the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 27 Mar 2025
| 27 Mar 2025
A Bayesian method for predicting background radiation at environmental monitoring stations in local-scale networks
Jens Peter Karolus Wenceslaus Frankemölle
Johan Camps
Pieter De Meutter
Johan Meyers
Detector networks that measure environmental radiation serve as radiological surveillance and early warning networks in many countries across Europe and beyond. Their goal is to detect anomalous radioactive signatures that indicate the release of radionuclides into the environment. Often, the background ambient dose equivalent rate is predicted using meteorological information. However, in dense detector networks, the correlation between different detectors is expected to contain markedly more information. In this work, we investigate how the joint observations by neighbouring detectors can be leveraged to predict the background . Treating it as a stochastic vector, we show that its distribution can be approximated as multivariate normal. We reframe the question of background prediction as a Bayesian inference problem including priors and likelihood. Finally, we show that the conditional distribution can be used to make predictions. To perform the inferences we use PyMC. All inferences are performed using real data for the nuclear sites in Doel and Mol, Belgium. We validate our calibrated model on previously unseen data. Application of the model to a case with known anomalous behaviour – observations during the operation of Belgian Reactor 1 (BR1) in Mol – highlights the relevance of our method for anomaly detection and quantification.
- Article
(6353 KB) - Full-text XML
- BibTeX
- EndNote




Networks that measure environmental radiation are operational in countries across Europe and beyond. Such networks monitor the environment for aberrant radioactivity that could, for example, indicate the anomalous release of radionuclides from a nuclear facility. Within Europe, observations of national networks are collected on the EUropean Radiological Data Exchange Platform, EURDEP (European Commission, 2024; Sangiorgi et al., 2020), including those of the Belgian radiological surveillance network and early warning system TELERAD (Sonck et al., 2010). Some stations come equipped with gamma-spectrometric capabilities that allow for observing the contributing gamma energies, which can be used to tease out the responsible radionuclides. More often, however, stations use Geiger–Müller tubes to measure the ambient gamma dose equivalent rate (nSv h−1), denoted as . A difficulty with detecting and quantifying anomalies based on is that gamma radiation also occurs naturally and varies as a function of time. To distinguish anomalous from normal behaviour using these detectors, therefore, one must establish what normal really means.
Under normal conditions, terrestrial radiation contributes significantly to . Potassium-40 is abundant in nature, as are the radionuclides in the uranium and thorium decay chains. When those decay chains reach radon (radon-222) and thoron (radon-220), both noble gases, exhalation occurs from the soil to the atmosphere. Radon is usually dominant over thoron due to its much longer decay time (3.8 d versus 56 s). Only radon is long-lived enough for it to be able to be transported over considerable distances through air. During precipitation events, radon daughters (lead-214 and bismuth-214) are deposited on the ground again via wet scavenging (Sportisse, 2007), which accounts for increased (Mercier et al., 2009; Livesay et al., 2014). Besides natural radionuclides, anthropogenic contributions also exist. Caesium-137 fallout from the atmospheric nuclear weapons tests of the 1950s and early 1960s, with some as late as 1980 (Bergan, 2002), and of the Chornobyl accident in 1986 still contributes to due to its long half-life of 30.8 years according to a complex spatial pattern (European Commission et al., 1998). Other anthropogenic sources (e.g. medical or industrial) also contribute to the inventory of environmental radionuclides (Maurer et al., 2018) although these will usually be too small to affect . Finally, cosmic radiation, at ground level mainly muons, contributes significantly to the background . We refer to the sum of these processes as background radiation. In the rest of this work, we will exclusively refer to background radiation to mean these normally occurring processes and anomalous radiation to be everything other than these normally occurring processes.
Our ability to identify and quantify anomalous radiation hinges on our ability to predict the behaviour of the background. This is relevant not only for the aforementioned detector networks, but also for mobile measurement campaigns which were used, for example, in the aftermath of the Fukushima nuclear accident (Querfeld et al., 2020; Nomura et al., 2015). Even without factoring in unknown sources, the background is a complex function of space and time governed by, for example, geological properties of the soil, land use, and (space) weather. The multifaceted nature of environmental radioactivity precludes first-principles modelling, which makes predicting the background a difficult problem. In lieu of comprehensive first-principles approaches, a rich variety of data-driven solutions exist. Various machine learning approaches have been investigated to forecast background radiation based on dose rate time series (Arahmane et al., 2024; Breitkreutz et al., 2023). Recently, long short-term memory networks (LSTMs) have shown promise in predicting background radiation based on meteorological parameters like temperature, humidity, and wind speed (Liu and Sullivan, 2019; Breitkreutz et al., 2023). When the goal is spatial interpolation rather than temporal prediction, kriging methods have been successfully employed to construct, for example, national maps based on (airborne) radiation measurements (Chernyavskiy et al., 2016; Folly et al., 2021). Bayesian approaches to background estimation exist predominantly in the context of source localisation, using either spectral data (Howarth et al., 2022) or gross count rates (Michaud et al., 2021; Brennan et al., 2005). Often, such approaches do not resolve full posterior distributions, instead relying on more computationally efficient maximum likelihood estimation (MLE). MLE approaches have also been used to discriminate between spatial background inhomogeneity in the built environment and temporal inhomogeneity due to precipitation (Liu et al., 2018).
In the current work, we present a Bayesian inference framework for the estimation of the background ambient dose equivalent rate observed in densely packed local detector networks. We assume that the processes that drive changes in the background occur at a scale that is larger than the typical scale of the local networks under consideration, and we model the response to such an external driver by looking at the effect that it has on all detectors. What sets our work apart from other work is the fact that we allow for correlations between the different detectors in the network, so the external driver does not necessarily affect all detectors equally. The Bayesian approaches mentioned in the previous paragraph all assume that the different observations are independent so that the likelihood given a large set of data simply becomes the product of the likelihoods of the individual data points. Doing so simplifies sampling the posterior significantly. In allowing for correlations, we add significantly to the dimensionality of the Bayesian inference problem – because it requires the estimation of a correlation matrix between the detectors in the network – but we get a more truthful parameterisation. Using this model, we can estimate independent means for each detector, the variance that is intrinsic to each detector due to a combination of counting statistics and measurement noise, and the collective response of the network to meteorological drivers.
The rest of this paper is structured as follows. In Sect. 2, the data and methods are described. Starting from an introduction of the TELERAD detector network, specifically the sub-networks around two nuclear facilities in Belgium, we derive a Bayesian inference problem and describe how to solve it. Additionally, we describe how the Bayesian inference problem can be extended to also allow for predictive modelling. In Sect. 3, we describe calibration and verification of our Bayesian model using various subsets of TELERAD data. In Sect. 4, we show how calibrated models can be leveraged to make predictions. Finally, in Sect. 5, we study a case that is relevant in an operational context. Using the detectors from one nuclear site (Doel) to predict the dose rate at detectors from another nuclear site (Mol) while an atmospheric release is ongoing at the latter shows how our work can be useful in anomaly detection.
2.1 The TELERAD detector network
We first present the detector network that we try to model. TELERAD, the radiological surveillance network and early warning system in Belgium (Sonck et al., 2010), measures the extent of radiological contamination both in air and soil and in water using a variety of techniques. For atmospheric measurements using gamma dosimetry, three sub-networks exist. The Immission Monitor for National area (IMN) covers the entire Belgian territory, the Immission Monitor for Agglomeration area (IMA) covers only those populated areas within several kilometres of nuclear facilities, and the Immission Monitor for Ring area (IMR) covers the immediate vicinity of nuclear facilities. Such a network is not unique to Belgium, as described in the Introduction (see Sect. 1), but the Belgian network is among the densest networks in the world. Hourly values for the IMN and IMA, dating back many years, are also publicly available on a Belgian national platform (Federal Agency for Nuclear Control, 2024) similar to EURDEP (European Commission, 2024).
We use data from IMR stations at two nuclear sites: the Belgian Nuclear Research Centre (SCK CEN) in Mol and the nuclear power plant (NPP) in Doel. The layouts of the detector networks at Doel and Mol, as well as their locations in Belgium, are shown in Fig. 1. Characteristic of the Doel site are the river Scheldt bordering it to the east and the flat farmland bordering it in other directions. Eighteen IMR stations, D01 through D18, sit along its perimeter. Characteristic of the Mol site is the largely forested area. IMR detectors are set up more complicatedly than in Doel owing to the presence of several nuclear facilities. Stations M07 through M13 surround Belgian Reactor 1 (BR1); detectors M01 through M04, M14, and M15 surround Belgian Reactor 2 (BR2); and stations M05, M06, and M16 are south of Belgian Reactor 3 (BR3). BR1 and BR2 are still operational today; BR3 has been decommissioned and is being dismantled. Of these detectors, we exclude M12 from further analysis because of several corrupted entries in the database.
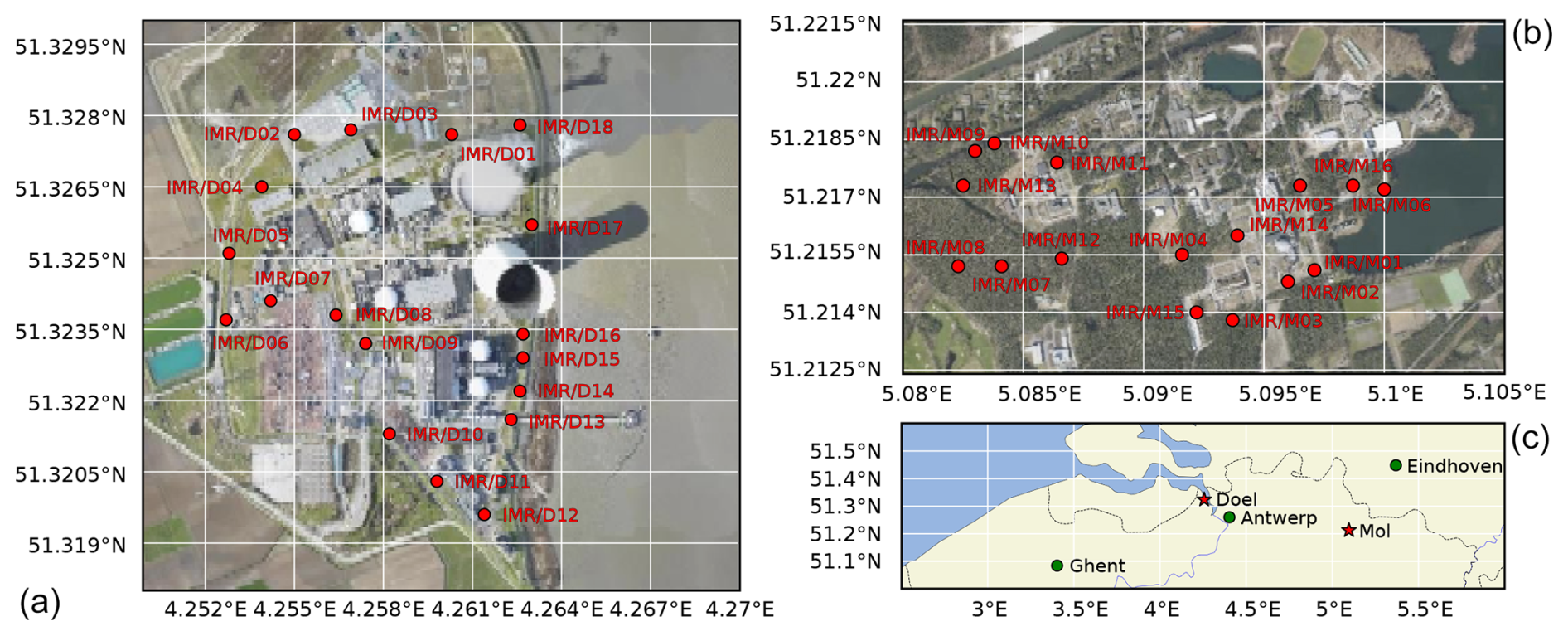
Figure 1Maps of the TELERAD stations at the (a) Doel and (b) Mol sites. (c) The locations of Doel and Mol in Belgium. The Cartopy package (Elson et al., 2024) was used to generate the maps using aerial footage from Agentschap Digitaal Vlaanderen (2016) and geographic vector data from Natural Earth (2024).
In this work, we analyse four different combinations of IMR stations. Case BR1 includes those IMR stations that form a ring around BR1. Case MOL includes all IMR stations at SCK CEN. Case DOEL includes all IMR stations at Doel NPP. Finally, case DOEL–BR1 includes a subset of IMR stations at Doel NPP and the IMR station included in case BR1. Details are listed in Table 1.
Table 1The four different combinations of IMR stations that are examined in this study.
All IMR stations measure the 10 min averaged ambient dose equivalent rate , which is measured in nanosieverts per hour (nSv h−1). According to the definition by the ICRP (2020), “the dose H*(d), at a point in a radiation field, is the dose equivalent that would be produced by the corresponding expanded and aligned field in the ICRU sphere at a depth, d, on the radius opposing the direction of the aligned field”. The ambient dose equivalent rate is the time derivative of the ambient dose equivalent evaluated at a depth of d=10 mm. Many IMR stations also have gamma-spectrometric capabilities, and at low dose rates the ambient dose rate is actually calculated as the accumulated spectrum rather than measured using the Geiger–Müller detector. In this work, we only look at dose rate data. Data from three periods are used: 6 August through 13 August 2022, 30 August through 1 September 2022, and 10 through 12 September 2022. Selection of these data was subject to BR1 non-operation and no precipitation. BR1 is not operated for a while during July–August, and we found the period from 6 through 13 August to also be without precipitation. The other two periods were chosen to be several weeks later than this initial period to check the temporal stability of the calibration, one requiring reactor non-operation (30 August through 1 September) and the other requiring reactor operation (10 through 12 September). Data for all three periods are available on Zenodo (Frankemölle et al., 2024a).
To supplement the data, we use source monitoring data for BR1 and precipitation data. The former are necessary because BR1 is an air-cooled reactor, the operation of which causes a noticeable artificial increase in on-site . This is not the case for the other facilities. Source term data are obtained from an in-stack monitor (Frankemölle et al., 2022b). Precipitation data are taken from nearby precipitation monitoring stations in Retie, approximately 2 km northwest of SCK CEN, and Melsele, approximately 10 km south of Doel NPP (Vlaamse Milieumaatschappij, 2023).
2.2 Modelling background radiation using Bayesian inference
To model measurements by the TELERAD sub-networks, we introduce a stochastic representation in Sect. 2.2.1 that we use to formulate a Bayesian inference problem in Sect. 2.2.2. In Sect. 2.2.3, we introduce the posterior predictive distribution to validate our Bayesian model.
2.2.1 Background radiation as a continuous stochastic vector
Consider the ambient dose equivalent (nSv) accumulated over a period T (equal to 10 min in the current study) as measured in our network:
with denoting the measurements reported in each sensor (), the real accumulated ambient dose equivalent in each sensor, and the sensor measurement errors. We note that, typically, a dose rate is reported that corresponds to (nSv h−1).
We represent the measured dose as a continuous stochastic (random) vector, which is driven by the real ambient dose equivalent, and the instrument error, both of which are stochastic processes themselves. We discuss the parameterisation of their distributions, which eventually leads to the parameterisation of the distribution of M.
Firstly, E represents the measurement noise. We can safely assume that errors are statistically independent between sensors. We further make the stronger assumption that the errors are normally distributed with zero mean, so with ΣE=diag [σE]I diag [σE], where denotes the standard deviations of the different sensor errors, which we infer in the Bayesian framework later. We note that the assumption of zero bias makes sense if instruments are properly calibrated, but validation of the Bayesian framework itself can also point to inconsistencies between sensor data which could point to the need for recalibration.
Secondly, we consider the real dose H. It is the accumulation of photons arising from the decay of a range of radionuclides that are present in the background around the sensor network. This is a process that is driven not only by the weather and other environmental phenomena, but also by the counting error resulting from the relatively low number of photons that hit the sensor. The latter can be approximated by a Gaussian distribution, but the former is much less trivial to describe. For lack of any detailed information on this distribution and to arrive at an elegant overall framework, we also presume the radionuclides' distribution to be Gaussian, but unlike E, we expect a large spatial correlation over the sensor network (although some aspects, such as the counting error or small-scale terrain effects, will not be correlated between sensors). With some further assumptions about the variabilities in both processes, we arrive at a Gaussian process for H as well, so , and consequently,
At this point, we do not know the covariance matrices ΣH and ΣE – in Sect. 2.2.2 we use Bayesian inference to train possible distributions of their elements. We have
where R with elements Rlm is the correlation matrix that we introduce here for later use. Thus, defining the diagonal matrix S=diag [σ] (with elements σl on the diagonal), we can also express Σ=SRS (Barnard et al., 2000).
Given k sensors and since R is symmetric, we have unknowns (in μ, ΣE, ΣH, and R), which we will train using Bayesian inference and a large dataset of measurements. However, given only measurements M and no additional information on the measurement errors, it is impossible to obtain separate information on σH and σE. Only σ can be determined, so in fact unknowns remain.
2.2.2 Training the mean vector and covariance matrix using Bayesian inference
Given a dataset , with 𝓜 an N×k matrix of measurements by the entire network of k detectors described in Sect. 2.1 at N different points in time, and given the stochastic variables of interest described in Sect. 2.2.1, we can write down Bayes's theorem (see Appendix A) for the posterior distribution . In terms of the likelihood , the prior , and the evidence f(𝓜), this posterior is given as
Strictly speaking, subscripts are required to indicate that Eq. (4) involves four different distributions. Instead, we denote all four distribution functions – of the posterior, likelihood, prior, and evidence – as f to avoid cluttering the equations. Their varying arguments are, after all, sufficient to tell them apart.
Here, we define the right-hand side of Eq. (4). The likelihood follows straightforwardly from Eqs. (2) and (3) as
where Σ=SRS with |Σ| being its determinant and Σ−1 its inverse. While Eq. (5) implies Mi and Mj are independent of each other for i≠j, we should be careful not to take that at face value. Rather, this is a consequence of using the marginal distribution of some unknown higher-dimensional distribution that includes time. Since we are not interested in time, we marginalise the distribution; i.e. we “integrate out” the time. This is allowed even in the extreme case that E=0 and H is perfectly correlated in time. Marginalisation relates to drawing random samples from the time series, and so the only assumption that we actually make is that the time series is sufficiently long for it to cover the realisations of M.
The likelihood can be evaluated for any combination of μ, S, and R to determine how likely the observations 𝓜 are given that combination. This difference is particularly important when considering the evidence. For given observations 𝓜, the evidence f(𝓜) is just a number that normalises the posterior. Since we are only interested in the shape of the posterior rather than exact values, we can safely neglect it.
Finally, we consider the priors. The joint prior distribution can be simplified by assuming independence between μ, S, and R; i.e.
For f(μ), we choose a weakly informative prior by following the principle of maximum entropy, which yields the least informative priors given certain bounds on the support and statistical moments (Park and Bera, 2009). We know that μ is always equal to or larger than zero. Furthermore, we expect it to be centred on the time-averaged background level. The least informative prior with support [0, ∞) and a given mean is the exponential distribution
where and .
For f(S), we choose the half-normal distribution (Gelman, 2006)
where for x≥0.
Finally, we formulate f(R). This is not trivial because not every combination of factors Rlm yields a matrix that is symmetric and positive semi-definite. To this end, we employ the LKJ correlation distribution (Lewandowski et al., 2009) over all possible correlation matrices. The advantage of the LKJ distribution is that it can be used as a prior for the correlation matrix R, allowing us to give a separate prior for the diagonalised scale vector S, as opposed to, for example, the inverse-Wishart distribution, which can only be used as a prior for the full covariance matrix (Gelman et al., 2013). We need the LKJ distribution, in effect, to work with the decomposition Σ=SRS (Barnard et al., 2000) that was introduced in Sect. 2.2.1. To be complete, here we reproduce from Lewandowski et al. (2009) the LKJ distribution function as
with |R| being the determinant of the k×k correlation matrix R; η being the sole shape parameter of the distribution; and ck being the normalising constant, which only depends on the dimensionality k, as
Here B is the beta function, defined for two complex numbers z1 and z2 with positive real numbers, given as
The shape parameter η governs the probability of off-diagonal elements. For η>1, the mode of the distribution is the identity matrix (i.e. not favouring correlations); for , there is a dip in the distribution at the identity matrix (i.e. favouring correlations); and for η=1, all correlation matrices are equally likely. In this work, we select η=1, which is a special case where the dependence on R drops out; i.e.
Combining Eqs. (4)–(12), we obtain the full posterior distribution. In a network of k detectors, there are k means, 2k scale parameters, and off-diagonal elements so that the dimensionality of the posterior scales as . As a result, brute-force computation of the posterior is generally not possible. Therefore, we will employ a Markov chain Monte Carlo (MCMC) technique instead.
The posterior is calculated using the No-U-Turn Sampler (NUTS) (Hoffman and Gelman, 2014) in PyMC (v5.13.1), a Python-based framework for Bayesian inference using MCMC (Abril-Pla et al., 2023; Wiecki et al., 2024). To check for convergence, PyMC samples several independently initialised chains and then calculates the convergence metric (Gelman and Rubin, 1992; Vehtari et al., 2021), since it is in general not feasible to check the traces of all different parameters. For the actual implementation of this convergence check and many other postprocessing features (e.g. summary statistics, advanced plotting), PyMC relies on ArviZ (Kumar et al., 2019; Martin et al., 2024). All computations are performed on a Lenovo ThinkPad with an 11th-generation Intel Core i5-1135G7 (four cores, eight threads, 2.4 GHz base clock, and 4.2 GHz maximum turbo frequency) and 8 GB of RAM.
2.2.3 Validating the calibrated model using the posterior predictive distribution
It is important to realise that a posterior distribution is contingent on the choice of parameterisation for the likelihood and priors. Should the choice of parameterisation be poor, so are the results. Intuitively, we expect that, if we draw new samples from our posterior and use these to generate new “observations”, the distribution of those new observations should be the same as that of the original dataset. The posterior predictive distribution formalises this as
where represents the new observations. Here is the likelihood over all new samples given a set of governing parameters and is the posterior of those governing parameters given the original data 𝓜. By integrating the product over the entire sample space Ω of possible values for the governing parameters, the posterior predictive distribution is obtained. A good match between the posterior predictive distribution and the distribution of the original dataset shows the choice for the parameterisation of the likelihood and priors is a good one.
2.3 Estimating the 10 min background using Bayesian inference
While the foregoing stochastic representation is interesting in its own right to understand the behaviour of the background radiation in a detector network, there are other potential applications of Bayesian inference for background modelling. For one, might we hope to estimate the noise-free background vector H from the noisy measurements M? This is a different question from the one encapsulated in Eq. (4). Moreover, since Bayesian inference is also used for data imputation (Holt and Nguyen, 2023), we could think of a use case with missing observations. Here, missing can actually mean missing – one or more detectors could be broken – or it might just mean compromised. In the latter case, the connection with anomaly detection is readily made: in case of a local radiation source that impacts a limited number of detectors in the network, we can use the remaining detectors to predict what background these detectors should have measured in lieu of the anomaly and within what uncertainty bounds. That in turn allows us to quantify the size of the anomaly.
This does, however, still require “expert knowledge” in the sense that the model itself does not know which detectors are affected. Physics-wise, this is related to the fact that the model is, by construction, time-independent (see Sect. 2.2.2). Correlations in time of the individual detectors, a strong drop in which could point at atypical excursions of the dose rate (like the ones discussed later in Sect. 5), are not taken into account. While there may be engineering solutions even within the frame of the currently discussed method that could allow for this method to autonomously detect anomalies, consideration of those is beyond the scope of this work.
To estimate the distribution of the background radiation vector H of a given 10 min time interval, for which data M are available and using the distribution for Σ (e.g. obtained using the method described in Sect. 2.2) as prior information, we write down a different inference problem from Eq. (4). Here, we are interested in the posterior f(H|M), which is equal, by Bayes's theorem (see Appendix A), to
Neglecting the evidence as before, we can fill in the likelihood and priors which follow from the discussion in Sect. 2.2.1 to obtain
where in the second step we use . We observe that the argument of the exponent in Eq. (15) is equal to the cost function associated with the Kalman filter (Evensen et al., 2022, p. 67), where in the current case the measurement operator is the identity matrix I. Clearly, the above relation can only be used meaningfully if we can estimate σE. For this, extra data are needed since we only have knowledge of S from the calibration described in Sect. 2.2.2.
We now elaborate on a particular scenario that is of interest to anomaly detection. We presume that we know ΣH either because we have extra information σE or because measurement errors in the calibration data are small, i.e. , so that . For the spectroscopic detectors at least, which have counting-statistics-driven uncertainties on the order of 0.5 nSv h−1 while typical excursions due to meteorological drivers (captured by H) are much larger, this assumption is very acceptable.
Let us further assume that in the current 10 min time interval, we do not use measurements from all sensors, e.g. because they are not available or we do not trust them. Whatever the reason, we are limited to a subset of observations Mo. Thus, we split the detector network into an observed part and an unobserved part, and we reorder the sensors and backgrounds at these detectors such that . Then Eqs. (14) and (15) are reduced to
We now introduce the block matrices
and partition the mean vector as . This allows us to split the inference problem into two parts. The first one is for the sensors that are observed and gives
which can be calculated first. A second inference problem follows from applying the chain rule in two different ways:
This gives us two known distributions (see Eqs. 16 and 18) and two unknown distributions: and f(Mo). By equating Eqs. (19) and (20), we can eliminate the latter unknown to finally obtain
Given Eq. (21), a closed form of can in fact be found. Using the block matrices described in Eq. (17), it can be shown (Holt and Nguyen, 2023) that the posterior is normally distributed: , where
These are the mean vector and covariance matrix, respectively, of the unobserved part of the network conditional on the observed part of the network (Holt and Nguyen, 2023). It is tempting at this point to insert the maximum a posteriori (MAP) estimates of μ and Σ to calculate MAP estimates of μu|o and Σu|o. However, since the posterior distributions of μ and Σ are actually available (see Sect. 2.2), we choose to construct the full posterior distributions of μu|o and Σu|o instead.
For the calibration of μ, S, and R, we select an 8 d period in the summer of 2022, 6 August through 13 August. We check that BR1 is not operational in this period and there is no rain. We calibrate our model for the four different cases described in Table 1. In all cases, the NUTS algorithm is set up to discard the first 1000 samples (the “burn-in”) and then to take another 1000 samples that are used to construct the posterior. To test whether the calibrated models adequately describe the data, we calculate posterior predictive checks.
Posterior predictive distributions, plotted in Fig. 2, are a powerful tool to test the quality of Bayesian models. In all four cases, the close agreement between the black lines (observations) and orange lines (model) shows that the multivariate normal distribution is an excellent parameterisation for the distribution of the ambient dose equivalent rate vector . It shows that even if some detectors experience much higher local dose rates – the rightmost peak for the MOL case (Fig. 2b) corresponds to detector M06, which is adjacent to radioactive waste storage – the way that they covary can still be captured with a multivariate normal distribution. Likewise, it does not matter that some detectors are of a different make – the much wider central peak for the DOEL case (Fig. 2c) is due to the larger intrinsic variance of some of the detectors.
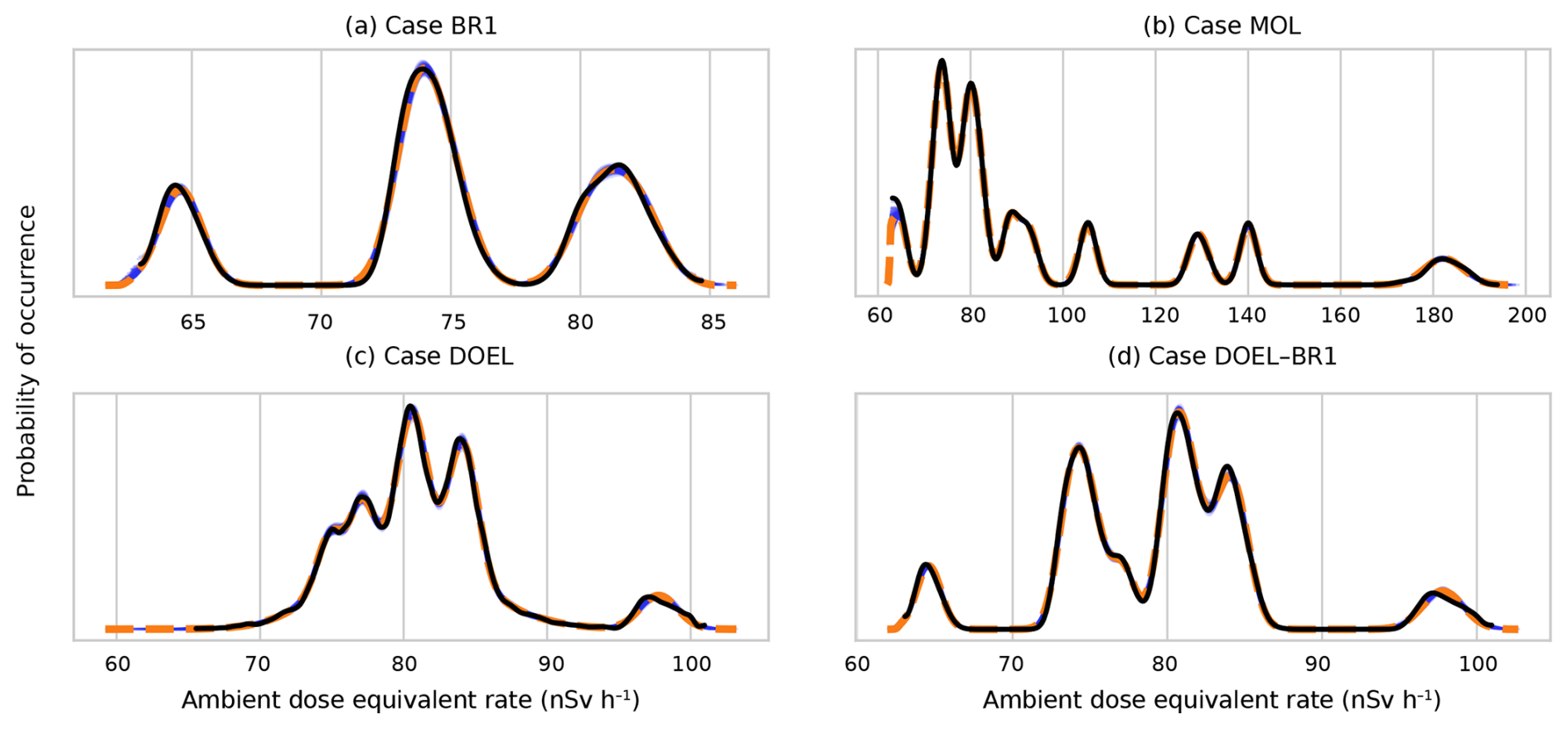
Figure 2Posterior predictive distributions for all four analysed cases. Solid blue lines represent predicted distributions of observations. Each line is made by randomly drawing a set of parameters from the posterior distributions of parameters. Dashed orange lines represent the mean predicted distributions. Finally, the distribution of actual observations is represented in black – a kernel is used for interpolation to a continuous distribution.
The quality of the Bayesian model also becomes clear using the predictive formalism described in Sect. 2.3. Using the original training data but leaving out one or more detectors, the conditional distribution can be used to “predict” the observations by the excluded detectors. Here, we show the results for two cases: BR1 and DOEL. For the BR1 case, we predict the observations by M13 using observations by M07 through M11. Results of these “predictions” versus actual observations are plotted in Fig. 3. Again, the agreement is excellent. The calibrated model correctly captures not only the offset and the diurnal variations but also the generally rising trend. Moreover, the 1σ (68 % confidence) and 2σ (95 % confidence) intervals predicted by the model match the spread of the observations very well. This shows that the model captures not only the trends but also remaining uncertainties.
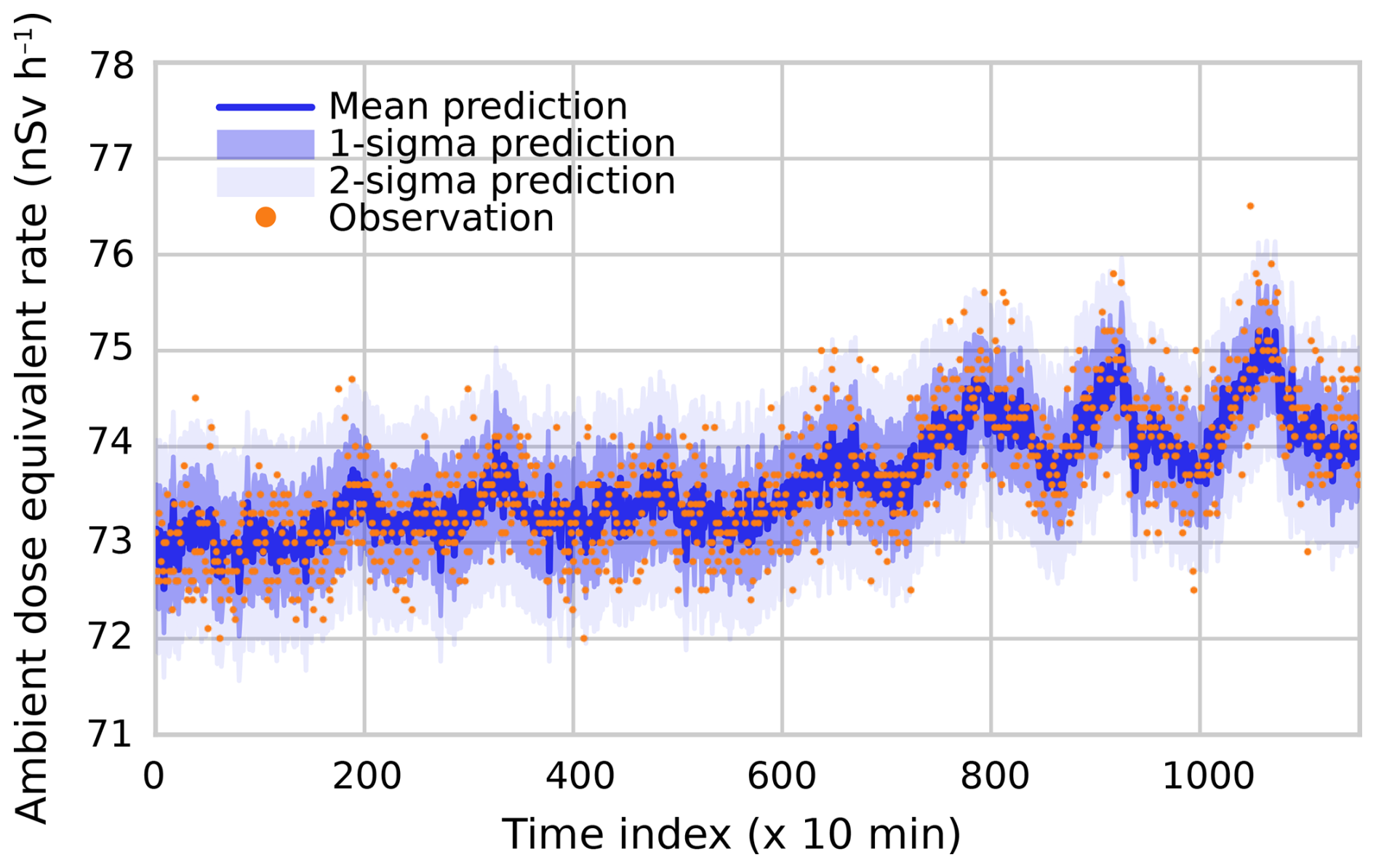
Figure 3A prediction of detector M13 based on observations by M07 through M11. Time indices denote consecutive 10 min periods starting at 00:00 CEST on 6 August 2022 and ending at 00:00 CEST on 14 August 2022.
For the DOEL case, we predict the observations by D01 through D09 using observations by D10 through D18. These results are plotted in Fig. 4. The even-numbered stations have similar characteristics to the detectors around BR1. While offsets vary, the diurnal fluctuations, rising trend, and approximate uncertainties do not vary much between these detectors and their BR1 counterparts. Meanwhile, the odd-numbered detectors have almost an order of magnitude more uncertainty compared to the even-numbered detectors – likely owing to considerably worse counting statistics – in their model predictions, which is in excellent agreement with the actual spread in the TELERAD time traces, as evidenced by the fact that the shaded areas in Fig. 4 (which represent the uncertainty in the measurements) are much larger for the odd-numbered than for the even-numbered detectors. There is no evidence of diurnal variations or the rising trend any more, as these are dwarfed by the uncertainty inherent in the detectors. We observe that the predictions by the Bayesian algorithm are not impacted. The algorithm simply sets Sl of those detectors to high values while setting Rlm to low values so that the covariance with other detectors, SlSmRlm, remains low.
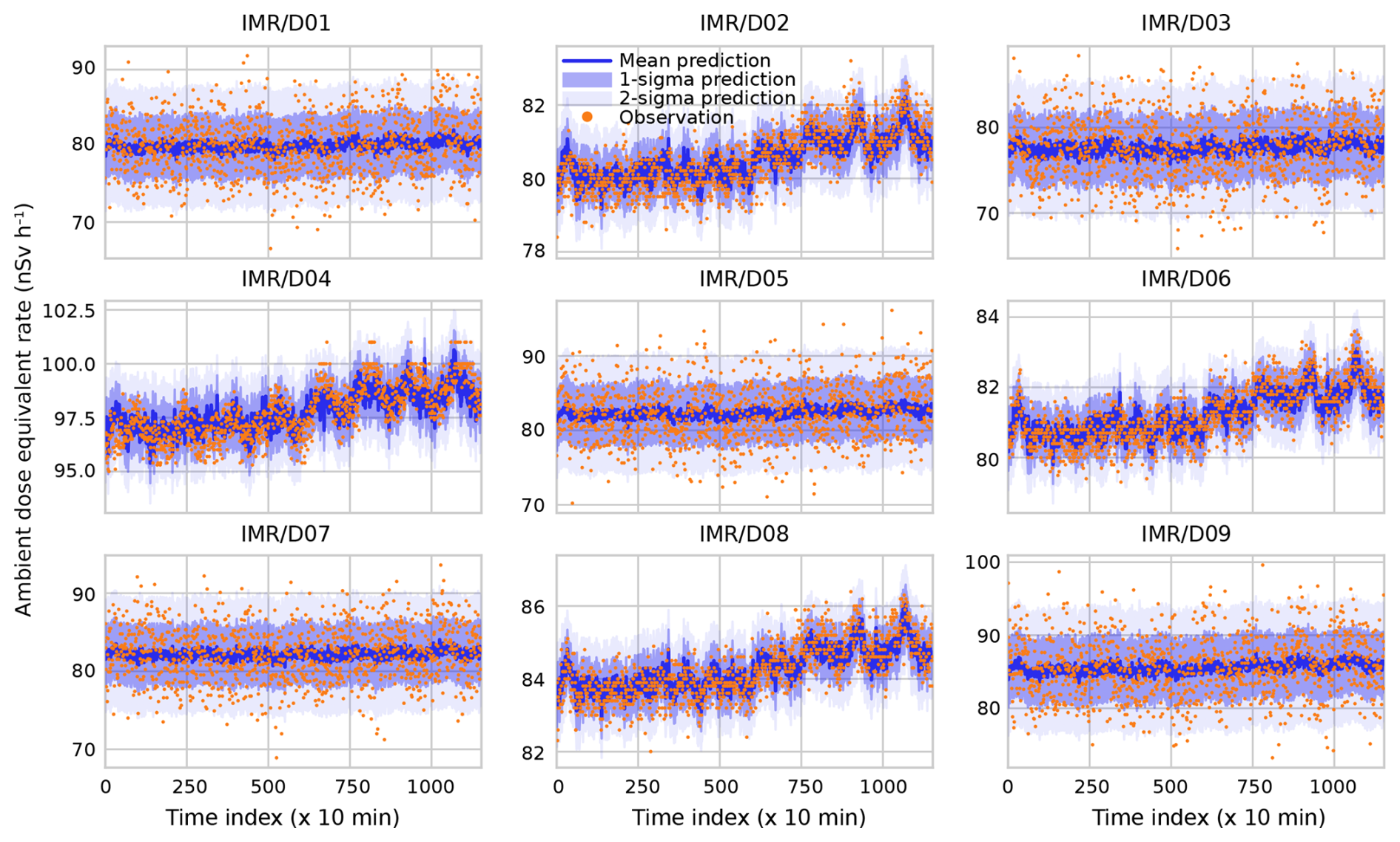
Figure 4Predictions for the Doel detectors D01 through D09 based on observations by D10 through D18. Time indices denote consecutive 10 min periods starting at 00:00 CEST on 6 August 2022 and ending at 00:00 CEST on 14 August 2022.
Using the calibrated models described in Sect. 3, trained on data between 6 and 13 August 2022, we now make predictions using data that were obtained at a different point in time in order to validate our Bayesian model. Here, we present the results for two cases, MOL and DOEL, for 10–12 September 2022. We start with the former. Similarly to the BR1 case, we exclude detector M13 and try to predict observations made by that detector using the other detectors as inputs. We then compare the prediction to the actual observations. The results can be found in Fig. 5. Focusing first on days two and three (from time index 150 onwards), the calibrated model predicts both the baseline dose rate and the peaks (around 200 and 350, so around dawn) quite well, while the variance appears to be slightly overestimated over the entire period. This is confirmed by comparing the mean of the 1 h running variances of the TELERAD data, , to the mean of the predicted variances, (excluding time indices smaller than 100 because of the rain peak).
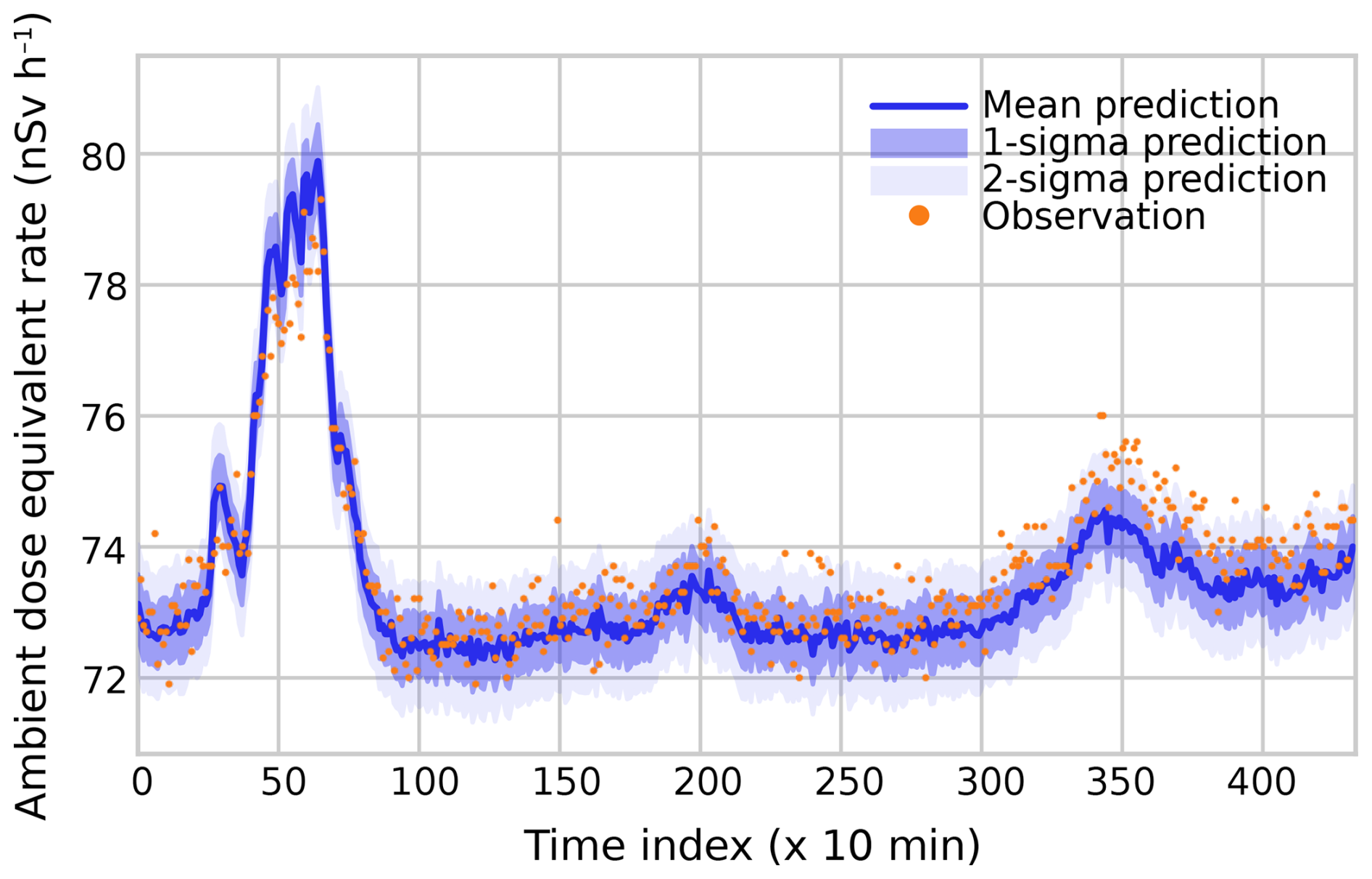
Figure 5Prediction of the dose rate measured by detector M13 based on observations by the other detectors on the SCK CEN site. Time indices denote consecutive 10 min periods starting at 00:00 CEST on 10 September 2022 and ending at 00:00 CEST on 13 September 2022, so three diurnal cycles are included in the prediction. The larger peak between time index 25 and 75 coincided with a period of precipitation.
Most striking in Fig. 5 is the larger peak between time indices 25 and 75. It coincides with a period of precipitation measured by the station in Retie (Vlaamse Milieumaatschappij, 2023), which is known to coincide which rising dose rates (Mercier et al., 2009; Livesay et al., 2014). While our model was not trained on precipitation data, the match is nonetheless quite good. It appears that over the extent of the Mol site, precipitation has the same effect as other meteorological drivers (e.g. pressure), which cause the variations over time observed in Figs. 3 and 4. However, that does not mean that our choice of parameterisation is ideal in precipitating conditions: part of the variance in such cases might be driven by, for example, fluctuations in the precipitation rate, which may not necessarily be Gaussian. Moreover, that our model can describe the effect of precipitation has a downside in an operational context. A plume (cloud) of radioactivity that is released far enough from the site is homogeneously distributed over the site and cannot be distinguished from other background effects by on-site detectors. Our model is thus only useful to spot aberrant radioactivity at a typical scale that is smaller than that of the network, i.e. local releases.
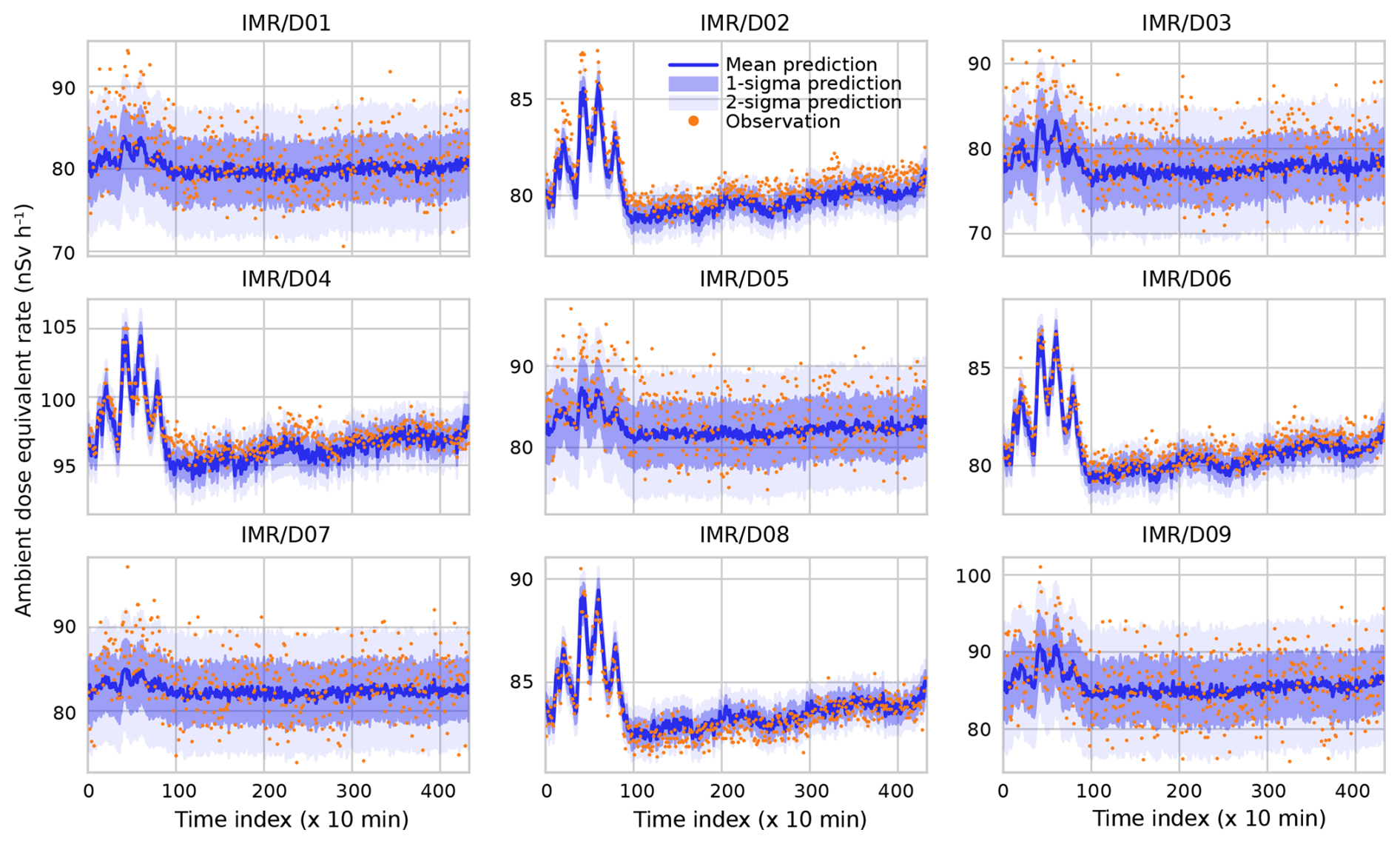
Figure 6Prediction of the dose rate measured by detectors D01 through D09 based on observations by detectors D10 through D18. Time indices denote consecutive 10 min periods starting at 00:00 CEST on 10 September 2022 and ending at 00:00 CEST on 13 September 2022, so three diurnal cycles are included in the prediction.
Next, we present the DOEL case. Based on the observations made by detectors D10 through D18, the calibrated model predicts the observations by D01 through D09. The results are plotted in Fig. 6. Overall, the same conclusions can be drawn as for the MOL case. The precipitation peak, although a fair bit more jagged than before, is still resolved well. Some limited drift on the mean vector μ is present, and small under- or overestimations are present for some of the detectors. The fluctuations in the dose rates are still captured well however. That there should be a drift in the vector of means is interesting and suggests the involvement of a process that causes decorrelation in time. Such a process cannot be modelled under the assumptions presented in our work because we have chosen to neglect temporal correlations. Moving from a temporally independent model into, for example, a first-order Markov system would increase the dimensionality of the joint probability density function (pdf) from k2 to (2k)2. This would have significant computational repercussions and may not be feasible.
In the special case of the multivariate normal distribution presented in this work, solutions might exist (e.g. Kalman filtering). However, by moving to the Kalman filter approach, one loses the option to move away from the normality assumption at a later stage – this could be a problem, potentially, when introducing the effect of precipitation. An alternative that would not necessitate moving away from the Bayesian inference method would be to serve the calibrated coefficients of the background model as a prior in the predictive step and to allow small posterior updates to the vector of means to correct for drift.
Finally, we present simulations for the DOEL–BR1 case between 30 August and 1 September 2022. To expedite the calibration and prediction steps, we only include the even-numbered detectors in Doel. As can be seen in Figs. 4 and 6, these detectors have a considerably higher dose rate resolution than their odd-numbered counterparts and hence contain much more information. The results are shown in Fig. 7. The match between the background prediction and the actual observations is poor during several intervals which coincide with operation of BR1. BR1 was operational between approximately 09:00 and 16:00 CEST in this 3 d period (time indices 54–96, 198–240, and 342–384). Outside of those intervals, the predictions by our model and the observations match very well.
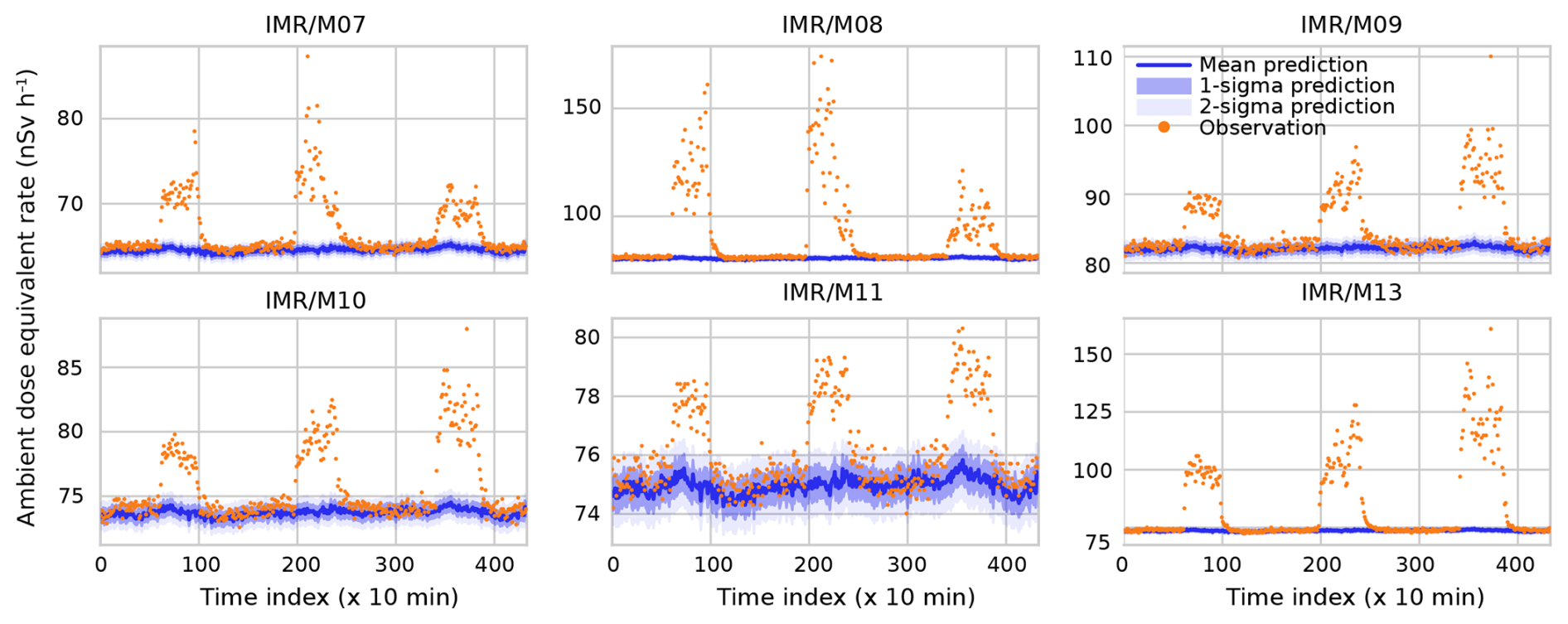
Figure 7Prediction of the dose rate measured by the BR1 ring detectors (M07 through M11 and M13) using as inputs measurement by the even-numbered Doel detectors. Time indices denote consecutive 10 min periods starting at 00:00 CEST on 30 August 2022 and ending at 00:00 CEST on 2 September 2022, so three diurnal cycles were included in the prediction. During this period, BR1 was turned on for 3 d on end, which is apparent from the three large peaks that are not described by the background model prediction.
It is perfectly possible to describe the effect that BR1 – which is an air-cooled reactor that emits argon-41 during operation – has on the detectors using atmospheric dispersion modelling (Frankemölle et al., 2022b). However, because it is an effect that varies over a characteristic length scale that is much smaller than that of the network (ca. 50 km here), it cannot be captured by our background model. This is exactly where our background modelling can be useful for spotting anomalies. To quantify the size of the anomaly, a good estimate of the background level can be crucial, particularly for smaller atmospheric releases. While small errors in the mean and the intrinsic variance of the background are largely irrelevant for large anomalies (e.g. M08), they are relevant in situations where both effects are of the same order (e.g. M11). When release levels are even lower and occur during a much shorter interval – as was the case for the selenium-75 incident at SCK CEN for example (Frankemölle et al., 2022a) – a good understanding of the background becomes even more critical.
In this work, we presented a Bayesian inference framework for background estimation in densely packed local detector networks. We treated the background ambient dose equivalent rate observed in a dense detector network as a multivariate stochastic vector. We derived a physics-informed likelihood – a multivariate normal distribution – and priors and used these to calculate the posterior pdf's of several parameters of interest. Using data from the Immission Monitor for the Ring area (IMR) sub-network, part of the TELERAD network (Sonck et al., 2010), on the sites of the Belgian Nuclear Research Centre in Mol (SCK CEN) and the Doel nuclear power plant (NPP) in Belgium, we then put the Bayesian framework to the test.
In Sect. 3, we validated the suitability of our chosen parameterisation. That this parameterisation was a suitable choice became clear from the posterior predictive checks. The actual distribution of the observations matched very well with the modelled distribution of observations. Moreover, leave-one-out and leave-many-out checks, which leveraged the conditional distribution, were successfully used to reconstruct the training data. In Sect. 4, actual leave-one-out and leave-many-out predictions were made using new observational data in combination with a model that was calibrated using month-old training data. While the model predictions had drifted away slightly from the actual observations, the calibration overall proved to be rather stable. Diurnal fluctuations were reproduced well, and the short-term variance was matched decently. Finally, Sect. 5 showed an application of our model where detectors at Doel NPP were used to predict the observations by detectors at SCK CEN during operation of BR1. This application demonstrates the relevance of our work in the field of anomaly detection and, importantly, quantification.
Looking at the model from an operational perspective, the slow drift of the mean vector away from its calibration precludes usage of year-old calibrated models. However, the drift within a month is only very limited, so if the Bayesian model were recalibrated every week using the latest available data – which is possible thanks to the limited computational cost – the drift should not be a problem. In fact, the model itself could be used to automatically determine whether next week's data are suitable for recalibration (which amounts to checking whether no anomalies are present). Of course, in the specific case of SCK CEN – with regular anomalies due to BR1 – finding non-anomalous data can be problematic. In this case, coupling to a near-range atmospheric dispersion model is likely necessary. This would also require extending the Bayesian framework to include additional uncertainties arising from the dispersion modelling. Ideally, a similar provision would be made for precipitation, which – as discussed in this work – might come with its own temporal and spatial uncertainties.
Finally, future work could include a temporal correlation to the parameterisation of the background vector, but care should be taken that the computational complexity does not get out of hand. Should the multivariate normal distribution that was used in this work remain the best fit for the job, then recasting this work into a Kalman filter formulation might do much to alleviate these issues. Conversely, rather than taking the calibration as fixed, the vector of means might be updated as part of the prediction process, i.e. formalising the recalibration process described in the previous paragraph. The posterior obtained by calibration on training data then becomes a prior for the prediction data.
To describe the detector networks, we use statistical inference. Statistical inference is the process of inferring the properties of a population from a limited sample or, in other words, the process of determining the probability distribution of a stochastic (random) variable (SV) from a limited number of observations of that SV. Statistical inference comes in two flavours: the Bayesian and the frequentist. Bayesian approaches treat the properties of a population as intrinsically random SVs in turn, whose distributions are constrained by the available observations and by a subjective belief, while frequentist approaches treat them as fixed values that can be determined up to some uncertainty threshold based solely on the available data (Pishro-Nik, 2014). In our work, we take the former perspective. The simplest form of Bayes's theorem, which can be found in statistics handbooks (e.g. Pishro-Nik, 2014; Hogg et al., 2018), is
which defines the posterior probability mass function as the product of the likelihood function and the prior probability mass function PX(x) over the marginal likelihood function PY(y). They are usually simply referred to as the posterior, likelihood, prior, and evidence. The subscripts X and Y are SVs, and X=x and Y=y are realisations of those SVs. When dealing with multiple unknowns, SVs generalise to stochastic (random) vectors whose elements are SVs. Rather than with X and Y, we then deal with and with realisations and . Moreover, when dealing with continuous rather than discrete SVs, probability mass functions P (pmf's) become probability density functions f (pdf's). The multivariate formulation of Bayes's theorem for continuous stochastic vectors finally reads
where the posterior, likelihood, prior, and evidence are now joint pdf's. Since, in the current work, we are always dealing with joint pdf's, we often refer to them as joint distributions or even simply as distributions.
Formally, we should always distinguish between stochastic variables and vectors (X and X) and their realisations (x and x). However, this makes notation cumbersome and does not always add much in the way of clarity, so in the main text we often ignore the difference.
The Python code that contains the Bayesian model (calibration and prediction) and the analysis scripts is available at https://doi.org/10.5281/zenodo.12644422 (Frankemölle et al., 2024b). The TELERAD data for the periods and locations discussed in this work are available at https://doi.org/10.5281/zenodo.12581795 (Frankemölle et al., 2024a).
JPKWF: conceptualisation, methodology, validation, formal analysis, data curation, writing (original draft). JC: conceptualisation, writing (review and editing), supervision. PDM: formal analysis, writing (review and editing), supervision. JM: conceptualisation, formal analysis, writing (review and editing), supervision.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The authors thank François Menneson from FANC–AFCN for providing access to the TELERAD data, users of PyMC Discourse for valuable insights into working with PyMC (https://discourse.pymc.io/t/calculating-conditional-posterior-predictive-samples-in-high-dimensional-observation-spaces/12450, last access: 25 March 2025), and the reviewers of the preprint via the associated Geoscientific Model Development interactive discussion for taking the time to study and give feedback on our work.
This paper was edited by Dan Lu and reviewed by two anonymous referees.
Abril-Pla, O., Andreani, V., Carroll, C., Dong, L., Fonnesbeck, C. J., Kochurov, M., Kumar, R., Lao, J., Luhmann, C. C., Martin, O. A., Osthege, M., Vieira, R., Wiecki, T., and Zinkov, R.: PyMC: a modern, and comprehensive probabilistic programming framework in Python, PeerJ Computer Science, 9, e1516, https://doi.org/10.7717/peerj-cs.1516, 2023. a
Agentschap Digitaal Vlaanderen: Orthofotomozaïek, grootschalig, winteropnamen, kleur, 2013–2015, Vlaanderen, https://www.vlaanderen.be/datavindplaats/catalogus/ orthofotomozaiek-grootschalig-winteropnamen-kleur-2013-2015-vlaanderen, (last access: 25 March 2025), 2016. a
Arahmane, H., Dumazert, J., Barat, E., Dautremer, T., Carrel, F., Dufour, N., and Michel, M.: Statistical approach for radioactivity detection: A brief review, J. Environ. Radioactiv., 272, 107358, https://doi.org/10.1016/j.jenvrad.2023.107358, 2024. a
Barnard, J., McCulloch, R., and Meng, X.-L.: Modeling covariance matrices in terms of standard deviations and correlations, with application to shrinkage, Stat. Sinica, 10, 1281–1311, 2000. a, b
Bergan, T. D.: Radioactive fallout in Norway from atmospheric nuclear weapons tests, J. Environ. Radioactiv., 60, 189–208, https://doi.org/10.1016/S0265-931X(01)00103-5, 2002. a
Breitkreutz, H., Mayr, J., Bleher, M., Seifert, S., and Stöhlker, U.: Identification and quantification of anomalies in environmental gamma dose rate time series using artificial intelligence, J. Environ. Radioactiv., 259–260, 107082, https://doi.org/10.1016/j.jenvrad.2022.107082, 2023. a, b
Brennan, S., Mielke, A., and Torney, D.: Radioactive source detection by sensor networks, IEEE T. Nucl. Sci., 52, 813–819, https://doi.org/10.1109/TNS.2005.850487, 2005. a
Chernyavskiy, P., Kendall, G., Wakeford, R., and Little, M.: Spatial prediction of naturally occurring gamma radiation in Great Britain, J. Environ. Radioactiv., 164, 300–311, https://doi.org/10.1016/j.jenvrad.2016.07.029, 2016. a
Elson, P., Sales de Andrade, E., Lucas, G., May, R., Hattersley, R., Campbell, E., Comer, R., Dawson, A., Little, B., Raynaud, S., scmc72, Snow, A. D., Igolston, Blay, B., Killick, P., Ibdreyer, Peglar, P., Wilson, N., Andrew, Szymaniak, J., Berchet, A., Bosley, C., Davis, L., Filipe, Krasting, J., Bradbhury, M., stephenworsley, and Kirkham, D.: SciTools/cartopy: REL: v0.24.1, Zenodo [code], https://doi.org/10.5281/zenodo.13905945, 2024. a
European Commission: EUropean Radiological Data Exchange Platform, https://remon.jrc.ec.europa.eu/About/Rad-Data-Exchange (last access: 25 March 2025), 2024. a, b
European Commission, Directorate-General for Research and Innovation, De Cort, M., Dubois, G., Fridman, S., Germenchuk, M., Izrael, Y., Janssens, A., Jones, A., Kelly, G., Kvasnikova, E., Matveenko, I., Nazarov, I., Pokumeiko, Y., Sitak, V., Stukin, E., Tabachny, L., Tsaturov, Y., and Avdyushin, S.: Atlas of caesium deposition on Europe after the Chernobyl accident, Publications Office of the European Union, https://op.europa.eu/publication-detail/-/publication/110b15f7-4df8-49a0-856f-be8f681ae9fd (last access: 25 March 2025), 1998. a
Evensen, G., Vossepoel, F. C., and van Leeuwen, P. J.: Kalman Filters and 3DVar, in: Data Assimilation Fundamentals: A Unified Formulation of the State and Parameter Estimation Problem, Springer International Publishing, Cham, 63–71, https://doi.org/10.1007/978-3-030-96709-3_6, 2022. a
Federal Agency for Nuclear Control: Telerad, https://www.telerad.be (last access: 25 March 2025), 2024. a
Folly, C. L., Konstantinoudis, G., Mazzei-Abba, A., Kreis, C., Bucher, B., Furrer, R., and Spycher, B. D.: Bayesian spatial modelling of terrestrial radiation in Switzerland, J. Environ. Radioactiv., 233, 106571, https://doi.org/10.1016/j.jenvrad.2021.106571, 2021. a
Frankemölle, J. P. K. W., Camps, J., De Meutter, P., Antoine, P., Delcloo, A., Vermeersch, F., and Meyers, J.: Near-range atmospheric dispersion of an anomalous selenium-75 emission, J. Environ. Radioactiv., 255, 107012, https://doi.org/10.1016/j.jenvrad.2022.107012, 2022a. a
Frankemölle, J. P. K. W., Camps, J., De Meutter, P., and Meyers, J.: Near-range Gaussian plume modelling for gamma dose rate reconstruction, in: 21st International Conference on Harmonisation within Atmospheric Dispersion Modelling for Regulatory Purposes, 27–30 September 2022, Aveiro, Portugal, https://www.harmo.org/Conferences/Proceedings/_Aveiro/publishedSections/00514_172_h21-023-jens-peter-frankemolle.pdf (last access: 25 March 2025), 2022b. a, b
Frankemölle, J. P. K. W., Camps, J., De Meutter, P., and Meyers, J.: Accompanying dataset for: “A Bayesian Method for predicting background radiation at environmental monitoring stations”, Zenodo [data set], https://doi.org/10.5281/zenodo.12581795, 2024a. a, b
Frankemölle, J. P. K. W., Camps, J., De Meutter, P., and Meyers, J.: Accompanying software for: “A Bayesian Method for predicting background radiation at environmental monitoring stations”, Zenodo [code], https://doi.org/10.5281/zenodo.12644422, 2024b. a
Gelman, A.: Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper), Bayesian Anal., 1, 515–534, https://doi.org/10.1214/06-BA117A, 2006. a
Gelman, A. and Rubin, D. B.: Inference from Iterative Simulation Using Multiple Sequences, Stat. Sci., 7, 457–472, https://doi.org/10.1214/ss/1177011136, 1992. a
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B.: Bayesian Data Analysis, in: 3rd Edn., Chapman and Hall/CRC, https://doi.org/10.1201/b16018, 2013. a
Hoffman, M. D. and Gelman, A.: The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo, J. Mach. Learn. Res., 15, 1593–1623, 2014. a
Hogg, R., McKean, J., and Craig, A.: Introduction to Mathematical Statistics, ib: 8th Edn., Pearson, ISBN 9780134686998, 2018. a
Holt, W. and Nguyen, D.: Essential Aspects of Bayesian Data Imputation, https://doi.org/10.2139/ssrn.4494314, 2023. a, b, c
Howarth, D., Miller, J. K., and Dubrawski, A.: Analyzing the Performance of Bayesian Aggregation Under Erroneous Environmental Beliefs, IEEE T. Nucl. Sci., 69, 1257–1266, https://doi.org/10.1109/TNS.2022.3169990, 2022. a
ICRP: Dose coefficients for external exposures to environmental sources. ICRP Publication 144, Ann. ICRP, https://www.icrp.org/publication.asp?id=ICRP Publication 144 (last access: 25 March 2025), 2020. a
Kumar, R., Carroll, C., Hartikainen, A., and Martin, O.: ArviZ a unified library for exploratory analysis of Bayesian models in Python, Journal of Open Source Software, 4, 1143, https://doi.org/10.21105/joss.01143, 2019. a
Lewandowski, D., Kurowicka, D., and Joe, H.: Generating random correlation matrices based on vines and extended onion method, J. Multivariate Anal., 100, 1989–2001, https://doi.org/10.1016/j.jmva.2009.04.008, 2009. a, b
Liu, Z. and Sullivan, C. J.: Prediction of weather induced background radiation fluctuation with recurrent neural networks, Radiat. Phys. Chem., 155, 275–280, https://doi.org/10.1016/j.radphyschem.2018.03.005, 2019. a
Liu, Z., Abbaszadeh, S., and Sullivan, C. J.: Spatial-temporal modeling of background radiation using mobile sensor networks, PLoS One, 13, 1–14, https://doi.org/10.1371/journal.pone.0205092, 2018. a
Livesay, R., Blessinger, C., Guzzardo, T., and Hausladen, P.: Rain-induced increase in background radiation detected by Radiation Portal Monitors, J. Environ. Radioactiv., 137, 137–141, https://doi.org/10.1016/j.jenvrad.2014.07.010, 2014. a, b
Martin, O. A., Hartikainen, A., Abril-Pla, O., Carroll, C., Kumar, R., Naeem, R., Arroyuelo, A. Gautam, P., rpgoldman, Banerjea, A., Pasricha, N., Sanjay, R., Gruevski, P., Axen, S., Rochford, A., Mahweshwari, U., Kazantsev, V., Zinkov, R., Phan, D., Matamoros, A. A., Arunava, Shekhar, M., Andorra, A., Carrera, E., Osthege, M., Munoz, H., Gorelli, M. E., Capretto, T., Kunanuntakij, T., and Sarina: ArviZ (v0.18.0), Zenodo [code], https://doi.org/10.5281/zenodo.10929056, 2024. a
Maurer, C., Baré, J., Kusmierczyk-Michulec, J., Crawford, A., Eslinger, P. W., Seibert, P., Orr, B., Philipp, A., Ross, O., Generoso, S., Achim, P., Schoeppner, M., Malo, A., Ringbom, A., Saunier, O., Quèlo, D., Mathieu, A., Kijima, Y., Stein, A., Chai, T., Ngan, F., Leadbetter, S. J., De Meutter, P., Delcloo, A., Britton, R., Davies, A., Glascoe, L. G., Lucas, D. D., Simpson, M. D., Vogt, P., Kalinowski, M., and Bowyer, T. W.: International challenge to model the long-range transport of radioxenon released from medical isotope production to six Comprehensive Nuclear-Test-Ban Treaty monitoring stations, J. Environ. Radioactiv., 192, 667–686, https://doi.org/10.1016/j.jenvrad.2018.01.030, 2018. a
Mercier, J.-F., Tracy, B., d'Amours, R., Chagnon, F., Hoffman, I., Korpach, E., Johnson, S., and Ungar, R.: Increased environmental gamma-ray dose rate during precipitation: a strong correlation with contributing air mass, J. Environ. Radioactiv., 100, 527–533, https://doi.org/10.1016/j.jenvrad.2009.03.002, 2009. a, b
Michaud, I. J., Schmidt, K., Smith, R. C., and Mattingly, J.: A hierarchical Bayesian model for background variation in radiation source localization, Nucl. Instrum. Meth. A, 1002, 165288, https://doi.org/10.1016/j.nima.2021.165288, 2021. a
Natural Earth: Free vector and raster map data, https://www.naturalearthdata.com (last access: 25 March 2025), 2024. a
Nomura, S., Tsubokura, M., Hayano, R., Furutani, T., Yoneoka, D., Kami, M., Kanazawa, Y., and Oikawa, T.: Comparison between Direct Measurements and Modeled Estimates of External Radiation Exposure among School Children 18 to 30 Months after the Fukushima Nuclear Accident in Japan, Environ. Sci. Technol., 49, 1009–1016, https://doi.org/10.1021/es503504y, 2015. a
Park, S. Y. and Bera, A. K.: Maximum entropy autoregressive conditional heteroskedasticity model, J. Econometrics, 150, 219–230, https://doi.org/10.1016/j.jeconom.2008.12.014, 2009. a
Pishro-Nik, H.: Introduction to probability statistics, and random processes, Kappa Research, LLC, https://www.probabilitycourse.com/ (last access: 25 March 2025), 2014. a, b
Querfeld, R., Hori, M., Weller, A., Degering, D., Shozugawa, K., and Steinhauser, G.: Radioactive Games? Radiation Hazard Assessment of the Tokyo Olympic Summer Games, Environ. Sci. Technol., 54, 11414–11423, https://doi.org/10.1021/acs.est.0c02754, 2020. a
Sangiorgi, M., Hernández-Ceballos, M. A., Jackson, K., Cinelli, G., Bogucarskis, K., De Felice, L., Patrascu, A., and De Cort, M.: The European Radiological Data Exchange Platform (EURDEP): 25 years of monitoring data exchange, Earth Syst. Sci. Data, 12, 109–118, https://doi.org/10.5194/essd-12-109-2020, 2020. a
Sonck, M., Desmedt, M., Claes, J., and Sombré, L.: TELERAD: the radiological surveillance network and early warning system in Belgium, in: 12th Congress of the International Radiation Protection Association (IRPA12): Proceedings of a Conference Held in Buenos Aires, Argentina, 19–24 October, 2008, Proceedings Series, International Atomic Energy Agency, Vienna, https://www.iaea.org/publications/8450/12th-congress-of-the-international-radiation-protection-association-irpa12 (last access: 22 November 2021), 2010. a, b, c
Sportisse, B.: A review of parameterizations for modelling dry deposition and scavenging of radionuclides, Atmos. Environ., 41, 2683–2698, https://doi.org/10.1016/j.atmosenv.2006.11.057, 2007. a
Vehtari, A., Gelman, A., Simpson, D., Carpenter, B., and Bürkner, P.-C.: Rank-Normalization, Folding, and Localization: An Improved for Assessing Convergence of MCMC (with Discussion), Bayesian Anal., 16, 667–718, https://doi.org/10.1214/20-BA1221, 2021. a
Vlaamse Milieumaatschappij: Waterinfo, https://www.waterinfo.be/ (last access: 25 March 2025), 2023. a, b
Wiecki, T., Salvatier, J., Vieira, R., Kochurov, M., Patil, A., Osthege, M., Willard, B. T., Engels, B., Martin, O. A., Carroll, C., Seyboldt, A., Rochford, A., Paz, L., rpgoldman, Meyer, K., Coyle, P., Abril-Pla, O., Gorelli, M. E., Andreani, V., Kumar, R., Lao, J., Yoshioka, T., Ho, G., Kluyver, T., Andorra, A., Beauchamp, K., Pananos, D., Spaak, E., and larryshamalama: pymcdevs/pymc: v5.13.1, Zenodo [code], https://doi.org/10.5281/zenodo.10973000, 2024. a
- Abstract
- Introduction
- Data and methods
- Calibration and verification
- Predictions using the conditional distribution
- Predictions during operation of BR1
- Conclusions and outlook
- Appendix A: Bayesian inference
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References
anomalous event.
- Abstract
- Introduction
- Data and methods
- Calibration and verification
- Predictions using the conditional distribution
- Predictions during operation of BR1
- Conclusions and outlook
- Appendix A: Bayesian inference
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References