the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 08 Sep 2023
| 08 Sep 2023
Metrics for evaluating the quality in linear atmospheric inverse problems: a case study of a trace gas inversion
Vineet Yadav
Charles E. Miller
Several metrics have been proposed and utilized to diagnose the performance of linear Bayesian and geostatistical atmospheric inverse problems. These metrics primarily assess the reductions in the prior uncertainties, compare modeled observations to true observations, and check distributional assumptions. Although important, these metrics should be augmented with a sensitivity analysis to obtain a comprehensive understanding of the atmospheric inversion performance and improve the quality and confidence in the inverse estimates. In this study, we derive closed-form expressions of local sensitivities for various input parameters, including measurements, covariance parameters, covariates, and a forward operator. To further enhance our understanding, we complement the local sensitivity analysis with a framework for a global sensitivity analysis that can apportion the uncertainty in input parameters to the uncertainty associated with inverse estimates. Additionally, we propose a mathematical framework to construct nonstationary correlation matrices from a precomputed forward operator, which is closely tied to the overall quality of inverse estimates. We demonstrate the application of our methodology in the context of an atmospheric inverse problem for estimating methane fluxes in Los Angeles, California.
- Article
(4192 KB) - Full-text XML
-
Supplement
(3816 KB) - BibTeX
- EndNote





© 2022 Jet Propulsion Laboratory, California Institute of Technology. Government sponsorship acknowledged.
In atmospheric applications, inverse models are frequently used to estimate global- to regional-scale fluxes of trace gases from atmospheric measurements (Enting, 2002). At a global scale, data assimilation remains the primary inverse modeling framework, which assimilates observations sequentially and updates the prior estimates of fluxes by utilizing an atmospheric model coupled with chemistry (for further details on data assimilation, see Wikle and Berliner, 2007). At a regional scale, inversions that assimilate all observations simultaneously by utilizing a precomputed forward operator (Lin et al., 2003) that describes the relationship between observations and fluxes are commonly used (for details, see Enting, 2002). This work focuses on the use of precomputed forward operators for atmospheric inverse modeling and addresses the sensitivity analysis and correlation in the forward operator in the context of Bayesian (e.g., Lauvaux et al., 2016) and geostatistical inverse methods (e.g., Kitanidis, 1996).
The sensitivity analysis in this work is covered under local and global themes. Primarily, we focus on local sensitivity analysis (LSA), which measures the effect of a given input on a given output and is obtained by computing the partial derivatives of an output quantity of interest for an input factor (see Rabitz, 1989, and Turányi, 1990). Within the global theme (designated as a global sensitivity analysis), we focus on how uncertainty in the model output can be apportioned to different model input parameters (Saltelli et al., 2008).
Overall, in atmospheric trace gas inversions, the LSA is mostly performed. Within this context, the LSA assesses how sensitive the posterior estimates of fluxes are regarding the underlying choices or assumptions, like the (1) observations included, (2) model data error covariance, (3) input prior information and its error, and (4) forward operator (for a discussion, see Michalak et al., 2017). This task is sometimes performed to arrive at a robust estimate of fluxes and their uncertainties by running an inverse model multiple times, while varying the input parameters and assessing their impact on the estimated fluxes and uncertainties. Another complementary way to do the LSA is by computing the local partial derivatives of input parameters that go into an inversion.
The LSA can be grouped with standard information content approaches such as an averaging kernel and degrees of freedom for signal (DOFS; for details, see Sect. 2.2.1 of this paper, Rodgers, 2000, and Brasseur and Jacob, 2017). However, the LSA is more informative than these approaches alone, as it examines individual components (see Sect. 2.2) that determine DOFS and quantifies the impact and relative importance of various components of an inversion.
In this study, we focus on the quality of the inverse estimates of the fluxes, which means providing diagnostic metrics to improve our understanding of the impact of input choices on the inverse estimates of fluxes and thus improve the quality of the inverse model. Specifically, in this technical note, we provide (1) closed-form expressions to conduct LSA by computing partial derivatives, (2) a scientifically interpretable framework for ranking thousands of spatiotemporally correlated input parameters with the same or different units of measurement, (3) a mathematical schema for conducting a global sensitivity analysis (GSA), and (4) a technique to assess the spatiotemporal correlation between the forward operators of two or multiple observations, which is tied to the overall diagnostics of the estimated fluxes and can lead to improved representation of errors in the forward operator.
In generic form, a linear inverse problem can be written as follows:
where H is a forward operator that maps model parameters (fluxes in the context of this work) to measurements z and encapsulates our understanding of the physics of the measurements. The error ϵ in Eq. (1) describes the mismatch between measurements and the modeled measurements (see Sect. 3).
In a typical linear atmospheric inverse problem (see Fig. 1), the estimates of fluxes (box 8 in Fig. 1) are obtained in a classical one-stage-batch Bayesian setup (for details, see Enting, 2002; Tarantola, 2005). In this setup, the a priori term (box 3 in Fig. 1) is based on a fixed flux pattern, and the errors (box 6 in Fig. 1) are either assumed to be independent or are governed by a predefined covariance structure (for details, see Gurney et al., 2003; Rödenbeck et al., 2003, 2006).
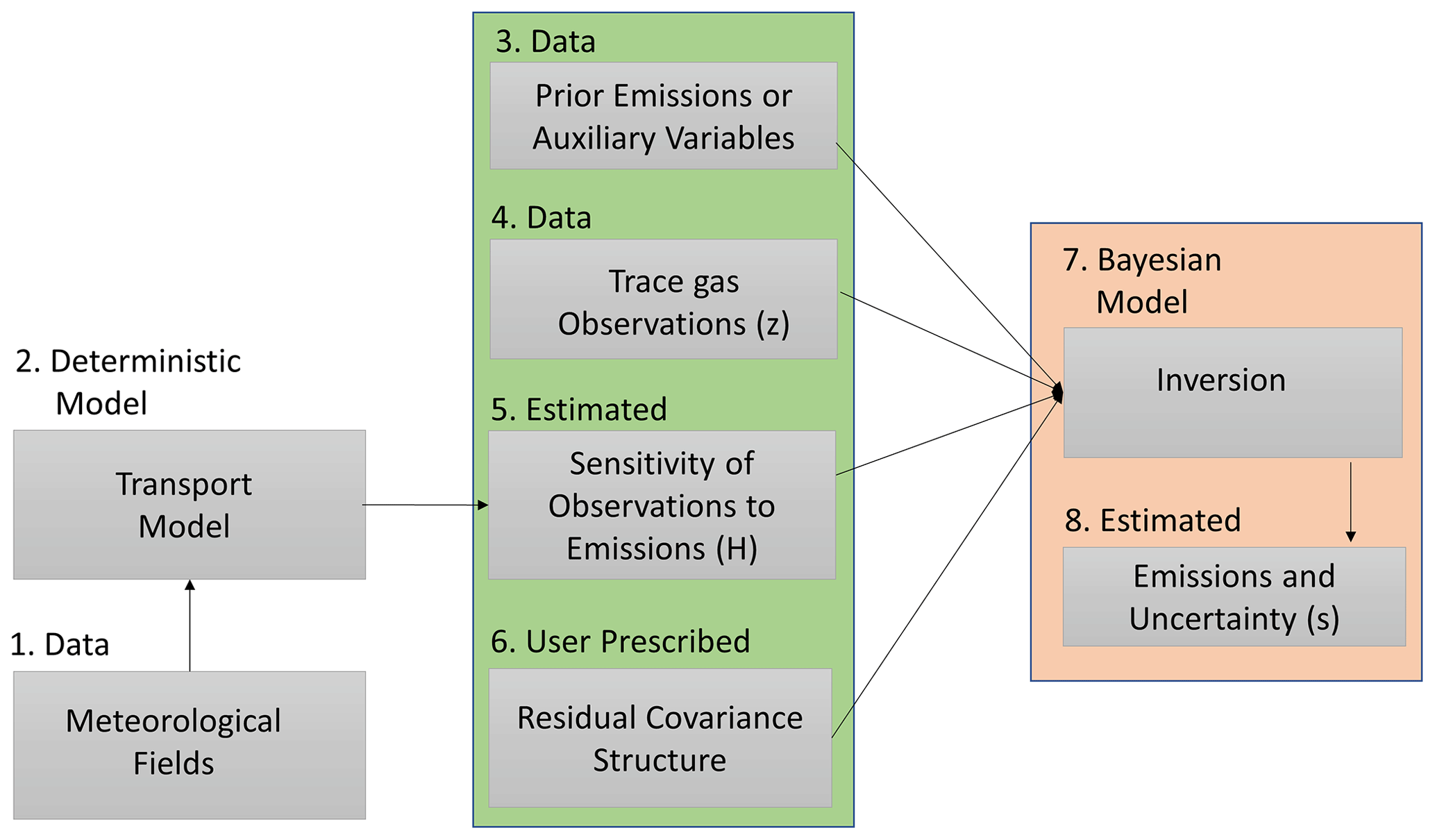
Figure 1The schema for performing a linear atmospheric inversion to obtain the estimates of the emissions of greenhouse gases. The middle column (the box with a green background) lists all of the input parameters that are required to perform an inversion, whereas the right column (the box with an orange background) lists the modeling process (box 7) and the output obtained after performing an inversion (box 8). Note that this work focuses on understanding and ranking the impact of the input parameters (boxes 3, 4, and 6) on the estimates of fluxes (box 8) and developing correlation structures from the forward operator (box 5).
Within the previously mentioned setup, the choice of the input parameters, including the forms of error structures, profoundly impacts the quality of the inverse estimates of fluxes. Understanding the impact of these input parameters is critical for evaluating the quality of the estimated fluxes. Thus, we first (Sect. 2.1) utilize the understanding of the physics of the measurements, encapsulated in H, to generate scientifically interpretable correlation matrices (box 6 in Fig. 1). Second, we assess and rank the importance of the input parameters (Sect. 2.2) shown in the middle column (the box with a green background ) in Fig. 1 (box 8 in Fig. 1), which is finally followed by a methane (CH4) case study that demonstrates the applicability of our methods (see Sect. 2).
2.1 Analysis of the forward operator
In inversions that assimilate all observations simultaneously, a forward operator for each observation included in an inversion is obtained from a transport model. These observations can be obtained from multiple platforms, including an in situ network of fixed locations on the surface, intermittent aircraft flights, and satellites. In most situations, the spatiotemporal coverage of these forward operators is visually assessed by plotting an aggregated sum or mean of their values over a spatial domain. However, the standard quantitative metrics to evaluate their coverage and intensity in space and time remain absent. In this study, we present two metrics for this assessment, which are defined below. These metrics are in accordance with the triangular inequality and are distances in their respective metric spaces.
Note that, in the published literature on trace gas inversions, sometimes the forward operator obtained from a transport model is referred to as a sensitivity matrix, Jacobian, or footprint. Henceforth, we always refer to the Jacobian, sensitivity matrix, or footprint as a forward operator to avoid misinterpretation. We show our application through forward operators constructed by running a Lagrangian transport model. However, the proposed methods can also be applied in the Eulerian framework (see Brasseur and Jacob, 2017, for details).
2.1.1 Integrated area overlap measurement index (IAOMI)
The integrated area overlap measurement index (IAOMI) summarizes the shared information content between two forward operators and hence indirectly between two observations. It is, therefore, a measure of the uniqueness of the flux signal associated with an observation compared to other observations.
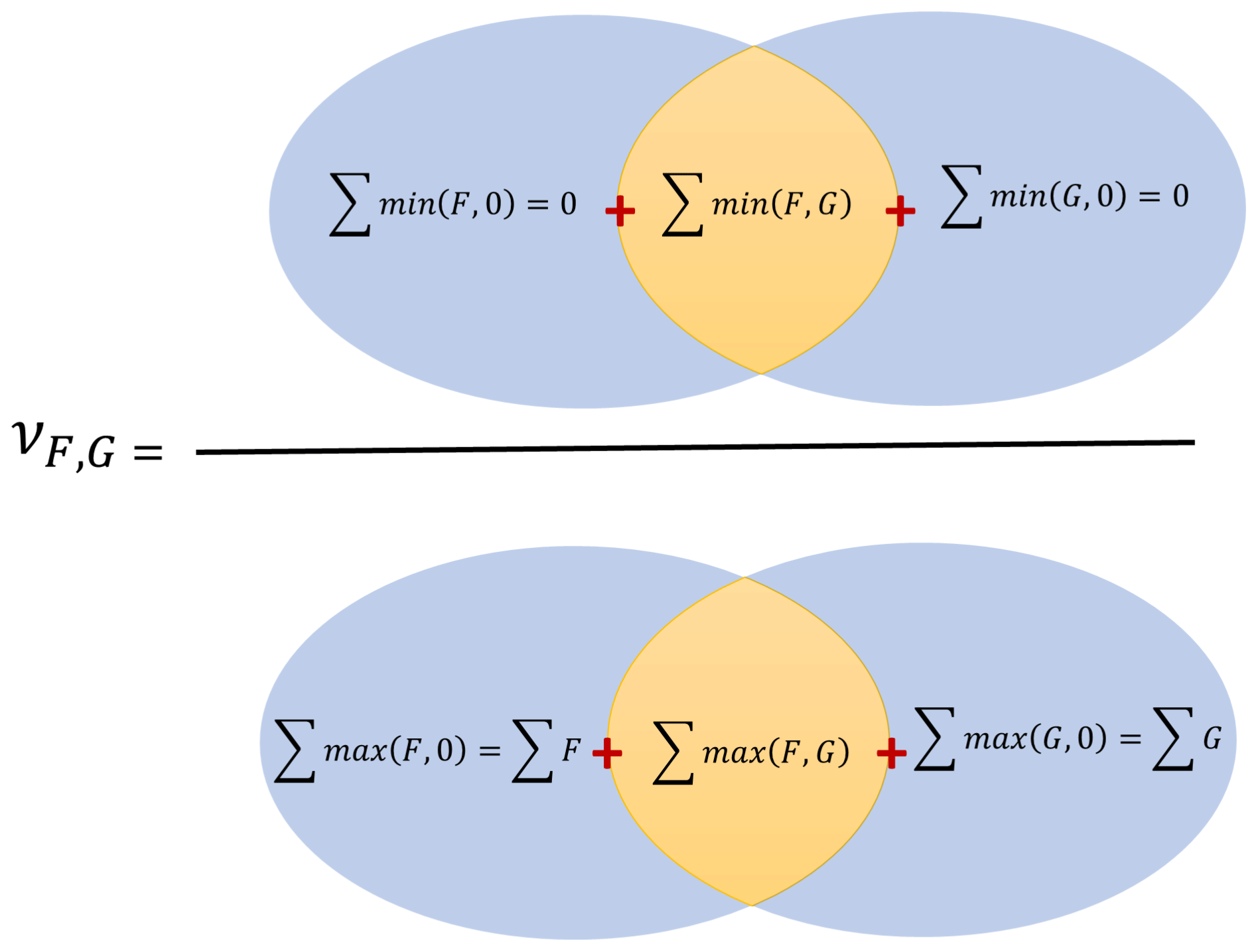
Figure 2A Venn diagram that defines IAOMI in terms of two hypothetical forward operators F and G.
Intuitively, IAOMI can be better understood spatially. For a given time point, consider two forward operators F and G as the two vector-valued functions over an area. The IAOMI index is the proportion of the common contribution of the two forward operators for the intersected area with respect to the overall contribution of the two forward operators. This is demonstrated through a Venn diagram in Fig. 2. Thus, IAOMI can be defined as follows:
where, for any forward operator S, the corresponding set AS, on which the forward operator is always positive, is defined as and the two vector-valued functionals f1 and f2 can be given as follows:
Note that the IAOMI defined in Eq. (2) can also be written as a ratio of the sum of minimums over the sum of the maximums, as follows:
IAOMI ν can also be thought of as a measure of the similarity between two forward operators. It is evident from Eq. (4) that this is a weighted Jaccard similarity index or Ruzicka index (Cha, 2007), which describes the similarity between two forward operators F and G. It follows that ν is closed and bounded in [0,1] and accounts for both the spatiotemporal spread and the intensity of the forward operator. A stronger ν implies that there is a larger overlap of the intensity in space and time, that it is analogous to finding the common area within two curves, and that it is indicative of the magnitude of overlapping information, knowledge which is beneficial in the context of satellite observations with a higher potential for sharing information content.
A dissimilarity measure can be obtained from ν and be defined by 1−ν. The smaller the overlap or the larger the value of 1−ν, the more significant the disparity. Note that the ν metric is only indicative of the overlap in the spatiotemporal intensity between two forward operators. To measure how much of the shared intensity has come from either forward operator, we use a metric υF|(F,G), which is defined as follows:
where f3(F)=F on AF and 0 everywhere else. Similarly, we can define υG|(F,G), which shows the proportional contribution of the forward operator G on the shared intensity. Both ν and υ can be computed from the observations taken from the same or different platforms, at the same or different times, or for two different in situ measurement sites over a specified time interval.
2.1.2 Spatiotemporal area of dominance (STAD)
The spatiotemporal area of dominance (STAD) stems naturally from IAOMI. For any two forward operators, F and G, we can find the left over dominant contribution of F and G by computing the quantities F−G and G−F that lead to the determination of the areas where F or G is dominant.
For two forward operators F and G, the STAD of F with respect to G is defined as follows:
The IAOMI and STAD of any forward operator F, with respect to the forward operators F and G, are linked by the following equation:
Given a number of forward operators , the STAD for any particular forward operator F with respect to all other forward operators can be generalized from Eq. (6) as FSTAD(F,Gmax), where on AG; and is the set on which the forward operator Gk is always positive (see Sect. 2.1.1 for its definition). The STAD can be aggregated over any time period. Intuitively, STAD determines areas in space–time in which one forward operator dominates over other forward operators, and this is especially useful for locating the primary flux sources that influence an observation.
One can use 1−IAOMI or a distance metric like the Jensen–Shannon distance (JSD; see Appendix B) matrix of all pairwise forward operators as a representative distance matrix for describing the correlations in model data errors (i.e., R in Eq. 7). As JSD or 1−IAOMI matrices are real, symmetric, and admit orthogonal decomposition, the entry-wise exponential of such symmetric diagonalizable matrices is positive semi-definite and can be incorporated in a model data mismatch matrix R (see Ghosh et al., 2021). Furthermore, the IAOMI matrix itself is a positive semi-definite (Bouchard et al., 2013) matrix and can also be directly incorporated in R as a measure of the correlation. This is an example of how IAOMI or 1−IAOMI could be particularly useful for satellite-data-based inversions with a higher degree of spatial overlap of the forward operators. However, we do not explore this area of research in this work.
2.2 Local sensitivity analysis (LSA) in inversions
For linear Bayesian and geostatistical inverse problems, the solutions (see Tarantola, 2005, for the batch Bayesian and Kitanidis, 1996, for the geostatistical case) can be obtained by minimizing their respective objective functions. These objective functions can be given as follows:
where lowercase symbols represent vectors, and uppercase symbols represent matrices, and this exact representation is adopted throughout the paper. In Eqs. (7) and (8), z is an (n×1) vector of the available measurements, with the unit of each entry being in parts per million (ppm). The forward operator H is an (n×m) matrix (with the unit of each entry being ppm µmol−1 m2 s). The matrix H is obtained from a transport model that describes the relationship between measurements and unknown fluxes. The unknown flux s is a (m×1) vector (with the unit of entries being ). The covariance matrix R of the model data errors is an (n×n) matrix (with the unit of the entries being ppm2). The covariate matrix X is an (m×p) matrix of known covariates related to s. The unit of each of the entries in every column of the covariate matrix X is the unit of its measurement, or if it is standardized (e.g., subtract the mean from the covariate and divide by its standard deviation), then it is unitless. For further discussion on standardization and normalization, see Gelman and Hill (2006). The units of the (p×1) vector β are such that Xβ and s have the same units. The prior error covariance matrix Q is a (m×m) matrix that represents the errors between s and Xβ (with the unit of the entries being ).
The analytical solutions for the unknown fluxes s in the Bayesian case (denoted by subscript B) and the geostatistical case (denoted by subscript G) can be obtained from Eqs. (9) and (10), as given below.
In the linear Bayesian and geostatistical inverse problems described by Eqs. (7) and (8), the estimated fluxes can be expressed as the sum of the prior information and the update obtained from the observations. In Eqs. (9) and (10), the second term represents the observational constraint, while the first term describes the prior information (in Eq. 9) and the information about fluxes (through X in Eq. 10). When there is no additional information, the solution corresponds to the prior knowledge. Since the estimate of sG in Eq. (10) depends on the unknown β, it requires a prior estimation of β before obtaining . The solution for the can be obtained from predetermined quantities, as described earlier in the context of Eq. (8), and can be given as follows:
Plugging into Eq. (10) leads to Eq. (12), where all symbols have been defined previously, or in Eq. (13).
where
Note that and in Eqs. (9) and (10) are essentially functions that are represented by equations. This is the commonly adopted nomenclature that is used by researchers working in the field of atmospheric inversions. We differentiate Eq. (9), with respect to sprior, R, Q, and z, and Eq. (12), with respect to X, R, Q, and z, to obtain local sensitivities. There are two ways to differentiate with respect to z, X, H, Q, and R. In the first case, every entry in z, X, H, Q, and R can be considered to be a parameter that results in the differentiation of with respect to these quantities. An “entry” refers to each element of the matrix denoted by ij, where i represents the row number, and j represents the column number. On the other hand, if the structures of the covariance matrices Q and R are determined by parameters, then can be differentiated just with respect to these parameters. In the former case, Eqs. (9) and (12) are used to differentiate with respect to an entry at a time in z, X, H, Q, and R. Such an approach of entry-by-entry differentiation is useful if the computational cost in terms of the memory constraint is important, or if we would like to know the influence of a single entry on . We provide both sets of equations in this work.
2.2.1 LSA with respect to observations, priors, scaling factors, and forward operators
The local sensitivity of with respect to observations (z) can be given as follows:
where all quantities are as defined earlier. The units of the entries in are in micromoles per square meter per second per parts per million (), and the matrices are of dimension (m×n). These units are the inverse of the units of H. Local sensitivities with respect to an observation zi for both the Bayesian and the geostatistical case can be written as a vector of sensitivities times an indicator for the ith entry; i.e., , where is a vector of zeros with the entry ith equal to 1.
Note that by utilizing , we can also obtain an averaging kernel (or model resolution matrix) and DOFS (see Rodgers, 2000). The averaging kernel matrix for any linear inverse model can be written as follows:
where the V of dimension (m×m) is the local sensitivity of with respect to the true unknown fluxes. Then the DOFS can be computed by taking the trace of the averaging kernel matrix V. The DOFS represents the amount of information resolved by an inverse model when a set of observations has been assimilated (for a detailed discussion, see Rodgers, 2000, and Brasseur and Jacob, 2017). Theoretically, the value of the DOFS cannot exceed the number of observations (n) in an underdetermined system and the number of fluxes (m) in an overdetermined system.
We can directly compute the local sensitivity of with respect to the prior mean flux sprior in the Bayesian case. In the geostatistical case, the prior mean is modeled by two quantities, X and β. In this scenario, we need to find the sensitivities with respect to X and β. These local sensitivities can be given as follows:
where A=HX, B=QHt, , , , , and . The symbol ⊗ represents the Kronecker product. The quantity is of the dimension (m×m), and its entries are unitless. The quantity is of dimension (m×p), and the units of the entries in each column of are of the form micromoles per square meter per second () × (unit of βi)−1. The sensitivity matrix is of the dimension (m×mp), where every ith block of the m columns () of has units of the form micromoles per square meter per second () × (unit of Xi)−1. Note that the sensitivity matrix in Eq. (17) can also be considered to be a proportion of the posterior uncertainty to that of the prior uncertainty. In the context of the Bayesian case, a proportional uncertainty reduction becomes the averaging kernel.
Sometimes, it is essential to know the influence of the prior of any particular grid point or an area consisting of few grid cells within . The local sensitivity of with respect to the ith entry in sprior and is a matrix of dimension (m×1) and can be written as and , respectively. However, the entry-wise is more complex and can be given by the following:
where is a single entry matrix, with 1 for a Xij for which the differentiation is performed and 0 anywhere else. For z, an entry-by-entry differentiation can be easily performed since both Eqs. (9) and (12) result from linear models and are functions of the form Φz+n, where Φ and n are independent of z. For example, Φ and n for Eq. (9) are and , respectively, and are independent of z. In this case, can be written as Φei, where ei is a single entry vector, with a vector for a zi for which the differentiation is performed and 0 everywhere else. The local sensitivity can be defined similarly for the respective Φ. Here both quantities of and are matrices of dimension (m×1).
The local sensitivity of with respect to an entry in the forward operator has units of the form square meters squared per micromole squared per second squared per parts per million or ppm−1. In the Bayesian case, this sensitivity can be written as follows:
where is a sensitivity matrix of dimension (m×mn). In the geostatistical case, this sensitivity can be partitioned into two components; that is, and , as shown in Eq. (22), where and are obtained in an orderly sequence from Eqs. (23) and (24).
where
The expanded form of some of the symbols in Eqs. (21) through (24), which have not been expanded yet, can be written as D=ΨHsprior, , , , , and . The quantities , , and are sensitivity matrices of the dimensions (m×mn), (p×mn), and (m×mn), respectively. The units of the entries of are of the form square meters squared per micromole squared per second squared per parts per million or ppm−1.
There might be times when we would like to know the sensitivity of the transport (H) with respect to certain source locations only. In this case, we can use ij form of Eqs. (21) through (24) to obtain in parts. In this formulation, can be given as follows:
where
where , and the matrix is a single-entry matrix, with 1 for a Hij entry for which the differentiation is being performed and 0 everywhere else. The quantities , , , and are sensitivity matrices of the dimensions (m×1), (m×1), (p×1), and (m×1), respectively. The units of and are the same as their Kronecker product counterparts.
2.2.2 LSA with respect to error covariance matrices
In order to compute the local sensitivities of with respect to Q and R, consider that they are parameterized as Q(θQ) and R(θR), where θQ and θR are the parameter vectors. The differentiation with respect to error covariance parameters in Q and R can be accomplished from Eqs. (29) through (32), where the subscript i indicates the ith covariance parameter for which differentiation is being performed.
All of the quantities , , , and are sensitivity matrices of the dimension (m×1), and the units of the entries of and are of the form micromoles per square meter per second () × (unit of or )−1. It is also possible to find and directly, as shown in Eqs. (33) through (36).
The first two quantities and , are the sensitivity matrices of the dimension (m×m2). The second set of quantities, and , are the sensitivity matrices of the dimension (m×n2). Equations (33) through (36) are useful when Q and R are fully or partially nonparametric. However, the dimensions of these matrices can be quite large, and users need to be careful when realizing the full matrix.
2.3 Global sensitivity analysis (GSA): a variance-based approach
The GSA is a process of apportioning the uncertainty in the output to the uncertainty in the input parameters. The term “global” stems from accounting for the effect of all input parameters simultaneously. This is different from LSA, where the impact of a slight change in each parameter on the functional output is considered separately, while keeping all other parameters constant. Although quite significant, a detailed GSA is challenging, as it requires knowledge of the probabilistic variations in all the possible combinations (also known as covariance) of the input parameters, which is unavailable in most situations. However, sometimes it might be possible to know the approximate joint variation in a small subset of the input parameters (e.g., the covariance between Q and R parameters). In addition to the variance-based method, derivative-based global sensitivity measures or the active subspace technique (see Appendix A for a discussion) can also be used to conduct a GSA. However, this work uses the variance-based method, as it does not require sampling and can leverage previously computed partial derivatives. It uses a first-order Taylor approximation of the parameter estimates to compute the global sensitivities. This technique has been used in many research works, including environmental modeling (e.g., Hamby, 1994) and life cycle assessment (Groen et al., 2017; Heijungs, 1996), among others.
Broadly, we can consider to be a function of the covariates , and z; i.e., sprior),z). We can then calculate how the uncertainties in the individual components of f are accounted for in the overall uncertainty of by applying the multivariate Taylor series expansion of to its mean. The approximation up to the first-order polynomial of the Taylor series expansion leads to the following equation:
where is the vector of parameters, and W=Var(θ) is the covariance matrix of the parameters.
It is challenging to estimate covariance quantities such as the cross-covariance between θR and θH or between θH and θQ to obtain the best possible estimate of the total uncertainty of . Assuming no cross-covariance between Q and R and ignoring other parameters not related to the variance parameters, the diagonal of the variance of the posterior fluxes can be approximated as follows:
where the subscript i on the right-hand side of Eq. (37) refers to the ith entry of the derivative vector, which is a scalar, and parameters and refer to the jth and kth parameters of the sets θQ and θR, respectively. From Eq. (37), we can see how the uncertainty in the flux estimate is apportioned between the variance of θQ and θR. No normalization is necessary for such a framework, as variance components on the right-hand side of Eq. (37) are naturally weighted, resulting in the same units of measurement. Once the two parts of (i.e., Eq. 37) are computed, they can also be summed over the solution space (e.g., number of grid cells × number of periods) of and ranked to find the relative importance of the parameters.
Even after simplification, the implementation of Eq. (37) is complex, as it requires knowledge of the uncertainties associated with the parameters of Q and R that are generally not known. We do not further discuss the GSA in the context of the case study presented in this work, but we have shown its application with respect to Q and R in MATLAB's Live Script.
Besides the variance-based method, there are many different approaches for performing a GSA, as described in Appendix A. However, they are either computationally expensive or assume the independence of the input parameters, which is not the case in atmospheric inverse problems. We do not pursue other approaches for quantifying the GSA associated with Q and R, as they would lead to similar results and would not add anything substantial to the contributions of this study.
2.4 Ranking importance of covariates, covariance parameters, and observations from LSA
In atmospheric inverse modeling, we encounter two situations while ranking the importance of the parameters. This involves ranking the parameters when they have the same or different units. The situation of ranking parameters with the same units arises when we want to study the influence of a group of parameters, like observations with the same units. Comparatively, the ranking of parameters with different units occurs when we want to explore the impact of groups of parameters with dissimilar units of measurements, like observations in z in comparison to the variance of observations in R. Both of these situations can be accounted for in the GSA described in Sect. 2.3. However, the GSA in most scenarios in atmospheric inverse modeling cannot be performed due to the reasons mentioned earlier. Therefore, in this work, we adopt a regression-based approach to rank the importance of the parameters. The proposed approach utilizes the output from LSA, accounts for multicollinearity, and results in importance scores that are bounded between 0 and 1. We define the regression model for ranking as follows:
where are fluxes obtained from an inversion, and E is a (m×number of derivatives) matrix of the previously estimated sensitivities. The vector of the unknown coefficients γ is of the dimension (number of derivatives×1), and ξ is a (m×1) vector of unobserved errors associated with the regression model. To exemplify, E in Eq. (38) can be arranged as follows:
In a regression-based approach, as described in Eq. (38), the multicollinearity between independent variables in E can pose a problem for determining the importance of the independent variables in influencing Γ. To avoid this problem, we can compute the relative importance weights by using the method outlined in Johnson (2000). These weights are obtained by first deriving the uncorrelated orthogonal counterparts of the covariates in E and then regressing on E to obtain the importance weights for each covariate. The coefficient of determination then standardizes the weights, i.e., R2, such that they range between 0 and 1, with the aggregated sum of 1. The implementation of this method is included in the Live Script submitted with this paper.
Note that the least absolute shrinkage and selection operator (LASSO) or principal component analysis (PCA) can also rank parameters under multicollinearity. However, both of these methods result in unbounded weights. Furthermore, an “inference after selection” approach is ambiguous for the LASSO coefficients (see Berk et al., 2013, or Chap. 6 of Hastie et al., 2015, for details). Consequently, interpreting the LASSO coefficients as ranks may not be the best approach.
The regression-based approach described above can rank parameters with the same and different units of measurement. However, an additional normalization step is required to obtain the overall rank of the parameters with varying units of measure, as in z, Q, and R. To perform this normalization, first, each column in every sensitivity matrix (e.g., , and so forth) that is to be ranked is normalized (min–max normalization; see Vafaei et al., 2020) between 0 and 1. Thereafter, all columns for a sensitivity matrix are summed and renormalized to vary between 0 and 1, resulting in one column representing a sensitivity matrix for a particular group. We denote this with the subscript “grouped” (e.g., ) in latter sections.
Once the normalized sensitivity vectors are obtained for each group, the regression methodology, as described above, can be used to rank the importance of each group. The ranking methodology proposed above does not account for the nonlinear relationship between the estimates of the fluxes and the derivatives. If this is a concern, then the strength of the nonlinear relationship among the derivative vectors can be first obtained by computing the distance correlation between the fluxes and the local derivatives of the parameters. If necessary, variable transformation techniques such as the Box–Cox transformation (see Sakia, 1992) can be used before adopting the regression methodology described above.
Note that in most batch inversion methods, the DOFS is used to assess the information content provided by observations. DOFS=0 in these inversions implies that no informational gain has happened. In this case, the estimated flux reverts to the prior. In Eq. (38), this means that the γ coefficient that corresponds to Q would have the most significant impact. Similarly, if DOFS is large, then the γ coefficients for z and R would be larger (and likely correlated). We show this correspondence in Sect. 3.
Finally, all diagnostic methods applied in the context of any regression-based model can be used to understand the relationship between dependent and independent variables; however, what covariates to include in E depends on the specific case study under consideration.
To demonstrate the applicability of our methods, we utilize data from our published work on CH4 fluxes in the Los Angeles megacity (see Yadav et al., 2019). In this previous work, fluxes were estimated for South Coast Air Basin (SoCAB) region (see Fig. 3) at 0.03∘ spatial (1826 grid cells) and 4 d temporal resolution from 27 January 2015 through 24 December 2016. However, in the current work, we utilize input data from 23 October 2015 through 31 October 2015, which is a single inversion period, to contextualize the applicability of our methods. This period overlaps with the beginning of the well-studied Aliso Canyon gas leak (Conley et al., 2016). As in previous work, R and Q are assumed to be diagonal, with a separate parameter for each site in R and a single parameter that governs the scaling of errors in Q. Similarly, X is a column vector consisting of the prior estimates of CH4 fluxes.
For each observation included in the case study, a forward operator was obtained by using Weather Research Forecasting stochastic time inverted Lagrangian model (see Yadav et al., 2019). These forward operators are used to demonstrate the application of the methodology for building IAOMI and JSD-based correlation matrices in MATLAB's Live Script. They are also used with measurements and prior information to estimate the fluxes and perform the LSA.
3.1 STAD from the forward operators
In this work, we identify STAD for the 4 d period during which the inversion was performed. The spatial domain of the study over this period is uniquely disaggregated by STAD, as shown in Fig. 3. The STAD for different sites is mostly spatially contiguous. Still, for some monitoring sites, we found isolated grid cells that were not within the adjacent zones. We manually combined these with STAD for the closest site to create a spatially continuous map, as shown in Fig. 3. The discontinuous version of the STAD (shown in Fig. 3) is included in the Live Script. The discontinuities in the STAD result mainly from an unequal number of observations across sites and indicate that aggregation over a more extended period is required to identify a noise-free STAD. We do not investigate the period of this aggregation, as this is beyond the scope of this work.
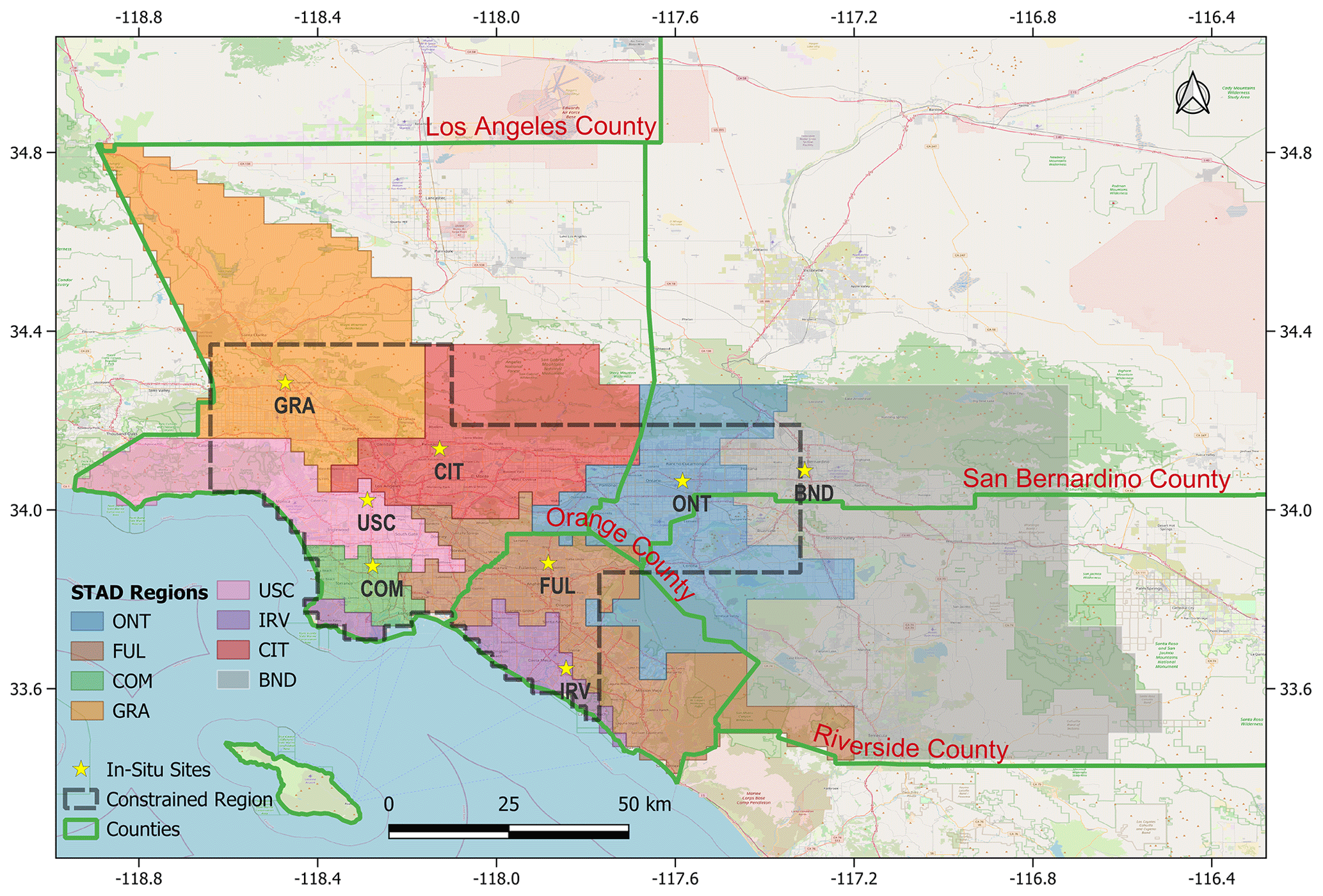
Figure 3Study area with county boundaries, measurement locations, and the spatiotemporal area of dominance of measurement locations. The dotted black line shows the area constrained by observations, as shown in Yadav et al. (2019). Map data copyrighted by © OpenStreetMap contributors 2023. Distributed under the Open Data Commons Open Database License (ODbL) v1.0.
Overall, STAD for each site indicates the spatial regions of fluxes over a period that contribute most to the observational signal observed at a site, thus allowing us to associate the change in fluxes with the specific area in the basin for which reductions or increases in emissions are likely to have occurred. Some information in the observational signal is shared between observations from different sites. This shared information (though not shown) can be computed as part of STAD and forms part of the overall basin-scale estimates of fluxes that combine measurements from all sites. Note that STAD does not represent the network's coverage (i.e., regions of emissions constrained by observations). These regions are shorter than STAD (see the gray outline in Fig. 3). They are obtained before performing an inversion by identifying the areas of continuous spatiotemporal coverage, as provided by atmospheric transport (Fig. 4), or by assessing the model resolution after performing an inversion (for an explanation, see Yadav et al., 2019).
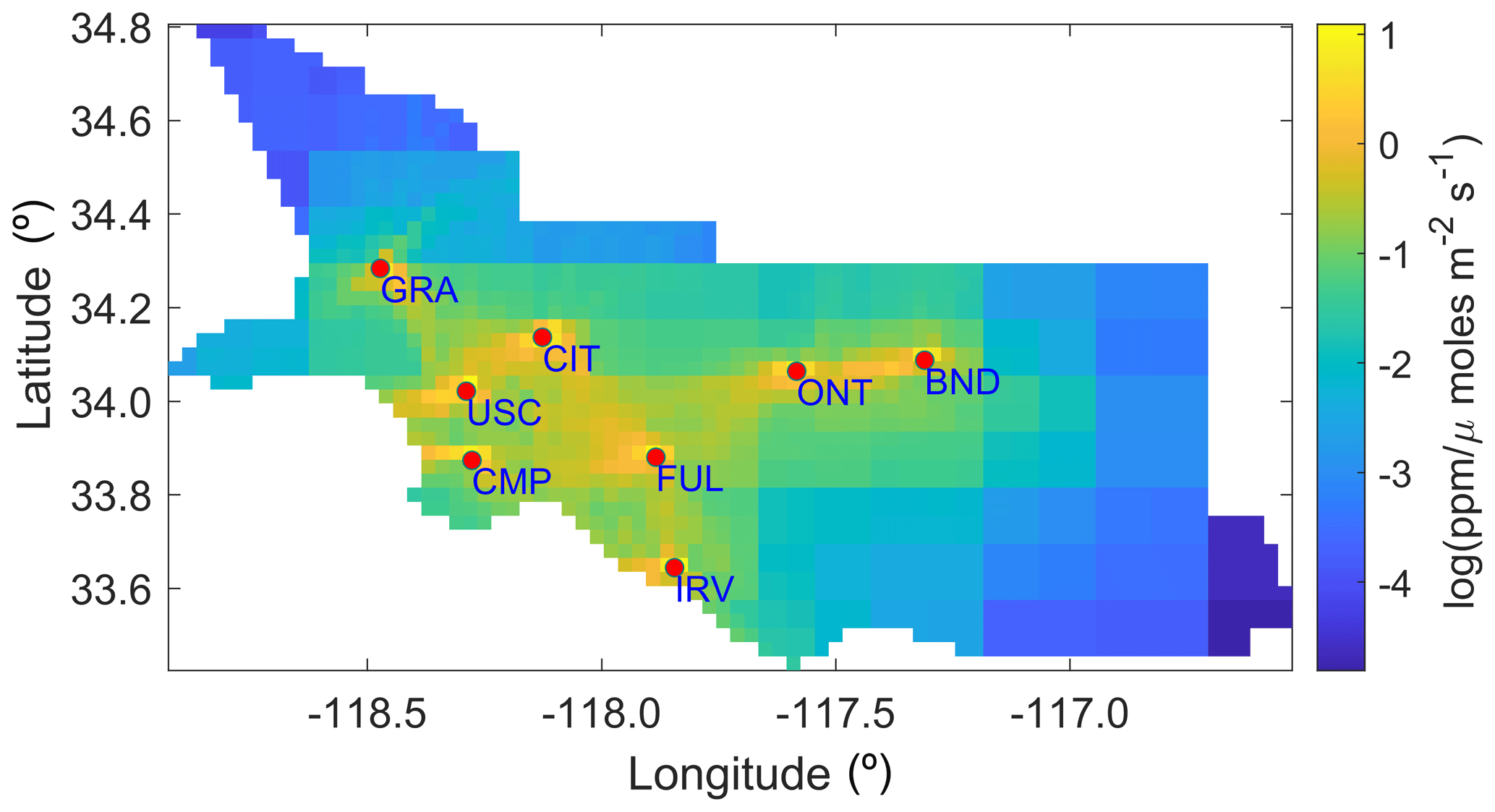
Figure 4Heatmap of the aggregated forward operators for the case study period.
3.2 Sensitivity analysis
One of the main goals of the sensitivity analysis after performing an inversion is to identify the observations that had the most influence on the flux estimates. Other than the observations, it is also essential to explore the importance of the different input parameters to an inversion, like variance parameters in R. We describe the process of performing this analysis within the context of the case study mentioned in Sect. 3, which discusses the relative importance of the input quantities in influencing , by utilizing local sensitivities.
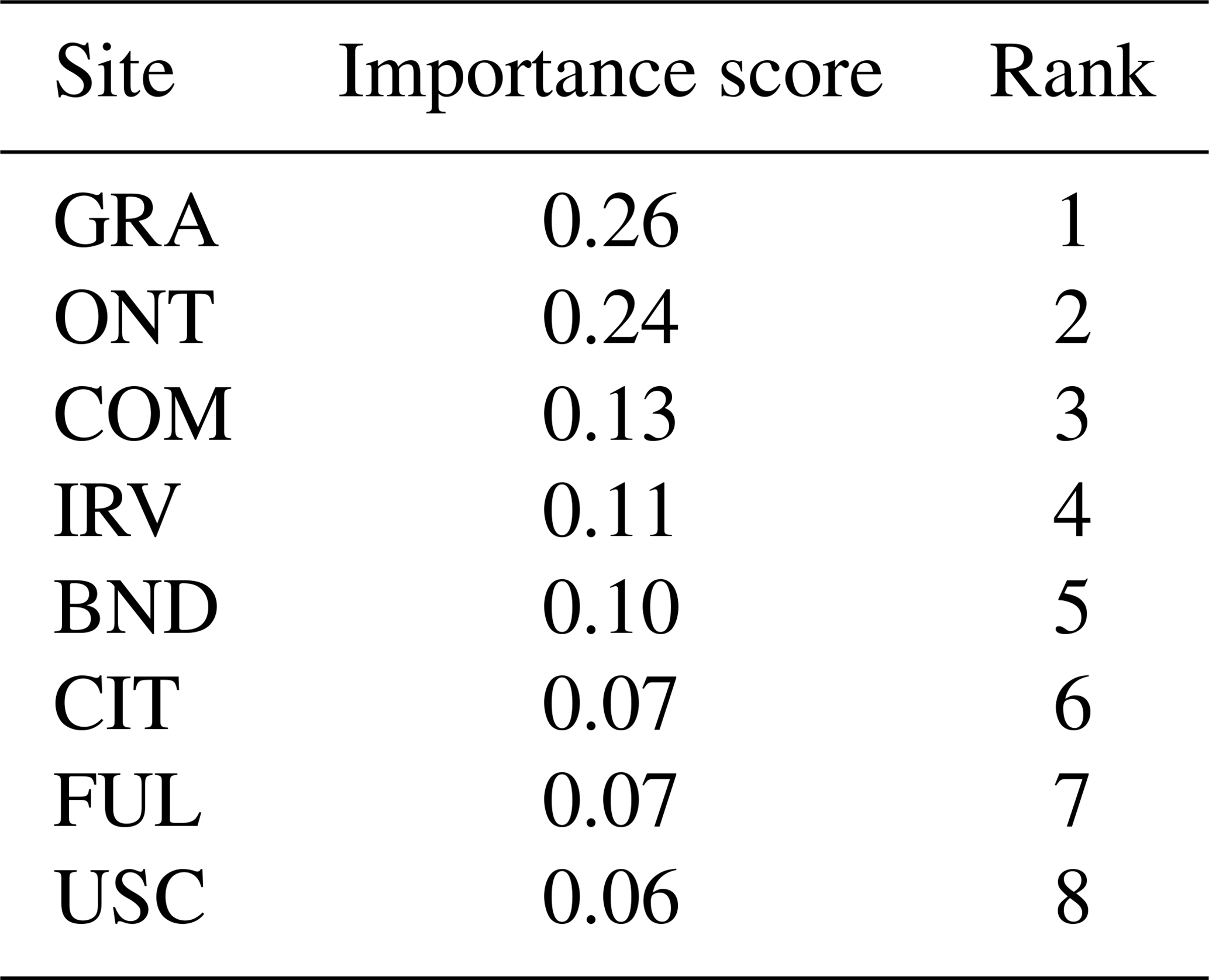
Table 1The importance scores and ranking of eight sites based on the sensitivity of the estimated fluxes () to observations (z).
3.2.1 Comparison and ranking of the observations
The importance of individual measurements in influencing , can be easily computed through the relative importance methodology described in Sect. 2.4. Although all entries of are in the same units of measurement, a direct ranking of the observations or sites without employing the relative importance technique can lead to misleading results, which happens due to the presence of large negative and positive values in that are governed by the overall spatiotemporal spread, the intensity of forward operators, and high enhancements.
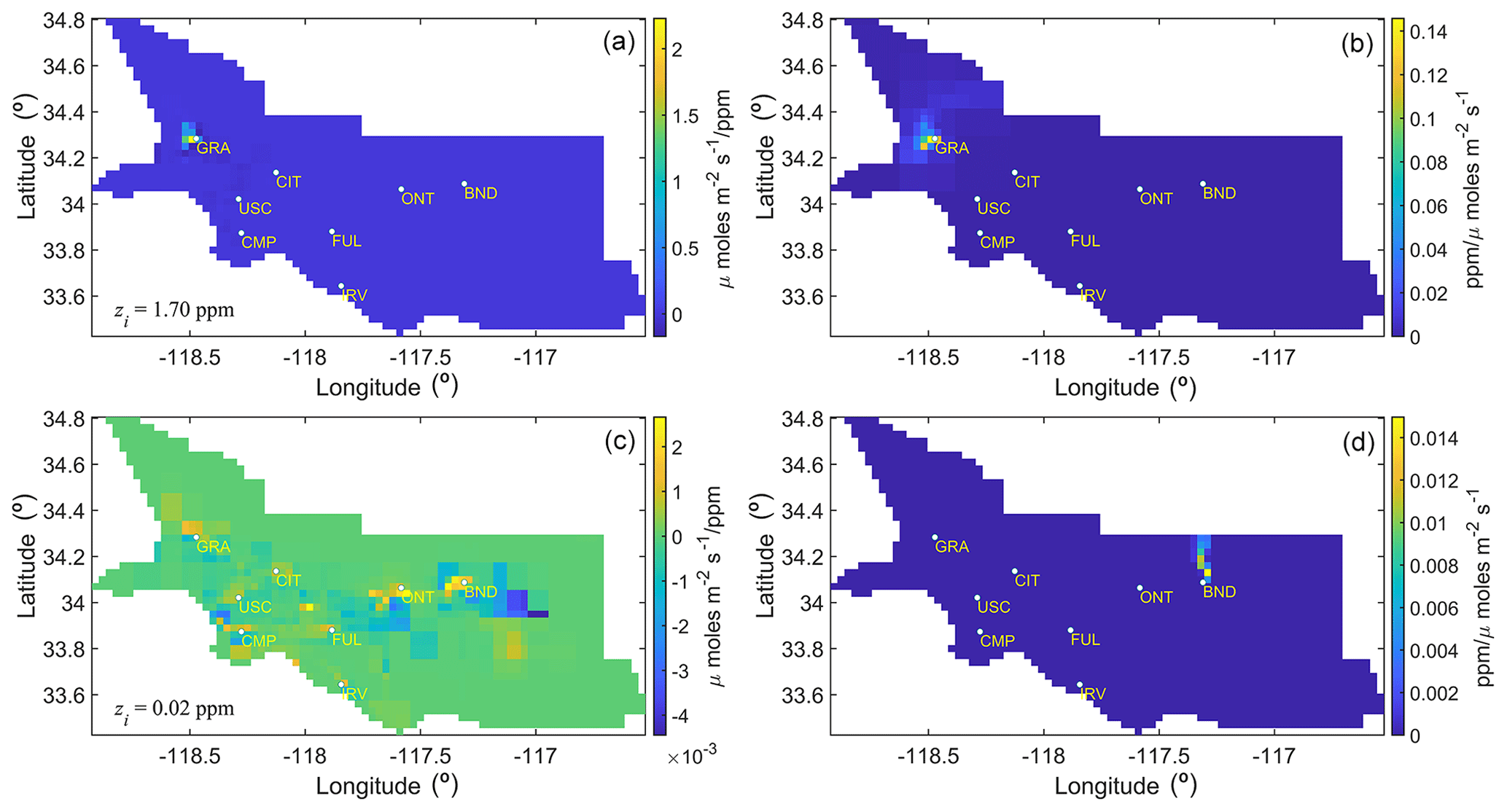
Figure 5The sensitivities and forward operators of the most and least important observations are shown here. Panels (a) and (c) depict the sensitivity of with respect to the most (a) and least (c) important observations, respectively, during the case study period. The CH4 enhancement corresponding to these observations is shown in the bottom-left corner of panels (a) and (c) and is denoted by the symbol zi. Panels (b) and (d) display the forward operators associated with the sensitivities shown in panels (a) and (c), respectively.
For the case study in this work, we find that the observations collected at the GRA site that is located nearest to the source of the Aliso Canyon gas leak are most influential in governing , as shown by site-based rankings in Table 1. These rankings primarily show the importance of the observations from a site for influencing the estimated fluxes for the period under consideration and are obtained by summing the weights for each observation by employing the relative importance methodology.
Outliers have a significant impact on these rankings. The high weight associated with even one observation from a site can make that site more important compared to other sites. For example, if we remove the observation with the highest weight from each site, ONT is the most important site, followed by GRA, CMP, IRV, CIT, FUL, BND, and USC. As part of the sensitivity analysis, examining the influence of the observations associated with high weights is crucial because they are likely to have an enormous impact on the flux estimates. Site-level importance should be judged not only by examining the aggregated ranking, as presented in Table 1, but also by looking at the distribution of weights shown through the box plot in the Live Script associated with Sect. 3.2. A site with evenly distributed weights is more important than one whose importance is just due to the presence of a few observations with high weights.
The ranking of each observation in influencing the estimates of fluxes can be obtained by examining the weights of the column vectors of and is provided in the Live Script. To exemplify, this ranking of weights showed that the observation from the GRA site with the enhancement of 1.7 ppm was most important, whereas an observation from the BND site with an enhancement of 0.02 ppm was found to be least important in influencing . Note this is not an observation with the lowest enhancement but with the least influence (Fig. 5).
3.2.2 Relative importance of and z
After the two-step normalization of , , , , , and , as described in Sect. 2.4, the spatial plots of all these grouped quantities that we call ,, , ,, and can be created to explore the regions of the low and high weights (see Fig. 6) at the grid scale.
Some of these quantities are correlated and should be seen in conjunction. For example, R describes the errors in z, among other errors, and implies that and should be evaluated together to understand their importance in the influence on flux estimates. Similarly, Q describes errors in s−Xβ, implying that and should be assessed together to understand their importance in the influence on flux estimates. A larger value of is likely to be found around in situ sites, due to the increased model resolution. However, if around these locations is larger in comparison to , then it suggests that errors in R should be adjusted, and therefore, observations should be more important in governing the flux estimates around in situ sites. In this case study, this is due to the large variability in the enhancement caused by the Aliso Canyon gas leak and the presence of large point sources near in situ sites. Overall, for the exact location, a larger should be accompanied by a lower , as confirmed by the correlation in Fig. 7a and b.
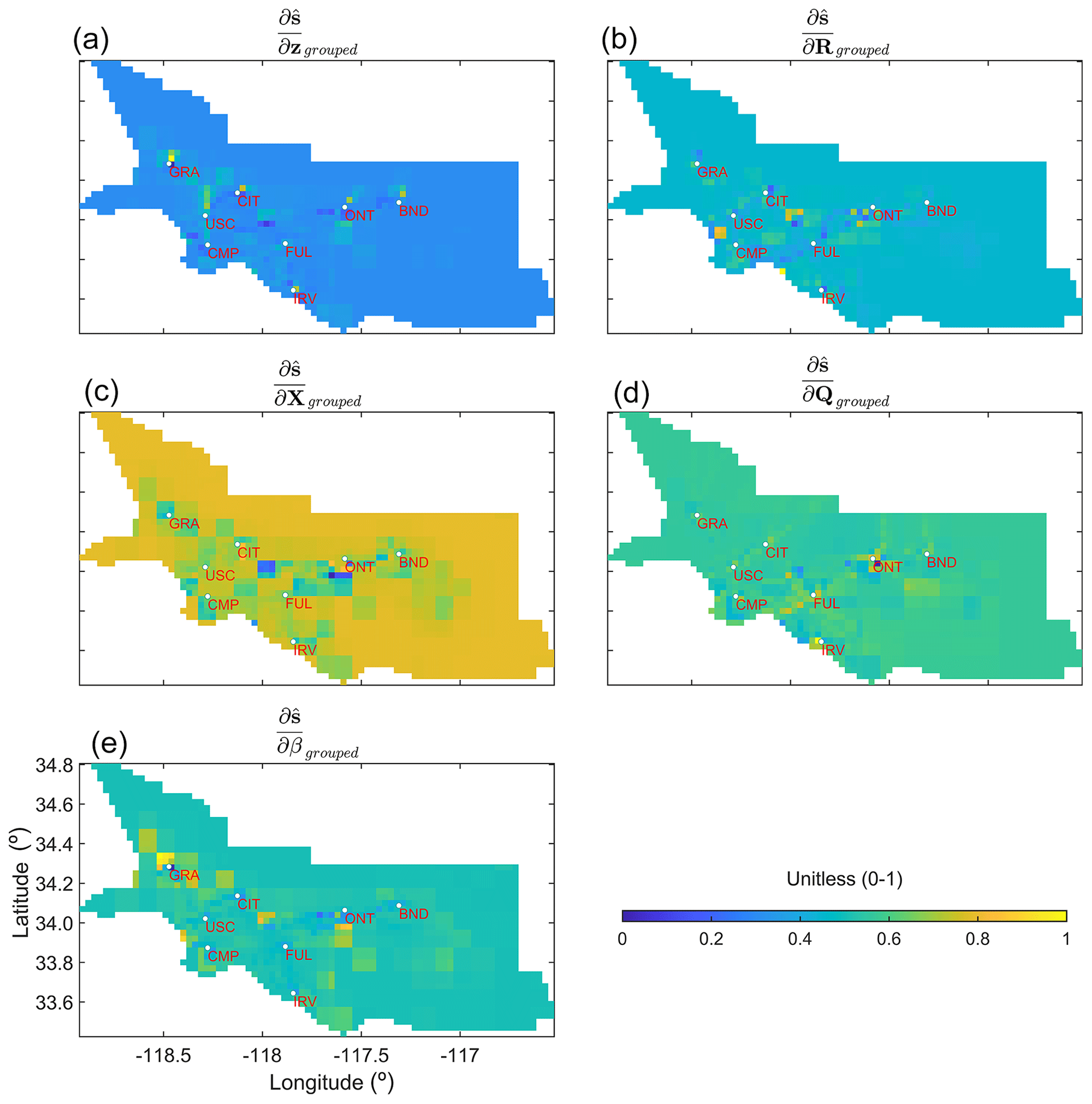
Figure 6Grouped local sensitivities of the estimated fluxes () with respect to z, R, X, Q, and β (from top left to bottom right, respectively). Note that, in the case of , , and , a two-step normalization is performed to generate the subplots associated with these quantities. Derivatives with respect to (1) observations in z, (2) parameters in R, and (3) entries in X are normalized between 0 and 1. Then, after aggregating these for every grid cell, another min–max normalization is performed to limit their ranges between 0 and 1. Only a single normalization is performed in the case of and , as they consist of only one parameter.
The increased model resolution also results in the lower importance of and around sites. However, the areas unconstrained by observations are likely to have larger , as seen in Fig. 6 for and quantities. If, in locations constrained by observations, is larger in comparison to , then X in these locations is incorrect and needs adjustment. Similarly, in the case of , a larger is generally accompanied by a lower , and vice versa, which is also visible in the correlation in Fig. 7c and d. The quantity provides information about the grid cells that are determining the value of , and in this case study, as expected, this is around the Aliso Canyon gas leak for which Xi is being adjusted due to the larger flux from that region. This can also be seen in Fig. 7e, where it is positively correlated with .
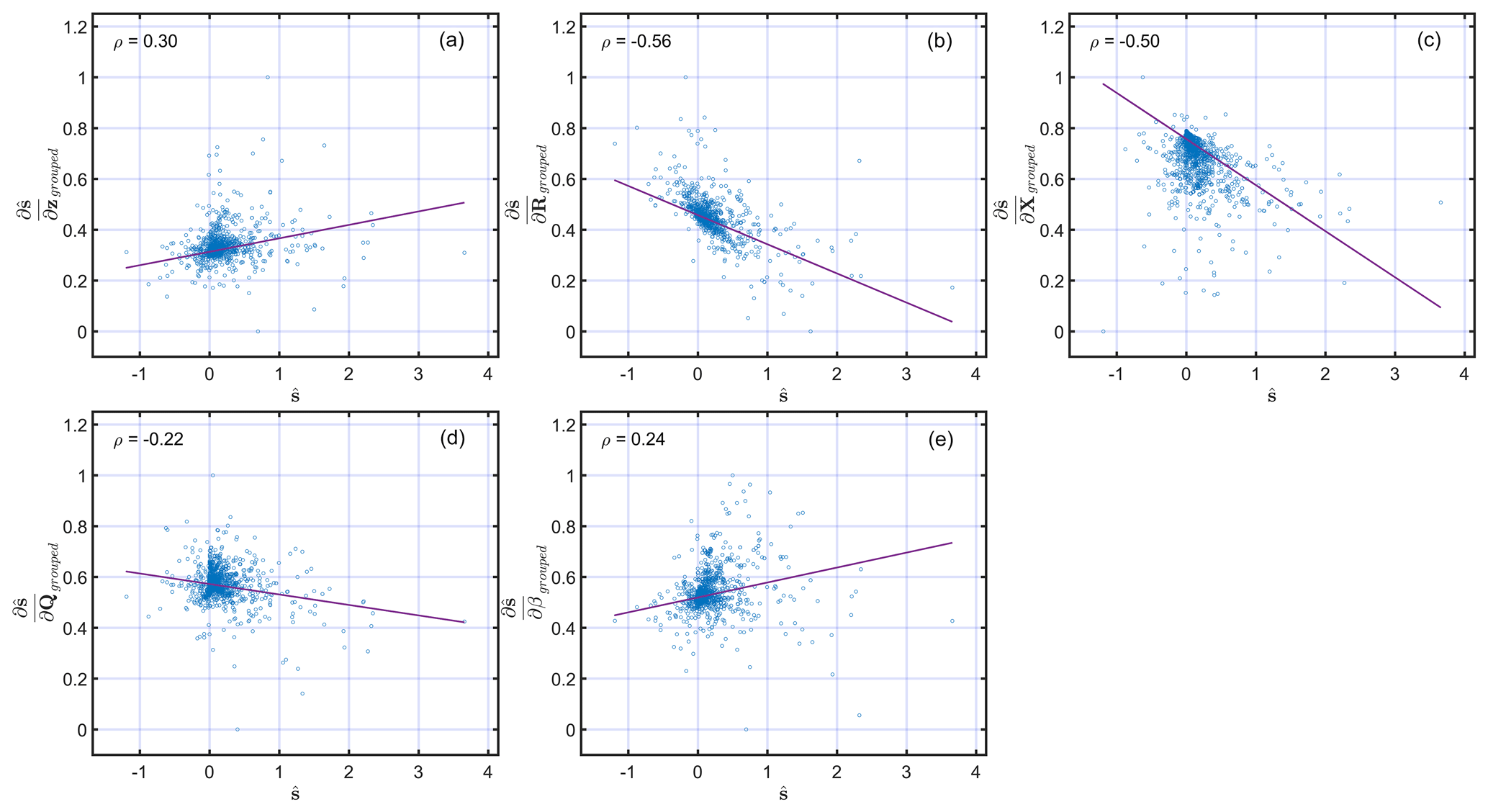
Figure 7Scatterplots of the relationships between and , , , , and . Note that, as in Fig. 6, all of the derivatives are normalized to limit their range to between 0 and 1. The correlation coefficient of the relationships shown in each scatterplot is reported in the top-left corner of the panels. The least square line of the best fit is shown with a solid red line in every panel.
This study lays out the techniques for assessing the quality of the inferred estimates of fluxes. A sensitivity analysis is an important diagnostic tool for understanding the impact of the choices made with respect to input parameters on the estimated fluxes. However, it is not a recipe for selecting the proper forms of X or the structure of Q or R before performing an inversion. Other tools or methods, such as the Bayesian information criterion and variance inflation factor, should be used to perform this task.
The case study in this work is designed only to demonstrate the methodologies described in Sect. 2. We do not impose nonnegativity constraints to obtain positive CH4 fluxes, as was done in the original 2019 study (Yadav et al., 2019). This is done because the posterior likelihood changes its functional form under nonnegativity constraints that invalidate the analytical forms of the sensitivity equations presented in this work. Thus, some CH4 fluxes obtained in this study have negative values, as can be seen in the map of in MATLAB's Live Script. Even in these situations, assessing sensitivity through an inversion without the imposition of nonnegativity is helpful, as it provides insights into the role of z, R, Q, and X in governing the estimates of nonnegative .
Like z, the importance of Q and R parameters can be directly obtained when all parameters have the same units of measurement, as in the case study presented in this study. However, this is not guaranteed, as R can be a function of the variance parameters and spatiotemporal correlation lengths expressed in the distance units in space and time. Furthermore, a nonstationary error covariance R can have parameters that have even more complicated units. This situation is not only limited to R but also applies to the prior error covariance, Q and X. Under these conditions, comparing the sensitivity matrices is only possible after normalization. Therefore, we recommend using a multiple linear-regression-based relative importance method to rank these quantities for comparative assessment.
The overall importance of is best explored by performing column-based normalization and then employing the relative importance method. Additionally, column-based normalization can be augmented by row-based normalization to assess and rank the influence of observations in governing grid-scale estimates of . Qualitatively, column- and row-based assessments increase our understanding of the spatiotemporal estimates of , which is especially important when point sources are the dominant sources of emissions. Moreover, it provides insight into the temporal aggregation error (e.g., Thompson et al., 2011), as the information encoded in an instantaneous measurement can become lost over the coarser inversion period. This aggregation error also manifests spatially and is determined by the resolution at which fluxes are obtained. In many situations, these aggregation errors are unavoidable, as the choice of the spatiotemporal resolution of the inversions is governed by the density of the observations in space and time.
Other than the aggregation error, the aggregation of the estimated fluxes also has profound implications, as it affects the robustness of the estimated fluxes. It can be proved (see Appendix C1) that the aggregation of in space and time from an inversion conducted at a finer resolution leads to a reduction in uncertainty. However, even though the ratio of the observations to the estimated fluxes increases, the number of fluxes uniquely resolved declines at a coarser resolution (see Appendix C2).
The computational cost for calculating the analytical partial derivatives is minimal, as it is a one-time operation and is bounded by the computational cost to perform matrix multiplications, which at max is O(n3). For the case study presented, we can compute the analytical derivatives and rank for approximately 4000 parameters in a few minutes on a laptop. Computing the derivatives by using the Kronecker form of the equations (Eqs. 18 and 21 through 24 and Eqs. 33 though 36) is faster for smaller problems. However, for large problems, the storage costs associated with these equations can become prohibitive. In these situations, we propose the use of the ij form of the equations (Eqs. 20 and 25 through 28 and Eqs. 29 though 32) for assessment. Furthermore, computational problems can also arise in ranking the input parameters if we have numerous derivatives (e.g., greater than 10 000), as the ranking method used in this work relies on the eigenvalue decomposition that has O(n3) computational complexity. To overcome this problem, we advise grouping the derivatives to reduce the dimension of the problem.
Finally, the estimation of STAD and the importance of sites can be influenced by data gaps; therefore, it is not advised in the presence of vast differences in the number of observations between sites.
Our work makes novel and significant contributions that can improve the understanding of linear atmospheric inverse problems. It provides (1) a framework for post hoc analysis of the impact of input parameters on the estimated fluxes and (2) a way to understand the correlations in the forward operators of an atmospheric transport model. The authors are unaware of any work in which the local sensitivities with different units of measurement are compared to rank the importance of input parameters in a linear atmospheric inverse model.
Concerning forward operators, we provide mathematical foundations for IAOMI and JSD-based metrics. These two metrics can be used to construct a nonstationary error covariance for the atmospheric transport component of the model data mismatch matrix R. Furthermore, IAOMI-based assessments can be extended to identify STAD from forward operators that can help to disaggregate the regions of influence for the observations over a chosen temporal duration. This helps us to understand the connection between the sources of flux and observations from a particular measurement location.
The IAOMI and JSD-based metrics provide essential insights into the two critical and only required components for an inversion, namely observations and forward operators (e.g., the influence of the observation on the sources of the fluxes through STAD), which can be accomplished before conducting an inversion and should be complemented by post hoc LSA, which is necessary for understanding the behavior of an inverse model. Overall, LSA can answer questions like in which locations and in what order of precedence an observation was important for the influence on the estimated fluxes. This kind of analysis is entirely different from estimating uncertainty, which tells us the prior uncertainty reduction due to observations.
LSA is not a replacement for statistical tests that check the inverse models' underlying assumptions and model specifications, nor is it a recipe for selecting input parameters to an inverse model. However, as explained above, it has an essential role that can lead to an improved understanding of an atmospheric inverse model.
Earlier, many methods have been proposed and utilized to perform sensitivity analysis. These can be categorized as global and local sensitivity analyses. Global sensitivity analysis (GSA) includes Morris's (e.g., Morris, 1991) one-step-at-a-time method (OAT), polynomial chaos expansion (PCE; e.g., Sudret, 2008), Fourier amplitude sensitivity test (FAST; e.g., Xu and Gertner, 2011), Sobol's method (e.g., Sobol, 2001), and derivative-based global sensitivity measures (DGSM; e.g., Sobol and Kucherenko, 2010), among others. These existing GSA methods (1) assume the independence of parameters (e.g., FAST and OAT), (2) are computationally expensive (e.g., Sobol's method), or (3) require knowledge of the joint probability distribution of the parameter space (e.g., DGSM and PCE). Therefore, these traditional methods cannot be directly applied to linear atmospheric inverse problems, which consist of tens of thousands of nonnormal, spatiotemporally correlated parameters (including observations). Constantine and Diaz (2017) proposed an active subspace-based GSA that uses a low-dimensional approximation of the parameter space. But it is still computationally expensive for problems with thousands of parameters (see the case study in Constantine and Diaz, 2017).
Compared to GSA, a local sensitivity method, such as Bayesian hyper-differential sensitivity analysis (HDSA; Sunseri et al., 2020), computes the partial derivatives regarding the maximum a posteriori probability (MAP) estimates of a quantity of interest. However, unlike Bayesian HDSA, we do not generate samples from the prior estimate to compute multiple MAP points, since we have limited knowledge of the prior distribution of the spatiotemporally correlated parameters. We derive the functional form of the local sensitivity equations based on the closed-form MAP solution. Our method is simple and amenable to tens of thousands of parameters. Note that, like all linear atmospheric inverse problems, one of the critical goals of this work is to study the importance of thousands of spatiotemporally varying parameters by ranking them, and the computation of the local sensitivities is a means to achieve that goal.
The dissimilarity between forward operators can also be measured via entropy-based distances (for a definition, see MacKay, 2003), which can capture differences between two probability distributions. One such metric is the Jensen–Shannon distance (JSD; Nielsen, 2019), which can be used to compute the distance between two forward operators after normalizing them by their total sum. For a forward operator F, this can be given as
where Fk denotes kth entry of F, resulting in the normalized forward operator P. We can then use JSD to compute the distance between two normalized forward operators from Eq. (B2) as follows:
where D stands for the Kullback–Leibler (KL) divergence (see MacKay, 2003, for details). The KL divergence D of any probability distribution p, with respect to another probability distribution q, is defined as , and M stands for . The symbol || is used to indicate that D(PF||M) and D(PG||M) are not conditional entropies (see MacKay, 2003). JSD is closed and bounded in [0,1] when the KL divergence is calculated with the base 2 logarithms. Intuitively, JSD and 1−ν (i.e., 1− IAOMI) are comparable, since both of them are measures of dissimilarity.
Here we show the proofs of two mathematical statements on the robustness and quality of the estimated fluxes, as mentioned in Sect. 4. First, we show why the marginal variance of the estimated fluxes (which is the diagonal of the covariance matrix of ) decreases when the estimated fluxes are post-aggregated to a coarser scale or upscaled (Appendix C1). Second, we show why, in such cases, the model resolution (termed the total information resolved by the observations) also decreases (Appendix C2). Note that the nomenclature used in the Appendix C should not be confused with the nomenclature introduced in Sect. 2. The abbreviations and symbols used here are independent of what is used in Sect. 2.
C1 Proof of the reduction in the marginal variance of when aggregation is performed
The post-inversion aggregation or upscaling of any flux field s is equivalent to the pre-multiplication by a weight matrix (in fact, a row stochastic matrix). This can be written as follows:
where J is a row stochastic (i.e., row sums are all unity) k×m weight matrix (k<m). The variance of can be written as JΣJt, where var. The general structure of J is as follows:
However, J is mostly sparse, with nonzero values in only a few places. The rest of the entries are zeros. Essentially, J can have any number of nonzero entries in a row that may or may not be consecutive. This is because, although adjacent grids are averaged on a map, they may not be adjacent upon vectorization. Moreover, the geometry of the map may not be exactly square or rectangular. Therefore, depending on the aggregation or upscaling factor and geometry, there may or may not be any neighboring grid for averaging around a particular grid. However, the rows are linearly independent, as nearby grids are considered only once for averaging. The properties of J are as follows:
-
J1=1 or
-
for i≠r.
We can rearrange the columns of J and the rows of Σ accordingly without the loss of any structure, such that nonzero entries are consecutive for each row of J. The matrix JΣJ′ under the column permutation can be written as follows:
where Jπ and Σπ are the permuted J and Σ, respectively. However, for notational clarity, we use l and Ξ as the sub-vector and sub-block matrix of the Jπ and Σπ, respectively. Note that any is a row vector with the dimension of (1,di), and Ξii is a square matrix with the dimension of (di,di), where . Thus, the diagonal entry is a scalar quantity. For any ith diagonal entry, the corresponding scalar quantity can be written as ∑jrllijlirΞjr. Through symmetry of Ξ, this reduces to the following:
Using the Cauchy–Schwarz inequality on Ξjr, this can be written as
This implies (by property 1 of the weight matrix J) that the ith diagonal entry is bounded by the following:
where is the sum of the marginal variance of the ith block of the non-averaged . Thus, the sum of the marginal variance of , which is the sum of the i diagonal , is also smaller than or equal to the sum total of marginal variance of . This implies that the marginal variance of the posterior mean decreases as a result of the diagonal of the variance matrix shrinking in magnitude upon averaging.
C2 Proof of the reduction in model resolution when aggregation is performed
The aggregated forward operator can be written as follows:
where B is the upscaling matrix. The dimension of B has the dimension of the transpose of J. The structural form of B is similar to the form of J explained in Eq. (C2). Nonzero entries of B are in the same place as J′, with the magnitude replaced by unity. This is evident from the fact that the forward operator is summed instead of being averaged for aggregation. The properties of B are as follows:
-
B1=1.
-
, where N is the vector of the number of neighboring grid cells for any particular grid cell, i.e., .
-
is a block diagonal matrix. Any block Ci of JA can be expressed as a varying dimension (depending on the number of neighboring grids of any particular grid cell) matrix of the following form: -
BJ is symmetric and positive semi-definite.
The first three properties are simple observations from the construction. So, here we provide proof of the fourth property.
Proof. By construction, . So, eigenvalues of BJ are the list of the eigenvalues of the block matrices. It can be proved that 1 and 0 are the only two distinct eigenvalues of Ci for any i. Below is a brief argument on that topic, where implies that one eigenvalue of Ci is 1. Observe that . Hence, the dimension of the null space . This implies that the other eigenvalue of Ci is 0, with multiplicity of k−1.
So, not only is Ci symmetric but also the eigenvalues of Ci are always nonnegative. Consequently, all eigenvalues of BJ are of a similar form i.e., BJ is a symmetric positive semi-definite.
Finally, the model resolution matrix for the inversion can be written as , where H is the forward operator. The post-inversion aggregated model resolution can be written as
The question is then as follows: what happens to the trace of the model resolution under the aggregated scenario? We provide proof for the simple batch Bayesian case in Lemma 1. The proof for the geostatistical case is similar and is left to the enthusiastic reader.
Lemma 1.
Proof. The model resolution for the aggregated scenario can be written as follows:
where S and W are both of the dimension of (m×m). S is a positive semi-definite matrix, since both Q and are positive semi-definite. For the Wm×m and Sm×m positive semi-definite, the trace of their product can be bounded by the following quantities (see Kleinman and Athans, 1968, and the discussion in Fang et al., 1994):
From property 4 of the weight matrix B, we know that and ; hence, the above reduces to . Therefore, the proof by Eq. (C14) can be seen.
All of the code and data utilized in this study are available in the Supplement.
The supplement related to this article is available online at: https://doi.org/10.5194/gmd-16-5219-2023-supplement.
VY and SG contributed equally to the conceptualization, methodology, formal analyses, preparation, review, and editing of the paper. CM funded the work.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors thank Anna Karion, Kimberly Mueller, James Whetstone (National Institute of Standards and technology, NIST), and Daniel Cusworth (University of Arizona, UA) for their review and advice on the paper.
This work has been partially funded by NIST's Greenhouse Gas Measurements Program, support to the University of Notre Dame has been provided by NIST (grant no. 70NANB19H132), and support for the Jet Propulsion Laboratory (JPL) has been provided via an interagency agreement between NIST and NASA. A portion of this research has been carried out at the JPL, California Institute of Technology, under a contract with NASA (contract no. 80NM0018D0004).
This paper was edited by Leena Järvi and reviewed by Peter Rayner, Bharat Rastogi, and two anonymous referees.
Berk, R., Brown, L., Buja, A., Zhang, K., and Zhao, L.: Valid post-selection inference, Ann. Stat., 41, 802–837, 2013. a
Bouchard, M., Jousselme, A.-L., and Doré, P.-E.: A proof for the positive definiteness of the Jaccard index matrix, Int. J. Approx. Reason., 54, 615–626, 2013. a
Brasseur, G. P. and Jacob, D. J.: Modeling of atmospheric chemistry, Cambridge University Press, https://doi.org/10.1017/9781316544754, 2017. a, b, c
Cha, S.-H.: Comprehensive survey on distance/similarity measures between probability density functions, City, 1, p. 1, 2007. a
Conley, S., Franco, G., Faloona, I., Blake, D. R., Peischl, J., and Ryerson, T.: Methane emissions from the 2015 Aliso Canyon blowout in Los Angeles, CA, Science, 351, 1317–1320, 2016. a
Constantine, P. G. and Diaz, P.: Global sensitivity metrics from active subspaces, Reliab. Eng. Syst. Safe., 162, 1–13, 2017. a, b
Enting, I. G.: Inverse problems in atmospheric constituent transport, Cambridge University Press, https://doi.org/10.1017/CBO9780511535741, 2002. a, b, c
Fang, Y., Loparo, K. A., and Feng, X.: Inequalities for the trace of matrix product, IEEE T. Automat. Contr., 39, 2489–2490, 1994. a
Gelman, A. and Hill, J.: Data analysis using regression and multilevel/hierarchical models, Cambridge University Press, https://doi.org/10.1017/CBO9780511790942, 2006. a
Ghosh, S., Mueller, K., Prasad, K., and Whetstone, J.: Accounting for transport error in inversions: An urban synthetic data experiment, Earth and Space Science, 8, e2020EA001272, https://doi.org/10.1029/2020EA001272, 2021. a
Groen, E. A., Bokkers, E. A., Heijungs, R., and de Boer, I. J.: Methods for global sensitivity analysis in life cycle assessment, Int. J. Life Cycle Ass., 22, 1125–1137, 2017. a
Gurney, K. R., Law, R. M., Denning, A. S., Rayner, P. J., Baker, D., Bousquet, P., Bruhwiler, L., Chen, Y.-H., Ciais, P., Fan, S., Fung, I. Y., Gloor, M., Heimann, M., Higuchi, K., John, J., Kowalczyk, E., Maki, T., Maksyutov, S., Peylin, P., Prather, M., Pak, B. C., Sarmiento, J., Taguchi, S., Takahashi, T., and Yuen, C.-W.: TransCom 3 CO2 inversion intercomparison: 1. Annual mean control results and sensitivity to transport and prior flux information, Tellus B, 55, 555–579, 2003. a
Hamby, D. M.: A review of techniques for parameter sensitivity analysis of environmental models, Environ. Monit. Assess., 32, 135–154, 1994. a
Hastie, T., Tibshirani, R., and Wainwright, M.: Statistical learning with sparsity, CRC press, https://doi.org/10.1201/b18401, 2015. a
Heijungs, R.: Identification of key issues for further investigation in improving the reliability of life-cycle assessments, J. Clean. Prod., 4, 159–166, 1996. a
Johnson, J. W.: A heuristic method for estimating the relative weight of predictor variables in multiple regression, Multivar. Behav. Res., 35, 1–19, 2000. a
Kitanidis, P. K.: On the geostatistical approach to the inverse problem, Adv. Water Resour., 19, 333–342, 1996. a, b
Kleinman, D. and Athans, M.: The design of suboptimal linear time-varying systems, IEEE T. Automat. Contr., 13, 150–159, 1968. a
Lauvaux, T., Miles, N. L., Deng, A., Richardson, S. J., Cambaliza, M. O., Davis, K. J., Gaudet, B., Gurney, K. R., Huang, J., O'Keefe, D., Song, Y., Karion, A., Oda, T., Patarasuk, R., Razlivanov, I., Sarmiento, D., Shepson, P., Sweeney, C., Turnbull, J., and Wu, K.: High-resolution atmospheric inversion of urban CO2 emissions during the dormant season of the Indianapolis Flux Experiment (INFLUX), J. Geophys. Res.-Atmos., 121, 5213–5236, 2016. a
Lin, J., Gerbig, C., Wofsy, S., Andrews, A., Daube, B., Davis, K., and Grainger, C.: A near-field tool for simulating the upstream influence of atmospheric observations: The Stochastic Time-Inverted Lagrangian Transport (STILT) model, J. Geophys. Res., 108, 4493, https://doi.org/10.1029/2002JD003161, 2003. a
MacKay, D. J. C.: Information theory, inference and learning algorithms, Cambridge University Press, ISBN 9780521642989, 2003. a, b, c
Michalak, A. M., Randazzo, N. A., and Chevallier, F.: Diagnostic methods for atmospheric inversions of long-lived greenhouse gases, Atmos. Chem. Phys., 17, 7405–7421, https://doi.org/10.5194/acp-17-7405-2017, 2017. a
Morris, M. D.: Factorial sampling plans for preliminary computational experiments, Technometrics, 33, 161–174, 1991. a
Nielsen, F.: On the Jensen–Shannon symmetrization of distances relying on abstract means, Entropy, 21, 485, https://doi.org/10.3390/e21050485, 2019. a
Rabitz, H.: Systems analysis at the molecular scale, Science, 246, 221–226, 1989. a
Rödenbeck, C., Houweling, S., Gloor, M., and Heimann, M.: Time-dependent atmospheric CO2 inversions based on interannually varying tracer transport, Tellus B, 55, 488–497, 2003. a
Rödenbeck, C., Conway, T. J., and Langenfelds, R. L.: The effect of systematic measurement errors on atmospheric CO2 inversions: a quantitative assessment, Atmos. Chem. Phys., 6, 149–161, https://doi.org/10.5194/acp-6-149-2006, 2006. a
Rodgers, C. D.: Inverse methods for atmospheric sounding: theory and practice, Vol. 2, World Scientific, https://doi.org/10.1142/3171, 2000. a, b, c
Sakia, R. M.: The Box-Cox transformation technique: a review, J. Roy. Stat. Soc.-D, 41, 169–178, 1992. a
Saltelli, A., Ratto, M., Andres, T., Campolongo, F., Cariboni, J., Gatelli, D., Saisana, M., and Tarantola, S.: Global sensitivity analysis: the primer, John Wiley & Sons, https://doi.org/10.1002/9780470725184.fmatter, 2008. a
Sobol, I. and Kucherenko, S.: Derivative based global sensitivity measures, Procd. Soc. Behv., 2, 7745–7746, 2010. a
Sobol, I. M.: Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates, Math. Comput. Simul., 55, 271–280, 2001. a
Sudret, B.: Global sensitivity analysis using polynomial chaos expansions, Reliab. Eng. Syst. Safe., 93, 964–979, 2008. a
Sunseri, I., Hart, J., van Bloemen Waanders, B., and Alexanderian, A.: Hyper-differential sensitivity analysis for inverse problems constrained by partial differential equations, Inverse Probl., 36, 125001, https://doi.org/10.1088/1361-6420/abaf63, 2020. a
Tarantola, A.: Inverse problem theory and methods for model parameter estimation, SIAM, https://doi.org/10.1137/1.9780898717921, 2005. a, b
Thompson, R. L., Gerbig, C., and Rödenbeck, C.: A Bayesian inversion estimate of N2O emissions for western and central Europe and the assessment of aggregation errors, Atmos. Chem. Phys., 11, 3443–3458, https://doi.org/10.5194/acp-11-3443-2011, 2011. a
Turányi, T.: Sensitivity analysis of complex kinetic systems. Tools and applications, J. Math. Chem., 5, 203–248, 1990. a
Vafaei, N., Ribeiro, R. A., and Camarinha-Matos, L. M.: Selecting normalization techniques for the analytical hierarchy process, in: Doctoral Conference on Computing, Electrical and Industrial Systems, Springer, 43–52, https://doi.org/10.1007/978-3-030-45124-0_4, 2020. a
Wikle, C. K. and Berliner, L. M.: A Bayesian tutorial for data assimilation, Physica D, 230, 1–16, 2007. a
Xu, C. and Gertner, G.: Understanding and comparisons of different sampling approaches for the Fourier Amplitudes Sensitivity Test (FAST), Comput. Stat. Data An., 55, 184–198, 2011. a
Yadav, V., Duren, R., Mueller, K., Verhulst, K. R., Nehrkorn, T., Kim, J., Weiss, R. F., Keeling, R., Sander, S., Fischer, M. L., Newman, S., Falk, M., Kuwayama, T., Hopkins, F., Rafiq, T., Whetstone, J., and Miller, C.: Spatio-temporally resolved methane fluxes from the Los Angeles Megacity, J. Geophys. Res.-Atmos., 124, 5131–5148, 2019. a, b, c, d, e
- Abstract
- Copyright statement
- Introduction
- Methods and derivation
- Results
- Discussion
- Conclusions
- Appendix A: Review of previously employed methods to conduct sensitivity analyses
- Appendix B: Jensen–Shannon distance (JSD) for forward operators
- Appendix C: Uncertainty and model resolution under aggregation
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Copyright statement
- Introduction
- Methods and derivation
- Results
- Discussion
- Conclusions
- Appendix A: Review of previously employed methods to conduct sensitivity analyses
- Appendix B: Jensen–Shannon distance (JSD) for forward operators
- Appendix C: Uncertainty and model resolution under aggregation
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement