the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 28 Oct 2025
| 28 Oct 2025
Tensorweave 1.0: interpolating geophysical tensor fields with spatial neural networks
Samuel T. Thiele
Hernan Ugalde
Bill Morris
Raimon Tolosana-Delgado
Moritz Kirsch
Richard Gloaguen
Tensor fields, as spatial derivatives of scalar or vector potentials, offer powerful insight into subsurface structures in geophysics. However, accurately interpolating these measurements–such as those from full-tensor potential field gradiometry–remains difficult, especially when data are sparse or irregularly sampled. We present a physics-informed spatial neural network that treats tensors according to their nature as derivatives of an underlying scalar field, enabling consistent, high-fidelity interpolation across the entire domain. By leveraging the differentiable nature of neural networks, our method not only honours the physical constraints inherent to potential fields but also reconstructs the scalar and vector fields that generate the observed tensors. We demonstrate the approach on synthetic gravity gradiometry data and real full-tensor magnetic data from Geyer, Germany. Results show significant improvements in interpolation accuracy, structural continuity, and uncertainty quantification compared to conventional methods.
- Article
(13301 KB) - Full-text XML
- BibTeX
- EndNote




Full-tensor gravity and magnetic gradiometry measurements capture the spatial derivatives of potential fields, offering rich detail about subsurface density and magnetisation variations. These tensor fields enhance geological imaging by encoding directional and gradient information that scalar fields do not straightforwardly provide (Brewster, 2011; Ugalde et al., 2024). However, gradiometry data are typically sparse and anisotropically sampled – often along sub-parallel flight lines – posing significant challenges for downstream analysis, which relies on gridded representations.
Interpolating these tensor fields accurately is far from trivial. Conventional methods often treat tensor components as independent scalar fields, leading to noise amplification, loss of directional trends, and violations of physical constraints like symmetry and harmonicity. More advanced approaches, such as eigen-decomposition-based interpolation (Fitzgerald et al., 2012; Satheesh et al., 2023), attempt to preserve tensor structure, but remain limited in generalisability and scalability.
Recent advances in neural fields (Xie et al., 2022) – also known as coordinate-based or implicit neural representations – offer a promising alternative. These models learn continuous functions that map spatial coordinates to field values. Their differentiable nature allows them to incorporate gradient information directly into training – a key advantage for geophysical applications where tensor data often represents derivatives of an underlying field (Raissi et al., 2019). However, standard multilayer perceptron (MLP) architectures suffer from spectral bias (Rahaman et al., 2018), meaning they struggle to capture high-frequency features common in geophysical signals. To address this, techniques like Random Fourier Feature mapping (Tancik et al., 2020), periodic activation functions (e.g. SiREN, Sitzmann et al., 2020), and wavelet activations (Saragadam et al., 2023) have been introduced, enabling neural fields to model fine-scale spatial variations more effectively.
In this paper, we introduce a physics-informed neural field approach tailored for interpolating geophysical tensor data. Our model learns a single scalar potential field from sparse tensor measurements, leveraging RFF mappings and embedded physical constraints (e.g., symmetry, Laplacian properties) to reconstruct consistent, physically meaningful tensor fields. We further introduce an ensemble strategy to quantify uncertainty in the interpolations, offering insights into data sensitivity and model confidence. We demonstrate this framework on both synthetic gravity gradiometry data and real airborne magnetic gradiometry from Geyer, Germany, highlighting clear improvements over traditional methods in accuracy and structural continuity, as well as opening the door to uncertainty quantification.
A tensor is an algebraic object that encodes multilinear relationships between sets of vectors and linear functionals (Lee, 2012). A tensor field assigns a tensor to every point in space, describing the local structure of a vector field or scalar potential throughout a region. In geophysical applications, tensors naturally arise as derivatives of vector and scalar fields, extending classical multivariable calculus into field-based formulations.
2.1 Potential fields
Many measured geophysical quantities, such as gravitational acceleration g and the magnetic field b, are conservative vector fields – i.e., they are gradients of scalar potential fields (Blakely, 1995). Within ℝ3, a conservative vector field v is irrotational at all points (given by the position vector r), satisfying
where is the gradient operator. For instance, the magnetic field can be expressed as the gradient of a scalar magnetic potential in regions free of electric currents – a condition typically met outside source distributions. Taking the gradient of v yields the Hessian tensor H, a second-order tensor that captures the local curvature of the scalar potential
In source-free regions, these fields are not only irrotational but also solenoidal – i.e., divergence-free. The divergence of v corresponds to the trace of the Hessian, which reflects the Laplace equation
This implies that, outside source regions, scalar potentials are harmonic functions, and their Hessians are traceless. Additionally, since mixed partial derivatives commute (by Schwarz's theorem), the Hessians are symmetric and thus comprise five independent components.
2.2 Full tensor gradiometry
Direct measurements of second-order Hessian tensors – particularly gravity and magnetic gradient tensors – represent the current frontier in potential field surveying (Rudd et al., 2022; Stolz et al., 2021). Access to the full tensor enables characterisation of scalar field curvature, aiding in tasks such as edge detection, structure delineation (Zuo and Hu, 2015), and magnetic remanence characterisation (Ugalde et al., 2024). These measurements are typically acquired via airborne surveys, which are highly anisotropic in their sampling: dense along flight lines and sparse across them. Vector fields are frequently reconstructed from tensor components using Fourier-domain transfer functions, which integrate the measured gradients into vector components while suppressing noise (Vassiliou, 1986). Since most downstream analyses, including Fourier-based reconstructions, require gridded tensor and vector fields, interpolation is a critical preprocessing step.
Rudd et al. (2022) note that, in practice, tensor components are often treated as separate scalar fields and interpolated using standard methods like minimum curvature or radial basis functions (RBFs). Several alternative approaches have been proposed to enforce physical or geometric constraints during interpolation. For example, Brewster (2011) uses iterative Fourier-domain transformations, while Fitzgerald et al. (2012) suggest interpolating eigenvalues and eigenvectors separately, using a quaternion-based interpolation technique. In essence, the quaternion interpolation algorithm decomposes the process into two parts: interpolating the eigenvalues and the corresponding eigenvectors. Two of the three eigenvalues are interpolated using standard schemes (e.g., RBF or minimum curvature), with the third computed such that their sum is zero – a direct consequence of the Hessian's traceless-ness. The eigenvector matrix of any symmetric real matrix is guaranteed to be real and orthogonal, allowing it to be represented as a 3D orientation and encoded as a quaternion (Hamilton, 1844), provided some constraints on ordering and sign convention are imposed (Satheesh et al., 2023). These quaternions are then interpolated using Spherical Linear Interpolation or SLERP (Shoemake, 1985), which ensures smooth variation of orientation across space. While SLERP works for two quaternions, Markley et al. (2007) devised a scheme that works across a set of weighted quaternions.
Another widely used approach for interpolating and transforming potential-field (and gradient) data is the equivalent-source/equivalent-layer method: one replaces the true 3D distribution of sources by a 2D layer of hypothetical monopoles or dipoles beneath the observation surface whose field exactly reproduces the measured data on that surface (Dampney, 1969; Blakely, 1995). In practice the infinite layer is discretised into a finite set of sources and the corresponding dense sensitivity matrix is solved – often with regularisation – to obtain source strengths that honour the physical constraints of potential fields and enable stable continuation and derivative transforms (Hansen and Miyazaki, 1984; Blakely, 1995; Oliveira Junior et al., 2023). This formulation is powerful but computationally demanding for large surveys. Consequently, a substantial literature focuses on accelerating the method by exploiting data geometry and matrix structure: scattered equivalent-source gridding (Cordell, 1992); the “equivalent data” concept to reduce system size (Mendonça and Silva, 1994); wavelet compression and adaptive meshing to sparsify sensitivities (Li and Oldenburg, 2010; Davis and Li, 2011); fast iterative schemes in the space/wavenumber domains (Xia and Sprowl, 1991; Siqueira et al., 2017); and scalable algorithms that leverage the block-Toeplitz Toeplitz-block (BTTB) structure of the sensitivity matrix (Piauilino et al., 2025). Recent machine-learning – inspired variants (e.g., gradient-boosted equivalent sources) further cut memory and runtime for continental-scale datasets (Soler and Uieda, 2021). Open-source implementations, notably Harmonica, provide practical tools for gravity and magnetic datasets using these ideas (Fatiando a Terra Project et al., 2024).
However, these methods still have limitations: component-wise methods can be insensitive to the true shape of the tensor, whereas full-tensor schemes involve complex handling of 3D rotations, which are complicated due to the existence of indeterminate points and the need for shifting reference frames due to non-uniqueness of 3D rotations. Equivalent source methods offer a physically consistent approach, but suffer from the trade-off between computational expense and fidelity of the interpolated result (e.g., Piauilino et al., 2025). In this contribution, we propose a neural field method that interpolates the scalar potential field directly – constrained by physical laws and Hessian measurements – to produce consistent, noise-minimising tensor and vector fields that respect observations and preserve geologically meaningful structures.
2.3 Neural fields
Neural fields – also known as implicit neural representations, or spatial neural networks – are models that represent continuous spatial functions using neural networks. Unlike traditional methods that store information in discrete grids or meshes, neural fields encode spatial structure within the weights and biases of a neural network, enabling resolution-independent, continuous representations of complex signals.
The application of spatial neural networks in geoscience dates back to Openshaw (1993), who used them for interpolating sparse spatial data and found their performance competitive with fuzzy logic and genetic algorithms, a conclusion also reached by Hewitson et al. (1994). More recently, neural fields have gained traction in computer vision – for example, in volumetric radiance field modelling (Mildenhall et al., 2020) – and in geoscience applications such as 3D geological modelling (Hillier et al., 2023) and potential field representation (Smith et al., 2025).
A key advantage of neural fields is their differentiability: they allow access not only to predicted signals but also to their spatial derivatives via automatic differentiation. This is especially useful when the scalar field itself is unmeasurable or physically arbitrary, but its gradients are measurable – as is often the case in geological modelling using structural orientation data (Kamath et al., 2025; Thiele et al., 2025), or in reconstructing potential fields from tensor gradiometry data.
This section outlines the key components of our proposed framework, including the use of random Fourier features, a harmonic feature embedding, model architecture, training regimen, and loss function. We also describe the methodology used to generate the synthetic dataset used in our study.
3.1 Random Fourier Feature mapping
A common challenge in implicit neural representations is the mismatch between low-dimensional input coordinates and the complex, high-frequency structure of the target signal. To address this, we employ Random Fourier Feature (RFF) mapping – a kernel approximation technique introduced by Rahimi and Recht (2007) and adapted to deep learning by Tancik et al. (2020). RFF mapping projects spatial coordinates into a higher-dimensional space, making it easier for the network to learn fine-scale spatial variation.
Given the position vector r∈ℝN, we define a frequency (also called weights) matrix W, of the dimension M×N, with every component sampled from a standard Gaussian distribution, where M is the number of Fourier features (i.e., frequencies). To encode known signal frequency characteristics (e.g., the maximum possible frequency based on sampling resolution), we rescale the weights matrix using different length scales. Therefore, for a 3D input, we get a 2M dimensional feature vector νs for every length scale ℓs given by
where , , sin (x):=[sin (xi)]i, and represents concatenation along the feature axis. Hence, for L length scales, as the feature vectors are concatenated, we get a 2ML-dimensional feature vector. This feature vector is then fed into the subsequent multi-layer perceptron to get the scalar potential at the input coordinate.
The transformation enables the model to capture high-frequency details more effectively, while the random sampling of frequencies introduces a useful stochastic component. When followed by a linear MLP with no non-linear activations, the resulting mapping approximates a full Fourier reconstruction of the signal (Bracewell and Kahn, 1966). Non-linear activations help the model fit sparse data more flexibly (LeCun et al., 2015), albeit at the cost of simplicity, interpretability, and gradient stability.
3.2 Harmonic feature embedding
Applying Fourier features uniformly in all dimensions can hinder convergence when modelling harmonic fields. By Liouville's Theorem (Axler et al., 2001), any bounded harmonic function on ℝN is constant, so naive periodic embeddings can bias the network toward trivial solutions. We therefore introduce a harmonic Fourier mapping that uses Fourier features in the horizontal plane and an analytically motivated vertical decay. Since our model reconstructs the spatial domain signal from a combination of sinusoids, we use the frequencies of the sinusoids to encode the harmonicity condition into the mapping. Specifically, in the Fourier domain, if we couple Laplace's equation with the standard separation-of-variables method for a scalar potential ϕ, we get an ordinary differential equation of the form
where is the 2D Fourier transform operator, represents the horizontal wavenumbers (i.e., frequencies), and kz is the vertical wavenumber (Lacava, 2022). This implies that the vertical wavenumber is constrained by , making the vertical dependence evanescent and not oscillatory. This is the classical half-space solution of Laplace's equation and underpins upward/downward continuation in potential-field geophysics (Blakely, 1995; Parker, 1973). Our harmonic embedding scheme simply bakes in the same physics at a feature-level, helping with convergence while training on mostly co-planar datasets, and potentially allowing robust upward/downward continuation.
For a 3D input , we extract the horizontal coordinates . As defined in the previous section, we generate a random weights matrix WM×2 with the entries independently drawn from a standard normal distribution , and scale it with the length scale ℓs to acquire a scaled matrix . For every length scale, we define a new vector, κs, such that
where m refers to the mth row of the Ws matrix, giving us a vector of length M i.e., one norm per row (per feature). With element-wise sine/cosine and Hadamard product ⊙, the new feature vector νs for the scale ℓs is
where z is the vertical coordinate, and the exponential is applied element-wise, producing a 2M-dimensional vector. Concatenating across L scales yields a 2ML-dimensional embedding that encodes horizontal oscillations with physically consistent vertical decay, aligning the features with solutions of Laplace's equation and improving generalisation in under-sampled regions.
3.3 Synthetic dataset
To evaluate our method, we generated a synthetic gravity gradiometry dataset (Fig. 1) using SimPEG (Cockett et al., 2015). The model consists of three density-contrast anomalies within a zero-density half-space:
-
Torus: +1 g cm−3, semi-major axis 450 m, semi-minor axis 220 m, cross-section radius 40 m, lying in the xy plane and rotated 12° CCW from the y axis.
-
Dyke: +0.15 g cm−3, 60 m aperture, striking at 45° to the y axis.
-
Cube: −0.2 g cm−3, 400 m side length, rotated 45° about the vertical (z) axis.
The simulation mesh has a voxel size of 20 m. This geometry offers a challenging mix of sharp discontinuities and smooth curvature for testing interpolation. We generated a high-resolution ground truth dataset sampled at 25 m spacing both along and across the lines, as well as a low-resolution airborne-style dataset with flight lines 200 m apart in the y direction (perpendicular to the flight line), and sampled densely (15 m) along the x direction (Fig. 1b–f). Furthermore, to make the data more realistic, We corrupt the full-tensor gradiometry data with additive white Gaussian noise at a prescribed signal-to-noise ratio (SNR). For each independent component of the Hessian Hk (where ), we estimate the power spectrum , convert the target SNR from dB to linear units as:
Using this SNR, we set the noise variance of the signal as . Independent samples are then added to each datum, to acquire a noisy synthetic dataset (), given by:
where P is the number of points in the dataset.
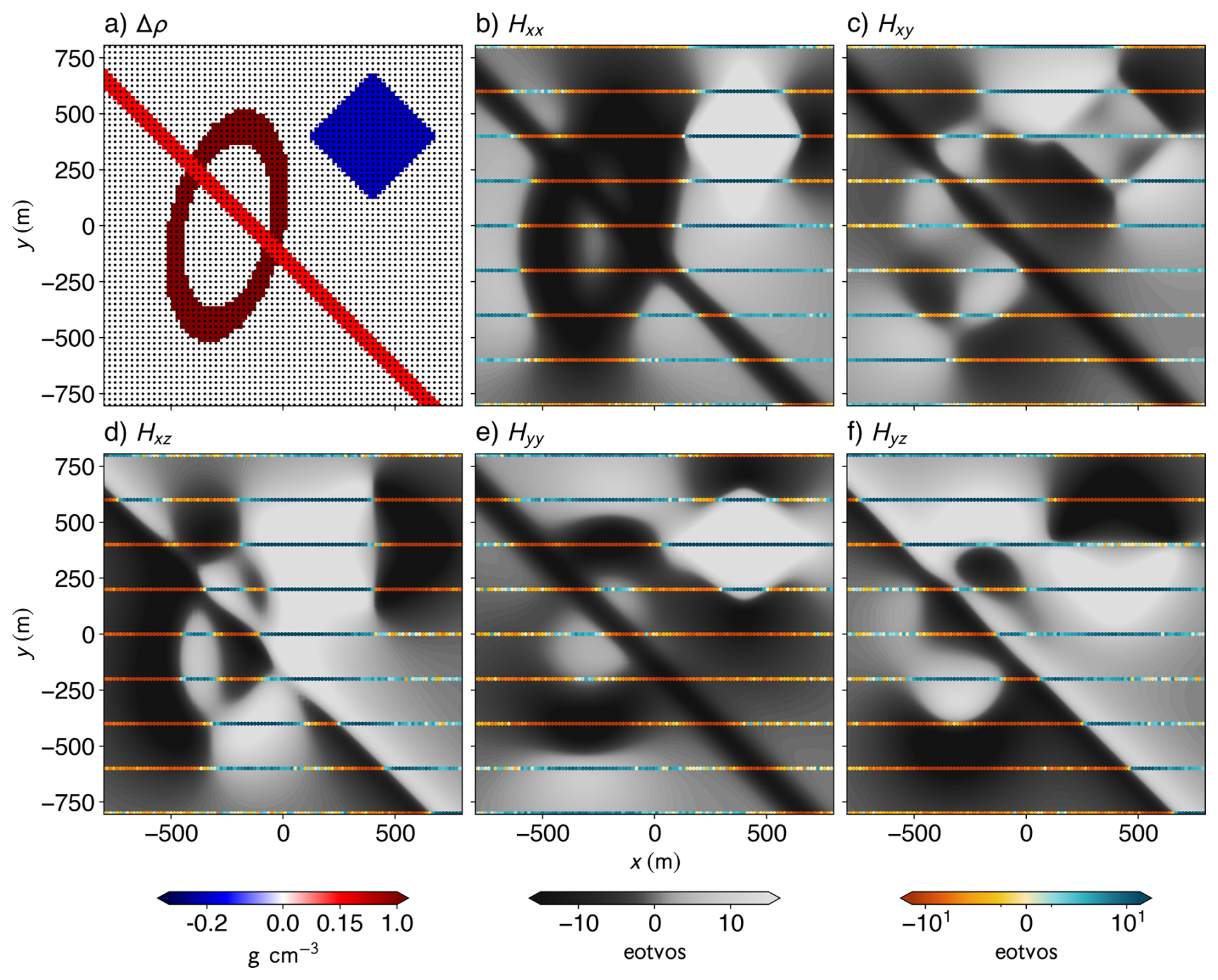
Figure 1Synthetic subsurface model and corresponding gravity gradiometry data. (a) Horizontal cross-section of the synthetic geological model at a depth of 140 m, with high-resolution observation points shown as black dots. The five independent components of the gravity gradiometry tensor generated via forward modelling using SimPEG are also shown (b–f). Each panel displays both the high-resolution dataset (grey scale; cell size of 25 m) and the low-resolution dataset (colour; 200 m cross-line spacing and 15 m inline spacing) for the corresponding tensor component.
To test robustness to data sparsity, we also computed 10 versions of the low-resolution dataset with line spacings varying from 80 to 560 m. These were used to benchmark interpolation quality and information loss under varying acquisition densities. Comparisons were made with a truncated RBF interpolator (250 nearest neighbours, smoothing factor 100), as well as results from the quaternion interpolation (QUAT; Fitzgerald et al., 2012), combining RBF-interpolated eigenvalues with SLERP-interpolated quaternions. All results were evaluated on the same high-resolution grid using the R2 (coefficient of determination), MSE (Mean Squared Error), and SSIM (Structural Similarity Index Measure).
3.4 Model architecture, training regimen, and loss functions
Our model has two main components: a RFF mapping block followed by a sequence of fully-connected feed-forward layers that together produce a continuous scalar field representation (Fig. 2). In our tests, we varied the number of Fourier features from anywhere between 16 to 64, depending on the complexity of underlying field. The specifications of each individual model showcased in this contribution can be found in the following sections.
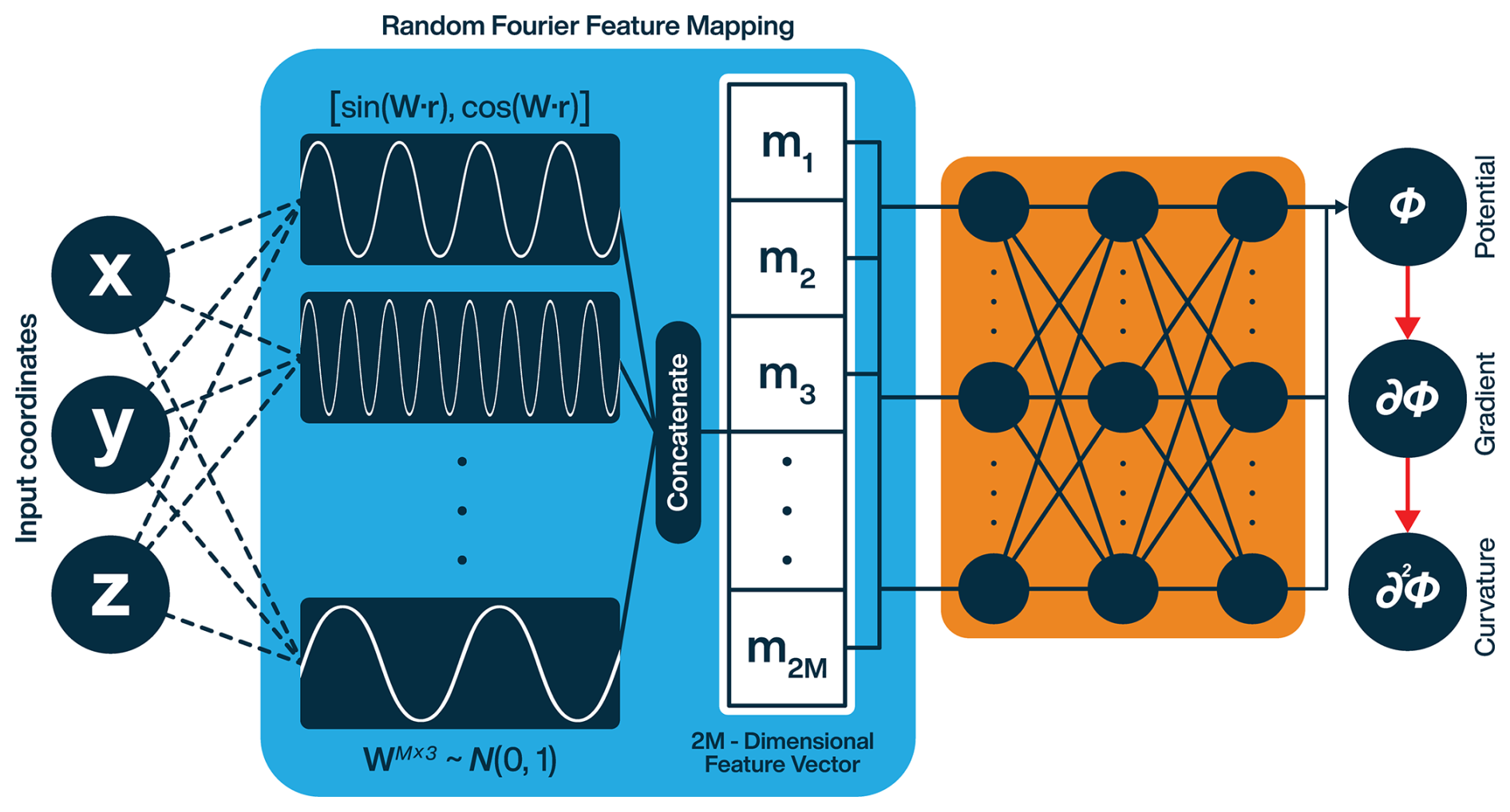
Figure 2Neural Fourier Field model architecture. The blue block projects the input position vector into a feature space and passes it through the fully-connected layers (orange block) to acquire the scalar potential. The red arrows signify the use of automatic differentiation to acquire the first (gradient) and second (curvature) spatial derivatives of the potential.
The MLP block in our model uses non-linear activations for all layers except the output layer. As our framework involves computing second derivatives with AD, activation functions like ReLU (which do not satisfy the C2 differentiability criterion) resulted in abrupt edges within the resultant interpolation. Notably, even within the activations that satisfy the aforementioned criterion, some functions performed better than the others. For example, the Hyperbolic Tangent activation function has extremely small second order derivatives which tend to get saturated, impeding convergence. These activations are stable, but not ideal for our models. Among the various activation functions tested, Swish (Sigmoid Linear Unit, SiLU; Ramachandran et al., 2017) and Mish (Misra, 2019) activations provided the best results.
The loss function used to train our model involves two types of losses – a data loss and a Laplacian loss. The data loss is computed at the points of measurement between the measured tensor components and the Hessians acquired from the predicted scalar field through automatic differentiation (AD) (Margossian, 2019). Since the model is built with PyTorch (v2.8.0; Paszke et al., 2019), we use the inbuilt autograd engine to compute Hessians from the scalar field output. For the predicted scalar field ϕ, the data loss term is given by
where ∂iϕp refers to the partial derivative with the respect to the ith input computed with AD at the pth location, and Hp is the corresponding measured hessian tensor. The first, second, and third indices correspond to x (East–West), y (North–South) and z (Up–Down) axes respectively. Only the upper-triangular part of the Hessian is used for loss computation i.e., the losses for the off-diagonal components are only considered once per measurement. Hence we get a six-component data loss vector, consisting of the misfit between the xx, xy, xz, yy, yz and zz components.
The second term in the loss function is derived to encourage the predicted scalar field to conform with a partial differential equation defined across the whole domain of interest. Since the predicted field has to be harmonic not only at the points of measurement, but everywhere, we thus penalise non-zero traces of the predicted Hessian tensors, hereafter referred to as the Laplacian loss. During every training epoch, we use a Poisson disk sampling routine based on a hierarchical dart throwing approach (White et al., 2007), to select evenly spaced points within a predefined grid that covers the area of interest. The spacing for these points is evaluated using an exponentially decaying function that goes from a user specified large spacing (at the start of training) to a tighter spacing (towards the final epochs). For the Q sampled points in any epoch, the Laplacian loss is given by:
Here, the Einstein summation convention is used to represent the Laplacian, and the superscript refers to the point of evaluation. This loss penalises high values of the trace of the predicted hessian tensor outside the measured points, thereby encouraging harmonicity on the underlying scalar field within the domain of interest. Hence, for every epoch, we get a seven component combined loss vector, with the first six components corresponding to the data loss, and the seventh component referring to the global Laplacian loss.
When combined, the total loss acquired from Eqs. (10) and (11) is thus
where ℒi is the ith component of the combined loss vector, [αi] are the corresponding hyperparameters. Instead of manually fine-tuning these hyperparameters, we tested various multi-objective optimisation schemes for our framework. The best-performing scheme involved dynamically updating hyperparameters, such that every loss function was scaled by the real-time magnitude of the loss. Mathematically, we replace the [αi] in Eq. (12) as follows:
where refers to the magnitude of the loss, detached from the computational graph. This ensures that the gradients only flow through the numerator of the scaled loss, even when the real-time value of the loss is always equal to 1. This real-time normalisation yields a scale-invariant objective whose update is approximately (where ∇θ is the gradient with respect to the network parameters), encouraging proportional improvements across terms. Similar in spirit to uncertainty-based weighting (Kendall et al., 2017), GradNorm (Chen et al., 2017), and Density Weight Averaging (Liu et al., 2019), this variant requires no extra parameters or gradient-norm computations and worked reliably in our setting.
We train the MLP parameters (weights and biases) with Adam (Kingma and Ba, 2014), while keeping the RFF encoder fixed after initialisation. The initial learning rate is set to 10−3 (occasionally 10−2 when the initial loss scale is large). We apply a plateau scheduler that reduces the learning rate by a factor of 0.8 whenever the loss fails to improve for 20 epochs. Optionally, we also optimise a set of learnable length-scale parameters that modulate the Fourier features; the log-values of these scales are stored as parameters and updated jointly with the MLP. However, the learnable nature of these length scales did not help the model convergence greatly, reproducing results explored by Tancik et al. (2020), which suggested that neural fields fail to suitably optimise these length scale parameters.
To make the stopping criterion robust to small oscillations, we monitor an exponential moving average (EMA) of the pre-scaled loss:
where denotes the smoothed loss on the nth epoch. This combination – Adam for fast, well-scaled updates, plateau-based learning-rate decay, and EMA-stabilised early stopping – follows common best practices for training smooth function approximators and has been shown to curb overfitting while maintaining convergence speed (Goodfellow et al., 2016; Prechelt, 1998; Bottou, 2012).
3.5 Uncertainty estimation
A key benefit of using RFF embeddings is that their stochastic nature allows for ensemble-based uncertainty estimation. As a result of the stochasticity, each initialisation of the RFF mapping induces a unique basis in the feature space, causing the neural network to converge on a solution that represents a random sample from a broader distribution of plausible scalar fields conditioned on the training data.
To exploit this property for uncertainty quantification, we generate an ensemble of model outputs by varying the random seed used to sample the RFF projection matrix. Ensemble-based uncertainty quantification has a long and successful history in geophysics, particularly in subsurface modelling and inversion. In seismic full waveform inversion (FWI), ensembles have been used to assess the variability and reliability of recovered velocity models under data noise and model ambiguities (Fichtner et al., 2011). In reservoir geophysics, the Ensemble Kalman Filter (EnKF) has become a widely used tool to propagate uncertainty in dynamic reservoir simulation and history matching (Evensen, 2009). More recently, ensemble-based methods have also been applied to probabilistic gravity and magnetotelluric inversion (Tveit et al., 2020; Giraud et al., 2023), demonstrating their utility in quantifying non-uniqueness and guiding data acquisition strategies.
In our implementation, each ensemble member corresponds to a different realisation of the frequency space, leading to stochastically independent function approximations that depend, largely, on the degree to which the solution is constrained by the available data. This ensemble-based approach provides a Monte Carlo-style estimate of the model's epistemic uncertainty. Furthermore, because the scalar field is modelled continuously, we can propagate this ensemble approach to the field's derivatives, helping us quantify uncertainty in derived physical quantities. Therefore, we showcase our results as the Ensemble Neural Field (ENF) method, which corresponds to the average prediction from an ensemble of models. We also compute results from the individual models within the ensemble (shown as the Neural Field or NF result), to ascertain the effect of averaging over multiple predictions.
4.1 Synthetic data
We first evaluate the Ensemble Neural Field (ENF) method on the synthetic gravity gradiometry dataset, comparing it against a Truncated Radial Basis Function (RBF) interpolator (Fig. 3). The ensemble showcased here has 25 models, each with 16 Fourier features, three length scales of [200, 400, 1000], and two hidden layers with 256 neurons each. Each model within the ensemble was trained for 400 epochs. A predefined grid with a cell-size of 25 m was provided for evaluating the Laplacian loss, with the Poisson sampling radius going from 250 to 80 m. Figure 3a and b shows the residuals between predicted and true Hxy values for the RBF and ENF methods, respectively. The RBF output exhibits high-amplitude residuals (MSE = 4.60 eotvos) between flight lines, indicating overfitting to sampled regions and poor generalisation across them. It also fails to preserve continuity in linear trends that lie at high angles to the flight direction. In contrast, the ENF method yields spatially smoother residuals with significantly lower error (MSE = 0.30 eotvos; improvement of ≈93.4 % over the RBF), suggesting homogeneous improved performance across the domain. Insets in both panels show 1:1 kernel density plots, where the ENF predictions cluster more tightly along the identity line – further confirming its accuracy.
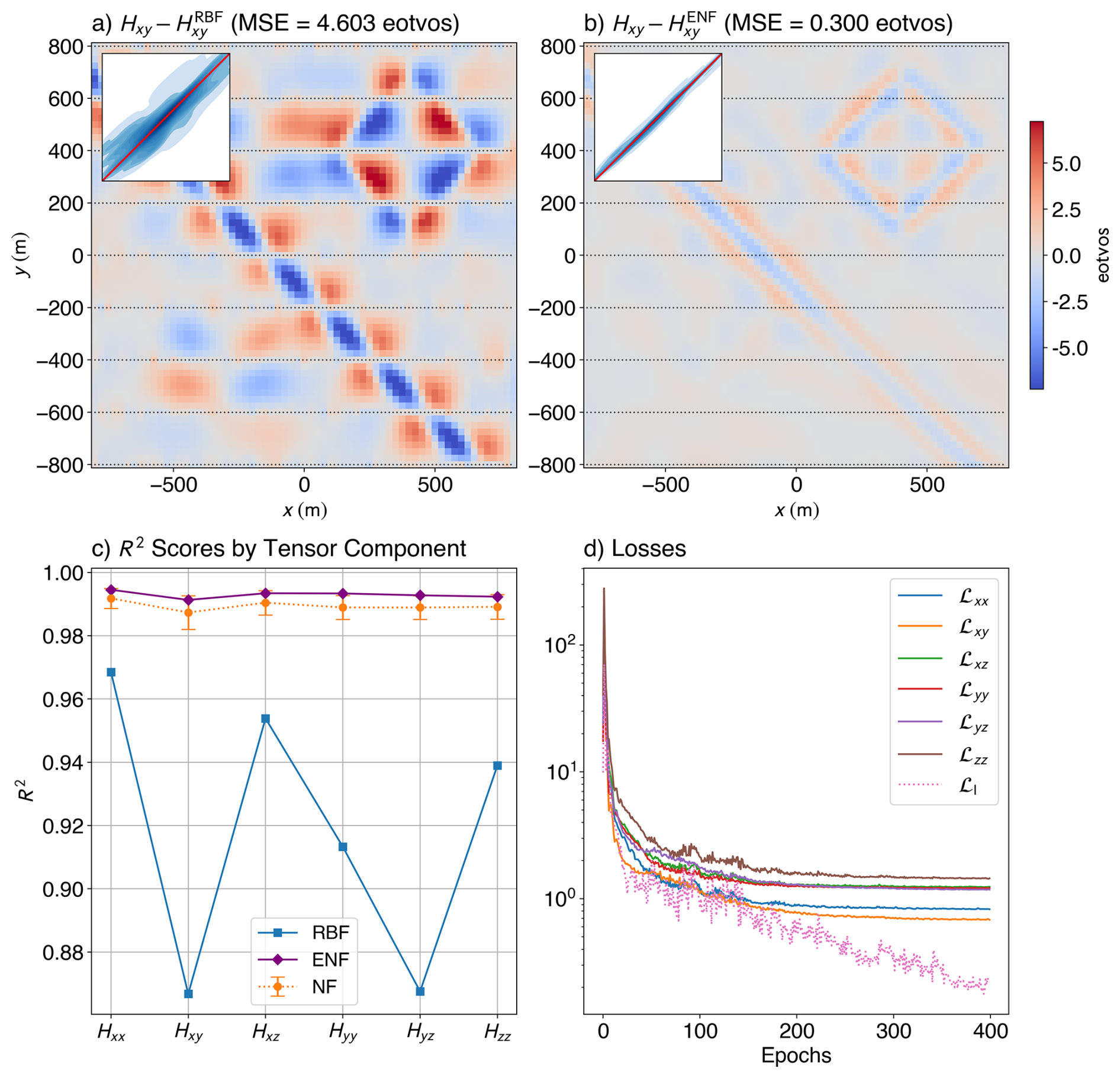
Figure 3Quantitative comparison of interpolation performance for the synthetic dataset. Spatial distribution of residuals between the true and predicted Hxy tensor component using (a) the Truncated Radial Basis Function (RBF) method and (b) the Ensemble Neural Field (ENF) approach (with 25 models in the ensemble). Insets show 1:1 parity kernel density plots comparing predicted and true values. (c) R2 scores for each tensor component (Hxx, Hxy, Hxz, Hyy, Hyz, Hzz) across three interpolation methods: RBF, the mean of the individual Neural Field (NF) scores from the models within the ensemble, and ENF. The ENF and NF models consistently achieve higher accuracy across all components, while RBF exhibits reduced performance. The loss curves (d) for various components of the loss show the data fitting parts (solid lines) plateau while the Laplacian part (dotted line) keeps decreasing owing to increased sampling with each progressive epoch.
For a quantitative measure of the improvement offered by our method, we plot the R2 scores for each tensor component across three interpolation methods: RBF, and two neural field-based (NF and ENF) (Fig. 3c). The NF method reflects the mean R2 from 25 independently trained models, with error bars showing standard deviation. The ENF method, by contrast, uses the averaged prediction across those same models. Both neural field approaches outperform classical methods, with ENF showing a slight edge – demonstrating that ensemble averaging reduces variance and enhances prediction stability. Figure 3d shows the loss curves for the various losses for one of the models within the ensemble, as a function of epochs. The data loss terms reasonably plateau after reaching values of ≈1 eotvos, while the real-time updating hyperparameters help avoid overfitting to a single component. The Laplacian loss (dotted pink line; ℒl) keeps steadily decreasing as the sampling gets tighter and ever more points are sampled from the grid.
To further evaluate structural accuracy, we compute the Structural Similarity Index Measure (SSIM) between predicted and true tensor fields (Fig. 4). The ENF method achieves higher SSIM scores across all three components – 0.95 (Hxx), 0.97 (Hxy), and 0.96 (Hxz) – compared to 0.78, 0.64, and 0.76 for RBF. The greatest improvement is seen in Hxy (improvement of ≈50.46 %), where RBF results show structural distortion, over-smoothing, and “boudinage” artefacts along flight lines (Naprstek and Smith, 2019). ENF, on the other hand, preserves coherent anomalies and directional continuity even across sparsely sampled regions.
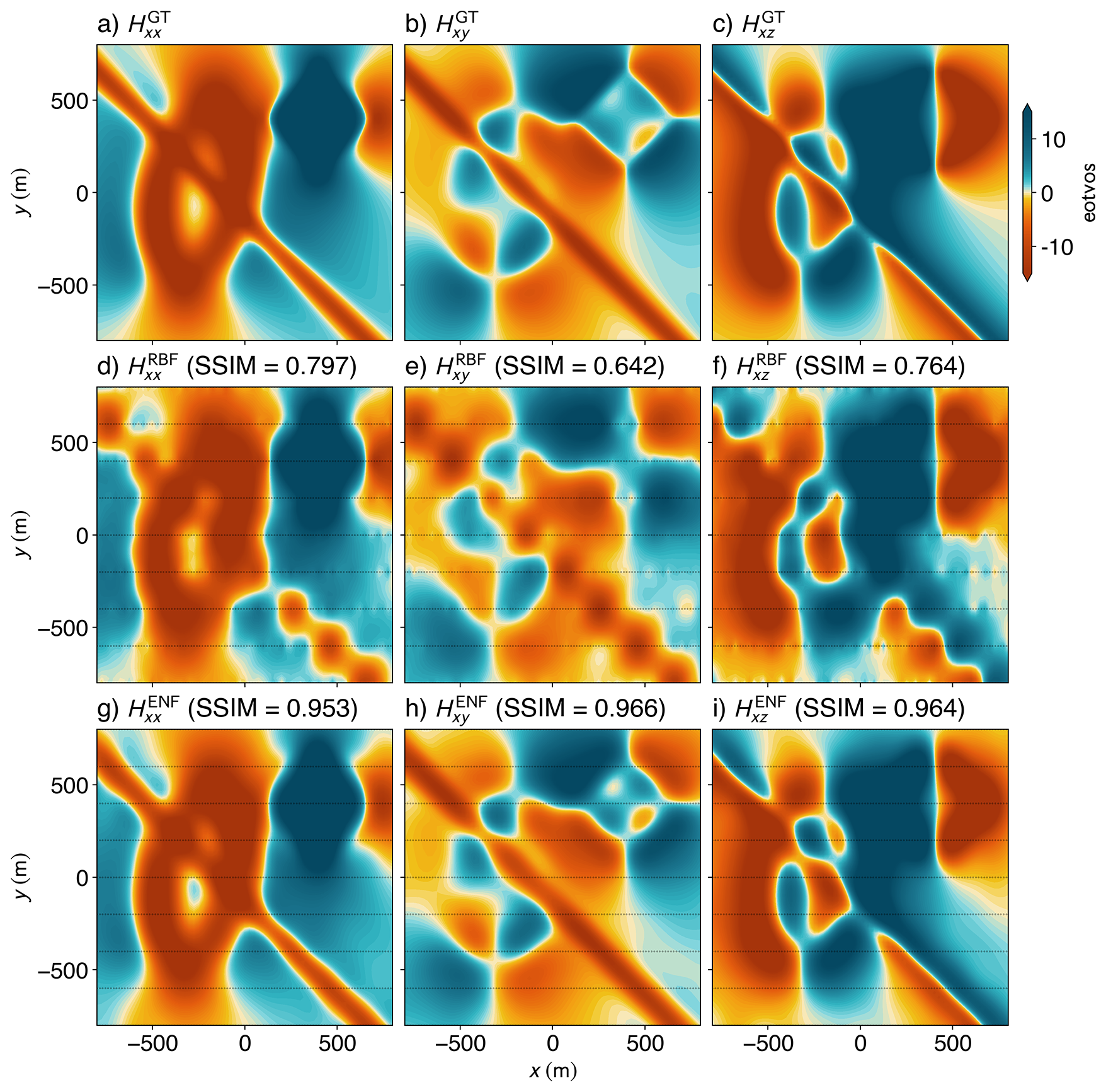
Figure 4Comparison of gravity gradiometry tensor components derived from two interpolation methods applied to the synthetic dataset. The ground truth Hxx, Hxy, and Hxz components (a–c) are compared with the results from the Truncated Radial Basis Function (RBF) (d–f) interpolation with 250 nearest neighbours and a smoothing factor of 100, and corresponding results produced by the Ensemble Neural Field (ENF) method (g–i) with 25 models in the ensemble. Black lines in interpolated results (d–i) indicate the input flight lines used for interpolation.
4.2 Rate of information loss
To assess robustness under sparse sampling, we compare the interpolation results for varying line spacings from 80 to 560 m (Fig. 5). Classical methods (RBF and quaternion-based interpolation, or QUAT) show sharp drops in accuracy beyond 200 m spacing. For example, the RBF method's root-mean-squared R2 (computed over the components) drops to 0.54, and the root-mean-squared SSIM plummets to 0.26 at 560 m. In contrast, NF interpolation maintains relatively stable performance up to ≈400 m spacing, with a much gentler decline at wider gaps. At 560 m, the NF model still achieves a root-mean-squared R2 of 0.91 and an SSIM of 0.65.
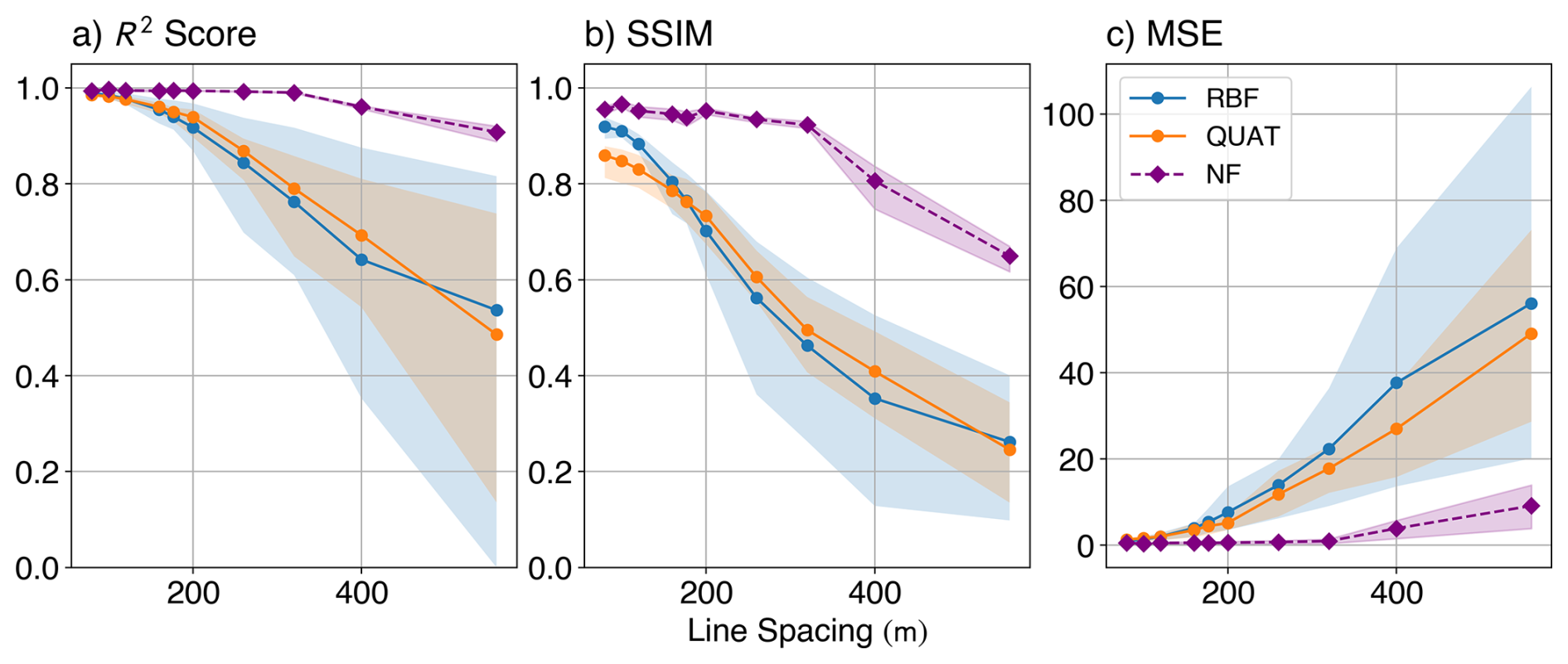
Figure 5Accuracy metrics as a function of increasing line spacing for the synthetic dataset. R2 score (a), Structural Similarity Index Measure (SSIM) (b), and Mean Squared Error (MSE) (c) were computed between the ground truth and the gridded results from the interpolation methods. The Radial Basis Function (RBF) used 250 nearest neighbours, with a smoothing factor of 100, and the Neural Field (NF) model used the same architecture as discussed in Sect. 3.3. The full tensor interpolation algorithm (QUAT; Fitzgerald et al., 2012) was also included for comparison, using the aforementioned RBF for the eigenvalue interpolation, and SLERP for rotational interpolation. The shaded regions show the minimum and maximum metric across all the components, and the plotted line shows the root-mean-squared metric computed across the components.
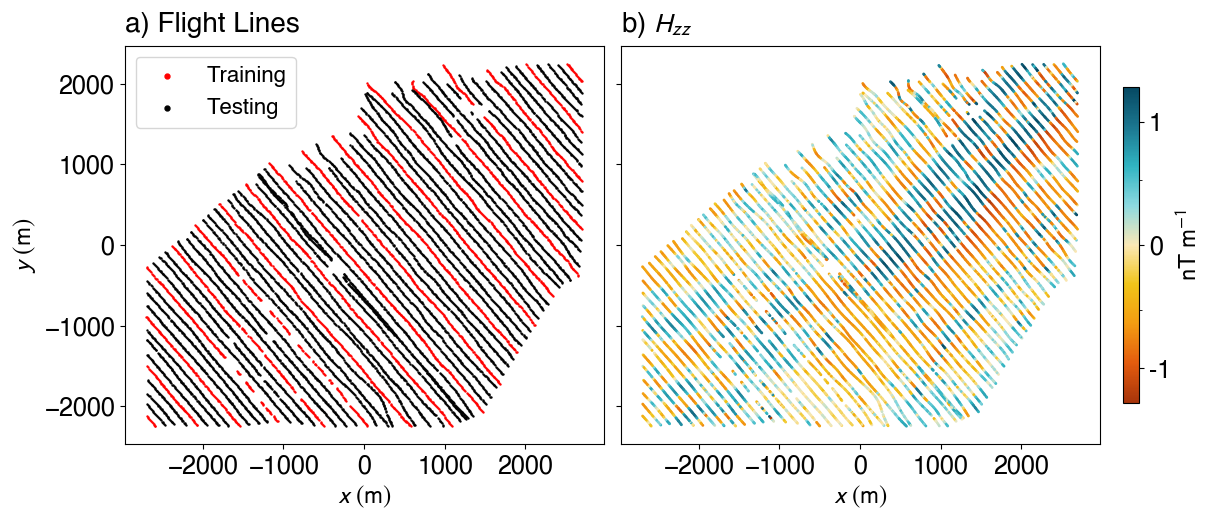
Figure 6Case study site near Geyer, Erzgebirge, Germany. Flight lines from a subset of the airborne magnetic gradiometry survey (a), with every fourth line (red) used as input for interpolation and the remaining lines (black) reserved for validation. (b) Spatial distribution of the measured zz-component of the magnetic gradiometry tensor across the survey region.
The MSE trends mirror this behaviour: classical methods exhibit steep error increases with sparser lines, while the NF model degrades more gracefully. QUAT offers minor improvements over component-wise interpolation but follows a similar performance trajectory. This suggests that the main bottleneck in full tensor interpolation lies in the eigenvalue interpolation step, which – like the component-wise case – relies on RBF methods.
4.3 Magnetic gradiometry from Geyer
Finally, we validated the method on real airborne magnetic gradiometry data from Geyer, located in Germany's Erzgebirge region – part of the Central European Variscides. The area features high- and medium-pressure metamorphic units, orthogneiss domes, and post-orogenic granites (Kroner and Romer, 2013), with abundant ore-forming skarns containing magnetic minerals (Burisch et al., 2019; Lefebvre et al., 2019) as well as magnetite-rich quartzites and amphibolites that occur as intercalations within the metamorphic rocks. These rocks contribute to complex magnetic anomalies ideal for real-world evaluation.
We test the ENF method on a real airborne magnetic gradiometry dataset from Geyer (Fig. 6), acquired by Supracon AG in 2016 as part of the E3 (ErzExploration Erzgebirge) project. As in the synthetic case, we compare ENF to RBF interpolation. Due to the complex nature of the signal, we run a 50 model ensemble for the Geyer dataset. Each model uses 64 Fourier features, with four length scales of [220, 400, 1000, 100 000]. The number of hidden layers is increased to three, with 1024, 512 and 256 neurons respectively. Each model is trained for 600 epochs, with early stopping triggered after 30 epochs of no improvement. A predefined grid with a cell-size of 20 m is used to evaluate the Laplacian loss, with the Poisson sampling radius starting at 500 m, and going to 200 m. Every fourth flight line is used for training, with the others reserved for testing the interpolation. Since ground-truth grids are unavailable, we assess accuracy using residual analysis and R2 scores computed for points in the withheld lines.
We plot the residual maps for Hxy on test lines (Fig. 7). While absolute R2 scores are lower than in the synthetic case – owing to added geological complexity and noise – ENF still achieves more than 30 % better performance than RBF across most tensor components, with a whopping increase of ≈157 % in the R2 score for Hyy, and an average increase of approximately 57.27 %. Both NF and ENF results are better than the RBF across all components. Residuals show that ENF (Fig. 7a) reduces systematic bias between lines and preserves anomaly shapes more faithfully. RBF (Fig. 7b), by contrast, displays patchy behaviour with abrupt shifts between lines – a well-known artifact of interpolating sparse or anisotropically sampled data (Hillier et al., 2014; Wittwer, 2009). The loss curves (Fig. 7d) show a similar trend to the synthetic case, with the data loss terms plateauing around 0.1 nT m−1, and the Laplacian loss steadily decreasing.
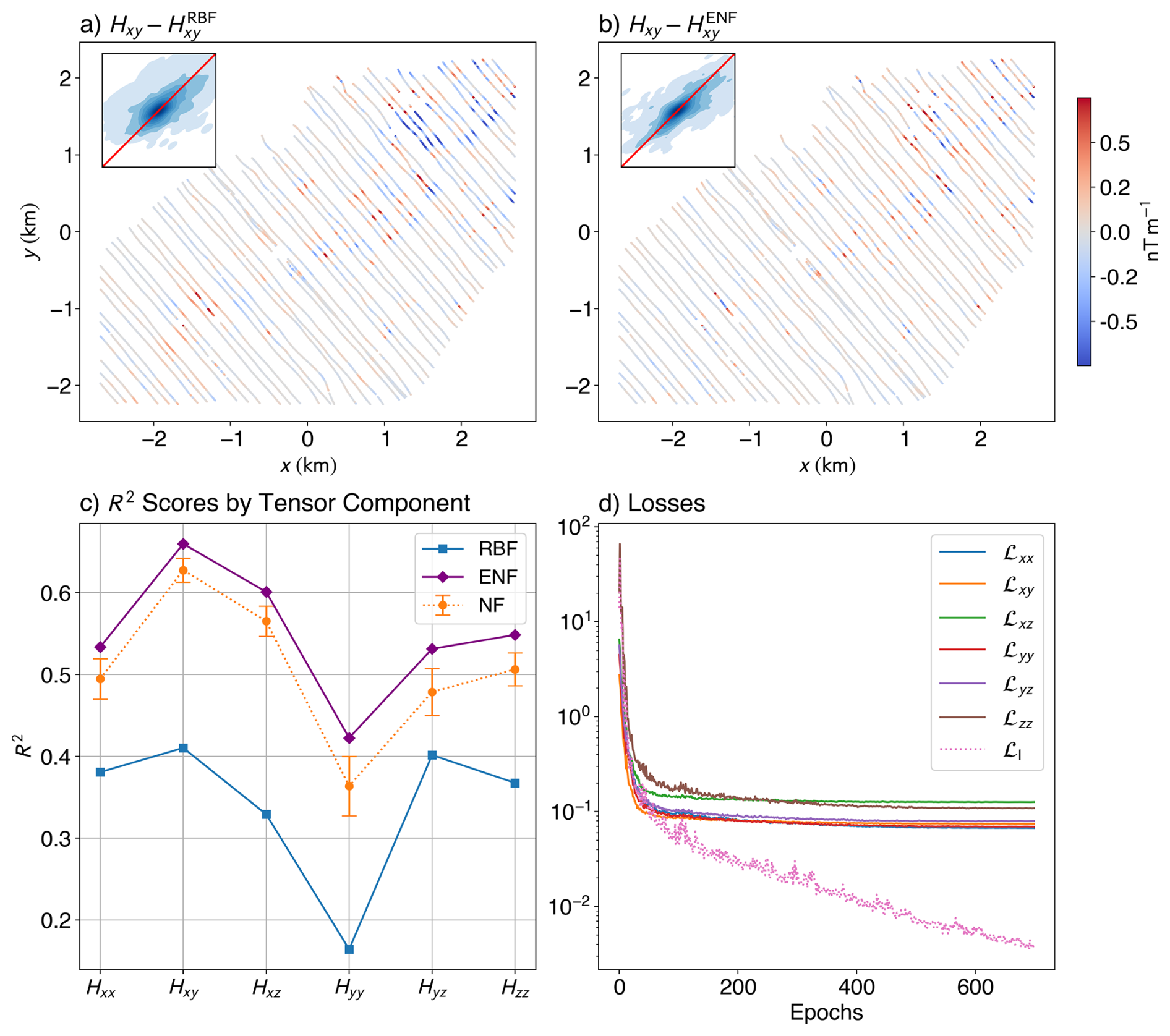
Figure 7Quantitative comparison of interpolation performance for the Geyer dataset. Spatial distribution of residuals between the true and predicted Hxy tensor component along the test flight lines using the Truncated Radial Basis Function (RBF) (a) method and the Ensemble Neural Field (ENF) (b) approach (with 50 models in the ensemble). Insets show 1:1 parity kernel density plots comparing predicted and true values. (c) R2 scores for each tensor component (Hxx, Hxy, Hxz, Hyy, Hyz, Hzz) across three interpolation methods: RBF, mean of the individual Neural Field (NF) scores from the models within the ensemble, and ENF. The ENF and NF models consistently achieve higher scores across all components, while RBF exhibits reduced performance. The loss curves (d) for various components of the loss show similar characteristics to the synthetic loss curve.
To get a qualitative overview of the overall result, we plot the gridded visualisations of the Hxx, Hxy, and Hxz tensor components (Fig. 8). We also compute a result from using all of the flight lines with an RBF interpolator (Fig. 8a–c), serving as our ground-truth. The RBF results from using every fourth line (Fig. 8d–f) reveal strong aliasing and inconsistent behaviour between flight lines – hallmarks of inadequate cross-line interpolation. In contrast, the ENF interpolations (Fig. 8g–i) exhibit smoother transitions and clearer structural trends, especially in directions orthogonal to flight lines. The ENF model successfully mitigates high-frequency striping and captures geologically meaningful features.
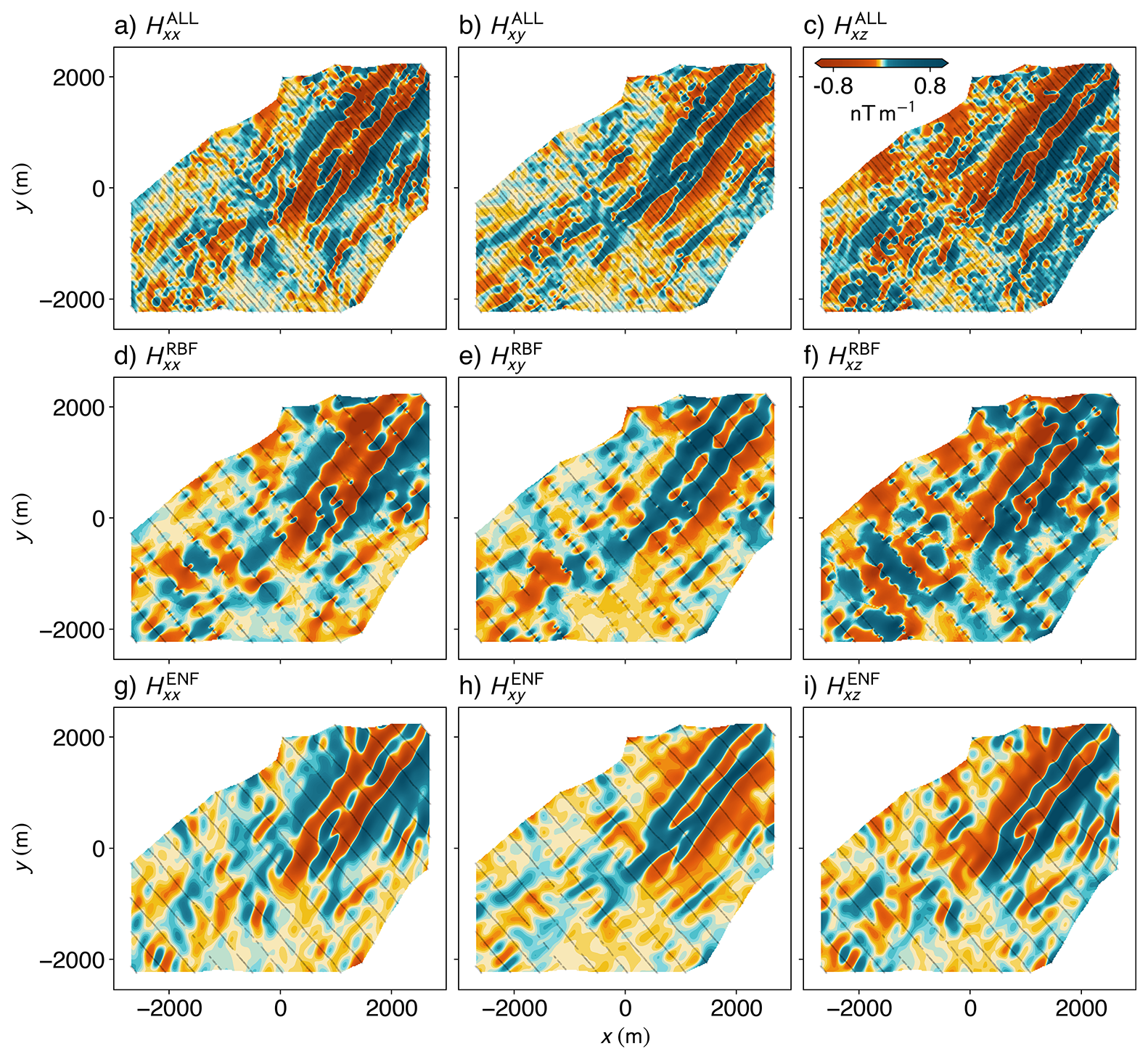
Figure 8Comparison of magnetic gradient tensor components interpolated onto a uniform grid (cell size = 20 m) using two methods. Gridded Hxx, Hxy, and Hxz components obtained using the Truncated Radial Basis Function (RBF) interpolation method, with 250 nearest neighbours and a smoothing factor of 100 for all of the flight lines (a–c) are used as the ground truth. We compare the ground truth with the corresponding components interpolated with RBF using every fourth flight line (d–f), and the corresponding components interpolated using the Ensemble Neural Field (ENF) approach (g–i) with 50 models in the ensemble. Each column visualises a distinct component of the tensor. Black lines within the plots indicate the locations of the input flight lines used in the interpolation process.
5.1 Accurately reconstructing tensor fields
The proposed Neural Field (NF) Interpolator has shown remarkable success in interpolating tensor gradiometry data. Our results show that the additional information contained within the hessian tensor can help derive a more accurate reconstruction of the entire field as sampling gets sparser (Fig. 5), provided the interpolation algorithm can access the full tensor constraints. For equivalent inputs, the NF interpolation recovers a signal that better fits all the tensor components, while maintaining the integrability and physical properties inherent to a hessian tensor field.
We also see equivalent results from all methods when line spacings are tight (i.e., for line spacings of 80, 100 and 120 m in our synthetic tests). This suggests an oversampling with respect to the spatial frequencies in the signal, such that all the interpolation methods converge to the same (correct) result to yield high accuracy metrics. Results then diverge as line spacing increases to 200 m, indicating the neural field interpolation is able to leverage information in the shape of the tensors to continue to derive accurate reconstructions, while the RBF and quaternion methods cannot.
The reason that the results converge with close spatial sampling could be attributed to the equivalence of SLERP and standard linear interpolation as the angle between the quaternions describing the orientations of the input data points goes to zero. Since a tighter line spacing ensures a smoother graduation of the eigenvector orientations (i.e., a smaller change in the angle between the corresponding quaternions), the resulting interpolation is closer to what one would achieve with standard linear interpolation of the components. But, under sparse sampling conditions, the differences seen in the results indicate that an interpolation using neural field formulation better preserves the shape of interpolated tensors, without the need for cumbersome quaternion formalisms.
The interpolated tensor components for Geyer (Fig. 8) also showcase significant improvements over the component-wise interpolation of these tensors. The extension and continuation of the trend from the centre of the grid, towards the north-east is preserved in the ENF result, but is completely absent in the RBF result. Any interpretation of these grids would thus result in significantly different geological structures, highlighting the necessity for appropriate interpolation methods. The Laplacian constraint is handled with an objective minimisation approach in our method. One could potentially enforce harmonicity by design, however this is challenging for 3D (i.e. geophysical potential) fields and difficult to enforce through the non-linear activation functions inherent to neural networks. In 2D, holomorphic functions (i.e., complex-differentiable functions of multiple variables) consist of real and imaginary parts that are harmonic functions, a fact that is utilised by Harmonic Neural Networks (e.g., PIHNNs; Calafà et al., 2024) to yield exactly harmonic outputs. These concepts do not directly extend to 3D, promoting an objective driven enforcement of the constraint. Vector potential based formulations (e.g. CurlNet; Ghosh et al., 2022) enforce divergence-free fields but fail to enforce the zero curl constraint. Furthermore, as our network consists of non-linear activations, and as non-linear compositions do not generally preserve harmonicity (Reich, 1987), we are further motivated to rely on our new mapping that has harmonic elements (see Sect. 3.2) and use an objective to constrain the Laplacian.
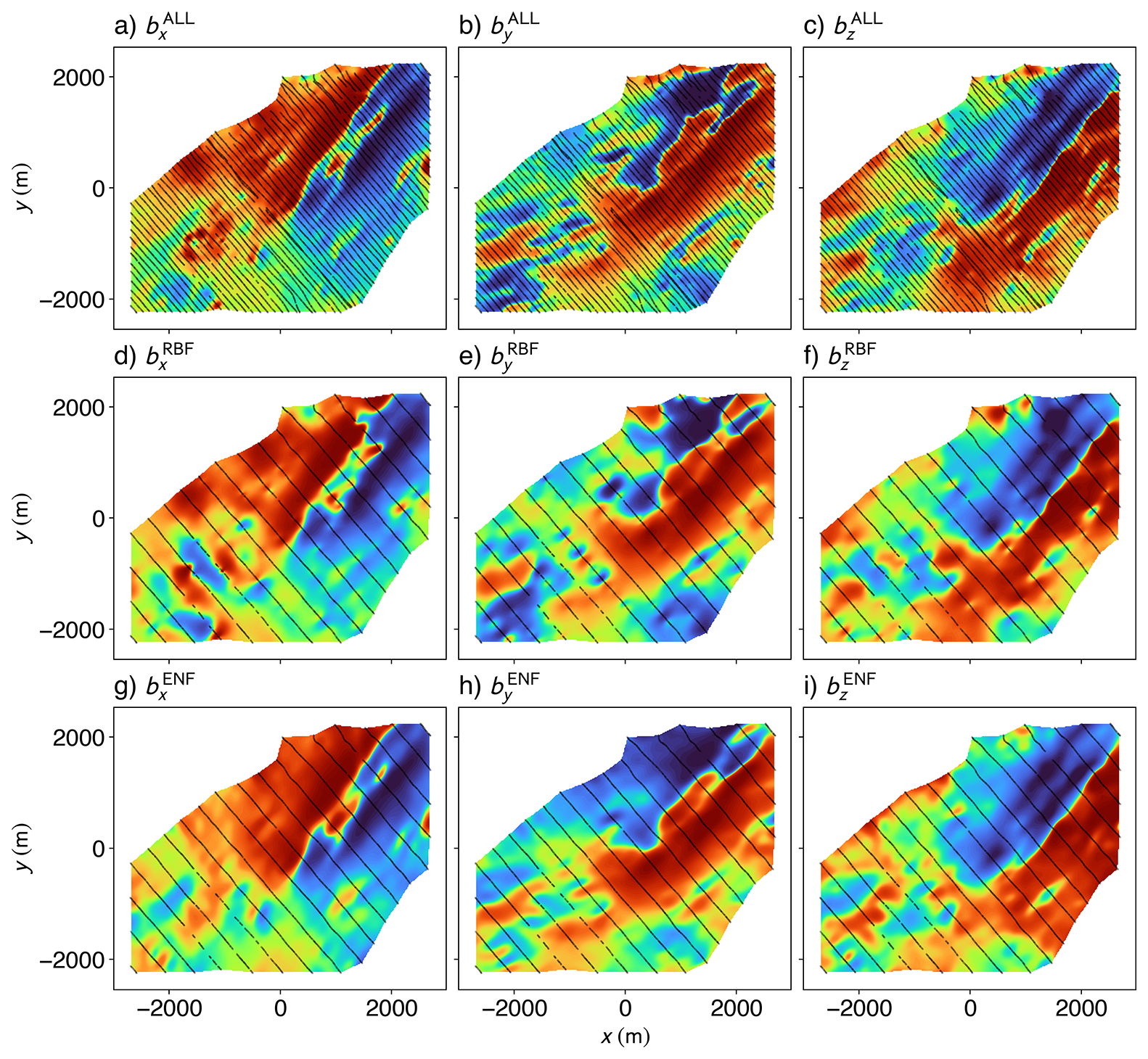
Figure 9Comparison of recovered vector magnetic field components from two interpolation methods, evaluated against a high-resolution reference model. We use vector components bx, by, and bz computed using Fourier domain transfer functions applied to magnetic tensor components gridded via the Truncated Radial Basis Function (RBF) from all available flight lines (a–c) as our reference. Fourier domain reconstruction of the vector components obtained using the RBF method on tensor data from the training set of flight lines (d–f), and the corresponding results computed from the spatial derivatives of the scalar field predicted by the Ensemble Neural Field (ENF) model (g–i) are shown. The black lines in each panel represent the flight lines used to generate the corresponding component. Each panel shows the histogram-equalised spatial distribution of the respective vector component across the subset of the Geyer survey area, mapped from 0 to 1.
5.2 Recovery of vector fields
Many analysis methods applied to tensor gradiometry data require a domain-wide integral to estimate the underlying vector field. The simplest way of computing this integral is by ignoring everything but the last row of the gradiometry tensor, and using the Hxz, Hyz, and Hzz components to get vector components. Due to the Fourier domain properties, vector components are defined as a vertical integral in the Fourier domain (Mickus and Hinojosa, 2001). Similarly, the power spectrum of these signals can also be used to generate vector components, using transfer functions that fit all of the signals while minimising noise (Vassiliou, 1986). However, in our method, we can completely avoid this potentially complex integral. We can use automatic differentiation to acquire the vector field components from the predicted scalar potential as the neural field predicts scalar potential and not the gradiometry tensor itself. Importantly, we thus estimate the vector field components exclusively from real measurements, rather than from an integral over a regularly spaced (i.e. interpolated) grid that is already one-step removed from the data.
To test the recovery of vector components from our model, we compared it to the benchmark generated using the RBF interpolation on all flight lines and then applying Fourier domain transfer functions to compute the integral. We also use the transfer functions on the RBF interpolation results for our training data for a baseline comparison (Fig. 9). Comparing the resulting bx (Fig. 9a, d and g) components, we see that features present in both the ground truth and the ENF results are completely erased from the RBF result. Similarly, the shape of the anomaly at the top-right corner of the grid is distorted in the RBF result, but completely preserved within the ENF grid. Slight changes in trend directions (i.e., the shift of the strike of the anomalies to having a smaller azimuth) also cannot be seen in the RBF results, which has prominent “boudinage” artefacts along the flight lines that cause a loss of trend and directional information perpendicular to the flight line. We suggest that these results highlight the ability of the neural field interpolation to extract sensible information (resembling the ground truth) from data acquired at four times the line spacing.
5.3 Uncertainty analysis and ensemble models
We also used the stochastic nature of our feature embeddings to do a preliminary uncertainty analysis for the results from our interpolator for the Geyer dataset (Fig. 10). The standard deviation plot shows higher variability in model predictions across regions without data points (i.e., between the flight lines), which could be interpreted as an uncertainty measure. Interestingly, the variance between flight lines seems to scale with the value of the underlying tensor component, leading to heteroscedasticity in the predictions. This might need correction in future developments of our methodology. It is also worth noting that the NF approach has parallels to the turning bands and spectral methods to simulate random fields (Mantoglou and Wilson, 1982), suggesting that a deeper stochastic link to other Gaussian process methods may be possible. This link could be exploited to better understand the variance of neural field ensembles or consider future modifications of the present NF algorithms towards tuned frequency matrix distributions.
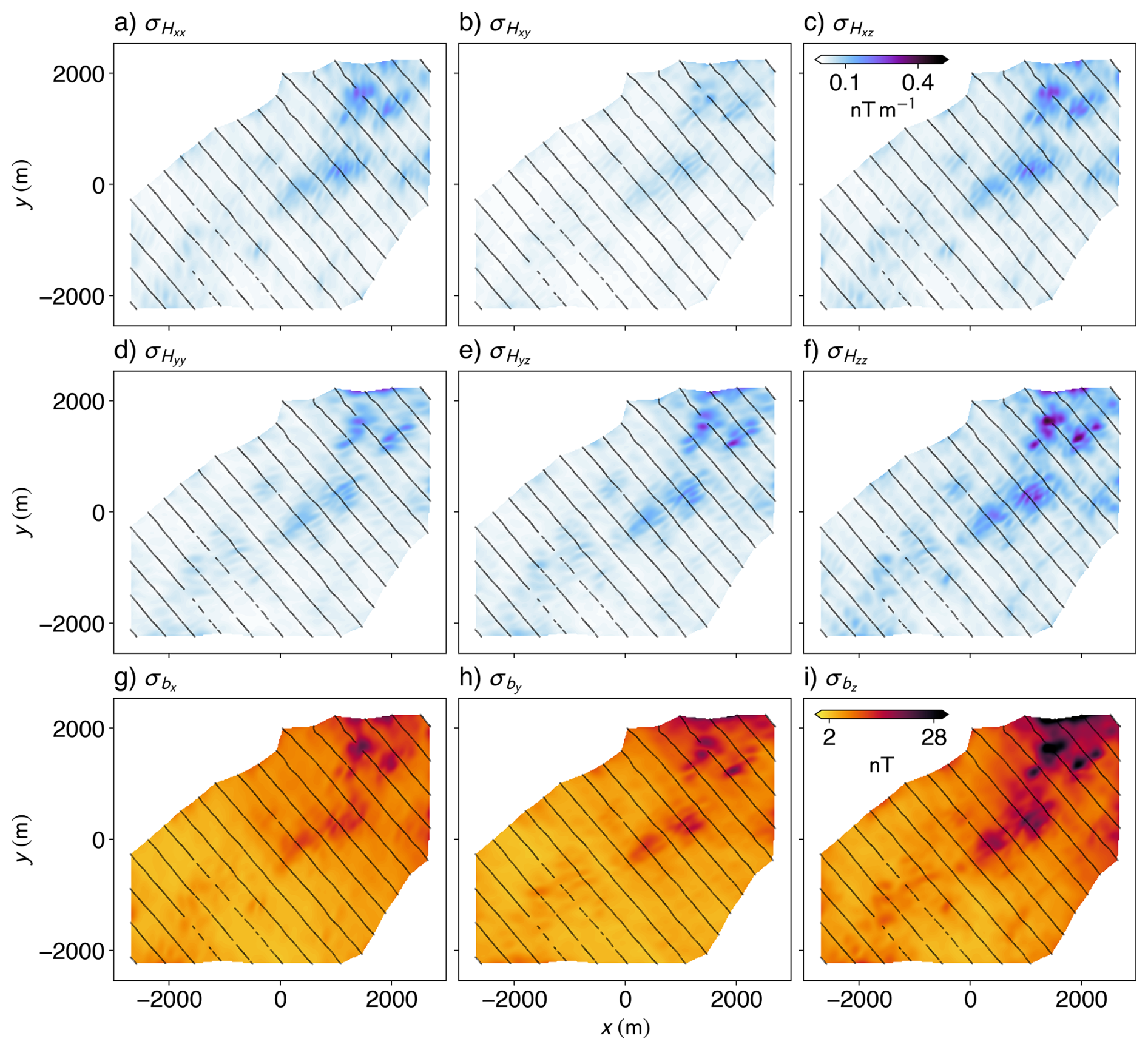
Figure 10Uncertainty maps for the 50-model ensemble. The standard deviation computed across 50 models for the Hxx (a), Hxy (b), Hxz (c), Hyy (d), Hyz (e), and Hzz (f) tensor components, and the recovered components bx (g), by (h), and bz (i) vector magnetic field.
The variance of our ensemble model is generally higher for the components with two derivatives in the same dimension (i.e., Hxx, Hyy, and Hzz), and for the derivatives involving the z component (i.e., Hxy seems to be the least uncertain). High same-dimension double derivative uncertainties might reflect the propagation of uncertainty through differentiation, as uncertainties in two variables have a chance of cancelling out, but are only amplified with multiple passes through the same derivative operator (Li and Oldenburg, 1998). The high uncertainty in the z components likely reflects the lack of information in the z direction, as all of our training data are close to co-planar. Furthermore, we also see that the uncertainty in the recovered vector components (Fig. 10g–i) never goes to zero (even where we have measurements of the tensor), reflecting the lack of information on the constant of integration.
Interpolated grids alter the observation error model: smoothing and continuation introduce spatially correlated errors that, if ignored, can bias ensemble-based inversions (EnKF). Best practice is naturally to invert at the real measurement locations, however when a grid is needed we suggest that our ENF ensemble could provide a mean and a sample covariance for the pseudo-observations. It is possible (although untested) that this might be used as the observation-error covariance in the inversion.
5.4 Challenges and future directions
We suggest that the proposed approach opens the door to using neural fields for potential field geophysics, and broader applications involving tensor quantities (e.g., stresses and strains). However, further work and research is needed in several areas. Firstly, our model is highly sensitive to the length scales chosen for the Fourier encoding. As shown by Tancik et al. (2020), optimisation algorithms fail to tweak these scales, meaning they need to be selected with careful empirical tuning. Furthermore, while we have utilised a real-time updating hyperparameter based on the magnitude of the loss, research into other possible avenues of automatising hyper-parameter tuning could boost the usability of our method and help to ensure robust results.
In addition, while the recovery of integrated vector fields is a big advantage of our approach, these have arbitrary integration constants. This ambiguity means that, for every vector component, there is a constant that is unbounded in the other two dimensions. The same problem occurs when we use the Fourier domain transfer functions, as a fundamental lack on long wavelength information leads us to misrepresenting the baseline for the recovered vector field (Ugalde et al., 2024). However, in our methodology, this could be resolved with a few measurements of the vector components included as constraints on the neural field. Therefore, one additional future direction would be to include multiple datasets (e.g., TMI measurements for magnetic gradiometry, satellite or ground gravity measurements for gravity gradiometry) during the training process. Further research on the propagation of uncertainties through our model, as well as impact of ensembles during inversion, would help in improving the robustness of our proposed framework.
Finally, the inclusion of a harmonic decaying term in the feature mapping makes our method a possible contender for an innovative downward continuation scheme, and thus help with the problem of noise amplification in the ill-posed downward continuation of potential field anomalies. This application needs further research, with proper tuning of the weight matrices and data acquired at multiple elevations for validation.
We introduce an innovative interpolation method tailored to tensor gradiometry data in potential field geophysics. This approach leverages the inherent physical relationships among tensor components by representing them as derivatives of an underlying scalar potential field. Our method clearly demonstrates advantages over conventional interpolation techniques, particularly in scenarios involving sparse and anisotropic data coverage, as are typical during aerial surveys.
Our method has shown substantial improvements in interpolation accuracy, structural fidelity, and robustness against data sparsity during evaluations on both synthetic gravity gradiometry data and a real-world magnetic gradiometry dataset from Geyer, Germany. Quantitative comparisons using metrics such as R2 scores and Structural Similarity Index Measure (SSIM) highlights the NF interpolator's performance across all tensor components, a preservation of geological trends that are typically used during interpretation, and a reduction of common artefacts caused by line-to-line inconsistencies.
Furthermore, by incorporating stochastic random Fourier features, our model likely opens the possibility to quantify uncertainty. Our analysis reveals heteroscedastic behaviour in the interpolations, and also highlights regions that require further data acquisition or refinement. Additionally, our approach seamlessly integrates vector and scalar field reconstructions through automatic differentiation, simplifying subsequent geophysical analyses and interpretations.
Overall, we argue that the proposed neural field interpolation method represents a significant advancement in processing tensor gradiometry data. Future developments should focus on larger scale applications, better understanding uncertainty of the model predictions, extended vertical interpolation capabilities (e.g., up- and downward continuations), and the integration of this approach into broader geophysical inversion and interpretation frameworks.
Tensorweave is an open-source Python library licensed under the GNU Public License v3.0. It is currently hosted on https://github.com/k4m4th/tensorweave (last access: 25 August 2025), and the version associated with this publication (including all data and code needed to reproduce our results) is archived at https://doi.org/10.5281/zenodo.16947831 (Kamath, 2025a). Notebooks to replicate the figures presented in this paper can be found within the Notebooks directory of this repository. The python environment (packages and specific versions) used is specified in the tensorweave.yml file. The synthetic gravity gradiometry dataset (with all the different line spacings), along with the synthetic density model and the magnetic gradiometry data from Geyer, Germany, can be found in the Datasets directory (in readily readable CSV format). The pre-trained ensemble for Geyer can be found at https://doi.org/10.14278/RODARE.3943 (Kamath, 2025b).
AVK: Conceptualisation, Formal analysis, Investigation, Methodology, Visualisation, Writing – original draft; STT: Conceptualisation, Methodology, Writing – original draft, review & editing; HU: Writing – review & editing; BM: Writing – review & editing; RTD: Discussion, Writing – review & editing; MK: Writing – review & editing; RG: Writing – review & editing.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
The authors gratefully acknowledge the Federal Institute for Geosciences and Natural Resources (BGR) and Supracon AG for providing the airborne full-tensor magnetic gradiometry dataset from Geyer, acquired in 2016 as part of the E3 (ErzExploration Erzgebirge) project. The authors thank Ítalo Gonçalves, David Nathan, and one anonymous reviewer for their constructive comments which helped tremendously to improve the manuscript. Akshay V. Kamath would also like to thank Vinit Gupta, Ralf Hielscher, and Parth Naik for their valuable insights and delightful discussions, which significantly contributed to improving the clarity and depth of the manuscript.
This research was supported by funding from the European Union's HORIZON Europe Research Council and UK Research and Innovation (UKRI) under grant agreement no. 101058483 (VECTOR).
The article processing charges for this open-access publication were covered by the Helmholtz-Zentrum Dresden-Rossendorf (HZDR).
This paper was edited by Thomas Poulet and reviewed by Italo Goncalves, David Nathan, and one anonymous referee.
Axler, S., Bourdon, P., and Ramey, W.: Harmonic Function Theory, in: vol. 137 of Graduate Texts in Mathematics, Springer, New York, NY, ISBN 978-1-4419-2911-2 978-1-4757-8137-3, https://doi.org/10.1007/978-1-4757-8137-3, 2001. a
Blakely, R. J.: Potential Theory in Gravity and Magnetic Applications, in: 1st Edn., Cambridge University Press, ISBN 978-0-521-41508-8, https://doi.org/10.1017/CBO9780511549816, 1995. a, b, c, d
Bottou, L.: Stochastic Gradient Descent Tricks, Springer, Berlin Heidelberg, 421–436, ISBN 9783642352898, https://doi.org/10.1007/978-3-642-35289-8_25, 2012. a
Bracewell, R. and Kahn, P. B.: The Fourier Transform and Its Applications, Am. J. Phys., 34, 712–712, https://doi.org/10.1119/1.1973431, 1966. a
Brewster, J.: Description and evaluation of a full tensor interpolation method, in: SEG Technical Program Expanded Abstracts 2011, Society of Exploration Geophysicists, 811–814, https://doi.org/10.1190/1.3628199, 2011. a, b
Burisch, M., Gerdes, A., Meinert, L. D., Albert, R., Seifert, T., and Gutzmer, J.: The essence of time – fertile skarn formation in the Variscan Orogenic Belt, Earth Planet. Sc. Lett., 519, 165–170, https://doi.org/10.1016/j.epsl.2019.05.015, 2019. a
Calafà, M., Hovad, E., Engsig-Karup, A. P., and Andriollo, T.: Physics-Informed Holomorphic Neural Networks (PIHNNs): Solving 2D linear elasticity problems, Comput. Meth. Appl. Mech. Eng., 432, 117406, https://doi.org/10.1016/j.cma.2024.117406, 2024. a
Chen, Z., Badrinarayanan, V., Lee, C.-Y., and Rabinovich, A.: GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks, arXiv [preprint], https://doi.org/10.48550/ARXIV.1711.02257, 2017. a
Cockett, R., Kang, S., Heagy, L. J., Pidlisecky, A., and Oldenburg, D. W.: SimPEG: An open source framework for simulation and gradient based parameter estimation in geophysical applications, Comput. Geosci., 85, 142–154, https://doi.org/10.1016/j.cageo.2015.09.015, 2015. a
Cordell, L.: A scattered equivalent‐source method for interpolation and gridding of potential‐field data in three dimensions, Geophysics, 57, 629–636, https://doi.org/10.1190/1.1443275, 1992. a
Dampney, C. N. G.: The equivalent source technique, Geoophysics, 34, 39–53, https://doi.org/10.1190/1.1439996, 1969. a
Davis, K. and Li, Y.: Fast solution of geophysical inversion using adaptive mesh, space-filling curves and wavelet compression, Geophys. J. Int., 185, 157–166, https://doi.org/10.1111/j.1365-246x.2011.04929.x, 2011. a
Evensen, G.: Data Assimilation: The Ensemble Kalman Filter, in: 2nd Edn., Springer, ISBN-10 3642424767, 2009. a
Fatiando a Terra Project, Castro, Y. M., Esteban, F. D., Li, L., Oliveira Jr., V. C., Pesce, A., Shea, N., Soler, S. R., Souza-Junior, G. F., Tankersley, M., Uieda, L., and Uppal, I.: Harmonica v0.7.0: Forward modeling, inversion, and processing gravity and magnetic data, Zenodo [code and data set], https://doi.org/10.5281/ZENODO.3628741, 2024. a
Fichtner, A., Kennett, B. L. N., Igel, H., and Bunge, H.-P.: Full seismic waveform tomography for upper-mantle structure in the Australasian region using adjoint methods, Geophys. J. Int., 186, 1459–1473, 2011. a
Fitzgerald, D., Paterson, R., and Holstein, H.: Comparing Two Methods for Gridding and Honouring Gravity Gradient Tensor Data, Copenhagen, Denmark, EarthDoc, https://doi.org/10.3997/2214-4609.20148284, 2012. a, b, c, d
Ghosh, A., Gentile, A. A., Dagrada, M., Lee, C., Kim, S.-H., Cha, H., Choi, Y., Kim, B., Kye, J.-I., and Elfving, V. E.: Harmonic (Quantum) Neural Networks, arXiv [preprint], https://doi.org/10.48550/ARXIV.2212.07462, 2022. a
Giraud, J., Seillé, H., Lindsay, M. D., Visser, G., Ogarko, V., and Jessell, M. W.: Utilisation of probabilistic magnetotelluric modelling to constrain magnetic data inversion: proof-of-concept and field application, Solid Earth, 14, 43–68, https://doi.org/10.5194/se-14-43-2023, 2023. a
Goodfellow, I., Bengio, Y., and Courville, A.: Deep learning, Adaptive computation and machine learning, The MIT Press, Cambridge, Mass., ISBN 978-0-262-03561-3, 2016. a
Hamilton, W. R.: II. On quaternions; or on a new system of imaginaries in algebra, The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 25, 10–13, https://doi.org/10.1080/14786444408644923, 1844. a
Hansen, R. O. and Miyazaki, Y.: Continuation of potential fields between arbitrary surfaces, Geophysics, 49, 787–795, https://doi.org/10.1190/1.1441707, 1984. a
Hewitson, B. C., Crane, R. G., and Tietze, W. (Eds.): Neural Nets: Applications in Geography, in: vol. 29 of The GeoJournal Library, Springer Netherlands, Dordrecht, ISBN 978-94-010-4490-5, https://doi.org/10.1007/978-94-011-1122-5, 1994. a
Hillier, M., Wellmann, F., De Kemp, E. A., Brodaric, B., Schetselaar, E., and Bédard, K.: GeoINR 1.0: an implicit neural network approach to three-dimensional geological modelling, Geosci. Model Dev., 16, 6987–7012, https://doi.org/10.5194/gmd-16-6987-2023, 2023. a
Hillier, M. J., Schetselaar, E. M., De Kemp, E. A., and Perron, G.: Three-Dimensional Modelling of Geological Surfaces Using Generalized Interpolation with Radial Basis Functions, Math. Geosci., 46, 931–953, https://doi.org/10.1007/s11004-014-9540-3, 2014. a
Kamath, A., Thiele, S., and Gloaguen, R.: (Auto) Differentiating geology: Geological modelling with random Fourier features and neural fields, EGU General Assembly 2025, Vienna, Austria, 27 April–2 May 2025, EGU25-9746, https://doi.org/10.5194/egusphere-egu25-9746, 2025. a
Kamath, A. V.: k4m4th/tensorweave: tensorweave-1.0, Zenodo [code and data set], https://doi.org/10.5281/ZENODO.16947831, 2025a. a
Kamath, A. V.: Pre-trained ensemble for Geyer Data (Tensorweave), Rodare [data set], https://doi.org/10.14278/RODARE.3943, 2025b. a
Kendall, A., Gal, Y., and Cipolla, R.: Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics, arXiv [preprint], https://doi.org/10.48550/ARXIV.1705.07115, 2017. a
Kingma, D. P. and Ba, J.: Adam: A Method for Stochastic Optimization, arXiv [preprint], https://doi.org/10.48550/ARXIV.1412.6980, 2014. a
Kroner, U. and Romer, R.: Two plates – Many subduction zones: The Variscan orogeny reconsidered, Gondwana Res., 24, 298–329, https://doi.org/10.1016/j.gr.2013.03.001, 2013. a
Lacava, F.: Separation of Variables in Laplace Equation, Springer International Publishing, 137–177, ISBN 9783031050992, https://doi.org/10.1007/978-3-031-05099-2_8, 2022. a
LeCun, Y., Bengio, Y., and Hinton, G.: Deep learning, Nature, 521, 436–444, https://doi.org/10.1038/nature14539, 2015. a
Lee, J. M.: Introduction to Smooth Manifolds, in: vol. 218 of Graduate Texts in Mathematics, Springer, New York, NY, ISBN 978-1-4419-9981-8, https://doi.org/10.1007/978-1-4419-9982-5, 2012. a
Lefebvre, M. G., Romer, R. L., Glodny, J., Kroner, U., and Roscher, M.: The Hämmerlein skarn-hosted polymetallic deposit and the Eibenstock granite associated greisen, western Erzgebirge, Germany: two phases of mineralization – two Sn sources, Mineralium Deposita, 54, 193–216, https://doi.org/10.1007/s00126-018-0830-4, 2019. a
Li, Y. and Oldenburg, D. W.: 3-D inversion of gravity data, Geophysics, 63, 109–119, https://doi.org/10.1190/1.1444302, 1998. a
Li, Y. and Oldenburg, D. W.: Rapid construction of equivalent sources using wavelets, Geophysics, 75, L51–L59, https://doi.org/10.1190/1.3378764, 2010. a
Liu, S., Johns, E., and Davison, A. J.: End-To-End Multi-Task Learning With Attention, in: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1871–1880, https://doi.org/10.1109/cvpr.2019.00197, 2019. a
Mantoglou, A. and Wilson, J. L.: The Turning Bands Method for simulation of random fields using line generation by a spectral method, Water Resour. Res., 18, 1379–1394, https://doi.org/10.1029/WR018i005p01379, 1982. a
Margossian, C. C.: A Review of automatic differentiation and its efficient implementation, Wires, 9, e1305, https://doi.org/10.1002/WIDM.1305, 2019. a
Markley, F. L., Cheng, Y., Crassidis, J. L., and Oshman, Y.: Averaging Quaternions, J. Guidance Control Dynam., 30, 1193–1197, https://doi.org/10.2514/1.28949, 2007. a
Mendonça, C. A. and Silva, J. B. C.: The equivalent data concept applied to the interpolation of potential field data, Geophysics, 59, 722–732, https://doi.org/10.1190/1.1443630, 1994. a
Mickus, K. L. and Hinojosa, J. H.: The complete gravity gradient tensor derived from the vertical component of gravity: a Fourier transform technique, J. Appl. Geophys., 46, 159–174, https://doi.org/10.1016/S0926-9851(01)00031-3, 2001. a
Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., and Ng, R.: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, arxiv, https://doi.org/10.48550/ARXIV.2003.08934, 2020. a
Misra, D.: Mish: A Self Regularized Non-Monotonic Activation Function, arXiv [preprint], https://doi.org/10.48550/ARXIV.1908.08681, 2019. a
Naprstek, T. and Smith, R. S.: A new method for interpolating linear features in aeromagnetic data, Geophysics, 84, JM15–JM24, https://doi.org/10.1190/geo2018-0156.1, 2019. a
Oliveira Junior, V. C., Takahashi, D., Reis, A. L. A., and Barbosa, V. C. F.: Computational aspects of the equivalent-layer technique: review, Front. Earth Sci., 11, https://doi.org/10.3389/feart.2023.1253148, 2023. a
Openshaw, S.: Modelling spatial interaction using a neural net, in: Geographic Information Systems, Spatial Modelling and Policy Evaluation, edited by: Fischer, M. M. and Nijkamp, P., Springer, Berlin, Heidelberg, 147–164, ISBN 978-3-642-77502-4, https://doi.org/10.1007/978-3-642-77500-0_10, 1993. a
Parker, R. L.: The Rapid Calculation of Potential Anomalies, Geophys. J. Int., 31, 447–455, https://doi.org/10.1111/j.1365-246x.1973.tb06513.x, 1973. a
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Köpf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S.: PyTorch: An Imperative Style, High-Performance Deep Learning Library, version Number: 1, arXiv [preprint], https://doi.org/10.48550/ARXIV.1912.01703, 2019. a
Piauilino, L. S., Oliveira Junior, V. C., and Barbosa, V. C. F.: A Scalable and Consistent Method for Multi-Component Gravity-Gradient Data Processing, Appl. Sci., 15, 8396, https://doi.org/10.3390/app15158396, 2025. a, b
Prechelt, L.: Early Stopping – But When?, Springer, Berlin, Heidelberg, 55–69, ISBN 9783540494300, https://doi.org/10.1007/3-540-49430-8_3, 1998. a
Rahaman, N., Baratin, A., Arpit, D., Draxler, F., Lin, M., Hamprecht, F. A., Bengio, Y., and Courville, A.: On the Spectral Bias of Neural Networks, arXiv, https://doi.org/10.48550/ARXIV.1806.08734, 2018. a
Rahimi, A. and Recht, B.: Random features for large-scale kernel machines, in: Proceedings of the 21st International Conference on Neural Information Processing Systems, NIPS'07, Curran Associates Inc., Red Hook, NY, USA, 1177–1184, ISBN 9781605603520, 2007. a
Raissi, M., Perdikaris, P., and Karniadakis, G. E.: Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, J. Comput. Phys., 378, 686–707, https://doi.org/10.1016/j.jcp.2018.10.045, 2019. a
Ramachandran, P., Zoph, B., and Le, Q. V.: Searching for Activation Functions, arXiv [preprint], https://doi.org/10.48550/ARXIV.1710.05941, 2017. a
Reich, E.: The composition of harmonic mappings, Ann. Acad. Sci. Fenn. Ser. A I Math., 12, 47–53, https://doi.org/10.5186/aasfm.1987.1230, 1987. a
Rudd, J., Chubak, G., Larnier, H., Stolz, R., Schiffler, M., Zakosarenko, V., Schneider, M., Schulz, M., and Meyer, M.: Commercial operation of a SQUID-based airborne magnetic gradiometer, Leading Edge, 41, 486–492, https://doi.org/10.1190/tle41070486.1, 2022. a, b
Saragadam, V., LeJeune, D., Tan, J., Balakrishnan, G., Veeraraghavan, A., and Baraniuk, R. G.: WIRE: Wavelet Implicit Neural Representations, arXiv [preprint], https://doi.org/10.48550/ARXIV.2301.05187, 2023. a
Satheesh, A., Schmidt, C. P., Wall, W. A., and Meier, C.: Structure-preserving invariant interpolation schemes for invertible second‐order tensors, Int. J. Numer. Meth. Eng., 125, https://doi.org/10.1002/nme.7373, 2023. a, b
Shoemake, K.: Animating rotation with quaternion curves, ACM SIGGRAPH Comput. Graph., 19, 245–254, https://doi.org/10.1145/325165.325242, 1985. a
Siqueira, F. C. L., Oliveira Jr., V. C., and Barbosa, V. C. F.: Fast iterative equivalent-layer technique for gravity data processing: A method grounded on excess mass constraint, Geophysics, 82, G57–G69, https://doi.org/10.1190/geo2016-0332.1, 2017. a
Sitzmann, V., Martel, J. N. P., Bergman, A. W., Lindell, D. B., and Wetzstein, G.: Implicit Neural Representations with Periodic Activation Functions, CoRR, abs/2006.09661, arXiv [preprint], https://doi.org/10.48550/arXiv.2006.09661, 2020. a
Smith, L. T., Horrocks, T., Akhtar, N., Holden, E.-J., and Wedge, D.: Implicit neural representation for potential field geophysics, Sci. Rep., 15, 9799, https://doi.org/10.1038/s41598-024-83979-z, 2025. a
Soler, S. R. and Uieda, L.: Gradient-boosted equivalent sources, Geophys. J. Int., 227, 1768–1783, https://doi.org/10.1093/gji/ggab295, 2021. a
Stolz, R., Schmelz, M., Zakosarenko, V., Foley, C. P., Tanabe, K., Xie, X., and Fagaly, R.: Superconducting sensors and methods in geophysical applications, Supercond. Sci. Technol., 34, 033001, https://doi.org/10.1088/1361-6668/abd7ce, 2021. a
Tancik, M., Srinivasan, P. P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Singhal, U., Ramamoorthi, R., Barron, J. T., and Ng, R.: Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains, arXiv [preprint], https://doi.org/10.48550/ARXIV.2006.10739, 2020. a, b, c, d
Thiele, S., Kamath, A., and Gloaguen, R.: Less is more: Weakly supervised interpolation using geological neural fields, EGU General Assembly 2025, Vienna, Austria, 27 April–2 May 2025, EGU25-8735, https://doi.org/10.5194/egusphere-egu25-8735, 2025. a
Tveit, S., Mannseth, T., Park, J., Sauvin, G., and Agersborg, R.: Combining CSEM or gravity inversion with seismic AVO inversion, with application to monitoring of large-scale CO2 injection, Comput. Geosci., 24, 1201–1220, https://doi.org/10.1007/s10596-020-09934-9, 2020. a
Ugalde, H., Morris, B., Kamath, A., and Parsons, B.: Full‐tensor magnetic gradiometry: Comparison with scalar total magnetic intensity, processing and visualization guidelines, Geophys. Prospect., 73, 303–314, https://doi.org/10.1111/1365-2478.13629, 2024. a, b, c
Vassiliou, A.: Numerical techniques for processing airborne gradiometer data, University of Calgary, https://doi.org/10.11575/PRISM/23539, 1986. a, b
White, K. B., Cline, D., and Egbert, P. K.: Poisson Disk Point Sets by Hierarchical Dart Throwing, in: 2007 IEEE Symposium on Interactive Ray Tracing, 129–132, https://doi.org/10.1109/rt.2007.4342600, 2007. a
Wittwer, T.: Regional gravity field modeling with radial basis functions, vol. 72 of Publications on Geodesy, Nederlandse Commissie voor Geodesie, ISBN 978-90-6132-315-0, https://doi.org/10.54419/hboxky, 2009. a
Xia, J. and Sprowl, D. R.: Correction of topographic distortion in gravity data, Geophysics, 56, 537–541, https://doi.org/10.1190/1.1443070, 1991. a
Xie, Y., Takikawa, T., Saito, S., Litany, O., Yan, S., Khan, N., Tombari, F., Tompkin, J., Sitzmann, V., and Sridhar, S.: Neural Fields in Visual Computing and Beyond, Comput. Graph. Forum, 41, 641–676, https://doi.org/10.1111/cgf.14505, 2022. a
Zuo, B. and Hu, X.: Edge detection of gravity field using eigenvalue analysis of gravity gradient tensor, J. Appl. Geophys., 114, 263–270, https://doi.org/10.1016/j.jappgeo.2015.01.013, 2015. a