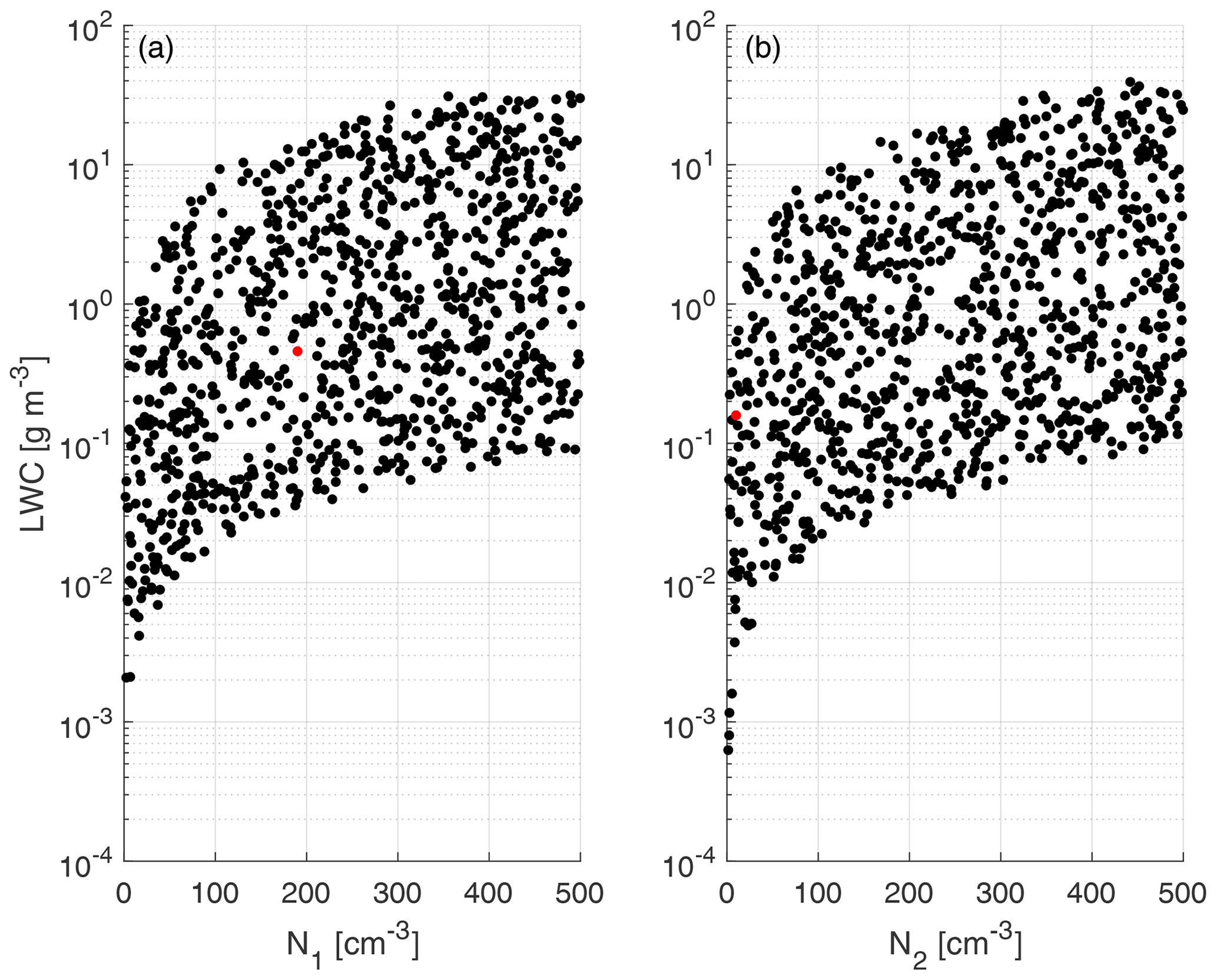
Figure 4Scatterplot of liquid water content (LWC) calculated from the input parameters of f1 (a) and f2 (b) vs. drop number concentration. The LWC values are obtained from the statistical moment of order 3 using the parameters depicted in Table 1 and were calculated from Eq. (4). The red dots represent the initial conditions for the experiment case included in Table 4. Only 1 in 100 data points are shown.
Table 1Statistical description of the input values used in the training and test data sets. The means, standard deviation and ranges are shown for each input variable.
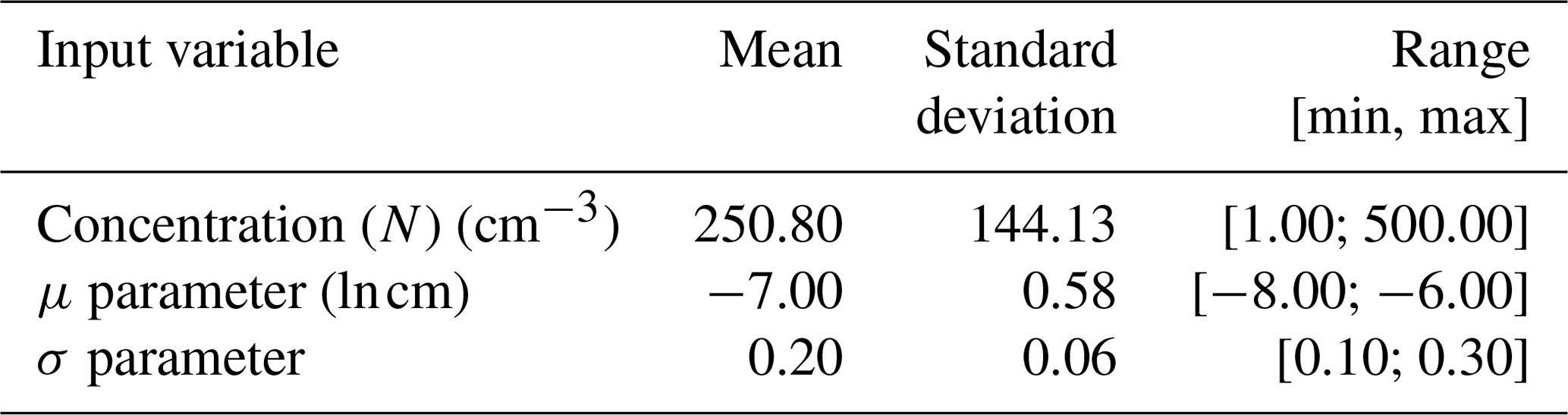
Figure 4 shows that within the ranges of the training data (concentration from 1 to 500 cm−3), the corresponding liquid water contents (LWCs) are between 10−10 and 10−4 g cm−3, with the majority of the data concentrated between the limits of 10−8 and 10−5 g cm−3. Those values cover a sufficiently wide range of liquid water content to adequately represent warm clouds within the parameterization.
3.3 Training and testing of the deep neural network
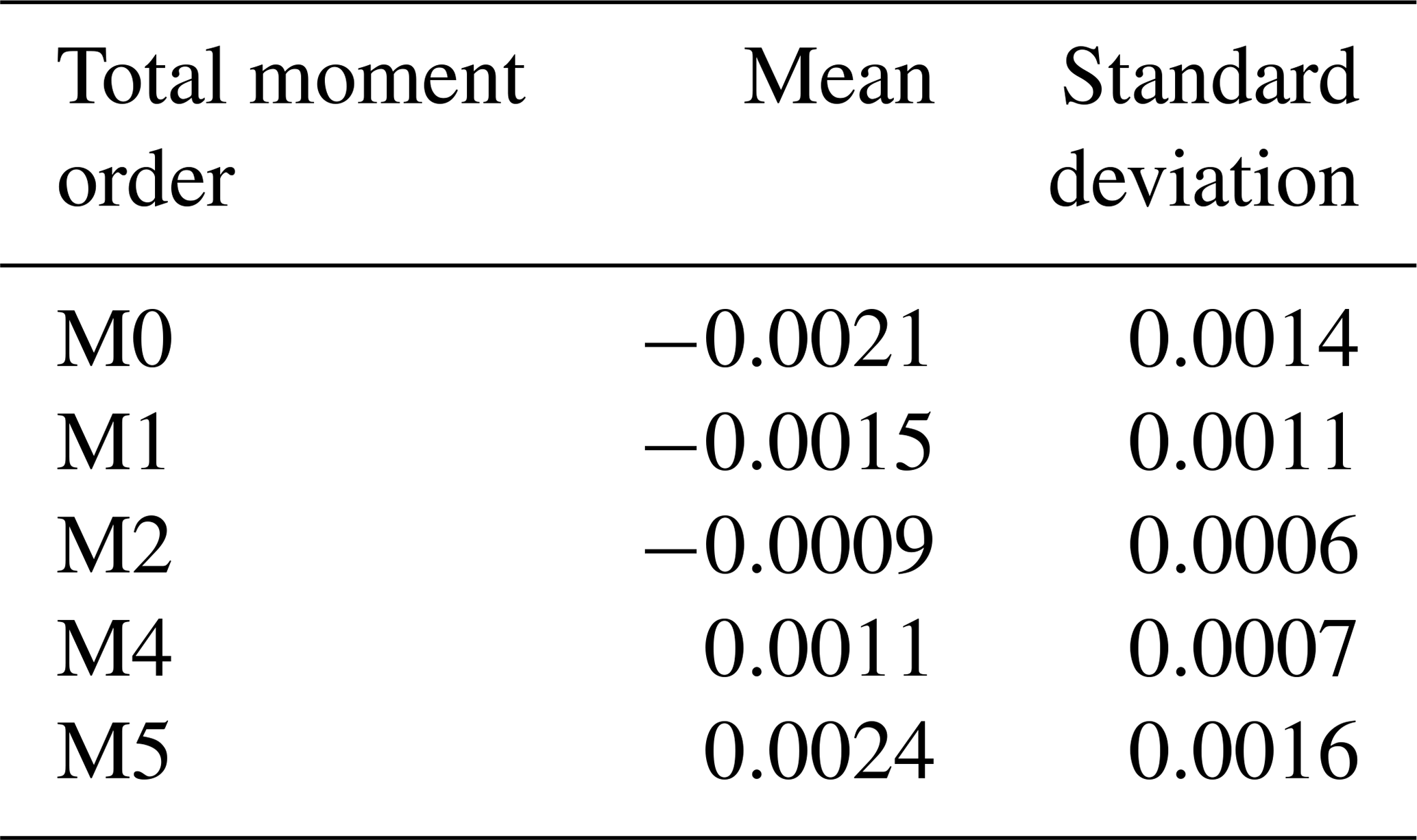
From the available data, 80 % is employed in training the DNN, and the remaining 20 % is used for testing purposes. The total moment tendencies (Eq. 13) are solved using a trapezoidal rule over a logarithmic radius grid with the ranges of 1 µm µm. The solutions of Eq. (13) are called the target values. The mean and standard deviation for each calculated total moment rate are shown in Table 2.
Table 2Means and standard deviations of total moment tendencies (target values) for each statistical moment used. The data are calculated from Eq. (13) with the distribution parameters (N1, μ1, σ1, N2, μ2 and σ2) as input values.
Both input and target values are normalized as follows
The input and target values require normalization to facilitate the work of the optimization algorithm. All nodes in each layer of the DNN use the MSE as a loss function. The training procedure for an NN consists of processing a fragment of the total training data through the network learning architecture, then determining the prognostic error and the gradient of the loss function (MSE) back through the network in order to update the weight values. This algorithm is repeated via an iterative process over all training data until the performance index (MSE) is small enough or a predefined number of passes through all data are completed. One pass through all training data is known as an epoch. In this case, a maximum number of 1000 epochs is established, and a minimum value of 10−7 is considered for the gradient function.
Five DNNs are trained, one for each total moment tendency involved in the formulation of the parameterization (moment orders ranged from 0 to 5, except the third moment). A variant of the training process, known as cascade-forward neural network training, is employed. This enables the network to establish more precise nonlinear connections between the data provided but results in a more computationally expensive training process (Karaca, 2016; Warsito et al., 2018). The main difference with the standard training procedure (feed-forward) is that it includes a connection from the input and every previous layer to following layers (see Fig. 2). As with feed-forward networks, a two-layer or more cascade network can learn any finite input–target relationship arbitrarily well given enough hidden neurons. The total moment tendencies for the statistical moment of order 3 are not calculated because the collision–coalescence process does not affect total mass.
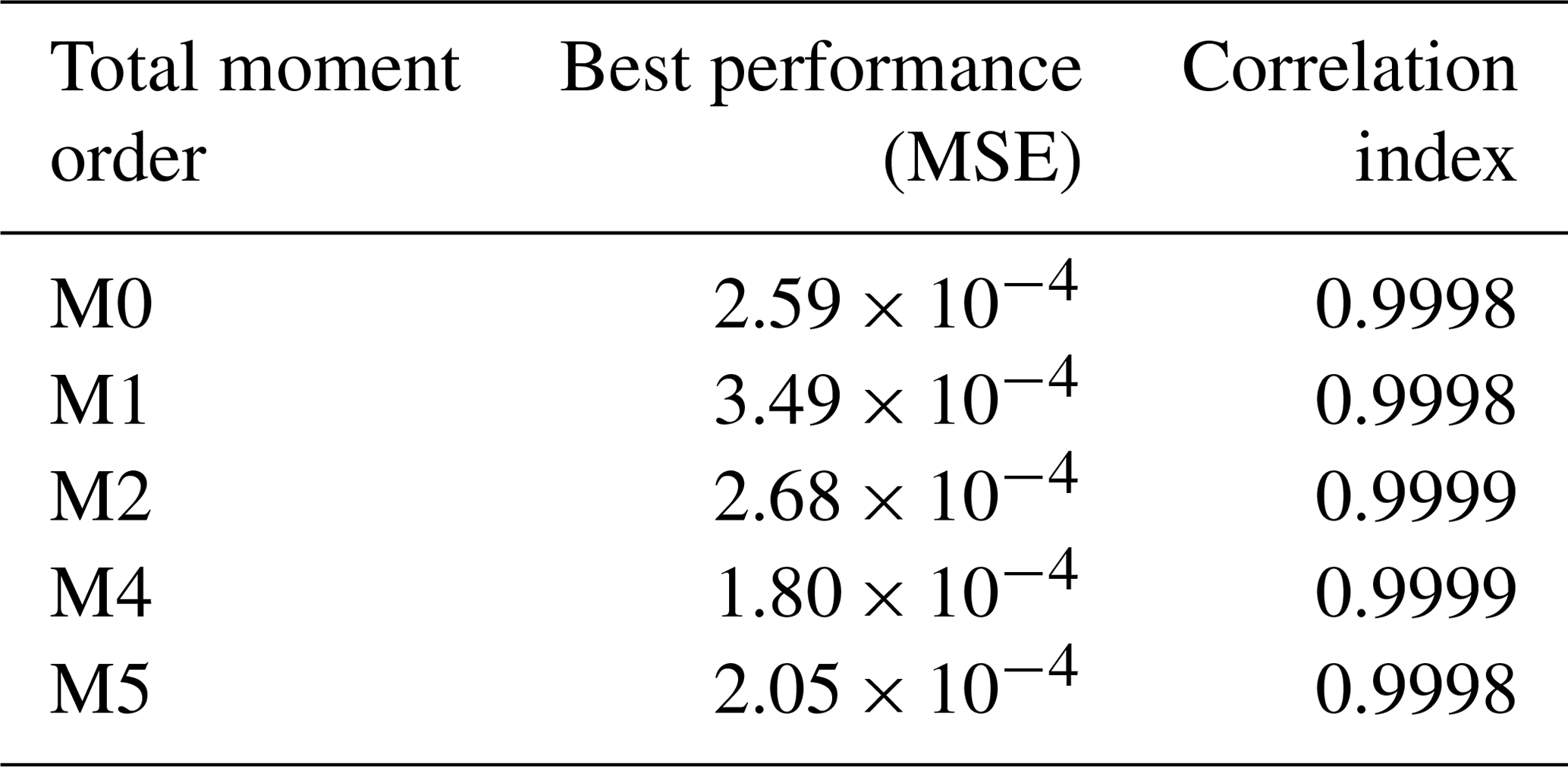
Performance (MSE) training records for the total moment tendencies calculated from Eq. (13) are depicted in Fig. 5. The speed of convergence is similar in all cases, and all networks converged at epoch 1000. This occurs because the gradient value was never below the minimum, so the training process kept refining the results until it reached the maximum number of epochs previously defined. Despite that, a good performance is achieved, with the MSE of the order of 10−4 for all orders of the total moment tendencies in Table 3, where the best (final) MSE values for each trained DNN are shown in detail. Since the values of the total moments are normalized in the DNN model (scale of 100), these values of MSE are considered to be the indications of high accuracies for the scale of the problem. Thus, the NN model developed reproduces the rates of the moments very well following the formulation of Clark (1976), which is a main objective in this research.

Figure 5Performance training records of total moment tendencies for the moments from order 0 to 5 (the third order is excluded). The shown data correspond to the total moment tendencies obtained from the trained neural networks, with input values and reference targets taken from the validation data set. The performance measure is the mean square error (MSE).
Table 3Best performance in the training process of the DNNs. The performance measures are the mean squared error (MSE) and the Pearson correlation index. The shown data correspond to the total moment tendencies obtained from the trained neural networks, with input values and reference targets taken from the validation data set.
Regression plots for the trained networks are depicted in Fig. 6. It is a comparison between the outputs obtained from evaluating the trained NNs using the test inputs and the targets from the test data set corresponding to each of the total moment tendencies obtained from Eq. (13). Minor differences can be seen in the graphics, with the trained DNN models overestimating or underestimating the actual values. However, good agreement was reached for all trained DNNs, with the predicted values from the DNN matching the actual output from the solution of Eq. (13) with a coefficient of correlation between 0.9998 and 0.9999 in all cases (as shown in Table 3). The axis ranges of the graphics vary because the plotted data are non-normalized; thus, there are different ranges for each of the calculated total moment tendencies. This result means that the rates of the total moments obtained from Clark's parameterization of collision–coalescence (Clark, 1976) are accurately reproduced by the NN model developed.
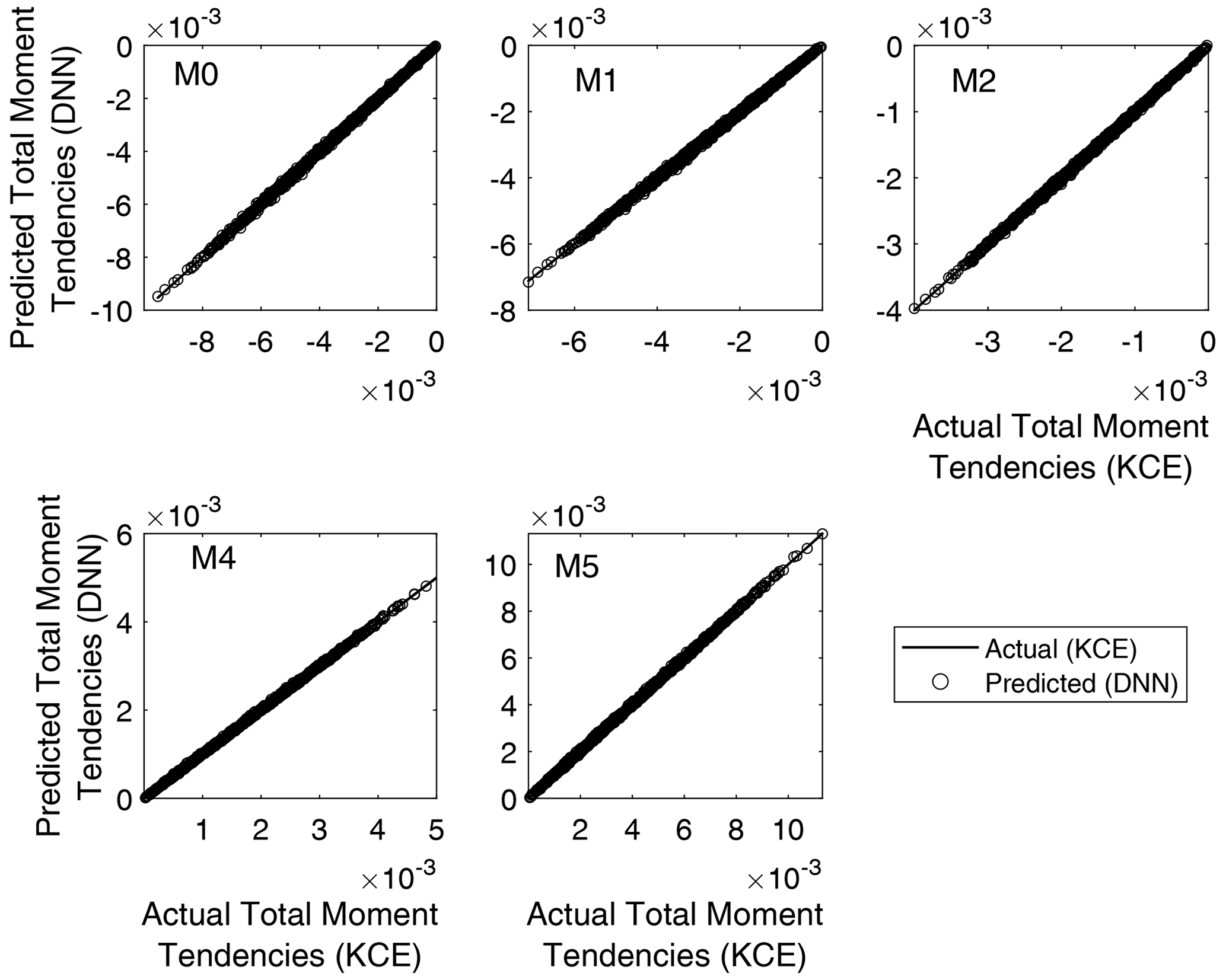
Figure 6Regression plots for the five DNN trained. It is a comparison between the outputs obtained from evaluating the trained neural networks using the test inputs and the targets from the validation data set corresponding to each of the total moment tendencies obtained from Eq. (13). The y axis varies for each panel because the plotted data are non-normalized.
Experiments with non-normalized training data were performed, yielding results with MSE at least an order of magnitude higher. Those results are not shown in the present article due to the lower accuracy of the regression outputs.
Neural networks give us a better way to estimate the values of the integral (13). The neural networks of course do not replace the computation of integrals, but since they have the ability to learn and model complex nonlinear functions, they allow (once trained) the estimation of them efficiently for values of the parameters (N1, μ1, σ1, N2, μ2 and σ2) for which it has not been previously calculated.
Before the widespread adoption of machine learning, the alternative previously used by other authors (Clark, 1976; Clark and Hall, 1983; Feingold et al., 1998) was the lookup tables, which are tables that store a list of predefined values (the moment tendencies in this case). Then, in the context of our work, the lookup table is a mapping function that relates the parameters of the basis functions (N1, μ1, σ1, N2, μ2 and σ2) with the total moment tendencies .
However, usually, functions computed from lookup tables have a limited domain. Preferably, we need functions whose domain is a set with contiguous values. Furthermore, every time we need to calculate the integral (13), a search algorithm must be executed in order to retrieve the moment tendency for a given set of parameters, and some kind of interpolation will be needed to compute moment tendencies for values of the parameters for which it has not been calculated.
The advantage of the neural networks is that all the computational effort is dedicated to the training phase. Once we train the networks, they replace the lookup tables and are able to map the parameters of the basis functions with total moment tendencies.
An experiment is performed with the objective of illustrating the behavior of the ML-based parameterized model (P-DNN) and how it compares with the results of a traditional bulk parameterization and the reference model (KCE). This experiment should not be interpreted as an evaluation of the overall behavior of P-DNN but as an example of how it predicts the DSD and bulk variables. A detailed evaluation of the novel components of the P-DNN scheme was already carried out in the previous chapter.
4.1 Initial conditions and experiment design
A simulation covering t=900 s (15 min) of system evolution is considered for all models, with a time step of Δt=0.1 s. The initial parameters for the distribution functions of the parameterized model are as shown in Table 4.
Table 4Initial parameters for the distribution functions of P-DNN. Each distribution is characterized by a concentration parameter (N), expected value (μ) and standard deviation (σ). The initial parameters are shown for the two lognormal distribution functions employed in the formulation of P-DNN.

The values from Table 4 are well within the parameters established in Table 1 and were set following Clark (1976). The initial spectrum for the KCE was calculated from these parameters to ensure the same initial conditions for both models. A 300-point logarithmic equidistant grid was generated for the integration of the KCE, with radii values in the range of 0.25 µm µm. Equations (16) and (17) were used to transform the output of both models to make them comparable, while the bulk quantities from the KCE were integrated from the calculated spectra.
4.2 WDM6 parameterization
To better establish the accuracy of the P-DNN, an extra parameterization was included in the comparison with the reference solution. The selected parameterization is the WRF double-moment six-class bulk mode (WDM6) (Lim and Hong, 2010), which was chosen to be implemented in a well-known three-dimensional atmospheric model (WRF). The collision–coalescence section of that parameterization is explained in detail in Cohard and Pinty (2000) and treats the main warm microphysical processes in the context of a bulk two-moment framework. A scheme of such a type is believed to be a pragmatic compromise between bulk parameterizations of precipitation as proposed by Kessler (1969) and very detailed bin models. Inclusion of a prognostic equation for the number concentration of raindrops provides better insight into the growth of large drops, which in turn can only improve the time evolution of the mixing ratios.
The scheme makes use of analytical solutions of the KCE for accretion and self-collection processes, while autoconversion follows the formulation of Berry and Reinhardt (1974). This has been done by using the generalized gamma distribution, which enables fine tuning of the DSD shape through the adjustment of two dispersion parameters. All the tendencies, except the autoconversion of the cloud droplets, are parameterized based on continuous integrals that encompass the whole range of drop diameters within each water substance category (cloud droplets and raindrops). The threshold for considering a change of category is r=41 µm. Thus, the gamma distributions employed are truncated in this radius value. With this method, the treatment of autoconversion is the weakest link in the scheme because this process acts in the diameter range in which the fuzzy transition between cloud droplets and raindrops is hardly compliant with a bimodal and spectrally wide (from zero to infinity) representation of the drops. As neither the KCE model (Bott, 1998a), the Clark's parameterization (Clark, 1976) nor the developed ML model take into account drop breakup, the formulation of this process included in Cohard and Pinty (2000) has been left out of the current implementation. This model is referred to as P-CP2000 in the following sections. For comparison purposes, all simulations share the same initial conditions. It should be noted that WDM6, being a conventional two-moment scheme, is focused on the evolution of the moments of order 0 and 3 of a truncated gamma distribution function.
The results shown in this section were obtained using the parameterized model COLNETv1.0.0 (Rodríguez Genó and Alfonso, 2021a, c, b).
5.1 Spectra comparison
The outputs of this parameterized deep neural network model (P-DNN) are the updated distribution parameters at every time step (N1, μ1, σ1, N2, μ2 and σ2). The physical variables related to the moments of the distributions, such as mean radius and liquid water content (LWC), are diagnosed from those parameters. Also, we can calculate the shape and scale of the drop spectrum at any given time by integrating the distribution functions defined by its parameters.
Figure 7 shows a comparison between the mass density spectra derived from P-DNN and KCE models for three chosen times (300, 600 and 900 s).
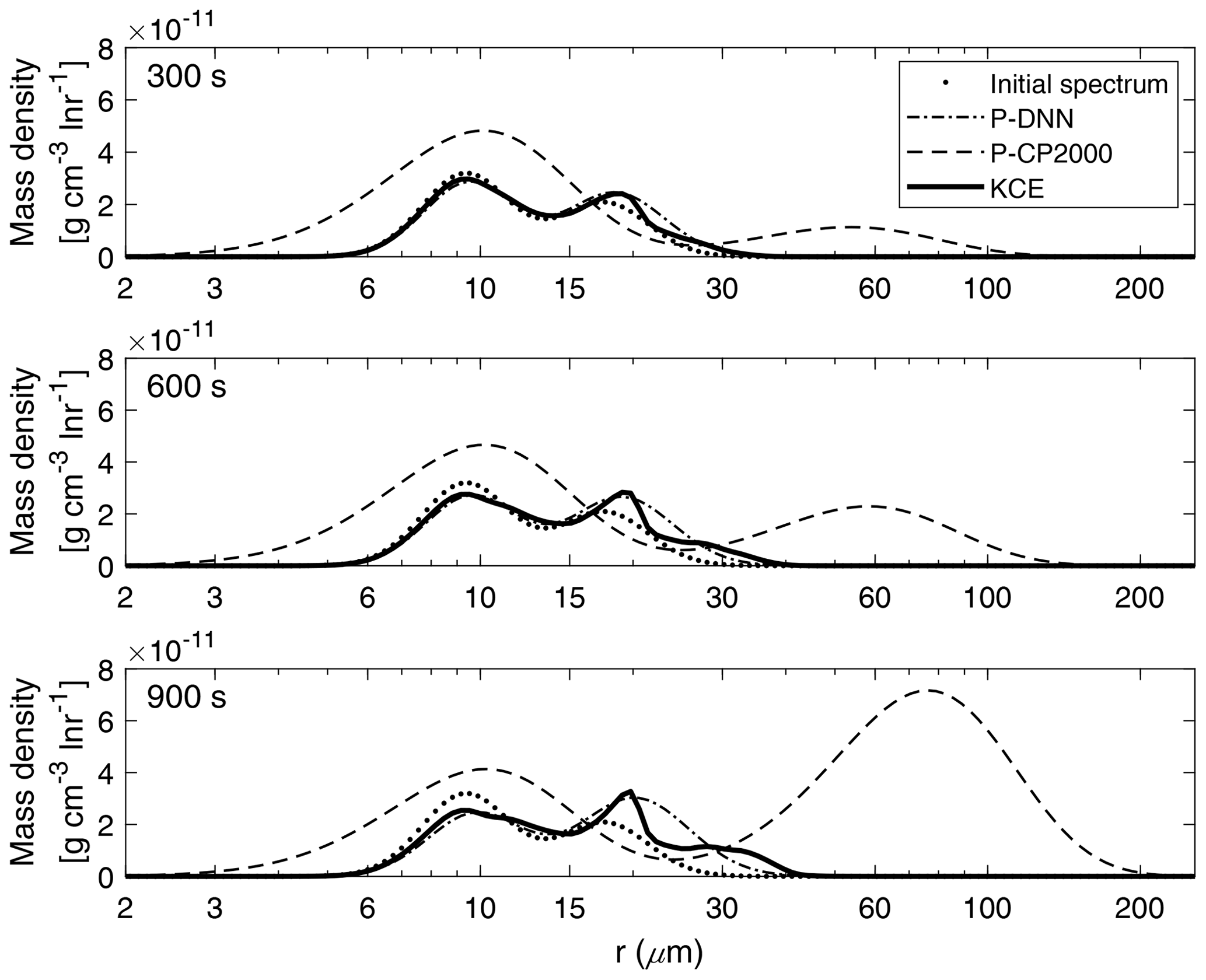
Figure 7Mass density functions from P-DNN, P-CP2000 and KCE. The represented times are 300, 600 and 900 s from top to bottom. Equation (16) was used to transform the drop number concentration spectra from P-DNN to the mass density spectra.
At 300 s (first row of Fig. 7), there is a slow development of the total spectrum, with a clear mass transfer between the two modes of the presented models. The parameter-generated spectrum from P-DNN fits the reference solution well, with a slight overestimation of the maximum mass in the second mode. The mean radius of the distributions is well represented by P-DNN. At 600 and 900 s (second and third row of Fig. 7), there is a development of a third mode in the evolution of KCE that is not reproduced by P-DNN, producing instead a wider second mode representing the mean radius and mass distribution well. The first mode is accurately represented at those times. An increase in mean radius can be observed due to the effect of the collision–coalescence process.
The simulation results with P-CP2000 are clearly different from the others. The first noticeable difference is the existence of droplets that are smaller than the initial distribution. This is caused by the fixed distribution parameters employed in its formulation. The slope parameter is determined by an analytical expression and evolves with time within certain limits, but the parameters related to the spectral breadth are held fixed. For more information please refer to Cohard and Pinty (2000). Besides that, P-CP2000 performs poorly at all the represented simulation times when compared with KCE. It presents a pronounced tendency to go ahead of the KCE, leading to a faster-than-normal development of larger drops. Particularly, the mass transfer is very noticeable at the end of the simulation. However, the first mode of P-CP2000 does not decrease proportionally.
Figure 8 shows a comparison between the drop number concentration spectra derived from P-DNN, P-CP2000 and KCE for three chosen times (300, 600 and 900 s). Generally good agreement is seen at all times for P-DNN, with its concentration values slightly underestimating the results from KCE. As the collision–coalescence process decreases the drop number concentration, there is no noticeable increase in the number of drops in the second mode of the distributions. However, an increase in the mean radius is observed that is consistent with the behavior described in Fig. 7, where a related mass transfer between the two distribution functions is seen.
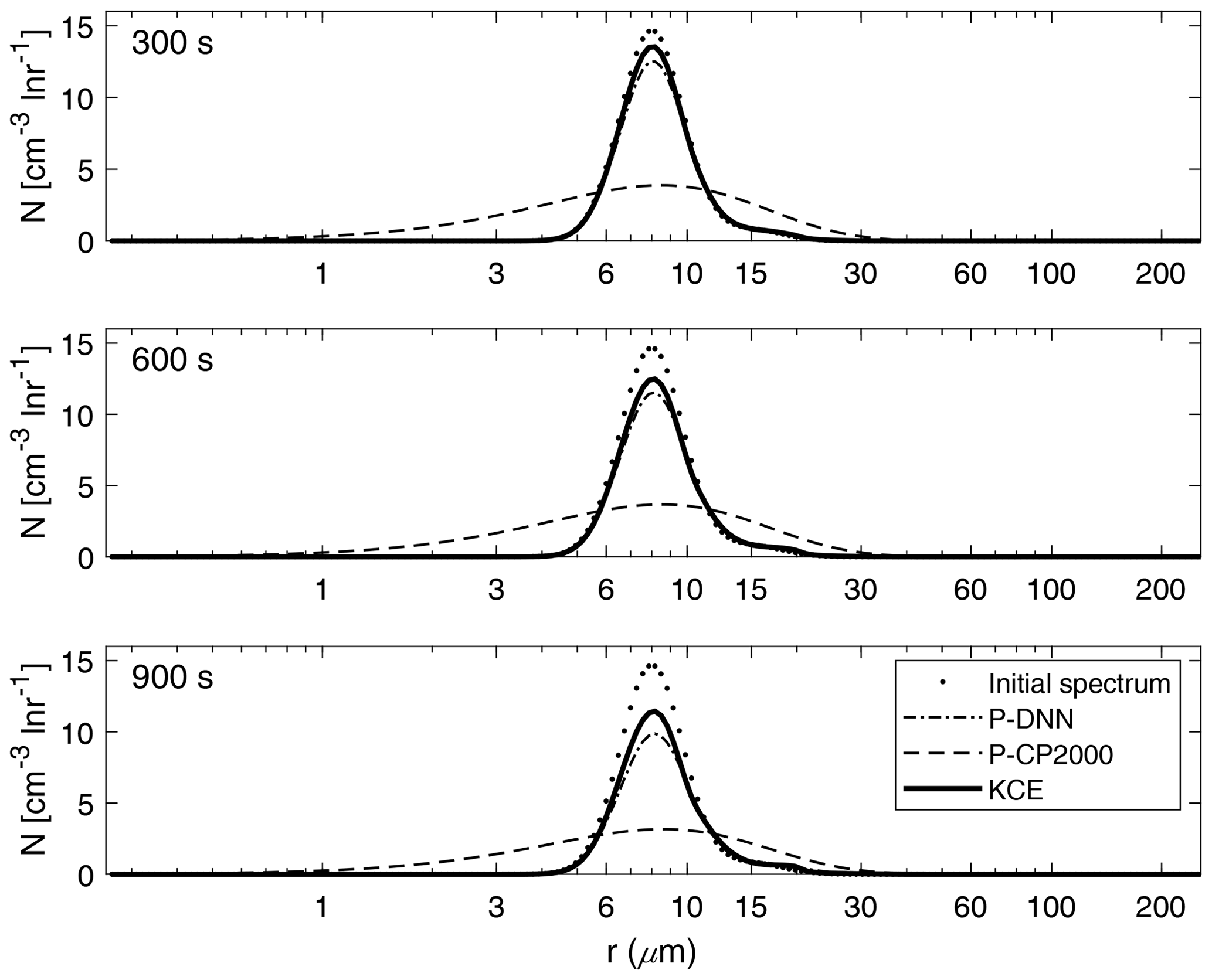
Figure 8Drop number concentration spectra for P-DNN, P-CP2000 and KCE. The selected times are 300, 600 and 900 s from top to bottom. Equation (17) was used to transform the mass density spectra from KCE to the drop number concentration spectra.
Regarding P-CP2000, its spectra underestimate the KCE, and the lack of a second mode reaffirms the behavior shown in Fig. 7. However, being a bulk parameterization, its strong points are not related to the description of the drop spectra but to the representation of bulk quantities such as the total number concentration and mass content of the clouds.
5.2 Bulk quantity comparison
Figure 9 shows a comparison of two main bulk quantities (total number concentration and mean radius) obtained from P-DNN, P-CP2000 and KCE. The concentration and mean radius of KCE were obtained by integrating the drop number concentration spectra for the corresponding moment order (0 and 1, respectively). As expected, number concentration decreases with time due to the coalescence of drops, ranging from an initial value of 200 to around 160 cm−3 in KCE. The predicted concentration from P-DNN underestimates the KCE values throughout most of the simulation time, with the differences reaching 10 cm−3 at 900 s. The P-CP2000 model achieves a relatively better representation of drop number concentration, although it reaches the same differences as P-DNN by the end of the simulation.
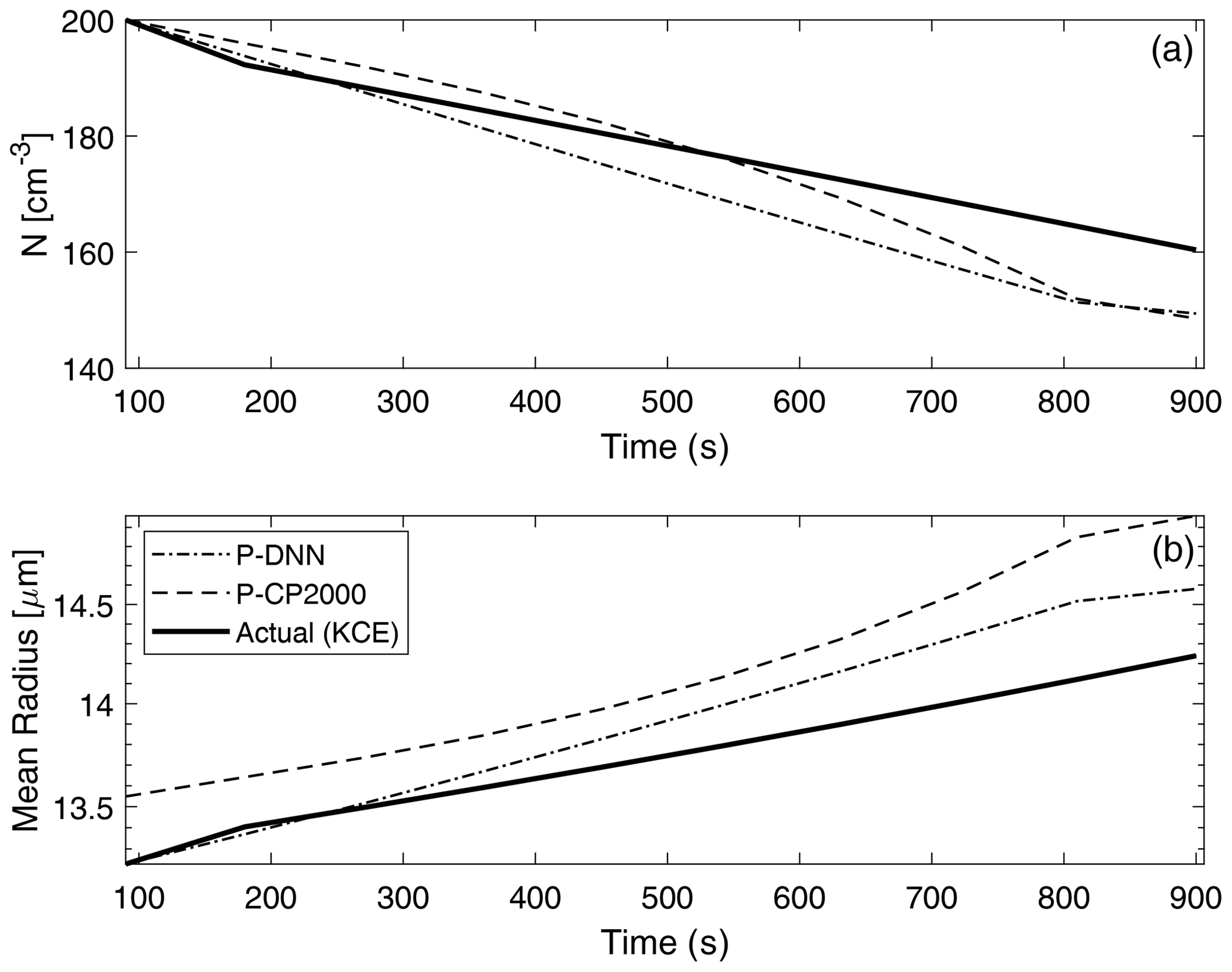
Figure 9Drop number concentration (a) and mean radius (b) comparison with KCE. The concentration and mean radius of KCE were obtained by integrating the drop number concentration spectra for the corresponding moment order (0 and 1, respectively). The data points are plotted every 60 s.
A similar behavior is observed in the mean radius results, with growth in the drop size consistent with the decreasing values of the drop number concentration for P-DNN. However, both P-DNN and P-CP2000 predict the mean radius rather well (considering that their values are diagnosed in both models), with differences reaching only 5 µm. This result is very important for P-DNN, since radius is the independent variable in the lognormal distributions that act as basis functions for this parameterization. In this regard, P-CP2000 performs somehow worse than P-DNN for the mean radius, with the mean difference almost reaching 1 µm, although it shows a monotony similar to both the KCE and P-DNN models.
There is a correlation between these results and those depicted in Fig. 8, where concentration decreases with time, and mean radius changes little throughout the simulation when considering the total moment of order 1. The differences reached in this figure are related to the base model from which the NN model was created. Since the NN model only reproduces (very accurately) the rates of the moments as in Clark (1976), an accuracy improvement of the overall parameterization should not be expected. Despite that, the P-DNN model achieves physical consistency and behaves following the rules of the simulated process, as evidenced in the increase in the mean radius (drop growth) and decrease in the number concentration (drop coalescence).
Figure 10 depicts the evolution of two main bulk quantities (drop number concentration and liquid water content) for the individual distributions that form P-DNN (f1 and f2), as well as the combined (total) values of the variables (calculated as f1+f2). Regarding concentration, a decrease in f1 values is observed due to the coalescence process, while a consistent increase in f2 is also seen. However, the increase in drop number concentration in f2 is not proportional because there are fewer bigger drops in the distribution, which are also colliding within the same distribution function (the equivalent of self-collection in bulk parameterizations). This is consistent with Fig. 8, in which the second mode in the concentration DSD is barely developed after 900 s of simulation time. However, a general decrease in the total concentration value represents the theory and observations of the parameterized process well. Barros et al. (2008) found this same behavior while revisiting the validity of the experimental results obtained by Low and List (1982), excluding drop breakup.
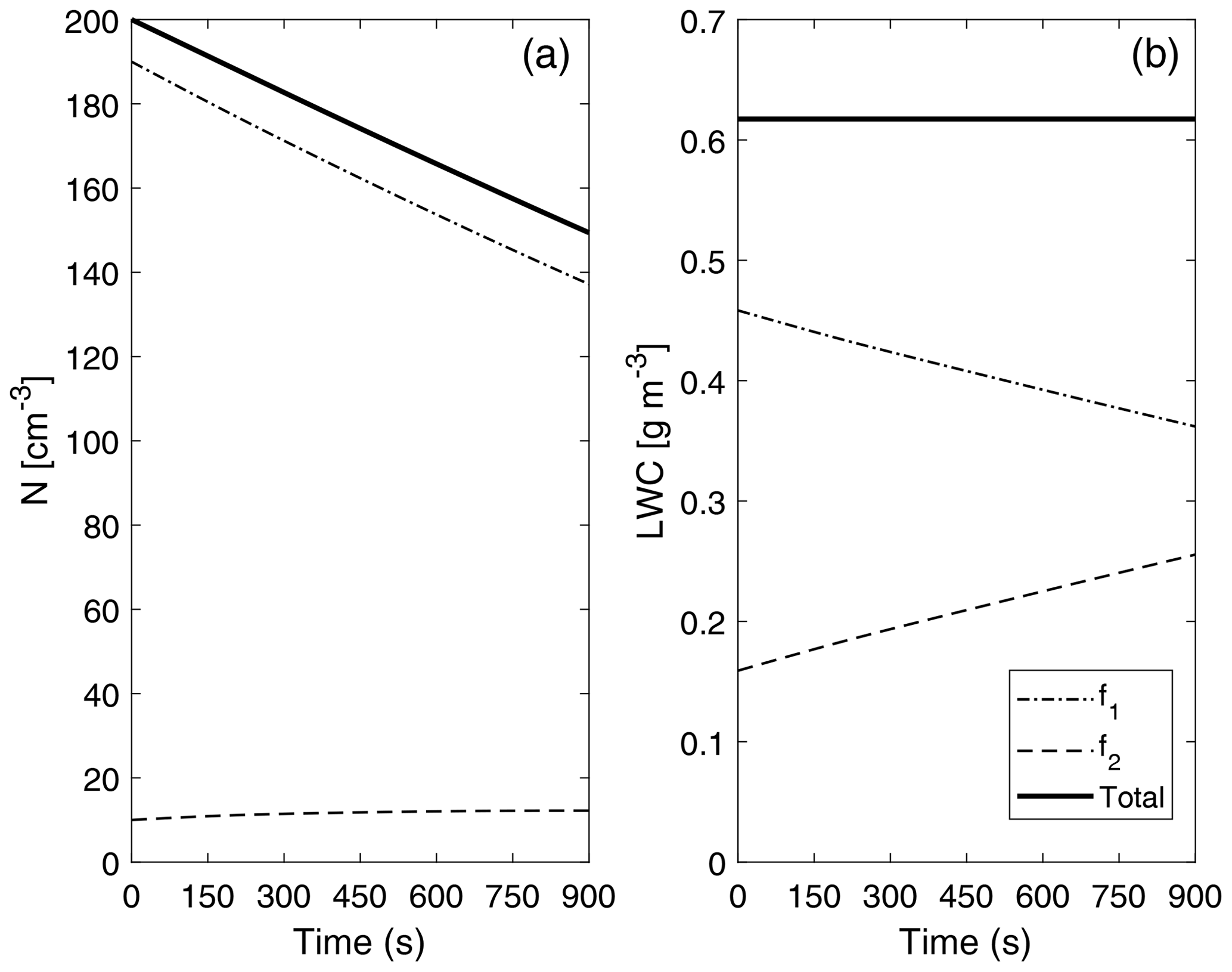
Figure 10Evolution of drop number concentration N (a) and liquid water content (LWC) (b) of the individual distributions that form P-DNN. The liquid water content of each of the distribution functions (f1 and f2) was obtained from the corresponding moment (order 3) calculated from Eq. (4). The combined (total) values of the variables are also shown and were calculated from Eq. (5).
The liquid water content (LWC) values (diagnosed) are depicted only to verify that mass is conserved under the formulation of P-DNN. The LWC of each of the distribution functions (f1 and f2) was obtained from the corresponding moment (order 3) calculated from Eq. (4). Effectively, total mass remains constant during the entire simulation, with a proportional mass transfer between f1 and f2. These results demonstrate that the P-DNN parameterization behavior is physically sound, with remarkable consistency between the different variables calculated, both bulk (N, r and LWC) and DSD related (concentration and mass density spectra).
5.3 Total moment errors
An analysis of the predicted total moments was performed with the objective to further test the precision of P-DNN due to the importance of the statistical moments in calculating physical variables such as mean radius and LWC. Table 5 shows the mean percent errors of the total moments predicted by P-DNN and P-CP2000. The percent error is taken relative to the moments of KCE. The data were obtained by calculating the mean of the percent errors of the entire simulation. The moments for the solution of the KCE were computed by integrating the reference drop number concentration spectra using Eq. (3), while the total moments from P-DNN and P-CP2000 were calculated using the predicted distribution parameters and solving Eq. (5). The defined gamma distribution equations for the moments are used in the case of P-CP2000. A reasonable degree of accuracy was achieved by P-DNN, with the mean error never surpassing 4 %. However, the data show that the total moments of order 0 to 2 are usually underestimated, while those of order 4 and 5 are slightly overestimated. This could result in calculations of drop number concentration values lower than the actual ones, as seen in Fig. 9. As for P-CP2000, the model is not formulated to predict individual moments other than the zeroth and third moments. Thus, the other moments of the distributions are not well represented, as observed in the mean percent error, which reaches almost −61 % for the moment of order 5. That value is a great difference from the zeroth moment, for example, whose percent error is only −1.3 %. This result indicates that P-DNN is adequate to represent the evolution of individual moments within certain ranges when compared with more conventional bulk schemes.
Table 5Total moment mean errors. The percent error is taken relative to the moments of KCE. The shown data were obtained by calculating the mean of the percent errors of the entire simulation.
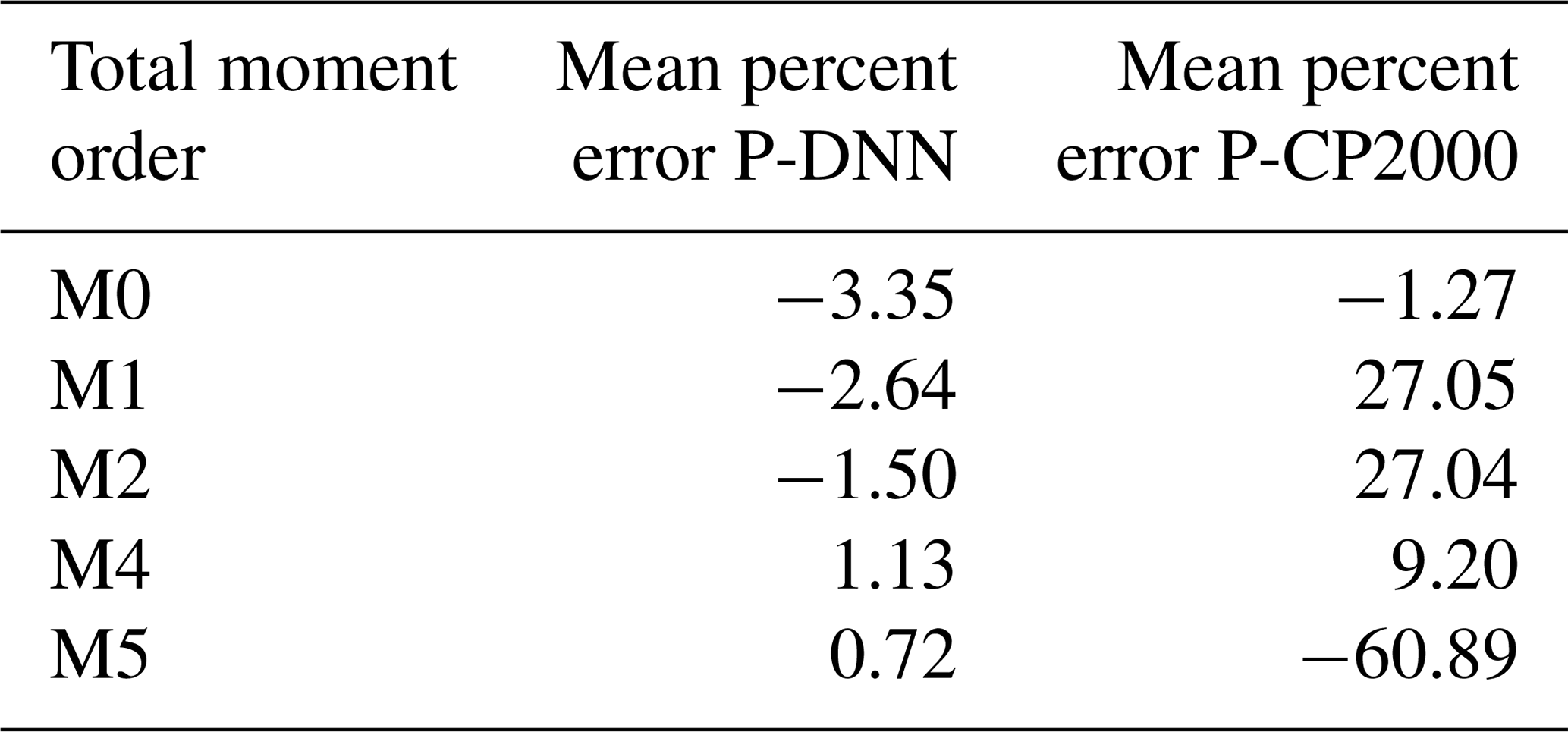
Figure 11 shows the time evolution of the percent error of the total moments throughout the simulation for P-DNN. The percent error is taken relative to the moments of KCE. The moments of KCE were calculated by integrating the reference drop number concentration spectra using Eq. (3), while the total moments from P-DNN were calculated using the predicted distribution parameters to solve Eq. (5). The error of total moment of order 3 is 0 during the entire simulation because mass is not affected by the collision–coalescence process. The total moments from order 0, 1 and 2 overestimate the KCE in the first 300 s of simulation and underestimate them for the rest of the P-DNN run, with the percent error reaching a minimum value of −8 %. The opposite behavior is observed for the total moments of order 4 and 5; they initially underestimate the KCE and overestimate it for the rest of the simulation. However, for these orders the percent error is usually lower, with a maximum of 4 %. Generally, P-DNN performs well, with the percent error never reaching the 10 % threshold. However, further analysis on this topic is recommended, to improve the accuracy of the parameterization.
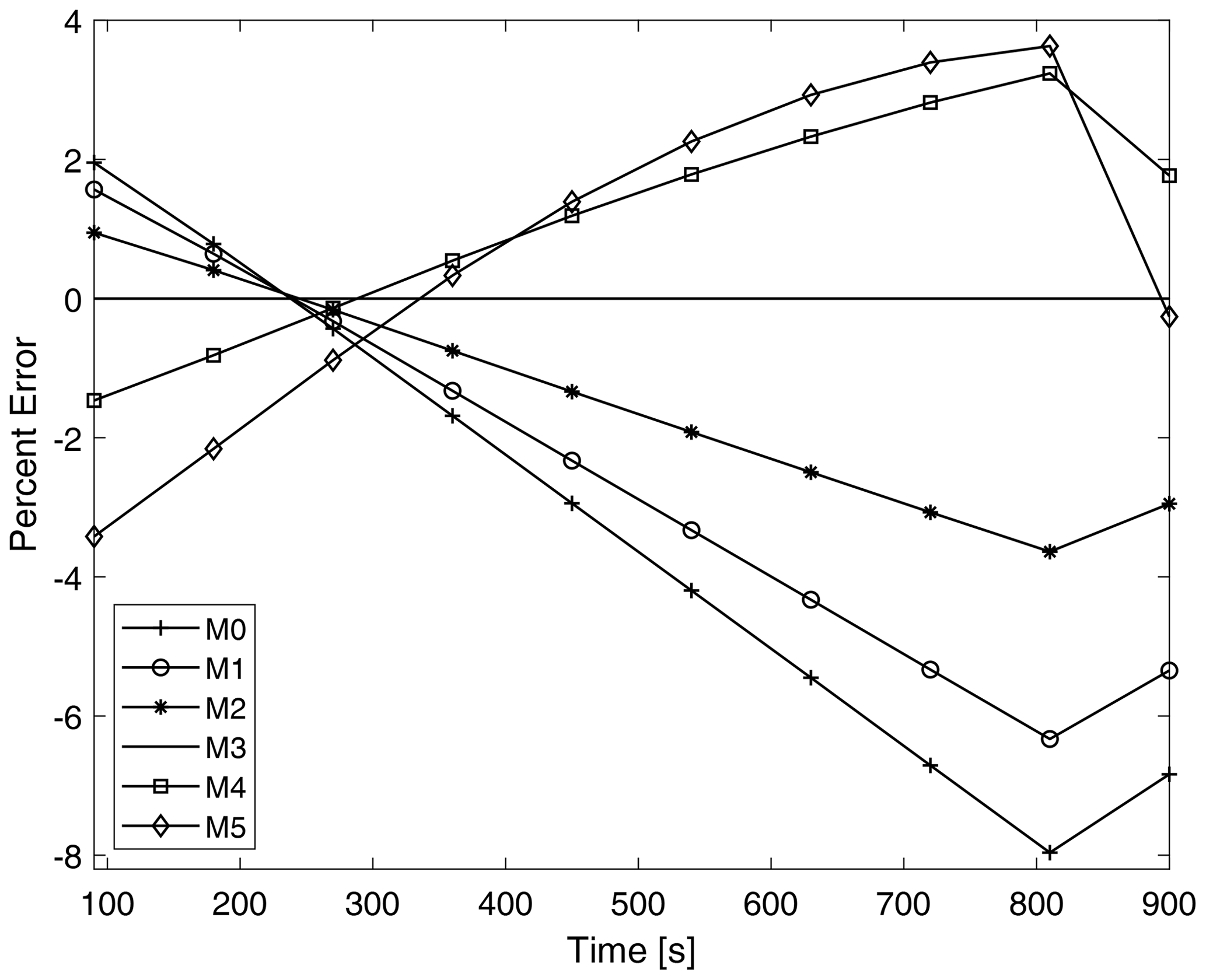
Figure 11Time evolution of the errors corresponding to the predicted moments from P-DNN. The percent error is taken relative to the moments of KCE. The moments of KCE were calculated by integrating the reference drop number concentration spectra using Eq. (3), while the total moments from the P-DNN were calculated using the predicted distribution parameters to solve Eq. (5).
The presented way to simulate the evolution of the droplet spectra due to collision–coalescence falls within the framework developed by Clark (1976) and Clark and Hall (1983). Under this approach, a dynamic framework has been established in Rodríguez Genó and Alfonso (2021e). A hybrid parameterization for the process of collision–coalescence based on the methodology of basis functions employing a linear combination of two lognormal distributions was formulated and implemented. All the parameters of the distributions are derived from the total moment tendencies, which in turn are calculated by means of five trained deep neural networks. By doing this, we obtained a parameterized model that determines the distribution parameters' evolution and hence the evolution of the DSD. The physical variables are diagnosed from the distribution moments. Within the framework of this parameterized model, there is no artificial classification of the water substance (cloud droplets or raindrops). Instead, we consider a full set of distribution parameters for each of the distribution functions considered in the formulation of the parameterization in order to describe the DSD in radius space. This kind of microphysical parameterization allows the use of an arbitrary number of probability density functions in linear combination to reproduce the drop spectrum.
The novel components of the P-DNN model were introduced and evaluated in Sect. 3. A total of five deep neural networks were trained to calculate the rates of the total moments following Clark (1976) using a novel training approach called a cascade-forward neural network instead of the traditional sequential networks. By doing this, the trained NNs were able to accurately reproduce the total moment tendencies, showing a very high correlation and small MSE when compared with those calculated with the original formulation (Clark, 1976) (see Figs. 5–6 and Table 3). Thus, the precision and ability of the ML-based method to reproduce the rates of the total moments due to collision–coalescence when trained with a sufficient number of data samples (100 000 combinations) were demonstrated.
One experiment was performed to illustrate the behavior of the DNN-based parameterization at the initial stages of precipitation formation. The simulation results from P-DNN showed good agreement when compared to a reference solution (KCE) for both the predicted DSD and the bulk quantities considered. Moreover, the P-DNN model demonstrated a physically sound behavior, adhering to the theory of the collision–coalescence process, with overall consistency in the values of both prognosed and diagnosed variables. With the development of P-DNN, a parameterization for solving the entire collision–coalescence process has been developed (with the exception of drop breakup) using ML methodology. To the best of the authors' knowledge, previous attempts at describing collision–coalescence using the same methodology have been focused on super-parameterizations for sub-grid processes (Brenowitz and Bretherton, 2018) or formulations for specific sub-processes such as autoconversion (Alfonso and Zamora, 2021; Loft et al., 2018) and accretion (Seifert and Rasp, 2020).
For comparison purposes, the bulk parameterization developed by Cohard and Pinty (2000) (P-CP2000) was also implemented. According to the comparison with the bulk model, the main strength of P-DNN is the superior ability to represent the evolution of the total moments and the shape of the DSD because of its formulation based on time-varying distribution parameters. The predicted P-DNN concentration and mass spectra closely match that of the reference bin model (KCE), while showing good accuracy at forecasting bulk variables such as drop number concentration and the parameter-derived mean radius. Furthermore, total mass is conserved throughout the entire simulation, which is remarkable due to the inherent numerical diffusion of the first-order finite-difference method applied to update the parameters at each time step. An analysis of the accuracy of the predicted total moments of P-DNN was performed, with the percent error relative to the KCE never exceeding 8 %. However, there is room for improvement in the calculations of the total moments. Thus, it is the recommendation of the authors to retrain the DNNs with a finer resolution in the parameter values and with a wider range of values in order to cover all possible combination of parameters. Another recommendation is the inclusion of the drop breakup process in the formulation, which is currently not included in the parameterization, despite its influence on the behavior at the edge of raindrop distributions. In addition, the use of ML eliminated the requirement of numerically integrating the total moment tendencies at each time step, and the use of lookup tables for each predicted moment is no longer needed under this formulation.
To obtain a full warm cloud model, an extension of this neural network algorithm applied to condensation is proposed, following the same methodology of series of basis functions. A parameterization scheme such as this could be included in regional weather and climate models, as its initial conditions can be calculated from variables needed by more traditional bulk models.
The current version of COLNET (COLNETv1.0.0) used to produce the results presented in this paper is archived on Zenodo (https://doi.org/10.5281/zenodo.4740061, Rodríguez Genó and Alfonso, 2021a) under the GNU Affero General Public License v3 or later, along with all needed scripts to run the model. The outputs of the model used to generate the figures included in the present paper are also included. The scripts used in the generation of training data sets and for training the neural networks used in COLNETv1.0.0 can be found on Zenodo (https://doi.org/10.5281/zenodo.4740129, Rodríguez Genó and Alfonso, 2021c), while the codes for plotting the figures are stored at https://doi.org/10.5281/zenodo.4740184 (Rodríguez Genó and Alfonso, 2021b). The original FORTRAN77 code of the explicit bin model is archived at https://doi.org/10.5281/zenodo.5660185 (Bott, 1998b) and has been licensed (GNU Affero General Public License v3 or later) and versioned (V1.0.0) with the permission of the author. The code used for the WDM6 parameterization simulation can be found on Zenodo (https://doi.org/10.5281/zenodo.5196706, Rodríguez Genó and Alfonso, 2021d). The models and related scripts were written using MATLAB R2020a, with exception of the explicit model.
The data set was generated using a random number generator. The data were created following a uniform distribution, with means, standard deviations and ranges provided in Table 1. The MATLAB code used for generating the training data can be found at https://doi.org/10.5281/zenodo.4740129 (Rodríguez Genó and Alfonso, 2021c).
LA performed the conceptualization of the article, designed the methodology, acquired funding and resources, and supervised, reviewed, and edited the original draft. CFRG realized the formal analysis and investigation, developed and implemented the software and code for simulation and visualization, validated the results, and wrote the original draft.
The contact author has declared that neither they nor their co-author has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Camilo Fernando Rodríguez Genó is a doctoral student from the Programa de Posgrado en Ciencias de la Tierra at Universidad Nacional Autónoma de México and received fellowship 587822 from Consejo Nacional de Ciencia y Tecnología (CONACyT). This study was funded by grant no. CB-284482 from the Consejo Nacional de Ciencia y Tecnología (SEP-CONACyT). The authors thank the anonymous referees and the editor for their helpful comments that improved the quality of the paper.
This research has been supported by the Consejo Nacional de Ciencia y Tecnología (CONACyT) (grant nos. CB-284482 and 587822).
This paper was edited by Sylwester Arabas and reviewed by two anonymous referees.
Alfonso, L. and Zamora, J. M.: A two-moment machine learning parameterization of the autoconversion process, Atmos. Res., 249, 105269, https://doi.org/10.1016/j.atmosres.2020.105269, 2021.
Alfonso, L., Raga, G. B., and Baumgardner, D.: The validity of the kinetic collection equation revisited, Atmos. Chem. Phys., 8, 969–982, https://doi.org/10.5194/acp-8-969-2008, 2008.
Alfonso, L., Raga, G., and Baumgardner, D.: A Monte Carlo framework to simulate multicomponent droplet growth by stochastic coalescence, in: Applications of Monte Carlo Method in Science and Engineering, edited by: Mordechai, S., InTech., https://doi.org/10.5772/14522, 2011.
Barros, A. P., Prat, O. P., Shrestha, P., Testik, F. Y., and Bliven, L. F.: Revisiting Low and List (1982): Evaluation of raindrop collision parameterizations using laboratory observations and modeling, J. Atmos. Sci., 65, 2983–2993, https://doi.org/10.1175/2008JAS2630.1, 2008.
Berry, E. X.: Cloud droplet growth by collection, J. Atmos. Sci., 24, 688–701, https://doi.org/10.1175/1520-0469(1967)024<0688:CDGBC>2.0.CO;2, 1967.
Berry, E. X. and Reinhardt, R. L.: An analysis of cloud drop growth by collection: Part I. Double distributions, J. Atmos. Sci., 31, 1814–1824, https://doi.org/10.1175/1520-0469(1974)031<1814:AAOCDG>2.0.CO;2, 1974.
Bott, A.: A flux method for the numerical solution of the stochastic collection equation, J. Atmos. Sci., 55, 2284–2293, https://doi.org/10.1175/1520-0469(1998)055<2284:AFMFTN>2.0.CO;2, 1998a.
Bott, A.: Program for the solution of the stochastic coalescence equation: One-dimensional cloud microphysics, Zenodo [code], https://doi.org/10.5281/zenodo.5660185, 1998b.
Brenowitz, N. D. and Bretherton, C. S.: Prognostic validation of a neural network unified physics parameterization, Geophys. Res. Lett., 45, 6289–6298, https://doi.org/10.1029/2018GL078510, 2018.
Clark, T. L.: Use of log-normal distributions for numerical calculations of condensation and collection, J. Atmos. Sci., 33, 810–821, https://doi.org/10.1175/1520-0469(1976)033<0810:UOLNDF>2.0.CO;2, 1976.
Clark, T. L. and Hall, W. D.: A cloud physical parameterization method using movable basis functions: Stochastic coalescence parcel calculations, J. Atmos. Sci., 40, 1709–1728, https://doi.org/10.1175/1520-0469(1983)040<1709:ACPPMU>2.0.CO;2, 1983.
Cohard, J.-M. and Pinty, J.-P.: A comprehensive two-moment warm microphysical bulk scheme. I: Description and tests, Q. J. R. Meteorol. Soc., 126, 1815–1842, https://doi.org/10.1002/qj.49712656613, 2000.
Dan Foresee, F. and Hagan, M. T.: Gauss-Newton approximation to Bayesian learning, in: Proceedings of International Conference on Neural Networks (ICNN'97), 12 June 1997, Houston, Texas, USA, vol. 3, 1930–1935, IEEE, Houston, USA, https://doi.org/10.1109/ICNN.1997.614194, 1997.
Feingold, G. and Levin, Z.: The lognormal fit to raindrop spectra from frontal convective clouds in Israel, J. Clim. Appl. Meteorol., 25, 1346–1363, https://doi.org/10.1175/1520-0450(1986)025<1346:TLFTRS>2.0.CO;2, 1986.
Feingold, G., Walko, R. L., Stevens, B., and Cotton, W. R.: Simulations of marine stratocumulus using a new microphysical parameterization scheme, Atmos. Res., 47–48, 505–528, https://doi.org/10.1016/S0169-8095(98)00058-1, 1998.
Gillespie, D. T.: The stochastic coalescence model for cloud droplet growth, J. Atmos. Sci., 29, 1496–1510, https://doi.org/10.1175/1520-0469(1972)029<1496:TSCMFC>2.0.CO;2, 1972.
Hall, W. D.: A detailed microphysical model within a two-dimensional dynamic framework: Model description and preliminary Results, J. Atmos. Sci., 37, 2486–2507, https://doi.org/10.1175/1520-0469(1980)037<2486:ADMMWA>2.0.CO;2, 1980.
Huang, W. T. K.: Reformulation of the Milbrandt and Yau microphysics parameterization: A triple-moment lognormal scheme, McGill University, available at: https://www.proquest.com/dissertations-theses/reformulation-milbrandt-yau-microphysics/docview/2512357588/se-2?accountid=12874 (last access: 13 January 2022), 2014.
Karaca, Y.: Case study on artificial neural networks and applications, Appl. Math. Sci., 10, 2225–2237, https://doi.org/10.12988/ams.2016.65174, 2016.
Kessler, E.: On the distribution and continuity of water substance in atmospheric circulations, Meteorol. Monogr., 10, 1–84, https://doi.org/10.1007/978-1-935704-36-2_1, 1969.
Khain, A., Pokrovsky, A., Pinsky, M., Seifert, A., and Phillips, V.: Simulation of effects of atmospheric aerosols on deep turbulent convective clouds using a spectral microphysics mixed-phase cumulus cloud model. Part I: Model description and possible applications, J. Atmos. Sci., 61, 2963–2982, https://doi.org/10.1175/JAS-3350.1, 2004.
Khain, A., Lynn, B., and Dudhia, J.: Aerosol effects on intensity of landfalling hurricanes as seen from simulations with the WRF model with spectral bin microphysics, J. Atmos. Sci., 67, 365–384, https://doi.org/10.1175/2009JAS3210.1, 2010.
Khain, A. P., Beheng, K. D., Heymsfield, A., Korolev, A., Krichak, S. O., Levin, Z., Pinsky, M., Phillips, V., Prabhakaran, T., Teller, A., van den Heever, S. C., and Yano, J.-I.: Representation of microphysical processes in cloud-resolving models: Spectral (bin) microphysics versus bulk parameterization, Rev. Geophys., 53, 247–322, https://doi.org/10.1002/2014RG000468, 2015.
Khairoutdinov, M. and Kogan, Y.: A new cloud physics parameterization in a large-eddy simulation model of marine stratocumulus, Mon. Weather Rev., 128, 229–243, https://doi.org/10.1175/1520-0493(2000)128<0229:ANCPPI>2.0.CO;2, 2000.
Koza, J. R., Bennett, F. H., Andre, D., and Keane, M. A.: Automated design of both the topology and sizing of analog electrical circuits using genetic programming, in: Artificial Intelligence in Design '96, edited by: Gero, J. S. and Sudweeks, F., Springer Netherlands, Dordrecht, the Netherlands, 151–170, https://doi.org/10.1007/978-94-009-0279-4_9, 1996.
Lee, K. W., Chen, J., and Gieseke, J. A.: Log-normally preserving size distribution for brownian coagulation in the free-molecule regime, Aerosol Sci. Technol., 3, 53–62, https://doi.org/10.1080/02786828408958993, 1984.
Lee, K. W., Lee, Y. J., and Han, D. S.: The log-normal size distribution theory for Brownian coagulation in the low Knudsen number regime, J. Colloid Interface Sci., 188, 486–492, https://doi.org/10.1006/jcis.1997.4773, 1997.
Lim, K.-S. S. and Hong, S.-Y.: Development of an effective double-moment cloud microphysics scheme with prognostic cloud condensation nuclei (CCN) for weather and climate models, Mon. Weather Rev., 138, 1587–1612, https://doi.org/10.1175/2009MWR2968.1, 2010.
Loft, R., Sobhani, N., Gettelman, A., Chen, C. C., and Gagne, D. J., I.: Using Machine Learning to emulate critical cloud microphysical processes, in: American Geophysical Union, Fall Meeting 2018, 10 December 2018, Washington, D.C., USA, IN13C-0686, available at: https://agu.confex.com/agu/fm18/prelim.cgi/Paper/466907 (last access: 22 February 2021), 2018.
Long, A. B.: Solutions to the droplet collection equation for polynomial kernels, J. Atmos. Sci., 31, 1040–1052, https://doi.org/10.1175/1520-0469(1974)031<1040:STTDCE>2.0.CO;2, 1974.
Low, T. B. and List, R.: Collision, coalescence and breakup of raindrops. Part I: Experimentally established coalescence efficiencies and fragment size distributions in breakup, J. Atmos. Sci., 39, 1591–1606, https://doi.org/10.1175/1520-0469(1982)039<1591:CCABOR>2.0.CO;2, 1982.
MacKay, D. J. C.: Bayesian interpolation, Neural Comput., 4, 415–447, https://doi.org/10.1162/neco.1992.4.3.415, 1992.
Marquardt, D. W.: An algorithm for least-squares estimation of nonlinear parameters, J. Soc. Ind. Appl. Math., 11, 431–441, https://doi.org/10.1137/0111030, 1963.
Marshall, J. S. and Palmer, W. M. K.: The distribution of raindrops with size, J. Meteorol., 5, 165–166, https://doi.org/10.1175/1520-0469(1948)005<0165:TDORWS>2.0.CO;2, 1948.
Milbrandt, J. A. and McTaggart-Cowan, R.: Sedimentation-induced errors in bulk microphysics schemes, J. Atmos. Sci., 67, 3931–3948, https://doi.org/10.1175/2010JAS3541.1, 2010.
Milbrandt, J. A. and Yau, M. K.: A multimoment bulk microphysics parameterization. Part I: Analysis of the role of the spectral shape parameter, J. Atmos. Sci., 62, 3051–3064, https://doi.org/10.1175/JAS3534.1, 2005.
Mitchell, T. M.: Machine Learning, McGraw-Hill, available at: https://books.google.ca/books?id=EoYBngEACAAJ (last access: 12 March 2021), 1997.
Morrison, H., Thompson, G., and Tatarskii, V.: Impact of cloud microphysics on the development of trailing stratiform precipitation in a simulated squall line: Comparison of one- and two-moment schemes, Mon. Weather Rev., 137, 991–1007, https://doi.org/10.1175/2008MWR2556.1, 2009.
Noh, Y., Oh, D., Hoffmann, F., and Raasch, S.: A cloud microphysics parameterization for shallow cumulus clouds based on Lagrangian cloud model simulations, J. Atmos. Sci., 75, 4031–4047, https://doi.org/10.1175/JAS-D-18-0080.1, 2018.
Pruppacher, H. R. and Klett, J. D.: Microphysics of clouds and precipitation, Springer Netherlands, Dordrecht, the Netherlands, https://doi.org/10.1007/978-0-306-48100-0, 2010.
Rasp, S., Pritchard, M. S., and Gentine, P.: Deep learning to represent subgrid processes in climate models, Proc. Natl. Acad. Sci. USA, 115, 9684–9689, https://doi.org/10.1073/pnas.1810286115, 2018.
Rodríguez Genó, C. F. and Alfonso, L.: COLNETv1.0.0, Zenodo [code], https://doi.org/10.5281/zenodo.4740061, 2021a.
Rodríguez Genó, C. F. and Alfonso, L.: COLNETv1.0.0 graphics generation scripts, Zenodo [code], https://doi.org/10.5281/zenodo.4740184, 2021b.
Rodríguez Genó, C. F. and Alfonso, L.: COLNETv1.0.0 neural network training scripts, Zenodo [code], https://doi.org/10.5281/zenodo.4740129, 2021c.
Rodríguez Genó, C. F. and Alfonso, L.: CP2000CCv1.0.0 WDM6 Parameterization, Zenodo [code], https://doi.org/10.5281/zenodo.5196706, 2021d.
Rodríguez Genó, C. F. and Alfonso, L.: Sedimentation calculations within an Eulerian framework using series of basis functions, Q. J. R. Meteorol. Soc., 147, 2053–2066, https://doi.org/10.1002/qj.4009, 2021e.
Russell, S. and Norvig, P.: Artificial intelligence: a modern approach, 3rd edn., Prentice Hall, ISBN 978-0-2620-1825-8, 2010.
Schmidhuber, J.: Deep learning in neural networks: An overview, Neural Networks, 61, 85–117, https://doi.org/10.1016/j.neunet.2014.09.003, 2015.
Seifert, A. and Beheng, K. D.: A double-moment parameterization for simulating autoconversion, accretion and selfcollection, Atmos. Res., 59–60, 265–281, https://doi.org/10.1016/S0169-8095(01)00126-0, 2001.
Seifert, A. and Rasp, S.: Potential and limitations of Machine Learning for modeling warm-rain cloud microphysical processes, J. Adv. Model. Earth Syst., 12, e2020MS002301, https://doi.org/10.1029/2020MS002301, 2020.
Straka, J. M.: Cloud and precipitation microphysics: Principles and parameterizations, Cambridge University Press, Cambridge, https://doi.org/10.1017/CBO9780511581168, 2009.
Thompson, G., Field, P. R., Rasmussen, R. M., and Hall, W. D.: Explicit forecasts of winter precipitation using an improved bulk microphysics scheme. Part II: Implementation of a new snow parameterization, Mon. Weather Rev., 136, 5095–5115, https://doi.org/10.1175/2008MWR2387.1, 2008.
Thompson, P. D.: A transformation of the stochastic equation for droplet coalescence, in: Proceedings of the International Conference on Cloud Physics, 26–30 August 1968, Toronto, Canada, 115–126, 1968.
Ulbrich, C. W.: Natural variations in the analytical form of the raindrop size distribution, J. Clim. Appl. Meteorol., 22, 1764–1775, https://doi.org/10.1175/1520-0450(1983)022<1764:NVITAF>2.0.CO;2, 1983.
von Smoluchowski, M.: Drei vorträge über diffusion, Brownsche molekularbewegung und koagulation von kolloidteilchen [Part 1]. Diffusion im unbegrenzten raum, Phys. Z., 17, 557–572, 1916a.
von Smoluchowski, M.: Drei vorträge über diffusion, Brownsche molekularbewegung und koagulation von kolloidteilchen [Part 2], Phys. Z., 17, 585–599, 1916b.
Warsito, B., Santoso, R., Suparti and Yasin, H.: Cascade Forward Neural Network for time series prediction, J. Phys. Conf. Ser., 1025, 012097, https://doi.org/10.1088/1742-6596/1025/1/012097, 2018.
- Abstract
- Introduction
- Description of the collision–coalescence parameterization
- Machine learning architecture and training data set
- WDM6 parameterization and experiment design
- Discussion of results
- Conclusions
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Description of the collision–coalescence parameterization
- Machine learning architecture and training data set
- WDM6 parameterization and experiment design
- Discussion of results
- Conclusions
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References