the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 16 Mar 2022
| 16 Mar 2022
Towards physics-inspired data-driven weather forecasting: integrating data assimilation with a deep spatial-transformer-based U-NET in a case study with ERA5
Ashesh Chattopadhyay
Mustafa Mustafa
Eviatar Bach
Karthik Kashinath
There is growing interest in data-driven weather prediction (DDWP), e.g., using convolutional neural networks such as U-NET that are trained on data from models or reanalysis. Here, we propose three components, inspired by physics, to integrate with commonly used DDWP models in order to improve their forecast accuracy. These components are (1) a deep spatial transformer added to the latent space of U-NET to capture rotation and scaling transformation in the latent space for spatiotemporal data, (2) a data-assimilation (DA) algorithm to ingest noisy observations and improve the initial conditions for next forecasts, and (3) a multi-time-step algorithm, which combines forecasts from DDWP models with different time steps through DA, improving the accuracy of forecasts at short intervals. To show the benefit and feasibility of each component, we use geopotential height at 500 hPa (Z500) from ERA5 reanalysis and examine the short-term forecast accuracy of specific setups of the DDWP framework. Results show that the spatial-transformer-based U-NET (U-STN) clearly outperforms the U-NET, e.g., improving the forecast skill by 45 %. Using a sigma-point ensemble Kalman (SPEnKF) algorithm for DA and U-STN as the forward model, we show that stable, accurate DA cycles are achieved even with high observation noise. This DDWP+DA framework substantially benefits from large (O(1000)) ensembles that are inexpensively generated with the data-driven forward model in each DA cycle. The multi-time-step DDWP+DA framework also shows promise; for example, it reduces the average error by factors of 2–3. These results show the benefits and feasibility of these three components, which are flexible and can be used in a variety of DDWP setups. Furthermore, while here we focus on weather forecasting, the three components can be readily adopted for other parts of the Earth system, such as ocean and land, for which there is a rapid growth of data and need for forecast and assimilation.
- Article
(4257 KB) - Full-text XML
- BibTeX
- EndNote





Motivated by improving weather and climate prediction, using machine learning (ML) for data-driven spatiotemporal forecasting of chaotic dynamical systems and turbulent flows has received substantial attention in recent years (e.g., Pathak et al., 2018; Vlachas et al., 2018; Dueben and Bauer, 2018; Scher and Messori, 2018, 2019; Chattopadhyay et al., 2020b, c; Nadiga, 2020; Maulik et al., 2021). These data-driven weather prediction (DDWP) models leverage ML methods such as convolutional neural networks (CNNs) and/or recurrent neural networks (RNNs) that are trained on state variables representing the history of the spatiotemporal variability and learn to predict the future states (we have briefly described some of the technical ML terms in Table 1). In fact, a few studies have already shown promising results with DDWP models that are trained on variables representing the large-scale circulation obtained from numerical models or reanalysis products (Scher, 2018; Chattopadhyay et al., 2020a; Weyn et al., 2019, 2020; Rasp et al., 2020; Arcomano et al., 2020; Rasp and Thuerey, 2021). Chattopadhyay et al. (2020d) showed that DDWP models trained on general circulation model (GCM) outputs can be used to predict extreme temperature events. Excellent reviews and opinion pieces on the state of the art of DDWP can be found in Chantry et al. (2021), Watson-Parris (2021), and Irrgang et al. (2021). Other applications of DDWP may include post-processing of ensembles (Grönquist et al., 2021) and sub-seasonal to seasonal prediction (Scher and Messori, 2021; Weyn et al., 2021).
(Lütkepohl, 2013)(Goodfellow et al., 2016)(Goodfellow et al., 2016)(Evensen, 1994)(Wang et al., 2020; Bronstein et al., 2021)(Goodfellow et al., 2016)(Tang et al., 2014)(Jaderberg et al., 2015)(Wan et al., 2001)Table 1List of acronyms and technical ML and DA terms along with their brief descriptions.
The increasing interest (Schultz et al., 2021; Balaji, 2021) in these DDWP models stems from the hope that they improve weather forecasting because of one or both of the following reasons: (1) trained on reanalysis data and/or data from high-resolution NWP models, these DDWP models may not suffer from some of the biases (or generally, model error) of physics-based, operational numerical weather prediction (NWP) models, and (2) the low computational cost of these DDWP models allows for generating large ensembles for probabilistic forecasting (Weyn et al., 2020, 2021). Regarding reason (1), while DDWP models trained on reanalysis data have skills for short-term predictions, so far they have not been able to outperform operational NWP models (Weyn et al., 2020; Arcomano et al., 2020; Schultz et al., 2021). This might be, at least partly, due to the short training sets provided by around 40 years of high-quality reanalysis data (Rasp and Thuerey, 2021). There are a number of ways to tackle this problem; for example, transfer learning could be used to blend data from low- and high-fidelity data or models (e.g., Ham et al., 2019; Chattopadhyay et al., 2020e; Rasp and Thuerey, 2021), and/or physical constraints could be incorporated into the often physics-agnostic ML models, which has been shown in applications of high-dimensional fluid dynamics (Raissi et al., 2020) as well as toy examples of atmospheric or oceanic flows (Bihlo and Popovych, 2021). The first contribution of this paper is to provide a framework for the latter, by integrating the convolutional architectures with deep spatial transformers that capture rotation, scaling, and translation within the latent space that encodes the data obtained from the system. The second contribution of this paper is to equip these DDWP models with data assimilation (DA), which provides improved initial conditions for weather forecasting and is one of the key reasons behind the success of NWP models. Below, we further discuss the need for integrating DA with DDWP models which can capture rotation and scaling transformations in the flow and briefly describe what has been already done in these areas in previous studies.
Many of the DDWP models built so far are physics agnostic and learn the spatiotemporal evolution only from the training data, resulting sometimes in physically inconsistent predictions and an inability to capture key invariants and symmetries of the underlying dynamical system, particularly when the training set is small (Reichstein et al., 2019; Chattopadhyay et al., 2020d). There are various approaches to incorporating some physical properties into the neural networks; for example, Kashinath et al. (2021) have recently reviewed 10 approaches (with examples) for physics-informed ML in the context of weather and climate modeling. One popular approach, in general, is to enforce key conservation laws, symmetries, or some (or even all) of the governing equations through custom-designed loss functions (e.g., Raissi et al., 2019; Beucler et al., 2019; Daw et al., 2020; Mohan et al., 2020; Thiagarajan et al., 2020; Beucler et al., 2021).
Another approach – which has received less attention particularly in weather and climate modeling – is to enforce the appropriate symmetries, which are connected to conserved quantities through Noether's theorem (Hanc et al., 2004), inside the neural architecture. For instance, conventional CNN architectures enforce translational and rotational symmetries, which may not necessarily exist in the large-scale circulation; see Chattopadhyay et al. (2020d) for an example based on atmospheric blocking events and rotational symmetry. Indeed, recent research in the ML community has shown that preserving a more general property called “equivariance” can improve the performance of CNNs (Maron et al., 2018, 2019; Cohen et al., 2019). Equivariance-preserving neural network architectures learn the existence of (or lack thereof) symmetries in the data rather than enforcing them a priori and better track the relative spatial relationship of features (Cohen et al., 2019). In fact, in their work on forecasting midlatitude extreme-causing weather patterns, Chattopadhyay et al. (2020d) have shown that capsule neural networks, which are equivariance-preserving (Sabour et al., 2017), outperform conventional CNNs in terms of out-of-sample accuracy while requiring a smaller training set. Similarly, Wang et al. (2020) have shown the advantages of equivariance-preserving CNN architectures in data-driven modeling of Rayleigh–Bénard and ocean turbulence. More recently, using two-layer quasi-geostrophic turbulence as the test case, Chattopadhyay et al. (2020c) have shown that capturing rotation, scaling, and translational features in the flow in the latent space of a CNN architecture through a deep-spatial-transformer architecture (Jaderberg et al., 2015) improves the accuracy and stability of the DDWP models without increasing the network's complexity or computational cost (which are drawbacks of capsule neural networks). Building on these studies, here our first goal is to develop a physics-inspired, autoregressive DDWP model that uses a deep spatial transformer in an encoder–decoder U-NET architecture (Ronneberger et al., 2015). Note that our approach to use a deep spatial transformer is different from enforcing invariants in the loss function in the form of partial differential equations of the system (Raissi et al., 2019).
DA is an essential component of modern weather forecasting (e.g., Kalnay, 2003; Carrassi et al., 2018; Lguensat et al., 2019). DA corrects the atmospheric state forecasted using a forward model (often a NWP model) by incorporating noisy and partial observations from the atmosphere (and other components of the Earth system), thus estimating a new corrected state of the atmosphere called “analysis”, which serves as an improved initial condition for the forward model to forecast the future states. Most operational forecasting systems have their NWP model coupled to a DA algorithm that corrects the trajectory of the atmospheric states, e.g., every 6 h with observations from remote sensing and in situ measurements. State-of-the-art DA algorithms use variational and/or ensemble-based approaches. The challenge with the former is computing the adjoint of the forward model, which involves high-dimensional, nonlinear partial differential equations (Penny et al., 2019). Ensemble-based approaches, which are usually variants of ensemble Kalman filter (EnKF; Evensen, 1994), bypass the need for computing the adjoint but require generating a large ensemble of states that are each evolved in time using the forward model, which makes this approach computationally expensive (Hunt et al., 2007; Houtekamer and Zhang, 2016; Kalnay, 2003).
In recent years, there has been a growing number of studies at the intersection of ML and DA (Geer, 2021). A few studies have aimed, using ML, to accelerate and improve DA frameworks, e.g., by taking advantage of their natural connection (Abarbanel et al., 2018; Kovachki and Stuart, 2019; Grooms, 2021; Hatfield et al., 2021). A few other studies have focused on using DA to provide suitable training data for ML from noisy or sparse observations (Brajard et al., 2020, 2021; Tang et al., 2020; Wikner et al., 2021). Others have integrated DA with a data-driven or hybrid forecast model for relatively simple dynamical systems (Hamilton et al., 2016; Lguensat et al., 2017; Lynch, 2019; Pawar and San, 2020). However, to the best of our knowledge, no study has yet integrated DA with a DDWP model. Here, our second goal is to present a DDWP+DA framework in which the DDWP is the forward model that efficiently provides a large, O(1000), ensemble of forecasts for a sigma-point ensemble Kalman filter (SPEnKF) algorithm.
To provide proofs of concept for the DDWP model and the combined DDWP+DA framework, we use sub-daily 500 hPa geopotential height (Z500) from the ECMWF Reanalysis 5 (ERA5) dataset (Hersbach et al., 2020). The DDWP model is trained on hourly, 6, or 12 h Z500 samples. The spatiotemporal evolution of Z500 is then forecasted from precise initial conditions using the DDWP model or from noisy initial conditions using the DDWP+SPEnKF framework. Our main contributions in this paper are three-fold, namely,
-
Introducing the spatial-transformer-based U-NET that can capture rotational and scaling features in the latent space for DDWP modeling and showing the advantages of this architecture over a conventional encoder–decoder U-NET.
-
Introducing the DDWP+DA framework, which leads to stable DA cycles without the need for any localization or inflation by taking advantage of the large forecast ensembles produced in a data-driven fashion using the DDWP model.
-
Introducing a novel multi-time-step method for improving the DDWP+DA framework. This framework utilizes virtual observations produced using more accurate DDWP models that have longer time steps. This framework exploits the non-trivial dependence of the accuracy of autoregressive data-driven models on the time step size.
The remainder of the paper is structured as follows. The data are described in Sect. 2. The encoder–decoder U-NET architecture with the deep spatial transformer and the SPEnKF algorithm are introduced in Sect. 3. Results are presented in Sect. 4, and the discussion and summary are in Sect. 5.
We use the ERA5 dataset from the WeatherBench repository (Rasp et al., 2020), where each global sample of Z500 at every hour is downsampled to a rectangular longitude–latitude (x,y) grid of 32×64. We have chosen the variable Z500 following previous work (Weyn et al., 2019, 2020; Rasp et al., 2020) as an example, because it is representative of the large-scale circulation in the troposphere and influences near-surface weather and extremes. This coarse-resolution Z500 dataset from the WeatherBench repository has been used in a number of recent studies to perform data-driven weather forecasting (Rasp et al., 2020; Rasp and Thuerey, 2021). Here, we use Z500 data from 1979 to 2015 (≈315 360 samples) for training, 2016–2017 (≈17 520 samples) for validation, and 2018 (≈8760 samples) for testing.
3.1 The spatial-transformer-based DDWP model: U-NET with a deep spatial transformer (U-STN)
The DDWP models used in this paper are trained on Z500 data without access to any other atmospheric fields that might affect the atmosphere's spatiotemporal evolution. Once trained on past Z500 snapshots sampled at every Δt, the DDWP model takes Z500 at a particular time t (Z(t) hereafter) as the input and predicts Z(t+Δt), which is then used as the input to predict Z(t+2Δt), and this autoregressive process continues as needed. We use Δt, i.e., 1, 6, or 12 h. The baseline DDWP model used here is a U-NET similar to the one used in Weyn et al. (2020). For the DDWP introduced here, the encoded latent space of the U-NET is coupled with a deep spatial transformer (U-STN hereafter) to capture rotational and scaling features between the latent space and the decoded output. The spatial-transformer-based latent space tracks translation, rotation, and stretching of the synoptic- and larger-scale patterns, and it is expected to improve the forecast of the spatiotemporal evolution of the midlatitude Rossby waves and their nonlinear breaking. In this section, we briefly discuss the U-STN architecture, which is schematically shown in Fig. 1. Note that from now on “x” in U-STNx (and U-NETx) indicates the Δt (in hours) that is used; for example, U-STN6 uses Δt=6 h.
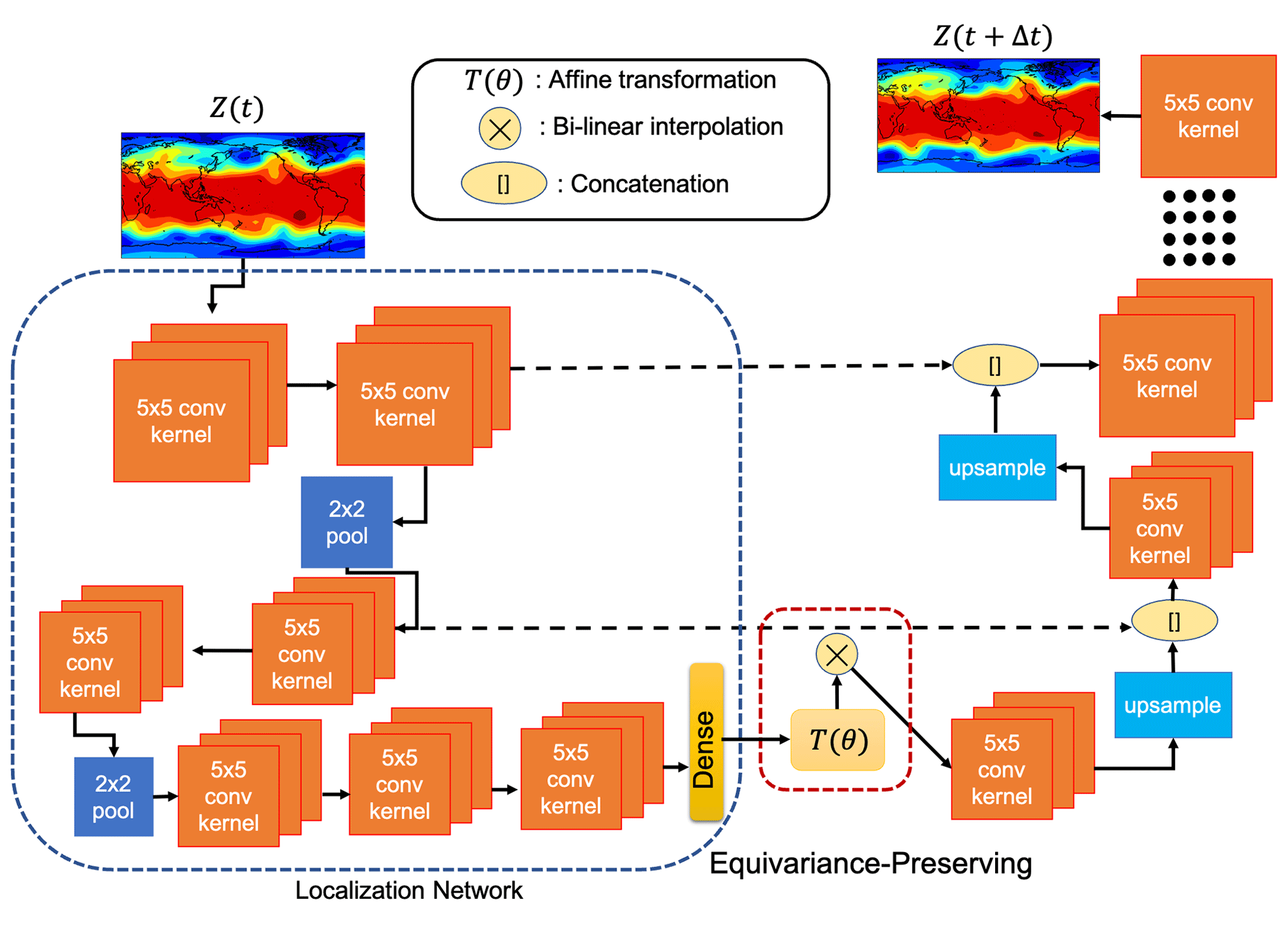
Figure 1A schematic of the architecture of U-STNx. The architecture captures rotation and scaling transformations between the input to the latent space and the decoded output owing to the spatial transformer module implemented through the affine transformation, T(θ), along with the differentiable bilinear interpolation kernel. The network integrates Z(t) to Z(t+Δt). The size of the bottleneck layer is 8×16. Note that the schematic does not show the exact number of layers or number of filters used in U-STNx and U-NETx for the sake of clarity. The information on the number of layers and number of filters along with the activation function used is shown in Table 2.
3.1.1 Localization network or encoding block of U-STN
The network takes in an input snapshot of Z500, Z(t)32×64, as initial condition and projects it onto a low-dimensional encoding space via a U-NET convolutional encoding block. This encoding block performs two successive sets of two convolution operations (without changing the spatial dimensions) followed by a max-pooling operation. It is then followed by two convolutions without max pooling and four dense layers. More details on the exact set of operations inside the architecture are reported in Table 2. The convolutions inside the encoder block account for Earth's longitudinal periodicity by performing circular convolutions (Schubert et al., 2019) on each feature map inside the encoder block. The encoded feature map, which is the output of the encoding block and consists of the reduced Z and coordinate system, and where , is sent to the spatial transformer module described below.
3.1.2 Spatial transformer module
The spatial transformer (Jaderberg et al., 2015) applies an affine transformation T(θ) to the reduced coordinate system to obtain a new transformed coordinate system :
where
The parameters θ are predicted for each sample. A differentiable sampling kernel (a bilinear interpolation kernel in this case) is then used to transform , which is on the old coordinate system , into , which is on the new coordinate system . Note that in this architecture, the spatial transformer is applied to the latent space and its objective is to ensure that no a priori symmetry structure is assumed in the latent space. The parameters in T(θ) learn the transformation (translation, rotation, and scaling) between the input to the latent space and the decoded output. It must be noted here that this does not ensure that the entire network is equivariant by construction.
We highlight that in this paper we are focusing on capturing effects of translation, rotation, and scaling of the input field, because those are the ones that we expect to matter the most for the synoptic patterns on a 2D plane. Furthermore, here we focus on an architecture with a transformer that acts only on the latent space. More complex architectures, with transformations like Eq. (1) after every convolution layer, can be used too albeit with a significant increase in computational cost (de Haan et al., 2020; Wang et al., 2020). Our preliminary exploration shows that, for this work, the one spatial transformer module applied on the latent space of the U-NET yields sufficiently superior performance (over the baseline, U-NET), but further exhaustive explorations should be conducted in future studies to find the best-performing architecture for each application. Moreover, recent work in neural architecture search for geophysical turbulence shows that, with enough computing power, one can perform exhaustive searches over optimal architectures, a direction that should be pursued in future work (Maulik et al., 2020).
Finally we point out that without the transformer module, , and the network becomes a standard U-NET.
3.1.3 Decoding block
The decoding block is a series of deconvolution layers (convolution with zero-padded up-sampling) concatenated with the corresponding convolution outputs from the encoder part of the U-NET. The decoding blocks bring the latent space back into the original dimension and coordinate system at time t+Δt, thus outputting . The concatenation of the encoder and decoder convolution outputs allows the architecture to learn the features in the small-scale dynamics of Z500 better (Weyn et al., 2020).
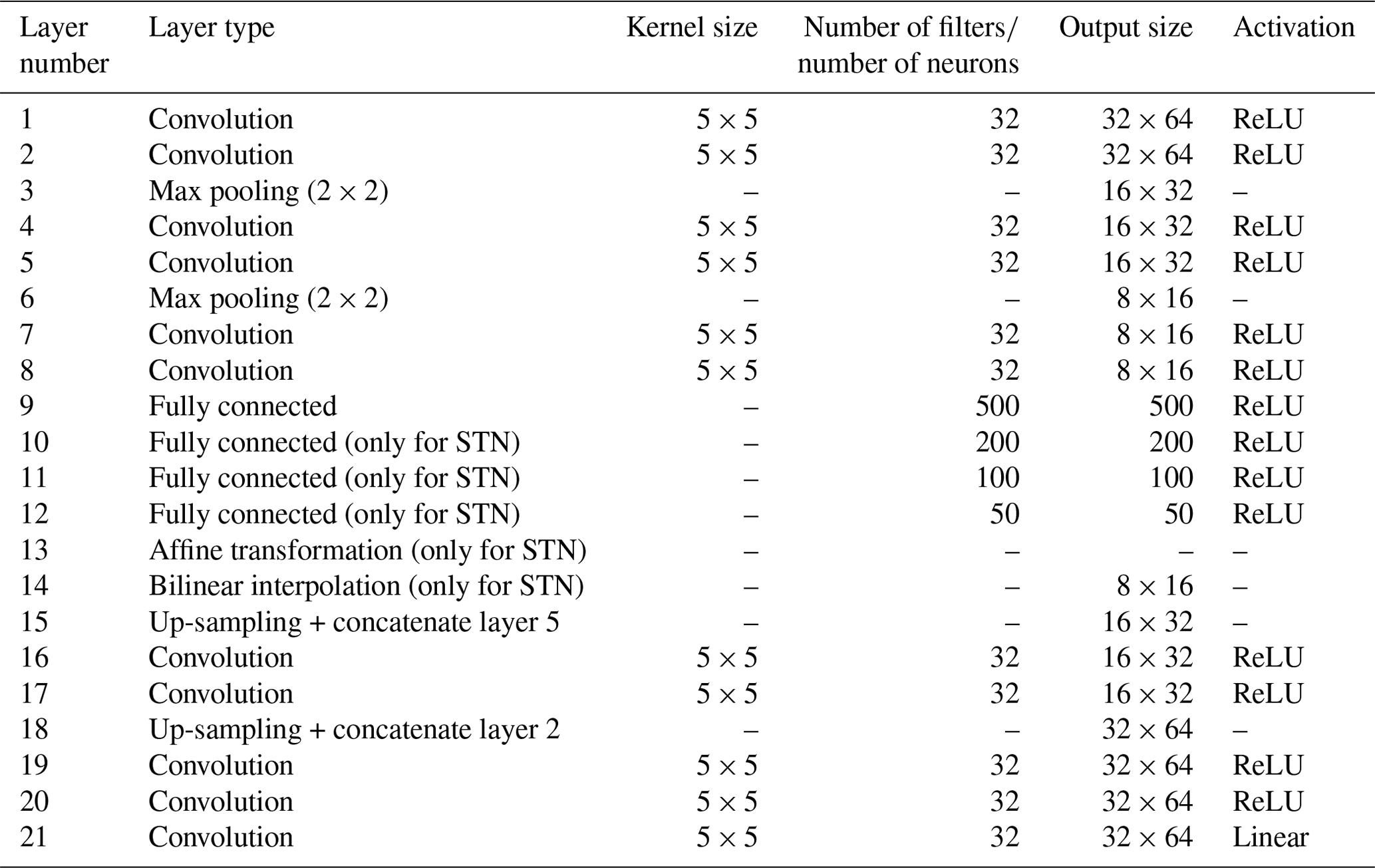
The loss function L to be minimized is
where N is the number of training samples, t=0 is the start time of the training set, and λ represents the parameters of the network that are to be trained (in this case, the weights, biases, and θ of U-STNx). In both encoding and decoding blocks, the rectified linear unit (ReLU) activation functions are used. The number of convolutional kernels (32 in each layer), size of each kernel (5×5), Gaussian initialization, and the learning rate () have been chosen after extensive trial and error. All codes for these networks (as well as DA) have been made publicly available on GitHub and Zenodo (see the “Code and data availability” statement). A comprehensive list of information about each of the layers in both the U-STNx and U-NETx architectures is presented in Table 2 along with the optimal set of hyperparameters that have been obtained through extensive trial and error.
Note that the use of U-NET is inspired from the work by Weyn et al. (2020); however, the architecture used in this study is different from that by Weyn et al. (2020). The main differences are in the number of convolution layers and filters used in the U-NET along with the spatial transformer module. Apart from that, in Weyn et al. (2020) the mechanism by which autoregressive prediction is done is different from this paper. Two time steps (6 and 12 h) are predicted directly as the output by Weyn et al. (2020) using the U-NET. Moreover, the data for training and testing in Weyn et al. (2020) are on the gnomonic cubed sphere.
Table 2Table presenting information on the U-STNx and U-NETx architecture with the optimal set of hyperparameters that have been obtained after extensive trial and error. Note that apart from the affine transformation and bilinear interpolation layer, the U-STNx and U-NETx architectures are similar. The networks have been implemented in Tensorflow and Keras.
3.2 Data assimilation algorithm and coupling with DDWP
For DA, we employ the SPEnKF algorithm, which unlike the EnKF algorithm, does not use random perturbations to generate an ensemble but rather uses an unscented transformation (Wan et al., 2001) to deterministically find an optimal set of points called sigma points (Ambadan and Tang, 2009). The SPEnKF algorithm has been shown to outperform EnKF on particular test cases for both chaotic dynamical systems and ocean dynamics (Tang et al., 2014), although whether it is always superior to EnKF is a matter of active research (Hamill et al., 2009) and beyond the scope of this paper. Our DDWP+DA framework can use any ensemble-based algorithm.
In the DDWP+DA framework, shown schematically in Fig. 2, the forward model is a DDWP, which is chosen to be U-STN1 and denoted as Ψ below. We use σobs for the standard deviation of the observation noise, which in this paper is either σobs=0.5σZ or σobs=σZ, where σZ is the standard deviation of Z500 over all grid points and over all years between 1979–2015. Here, we assume that the noisy observations are assimilated every 24 h (again, the framework can be used with any DA frequency, such as 6 h, which is used commonly in operational forecasting).
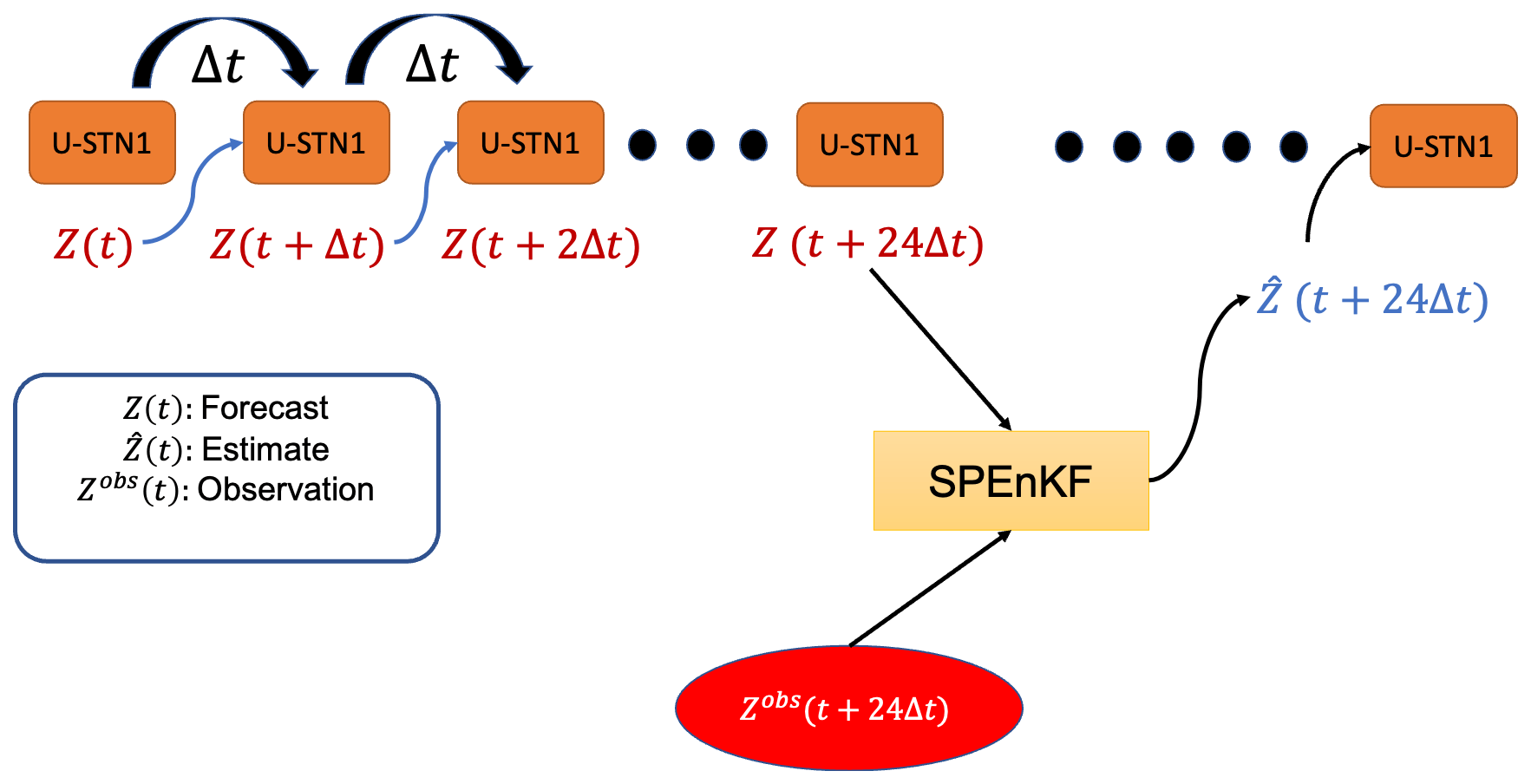
Figure 2The framework for a synergistic integration of a DA algorithm (SPEnKF) with a DDWP (U-STN1). Once the DDWP+DA framework is provided with a noisy Z(t), it uses U-STN1 to autoregressively predict Z(t+23Δt). A large ensemble is then generated using Eq. (4), and for each member k, is predicted using U-STN1. Following that, an SPEnKF algorithm assimilates a noisy observation at the 24th h to provide the estimate (analysis) state of Z500, . U-STN1 then uses this analysis state as the new initial condition and evolves the state in time, with DA occurring every 24 h.
We start with a noisy initial condition Z(t), and we use U-STN1 to autoregressively (with Δt=1 h) predict the next time steps, i.e., Z(t+Δt), Z(t+2Δt), Z(t+3Δt), up to Z(t+23Δt). For a D-dimensional system (i.e., Z∈ℝD), the optimal number of ensemble members for SPEnKF is 2D (Ambadan and Tang, 2009). Because here , then 4096 ensemble members are needed. While this is a very large ensemble size if the forward model is a NWP (operationally, ∼50–100 members are used; Leutbecher, 2019), the DDWP can inexpensively generate O(1000) ensemble members, a major advantage of DDWP as a forward model that we will discuss later in Sect. 5.
To do SPEnKF, an ensemble of states at the 23rd hour of each DA cycle (24 h is one DA cycle) is generated using a symmetric set of sigma points (Julier and Uhlmann, 2004) as
where are indices of the 2D ensemble members. Vectors Ai and Aj are columns of matrix , where U and S are obtained from the singular value decomposition of the analysis covariance matrix Pa, i.e., Pa=USVT. The D×D matrix Pa is either available from the previous DA cycle (see Eq. 10 below) or is initialized as an identity matrix at the beginning of DA. Note that here we generate the ensemble at one Δt before the next DA; however, the ensembles can be generated at any time within the DA cycle and carried forward, although that would increase the computational cost of the framework. We have explored generating the ensembles at t+0Δt (i.e., the beginning) but did not find any improvement over Eq. (4). It must however be noted that by not propagating the ensembles for 24 h, the spread of the ensembles underestimates the background error.
Once the ensembles are generated via Eq. (4), every ensemble member is fed into Ψ to predict an ensemble of forecasted states at t+24Δt:
where . In general, the modeled observation is , where H is the observation operator, and ϵ(t) is the Gaussian random process with standard deviation σobs that represents the uncertainty in the observation. 〈.〉 denotes ensemble averaging. In this paper, we assume that H is the identity matrix while we acknowledge that, in general, it could be a nonlinear function. The SPEnKF algorithm can account for such complexity, but here, to provide a proof of concept, we have assumed that we can observe the state, although with a certain level of uncertainty. With H=I, the background error covariance matrix Pb becomes
where [.]T denotes the transpose operator, and E[.] denotes the expectation operator. The innovation covariance matrix is defined as
where the observation noise matrix R is a constant diagonal matrix of the variance of observation noise, i.e., . The Kalman gain matrix is then given by
and the estimated (analysis) state is calculated as
where Zobs(t+24Δt) is the noisy observed Z500 at t+24Δt, i.e., ERA5 value at each grid point plus random noise drawn from . While adding Gaussian random noise to the truth is an approximation, it is a quite common in the DA literature (Brajard et al., 2020, 2021; Pawar et al., 2020). The analysis error covariance matrix is updated as
The estimated state becomes the new initial condition to be used by U-STN1, and the updated Pa is used to generate the ensembles in Eq. (4) after another 23 h for the next DA cycle.
Finally, we remark that often with low ensemble sizes, the background covariance matrix, Pb (Eq. 6), suffers from spurious correlations which are corrected using localization and inflation strategies (Hunt et al., 2007; Asch et al., 2016). However, due to the large ensemble size used here (with 4096 ensemble members that are affordable because of the computationally inexpensive DDWP forward model), we do not need to perform any localization or inflation on Pb to get stable DA cycles as shown in the next section.
4.1 Performance of the spatial-transformer-based DDWP: noise-free initial conditions (no DA)
First, we compare the performance a U-STN and a conventional U-NET, where the only difference is in the use of the spatial transformer module in the former. Using U-STN12 and U-NET12 as representatives of these architectures, Fig. 3 shows the anomaly correlation coefficients (ACCs) between the predictions from U-STN12 or U-NET12 and the truth (ERA5) for 30 noise-free, random initial conditions. ACC is computed every 12 h as the correlation coefficient between the predicted Z500 anomaly and the Z500 anomaly of ERA5, where anomalies are derived by removing the 1979–2015 time mean of Z500 of the ERA5 dataset. U-STN12 clearly outperforms U-NET12, most notably after 36 h, reaching ACC=0.6 after around 132 h, a 45 % (1.75 d) improvement over U-NET12, which reaches ACC=0.6 after around 90 h.
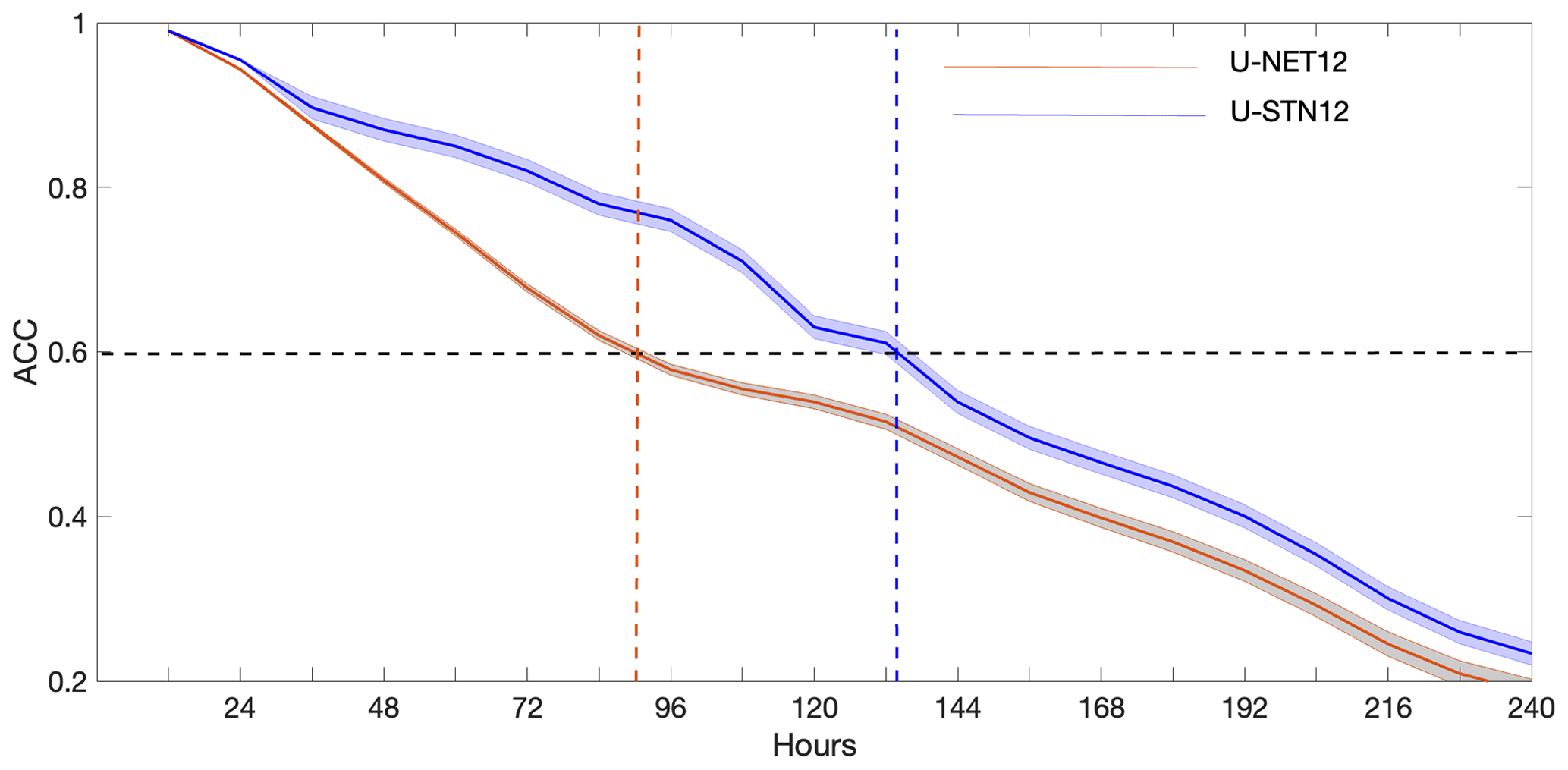
Figure 3Anomaly correlation coefficient (ACC) calculated between Z500 anomalies of ERA5 and Z500 anomalies predicted using U-STN12 or U-NET12 from 30 noise-free, random initial conditions. The solid lines and the shading show the mean and the standard deviation over the 30 initial conditions.
To further see the source of this improvement, Fig. 4 shows the spatiotemporal evolution of Z500 patterns from an example of prediction using U-STN12 and U-NET12. Comparing with the truth (ERA5), U-STN12 can better capture the evolution of the large-amplitude Rossby waves and the wave-breaking events compared to U-NET12; for example, see the patterns over Central Asia, Southern Pacific Ocean, and Northern Atlantic Ocean on days 2–5. We cannot rigorously attribute the better capturing of wave-breaking events to an improved representation of physical features by the spatial transformer. However, the overall improvement in performance of U-STN12 due to the spatial transformer (which is the only difference between U-STN12 and U-NET12) may lead to capturing some wave-breaking events in the atmosphere as can be seen from exemplary evidence in Fig. 4. Furthermore, on days 4 and 5, the predictions from U-NET12 have substantially low Z500 values in the high latitudes of the Southern Hemisphere, showing signs of unphysical drifts.
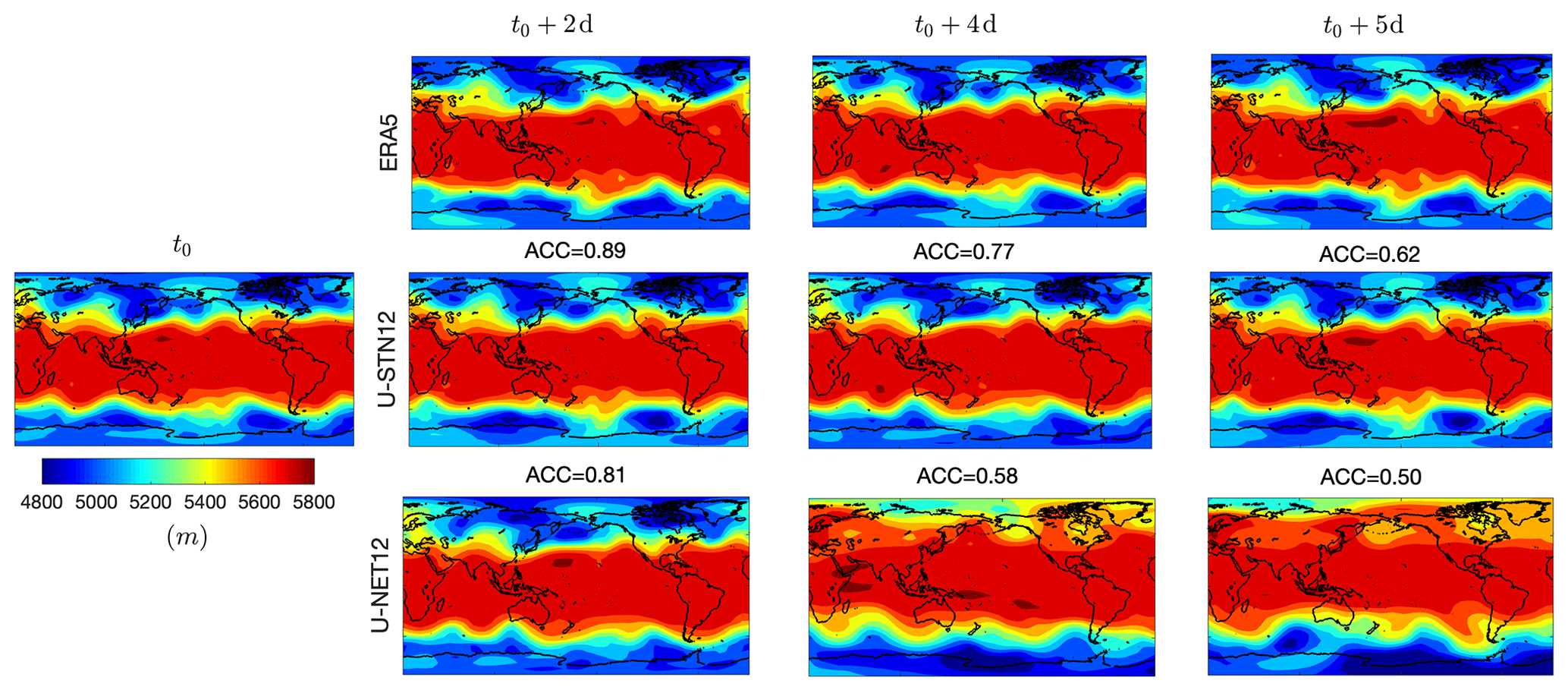
Figure 4Examples of the spatiotemporal evolution of Z500 predicted from a noise-free initial condition (t0) using U-STN12 and U-NET12 and compared with the truth from ERA5. For the predicted patterns, the anomaly correlation coefficient (ACC) is shown above each panel (see the text for details).
Overall, the results of Figs. 3 and 4 show the advantages of using the spatial-transformer-enabled U-STN in DDWP models. It is important to note that it is difficult to assert whether the transformation with T(θ) in the latent space actually leads to physically meaningful transformations in the decoded output. However, we see that the performance of the network improves with the addition of the spatial transformer module. Future studies need to focus on more interpretation of what the T(θ) matrix inside neural networks captures (Bronstein et al., 2021). Note that while here we show results with Δt=12 h, similar improvements are seen with Δt=1 and Δt=6 h (see Sect. 4.3). Furthermore, to provide a proof of concept for the U-STN, in this paper we focus on Z500 (representing the large-scale circulation) as the only state variable to be learned and predicted. Even without access to any other information (e.g., about small scales), the DDWP model can provide skillful forecasts for some time, consistent with earlier findings with the multi-scale Lorenz 96 system (Dueben and Bauer, 2018; Chattopadhyay et al., 2020b). More state variables can be easily added to the framework, which is expected to extend the forecast skill, based on previous work with U-NET (Weyn et al., 2020). In this work, we have considered Z500 as an example for a proof of concept. We have also performed experiments (not shown for brevity) by adding T850 as one of the variables to the input along with Z500 in U-NETx and U-STNx and found similarly good prediction performance for the T850 variable.
A benchmark for different DDWP models has been shown in Rasp et al. (2020), with different ML algorithms such as CNN, linear regression, etc. In terms of RMSE for Z500 (Fig. 6, left panel, shows RMSE of U-STNx and U-NETx in this paper with different Δt), U-STN12 outperforms the CNN model in WeatherBench (Rasp et al., 2020) by 33.2 m at lead time of 3 d and 26.7 m at lead time of 5 d. Similarly, U-STN12 outperforms the linear regression in WeatherBench by 39.9 m at lead time of 3 d and by 29.3 m at lead time of 5 d. Note that in more recent work (Weyn et al., 2020; Rasp and Thuerey, 2021), prediction horizons outperforming the WeatherBench models (Rasp et al., 2020) have also been shown.
4.2 Performance of the DDWP+DA framework: noisy initial conditions and assimilated observations
To analyze the performance of the DDWP+DA framework, we use U-STN1 as the DDWP model and SPEnKF as the DA algorithm, as described in Sect. 3.2. In this U-STN1+SPEnKF setup, the initial conditions for predictions are noisy observations and every 24 h, noisy observations are assimilated to correct the forecast trajectory (as mentioned before, noisy observations are generated by adding random noise from 𝒩(0,σobs) to the Z500 of ERA5).
In Fig. 5, for 30 random initial conditions and two noise levels (σobs=0.5σZ or 1σZ), we report the spatially averaged root-mean-square error (RMSE) and the correlation coefficient (R) of the forecasted full Z500 fields as compared to the truth, i.e., the (noise-free) Z500 fields of ERA5. For both noise levels, we see that within each DA cycle, the forecast accuracy decreases between 0 and 23 h until DA with SPEnKF occurs at the 24th hour, wherein information from the noisy observation is assimilated to improve the estimate of the forecast at the 24th hour. This estimate acts as the new improved initial condition to be used by U-STN1 to forecast future time steps. In either case, the RMSE and R remain below 30 m (80 m) and above 0.7 (0.3) with σobs=0.5σZ (σobs=1σZ) for the first 10 d. The main point here is not the accuracy of the forecast (which as mentioned before and could be further extended, e.g., by adding more state variables), but the stability of the U-STN1+SPEnKF framework (without localization or inflation), which even with the high noise level, can correct the trajectory and increase R from ∼0.3 to 0.8 in each cycle. Although not shown in this paper, the U-STN1+SPEnKF framework remains stable beyond 10 d and shows equally good performance for longer periods of time.
One last point to make here is that within each DA cycle, the maximum forecast accuracy is not when DA occurs but 3–4 h later (this is most clearly seen for the case with σobs=1σZ in Fig. 5). A likely reason behind the further improvement of the performance after DA is the de-noising capability of neural networks when trained on non-noisy training data (Xie et al., 2012).

Figure 5Panel (a) shows R and panel (b) shows RMSE (in meters) between noise-free data from ERA5 and the forecasts from U-STN1+SPEnKF for two levels of observation noise. Predictions are started from 30 random noisy observations. The lines (shading) show the mean (standard deviation) of the 30 forecasts. Noisy observations are assimilated every 24 h (indicated by black, dashed vertical lines).
4.3 DDWP+DA with virtual observations: a multi-time-step framework
One might wonder how the performance of the DDWP model (with or without DA) depends on Δt. Figure 6 compares the performance of U-STNx as well as U-NETx for Δt=1, 6, and 12 h for 30 random noise-free initial conditions (no DA). It is clear that the DDWP models with larger Δt outperform the ones with smaller Δt; that is, in terms of forecast accuracy, . This trends hold true for both U-STNx and U-NETx, while as discussed before, for the same Δt, the U-STN outperforms U-NET.
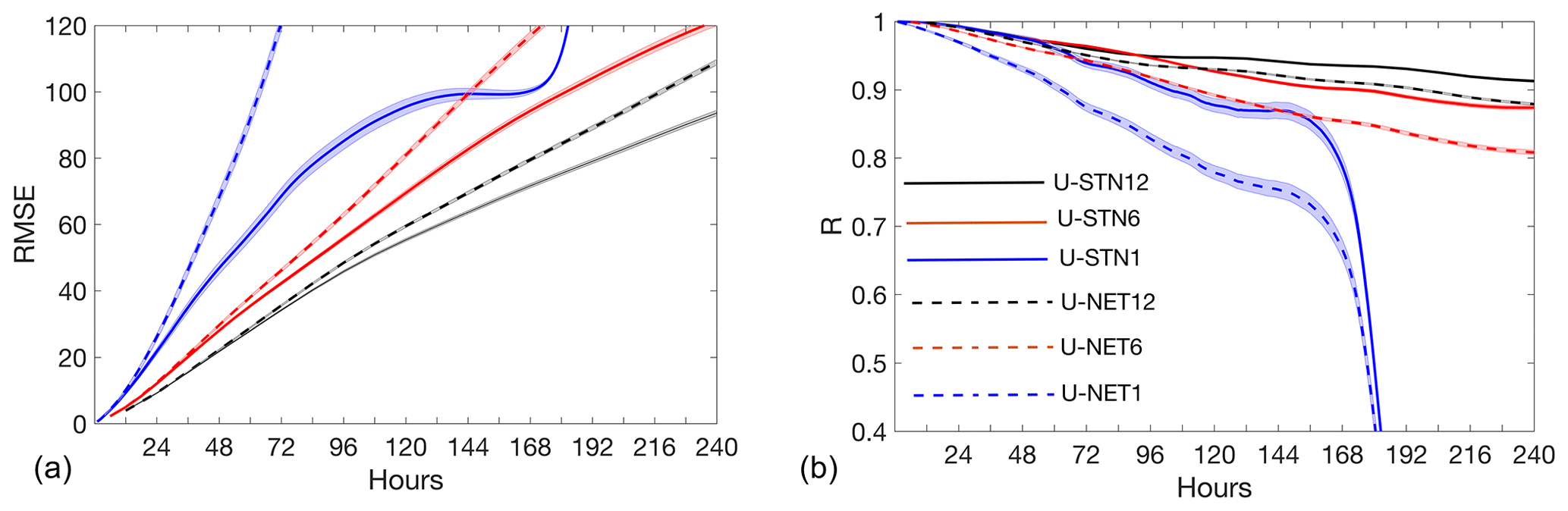
Figure 6Panels (a) and (b) show RMSE (R) between noise-free data from ERA5 and the forecasts from U-STNx or U-NETx from 30 random, noise-free initial conditions. No DA is used here. RMSE is in meters. The lines (shading) show the mean (standard deviation) of the 30 forecasts.
This dependence on Δt might seem counterintuitive as it is opposite of what one sees in numerical models, whose forecast errors decrease with smaller time steps. The increase in the forecast errors of these DDWP models when Δt is decreased is likely due to the non-additive nature of the error accumulation of these autoregressive models. The data-driven models have some degree of generalization error (for out-of-sample prediction), and every time the model is invoked to predict the next time step, this error is accumulated. For neural networks, this accumulation is not additive and propagates nonlinearly during the autoregressive prediction. Currently, these error propagations are not understood well enough to build a rigorous framework for estimating the optimal Δt for data-driven, autoregressive forecasting; however, this behavior has been reported in other studies on nonlinear dynamical systems and can be exploited to formulate multi-time-step data-driven models; see Liu et al. (2020) for an example (though without DA).
Based on the trends seen in Fig. 6, we propose a novel idea for a multi-time-step DDWP+DA framework, in which the forecasts from the more accurate DDWP with larger Δt are incorporated as virtual observations, using DA, into the forecasts of the less accurate DDWP with smaller Δt, thus providing overall more accurate short-term forecasts. Figure 7 shows a schematic of this framework for the case where the U-STN12 model provides the virtual observations that are assimilated using the SPEnKF algorithm in the middle of the 24 h DA cycles into the hourly forecasts from U-STN1. At 24th hour, noisy observations are assimilated using the SPEnKF algorithm as before.
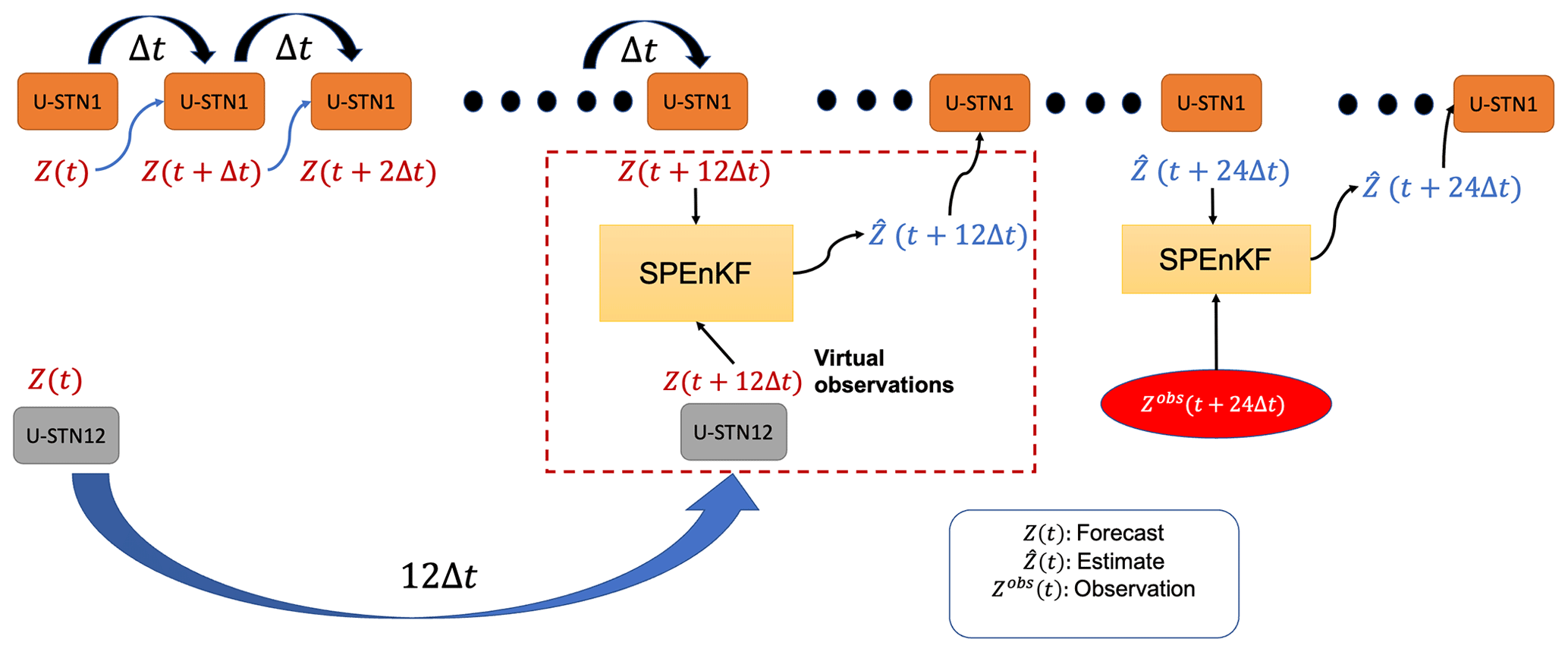
Figure 7Schematic of the multi-time-step DDWP+DA framework. The U-STN12 model provides forecasts every 12 h, which are assimilated as virtual observations using SPEnKF into the U-STN1+SPEnKF framework that has a 24 h DA cycle for assimilating noisy observations. At 12th hours, the U-STN12 forecasts are more accurate than those from the U-STN1 model, enabling the framework to improve the prediction accuracy every 12th hour, thereby improving the initial condition used for the next forecasts before DA with noisy observations (every 24 h).
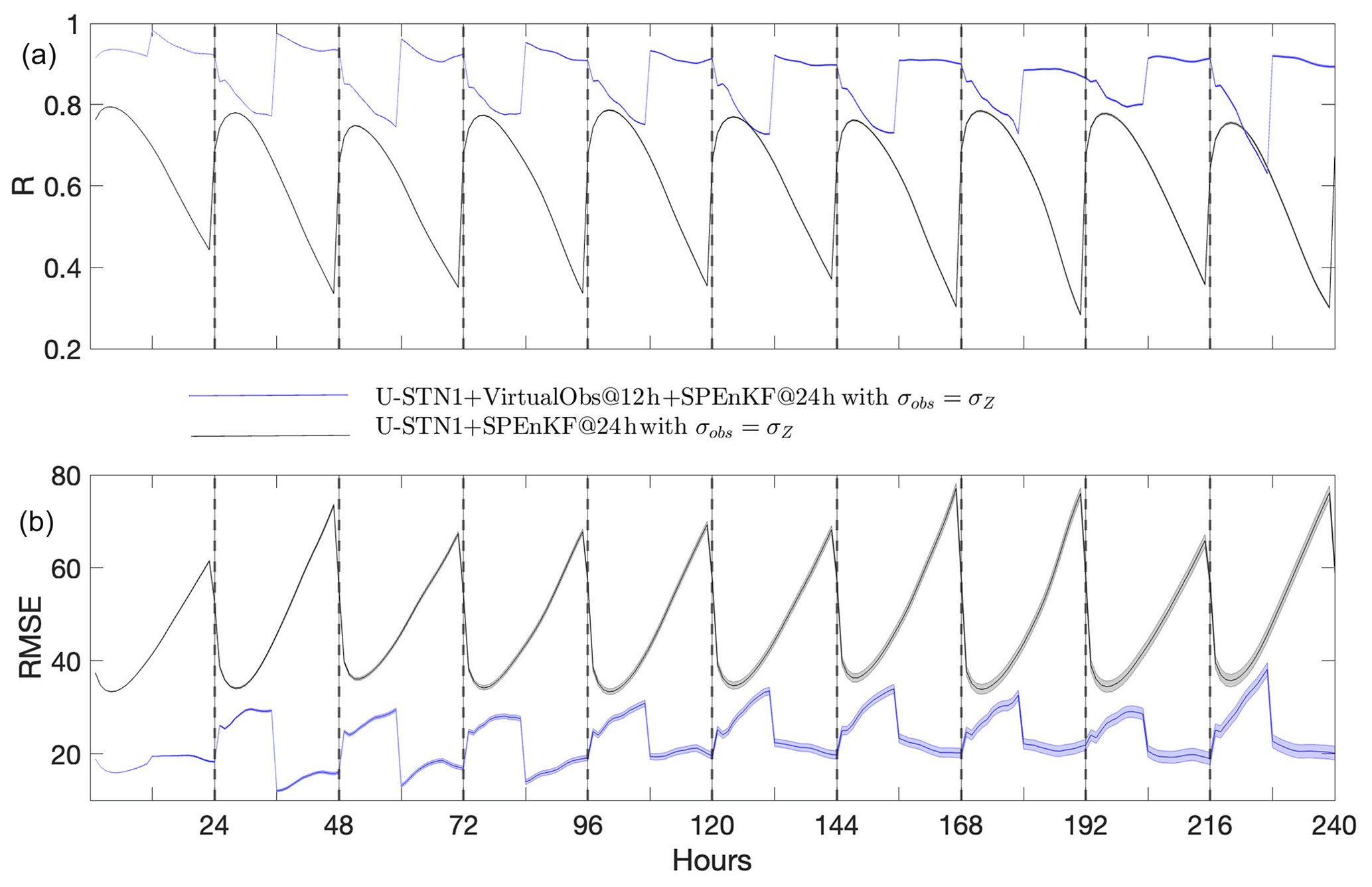
Figure 8 compares the performance of the multi-time-step U-STNx+SPEnKF framework, which uses virtual observations from U-STN12, with that of U-STN1+SPEnKF, which was introduced in Sect. 4.2, for the case with σobs=0.5σZ. In terms of both RMSE and R, the multi-time-step U-STNx+SPEnKF framework outperforms the U-STN1+SPEnKF framework, as for example, the maximum RMSE of the former is often comparable to the minimum RMSE of the latter. Figure 9 shows the same analysis but for the case with larger observation noise σobs=σZ, which further demonstrates the benefits of the multi-time-step framework and use of virtual observations.

Figure 8Performance of the multi-time-step U-STNx+SPEnKF framework (with virtual observations at the 12th hour of every 24 h DA cycle) compared to that of the U-STN+SPEnKF framework for the case with σobs=0.5σZ. Panels (a) and (b) show R (RMSE in meters). The black, dashed vertical lines indicate DA of noisy observations at every 24 h. Forecasts are started from 30 random, noisy initial conditions. The lines (shading) show the mean (standard deviation) of the 30 forecasts.
The multi-time-step framework with assimilated virtual observations introduced here improves the forecasts of short-term intervals by exploiting the non-trivial dependence of the accuracy of autoregressive, data-driven models on time step size. While hourly forecasts of Z500 may not be necessarily of practical interest, the framework can be applied in general to any state variable and can be particularly useful for multi-scale systems with a broad range of spatiotemporal scales. A similar idea was used in Bach et al. (2021), wherein data-driven forecasts of oscillatory modes with singular spectrum analysis and an analog method were used as virtual observations to improve the prediction of a chaotic dynamical system.
In this paper, we propose three novel components for DDWP frameworks to improve their performance: (1) a deep spatial transformer in the latent space to encode the relative spatial relationships of features of the spatiotemporal data in the network architecture, (2) a stable and inexpensive ensemble-based DA algorithm to ingest noisy observations and correct the forecast trajectory, and (3) a multi-time-step algorithm, in which the accurate forecasts of a DDWP model that uses a larger time step are assimilated as virtual observations into the less accurate forecasts of a DDWP that uses a smaller time step, thus improving the accuracy of forecasts at short intervals.
To show the benefits of each component, we use downsampled Z500 data from ERA5 reanalysis and examine the short-term forecast accuracy of the DDWP framework. To summarize the findings, we present the following points.
-
As show in Sect. 4.1 for noise-free initial conditions (no DA), U-STN12, which uses a deep spatial transformer and Δt=12 h, outperforms U-NET12, e.g., extending the average prediction horizon (when ACC reaches 0.6) from 3.75 d (U-NET12) to 5.5 d (U-STN12). Examining a few examples of the spatiotemporal evolution of the forecasted Z500 patterns, we can see that U-STN better captures phenomena such as wave breaking. We further show in Sect. 4.3 based on other metrics that with the same Δt U-STN outperforms U-NET. These results demonstrate the benefits of adding deep spatial transforms to convolutional networks such as U-NET.
-
As shown in Sect. 4.2, an SPEnKF DA algorithm is coupled with the U-STN1 model. In this framework, the U-STN1 serves as the forward model to generate a large ensemble of forecasts in a data-driven fashion in each DA cycle (24 h), when noisy observations are assimilated. Because U-STN1 is computationally inexpensive, for a state vector of size D, ensembles with 2D=4096 members are easily generated in each DA cycle, leading to stable, accurate forecasts without the need for localization or inflation of covariance matrices involved in the SPEnKF algorithm. The results show that DA can be readily coupled with DDWP models when dealing with noisy initial conditions. The results further show that such coupling is substantially facilitated by the fact that large ensembles can be easily generated with data-driven forward models. Note however that NWP models have a larger number of state variables (O(108)) which would make SPEnKF very computationally expensive; in such cases, further parallelization of the SPEnKF algorithm would be required.
-
As shown in Sect. 4.3, the autoregressive DDWP models (U-STN or U-NET) are more accurate with larger Δt, which is attributed to the nonlinear error accumulation over time. Exploiting this trend and the ease of coupling DA with DDWP, we show that assimilating the forecasts of U-STN12 into U-STN1+SPEnKF as virtual observations in the middle of the 24 h DA cycles can substantially improve the performance of U-STN1+SPEnKF. These results demonstrate the benefits of the multi-time-step algorithm with virtual observations.
Note that to provide proofs of concept here we have chosen specific parameters, approaches, and setups. However, the framework for adding these three components is extremely flexible, and other configurations can be easily accommodated. For example, other DA frequencies, Δt, U-NET architectures, or ensemble-based DA algorithms could be used. Furthermore, here we assume that the available observations are noisy but not sparse. The gain from adding DA to DDWP would be most significant when the observations are noisy and sparse. Moreover, the ability to generate O(1000) ensembles inexpensively with a DDWP would be particularly beneficial for sparse observations for which the stability of DA is more difficult to achieve without localization and inflation (Asch et al., 2016). The advantages of the multi-time-step DDWP+DA framework would be most significant when multiple state variables, of different temporal scales, are used, or more importantly, when the DDWP model consists of several coupled data-driven models for different sets of state variables and processes (Reichstein et al., 2019; Schultz et al., 2021). Moreover, while here we show that ensemble-based DA algorithms can be inexpensively and stably coupled with DDWP models, variational DA algorithms (Bannister, 2017) could be also used, given that computing the adjoint for the DDWP models can be easily done using automatic differentiation.
The DDWP models are currently not as accurate as operational NWP models (Weyn et al., 2020; Arcomano et al., 2020; Rasp and Thuerey, 2021; Schultz et al., 2021). However, they can still be useful through generating large forecast ensembles (Weyn et al., 2021), and there is still much room for improving DDWP frameworks, e.g., using the three components introduced here as well as using transfer learning, which has been shown recently to work robustly and effectively across a range of problems (e.g., Ham et al., 2019; Chattopadhyay et al., 2020e; Subel et al., 2021; Guan et al., 2022).
Finally, we point out that while here we focus on weather forecasting, the three components can be readily adopted for other parts of the Earth system, such as ocean and land, for which there is a rapid growth of data and need for forecast and assimilation (e.g., Kumar et al., 2008b, a; Yin et al., 2011; Edwards et al., 2015; Liang et al., 2019).
A1 Forecast results with T850 variable
In this section, we have show an example of prediction performance with T850 instead of Z500. In Fig. A1, we can see that U-STN12 shows improved performance as compared to U-NET12 in T850 as well.
A2 Comparison with two WeatherBench models
In this section, we present Table A1 to compare U-STN12 model with two WeatherBench models at day 3 and day 5 in terms of RMSE (m2 s−2) for Z500. Please note that the comparisons made here are with the U-STN12 without DA and is hence a fair comparison.
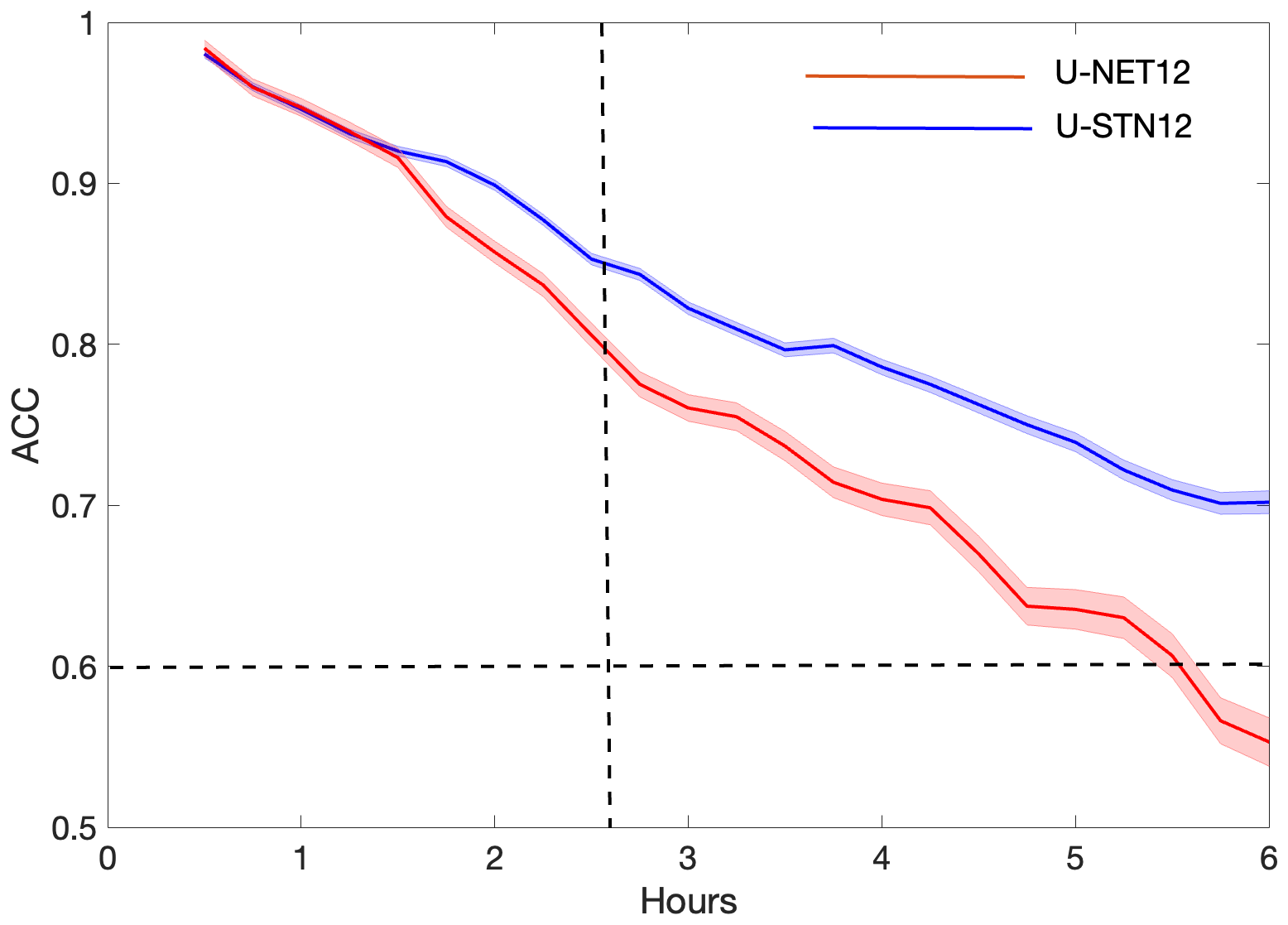
Figure A1Performance of U-STN12 and U-NET12 on T850. Shading represents standard deviation over 30 initial conditions.

All codes used in this study are publicly available at https://doi.org/10.5281/zenodo.6112374 (Chattopadhyay, 2021). The data are available from the WeatherBench repository at https://github.com/pangeo-data/WeatherBench (last access: 16 February 2022).
AC, MM, and KK designed the study. AC conducted research. AC and PH wrote the article. All authors analyzed and discussed the results. All authors contributed to writing and editing of the article.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We thank Jaideep Pathak, Rambod Mojgani, and Ebrahim Nabizadeh for helpful discussions. We would like to thank Tom Beucler, one anonymous referee and the editor, whose insightful comments, suggestions, and feedback have greatly improved the clarity of the article. This work was started at National Energy Research Scientific Computing Center (NERSC) as a part of Ashesh Chattopadhyay's internship in the summer of 2020, under the mentorship of Mustafa Mustafa and Karthik Kashinath, and continued as a part of his PhD work at Rice University, under the supervision of Pedram Hassanzadeh. This research used resources of NERSC, a U.S. Department of Energy Office of Science User Facility operated under contract no. DE-AC02-05CH11231. Ashesh Chattopadhyay and Pedram Hassanzadeh were supported by ONR grant N00014-20-1-2722 and NASA grant 80NSSC17K0266. Ashesh Chattopadhyay also thanks the Rice University Ken Kennedy Institute for a BP high-performance computing (HPC) graduate fellowship. Eviatar Bach was supported by the University of Maryland Flagship Fellowship and Ann G. Wylie Fellowship, as well as by Monsoon Mission II funding (grant IITMMMIIUNIVMARYLANDUSA2018INT1) provided by the Ministry of Earth Science, Government of India.
This research has been supported by the U.S. Department of Energy, Office of Science (grant no. DE-AC02-05CH11231), the Office of Naval Research (grant no. N00014-20-1-2722), and the National Aeronautics and Space Administration (grant no. 80NSSC17K0266).
This paper was edited by Xiaomeng Huang and reviewed by Tom Beucler and one anonymous referee.
Abarbanel, H. D., Rozdeba, P. J., and Shirman, S.: Machine learning: Deepest learning as statistical data assimilation problems, Neural Comput., 30, 2025–2055, 2018. a
Ambadan, J. T. and Tang, Y.: Sigma-point Kalman filter data assimilation methods for strongly nonlinear systems, J. Atmos. Sci., 66, 261–285, 2009. a, b
Arcomano, T., Szunyogh, I., Pathak, J., Wikner, A., Hunt, B. R., and Ott, E.: A Machine Learning-Based Global Atmospheric Forecast Model, Geophys. Res. Lett., 47, e2020GL087776, https://doi.org/10.1029/2020GL087776, 2020. a, b, c
Asch, M., Bocquet, M., and Nodet, M.: Data assimilation: methods, algorithms, and applications, SIAM, ISBN 978-1-61197-453-9, 2016. a, b
Bach, E., Mote, S., Krishnamurthy, V., Sharma, A. S., Ghil, M., and Kalnay, E.: Ensemble Oscillation Correction (EnOC): Leveraging oscillatory modes to improve forecasts of chaotic systems, J. Climate, 34, 5673–5686, 2021. a
Balaji, V.: Climbing down Charney's ladder: machine learning and the post-Dennard era of computational climate science, Philos. T. Roy. Soc. A, 379, 20200085, https://doi.org/10.1098/rsta.2020.0085, 2021. a
Bannister, R.: A review of operational methods of variational and ensemble-variational data assimilation, Q. J. Roy. Meteor. Soc., 143, 607–633, 2017. a
Beucler, T., Rasp, S., Pritchard, M., and Gentine, P.: Achieving conservation of energy in neural network emulators for climate modeling, arXiv [preprint], arXiv:1906.06622, 2019. a
Beucler, T., Pritchard, M., Rasp, S., Ott, J., Baldi, P., and Gentine, P.: Enforcing analytic constraints in neural networks emulating physical systems, Phys. Rev. Lett., 126, 098302, https://doi.org/10.1103/PhysRevLett.126.098302, 2021. a
Bihlo, A. and Popovych, R. O.: Physics-informed neural networks for the shallow-water equations on the sphere, arXiv [preprint], arXiv:2104.00615, 2021. a
Brajard, J., Carrassi, A., Bocquet, M., and Bertino, L.: Combining data assimilation and machine learning to emulate a dynamical model from sparse and noisy observations: a case study with the Lorenz 96 model, J. Comput. Sci., 44, 101171, https://doi.org/10.1016/j.jocs.2020.101171, 2020. a, b
Brajard, J., Carrassi, A., Bocquet, M., and Bertino, L.: Combining data assimilation and machine learning to infer unresolved scale parametrization, Philos. T. Roy. Soc. A, 379, 20200086, https://doi.org/10.1098/rsta.2020.0086, 2021. a, b
Bronstein, M. M., Bruna, J., Cohen, T., and Veličković, P.: Geometric deep learning: Grids, groups, graphs, geodesics, and gauges, arXiv [preprint], arXiv:2104.13478, 2021. a, b
Carrassi, A., Bocquet, M., Bertino, L., and Evensen, G.: Data assimilation in the geosciences: An overview of methods, issues, and perspectives, WIRes Clim. Change, 9, e535, https://doi.org/10.1002/wcc.535, 2018. a
Chantry, M., Christensen, H., Dueben, P., and Palmer, T.: Opportunities and challenges for machine learning in weather and climate modelling: hard, medium and soft AI, Philos. T. Roy. Soc. A, 379, 20200083, https://doi.org/10.1098/rsta.2020.0083, 2021. a
Chattopadhyay, A.: Towards physically consistent data-driven weather forecasting: Integrating data assimilation with equivariance-preserving deep spatial transformers, Zenodo [code], https://doi.org/10.5281/zenodo.6112374, 2021. a
Chattopadhyay, A., Hassanzadeh, P., and Pasha, S.: Predicting clustered weather patterns: A test case for applications of convolutional neural networks to spatio-temporal climate data, Sci. Rep., 10, 1–13, 2020a. a
Chattopadhyay, A., Hassanzadeh, P., and Subramanian, D.: Data-driven predictions of a multiscale Lorenz 96 chaotic system using machine-learning methods: reservoir computing, artificial neural network, and long short-term memory network, Nonlin. Processes Geophys., 27, 373–389, https://doi.org/10.5194/npg-27-373-2020, 2020b. a, b
Chattopadhyay, A., Mustafa, M., Hassanzadeh, P., and Kashinath, K.: Deep spatial transformers for autoregressive data-driven forecasting of geophysical turbulence, in: Proceedings of the 10th International Conference on Climate Informatics, Oxford, UK, 106–112, https://doi.org/10.1145/3429309.3429325, 2020c. a, b
Chattopadhyay, A., Nabizadeh, E., and Hassanzadeh, P.: Analog forecasting of extreme-causing weather patterns using deep learning, J. Adv. Model. Earth Sy., 12, e2019MS001958, https://doi.org/10.1029/2019MS001958, 2020d. a, b, c, d
Chattopadhyay, A., Subel, A., and Hassanzadeh, P.: Data-driven super-parameterization using deep learning: Experimentation with multi-scale Lorenz 96 systems and transfer-learning, J. Adv. Model. Earth Sy., 12, e2020MS002084, https://doi.org/10.1029/2020MS002084, 2020e. a, b
Cohen, T., Weiler, M., Kicanaoglu, B., and Welling, M.: Gauge equivariant convolutional networks and the icosahedral CNN, in: International Conference on Machine Learning, PMLR, Long Beach, California, 97, 1321–1330, 2019. a, b
Daw, A., Thomas, R. Q., Carey, C. C., Read, J. S., Appling, A. P., and Karpatne, A.: Physics-guided architecture (pga) of neural networks for quantifying uncertainty in lake temperature modeling, in: Proceedings of the 2020 Siam International Conference on Data Mining, SIAM, Cincinnati, Ohio, 532–540, https://doi.org/10.1137/1.9781611976236.60, 2020. a
de Haan, P., Weiler, M., Cohen, T., and Welling, M.: Gauge equivariant mesh CNNs: Anisotropic convolutions on geometric graphs, arXiv [preprint], arXiv:2003.05425, 2020. a
Dueben, P. D. and Bauer, P.: Challenges and design choices for global weather and climate models based on machine learning, Geosci. Model Dev., 11, 3999–4009, https://doi.org/10.5194/gmd-11-3999-2018, 2018. a, b
Edwards, C. A., Moore, A. M., Hoteit, I., and Cornuelle, B. D.: Regional ocean data assimilation, Annu. Rev. Mar. Sci., 7, 21–42, 2015. a
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res.-Oceans, 99, 10143–10162, 1994. a, b
Geer, A.: Learning earth system models from observations: machine learning or data assimilation?, Philos. T. Roy. Soc. A, 379, 20200089, https://doi.org/10.1098/rsta.2020.0089, 2021. a
Goodfellow, I., Bengio, Y., and Courville, A.: Deep learning, MIT Press, ISBN 9780262035613, 2016. a, b, c
Grönquist, P., Yao, C., Ben-Nun, T., Dryden, N., Dueben, P., Li, S., and Hoefler, T.: Deep learning for post-processing ensemble weather forecasts, Philos. T. Roy. Soc. A, 379, 20200092, https://doi.org/10.1098/rsta.2020.0092, 2021. a
Grooms, I.: Analog ensemble data assimilation and a method for constructing analogs with variational autoencoders, Q. J. Roy. Meteor. Soc., 147, 139–149, 2021. a
Guan, Y., Chattopadhyay, A., Subel, A., and Hassanzadeh, P.: Stable a posteriori LES of 2D turbulence using convolutional neural networks: Backscattering analysis and generalization to higher Re via transfer learning, J. Computat. Phys., 458, 111090, https://doi.org/10.1016/j.jcp.2022.111090, 2022. a
Ham, Y.-G., Kim, J.-H., and Luo, J.-J.: Deep learning for multi-year ENSO forecasts, Nature, 573, 568–572, 2019. a, b
Hamill, T. M., Whitaker, J. S., Anderson, J. L., and Snyder, C.: Comments on “Sigma-point Kalman filter data assimilation methods for strongly nonlinear systems”, J. Atmos. Sci., 66, 3498–3500, 2009. a
Hamilton, F., Berry, T., and Sauer, T.: Ensemble Kalman Filtering without a Model, Phys. Rev. X, 6, 011021, https://doi.org/10.1103/PhysRevX.6.011021, 2016. a
Hanc, J., Tuleja, S., and Hancova, M.: Symmetries and conservation laws: Consequences of Noether's theorem, Am. J. Phys., 72, 428–435, 2004. a
Hatfield, S. E., Chantry, M., Dueben, P. D., Lopez, P., Geer, A. J., and Palmer, T. N.: Building tangent-linear and adjoint models for data assimilation with neural networks, Earth and Space Science Open Archive ESSOAr, https://doi.org/10.1002/essoar.10506310.1, 2021. a
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., Chiara, G. D., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, 2020. a
Houtekamer, P. L. and Zhang, F.: Review of the Ensemble Kalman Filter for Atmospheric Data Assimilation, Mon. Weather Rev., 144, 4489–4532, 2016. a
Hunt, B. R., Kostelich, E. J., and Szunyogh, I.: Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter, Physica D, 230, 112–126, 2007. a, b
Irrgang, C., Boers, N., Sonnewald, M., Barnes, E. A., Kadow, C., Staneva, J., and Saynisch-Wagner, J.: Towards neural Earth system modelling by integrating artificial intelligence in Earth system science, Nature Machine Intelligence, 3, 667–674, 2021. a
Jaderberg, M., Simonyan, K., Zisserman, A., and Kavukcuoglu, K.: Spatial transformer networks, in: Advances in Neural Information Processing Systems, Proceedings of Neural Information Processing Systems, Montreal, Canada, 2, 2017–2025, 2015. a, b, c
Julier, S. J. and Uhlmann, J. K.: Unscented filtering and nonlinear estimation, P. IEEE, 92, 401–422, 2004. a
Kalnay, E.: Atmospheric modeling, data assimilation and predictability, Cambridge University Press, ISBN 9780521796293, 2003. a, b
Kashinath, K., Mustafa, M., Albert, A., Wu, J., Jiang, C., Esmaeilzadeh, S., Azizzadenesheli, K., Wang, R., Chattopadhyay, A., Singh, A., Manepalli, A., Chirila, D., Yu, R., Walters, R., White, B., Xiao, H., Tchelepi, H. A., Marcus, P., Anandkumar, A., Hassanzadeh, P., and Prabhat: Physics-informed machine learning: case studies for weather and climate modelling, Philos. T. Roy. Soc. A, 379, 20200093, https://doi.org/10.1098/rsta.2020.0093, 2021. a
Kovachki, N. B. and Stuart, A. M.: Ensemble Kalman inversion: a derivative-free technique for machine learning tasks, Inverse Probl., 35, 095005, https://doi.org/10.1088/1361-6420/ab1c3a, 2019. a
Kumar, S., Peters-Lidard, C., Tian, Y., Reichle, R., Geiger, J., Alonge, C., Eylander, J., and Houser, P.: An integrated hydrologic modeling and data assimilation framework, Computer, 41, 52–59, 2008a. a
Kumar, S. V., Reichle, R. H., Peters-Lidard, C. D., Koster, R. D., Zhan, X., Crow, W. T., Eylander, J. B., and Houser, P. R.: A land surface data assimilation framework using the land information system: Description and applications, Adv. Water Resour., 31, 1419–1432, 2008b. a
Leutbecher, M.: Ensemble size: How suboptimal is less than infinity?, Q. J. Roy. Meteor. Soc., 145, 107–128, 2019. a
Lguensat, R., Tandeo, P., Ailliot, P., Pulido, M., and Fablet, R.: The analog data assimilation, Mon. Weather Rev., 145, 4093–4107, 2017. a
Lguensat, R., Viet, P. H., Sun, M., Chen, G., Fenglin, T., Chapron, B., and Fablet, R.: Data-driven interpolation of sea level anomalies using analog data assimilation, Remote Sens., 11, 858, https://doi.org/10.3390/rs11070858, 2019. a
Liang, X., Losch, M., Nerger, L., Mu, L., Yang, Q., and Liu, C.: Using sea surface temperature observations to constrain upper ocean properties in an Arctic sea ice-ocean data assimilation system, J. Geophys. Res.-Oceans, 124, 4727–4743, 2019. a
Liu, Y., Kutz, J. N., and Brunton, S. L.: Hierarchical Deep Learning of Multiscale Differential Equation Time-Steppers, arXiv [preprint], arXiv:2008.09768, 2020. a
Lütkepohl, H.: Vector autoregressive models, in: Handbook of research methods and applications in empirical macroeconomics, Edward Elgar Publishing, ISBN 978 1 78254 507 1, 2013. a
Lynch, E. M.: Data Driven Prediction Without a Model, Doctoral thesis, University of Maryland, College Park, https://doi.org/10.13016/quty-dayf, 2019. a
Maron, H., Ben-Hamu, H., Shamir, N., and Lipman, Y.: Invariant and equivariant graph networks, arXiv [preprint], arXiv:1812.09902, 2018. a
Maron, H., Fetaya, E., Segol, N., and Lipman, Y.: On the universality of invariant networks, in: International Conference on Machine Learning, Long beach, California, PMLR, 97, 4363–4371, 2019. a
Maulik, R., Egele, R., Lusch, B., and Balaprakash, P.: Recurrent neural network architecture search for geophysical emulation, in: SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, Georgia, IEEE, 1–14, ISBN 978-1-7281-9998-6, 2020. a
Maulik, R., Lusch, B., and Balaprakash, P.: Reduced-order modeling of advection-dominated systems with recurrent neural networks and convolutional autoencoders, Phys. Fluids, 33, 037106, https://doi.org/10.1063/5.0039986, 2021. a
Mohan, A. T., Lubbers, N., Livescu, D., and Chertkov, M.: Embedding hard physical constraints in neural network coarse-graining of 3D turbulence, arXiv [preprint], arXiv:2002.00021, 2020. a
Nadiga, B.: Reservoir Computing as a Tool for Climate Predictability Studies, J. Adv. Model. Earth Sy., e2020MS002290, https://doi.org/10.1029/2020MS002290, 2020. a
Pathak, J., Hunt, B., Girvan, M., Lu, Z., and Ott, E.: Model-free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach, Phys. Rev. Lett., 120, 024102, https://doi.org/10.1103/PhysRevLett.120.024102, 2018. a
Pawar, S. and San, O.: Data assimilation empowered neural network parameterizations for subgrid processes in geophysical flows, arXiv [preprint], arXiv:2006.08901, 2020. a
Pawar, S., Ahmed, S. E., San, O., Rasheed, A., and Navon, I. M.: Long short-term memory embedded nudging schemes for nonlinear data assimilation of geophysical flows, Phys. Fluids, 32, 076606, https://doi.org/10.1063/5.0012853, 2020. a
Penny, S., Bach, E., Bhargava, K., Chang, C.-C., Da, C., Sun, L., and Yoshida, T.: Strongly coupled data assimilation in multiscale media: Experiments using a quasi-geostrophic coupled model, J. Adv. Model. Earth Sy., 11, 1803–1829, 2019. a
Raissi, M., Perdikaris, P., and Karniadakis, G. E.: Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, J. Comput. Phys., 378, 686–707, 2019. a, b
Raissi, M., Yazdani, A., and Karniadakis, G. E.: Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations, Science, 367, 1026–1030, 2020. a
Rasp, S. and Thuerey, N.: Data-driven medium-range weather prediction with a Resnet pretrained on climate simulations: A new model for WeatherBench, J. Adv. Model. Earth Sy., e2020MS002405, https://doi.org/10.1029/2020MS002405, 2021. a, b, c, d, e, f
Rasp, S., Dueben, P. D., Scher, S., Weyn, J. A., Mouatadid, S., and Thuerey, N.: WeatherBench: A Benchmark Data Set for Data-Driven Weather Forecasting, J. Adv. Model. Earth Sy., 12, e2020MS002203, https://doi.org/10.1029/2020MS002203, 2020. a, b, c, d, e, f, g
Reichstein, M., Camps-Valls, G., Stevens, B., Jung, M., Denzler, J.,Carvalhais, N., and Prabhat: Deep learning and process understanding for data-driven Earth system science, Nature, 566, 195–204, https://doi.org/10.1038/s41586-019-0912-1, 2019. a, b
Ronneberger, O., Fischer, P., and Brox, T.: U-net: Convolutional networks for biomedical image segmentation, in: International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, Springer, 234–241, 2015. a
Sabour, S., Frosst, N., and Hinton, G. E.: Dynamic routing between capsules, arXiv [preprint], arXiv:1710.09829, 2017. a
Scher, S.: Toward data-driven weather and climate forecasting: Approximating a simple general circulation model with deep learning, Geophys. Res. Lett., 45, 12–616, 2018. a
Scher, S. and Messori, G.: Predicting weather forecast uncertainty with machine learning, Q. J. Roy. Meteor. Soc., 144, 2830–2841, 2018. a
Scher, S. and Messori, G.: Weather and climate forecasting with neural networks: using general circulation models (GCMs) with different complexity as a study ground, Geosci. Model Dev., 12, 2797–2809, https://doi.org/10.5194/gmd-12-2797-2019, 2019. a
Scher, S. and Messori, G.: Ensemble methods for neural network-based weather forecasts, J. Adv. Model. Earth Sy., e2020MS002331, https://doi.org/10.1029/2020MS002331, 2021. a
Schubert, S., Neubert, P., Pöschmann, J., and Pretzel, P.: Circular convolutional neural networks for panoramic images and laser data, in: 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, IEEE, 653–660, 2019. a
Schultz, M., Betancourt, C., Gong, B., Kleinert, F., Langguth, M., Leufen, L., Mozaffari, A., and Stadtler, S.: Can deep learning beat numerical weather prediction?, Philos. T. Roy. Soc. A, 379, 20200097, https://doi.org/10.1098/rsta.2020.0097, 2021. a, b, c, d
Subel, A., Chattopadhyay, A., Guan, Y., and Hassanzadeh, P.: Data-driven subgrid-scale modeling of forced Burgers turbulence using deep learning with generalization to higher Reynolds numbers via transfer learning, Phys. Fluids, 33, 031702, https://doi.org/10.1063/5.0040286, 2021. a
Tang, M., Liu, Y., and Durlofsky, L. J.: A deep-learning-based surrogate model for data assimilation in dynamic subsurface flow problems, J. Comput. Phys., 109456, https://doi.org/10.1016/j.jcp.2020.109456, 2020. a
Tang, Y., Deng, Z., Manoj, K., and Chen, D.: A practical scheme of the sigma-point Kalman filter for high-dimensional systems, J. Adv. Model. Earth Sy., 6, 21–37, 2014. a, b
Thiagarajan, J. J., Venkatesh, B., Anirudh, R., Bremer, P.-T., Gaffney, J., Anderson, G., and Spears, B.: Designing accurate emulators for scientific processes using calibration-driven deep models, Nat. Commun., 11, 1–10, 2020. a
Vlachas, P. R., Byeon, W., Wan, Z. Y., Sapsis, T. P., and Koumoutsakos, P.: Data-driven forecasting of high-dimensional chaotic systems with long short-term memory networks, P. Roy. Soc. A-Math. Phy., 474, 20170844, https://doi.org/10.1098/rspa.2017.0844, 2018. a
Wan, E. A., Van Der Merwe, R., and Haykin, S.: The unscented Kalman filter, Kalman filtering and neural networks, Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium, Lake Louise, AB, Canada, 5, 221–280, https://doi.org/10.1109/ASSPCC.2000, 2001. a, b
Wang, R., Walters, R., and Yu, R.: Incorporating Symmetry into Deep Dynamics Models for Improved Generalization, arXiv [preprint], arXiv:2002.03061, 2020. a, b, c
Watson-Parris, D.: Machine learning for weather and climate are worlds apart, Philos. T. Roy. Soc. A, 379, 20200098, https://doi.org/10.1098/rsta.2020.0098, 2021. a
Weyn, J. A., Durran, D. R., and Caruana, R.: Can machines learn to predict weather? Using deep learning to predict gridded 500 hPa geopotential height from historical weather data, J. Adv. Model. Earth Sy., 11, 2680–2693, 2019. a, b
Weyn, J. A., Durran, D. R., and Caruana, R.: Improving Data-Driven Global Weather Prediction Using Deep Convolutional Neural Networks on a Cubed Sphere, J. Adv. Model. Earth Sy., 12, e2020MS002109, https://doi.org/10.1029/2020MS002109, 2020. a, b, c, d, e, f, g, h, i, j, k, l, m, n
Weyn, J. A., Durran, D. R., Caruana, R., and Cresswell-Clay, N.: Sub-seasonal forecasting with a large ensemble of deep-learning weather prediction models, arXiv [preprint], arXiv:2102.05107, 2021. a, b, c
Wikner, A., Pathak, J., Hunt, B. R., Szunyogh, I., Girvan, M., and Ott, E.: Using Data Assimilation to Train a Hybrid Forecast System that Combines Machine-Learning and Knowledge-Based Components, arXiv [preprint], arXiv:2102.07819, 2021. a
Xie, J., Xu, L., and Chen, E.: Image denoising and inpainting with deep neural networks, Adv. Neur. In., 25, 341–349, 2012. a
Yin, Y., Alves, O., and Oke, P. R.: An ensemble ocean data assimilation system for seasonal prediction, Mon. Weather Rev., 139, 786–808, 2011. a