the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 08 Oct 2020
| 08 Oct 2020
Optimizing high-resolution Community Earth System Model on a heterogeneous many-core supercomputing platform
Shaoqing Zhang
Haohuan Fu
Lixin Wu
Yuxuan Li
Hong Wang
Yunhui Zeng
Xiaohui Duan
Wubing Wan
Li Wang
Yuan Zhuang
Hongsong Meng
Kai Xu
Ping Xu
Lin Gan
Zhao Liu
Sihai Wu
Yuhu Chen
Haining Yu
Shupeng Shi
Lanning Wang
Shiming Xu
Wei Xue
Weiguo Liu
Qiang Guo
Jie Zhang
Guanghui Zhu
Yang Tu
Jim Edwards
Allison Baker
Jianlin Yong
Yangyang Yu
Qiuying Zhang
Zedong Liu
Mingkui Li
Dongning Jia
Guangwen Yang
Zhiqiang Wei
Jingshan Pan
Ping Chang
Gokhan Danabasoglu
Stephen Yeager
Nan Rosenbloom
Ying Guo
With semiconductor technology gradually approaching its physical and thermal limits, recent supercomputers have adopted major architectural changes to continue increasing the performance through more power-efficient heterogeneous many-core systems. Examples include Sunway TaihuLight that has four management processing elements (MPEs) and 256 computing processing elements (CPEs) inside one processor and Summit that has two central processing units (CPUs) and six graphics processing units (GPUs) inside one node. Meanwhile, current high-resolution Earth system models that desperately require more computing power generally consist of millions of lines of legacy code developed for traditional homogeneous multicore processors and cannot automatically benefit from the advancement of supercomputer hardware. As a result, refactoring and optimizing the legacy models for new architectures become key challenges along the road of taking advantage of greener and faster supercomputers, providing better support for the global climate research community and contributing to the long-lasting societal task of addressing long-term climate change. This article reports the efforts of a large group in the International Laboratory for High-Resolution Earth System Prediction (iHESP) that was established by the cooperation of Qingdao Pilot National Laboratory for Marine Science and Technology (QNLM), Texas A&M University (TAMU), and the National Center for Atmospheric Research (NCAR), with the goal of enabling highly efficient simulations of the high-resolution (25 km atmosphere and 10 km ocean) Community Earth System Model (CESM-HR) on Sunway TaihuLight. The refactoring and optimizing efforts have improved the simulation speed of CESM-HR from 1 SYPD (simulation years per day) to 3.4 SYPD (with output disabled) and supported several hundred years of pre-industrial control simulations. With further strategies on deeper refactoring and optimizing for remaining computing hotspots, as well as redesigning architecture-oriented algorithms, we expect an equivalent or even better efficiency to be gained on the new platform than traditional homogeneous CPU platforms. The refactoring and optimizing processes detailed in this paper on the Sunway system should have implications for similar efforts on other heterogeneous many-core systems such as GPU-based high-performance computing (HPC) systems.
- Article
(8007 KB) - Full-text XML
- BibTeX
- EndNote




The development of numerical simulations and the development of modern supercomputers have been like two entangled streams, with numerous interactions at different stages. The very first electronic computer, ENIAC (Lynch, 2008), produced the simulation of the first numerical atmospheric model in the 1950s, with a spatial resolution of 500–800 km. In the 1960s, the first supercomputer (as compared to a regular electronic computer), CDC 3300 and 6600, designed by Seymour Cray, was installed at the National Center for Atmosphere Research (NCAR) to provide large-scale computing to the US national community engaging in atmospheric and related research. Since then, a constant increase in both the computing power of supercomputers and complexity of numerical models has been witnessed by the global community. Over the decades, the peak performance of a supercomputer system has evolved from the scale of 1 megaflop (e.g. CDC 3300) to 100 petaflops (e.g. Sunway TaihuLight), which is an increase of 11 orders of magnitude. Meanwhile, the numerical weather model has also evolved into a highly complex Earth system model, with increased resolution and better representation of physics and interpretation of decades of accumulated scientific knowledge.
One major development in supercomputing hardware in recent years is the architectural changes of the processors. Due to the physical limitations, regular increases in frequency came to a stop roughly 1 decade ago. Since then, the increase in computing power is largely due to an increased density of computing units in the processors. As a result, for the leading-edge supercomputers that were developed after 2010, the majority of computing power is provided by many-core accelerators, such as NVIDIA GPUs (Vazhkudai et al., 2018) and Intel Xeon Phi MICs (many integrated cores; Liao et al., 2014). As a result, recent machines contain two major architectural changes. One change is from a homogeneous architecture to a heterogeneous architecture, for which one now faces an environment with multiple types of computing devices and cores instead of programming and scheduling a single kind of core in a system. The other change is the significant increase in the number of cores, which usually comes with a reduced complexity for each single core. The huge number of available parallel cores requires a complete rethinking of algorithms and data structures, which is a significant challenge when taking advantage of the new supercomputers.
Climate science advances and societal needs require Earth system modelling to resolve more details of geophysical processes in the atmosphere, ocean, sea-ice, and land-soil components. However, the model resolution must be sufficiently fine to better resolve regional changes or variations as well as extreme events (Delworth et al., 2012; Small et al., 2014; Roberts et al., 2018). Scientifically, there are two important questions that need further understanding in current Earth climate sciences: (1) how global and large-scale changes or variations influence the local weather or climate anomalies, and (2) how local weather or climate perturbations feed back to the large-scale background. To address these questions, Earth system models must be able to explicitly resolve more and more local fine-scale physical processes with higher and higher resolutions. While such high-resolution modelling efficiently advances the understanding of the attribution and impact of large-scales such as global changes, it also provides an opportunity to link scientific advances with local severe weather or climate alerts and promote societal services. Given that the model resolution is intractable with computing resources available, higher and higher resolution Earth modelling demands greener supercomputing platforms with more affordable energy consumption.
In the recent decade, with the power consumption of a single supercomputer surpassing the boundary of 10 MW (equivalent to the power consumption of three world-class universities like Tsinghua), the energy issue has become a major factor in both the design and the operation process. As a result, discussions are raised for the community of climate change studies. Taking CMIP (e.g. Meehl et al., 2000) as an example, while the goal is to reduce emissions and to mitigate global warming effects, the huge computing cost and the related power consumption also generate a considerably large carbon footprint. Similar concerns are also expressed for recent artificial intelligence (AI) efforts that utilize enormous computing resources to train various deep neural networks (e.g. Schwartz et al., 2019), and ideas are proposed to report the financial cost or “price tag” for performing such research operations. Therefore, reducing the energy consumption is the other major factor that drives us to port and to refactor the model to new architectures.
While we have stated multiple benefits for redesigning the models for new supercomputer platforms, the challenge, especially in the coding parts, is also manyfold. The first major challenge comes from the heavy burden of the legacy climate code (Fu et al., 2017). The second major challenge comes from the computation load pattern of the code. Unlike an earthquake model with large hotspots (You et al., 2013) in which several kernels consume over 90 % of the computing cycles, in a climate model system usually hundreds of hotspots consume a small portion of the computation cycles. The third challenge comes from the dramatic change in architecture.
With the GPU devices introduced as accelerators for general-purpose computing around 2007 (Owens et al., 2007), most early efforts related to climate or weather modelling only focused on certain parts of the models, mostly physical or chemical parameterization schemes that are structurally suitable for parallel architectures, such as the chemical kinetics modules (Linford et al., 2009) and the microphysics scheme (Mielikainen et al., 2013) in WRF (Weather Research and Forecasting model), the shortwave radiation parameterization of CAM5 (the fifth version of the Community Atmospheric Model) (Kelly, 2010), and the microphysics module of Global/Regional Assimilation and PrEdiction System (GRAPES) (Xiao et al., 2013). With both a high parallelism and a high arithmetic density, these modules demonstrate a high speedup (ranging from 10 to 70 times or even up to 140 times) when migrating from CPU to GPU. In contrast, the dynamical core code, which involves both time-stepping integration and communication among different modules is more challenging to port to heterogeneous accelerators. Examples include NIM (Govett et al., 2017), GRAPES (Wang et al., 2011), CAM-SE (Carpenter et al., 2013), HIRLAM (Vu et al., 2013), and NICAM (Demeshko et al., 2012), with a speedup of 3 to 10 times. For migrating an entire model, the efforts are even fewer in number. One early example is a GPU-based acceleration of ASUCA, which is the next-generation high-resolution mesoscale atmospheric model developed by the Japan Meteorological Agency (JMA) (Shimokawabe et al., 2019), with an 80-fold speedup with a GPU as compared to a single CPU core. In recent years, we see complete porting of several models from CPU to the GPU platforms, such as the GPU-based Princeton Ocean Model (POM) (Xu et al., 2015) and the GPU-based COSMO regional weather model by MeteoSwiss (Fuhrer et al., 2018). For the porting of a model at such a level, the three challenges mentioned above (heavy burden of legacy code, hundreds of hotspots distributed through the code, and the mismatch between the existing code and the emerging hardware) have apparently combined to produce more challenges. Facing the problem of tens of thousands of lines of code, the researchers and developers have to either perform an extensive rewriting of the code (Xu et al., 2014) or invest years of effort into redesign methodologies and tools (Gysi et al., 2015).
This article reports the efforts of a large group in the International Laboratory for High-Resolution Earth System Prediction (iHESP) that was established by the cooperation of Qingdao Pilot National Laboratory for Marine Science and Technology (QNLM), Texas A&M University (TAMU), and the National Center for Atmospheric Research (NCAR), with the goal of enabling highly efficient simulation of the Community Earth System Model high-resolution version (25 km atmosphere and 10 km ocean) (CESM-HR) on Sunway TaihuLight. With the early-stage efforts focusing on the atmospheric component CAM5 (Fu et al., 2016a, 2017), the work in this article finally extends to the complete scope of CESM-HR by creating a redesigned software with millions of lines of code transformed into a heterogeneous many-core architecture and delivering substantial performance benefits. Compared with the existing work mentioned above (GPU-based ASUCA, POM, WRF, and COSMO), our work optimizes an Earth system model, which demonstrates the next level of complexity in both components and numerical methods. This requires better accuracy and better conservation of matter and energy so as to perform simulation of hundreds of years instead of just hundreds of days; although, as the first step, we are not changing the original algorithm design to minimize the uncertainties of code and results. The refactoring and optimizing efforts have improved the simulation speed of CESM-HR from 1 SYPD (simulation years per day) to 3.4 SYPD and support several years of pre-industrial control simulations. Although our current work targets a single system with a specifically designed Sunway processor and does not consider performance portability, our successful first experiences provide encouraging references for general scientific modelling on heterogeneous many-core machines such as GPU-based high-performance computing (HPC) systems, and this work potentially opens the door for further addressing performance portability in the future.
The rest of the paper is organized as follows. Section 2 describes the major features of the Sunway TaihuLight supercomputer, including its architecture, energy consumption details, the corresponding parallelization strategies, etc. Next, Sect. 3 details our methods for refactoring and optimizing CESM-HR on Sunway TaihuLight. Section 4 demonstrates stable and sound scientific results for the first few hundred years of CESM-HR simulations on the new architecture. Finally, the summary and discussions are given in Sec. 5.
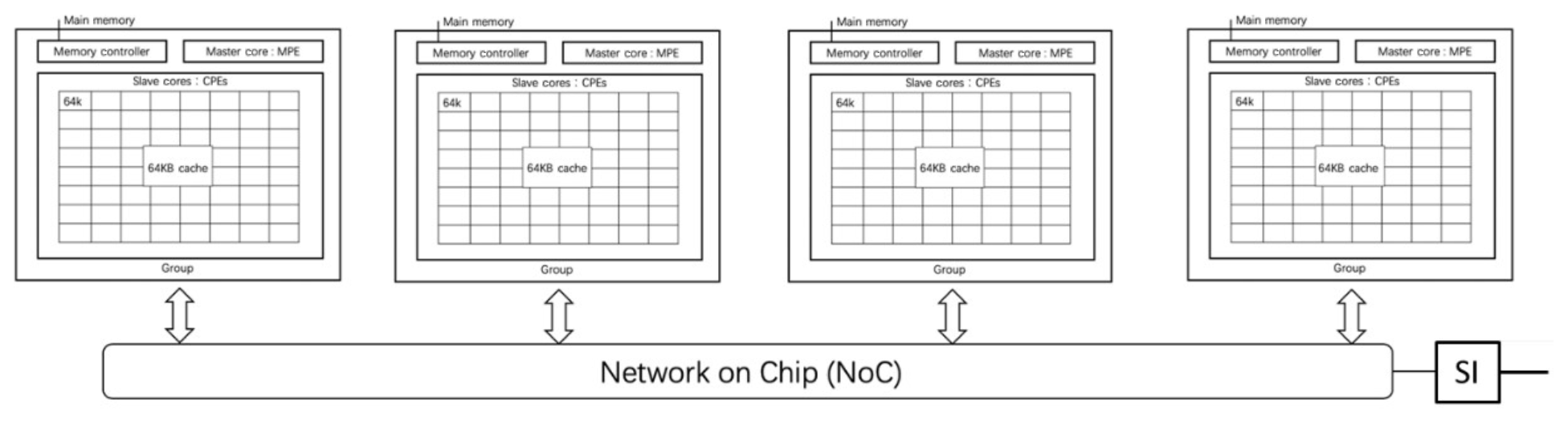
Figure 1A schematic illustration of the general architecture of the Sunway SW26010 CPU. Each CPU consists of four core groups, and each core group includes a memory controller, a master core (i.e. MPE – management processing element), and 64 slave cores (i.e. CPEs – computing processing elements), each of which has a 64 KB scratchpad fast memory that is called LDM (local data memory). The four core groups are linked together by the network on a chip, and the whole CPU is linked with other CPUs by the system interface (SI) network.
2.1 The design philosophy of the Sunway machine
2.1.1 Hardware
The new processor architecture
Considered a major milestone in the HPC development history of China, Sunway TaihuLight (Fu et al., 2016b; Dongarra, 2016) is the first Chinese system that is built using homegrown processors to reach number one on the top-500 list. The heterogeneous many-core processor SW26010 (as shown in the name, a 260-core CPU) provides all of the computing capabilities of the system. Each SW26010 processor, as shown in Fig. 1, can be divided into four identical core groups (CGs), which are connected through the network on a chip. Each CG includes one management processing element (MPE), one computing processing element (CPE) cluster with 8×8 CPEs, and one memory controller that shares and manages the memory bandwidth to 8 GB DDR3 memory (Double Data Rate 3). Within the 8×8 mesh, the CPEs can transfer data along the rows or columns through the low-latency register communication feature, which provides low-cost data sharing schemes within the cluster. The running frequency of each element is 1.45 GHz.
A different memory hierarchy
Most current scientific computing models are constrained by the memory bandwidth rather than the computing speed. Climate models are typical examples of models that achieve less than 5 % of the peak performance of current computers. As a result, a large part of our effort tries to achieve a suitable mapping of the CESM model to the unique memory hierarchy of Sunway TaihuLight. The outermost memory layer is the 32 GB DDR3 memory equipped in each compute node, shared among the four CGs and 260 cores, which is quite similar to the DDR memory in traditional IBM or Intel CPU machines. A major difference is that the same level of DDR3 memory bandwidth needs to be shared among a significantly larger number of cores (from dozens to hundreds). Inside the processor, the MPE, which is designed to provide similar functions to traditional CPUs, also adopts a similar cache hierarchy, with a 32 KB L1 instruction cache, a 32 KB L1 data cache, and a 256 KB L2 cache for both instruction and data. The major changes are in the CPEs. To meet the hardware and power constraints with a maximized level of computing density, inside each CPE, the cache is replaced by a 64 KB user-controlled scratchpad memory that is called LDM (local data memory). Such a change in cache hierarchy requires a complete rethinking of both data and loop structures. Previous programmers could rely on the cache hierarchy to achieve a reasonable buffering of temporary variables when using OpenMP (Open Multi-Processing) to start independent threads in different CPU cores. Migrating to Sunway, the programmers need to handle the memory part more elegantly to achieve any meaningful utilization of the system. The scratchpad fast buffer also becomes the last weapon for the programmers to address the proportionally reduced memory bandwidth of the system. In many cases, the manually designed buffering scheme would improve data reuse and increase the computing performance. As a result, instead of directly reading from the DDR memory, most kernels would load the data into LDM manually, and start the computation from there.
Customized system integration
Using the SW26010 CPU as the most basic building block, the Sunway TaihuLight system is built by a fully customized integration at different levels: (1) a computing node with one processor and 32 GB memory, (2) a super-node with 256 computing nodes that are tightly coupled using a fully connected crossing switch, (3) a cabinet with four super-nodes, and (4) the entire computing system with 40 cabinets. Such an integration approach can provide high-performance computing power in a high-density form. With 40 cabinets, the entire Sunway TaihuLight system provides in total CPUs and parallel cores. The TaihuLight computing nodes are connected via a two-level InfiniBand network. A single switch with full bisection bandwidth connects all 256 nodes within a super-node, while a fat-tree network with one-quarter of the full bisection bandwidth connects all super-nodes, with bisection communication bandwidth at different levels.
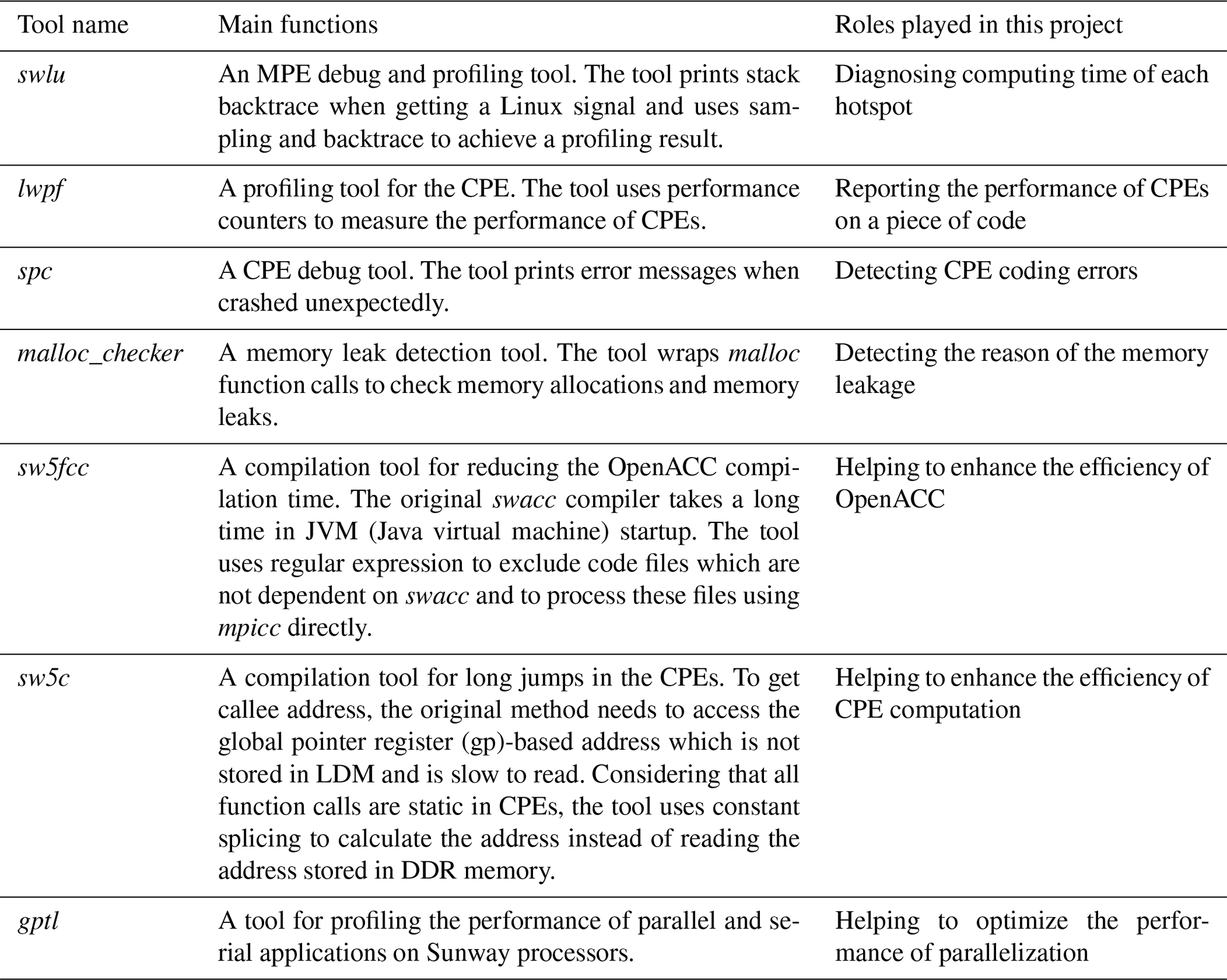
Table 1The list of diagnostic software tools in the Sunway system.
2.1.2 Software
The original compiling tools
Targeting a completely new many-core processor and system with over 10 million cores, the compiler tools are probably the most important tools to support application development of the Sunway TaihuLight. The set of compilation tools includes the basic compiler components, such as the C/C++, and Fortran compilers. In addition to that, a parallel compilation tool supports the OpenACC 2.0 syntax and targets the CPE clusters. This customized Sunway OpenACC tool supports management of parallel tasks, extraction of heterogeneous code, and description of data transfers. Moreover, according to the specific features of the Sunway processor architecture, the Sunway OpenACC tool has also made several syntax extensions from the original OpenACC 2.0 standard, such as a fine control over buffering of a multidimensional array and packing of distributed variables for data transfer. In addition to Sunway OpenACC, the Sunway platform also provides an Athread interface for the programmers to write specific instructions for both the computing and the memory parts. As discussed in later sections, different approaches are taken for the redesign of different parts of the CESM model.
The compiling and profiling tools developed along this project
Earth system models are some of the most complex numerical models that scientists have ever built. Unfortunately, these models are also some of the very first software that were ported to the new Sunway TaihuLight system and tested with the relatively new compiler system. As a result, to facilitate the development, a number of new compiling and profiling tools that have been developed along the way of porting and redesigning the model are listed in Table 1, which describes the main function of each tool and the role it plays in this project. For example, the hotspots analysis tool called swlu is particularly useful as the Community Earth System Model high-resolution version (CESM-HR) is refactored and optimized on the Sunway machine. Once the points of swlu_prof_start and swlu_prof_stop are set, an output file that contains the detailed information of computing consumption analysis of the targeted code block is produced at the end of the test experiment. This will be discussed in more detail in Sect. 3.3 when the CESM-HR is refactored and optimized on the Sunway machine.
2.1.3 The second-level parallelism between MPE and CPEs
As shown in Fig. 2, after the domain-based task decomposition in the traditional Message Passing Interface (MPI) parallelism (we refer to this as the first-level parallelism) among the core groups, within each core group, the Sunway machine requires a CPE-based task decomposition and communication between the MPE and CPEs (we refer to this as the second-level parallelism). Since each CPE only has a 64 KB scratchpad memory as the fast buffer, each piece of work in the CPE-based task must be divided to utilize this fast buffer efficiently. Finding an optimal balance between the computational load on CPEs and the communication of between MPEs and CPEs is the core of CPE parallelism and the major challenge to obtaining computational efficiency of a large model on the Sunway machine, which will be discussed in more detail in Sect. 3.3.
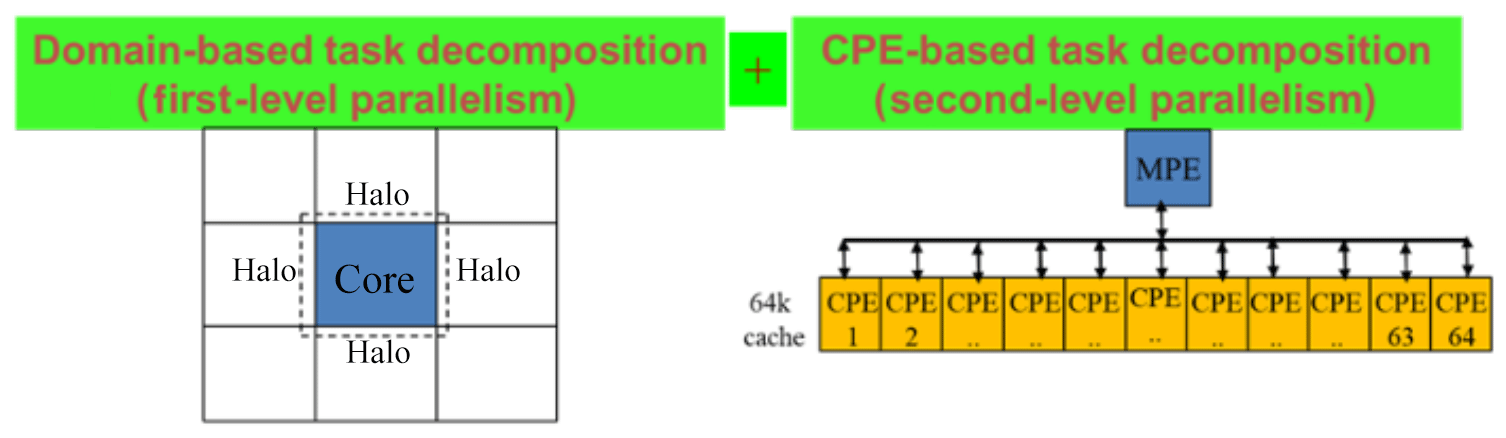
Figure 2Illustration of the second-level parallelism of CPE-based task decomposition required on the Sunway heterogeneous many-core machine, which is additional to the first-level parallelism of domain-based task decomposition among core groups and the MPI parallelism as in the homogeneous multicore system.
2.2 Major characteristics
2.2.1 Architectural pros and cons
In order to achieve extreme performance and power efficiency, the computing chip of Sunway TaihuLight (SW26010 CPU) abandons the cache structure so as to spare the on-chip resources for more computing occupancy. As a result, each CG of the SW26010 is able to deploy 64 slave cores, and the 64 slave cores can communicate with each other based on register communications. Therefore, a more fine-grained communication mechanism is provided to allow for more sophisticated operations and optimizations on dealing with data.
The on-chip heterogeneity of the SW26010 processor enables a uniform memory space between MPE and CPEs to facilitate the data transfer. Such a behaviour is different from the conventional cases such as the CPU–GPU scenario where data transfer has to go between different processors and accelerators. On the other hand, the on-chip heterogeneity also leads to the uniform programming model between MPE and CPEs, and it is promising for resolving problems such as the loop code. This can be thought of as an MPI-based intelligent programming model that knows when communications within a CPU task group or to an MPE are needed. In that sense, the Sunway architecture may be more plausible for scientific computation like Earth system modelling than a GPU system.
2.2.2 Power efficiency
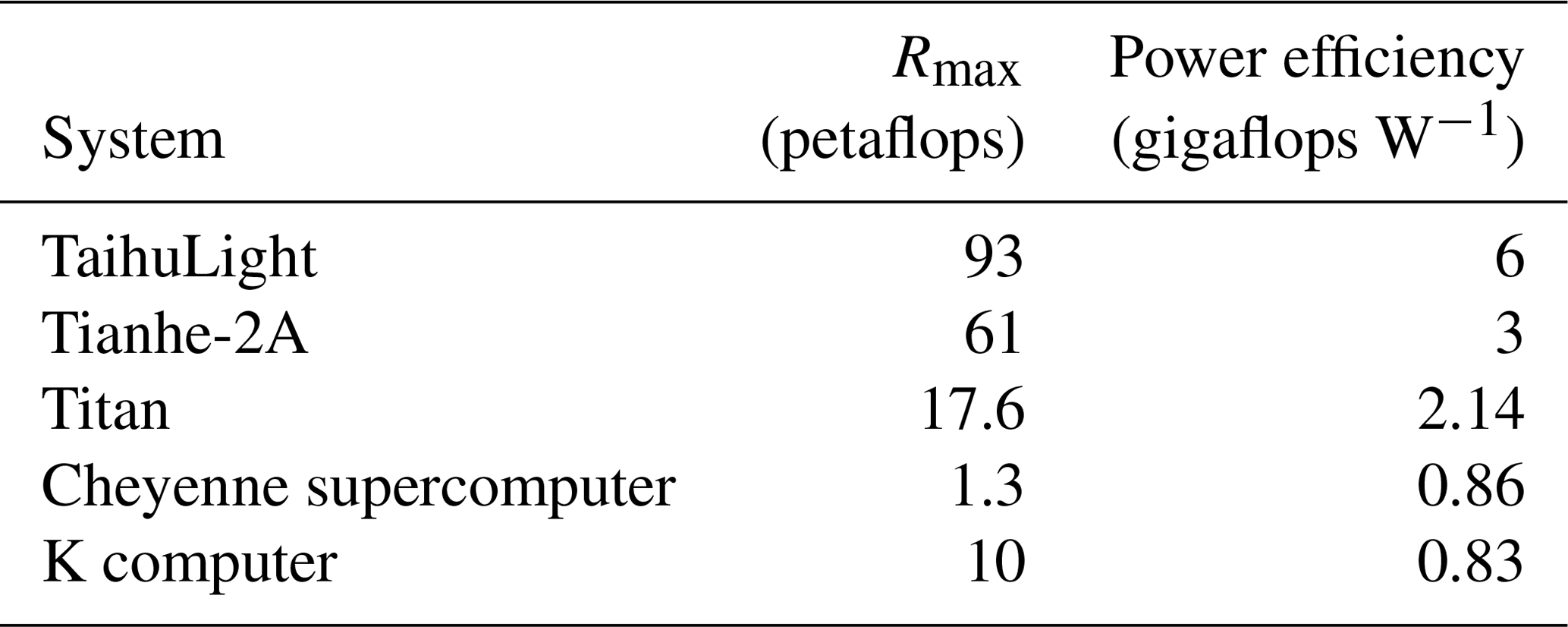
Table 2 lists the power efficiency of the Sunway TaihuLight system and some major systems around the world containing different processors such as CPU, GPU, Xeon Phi, etc. It can be seen that the Sunway TaihuLight, due to the lower chip frequency (1.45 GHz per SW26010), as well as a sophisticated water-cooling system for the whole machine, in terms of gigaflops per watt, seems to be greener than some major systems widely used for doing climate simulations. However, considering that weather and climate applications do not maximize the floating-point operations per second (FLOPS) provided by the computer, those numbers do not demonstrate that the Sunway TaihuLight system has any real advantage in actual power efficiency. To conclude on this point, more precise calculations taking into account the real FLOPS of the applications and including the human labour cost of the porting and optimization effort (given that Sunway TaihuLight is a unique system) have to be realized.
3.1 An overview of the Community Earth System Model high-resolution version (CESM-HR)
The CESM version used in the present study is tagged as CESM1.3-beta17_sehires38, which is an extension of the CESM1.3-beta17_sehires20 described in Meehl et al. (2019). This latter model tag was developed specifically for supporting a high-resolution CESM version with 0.25∘ CAM5 (the fifth version of the Community Atmospheric Model) atmosphere and 0.1∘ POP2 (the second version of Parallel Ocean Program) ocean model. The details of this progression from CESM1.1 to CESM1.3-beta17 are provided in Meehl et al. (2019), where it is concluded that the most impactful developments were in the atmospheric model with changes to vertical advection, the gravity wave scheme, dust parameterization, and move from the finite volume (FV) dynamical core to the spectral element (SE) dynamical core with better scaling properties at high processor counts. The new atmospheric physics results in better positioning of the Southern Hemisphere jet and improved high- and low-cloud simulations, with general increases in low cloud, producing better agreement with observations. Notable developments from beta17_sehires20 to the current beta17_sehires38 include two modifications in the ocean model. The first one is a new iterative solver for the barotropic mode to reduce communication costs, which is especially good for high-resolution simulations on large processor counts (e.g. Hu et al., 2015; Huang at al., 2016) (indicating a contribution of the Chinese climate modelling community to the CESM development). The second one is a change of the ocean coupling frequency from 1 h to 30 min to alleviate any potential coupling instabilities that may arise with longer coupling frequencies between the ocean and sea-ice models. In addition, the shortwave calculation method is updated to the “delta-Eddington” shortwave computation of Briegleb and Light (2007). There were also a few sea-ice namelist parameter changes as in Small et al. (2014) that affect the computation of shortwave radiation in the sea-ice model for this high-resolution configuration. Finally, to improve sea-ice thickness and extent simulation, further adjustments have been done to the melting snow grain radius and the melt onset temperature to increase the sea-ice albedo with the effect of thickening the sea ice and increasing the extent. Note that although these CESM 1.3 tags are informal, they are available to the community upon request via the CESM web pages. The Sunway version of the model is available via GitHub at https://github.com/ihesp/CESM_SW (last access: 5 February 2020). The structure of the CESM-HR model illustrates the challenge of the project: migrating a combination of several complex models onto a completely new architecture. The atmosphere, the ocean, the land, the sea-ice, and the coupler models can each be fairly complicated on their own with hundreds of thousands of lines of code.
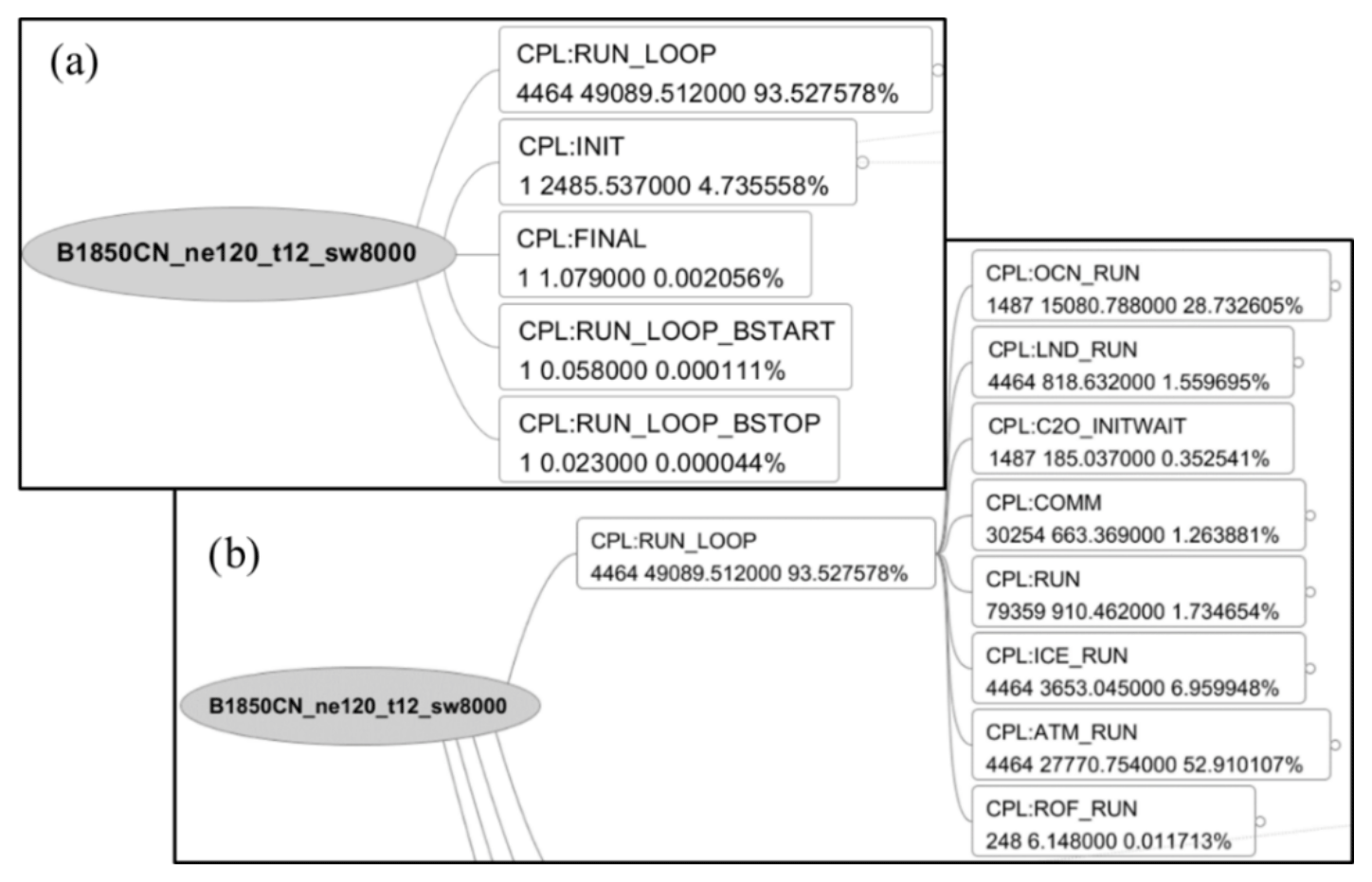
Figure 3An example of tracking computing hotspots in major components of the 10 km ocean + 25 km atmosphere high-resolution CESM for the pre-industrial control experiment with the 1850 fixed-year radiative forcing using 8000 core groups on the Sunway machine (B1850CN_ne120_t12_sw8000) for 1-month integration; (a) the total number of calls (in integer, 4464 calls of RUN_LOOP in this experiment, for instance), the total seconds of computing time (in real, 49089.512 s for the 4464 calls of RUN_LOOP, for instance) and projected percentage (93.528 % for the 4464 calls of RUN_LOOP, for instance) in five items of the main driver; (b) further partitions of the 93.528 % RUN_LOOP in eight model components.
Using the analysis tool swlu mentioned in Sect. 2.1.2 to produce output file swlu_prof.dot and conducting a command such as “dot-Tpdf swlu_prof.dot-o B1850CN_ne120_t12_sw8000.pdf”, we obtain the analysis flow chart as shown in Fig. 3. Figure 3 first shows that the main computing consumption is for the main body RUN_LOOP in the five parts of the model driver, about 93.53 %, and the next is the model initialization, 4.74 %. Extending RUN_LOOP, we can see that the major computing consumption is for the atmosphere ATM_RUN (52.91 %) and ocean OCN_RUN (28.73 %), and the next consumption is for the sea-ice ICE_RUN (6.96 %).
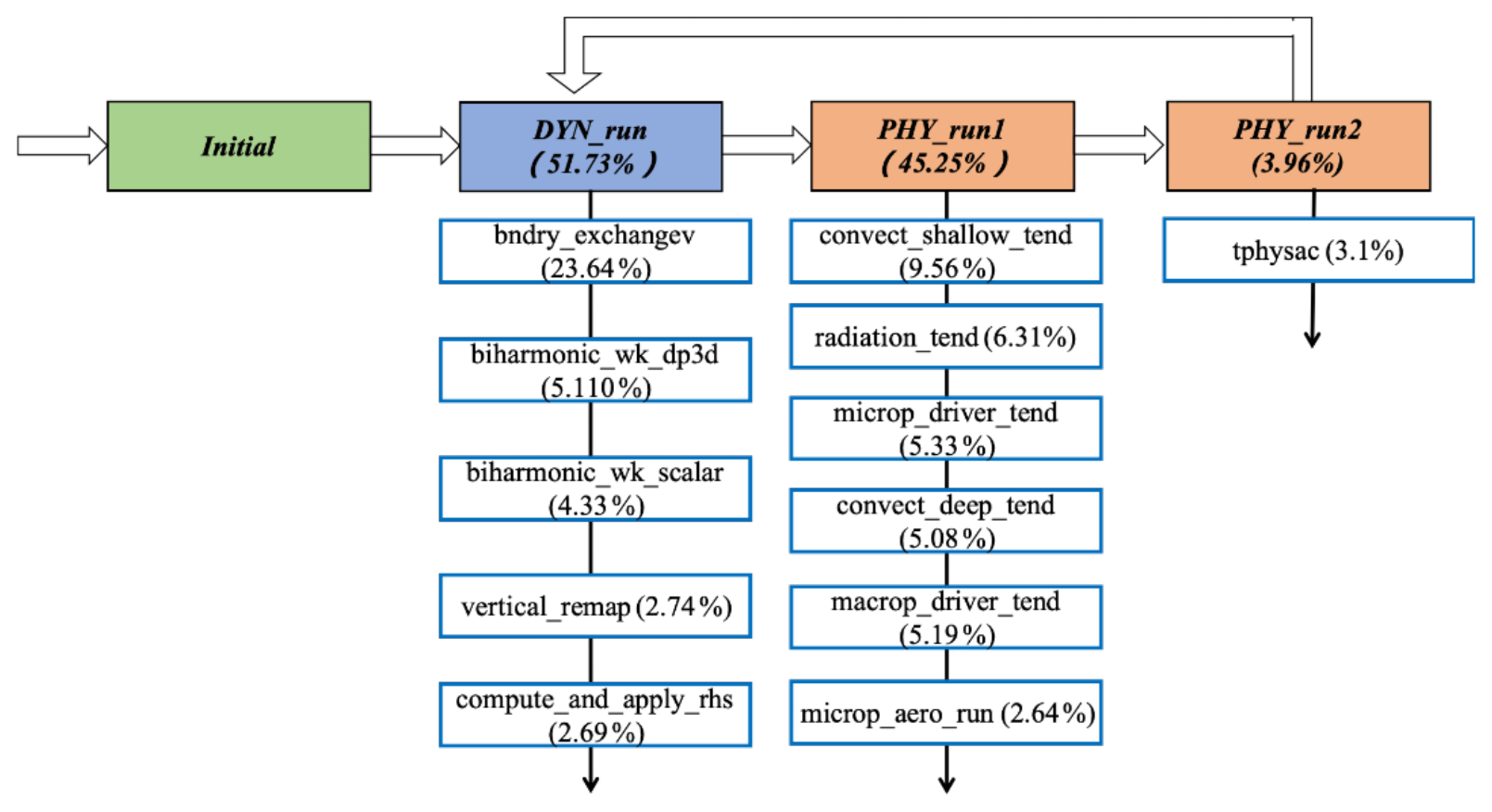
Figure 4The major consumers of run time in the CAM5 model. The profiling is performed with a 25 km CAM5 run using 29 000 MPI processes.
In the entire model, the atmosphere (CAM5) and the ocean (POP2) are still the dominant consumers of computing cycles. Therefore, in the process of migrating towards a new machine, CAM5 and POP2 are the main targets that require refactoring and redesign, while the other components require only porting effort. However, even by only considering CAM5 and POP2, the complexity is at a level that requires tremendous efforts. Figures 4 and 5 show the major hotspots (the functions that consume the most run time, i.e. conducting significant computation) of CAM5 and POP2, respectively. Looking into the major functions in both CAM5 and POP2, it is clear that most major computing kernels only consume around 5 % of the total run time. In CAM5, the only substantial component that takes more than 10 % run time is the bndry_exchangev function, which performs the MPI communication between different MPI processes and takes a substantial part of the total run time when the parallel scale increases to over 20 000 MPI processes. In POP2, the only clear hotspot is the kpp function, which performs the computation of K-profile vertical mixing parameterization (KPP) (Large et al., 1994). Note that, when going further down, these functions would be further decomposed into even more functions at a lower level. As a result, for both CAM5 and POP2, hundreds of functions were redesigned to achieve a reasonable performance improvement of the entire CESM-HR model.
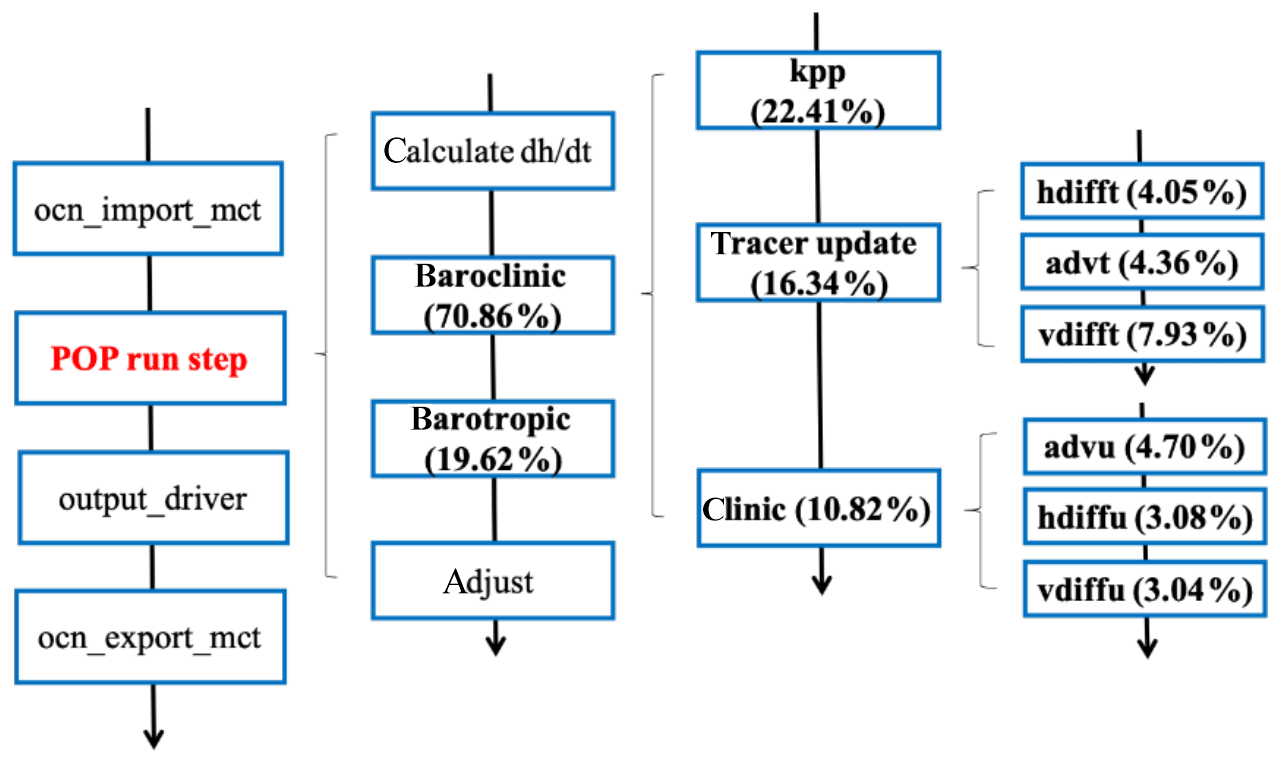
Figure 5The major consumers of run time in the POP2 model. The profiling is performed with a 10 km POP2 run using 18 300 MPI processes.
3.2 Porting of CESM-HR
3.2.1 Migrating the code from Intel to Sunway processors
The new CESM-HR is first run on Intel multicore supercomputing platforms (Intel Xeon E5-2667 CPU) at TAMU and QNLM. The run on Intel CPUs is used as a stable climate simulation with a good radiative balance at the top of atmosphere (TOA). Roughly, using 11 800 Intel CPU cores, the model can achieve a simulation speed of 1.5 SYPD with standard output frequency (monthly or daily 3D fields and 6 h 2D fields). As we know, when a climate model with over a million lines of code such as CESM-HR is ported to a different supercomputing system, due to the differences in computing environment (compiler version, for example), numerical solutions cannot be guaranteed to be bitwise identical. The CESM-HR is first run and tested on the TAMU Intel multicore machine (iHESP's first HPC system). To minimize the uncertainties of the model porting to the completely new architecture Sunway TaihuLight, we first port the model from the TAMU machine to QNLM Intel multicore machine (iHESP's second HPC system installed at Qingdao later). We first establish the benchmark of the correct model on the Intel multicore machines. We use the CESM ensemble consistency test (ECT) (e.g. Baker et al., 2015; Milroy et al., 2018) to evaluate the simulation results. In particular, we use the UF-CAM-ECT test (Milroy et al., 2018) tool from CESM-ECT to determine whether three short test runs (of nine time steps in length) on the TAMU and QNLM machines are statistically indistinguishable from a large “control” ensemble (1000 members) of simulations generated on NCAR's Cheyenne machine. The general ECT idea is that the large control ensemble, whose spread is created by round-off-level perturbations to the initial temperature, represents the natural variability in the climate model system and thus can serve as a baseline against which modified simulations can be statistically compared using principal component (PC) analysis on more than 100 physical variables including normal atmosphere state variables such as wind, temperature, moisture, etc. and other derived diagnostic fields. The code ports to the TAMU and QNLM Intel multicore supercomputing platforms both passed the ECT tests (meaning that the simulations were statistically indistinguishable from the control).
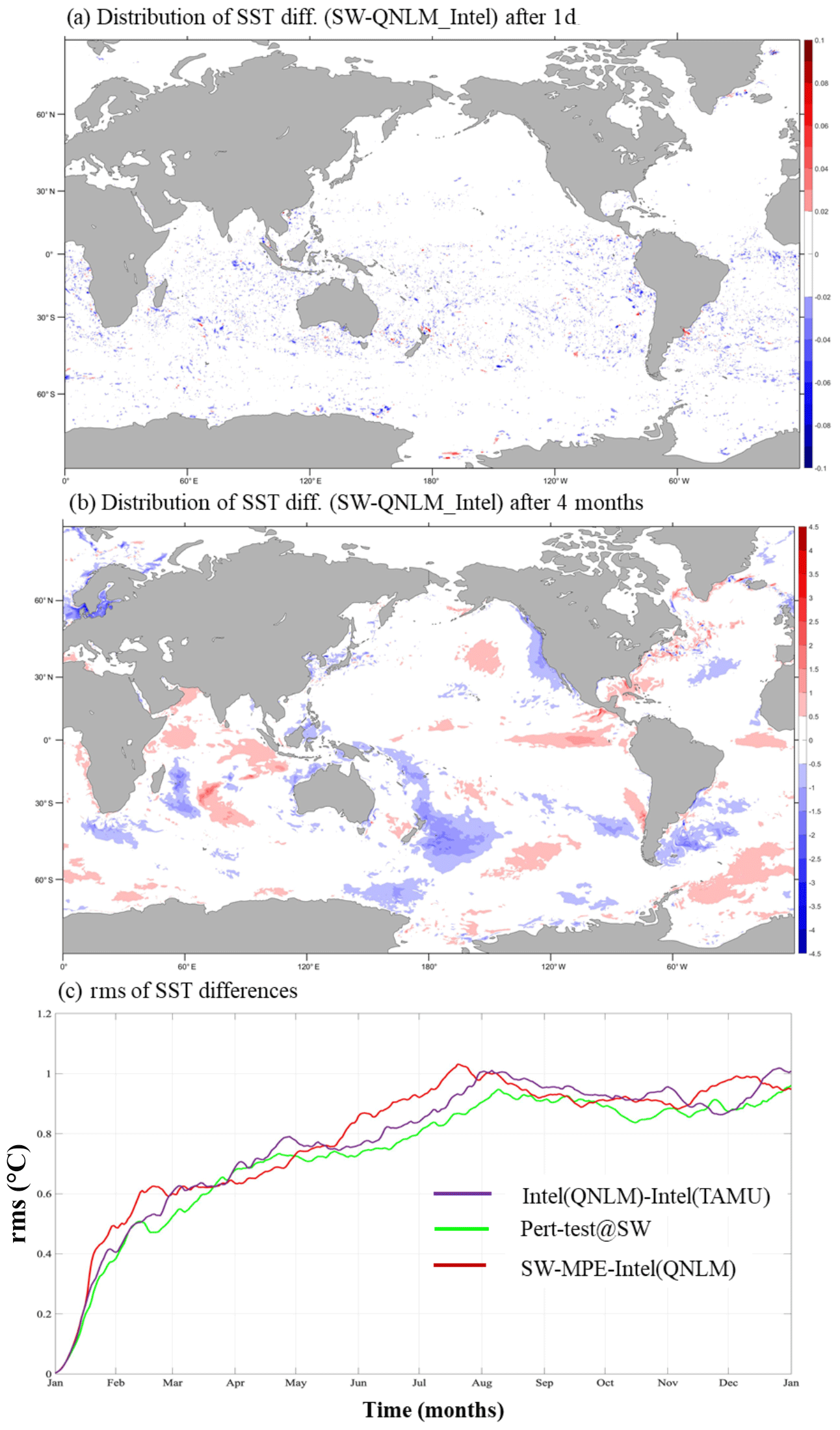
Figure 6The distribution of differences in sea surface temperatures produced by the Sunway machine and Intel machine at TAMU after (a) 1 d, (b) 1-year integration, and (c) the time series of root mean square (rms) of the differences between different machines and the perturbation test.
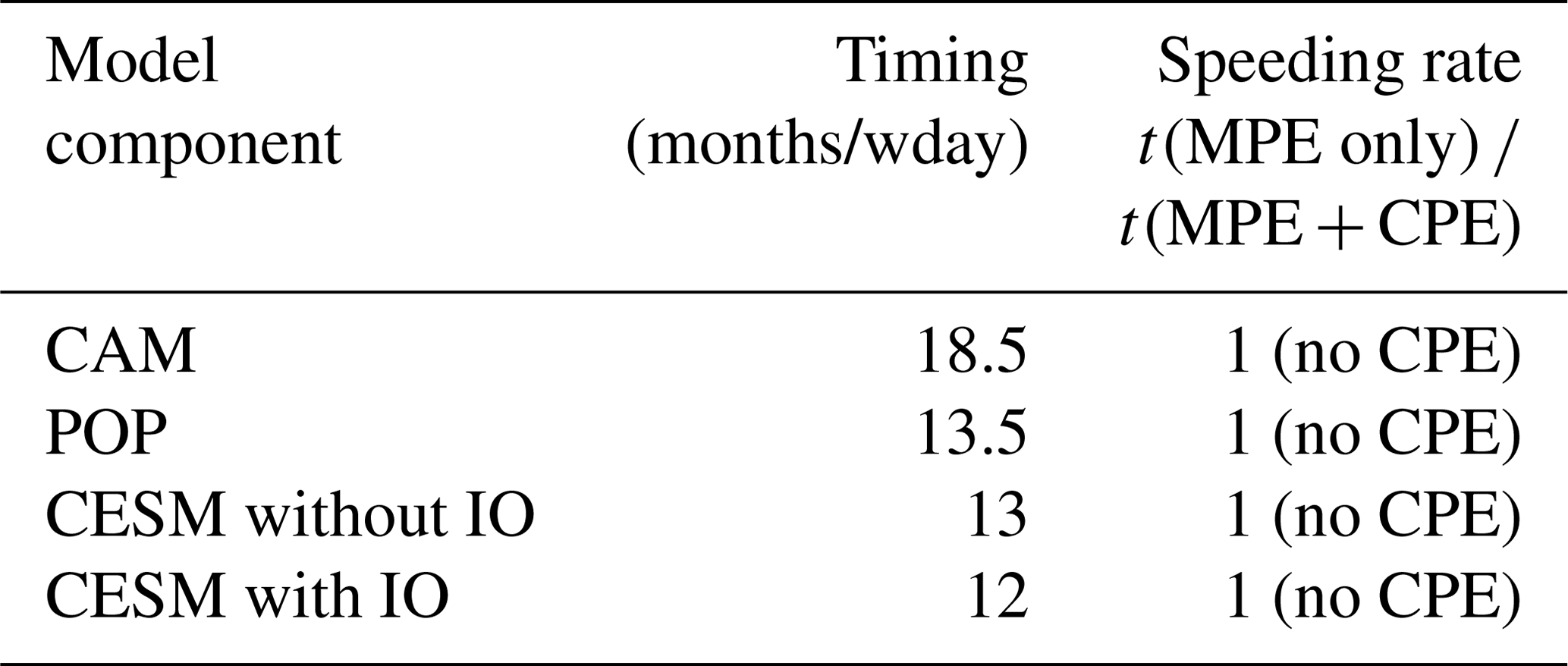
The porting of the CESM-HR from the Intel homogeneous multicore platform to the Sunway MPE-only system began on 3 December 2017. The major task of this stage was to resolve compatibility issues of the Sunway and standard Fortran compilers. With support from both the Sunway compiler team and the maintenance team of the National Supercomputing Center in Wuxi, the team spent roughly 6 months going through over 1 million lines of CESM code. Beginning on 1 October 2018, the Sunway MPE-only version of CESM-HR was able to stably run on Sunway TaihuLight. The timing results are shown in Table 3. Without the utilization of CPEs, the speed is roughly 1 SYPD.
3.2.2 Correctness verification
Given that different supercomputing platforms with different architectures generally produce non-identical arithmetic results (due to the differences from architecture, compiler, rounding, truncation, etc.), it is challenging to ensure the correctness of the code porting process between different machines with different hardware architectures. We initially evaluate the Sunway MPE-only port by looking at the effect of a small O(10−15) perturbation in the initial sea surface temperature (SST). Figure 6a and b give the systematic “error” growth in the SST that resulted from such a tiny initial error (mainly over the North Pacific and North Atlantic as well as Southern Ocean and North Indian Ocean) after a few months of model integration due to the model internal variability. Figure 6c shows that the difference produced by the Sunway MPE-only version and the homogeneous multicore Intel machines are within a similar range of differences produced by perturbation runs (either a round-off initial error or different Intel machines). Then, we again use CESM-ECT to evaluate the Sunway MPE-only version of CESM-HR, using three different compiling optimization options (labelled -O1, -O2, and -O3) and show the results in Table 4. Note that by default, CESM-ECT evaluates three simulations for each test scenario and issues an overall fail (meaning the results are statistically distinguishable) if more than two of the PC scores are problematic in at least two of the test runs. We see that with -O1 and -O3 compiling optimization options, the Sunway MPE-only version passes the ECT test, but it fails with -O2 optimization. This -O2 result is not concerning as the failure with three PCs (out of 50 total) is just outside the passing range and small uncertainties are not uncommon (Milroy et al., 2016). More discussions on the uncertainties of the ECT metrics are given in Sect. 3.6 when the correctness of the Sunway CESM-HR is evaluated.
Table 4Results of the ECT tests for the Sunway MPE-only CESM-HR version with different compiling optimization options.

3.3 Refactoring and redesign of CAM5 and POP2: major strategies
3.3.1 Transformation of independent loops
In a scientific simulation program, loops are generally the most computing-intensive parts. Especially for the time integration in climate models, a major part is to advance the time step in both dynamic and physics processes. In such processes, the major form is usually independent loops that iterate through all the different points in a 3D mesh grid. As the computation of each point is generally independent (or in some cases dependent on a small region of neighbouring points), assigning different partitions of the loop to different MPI processes or threads is the most important approach to achieving parallelism.
Migrating from Intel CPU to Sunway CPU, the approach to parallelism is still the same, with different processes at the first level and different threads at the second level. The major change comes from the significantly increased parallelism inside each processor and the architectural change of the cache part.
In Intel CPU machines, we have dozens of complex cores, each of which has its own cache and support for a complex set of instructions. In the SW26010 many-core processor, we have 256 CPEs, each of which only has 64 KB LDM and a reduced set of computational instructions. Therefore, the challenge becomes how to remap the loops to fit the increased number of cores and limited scratchpad fast buffer allocated to each core.
Figure 7 demonstrates some of the typical loop transformations that we perform for both the dynamic parts and physics parts so as to produce the most suitable loop bodies that fit the number of parallel cores and the size of the fast buffer in each core of the SW26010 many-core processor. The first kind of transform is a preprocessing step. We aggregate all the loop bodies into the most inner loop so that afterwards we can more easily interchange or partition different loops. A typical example is the euler_step loop in the dynamic core of CAM. We perform such an aggregation at the very beginning so that all the computation instructions reside in the most inner loop, and the dependencies are reduced to a minimum level. The second kind of transform, loop interchange, is one of the most frequently used transforms in our refactoring and redesign of CAM5 and POP. The loop interchange transform is often used to expose the maximum level of parallelism for the 256 parallel CPEs in each Sunway processor. The third kind of transform merges two loops into one. The purpose of such a transform is similar to the second one. If none of the loops can provide enough parallelism for the many-core processor, we choose to merge some of the loops to release enough parallel threads.
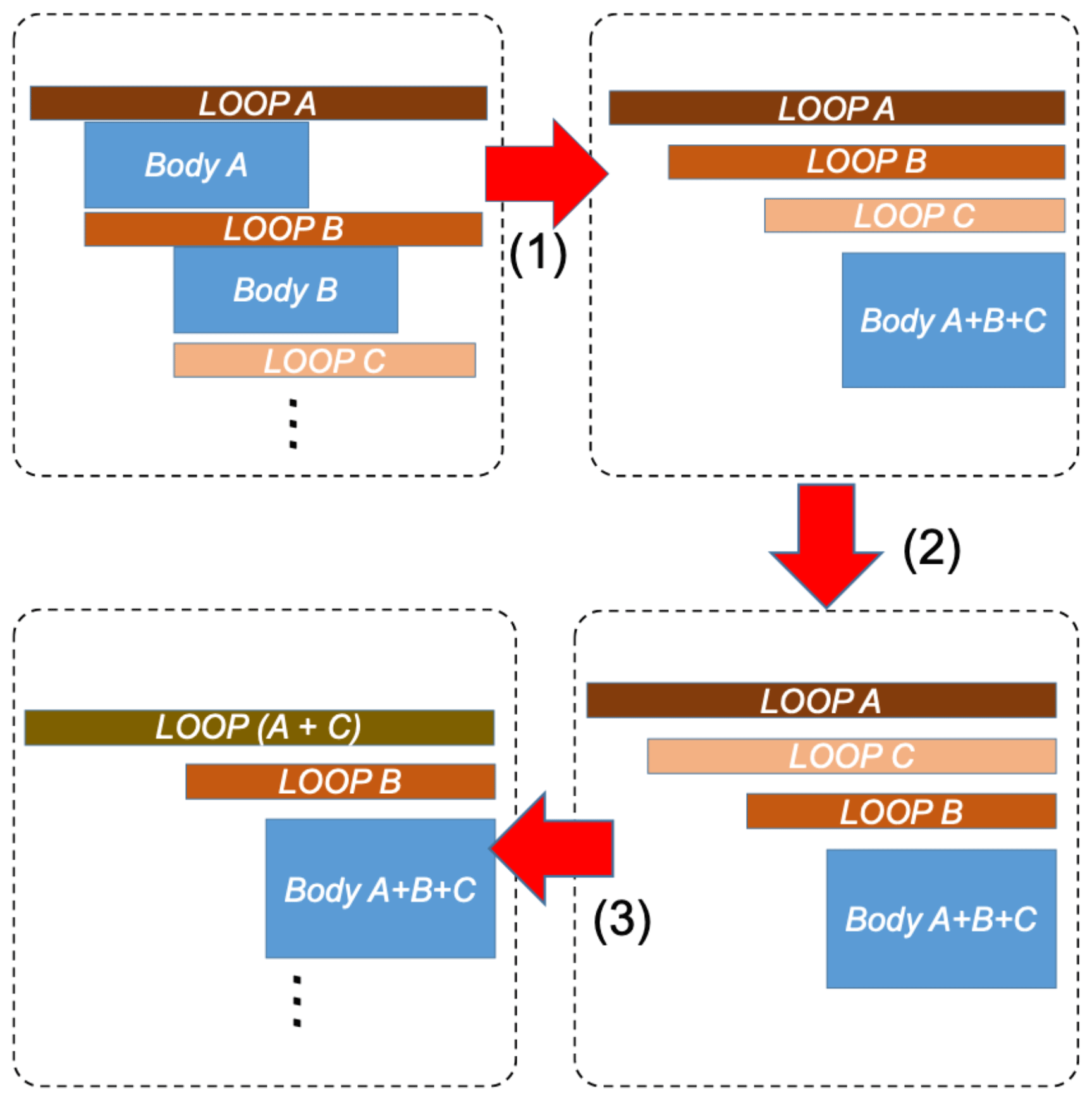
Figure 7Typical loop transformations performed to achieve the most suitable loop bodies that fit the number of parallel cores and the size of fast buffer in each core of the SW26010 many-core processor. (1) Aggregation of the loop body into the most inner loop, (2) interchange of loops B and C, and (3) merging of loops A and C.
After transforming the loops, in most scenarios, we can achieve a suitable level of both parallelism and variable storage space for the CPE cluster architecture. Afterwards, we can apply the OpenACC directives to achieve automated multithreading of the loops and to allocate different iterations to different CPEs. However, in certain cases, either to remove certain constraints in the existing algorithms or to achieve better vectorization, we need to perform a more fine-grained Athread-based approach, which is detailed in the following section.
3.3.2 Register communication-based parallelization of dependent loops
In addition to independent loops that process different points in the mesh grid, scientific code also includes dependent loops that are not straightforward to parallelize on different cores. A typical case is the summation process. For example, in the compute_and_ apply_rhs kernel, we need to compute the geopotential height using the following loop:
where the initial value p0 (the value of pi−1 when i=1) is the initial geopotential height, and ai is the pressure differences between two neighbouring layers i and i−1. Such a loop is clearly data dependent, as the computation of pi relies on the computation of pi−1. Therefore, we cannot directly allocate different iterations to different cores; otherwise, each core would wait for the result of the previous element and could not compute in parallel.
To achieve parallel computation in such a scenario, we compute the accumulative pressure difference for the corresponding layers within each CPE, and we achieve efficient data transfer among different CPEs through register communication. As shown in Fig. 8, we compute the result in three stages. Assume that we parallelize the computation of 128 layers in eight parallel CPEs and each CPE would store 16 pi and ai values.
-
In stage 1 (local accumulation), each CPE computes the local accumulation sum of its own layers.
-
In stage 2 (partial sum exchange), each CPE Ci which is not in the first waits for the sent from Ci−1 through the register communication feature and then computes . Afterwards, CPE Ci sends to the next CPE Ci+1 if Ci is not in the last one in the row.
-
Stage 3 (global accumulation) computes all the atmospheric pressures within each CPE.
In such a way, we can maximize the parallel computation happening in each CPE and utilize the register communication feature to achieve fast data transfer among the different CPEs.
Such three-stage optimizations can be efficiently used to solve a specific prefix summation calculation with register communication. In our case (for the subroutines compute_and_apply_rhs and vertical_remap, for instance), the optimization rate gained is up to 27 times faster than original single-loop computation. Note that this sort of strategy to parallelize dependent loops has general applicability to modelling on heterogeneous many-core HPC systems.
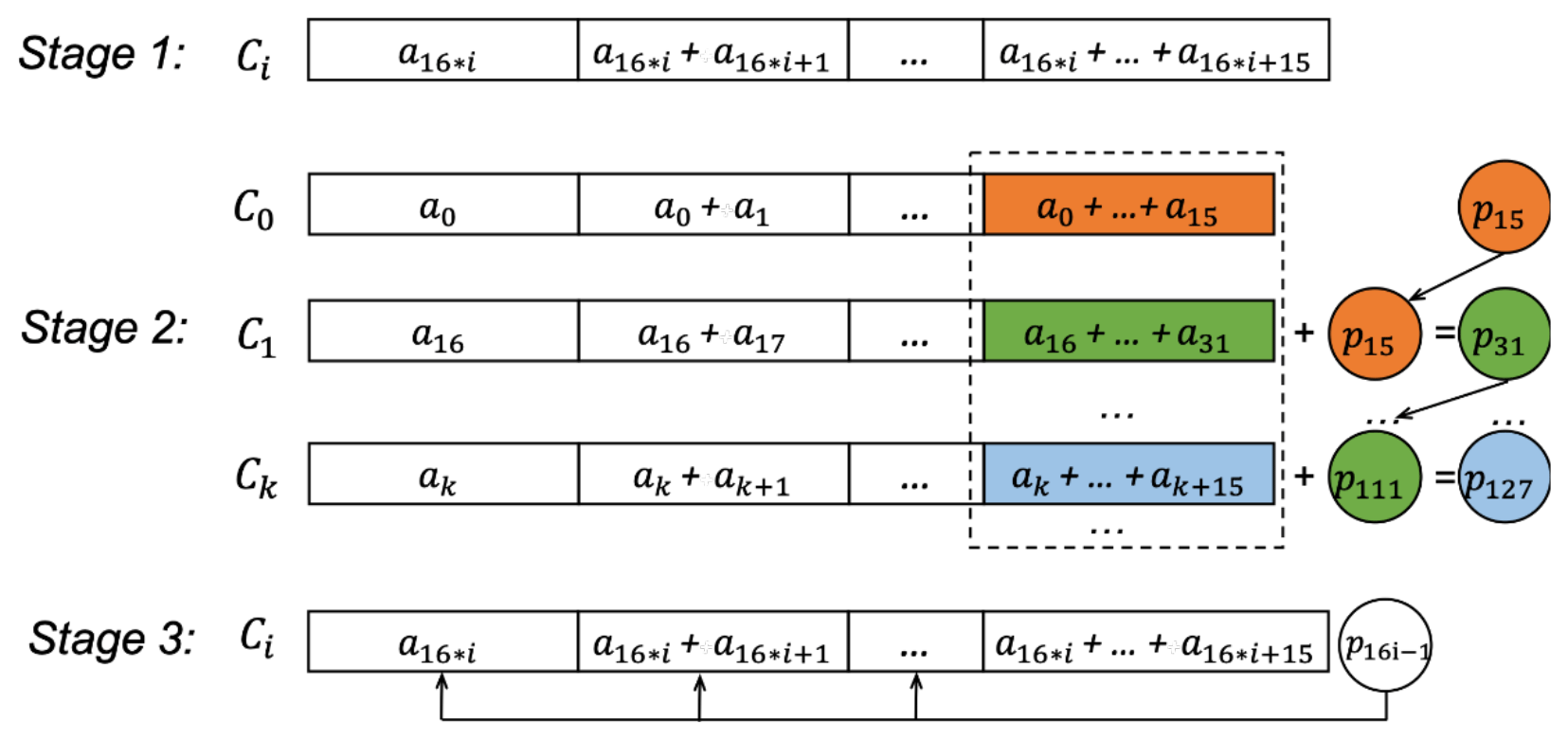
Figure 8Register-communication-based parallelization of dependent loops: an example of computing the geopotential height at 128 different layers, which is parallelized as eight CPE threads.
3.3.3 Athread-based redesign of the code
Even after identifying the most suitable form of loops to be parallelized, the OpenACC approach which has good portability sometimes still provides disappointing performance. For example, in certain kernels in the euler_step function, the 64 CPEs would only provide equivalent performance to 1.5 Intel cores. There are multiple reasons behind this poor performance improvement. The most essential factor is that the algorithm and the data structure were all designed for the previous multicore CPU architecture and are inherently not suitable for the emerging many-core architecture. As a result, the OpenACC approach, which minimizes the code changes but also removes the possibility of an algorithmic redesign, leads to a program that would underperform on the new architecture. Therefore, for the cases that OpenACC performs poorly, we take a more aggressive fine-grained redesign approach and rewrite CAM5 using the Athread interface – an explicit programming tool for CPE parallelization. In such an approach, we make careful algorithmic adjustments.
Taking the OpenACC-refactored version as a starting point, we first rewrite the OpenACC Fortran code to the Athread C version. The second step is to perform manual vectorization for certain code regions. We can specifically declare vectorized data types and write vectorized arithmetic operations so as to improve the vectorization efficiency of the corresponding code regions. Compared to the OpenACC, the fine-grained Athread CPE parallelization has lower general portability, although its design has a general application to modelling on heterogeneous many-core HPC systems.
3.3.4 Other tuning techniques at a glimpse
- a.
Data reversing for vectorization. Single-instruction multiple data (SIMD) vectorization (Eichenberger et al., 2004) is an important approach to further explore the parallelism within each core. To achieve a better vectorization performance, we need a careful modification of the code to achieve rearrangement of either the execution order or the data layout. In certain cases, reversing the order of the data is necessary to have a more optimal pattern.
- b.
Optimizing of direct memory access (DMA). Directly calling the DMA functions will add additional overhead and lower the overall performance. For occasions when the DMA function call becomes annoying, we can try bypassing it using DMA intrinsic, for instance.
- c.
Tiling of data. For certain operations such as stencil computation (Gan et al., 2017) that have complicated data accessing patterns, the computing and accessing can be done in a tiling pattern (Bandishti et al., 2012) so that the computation of different lines, planes, or cubes can be pipelined and overlapped.
- d.
Fast and LDM-saved math library. The original math library (e.g. xmath; Zhang et al., 2016) for the Sunway system is not specifically designed for LDM saving, as data accommodation in LDM may not be released in time after the library is called. Therefore, we modified the library to use instant LDM space creation or releasing, saving more LDM for other usages.
- e.
Taking control logic out of loops. This is a common and popular idea to reduce the overhead or number of branches and thus to increase the performance.
- f.
Vertical layer partition. This is a specific idea for some kernels in the physics part with too many parameters or variables. We can vertically decompose these kernels into several sub-kernels, which are then assigned to several CPEs that are also divided into several groups.
- g.
Grouping of CPEs. Instead of using all 64 CPEs to deal with one thing, we can separate them into several groups for different simultaneous things. (The vertical layer partition mentioned above is an example of using this method.)
- h.
Double buffer. The DMA double buffer mechanism can help load data ahead of time before it is required. Such a strategy can therefore push data closer to the computation.
- i.
Function inline. For some functions that have too much calling overhead, we can try to make them inline so that the function calling overhead can be reduced.
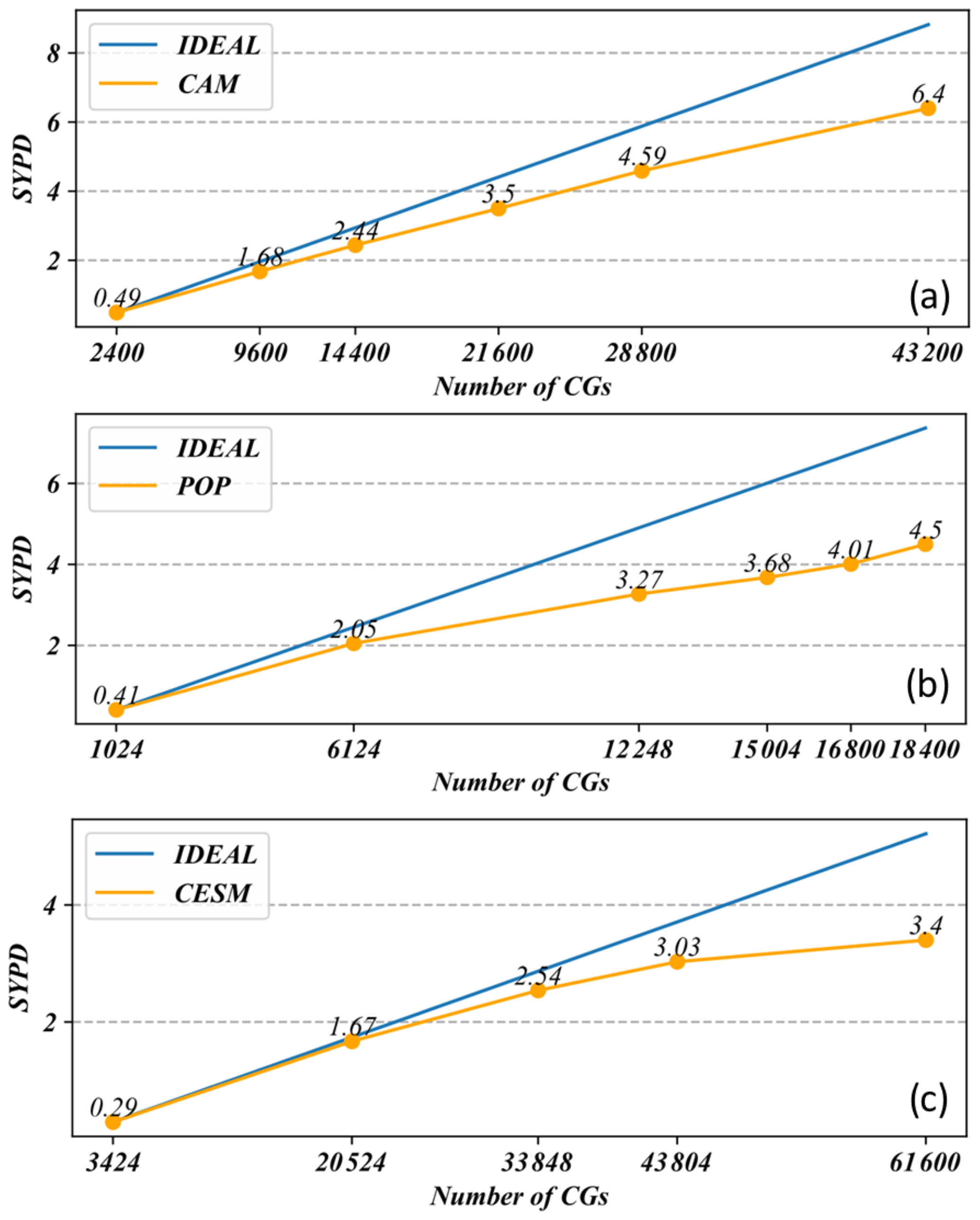
Figure 9Scalability of (a) CAM5, (b) POP2, and (c) CESM-HR optimization. The performance of the model is given in terms of simulation years per day (SYPD) and number of core groups (CGs).
3.4 Refactoring and optimizing of the CAM5 computing hotspots
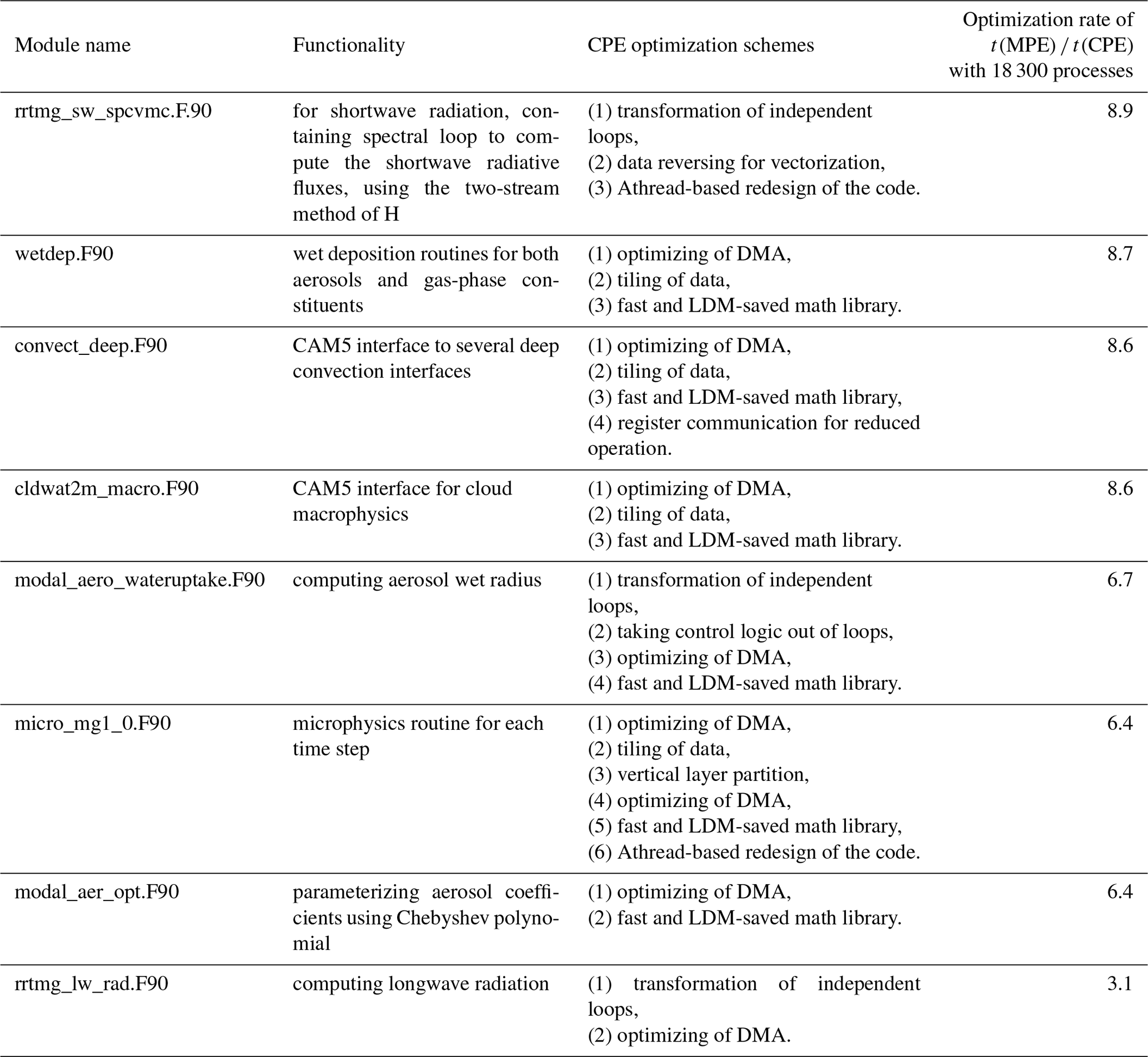
Following the profiling procedure described in Sect. 3.1, we identify the bottom modules, subroutines, and/or functions which have significant computing consumption in the CAM5 dynamic core and physics modules. We list the examples of CAM5 physics in Table 5 by the order of optimization rate shown in the last column. We can see that for most physics modules that are implemented as columnwise computations with no dependent data communications, our refactor and optimization efforts demonstrate a reasonable performance improvement, ranging from 3 to 9 times. Table 5 also demonstrates the major strategies and tuning techniques (Sect. 3.3.4) used for each hotspot function. The scalability along the CAM5 optimization is shown in Fig. 9a.
Table 5List of refactoring and optimizing schemes for CAM5 physics modules with significant computing hotspots.
3.5 Refactoring and optimizing of the POP2 computing hotspots
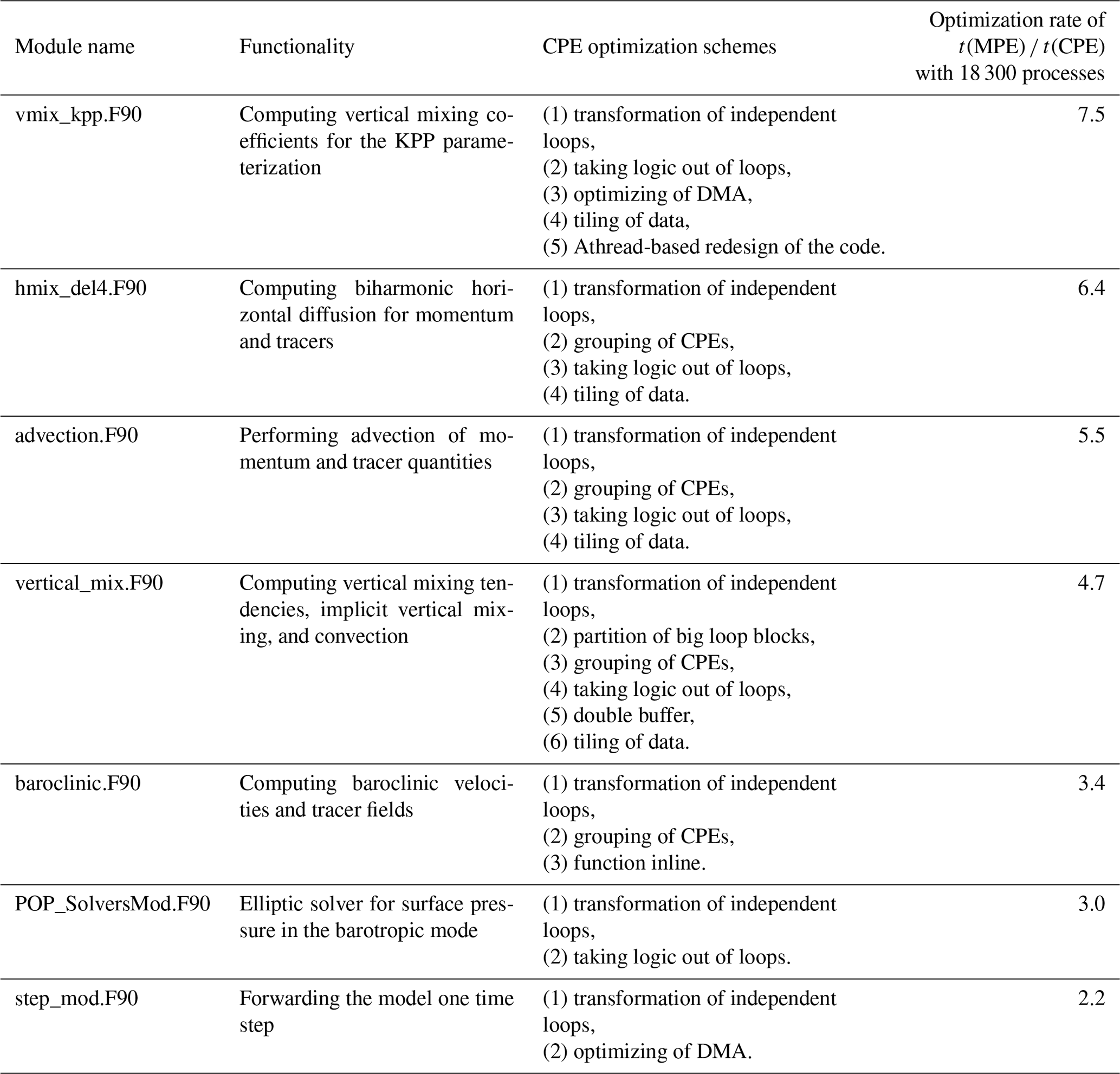
Extending the procedure of tracking the computing hotspots into OCN_RUN, we locate the modules that have the most computing consumption as listed in Table 6. The last column lists the optimization rate with the CPE parallelism, which is defined as the ratio of the MPE computing time over CPE parallelized computing time using 18 300 CGs. The optimization rate of the kpp vertical mixing module (vmix_kpp.F90), which is one of the most time-consuming modules in POP, is up to 7.49, demonstrating an improved efficiency of the refactored and redesigned code. Table 6 also describes the tuning techniques (Sect. 3.3.4) applied to each hotspot function. The scalability plot for POP2 optimization is shown in Fig. 9b.
Table 6List of refactoring and optimizing schemes for POP2 computing hotspot.
3.6 Evaluation of numerical differences after applying CPE parallelization of the code
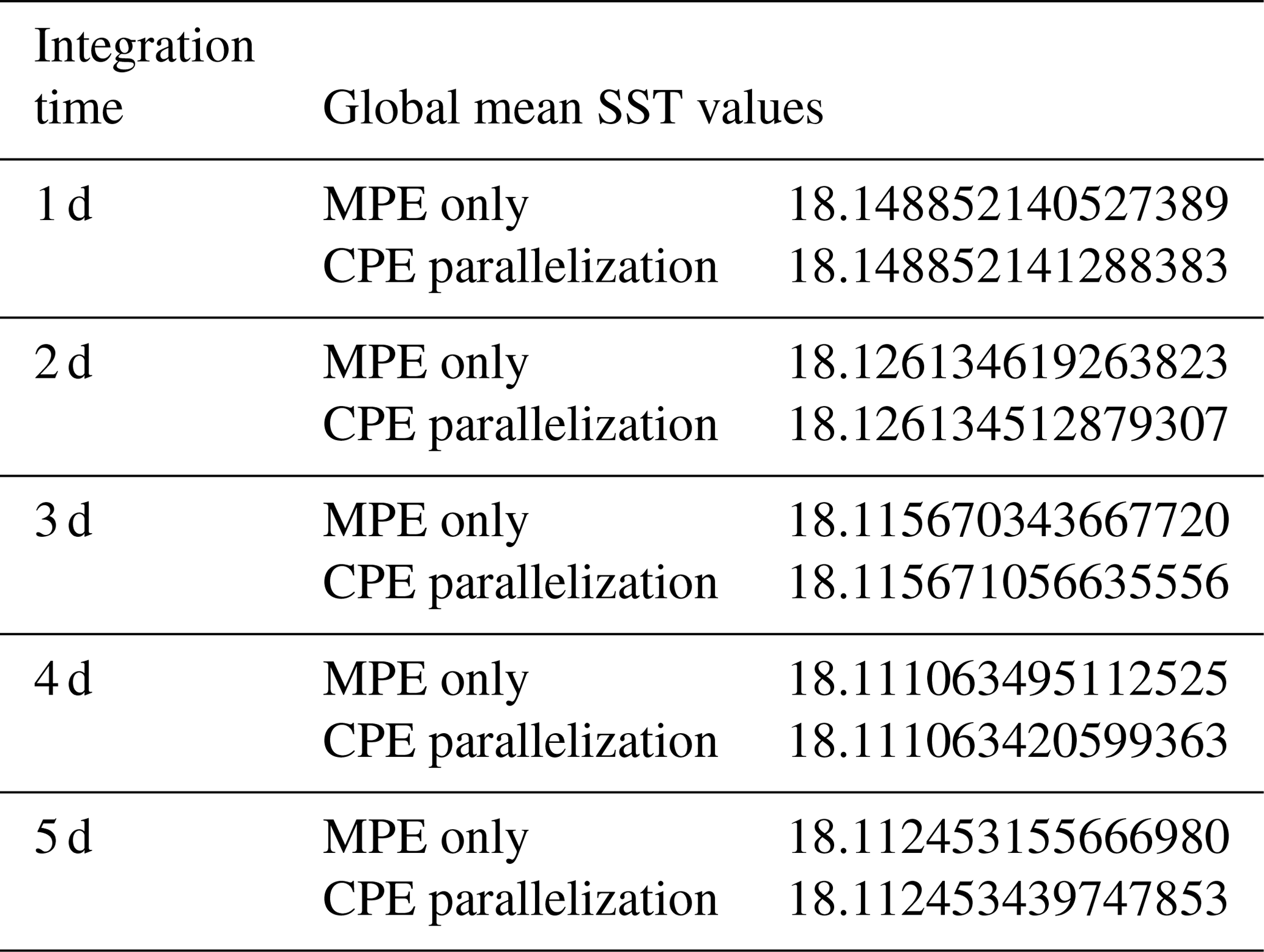
Refactoring and optimizing the majority of CESM-HR resulted in a version that we refer to as SW-CPE CESM-HR, with scalability shown in Fig. 9c. Although the coding changes in refactoring and optimizing described in Sect. 3.4 and 3.5 are not expected to change the model results, as the arithmetic behaviours (e.g. truncation errors) of MPE and CPE in the Sunway processor are not completely identical, depending on non-linearity levels of computation, the CPE-parallelized code may produce slight differences from the MPE-only code with deviations in the last few digits. Table 7 shows a few examples of accuracy verification of subroutines in major modules of POP2. We can see that for simple array addition and multiplication (in the barotropic solver module, for instance), the result of the CPE-parallelized code is identical to the result produced by the MPE-only code. However, for multilevel array multiplication or strongly non-linear function computation (in advection and vertical mixing modules, for instance), the result of the CPE-parallelized code can deviate from the result produced by the MPE-only code in the last five digits in double precision. Table 8 gives an example for which the deviated digits of the global mean SST are moved toward the left as the model integration moves forwards in the CPE-parallelized version of POP2 compared to its MPE-only version.
Table 7List of refactoring and optimizing schemes for POP2 computing hotspots.

Table 8Movement of the difference of global mean SST in digits caused by CPE parallelization by the forwarding of POP2 integration.
We also created a four-member ensemble (only four due to the constraint of computing resources) of 1-year SW-CPE CESM-HR simulations (that differ by a round-off level perturbation to the initial temperature) and computed the root mean square (rms) of their differences on global SST fields. We also compute the rms of the differences between the SW-CPE and SW-MPE CESM-HR versions. These results are shown in Fig. 10. From Fig. 10, we found that the ensemble of the differences between the results of SW-CPE CESM-HR version and the SW-MPE CESM-HR version was overall undistinguishable from the ensemble of the differences between either “Intel(QNLM)” and “Intel(TAMU)” machines or the SW-CPE perturbation runs; i.e. these simulations appear equivalent in terms of the SST.
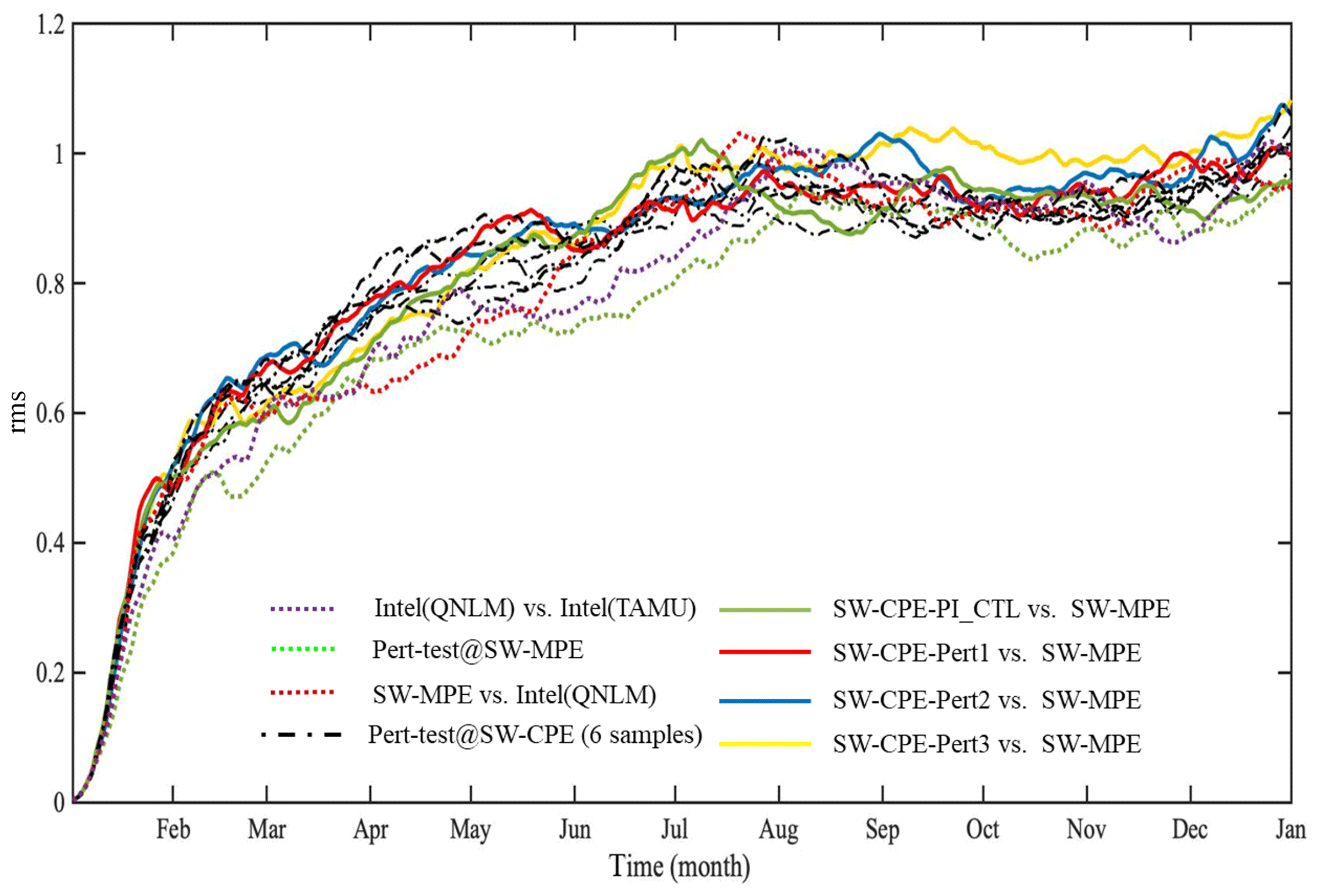
Figure 10Time series of the root mean square (rms) global SST differences between each of the three perturbation and PI_CTL simulations of the CESM-HR SW-CPE version and the CESM-HR SW-MPE simulation (four solid coloured lines) and any two of the four CESM-HR SW-CPE simulations (each pair of simulations produces a black dashed-dotted line so the total is six black dashed-dotted lines). Time series of rms global SST differences shown in Fig. 6 between the Intel(QNLM) and Intel(TAMU) (purple dotted), and two perturbed SW-MPE simulations (green dotted) as well as the SW-MPE and Intel(QNLM) (red dotted) are also plotted as the reference.
We then applied the CESM-ECT tool using the same procedure as for the SW-MPE-only version described in Sect. 3.2.2. In particular, we used UF-CAM-ECT to compare three 9-time-step simulations with SW-CPE CESM-HR against the control ensemble from NCAR's Cheyenne machine. The overall ECT result for this comparison was a “fail”, with nearly all of the 50 PCs tagged as failing. This result, while concerning, requires further investigation for several reasons. First, while the CESM-ECT tools have been very thoroughly tested at lower resolutions (e.g. 1∘), this is their first application to a high-resolution run, and perhaps an adjustment to the test procedure would be required for finer grids. Second, it is possible for CESM-ECT to legitimately fail at nine time steps due to a statistical difference at that time step and then issue a pass for the same simulation when evaluating the 1-year annual average. This conflicting result means that the difference is not significant over the longer term (an example of such a scenario is changing the type of random number generator, as detailed in Milroy et al., 2018). For the CESM-ECT tools, the nine-time-step test is always recommended as a first step due to its minimal computational cost and general utility. Given its failing result in this case, creating a large ensemble of 1-year high-resolution simulations is an important next step. Unfortunately, due to the computational cost required, this task remains future work. The CESM-ECT is a sensitive test, and it will be challenging to determine the reason for failure even with the current tools available (Milroy et al., 2019). However, in the meantime, the results of the multi-century control simulation (as discussed in Sect. 4) continue to look quite promising with no noticeable issues.
3.7 The current CPE-parallelized version of CESM-HR
Following the refactoring and optimizing procedures for CAM5 and POP2, as well as other optimization strategies presented in Fig. 11, the optimization of CESM-HR on the Sunway machine resulted in a simulation rate of 3.4 SYPD at the end of June 2019, as shown in Fig. 11. There are three important stages that are worth mentioning in this optimization process: (1) at the end of 2018, based on MPE-scaling and load balancing, using 48 000 CGs, after the CPE parallelization for CAM5 dynamic core and physics modules, the model had a 1.2 SYPD integration speed; (2) with the CPE parallelization for POP2 hotspot subroutines and further optimization on CAM5 dynamic core communication and CAM5 load balancing, the model integration speed improved to 2.4 SYPD at the end of March 2019; (3) after the optimization for the malloc function and sea-ice initialization, as well as further scaling and load balancing with 65 000 CGs, the model reached the current integration speed of 3.4 SYPD (Table 9).
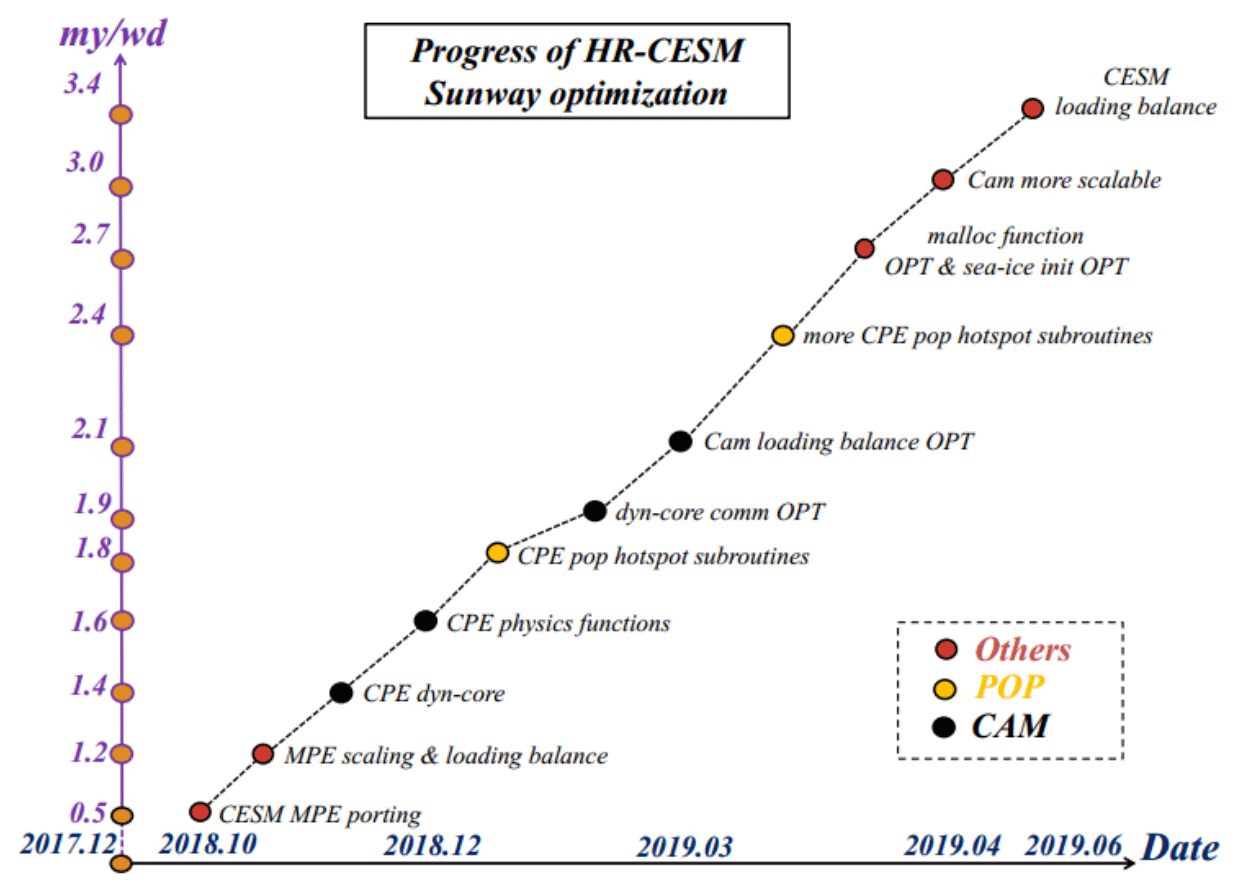
Table 9The current CPE parallelism speeding rate of CESM-HR configured on 65 000 CGs.
Currently, the CPE-parallelized CESM-HR has finished the PI_CTL simulation on the Sunway machine over 400 years. While more diagnostics will be presented in the follow-up studies, the next section will give some fundamental pictures of the Sunway machine integration results.
The first important piece of production simulations with CESM-HR is to complete a 500-year pre-industrial control (PI_CTL) integration. We continue the PI_CTL simulation starting from the initial conditions of 1 January 0021, which has been done on the Intel(TAMU) machine (for 20 years). Currently, another 400 years have been done and the model integration keeps continuing with a stable rate.
4.1 The feature of radiative balance at the top of atmosphere
As discussed in Sect. 3.3, once the model includes CPE parallelization, the CPE loop computation carried out by the C language and its compiler could introduce a very small perturbation into the model integration. A traditional model computed on a homogeneous multicore Intel machine is a self-enclosed system in terms of machine precision (reproducible 16 digits in double precision, for instance). The Sunway CESM-HR computed in a hybrid mode in which the MPE major task (in Fortran 90) manages the CPE sub-tasks (in C language) appears a frequently vibrating balance at the top of atmosphere (TOA) in such a frequently perturbed system, having a little different behaviour from that of a self-enclosed system (see Fig. 12). In the self-enclosed model system on the multicore Intel machine (TAMU's Frontera in this case), from an imbalanced default initial state (1.2 W m−2 of the difference between shortwave in and longwave out) (green dot in Fig. 12), the model quickly reaches the nearly balanced states (0.07 W m−2 of in-out mean difference) (red dot in Fig. 12) by roughly 10 years and then remains in oscillation with a small amplitude of ±0.1 W m−2. However, in the heterogeneous many-core Sunway system with a frequently perturbed hybrid mode, the time by which the model integration reaches a quasi-equilibrium is much longer (about 60 years), and the oscillation amplitude is much bigger (±0.6 W m−2).
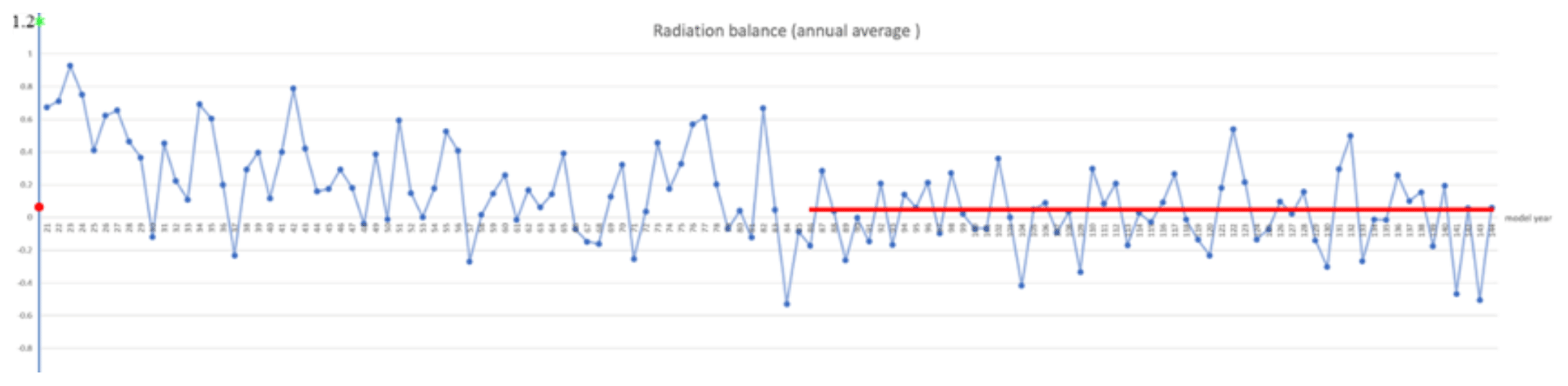
Figure 12Time series of annual mean global average radiation balance at the top of the atmosphere (difference of shortwave radiation in and longwave radiation out). The red line marks the time average over 85 to 142 years as a value of 0.05 W m−2. The green dot (1.2 W m−2) marks the initial value when the model starts from the default initial conditions, while the red dot marks the last 5-year mean value (0.07 W m−2) after the model finishes the 20-year integration on the Intel(TAMU) machine.
4.2 Model bias
The SST bias with the last 100-year data and the bias of the global mean ocean temperature and salinity against the climatological data are shown in Figs. 13 and 14. Compared to the simulation results of coarse-resolution coupled model (Delworth et al., 2006; Collins et al., 2006), the bias of ocean temperature and salinity simulated by CESM-HR is reduced by roughly 10 %. As expected, the major model error regions by order are the North Atlantic, the North Pacific, and the Southern Ocean Antarctic Circumpolar Current area.
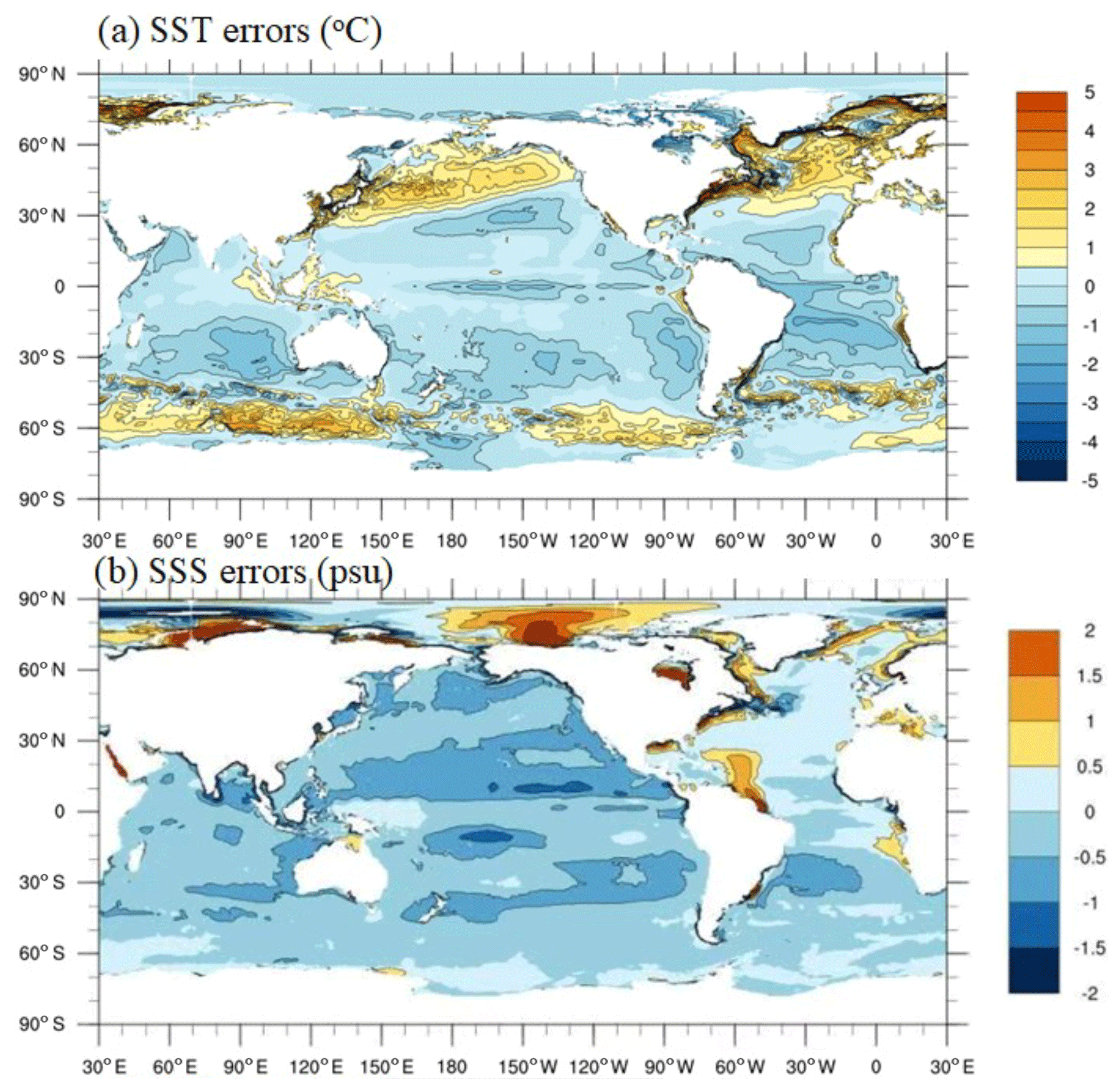
Figure 13The spatial distribution of time mean errors of (a) sea surface temperature (SST) and (b) sea surface salinity (SSS) simulated by the CPE-parallelized CESM-HR on the Sunway machine.
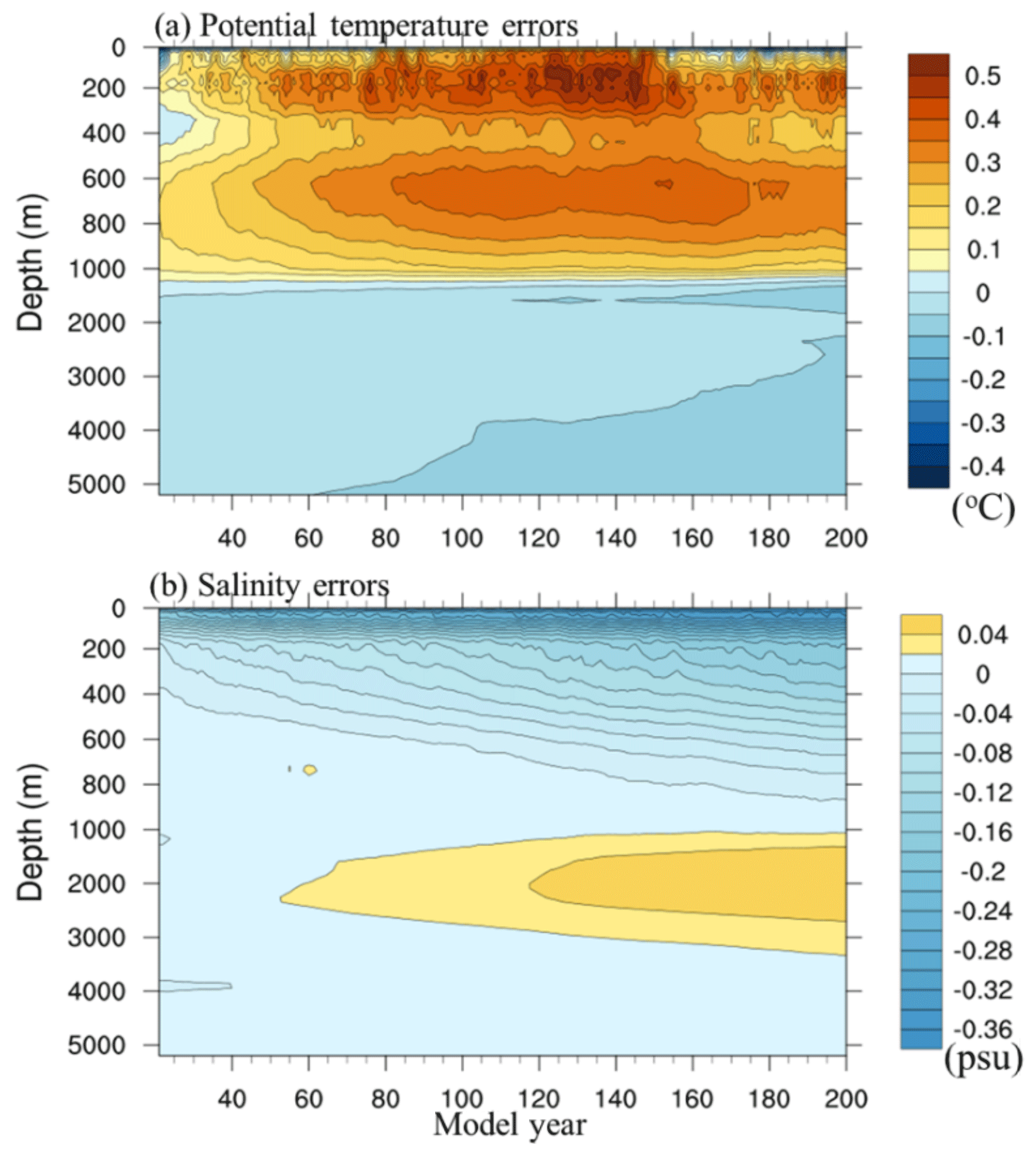
Figure 14Time series of global averaged errors of ocean (a) temperature and (b) salinity simulated by the CPE-parallelized CESM-HR on the Sunway machine against the climatological data.
Science advancement and societal needs require Earth system modelling with higher and higher resolutions which demand tremendous computing power. However, as current semiconductor technology gradually approaches its physical and thermal limits, recent supercomputers have adopted major architectural changes to continue increasing the performance through more power-efficient (faster but greener) heterogeneous many-core systems. The Sunway TaihuLight supercomputing platform is an outstanding example of a heterogeneous many-core system, consisting of management processing elements (MPEs) and computing processing elements (CPEs) inside one processor. Adapting legacy programs and enabling the models on such a new supercomputer is challenging but of great value for the global community. The Community Earth System Model with a high resolution of 10 km ocean and 25 km atmosphere (CESM-HR) has been successfully ported to and optimized on the Sunway TaihuLight, with millions of lines of legacy code being parallelized and redesigned on CPEs by a large group in iHESP (International Laboratory for High-Resolution Earth System Prediction) – a major international collaboration among QNLM (Qingdao Pilot National Laboratory for Marine Science and Technology), TAMU (Texas A&M University) and NCAR (National Center for Atmospheric Research). The current CPE-parallelized version has reached a simulation rate of 3.4 model years per wall clock day and has completed an unprecedented long high-resolution simulation (400 years) of the pre-industrial climate. With further strategies on deeper refactoring and optimizing on computing hotspots, it is expected that the CPE-parallelized CESM-HR will have a work efficiency that is equivalent to even beyond that of the Intel efficiency.
The heterogeneous many-core systems have a new architecture and therefore require new programming strategies. Our current efforts focus on adapting the legacy code that was designed and developed for traditional homogeneous multicore processors for the new architecture without changing the significant algorithm design. Theoretically, the computational capacity of a Sunway core group (1 MPE + 64 CPEs) with a dominant frequency of 1.45 GHz is 35.4 times that of a traditional homogeneous core with a dominant frequency of 2.66 GHz. Due to the small CPE LDM (only 64 KB in each CPE, plus needing to be managed by the users) and the cost of frequent communication between MPE and CPEs, the current CPE optimization has constraints that relate to both the architecture and the existing software. In follow-up studies, we may significantly redesign the algorithms as new architecture-based numerical implementations fully consider the nature of CPE parallelization with a small user-controlled cache to minimize the communication cost. Moreover, since Earth system modelling with higher resolution is one of the major demands for supercomputing capacity and has its own scientific algorithm characteristics, in the new machine design, considering Earth system modelling-oriented architecture or partial functions may advance the development of both supercomputer and Earth system modelling.
Although the focus of this paper is on the specific Sunway TaihuLight supercomputing system, we believe many of the refactoring and optimizing processes detailed in the paper can also be useful to the design of code porting and optimization strategies on other heterogeneous many-core systems such as GPU-based high-performance computing (HPC) systems. As the first piece of modelling on heterogeneous many-core supercomputing systems, this work has not addressed general performance portability as a factor. Given the increasing demand on heterogeneous HPC modelling, the issue of general performance portability will be an important and interesting topic in the future studies. We also acknowledge that the verification of correctness of recoding on a heterogeneous many-core supercomputing platform is very challenging, and we plan follow-up studies on using CESM-ECT for high-resolution simulations in general and its specific application to the current CPE optimization. Given the rapid development of heterogeneous many-core supercomputing platforms, evaluating high-resolution code refactoring efforts is quite important to the community.
The Sunway version of the model is available at Zenodo via the following URL: https://doi.org/10.5281/zenodo.3637771 (Ruo, 2020). The corresponding data are provided at http://ihesp.qnlm.ac/data (Zhang, 2020). For extra needs, please send requests to szhang@ouc.edu.cn.
LW, SZ, PC, and GD initiated this research, proposed most ideas, and co-led paper writing. SZ and HF led the process of development and research. YL, HW, YZ, XD, WW, LW, YZ, HM, KX, PX, LG, ZL, SW, YC, HY, and SS were responsible for code development, performance testing, and experimental evaluation. GY, ZW, GP, and YG participated in organization of working resources. HF, YL, WW, and LG were responsible for code release and technical support.
All authors contributed to the improvement of ideas, software testing, experimental evaluation, and paper writing and proofreading.
The authors declare that they have no conflict of interest.
The research is supported by the Key R&D program of Ministry of Science and Technology of China (2017YFC1404100 and 2017YFC1404104), the Chinese NFS (projects 41775100 and 41830964), Shandong “Taishan” Scholar, and Qingdao “Development Initiative” programs. Finally, this research is completed through the International Laboratory for High-Resolution Earth System Prediction (iHESP) – a collaboration among QNLM, TAMU, and NCAR.
This research has been supported by the Key R&D program of Ministry of Science and Technology of China (grant nos. 2017YFC1404100), and 2017YFC1404102) and the Chinese NFS project (grant nos. 41775100 and 41830964).
This paper was edited by Sophie Valcke and reviewed by Mark Govett and Carlos Osuna.
Baker, A. H., Hammerling, D. M., Levy, M. N., Xu, H., Dennis, J. M., Eaton, B. E., Edwards, J., Hannay, C., Mickelson, S. A., Neale, R. B., Nychka, D., Shollenberger, J., Tribbia, J., Vertenstein, M., and Williamson, D.: A new ensemble-based consistency test for the Community Earth System Model (pyCECT v1.0), Geosci. Model Dev., 8, 2829–2840, https://doi.org/10.5194/gmd-8-2829-2015, 2015.
Bandishti, V., Pananilath, I., and Bondhugula, U.: Tiling stencil computations to maximize parallelism, in: Sc'12: Proceedings of the international conference on high performance computing, networking, storage and analysis, 10–16 November 2012, https://doi.org/10.1109/SC.2012.107, 2012.
Briegleb, B. P. and Light, B.: A Delta-Eddington Multiple Scattering Parameterization for Solar Radiation in the Sea Ice Component of the Community Climate System Model, NCAR Tech. Note NCAR/TN-472+STR, University Corporation for Atmospheric Research, https://doi.org/10.5065/D6B27S71, 2007.
Carpenter, I., Archibald, R., Evans, K. J., Larkin, J., Micikevicius, P., Norman, M., Rosinski, J., Schwarzmeier, J., and Taylor, M. A.: Progress towards accelerating HOMME on hybrid multi-core systems, Int. J. High Perform. Comput. Appl., 27, 335–347, 2013.
Collins, W. D., Blackman, M. L., Bonan, G. B., Hack, J. J., Henderson, T. B., Kiehl, J. T., Large, W. G., and Mckenna, D. S.: The Community Climate System Model version 3 (CCSM3), J. Climate, 19, 2122–2143, 2006.
Delworth, T. L., Broccoli, A. J., Rosati, A., Stouffer, R. J., Balaji, V., Beesley, J. A., Cooke, W. F., Dixon, K. W., Dunne, J., Durachta, K. A. D. J. W., Findell, K. L., Ginoux, P., Gnanadesikan, A., Gordon, C. T., Griffies, S. M., Gudgel, R., Harrison, M. J., Held, I. M., Hemler, R. S., Horowitz, L. W., Klein, S. A., Knutson, T. R., Kushner, P. J., Langenhorst, A. R., Lee, H.-C., Lin, S.-J., Lu, J., Malyshev, S. L., Milly, P. C. D., Ramaswamy, V., Russell, J., Schwarzkopf, M. D., Shevliakova, E., Sirutis, J. J., Spelman, M. J., Stern, W. F., Winton, M., Wittenberg, A. T., Wyman, B., Zeng, F., and Zhang, R.: GFDL's CM2 global coupled climate models. Part I: Formulation and simulation characteristics, J. Climate, 19, 643–674, 2006.
Delworth, T. L., Rosati, A., Anderson, W., Adcroft, A. J., Balaji, V., Benson, R., Dixon, K., Griffies, S. M., Lee, H. C., Pacanowski, R. C., Vecchi, G. A., Wittenberg, A. T., Zeng, F., and Zhang, R.: Simulated climate and climate change in the GFDL CM2.5 high-resolution coupled climate model, J. Climate, 25, 2755–2781, 2012.
Demeshko, I., Maruyama, N., Tomita, H., and Matsuoka, S.: Multi-GPU implementation of the NICAM5 atmospheric model, in: European conference on parallel processing, Springer, 175–184, 2012.
Dongarra, J.: Sunway taihulight supercomputer makes its appearance, Nat. Sci. Rev., 3, 265–266, 2016.
Eichenberger, A. E., Wu, P., and O'brien, K.: Vectorization for simd architec- tures with alignment constraints, in: Acm sigplan notices, 39, 82–93, 2004.
Fu, H., Liao, J., Ding, N., Duan, X., Gan, L., Liang, Y., Wang, X., Yang, J., Zheng, Y., Liu, W., Wang, L., and Yang, G.: Redesigning cam-se for peta-scale climate modeling performance and ultra-high resolution on sunway taihulight, in: Proceedings of the international conference for high performance computing, networking, storage and analysis, ACM/IEEE, p. 1, 2017.
Fu, H., Liao, J., Xue, W., Wang, L., Chen, D., Gu, L., Xu, J., Ding, N., Wang, X., He, C., Xu, S., Liang, Y., Fang, J., Xu, Y., Zheng, Z., Wei, W., Ji, X., Zhang, H. Chen, B., Li, K., Huang, X., Chen, W., and Yang, G.: Refactoring and optimizing the community atmosphere model (CAM) on the sunway taihu-light supercomputer, in: sc16: International conference for High performance computing, networking, storage and analysis, IEEE Xplore, 969–980, 2016a.
Fu, H., Liao, J., Yang, J., Wang, L., Song, Z., Huang, X., Huang, X., Yang, C., Xue, W., Liu, F., Qiao, F., Zhao, W., Yin, X., Hou, C., Zhang, C., Ge, W., Zhang, J., Wang, Y., Zhou, C., and Yang, G.: The sunway taihulight supercomputer: system and applications, Sci. China Inf. Sci., 59, 072001, 2016b.
Fuhrer, O., Chadha, T., Hoefler, T., Kwasniewski, G., Lapillonne, X., Leutwyler, D., Lüthi, D., Osuna, C., Schär, C., Schulthess, T. C., and Vogt, H.: Near-global climate simulation at 1 km resolution: establishing a performance baseline on 4888 GPUs with COSMO 5.0, Geosci. Model Dev., 11, 1665–1681, https://doi.org/10.5194/gmd-11-1665-2018, 2018.
Gan, L., Fu, H., Xue, W., Xu, Y., Yang, C., Wang, X., Lv, Z., You, Y., Yang, G., and Ou, K.: Scaling and analyzing the stencil performance on multi-core and many-core architectures, in: 2014 20th ieee international conference on parallel and distributed systems (icpads), 103–110, 2017.
Govett, M., Rosinski, J., Middlecoff, J., Henderson, T., Lee, J., Alexander MacDonald, A., Wang, N., Madden, P., Schramm, J., and Duarte, A.: Parallelization and Performance of the NIM Weather Model on CPU, GPU, and MIC Processors, B. Am. Meteorol. Sci., 98, 2201–2213, https://doi.org/10.1175/BAMS-D-15-00278.1, 2017.
Gysi, T., Osuna, C., Fuhrer, O., Bianco, M., and Schulthess, T. C.: Stella: A domain-specific tool for structured grid methods in weather and climate models, in: Proceedings of the international conference for high performance computing, networking, storage and analysis, no. 41, 1–12, https://doi.org/10.1145/2807591.2807627, 2015.
Hu, Y., Huang, X., Baker, A. H., Tseng, Y., Bryan, F. O., Dennis, J. M., and Guangweng, Y.: Improving the Scalability of the Ocean Barotropic Solver in the Community Earth System Model, in: Proceedings of the International Conference for High Performance Computing, Networking, and Storage, SC '15, Austin, TX, 42, 1–12, 2015.
Huang, X., Tang, Q., Tseng, Y., Hu, Y., Baker, A. H., Bryan, F. O., Dennis, J., Fu, H., and Yang, G.: P-CSI v1.0, an accelerated barotropic solver for the high-resolution ocean model component in the Community Earth System Model v2.0, Geosci. Model Dev., 9, 4209–4225, https://doi.org/10.5194/gmd-9-4209-2016, 2016.
Kelly, R.: GPU Computing for Atmospheric Modeling, Comput. Sci. Eng., 12, 26–33, 2010.
Liao, X., Xiao, L., Yang, C., and Lu, Y.: Milkyway-2 supercomputer: system and application, Front. Comput. Sci., 8, 345–356, 2014.
Large, W. G., McWilliams, J. C., and Doney, S. C.: Oceanic vertical mixing: a review and a model with a nonlocal boundary layer parameterization, Rev. Geophys. 32, 363–403, 1994.
Linford, J., Michalakes, J., Vachharajani, M., and Sandu, A.: Multi-core acceleration of chemical kinetics for simulation and prediction, in: Proceedings of the conference on High performance computing networking, storage and analysis, ACM/IEEE, 1–11, 2009.
Lynch, P.: The eniac forecasts: A re-creation, B. Am. Meteorol. Soc., 89, 45–56, 2008.
Meehl, G. A., Boer, G. J., Covey, C., Latif, M., and Stouffer, R. J.: The coupled model intercomparison project (cmip), B. Am. Meteorol. Soc., 81, 313–318, 2000.
Meehl, G. A., Yang, D., Arblaster, J. M., Bates, S. C., Rosenbloom, N., Neale, R., Bacmeister, J., Lauritzen, P. H., Bryan, F., Small, J., Truesdale, J., Hannay, C., Shields, C., Strand, W. G., Dennis, J., and Danabasoglu, G.: Effects of model resolution, physics, and coupling on Southern Hemisphere storm tracks in CESM1.3, Geophys. Res. Lett., 46, 12408–12416, https://doi.org/10.1029/2019GL084057, 2019.
Mielikainen, J., Huang, B., Wang, J., Huang, H.-L. A., and Goldberg, M. D.: Compute unified device architecture (CUDA)-based parallelization of WRF Kessler cloud microphysics scheme, Comput. Geosci., 52, 292–299, 2013.
Milroy, D. J., Baker, A. H., Hammerling, D. M., Dennis, J. M., Mickelson, S. A., and Jessup, E. R.: Towards characterizing the variability of statistically consistent Community Earth System Model simulations, Proc. Comput. Sci., 80, 1589–1600, 2016.
Milroy, D. J., Baker, A. H., Hammerling, D. M., and Jessup, E. R.: Nine time steps: ultra-fast statistical consistency testing of the Community Earth System Model (pyCECT v3.0), Geosci. Model Dev., 11, 697–711, https://doi.org/10.5194/gmd-11-697-2018, 2018.
Milroy, D. J., Baker, A. H., Hammerling, D. M., Kim, Y., Hauser, T., and Jessup, E. R.: Making root cause analysis feasible for large code bases: a solution approach for a climate model, Proceedings of the 28th International Symposium on High-Performance Parallel and Distributed Computing: HPDC2019, Phoenix, AZ, edited by: Weissman, J. B., Raza Butt, A., and Smirni, E., https://doi.org/10.1145/3307681, 2019.
Owens, J. D., Luebke, D., Govindaraju, N. K., Harris, M. J., Kruger, J. H., Lefohn, A. E., and Purcell, T. J.: A survey of general-purpose computation on graphics hardware, Eurographics, 26, 80–113, 2007.
Roberts M. J., Vidale P. L., Senior, C., Hewitt, H. T, Bates, C., Berthou, S., Chang, P., Christensen, H. M., Danilov, S., Demory, M.-E., Griffies, S. M., Haarsma, R., Jung, T., Martin, G., Minob, S., Ringler, R., Satoh, M., Schiemann, R., Scoccimarro, E., Stephens, G., and Wehner, M. F.: The Benefits of Global High Resolution for Climate Simulation: Process Understanding and the Enabling of Stakeholder Decisions at the Regional Scale, B. Am. Meteorol. Soc., 2018, 99, 2341–2359, 2018.
Ruo: lgan/cesm_sw_1.0.1: Some efforts on refactoring and optimizing the Community Earth System Model(CESM1.3.1) on the Sunway TaihuLight supercomputer (Version cesm_sw_1.0.1), Zenodo, https://doi.org/10.5281/zenodo.3637771, 2020.
Shimokawabe, T., Aoki, T., Muroi, C., Ishida, J., Kawano, K., Endo, T., Nukada A., Maryuama, N., and Matsuoka, S.: An 80-fold speedup, 15.0 TFlops full GPU acceleration of non-hydrostatic weather model ASUCA production code, in: Proceedings of the 2010 acm/ieee international conference for high performance computing, networking, storage and analysis, ACM/IEEE, 1–11, 2019.
Small, R. J., Bacmeister, J., Bailey, D., Baker, A., Bishop, S., Bryan, F., Caron, J., Dennis, J., Gent, P., Hsu, H. M., Jochum, M., Lawrence, D., Muñoz, E., diNezio, P., Scheitlin, T., Tomas, R., Tribbia, J., Tseng, Y. H., and Vertenstein, M.: A new synoptic scale resolving global climate simulation using the Community Earth System Model, J. Adv. Model. Earth Sy., 6, 1065–1094, 2014.
Vazhkudai, S. S., de Supinski, B. R., Bland, A. S., Geist, A., Sexton, J., Kahle, J., Zimmer, C.J., Atchley, S., Oral, S., Maxwell, D. E., Larrea, V. G. V., Bertsch, A., Goldstone, R., Joubert, W., Chambreau, C., Appelhans, D., Blackmore, R., Casses, B., Chochia, G., Ezell, M. A., Gooding, T., Gonsiorowski, E., Grinberg, L, Hanson, B., Harner, B., Karlin, I., Leininger, M. L., leverman, D., Ohmacht, M., Pankajakshan, R., Pizzano, F., Rogers, J. H., Rosenburg, B., Schmidt, D., Shankar, M., Wang, F., Watson, P., Walkup, B., Weems, L. D., and Yin, J.: The design, deployment, and evaluation of the coral pre-exascale systems, in: Proceedings of the international conference for high performance computing, networking, storage, and analysis, ACM/IEEE, p. 52, 2018.
Vu, V., Cats, G., and Wolters, L.: Graphics processing unit optimizations for the dynamics of the HIRLAM weather forecast model, Concurrency and Computation, Practice and Experience, 25, 1376–1393, 2013.
Wang, Z., Xu, X., Xiong, N., Yang, L. T., and Zhao, W.: GPU Acceleration for GRAPES Meteorological Model, in: 2011 ieee 13th international conference on High performance computing and communications (hpcc), IEEE, 365–372, 2011.
Xiao, H., Sun, J., Bian, X., and Dai, Z.: GPU acceleration of the WSM6 cloud microphysics scheme in GRAPES model, Comput. Geosci., 59, 156–162, 2013.
Xu, S., Huang, X., Oey, L.-Y., Xu, F., Fu, H., Zhang, Y., and Yang, G.: POM.gpu-v1.0: a GPU-based Princeton Ocean Model, Geosci. Model Dev., 8, 2815–2827, https://doi.org/10.5194/gmd-8-2815-2015, 2015.
You, Y., Fu, H., Huang, X., Song, G., Gan, L., Yu, W., and Yang, G.: Accelerating the 3D elastic wave forward modeling on gpu and mic, in: 2013 ieee international symposium on parallel & distributed processing, workshops and phd forum, IEEE, 1088–1096, 2013.
Zhang, S.: Data of Pre-industrial control simulation (310 years, 0021-0330) and High_&Low_Resolution CESM HighResMIP contribution (100 years, 0031-0131), available at: http://ihesp.qnlm.ac/data, last access: 5 February 2020.
Zhang, J., Zhou, C., Wang, Y., Ju, L., Du, Q., Chi, X., Xu, D. Chen, D., Liu, Y., and Liu, Z.: Extreme-scale phase field simulations of coarsening dynamics on the sunway taihulight supercomputer, in: Proceedings of the international conference for high performance computing, networking, storage and analysis, ACM/IEEE, p. 4, 2016.
- Abstract
- Introduction
- A heterogenous many-core supercomputer: Sunway TaihuLight
- Enabling CESM-HR on Sunway TaihuLight
- The PI_CTL simulation by CESM-HR on the Sunway TaihuLight
- Summary and discussions
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- A heterogenous many-core supercomputer: Sunway TaihuLight
- Enabling CESM-HR on Sunway TaihuLight
- The PI_CTL simulation by CESM-HR on the Sunway TaihuLight
- Summary and discussions
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References