the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 21 Nov 2022
| 21 Nov 2022
Development of an LSTM broadcasting deep-learning framework for regional air pollution forecast improvement
Haochen Sun
Jimmy C. H. Fung
Yiang Chen
Zhenning Li
Dehao Yuan
Wanying Chen
Deep-learning frameworks can effectively forecast the air pollution data for individual stations by decoding time series data. However, most of the existing time-series-based deep-learning models use offline spatial interpolation strategies and thus cannot reliably project the station-based forecast to the spatial region of interest. In this study, the station-based long short-term memory (LSTM) technique was extended for spatial air quality forecasting by combining a novel deep-learning layer, termed the broadcasting layer, which incorporates a learnable weight decay parameter designed for point-to-area extension. Unlike most existing deep-learning-based methods that isolate the interpolation from the model training process, the proposed end-to-end LSTM broadcasting framework can consider the temporal characteristics of the time series and spatial relationships among different stations. To validate the proposed deep-learning framework, PM2.5 and O3 forecasts for the next 48 h were obtained using 3D chemical transport model simulation results and ground observation data as the inputs. The root mean square error associated with the proposed framework was 40 % and 20 % lower than those of the Weather Research and Forecasting–Community Multiscale Air Quality model and an offline combination of the deep-learning and spatial interpolation methods, respectively. The novel LSTM broadcasting framework can be extended for air pollution forecasting in other regions of interest.
- Article
(4050 KB) - Full-text XML
-
Supplement
(1260 KB) - BibTeX
- EndNote





Aggravated by industrialization and economic development, air pollution has received increasing attention in recent years. Fine suspended particulate matter (PM2.5) and ozone (O3), as prominent secondary air pollutants, can adversely influence human health and society (e.g., poor visibility may lead to traffic delays). Accurately forecasting the levels of these two pollutants at the regional scale can provide the information necessary for relevant parties and the general public to address the threats posed by air pollution and implement appropriate counteractive measures (e.g., emission reduction or curtailment of unnecessary outdoor activities). To this end, several forecasting models have been developed. Three-dimensional (3D) numerical models have been applied worldwide to obtain regional forecasts of air pollution levels. Based on historical emission inventories and physical or chemical parameterization schemes, these numerical models simulate the formation, transmission, and destruction of air pollutants and forecast the regional air quality over a long prediction horizon (e.g., 120 h). However, the forecasts provided by such numerical models are prone to significant errors, owing to the uncertainty and hysteresis of the emission inventories and bias in the simplified parameterization schemes and meteorological simulations (Gilliam et al., 2015; Holnicki and Nahorski, 2015; Tang et al., 2009).
In recent years, machine learning algorithms have been widely applied to predict air quality (Janarthanan et al., 2021; Mao et al., 2021; Samal et al., 2021; Wu and Lin, 2019; Kim et al., 2019). As the future air quality is correlated with historical values, ground observations can be input to machine learning models to obtain forecasts. The forecasting process can be formulated as a time series task, with the input and training targets being hourly ground observations. Most studies (Ayturan et al., 2018; Huang and Kuo, 2018; Tsai et al., 2018; Zhao et al., 2019) have applied long short-term memory (LSTM; Hochreiter and Schmidhuber, 1997) frameworks – a variant of recurrent neural networks (RNNs) and a state-of-the-art deep-learning technique – to accomplish the time series tasks. Different LSTM frameworks (or other variants of RNNs) can be applied for different time series tasks. For example, if the output temporally postdates the input, then LSTM encoder–decoders (Sutskever et al., 2014) can be applied. In contrast, if the output and input are in the same temporal domain, then bidirectional LSTMs (Schuster and Paliwal, 1997) can be used. However, because the air quality depends on many factors other than historical values, the correlation between the future air pollution conditions and past ground observations is weak, especially in the case of large time lags, and the effective prediction horizon is constrained, typically to no more than 24 h (Bui et al., 2018; Li et al., 2020; Qin et al., 2019). Moreover, most of the abovementioned studies focused on obtaining accurate forecasts for specific ground monitoring stations, and thus, deep-learning models that can forecast the air quality on a regional scale are lacking.
Several studies have attempted to develop deep-learning-based models to obtain regional air pollution forecasts by combining ground observation data and numerical model results through spatial interpolation methods. For example, the LSTM 3D-variational assimilation (3D-VAR) model (X. Lu et al., 2021) combines ground observations and 3D numerical models with the LSTM and 3D-VAR data assimilation techniques. This model can achieve accurate regional forecasts with a prediction horizon of 24 h; however, substantial computation power is required (1 h of computing time is required to obtain a 24 h forecast using two AMD EPYC 32 core processors). The LSTM Weather Research and Forecasting–Community Multiscale Air Quality (WRF-CMAQ) model (Sun et al., 2021) combines ground observations and WRF-CMAQ models to achieve highly accurate regional forecasts with a prediction horizon of 48 h. However, the system requires a customized spatial correction (SC) scheme (e.g., numerical interpolation methods), and the accuracy at general locations is lower than that at the ground monitoring stations, the data of which are used for deep-learning model training. Sayeed et al. (2021a, b) and H. Lu et al. (2021) improved the accuracy of CMAQ forecast by ground observations using deep-learning techniques, but the improvements were still limited to the ground monitor stations rather than the whole region. On the other hand, Lyu et al. (2019) developed an ensemble model that combines the chemical transport models and the ground observations, but the regional forecast still depends on the traditional kriging method. Similarly, Bi et al. (2022) used the random forest algorithm to calibrate the numerical simulation based on chemical transport models. However, this model also relies on interpolation methods (e.g., ordinary kriging). Moreover, the parameters needed for the spatial interpolation schemes are not included in the training process when constructing the deep-learning framework, and the spatial correlations between different stations cannot be introduced as a constraint (Zhou et al., 2020; Hähnel et al., 2020).
With advances in deep-learning techniques, sophisticated architectures have been developed to incorporate spatiotemporal correlations for regional air pollution forecasting. Pak et al. (2020) developed a spatiotemporal convolutional neural network (CNN) LSTM network to predict the next day's daily average PM2.5 concentration in Beijing, China. Qi et al. (2019) applied a graph neural network (GNN) to take into account the spatial correlations of multiple ground monitoring stations in the Jing-Jin-Ji region, China, and enhance the forecast accuracy at these stations. Han et al. (2021) proposed a MasterGNN structure to explore the spatiotemporal information and forecast the air quality and weather at a given set of ground monitoring stations. However, the forecasts obtained by these architectures are restricted to a city-wide average or fixed set of ground monitoring stations. Therefore, these models cannot be applied for regional forecasting and predicting the pollutant concentrations at specific locations.
In this study, to obtain accurate forecasts for a longer period and consider the spatial characteristics, an end-to-end deep-learning model that can forecast the regional air pollution values for the next 48 h (starting at 09:00 LT (local time hereinafter, unless otherwise indicated) on each day) was developed. A novel broadcasting layer was incorporated in the model to introduce a spatial interpolation parameter into the deep-learning model training, and various LSTM-based deep-learning structures were used to support the end-to-end computation.
The proposed model, which combines ground observation data and WRF-CMAQ numerical models as the inputs, can forecast the air quality for any location within a region. In tests pertaining to China's Guangdong–Hong Kong–Macau Greater Bay Area (GBA) and the surrounding regions, the proposed model outperformed the CMAQ model and an offline combination of the LSTM and SC methods in terms of the forecasting accuracy.
2.1 Data
Ground observation data and WRF-CMAQ results from 2015 to 2021 in the GBA and surrounding regions (21.6–24.5∘ N, 111.2–115.6∘ E; referred to as the target region hereinafter), with a spatial resolution of 3 km, were extracted. Details of the model domain coverage and configuration of the parameterization schemes can be found in the work of Lu et al. (2015, 2018). The proposed model was built using the data from 2015 to 2020 (training period) and tested using the data from 2021 (testing period) to ensure temporal generalizability.
The ground observation data of air pollutant concentrations from several ground monitoring stations distributed across the region were used to partially represent the spatial distribution of the pollutants. In the training period, the ground monitoring stations with at least 90 % valid records (2015 to 2020) for both the target species, PM2.5 and O3, were selected as the training target stations. The same criterion was applied to select the testing target stations (2021) from the testing period. The ground monitoring stations with at least 95 % valid records for both the target species in both periods were selected as the source stations (denoted S), and the corresponding data were used as the ground truth for model training. Given these criteria, each source station was automatically a target station in both periods. As shown in Fig. 1, the criteria yielded 32 source stations, 90 training target stations, and 61 testing target stations. A total of 21 testing target stations that were neither source stations nor training target stations were used as the primary benchmark for quantitatively evaluating the results (referred to as benchmark stations hereinafter; see Sect. 3). As the model did not encounter the data of these stations during training, satisfactory performances for these stations were expected to be indicative of spatial and temporal generalizability.
Note that the threshold values of the selection criterion are determined adaptively from the nature of the dataset. The values were set relatively high, such that the quality of the data could be guaranteed. However, to ensure that an adequate number of stations are selected to represent different areas of the target region, the threshold values could not be set too close to 100 %.
The WRF and CMAQ models can output the future weather situations and air pollutant concentrations, which represent valuable information for the deep-learning model. Therefore, the hourly WRF and CMAQ results for the forecast period at the locations of interest were input to the model. In other words, the WRF and CMAQ results for the training target stations were used for the model training, and those for the testing target stations were used for the model testing. The WRF and CMAQ features are given in List 1 in the Supplement.
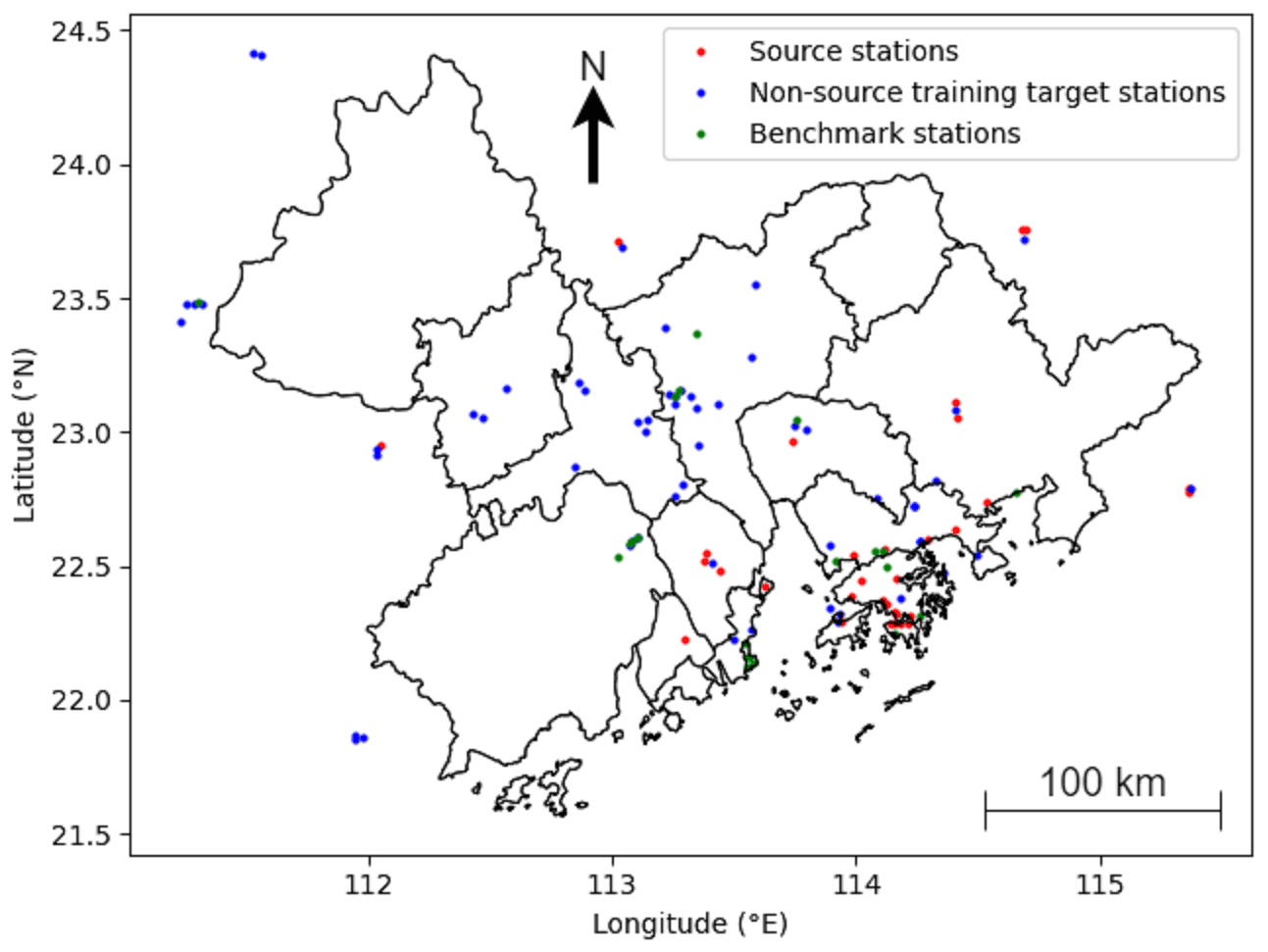
Figure 1Locations of the source and target stations (including the benchmark stations).
Table 1Overall performance values for the PM2.5 forecast. Note: mean bias error (MBE), mean absolute value (MAE), root mean square error (RMSE), symmetric mean absolute percentage error (SMAPE), and Pearson correlation coefficient (R) are shown. NN is for neural network, and IDW is for inverse distance weighting.
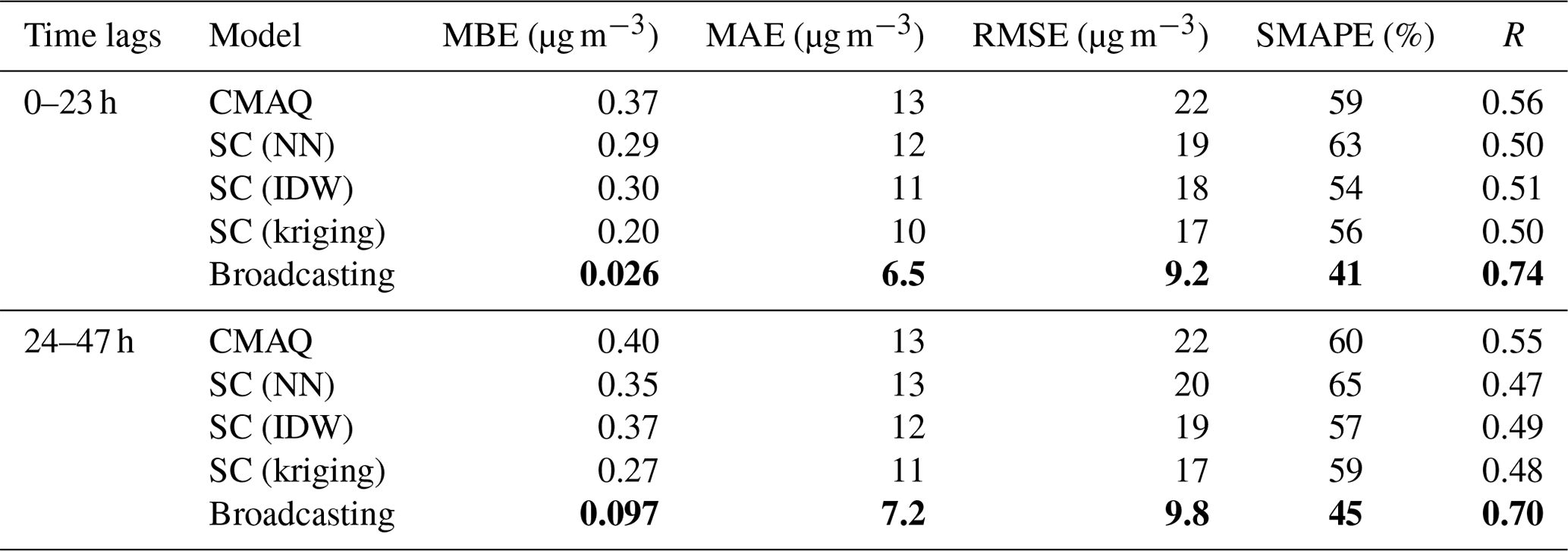
The boldface values represent the highest performance for each period and metric.
For each day, d, the proposed model took the following inputs:
-
The hourly ground observation data at the source stations from 09:00 on day d−3 to 08:00 on day d (both ends inclusive; 72 time steps).
-
The hourly WRF-CMAQ data at the locations of interest from 09:00 on day d to 08:00 on day d+2 (48 time steps). Note that the WRF-CMAQ model can also work as a forecasting model, and therefore, these data are available and can be used before the beginning of the forecast.
The model then outputs the hourly forecast of PM2.5 and O3 concentrations at the locations of interest from 09:00 on day d to 08:00 on day d+2 (48 time steps).
2.2 LSTM encoder–decoders
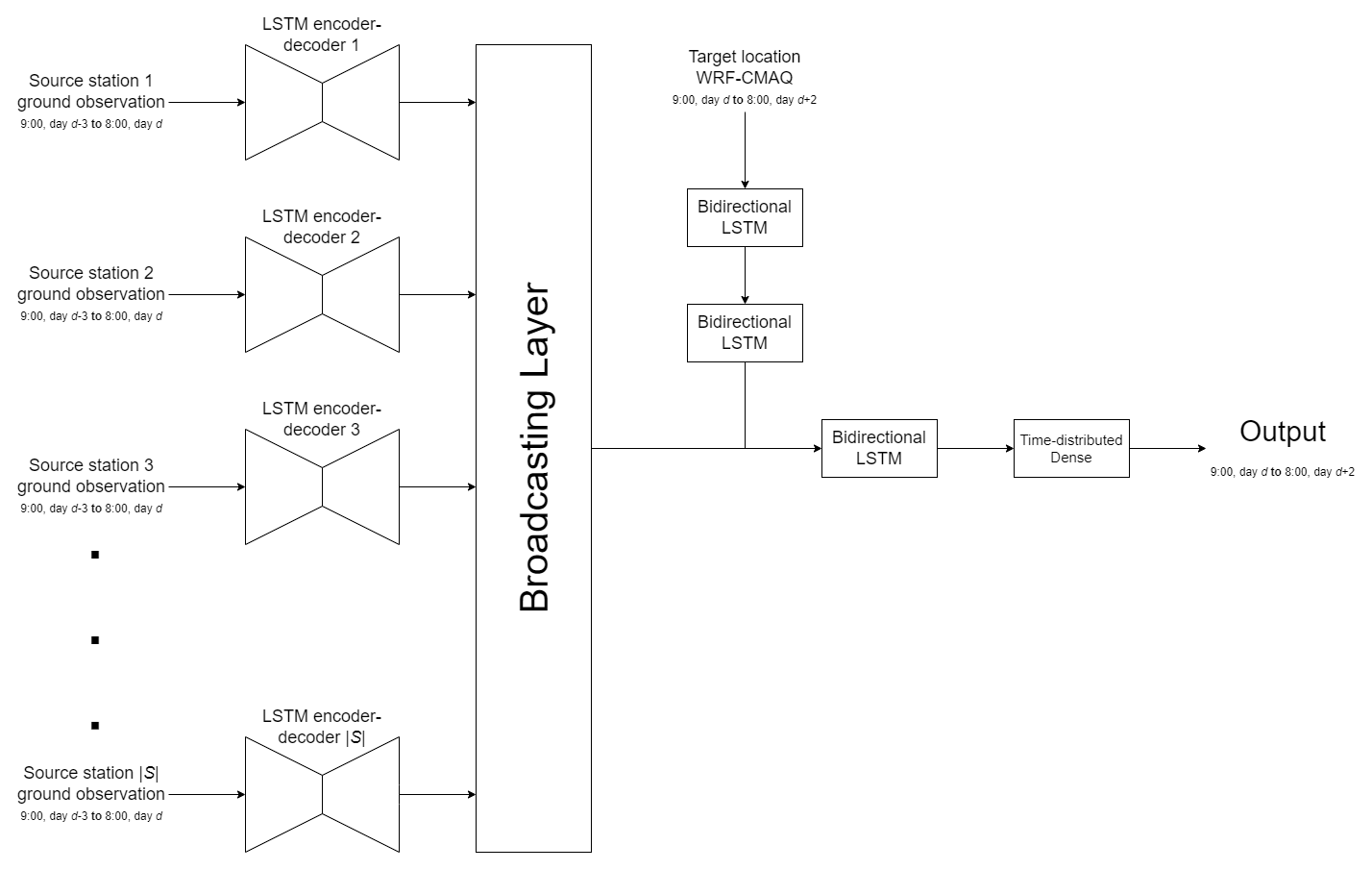
The ground observation data at the source stations were processed using LSTM encoder–decoders, with one LSTM encoder–decoder associated with each source station. The LSTM encoder–decoder of a source station s is assumed to map the source-station-specific space Xs of the past 72 h ground observation data (which may contain a different number of features for different source stations) to a homogeneous space H, which represents the information related to the PM2.5 and O3 concentrations for the future 48 h of any location in the target region as derived from the past ground observations.
Figure 2 shows the structure of the LSTM encoder–decoders used in this study. The LSTM encoder–decoder contains an encoder LSTM, a decoder LSTM, and a dense layer. First, the ground observation data for the past air pollutant concentrations and meteorological factors (denoted , where Tin=72 h is the length of the past observations) are input to the encoder LSTM to generate the encoding vector of the input time series, h. Subsequently, h is passed to the decoder LSTM with Tout time steps, where Tout=48 h is the length of the prediction. The hidden states of each time step are subsequently passed to a dense layer, activated by the rectified linear unit function (ReLU), where , and applied to the output of the dense layer in an element-wise manner.
In this study, the LSTM encoder–decoder associated with each source station, regardless of the number of ground observation features, had an encoding dimension of 64. The output dimension of the dense layer was set as 64 (for each time step). The mathematical and technical details of encoder LSTM and decoder LSTM can be found in Sects. S1 and S2 in the Supplement.

2.3 Bidirectional LSTM
Because several inputs and intermediate outputs (e.g., the WRF-CMAQ input at the locations of interest and outputs of the LSTM encoder–decoders) were in the same temporal space as that of the final output, bidirectional LSTMs were applied to extract the information embedded in these time series. A bidirectional LSTM contains two ordinary LSTM structures. When a time series is input to a bidirectional LSTM, then it is passed to the two LSTM layers in the ordinary and reversed temporal orders, and the two hidden states of each time step are concatenated as the output of the bidirectional LSTM. More details regarding the bidirectional LSTM (as a variant of bidirectional RNNs) can be found in the work of Schuster and Paliwal (1997).
Table 2Overall performance values for the O3 forecast. Note: ppbv is parts per billion by volume.

The boldface values represent the highest performance for each period and metric.
2.4 Broadcasting layer
The spatial correction (SC) method, which is based on numerical interpolation, has been introduced into the process of forecasting regional air quality to address the asymmetry between the availability of information at a limited number of locations and the need to predict the air quality for a complete region. For example, Sun et al. (2021) used the inverse distance weight to calibrate the difference between the deep-learning forecast and CMAQ forecast. Ma et al. (2019) proposed a geolayer to filter the data used for interpolation and combined this layer with LSTM-based models. However, in such offline combinations, the hidden connection among different stations cannot be included in the deep-learning model building procedure. In addition, offline numerical interpolation methods do not have degrees of freedom. Several methods of this type are not differentiable (e.g., nearest interpolation) or may incur numerical problems (e.g., inverse distance interpolation). Therefore, in order to better reveal the spatial characteristics of the air pollutant concentration field, we introduced a novel broadcasting layer to enable the end-to-end deep-learning model for a regional air quality forecast.
In this framework, each ground observation station s∈S is associated with a learnable weight decay parameter θs≥0 (which can be trained while building the deep-learning model). At any target location t, when the input is received from the source stations, the output of the layer at location t is computed as a weighted sum as follows:
with the weights calculated as
where ) denotes the distance between two locations, measured in kilometers. The computation of the weights is similar to that implemented in the conventional softmax function. Therefore, the weights sum to 1 for each location t, and the numerical problems that may occur during the differentiation of other forms (e.g., the inverse of the distance) are avoided. Because the weighted sum preserves the dimensions, the output of the broadcasting layer (at a target location t) is a time series of 48 time steps and 64 dimensions.
2.5 Model structure and training
Figure 3 shows the architecture of the proposed model. First, the ground observations of the source stations are passed through the LSTM encoder–decoders, as described in Sect. 2.2. Broadcasting to any location in the target region that requires using the novel layer is introduced in Sect. 2.4 (such a location is referred to as a target location). Then, the WRF-CMAQ result for the target location and target hours (as a time series with a length of 48 and dimension of 10) is passed through two bidirectional LSTM layers, both of which have an output dimension of 64. Next, the outputs of the broadcasting layers and bidirectional LSTM layers are concatenated at each time step, forming a time series with 48 time steps and 128 dimensions. Finally, the combined time series is passed to another bidirectional LSTM layer with an output dimension of 64 and a time-distributed dense layer (i.e., a dense layer associated with each of the 48 time steps) with an output dimension of 2, corresponding to the 48 h forecasts of the two air pollutant species.
In this study, the model was trained for 32 epochs using the ADAM optimizer (Kingma and Ba, 2014) by minimizing the mean absolute error (MAE) of the prediction for all valid records, with a learning rate of 10−3 and batch size of 64. The following measures were introduced to prevent overfitting:
-
A dropout layer (Srivastava et al., 2014) with a rate of 0.5 was applied before the dense layer in each LSTM encoder–decoder and before the final time-distributed dense layer.
-
A batch-normalization layer (Ioffe and Szegedy, 2015) was applied after each bidirectional LSTM layer (including the layers enclosed in the broadcasting layer). The WRF-CMAQ results and ground observations of the PM2.5 and O3 concentrations of the multiple training target stations were simultaneously fed to the model during each minibatch to attain a larger batch size for the batch normalization layers to take effect.
This model is referred to as the broadcasting model hereinafter.
The effectiveness of the broadcasting model was evaluated by comparing its results with the following two baselines:
-
The CMAQ model simulation.
-
The SC method introduced by Sun et al. (2021). Different interpolation methods (nearest neighbor, NN, inverse distance weighting, IDW, and kriging) were used to enhance the performance of the SC method on the test set.
The performance was evaluated using five metrics, namely mean bias error (MBE), mean absolute value (MAE), root mean square error (RMSE), symmetric mean absolute percentage error (SMAPE), and Pearson correlation coefficient (R). The formulas to determine these metrics are listed in Table S1 in the Supplement.
3.1 Overview
This subsection describes the performance evaluation of the broadcasting model against the baselines on the benchmark stations. Once the WRF-CMAQ forecast was available, the LSTM broadcasting model required only several seconds to obtain the forecast for the next 48 h. Notably, the deep-learning-based structures of the SC were directly optimized to maximize the performance over the source stations. Therefore, the performance of SC on the target stations that were also source stations could not be taken to represent its regional forecast performance.
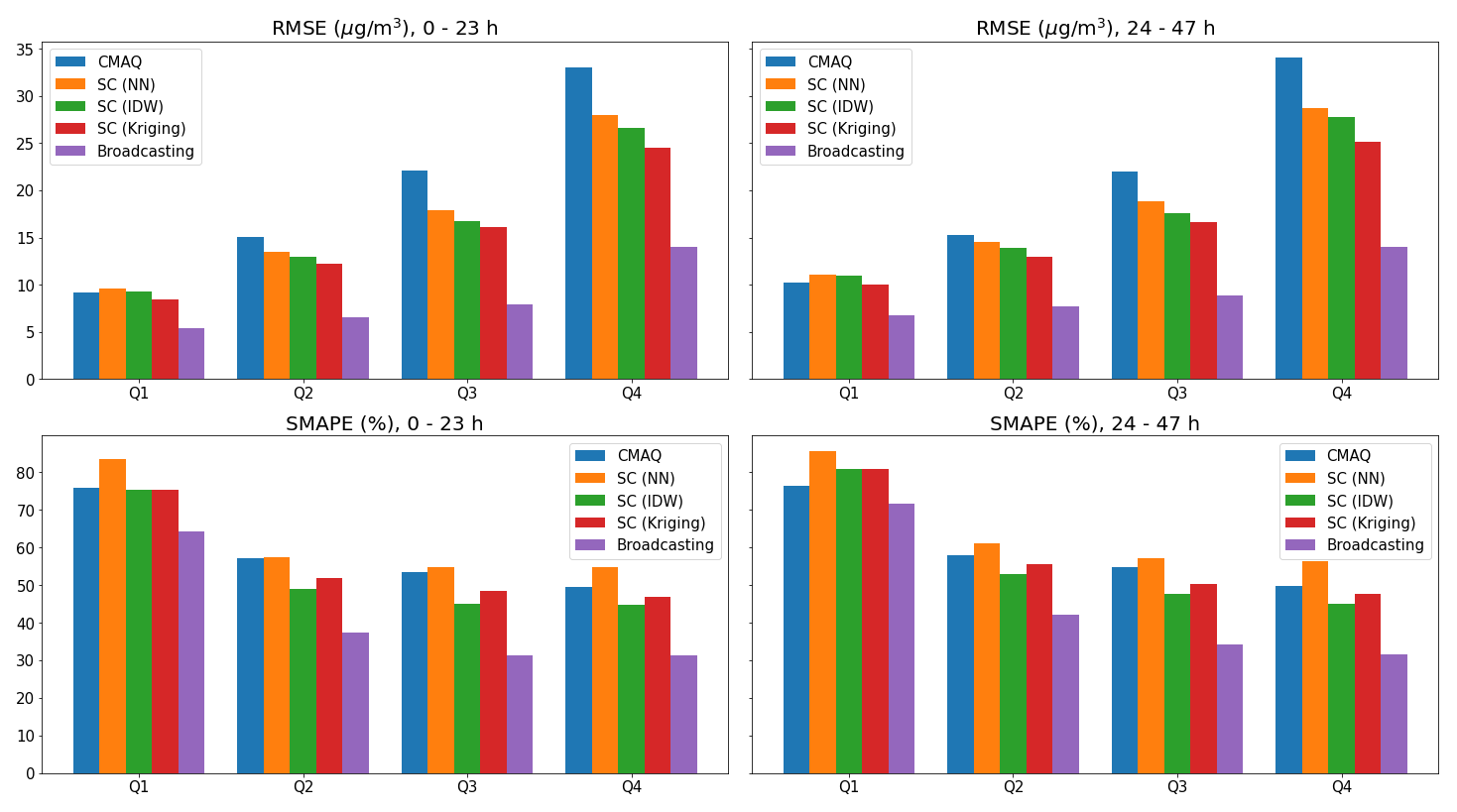
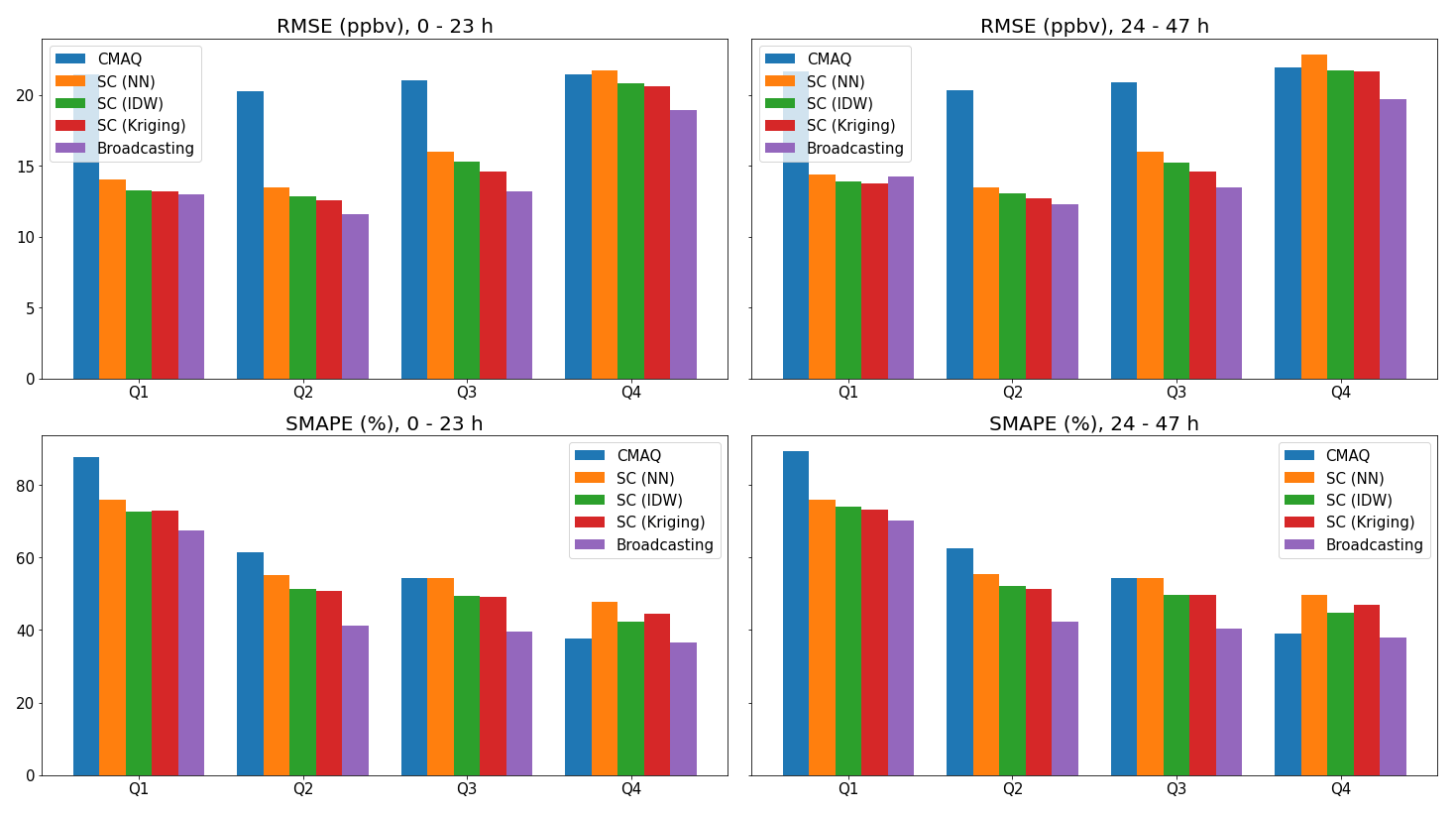
The broadcasting model outperformed the baselines for all metrics for both PM2.5 and O3. Tables 1 and 2 summarize the performance values of the broadcasting model and baselines, temporally differentiated by two classes of time lag, i.e., 0–23 and 24–47 h.
In terms of PM2.5, the performance of all models in the first 24 h was superior to that in the second 24 h. According to the MBE values, the CMAQ model was highly biased, and the SC only partially resolved this issue. The broadcasting model exhibited a significantly decreased bias for both the 24 h periods, and the forecast for the first 24 h was generally unbiased. Moreover, although the SC method outperformed the CMAQ model in terms of the MAE, RMSE, and SMAPE (especially with NN and IDW interpolations), it exhibited an inferior R value. In contrast, the broadcasting model exhibited an improved R value, indicating a decreased variance. Therefore, the overall error for the proposed model was considerably lower than those for the baselines. For example, the RMSE was 60 % and 50 % lower than those for the CMAQ and SC models, respectively, and the improvement margins for the other metrics were significantly broader than those for the SC.
Table 3Quartiles of PM2.5 and O3 concentrations. Note: ppbv is parts per billion by volume.

For O3, similar to the case of PM2.5, all models were more accurate in forecasting the O3 concentrations in the first 24 h than in the latter 24 h. However, unlike PM2.5, the SC models outperformed the CMAQ model in terms of all metrics for O3 forecasting, including R. The CMAQ was severely biased for both 24 h periods, although the SC solved the bias issue more effectively than that in the case of PM2.5. Notably, the broadcasting model calibrated the bias such that the model was generally unbiased for both 24 h periods. In terms of the other metrics, the SC (especially with NN and IDW interpolations) exhibited significant improvements over the CMAQ model (approximately 25 % in terms of the MAE and RMSE and approximately 10 % in terms of the SMAPE and R). Nevertheless, the broadcasting model outperformed the SC, with improvements of nearly 10 % for all the metrics.
Figure 4 shows the hourly RMSE (representing the absolute error) and SMAPE (representing the relative error) of the forecasts for the two pollutants. Owing to the daily scale variations in the pollution levels, the RMSE and SMAPE trends were not always consistent with one another, especially for O3. In the case of PM2.5, the performance of the baselines was unsatisfactory at certain time lags (e.g., 11, 22, 35, and 46 h, corresponding to 08:00 and 07:00 on each day). In comparison, the broadcasting model achieved satisfactory performance values over all time lags. In the case of O3, the SC (especially with IDW and kriging interpolations) outperformed the CMAQ model for all metrics. The performance of the LSTM broadcasting model at each time lag was comparable to, if not better than, those of the baselines, and for most time lags, a significant margin of improvement was observed.

Figure 5 compares the forecasts of the broadcasting model and baselines with the ground observation data in February, May, August, and November 2021 (rows 1–4, respectively), considering the daily average over the benchmark stations. Consistent with the previous analyses, the forecast for the first 24 h was more accurate than that for the second 24 h. In the case of PM2.5, the broadcasting model could better capture the trends of ground observations and was less vulnerable to systematic bias over long periods than the baselines. In the case of O3, the SC model considerably outperformed CMAQ, and the broadcasting model was not evidently more accurate than SC. Nevertheless, the results of the previous quantitative analysis demonstrated the excellent capability of the broadcasting model in O3 forecasting.
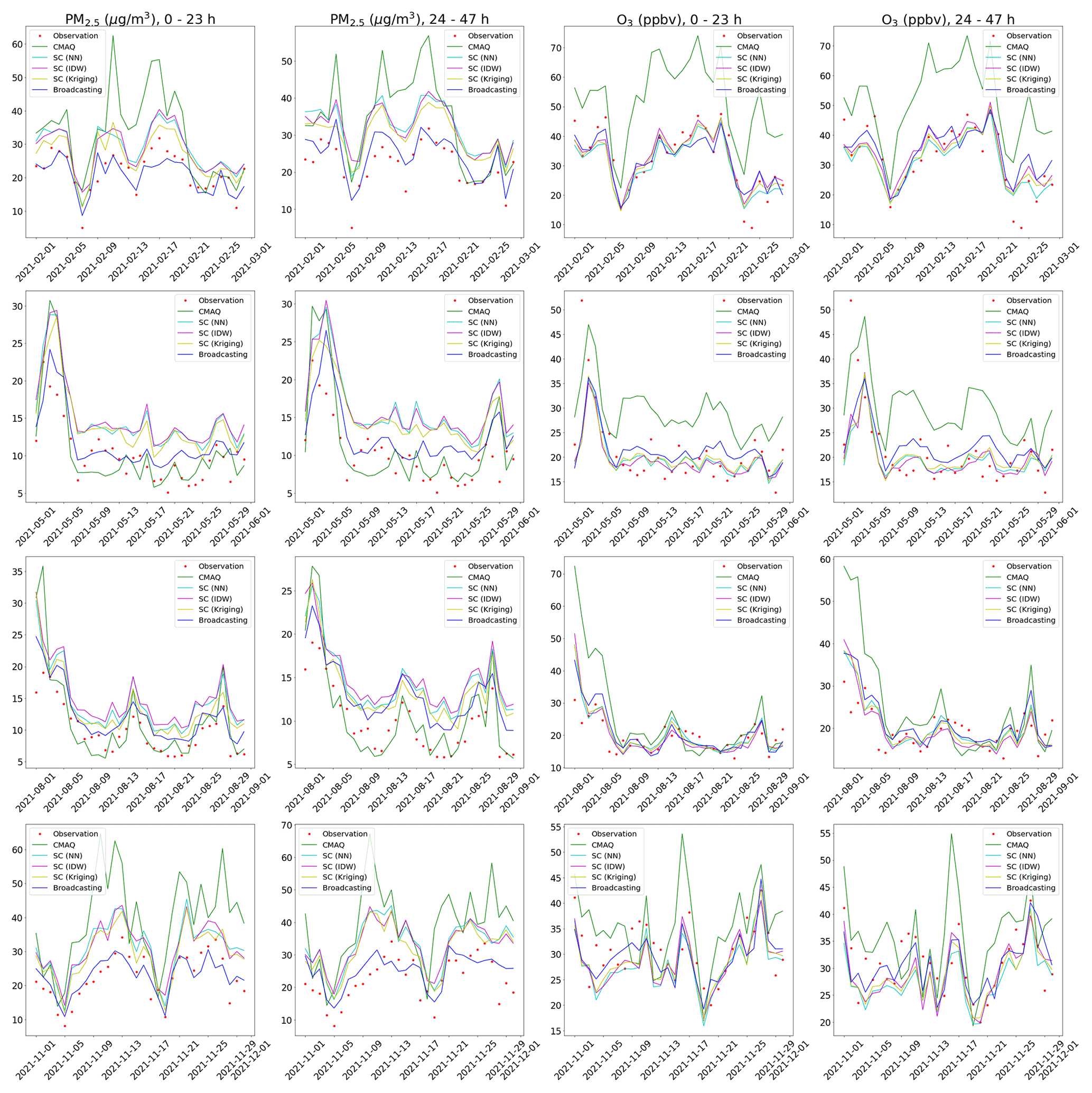
Figure 5Comparisons of ground observations and forecasts for February, May, August, and November 2021 (rows 1–4, respectively).
3.2 Performance for different pollution levels
As described in Sect. 3.1, the proposed model achieved enhanced predictions compared with the baselines. The effectiveness of the broadcasting model was further evaluated considering different levels of air pollution. The same 21 benchmark stations as those in the analysis described in Sect. 3.1 were used.
For each target pollutant, the daily averages of the ground observation values at the different stations were divided into four quartiles (Q1, Q2, Q3, and Q4, in increasing order), as indicated in Table 3.
Figures 6 and 7 show the performance values (absolute and relative errors, indicated by the RMSE and SMAPE, respectively) of the broadcasting model and baselines for the four quartiles. For both the pollutants and all models, as the pollution levels increased, the absolute error increased, and the relative error decreased. Similar to the overall performance trends, different models were generally more accurate in the first 24 h in each quartile. However, the broadcasting model achieved significantly improved PM2.5 forecasts for all pollution levels. In particular, the RMSE of the broadcasting model was around 50 % lower than that of the strongest baseline (SC with kriging interpolation) and was especially low at higher levels of pollution. A clear margin of improvement in the SMAPE was also observed at each quartile.
The improvements in the broadcasting model for the O3 forecasts were not as significant as those for the PM2.5 forecasts. In certain cases (e.g., RMSE of the second 24 h for Q1), the broadcasting model did not outperform the SC (but still significantly outperformed the CMAQ model). However, in most cases, the broadcasting model still outperformed the CMAQ and SC models, even given that SC (especially with IDW and kriging interpolations) already supersedes CMAQ by a large margin in many cases.
In conclusion, in addition to the overall improvement in the forecast performance, as described in Sect. 3.1, the broadcasting model exhibits a satisfactory performance at different pollution levels. Therefore, the broadcasting model is robust against different scenarios and can be applied for high or low pollution levels.
3.3 Regional forecast
Figure 8 shows the regional forecast of the broadcasting model and baselines considering the monthly average of February 2021. The monthly average of the ground observations at the testing target stations is also shown for comparison. The regional forecasts for May, August, and November 2021 are presented in the Supplement (Figs. S1–S3).
The ground observations (dots) were typically inconsistent with the predictions (background) made by the CMAQ model. In other words, the CMAQ forecasts were generally inaccurate and biased (mainly positively) and could not accurately model the regional air pollution. The SC only partially resolved this issue, with occasional incompatibilities between the ground observations and forecasts. Moreover, owing to the mathematical characteristics of the different interpolation methods, the spatial distribution modeled using the SC framework was evidently unrealistic. For example, the SC forecast with NN interpolation exhibited apparent spatial discontinuities over several straight-line segments in the region, which is highly unrealistic.
In comparison, the ground observations and forecasts of the broadcasting model were consistent, which indicated that the broadcasting model could resolve the inaccuracies, especially the bias issue, encountered by the other models. Another key observation of the broadcasting model's prediction is that the spatial distribution simulated by the broadcasting model was smoother than those of the other models. However, the model that achieved the most realistic spatial smoothness cannot be identified from the given information owing to the lack of data in other regions. In fact, the smoothing effect may not align with the fact that some cities (e.g., Guangzhou and Foshan) have higher emission levels than other locations in the target region. However, this inconsistency may also be attributable to the limited number of source stations in these cities (see Fig. 1). Nevertheless, in Hong Kong, in which the source stations are densely distributed, the broadcasting model successfully predicted a significantly lower pollution level, especially for PM2.5.
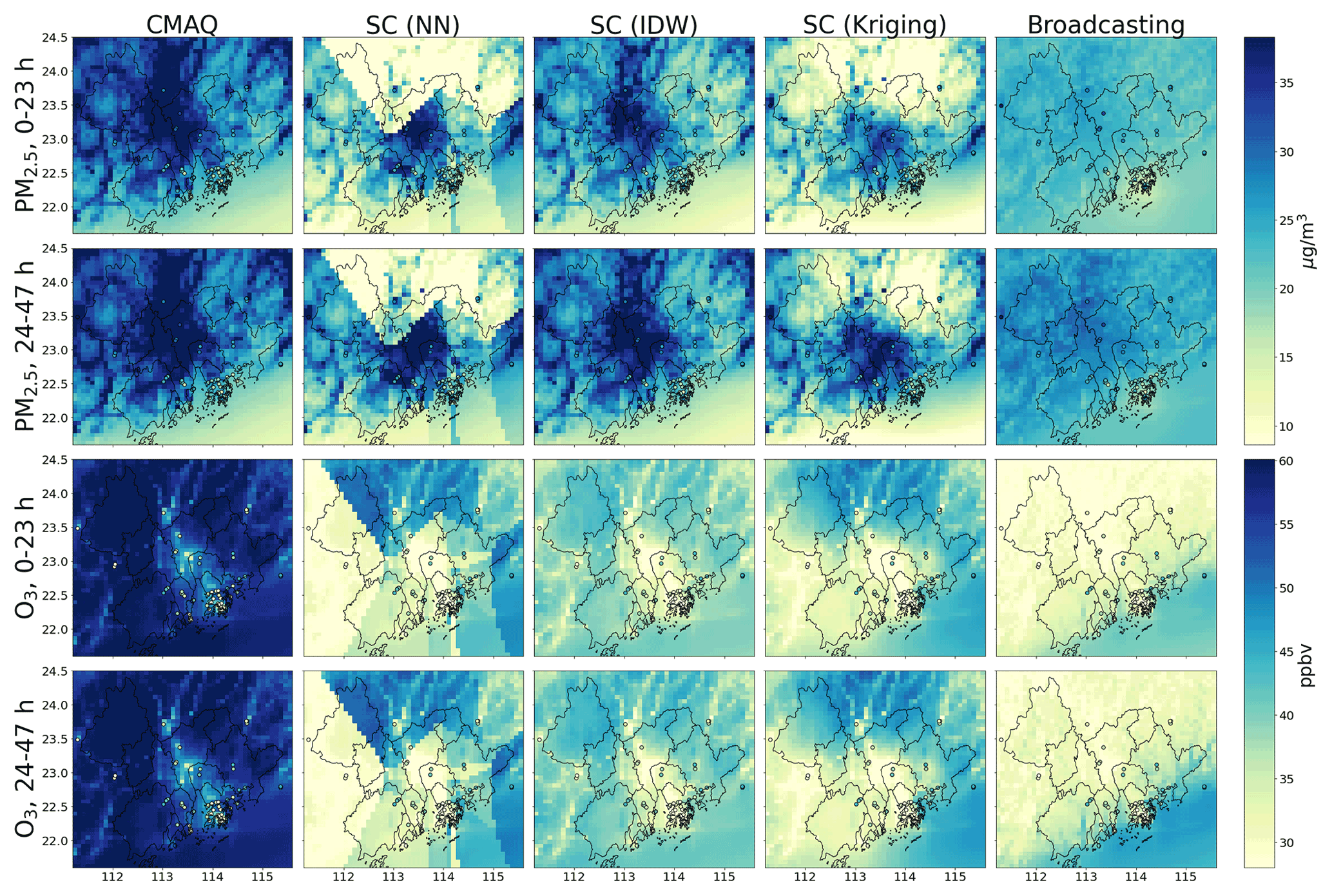
Figure 8Regional forecast results for February 2021.
Moreover, the running time of the Broadcasting model is also reasonable. With the graphics processing unit (GPU; K80 in the Google Colaboratory (CoLab) environment) support, it only takes several seconds to finish the computation for the regional forecast of 1 d after the ground observation results and WRF-CMAQ data are available. Therefore, the broadcasting model satisfies the efficiency requirements of real applications (Lee et al., 2020; Zhang et al., 2012). On the other hand, SC may take several seconds (NN and IDW) to about 3–5 min (kriging), depending on whether interpolation methods can be fully parallelized. By contrast, the LSTM 3D-VAR-CAMx (Comprehensive Air Quality Model with Extensions) will cost about 90 min (tested on a cluster machine with 40 cores and 128 GB of memory), given the ground observation and WRF-CAMx results as input, which may render the approach infeasible when instant forecasts are needed.
This paper proposes an end-to-end deep-learning model for a regional air pollution forecast. The key structure enabling this feature is the broadcasting layer, which inputs the information extracted from the past ground observations at the discrete source stations and projects it to any location in the target region as a weighted sum over all source stations. This layer can help overcome the geographical barrier and is a promising alternative to traditional customized SC methods that are typically based on inflexible assumptions and result in exacerbated inaccuracies relative to the data of the ground monitoring stations. In addition, owing to the small number of parameters, the proposed model is unlikely to overfit spatially to the ground observation stations. The described structure can also be extended to regional air pollution forecasting or other deep-learning tasks for regions for which information for only a limited number of locations is available. However, this study only assumed that the impact of a source station decreases exponentially with the increase in the distance. Future work can be aimed at considering different patterns and factors other than the distance (e.g., terrains).
Also, our study has extensively exploited the power of LSTM in time-series-related deep-learning tasks. LSTM is one of the most powerful deep-learning tools for time series forecasting (Greff et al., 2017; Karim et al., 2017; Siami-Namini et al., 2018). As a variation in RNNs, it resolves the inherent gradient explosion and vanishing problem, significantly extending the forecast horizon. By carefully examining the nature of different input and output components, we proposed combining two variations in LSTM, i.e., LSTM encoder–decoders and bi-directional LSTMs to construct the model, and achieved relatively good results. From this, we find that, in complex time-series-related deep-learning tasks, careful and ad hoc analysis of the nature of the different input and output time series is needed to construct the most effective model and achieve higher accuracy.
Moreover, the end-to-end deep-learning forecast does not incur a significant overhead, given that the ground observations and WRF-CMAQ results are available. As in Sect. 3.3, with GPU acceleration, the proposed model can obtain forecasts for thousands or even tens of thousands of locations spread across the target region within several seconds. In contrast, if the interpolation methods (e.g., kriging) used by SC cannot be fully parallelized, then the forecasting is associated with a prohibitive runtime, which decreases the applicability of such methods.
Instead of the conventional random splitting of the training and test sets, two disjoint periods were used for training and testing in this study. This design was motivated by the systematic long-term changes in the probability distributions of the pollutant concentrations, which partially arise because of the implementation of emission reduction (Lu et al., 2020) and COVID-19 control measures (Fan et al., 2020), which must be considered when fine-tuning the model. If random splitting were applied, then the trained and fine-tuned models would only be guaranteed to be valid on the data from 2015 to 2021 and may fail beyond this period.
In this study, a fixed set of source stations was considered, assuming that these stations would continuously output valid results over the years. However, this design may result in loss of information. For example, if a ground observation station produced high-quality records between 2015 and 2018 but was later demolished, then it was not selected as a source station. Moreover, this setting may cause some selected source stations to be invalidated in the future (e.g., if they are demolished in 2023). This problem could only be solved by considering an alternative setting in which the source stations are not selected statically but dynamically at each time step (i.e., hour). However, this alternative setting would require the efficient management of the varying source stations (and even the variations in the number of these stations).
In our setting, the source and training target stations play an essential role in the model's accuracy. The forecast quality generally increases as the number of source and training target stations increases. Therefore, the model's performance has been uneven across different areas of the target region. For example, as shown in Sect. 3.3, the performance in Hong Kong is generally better than that in other regions. In future works, other selection criteria of source stations and training target stations, in place of those introduced in Sect. 2.1, may be developed to resolve this issue.
WRF-CMAQ simulation shows severe overestimations for both the PM2.5 and O3 forecasts, especially during 24–47 h. The errors can be caused by several factors, such as the emission inventory, boundary and initial conditions, chemical and physical parameterization schemes, and meteorological factors simulation. The emission inventory cannot always be up-to-date, since substantial efforts are needed to compile a new set of regional emission inventories in high resolution. In addition, the scientific community has not yet fully understood many of the chemical and physical mechanisms in the atmosphere. Therefore, current state-of-the-art parameterization schemes still have a long way to go to be further improved. Besides devoting time and effort to improving the performance of the prognostic model from the abovementioned perspectives, from this work, we can find that combining the observation data-driven skills (e.g., deep-learning methods) can work as a feasible and efficient option to make up the current deficiency inherent in 3D chemical transport model and thus improve the forecast performance.
Ground observations of recent hours can provide information regarding the most immediate meteorological and air pollution conditions. However, this information is typically available only for ground monitoring stations, and the absence of information regarding the forecast period limits the accuracy of forecasts in the spatial and temporal dimensions. In this study, the parameters of spatial interpolation were incorporated into the training process by introducing a novel broadcasting layer. This configuration could overcome the problems related to the offline SC methods and the spatial barrier, allowing information to be broadcast to all locations in the target region. Combined with the broadcasting layer, the end-to-end deep-learning model incorporated the ground observation and WRF-CMAQ results through different LSTM-based structures suitable for various formats of time series data. The proposed model outperformed the existing models in terms of the PM2.5 and O3 forecasts. For the two pollutants, the absolute error (e.g., RMSE) of the proposed model was 55 % and 30 % lower than those of the CMAQ model and 45 % and 10 % lower than those of the SC model. SMAPE of the proposed model was 30 % and 20 % lower than those of the CMAQ and 25 % and 15 % lower than those of the SC model. The proposed model structure can serve as a novel framework for regional air pollution forecasting. Specifically, this model can be applied to forecast the concentrations of PM2.5, O3, and other pollutants in different regions worldwide if adequate ground observations for the region are available and the numerical models (not necessarily WRF-CMAQ) can cover the target hours. The broadcasting layer may also be further applied to a wide range of tasks that would otherwise require interpolation, thereby facilitating the development of end-to-end deep-learning models for these tasks. Considering the diverse nature of different tasks, ad hoc variations in the broadcasting layer may be designed to adapt to task-specific requirements.
The ground air pollutant observation data were released by the China National Environmental Monitoring Center and the Hong Kong Environmental Protection Department. The ground observation data used in this study can be found at https://doi.org/10.5281/zenodo.6598377 (Sun et al., 2022a). The PM2.5 and O3 forecast results from different models and the setting of the WRF-CMAQ model are available at https://doi.org/10.5281/zenodo.6833673 (Sun et al., 2022b). The WRF model v3.7 and CMAQ model v5.0.2 can be downloaded from https://www2.mmm.ucar.edu/wrf/users/download/get_source.html (Skamarock et al., 2008) and https://doi.org/10.5281/zenodo.1079898 (United States Environmental Protection Agency, 2014). The official implementation of this work is at https://doi.org/10.5281/zenodo.7019243 (Sun, 2022), and the deep-learning model parameters and the input/output data with compatible formats are available at https://doi.org/10.5281/zenodo.6827585 (Sun et al., 2022c) and https://doi.org/10.5281/zenodo.6601173 (Sun et al., 2022d), respectively.
The supplement related to this article is available online at: https://doi.org/10.5194/gmd-15-8439-2022-supplement.
HS, XL, and JCHF conceived the research. HS developed the model and performed the simulations. HS, XL, JCHF, and YC conducted the analysis. ZL, DY, and WC provided useful comments on the paper. HS prepared the paper, with contributions from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We appreciate the assistance of the Hong Kong Observatory (HKO), which provided the meteorological data. We thank the constructive comments from reviewers and editor.
This work has been supported by the Guangzhou Scientific and Technological Planning Project (grant no. 202102021297), the National Natural Science Foundation of China (grant no. 42007203), the Research Grants Council of Hong Kong Government (grant nos. 16305921, 16302220, and R6011-18), the Guangdong–Hong Kong–Macau Joint Laboratory Grant (grant no. GDST20IP05), and the Environment and Conservation Fund (grant no. ECF 2020123).
This paper was edited by David Topping and reviewed by two anonymous referees.
Ayturan, Y. A., Ayturan, Z. C., and Altun, H. O.: Air pollution modelling with deep learning: a review, International Journal of Environmental Pollution and Environmental Modelling, 1, 58–62, 2018.
Bi, J., Knowland, K. E., Keller, C. A., and Liu, Y.: Combining Machine Learning and Numerical Simulation for High-Resolution PM2.5 Concentration Forecast, Environ. Sci. Technol., 56, 1544–1556, 2022.
Bui, T.-C., Le, V.-D., and Cha, S.-K.: A deep learning approach for forecasting air pollution in South Korea using LSTM, arXiv [preprint], https://doi.org/10.48550/arXiv.1804.07891, 2018.
Fan, C., Li, Y., Guang, J., Li, Z., Elnashar, A., Allam, M., and de Leeuw, G.: The impact of the control measures during the COVID-19 outbreak on air pollution in China, Remote Sensing, 12, 1613, https://doi.org/10.3390/rs12101613, 2020.
Gilliam, R. C., Hogrefe, C., Godowitch, J. M., Napelenok, S., Mathur, R., and Rao, S. T.: Impact of inherent meteorology uncertainty on air quality model predictions, J. Geophys. Res.-Atmos., 120, 12259–12280, 2015.
Greff, K., Srivastava, R., Koutník, J., Steunebrink, B., and Schmidhuber, J.: LSTM: A search space odyssey, IEEE Transactions on Neural Networks Learning Systems, https://doi.org/10.1109/TNNLS.2016.2582924, 2017.
Hähnel, P., Mareček, J., Monteil, J., and O'Donncha, F.: Using deep learning to extend the range of air pollution monitoring and forecasting, J. Comput. Phys., 408, 109278, 2020.
Han, J., Liu, H., Zhu, H., Xiong, H., and Dou, D.: Joint air quality and weather prediction based on multi-adversarial spatiotemporal networks, Proceedings of the AAAI Conference on Artificial Intelligence, 2–9 February 2021, virtual conference, 4081–4089, https://doi.org/10.48550/arXiv.2012.15037, 2021.
Hochreiter, S. and Schmidhuber, J.: Long short-term memory, Neural Comput., 9, 1735–1780, 1997.
Holnicki, P. and Nahorski, Z.: Emission data uncertainty in urban air quality modeling–case study, Environ. Model. Assess., 20, 583–597, 2015.
Huang, C.-J. and Kuo, P.-H.: A deep CNN-LSTM model for particulate matter (PM2.5) forecasting in smart cities, Sensors, 18, 2220, https://doi.org/10.3390/s18072220, 2018.
Ioffe, S. and Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift, International conference on machine learning, 6–11 July 2015, Lille, France, 448–456, https://doi.org/10.48550/arXiv.1502.03167, 2015.
Janarthanan, R., Partheeban, P., Somasundaram, K., and Elamparithi, P. N.: A deep learning approach for prediction of air quality index in a metropolitan city, Sustain. Cities Soc., 67, 102720, 2021.
Karim, F., Majumdar, S., Darabi, H., and Chen, S.: LSTM fully convolutional networks for time series classification, IEEE access, 6, 1662–1669, 2017.
Kim, H. S., Park, I., Song, C. H., Lee, K., Yun, J. W., Kim, H. K., Jeon, M., Lee, J., and Han, K. M.: Development of a daily PM10 and PM2.5 prediction system using a deep long short-term memory neural network model, Atmos. Chem. Phys., 19, 12935–12951, https://doi.org/10.5194/acp-19-12935-2019, 2019.
Kingma, D. P. and Ba, J.: Adam: A method for stochastic optimization, arXiv [preprint],https://doi.org/10.48550/arXiv.1412.6980, 2014.
Lee, K., Yu, J., Lee, S., Park, M., Hong, H., Park, S. Y., Choi, M., Kim, J., Kim, Y., Woo, J.-H., Kim, S.-W., and Song, C. H.: Development of Korean Air Quality Prediction System version 1 (KAQPS v1) with focuses on practical issues, Geosci. Model Dev., 13, 1055–1073, https://doi.org/10.5194/gmd-13-1055-2020, 2020.
Li, T., Hua, M., and Wu, X.: A hybrid CNN-LSTM model for forecasting particulate matter (PM2.5), Ieee Access, 8, 26933–26940, 2020.
Lu, H., Xie, M., Liu, X., Liu, B., Jiang, M., Gao, Y., and Zhao, X.: Adjusting prediction of ozone concentration based on CMAQ model and machine learning methods in Sichuan-Chongqing region, China, Atmos. Pollut. Res., 12, 101066, https://doi.org/10.1016/j.apr.2021.101066, 2021.
Lu, X., Fung, J. C. H., and Wu, D.: Modeling wet deposition of acid substances over the PRD region in China, Atmos. Environ., 122, 819–828, 2015.
Lu, X., Wang, Y., Li, J., Shen, L., and Fung, J. C.: Evidence of heterogeneous HONO formation from aerosols and the regional photochemical impact of this HONO source, Environ. Res. Lett., 13, 114002, https://doi.org/10.1088/1748-9326/aae492, 2018.
Lu, X., Zhang, S., Xing, J., Wang, Y., Chen, W., Ding, D., Wu, Y., Wang, S., Duan, L., and Hao, J.: Progress of air pollution control in China and its challenges and opportunities in the ecological civilization era, Engineering, 6, 1423–1431, 2020.
Lu, X., Sha, Y. H., Li, Z., Huang, Y., Chen, W., Chen, D., Shen, J., Chen, Y., and Fung, J. C.: Development and application of a hybrid long-short term memory–three dimensional variational technique for the improvement of PM2.5 forecasting, Sci. Total Environ., 770, 144221, https://doi.org/10.1016/j.scitotenv.2020.144221, 2021.
Lyu, B., Hu, Y., Zhang, W., Du, Y., Luo, B., Sun, X., Sun, Z., Deng, Z., Wang, X., and Liu, J.: Fusion method combining ground-level observations with chemical transport model predictions using an ensemble deep learning framework: application in China to estimate spatiotemporally-resolved PM2.5 exposure fields in 2014–2017, Environ. Sci. Technol., 53, 7306–7315, 2019.
Ma, J., Ding, Y., Cheng, J. C., Jiang, F., and Wan, Z.: A temporal-spatial interpolation and extrapolation method based on geographic Long Short-Term Memory neural network for PM2.5, J. Clean. Prod., 237, 117729, https://doi.org/10.1016/j.jclepro.2019.117729, 2019.
Mao, W., Wang, W., Jiao, L., Zhao, S., and Liu, A.: Modeling air quality prediction using a deep learning approach: Method optimization and evaluation, Sustain. Cities Soc., 65, 102567, https://doi.org/10.1016/j.scs.2020.102567, 2021.
Pak, U., Ma, J., Ryu, U., Ryom, K., Juhyok, U., Pak, K., and Pak, C.: Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China, Sci. Total Environ., 699, 133561, https://doi.org/10.1016/j.scitotenv.2019.07.367, 2020.
Qi, Y., Li, Q., Karimian, H., and Liu, D.: A hybrid model for spatiotemporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory, Sci. Total Environ., 664, 1–10, 2019.
Qin, D., Yu, J., Zou, G., Yong, R., Zhao, Q., and Zhang, B.: A novel combined prediction scheme based on CNN and LSTM for urban PM2.5 concentration, IEEE Access, 7, 20050–20059, 2019.
Samal, K. K. R., Panda, A. K., Babu, K. S., and Das, S. K.: An improved pollution forecasting model with meteorological impact using multiple imputation and fine-tuning approach, Sustain. Cities Soc., 70, 102923, https://doi.org/10.1016/j.scs.2021.102923, 2021.
Sayeed, A., Choi, Y., Eslami, E., Jung, J., Lops, Y., Salman, A. K., Lee, J.-B., Park, H.-J., and Choi, M.-H.: A novel CMAQ-CNN hybrid model to forecast hourly surface-ozone concentrations 14 days in advance, Sci. Rep.-UK, 11, 1–8, 2021a.
Sayeed, A., Lops, Y., Choi, Y., Jung, J., and Salman, A. K.: Bias correcting and extending the PM forecast by CMAQ up to 7 days using deep convolutional neural networks, Atmos. Environ., 253, 118376, https://doi.org/10.1016/j.atmosenv.2021.118376, 2021b.
Schuster, M. and Paliwal Kuldip, K.: Bidirectional recurrent neural networks, IEEE T. Signal Proces., 45, 2673–2681, 1997.
Siami-Namini, S., Tavakoli, N., and Namin, A. S.: A comparison of ARIMA and LSTM in forecasting time series, 2018 17th IEEE international conference on machine learning and applications (ICMLA), 17–20 December 2018, Orlando, Florida, USA, 1394–1401, https://doi.org/10.1109/ICMLA.2018.00227, 2018.
Skamarock, W. C., Klemp, J. B., Dudhia, J., Gill, D. O., Barker, D., Duda, M. G., Huang, X. Y., Wang W., and Powers, J. G.: A description of the Advanced Research WRF version 3, NCAR Technical note-475+ STR, https://doi.org/10.5065/D68S4MVH, 2008 (data available at https://www2.mmm.ucar.edu/wrf/users/download/get_source.html, last access: 14 November 2022).
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting, J. Mach. Learn. Res., 15, 1929–1958, 2014.
Sun, H., Fung, J. C., Chen, Y., Chen, W., Li, Z., Huang, Y., Lin, C., Hu, M., and Lu, X.: Improvement of PM2.5 and O3 forecasting by integration of 3D numerical simulation with deep learning techniques, Sustain. Cities Soc., 75, 103372, https://doi.org/10.1016/j.scs.2021.103372, 2021.
Sun, H., Fung, J. C. H., Chen, Y., Li, Z., Yuan, D., Chen, W., and Lu, X.: Ground obeservation data (meteorological factors and air pollution) in Greater Bay Area, 2015–2021, Zenodo [data set], https://doi.org/10.5281/zenodo.6598377, 2022a.
Sun, H., Fung, J. C. H., Chen, Y., Li, Z., Yuan, D., Chen, W., and Lu, X.: Prediction of the broadcasting model and various baselines, Zenodo [data set], https://doi.org/10.5281/zenodo.6833673, 2022b.
Sun, H., Fung, J. C. H., Chen, Y., Li, Z., Yuan, D., Chen, W., and Lu, X.: Deep learning models in the study “Development of an LSTM-Broadcasting deep-learning framework for regional air pollution forecast improvement”, Zenodo [data set], https://doi.org/10.5281/zenodo.6827585, 2022c.
Sun, H., Fung, J. C. H., Chen, Y., Li, Z., Yuan, D., Chen, W., and Lu, X.: Processed ground observation and WRF-CAMQ data for Greater Bay Area, 2015–2021, Zenodo [data set], https://doi.org/10.5281/zenodo.6601173, 2022d.
Sun, J. H.: jvhs0706/regional-forecast-new: GMD paper code, Zenodo [code], https://doi.org/10.5281/zenodo.7019243, 2022.
Sutskever, I., Vinyals, O., and Le, Q. V.: Sequence to sequence learning with neural networks, Adv. Nur. In., 27, 3104–3112, https://doi.org/10.48550/arXiv.1409.3215, 2014.
Tang, Y., Lee, P., Tsidulko, M., Huang, H.-C., McQueen, J. T., DiMego, G. J., Emmons, L. K., Pierce, R. B., Thompson, A. M., and Lin, H.-M.: The impact of chemical lateral boundary conditions on CMAQ predictions of tropospheric ozone over the continental United States, Environ. Fluid Mech., 9, 43–58, 2009.
Tsai, Y.-T., Zeng, Y.-R., and Chang, Y.-S.: Air pollution forecasting using RNN with LSTM, 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), 12–15 August 2018, Athens, Greece, 1074–1079, https://doi.org/10.1109/DASC/PiCom/DataCom/CyberSciTec.2018.00178, 2018.
United States Environmental Protection Agency: CMAQ (Version 5.0.2), Zenodo [software], https://doi.org/10.5281/zenodo.1079898, 2014.
Wu, Q. and Lin, H.: Daily urban air quality index forecasting based on variational mode decomposition, sample entropy and LSTM neural network, Sustain. Cities Soc., 50, 101657, https://doi.org/10.1016/j.scs.2019.101657, 2019.
Zhang, Y., Bocquet, M., Mallet, V., Seigneur, C., and Baklanov, A.: Real-time air quality forecasting, part II: State of the science, current research needs, and future prospects, Atmos. Environ., 60, 656–676, 2012.
Zhao, J., Deng, F., Cai, Y., and Chen, J.: Long short-term memory-Fully connected (LSTM-FC) neural network for PM2.5 concentration prediction, Chemosphere, 220, 486–492, 2019.
Zhou, X., Tong, W., and Li, L.: Deep learning spatiotemporal air pollution data in China using data fusion, Earth Sci. Inform., 13, 859–868, 2020.