the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 19 Sep 2025
| 19 Sep 2025
Evaluating the performance of CE-QUAL-W2 version 4.5 sediment diagenesis model
Pedro Coelho
This research evaluates the performance of the CE-QUAL-W2 v4.5 sediment diagenesis model in simulating water temperature, dissolved oxygen, total phosphorus, total nitrogen, chlorophyll a, and biochemical oxygen demand in a Portuguese reservoir over a six-year period (2016–2021). The model was calibrated using 35 observed profiles of temperature and dissolved oxygen, as well as six annual measurements of total nitrogen, total phosphorus, chlorophyll a, and biochemical oxygen demand at multiple depths. To benchmark performance to the sediment diagenesis model, three alternative sediment oxygen demand formulations – a Zero-order, First-order, and a Hybrid model combining both approaches – were also implemented and compared. All models achieved NSE and RMSE values within or near the ranges reported in the literature, effectively capturing the system's water quality dynamics. Among them, the Hybrid model yielded the best overall performance while maintaining a simpler structure (Water temperature – NSE: 0.96±0.18; RMSE: 1.09±0.23 °C; Dissolved oxygen – NSE: 0.76±0.30; RMSE: 1.87±0.72 mg L−1). The sediment diagenesis model exhibited similar performance metrics (Water temperature – NSE: 0.95±0.18; RMSE: 1.13±0.28 °C; Dissolved oxygen – NSE: 0.71±0.14; RMSE: 2.01±0.59 mg L−1). Overall, the results suggest that the diagenesis model may be better suited for capturing detailed process-based dynamics over extended timeframes, whereas simpler models, such as the Hybrid model, are more appropriate for short- to medium-term applications or situations with limited data availability. Hopefully, the results of this study will help improve water management strategies by supporting more informed model selection tailored to the temporal scope and data constraints of reservoir monitoring programs.
- Article
(15049 KB) - Full-text XML
- BibTeX
- EndNote




Modeling water quality plays a crucial role in managing lakes and reservoirs, providing essential insights into the dynamics of nutrients, organic matter, and phytoplankton within aquatic systems (Abbaspour et al., 2015; Whitehead et al., 2009). These models simulate the physical, chemical, and biological processes that influence water quality, with examples including widely-used tools like CE-QUAL-W2 (Wells, 2021), MIKE21 (Chapman, 1996), and DYRESM (Hamilton and Schladow, 1997). The value of such modeling lies in its capacity to aid researchers and policymakers in understanding the complex interactions between various factors that impact the ecological health of water bodies (Varis et al., 1994; Loucks and Beek, 2017). However, the intricacy of these systems, combined with the substantial data requirements, often presents significant challenges for those developing and applying water quality models. Effective inflow data characterization (quantity and quality) is hard to obtain, both for major river branches and small tributaries, as is waterbody sediment characterization related to carbon and nutrients due to the significant cost associated with the sampling and laboratorial analysis process and the fact that water management stakeholders are still more focused on the classification of waterbody water quality rather than the collection of water quality forcing data. The absence of sediment initial particulate organic carbon (POC), particulate organic nitrogen (PON) and particulate organic phosphorus (POP) data can be decisive to the overall performance of a water quality model, in essence generating an imbalance right from the start of the simulation with regard to the sediment concentration of POC, PON and POP, which then has a considerable impact on the SOD and, consequently, the waterbody dissolved oxygen (DO). When calibrating the model, water quality modelers therefore need to plug this gap by evaluating the model performance considering: (i) different initial sediment oxygen demand (SOD) where a zero-order model is applied, (ii) different POC, PON and POP values where a predictive diagenesis model is considered.
The main challenge with these modeling approaches is that the sources of DO depletion – such as the inflow of organic matter and net algae growth and settling – can significantly influence DO dynamics, and these sources must be well characterized to ensure accurate predictions. While the baseline model can reproduce observed DO profiles with reasonable accuracy, its predictive reliability may be compromised if key DO sinks and sources are not well defined.
For example, the model's response to a reduction in external phosphorus loading is influenced by internal phosphorus release from sediments during anoxic periods. In CE-QUAL-W2, when a zero-order SOD model is used, the anoxic release of orthophosphate (PO4) is modeled as a linear function of SOD: SOD [g O2 m−2 d−1] × PO4 release rate [g P g−1 O2]. Thus, any error in the estimation of SOD will directly affect the predicted internal phosphorus loading, and by extension, the overall phosphorus balance in the waterbody. In contrast, when using the predictive sediment diagenesis model, internal phosphorus loading depends on the organic and nutrient inputs from particulate matter in the water column and the sediment's biogeochemical response, which is highly influenced by the initial value of particulate organic carbon (POC). As a result, this approach introduces additional uncertainty when key particulate components are not adequately measured or constrained in both the water column and sediments. Calibrating other constituents, such as P-PO4, can help reduce uncertainty. P-PO4 is released from sediments under anaerobic conditions, and its calibration can enhance the accuracy of DO modeling. Still, this release is influenced by multiple factors, including the initial sediment P-PO4 concentration and the release rate (in the zero-order model), or the mineralization of POP (in the diagenesis model). In both cases, significant uncertainty remains without observed data for POC, PON, and POP in both the water column and sediments. Of these, POC has the most significant influence on SOD, making access to sediment POC data essential for improving model accuracy, even when PON and POP measurements are lacking. The CE-QUAL-W2 model has been widely used to simulate various water bodies and water quality scenarios, including reservoir physical and biochemical dynamics in response to warming projections (Mi et al., 2020, 2023). This model has also been used to predict DO in a number of water bodies worldwide, although the SOD has always been modeled with a zero-order and/or 1-order model (e.g. Park et al., 2014; Zouabi-Aloui et al., 2015; Terry et al., 2017; Sadeghian et al., 2018; Lindenschmidt et al., 2019). The bibliographic research conducted before and during this study suggests that the CE-QUAL-W2 sediment diagenesis model has not been applied to any waterbodies other than the Wahiawa Reservoir in central Oahu (Berger and Wells, 2014). Moreover, no scientific publications on the evaluation of this model in other contexts have been identified, further highlighting the importance of the primary motivation for this study, namely, to evaluate the performance of the CE-QUAL-W2 model with its new sediment diagenesis component. This study benefited from having access to observed reservoir sediment total organic carbon (TOC) values, which are rare. Although, in theory, these values are typically higher than particulate organic carbon (POC) values, they provided an excellent starting point for this study. The methodological approach was, therefore, defined to evaluate the performance of the CE-QUAL-W2 model considering the new state-of the art sediment diagenesis model in modeling a reservoir, DO, Total Phosphorus (Total P); Total Nitrogen (Total N), Biochemical Oxygen Demand (BOD5), Chlorophyll a (Chl a) and SOD.
To achieve this, the water quality of a highly productive reservoir was simulated over a six-year period (2016–2021) using the CE-QUAL-W2 v4.5 model. The simulation incorporated a Zero-order sediment model, a First-order model, a Hybrid model combining both approaches, and a sediment diagenesis model. The Zero-order, First-order, and Hybrid models were included to provide alternative representations of sediment oxygen demand, enabling comparative analysis and supporting the calibration and evaluation of the more complex sediment diagenesis model. In the case of water temperature and DO, the modeling results were compared with 35 water column profiles observed near the dam. The remaining parameters were calibrated using time series datasets collected at multiple depths, with six annual values available for each parameter. A sensitivity analysis was performed to evaluate the reservoir water quality response, namely DO, to the variation of POC, PON and POP concentration in the reservoir sediments. The results of this study will hopefully prove useful by helping to improve lake and reservoir water quality modeling and, therefore, the water management process from a practical perspective.
2.1 Site location and main characteristics
Portugal experiences a temperate maritime climate characterized by a wet, cool season and a dry summer. Despite most of the precipitation occurring during the winter months, there is significant inter-annual variability. Precipitation patterns are spatially and temporally heterogeneous, with annual maxima exceeding 2500 mm in the rugged highlands of the northwest, while the low-lying plains of the southeast receive around 400 mm yr−1 (Cardoso et al., 2013; Soares et al., 2015) (Fig. 1). The Torrão dam, located in the northern region of mainland Portugal in the Tâmega River, is a significant hydraulic structure designed for multiple purposes, including water supply, irrigation, and hydroelectric power generation. The reservoir has a substantial storage capacity, contributing to regional water management and flood control (Table 1). This infrastructure plays a crucial role in the socio-economic development of the region, balancing resource management and environmental preservation. However, it is also important to note that the reservoir was classified as eutrophic for all the simulated years, a condition that can lead to persistent water quality issues.
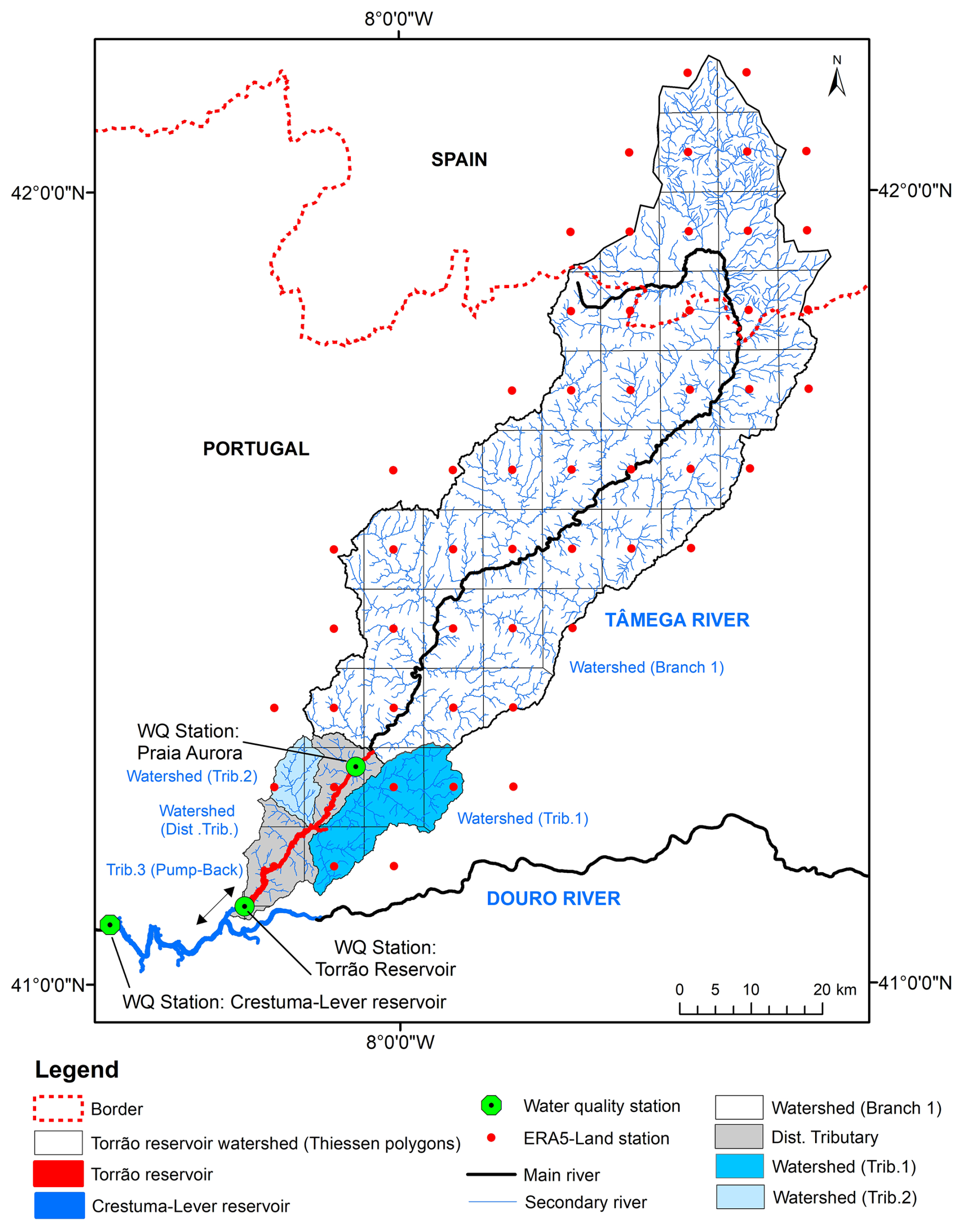
Figure 1Torrão reservoir watershed. Thiessen polygons. Water quality stations.
Table 1Main features of Torrão dam and reservoir.

* Classification according to OECD Trophic State limits (OECD, 1982).
2.2 CE-QUAL-W2 v4.5 model
This study employed the latest version of CE-QUAL-W2 (Version 4.5), a model originally developed in 1975 by the US Army Corps of Engineers and written in Fortran. Since its inception, the model has undergone regular updates and enhancements, primarily by researchers at Portland State University (Cole and Wells, 2006). CE-QUAL-W2 is a two-dimensional, laterally averaged hydrodynamic and water quality model capable of simulating free surface elevation, hydrostatic pressure, density, horizontal and vertical velocities, as well as constituent concentrations. The model uses the finite difference method to solve key equations, including mean transverse momentum in the x- and z-directions, the continuity equation, state equations, and water surface elevation equations (Tavera-Quiroz et al., 2023; Wells, 2021). This model represents SOD through four distinct approaches: (i) a user-defined zero-order formulation that is decoupled from the water column, (ii) a simple predictive first-order model, (iii) a hybrid approach combining the zero- and first-order methods, and (iv) a comprehensive sediment diagenesis model. The zero-order model is not a predictive approach, as, other than variations resulting from the temperature dependence of the decay rate, the rates remain constant over time (Wells, 2021). Additionally, under anoxic conditions in the water column, SOD is disabled in the model. The first-order sediment model does not function as a full sediment diagenesis model, as it lacks the capability to track the fate of organic nutrients delivered to the sediments, their breakdown, and the release of byproducts into the water column under low-oxygen conditions. However, it does represent the deposition of particulate organic matter and dead algal biomass, along with the resulting oxygen demand imposed on the water column. By including this first-order sediment process, the model becomes sensitive to increased organic loading to the sediment, which in turn influences sediment oxygen demand. A combination of the zero and first order model can be considered where organic materials accumulate and decay in the sediments under aerobic conditions and are released based on the SOD zero-order decay rate under anaerobic conditions. In contrast, the sediment diagenesis model simulates kinetic processes occurring within the sediment and at the sediment–water interface. This module originally developed for application in oil sand pit lakes, has been adapted for application in other aquatic environments and integrated into version 4.0 (Vandenberg et al., 2015). The conceptual framework of the model has been elaborated in works by Prakash et al., (2015), Berger and Wells (2014), and Vandenberg et al. (2015). It is important to note that significant enhancements to the sediment diagenesis module were introduced in version 4.5 of the model, as detailed in the User Manual (Wells, 2021). These improvements mark a substantial advancement over the initial version 4, which was more limited in its capabilities. The CE-QUAL-W2 model has demonstrated its utility in simulating hydrodynamic and ecological processes – such as stratification, internal waves, DO dynamics, and phytoplankton blooms – in lakes and reservoirs worldwide (Zhang et al., 2015; Chuo et al., 2019; Kobler et al., 2018; Uhlmann, 2017; Terry et al., 2017; Mi et al., 2020). Additional details about the model's structure, algorithms, and historical applications can be found in the user manual (Wells, 2021).
Model setup
The bathymetry of the Torrão reservoir was initially defined using a Digital Elevation Model (DEM) provided by Energies of Portugal, SA (EDP) and structured according to the methodology outlined in Wells (2021). The reservoir comprises one main branch (the Tâmega River), three tributaries and one distributed tributary (Fig. 1). Tributaries 1 and 2 are depicted in Fig. 1. Tributary 3 represents the inflow from the Douro River into the pump-back system of the Torrão Reservoir. The bathymetric map includes 27 segments, each measuring 1000 m in length, and a maximum number of 58 layers, each with a depth of 1 m. Following this preliminary step, the reservoir boundary conditions (including water quality, hydrology, meteorology, and sediment characterization) were defined according to the methods described in Sect. 2.4. Due to the lack of available information, the model structure only includes a single algae group (Diatoms).
2.3 Modeling approach
To thoroughly evaluate the capability of CE-QUAL-W2 in modeling dissolved oxygen using the sediment diagenesis module, the four available SOD modeling approaches were considered: Zero-order model; First-order model; Zero/First-order model (Hybrid model) and the sediment diagenesis model (SG model). The models were calibrated for the 2016–2021 period (see Sect. 2.5). During the results analysis, the performance metrics obtained during each model's calibration process were compared, along with the SOD values across the bottom layers of each model. A sensitivity analysis was conducted following calibration to evaluate each model's response: (a) to varying POC, PON, and POP values in the case of the SG model; (b) to different SOD values in the Zero-order and Hybrid models and (c) to varying the initial first order sediment concentration in the case of the First-order model. Section 2.6 details the methodological approach used for the sensitivity analysis. To assess the sensitivity of each model to reductions in external organic matter (OM) and P-PO4 inputs, two separate scenario analyses were conducted. The first scenario involved an 80 % reduction in OM inflow load, while the second applied an 80 % reduction in both OM and P-PO4 inflow loads. These reductions were implemented specifically in the main reservoir branch (Branch 1 – Tâmega River), where the majority of nutrient and organic inputs occur. Each sediment model – SD, Zero-order, First-order, and Hybrid – was run under baseline conditions and under both reduction scenarios. The impact on DO dynamics was evaluated using time series of depth- and segment-averaged DO concentrations. The evaluation of model performance, along with the results of the sensitivity analysis, provided deeper insights into simulating SOD dynamics using the sediment diagenesis approach in comparison to the other SOD formulations.
2.4 Model forcing datasets
The meteorological data used to drive the model, including hourly air temperature, dew point, solar radiation, cloud cover, and wind characteristics, were sourced from ERA5-Land, a high-resolution reanalysis dataset optimized for land applications (Muñoz-Sabater, 2019). Although no on-site meteorological stations are available in the study area for direct validation, studies by Almeida and Coelho (2023b) and Barbosa and Scotto (2022) have demonstrated a strong correlation between ERA5-Land air temperature data and observed measurements at regional scales, supporting the reliability of this dataset for our modeling purposes. Furthermore, the accuracy of water temperature predictions in our simulations indicates that the meteorological forcing was well represented, confirming the suitability of ERA5-Land data for driving the model. Reservoir data, such as daily inflow/outflow, water levels, and water quality, covering the years 2016–2021, were provided by EDP. Water quality data specific to Branch 1 originated from the Praia Aurora Station, accessed via the Portuguese National Water Resources Information System (SNIRH, 2024). With only 21 recorded measurements for Branch 1 during this period, three modeling methods were employed to address the 99.04 % of missing data. The variables include: water temperature; DO; Total P; Ammonium (N-NH4); Nitrate+Nitrite (N-NOx); BOD5; Chl a; Alkalinity; Conductivity and Total Suspended Solids (SST). The first method employed regression models implemented through the LOADEST package (Runkel et al., 2004) developed by the US Geological Survey. The second method utilized the Extreme Gradient Boosting (XGBoost) machine learning algorithm, implemented using the Chen and Guestrin (2016) open-source library, a method proven effective in various environmental studies (Feigl et al., 2021; Adedeji et al., 2022; Xu et al., 2022). For additional details on the algorithm, refer to Almeida and Coelho (2023a). The third approach relied on Support Vector Regression (SVR), implemented via the scikit-learn library (Pedregosa et al., 2011), which has also demonstrated strong performance in environmental modeling applications (Adedeji et al., 2022; Ji and Lu, 2018). For machine learning approaches, datasets were split into training (80 %) and testing (20 %) sets. Hyperparameters for these models were optimized using the Tree-structured Parzen Estimators (TPE) algorithm, executed with the Hyperopt library (Bergstra et al., 2013) and 100 iterations. The Nash–Sutcliffe Efficiency (NSE) was used to determine the best model. Table A1 describes the input features of each model. Correlations derived from Branch 1 informed data extrapolation to other tributaries using flow as the predictor. Observed data for Tributary 3 was retrieved from the Crestuma–Lever reservoir monitoring station.
Water quality variables used for model inputs included water temperature, DO, P-PO4, N-NH4, N-NOx, labile and refractory dissolved and particulate organic matter (LDOM, RDOM, LPOM, RPOM), alkalinity, inorganic suspended solids (ISS), total dissolved solids (TDS), total inorganic carbon (TIC), and algal biomass (diatoms). For non-monitored variables, estimations were made based on available data: (i) P-PO4: Derived from total phosphorus, assuming inorganic phosphorus represents 70 % of the total; (ii) Organic matter: BOD5 was converted to organic matter using a stoichiometric ratio of 1.4 g O2 per 1.0 g organic matter, with 60 % assumed refractory and 40 % labile; (iii) ISS: Estimated as 97.4 % of TSS; (iv) TDS: Calculated from electrical conductivity (Eq. 1); (v) TIC: Estimated from alkalinity (Eq. 2); (vi) Algae biomass: Chl a was converted to biomass using the following ratio: Algal Biomass (mg L−1)/Chl a(µg L−1) = 5.0
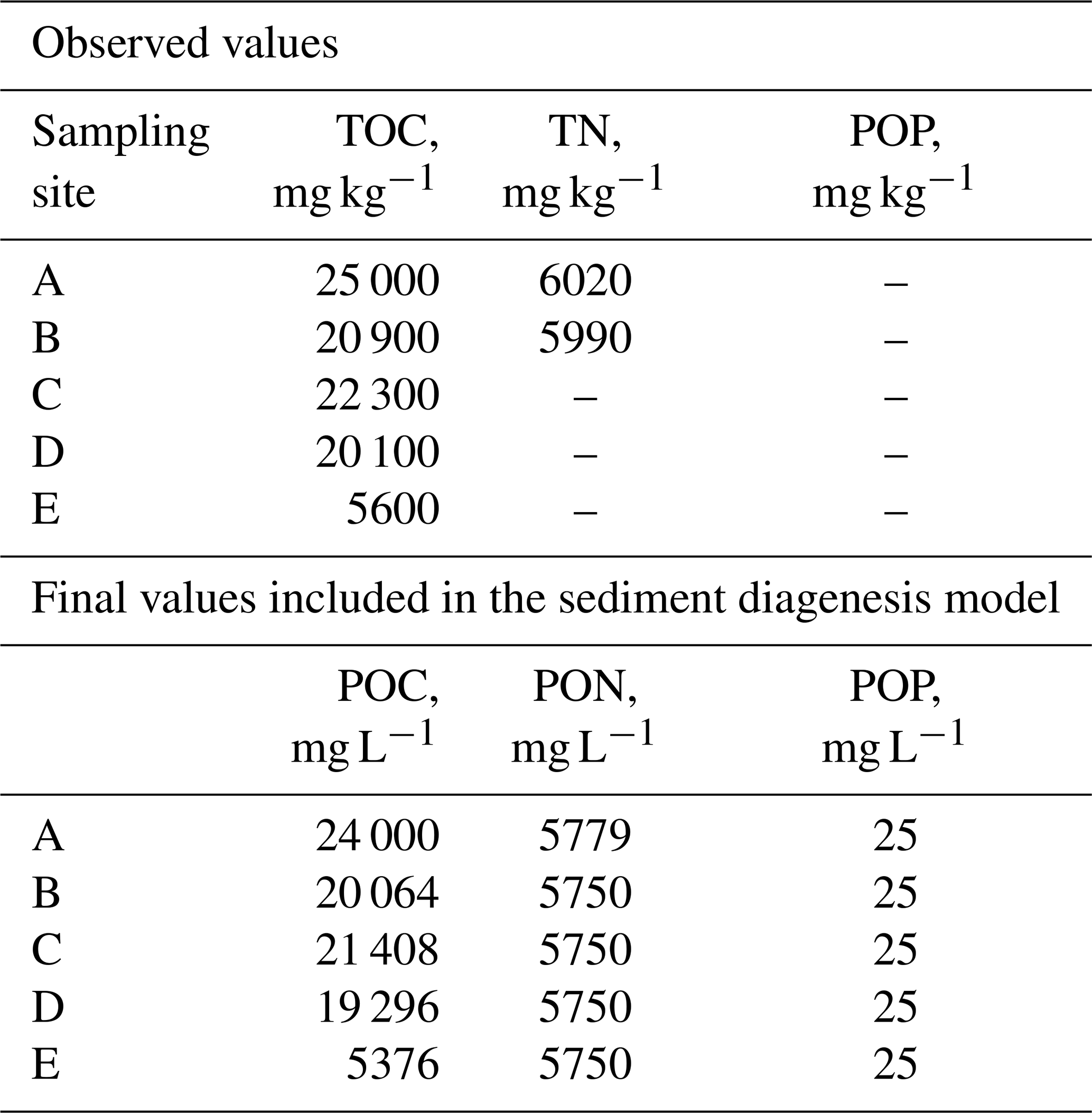
This equation was derived from the relationship between TIC and alkalinity values observed in four reservoirs within the United States, utilizing a dataset comprising 55232 value pairs available in the CE-QUAL-W2 v4.5 model examples (Wells, 2021). The analysis achieved an R2 value of 0.99. Figure 2 illustrates the locations of the five sediment sampling sites used to define the SD model baseline run. The spatial distribution of the sediment samples depicted in the figure were linked to specific reservoir segments to characterize the initial sediment content of POC, PON, and POP, as detailed in Table 2. Sediment values were assigned as follows: site A to segments 25–28, site B to segments 20–24, site C to segments 16–19, site D to segments 11–15, and site E to segments 2–10. Several assumptions were made to establish the sediment characterization: (i) a sediment density of 960 kg m−3(density of dried sediment with air in the pore space) (Minear and Kondolf, 2009) was applied to convert sample values from mg kg−1 to mg L−1; (ii) POP values were set at 25 mg L−1, based on established literature benchmarks (Wells, 2021); (iii) the TN value observed at site B was used to characterize sites C, D, and E; (iv) TOC and TN were assumed to exist entirely in particulate form, represented as particulate organic carbon and nitrogen. This approach ensured a consistent and representative characterization of sediment properties across the reservoir segments.
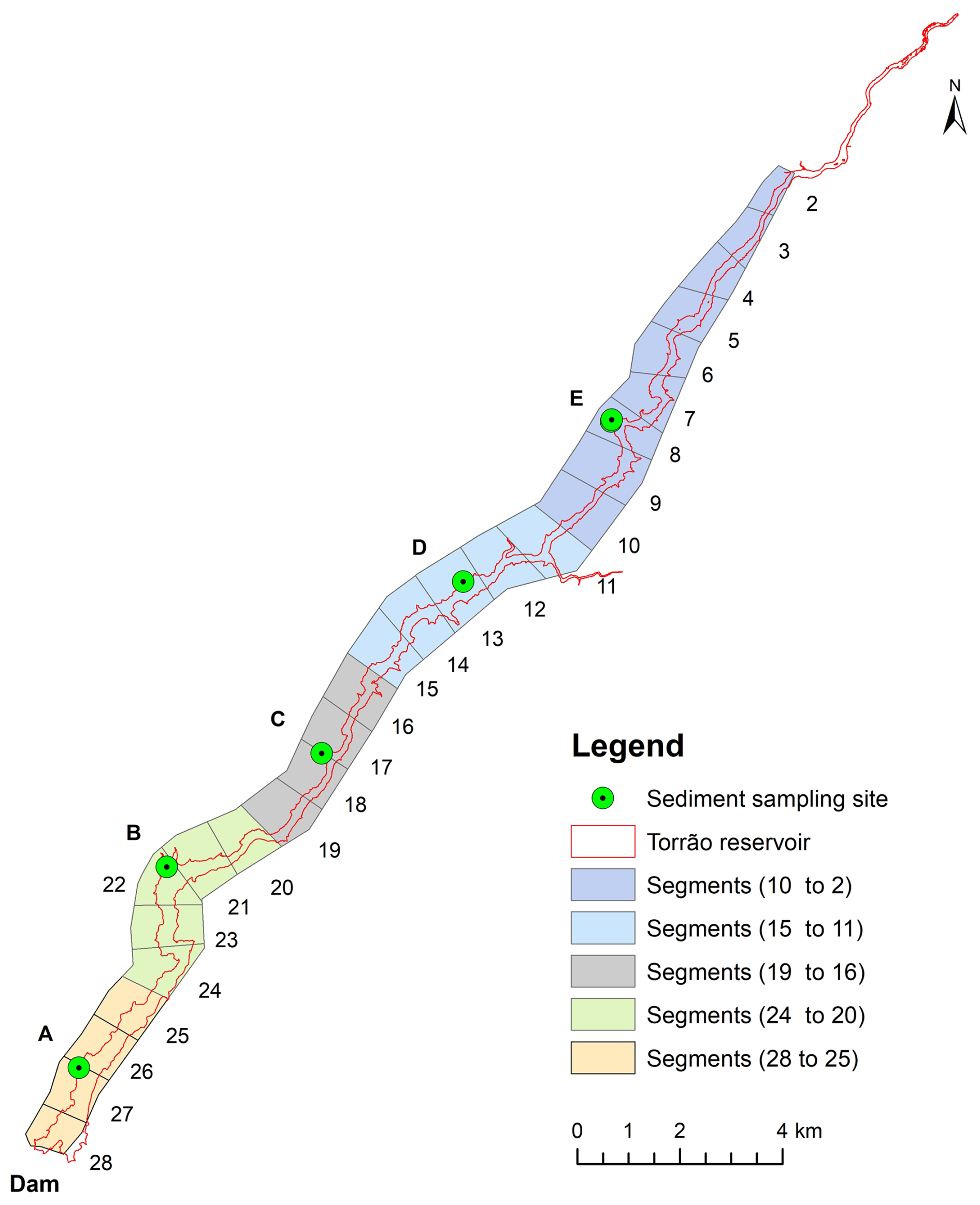
Figure 2Sediment sampling sites. CE-QUAL-W2 model segments.
Table 2Torrão Reservoir sediment chemical characterization obtained for each sampling site.
2.5 Water quality model (CE-QUAL-W2) calibration
The simulation period considered for this study spanned 2016 to 2021. This period was selected due to the availability of flow and water quality data. The trial-and-error technique was applied to calibrate the model for the simulation period, considering the default calibration parameters described in Wells, 2021. The error between observed and predicted values of six state variables was evaluated with five different metrics (see Sect. 2.7). The observed data included six annual values for water temperature, DO, TP, TN, BOD5, and Chl a. These time series were obtained from: (a) an integrated sample between the reservoir surface and a depth of 5.8 m, (b) a depth of 23 m, and (c) a depth of 43.7 m. In addition, 35 water temperature and DO profiles – six per year from 2016 to 2021 – were also included. These profiles were observed 300 meters upstream from the Torrão Dam. Details on the models' initial conditions, parameters, constants, and forcing datasets can be found in Almeida and Coelho (2025) and in Tables A2 to A8. The models were calibrated by adjusting their parameters to improve the fit between the model output and observed data. Please refer to Wells (2021) for a detailed account of the model calibration parameters and default values. Water temperature was the first constituent to be calibrated. The wind sheltering coefficient (WSC) was manually adjusted to achieve the best fit between the modeled and observed water temperature profiles, resulting in a final value of 1. A value of 1 implies that the WSC has no effect over the wind velocity forcing the model. The zero-order model for SOD was then manually adjusted to improve DO predictions based on 35 DO profiles. The optimal result was achieved with a zero-order SOD value of 2.5 g O2 m−2 d−1. Following this calibration, the phosphorus sediment release rate (PO4R) in the zero-order model was modified from its default value of 0.015 to 0.001. The same process was applied to the Hybrid model, where the best results were achieved using a PO4R of 0.001 and a zero-order SOD value of 1.0 g O2 m−2 d−1. In the first-order model, the PO4R parameter was adjusted to 0.001, and the initial concentration of first-order sediment was set to 0.5 g m−2. All other parameters were kept at their relevant default values and the default settings for the sediment diagenesis model were also maintained. The observed data included water temperature, DO, TP, TN, BOD5, and Chl a.
2.6 Sensitivity analysis
A sensitivity analysis was conducted after the calibration process to evaluate the model's response:
- i.
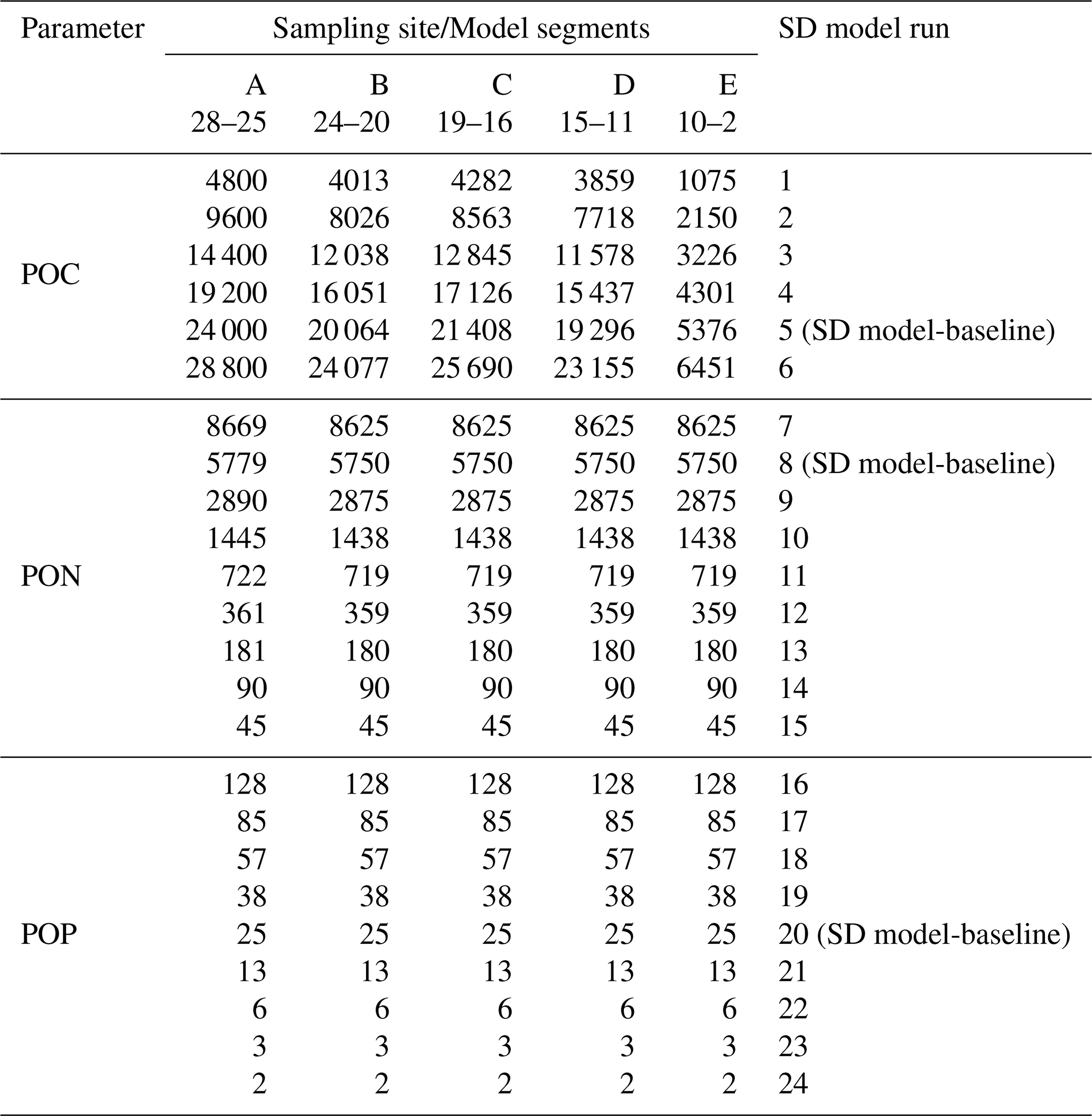
Different initial sediment values for POC, PON, and POP were used in the SD model (Table 3). It is important to note that for each of the 24 runs described in Table 2, only the corresponding parameter was modified, while the other two parameters retained their default values shown in Table 3. The number of runs varying the PON and POP values is higher than the number of runs considered for POC, with 6 versus 9 runs, respectively. This adjustment was necessary to achieve a minimal RMSE in the predictions of dissolved oxygen in the water column;
- ii.
Different zero-order SOD values for the Zero-order model (0.5, 1.0, 1.5, 2.0, 2.5 and 3.0 g O2 m−2 d−1);
- iii.
Different initial first order sediment concentration (ISC) for the First-order model (0.0, 0.5, 1.0, 1.5, 2.0, 2.5 and 3.0 g m−2);
- iv.
Different zero-order SOD values for the Hybrid model (0.5, 1.0, 1.5, 2.0, 2.5 and 3.0 g O2 m−2 d−1.
In the results analysis for each run and for both scenarios (i) and (ii), the prediction error for DO was compared with the SOD values derived from each model. Specifically, runs 5, 8, and 20 were forced with the POC, PON, and POP values defined in the SD model baseline run.
Table 3TOC, PON, and POP initial sediment values for the SD model sensitivity analyses.
2.7 Metrics
The evaluation of model calibration and the analysis of quantitative differences across simulation scenarios utilized various performance metrics. These included the root mean square error (RMSE), mean absolute error (MAE), Nash–Sutcliffe efficiency (NSE) (Nash and Sutcliffe, 1970), percent bias (PBIAS), and the coefficient of determination (R2). The calculations were carried out using equations where mi and oi represent the simulated and observed values, respectively, and the observed values mean.
3.1 Observed inflow water quality characterization
The SVR algorithm was more effective at predicting the inflow water temperature compared to the other models. The R2 and PBIAS values achieved with the SVR were 0.87, and 3.77 %, respectively, indicating that the water temperature trends and average magnitudes are well described (Table A1). Additionally, the RMSE and MAE values of 2.1 and 1.6 °C, respectively, demonstrate an accurate approximation of the observed datasets. The SVR algorithm was also the best model in predicting DO. The R2, PBIAS, RMSE, and MAE values reached, 0.91, 0.92 %, 0.40 and 0.26 mg L−1, respectively, indicating that the model performed well. This was not the case for the remaining parameters. In fact, the Loadest regression outperformed the other models for the remaining water quality variables. This was primarily due to the limited number of training samples. Simpler models like regressions can have lower variance (i.e., be less susceptible to overfitting) compared to SVR and XBOOST algorithms. Overall, the PBIAS obtained for NH4, N-NOx, and Chl a (10.88 %, 43.64 %, and 30.00 %) suggests that the average magnitude was reasonably well represented.
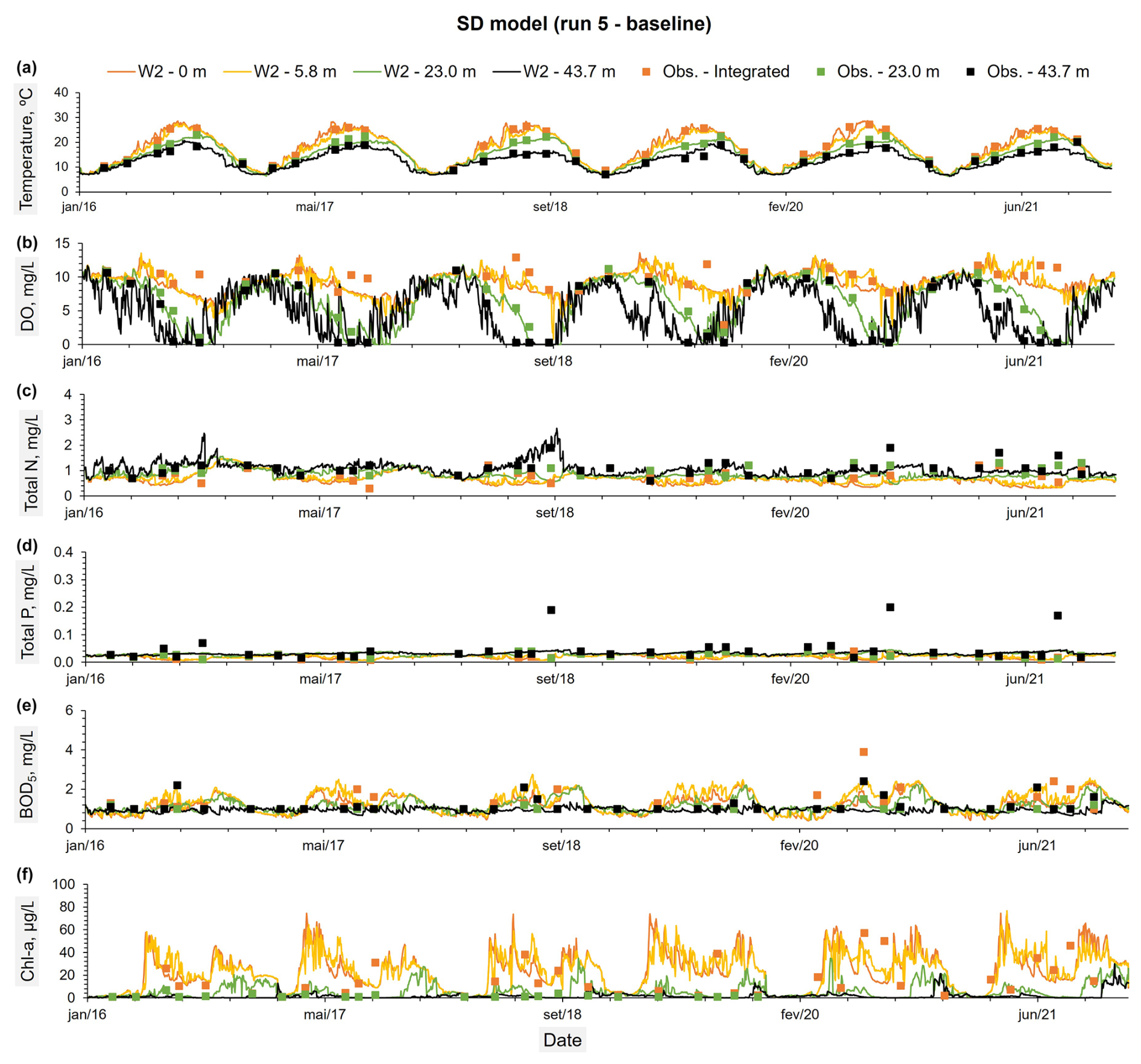
Figure 3Constituents observed values at three different depths: (a) an integrated sample between the reservoir surface and an average depth of 5.8 m, (b) an average depth of 23 m, and (c) an average depth of 43.7 m. These observed values were compared with the predicted time series from the SD model (run 5 – baseline) (A to F) for the same depths.
3.2 CE-QUAL-W2 calibration
Tables A2 through A8 display the most significant CE-QUAL-W2 coefficients obtained after the calibration process. The results of the calibration process for all models, are presented in Tables 4 and A9 and illustrated in Figs. 3 to 6 and Figs. 8 and 9. The performance metrics for water temperature across the different sediment models show consistent accuracy, with NSE and R2 values ranging from 0.95 to 0.96 and minimal variation across models. The RMSE and MAE for temperature also remain low, indicating reliable thermal performance regardless of the sediment model applied. In contrast, DO predictions show more variability. The Hybrid model achieved the best overall DO performance, with the highest NSE (0.76±0.30) and R2 (0.76±0.31), as well as the lowest RMSE (1.87±0.72) and MAE (1.22±0.55), while maintaining a near-zero PBIAS (), indicating minimal systemic bias. The Zero-order model also performed reasonably well, with slightly lower error metrics than the SD model. The First-order model, however, showed the weakest DO performance, with a lower NSE (0.68±0.22), higher RMSE (2.15±0.82), and a significant negative PBIAS (), suggesting an underestimation of oxygen concentrations. Overall, the results suggest that while temperature simulation is robust across all models, DO dynamics are better captured using the Hybrid or Zero-order models, with the Hybrid model offering the most balanced and accurate representation under the tested conditions. However, the differences in performance metrics for DO among the models are relatively small and often fall within overlapping standard deviations, with the exception of the First-order model, which consistently shows lower accuracy and higher bias, suggesting that while the Hybrid model offers slightly better overall performance, the improvements over the SD and Zero-order models are modest and should be interpreted with caution. In terms of nutrient dynamics, the Hybrid and Zero-order models improve TN and TP predictions relative to the SD and First-order models. The Hybrid model, for example, improves TN R2 to 0.31 and TP to 0.27, although the associated biases remain significant (e.g., −18.75 % for TN and +36.49 % for TP). BOD5 and Chl a remain poorly simulated across all models, with R2 values consistently low (≤0.06 for Chl a and ≤0.03 for BOD5), and large PBIAS values, particularly in the SD and First-order configurations. The Zero-order model slightly reduces bias in Chl a and Total N compared to the SD model but performs poorly for TP due to a large overestimation (PBIAS = 103.43 %) (Fig. 4d). Notably, the SD and First-order models failed to reproduce observed phosphorus release events from sediments on 18 September 2018, 8 September 2020, and 31 August 2021 (Figs. 3d and 5d). In contrast, the Hybrid model successfully captured these events by modeling phosphorus release as a linear function of SOD, providing a more realistic representation of sediment–water nutrient interactions (Fig. 6d). Overall, while no model fully captures the complexity of all constituents, the Hybrid model consistently provides the most balanced and improved representation, particularly for DO and nutrient parameters.
Table 4Metrics between observed and predicted values for all models. Water temperature and DO metrics were obtained from 36 observed and predicted profiles.
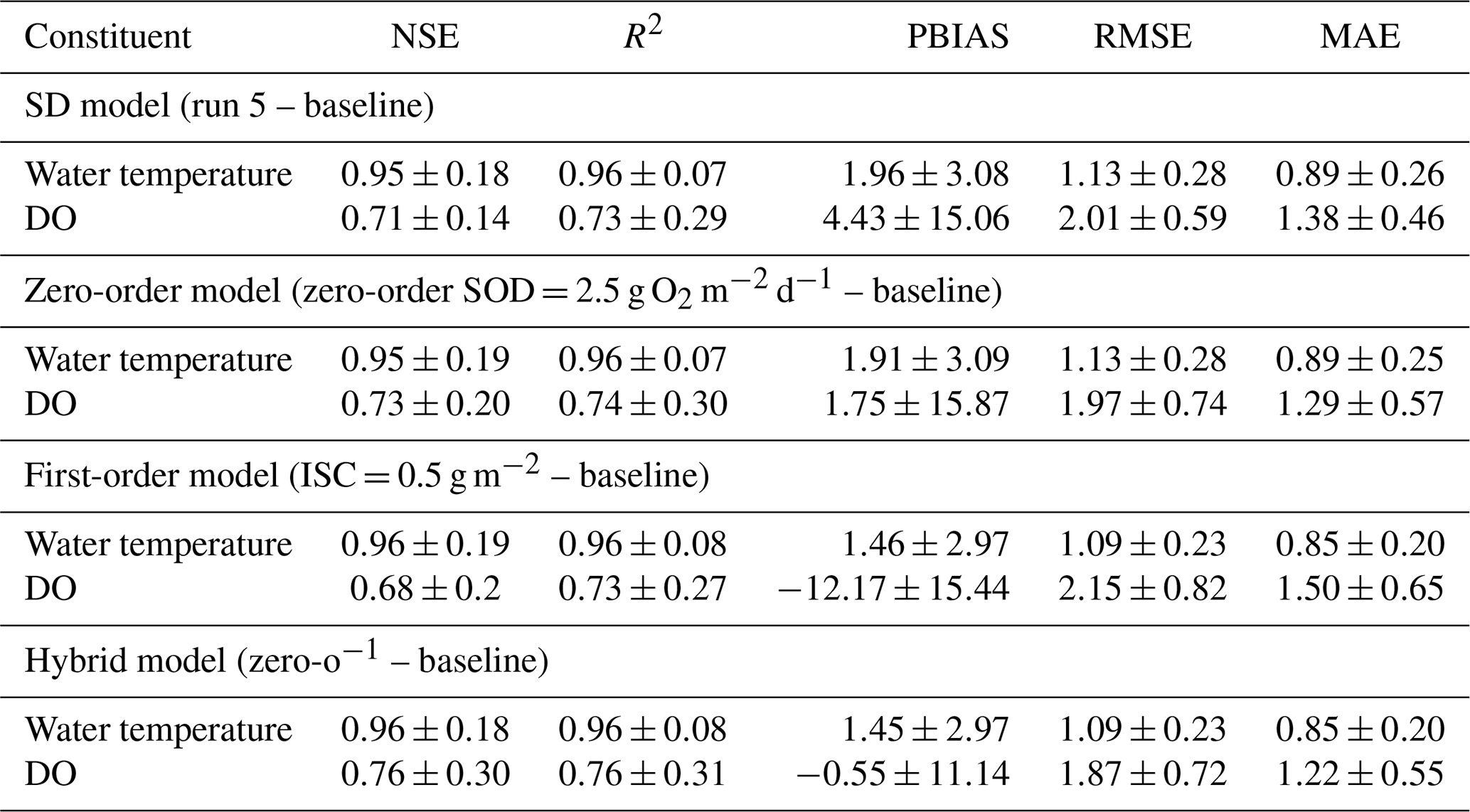
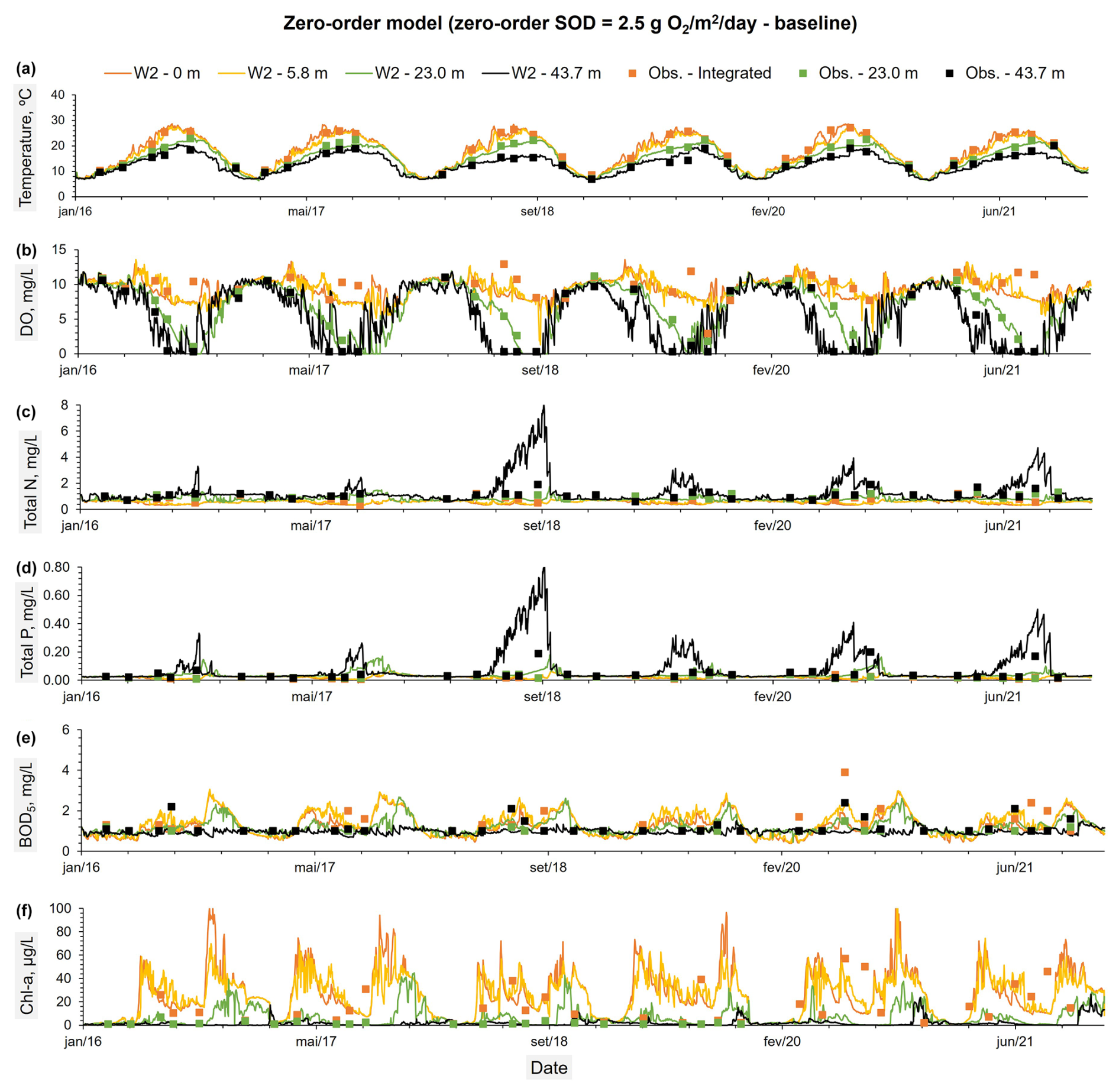
Figure 4Constituents observed values at three different depths: (a) an integrated sample between the reservoir surface and an average depth of 5.8 m, (b) an average depth of 23 m, and (c) an average depth of 43.7 m. These observed values were compared with the predicted time series from the Zero-order model (zero order SOD = 2.5 g O2 m−2 d−1 – baseline) (A to F) for the same depths.
Figure 5Constituents observed values at three different depths: (a) an integrated sample between the reservoir surface and an average depth of 5.8 m, (b) an average depth of 23 m, and (c) an average depth of 43.7 m. These observed values were compared with the predicted time series from the First-order model (ISC = 0.5 g m−2 – baseline) (A to F) for the same depths.
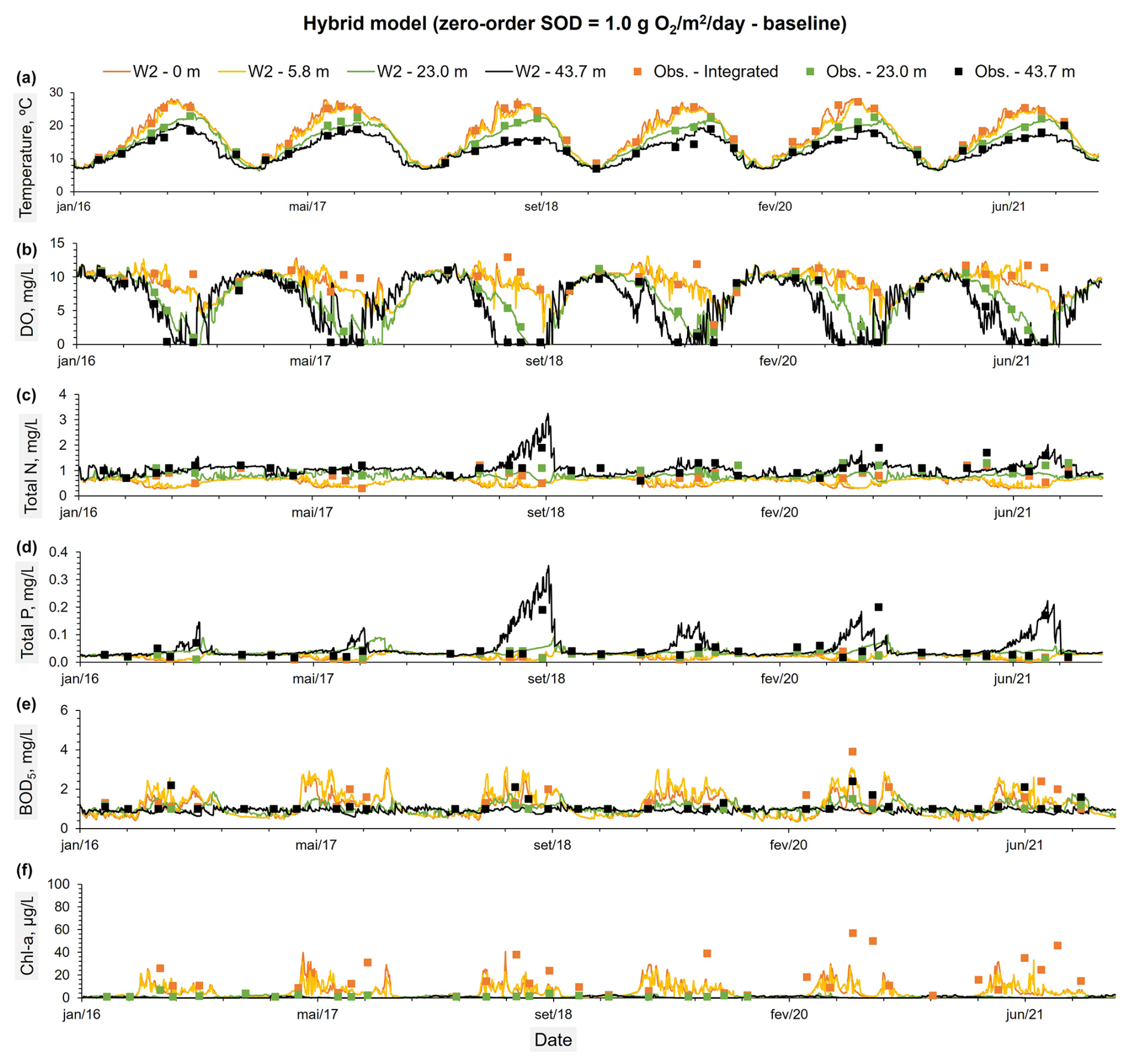
Figure 6Constituents observed values at three different depths: (a) an integrated sample between the reservoir surface and an average depth of 5.8 m, (b) an average depth of 23 m, and (c) an average depth of 43.7 m. These observed values were compared with the predicted time series from the Hybrid model (zero order SOD = 1.0 g O2 m−2 d−1 – baseline) (A to F) for the same depths.
3.3 Sensitivity analysis
The SOD values strongly influence the water column DO; therefore, this parameter was considered to support this analysis. Figure 7 shows the SOD values from the reservoir bottom layer, predicted by the SD model for Runs 1 to 6, compared with the RMSE (Fig. 7a) and the NSE (Fig. 7b) values obtained between the predicted water column DO profiles and the mean initial POC values (across all sites values) for each run. These results suggest that Run 4 was the best modeling solution. Considering the results obtained for Run 5 (baseline), Run 4 reduced the RMSE from 2.015 mg L−1 (Run 5) to 2.011 mg L−1 (Run 4) and increased the NSE from 0.714 (Run 5) to 0.716 (Run 4). The average SOD value in the bottom layer of the reservoir (across all model segments) decreased from 1.162ġ O2 m−3 d−1 (Run 5) to 1.071 g O2 m−3 d−1 (Run 4). Although the reduction is modest and had only a minor effect on the DO profile predictions (Fig. 9), it suggests that the initial POC values used in Run 5 were likely overestimated. This outcome aligns with the assumption made in Run 5, where all observed TOC was considered to exist entirely as POC. In contrast, Run 4 was characterized using a lower average sediment concentration. Specifically, the mean value used in Run 4 (14 170 mg L−1) represents approximately 80 % of the TOC value used in Run 5 (17 712 mg L−1), which was derived from observed TOC measurements (see Table 3). This comparison suggests that a more realistic estimate is that about 80 % of the total organic carbon exists in particulate form, with the remainder composed of dissolved organic carbon. Run 4 and Run 5 show negligible differences in the predicted water temperature and DO profiles (Figs. 8 and 9). Table A10 presents the performance metrics for water temperature, DO, TN, TP, BOD5, and Chl a obtained for Run 4. While this run improved the DO simulation in the reservoir, results for the other constituents remained very similar to those of Run 5 (baseline). Overall, the water temperature profiles are very well captured by all models (Fig. 8), reflecting their robustness in simulating thermal dynamics. In contrast, DO profiles are more complex and challenging to model due to their sensitivity to multiple interacting processes. Nevertheless, the models were able to capture the main seasonal and vertical trends in DO concentrations, including stratification patterns and general oxygen depletion in bottom layers during warmer months (Fig. 9).
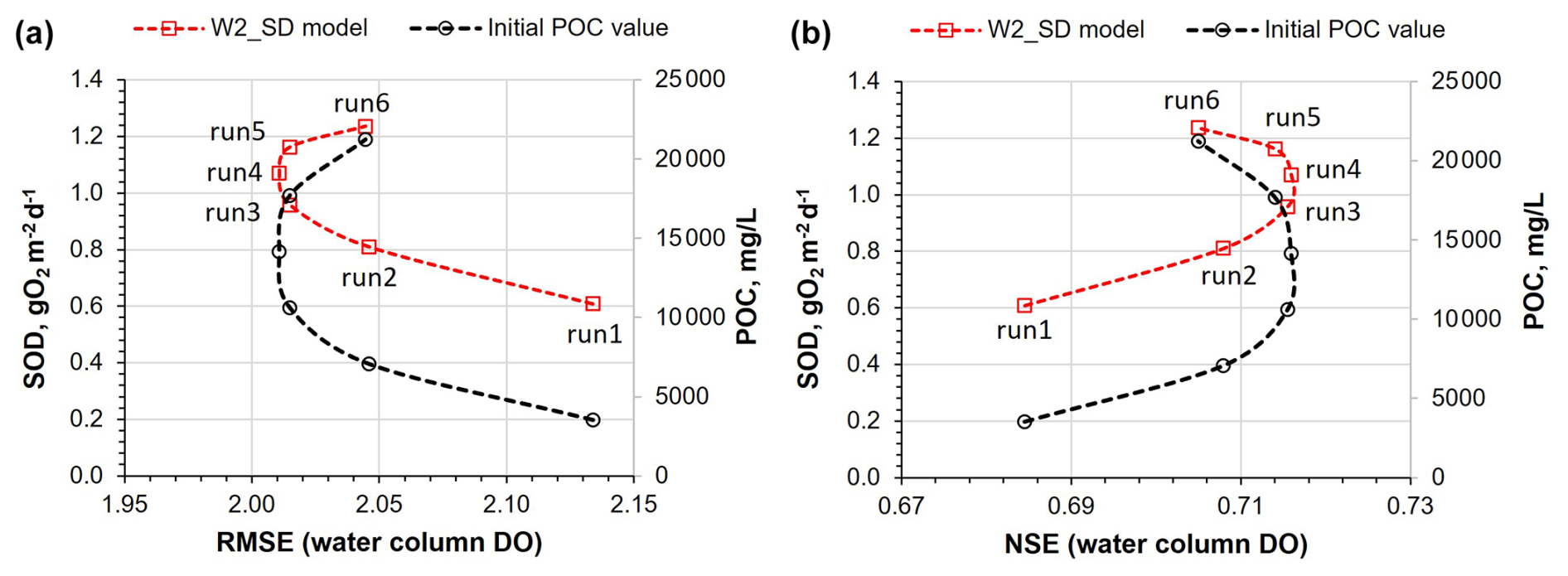
Figure 7(a) SOD values from the reservoir bottom layer, predicted by the SD_model for Runs 1 to 6, compared with the RMSE obtained between the predicted water column DO profiles and the mean initial POC values (across all sites values) for each run of the SD_model. (b) Similar to (a) but considering the NSE metric.
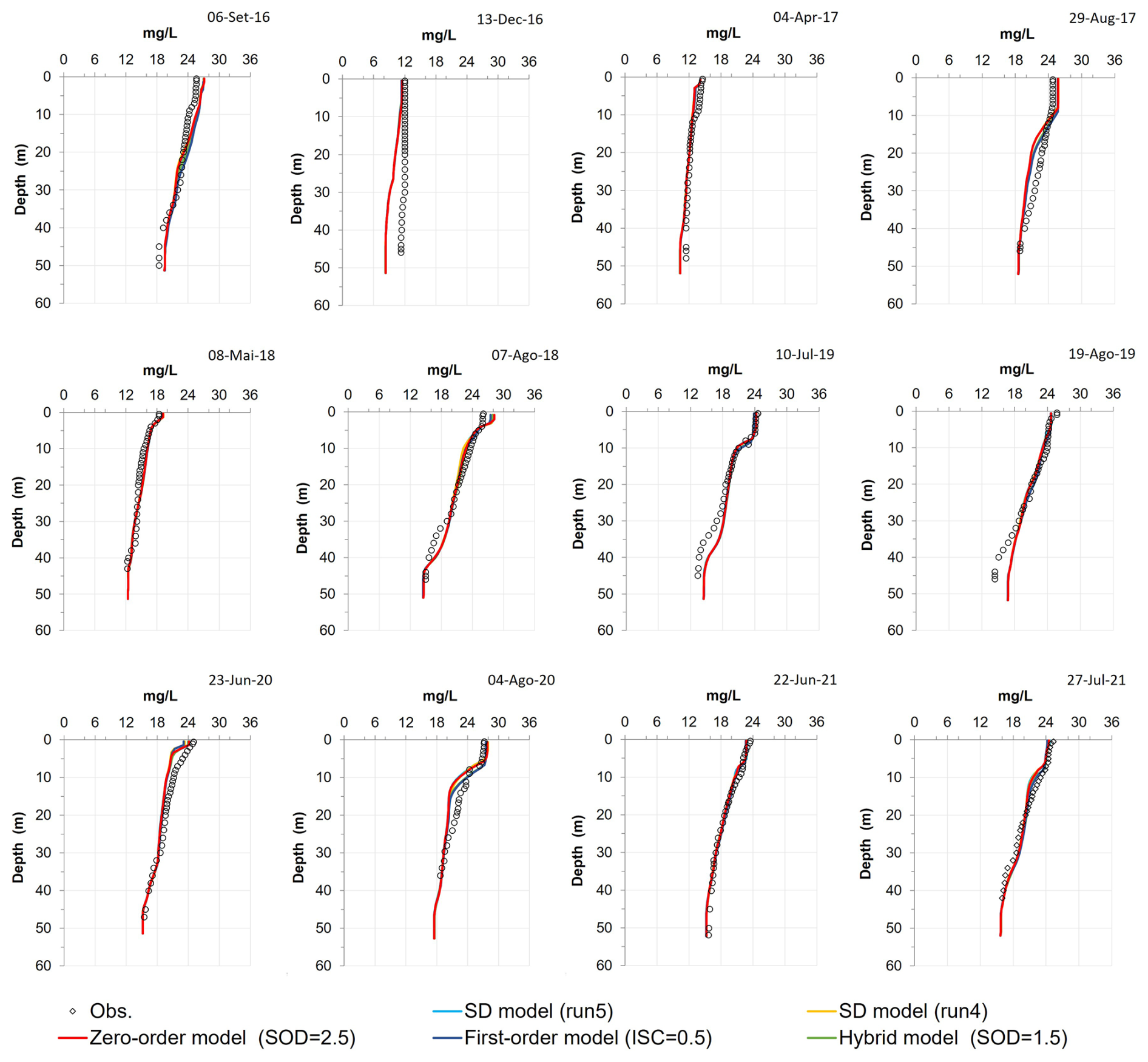
Figure 8Observed water temperature profiles (300 m from the dam) compared to predicted profiles using the SD model (Run 4) and (Run 5 – baseline), Zero-order model (zero-order SOD = 2.5 g O2 m−2 d−1 – baseline); First-order model (ISC = 0.5 g m−2 – baseline) and the Hybrid model (zero order SOD = 1.0 g O2 m−2 d−1 – baseline).
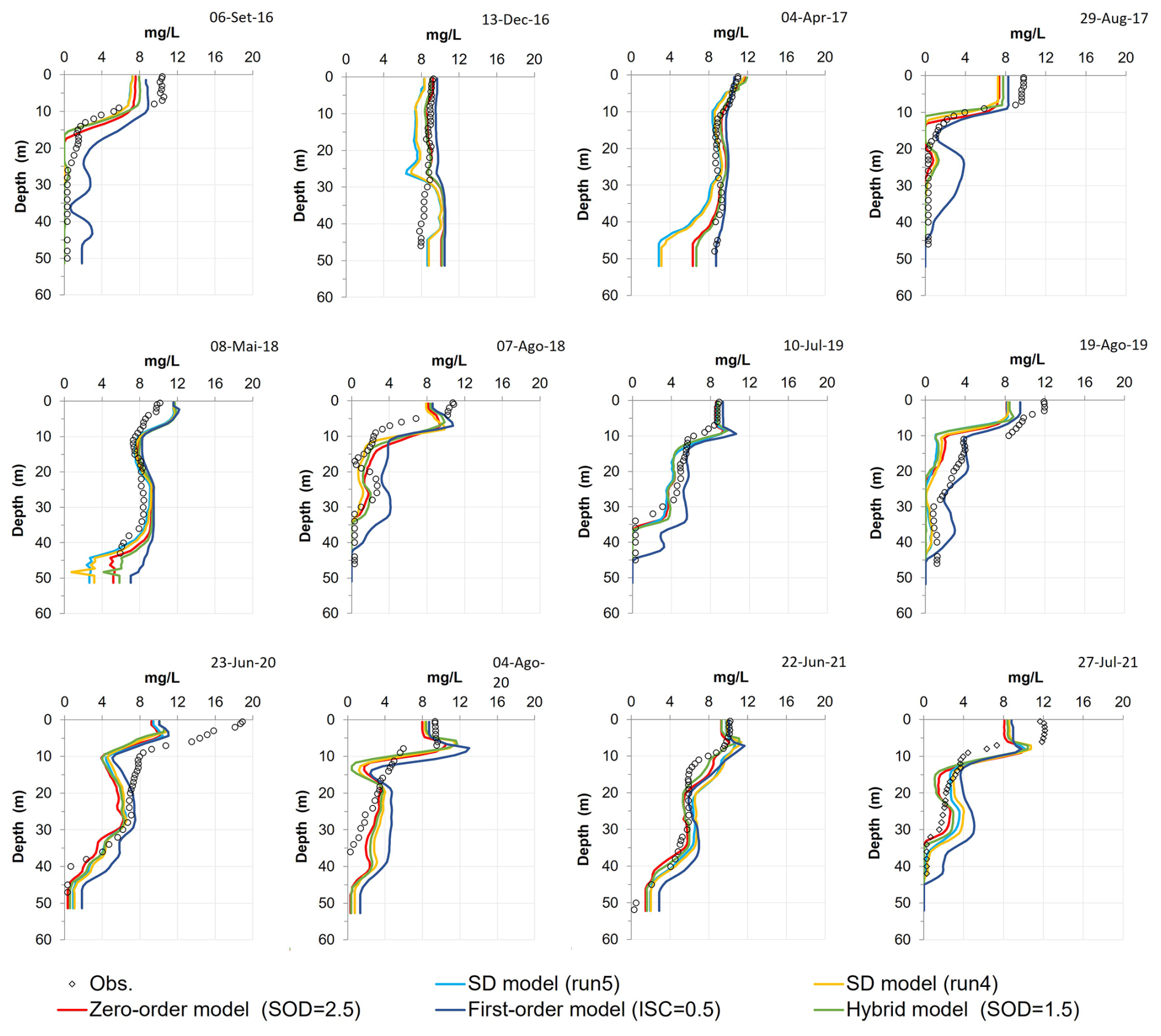
Figure 9Observed DO profiles (300 m from the dam) compared to predicted profiles using the SD model (Run 4) and (Run 5 – baseline), Zero-order model (zero-order SOD = 2.5 g O2 m−2 d−1 – baseline); First-order model (ISC = 0.5 g m−2 – baseline) and the Hybrid model (zero order SOD = 1.0 g O2 m−2 d−1 – baseline).
The sensitivity analysis also involved varying the initial values of PON and POP for each run. The results indicate that mean reservoir SOD values remained nearly constant, as depicted in Fig. 10, suggesting that the SD model was not significantly affected by variations in the initial PON and POP values in the sediments. However, in Runs 7, 8, and 9, where PON values were higher, there was a significant increase in the release of N-NH4 and N-NOx from the reservoir sediments, leading to an impact on water column DO. This is evidenced by the notable increase in RMSE and the reduction of NSE values, as shown in Fig. 10a and b.
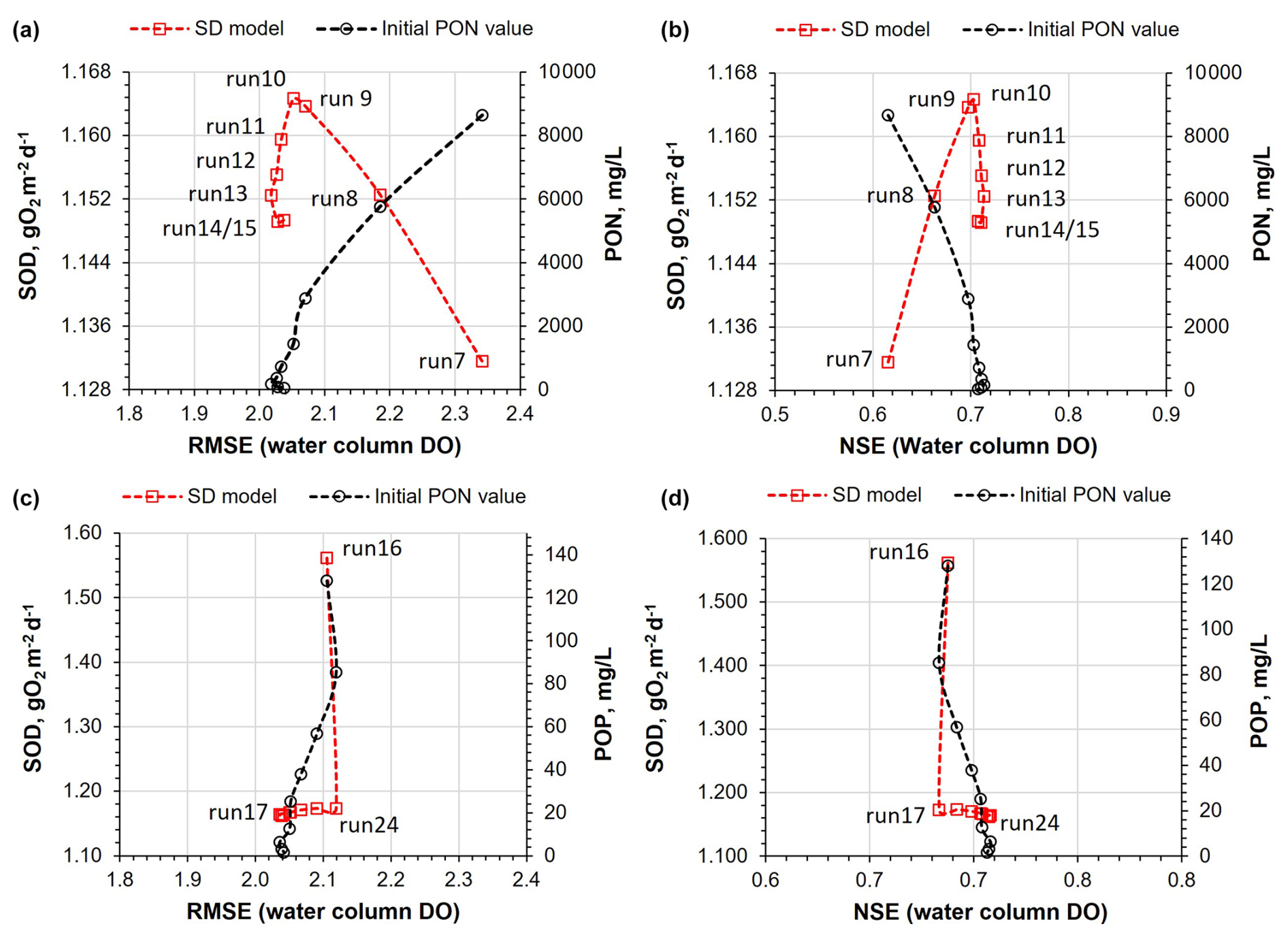
Figure 10(a) SOD values from the reservoir bottom layer, predicted by the SD model for Runs 7 to 15, compared with the RMSE obtained between the predicted water column DO profiles and the mean initial PON values (across all sites) for each run. (b) Similar to (a) but considering the NSE metric. (c) SOD values from the reservoir bottom layer, predicted by the SD model for Runs 16 to 24, compared with the RMSE obtained between the predicted water column DO profiles and the mean initial POP values (across all sites) for each run. (d) Similar to (c) but considering the NSE metric.
Figure 11 shows the RMSE (Fig. 11a) and the NSE (Fig. 11b) values between observed and predicted water column DO profiles for all models: SD model (Runs 1 to 6), Zero-order model and Hybrid model, each with six different SOD values ranging from 0.5 to 3.0 g m−2 d−1, along with the corresponding reservoir SOD values. Additionally, this figure illustrates how the First-order model varies with the initial sediment concentration. Among the four models evaluated, the Hybrid model demonstrated the best overall performance in predicting DO concentrations in the reservoir. With an average SOD of 1.49 g O2 m−2 d−1, the hybrid model achieved the lowest RMSE (1.87 mg L−1) and highest NSE (0.76), demonstrating superior predictive accuracy. The Zero-order model followed closely, reaching optimal performance at an average zero-order SOD of 1.43 g O2 m−2 d−1, with an RMSE of 1.965 mg L−1 and an NSE of 0.732. The SD model also performed well, attaining its best accuracy at an average SOD of 1.07 g O2 m−2 d−1, where the RMSE decreased to 2.011 mg L−1 and the NSE peaked at 0.716; however, further improvements plateaued beyond this point. In contrast, the First-order model consistently exhibited higher RMSE values (ranging from 2.15 to 2.22 mg L−1) and lower NSE values (between 0.66 and 0.68), regardless of the initial sediment concentration. Moreover, its SOD at the bottom layer remained relatively stable, indicating limited sensitivity to input variations. Overall, these results underscore the hybrid model's robustness and accuracy, followed by the Zero-order and SD models, while the First-order model demonstrated the weakest performance in this context.
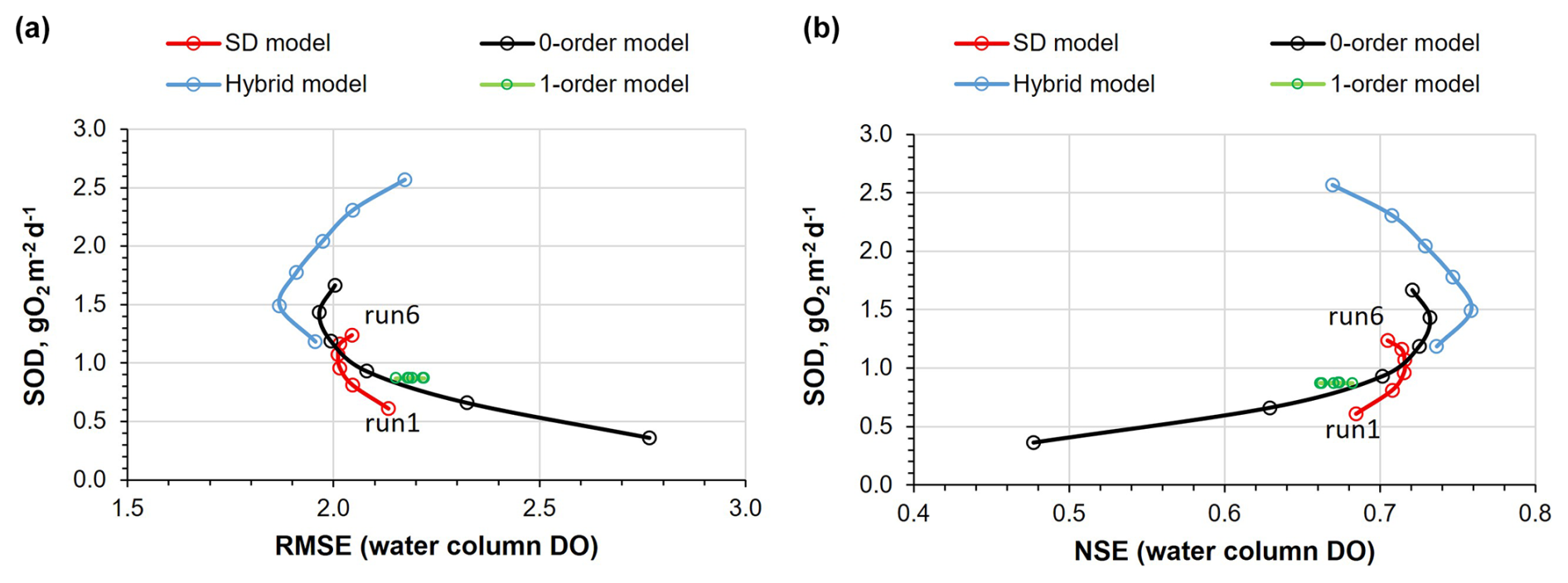
Figure 11(a) RMSE between observed and simulated DO profiles in the water column for all models: the SD model (Runs 1–6), the Zero-order model, the Hybrid model with six SOD values ranging from 0.5 to 3.0 g O2 m−2 d−1, and the First-order model with initial sediment organic matter concentrations from 0.0 to 3.0 g m?−2. (b) Same as (a), but using the Nash–Sutcliffe Efficiency (NSE) as the performance metric.
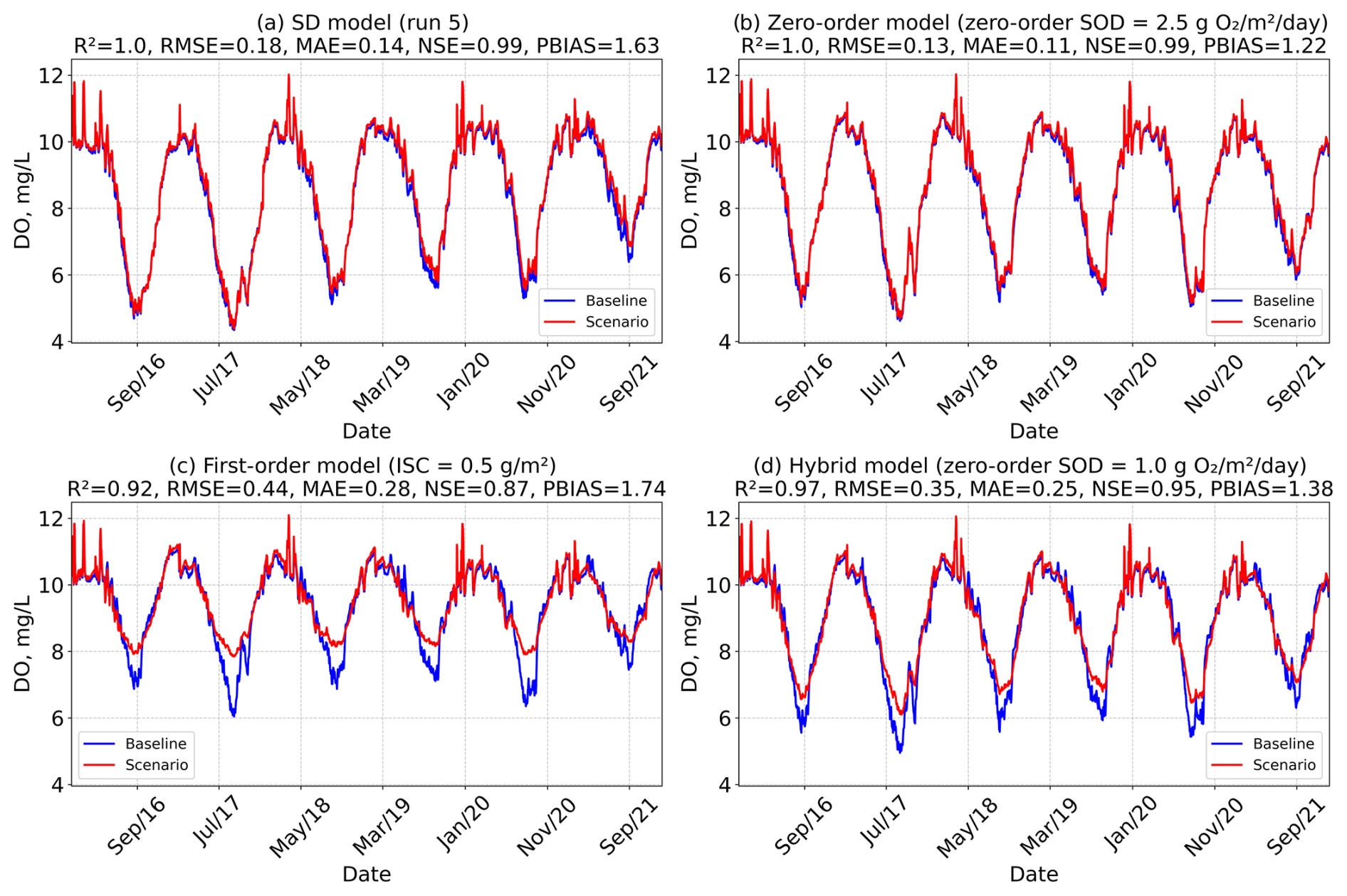
Figure 12Time series of DO, averaged across all model layers and segments, for each baseline model scenario: SD model (Run 5), Zero-order model (SOD = 2.5 g O2 m−2 d−1), First-order model (initial sediment concentration = 0.5 g m−2), and Hybrid model (Zero-order SOD = 1.0 g O2 m−2 d−1). The figure compares baseline conditions with an 80 % reduction in organic matter inflow load in the main reservoir branch (Branch 1 – Tâmega River). Performance metrics (R2, RMSE, MAE, NSE, and PBIAS) are also shown for each case.
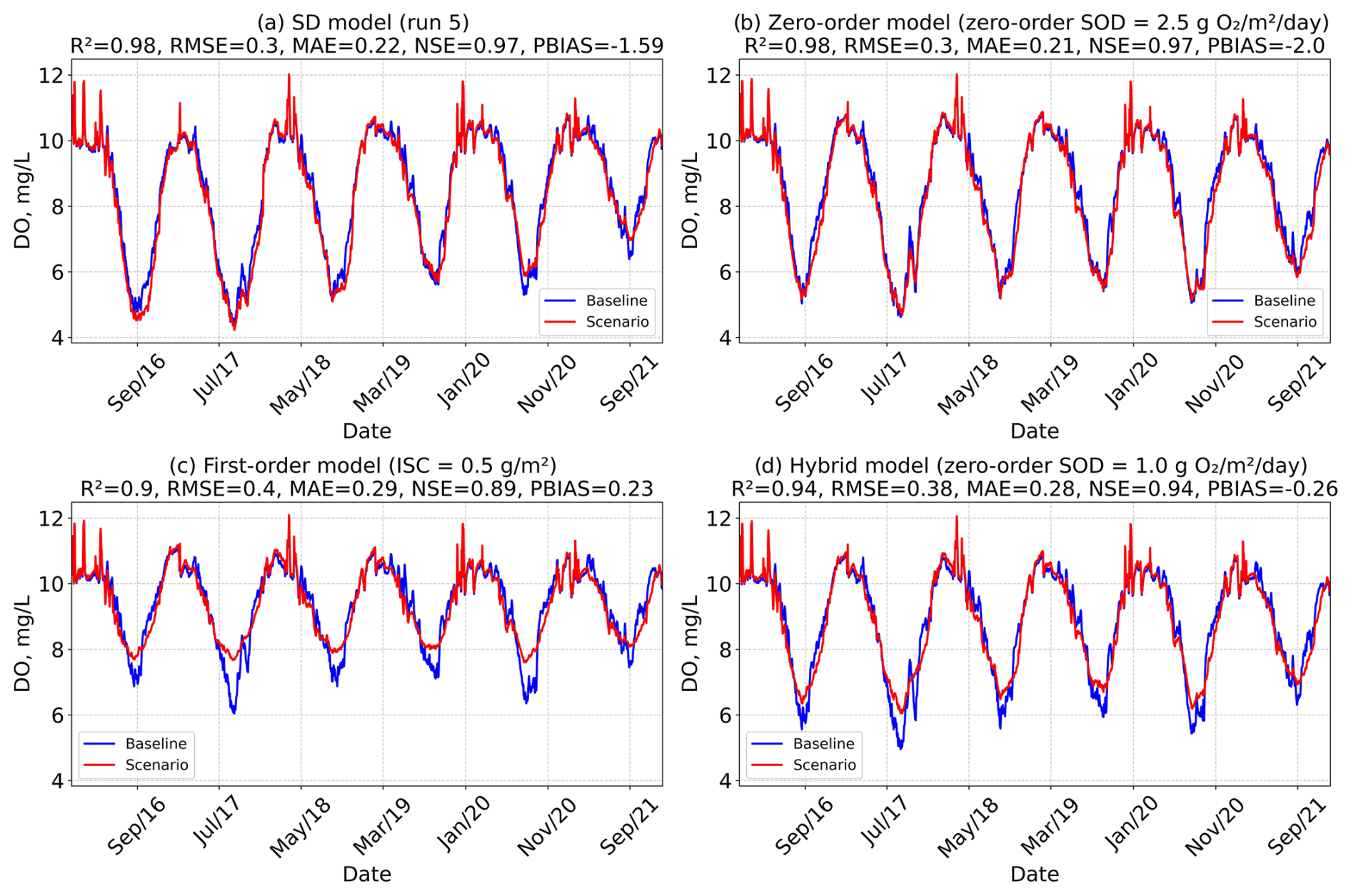
Figure 13Time series of DO, averaged across all model layers and segments, for each baseline model scenario: SD model (Run 5), Zero-order model (SOD = 2.5 g O2 m−2 d−1), First-order model (initial sediment concentration = 0.5 g m−2), and Hybrid model (Zero-order SOD = 1.0 g O2 m−2 d−1). The figure compares baseline conditions with an 80 % reduction in organic matter and P-PO4 inflow loads in the main reservoir branch (Branch 1 – Tâmega River). Performance metrics (R2, RMSE, MAE, NSE, and PBIAS) are also shown for each case.
3.4 Inflow organic matter and phosphorus load reduction scenarios
The results reveal clear differences in model sensitivity to inflow load reductions, with the First-order and Hybrid models exhibiting a stronger response compared to the SD and Zero-order models (Figs. 12 and 13). The SD model showed minimal change, indicating limited sensitivity to external loading (Figs. 12a and 13a), likely due to strong internal loading feedback from legacy phosphorus and organic matter stored in sediments. The Zero-order model demonstrated limited utility for management scenarios because it is decoupled from the water column, reducing its responsiveness to external changes. The First-order model may overestimate sensitivity as it tends to underestimate internal loading contributions. The Hybrid model, which combines both approaches, is less reactive than the First-order model due to the influence of the Zero-order component, offering a more balanced response. However, the Zero-order SOD component in the Hybrid model depends solely on temperature and remains decoupled from water column conditions; this limitation may gradually reduce the model's accuracy in long-term simulations. These differences in model sensitivity are further reflected in the evolution of average SOD across scenarios (Table 5). While the Zero-order and SD models show virtually no change in bottom-layer SOD under reduced loading conditions, the First-order and Hybrid models register clear declines. The First-order model's SOD drops from 0.87 to 0.42 g O2 m−2 d−1 (80 % OM reduction) and 0.29 g O2 m−2 d−1 (80 % OM and P reduction) and the Hybrid model from 1.49 to 1.07 g O2 m−2 d−1 (80 % OM reduction) and 0.94 g O2 m−2 d−1 (80 % OM and P reduction).
Table 5Average sediment oxygen demand (SOD) in the bottom layers of the reservoir, calculated across all segments, for each model under three scenarios: Reference (baseline conditions), 80 % reduction in organic matter inflow (OM 80 %), and combined 80 % reduction in organic matter and phosphorus inflow (OM and P %) in the in the main reservoir branch (Branch 1 – Tâmega River).

Overall, the temperature and DO predictions for the reservoir boundary conditions (Tâmega river) were quite good: PBIAS: 0.76 % and 0.92 %, respectively. When a significant number of samples and forcing variables are available the accuracy of machine learning algorithms can be greatly enhanced. This was demonstrated in the studies by Lu and Ma (2020), Rajesh and Rehana (2021), and Feigl et al. (2021), where the RMSE for river water temperature prediction reached 1.04, 1.03, and 0.58 °C, respectively. The results obtained for alkalinity, conductivity and TSS were also good: Alkalinity-PBIAS: 17.44 %; Conductivity – PBIAS: 8.23 %; TSS – PBIAS: 11.86 %. However, as expected, the PBIAS values obtained for the remaining constituents were not as favorable (Total P – PBIAS: 7.11 %; N-NOx – PBIAS: 3.92 %; BOD5 – PBIAS: 6.93 %; Chl a – PBIAS: 30 %). The modeling of these constituents involves complex biological, chemical, and physical processes that are harder to model accurately. However, except for Chl a, the PBIAS values were generally less than 10 %, reflecting acceptable levels of bias. Ammonium (N-NH4) was the only parameter for which performance was significantly lower, generating a PBIAS of 28.27 %. Moriasi et al. (2015) suggest that ±10 ≤ PBIAS ≤ ±25 is indicative of a satisfactory model performance.
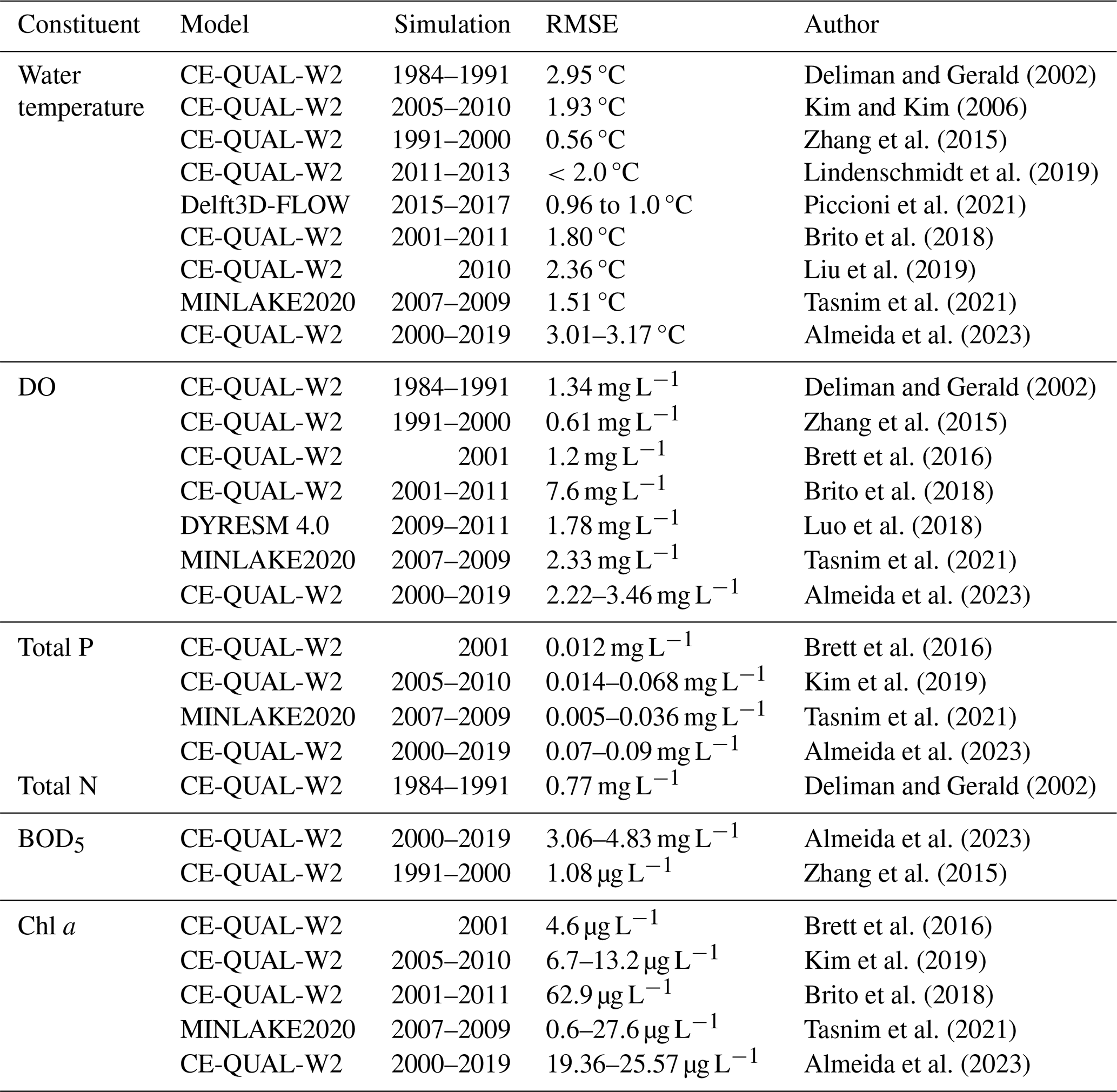
Based on the RMSE, the overall reservoir calibration results obtained for all constituents with all models for the 2016–2021 period were consistent with the results seen in other studies (see Table A11). The mean RMSE values for Chl a obtained with all models (SD model (run 5 – baseline): 17.72 µg L−1; Zero-order model (zero-order SOD = 2.5 g O2 m−2 d−1 – baseline): 17.78 µg L−1; First-order model (ISC = 0.5 g m−2 – baseline): 14.88 µg L−1 and the Hybrid model (zero-order SOD =1.0 g O2 m−2 d−1 – baseline): 14.88 µg L−1) are aligned with the results of other modeling studies (Brito et al., 2018: 62.9 µg L−1; Kim et al., 2019: 6.7 to 13.2 µg L−1; Tasnim et al., 2021: 0.6 to 27.6 µg L−1; Almeida et al., 2023: 19.36 to 25.57 µg L−1). For TP, the mean RMSE values were 0.03 mg L−1 for both the SD model (Run 5 – baseline) and the First-order model (ISC = 0.5 g m−2 – baseline), while the Hybrid model (zero-order SOD = 1.0 g O2 m−2 d−1 – baseline) showed a slightly higher value of 0.04 mg L−1. These results fall within the range reported in previous studies, including Brett et al. (2016) at 0.012 mg L−1, Kim et al. (2019) between 0.014 and 0.068 mg L−1, Tasnim et al. (2021) from 0.005 to 0.036 mg L−1, and Almeida et al. (2023) ranging from 0.07 to 0.09 mg L−1. The only exception was the Zero-order model (SOD = 2.5 g O2 m−2 d−1 – baseline), which overestimated phosphorus export from sediments during the summer months (July to September) of 2018 to 2021, resulting in a notably higher RMSE of 0.1 mg L−1. Even with a very low phosphorus release rate from the sediments – representing a fraction of the SOD (0.001) – the Zero-order model still overestimated phosphorus concentrations, particularly during periods of elevated sediment oxygen demand. This suggests that the model may lack the sensitivity needed to accurately simulate low-level sediment-phosphorus interactions under such conditions. The mean RMSE values obtained for TN were lower than the only reference value available in the literature – 0.77 mg L−1 reported by Deliman and Gerald (2002). Specifically, the SD model (Run 5 – baseline) yielded an RMSE of 0.33 mg L−1, the First-order model (ISC = 0.5 g m−2 – baseline) produced 0.36 mg L−1, and the Hybrid model (zero-order SOD = 1.0 g O2 m−2 d−1 – baseline) resulted in 0.35 mg L−1. The only exception was the Zero-order model (SOD = 2.5 g O2 m−2 d−1 – baseline), which had a significantly higher RMSE of 0.79 mg L−1 – slightly exceeding the value reported by Deliman and Gerald (2002) yet still within a comparable range. The RMSE obtained with the SD model (Run 5 - baseline), Zero-order model (zero-order SOD = 2.5 g O2 m−2 d−1 – baseline); First-order model (ISC = 0.5 g m−2 – baseline) and the Hybrid model (zero order SOD = 1.0 g O2 m−2 d−1 – baseline) for DO, 2.01, 1.97, 2.15 and 1.87 mg L−1 respectively) are also in line with the results obtained in other studies (e.g., Deliman and Gerald (2002): 1.34 mg L−1; Brett et al., 2016: 1.2 mg L−1; Brito et al., 2018: 7.6 mg L−1; Luo et al., 2018: 1.78 mg L−1; Tasnim et al., 2021: 2.33 mg L−1). In the SD model (Run 5 – baseline), bottom-layer SOD values ranged from 0.015 to 5.152 g O2 m−2 d−1 ( σ=0.823), reflecting moderate variability driven by seasonal biogeochemical processes. In comparison, the Zero-order model (SOD = 2.5 g O2 m−2 d−1 – baseline) showed a broader but more temperature-driven range, from 0.000 to 15.640 g O2 m−2 d−1 (μ=1.432; σ=2.122). The First-order model (ISC = 0.5 g m−2 – baseline) yielded values between 0.000 and 20.000 g O2 m−2 d−1, with a much lower mean (μ=0.870) and relatively high variability (σ=1.920), consistent with its sensitivity to organic matter loading. The Hybrid model (zero-order SOD = 1.0 g O2 m−2 d−1 – baseline) incorporated both zero- and first-order processes and produced the widest overall range, from 0.000 to 21.938 g O2 m−2 d−1 (μ=1.491; σ=2.024), highlighting its enhanced responsiveness to both physical (e.g., temperature) and biogeochemical (e.g., organic matter) drivers. The monthly variation in SOD across the four models reveals distinct seasonal patterns influenced by their underlying formulations (Fig. A2). All models show notable peaks in May and October, corresponding to periods of elevated organic matter inflow, while a consistent decline is observed during the summer months (June to August), when external organic inputs are comparatively low. The Zero-order model (baseline SOD = 2.5 g O2 m−2 d−1) exhibits a sharp rise from winter to a peak of 1.919 g O2 m−2 d−1 in May, then gradually declines over the summer, before increasing again in October (1.910 g O2 m−2 d−1). A similar double-peak pattern is observed in the Hybrid model (zero-order SOD = 1.0 g O2 m−2 d−1, baseline), with SOD reaching 1.715 g O2 m−2 d−1 in May and a more pronounced maximum of 2.338 g O2 m−2 d−1 in October, reflecting the combined effects of temperature and organic matter availability. The SD model (Run 5 – baseline) shows more moderate seasonal variation, with values dipping to 0.679 g O2 m−2 d−1 in August, then rising to 1.501 g O2 m−2 d−1 in November, consistent with internal sediment dynamics. The First-order model (ISC = 0.5 g m−2, baseline), which is most sensitive to organic matter loading, also mirrors this seasonal structure, peaking in October (1.235 g O2 m−2 d−1) after a gradual summer decline. Collectively, these patterns underscore the importance of organic matter availability – particularly in spring and autumn – as a key driver of SOD across the different modeling approaches. This pattern indicates the model's responsiveness to both organic matter inputs and temperature, leading to a more nuanced representation of seasonal variation compared to the other models. These values are consistent with the SOD values obtained in other studies, such as those of Schnoor and Fruh (1979), which concluded that the SOD values of Lake Lydon B. Johnson (located in the US) ranged from 1.7 to 5.8 g O2 m−2 d−1, and of Beutel (2015), which measured SOD values in different locations around Lake Hodges (located in the US) ranging from 0.6 to 2.3 g O2 m−2 d−1. It would be useful to be able to compare these results with SOD values measured at different sites within the Torrão reservoir.
It is important to emphasize that this study was primarily designed to evaluate the performance of the sediment diagenesis model. However, by incorporating alternative SOD modeling approaches, it inevitably allowed for a comparative ranking of model performance, highlighting the relative strengths and limitations of each formulation. The performance limitations of the Zero-order and First-order models can be attributed to their structural simplifications. Specifically, the Zero-order model's strong temperature dependence, coupled with its disregard for the dynamics of organic matter loading, reduces its ability to capture temporal variability driven by external inputs. Similarly, the lower accuracy of the First-order model likely stems from its exclusion of anaerobic decay processes and limited representation of sediment biogeochemistry, which becomes especially relevant under low-oxygen conditions. The Hybrid model outperformed all other approaches. Considering the principle of parsimony (Occam's razor) (Burnham and Anderson, 2002), the simpler Hybrid model proved more effective than the complex SD model, making it the preferred choice for simulating SOD dynamics in the reservoir. These findings underscore the importance of selecting models that align with the specific characteristics of the system being studied. Simpler models, such as the Hybrid model, may be adequate for steady-state conditions, short- to medium-term forecasts, or scenarios with limited data. The zero-order SOD component of the Hybrid model relies solely on temperature and is decoupled from the water column; therefore, in long-term simulations, this limitation can gradually undermine the model's accuracy. In contrast, the SD model may be more appropriate when the goal is to explore system-wide feedbacks and temporal dynamics over extended periods – especially those involving sediment accumulation and nutrient cycling – where it may provide valuable insight into underlying processes, provided that sufficient observational data become available to support its additional state variables. Moreover, a model's effectiveness heavily depends on the user's familiarity with its structure and their skill in calibration. Yet, it is unrealistic to expect researchers to master the implementation of every available modeling approach. As such, comparisons between models should be interpreted carefully, acknowledging the influence of user expertise on performance outcomes (Piccolroaz et al., 2024). Overall, to strengthen the analysis, it is recommended that users apply all available SOD modeling approaches in the case of the CE-QUAL-W2 model and assess the model's behavior. This comprehensive evaluation provides a solid foundation for further modeling efforts and helps ensure that the chosen approach is well-suited to the system's specific conditions and objectives.
The results also revealed that the particulate fraction of organic carbon in the reservoir sediments corresponded to 80 % of the TOC. This value is small compared to the results obtained for Taihu Lake by Yu et al. (2022), where the ratio of POP to TOC varied from 97.85 % to 89.53 %. However, this value (80 %) was obtained indirectly through the analysis of the reservoir's predicted SOD values as a function of different initial POC values and may, therefore, reflect other sources of uncertainty, such as inflow organic matter characterization. Given the fact that the magnitude of TOC in the sediment can be affected by numerous factors, including water column productivity, terrestrial inputs of organic materials, sediment properties, and microbial activity rates (Gireeshkumar et al., 2013), and that, partly due to differences in reservoir productivity and morphology, the spatial distribution and sources of organic carbon vary greatly across regions (Anderson et al., 2009), it is reasonable to assume that the only way to accurately assess the POC prediction is by monitoring the reservoir POC content. Furthermore, this study has highlighted the need to expand research to additional waterbodies across diverse regions to improve our understanding of the CE-QUAL-W2 diagenesis model's performance under varying environmental conditions. This includes evaluating its applicability in long-term scenarios, which are essential for capturing cumulative sediment dynamics and climate-driven trends. Additional SOD monitoring studies need to be conducted in lakes and reservoirs and extended to other latitudes, with particular focus on the chemical characterization of sediments and the definition of sediment burial rates.
This research evaluates the performance of the CE-QUAL-W2 v4.5 sediment diagenesis model in simulating water temperature, dissolved oxygen, total phosphorus, total nitrogen, chlorophyll a, and biochemical oxygen demand in a Portuguese reservoir over the period from 2016 to 2021. Calibration was based on 35 sets of observed temperature and dissolved oxygen profiles, supplemented by six annual measurements of total nitrogen, total phosphorus, chlorophyll a, and biochemical oxygen demand collected at various depths. To evaluate model accuracy, three alternative sediment oxygen demand formulations – a Zero-order model, a First-order model, and a Hybrid approach combining features of both – were also applied and compared. The Hybrid model consistently outperformed the other formulations, striking an effective balance between accuracy and simplicity. It therefore represents the most suitable choice for modeling the reservoir. In contrast, the Zero- and First-order models exhibited limitations related to temperature dependence and inadequate sediment process representation, respectively. Simpler models, such as the Hybrid model, may be adequate for steady-state conditions, short- to medium-term forecasts, or scenarios with limited data. In contrast, the SD model –despite its good performance – may be more appropriate when the goal is to explore system-wide feedbacks and temporal dynamics over extended periods, especially in cases involving sediment accumulation and nutrient cycling. In such contexts, it may offer valuable insights, provided that sufficient observational data are available to support its additional state variables. Overall, the study reinforces the importance of choosing models based on site characteristics, available data, and simulation goals. Future work should broaden the evaluation of these models across various waterbodies and extended timeframes, while highlighting the need for enhanced sediment monitoring to support detailed process-based modelling.
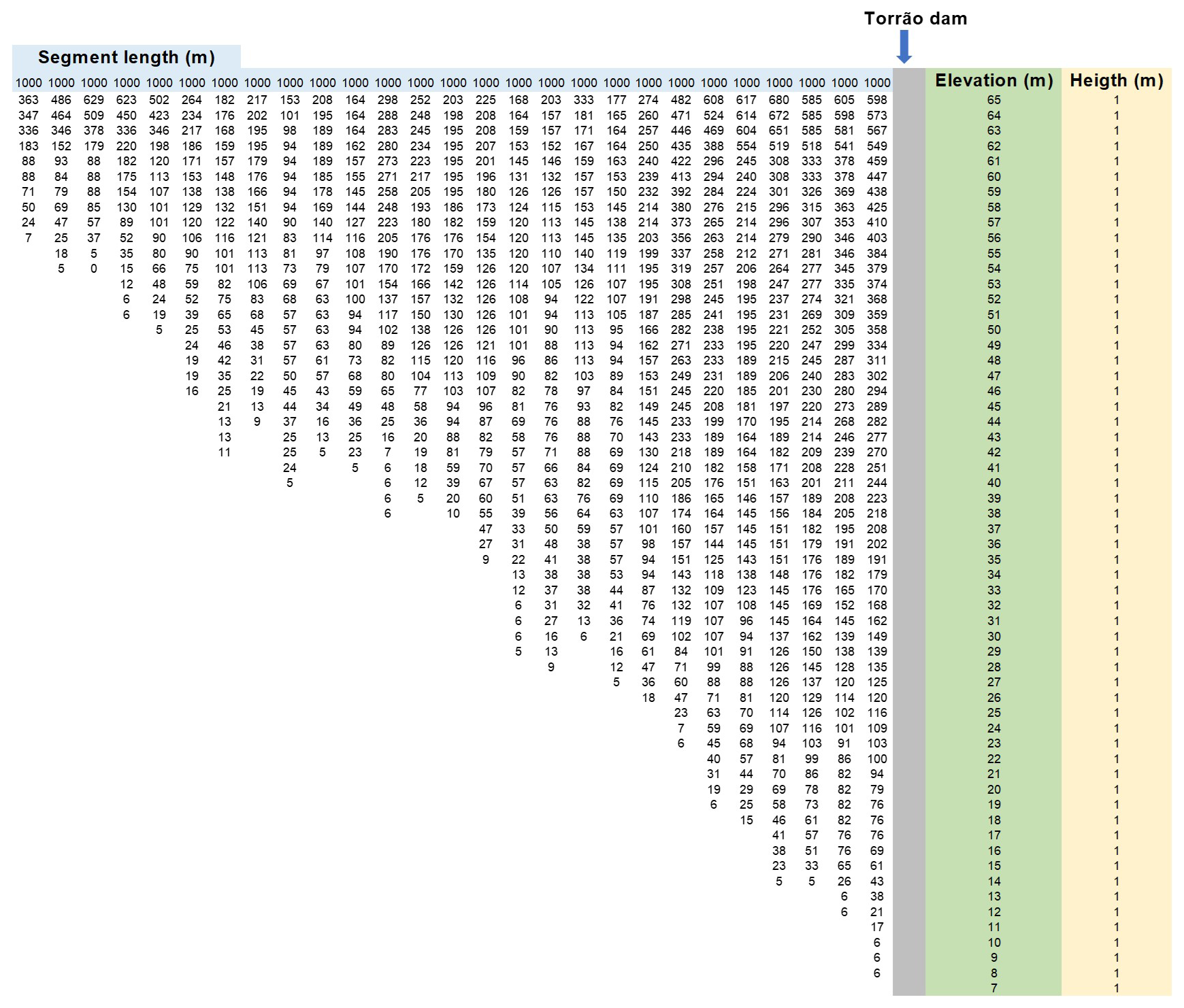
Figure A1CE-QUAL-W2 bathymetry – Cross section of the Tâmega River with the average segment width.
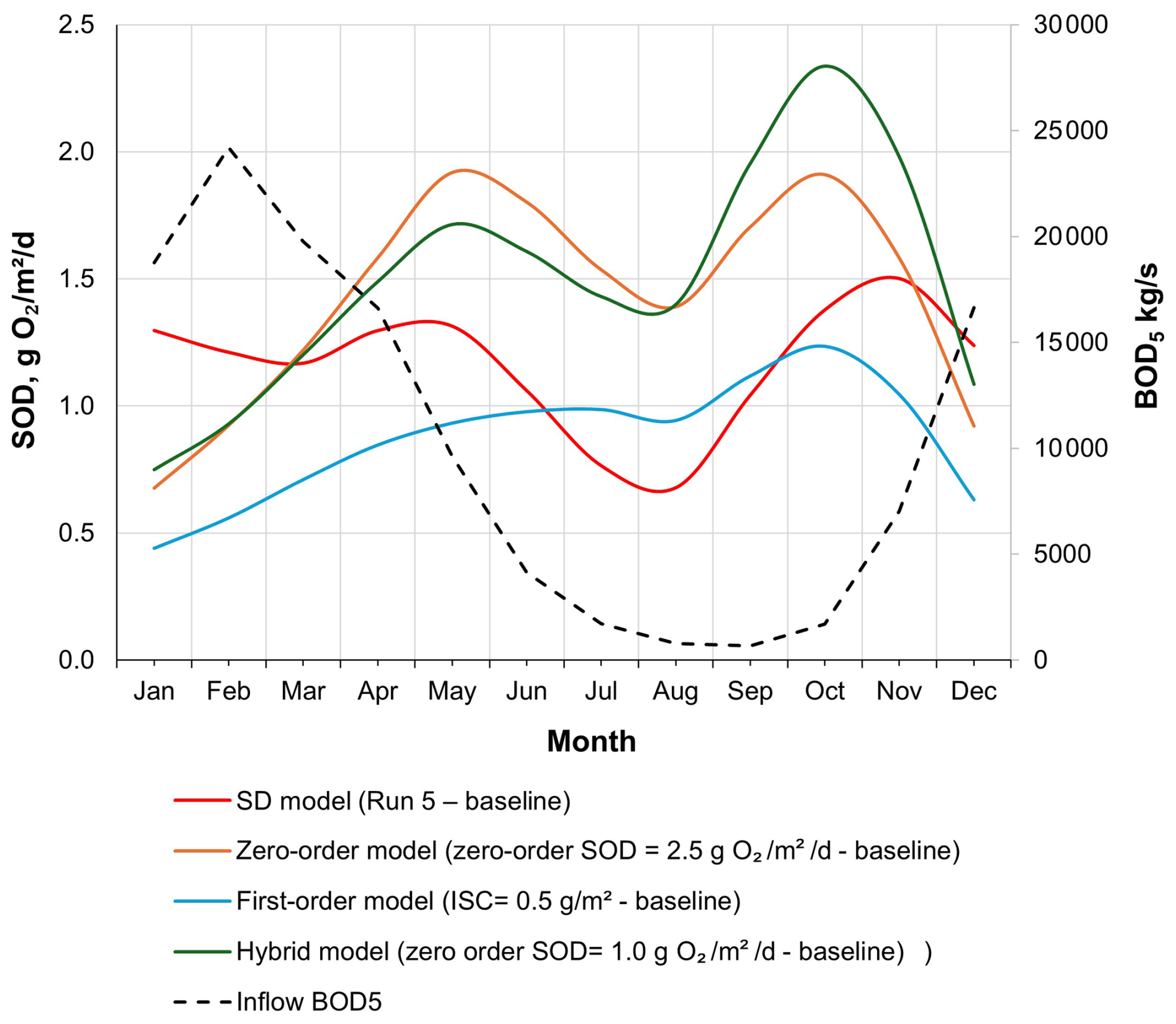
Figure A2Average monthly sediment oxygen demand (SOD) at the reservoir bottom layer predicted by the SD model (Run 5 – baseline), Zero-order model (baseline: SOD = 2.5 g O2 m−2 d−1), First-order model (baseline: ISC = 0.5 g m−2), and Hybrid model (baseline: zero-order SOD = 1.0 g O2 m−2 d−1). Also shown is the inflow BOD5 load from the reservoir's main branch.
Table A1Model metrics. Characterization of Tâmega river inflow.
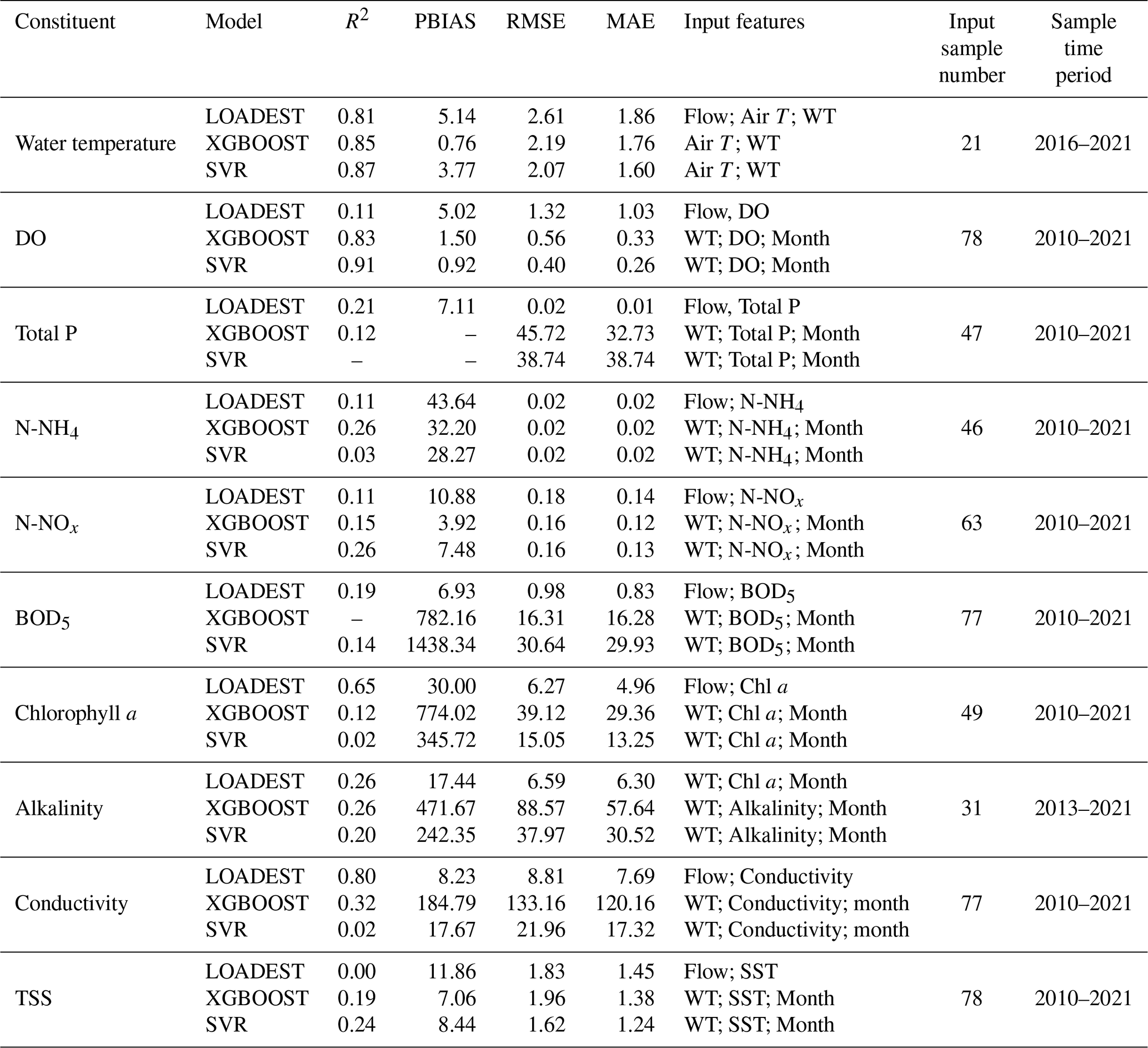


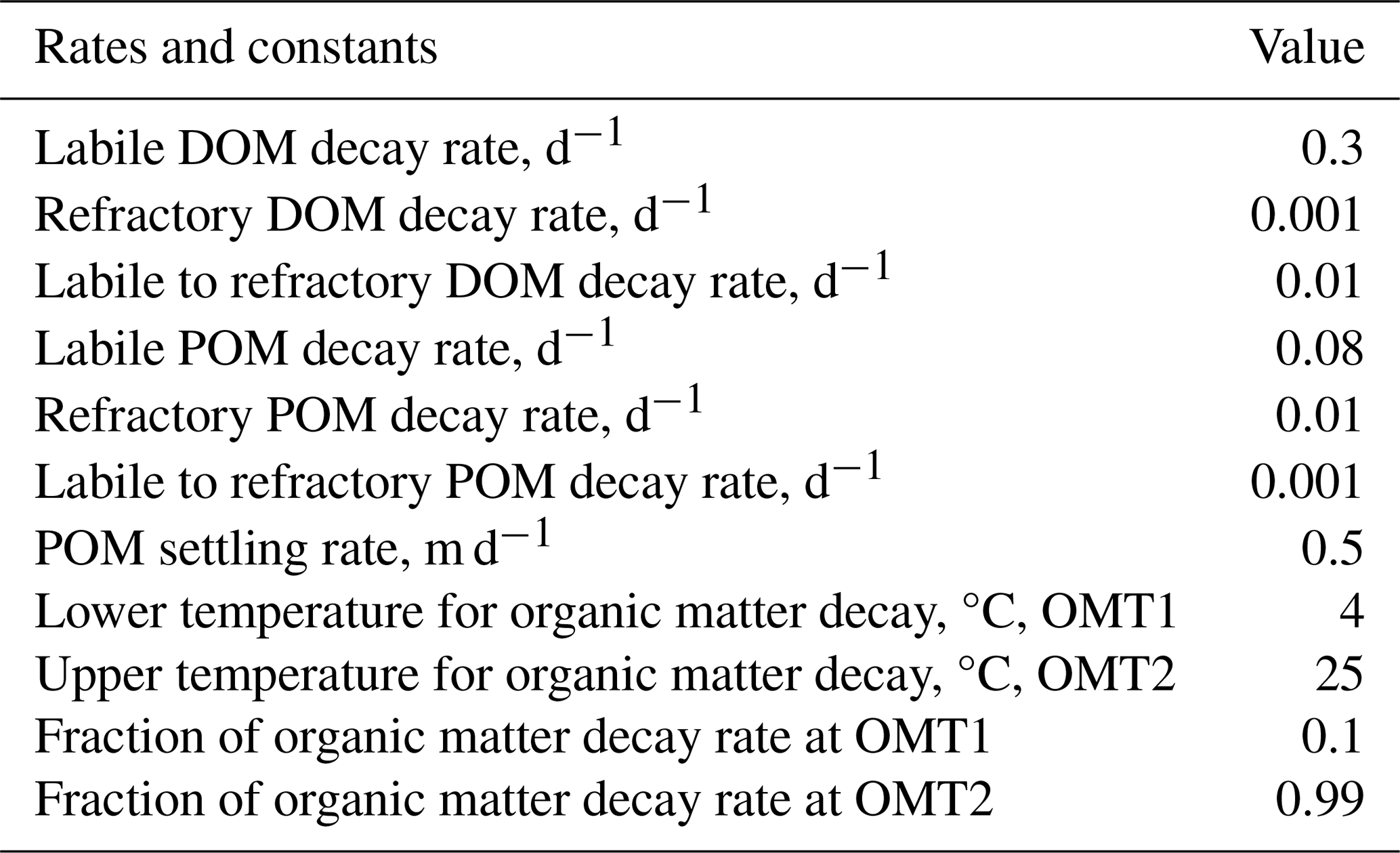



Table A9Metrics between observed and predicted values for both models. The predicted values were compared with observed values at three different depths: (a) an integrated sample between the reservoir surface and an average depth of 5.8 m, (b) an average depth of 23 m, and (c) an average depth of 43. m. The values shown in this table represent the mean value of the metrics obtained for each date and the corresponding standard deviation.
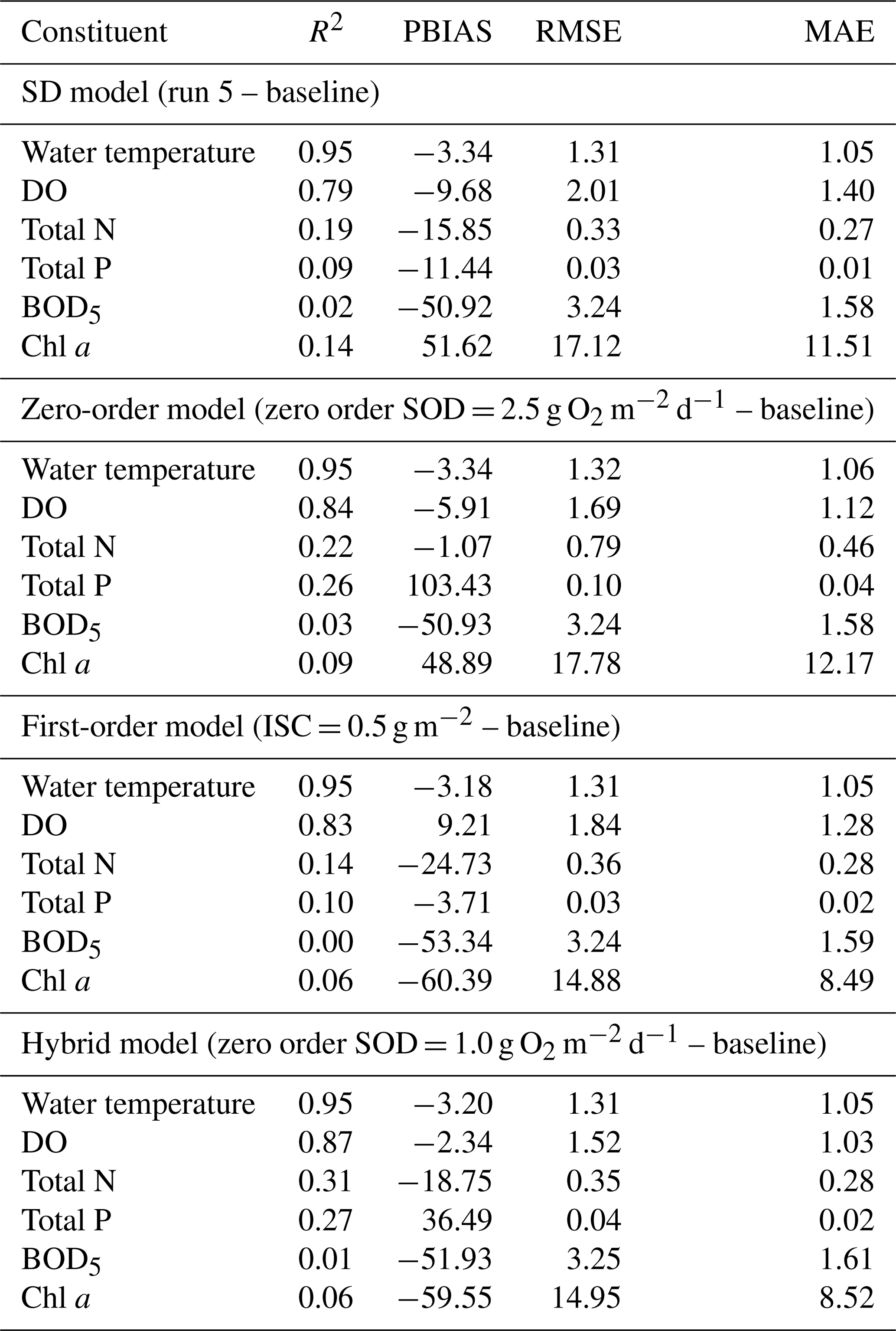
Table A10Metrics between observed and predicted values for SD model (run 4). Water temperature and DO metrics were obtained from 36 observed and predicted profiles. The predicted values for the remaining constituents were compared with observed values at three different depths: (a) an integrated sample between the reservoir surface and an average depth of 5.8 m, (b) an average depth of 23 m and (c) an average depth of 43.7 m. The values in this table represent the mean value of the metrics obtained at each date and the corresponding standard deviation or, in the case of water temperature and DO, the mean value of the metrics obtained for each profile and the standard deviation.
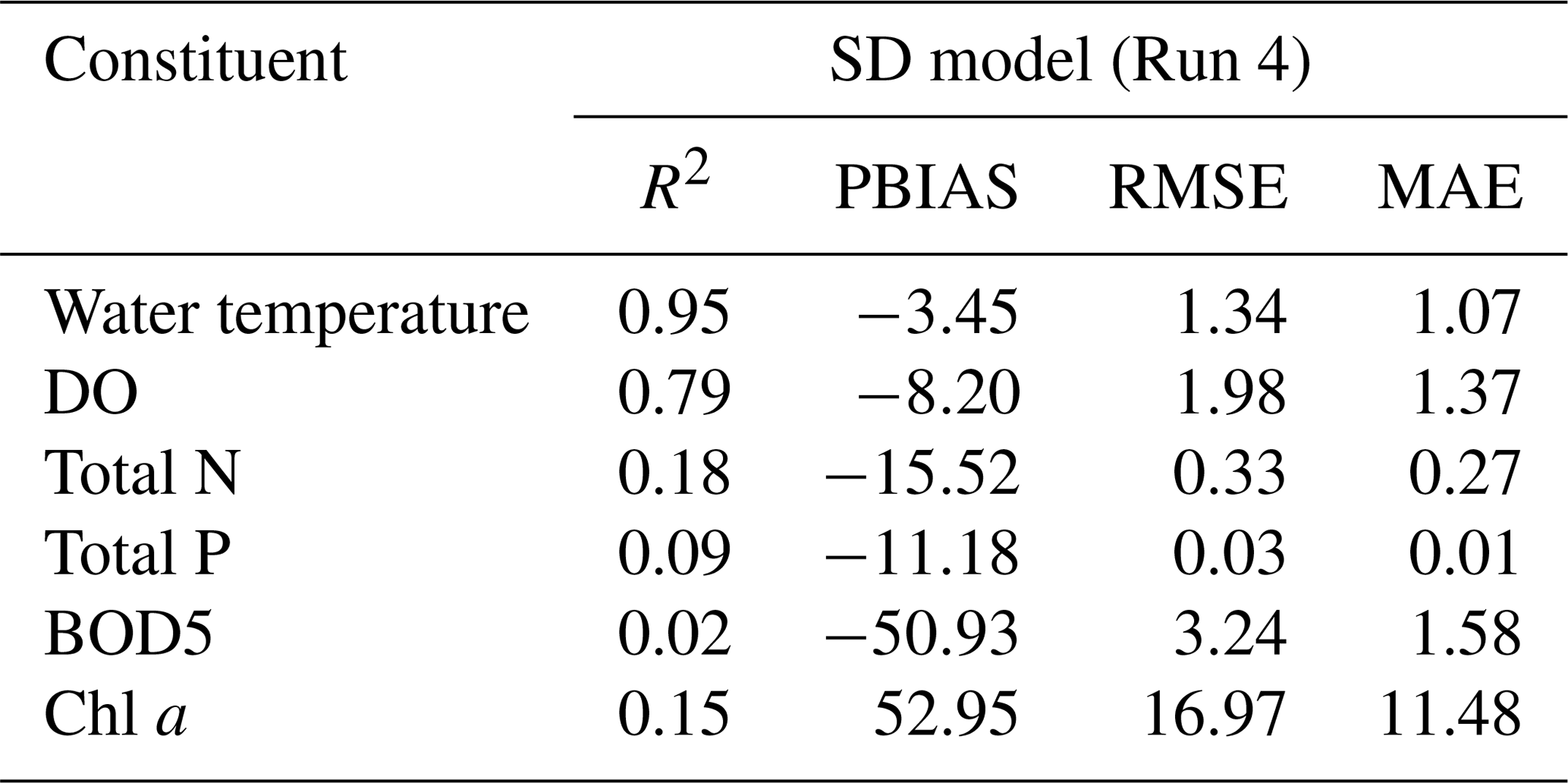
Table A11Root mean square error values obtained with different models and across different time frames.
The exact version of the models' source code is archived on Zenodo at https://doi.org/10.5281/zenodo.14606105 (Almeida and Coelho, 2025). The current version of the open-source CEQUAL-W2 model (version 4.5) used in this study is also available from the project website (http://www.ce.pdx.edu/w2/, last access: 24 January 2024).
Input files needed to run the models' and the hydrometric water quality and meteorological datasets used to force and validate each model are freely available and are archive on Zenodo at https://doi.org/10.5281/zenodo.14606105 (Almeida and Coelho, 2025).
MA conceptualized the study, developed the methodology, and handled software and data curation, as well as writing the original draft. PC administered the project and contributed to reviewing and editing the manuscript.
The contact author has declared that neither of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors. Also, please note that this paper has not received English language copy-editing. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
The authors acknowledge the funding received from Fundação para a Ciência e a Tecnologia (FCT, Portugal), through the UIDB/04292/2020 and UIDP/04292/2020 strategic projects granted to the Marine and Environmental Sciences Centre (MARE) and the LA/P/0069/2020 project granted to the Aquatic Research Network Associate Laboratory (ARNET).
This research has been supported by the Fundação para a Ciência e a Tecnologia (grant nos. UIDB/04292/2020, UIDP/04292/2020, and LA/P/0069/2020).
This paper was edited by Wolfgang Kurtz and reviewed by two anonymous referees.
Abbaspour, K. C., Rouholahnejad, E., Vaghefi, S., Srinivasan, R., Yang, H. and Kløve, B.: A continental-scale hydrology and water quality model for Europe: Calibration and uncertainty of a high-resolution large-scale SWAT model, J. Hydrol., 524, 733–752, https://doi.org/10.1016/j.jhydrol.2015.03.027, 2015.
Adedeji, I. C., Ahmadisharaf, E., and Sun, Y.: Predicting in-stream water quality constituents at the watershed scale using machine learning. J. Contam. Hydrol., https://doi.org/10.1016/j.jconhyd.2022.104078, 2022.
Almeida, M. and Coelho, P. S.: An integrated approach based on the correction of imbalanced small datasets and the application of machine learning algorithms to predict total phosphorus concentration in rivers, Ecol. Inform., 76, 102138, https://doi.org/10.1016/j.ecoinf.2023.102138, 2023a.
Almeida, M. and Coelho, P.: A first assessment of ERA5 and ERA5-Land reanalysis air temperature in Portugal, In. J. Climatol., 43, 6643–6663, https://doi.org/10.1002/JOC.8225, 2023b.
Almeida, M. and Coelho, P.: Evaluating the performance of CE-QUAL-W2 version 4.5 sediment diagenesis model (Manuscript related material: input data and source code) (1.0.0), Zenodo [data set and code], https://doi.org/10.5281/zenodo.14606105, 2025.
Almeida, M., Rebelo, R., Costa, S. Rodrigues, A. C., and Coelho, P. S.: Long-Term Water Quality Modeling of a Shallow Eutrophic Lagoon with Limited Forcing Data, Environ. Model. Assess., https://doi.org/10.1007/s10666-022-09844-3, 2023.
Anderson, N. J., D'Andrea, W., and Fritz, S. C.: Holocene carbon burial by lakes in SW Greenland, Glob. Change Biol., 15, 2590–2598, https://doi.org/10.1111/j.1365-2486.2009.01942.x, 2009.
Barbosa, S. and Scotto, M. G.: Extreme heat events in the Iberia Peninsula from extreme value mixture modeling of ERA5-Land air temperature, Weather Clim. Extrem. 36, 100448, https://doi.org/10.1016/j.wace.2022.100448, 2022.
Berger, C. and Wells, S.: Updating the CEMA Oil Sands Pit Lake Model, Prepared for CEMA, 2014.
Bergstra, J., Yamins, D., and Cox, D. D.: Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures, in: Proc. of the 30th International Conference on Machine Learning (ICML 2013), http://nrs.harvard.edu/urn-3:HUL.InstRepos:12561000, 2013.
Beutel, M.: Lake Hodges Reservoir Oxygen Demand Study. Final Assessment Report, City of San Diego Public Utilities Department, https://www.sandiego.gov/sites/default/files/ceqa-hodges-reservoir-oxygen.pdf (last access: 15 August 2024), 2015.
Brett, M. T., Ahopelto, S. K., Brown, H. K., Brynestad, B. E., Butcher, T. W., Coba, E. E., Curtis, C. A., Dara, J. T., Doeden, K. B., Evans, K. R., Fan L., Finley, J. D., Garguilo, N. J., Gebreeyesus, S. M., Goodman, M. K., Gray, K. W., Grinnell, C., Gross, K. L., Hite, B. R. E., Jones, A. J., Kenyon, P. T., Klock, A. M., Koshy, R. E., Lawler, A. M., Lu, M., Martinkosky, L., Miller-Schulze, J. R., Nguyen, Q. T. N., Runde, E. R., Stultz, J. M., Wang, S., White, F. P., Wilson, C. H., Wong, A. S., Wu, S. Y., Wurden, P. G., Young, T. R., and Arhonditsis, G. B.: The modeled and observed response of Lake Spokane hypolimnetic dissolved oxygen concentrations to phosphorus inputs, Lake Reserv. Manage., 32–33, 246–258, https://doi.org/10.1080/10402381.2016.1170079, 2016.
Brito, D., Ramos, T. B., Gonçalves, M. C., Morais, M., and Neves, R.: Integrated modelling for water quality management in a eutrophic reservoir in south – eastern Portugal, Environ. Earth Sci., 77, https://doi.org/10.1007/s12665-017-7221-5, 2018.
Burnham, K. P. and Anderson, D. R.: Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach, in: 2nd Edn., Springer, ISBN 978-0-387-95364-9, 2002.
Cardoso, R. M., Soares, P. M. M., Miranda, P. M. A., and Belo-Pereira, M.: WRF High resolution simulation of Iberian mean and extreme precipitation climate, Int. J. Climatol., 33, 2591–2608, https://doi.org/10.1002/joc.3616, 2013.
Chapman, D. V.: Water quality assessments: A guide to the use of biota, sediments, and water in environmental monitoring, in2nd Edn., CRC Press, ISBN 0 419 21590 5, 1996.
Chen, T. and Guestrin, C.: XGBoost: A Scalable Tree Boosting System, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, New York, NY, USA, 785–794, https://doi.org/10.1145/2939672.2939785, 2016.
Chuo, M., Ma, J., Liu, D., and Yang, Z.: Effects of the impounding process during the flood season on algal blooms in Xiangxi Bay in the Three Gorges Reservoir, China, Ecol. Model., 392, 236–249, https://doi.org/10.1016/j.ecolmodel.2018.11.017, 2019.
Cole, T. M. and Wells, S. A.: CE-QUAL-W2: A Two-dimensional, Laterally Averaged, Hydrodynamic and Water Quality Model, Version 3.5, https://pdxscholar.library.pdx.edu/cengin_fac/130/ (last access: 20 August 2024), 2006.
Deliman, P. N. and Gerald, J. A.: Application of the Two- Dimensional Hydrothermal and Water Quality Model, CE-QUAL-W2, to the Chesapeake Bay – Conowingo Reservoir, Lake Reserv. Manage., 18, 10–19, https://doi.org/10.1080/07438140209353925, 2002.
Feigl, M., Lebiedzinski, K., Herrnegger, M., and Schulz, K.: Machine-learning methods for stream water temperature prediction, Hydrol. Earth Syst. Sci. 25, 2951–2977, https://doi.org/10.5194/hess-25-2951-2021, 2021.
Gireeshkumar,. R., Deepulal, P. M., and Chandramohanakumar, N.: Distribution and sources of sedimentary organic matter in a tropical estuary, southwest coast of India (Cochin estuary): A baseline study, Mar. Pollut. Bull., 66, 239–245, https://doi.org/10.1016/j.marpolbul.2012.10.002, 2013.
Hamilton, D. P. and Schladow, S. G.: Prediction of water quality in lakes and reservoirs. Part I – model description, Ecol. Model., 96, 91–110, https://doi.org/10.1016/S0304-3800(96)00062-2, 1997.
Ji, X. and Lu, J.: Forecasting riverine total nitrogen loads using wavelet analysis and support vector regression combination model in an agricultural watershed, Environ. Sci. Pollut. Res. Int., 25, 26405–26422, https://doi.org/10.1007/s11356-018-2698-3, 2018.
Kim, D., Kim, Y., and Kim, B.: Simulation of eutrophication in a reservoir by CE-QUAL-W2 for the evaluation of the importance of point sources and summer monsoon. Lake Reserv. Manage., 35, 64–76, https://doi.org/10.1080/10402381.2018.1530318, 2019.
Kim, Y. and Kim, B.: Application of a 2-dimensional water quality model (CE-QUAL-W2) to the turbidity interflow in a deep reservoir (Lake Soyang, Korea), Lake Reserv. Manage, 22, 213–222, https://doi.org/10.1080/10402381.2018.1530318, 2006.
Kobler, U. G., Wüest, A., and Schmid, M.: Effects of lake–reservoir pumped-storage operations on temperature and water quality, Sustainability, 10, 1968, https://doi.org/10.3390/su10061968, 2018.
Lindenschmidt, K. E., Carr, M. K., Sadeghian, A., and Morales-Marin, L.: CE-QUAL-W2 model of dam outflow elevation impact on temperature, dissolved oxygen and nutrients in a reservoir, Sci. Data, 6, 312, https://doi.org/10.1038/s41597-019-0316-y, 2019.
Liu, M., Chen, X., Chen, Y., Gao, L., and Deng, H.: Nitrogen retention effects under reservoir regulation at multiple time scales in a subtropical river basin, Water, 11, 1685, https://doi.org/10.3390/w11081685, 2019.
Loucks, D. P. and van Beek, E.: Water Quality Modeling and Prediction, in: Water Resource Systems Planning and Management, Springer, Cham, https://doi.org/10.1007/978-3-319-44234-1_10, 2017.
Lu, H. and Ma, X.: Hybrid decision tree-based machine learning models for short-term water quality prediction, Chemosphere, 249, 126169, https://doi.org/10.1016/j.chemosphere.2020.126169, 2020.
Luo, L., Hamilton, D., Lan, J., McBride, C., and Trolle, D.: Autocalibration of a one-dimensional hydrodynamic-ecological model (DYRESM 4.0-CAEDYM 3.1) using a Monte Carlo approach: simulations of hypoxic events in a polymictic lake, Geosci. Model Dev., 11, 903–913, https://doi.org/10.5194/gmd-11-903-2018, 2018.
Mi, C., Shatwell, T., Ma, J., Xu, Y., Su, F., and Rinke, K.: Ensemble warming projections in Germany's largest drinking water reservoir and potential adaptation strategies, Sc. Total Environ., 748, 141366, https://doi.org/10.1016/j.scitotenv.2020.141366, 2020.
Mi, C., Shatwell, T., Kong, X., and Rinke, K.: Cascading climate effects in deep reservoirs: Full assessment of physical and biogeochemical dynamics under ensemble climate projections and ways towards adaptation, Ambio, https://doi.org/10.1007/s13280-023-01950-0, 2023.
Minear, J. T. and Kondolf, G. M.: Estimating reservoir sedimentation rates at large spatial and temporal scales: A case study of California, Water Resour. Res., 45, W12502, https://doi.org/10.1029/2007WR006703, 2009.
Moriasi, D. N., Gitau, M. W., Pai, N., and Daggupati, P.: Hydrologic and water quality models: performance measures and evaluation criteria, T. ASABE, 58, 1763–1785, https://doi.org/10.13031/trans.58.10715, 2015.
Muñoz-Sabater, J.: ERA5-Land hourly data from 1981 to present, Copernicus Climate Change Service (C3S) Climate Data Store (CDS) [data set], https://doi.org/10.24381/cds.e2161bac, 2019.
Nash, J. E. and Sutcliffe, J. V.: River flow forecasting through conceptual models: Part 1. A discussion of principles, J. Hydrol., 10, 282–290, https://doi.org/10.1016/0022-1694(70)90255-6, 1970.
OECD: Organisation for the Economic Cooperation and Development. Eutrophication of Waters – Monitoring Assessment and Control, OECD, Paris, 125 pp., 1982.
Park, Y., Cho, K. H., Kang, J.-H., Lee, S. W., and Kim, J. H.: Developing a flow control strategy to reduce nutrient load in a reclaimed multi-reservoir system using a 2D hydrodynamic and water quality model, Sci. Total. Environ., 466–467, 871–880, 2014.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E.: Scikit-learn: machine learning in Python, arXiv [preprint], 2825–2830, https://doi.org/10.48550/arXiv.1201.0490, 2011.
Piccioni, F., Casenave, C., Lemaire, B. J., Le Moigne, P., Dubois, P., and Vinçon-Leite, B.: The thermal response of small and shallow lakes to climate change: new insights from 3D hindcast modelling, Earth Syst. Dynam., 12, 439–456, https://doi.org/10.5194/esd-12-439-2021, 2021.
Piccolroaz, S., Zhu, S., Ladwig, R.,Carrea, L., Oliver, S., Piotrowski, A. P., Ptak. M., Shinohara, R., Sojka, M., Woolway, R. I., and Zhu, D. Z.: Lake water temperature modeling in an Era of climate change: Data sources, models, and future prospects, Rev. Geophys., 62, e2023RG000816, https://doi.org/10.1029/2023RG000816, 2024.
Prakash, S., Vandenberg, J. A., and Buchak, E. M.: Sediment Diagenesis Module for CE-QUAL-W2 Part 2: Numerical Formulation, Environ. Model. Assess., 20, 249–258, https://doi.org/10.1007/s10666-015-9459-1, 2015.
Rajesh, M. and Rehana, S.: Prediction of river water temperature using machine learning algorithms: a tropical river system of India, J. Hydroinf., 23, 605–626, https://doi.org/10.2166/hydro.2021.121, 2021.
Runkel, R. L., Crawford, C. G., and Cohn, T. A.: Load estimator (LOADEST): a FORTRAN program for estimating constituent loads in streams and rivers, in: USGS Techniques and Methods Book 4, Chap. A5, US Geological Survey, Reston, Virginia, USA, https://doi.org/10.3133/tm4A5, 2004.
Sadeghian, A., Chapra, S. C., Hudson, J., Wheater, H., and Lindenschmidt, K. E.: Improving in-lake water quality modeling using variable chlorophyll a/algal biomass ratios, Environ. Model. Softw., 101, 73–85, 2018.
Schnoor, J. L. and Fruh, E. G.: Dissolved Oxygen Model of a Short Detention Time Reservoir with Anaerobic Hypolimnion, Water Resour. Bull., 15, 506–518, 1979.
SNIRH: National information system of water resources, Portuguese Environmental Agency – Sistema Nacional de Informacao de Recursos Hidricos, http:// www. https:// snirh.apambiente.pt (last access: 23 April 2024), 2024.
Soares, P. M. M, Cardoso, R. M., Ferreira, J. J., and Miranda, P. M. A.: Climate change and the Portuguese precipitation: ENSEMBLES regional climate models results, Clim Dynam. 45, 1771–1787, https://doi.org/10.1007/s00382-014-2432-x, 2015.
Tasnim, B., Fang, X., Hayworth, J. S., and Tian, D.: Simulating Nutrients and Phytoplankton Dynamics in Lakes: Model Development and Applications, Water, 13, 2088, https://doi.org/10.3390/w13152088, 2021.
Tavera-Quiroz, H., Rosso-Pinto, M., Hernández, G., Pinto, S., Canales, F. A.: Water Quality Analysis of a Tropical Reservoir Based on Temperature and Dissolved Oxygen Modeling by CE-QUAL-W2, Water, 15, 1013, https://doi.org/10.3390/w15061013, 2023.
Terry, J. A., Sadeghian, A., and Lindenschmidt, K. E.: Modelling Dissolved Oxygen/Sediment Oxygen Demand under Ice in a Shallow Eutrophic Prairie Reservoir, Water, 9, 131, https://doi.org/10.3390/w9020131, 2017.
Uhlmann, W.: A Model-based Study on the Discharge of Iron-rich Groundwater Into the Lusatian Post-mining Lake Lohsa, Mine Water and Circular Economy, Germany, http://www.imwa.de/docs/imwa_2017/IMWA2017_Uhlmann_626.pdf (last acess: 24 June 2024), 2017.
Vandenberg, J. A., Prakash, S., and Buchak, E. M.: Sediment Diagenesis Module for CE-QUAL-W2. Part 1: Conceptual Formulation, Environ. Model. Assess., 20, 239–247, https://doi.org/10.1007/s10666-014-9428-0, 2015.
Varis, O., Kuikka, S., and Taskinen, A.: Modeling for water quality decisions: Uncertainty and subjectivity in information, in objectives, and in model structure, Ecol. Model., 74, 91–101, https://doi.org/10.1016/0304-3800(94)90113-9, 1994.
Wells, S. A.: CE-QUAL-W2: A Two-Dimensional, Laterally Averaged, Hydrodynamic and Water Quality Model, Version 4.5, Department of Civil and Environmental Engineering Portland State University, https://www.ce.pdx.edu/w2/ (last access: 21 January 2024), 2021.
Whitehead, P., Wilby, R., Battarbee, R., Kernan, M., and Wade, A. J.: A review of the potential impacts of climate change on surface water quality. Hydrological Sciences Journal, 54(1), 101–123, doi.org/10.1623/hysj.54.1.101, 2009.
Xu, G., Fan, H., Oliver, D.M., Dai, Y., Li, H., Shi, Y., Long, H., Xiong, K., and Zhao, Z.: Decoding river pollution trends and their landscape determinants in an ecologically fragile karst basin using a machine learning model, Environ. Res., 214, 113843, https://doi.org/10.1016/j.envres.2022.113843, 2022.
Yu, K., Zhang, Y., He, X., Zhao, Z., Zhang, M., Chen, Y., Lang, X., and Wang, Y.: Characteristics and environmental significance of organic carbon in sediments from taihu Lake, China, Ecol. Indic., 138, 108796, https://doi.org/10.1016/j.ecolind.2022.108796, 2022.
Zhang, Z., Sun, B., and Johnson, B. E.: Integration of a benthic sediment diagenesis module into the two dimensional hydrodynamic and water quality model – CE-QUAL-W2, Ecol. Model., 297, 213–231, https://doi.org/10.1016/j.ecolmodel.2014.10.025, 2015.
Zouabi-Aloui, B., Adelana, S. M., and Gueddari, M.: Effects of selective withdrawal on hydrodynamics and water quality of a thermally stratified reservoir in the southern side of the Mediterranean Sea: a simulation approach, Environ. Monit. Assess., 187, 292–311, 2015.