| 20 Feb 2023
| 20 Feb 2023
The impact of altering emission data precision on compression efficiency and accuracy of simulations of the community multiscale air quality model
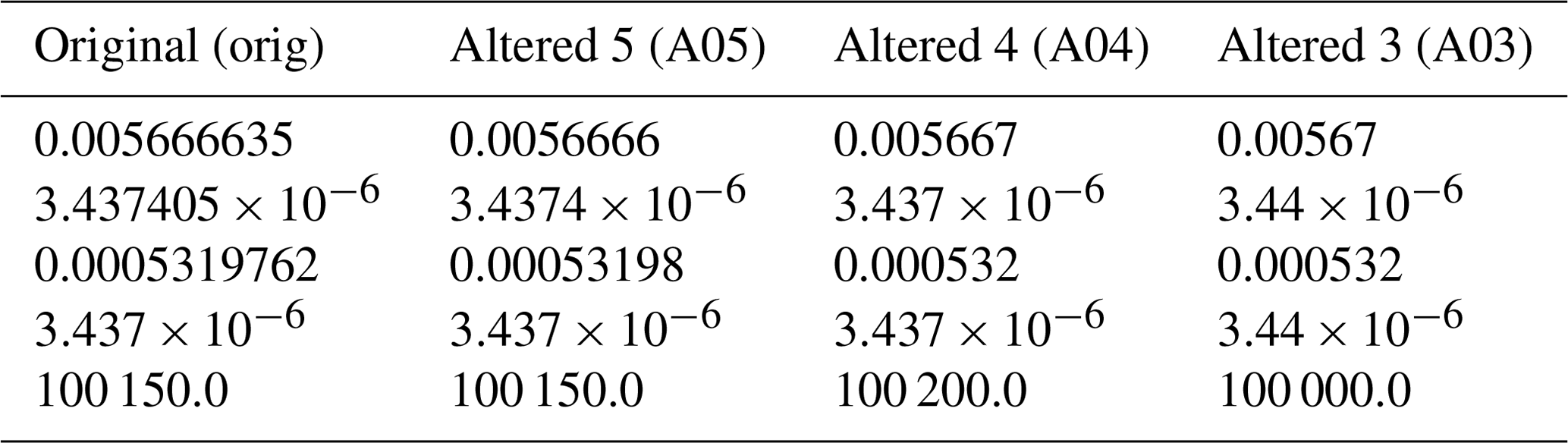
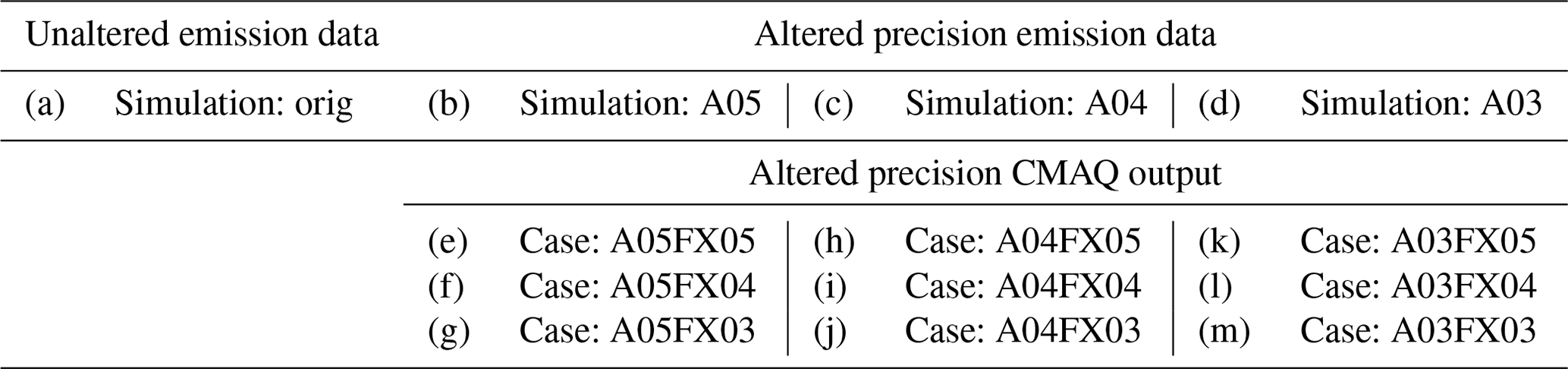
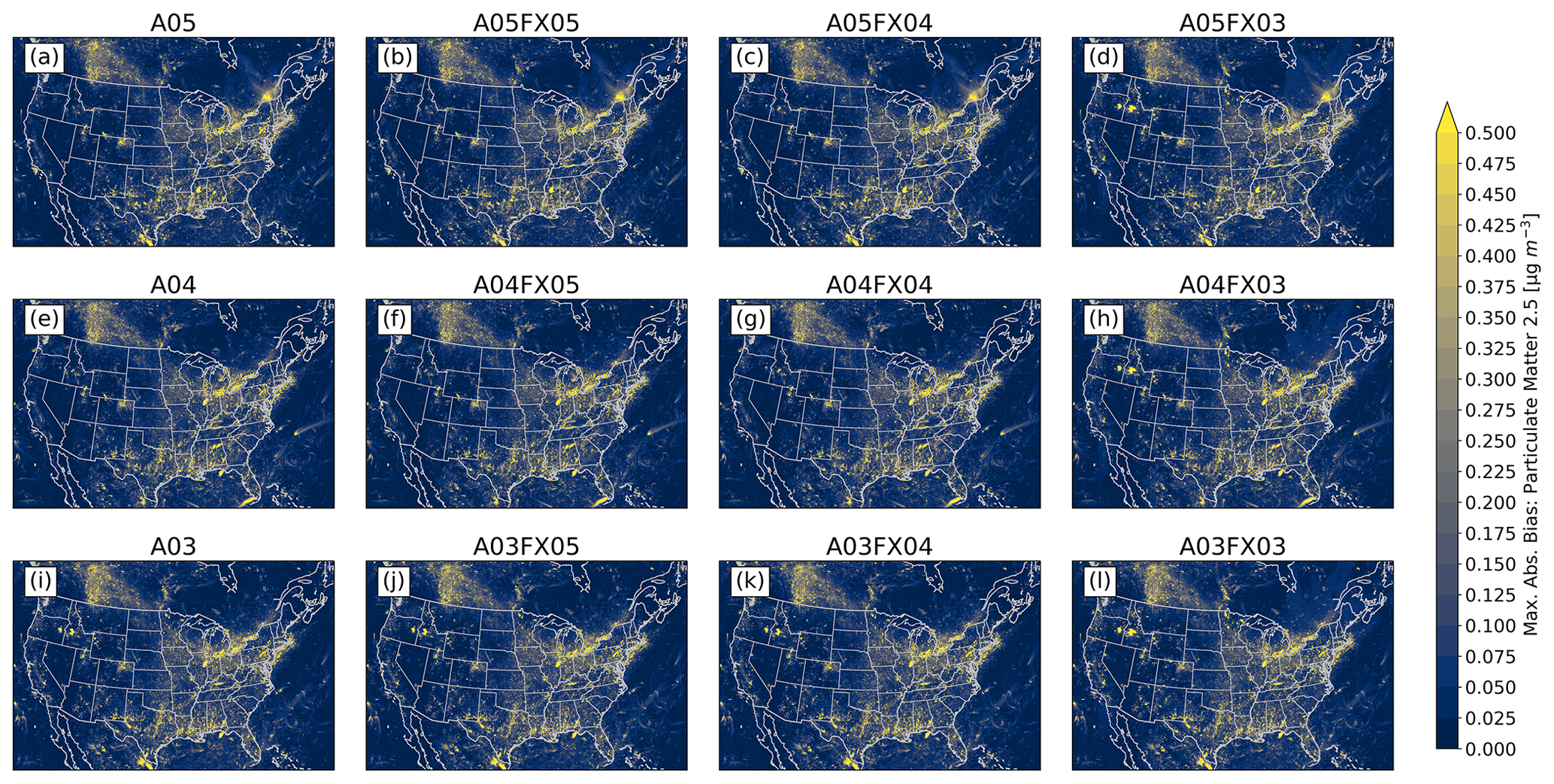
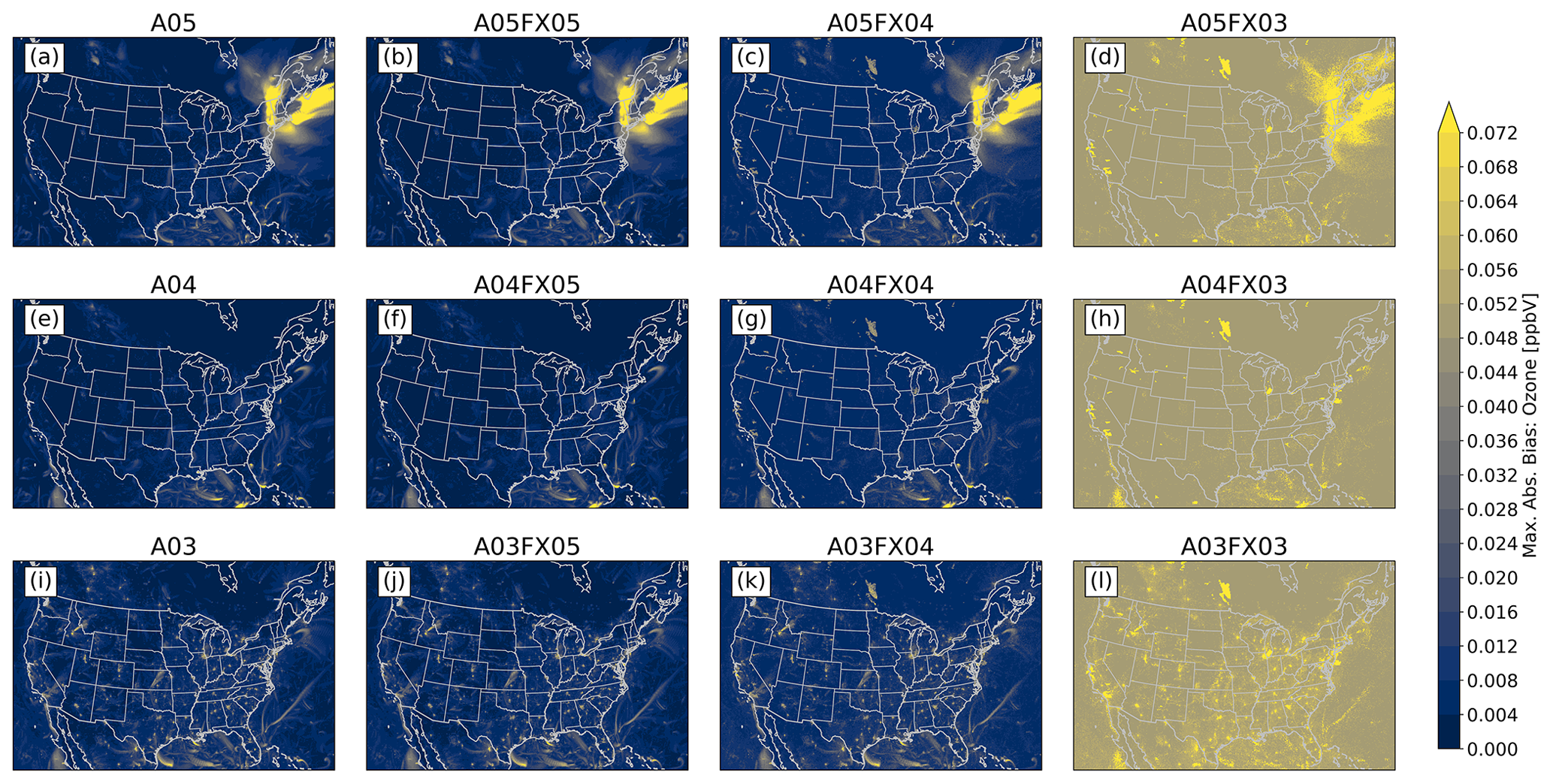
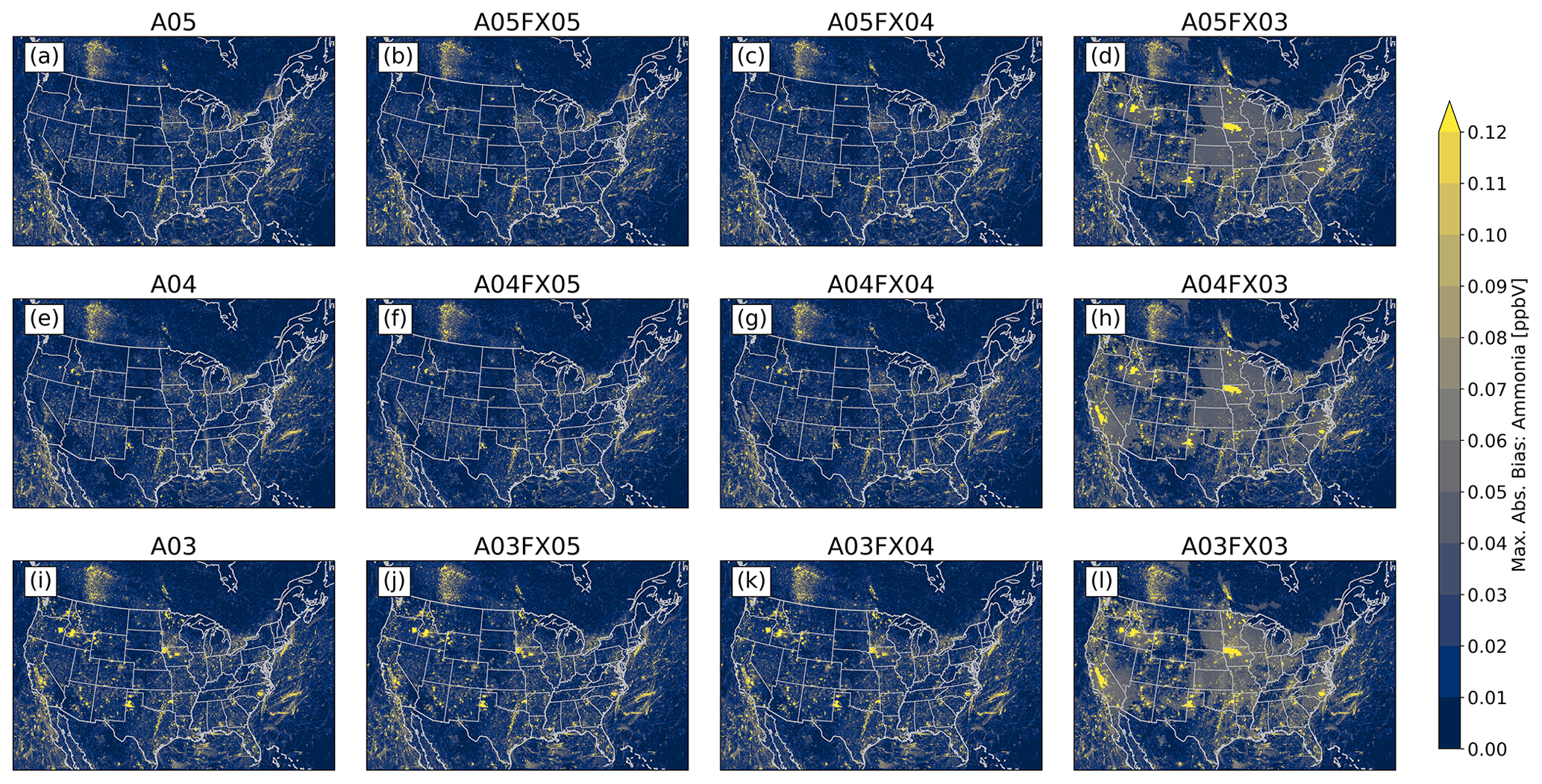
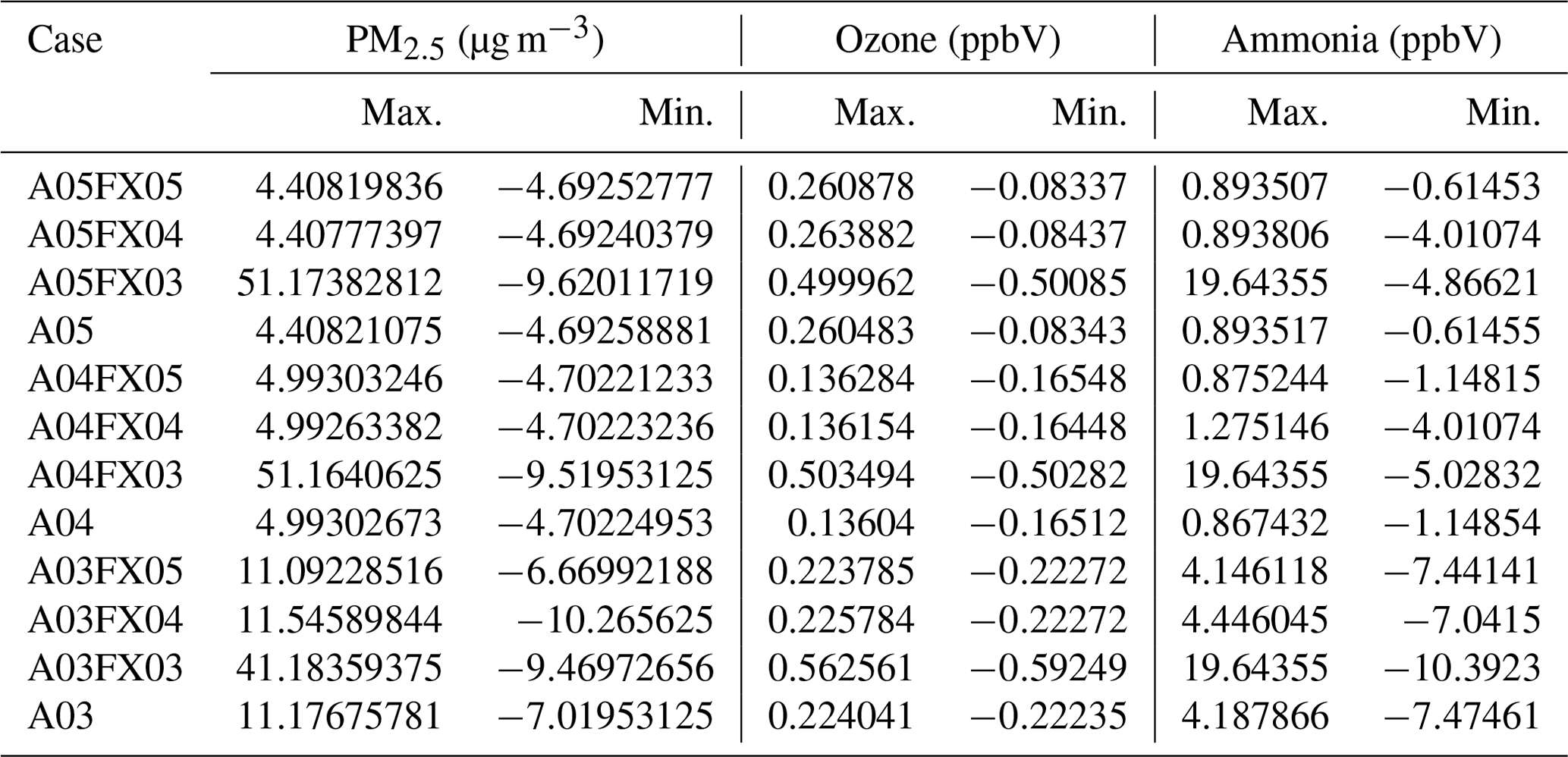
The Community Multiscale Air Quality (CMAQ) model has been a vital tool for air quality research and management at the United States Environmental Protection Agency (US EPA) and at government environmental agencies and academic institutions worldwide. The CMAQ model requires a significant amount of disk space to store and archive input and output files. For example, an annual simulation over the contiguous United States (CONUS) with horizontal grid-cell spacing of 12 km requires 2–3 TB of input data and can produce anywhere from 7–45 TB of output data, depending on modeling configuration and desired post-processing of the output (e.g., for evaluations or graphics). After a simulation is complete, model data are archived for several years, or even decades, to ensure the replicability of conducted research. As a result, careful disk space management is essential to optimize resources and ensure the uninterrupted progress of ongoing research and applications requiring large-scale, air quality modeling. Proper disk-space management may include applying optimal data-compression techniques that are executed on input and output files for all CMAQ simulations. There are several (not limited to) such utilities that compress files using lossless compression, such as GNU Gzip (gzip) and Basic Leucine Zipper Domain (bzip2). A new approach is proposed in this study that reduces the precision of the emission input for air quality modeling to reduce storage requirements (after a lossless compression utility is applied) and accelerate runtime. The new approach is tested using CMAQ simulations and post-processed CMAQ output to examine the impact on the performance of the air quality model. In total, four simulations were conducted, and nine cases were post-processed from direct simulation output to determine disk-space efficiency, runtime efficiency, and model (predictive) accuracy. Three simulations were run with emission input containing only five, four, or three significant digits. To enhance the analysis of disk-space efficiency, the output from the altered precision emission CMAQ simulations were additionally post-processed to contain five, four, or three significant digits. The fourth, and final, simulation was run using the full precision emission files with no alteration. Thus, in total, 13 gridded products (4 simulations and 9 altered precision output cases) were analyzed in this study.
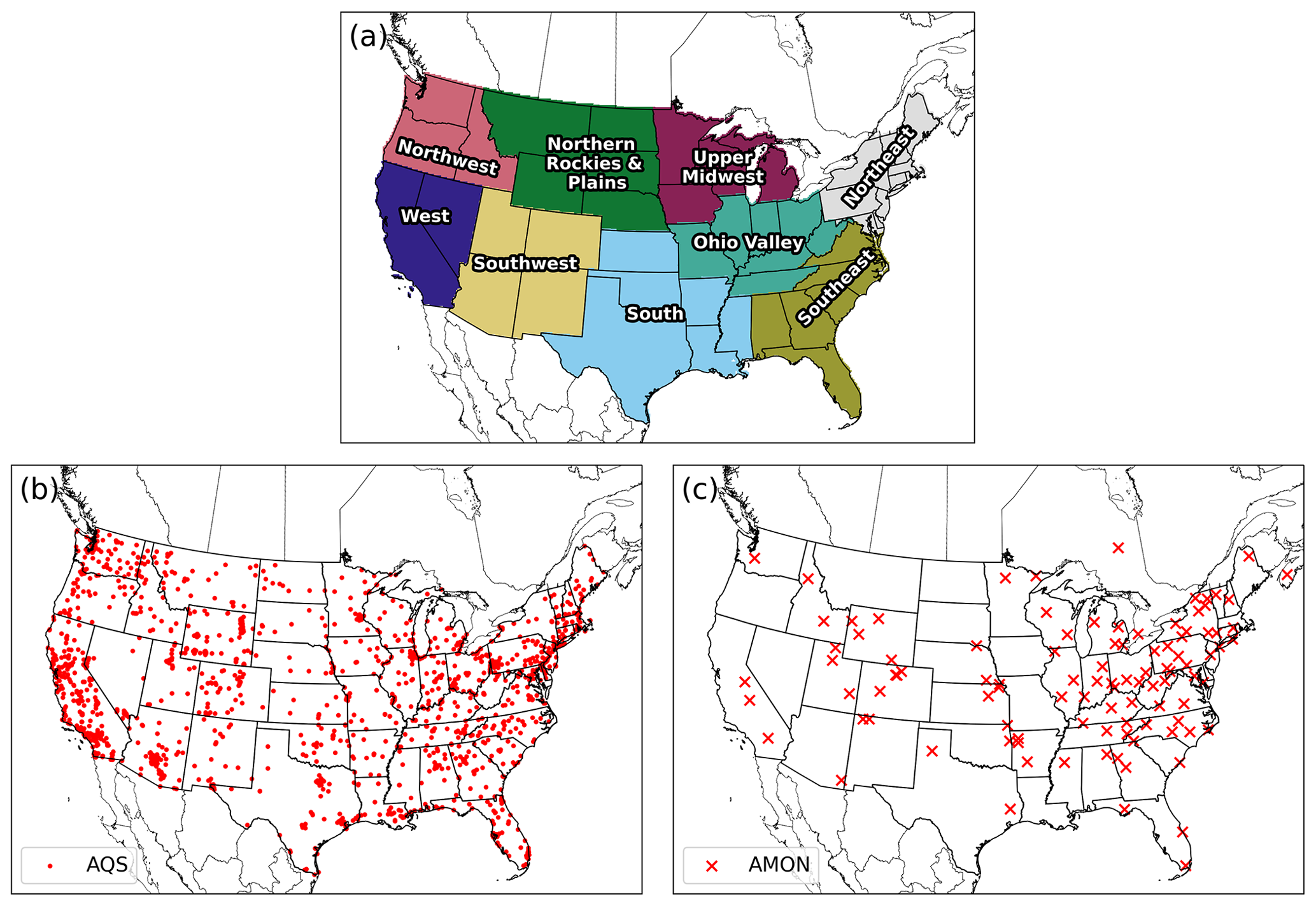
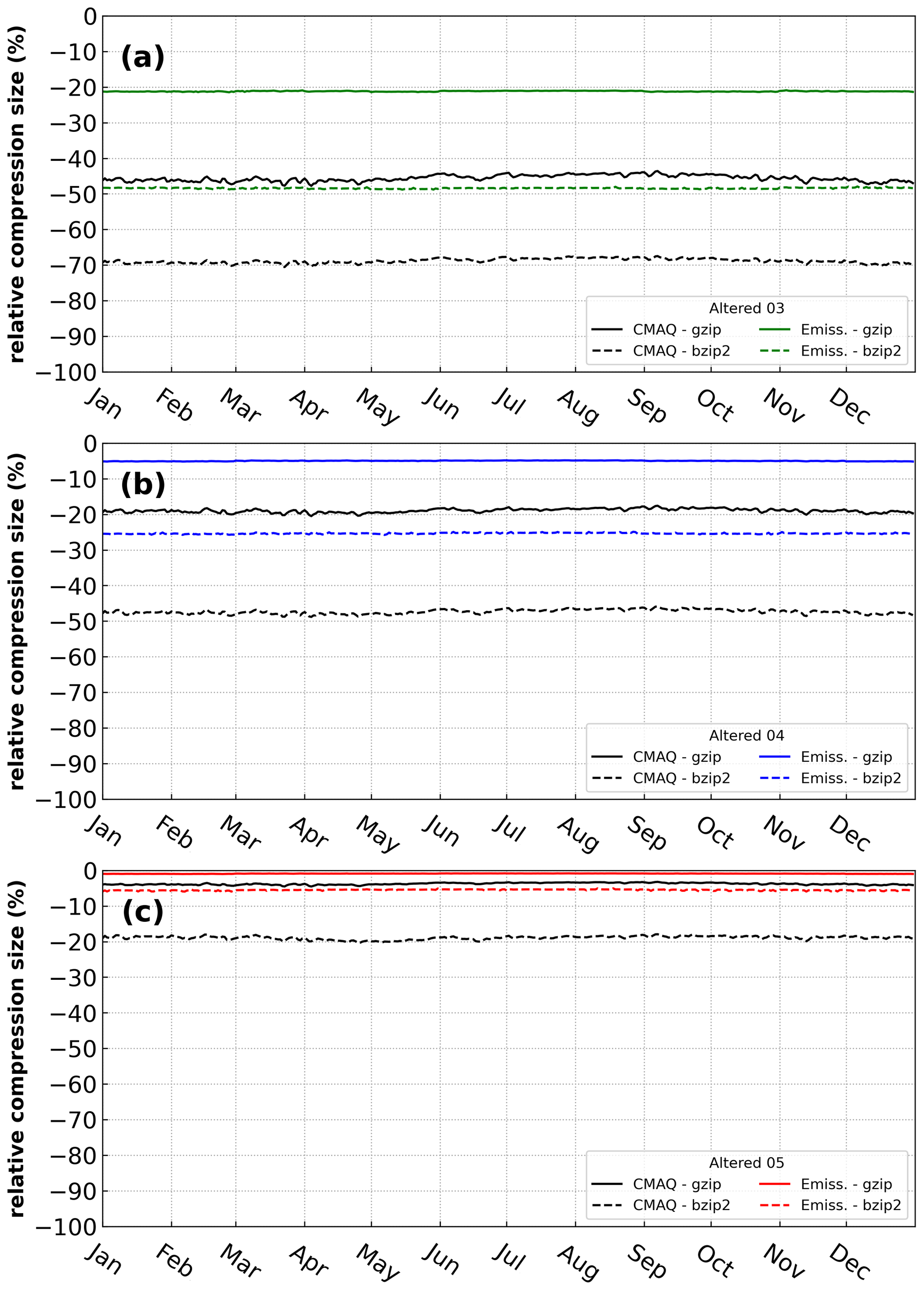
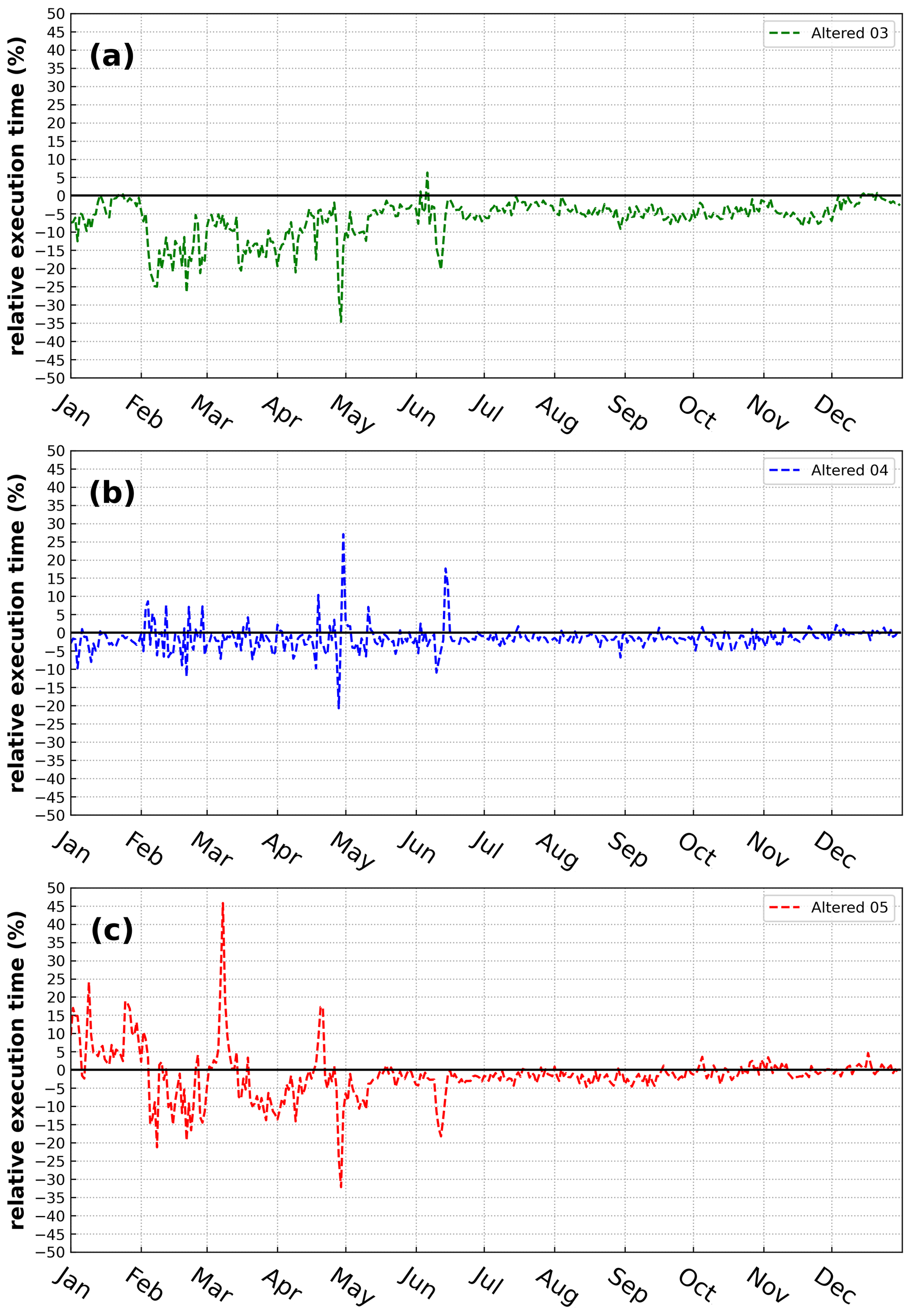
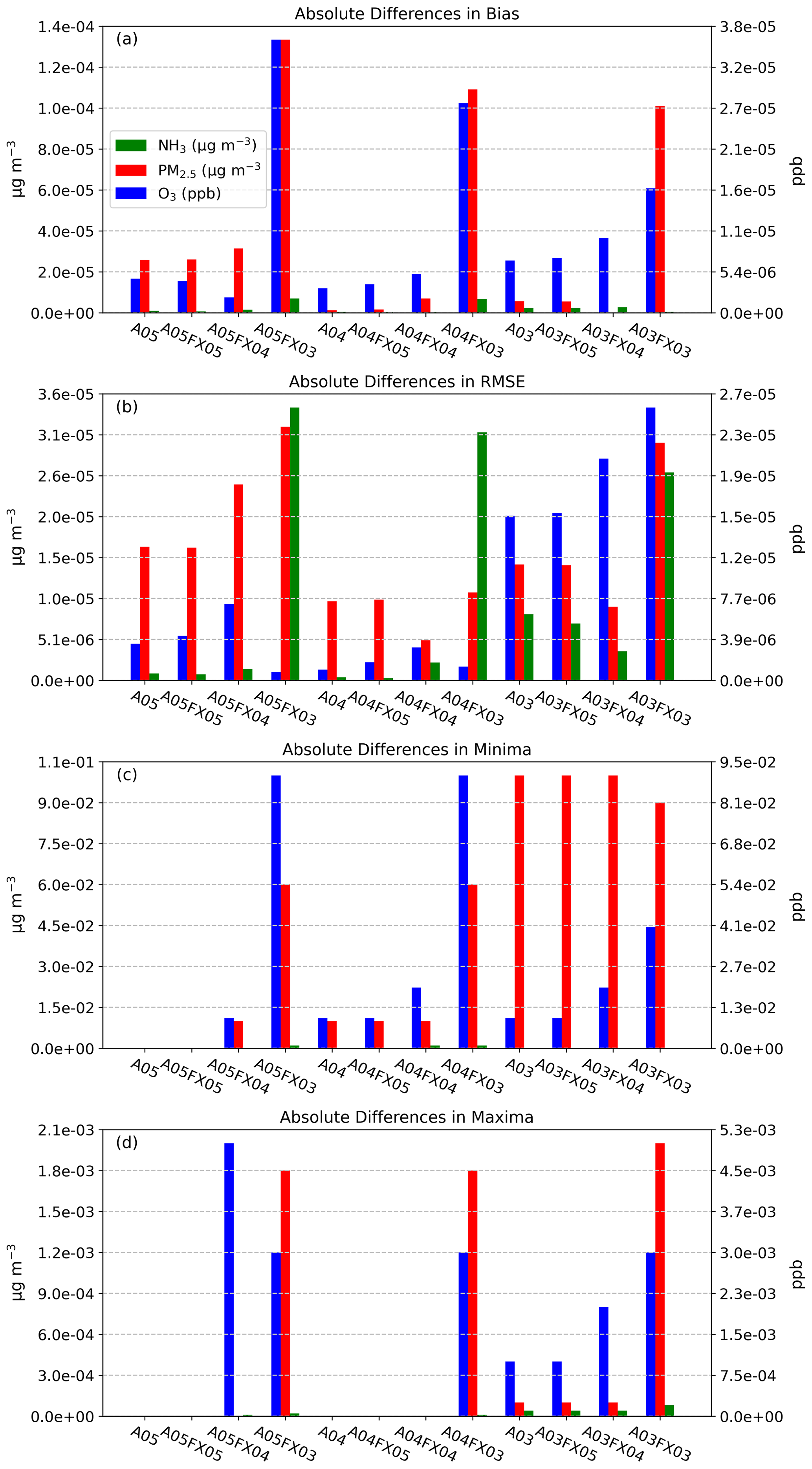
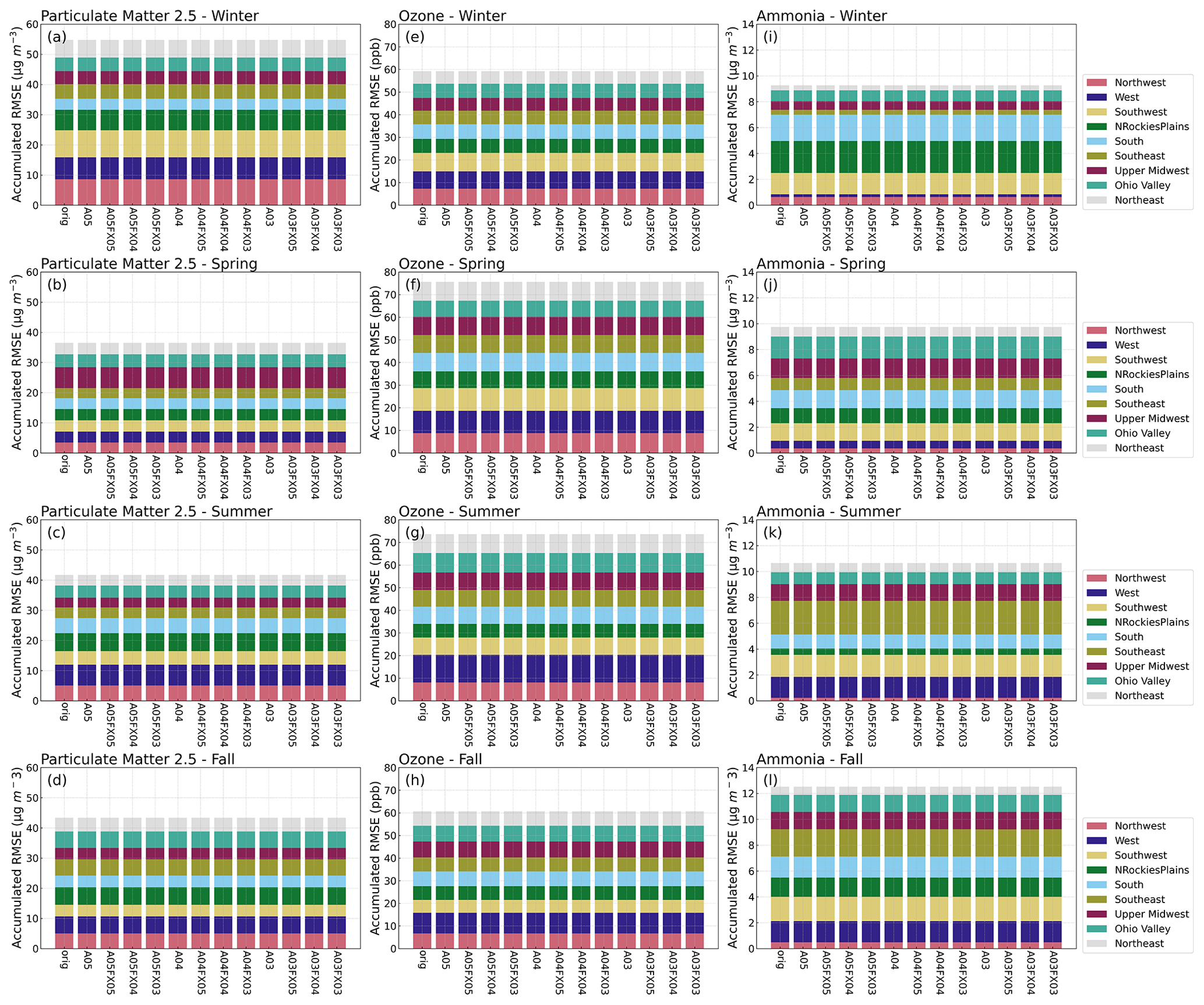
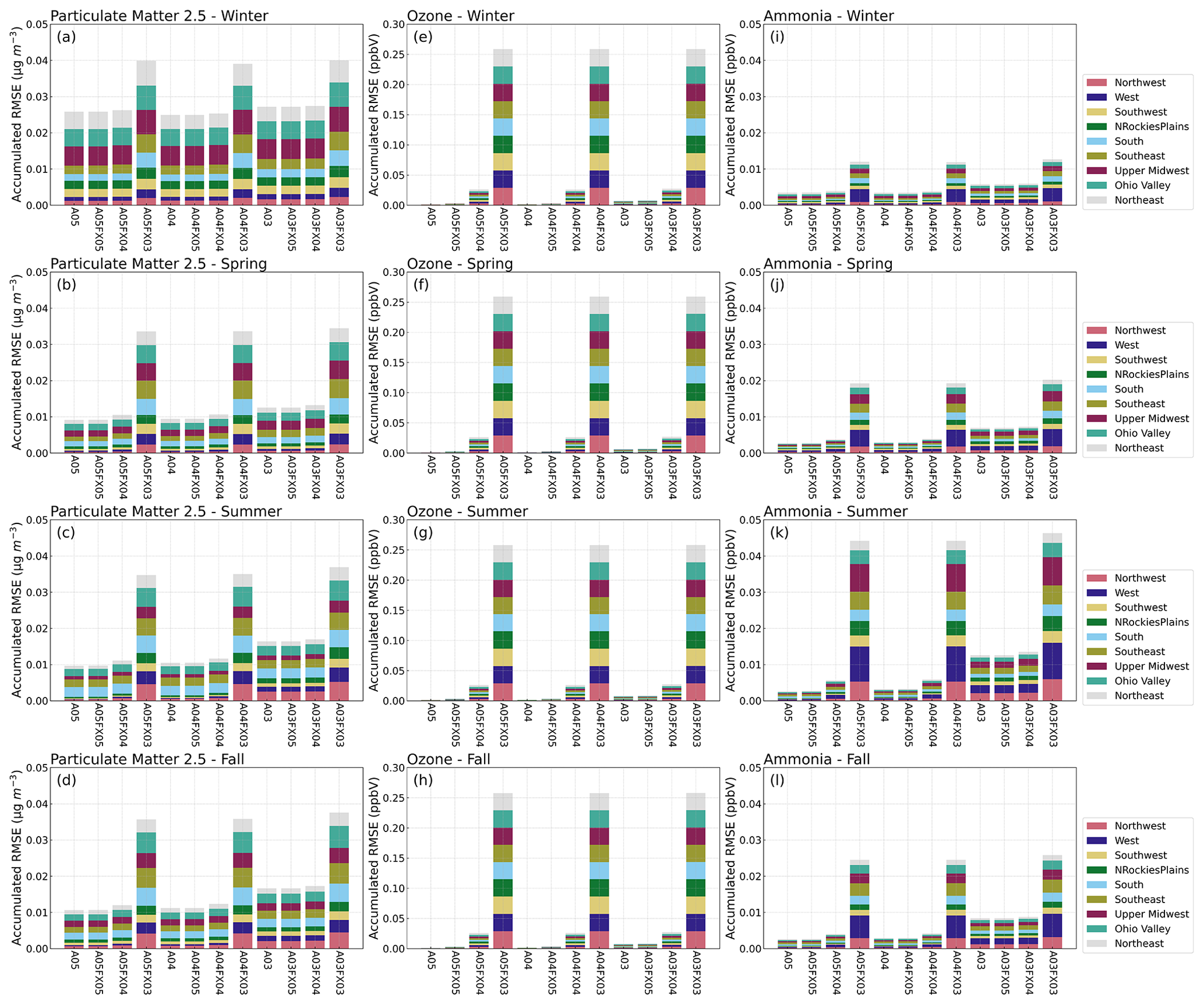
Results demonstrate that the altered precision emission files reduced the disk-space footprint by 6 %, 25 %, and 48 % compared to the unaltered emission files when using the bzip2 compression utility for files containing five, four, or three significant digits, respectively. Similarly, the altered output files reduced the required disk space by 19 %, 47 %, and 69 % compared to the unaltered CMAQ output files when using the bzip2 compression utility for files containing five, four, or three significant digits, respectively. For both compressed datasets, bzip2 performed better than gzip, in terms of compression size, by 5 %–27 % for emission data and 15 %–28 % for CMAQ output for files containing five, four, or three significant digits. Additionally, CMAQ runtime was reduced by 2 %–7 % for simulations using emission files with reduced precision data in a non-dedicated environment. Finally, the model-estimated pollutant concentrations from the four simulations were compared to observed data from the US EPA Air Quality System (AQS) and the Ammonia Monitoring Network (AMoN). Model performance statistics were impacted negligibly. In summary, by reducing the precision of CMAQ emission data to five, four, or three significant digits, the simulation runtime in a non-dedicated environment was slightly reduced, disk-space usage was substantially reduced, and model accuracy remained relatively unchanged compared to the base CMAQ simulation, which suggests that the precision of the emission data could be reduced to more efficiently use computing resources while minimizing the impact on CMAQ simulations.