the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Apr 2020
| 02 Apr 2020
Geostatistical inverse modeling with very large datasets: an example from the Orbiting Carbon Observatory 2 (OCO-2) satellite
Arvind K. Saibaba
Michael E. Trudeau
Marikate E. Mountain
Arlyn E. Andrews
Geostatistical inverse modeling (GIM) has become a common approach to estimating greenhouse gas fluxes at the Earth's surface using atmospheric observations. GIMs are unique relative to other commonly used approaches because they do not require a single emissions inventory or a bottom–up model to serve as an initial guess of the fluxes. Instead, a modeler can incorporate a wide range of environmental, economic, and/or land use data to estimate the fluxes. Traditionally, GIMs have been paired with in situ observations that number in the thousands or tens of thousands. However, the number of available atmospheric greenhouse gas observations has been increasing enormously as the number of satellites, airborne measurement campaigns, and in situ monitoring stations continues to increase. This era of prolific greenhouse gas observations presents computational and statistical challenges for inverse modeling frameworks that have traditionally been paired with a limited number of in situ monitoring sites. In this article, we discuss the challenges of estimating greenhouse gas fluxes using large atmospheric datasets with a particular focus on GIMs. We subsequently discuss several strategies for estimating the fluxes and quantifying uncertainties, strategies that are adapted from hydrology, applied math, or other academic fields and are compatible with a wide variety of atmospheric models. We further evaluate the accuracy and computational burden of each strategy using a synthetic CO2 case study based upon NASA's Orbiting Carbon Observatory 2 (OCO-2) satellite. Specifically, we simultaneously estimate a full year of 3-hourly CO2 fluxes across North America in one case study – a total of 9.4×106 unknown fluxes using 9.9×104 synthetic observations. The strategies discussed here provide accurate estimates of CO2 fluxes that are comparable to fluxes calculated directly or analytically. We are also able to approximate posterior uncertainties in the fluxes, but these approximations are, typically, an over- or underestimate depending upon the strategy employed and the degree of approximation required to make the calculations manageable.
- Article
(4299 KB) - Full-text XML
-
Supplement
(261 KB) - BibTeX
- EndNote





Atmospheric observations of air pollutants and greenhouse gases have evolved dramatically over the past decade. Atmospheric monitoring of carbon dioxide (CO2) is a prime example. The number of in situ observation sites in the US, Canada, Europe, and elsewhere has greatly expanded since the early 2000s. For example, a recent geostatistical inverse modeling (GIM) study of CO2 fluxes across North America used observations from 6 times as many continuous tower-based observation sites as a GIM study of the same region published 6 years earlier (Gourdji et al., 2012; Shiga et al., 2018). Aircraft-based observations have also greatly expanded, including regular observations from civilian aircraft based in both Germany and Japan (Petzold et al., 2015; Machida et al., 2008).
Several CO2-observing satellites have also launched in the past decade, greatly expanding both the quantity and spatial extent of atmospheric CO2 observations. For example, the Greenhouse Gases Observing Satellite (GOSAT) launched in 2009 (e.g., Butz et al., 2011), Orbiting Carbon Observatory 2 (OCO-2) in 2014 (e.g., Eldering et al., 2017), TanSat in 2016 (Yang et al., 2018), GOSAT-2 in 2018 (e.g., Masakatsu et al., 2012), and OCO-3 in 2019 (e.g., Eldering et al., 2019).
These new in situ and remote-sensing datasets provide an unprecedented new window into surface fluxes of CO2 and other atmospheric trace gases. However, the sheer quantity and geographic scope of the data present enormous computational challenges for inverse modeling frameworks that estimate trace gas emissions. The OCO-2 satellite, for example, collects approximately 2×106 CO2 observations per month that pass quality screening (Eldering et al., 2017). The number of total available observations will only increase as the current fleet of CO2-observing satellites continues to collect observations and as additional satellites launch into orbit. Approaches to inverse modeling that are well-suited to “big data” will arguably be able to make the most of these new datasets to constrain CO2 sources and sinks.
This paper discusses the challenges of using large atmospheric air pollution and greenhouse gas datasets through the lens of GIMs. A GIM is unique relative to a classical Bayesian inversion that uses a prior emissions inventory or a bottom–up flux model. In place of a traditional prior emissions estimate, a GIM can incorporate a wide variety of environmental, economic, or population data that may help predict the distribution of surface fluxes (e.g., Gourdji et al., 2012; Miller et al., 2013, 2016; Shiga et al., 2018). The GIM will then weight each of these predictor datasets to best match the atmospheric observations. A GIM will further estimate grid-scale flux patterns that are implied by the atmospheric observations but do not match any patterns in the predictor datasets. For example, existing GIM studies have used predictors drawn from reanalysis products and satellites, including air temperature, soil moisture, and solar-induced fluorescence (SIF) (e.g., Gourdji et al., 2012; Miller et al., 2016; Shiga et al., 2018). Other studies have used predictors of anthropogenic activity, including maps of human population density and agricultural activity (e.g., Miller et al., 2013). Alternatively, one can also build a GIM without any predictor datasets (e.g., Michalak et al., 2004; Mueller et al., 2008; Miller et al., 2012). In this case, the GIM will rely entirely on the atmospheric observations to estimate the surface fluxes.
The purpose of this study is to adapt recent computational innovations in inverse modeling from other academic disciplines, including hydrology and seismology, to GIMs of atmospheric gases. The primary goal is to develop inverse modeling strategies that can assimilate very large atmospheric datasets. An additional aim of this work is to develop flexible approaches that can be paired with many different types of atmospheric models (e.g., gridded, Eulerian models and particle-following models). To this end, we first provide an overview of GIMs and the specific challenges posed by large datasets. We subsequently discuss two options for calculating the best estimate of the fluxes and two options for estimating the posterior uncertainties, and we have published the associated code in a public repository (Miller and Saibaba, 2019). Lastly, we develop a case study using the OCO-2 satellite as a lens to evaluate the advantages and drawbacks of each approach. OCO-2 collects millions of observations per year and is, therefore, prototypical of many current, and likely future, big data inverse modeling problems.
A GIM will estimate a set of fluxes s (dimensions m×1) that match atmospheric observations z (n×1), using a forward operator H (n×m) which represents an atmospheric transport model:
The fluxes (s), when passed through the atmospheric model (H) will never exactly match the data (z) due to a variety of errors (ϵ, dimensions n×1), including errors in the measurements (z) and errors in the atmospheric transport model (H). However, Hs should match the observations within a specified error, and many inverse models, including a GIM, require that the modeler input a covariance matrix defining the characteristics of these errors (e.g., Rodgers, 2000; Michalak et al., 2004):
where ∼ means “is distributed as”, 𝒩 is a multivariate normal distribution, and R (n×n) is the covariance matrix that must be defined by the modeler before running the GIM.
Furthermore, the fluxes (s) in a GIM have two different components, and both components are estimated as part of the inverse model (e.g., Kitanidis and Vomvoris, 1983; Michalak et al., 2004):
where X (m×p) is a matrix of p predictor datasets or covariates that may help describe patterns in the unknown fluxes (s) (refer to Sect. 1). The coefficients β (p×1) will scale the variables in X. These coefficients are unknown and estimated as part of the GIM. Collectively, Xβ is referred to as the model of the trend or the deterministic model. Furthermore, ζ (m×1) contains grid-scale patterns in the fluxes that are implied by the atmospheric observations (z) but do not exist in any predictor dataset (i.e., do not match any patterns in Xβ). This term is often referred to as the stochastic component of the fluxes and is also estimated as part of the GIM. This stochastic component (ζ) can have a variety of spatial or temporal patterns. However, its structure is represented by a covariance matrix, termed Q (m×m), where (e.g., Kitanidis and Vomvoris, 1983; Michalak et al., 2004).
Note that it has become standard practice in GIM studies to estimate the fluxes (s) at the highest spatial and temporal resolution possible (e.g., Gourdji et al., 2010). This setup accounts for small-scale variability in surface fluxes down to the resolution of the atmospheric model, thereby yielding a more accurate flux estimate and more realistic uncertainty bounds (e.g., Gourdji et al., 2010). However, the number of unknown fluxes (s) usually far exceeds the number of observations (z), and the inverse problem of estimating the fluxes from the data is typically underdetermined, meaning that multiple solutions consistent with the data are possible (e.g., Mueller et al., 2008; Gourdji et al., 2012; Miller et al., 2013, 2016; Shiga et al., 2018). To address this issue, existing GIM studies and many classical Bayesian inverse modeling studies use additional information to help determine the structure of the fluxes (s). In particular, rather than choosing a diagonal prior covariance matrix Q, which ignores spatiotemporal interactions, these studies include nonzero off-diagonal elements. These elements guide the spatial and temporal structure of the flux estimate and help interpolate fluxes in locations without a perfect data constraint. Kitanidis (1997) and Wackernagel (2003) review different approaches to modeling these off-diagonal elements.
The geostatistical approach then uses Bayes formula to derive the posterior distribution as
where ∝ denotes proportionality. The expressions for the likelihood can be derived from Eqs. (1) and (2), and the prior p(s|β) can be derived from Eq. (3). Furthermore, taking p(β)∝1, we can derive
The best estimate of the fluxes can be computed by maximizing , the posterior distribution; alternatively, it can be obtained by minimizing the negative logarithm of the posterior density which yields the objective function (e.g., Kitanidis and Vomvoris, 1983; Michalak et al., 2004):
Both the fluxes (s) and the coefficients (β) are unknown in this equation and are estimated as part of the GIM. Typically, the number of coefficients (β) is relatively small (e.g., ), but the number of unknown fluxes can be very large (e.g., ) (e.g., Gourdji et al., 2012; Miller et al., 2016; Shiga et al., 2018). The next section reviews a direct approach for minimizing the function in Eq. (6) and solving the GIM.
The classical solution to the GIM requires solving a single system of linear equations (e.g., Kitanidis, 1996; Saibaba and Kitanidis, 2012); the best estimate is obtained by minimizing Eq. 6:
where ξ (n×1) is an unknown vector of weights and β (p×1) are the unknown coefficients, as in Eq. (6). These vectors are obtained by solving a linear system of equations:
Note that there are several equivalent sets of equations for estimating the fluxes (e.g., Michalak et al., 2004), and the set of equations shown above is commonly referred to as the dual function form. When this linear system is solved using a direct method, such as Gaussian elimination, or LU factorization, we refer to it as the direct solution.
Over the past decade, the in situ and satellite greenhouse gas observation networks have expanded and so have the dimensions of the data and unknown parameters of many inverse problems, resulting in major computational costs associated with solving Eq. (8). The first issue involves computing the prior covariance matrix Q, which is affected by the number of unknown fluxes (m). This number is typically the product of the number of model grid boxes and the number of time periods in the inverse model, and the total number of unknown fluxes can therefore exceed 1×106 even if the number of model grid boxes or the number of time periods is modest (e.g., Gourdji et al., 2012; Miller et al., 2016; Shiga et al., 2018). The second issue involves multiplying H and Q, and the third involves solving the linear system in Eq. (8). We examine each of these issues and possible strategies to address them.
The first issue is that the covariance matrix Q can be too large to store in memory, to invert, and/or to feasibly use in matrix–matrix multiplication if the number of unknown fluxes is large. The covariance matrix Q is often defined by a relatively small number of parameters (e.g., a variance, a decorrelation length, and a decorrelation time; Gourdji et al., 2012; Miller et al., 2016), but the matrix is nonetheless large and is often non-sparse (e.g., Yadav and Michalak, 2013).
Several studies develop strategies for solving the GIM system of equations when the number of unknown fluxes is large (e.g., Fritz et al., 2009; Yadav and Michalak, 2013; Saibaba and Kitanidis, 2012; Ambikasaran et al., 2013a, b). Many GIM studies circumvent this computational bottleneck by decomposing the covariance matrix Q into a spatial component and a temporal component (Yadav and Michalak, 2013):
where is a parameter that controls the variance in Q, D describes the temporal covariance, E describes the spatial covariance, and ⊗ is the Kronecker product. One can multiply Q or Q−1 by a vector or matrix using , D, and E without ever explicitly formulating Q. This approach can dramatically improve computational tractability and is described in detail in Yadav and Michalak (2013). In this paper, we also model the entries of Q using a spherical covariance model (e.g., Kitanidis, 1997; Wackernagel, 2003). Unlike other potential choices of covariance models, a spherical model decays to zero at the correlation length and correlation time. This property means that D and E will be sparse matrices, saving both memory and computing time. Several recent papers discuss additional strategies if D and E still pose a computational bottleneck. These include formulating the components of Q as a hierarchical matrix or a structured matrix (such as Toeplitz or block Toeplitz) (e.g., Fritz et al., 2009; Saibaba and Kitanidis, 2012; Ambikasaran et al., 2013a, b).
A second computational bottleneck is the cost of forming the matrix . Many atmospheric models do not explicitly formulate H. Instead, these atmospheric models pass a vector through the forward or adjoint model. In other words, they calculate the product of H or HT and a vector. In these cases, the direct solution to the GIM would require thousands or millions of atmospheric model simulations to calculate HQHT, an approach that would be computationally burdensome and impractical. Many studies that employ classical Bayesian inverse modeling circumvent this problem by iterating toward the solution in a way that does not require calculating the product HQ (e.g., Baker et al., 2006; Henze et al., 2007; Meirink et al., 2008). This approach is often referred to as a variational or adjoint-based inverse model (e.g., Brasseur and Jacob, 2017).
A third issue involves solving the linear system in Eq. (8) when the number of measurements (n) is large. The direct solution to the GIM requires inverting a matrix of dimensions that is often non-sparse. Greenhouse-gas-observing satellites can collect millions of observations per year, yielding a matrix that is too large to feasibly invert. The number of available observations will continue to grow as more greenhouse-gas-observing satellites launch into orbit and as the existing observational record becomes longer.
To solve this third issue, one could reduce the dimensions of the inverse model to the point where it is computationally manageable, but these strategies have drawbacks. First, one could average down the data until n is much smaller, and the matrix inverse required by the direct solution is computationally feasible. However, this strategy can require a large degree of averaging, and one might average over meaningful variability in the observations and/or in the meteorology, reducing the accuracy of the flux estimate. A second option is to break up the inverse model into smaller time periods until the number of data points (n) in each time period is manageable. This approach, however, brings several pitfalls. The number of satellite observations can be large even for relatively short time periods. In addition, the stochastic component of the fluxes may covary across long time periods or from one year to another, and it can be important to account for these covariances in the inverse model via the covariance matrix Q. Furthermore, one may want to make inferences about the fluxes across longer time periods. For example, inverse modeling studies commonly report estimated total annual carbon budgets and associated uncertainties. A third option is to use ensemble-based approaches (e.g., an ensemble Kalman smoother) (e.g., Chatterjee et al., 2012; Chatterjee and Michalak, 2013). These approaches generally require a large number of ensemble members to accurately reproduce the flux field, and one must run the forward model once for each ensemble member. As a result, this approach can require hundreds or thousands of forward model simulations to produce an estimate that is close to the direct solution, depending upon the dimensions and complexity of the inverse problem (e.g., Chatterjee et al., 2012). In this study, we explore several approaches to GIMs (Eq. 6) that are practical for very large datasets and do not necessarily require the dimension reduction strategies described above. These approaches are also compatible with atmospheric models that do not explicitly formulate the matrix H (i.e., the variational or adjoint-based approach).
The direct solution is often intractable for inverse problems with large datasets. An alternate is to use an iterative or variational approach to reach the best estimate of the fluxes, and we discuss two approaches. Each uses a different form of the GIM equations and uses a different type of numerical solver to iterate toward the best estimate.
4.1 Quasi-Newton approach
Many existing variational or adjoint-based inverse modeling studies use an iterative, quasi-Newton approach to estimate the fluxes (e.g., Baker et al., 2006; Henze et al., 2007). This strategy requires creating scripts that calculate the cost function (Eq. 6) and gradient, and the quasi-Newton solver will iterate toward the solution using these two inputs. The most common quasi-Newton solver in existing studies is the limited-memory Broyden–Fletcher–Goldfarb–Shanno algorithm (L-BFGS) (Nocedal, 1980; Liu and Nocedal, 1989). Furthermore, one variant of this algorithm, L-BFGS-B, will estimate the fluxes (s) subject to a bound. For example, some trace gases do not have large surface sinks, and L-BFGS-B can ensure that the estimated fluxes are non-negative. Refer to Miller et al. (2014) for a full discussion of strategies to enforce bounds on atmospheric inverse problems.
The implementation of L-BFGS or L-BFGS-B for a GIM is more complicated than in a classical Bayesian inverse model. Specifically, the goal is to use one of these algorithms to estimate the fluxes (s), but the cost function in the GIM has an additional unknown variable (β, Eq. 6). We substitute the equation for the unknown coefficients (β) into the GIM cost function (Eq. 6), thereby removing β (e.g., Kitanidis, 1995):
where G has dimensions m×m. Note that we never formulate G explicitly when calculating Eq. (11) because it is often a large, non-sparse m×m matrix. Rather, we successively multiply s by the individual components of Eq. (12) to avoid formulating a full m×m matrix. In addition, we use the Kronecker product identity in Eq. (10) to avoid explicitly formulating Q−1. The SI describes this approach in greater detail.
We can further speed up the convergence of L-BFGS using a variable transformation. We transform the fluxes from s to s*, similar to the approach used in a handful of atmospheric inverse modeling studies (e.g., Baker et al., 2006; Meirink et al., 2008). The strategy is to first solve a transformed optimization problem for s* and then to obtain s using the following relations:
where Q½ is the symmetric square root of Q. Note that we never explicitly formulate Q½ but instead do all matrix operations on the individual components of Q½. We then substitute the equation for s* into the cost function (Ls):
The functions and ∇L(s*) are then used as inputs to the L-BFGS algorithm, and the resulting optimization can converge in fewer iterations than using the cost function without the transformation (Eq. 11). Section 7 includes further discussion of why L-BFGS without a transformation may converge slowly and how a variable transformation can remedy the problem.
4.2 Minimum-residual approach
The minimum-residual approach described here uses a very different strategy for the iterative optimization (Paige and Saunders, 1975). The quasi-Newton approach described above will search for the minimum of the cost function with the help of the gradient (Eqs. 16–17). By contrast, there is a class of solvers that will estimate the solution to a linear system of equations where one side is too large to invert, and this class of solvers offers an alternative strategy. Specifically, these methods will solve a system of equations of the form Ax=b, where x is a vector of unknown values, b is a known vector, and A is a matrix that is too large to store in memory or too expensive to form explicitly. This strategy has been employed by inverse modeling studies in hydrology and seismology (Saibaba and Kitanidis, 2012; Saibaba et al., 2012; Liu et al., 2014b; Lee et al., 2016).
This strategy can also be employed to estimate the fluxes using Eq. (8). We cannot solve these equations directly for inverse problems with large datasets (i.e., large n); the left-hand side of Eq. (8) becomes too large to invert and too expensive to explicitly form. Instead, we use the minimum-residual method to estimate ξ and β (e.g., Barrett et al., 1994). This class of algorithms only require a function that will calculate the left-hand side of Eq. (8) given some guess for ξ and β. Then, one can iteratively compute an approximate solution by forming a series of matrix–vector products – the product of ξ and β with the matrices on the left-hand side of Eq. (8). This approach also makes it feasible to estimate the fluxes (s) even if the atmospheric model does not explicitly calculate H or HT. One can pass the vector ξ through the model adjoint to calculate HTξ and then pass the vector QHTξ through the forward model to calculate H(QHTξ). As a result, one never needs to calculate or store the matrix on the left-hand side of Eq. (8) or invert that matrix.
Note that some studies use a preconditioner to help the minimum-residual algorithm converge more quickly to a solution (e.g., Saibaba and Kitanidis, 2012; Liu et al., 2014b; Lee et al., 2016). The preconditioner can speed up convergence by reducing the condition number and/or clustering the eigenvalues near 1. Saibaba and Kitanidis (2012) detail one possible strategy for preconditioning the GIM, and this approach has subsequently been employed in several studies (e.g., Liu et al., 2014b; Lee et al., 2016). We do not detail the implementation here, but Saibaba and Kitanidis (2012) describe the step-by-step procedure. The preconditioner detailed in that study can dramatically speed up convergence (Sect. 7) but may require tens to thousands of forward model runs as a precomputational cost to realize these improvements in convergence, depending upon the complexity of the covariance matrix Q. Note that these forward model runs can be done simultaneously in parallel. A discussion of the computational cost is provided in Sect. 7.
It is often not possible to estimate the full, posterior covariance matrix when the number of observations and the number of unknown fluxes are large. Two very different general approaches are often used in atmospheric and hydrologic data assimilation, and we discuss both here in the context of GIMs. One entails creating an ensemble of randomized simulations or realizations. The other uses a low-rank approximation of one matrix in the posterior covariance calculations, and this approximation makes the overall calculations computationally feasible.
5.1 Conditional realizations or simulations
One approach to estimate the posterior uncertainties is to generate conditional realizations or Monte Carlo simulations, and several variational or adjoint-based studies of greenhouse gases have employed this strategy (e.g., Chevallier et al., 2007; Liu et al., 2014a; Bousserez et al., 2015). A conditional realization is a random sample from the posterior distribution (e.g., Kitanidis, 1995; Michalak et al., 2004; Chevallier et al., 2007), and the statistics of many conditional realizations will approximate the posterior variances and covariances. These variances and covariances can have complex spatial and temporal patterns, and it can be challenging to adequately sample the tails of the posterior distribution. As a result, several studies of atmospheric trace gases use thousands of realizations to sample the posterior distribution and approximate the uncertainties (e.g., Rigby et al., 2011; Ganesan et al., 2014). In other cases, computational constraints make it impractical to generate more than tens or hundreds of realizations, especially for very large variational or adjoint-based inverse problems (e.g., Chevallier et al., 2007; Liu et al., 2014a).
One approach for generating a single conditional realization is similar to the procedure for calculating the best estimate of the fluxes. To generate a conditional realization, we first generate random samples from 𝒩(0,R) and 𝒩(0,Q) and use these samples to perturb the data and the parameters respectively; we then solve the GIM using any of the three approaches described previously. In each case, the equations are slightly different, and we therefore do not list all of the equations here. Michalak et al. (2004) and Saibaba and Kitanidis (2012) describe how to generate conditional realizations using the direct approach in Sect. 3, Kitanidis (1995) and Snodgrass and Kitanidis (1997) and the SI describe how to generate realizations using quasi-Newton methods (Sect. 4.1), and Kitanidis (1996) and Saibaba and Kitanidis (2012) describe how to generate realizations using the minimum-residual approach (Sect. 4.2).
5.2 Reduced-rank approach
A number of studies reduce the computational burden of uncertainty estimation by replacing one matrix in the calculations with a low-rank approximation. This strategy is based upon the direct calculation of the posterior covariance matrix () (e.g., Saibaba and Kitanidis, 2015):
where and V1 have dimensions m×m, V2 dimensions m×p, and V3 dimensions p×p. Note that V1 is the posterior covariance matrix in a classical Bayesian inverse model. The uncertainty calculations in a GIM include an additional term, notably . This term accounts for the effect of uncertain coefficients (β) on the estimated fluxes. These coefficients are estimated as part of the GIM, and uncertainty in these coefficients contributes additional uncertainty to the posterior flux estimate (). Also note that there are many equivalent equations for calculating the posterior covariance matrix, and the form in Eq. (19) is particularly conducive to a low-rank approximation strategy.
This direct calculation of the posterior covariance matrix is not tractable for large inverse problems, in part, because it requires inverting the matrix sum in V1. Furthermore, it requires computing the matrix–matrix product HTR−1H, a step that can be impractical for models that do not explicitly formulate H.
Instead, we use a specific low-rank approximation in the calculations for V1. In other words, we approximate a matrix using a limited number of eigenvectors and eigenvalues, thereby making the calculations for V1 computationally feasible. A number of studies discuss this strategy in the context of classical Bayesian inverse modeling (e.g., Meirink et al., 2008; Flath et al., 2011; Spantini et al., 2015). Here, we review how this approach can be applied in the context of a GIM (e.g., Saibaba and Kitanidis, 2015). We summarize the procedure here, but refer to Flath et al. (2011), Spantini et al. (2015), and Saibaba and Kitanidis (2015) for additional detail. The main idea is to consider the matrix
where Q½ can be the symmetric square root or Cholesky decomposition of Q. This matrix is sometimes referred to as the prior-preconditioned data-misfit part of the Hessian. Previous studies have leveraged the fact that, in many applications, this matrix has rapidly decaying eigenvalues and therefore, can be accurately approximated using a low-rank matrix (e.g., Meirink et al., 2008; Flath et al., 2011; Spantini et al., 2015). This low-rank representation has a dual purpose: it is more efficient to store this matrix in memory and improves the efficiency of computations. There are several methods to compute this low-rank approximation, and these methods can estimate the eigenvalues and vectors without storing the above matrix (Eq. 23) in memory. Instead, these algorithms (e.g., Krylov subspace methods) iteratively estimate the largest eigenvalues and eigenvectors of a matrix A given some function that calculates Ax, where x is a vector that is provided by the algorithm and does not need to be specified by the user. For example, the eigs function in MATLAB offers an interface to these algorithms.
In this study, we estimate the eigenvectors and eigenvalues using a randomized algorithm developed in Halko et al. (2011). This approach requires just over two forward model runs and two adjoint model runs per (approximate) eigenpair, and this algorithm is therefore less computationally intensive than many other available algorithms. Furthermore, these forward and adjoint model runs can be generated in parallel, reducing the required computing time. Using this approach, we obtain the low-rank approximation
where U (n×ℓ) contains the approximate eigenvectors, Λ (ℓ×ℓ) is a diagonal matrix whose diagonals contain the approximate eigenvalues, and ℓ is the number of approximate eigenpairs computed. Note that Saibaba and Kitanidis (2015) and Saibaba et al. (2016) provide an alternative approach that does not require taking the symmetric square root or Cholesky decomposition of Q. That approach is a good choice if the symmetric square root or Cholesky decomposition of D and/or E are difficult to compute.
We can use these eigenvalues or vectors to approximate V1 using the Woodbury matrix identity (Flath et al., 2011; Spantini et al., 2015):
In this setup, V1 is written as an update to the prior covariance matrix. An intuitive way of understanding is that by observing data, the variance (i.e., the uncertainty) is reduced since we know more about the fluxes or emissions of interest. The prior covariance matrix (Q) in Eq. (25) is taken to be a positive definite, full-rank matrix and is not affected at all by the approximation. Rather, the update is approximated using a limited number of eigenvectors and eigenvalues. We subtract this positive semidefinite update, ensuring that the variance in V1 is reduced. The more eigenvectors and eigenvalues used in Eq. (25), the better the approximation of this update. The estimate for V1 can subsequently be plugged into the expression for to obtain an approximation for the posterior covariance matrix.
This reduced-rank approach greatly improves the tractability of posterior uncertainty calculations, but one computational road block remains; is usually too large to store in memory. However, one can calculate uncertainties for individual grid boxes or for aggregate regions without storing . To do so, multiply the right-hand side of Eq. (19) by a vector, resulting in a series of matrix–vector calculations. In this case, the vector should have a 1 in the flux grid box(es) of interest and a 0 elsewhere. If that vector has a 1 for multiple elements, then the calculation will yield the uncertainty in the flux estimate summed across several model grid boxes. For example, the following equation will compute the uncertainty in the total flux summed over all locations and times:
where 1 (m×1) is a vector of ones. Note that it may be necessary to convert the units of the fluxes in the course of these calculations. For example, atmospheric models that use a latitude–longitude grid will have grid boxes with different areas, and it may be necessary to multiply the vector 1 by the area of each grid box to account for these differing grid box areas.
We evaluate the inverse modeling algorithms described in this paper using two case studies based on NASA's OCO-2 satellite. OCO-2 was launched in September 2014 and is NASA's first satellite dedicated to observing atmospheric CO2 from space. This section provides an overview of the case studies while the Supplement provides additional, detailed descriptions.
The first case study is small enough such that it can be solved using the direct approach. We can therefore use it to compare the iterative GIM algorithms against the direct solution. The second case study, by contrast, is too large for a direct solution but is indicative of the typical size of the datasets encountered in satellite-based inverse modeling. In the first case study, we estimate 6 weeks of CO2 fluxes across terrestrial North America from late June through July 2015; we use a total of 1.92×104 synthetic OCO-2 observations to estimate 1.05×106 unknown CO2 fluxes. In the latter case study, we estimate a full year of CO2 fluxes (September 2014–August 2015) for the same geographic domain, a total of 9.88×104 synthetic observations, and 9.41×106 unknown CO2 fluxes.
We build these case studies using a synthetic data setup; we model XCO2 using CO2 fluxes from CarbonTracker (CT2017) (Peters et al., 2007; NOAA Global Monitoring Division, 2019) and an atmospheric transport model, add random noise to the model outputs to simulate measurement and model errors, and finally estimate CO2 fluxes using these synthetically generated XCO2 observations. Both CarbonTracker and the randomly generated noise are estimates that may differ from real-world conditions. Hence, the analysis presented in this synthetic case study is an approximation or prototypical example of the computational challenges one might encounter in an inverse model. For this case study, we specifically estimate the fluxes at a 3-hourly temporal resolution and a latitude–longitude resolution. The atmospheric transport simulations used here are from NOAA's CarbonTracker-Lagrange program (e.g., Hu et al., 2019; NOAA Global Monitoring Division, 2019) and were generated using the Weather Research and Forecasting (WRF) Stochastic Time-Inverted Lagrangian Transport Model (STILT) modeling system (e.g., Lin et al., 2003; Nehrkorn et al., 2010).
Note that one could also pair the inverse modeling algorithms here with an adjoint-based model that does not produce an explicit H matrix. However, WRF-STILT produces an explicit H matrix, making it straightforward to evaluate each GIM algorithm against the direct solution.
We also use a non-informative deterministic model (Xβ) in the case studies. In this setup, the matrix X only consists of columns of ones. As a result, any spatial or temporal patterns in the fluxes are only the result of the observational constraint and are not the reflection of any prior flux estimate.
In addition, the covariance matrix Q includes both spatial and temporal covariances. We estimate the spatial and temporal properties (e.g., variances and covariances) of CT2017 fluxes for 2014–2015 and use those properties to populate Q. The covariance matrix R is diagonal for the setup here, and we set the diagonal values at (2 ppm)2. This value is comparable to the combined model and data errors estimated in Miller et al. (2018). That study included a detailed error analysis using OCO-2 observations and atmospheric model simulations from the same time period as this study. In future studies, it may be important to include off-diagonal elements in R, and Sect. 7.1 details computational considerations for doing so.
7.1 Best estimate of the fluxes
We test several algorithms for estimating the fluxes (s), and all but one of these algorithms converges quickly toward the solution. The minimum-residual approach (with and without a preconditioner) and the L-BFGS with a variable transformation converge quickly for both case studies (Figs. 1, 2, and 3). Note that we cannot compare the larger case study to a direct solution, but we do compare the results against CO2 fluxes estimated using a very large number of iterations (250 in this case).
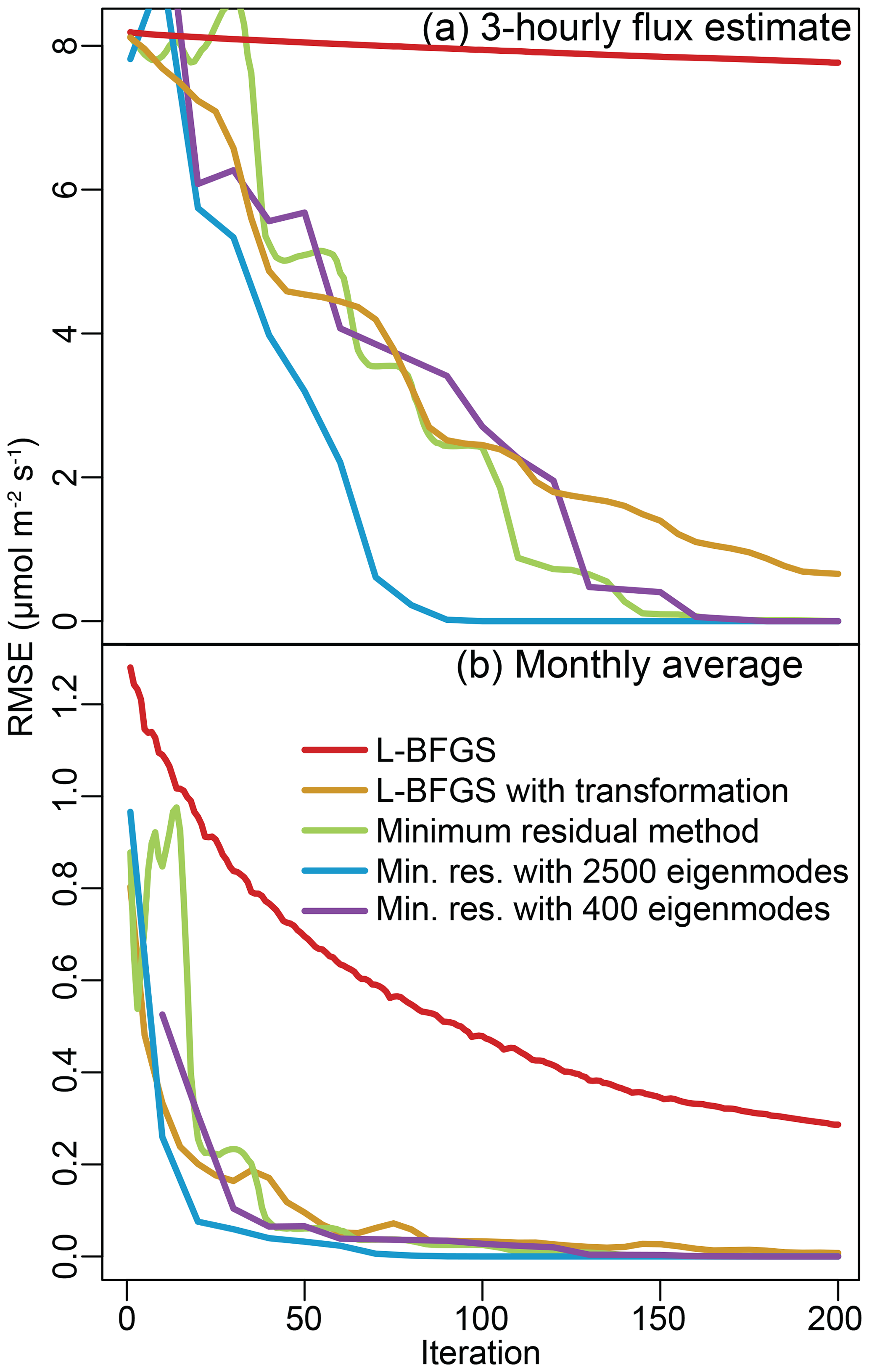
Figure 1Root mean squared error (RMSE) relative to the direct solution for the 6-week case study. The top panel (a) displays RMSE calculated using each of the 1.05×106 flux grid boxes. The minimum-residual method with a preconditioner converges most quickly on the direct solution while L-BFGS shows poor convergence. We also average the 3-hourly posterior flux estimate to obtain a monthly averaged flux for each model grid box, and the error in this monthly average is displayed in panel (b). The flux estimate, when averaged up to this aggregate monthly scale, converges more quickly to the direct solution than the individual 3-hourly fluxes.
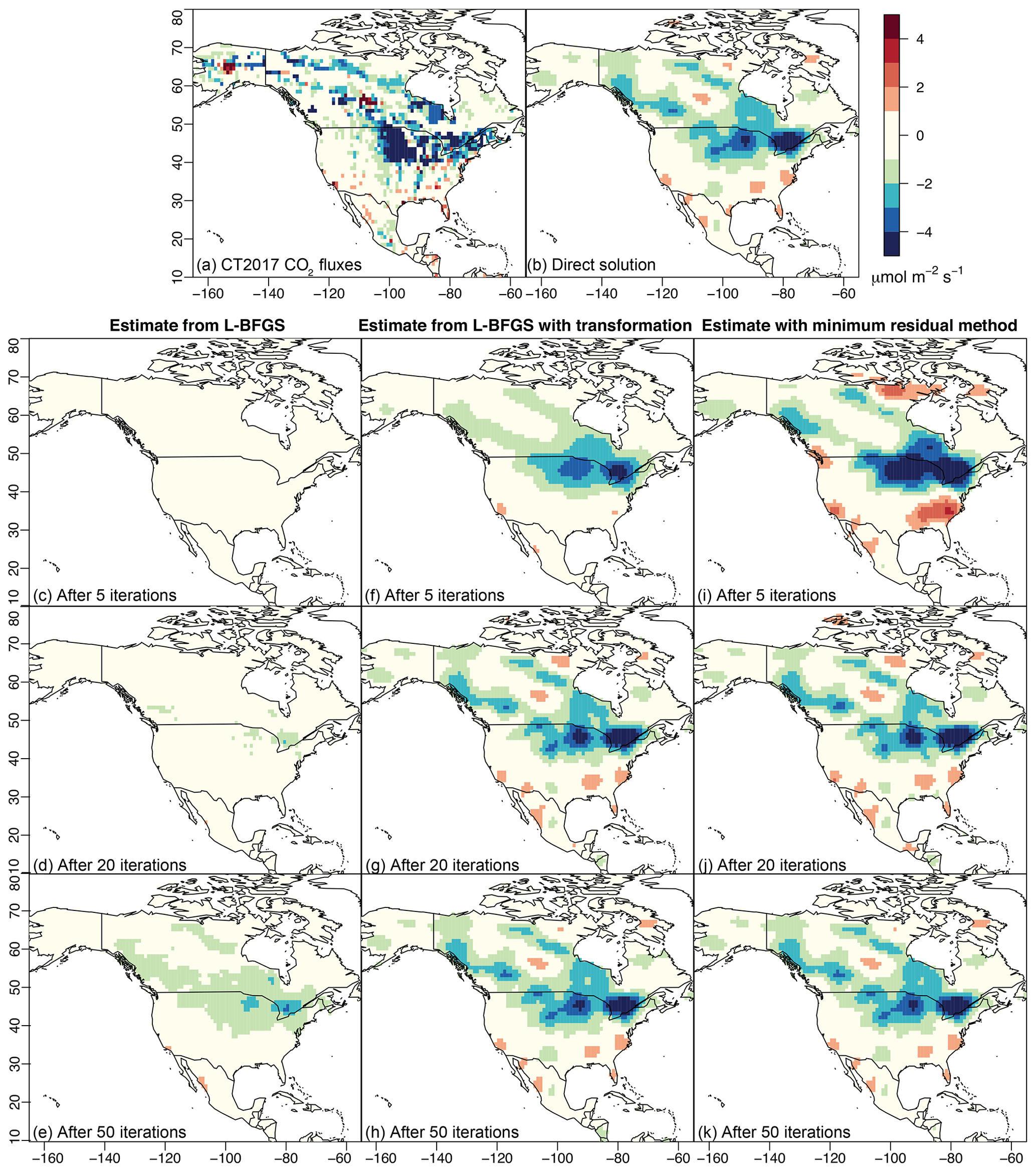
Figure 2The “true” CO2 fluxes from CT2017 used in the 6-week case study (a) and the direct estimate of the fluxes (b). We estimate 3-hourly fluxes but average them across the month of July in this figure. Panels (c–e) display the flux estimate from L-BFGS as a function of iteration number, panels (f–h) those from L-BFGS with a variable transformation, and panels (i–k) those from the minimum-residual approach. Both L-BFGS with the transformation and the minimum-residual approach resemble the direct solution after about 20 iterations (panels d, g, and j).
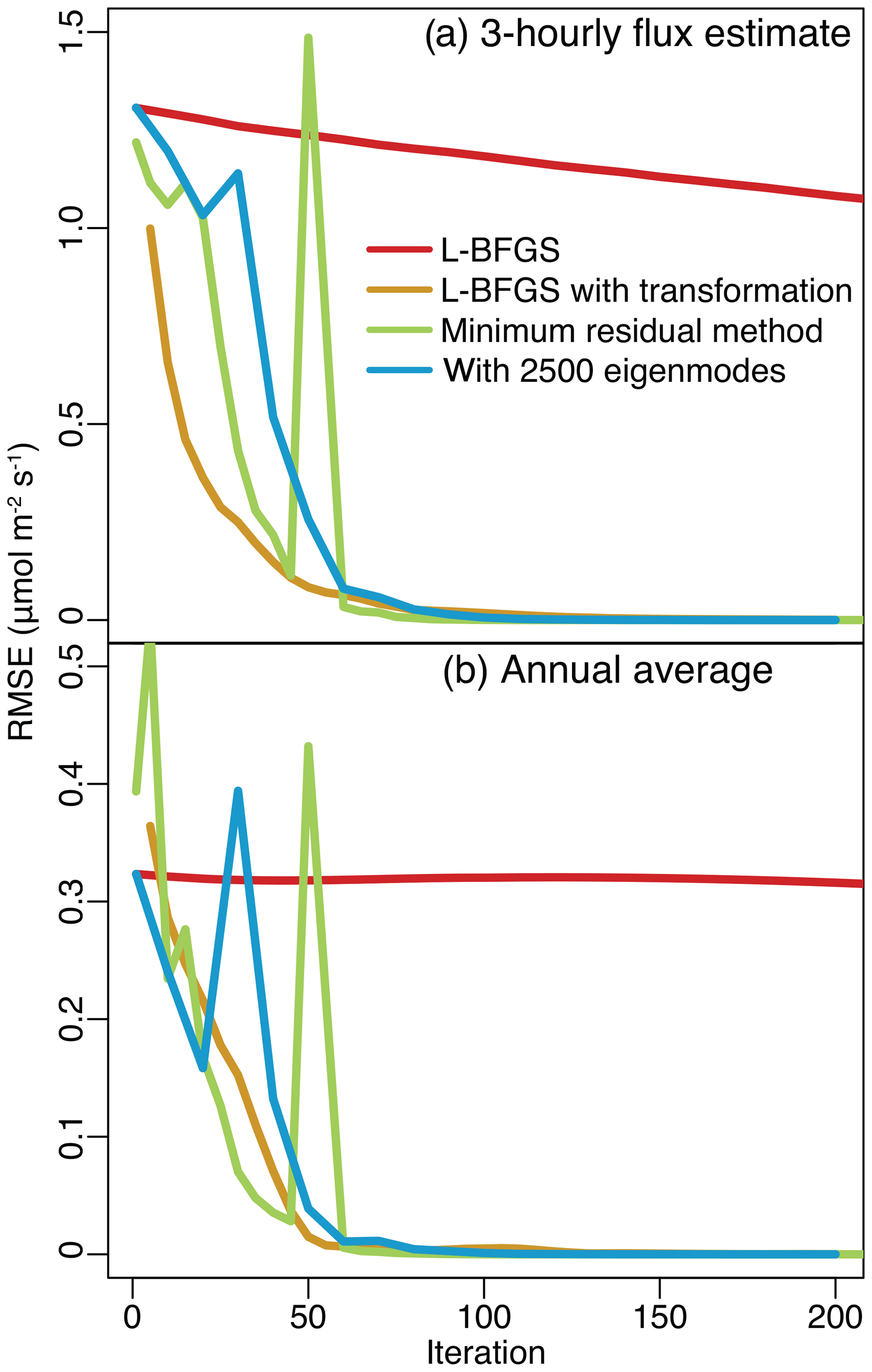
Figure 3RMSE relative to the direct solution for the full-year case study. The top panel (a) displays RMSE calculated using each of the 9.4×106 fluxes. We also average the 3-hourly posterior flux estimate to obtain an annually averaged flux for each model grid box (b). The full-year case study is much larger than the 6-week case study (i.e., includes more observations and unknowns), yet the flux estimate converges to the solution after a similar number of iterations.
By contrast, the L-BFGS algorithm without a variable transformation converges very slowly to the solution (Figs. 1 and 3). The L-BFGS algorithm makes a simple approximation for the posterior covariance matrix at each iteration (i.e., the inverse Hessian); it uses this approximation and the gradient of the cost function to determine the direction of steepest descent and iterate toward the solution (e.g., Nocedal, 1980; Liu and Nocedal, 1989). Most L-BFGS algorithms use a memory-saving sparse matrix like the identity matrix as an initial guess for the inverse Hessian. In the case studies here, the inverse Hessian without the variable transformation has complex off-diagonal elements, and the identity matrix is therefore a poor approximation. By contrast, the inverse Hessian with the variable transformation has relatively small off-diagonal elements, and the identity matrix is a much better approximation. This difference likely explains why the L-BFGS algorithm without the variable transformation converges far more slowly than the algorithm with the transformation.
Of all algorithms, the minimum-residual algorithm with preconditioning converges in the fewest number of iterations (Fig. 1). However, this faster convergence comes at a cost. We test a preconditioner with ℓ=400 and ℓ=2500 approximate eigenvectors. Only the preconditioner with 2500 eigenvectors yields faster convergence and only in the smaller of the two case studies. To construct this preconditioner, we had to apply each of the 2500 eigenvectors to the forward model (H). These forward model runs may be achievable if an explicit H matrix is available, if the forward model is not computationally expensive, and/or if a large computing cluster is available to distribute these runs across many cores. However, there are many instances when it may be impractical to generate such a large number of forward model runs. Since the preconditioner can be used for computing the best estimate as well as generating the conditional realizations, the upfront cost of constructing the preconditioner may be reutilized in the uncertainty quantification step in the following ways: (1) the cost can be amortized if hundreds or thousands of conditional realizations are generated, and (2) information collected during the construction can also be used in the reduced-rank computations. Moreover, the use of the randomized algorithm for constructing the preconditioners can be parallelized across the forward model runs. It may also be possible to develop a more computationally efficient preconditioner, but that objective is beyond the scope of this study.
It is also important to note that these algorithms converge more quickly on an accurate flux estimate for aggregate space and timescales. In this study, we always estimate the fluxes at a 3-hourly time resolution. After estimating the fluxes, we average the estimate within each grid box across the entire month or year and compare this time-averaged flux to the direct solution (Figs. 1 and 3). These monthly and annual averages are comparable to the direct solution after only a few iterations of the L-BFGS or minimum-residual algorithms. By contrast, it takes more iterations for each algorithm to converge on a flux estimate that is accurate relative to the direct solution for each 3 h time interval. Many GIM studies of CO2 report monthly flux totals (e.g., Gourdji et al., 2012; Shiga et al., 2018), and these monthly totals may therefore be a more important quantity to robustly estimate than 3-hourly fluxes.
Furthermore, the number of iterations required to converge on the solution does not appear to change dramatically with the size of the problem (Figs. 1 and 3). Most algorithms converge for aggregate time periods (Fig. 1b) after 50 iterations in the 6-week case study and after about 75 iterations in the year-long case study (Fig. 3b).
Ultimately, the best or optimal algorithm will likely depend upon the specifics of the inverse modeling problem in question. For example, several existing variational or adjoint-based inverse models are already built to work with the L-BFGS algorithm, and it may be more convenient to adapt this existing infrastructure to the geostatistical approach (e.g., Baker et al., 2006; Henze et al., 2007). By contrast, the minimum-residual approach does not require inverting or decomposing the covariance matrix components (e.g., R, D, E), and this approach is advantageous if any of these components is difficult to invert. For example, existing inverse modeling studies using OCO-2 observations construct R as a diagonal matrix, comparable to the setup here (e.g., Crowell et al., 2019). In future applications, it may be important to include off-diagonal elements or spatial and temporal error covariances in R – to better capture the information content of the satellite observations and to estimate robust uncertainty bounds, among other reasons. The quasi-Newton approach using L-BFGS requires inverting R, but this calculation may not be computationally feasible if R has off-diagonal elements. By contrast, the minimum-residual approach does not require the inverse of R. As a result, one could compute elements of R on the fly, without ever storing R in its entirety. In addition to these considerations, the choice of whether or not to use a preconditioner with minimum-residual approach depends upon the computational burden of passing many vectors through the forward model. However, the development of new preconditioning strategies could alter this trade-off.
7.2 Uncertainty quantification
The reduced-rank approach produces the most conservative uncertainty estimates; it will typically approximate uncertainties that are equal to or larger than the true uncertainties. By contrast, the conditional realizations will typically underestimate the posterior uncertainties. Figures 4 and 5 show the uncertainties estimated for both case studies as a function of the number of forward or adjoint model runs. Both approaches converge toward the true posterior uncertainties as the number of eigenvectors or conditional realizations increases.
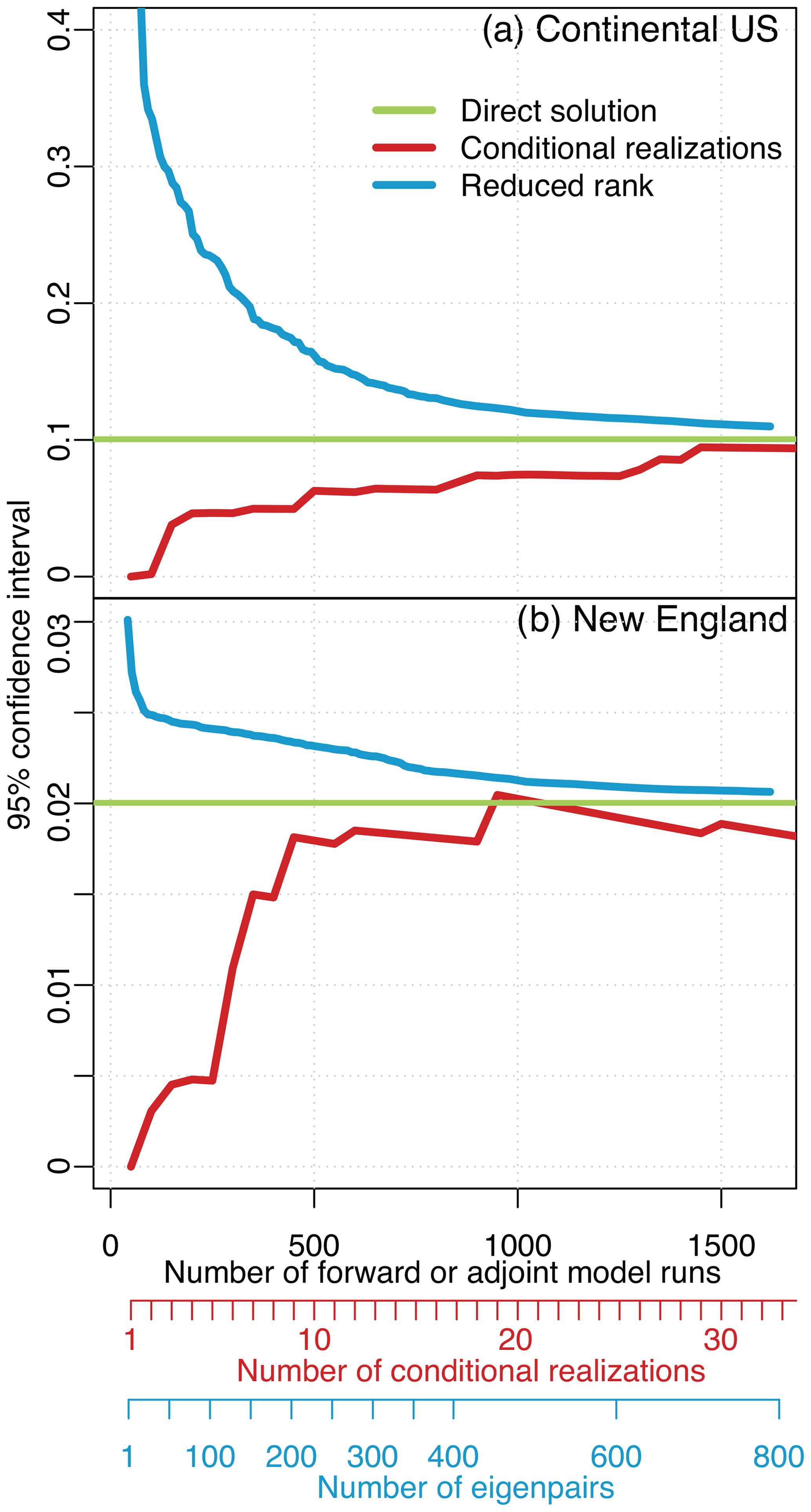
Figure 4Estimated uncertainties using conditional realizations and the reduced-rank approach for the 6-week case study. Panel (a) shows the estimated uncertainty in the total estimated CO2 flux for the US and panel (b) for New England. Both approaches converge on the direct estimate as the number of realizations and eigenpairs increase. Note that we estimate the uncertainties for each model grid box and each 3 h time period, but we report the uncertainties for broader aggregate regions in this figure. Most existing GIM studies report the uncertainties for large regions because these regions are either more ecologically or policy relevant than the individual model grid boxes. Additionally, the uncertainties are almost always smaller proportional to the total flux for large regions than for individual grid boxes; atmospheric observations usually provide a much more robust constraint on regional flux totals than for individual model grid boxes.
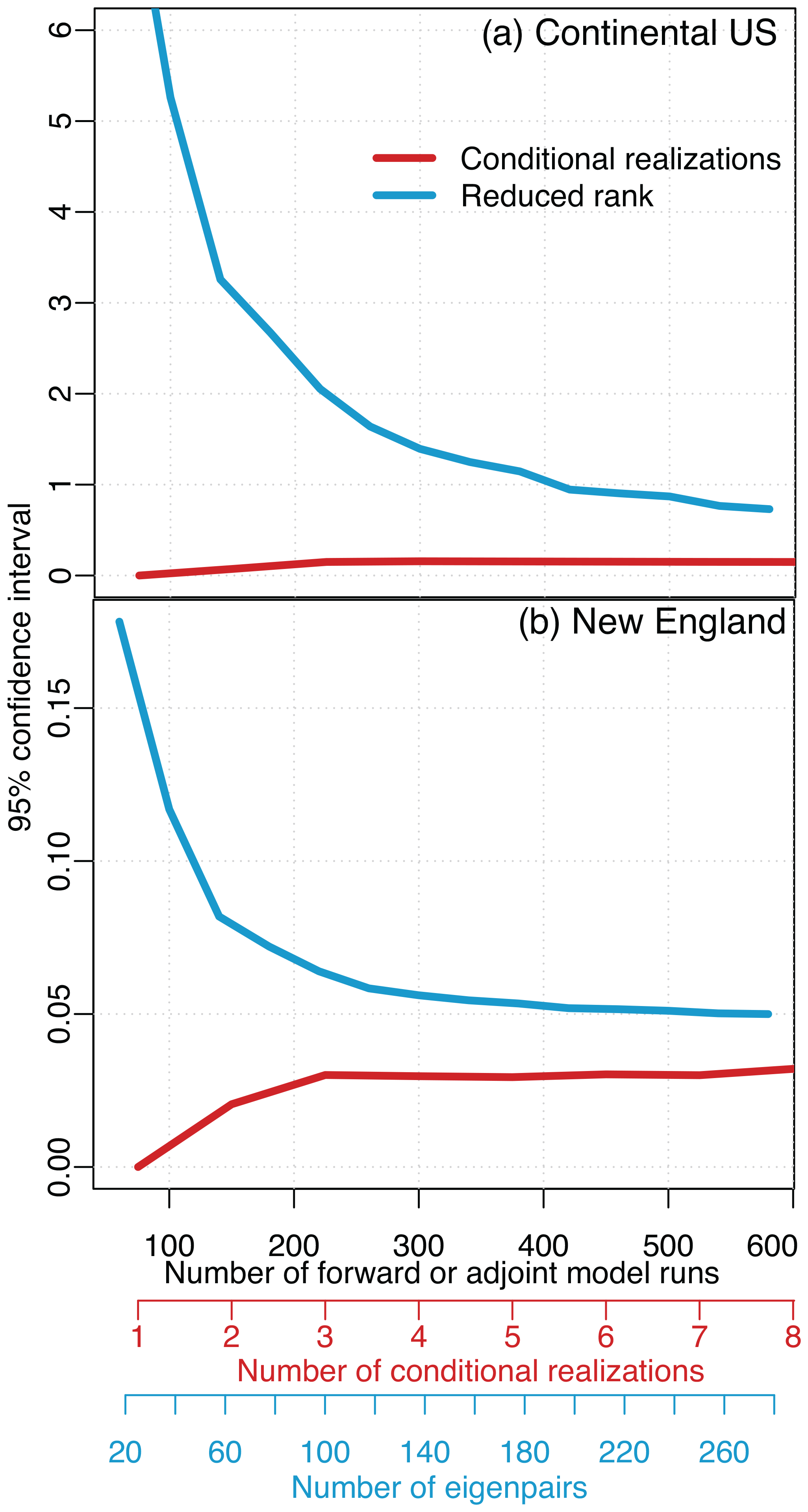
Figure 5Estimated uncertainties for the full-year case study, analogous to Fig. 4. The uncertainties estimated by the reduced-rank approach are consistently higher than the conditional realizations, though they begin to converge as the number of realizations and eigenpairs increases. Note that it is not possible to obtain a direct estimate for the uncertainties given the size of this case study, so we cannot evaluate the accuracy of the uncertainty estimates shown here.
These approaches will tend to under- and overestimate the uncertainties due to the approximations involved in each approach. Conditional realizations randomly sample from the posterior uncertainties, and one may need to generate hundreds or thousands of realizations to effectively sample the entire uncertainty space, particularly for large, complex inverse problems. By contrast, the reduced-rank approach approximates the posterior uncertainties by subtracting an update from the prior covariance matrix (Q) (Eq. 25). This update will always be too small if it is approximated using a limited number of eigenvectors and eigenvalues, yielding posterior uncertainties that are too large.
Neither of these approaches provides a silver bullet, so to speak, for estimating the uncertainties. Both require a large number of forward and adjoint model runs, a requirement that can be computationally intensive, depending on the requirements for the forward and adjoint models. These model runs can be generated in parallel for either approach, ameliorating this computational burden. By contrast, one can produce an uncertainty estimate using a smaller number of model runs, but the resulting uncertainty estimates will either be too small (using conditional realizations) or too large (using the reduced-rank approach). It is arguably more conservative to generate posterior uncertainties that are too large than too small; the latter may cause a modeler to overstate the results or incorrectly conclude that a result is statistically significant when it is not. However, neither of these outcomes is ideal.
The sheer number of global, atmospheric greenhouse gas observations has grown dramatically with the launch of new satellites and the expansion of in situ monitoring efforts. This article discusses several practical strategies for GIMs when the number of atmospheric observations is large. Specifically, we adapt computational and statistical strategies from a variety of academic disciplines to the problem of estimating greenhouse gas fluxes. We then use synthetic CO2 observations for OCO-2 as a lens to evaluate the strengths and weaknesses of each strategy.
We discuss two strategies for generating the best estimate of the fluxes: one that iterates toward the solution using a quasi-Newton approach and the other using a minimum-residual approach. Both strategies provide feasible options for estimating millions of unknown fluxes using large satellite or in situ atmospheric datasets. Both can be paired with different types of atmospheric transport models, including particle trajectory models like STILT or gridded Eulerian models that do not save an explicit adjoint matrix. The choice between these two approaches likely depends upon the specifics of the inverse problem in question and the ease of integrating each into any existing model infrastructure or code.
We further explore two possible strategies for approximating the posterior uncertainties – the generation of conditional realizations and a reduced-rank approach. Conditional realizations have numerous and varied applications in inverse problems (e.g., Kitanidis, 1997; Michalak et al., 2004), but we do not recommend them as the only means of estimating the posterior uncertainties unless it is tractable to generate hundreds to thousands of realizations. Otherwise, the estimated uncertainties will likely be too small and provide a misleading level of confidence in the estimated fluxes. The reduced-rank approach, by contrast, will not underestimate the posterior uncertainties and therefore provides a more conservative uncertainty estimate that will not overstate the results.
The code associated with this article is available on GitHub at https://doi.org/10.5281/zenodo.3241524 (Miller and Saibaba, 2019). This code repository includes general scripts that can be applied to a variety of inverse modeling problems and scripts that will specifically run the first case study described in this article. Furthermore, the input files for the first case study are available on Zenodo at https://doi.org/10.5281/zenodo.3241466 (Miller et al., 2019).
The supplement related to this article is available online at: https://doi.org/10.5194/gmd-13-1771-2020-supplement.
SMM and AKS designed and wrote the study. SMM conducted the analysis. MET, MEM, and AEA designed and created the WRF-STILT model simulations used in the study.
The authors declare that they have no conflict of interest.
We thank Zichong Chen (Johns Hopkins University) and Thomas Nehrkorn (Atmospheric And Environmental Research, Inc.) for their help with the article. CarbonTracker CT2017 results are provided by NOAA ESRL, Boulder, Colorado, USA, from the website at http://carbontracker.noaa.gov (last access: 30 March 2020).
This research has been supported by the NASA (grant no. 80NSSC18K0976) and the NSF (grant no. DMS-1720398).
This paper was edited by James Annan and reviewed by Peter Rayner and Ian Enting.
Ambikasaran, S., Li, J. Y., Kitanidis, P. K., and Darve, E.: Large-scale stochastic linear inversion using hierarchical matrices, Computat. Geosci., 17, 913–927, https://doi.org/10.1007/s10596-013-9364-0, 2013a. a, b
Ambikasaran, S., Saibaba, A. K., Darve, E. F., and Kitanidis, P. K.: Fast Algorithms for Bayesian Inversion, in: Computational Challenges in the Geosciences, edited by: Dawson, C. and Gerritsen, M., 101–142, Springer New York, New York, NY, https://doi.org/10.1007/978-1-4614-7434-0_5, 2013b. a, b
Baker, D. F., Doney, S. C., and Schimel, D. S.: Variational data assimilation for atmospheric CO2, Tellus B, 58, 359–365, https://doi.org/10.1111/j.1600-0889.2006.00218.x, 2006. a, b, c, d
Barrett, R., Berry, M., Chan, T., Demmel, J., Donato, J., Dongarra, J., Eijkhout, V., Pozo, R., Romine, C., and van der Vorst, H.: Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods, Other Titles in Applied Mathematics, Society for Industrial and Applied Mathematics, Philadelphia, PA, 1994. a
Bousserez, N., Henze, D. K., Perkins, A., Bowman, K. W., Lee, M., Liu, J., Deng, F., and Jones, D. B. A.: Improved analysis-error covariance matrix for high-dimensional variational inversions: application to source estimation using a 3D atmospheric transport model, Q. J. Roy. Meteorol. Soc., 141, 1906–1921, https://doi.org/10.1002/qj.2495, 2015. a
Brasseur, G. P. and Jacob, D. J.: Modeling of Atmospheric Chemistry, Chap. 11, Cambridge University Press, Cambridge, https://doi.org/10.1017/9781316544754, 2017. a
Butz, A., Guerlet, S., Hasekamp, O., Schepers, D., Galli, A., Aben, I., Frankenberg, C., Hartmann, J.-M., Tran, H., Kuze, A., Keppel-Aleks, G., Toon, G., Wunch, D., Wennberg, P., Deutscher, N., Griffith, D., Macatangay, R., Messerschmidt, J., Notholt, J., and Warneke, T.: Toward accurate CO2 and CH4 observations from GOSAT, Geophys. Res. Lett., 38, L14812, https://doi.org/10.1029/2011GL047888, 2011. a
Chatterjee, A. and Michalak, A. M.: Technical Note: Comparison of ensemble Kalman filter and variational approaches for CO2 data assimilation, Atmos. Chem. Phys., 13, 11643–11660, https://doi.org/10.5194/acp-13-11643-2013, 2013. a
Chatterjee, A., Michalak, A. M., Anderson, J. L., Mueller, K. L., and Yadav, V.: Toward reliable ensemble Kalman filter estimates of CO2 fluxes, J. Geophys. Res.-Atmos., 117, D22306, https://doi.org/10.1029/2012JD018176, 2012. a, b
Chevallier, F., Bréon, F.-M., and Rayner, P. J.: Contribution of the Orbiting Carbon Observatory to the estimation of CO2 sources and sinks: Theoretical study in a variational data assimilation framework, J. Geophys. Res.-Atmos., 112, D09307, https://doi.org/10.1029/2006JD007375, 2007. a, b, c
Crowell, S., Baker, D., Schuh, A., Basu, S., Jacobson, A. R., Chevallier, F., Liu, J., Deng, F., Feng, L., McKain, K., Chatterjee, A., Miller, J. B., Stephens, B. B., Eldering, A., Crisp, D., Schimel, D., Nassar, R., O'Dell, C. W., Oda, T., Sweeney, C., Palmer, P. I., and Jones, D. B. A.: The 2015–2016 carbon cycle as seen from OCO-2 and the global in situ network, Atmos. Chem. Phys., 19, 9797–9831, https://doi.org/10.5194/acp-19-9797-2019, 2019. a
Eldering, A., Wennberg, P. O., Crisp, D., Schimel, D. S., Gunson, M. R., Chatterjee, A., Liu, J., Schwandner, F. M., Sun, Y., O'Dell, C. W., Frankenberg, C., Taylor, T., Fisher, B., Osterman, G. B., Wunch, D., Hakkarainen, J., Tamminen, J., and Weir, B.: The Orbiting Carbon Observatory-2 early science investigations of regional carbon dioxide fluxes, Science, 358, eaam5745, https://doi.org/10.1126/science.aam5745, 2017. a, b
Eldering, A., Taylor, T. E., O'Dell, C. W., and Pavlick, R.: The OCO-3 mission: measurement objectives and expected performance based on 1 year of simulated data, Atmos. Meas. Tech., 12, 2341–2370, https://doi.org/10.5194/amt-12-2341-2019, 2019. a
Flath, H., Wilcox, L., Akçelik, V., Hill, J., van Bloemen Waanders, B., and Ghattas, O.: Fast Algorithms for Bayesian Uncertainty Quantification in Large-Scale Linear Inverse Problems Based on Low-Rank Partial Hessian Approximations, SIAM J. Sci. Stat. Comp., 33, 407–432, https://doi.org/10.1137/090780717, 2011. a, b, c, d
Fritz, J., Neuweiler, I., and Nowak, W.: Application of FFT-based Algorithms for Large-Scale Universal Kriging Problems, Math Geosci., 41, 509–533, https://doi.org/10.1007/s11004-009-9220-x, 2009. a, b
Ganesan, A. L., Rigby, M., Zammit-Mangion, A., Manning, A. J., Prinn, R. G., Fraser, P. J., Harth, C. M., Kim, K.-R., Krummel, P. B., Li, S., Mühle, J., O'Doherty, S. J., Park, S., Salameh, P. K., Steele, L. P., and Weiss, R. F.: Characterization of uncertainties in atmospheric trace gas inversions using hierarchical Bayesian methods, Atmos. Chem. Phys., 14, 3855–3864, https://doi.org/10.5194/acp-14-3855-2014, 2014. a
Gourdji, S. M., Hirsch, A. I., Mueller, K. L., Yadav, V., Andrews, A. E., and Michalak, A. M.: Regional-scale geostatistical inverse modeling of North American CO2 fluxes: a synthetic data study, Atmos. Chem. Phys., 10, 6151–6167, https://doi.org/10.5194/acp-10-6151-2010, 2010. a, b
Gourdji, S. M., Mueller, K. L., Yadav, V., Huntzinger, D. N., Andrews, A. E., Trudeau, M., Petron, G., Nehrkorn, T., Eluszkiewicz, J., Henderson, J., Wen, D., Lin, J., Fischer, M., Sweeney, C., and Michalak, A. M.: North American CO2 exchange: inter-comparison of modeled estimates with results from a fine-scale atmospheric inversion, Biogeosciences, 9, 457–475, https://doi.org/10.5194/bg-9-457-2012, 2012. a, b, c, d, e, f, g, h
Halko, N., Martinsson, P.-G., and Tropp, J. A.: Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions, SIAM Rev., 53, 217–288, https://doi.org/10.1137/090771806, 2011. a
Henze, D. K., Hakami, A., and Seinfeld, J. H.: Development of the adjoint of GEOS-Chem, Atmos. Chem. Phys., 7, 2413–2433, https://doi.org/10.5194/acp-7-2413-2007, 2007. a, b, c
Hu, L., Andrews, A. E., Thoning, K. W., Sweeney, C., Miller, J. B., Michalak, A. M., Dlugokencky, E., Tans, P. P., Shiga, Y. P., Mountain, M., Nehrkorn, T., Montzka, S. A., McKain, K., Kofler, J., Trudeau, M., Michel, S. E., Biraud, S. C., Fischer, M. L., Worthy, D. E. J., Vaughn, B. H., White, J. W. C., Yadav, V., Basu, S., and van der Velde, I. R.: Enhanced North American carbon uptake associated with El Niño, Sci. Adv., 5, eaaw0076, https://doi.org/10.1126/sciadv.aaw0076, 2019. a
Kitanidis, P.: Introduction to Geostatistics: Applications in Hydrogeology, Stanford-Cambridge program, Cambridge University Press, Cambridge, 1997. a, b, c
Kitanidis, P. K.: Quasi-Linear Geostatistical Theory for Inversing, Water Resour. Res., 31, 2411–2419, https://doi.org/10.1029/95WR01945, 1995. a, b, c
Kitanidis, P. K.: Analytical expressions of conditional mean, covariance, and sample functions in geostatistics, Stoch. Hydrol. Hydraul., 10, 279–294, https://doi.org/10.1007/BF01581870, 1996. a, b
Kitanidis, P. K. and Vomvoris, E. G.: A geostatistical approach to the inverse problem in groundwater modeling (steady state) and one-dimensional simulations, Water Resour. Res., 19, 677–690, https://doi.org/10.1029/WR019i003p00677, 1983. a, b, c
Lee, J., Yoon, H., Kitanidis, P. K., Werth, C. J., and Valocchi, A. J.: Scalable subsurface inverse modeling of huge data sets with an application to tracer concentration breakthrough data from magnetic resonance imaging, Water Resour. Res., 52, 5213–5231, https://doi.org/10.1002/2015WR018483, 2016. a, b, c
Lin, J. C., Gerbig, C., Wofsy, S. C., Andrews, A. E., Daube, B. C., Davis, K. J., and Grainger, C. A.: A near-field tool for simulating the upstream influence of atmospheric observations: The Stochastic Time-Inverted Lagrangian Transport (STILT) model, J. Geophys. Res.-Atmos., 108, D16, https://doi.org/10.1029/2002JD003161, 2003. a
Liu, D. C. and Nocedal, J.: On the limited memory BFGS method for large scale optimization, Math. Program., 45, 503–528, https://doi.org/10.1007/BF01589116, 1989. a, b
Liu, J., Bowman, K. W., Lee, M., Henze, D. K., Bousserez, N., Brix, H., Collatz, G. J., Menemenlis, D., Ott, L., Pawson, S., Jones, D., and Nassar, R.: Carbon monitoring system flux estimation and attribution: impact of ACOS-GOSAT XCO2 sampling on the inference of terrestrial biospheric sources and sinks, Tellus B, 66, 22486, https://doi.org/10.3402/tellusb.v66.22486, 2014a. a, b
Liu, X., Zhou, Q., Kitanidis, P. K., and Birkholzer, J. T.: Fast iterative implementation of large-scale nonlinear geostatistical inverse modeling, Water Resour. Res., 50, 198–207, https://doi.org/10.1002/2012WR013241, 2014b. a, b, c
Machida, T., Matsueda, H., Sawa, Y., Nakagawa, Y., Hirotani, K., Kondo, N., Goto, K., Nakazawa, T., Ishikawa, K., and Ogawa, T.: Worldwide Measurements of Atmospheric CO2 and Other Trace Gas Species Using Commercial Airlines, J. Atmos. Ocean. Technol., 25, 1744–1754, https://doi.org/10.1175/2008JTECHA1082.1, 2008. a
Masakatsu N., Akihiko K., and Suto, H.: The current status of GOSAT and the concept of GOSAT-2, Proc. SPIE, 8533, 21–30, https://doi.org/10.1117/12.974954, 2012. a
Meirink, J. F., Bergamaschi, P., and Krol, M. C.: Four-dimensional variational data assimilation for inverse modelling of atmospheric methane emissions: method and comparison with synthesis inversion, Atmos. Chem. Phys., 8, 6341–6353, https://doi.org/10.5194/acp-8-6341-2008, 2008. a, b, c, d
Michalak, A. M., Bruhwiler, L., and Tans, P. P.: A geostatistical approach to surface flux estimation of atmospheric trace gases, J. Geophys. Res.-Atmos., 109, d14109, https://doi.org/10.1029/2003JD004422, 2004. a, b, c, d, e, f, g, h, i
Miller, J. B., Lehman, S. J., Montzka, S. A., Sweeney, C., Miller, B. R., Karion, A., Wolak, C., Dlugokencky, E. J., Southon, J., Turnbull, J. C., and Tans, P. P.: Linking emissions of fossil fuel CO2 and other anthropogenic trace gases using atmospheric 14CO2, J. Geophys. Res.-Atmos., 117, d08302, https://doi.org/10.1029/2011JD017048, 2012. a
Miller, S. M. and Saibaba, A. K.: Geostatistical inverse modeling with large atmospheric datasets (Version v1.0), software library, https://doi.org/10.5281/zenodo.3241524, 2019. a, b
Miller, S. M., Wofsy, S. C., Michalak, A. M., Kort, E. A., Andrews, A. E., Biraud, S. C., Dlugokencky, E. J., Eluszkiewicz, J., Fischer, M. L., Janssens-Maenhout, G., Miller, B. R., Miller, J. B., Montzka, S. A., Nehrkorn, T., and Sweeney, C.: Anthropogenic emissions of methane in the United States, P. Natl. Acad. Sci. USA, 110, 20018–20022, https://doi.org/10.1073/pnas.1314392110, 2013. a, b, c
Miller, S. M., Michalak, A. M., and Levi, P. J.: Atmospheric inverse modeling with known physical bounds: an example from trace gas emissions, Geosci. Model Dev., 7, 303–315, https://doi.org/10.5194/gmd-7-303-2014, 2014. a
Miller, S. M., Miller, C. E., Commane, R., Chang, R. Y.-W., Dinardo, S. J., Henderson, J. M., Karion, A., Lindaas, J., Melton, J. R., Miller, J. B., Sweeney, C., Wofsy, S. C., and Michalak, A. M.: A multiyear estimate of methane fluxes in Alaska from CARVE atmospheric observations, Global Biogeochem. Cy., 30, 1441–1453, https://doi.org/10.1002/2016GB005419, 2016. a, b, c, d, e, f
Miller, S. M., Michalak, A. M., Yadav, V., and Tadić, J. M.: Characterizing biospheric carbon balance using CO2 observations from the OCO-2 satellite, Atmos. Chem. Phys., 18, 6785–6799, https://doi.org/10.5194/acp-18-6785-2018, 2018. a
Miller, S. M., Saibaba, A. K., Trudeau, M. E., Mountain, M. E., and Andrews, A. E.: Geostatistical inverse modeling with large atmospheric data: data files for a case study from OCO-2 (Version 1.0) [Data set], Zenodo, https://doi.org/10.5281/zenodo.3241466, 2019. a
Mueller, K. L., Gourdji, S. M., and Michalak, A. M.: Global monthly averaged CO2 fluxes recovered using a geostatistical inverse modeling approach: 1. Results using atmospheric measurements, J. Geophys. Res.-Atmos., 113, d21114, https://doi.org/10.1029/2007JD009734, 2008. a, b
Nehrkorn, T., Eluszkiewicz, J., Wofsy, S. C., Lin, J. C., Gerbig, C., Longo, M., and Freitas, S.: Coupled weather research and forecasting–stochastic time-inverted lagrangian transport (WRF–STILT) model, Meteorol. Atmos. Phys., 107, 51–64, https://doi.org/10.1007/s00703-010-0068-x, 2010. a
NOAA Global Monitoring Division: CarbonTracker – Lagrange, 2019 available at: https://www.esrl.noaa.gov/gmd/ccgg/carbontracker-lagrange/, last access: 7 June 2019. a
NOAA Global Monitoring Division: CarbonTracker CT2017, 2019 available at: https://www.esrl.noaa.gov/gmd/ccgg/carbontracker/index.php, last access: 7 June 2019. a
Nocedal, J.: Updating Quasi-Newton Matrices with Limited Storage, Math. Comput., 35, 773–782, https://doi.org/10.2307/2006193, 1980. a, b
Paige, C. C. and Saunders, M. A.: Solution of sparse indefinite systems of linear equations, SIAM J. Numer. Anal., 12, 617–629, https://doi.org/10.1137/0712047, 1975. a
Peters, W., Jacobson, A. R., Sweeney, C., Andrews, A. E., Conway, T. J., Masarie, K., Miller, J. B., Bruhwiler, L. M. P., Pétron, G., Hirsch, A. I., Worthy, D. E. J., van der Werf, G. R., Randerson, J. T., Wennberg, P. O., Krol, M. C., and Tans, P. P.: An atmospheric perspective on North American carbon dioxide exchange: CarbonTracker, P. Natl. Acad. Sci. USA, 104, 18925–18930, https://doi.org/10.1073/pnas.0708986104, 2007. a
Petzold, A., Thouret, V., Gerbig, C., Zahn, A., Brenninkmeijer, C. A. M., Gallagher, M., Hermann, M., Pontaud, M., Ziereis, H., Boulanger, D., Marshall, J., Nedelec, P., Smit, H. G. J., Friess, U., Flaud, J.-M., Wahner, A., Cammas, J.-P., Volz-Thomas, A., and TEAM, I.: Global-scale atmosphere monitoring by in-service aircraft – current achievements and future prospects of the European Research Infrastructure IAGOS, Tellus B, 67, 28452, https://doi.org/10.3402/tellusb.v67.28452, 2015. a
Rigby, M., Manning, A. J., and Prinn, R. G.: Inversion of long-lived trace gas emissions using combined Eulerian and Lagrangian chemical transport models, Atmos. Chem. Phys., 11, 9887–9898, https://doi.org/10.5194/acp-11-9887-2011, 2011. a
Rodgers, C.: Inverse Methods for Atmospheric Sounding: Theory and Practice, Series on atmospheric, oceanic and planetary physics, World Scientific, Singapore, 2000. a
Saibaba, A. K. and Kitanidis, P. K.: Efficient methods for large-scale linear inversion using a geostatistical approach, Water Resour. Res., 48, W05522, https://doi.org/10.1029/2011WR011778, 2012. a, b, c, d, e, f, g, h, i
Saibaba, A. K. and Kitanidis, P. K.: Fast computation of uncertainty quantification measures in the geostatistical approach to solve inverse problems, Adv. Water Resour., 82, 124–138, https://doi.org/10.1016/j.advwatres.2015.04.012, 2015. a, b, c, d
Saibaba, A. K., Lee, J., and Kitanidis, P. K.: Randomized algorithms for generalized Hermitian eigenvalue problems with application to computing Karhunen-Lóve expansion, Numer. Linear Algebr., 23, 314–339, https://doi.org/10.1002/nla.2026, 2016. a
Saibaba, A. K., Ambikasaran, S., Yue Li, J., Kitanidis, P. K., and Darve, E. F.: Application of hierarchical matrices to linear inverse problems in geostatistics, Oil Gas Sci. Technol., 67, 857–875, https://doi.org/10.2516/ogst/2012064, 2012. a
Shiga, Y. P., Michalak, A. M., Fang, Y., Schaefer, K., Andrews, A. E., Huntzinger, D. H., Schwalm, C. R., Thoning, K., and Wei, Y.: Forests dominate the interannual variability of the North American carbon sink, Eviron. Res. Lett., 13, 084015, https://doi.org/10.1088/1748-9326/aad505, 2018. a, b, c, d, e, f, g
Snodgrass, M. and Kitanidis, P.: A geostatistical approach to contaminant source identification, Water Resour. Res., 33, 537–546, https://doi.org/10.1029/96WR03753, 1997. a
Spantini, A., Solonen, A., Cui, T., Martin, J., Tenorio, L., and Marzouk, Y.: Optimal low-rank approximations of Bayesian linear inverse problems, SIAM J. Sci. Stat. Comp., 37, A2451–A2487, https://doi.org/10.1137/140977308, 2015. a, b, c, d
Wackernagel, H.: Multivariate Geostatistics: An Introduction with Applications, Springer, Berlin, 2003. a, b
Yadav, V. and Michalak, A. M.: Improving computational efficiency in large linear inverse problems: an example from carbon dioxide flux estimation, Geosci. Model Dev., 6, 583–590, https://doi.org/10.5194/gmd-6-583-2013, 2013. a, b, c, d
Yang, D., Liu, Y., Cai, Z., Chen, X., Yao, L., and Lu, D.: First global carbon dioxide maps produced from TanSat measurements, Adv. Atmos. Sci, 35, 621–623, https://doi.org/10.1007/s00376-018-7312-6, 2018. a
- Abstract
- Introduction
- Context on the geostatistical approach to inverse modeling
- Direct approach to solving the GIM and associated challenges for large datasets
- Approaches to calculating the best estimate
- Uncertainty estimation
- Case study from the OCO-2 satellite
- Discussion
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Introduction
- Context on the geostatistical approach to inverse modeling
- Direct approach to solving the GIM and associated challenges for large datasets
- Approaches to calculating the best estimate
- Uncertainty estimation
- Case study from the OCO-2 satellite
- Discussion
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement