the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 12 Feb 2021
| 12 Feb 2021
Current status on the need for improved accessibility to climate models code
Michael García-Rodríguez
Javier Rodeiro
Over the past few years, increasing attention has been focused on the need to publish computer code as an integral part of the research process. This has been reflected in improved policies on publication in scientific journals, including key related issues such as repositories and licensing. We explore the state of the art of code availability and the sharing of climate models using the Fifth Coupled Model Intercomparison Project (CMIP5) models as a test bed, and we include some particular reflections on this case. Our results show that there are many limitations in terms of access to the code for these climate models and that the climate modelling community needs to improve its code-sharing practice to comply with best practice in this regard and the most recent editorial publishing policies.
- Article
(365 KB) - Full-text XML
- BibTeX
- EndNote





Reproducibility of results is essential to comply with the scientific method when performing research. This has extraordinary implications in the field of earth system models (Añel, 2019; Gramelsberger et al., 2020). Because so much scientific output today relies on the use of computers, there are new requirements in terms of the description of any experiments performed to assure computational scientific reproducibility (CSR). CSR, as defined by the U.S. National Academies of Science, Engineering, and Medicine, means “obtaining consistent results using the same input data, computational methods, and conditions of analysis” (National Academies of Sciences, Engineering, and Medicine, 2019). This is widely known (Añel, 2011) and was recently discussed in a Sackler Colloquium on “Reproducibility of Research: Issues and Proposed Remedies” (Allison et al., 2018).
CSR is a problem of high complexity. In some cases, scientists may be unaware of some of the issues that have significant impacts on CSR and therefore reach the wrong conclusion that an experiment complies with CSR when it does not, as exposed in Añel (2017). Also, a researcher could decide to use a model based on judgements that have little to do with CSR from a scientific point of view, such as complying with the scientific method (Joppa et al., 2013). All this makes it necessary to consider a range of issues to comply with CSR in the design process and use of models (Añel, 2017), in particular for climate change models. Some of the issues are legal aspects of software distribution and intellectual property, which are usually unfamiliar to researchers. Recent examples have revealed some very low levels of CSR (Allison et al., 2018; Stodden et al., 2018). Steps are being taken to improve CSR, e.g. an increasing number of journals now have computer-code policies (Stodden et al., 2013; GMD Executive Editors, 2015; Nature, 2018) and recommendations have been made to ensure greater reproducibility of results (Wilson et al., 2017). They include maintaining appropriate documentation for the software, splitting the code into functions, submitting the code to DOI-issuing repositories, encouraging the participation of external collaborators, and making collaboration easy.
The study of climate change relies heavily on the use of large computer simulations with geoscientific models of varying levels of complexity. In projects involving the intercomparison of climate models, and in some research papers, it has become increasingly common to provide details of the simulations performed. These details include initial configurations, which are generally clear, accessible, and formalised in related outputs with digital object identifiers (DOIs) (e.g. Eyring et al., 2016; Morgenstern et al., 2017). However, it is somewhat perplexing that the code for the underlying models is not always made available. At best they are shared informally using links to repositories without any security regarding long-term availability or access, or via email addresses by which it is claimed that the code will be delivered after contact. Especially in a field where heated debates occasionally arise following the publication of results, it seems odd that this core element of the research is not made more widely accessible.
There are other reasons that justify the need for access to the code for climate models used in scientific research. One is to prevent the loss of knowledge on the cycles of development of these models. Some of them currently rely on “legacy” code that was written up to five decades ago, and new developers must understand why some decisions on implementation were undertaken so long ago. There is both an educational and practical dimension to this issue. In some cases, different models share sections of code, but its development remains fairly obscure (Knutti et al., 2013). It can be argued that adequate documentation of the code and the model is not necessary to prevent a potential loss of knowledge if the code used in the models includes appropriate comments. But, indeed, this is not the case for the models contributing to the Fifth Coupled Model Intercomparison Project (CMIP5). CMIP models are sophisticated software projects and they need full documentation of the experiments (Pascoe et al., 2020).
Moreover, it is the case that climate models do not comply with what would be the ideal level of programming practice (i.e. coding standards, number of comments, documentation, etc.), an idea already pointed out by Wieters and Fritzsch (2018). García-Rodríguez et al. (2021) show how programmers have tended to perform very poorly in this regard in particular, and the incidence of comments throughout the code of some CMIP5 models is very low. Another issue related to the need for code sharing of climate models is the replicability of results. In different computing environments it can also be challenging and should not be expected by default (Easterbrook, 2014), even when the same model is used (Massonnet et al., 2020).
Some informal efforts have been made to document the accessibility of some climate models (Easterbrook, 2009; RealClimate.org, 2009) and others more formally to check their quality (e.g. Pipitone and Easterbrook, 2012; García-Rodríguez et al., 2021). In light of these efforts, in this study, we intended to test the current status of accessibility to the most commonly used global climate models, in particular those that have contributed to the CMIP5. In the sections that follow, we describe our efforts to gain access to these models, the procedures we followed, and a classification of the models according to some metrics related to accessibility. We also provide a discussion containing reflections on the state of the art.
In our attempt to better understand the current status of CSR and the availability of climate models, we used the CMIP5 models (Taylor et al., 2012) as a test bed given their extensive use in climate research over the last five years. These served as a vital tool for the last IPCC AR5 (IPCC, 2013), and given the ongoing development of CMIP6, groups of modellers should now be more open to sharing the code due to the possible depreciation of the earlier version. We followed a standard procedure to obtain the code for each model. First, we checked the information available for each model on the CMIP5 web page. Then we contacted research groups where necessary using email, without disclosing ourselves as climate scientists, to provide a full explanation of our interest in studying the code. Our approach is detailed in the following sections.
2.1 Survey methods
Using a systematic methodology, we attempted to obtain the code for all the climate models involved (see Table 1). As the first step, this procedure included using the web addresses indicated on the CMIP5 web page for downloading the code (https://pcmdi.llnl.gov/?cmip5/, last access: 9 February 2021). When the code was not directly available for download, we looked for contact details (email addresses, online contact forms, etc.) on the web page. In some cases, there was an email address provided. However, in other cases, following the information on the CMIP5 website was not enough. In such cases, we searched the internet using a search engine. We looked for institutional web pages intending to find open repositories for the corresponding model. In a few cases, this was sufficient (see Table 1). However, in others, we had to proceed by making contact with development teams at different levels, e.g. by email (with follow-up emails two weeks after the first contact; see Appendix). In the case of the IPSL (Institut Pierre Simon Laplace) team, after sending the email in English and failing to get a reply, we sent the second email in French and got an answer. For the NASA-GMAO model, we were unable to get a response via email. However, we were approached by a member of the institution after a presentation during a conference. After discussing it, the development team granted us access to the model.
Table 1CMIP5 model list, research centre responsible for each model, and details on the procedure for accessing their code. Emails 1 and 2 can be found in Appendix A1. Email 3 (Appendix A2) is not listed because we did not receive any answers to this email.

For those cases where we needed to establish contact via email, we provide details in Table 1 of the different replies that we received. Michael García-Rodríguez, who had no previous involvement in the activities of the international climate modelling community, always sent the first email (see Appendix A1) from his student address (under the domain https://esei.uvigo.es, last access: 9 February 2021). The idea behind this was to check whether, after it had become evident that the models were not easily available, institutions and researchers would then share them with someone from outside the community. In the end, to assure CSR and accessibility, details of experiments must be open to everybody, not just to peers or other scientists. A second email, identical to the first one (Appendix A1), was sent to insist on our request. We intended to minimise the possibility of not getting a reply for reasons such as the contact person was too busy at the moment of receiving the first email or the email was unnoticed or filtered as spam. We waited for a reply for two weeks after sending the first email before sending the second. Finally, three weeks after the second email, we sent a final email (Appendix A2), where we identified ourselves and our team to make it clear that we were indeed climate scientists and thus to check whether we had a better chance of obtaining the code. Where access to the code was denied, we sent a survey with a few questions to better understand the reasons for this. All emails followed the templates given in the Appendix A.
It could have been possible to look for additional contact information in the published scientific literature. However, many papers continue to be accessible only through paywalls (they are not open access) and therefore not available to most people. Moreover, identifying the relevant person to contact from an author list requires a knowledge of the modelling groups that only a handful of experts in the field have. Also, additional contact information is available for another five models from the metadata included in the NetCDF files containing the results of the simulations in the CMIP5 repository. However, the ability to find and manage such data has computational requirements and needs knowledge that is beyond what could be considered reasonable for the general public, including part of the scientific community.
After all attempts and several months, we successfully gained access to 10 out of 26 models (27 out of the 61 model versions or configurations) contributing to CMIP5. Table 1 provides a summary of the details of the replies obtained from these centres, teams, or contacts that allowed access to the code. In terms of research centres or groups contributing to the CMIP5 project, this also represents 10 out of a possible 26. We found a strong regional bias in terms of the countries where models were made accessible. The USA, Germany, and Norway stood out as the best contributors in that we obtained the code for all their models (though Norway only contributes one). Together, these three countries represent 38 % of the research centres or CMIP5 models and 44 % of all the versions. For France, we gained access to one of two models (three out of five versions). We can speculate that in some cases the decision on whether to share the code for the models could have been influenced by national or regional regulations on software copyright, intellectual property, etc. For example, it is well known that the law in the USA, where for instance software can be patented, enables the possibility of enforcing a higher level of restriction on software sharing and distribution than in the EU (van Wendel de Joode et al., 2003; EPO, 2020). However, it is the case that we were able to get the code for 6 of the 7 models contributed by research centres from the USA and yet for the EU we only got 3 of 7. The fact that the models were developed in the USA suggests the participation of federal employees, which could partially explain this result. Under US copyright law (U.S. Code, 1976), all work produced by federal employees is in the public domain. Although they are not the same thing, the public domain could be considered closer to openness than those domains not having a license for the models. For the case of Norway, we can speculate that the fact that NorESM has been developed using core parts of CESM1 (Knutti et al., 2013) could have facilitated openness of the code through the inheritance of licenses and copyright. In the same way, not sharing the code for the models could be due to inheritance reasons.
Table 2Summary of the reasons behind granting us access to the source code for the models.
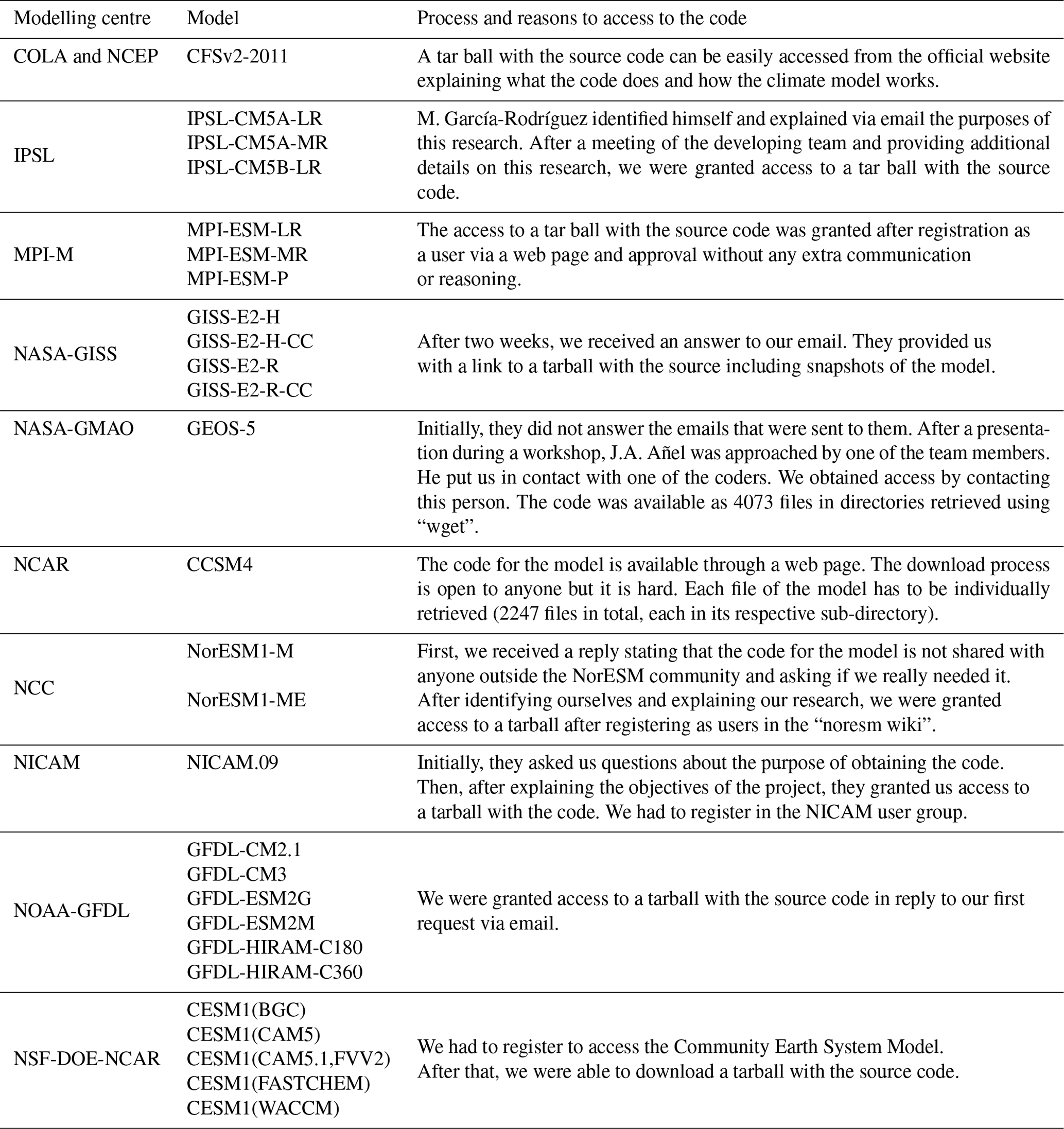
Figure 1 shows the percentage of models obtained from a global perspective, with specific plots for Europe and Asia. This makes it easier to visualise the rather narrow distribution of the regions on the maps and and how different countries could apply different national laws in order to share the code for the models.
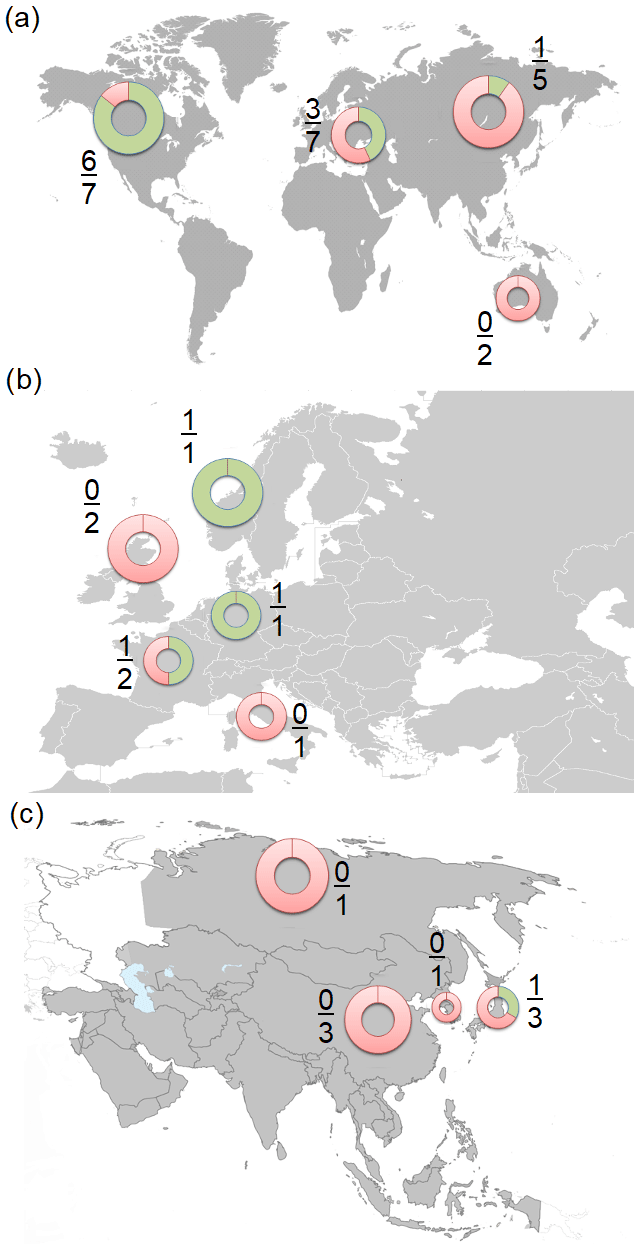
Figure 1Geographical map with the number of models obtained from each region: (a) worldwide; (b) Europe (EC-Earth is only included in the worldwide view because it is developed as a consortium of 16 European countries); and (c) Asia. Green shading and the fractions represent the obtained models from the total.
In some cases, a high number of email exchanges were required over periods of longer than one week to receive a reply or the code. In five cases, there was no obvious way to contact the development teams; in four cases, we received no answer at all. Seven research centres (corresponding to 18 models) replied that they did not share the code for their models. We decided to include EC-Earth in this final group because the code is said to be available to a given group of users. However, in practice, the procedure to access it makes it completely unfeasible for non-members of the regular team involved in its development. In no case did we receive a response to the questionnaire sent asking for the reasons why they did not want to share the code. For the models obtained, we performed a ranking, as shown in Table 2, taking into account licensing issues and availability for reuse by third parties, among other factors. We considered the level of requirements introduced by the GPLv3 license (https://www.gnu.org/licenses/gpl-3.0.en.html, last access: 9 February 2021) as the ideal case for a license under which the model can be shared, modified, and used without restriction. This is in line with the recent updates to the policy on code availability published by Geoscientific Model Development (GMD Executive Editors, 2019). Moreover, it has been argued that it is the license that best fits scientific projects to assure the benefits and openness of software (Morin et al., 2012).
Table 3CMIP5 models with code obtained and scores of reproducibility. The maximum value of three filled stars is given to models that are accessible through the internet without restriction and with a license that allows full testing and evaluation of the model. The score was reduced by one star for each of the following criteria: if in order to gain access to the model we had to contact a research centre or development group, sign license agreements, or identify ourselves as scientists undertaking climate research and according to the rights to evaluate and use the model as granted by the license (if applicable). An unfilled star means that the license of the model does not allow modification of the code.

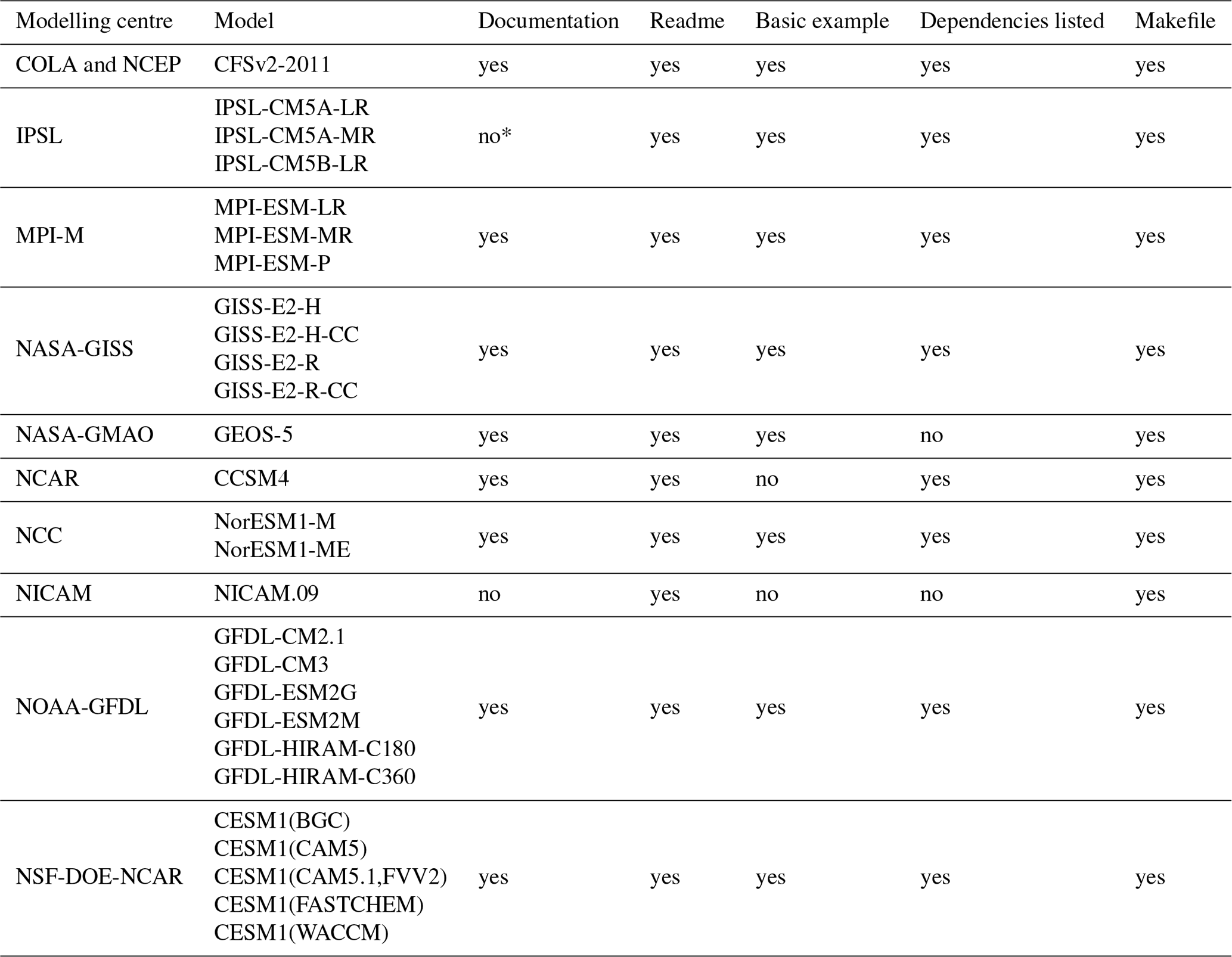
We also addressed other issues relevant for running the models. In some ways, accessibility or the ability to gain access to the code means nothing if adequate documentation for the model, a description of its components, instructions on how to compile or run it, and basic examples are not provided. This is in line with recommendations contained in the literature (Lee, 2018). The results are shown in Table 3. It can be seen that almost all the models obtained comply with all these criteria, except for NICAM.09, which only includes a “Readme” and a “Makefile”. For the IPSL, although the link to access the documentation does not work, it is possible to gain access to it by performing an internet search.
Table 4Availability of detailed information provided with the source code for the models in order to run them. “Documentation” refers to full documentation of the model (* for IPSL models a web address/link was included to access the documentation but it did not work). “Readme” corresponds to a file containing basic explanations on the files part of the model and basic instructions. “Basic example” refers to whether an example to explain the model is included. “Dependencies” refers to the basic information on libraries, compilers, or any other software and its version needed to run the model. “Makefile” refers to the existence of a single file that manages all the processes of compilation and model run.
In this work, for cases where we obtained the code for a given model, we were not provided with a reason for the license behind it. In fact, in some cases, despite getting the code, we did not see a license clearly explaining the terms of use. Some scientists or model development groups could be worried because of issues such as legal restrictions (national or institutional) that prevent them from publishing code. Also, they could be worried about potential dependencies of the model on third party proprietary software, lack of funding to maintain a public repository, or violation of property rights. For all these cases, there is a clear response or solution.
-
In the first case, if it is not possible to make the code available, any result obtained with such a model should not be accepted as scientifically valid because it is impossible to verify the findings. We acknowledge that this is currently the case for several models widely used in scientific research, and this situation must be solved by modification of the legal precepts applied to them. Consequently, those working with such models should look for a change in the legal terms so that the model complies with the scientific method.
-
If a part of the model depends on proprietary software, then it harms the possibility of distributing the whole model. Therefore, the model again does not comply with the scientific method. In this case, a good option can be to substitute the part of the model that is proprietary software with one that is free software.
-
Lack of funding to maintain a software repository can not be considered a real problem. There are many options available to host the code. For example, Zenodo is free, widely adopted, and assures hosting for at least the next 20 years.
-
Fears about a violation of property rights usually indicates more of a lack of awareness on how the law applies to software distribution than to real issues, as Añel (2017) points out. Intellectual property is usually detached of the norms that apply to the distribution of the model. Unless the developer specifically resigns to the intellectual property, it is generally retained despite their contractual obligations and despite the software being made available and distributed. Indeed, under some legal frameworks, it is impossible to resign to intellectual property. The best option is always to get specialised legal advice on these matters.
It is a matter of some regret that we obtained straightforward access to just 3 of the 26 models (7 of the 61 versions) in CMIP5 and that for 16 (34 versions) we were not able to obtain the code at all. For all others, some interaction was required, ranging from email exchanges to personal discussions at workshops. Indeed, we did not get access to the code for more than half of all the versions used in the CMIP5 despite identifying ourselves as research peers. Therefore, we have to report the very poor status of accessibility to climate models, which could generate serious doubts for the reproducibility of the scientific results produced by them. While there is no reason to doubt the validity of the results of the study of climate change obtained using the CMIP5 models (in a similar way to findings for other disciplines (Fanelli, 2018)), we encourage all model developers to improve the availability of the code for climate models and their CSR practices. Previous work has already shown that there is room for significant improvement in the structure of the code for the models, which is in some cases very poor (García-Rodríguez et al., 2021), and sharing it could help alleviate this situation. It would be desirable that future efforts on the development of climate models take into account the results presented here. In this vein, scientists starting model development from scratch, without the problems with legacy code, are in a great position to care from the beginning about licensing and reproducibility, doing it in the best way possible.
It is possible to speculate that some scientists could be reluctant to share code because of perceived potential damage to their reputations due to the code's quality (Barnes, 2010). It can be argued that this could be related to a lack of adequate education in computer programming (Merali, 2010). The issue with the quality of the code has been raised for the case of climate models (García-Rodríguez et al., 2021). Given that many scientists have no formal training as programmers, it may be presumed that they consider their code as not complying with the standards of excellence that they usually pursue in their primary fields of knowledge. Indeed, it has been documented that some climate scientists acknowledge that imperfections in climate models exist, and they address them through continuous improvement without paying too much attention to the common techniques of software development (Easterbrook and Johns, 2009).
Nevertheless, all scientists must believe that their code is good enough (Barnes, 2010) and that there are thus no reasons not to publish it (LeVeque, 2013). Barriers to code-sharing exist through licensing, imposed by, e.g. government bodies or propriety considerations. They are not due to technical difficulties or scientific reasons. When contributing to scientific studies and international efforts, where collaboration and trust are critical, such practice limits the reproducibility of the results (Añel, 2019).
We recommend that frozen versions of the climate models later used to support the results discussed in international reports on climate change should be made accessible along with the outputs from simulations in official data portals. Also, this should apply to any other Model Intercomparison Project. It must be considered that climate models are an essential piece in the evaluation of climate change and not sharing them can be perceived as a weakness of the methodology used to perform such assessments. Reproducibility should not be compromised; however, the simple fact that replicability (note that reproducibility and replicability are different concepts, ACM, 2018) can not be achieved because of the lack of the model code is unfortunate. In this way, frozen versions of the models combined with cloud computing solutions and technologies such as containers can be a step forward to achieve full replicability of results in earth system modelling (Perkel, 2019; Añel et al., 2020). Also, tools to validate climate models are becoming common. Such tools use metrics to validate the outputs of the models. The ESMValTool (Righi et al., 2020) has been designed with this purpose and evaluation of the accessibility and code for the model could be integrated as a part of the process to measure the performance of the models contributing to the CMIP.
An additional reason to request an open code software policy is that several scientific gaps have been pointed out for the CMIP5 (Stouffer et al., 2017). The lack of availability of the code for the models makes it difficult to address such gaps, as it is not possible to perform a complete evaluation of the source of discrepancies between the models. As it has been shown for other fields of software development, sharing the code can help improve the development process of climate models and their reliability (Boulanger, 2005; DoD CIO, 2009). Moreover, it would help to support the collaborative effort necessary to tackle the challenge of climate change (Easterbrook, 2010) and to do it in a way that complies better with the scientific method and the goals of scientific research (Añel, 2019). Funding should be allocated by agencies and relevant bodies to support such efforts. Notwithstanding that the whole framework of science faces challenges related to CSR, at the same time it presents opportunities for improvement in such a sensitive field as climate science.
A1 First email
Dear Sir/Madame,
my name is Michael García Rodríguez and I am an MSc Student at the EPhysLab in the Universidade de Vigo, Spain (http://ephyslab.uvigo.es). I am developing my MSc Thesis on the study of qualitative issues of climate models, mostly related to scientific reproducibility and copyright issues.
In order to do it, I have focused my research project on the study of the models that contributed to the last CMIP5 report. For it, I am trying to get access to the code of all the models that reported results of this effort.
Therefore I would like kindly request access to the code of your model, MODEL−NAME, namely the version that you used to produce CMIP5 results. Therefore, could you say me how could I get access to it?
Many thanks in advance.
Best regards,
Michael García Rodríguez
EPhysLab
Universidade de Vigo
http://ephyslab.uvigo.es
========================
A2 Third email
Dear Sir/Madame,
Two weeks ago I send you the following email:
(see email in Appendix A1)
Would you kindly answer me ? In case I am not allowed to access the code, could you explain me why? It would be of great help, in case of not being able to get the code of the model, know the answer. Please, if it's possible, mark with a cross one or more answers on below:
[] Copyright issues (please, if you mark this choice, could you send me a copy of the licenses?)
[] Development team policy
[] Legal restrictions of your country
[] Others reasons (please specify):
——————————————————————-
In this case, I will be able to write down the reasons why I was not allowed
access to the code and I could document it in my MSc Thesis on the
study of qualitative issues of climate models.
Many thanks in advance,
Best regards,
Michael García Rodríguez
EPhysLab
Universidade de Vigo
http://ephyslab.uvigo.es
========================
There is no code or data relevant to this paper.
All the authors participated in the design of the study and writing of the text. MGR and JAA made the attempts to get access to the code for the climate models.
The authors declare that they have no conflict of interest.
This research was partially supported by the ZEXMOD Project of the Government of Spain (CGL2015-71575-P) and the European Regional Development Fund (ERDF). Juan A. Añel was supported by a “Ramón y Cajal” Grant funded by the Government of Spain (RYC-2013-14560). We would like to thank Didier Roche, Julia Hargreaves, Rolf Sander, Richard Neale, and two anonymous referees for useful comments to improve this paper.
This research has been supported by the Government of Spain (grant nos. CGL2015-71575-P and RYC-2013-14560) and the European Regional Development Fund (grant no. CGL2015-71575-P). The EPhysLab is supported by the Xunta de Galicia (grant no. ED431C 2017/64-GRC).
This paper was edited by Richard Neale and reviewed by two anonymous referees.
ACM: Artifact Review and Badging, Tech. rep., available at: https://www.acm.org/publications/policies/artifact-review-badging (last access: 9 February 2021), 2018. a
Allison, D., Shiffrin, R., and Stodden, V.: Reproducibility of research: Issues and proposed remedies, P. Natl. Acad. Sci. USA, 115, 2561–2562, https://doi.org/10.1073/pnas.1802324115, 2018. a, b
Añel, J. A.: The importance of reviewing the code, Commun. ACM, 54, 40–41, https://doi.org/10.1145/1941487.1941502, 2011. a
Añel, J. A.: Comment on 'Most computational hydrology is not reproducible, so is it really science?' by Hutton et al., Water Resour. Res., 53, 2572–2574, https://doi.org/10.1002/2016WR020190, 2017. a, b, c
Añel, J. A.: Reflections on the Scientific Method at the beginning of the twenty-first century, Contemp. Phys., 60, 60–62, https://doi.org/10.1080/00107514.2019.1579863, 2019. a, b, c
Añel, J. A., Montes, D. P., and Rodeiro Iglesias, J.: Cloud and Serverless Computing for Scientists, Springer, Cham, Switzerland, https://doi.org/10.1007/978-3-030-41784-0, 2020. a
Barnes, N.: Publish your computer code: it is good enough, Nature, 467, 753, https://doi.org/10.1038/467753a, 2010. a, b
Boulanger, A.: Open-source versus proprietary software: Is one more reliable and secure than other?, IBM Syst. J., 44, 239–248, https://doi.org/10.1147/sj.442.0239, 2005. a
DoD CIO: Clarifying Guidance Regarding Open Source Software (OSS), Tech. rep., 6 pp., availabe at: https://dodcio.defense.gov/Portals/0/Documents/FOSS/2009OSS.pdf (last access: 21 February 2021), 2009. a
Easterbrook, S. M.: available at: https://www.easterbrook.ca/steve/2009/06/getting-the-source-code-for-climate-models (last access: 9 February 2021), 2009. a
Easterbrook, S. M.: Climate change: a grand software challenge, FoSER '10: Proceedings of the FSE/SDP workshop on Future of software engineering research, November 2010, Santa Fe, New Mexico, USA, 99–104, https://doi.org/10.1145/1882362.1882383, 2010. a
Easterbrook, S. M.: Open code for open science?, Nat. Geosci., 7, 779–781, https://doi.org/10.1038/ngeo2283, 2014. a
Easterbrook, S. M. and Johns, T.: Engineering the Software for Understanding Climate Change, Comput. Sci. Eng., 11, 65–74, https://doi.org/10.1109/MCSE.2009.193, 2009. a
EPO: European Patent Guide: How to get a European Patent, 20th Edn., Munich, Germany, available at: http://documents.epo.org/projects/babylon/eponet.nsf/0/8266ED0366190630C12575E10051F40E/$File/how_to_get_a_european_patent_2020_en.pdf (last access: 9 February 2021), 2020. a
Eyring, V., Bony, S., Meehl, G. A., Senior, C. A., Stevens, B., Stouffer, R. J., and Taylor, K. E.: Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization, Geosci. Model Dev., 9, 1937–1958, https://doi.org/10.5194/gmd-9-1937-2016, 2016. a
Fanelli, D.: Opinion: Is science really facing a reproducibility crisis, and do we need it to?, P. Natl. Acad. Sci. USA, 115, 2628–2631, https://doi.org/10.1073/pnas.1708272114, 2018. a
García-Rodríguez, M., Añel, J. A., Foujols, M.-A., and Rodeiro, J.: FortranAnalyser: a software tool to assess Fortran code quality, IEEE Access, submitted, 2021. a, b, c, d
GMD Executive Editors: Editorial: The publication of geoscientific model developments v1.1, Geosci. Model Dev., 8, 3487–3495, https://doi.org/10.5194/gmd-8-3487-2015, 2015. a
GMD executive editors: Editorial: The publication of geoscientific model developments v1.2, Geosci. Model Dev., 12, 2215–2225, https://doi.org/10.5194/gmd-12-2215-2019, 2019. a
Gramelsberger, G., Lenhard, J., and Parker, W.: Philosophical Perspectives on Earth System Modeling: Truth, Adequacy, and Understanding, J. Adv. Model. Earth Sy., 12, e2019MS001720, https://doi.org/10.1029/2019MS001720, 2020. a
IPCC: Climate Change 2013: The Physical Science Basis. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change, Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 2013. a
Joppa, L. N., McInerny, G., Harper, R., Salido, L., Takeda, K., O'Hara, K., Gavaghan, D., and Emmot, S.: Troubling Trends in Scientific Software Use, Science, 340, 814–815, https://doi.org/10.1126/science.1231535, 2013. a
Knutti, R., Masson, D., and Gettelman, A.: Climate model genealogy: Generation CMIP5 and how we got there, Geophys. Res. Lett., 40, 1194–1199, https://doi.org/10.1002/grl.50256, 2013. a, b
Lee, B. D.: Ten simple rules for documenting scientific software, Plos Comput. Biol., 14, e1006561, https://doi.org/10.1371/journal.pcbi.1006561, 2018. a
LeVeque, R. J.: Top Ten Reasons To Not Share Your Code (and why you should anyway), SIAM News, 46, 7–8, 2013. a
Massonnet, F., Ménégoz, M., Acosta, M., Yepes-Arbós, X., Exarchou, E., and Doblas-Reyes, F. J.: Replicability of the EC-Earth3 Earth system model under a change in computing environment, Geosci. Model Dev., 13, 1165–1178, https://doi.org/10.5194/gmd-13-1165-2020, 2020. a
Merali, Z.: Computational science: ...Error, Nature, 467, 775–777, https://doi.org/10.1038/467775a, 2010. a
Morgenstern, O., Hegglin, M. I., Rozanov, E., O'Connor, F. M., Abraham, N. L., Akiyoshi, H., Archibald, A. T., Bekki, S., Butchart, N., Chipperfield, M. P., Deushi, M., Dhomse, S. S., Garcia, R. R., Hardiman, S. C., Horowitz, L. W., Jöckel, P., Josse, B., Kinnison, D., Lin, M., Mancini, E., Manyin, M. E., Marchand, M., Marécal, V., Michou, M., Oman, L. D., Pitari, G., Plummer, D. A., Revell, L. E., Saint-Martin, D., Schofield, R., Stenke, A., Stone, K., Sudo, K., Tanaka, T. Y., Tilmes, S., Yamashita, Y., Yoshida, K., and Zeng, G.: Review of the global models used within phase 1 of the Chemistry–Climate Model Initiative (CCMI), Geosci. Model Dev., 10, 639–671, https://doi.org/10.5194/gmd-10-639-2017, 2017. a
Morin, A., Urban, J., and Sliz, P.: A Quick Guide to Software Licensing for the Scientist-Programmer, Plos Comput. Biol., 8, e1002598, https://doi.org/10.1371/journal.pcbi.1002598, 2012. a
National Academies of Sciences, Engineering, and Medicine: Reproducibility and Replicability in Science, The National Academies Press, Washington, DC, https://doi.org/10.17226/25303, 2019. a
Nature: Does your code stand up to scrutiny?, Nature, 555, p. 142, https://doi.org/10.1038/d41586-018-02741-4, 2018. a
Pascoe, C., Lawrence, B. N., Guilyardi, E., Juckes, M., and Taylor, K. E.: Documenting numerical experiments in support of the Coupled Model Intercomparison Project Phase 6 (CMIP6), Geosci. Model Dev., 13, 2149–2167, https://doi.org/10.5194/gmd-13-2149-2020, 2020. a
Perkel, J. M.: Containers in the Cloud, Nature, 575, 247–248, https://doi.org/10.1038/d41586-019-03366-x, 2019. a
Pipitone, J. and Easterbrook, S.: Assessing climate model software quality: a defect density analysis of three models, Geosci. Model Dev., 5, 1009–1022, https://doi.org/10.5194/gmd-5-1009-2012, 2012. a
RealClimate.org: available at: http://www.realclimate.org/index.php/data-sources (last access: 9 February 2021), 2009. a
Righi, M., Andela, B., Eyring, V., Lauer, A., Predoi, V., Schlund, M., Vegas-Regidor, J., Bock, L., Brötz, B., de Mora, L., Diblen, F., Dreyer, L., Drost, N., Earnshaw, P., Hassler, B., Koldunov, N., Little, B., Loosveldt Tomas, S., and Zimmermann, K.: Earth System Model Evaluation Tool (ESMValTool) v2.0 – technical overview, Geosci. Model Dev., 13, 1179–1199, https://doi.org/10.5194/gmd-13-1179-2020, 2020. a
Stodden, V., Guo, P., and Ma, Z.: Toward Reproducible Computational Research: An Empirical Analysis of Data and Code Policy Adoption by Journals, Plos One, 8, e67111, https://doi.org/10.1371/journal.pone.0067111, 2013. a
Stodden, V., Seiler, J., and Ma, Z.: An empirical analysis of journal policy effectiveness for computational reproducibility, P. Natl. Acad. Sci. USA, 115, 2584–2589, https://doi.org/10.1073/pnas.1708290115, 2018. a
Stouffer, R., Eyring, V., Meehl, G., Bony, S., Senior, C., Stevens, B., and Taylor, K.: CMIP5 Scientific Gaps and Recommendations for CMIP6 , B. Am. Meteorol. Soc., 98, 95–105, https://doi.org/10.1175/BAMS-D-15-00013.1, 2017. a
Taylor, K., Stouffer, R., and Meehl, G.: An Overview of CMIP5 and the Experiment Design, B. Am. Meteorol. Soc., 93, 485–498, https://doi.org/10.1175/BAMS-D-11-00094.1, 2012. a
U.S. Code: Copyright Act of 1976, 17 U.S. Code § Section 105. Subject matter of copyright: United States Government works, 1976. a
van Wendel de Joode, R., de Bruijn, J. A., and van Eeten, M. J. G.: Protecting the Virtual Commons, T.M.C. Asser Press, The Hague, 2003. a
Wieters, N. and Fritzsch, B.: Opportunities and limitations of software project management in geoscience and climate modelling, Adv. Geosci., 45, 383–387, https://doi.org/10.5194/adgeo-45-383-2018, 2018. a
Wilson, G., Bryan, J., Cranston, K., Kitzes, J., Nederbragt, L., and Teal, T.: Good enough practices in scientific computing, Plos Comput. Biol., 13, e1005510, https://doi.org/10.1371/journal.pcbi.1005510, 2017. a