the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 26 Aug 2021
| 26 Aug 2021
The Community Inversion Framework v1.0: a unified system for atmospheric inversion studies
Antoine Berchet
Espen Sollum
Rona L. Thompson
Isabelle Pison
Joël Thanwerdas
Grégoire Broquet
Frédéric Chevallier
Tuula Aalto
Adrien Berchet
Peter Bergamaschi
Dominik Brunner
Richard Engelen
Audrey Fortems-Cheiney
Christoph Gerbig
Christine D. Groot Zwaaftink
Jean-Matthieu Haussaire
Stephan Henne
Sander Houweling
Ute Karstens
Werner L. Kutsch
Ingrid T. Luijkx
Guillaume Monteil
Paul I. Palmer
Jacob C. A. van Peet
Wouter Peters
Philippe Peylin
Elise Potier
Christian Rödenbeck
Marielle Saunois
Marko Scholze
Aki Tsuruta
Yuanhong Zhao
Atmospheric inversion approaches are expected to play a critical role in future observation-based monitoring systems for surface fluxes of greenhouse gases (GHGs), pollutants and other trace gases. In the past decade, the research community has developed various inversion software, mainly using variational or ensemble Bayesian optimization methods, with various assumptions on uncertainty structures and prior information and with various atmospheric chemistry–transport models. Each of them can assimilate some or all of the available observation streams for its domain area of interest: flask samples, in situ measurements or satellite observations. Although referenced in peer-reviewed publications and usually accessible across the research community, most systems are not at the level of transparency, flexibility and accessibility needed to provide the scientific community and policy makers with a comprehensive and robust view of the uncertainties associated with the inverse estimation of GHG and reactive species fluxes. Furthermore, their development, usually carried out by individual research institutes, may in the future not keep pace with the increasing scientific needs and technical possibilities. We present here the Community Inversion Framework (CIF) to help rationalize development efforts and leverage the strengths of individual inversion systems into a comprehensive framework. The CIF is primarily a programming protocol to allow various inversion bricks to be exchanged among researchers. In practice, the ensemble of bricks makes a flexible, transparent and open-source Python-based tool to estimate the fluxes of various GHGs and reactive species both at the global and regional scales. It will allow for running different atmospheric transport models, different observation streams and different data assimilation approaches. This adaptability will allow for a comprehensive assessment of uncertainty in a fully consistent framework. We present here the main structure and functionalities of the system, and we demonstrate how it operates in a simple academic case.
- Article
(3625 KB) - Full-text XML
-
Supplement
(843 KB) - BibTeX
- EndNote





The role of greenhouse gases (GHGs) in climate change has motivated an exceptional effort over the last couple of decades to densify the observations of GHGs around the world (Ciais et al., 2014): from the ground (e.g., with the European Integrated Carbon Observation System, ICOS; https://www.icos-cp.eu/, last access: 23 August 2021), from mobile platforms (e.g., from aircraft or balloons equipped with Aircore sampling; Filges et al., 2016; Karion et al., 2010) and from space (e.g., Crisp et al., 2018; Janssens-Maenhout et al., 2020), despite occasional budgetary difficulties (Houweling et al., 2012). These observations quantify the effect of exchange between the surface and the atmosphere on GHG concentrations (e.g., Ramonet et al., 2020) and can thus be used to determine the surface fluxes of GHGs through the inversion of atmospheric chemistry and transport (e.g., Peylin et al., 2013; Houweling et al., 2017). Alongside improved observation capabilities, national and international initiatives pave the way towards an operational use of atmospheric inversions to support emissions reporting to the United Nations Framework Convention on Climate Change (UNFCCC; e.g., Say et al., 2016; Henne et al., 2016; Bergamaschi et al., 2018a; Janssens-Maenhout et al., 2020, or the EU projects CHE – CO2 Human Emissions; http://che-project.eu, last access: 23 August 2021 – or VERIFY – http://verify.lsce.ipsl.fr, last access: 23 August 2021).
In the past, research groups have developed various atmospheric inversion systems based on different techniques and atmospheric transport models, targeting specific trace gases or types of observations, as well as at various spatial and temporal scales, according to the particular scientific objectives of the study. All these systems have their own strengths and weaknesses and help explore the range of systematic uncertainty in the surface to atmosphere fluxes. Intercomparison exercises are regularly conducted to assess the strengths and weaknesses of various inversion systems (e.g., Gurney et al., 2003; Peylin et al., 2013; Locatelli et al., 2013; Babenhauserheide et al., 2015; Brunner et al., 2017; Bergamaschi et al., 2018b; Chevallier et al., 2019; Crowell et al., 2019; Monteil et al., 2020; Schuh et al., 2019; Saunois et al., 2020). Intercomparisons also provide an assessment of the systematic uncertainty on final flux estimates induced by the variety of options and choices in different inversion systems. However, although the inversion systems are referenced in peer-reviewed literature and are usually accessible to the research community, they are typically not at the level of transparency, documentation, flexibility and accessibility required to provide both the scientific community and policy makers with a comprehensive and robust view of the uncertainties associated with the inverse estimation of trace gas (primarily GHGs and reactive species) fluxes. In particular, the differences between inversion systems (such as the atmospheric transport model, prior and observation space uncertainties, and inversion algorithm) make comparing their results particularly challenging, even when they are applied to the same problem. Moreover, research inversion systems are so far not ready for operational use, and their development, usually carried out by individual research institutes or limited consortia, may not keep pace with the scientific and technical needs to come, such as those linked to the increasing availability of high-resolution satellite GHG and reactive species observations (Janssens-Maenhout et al., 2020). A unified system, as a community platform running multiple transport models and with diverse inversion methods, would provide new possibilities to effectively and comprehensively assess GHG and various reactive species budgets, trends and their uncertainties as well as quantifying limitations and development needs related to different approaches, all of which is needed in order to properly support emission reporting. Collaborative efforts towards unified systems are already happening in other data assimilation communities, with, for example, the Object-Oriented Prediction System (OOPS; coordinated by the European Centre for Medium-Range Weather Forecasts, UK) or the Joint Effort for Data Integration (led by UCAR/JCSDA; https://www.jcsda.org/jcsda-project-jedi, last access: 23 August 2021). The Data Assimilation Research Testbed (DART; Anderson et al., 2009) is also an example of collective effort proposing common data assimilation scripts for diverse applications (e.g., Earth system or reactive species inversions; Gaubert et al., 2020). The Community Inversion Framework (CIF) is an initiative by members of the GHG atmospheric inversion community to bring together the different inversion systems used in the community, and it is supported by the European Commission H2020 project VERIFY. The CIF will also support operational applications of atmospheric inversions in the CoCO2 project (http://coco2-project.eu, last access: 23 August 2021), which will design an operational inversion system based on OOPS and interfaced with the research community through the CIF.
Despite their differences in methodology, application and implementation, almost all inversion systems rely on the same conceptual and practical bases: in particular, they use model–observation mismatches in a statistical optimization framework (most of the time based on Bayes' theorem) and numerical atmospheric tracer transport and chemistry models to simulate mixing ratios of GHGs and trace gases based on surface fluxes. The objectives of the CIF are to develop a consistent input–model interface, to pool development efforts, and to have an inversion tool that is well documented, open-source and ready for implementation in an operational framework. The CIF is designed to be a flexible and transparent tool to estimate the fluxes of different GHGs (e.g., carbon dioxide, CO2; methane, CH4; nitrous oxide, N2O; or halocarbons) and other species, such as reactive species (e.g., CO, NO2, HCHO), based on atmospheric measurements. In particular, although primarily designed for GHG applications, the CIF is based on a general structure that will allow for applications in air quality data assimilation. It is also designed to run at any spatial and temporal scale and with different atmospheric (chemistry–)transport models (global and regional, Eulerian and Lagrangian), with various observation data streams (ground-based, remote sensing, etc.) and a variety of data assimilation techniques (variational, analytical, ensemble methods, etc.). It will be possible to run it on multiple computing environments, and corresponding set-ups and tutorials will be well documented. Community development will help in tackling the challenges in set-up and running and accelerate adoption of the tool into wider use. One of the main foreseen advantages of the CIF is the capability to quantify and compare the errors due to the modelling of atmospheric transport and the errors due to the choice of a given inversion approach and set-up to solve a specific problem, in a fully consistent framework. The CIF will provide a common platform for quickly developing and testing new inversion techniques with several transport models, and it is hoped that, with the combined community effort, it will be continuously improved and revised, keeping it state of the art.
In the present paper, we lay out the basis of the CIF, giving details on its underlying principles and overall implementation. The proof of concept focuses on the implementation of several inversion methods, illustrated with a test case. We will dedicate a future paper to the evaluation of the system on a real-life problem with a number of interfaced atmospheric (chemistry–)transport models. At the time of writing the present article, the following models are interfaced with the CIF: the global circulation models LMDZ (Chevallier et al., 2005) and TM5 (Krol et al., 2005; van der Laan-Luijkx et al., 2017), the regional chemistry–transport Eulerian model CHIMERE (Fortems-Cheiney et al., 2021), and the Lagrangian particle dispersion models FLEXPART (Pisso et al., 2019) and STILT (Trusilova et al., 2010). For the sake of simplicity, we refer to all types of (chemistry–)transport models generically as CTMs in the following. In Sect. 2, we describe the general theoretical framework for atmospheric inversions and how the CIF will include the theory in a flexible and general way. In Sect. 3, the practical implementation of the general design rules is explained, with details on the Python implementation of the CIF. In Sect. 4, we demonstrate the capabilities of the CIF in a simple test case, applying various inversion techniques in parallel.
The version of the CIF presented here is implemented around Bayesian data assimilation methods with Gaussian assumptions, which constitute the main framework used in the atmospheric inversion systems for GHG fluxes and other trace gases (e.g., Enting, 2002; Bocquet et al., 2015). However, some studies have proposed possible extensions to more general probability density functions beyond the classical Gaussian case (e.g., truncated Gaussian densities, log-normal distributions, etc.; Michalak and Kitanidis, 2005; Bergamaschi et al., 2010; Miller et al., 2014; Zammit-Mangion et al., 2015; Lunt et al., 2016; Miller et al., 2019). Therefore, we propose here a general and flexible structure for our system that will be independent of limiting assumptions, as described in Sect. 2.3, to allow for future extensions to more general theoretical frameworks. In the following, mathematical formulas are written following the notation based on Ide et al. (1997) and Rayner et al. (2019). We present the theoretical basis and several inversion methods that are implemented in the CIF as demonstrators.
2.1 General Bayesian data assimilation framework
The Bayesian approach consists of estimating the following conditional probability density function (pdf):
with x being the target vector, pa(x) the posterior distribution of the target vector, pb(x) the prior knowledge of the target vector (characterized by its mode xb), yo the observation vector gathering all observations implemented in the inversion and ℋ the observation operator linking the target vector to the observation vector. In the following, we also refer to 𝒳 and 𝒴 as the target and observation spaces, respectively, from where the target and observation vectors are sampled. Classically, for atmospheric inversions, the observation vector yo includes ground-based measurements of trace gas mixing ratios on fixed or mobile platforms and remote sensing observations such as satellite observations. The target vector x includes the variables to be optimized by the inversion; it includes the main variables of interest, such as the surface fluxes, but also variables related to atmospheric chemical sources and sinks, background concentrations in the case of limited-area transport models, model parameters, etc., which are required to make the inversion physically consistent. The observation operator ℋ mainly includes the computation of atmospheric transport and chemistry (if relevant) by numerical (chemistry–)transport models. These can be of various types: global transport models (e.g., LMDZ, Chevallier et al., 2010; TM5, Houweling et al., 2014; GEOS-Chem, van der Laan-Luijkx et al., 2017; Liu et al., 2015; Palmer et al., 2019; Feng et al., 2017; NICAM, Niwa et al., 2017), regional Eulerian chemistry–transport models (e.g., CHIMERE, Broquet et al., 2011; Fortems-Cheiney et al., 2021; WRF-Chem, Zheng et al., 2018; COSMO-GHG, Kuhlmann et al., 2019; LOTOS-EUROS, Curier et al., 2012) or Lagrangian particle dispersion models (e.g., FLEXPART, Thompson and Stohl, 2014; STILT, Bagley et al., 2017; Brioude et al., 2013; Trusilova et al., 2010). It also includes pre- and post-processing operations required to project the target vector to a format compatible with the model input and the model outputs to the observation vector; these operations can be the applications of, for example, averaging kernels in the case of satellite operations or interpolation of the target vector to higher resolution model inputs.
As errors in inversion systems come from a large variety of independent causes superimposing on each other, it is often assumed that the most relevant way of representing the distributions in Eq. (1) is to assume prior and observation spaces to be normal distributions, noted below, with the first argument representing the average of the distribution and the second argument the covariance matrix. In addition, when assuming that the distributions in the state vector space and the observation space are independent from each other and that errors in the observation and the state vector spaces have Gaussian, unbiased distributions, it is possible to mathematically derive the Bayes' theorem and to represent the distributions of Eq. (1) as follows:
with B and A being the prior and posterior covariance matrices of uncertainties in the target vector respectively, xb and xa the prior and posterior target vectors respectively, and R the covariance matrix of uncertainties in the observation vector and the observation operator.
The assumption that errors are unbiased, which makes it possible to write normal distributions in Eq. (1) with means xb, 0 and xa, is needed to simplify the formulation of the Bayesian problem in atmospheric inversions. Neglecting error biases have known impacts on inversion results (e.g., Masarie et al., 2011); they can be accounted for online as an unknown to be solved by the inversion (e.g., Zammit-Mangion et al., 2021), but they are often treated offline from the inversion, either through pre-processing of inputs or post-processing of outputs.
2.2 Computation modes in the CIF
The present version of the CIF includes three main categories of inversion methods: (1) analytical, i.e., algebraic solution of the unbiased Gaussian Bayesian problem; (2) ensemble methods with the ensemble square root filter (EnSRF); and (3) variational with two examples of minimizing algorithms (M1QN3 and CONGRAD). Other types of data assimilation methods (e.g., direct sampling of probability density functions through Monte Carlo approaches) are also used by the community. The choice of implementing the three aforementioned methods first is motivated by their dominant use and because these three use very different approaches for solving the Bayesian inversion problem, i.e., with/without random sampling of probability distributions and with/without the use of the adjoint of the observation operator. The adjoint of the observation operator, noted ℋ*, is built following the mathematical definition of the adjoint; heuristically, it operates backwards compared to the observation operator (e.g., Errico, 1997) in the sense that it determines the sensitivity to inputs (e.g., fluxes) given an incremental perturbation to outputs (e.g., concentrations). In addition to the mentioned data assimilation methods, the CIF also includes the possibility to run forward simulations and to test the adjoint and the tangent linear of the observation operator for given inversion configurations. In the following we call all inversion methods and other types of computation in the CIF “computation modes”. With these computation modes implemented in a flexible and general manner, it is anticipated that other inversion methods could be easily added to the CIF in the future (see Sect. 2.3).
2.2.1 Data assimilation methods
Analytical inversions
Analytical inversions compute the algebraic solution of the Gaussian Bayesian problem when it is linear, and they are used extensively at all scales (e.g., Stohl et al., 2009; Turner and Jacob, 2015; Kopacz et al., 2009; Bousquet et al., 2011; Wang et al., 2018; Palmer et al., 2006). When the observation operator is linear, ℋ equals its Jacobian matrix H; conversely, its adjoint ℋ* is the transpose of the Jacobian HT. In that case, xa and A can be explicitly written as matrix products. There are two equivalent formulations of the matrix products for the solution of the problem (e.g., Tarantola and Valette, 1982):
or
with K the Kalman gain matrix as .
Analytical inversions can also be used on slightly non-linear problems, by linearizing the observation operator around a given reference point using the tangent linear of the observation operator. It formulates as follows:
with δx a small deviation from xb within a domain where the linear assumption is valid, the tangent linear of ℋ at xb and the Jacobian matrix of ℋ at xb.
Then Eq. (3) can be easily adapted by replacing (yo−Hxb) by (yo−ℋ(xb)) and H by .
The computation of an analytical inversion faces two main computational limitations. First, the matrix H representing the observation operator ℋ must be built explicitly. This can be done either column by column, in the so-called response function method, or row by row, in the so-called footprint method. The two approaches require dim(𝒳), the dimension of the target space, and dim(𝒴), the dimension of the observation space, independent simulations. In the response function method, each column is built by computing with ℬχ being the canonical basis of the target space. For a given increment δxi, the corresponding column gives the sensitivity of observations to changes in the corresponding component of the target space. In the footprint method, each row is built by computing with ℬ𝒴 the canonical basis of the observation space. For a given perturbation of δyi of a component of the observation vector, the corresponding row of H gives the sensitivity of the inputs to that perturbation.
Depending on the number of available observations or the size of the target vector, one of the two is preferred to limit the number of observation operator computations to be carried out explicitly. When the dimension of the target vector is relatively small, the response function is generally preferred; conversely, when the observation vector is small, the footprint approach is preferred. The type of transport model used to compute the matrix H also plays a role in the choice of the approach; for Eulerian models, the response function approach is preferred for multiple reasons: (i) their adjoint is often much more costly than their forward, (ii) the adjoint may not be available for some models or is difficult to generate, and (iii) the computation time of the forward is constant no matter how numerous the observations are; for Lagrangian models, the footprint approach is preferred as they often compute backward transport simulations for each observation, allowing a straightforward computation of the adjoint (Seibert and Frank, 2004). In both cases, the explicit construction of the matrix H requires numerous independent simulations, which can be an insurmountable computational challenge.
The second obstacle consists of the fact that the computation of the Kalman gain matrix in Eq. (3) (left) requires inverting a matrix of the dimension of the observation space, dim(𝒴), while for the other formulation (Eq. 3, right) the matrix is of dimension dim(𝒳), which is the dimension of the target space. If the dimensions of both the observation and the target spaces are very high, as in many inversion applications, the explicit computation of Eq. (3) with matrix products and inverses is not computationally feasible. For this reason, smart adaptations of the inversion framework (including approximations and numerical solvers) are often necessary to tackle problems even when they are linear; in the following, we choose to elaborate on some of the most frequent approaches used in the atmospheric inversion community: the variational approach and one ensemble method, the Ensemble Square Root Filter (EnSRF). Less frequently, intermediate adaptations of the analytical inversion also include sequential applications (e.g., Michalak, 2008; Bruhwiler et al., 2005; Brunner et al., 2012), which are a compromise between tackling the above-mentioned computational obstacles while maintaining the simplicity of the analytical inversion; however, such sequential analytical inversions are limited to specific linear and simple cases.
Ensemble methods
Ensemble methods are commonly used to tackle high-dimensional problems and to approximately characterize the optimal solution. In ensemble methods, such as ensemble Kalman filters (EnKFs) or smoothers (e.g., Whitaker and Hamill, 2002; Peters et al., 2005; Zupanski et al., 2007; Zupanski, 2005; Feng et al., 2009; Chatterjee et al., 2012), the issue of high dimensions in the system of Eq. (3) is avoided using the two following main procedures:
-
Observations are first assimilated sequentially in the system to reduce the dimension of the observation space, making it possible to explicitly compute matrix products and inverses, and thus propagating information from the target space to the observation space; the overall inversion period is processed incrementally using a smaller running assimilation window including a manageable number of observations; intermediate inversions are solved on the smaller running window that is gradually moved from the beginning to the end of the overall data assimilation window; the running assimilation window with so-called analysis and forecast steps introduces complex technical challenges to rigorously propagate errors from one iteration of the running window to the next one; moreover, the sequential assimilation of observations is valid only under the assumption that observation errors are not correlated between assimilation windows, which may prove incorrect for high-density data sets, but is an assumption also done in, for example, variational inversions. For very dense observations, such as datasets from new-generation high-resolution satellites, the sequential assimilation of observations may not be sufficient, or at least methods may be needed to make the observation errors between sequential assimilation windows independent, e.g., by applying a whitening transformation to the observations to form a new set with uncorrelated errors as suggested by Tippett et al. (2003). The challenge is exacerbated for long-lived species such as CO2, for which assimilation windows must be long enough to maintain the propagation of information on the fluxes over long distances through transport; propagating a covariance matrix from assimilation windows to assimilation windows as accurate as possible could in principle limit the later issue, as suggested in Kang et al. (2011, 2012), but this could still prove hard to apply in very high resolution problems.
-
The posterior distribution at a given step of the filter is then characterized explicitly by applying Eq. (1) on each member of the ensemble; the new intermediate posterior distribution is then sampled and propagated to the next data assimilation window.
In the atmospheric inversion community, another ensemble method is widely used, based on the CarbonTracker system (Peters et al., 2005), which uses an ensemble square root filter (EnSRF; Whitaker and Hamill, 2002). In that approach, the observations are split using running data assimilation windows as for other ensemble methods, but instead of directly characterizing the posterior distribution from the ensemble, the statistics of the ensemble are used to solve the analytical equation, Eq. (3), approximately. Thus, the EnSRF method is less general than EnKFs methods, as it relies on the Gaussian assumption, as well as limited non-linearity in the inversion problem, but it proves very efficient at computing an approximated solution of the inversion problem. Matrix products in Eq. (3) involving the target vector covariance matrix B (HBHT and BHT) are approximated by reducing the space of uncertainties to a low-rank representation; this is done in practice by using a Monte Carlo ensemble of possible target vectors sampling the distribution 𝒩(xb,B); with such an approximation, matrix products can be written as follows:
where N is the size of the ensemble.
From there, Eq. (1) is solved analytically by replacing HBHT and BHT by their respective approximations.
By using random sampling, ensemble methods are able to approximate large dimensional matrices at a reduced cost without using the adjoint of the observation operator (see variational inversion below) that can be challenging to implement. Small ensembles generally cause the posterior ensemble to collapse; i.e., the posterior distribution is dominated by one or a very small number of members, which does not allow for a reliable assessment of the posterior uncertainties (Morzfeld et al., 2017); moreover, small ensembles introduce spuriousness in the posterior uncertainties, with unrealistic correlations being artificially generated. In the EnSRF, small ensembles rather cause a misrepresentation of uncertainty structures, which limits the accuracy of the computed solution and may require fixes as described in, for example, Bocquet (2011). In any case, the level of approximation necessary for this approach to work is strongly different for each problem, which requires preliminary studies before consistent application. In particular, the so-called localization of the ensemble can be used to improve the consistency of the inversion outputs (e.g., Zupanski et al., 2007; Babenhauserheide et al., 2015).
In the current version, only the EnSRF approach is implemented in the CIF. One should note that the EnSRF, as a direct approximation of the analytical solution, can be very sensitive to non-linearity in the observation operator (e.g., Tolk et al., 2011). It can generally cope only with slight non-linearity over the assimilation window; thus, the assimilation window length has to be chosen appropriately, contrary to other ensemble methods which are usually not sensitive to non-linearity.
Variational inversions
Variational inversions use the fact that finding the mode of the posterior Gaussian distribution in Eq. (2) is equivalent to finding the minimum xa of the cost function J:
In variational inversions, the minimum of the cost function in Eq. (6) is numerically estimated iteratively using quasi-Newtonian algorithms based on the gradient of the cost function:
Quasi-Newtonian methods are a group of algorithms designed to compute the minimum of a function iteratively. It should be noted that in high-dimensional problems it can take a very large number of iterations to reach the minimum of the cost function J, forcing the user to stop the algorithm before convergence, thus reaching only an approximation of xa; in addition, iterative algorithms can reach local minima without ever reaching the global minimum, making it essential to thoroughly verify variational inversion results; this can happen in non-linear cases but also due to numerical artefacts in linear cases (some points in the cost function have gradients so close to zero that the algorithm sees them as convergence points, whereas the unique global minimum is somewhere else). In the community, examples of quasi-Newtonian algorithms commonly used are the Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm (Zheng et al., 2018; Bousserez et al., 2015), M1QN3 (Gilbert and Lemaréchal, 1989) and the CONGRAD algorithm (applicable only to linear or linearized problems; Fisher, 1998; Chevallier et al., 2005) based on the Lanczos method, which iterates to find the eigenvalues and eigenvectors of the Hessian matrix, which is then used (in a single step) to calculate the analysis vector, xa. In general, quasi-Newtonian methods require an initial regularization, or “pre-conditioning” of x, the vector to be optimized, for better efficiency. In atmospheric inversions, such a regularization is generally made by optimizing instead of x; we denote 𝔄 as the regularization space: χ∈𝔄. This transformation translates in Eqs. (6) and (7) as follows:
Solving Eqs. (6) and (7) in the target vector space or Eq. (8) in the regularization space is mathematically fully equivalent, but the solution in the regularization space is often reached in fewer iterations. Moreover, in the regularization space, one can force the algorithm to focus on the main modes of the target vector space by filtering the smallest eigenvalues of the matrix B. This reduces the dimension of χ and accelerates further the rate of convergence, although the solution of the reduced problem is only an approximation of the solution of the full problem. In the following we thus prefer calling the “regularization space” the “reduction space”. The link between the two can be written as follows:
with , Q and Λ being the matrices of the eigenvector and the matrix of the corresponding eigenvalues of the matrix B respectively. Q′ and Λ′ are the reduced matrices of eigenvalues and eigenvectors with a given number of dominant eigenvalues.
Overall, variational inversions are a numerical approximation to the solution of the inversion problem: they involve the gradient of the cost function in Eq. (7) and require us to run forward and adjoint simulations iteratively (e.g., Meirink et al., 2008; Bergamaschi et al., 2010; Houweling et al., 2017, 2014; Fortems-Cheiney et al., 2021; Chevallier et al., 2010, 2005; Thompson and Stohl, 2014; Monteil and Scholze, 2021; Wang et al., 2019).
The variational formulation does not require calculation of complex matrix products and inversions, contrary to the analytical inversion, and is thus not limited by vector dimensions. Still, the inverses of the uncertainty matrices B and R need to be computed, potentially prohibiting the use of very large and/or complex general matrices; this challenge is often overcome by reducing B and R to manageable combinations of simple matrices (e.g., Kronecker products of simple shape covariance matrices; see Sect. 2.3.1).
When the observation operator is linear, the posterior uncertainty matrix A is equal to the inverse of the Hessian matrix at the minimum of the cost function. In most cases the Hessian cannot be computed explicitly because of memory limitations, which is a major drawback of variational inversions. But some variational algorithms such as CONGRAD provide a coarse approximation of the Hessian: in the case of CONGRAD based on the Lanczos method, leading eigenvectors of the Hessian can be computed, together with their eigenvalues (Fisher, 1998). The approximation of the posterior uncertainty matrix A in the case of CONGRAD reads as follows:
with being the dominant eigenvectors of the Hessian matrix at the point xa, and being the matrix of the dominant eigenvalues of the Hessian matrix. Please note that the dominant eigenvalues of the Hessian matrix correspond to components with low posterior uncertainties in A.
Another approach to quantify the posterior uncertainty matrix A, valid for both linear and non-linear cases, is to carry out a Monte Carlo ensemble of independent inversions with sampled prior vectors from the prior distribution 𝒩(xb,B) (e.g., Liu et al., 2017). An ensemble of posterior vectors are inferred and used to compute the posterior matrix as follows:
with N being the size of the Monte Carlo ensemble, the posterior vector corresponding to the prior of the Monte Carlo ensemble and the average over sampled posterior vectors.
2.2.2 Auxiliary computation modes
Forward simulations
Forward simulations simply use the observation operator to compute simulated observation equivalents. It reads as
This mode is used to make quick comparisons between observations and simulations to check for inconsistencies before running a full inversion. It is also used by the analytical inversion mode to build response functions.
Test of the adjoint
The test of the adjoint is a crucial diagnostic for any inversion system making use of the adjoint of the observation operator. Such a test is typically required after making any edits to the code (to the forward observation operator or its adjoint) before running an inversion. Coding an adjoint is prone to errors and even small errors can have significant impacts on the computation of the gradient of the cost function in Eq. (7). Thus, one needs to make sure that the adjoint rigorously corresponds to the forward. This test consists of checking the definition of the mathematical adjoint of the observation operator. It writes as follows for a given target vector x and incremental target perturbation δx:
where dℋx(δx) is the linearization of the observation operator ℋ at the point x for a given increment δx; it is computed with the tangent linear model, which is the numerical adaptation of dℋx(δx). Then, is calculated with the adjoint of the tangent linear of ℋ at the point x.
In practice, the two terms of the equation are rarely exactly equal. Nevertheless, the difference should never exceed a few times the machine epsilon. Besides, Eq. (13) should be verified for any given target vector and increment. In practice, it is not possible to explicitly verify all possible combinations; but as the result of the test is highly sensitive to any error in the code, it is assumed that a few typical couples (x, δx) are sufficient to certify the validity of the adjoint.
Table 1Elementary operations required for each data assimilation method. An: analytical inversion; EnKF: ensemble Kalman filter; Var: variational; Fwd: forward simulation; AdTest: test of the adjoint. We note 𝒳 and 𝒴 the target and observation spaces respectively, 𝔄 the regularization space in the minimization algorithm of variational inversions; the symbol depicts the adjoint of corresponding spaces.
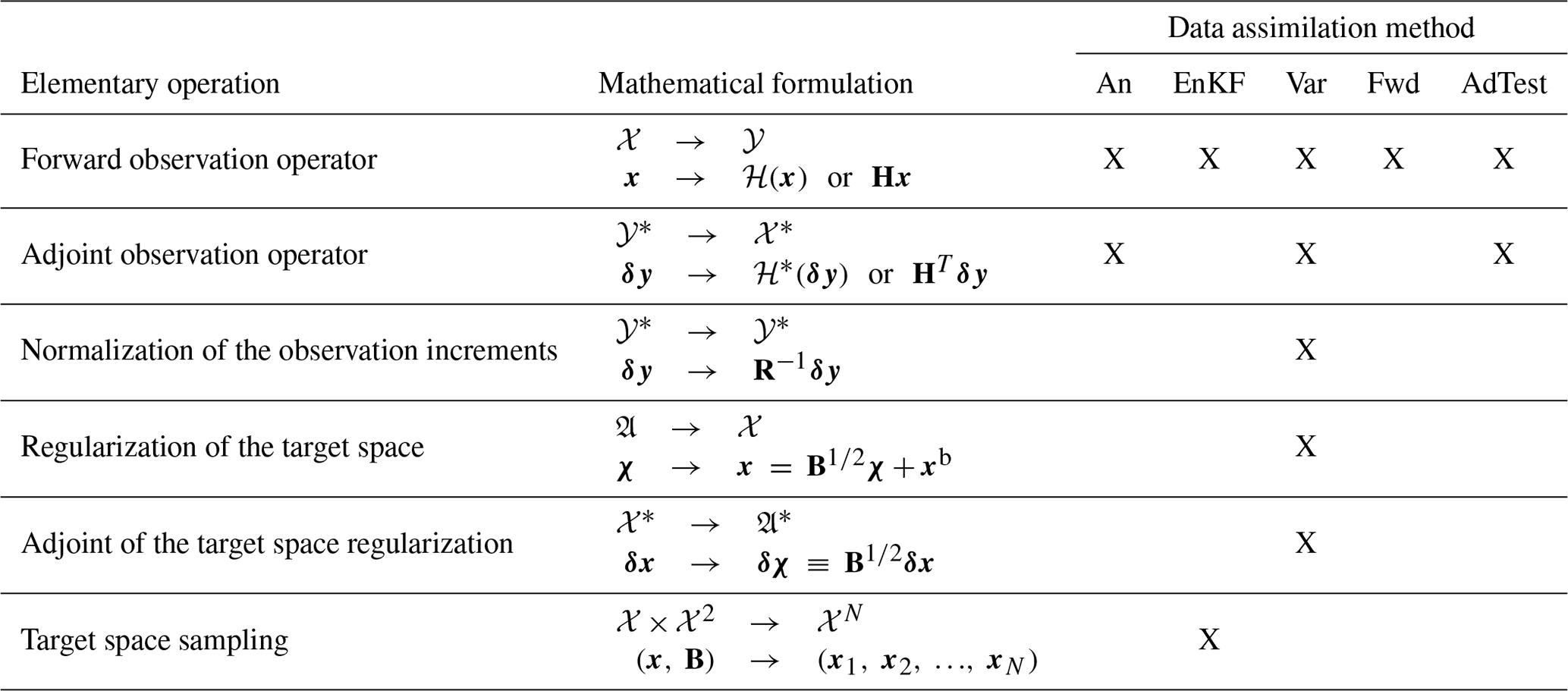
2.3 Identification of common elementary transformations
2.3.1 General purpose operations
Each inversion algorithm and computation mode mentioned above can be decomposed into a pipeline of elementary transformations. These transformations are listed in Table 1 and include the observation operator and its adjoint (their matrix representations in linear cases), matrix products with target and observation error covariance matrices as well as corresponding adjoints, and random sampling of normal distributions. To limit redundancy in the CIF as much as possible, these elementary transformations are included in the CIF as generic transformation blocks on the same conceptual level. Overall, the decomposition of computation modes presently implemented in the CIF into elementary transformations leads to the structure in Fig. 1.
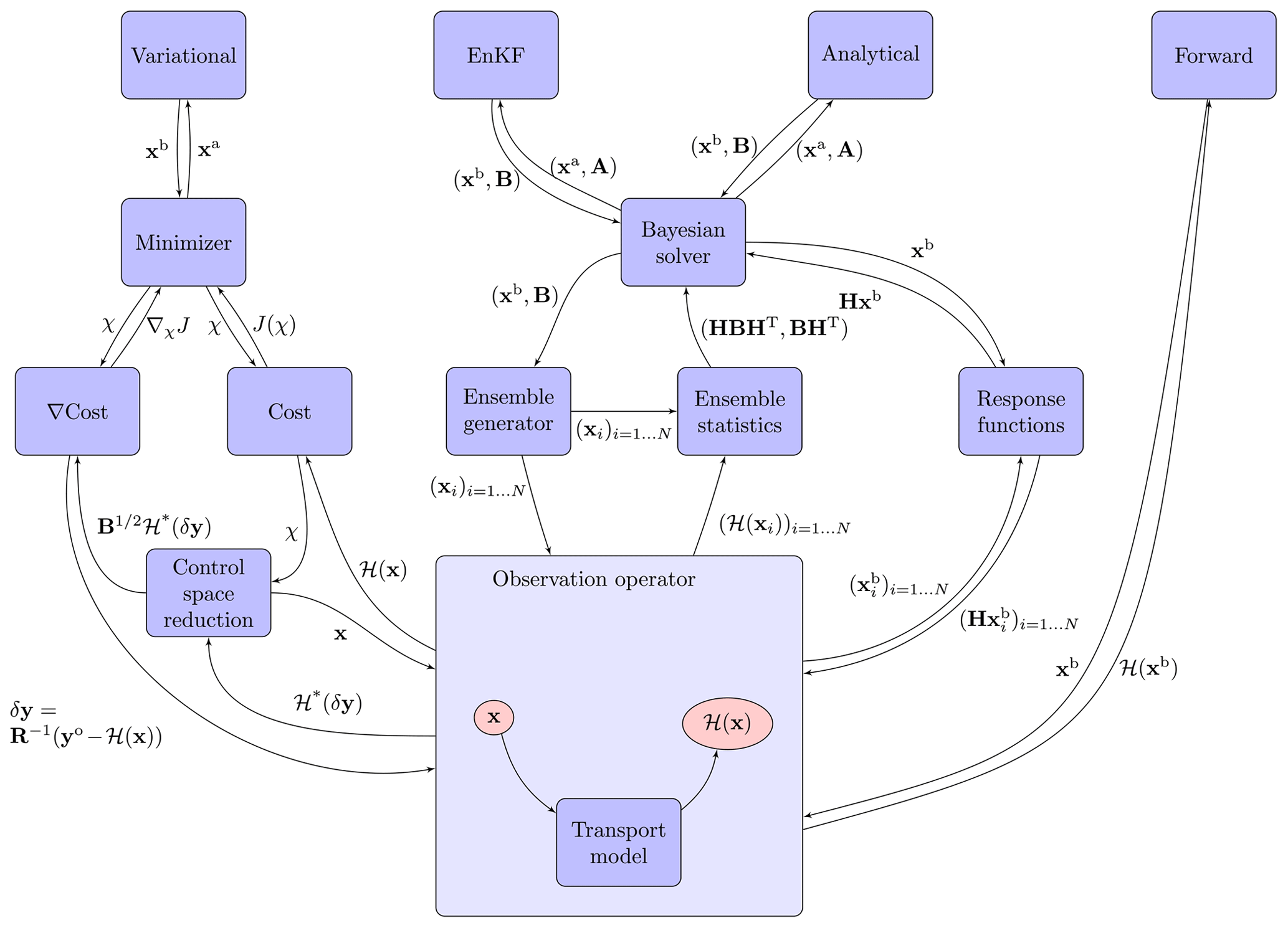
Avoiding redundancy makes the maintenance of the code much easier and provides a clear framework for extensions to other inversion methods or features. For instance, inverse methods based on probability density functions other than normal distributions could be easily implemented by updating the random ensemble generator or by implementing new cost functions representing non-Gaussian distributions while keeping the remaining code unmodified. In particular, non-Gaussian cost functions still rely on the computation of the observation operator. New combinations of elementary transformations can also directly lead to new methods. For instance, ensemble variational inversion (e.g., Bousserez and Henze, 2018) is a direct combination of the available variational pipeline and the random sampling pipeline. Inversions estimating hyper-parameters through maximum-likelihood or hierarchical Bayesian techniques (e.g., Michalak et al., 2005; Berchet et al., 2015; Ganesan et al., 2014) could be integrated into the CIF by adapting the Gaussian cost function and by implementing a corresponding computation pipeline.
The complexity of the selected elementary transformations spans a wide range, from one-line straightforward code to computationally expensive and complex code implementation. In small dimensional and/or linear problems, the computation of the observation operator using its Jacobian and matrix products may be computationally expensive, but it is in principle rather straightforward to implement. For non-linear and/or high-dimensional problems, these transformations require simplifications and numerous intermediate steps. For instance, applying matrix products to the error covariance matrices R and B and computing their inverse is easy in small dimensions but can be limiting in high-dimensional problems. For that reason, the error covariance matrices are often reduced to particular decompositions; for instance, the error covariance matrix on the target vector B is often written as a Kronecker product of multiple spatial and/or temporal covariance matrices of lower dimensions, making matrix products manageable (e.g., Chevallier et al., 2005; Meirink et al., 2008; Yadav and Michalak, 2013).
In any case, the observation operator (see details in Sect. 2.3.2) appears as the centre piece of any inversion method.
2.3.2 Observation operator
The observation operator is a key component of all inversion methods. It links the target space to the observation space, and conversely, its adjoint links the observation space to the target space. To do so, the observation operator projects its inputs through various intermediate spaces to the outputs. As atmospheric inversions need a representation of the atmospheric transport (and chemistry if relevant) to link the target vector (including surface fluxes, atmospheric sources and sinks, initial and boundary conditions for limited domains and time windows, etc.) to the observation vector (including some form of atmospheric concentration measurements), the observation operator is built around a given CTM in most cases: Eq. (14) illustrates the various projections in the common case.
with f being the target vector projected at the CTM's resolution (includes fluxes but also other types of inputs required by the CTM), and c being the raw outputs extracted from the run of the CTM's executable (in general four-dimensional concentration fields). Π operators are intermediate projectors: projects the target vector at the spatial and temporal resolutions of the CTM's inputs, dumps the input vector in files usable by the CTM's executable, reads the CTM's outputs, and reprojects the raw outputs at the observation vector resolution (mostly the temporal resolution as the model and the observation worlds do not follow the same time line).
The targeted structure of the CIF should allow for a full flexibility of observation operators, from the straightforward widely used decomposition detailed in Eq. (14) to more elaborated approaches including multiple transport models and/or complex super-observations (e.g., in Bréon et al., 2015; Staufer et al., 2016, authors implemented differences between observation sites and time in the observation vector instead of observations from individual sites in order to focus on spatial/temporal gradients, thus allowing them to limit the influence of background concentrations in the computation of local fluxes) and hyper-parameters (e.g., emission factors and model parameters used to produce emission maps; Rayner et al., 2010; Asefi‐Najafabady et al., 2014). Therefore, the observation operator is designed as a pipeline of elementary interchangeable transformations with standardized input and output formats such that
In such a formalism, all intermediate transformations have the same conceptual level in the code. They are functions ranging from spatial reprojection to temporal interpolations and to more complex operations such as the reconstruction of satellite total columns from concentrations simulated at individual levels in the transport model. In the CIF, all these transformations have the same input and output structure; thus, their order can be changed seamlessly to execute a given configuration. Please note that the commutative property of elementary transformations as pieces of code does not guarantee the commutative property of the corresponding physical operators.
Such a transformation-based design allows us to rigorously separate transformations and thus to implement and test their respective adjoints more easily. Once adjoints for each individual operation are implemented, the construction of the general adjoint is straightforward by reversing the order of forward operations:
Figure 2 shows an example of a typically targeted observation operator. Operators from Eq. (14) are reported for the illustration. It includes two numerical models chained with each other; they can be for instance a coarse global CTM and a finer-resolution regional CTM, such as in Rödenbeck et al. (2009) or Belikov et al. (2016). The system applies a series of transformations to the target vector, including spatial de-aggregation for the optimization of emissions by regions, sector de-aggregation to separate different activity sectors, reprojection to the CTM's resolution (a simple interpolation of mass-conserving regridding is available so far, with regular and irregular domains), application of temporal profiles (which is critical in air quality and anthropogenic CO2 applications) and unit conversions to the required inputs for the CTMs. On the observation vector side, observations can span multiple model time steps, requiring posterior temporal averages. In the case of super-observations (satellites retrievals, images, spatial gradients, etc.) in the observation vector, it is often necessary to combine multiple simulated point observations in given grid cells and time stamps into a single super-observation, to limit redundant observations and hence the size of the observation vector but also to limit representativeness issues. Super-observations are commonly used in the case for satellite observations being compared to all the model levels above a given location; concentration gradients comparing observations at different times and locations (see e.g., Bréon et al., 2015; Staufer et al., 2016) are another example of observation aggregation to reduce representativeness errors; isotopic ratios are also super-observations as they require researchers to simulate separate isotopologues and recombine them after the simulation (as done in, for example, van der Velde et al., 2018; Peters et al., 2018). The case of Fig. 2 also includes background concentrations in the target vector: a background is often used to fix some biases in initial and lateral concentrations in limited-area models, and in observations (mostly satellites); the background variables are processed at the very end of the pipeline when reconstructing the observations vector.
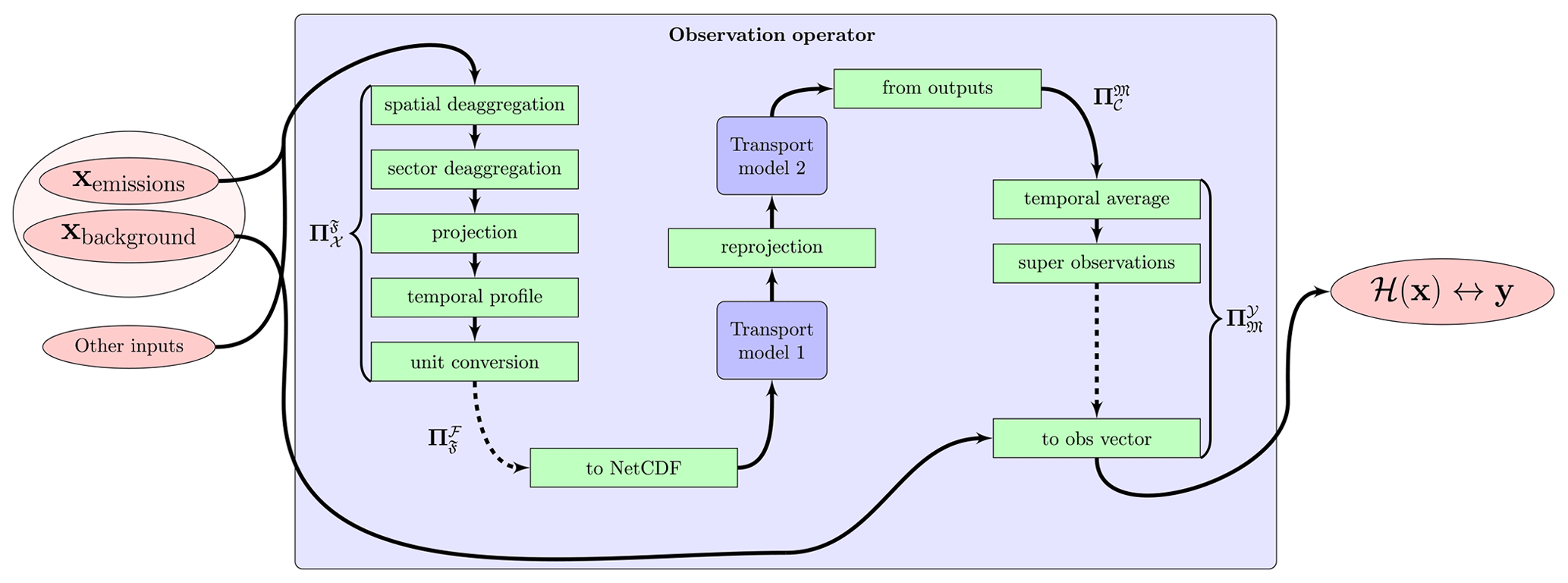
Figure 2Observation operator structure. Emissions are processed from the target vector to generate model inputs, as well as other inputs, not optimized by the inversion; in this example, some background for the simulations is also optimized by the inversion and is added to simulations at the end of the pipeline just before stacking outputs to the observation vector format.
The mathematical formalism of Eqs. (15) and (16) suggests that transformations are necessarily computed in a serialized way, thus limiting applications to simple target variables upstream of the transport model. However, each elementary transformation handles components of the inputs it is concerned with, leaving the rest identical and forwarding them to later transformations. Typically, it does not actually limit applications to simple target variables upstream of the CTM. For instance, in the case of target variables optimizing biases in the observations, the corresponding components of the target vector x are forwarded unchanged by all transformations in Fig. 2 until the very last operation, where they are used for the final comparison with the observation vector.
3.1 General rules
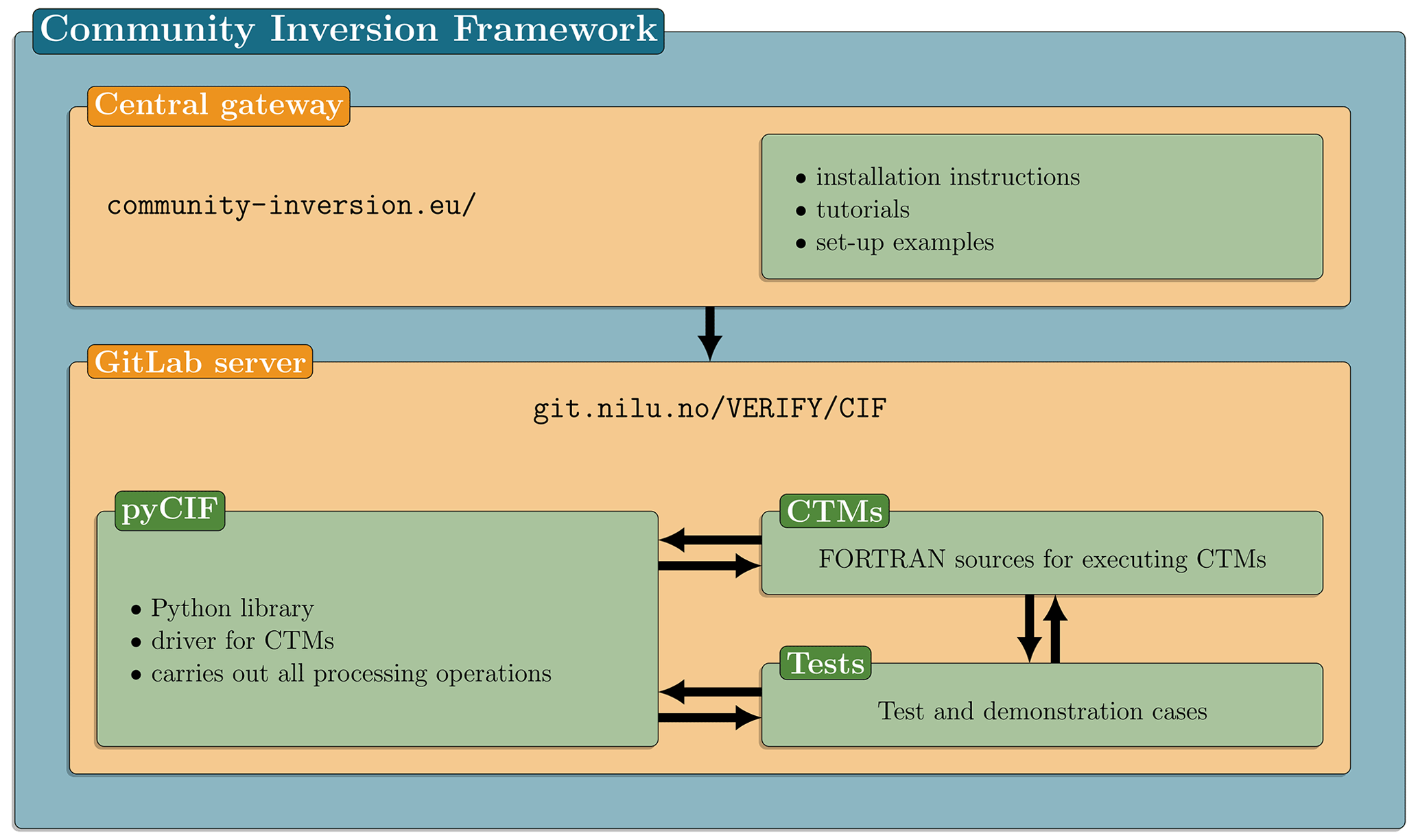
The Community Inversion Framework project follows the organization scheme of Fig. 3. A centralized website is available at http://community-inversion.eu, last access: 23 August 2021. The website includes all information given in the present paper, as well as further documentation details, practical installation instructions, tutorials and examples of possible set-ups. To foster the collaborative dynamics of our project, all open-access scripts and code files are available on a GitLab server at http://git.nilu.no/VERIFY/CIF, last access: 23 August 2021, where updates are published regularly. The frozen version of the code, documentation and data used for the present publication is available in Berchet et al. (2021). The repository includes the documentation, sources for the CTMs implemented in the CIF and the Python library pyCIF. Our project is distributed as an open-source project under the CeCILL-C licence of the French law (http://cecill.info, last access: 23 August 2021). The licence grants full rights for the users to use, modify and redistribute the original version of the CIF, conditional to the obligation to make their modifications available to the community and to properly acknowledge the original authors of the code. The authors of modifications own intellectual property of their modifications but under the same governing open licence. Software that may be built around the CIF in the future can have different licensing, but all parts of the code originating from the CIF will be governed by the original CeCILL-C licence; hence, it must remain open source. Similarly, some constituting pieces of the CIF can be adapted from other software governed by other licenses and simply interfaced to the CIF (e.g., transport models, minimizing algorithms, etc.); in that case, the corresponding software keeps its original licence, and its use and distribution in the CIF is subject to authorization by its owners (although open distribution and integration in the standard version of the CIF is encouraged). This is the case of the CONGRAD and M1QN3 algorithms which are used as minimizing algorithms in the variational inversions of the demonstration case in Sect. 4. The M1QN3 algorithm is distributed under the GNU General Public License, whereas CONGRAD is owned by ECMWF and is not open source; the later was interfaced with the CIF but is not openly distributed.
The pyCIF library, written in Python 3, is the practical embodiment of the CIF project. All theoretical operations described in Sect. 2 are computed by this module. It includes inversion computations, pre- and post-processing of CTM inputs and outputs, and target and observation vector reprojections, aggregation, etc., as written in Eq. (15). Python coding standards follow the community standards PEP-8 (http://python.org/dev/peps/pep-0008/, last access: 23 August 2021).
Test cases (including the ones presented in Sect. 4) are distributed alongside the CIF code files and scripts. To foster portability and dissemination, a dedicated Docker image is distributed with pyCIF, providing a stable environment to run the system and enabling full reproducibility of the results from one machine to the other.
3.2 Plugin-based implementation
To reflect the theoretical flexibility required in the computation of various inversion methods and observation operators, we made the choice of implementing pyCIF following an abstract structure with a variety of so-called Python plugins, which are dynamically constructed and inter-connected depending on the set-up.
3.2.1 Objects and classes in pyCIF
General classes of objects emerge from the definition of the abstract structure of the inversion framework. These classes are defined by the data and metadata they carry, as well as by the methods they include and their interaction with other classes. The main classes are the following:
-
Computation modes. Forward computations, the test of the adjoint, variational inversions, EnSRF and analytical inversions are available (see details in Sect. 2.2).
-
Models. These interface with CTMs and include generation of input files, executing the code and post-processing outputs; included are a Gaussian model described in Sect. 4 for the demonstration of the system, as well as CHIMERE, LMDZ, FLEXPART, TM5, and STILT, all of which will be described in a dedicated future publication.
-
Platforms. These deal with specific configurations on different clusters; it includes a standard platform as well as two supercomputers where the CIF was tested.
-
Target vectors. These store and apply operations related to the target vector, including spatial and temporal aggregation, de-aggregation and regularization of the target vector.
-
Observation vectors. These store and apply operations related to the observation vector, including application of observation errors.
-
observation operators. These drive CTMs and apply elementary operations between the control and observation vectors.
-
Transformations. These are elementary operations used to build the observation operator; they include temporal averaging or de-aggregating of the target and observation vectors, projection of the target vector at the model input resolution, etc.
-
Data vectors. These store all information on inputs for pyCIF; this vector is used by the observation and target vector classes to build themselves.
-
Minimizers. These are the algorithms used to minimize cost functions, including M1QN3 and CONGRAD algorithms so far.
-
Simulators. These are the cost functions to minimize in variational inversions; they only include the standard Gaussian cost function so far.
-
Domains. These store information about the CTM's grid, including coordinates of grid cell centres and corners, vertical levels, etc.
-
Fluxes, fields and meteo-data. These fetch, read and write different formats of inputs for CTMs (surface fluxes, 3D fields and meteorological fields respectively); so far they include only inputs specific to included CTMs, but they will ultimately include standard data streams, such as widely used emission inventories or meteorological fields such as those from ECMWF.
-
Measurements. These fetch, read and write different types of observation data streams; they only include the World Data Centre for Greenhouse Gases so far (https://gaw.kishou.go.jp/, last access: 23 August 2021) but classical data providers such as ICOS (http://icos-cp.eu, last access: 23 August 2021) or ObsPack (Masarie et al., 2014) will also be implemented in the CIF. Satellite products, in particular the formatting of averaging kernels and other metadata, should also be included in the CIF in the near future as they play a growing role in the community.

Figure 4(a) Prior fluxes and observation sites. (b) Perturbation from the prior data used to generate “true” observations. Observation sites are shown as circles coloured according to their height in metres above ground level (m a.g.l.). Fluxes are reported in arbitrary units (a.u.).
Details on metadata and operations for each class are given in the Supplement, Table S1. Our objective was to design a code that is fully recursive in the sense that modifying some instance of a class does not require users to update other classes calling or being called by the modified class. Thus, each class is built so that it only needs internal data, as well as data from the execution level just before and after it, in order to avoid complex dependencies while allowing proper recursive behaviour in building the transformation pipeline. For instance, the observation operator applies a pipeline of transformations from the target vector to the observation vector. Some transformations will use the model class to run the model or the domain class to carry out reprojections, or the target vector to aggregate/de-aggregate target dimensions, etc. Despite the many complex transformations carried out under the umbrella of the observation operator, only the sub-transformations of the pipeline are accessible at the observation operator level, which do not have to directly carry information about, for example, the model or other classes required at sub-levels. This makes the practical code of the observation operator much simpler and as easy to read as possible.
3.2.2 Automatic construction of the execution pipeline
To translate the principle scheme of Fig. 1, pyCIF is not built in a sequential rigid manner. Plugins are interconnected dynamically at the initializing step of pyCIF depending on the chosen set-up (see Sect. 3.3 for details on the way to configure the CIF). The main strength of such a programming structure is the independence of all objects in pyCIF. They can be implemented separately in a clean manner. The developer only needs to specify what other objects are required to run the one being developed, and pyCIF makes the links to the rest. It avoids unexpected impacts elsewhere in the code when modifying or implementing a feature in the system. In the following, we call this top-down relationship in the code a dependency.
For each plugin required in the configuration (primarily the computation mode), pyCIF initializes corresponding objects following simple rules. Following dependencies detailed in Table S1, for every object to initialize, pyCIF will fetch and initialize required plugins and attach them to the original plugin. If the required plugin is explicitly defined in the configuration, pyCIF will fetch this one. In some cases, some plugins can be built on default dependencies, which do not need to be defined explicitly in the configuration file. In that case, the required plugin can be retrieved using default plugin dependencies specified in the code itself and not needed in the configuration.
For instance, in the call graph in Fig. 1, “variational” (inversion) is a “computation mode” object in pyCIF. To execute, it requires a “minimizer” object (CONGRAD, M1QN3, etc.) that is initialized and attached to it. The minimizer requires a “simulator” object (the cost function) that itself will call functions in the “control vector” object and the “observation operator” object. Then the observation operator will initialize a pipeline of transformations including running the model and so on and so forth.
3.3 Definition of configurations in the CIF
In practice, pyCIF is configured using a YAML configuration file (http://yaml.org, last access: 23 August 2021). This file format was primarily chosen for its flexibility and intuitive implementation of hierarchical parameters. In the YAML language, key words are specified with associated values by the user. Indentations indicate sub-levels of parameters, which makes it a consistent tool with the coding language Python.
To set up a pyCIF computation, the user needs to define the computation mode and all related requirements in the YAML configuration file. Every plugin has mandatory and optional arguments. The absence of one mandatory argument raises an error at initialization. Optional arguments are replaced by corresponding default values if not specified. Examples of YAML configuration files used to carry out the demonstration cases are given in Supplement Sect. S3.
In the following we describe a demonstration case based on a simple implementation of a Gaussian plume dispersion model and simple inversion set-ups. The purpose of this demonstration case is a proof of concept of the CIF, with various inversion methods. We comment and compare inversion set-ups and methods for the purpose of the exercise, but conclusions are not made to be generalized to any inversion case study due to the simplicity of our example. The test application with a simple Gaussian plume model allows users to quickly carry out the test cases themselves, even on desktop computers, to familiarize themselves with the system. Nevertheless, the Gaussian plume model is not only relevant for teaching purposes but also for real applications, as it is used in many inversion studies from the scale of industrial sites with in situ fixed or mobile measurements (e.g., Kumar et al., 2020; Foster-Wittig et al., 2015; Ars et al., 2017) to the larger scales with satellite measurements to optimize individual clusters of industrial or urban emissions (e.g., Nassar et al., 2017; Wang et al., 2020). Other models implemented in the CIF will be presented in a future paper evaluating the differences when using different transport models with all other elements of the configuration identical. The purpose of such an evaluation is to produce a rigorous intercomparison exercise identifying the effect of transport errors on inversion systems.
4.1 Gaussian plume model
Gaussian plume models approximate real turbulent transport by a stable average Gaussian state (Hanna et al., 1982). Such models are not always suitable to compare with continuous measurements but can be adapted when using observations averaged over time. In the following, we consider the Gaussian plume assumption to be valid for comparing to hourly averaged observations. A simple application of the Gaussian plume model was implemented in the CIF as a testing and training utility. It is computationally easy to run, even on desktop computers. It includes the most basic Gaussian plume equations. In that application, concentrations 𝒞 at location downwind from a source of intensity f at are given by
with
where x is the downwind distance between the source and receptor points along the wind axis, y is the distance between the wind axis and the receptor point, v(source, receptor) is the vector linking the source and the receptor point, and z is the difference between the source and the receptor altitudes. u is the vectoral wind speed, with being the average wind speed in the domain of simulation. Symbols and depict the scalar and the vector products respectively. Parameters , and d are depending on the Pasquill–Gifford atmospheric vertical stability classes. There are seven Pasquill–Gifford stability classes, from (a) extremely unstable (mostly in summer during the afternoon) to (g) very stable (occurring mostly during nighttime in winter). As the purpose of the demonstration case is primarily to work on coarsely realistic concentration fields, with a computational cost as low as possible, our implementation of the Gaussian plume model does not include any representation of particle reflection on the ground or on the top of the planetary boundary layer.
To illustrate atmospheric inversions, we use a grid of point surface fluxes to simulate concentrations using the Gaussian plume equation. Thus, the concentration at a given point and time t is the sum of Gaussian plume contributions from all individual grid points:
This formulation highlights the linear relationship between concentrations and fluxes. As the concentrations can be expressed as a matrix product, the computation of the adjoint of the Gaussian model is straightforward and does not require extra developments:
For the purpose of our demonstration cases, meteorological conditions (wind speed, wind direction and stability class) are randomly generated for the simulation time window. Fixed seeds are selected for the generation of random conditions in order to make them reproducible.
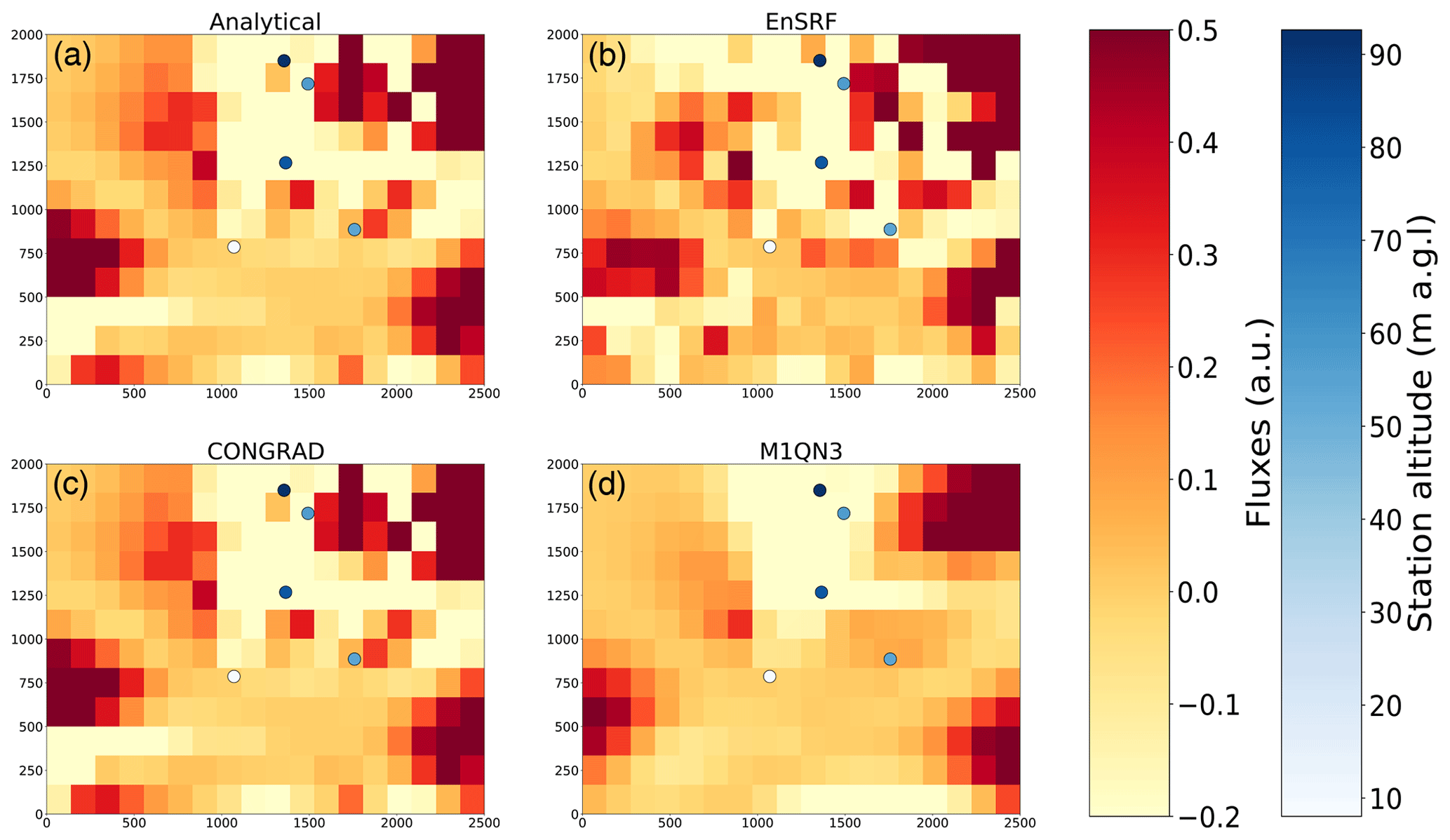
Figure 5Posterior increments for analytical, EnSRF, variational with CONGRAD and variational with M1QN3 (from top to bottom, left to right) for an inversion set-up at the pixel resolution with horizontal correlation length of 500 m.
4.2 Configuration
4.2.1 Modelling set-up
Cases discussed in Sect. 4.3 are based on the Gaussian model computed on a domain of 2.5×2 km2 with a grid of 18×12 grid cells. Surface point sources are located at the centre of the corresponding grid cells, with flux intensities as represented in Fig. 4. Five virtual measurement sites are randomly located in the domain with randomly selected altitudes above ground level as shown in Fig. 4. The inversion time window spans a period of 5 d with hourly observations and meteorological forcing conditions. Meteorological conditions are a combination of a wind speed, a wind direction and a stability class applicable to the whole simulation domain for each hour. The three parameters are generated randomly for the period, without respect for realistic relatively smooth transitions in wind speed and direction or stability class.
Truth observations are generated by running the Gaussian model in forward mode with known fluxes defined as the sum of prior fluxes f (used later in the inversions) in Eq. (21) and an arbitrary perturbation as defined in Eq. (22), illustrated in Fig. 4 (left and right respectively).
with f0 being an arbitrary reference flux, and scaling lengths , , , , and equal to 500, 1000, 200, 1000, 1000 and 300 m respectively. Reference fluxes and perturbations are constant over time.
A random noise of 1 % of the standard deviation of the forward simulations was added to the truth observations to generate measurements. Please note that the perturbation of the fluxes is generated using an explicit formula and not a random perturbation with a given covariance matrix. We discuss results with different possible target vectors and covariance matrices.
4.2.2 Inversion set-ups
The objective of our test case is to prove that our system enables users to easily compare the behaviour of different inversion methods in various configurations. To do so, we conduct three sets of four inversions for the demonstration of our system. Each set includes one analytical inversion, one EnSRF-based inversion and two variational inversions based on M1QN3 and CONGRAD minimization algorithms respectively. The sequential aspect of the EnSRF is not implemented in the CIF; hence, the comparison with the other inversion methods only includes the random sampling of the target vector distribution to solve Eq. (5).
The three sets of inversions differ by the dimension of the target vector and the spatial correlations of errors. The first set uses a target vector based on a grid of 3×3 pixel-aggregated regions or “bands” independent from each other, i.e., with no spatial error correlations. The target vectors of the second and third sets are defined at the grid cell's resolution with horizontal isotropic error correlations, following an exponential decay with a horizontal scale of 500 and 200 000 m respectively; the latter case is used to demonstrate that the implementation of correlation lengths is correct as very long correlations are equivalent to having only one spatial scaling factor in the target vector. For all inversion set-ups, the target vectors are defined as constant over time, i.e., only one coefficient per spatial dimension is optimized for the 5 d × 24 h, computed by the model. In all set-ups, the magnitude of the observation noise used to generate true observations is chosen as observation errors in the matrix R for consistency. In all cases, the diagonal terms of the B matrix are set to 100 %.
To assess the sensitivity of each set-up to the allocated computational resources, we computed the EnSRF and the two variational inversions with varying numbers of simulations N. In the case of the EnSRF, N simply depicts the size of the Monte Carlo ensemble. For variational inversions, each step, i.e., each computation of the cost function and its gradient, requires one forward simulation and one adjoint simulation. The Gaussian model is a simple auto-adjoint model, which makes the adjoint simulations as long as the forward one. Therefore, N is equal to twice the number of computations of the cost function (one for the forward and one for the adjoint) in the minimization algorithm. Note that in many real application cases, the adjoint of a CTM is more costly than the forward, reducing the number of iterations possible in N times the cost of a forward. Indeed, despite the adjoint being mathematically as expensive as the forward, in practice the computation of adjoint operations often requires the recomputation of intermediate forward computations, therefore increasing the computational burden of the adjoint model. More precisely, users and developers of adjoint transport models choose the number of forward recomputations to be carried out, based on a space–speed trade-off: by saving all forward intermediate states, the adjoint is as costly as the forward, but the disk space burden can be extremely challenging to manage, thus increasing the overall computation time in return.
4.3 Results and discussion
In the following, we present detailed figures for the test case at the pixel resolution with a correlation length of 500 m. For the sake of readability, figures for other test cases are grouped in Sect. S2 of the Supplement.
Posterior increments are presented in Fig. 5. Observation locations and heights are reported for information. The colour scale of flux increments is the same as in Fig. 4, which represent the true “increments” to be retrieved. In Fig. 8, we present the evolution of the cost function of Eq. (6) depending on the number of simulations used for each inversion method for the three demonstration cases (see details on the corresponding number of simulations of each inversion method in Sect. 4.2.2). The x axis has been cropped at the origin as the EnSRF value for small sizes of random ensembles diverges to infinity.
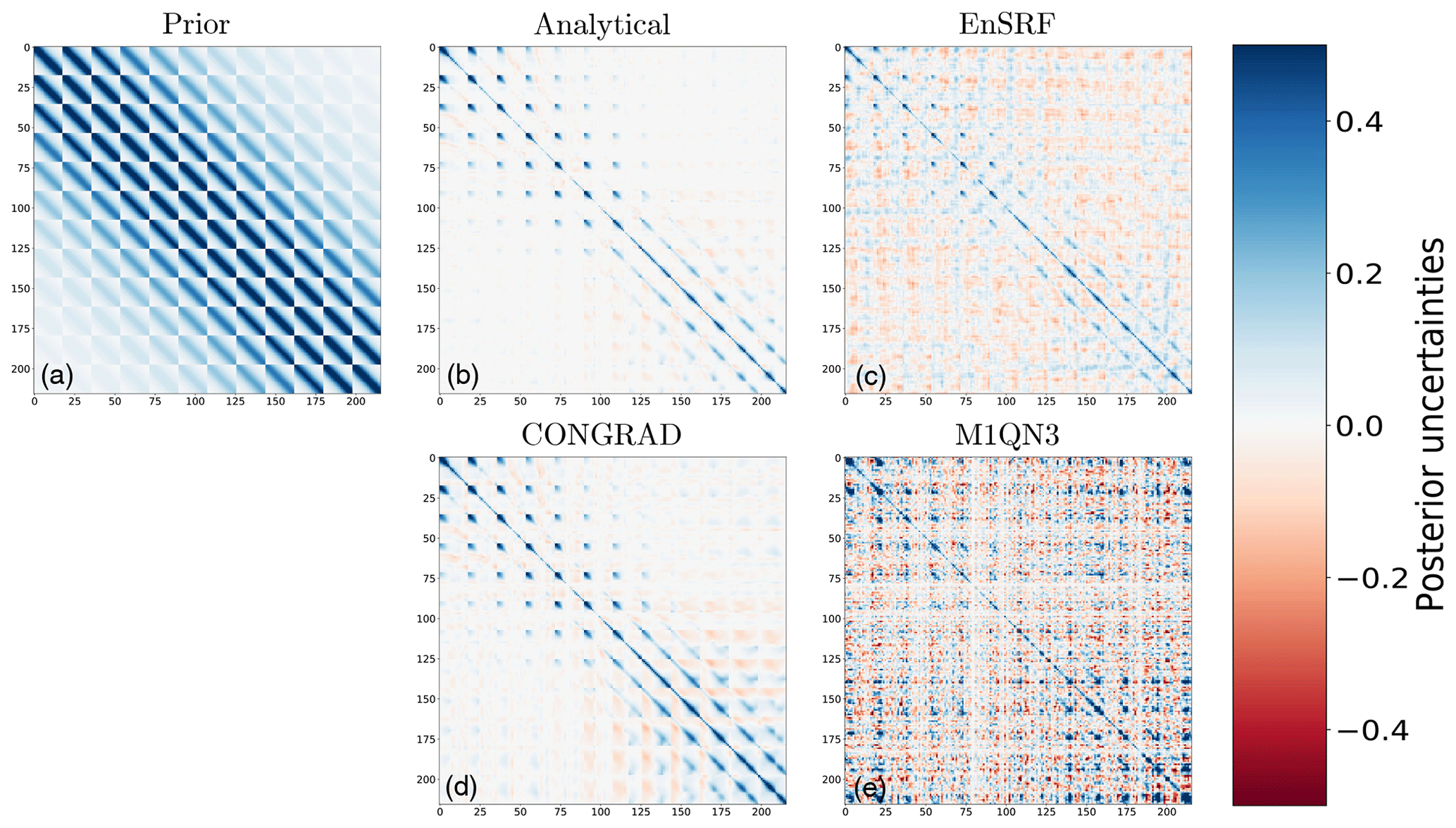
Figure 7Prior (a) and posterior (b–e) uncertainty matrices for analytical, EnSRF, variational with CONGRAD and variational with M1QN3 (from top to bottom, middle and right columns), with the same set-up as in Fig. 5. All matrices are reported with unitless values; i.e., a “1” on the diagonal corresponds to a 100 % uncertainty.
In the case with the target vector aggregated on groups of pixels, all inversion methods converge towards a very similar solution. In this case, the posterior increments reproduce the overall structure of the truth–prior difference, with one local minimum in the centre of the domain. However, the aggregated target vector results in too coarse patterns which are not representative of the actual truth–prior difference. In the case with the target vector at the grid's resolution with spatial correlations of 500 m, all methods capture well the true-prior difference structure. However, posterior increments are rather noisy compared to the truth. This is due to the spatial correlations being inconsistent with the smooth perturbation with fixed length scales in Eq. (22). Correlations help smoothing the posterior fluxes but not perfectly consistent with the truth. For the case with the target vector at the grid's resolution with spatial correlations of 200 000 m, all methods converge towards a very smooth and similar solution, consistent with what is expected with a very long correlation length. However, they do not converge towards the same solution, probably because a larger number of iterations/members would be needed to fully converge.
In all cases, CONGRAD converges at a faster pace than the other two methods, and after a limited number of iterations, the convergence rate is close to zero, suggesting additional simulations do not provide significant additional information to CONGRAD (although additional iterations bring new constraints on the posterior uncertainty matrix).
Overall, CONGRAD appears to be the most cost-efficient algorithm to estimate the analytical solution in the case of a linear inversion in our very simple demonstration case. Though not as efficient, the EnSRF method can approximate the analytical solution at a reduced cost. By design, its computation can easily be parallelized, which can allow for a faster computation than CONGRAD when computational resources are available in parallel. M1QN3 proves not as efficient as its CONGRAD counterpart, but contrary to CONGRAD, it can accommodate non-linear cases.
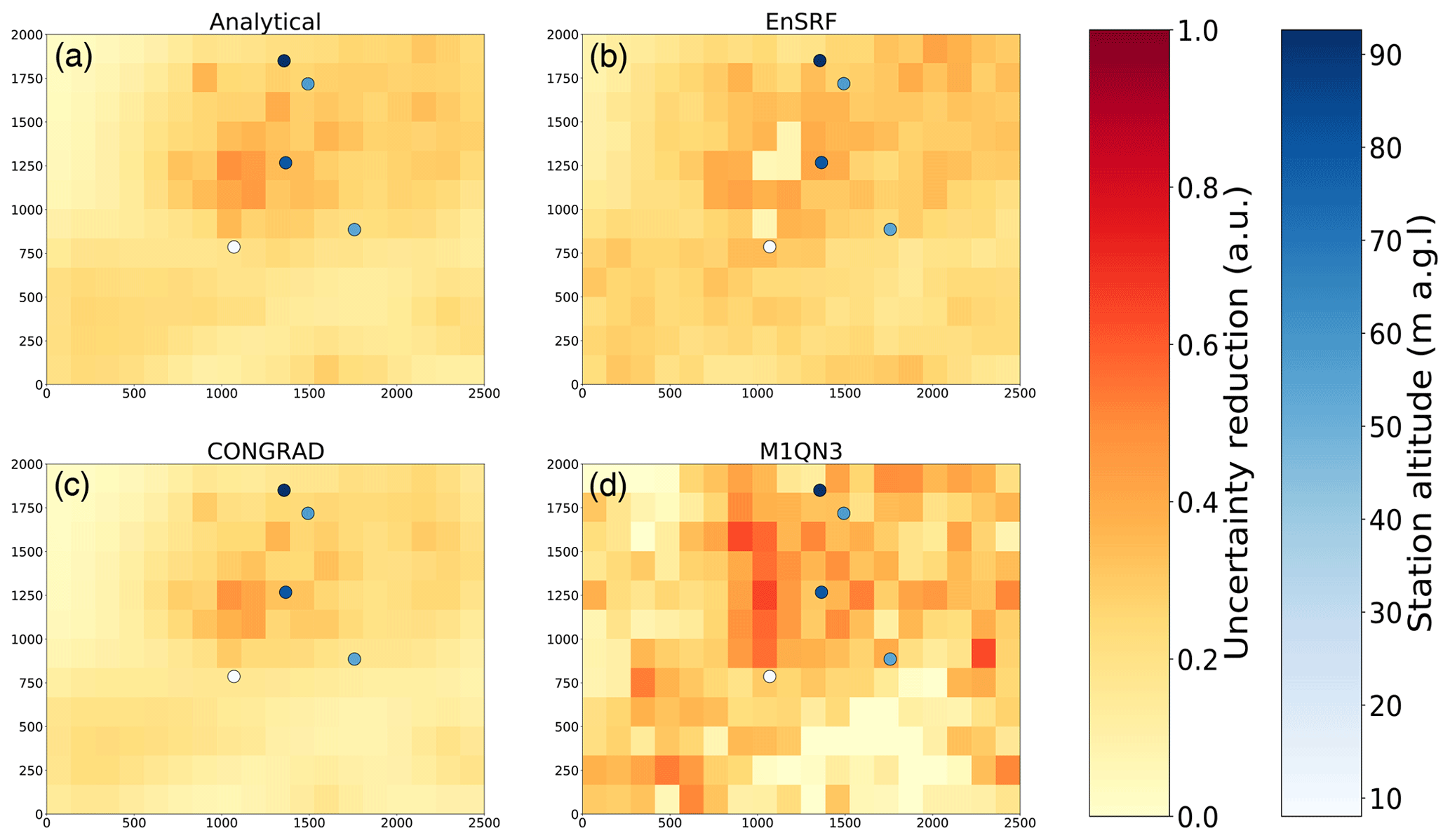
The reduction of uncertainties and posterior uncertainty matrices are shown in Figs. 6 and 7 (and equivalents in the Supplement). Regarding posterior uncertainties, CONGRAD proves relatively efficient to approximate the analytical solution, especially at the pixel resolution. The variational inversion with Monte Carlo and M1QN3 computations and the inversion with EnSRF are much noisier. Approximating posterior matrices requires a large number of Monte Carlo members and proves very challenging in real-world applications.
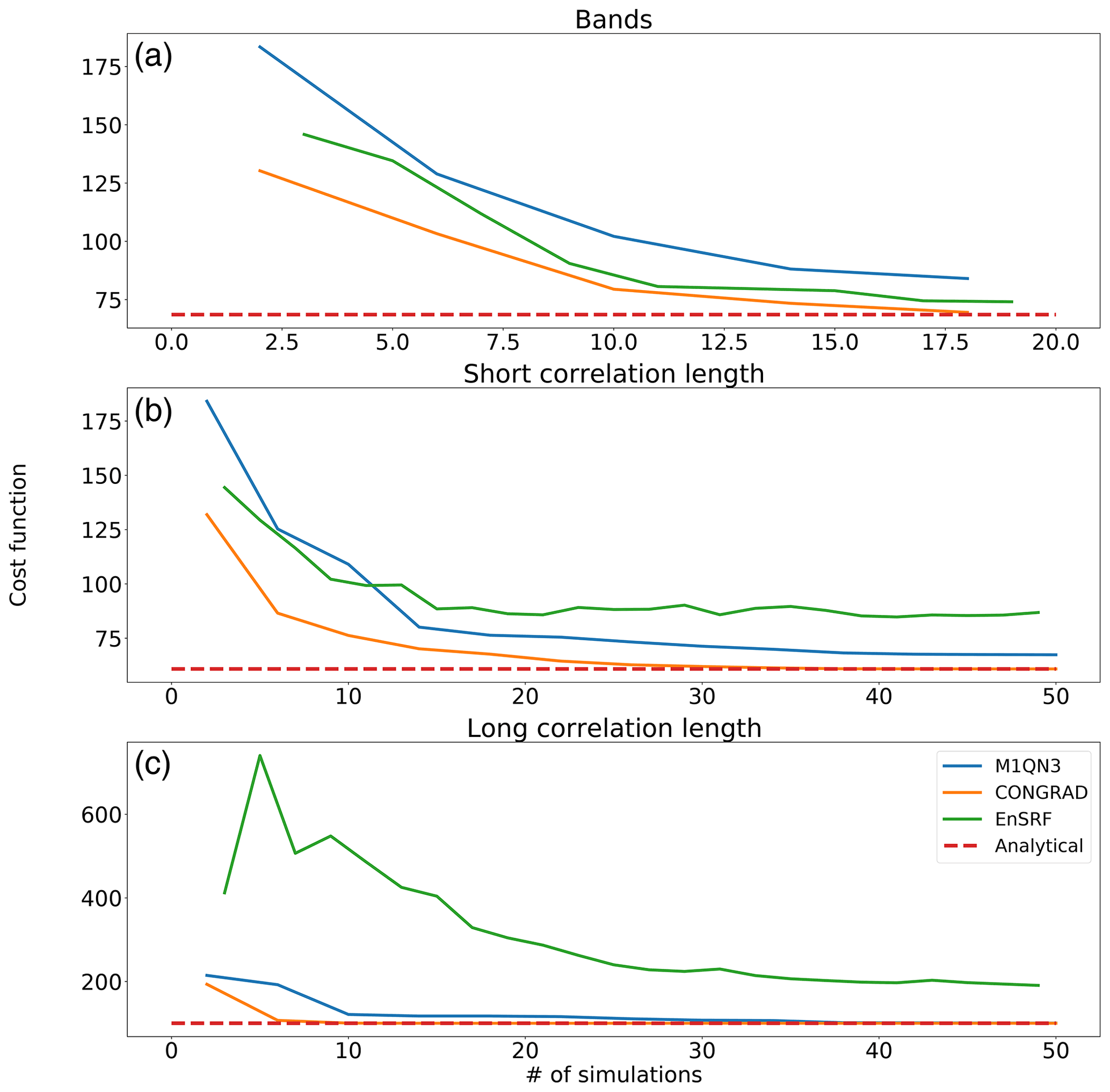
Figure 8Cost function evaluation for varying numbers of computed simulations for analytical (red), EnSRF (green), variational with CONGRAD (orange) and variational with M1QN3 (blue) methods. (a) Inversion set-up with aggregated regions of 3 × 3 pixels; (b) inversion set-up at the pixel resolution with horizontal correlation length of 500 m; (c) inversion set-up at the pixel resolution with horizontal correlation length of 200 000 m.
We have introduced here a new generic inversion framework that aims at merging existing inversion systems together, in order to share development and maintenance efforts and to foster collaboration on inversion studies. It has been implemented in a way that is fully independent from the inversion configuration: from the application scales, from the species of interest, from the CTM used, from the assumptions for data assimilation, and from the practical operations and transformations applied to the data in pre- and post-processing stages. This framework will prevent redundant developments from participating research groups and will allow for a very diverse range of applications within the same system. New developments will be made in an efficient manner with limited risks of unexpected side effects, and thanks to the generic structure of the code, specific developments for a given application can be directly applied to other applications. For instance, new inversion methods implemented in the CIF can be directly tested with various transport models. With modern inversion methods moving towards a hybrid paradigm of variational and ensemble methods, the flexibility of the CIF will be a valuable asset as abstract methods can be easily mixed with each other.
We have presented the first version of this Community Inversion Framework (CIF) alongside its Python-dedicated library pyCIF. As a first step, analytical inversions, variational inversions with M1QN3 and CONGRAD, and EnSRF have been implemented to demonstrate the general applicability of the CIF. The four inversion techniques were tested here on a test case with a Gaussian plume model and with observations generated from known true fluxes. The impact of spatial correlations and of spatial aggregation, which drive the shape of the control vectors used in this scientific community, has been illustrated. The analytical inversion is the most accurate approach to retrieve the true fluxes, as expected, followed by variational inversions with the CONGRAD algorithm in our simple linear case. In our simple case, EnSRF and M1QN3 generally take longer to converge towards the true pattern of the fluxes, even though EnSRF inversions have the advantage to be fully parallelizable, in contrast to variational inversions, that are sequential by design and therefore harder to parallelize (e.g., Chevallier, 2013).
The next step of the CIF is the implementation of a large variety of CTMs. The implementation of new CTMs already interfaced with other inversion systems should not bring particular conceptual challenges as all interface operations are already written in their original inversion system; in most cases, re-arranging existing routines is sufficient to interface a model to the CIF. One particular challenge concerns I/O optimizations: the generation of inputs and the processing of outputs can be time consuming and in some very heavy applications require specific numerical and coding optimizations. The very general formalism of the CIF may hamper the ability of applying these particular optimizations for some models. Best efforts will have to be deployed to take full advantage of advanced I/O and data manipulation libraries in Python to limit this weakness.
CHIMERE, LMDZ, TM5, FLEXPART, and STILT have already been implemented, and a sequel paper will evaluate and compare their behaviour in similar inversion set-ups. COSMO-GHG and WRF-Chem are also planned to be implemented in the near future to widen the developer and/or user community of the system. The use of various CTMs in identical inversion configurations (inversion method, observation and target vector, consistent interface, etc.) will allow for extensive assessments of transport errors in inversions. Despite many past efforts put into inter-comparison exercises, such a level of inter-comparability has never been reached and will be a natural by-product of the CIF in the future. In addition, comparing posterior uncertainties from different inversion methods and set-ups will make it possible to fully assess the consistency of different inversion results.
The flexibility of the CIF allows very complex operations to be included easily. They include the use of satellite observations, which will be evaluated in a future paper, inversions using observations of isotopic ratios and optimizing both surface fluxes and source signatures (Thanwerdas et al., 2021). In addition, even though greenhouse gas studies have been the main motivation behind the development of the CIF, the system will also be tested for multi-species inversions including air pollutants.
The code files, documentation pages (including installation instructions and tutorials) and demonstration data used in the present paper are registered under the following link https://doi.org/10.5281/zenodo.5045730 (Berchet et al., 2021).
The supplement related to this article is available online at: https://doi.org/10.5194/gmd-14-5331-2021-supplement.
All authors contributed to the elaboration of the concept of Community Inversion Framework. AB designed the structure of the CIF. AB, ES, IP and JT are the main developers of the Python library pyCIF. AB, ES and IP maintain the documentation and websites associated with the Community Inversion Framework.
The authors declare that they have no conflict of interest.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors thank the reviewers (Peter Rayner and an anonymous referee) for their fruitful comments on our manuscript.
The Community Inversion Framework is currently funded by the project (http://verify.lsce.ipsl.fr, last access: 23 August 2021), which received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement no. 776810.
This paper was edited by Christoph Knote and reviewed by Peter Rayner and one anonymous referee.
Anderson, J., Hoar, T., Raeder, K., Liu, H., Collins, N., Torn, R., and Avellano, A.: The Data Assimilation Research Testbed: A Community Facility, B. Am. Meteorol. Soc., 90, 1283–1296, https://doi.org/10.1175/2009BAMS2618.1, 2009. a
Ars, S., Broquet, G., Yver Kwok, C., Roustan, Y., Wu, L., Arzoumanian, E., and Bousquet, P.: Statistical atmospheric inversion of local gas emissions by coupling the tracer release technique and local-scale transport modelling: a test case with controlled methane emissions, Atmos. Meas. Tech., 10, 5017–5037, https://doi.org/10.5194/amt-10-5017-2017, 2017. a
Asefi‐Najafabady, S., Rayner, P. J., Gurney, K. R., McRobert, A., Song, Y., Coltin, K., Huang, J., Elvidge, C., and Baugh, K.: A multiyear, global gridded fossil fuel CO2 emission data product: Evaluation and analysis of results, J. Geophys. Res.-Atmos., 119, 10213–10231, https://doi.org/10.1002/2013JD021296, 2014. a
Babenhauserheide, A., Basu, S., Houweling, S., Peters, W., and Butz, A.: Comparing the CarbonTracker and TM5-4DVar data assimilation systems for CO2 surface flux inversions, Atmos. Chem. Phys., 15, 9747–9763, https://doi.org/10.5194/acp-15-9747-2015, 2015. a, b
Bagley, J. E., Jeong, S., Cui, X., Newman, S., Zhang, J., Priest, C., Campos-Pineda, M., Andrews, A. E., Bianco, L., Lloyd, M., Lareau, N., Clements, C., and Fischer, M. L.: Assessment of an atmospheric transport model for annual inverse estimates of California greenhouse gas emissions, J. Geophys. Res.-Atmos., 122, 1901–1918, https://doi.org/10.1002/2016JD025361, 2017. a
Belikov, D. A., Maksyutov, S., Yaremchuk, A., Ganshin, A., Kaminski, T., Blessing, S., Sasakawa, M., Gomez-Pelaez, A. J., and Starchenko, A.: Adjoint of the global Eulerian–Lagrangian coupled atmospheric transport model (A-GELCA v1.0): development and validation, Geosci. Model Dev., 9, 749–764, https://doi.org/10.5194/gmd-9-749-2016, 2016. a
Berchet, A., Pison, I., Chevallier, F., Bousquet, P., Bonne, J.-L., and Paris, J.-D.: Objectified quantification of uncertainties in Bayesian atmospheric inversions, Geosci. Model Dev., 8, 1525–1546, https://doi.org/10.5194/gmd-8-1525-2015, 2015. a
Berchet, A., Sollum, E., Pison, I., Thompson, R. L., Thanwerdas, J., Fortems-Cheiney, A., Peet, J. C. A. v., Potier, E., Chevallier, F., Broquet, G., and Adrien, B.: The Community Inversion Framework: codes and documentation, Zenodo, https://doi.org/10.5281/zenodo.5045730, 2021. a, b
Bergamaschi, P., Krol, M., Meirink, J. F., Dentener, F., Segers, A., van Aardenne, J., Monni, S., Vermeulen, A. T., Schmidt, M., Ramonet, M., Yver, C., Meinhardt, F., Nisbet, E. G., Fisher, R. E., O'Doherty, S., and Dlugokencky, E. J.: Inverse modeling of European CH$_4$ emissions 2001–2006, J. Geophys. Res., 115, D22309, https://doi.org/10.1029/2010JD014180, 2010. a, b
Bergamaschi, P., Danila, A., Weiss, R. F., Ciais, P., Thompson, R. L., Brunner, D., Levin, I., Meijer, Y., Chevallier, F., Janssens-Maenhout, G., Bovensmann, H., Crisp, D., Basu, S., Dlugokencky, E. J., Engelen, R., Gerbig, C., Günther, D., Hammer, S., Henne, S., Houweling, S., Karstens, U., Kort, E. A., Maione, M., Manning, A. J., Miller, J. B., Montzka, S. A., Pandey, S., Peters, W., Peylin, P., Pinty, B., Ramonet, M., Reimann, S., Röckmann, T., Schmidt, M., Strogies, M., Sussams, J., Tarasova, O. A., van Aardenne, J., Vermeulen, A. T., and Vogel, F.: Atmospheric monitoring and inverse modelling for verification of greenhouse gas inventories, EUR 29276 EN JRC111789, Publications Office of the European Union, Luxembourg, available at: https://ec.europa.eu/jrc/en/publication/eur-scientific-and-technical-research-reports/atmospheric-monitoring-and-inverse-modelling-verification-greenhouse-gas-inventories (last access: 23 August 2021), 2018a. a
Bergamaschi, P., Karstens, U., Manning, A. J., Saunois, M., Tsuruta, A., Berchet, A., Vermeulen, A. T., Arnold, T., Janssens-Maenhout, G., Hammer, S., Levin, I., Schmidt, M., Ramonet, M., Lopez, M., Lavric, J., Aalto, T., Chen, H., Feist, D. G., Gerbig, C., Haszpra, L., Hermansen, O., Manca, G., Moncrieff, J., Meinhardt, F., Necki, J., Galkowski, M., O'Doherty, S., Paramonova, N., Scheeren, H. A., Steinbacher, M., and Dlugokencky, E.: Inverse modelling of European CH4 emissions during 2006–2012 using different inverse models and reassessed atmospheric observations, Atmos. Chem. Phys., 18, 901–920, https://doi.org/10.5194/acp-18-901-2018, 2018b. a
Bocquet, M.: Ensemble Kalman filtering without the intrinsic need for inflation, Nonlin. Processes Geophys., 18, 735–750, https://doi.org/10.5194/npg-18-735-2011, 2011. a
Bocquet, M., Elbern, H., Eskes, H., Hirtl, M., Žabkar, R., Carmichael, G. R., Flemming, J., Inness, A., Pagowski, M., Pérez Camaño, J. L., Saide, P. E., San Jose, R., Sofiev, M., Vira, J., Baklanov, A., Carnevale, C., Grell, G., and Seigneur, C.: Data assimilation in atmospheric chemistry models: current status and future prospects for coupled chemistry meteorology models, Atmos. Chem. Phys., 15, 5325–5358, https://doi.org/10.5194/acp-15-5325-2015, 2015. a
Bousquet, P., Ringeval, B., Pison, I., Dlugokencky, E. J., Brunke, E.-G., Carouge, C., Chevallier, F., Fortems-Cheiney, A., Frankenberg, C., Hauglustaine, D. A., Krummel, P. B., Langenfelds, R. L., Ramonet, M., Schmidt, M., Steele, L. P., Szopa, S., Yver, C., Viovy, N., and Ciais, P.: Source attribution of the changes in atmospheric methane for 2006–2008, Atmos. Chem. Phys., 11, 3689–3700, https://doi.org/10.5194/acp-11-3689-2011, 2011. a
Bousserez, N. and Henze, D. K.: Optimal and scalable methods to approximate the solutions of large-scale Bayesian problems: theory and application to atmospheric inversion and data assimilation, Q. J. Roy. Meteor. Soc., 144, 365–390, https://doi.org/10.1002/qj.3209, 2018. a
Bousserez, N., Henze, D. K., Perkins, A., Bowman, K. W., Lee, M., Liu, J., Deng, F., and Jones, D. B. A.: Improved analysis-error covariance matrix for high-dimensional variational inversions: application to source estimation using a 3D atmospheric transport model, Q. J. Roy. Meteor. Soc., 141, 1906–1921, https://doi.org/10.1002/qj.2495, 2015. a
Brioude, J., Angevine, W. M., Ahmadov, R., Kim, S.-W., Evan, S., McKeen, S. A., Hsie, E.-Y., Frost, G. J., Neuman, J. A., Pollack, I. B., Peischl, J., Ryerson, T. B., Holloway, J., Brown, S. S., Nowak, J. B., Roberts, J. M., Wofsy, S. C., Santoni, G. W., Oda, T., and Trainer, M.: Top-down estimate of surface flux in the Los Angeles Basin using a mesoscale inverse modeling technique: assessing anthropogenic emissions of CO, NOx and CO2 and their impacts, Atmos. Chem. Phys., 13, 3661–3677, https://doi.org/10.5194/acp-13-3661-2013, 2013. a
Broquet, G., Chevallier, F., Rayner, P., Aulagnier, C., Pison, I., Ramonet, M., Schmidt, M., Vermeulen, A. T., and Ciais, P.: A European summertime CO$_2$ biogenic flux inversion at mesoscale from continuous in situ mixing ratio measurements, J. Geophys. Res.-Atmos., 116, D23303, https://doi.org/10.1029/2011JD016202, 2011. a
Bruhwiler, L. M. P., Michalak, A. M., Peters, W., Baker, D. F., and Tans, P.: An improved Kalman Smoother for atmospheric inversions, Atmos. Chem. Phys., 5, 2691–2702, https://doi.org/10.5194/acp-5-2691-2005, 2005. a
Brunner, D., Henne, S., Keller, C. A., Reimann, S., Vollmer, M. K., O'Doherty, S., and Maione, M.: An extended Kalman-filter for regional scale inverse emission estimation, Atmos. Chem. Phys., 12, 3455–3478, https://doi.org/10.5194/acp-12-3455-2012, 2012. a
Brunner, D., Arnold, T., Henne, S., Manning, A., Thompson, R. L., Maione, M., O'Doherty, S., and Reimann, S.: Comparison of four inverse modelling systems applied to the estimation of HFC-125, HFC-134a, and SF6 emissions over Europe, Atmos. Chem. Phys., 17, 10651–10674, https://doi.org/10.5194/acp-17-10651-2017, 2017. a
Bréon, F. M., Broquet, G., Puygrenier, V., Chevallier, F., Xueref-Remy, I., Ramonet, M., Dieudonné, E., Lopez, M., Schmidt, M., Perrussel, O., and Ciais, P.: An attempt at estimating Paris area CO2 emissions from atmospheric concentration measurements, Atmos. Chem. Phys., 15, 1707–1724, https://doi.org/10.5194/acp-15-1707-2015, 2015. a, b
Chatterjee, A., Michalak, A. M., Anderson, J. L., Mueller, K. L., and Yadav, V.: Toward reliable ensemble Kalman filter estimates of CO2 fluxes, J. Geophys. Res.-Atmos., 117, D22306, https://doi.org/10.1029/2012JD018176, 2012. a
Chevallier, F.: On the parallelization of atmospheric inversions of CO2 surface fluxes within a variational framework, Geosci. Model Dev., 6, 783–790, https://doi.org/10.5194/gmd-6-783-2013, 2013. a
Chevallier, F., Fisher, M., Peylin, P., Serrar, S., Bousquet, P., Bréon, F. M., Chédin, A., and Ciais, P.: Inferring CO$_2$ sources and sinks from satellite observations: Method and application to TOVS data, J. Geophys. Res., 110, D24309, https://doi.org/10.1029/2005JD006390, 2005. a, b, c, d
Chevallier, F., Ciais, P., Conway, T. J., Aalto, T., Anderson, B. E., Bousquet, P., Brunke, E. G., Ciattaglia, L., Esaki, Y., Fröhlich, M., Gomez, A., Gomez-Pelaez, A. J., Haszpra, L., Krummel, P. B., Langenfelds, R. L., Leuenberger, M., Machida, T., Maignan, F., Matsueda, H., Morguí, J. A., Mukai, H., Nakazawa, T., Peylin, P., Ramonet, M., Rivier, L., Sawa, Y., Schmidt, M., Steele, L. P., Vay, S. A., Vermeulen, A. T., Wofsy, S., and Worthy, D.: CO2 surface fluxes at grid point scale estimated from a global 21 year reanalysis of atmospheric measurements, J. Geophys. Res., 115, D21307, https://doi.org/10.1029/2010JD013887, 2010. a, b
Chevallier, F., Remaud, M., O'Dell, C. W., Baker, D., Peylin, P., and Cozic, A.: Objective evaluation of surface- and satellite-driven carbon dioxide atmospheric inversions, Atmos. Chem. Phys., 19, 14233–14251, https://doi.org/10.5194/acp-19-14233-2019, 2019. a
Ciais, P., Dolman, A. J., Bombelli, A., Duren, R., Peregon, A., Rayner, P. J., Miller, C., Gobron, N., Kinderman, G., Marland, G., Gruber, N., Chevallier, F., Andres, R. J., Balsamo, G., Bopp, L., Bréon, F.-M., Broquet, G., Dargaville, R., Battin, T. J., Borges, A., Bovensmann, H., Buchwitz, M., Butler, J., Canadell, J. G., Cook, R. B., DeFries, R., Engelen, R., Gurney, K. R., Heinze, C., Heimann, M., Held, A., Henry, M., Law, B., Luyssaert, S., Miller, J., Moriyama, T., Moulin, C., Myneni, R. B., Nussli, C., Obersteiner, M., Ojima, D., Pan, Y., Paris, J.-D., Piao, S. L., Poulter, B., Plummer, S., Quegan, S., Raymond, P., Reichstein, M., Rivier, L., Sabine, C., Schimel, D., Tarasova, O., Valentini, R., Wang, R., van der Werf, G., Wickland, D., Williams, M., and Zehner, C.: Current systematic carbon-cycle observations and the need for implementing a policy-relevant carbon observing system, Biogeosciences, 11, 3547–3602, https://doi.org/10.5194/bg-11-3547-2014, 2014. a
Crisp, D., Meijer, Y., Munro, R., et al.: A constellation architecture for monitoring carbon dioxide and methane from space, Prepared by the CEOS Atmospheric Constellation Greenhouse Gas Team, version, 1, 2018. a
Crowell, S., Baker, D., Schuh, A., Basu, S., Jacobson, A. R., Chevallier, F., Liu, J., Deng, F., Feng, L., McKain, K., Chatterjee, A., Miller, J. B., Stephens, B. B., Eldering, A., Crisp, D., Schimel, D., Nassar, R., O'Dell, C. W., Oda, T., Sweeney, C., Palmer, P. I., and Jones, D. B. A.: The 2015–2016 carbon cycle as seen from OCO-2 and the global in situ network, Atmos. Chem. Phys., 19, 9797–9831, https://doi.org/10.5194/acp-19-9797-2019, 2019. a
Curier, R. L., Timmermans, R., Calabretta-Jongen, S., Eskes, H., Segers, A., Swart, D., and Schaap, M.: Improving ozone forecasts over Europe by synergistic use of the LOTOS-EUROS chemical transport model and in-situ measurements, Atmos. Environ., 60, 217–226, https://doi.org/10.1016/j.atmosenv.2012.06.017, 2012. a
Enting, I. G.: Inverse problems in atmospheric constituent transport, Cambridge University Press, available at: http://books.google.fr/books?hl=fr&lr=&id=b61nA7D1XXUC&oi=fnd&pg=PP1&dq=enting+inverse+problem+atmospheric+constituent+transport+&ots=vc8hwiQ_YK&sig=u5npCEtl4WdBNLyRDn9V2EfD1SQ (last access: 23 August 2021), 2002. a
Errico, R. M.: What Is an Adjoint Model?, B. Am. Meteorol. Soc., 78, 2577–2592, https://doi.org/10.1175/1520-0477(1997)078<2577:WIAAM>2.0.CO;2, 1997. a
Feng, L., Palmer, P. I., Bösch, H., and Dance, S.: Estimating surface CO2 fluxes from space-borne CO2 dry air mole fraction observations using an ensemble Kalman Filter, Atmos. Chem. Phys., 9, 2619–2633, https://doi.org/10.5194/acp-9-2619-2009, 2009. a
Feng, L., Palmer, P. I., Bösch, H., Parker, R. J., Webb, A. J., Correia, C. S. C., Deutscher, N. M., Domingues, L. G., Feist, D. G., Gatti, L. V., Gloor, E., Hase, F., Kivi, R., Liu, Y., Miller, J. B., Morino, I., Sussmann, R., Strong, K., Uchino, O., Wang, J., and Zahn, A.: Consistent regional fluxes of CH4 and CO2 inferred from GOSAT proxy XCH4 : XCO2 retrievals, 2010–2014, Atmos. Chem. Phys., 17, 4781–4797, https://doi.org/10.5194/acp-17-4781-2017, 2017. a
Filges, A., Gerbig, C., Chen, H., Franke, H., Klaus, C., and Jordan, A.: The IAGOS-core greenhouse gas package: a measurement system for continuous airborne observations of CO2, CH4, H2O and CO, Tellus B, 68, 27989, https://doi.org/10.3402/tellusb.v67.27989, 2016. a
Fisher, M.: Minimization algorithms for variational data assimilation, in: Seminar on Recent Developments in Numerical Methods for Atmospheric Modelling, 7–11 September 1998, ECMWF, Shinfield Park, Reading, 364–385, available at: https://www.ecmwf.int/node/9400 (last access: 23 August 2021), 1998. a, b
Fortems-Cheiney, A., Pison, I., Broquet, G., Dufour, G., Berchet, A., Potier, E., Coman, A., Siour, G., and Costantino, L.: Variational regional inverse modeling of reactive species emissions with PYVAR-CHIMERE-v2019, Geosci. Model Dev., 14, 2939–2957, https://doi.org/10.5194/gmd-14-2939-2021, 2021. a, b, c
Foster-Wittig, T. A., Thoma, E. D., and Albertson, J. D.: Estimation of point source fugitive emission rates from a single sensor time series: A conditionally-sampled Gaussian plume reconstruction, Atmos. Environ., 115, 101–109, https://doi.org/10.1016/j.atmosenv.2015.05.042, 2015. a
Ganesan, A. L., Rigby, M., Zammit-Mangion, A., Manning, A. J., Prinn, R. G., Fraser, P. J., Harth, C. M., Kim, K.-R., Krummel, P. B., Li, S., Mühle, J., O'Doherty, S. J., Park, S., Salameh, P. K., Steele, L. P., and Weiss, R. F.: Characterization of uncertainties in atmospheric trace gas inversions using hierarchical Bayesian methods, Atmos. Chem. Phys., 14, 3855–3864, https://doi.org/10.5194/acp-14-3855-2014, 2014. a
Gaubert, B., Emmons, L. K., Raeder, K., Tilmes, S., Miyazaki, K., Arellano Jr., A. F., Elguindi, N., Granier, C., Tang, W., Barré, J., Worden, H. M., Buchholz, R. R., Edwards, D. P., Franke, P., Anderson, J. L., Saunois, M., Schroeder, J., Woo, J.-H., Simpson, I. J., Blake, D. R., Meinardi, S., Wennberg, P. O., Crounse, J., Teng, A., Kim, M., Dickerson, R. R., He, H., Ren, X., Pusede, S. E., and Diskin, G. S.: Correcting model biases of CO in East Asia: impact on oxidant distributions during KORUS-AQ, Atmos. Chem. Phys., 20, 14617–14647, https://doi.org/10.5194/acp-20-14617-2020, 2020. a
Gilbert, J. C. and Lemaréchal, C.: Some numerical experiments with variable-storage quasi-Newton algorithms, Math. Programm., 45, 407–435, https://doi.org/10.1007/BF01589113, 1989. a
Gurney, K. R., Law, R. M., Denning, A. S., Rayner, P. J., Baker, D., Bousquet, P., Bruhwiler, L., Chen, Y.-H., Ciais, P., Fan, S., Fung, I. Y., Gloor, M., Heimann, M., Higuchi, K., John, J., Kowalczyk, E., Maki, T., Maksyutov, S., Peylin, P., Prather, M., Pak, B. C., Sarmiento, J., Taguchi, S., Takahashi, T., and Yuen, C.-W.: TransCom 3 CO2 inversion intercomparison: 1. Annual mean control results and sensitivity to transport and prior flux information, Tellus B, 55, 555–579, https://doi.org/10.1034/j.1600-0889.2003.00049.x, 2003. a
Hanna, S. R., Briggs, G. A., and Hosker, J.: Handbook on atmospheric diffusion, Tech. Rep. DOE/TIC-11223, National Oceanic and Atmospheric Administration, Oak Ridge, TN (USA), Atmospheric Turbulence and Diffusion Lab., https://doi.org/10.2172/5591108, 1982. a
Henne, S., Brunner, D., Oney, B., Leuenberger, M., Eugster, W., Bamberger, I., Meinhardt, F., Steinbacher, M., and Emmenegger, L.: Validation of the Swiss methane emission inventory by atmospheric observations and inverse modelling, Atmos. Chem. Phys., 16, 3683–3710, https://doi.org/10.5194/acp-16-3683-2016, 2016. a
Houweling, S., Badawy, B., Baker, D. F., Basu, S., Belikov, D., Bergamaschi, P., Bousquet, P., Broquet, G., Butler, T., Canadell, J. G., Chen, J., Chevallier, F., Ciais, P., Collatz, G. J., Denning, S., Engelen, R., Enting, I. G., Fischer, M. L., Fraser, A., Gerbig, C., Gloor, M., Jacobson, A. R., Jones, D. B. A., Heimann, M., Khalil, A., Kaminski, T., Kasibhatla, P. S., Krakauer, N. Y., Krol, M., Maki, T., Maksyutov, S., Manning, A., Meesters, A., Miller, J. B., Palmer, P. I., Patra, P., Peters, W., Peylin, P., Poussi, Z., Prather, M. J., Randerson, J. T., Röckmann, T., Rödenbeck, C., Sarmiento, J. L., Schimel, D. S., Scholze, M., Schuh, A., Suntharalingam, P., Takahashi, T., Turnbull, J., Yurganov, L., and Vermeulen, A.: Iconic CO2 Time Series at Risk, Science, 337, 1038–1040, https://doi.org/10.1126/science.337.6098.1038-b, 2012. a
Houweling, S., Krol, M., Bergamaschi, P., Frankenberg, C., Dlugokencky, E. J., Morino, I., Notholt, J., Sherlock, V., Wunch, D., Beck, V., Gerbig, C., Chen, H., Kort, E. A., Röckmann, T., and Aben, I.: A multi-year methane inversion using SCIAMACHY, accounting for systematic errors using TCCON measurements, Atmos. Chem. Phys., 14, 3991–4012, https://doi.org/10.5194/acp-14-3991-2014, 2014. a, b
Houweling, S., Bergamaschi, P., Chevallier, F., Heimann, M., Kaminski, T., Krol, M., Michalak, A. M., and Patra, P.: Global inverse modeling of CH4 sources and sinks: an overview of methods, Atmos. Chem. Phys., 17, 235–256, https://doi.org/10.5194/acp-17-235-2017, 2017. a, b
Ide, K., Courtier, P., Ghil, M., and Lorenc, A. C.: Unified notation for data assimilation: operational, sequential and variational, J. Meteorol. Soc. Japan, 75, 181–189, https://doi.org/10.2151/jmsj1965.75.1B_181, 1997. a
Janssens-Maenhout, G., Pinty, B., Dowell, M., Zunker, H., Andersson, E., Balsamo, G., Bézy, J.-L., Brunhes, T., Bösch, H., Bojkov, B., Brunner, D., Buchwitz, M., Crisp, D., Ciais, P., Counet, P., Dee, D., Denier van der Gon, H., Dolman, H., Drinkwater, M. R., Dubovik, O., Engelen, R., Fehr, T., Fernandez, V., Heimann, M., Holmlund, K., Houweling, S., Husband, R., Juvyns, O., Kentarchos, A., Landgraf, J., Lang, R., Löscher, A., Marshall, J., Meijer, Y., Nakajima, M., Palmer, P. I., Peylin, P., Rayner, P., Scholze, M., Sierk, B., Tamminen, J., and Veefkind, P.: Toward an Operational Anthropogenic CO2 Emissions Monitoring and Verification Support Capacity, B. Am. Meteorol. Soc., 101, E1439–E1451, https://doi.org/10.1175/BAMS-D-19-0017.1, 2020. a, b, c
Kang, J.-S., Kalnay, E., Liu, J., Fung, I., Miyoshi, T., and Ide, K.: “Variable localization” in an ensemble Kalman filter: Application to the carbon cycle data assimilation, J. Geophys. Res.-Atmos., 116, D09110, https://doi.org/10.1029/2010JD014673, 2011. a
Kang, J.-S., Kalnay, E., Miyoshi, T., Liu, J., and Fung, I.: Estimation of surface carbon fluxes with an advanced data assimilation methodology, J. Geophys. Res.-Atmos., 117, D24101, https://doi.org/10.1029/2012JD018259, 2012. a
Karion, A., Sweeney, C., Tans, P., and Newberger, T.: AirCore: An Innovative Atmospheric Sampling System, J. Atmos. Ocean. Tech., 27, 1839–1853, https://doi.org/10.1175/2010JTECHA1448.1, 2010. a
Kopacz, M., Jacob, D. J., Henze, D. K., Heald, C. L., Streets, D. G., and Zhang, Q.: Comparison of adjoint and analytical Bayesian inversion methods for constraining Asian sources of carbon monoxide using satellite (MOPITT) measurements of CO columns, J. Geophys. Res., 114, D04305, https://doi.org/10.1029/2007JD009264, 2009. a
Krol, M., Houweling, S., Bregman, B., van den Broek, M., Segers, A., van Velthoven, P., Peters, W., Dentener, F., and Bergamaschi, P.: The two-way nested global chemistry-transport zoom model TM5: algorithm and applications, Atmos. Chem. Phys., 5, 417–432, https://doi.org/10.5194/acp-5-417-2005, 2005. a
Kuhlmann, G., Broquet, G., Marshall, J., Clément, V., Löscher, A., Meijer, Y., and Brunner, D.: Detectability of CO2 emission plumes of cities and power plants with the Copernicus Anthropogenic CO2 Monitoring (CO2M) mission, Atmos. Meas. Tech., 12, 6695–6719, https://doi.org/10.5194/amt-12-6695-2019, 2019. a
Kumar, P., Broquet, G., Yver-Kwok, C., Laurent, O., Gichuki, S., Caldow, C., Cropley, F., Lauvaux, T., Ramonet, M., Berthe, G., Martin, F., Duclaux, O., Juery, C., Bouchet, C., and Ciais, P.: Mobile atmospheric measurements and local-scale inverse estimation of the location and rates of brief CH4 and CO2 releases from point sources, Atmos. Meas. Tech. Discuss. [preprint], https://doi.org/10.5194/amt-2020-226, in review, 2020. a
Liu, J., Bowman, K. W., and Henze, D. K.: Source-receptor relationships of column-average CO2 and implications for the impact of observations on flux inversions, J. Geophys. Res.-Atmos., 120, 5214–5236, https://doi.org/10.1002/2014JD022914, 2015. a
Liu, Y., Haussaire, J.-M., Bocquet, M., Roustan, Y., Saunier, O., and Mathieu, A.: Uncertainty quantification of pollutant source retrieval: comparison of Bayesian methods with application to the Chernobyl and Fukushima Daiichi accidental releases of radionuclides, Q. J. Roy. Meteor. Soc., 143, 2886–2901, https://doi.org/10.1002/qj.3138, 2017. a
Locatelli, R., Bousquet, P., Chevallier, F., Fortems-Cheney, A., Szopa, S., Saunois, M., Agusti-Panareda, A., Bergmann, D., Bian, H., Cameron-Smith, P., Chipperfield, M. P., Gloor, E., Houweling, S., Kawa, S. R., Krol, M., Patra, P. K., Prinn, R. G., Rigby, M., Saito, R., and Wilson, C.: Impact of transport model errors on the global and regional methane emissions estimated by inverse modelling, Atmos. Chem. Phys., 13, 9917–9937, https://doi.org/10.5194/acp-13-9917-2013, 2013. a
Lunt, M. F., Rigby, M., Ganesan, A. L., and Manning, A. J.: Estimation of trace gas fluxes with objectively determined basis functions using reversible-jump Markov chain Monte Carlo, Geosci. Model Dev., 9, 3213–3229, https://doi.org/10.5194/gmd-9-3213-2016, 2016. a
Masarie, K. A., Pétron, G., Andrews, A., Bruhwiler, L., Conway, T. J., Jacobson, A. R., Miller, J. B., Tans, P. P., Worthy, D. E., and Peters, W.: Impact of CO2 measurement bias on CarbonTracker surface flux estimates, J. Geophys. Res.-Atmos., 116, D17305, https://doi.org/10.1029/2011JD016270, 2011. a
Masarie, K. A., Peters, W., Jacobson, A. R., and Tans, P. P.: ObsPack: a framework for the preparation, delivery, and attribution of atmospheric greenhouse gas measurements, Earth Syst. Sci. Data, 6, 375–384, https://doi.org/10.5194/essd-6-375-2014, 2014. a
Meirink, J. F., Bergamaschi, P., and Krol, M. C.: Four-dimensional variational data assimilation for inverse modelling of atmospheric methane emissions: method and comparison with synthesis inversion, Atmos. Chem. Phys., 8, 6341–6353, https://doi.org/10.5194/acp-8-6341-2008, 2008. a, b
Michalak, A. M.: Technical Note: Adapting a fixed-lag Kalman smoother to a geostatistical atmospheric inversion framework, Atmos. Chem. Phys., 8, 6789–6799, https://doi.org/10.5194/acp-8-6789-2008, 2008. a
Michalak, A. M. and Kitanidis, P. K.: A method for the interpolation of nonnegative functions with an application to contaminant load estimation, Stoch. Environ. Res. Ris. Assess., 19, 8–23, https://doi.org/10.1007/s00477-004-0189-1, 2005. a
Michalak, A. M., Hirsch, A., Bruhwiler, L., Gurney, K. R., Peters, W., and Tans, P. P.: Maximum likelihood estimation of covariance parameters for Bayesian atmospheric trace gas surface flux inversions, J. Geophys. Res.-Atmosp., 110, D24107, https://doi.org/10.1029/2005JD005970, 2005. a
Miller, S. M., Michalak, A. M., and Levi, P. J.: Atmospheric inverse modeling with known physical bounds: an example from trace gas emissions, Geosci. Model Dev., 7, 303–315, https://doi.org/10.5194/gmd-7-303-2014, 2014. a
Miller, S. M., Saibaba, A. K., Trudeau, M. E., Mountain, M. E., and Andrews, A. E.: Geostatistical inverse modeling with very large datasets: an example from the Orbiting Carbon Observatory 2 (OCO-2) satellite, Geosci. Model Dev., 13, 1771–1785, https://doi.org/10.5194/gmd-13-1771-2020, 2020. a
Monteil, G. and Scholze, M.: Regional CO2 inversions with LUMIA, the Lund University Modular Inversion Algorithm, v1.0, Geosci. Model Dev., 14, 3383–3406, https://doi.org/10.5194/gmd-14-3383-2021, 2021. a
Monteil, G., Broquet, G., Scholze, M., Lang, M., Karstens, U., Gerbig, C., Koch, F.-T., Smith, N. E., Thompson, R. L., Luijkx, I. T., White, E., Meesters, A., Ciais, P., Ganesan, A. L., Manning, A., Mischurow, M., Peters, W., Peylin, P., Tarniewicz, J., Rigby, M., Rödenbeck, C., Vermeulen, A., and Walton, E. M.: The regional European atmospheric transport inversion comparison, EUROCOM: first results on European-wide terrestrial carbon fluxes for the period 2006–2015, Atmos. Chem. Phys., 20, 12063–12091, https://doi.org/10.5194/acp-20-12063-2020, 2020. a
Morzfeld, M., Hodyss, D., and Snyder, C.: What the collapse of the ensemble Kalman filter tells us about particle filters, Tellus A, 69, 1283809, https://doi.org/10.1080/16000870.2017.1283809, 2017. a
Nassar, R., Hill, T. G., McLinden, C. A., Wunch, D., Jones, D. B. A., and Crisp, D.: Quantifying CO2 Emissions From Individual Power Plants From Space, Geophys. Res. Lett., 44, 10045–10053, https://doi.org/10.1002/2017GL074702, 2017. a
Niwa, Y., Tomita, H., Satoh, M., Imasu, R., Sawa, Y., Tsuboi, K., Matsueda, H., Machida, T., Sasakawa, M., Belan, B., and Saigusa, N.: A 4D-Var inversion system based on the icosahedral grid model (NICAM-TM 4D-Var v1.0) – Part 1: Offline forward and adjoint transport models, Geosci. Model Dev., 10, 1157–1174, https://doi.org/10.5194/gmd-10-1157-2017, 2017. a
Palmer, P. I., Suntharalingam, P., Jones, D. B. A., Jacob, D. J., Streets, D. G., Fu, Q., Vay, S. A., and Sachse, G. W.: Using CO2:CO correlations to improve inverse analyses of carbon fluxes, J. Geophys. Res.-Atmos., 111, D12318, https://doi.org/10.1029/2005JD006697, 2006. a
Palmer, P. I., Feng, L., Baker, D., Chevallier, F., Bösch, H., and Somkuti, P.: Net carbon emissions from African biosphere dominate pan-tropical atmospheric CO 2 signal, Nat. Commun., 10, 3344, https://doi.org/10.1038/s41467-019-11097-w, 2019. a
Peters, W., Miller, J. B., Whitaker, J., Denning, A. S., Hirsch, A., Krol, M. C., Zupanski, D., Bruhwiler, L., and Tans, P. P.: An ensemble data assimilation system to estimate CO2 surface fluxes from atmospheric trace gas observations, J. Geophys. Res.-Atmos., 110, D24304, https://doi.org/10.1029/2005JD006157, 2005. a, b
Peters, W., van der Velde, I. R., van Schaik, E., Miller, J. B., Ciais, P., Duarte, H. F., van der Laan-Luijkx, I. T., van der Molen, M. K., Scholze, M., Schaefer, K., Vidale, P. L., Verhoef, A., Wårlind, D., Zhu, D., Tans, P. P., Vaughn, B., and White, J. W. C.: Increased water-use efficiency and reduced CO2 uptake by plants during droughts at a continental scale, Nat. Geosci., 11, 744–748, https://doi.org/10.1038/s41561-018-0212-7, 2018. a
Peylin, P., Law, R. M., Gurney, K. R., Chevallier, F., Jacobson, A. R., Maki, T., Niwa, Y., Patra, P. K., Peters, W., Rayner, P. J., Rödenbeck, C., van der Laan-Luijkx, I. T., and Zhang, X.: Global atmospheric carbon budget: results from an ensemble of atmospheric CO2 inversions, Biogeosciences, 10, 6699–6720, https://doi.org/10.5194/bg-10-6699-2013, 2013. a, b
Pisso, I., Sollum, E., Grythe, H., Kristiansen, N. I., Cassiani, M., Eckhardt, S., Arnold, D., Morton, D., Thompson, R. L., Groot Zwaaftink, C. D., Evangeliou, N., Sodemann, H., Haimberger, L., Henne, S., Brunner, D., Burkhart, J. F., Fouilloux, A., Brioude, J., Philipp, A., Seibert, P., and Stohl, A.: The Lagrangian particle dispersion model FLEXPART version 10.4, Geosci. Model Dev., 12, 4955–4997, https://doi.org/10.5194/gmd-12-4955-2019, 2019. a
Ramonet, M., Ciais, P., Apadula, F., Bartyzel, J., Bastos, A., Bergamaschi, P., Blanc, P. E., Brunner, D., Caracciolo di Torchiarolo, L., Calzolari, F., Chen, H., Chmura, L., Colomb, A., Conil, S., Cristofanelli, P., Cuevas, E., Curcoll, R., Delmotte, M., di Sarra, A., Emmenegger, L., Forster, G., Frumau, A., Gerbig, C., Gheusi, F., Hammer, S., Haszpra, L., Hatakka, J., Hazan, L., Heliasz, M., Henne, S., Hensen, A., Hermansen, O., Keronen, P., Kivi, R., Komínková, K., Kubistin, D., Laurent, O., Laurila, T., Lavric, J. V., Lehner, I., Lehtinen, K. E. J., Leskinen, A., Leuenberger, M., Levin, I., Lindauer, M., Lopez, M., Myhre, C. L., Mammarella, I., Manca, G., Manning, A., Marek, M. V., Marklund, P., Martin, D., Meinhardt, F., Mihalopoulos, N., Mölder, M., Morgui, J. A., Necki, J., O'Doherty, S., O'Dowd, C., Ottosson, M., Philippon, C., Piacentino, S., Pichon, J. M., Plass-Duelmer, C., Resovsky, A., Rivier, L., Rodó, X., Sha, M. K., Scheeren, H. A., Sferlazzo, D., Spain, T. G., Stanley, K. M., Steinbacher, M., Trisolino, P., Vermeulen, A., Vítková, G., Weyrauch, D., Xueref-Remy, I., Yala, K., and Yver Kwok, C.: The fingerprint of the summer 2018 drought in Europe on ground-based atmospheric CO2 measurements, Philos. T. R. Soc. B, 375, 20190513, https://doi.org/10.1098/rstb.2019.0513, 2020. a
Rayner, P. J., Raupach, M. R., Paget, M., Peylin, P., and Koffi, E.: A new global gridded data set of CO2 emissions from fossil fuel combustion: Methodology and evaluation, J. Geophys. Res.-Atmos., 115, D19306, https://doi.org/10.1029/2009JD013439, 2010. a
Rayner, P. J., Michalak, A. M., and Chevallier, F.: Fundamentals of data assimilation applied to biogeochemistry, Atmos. Chem. Phys., 19, 13911–13932, https://doi.org/10.5194/acp-19-13911-2019, 2019. a
Rödenbeck, C., Gerbig, C., Trusilova, K., and Heimann, M.: A two-step scheme for high-resolution regional atmospheric trace gas inversions based on independent models, Atmos. Chem. Phys., 9, 5331–5342, https://doi.org/10.5194/acp-9-5331-2009, 2009. a
Saunois, M., Stavert, A. R., Poulter, B., Bousquet, P., Canadell, J. G., Jackson, R. B., Raymond, P. A., Dlugokencky, E. J., Houweling, S., Patra, P. K., Ciais, P., Arora, V. K., Bastviken, D., Bergamaschi, P., Blake, D. R., Brailsford, G., Bruhwiler, L., Carlson, K. M., Carrol, M., Castaldi, S., Chandra, N., Crevoisier, C., Crill, P. M., Covey, K., Curry, C. L., Etiope, G., Frankenberg, C., Gedney, N., Hegglin, M. I., Höglund-Isaksson, L., Hugelius, G., Ishizawa, M., Ito, A., Janssens-Maenhout, G., Jensen, K. M., Joos, F., Kleinen, T., Krummel, P. B., Langenfelds, R. L., Laruelle, G. G., Liu, L., Machida, T., Maksyutov, S., McDonald, K. C., McNorton, J., Miller, P. A., Melton, J. R., Morino, I., Müller, J., Murguia-Flores, F., Naik, V., Niwa, Y., Noce, S., O'Doherty, S., Parker, R. J., Peng, C., Peng, S., Peters, G. P., Prigent, C., Prinn, R., Ramonet, M., Regnier, P., Riley, W. J., Rosentreter, J. A., Segers, A., Simpson, I. J., Shi, H., Smith, S. J., Steele, L. P., Thornton, B. F., Tian, H., Tohjima, Y., Tubiello, F. N., Tsuruta, A., Viovy, N., Voulgarakis, A., Weber, T. S., van Weele, M., van der Werf, G. R., Weiss, R. F., Worthy, D., Wunch, D., Yin, Y., Yoshida, Y., Zhang, W., Zhang, Z., Zhao, Y., Zheng, B., Zhu, Q., Zhu, Q., and Zhuang, Q.: The Global Methane Budget 2000–2017, Earth Syst. Sci. Data, 12, 1561–1623, https://doi.org/10.5194/essd-12-1561-2020, 2020. a
Say, D., Manning, A. J., O’Doherty, S., Rigby, M., Young, D., and Grant, A.: Re-Evaluation of the UK’s HFC-134a Emissions Inventory Based on Atmospheric Observations, Environ. Sci. Technol., 50, 11129–11136, https://doi.org/10.1021/acs.est.6b03630, 2016. a
Schuh, A. E., Jacobson, A. R., Basu, S., Weir, B., Baker, D., Bowman, K., Chevallier, F., Crowell, S., Davis, K. J., Deng, F., Denning, S., Feng, L., Jones, D., Liu, J., and Palmer, P. I.: Quantifying the Impact of Atmospheric Transport Uncertainty on CO2 Surface Flux Estimates, Glob. Biogeochem. Cy., 33, 484–500, https://doi.org/10.1029/2018GB006086, 2019. a
Seibert, P. and Frank, A.: Source-receptor matrix calculation with a Lagrangian particle dispersion model in backward mode, Atmos. Chem. Phys., 4, 51–63, https://doi.org/10.5194/acp-4-51-2004, 2004. . a
Staufer, J., Broquet, G., Bréon, F.-M., Puygrenier, V., Chevallier, F., Xueref-Rémy, I., Dieudonné, E., Lopez, M., Schmidt, M., Ramonet, M., Perrussel, O., Lac, C., Wu, L., and Ciais, P.: The first 1-year-long estimate of the Paris region fossil fuel CO2 emissions based on atmospheric inversion, Atmos. Chem. Phys., 16, 14703–14726, https://doi.org/10.5194/acp-16-14703-2016, 2016. a, b
Stohl, A., Seibert, P., Arduini, J., Eckhardt, S., Fraser, P., Greally, B. R., Lunder, C., Maione, M., Mühle, J., O'Doherty, S., Prinn, R. G., Reimann, S., Saito, T., Schmidbauer, N., Simmonds, P. G., Vollmer, M. K., Weiss, R. F., and Yokouchi, Y.: An analytical inversion method for determining regional and global emissions of greenhouse gases: Sensitivity studies and application to halocarbons, Atmos. Chem. Phys., 9, 1597–1620, https://doi.org/10.5194/acp-9-1597-2009, 2009. a
Tarantola, A. and Valette, B.: Generalized nonlinear inverse problems solved using the least squares criterion, Rev. Geophys., 20, 219–232, https://doi.org/10.1029/RG020i002p00219, 1982. a
Thanwerdas, J., Saunois, M., Berchet, A., Pison, I., Vaughn, B. H., Michel, S. E., and Bousquet, P.: Variational inverse modelling within the Community Inversion Framework to assimilate δ13C(CH4) and CH4: a case study with model LMDz-SACS, Geosci. Model Dev. Discuss. [preprint], https://doi.org/10.5194/gmd-2021-106, in review, 2021. a
Thompson, R. L. and Stohl, A.: FLEXINVERT: an atmospheric Bayesian inversion framework for determining surface fluxes of trace species using an optimized grid, Geosci. Model Dev., 7, 2223–2242, https://doi.org/10.5194/gmd-7-2223-2014, 2014. a, b
Tippett, M. K., Anderson, J. L., Bishop, C. H., Hamill, T. M., and Whitaker, J. S.: Ensemble Square Root Filters, Mon. Weather Rev., 131, 1485–1490, https://doi.org/10.1175/1520-0493(2003)131<1485:ESRF>2.0.CO;2, 2003. a
Tolk, L. F., Dolman, A. J., Meesters, A. G. C. A., and Peters, W.: A comparison of different inverse carbon flux estimation approaches for application on a regional domain, Atmos. Chem. Phys., 11, 10349–10365, https://doi.org/10.5194/acp-11-10349-2011, 2011. a
Trusilova, K., Rödenbeck, C., Gerbig, C., and Heimann, M.: Technical Note: A new coupled system for global-to-regional downscaling of CO2 concentration estimation, Atmos. Chem. Phys., 10, 3205–3213, https://doi.org/10.5194/acp-10-3205-2010, 2010. a, b
Turner, A. J. and Jacob, D. J.: Balancing aggregation and smoothing errors in inverse models, Atmos. Chem. Phys., 15, 7039–7048, https://doi.org/10.5194/acp-15-7039-2015, 2015. a
van der Laan-Luijkx, I. T., van der Velde, I. R., van der Veen, E., Tsuruta, A., Stanislawska, K., Babenhauserheide, A., Zhang, H. F., Liu, Y., He, W., Chen, H., Masarie, K. A., Krol, M. C., and Peters, W.: The CarbonTracker Data Assimilation Shell (CTDAS) v1.0: implementation and global carbon balance 2001–2015, Geosci. Model Dev., 10, 2785–2800, https://doi.org/10.5194/gmd-10-2785-2017, 2017. a, b
van der Velde, I. R., Miller, J. B., van der Molen, M. K., Tans, P. P., Vaughn, B. H., White, J. W. C., Schaefer, K., and Peters, W.: The CarbonTracker Data Assimilation System for CO2 and δ13C (CTDAS-C13 v1.0): retrieving information on land–atmosphere exchange processes, Geosci. Model Dev., 11, 283–304, https://doi.org/10.5194/gmd-11-283-2018, 2018. a
Wang, F., Maksyutov, S., Tsuruta, A., Janardanan, R., Ito, A., Sasakawa, M., Machida, T., Morino, I., Yoshida, Y., Kaiser, J. W., Janssens-Maenhout, G., Dlugokencky, E. J., Mammarella, I., Lavric, J. V., and Matsunaga, T.: Methane Emission Estimates by the Global High-Resolution Inverse Model Using National Inventories, Remote Sensing, 11, 2489, https://doi.org/10.3390/rs11212489, 2019. a
Wang, J. S., Kawa, S. R., Collatz, G. J., Sasakawa, M., Gatti, L. V., Machida, T., Liu, Y., and Manyin, M. E.: A global synthesis inversion analysis of recent variability in CO2 fluxes using GOSAT and in situ observations, Atmos. Chem. Phys., 18, 11097–11124, https://doi.org/10.5194/acp-18-11097-2018, 2018. a
Wang, Y., Broquet, G., Bréon, F.-M., Lespinas, F., Buchwitz, M., Reuter, M., Meijer, Y., Loescher, A., Janssens-Maenhout, G., Zheng, B., and Ciais, P.: PMIF v1.0: assessing the potential of satellite observations to constrain CO2 emissions from large cities and point sources over the globe using synthetic data, Geosci. Model Dev., 13, 5813–5831, https://doi.org/10.5194/gmd-13-5813-2020, 2020. a
Whitaker, J. S. and Hamill, T. M.: Ensemble Data Assimilation without Perturbed Observations, Mon. Weather Rev., 130, 1913–1924, https://doi.org/10.1175/1520-0493(2002)130<1913:EDAWPO>2.0.CO;2, 2002. a, b
Yadav, V. and Michalak, A. M.: Improving computational efficiency in large linear inverse problems: an example from carbon dioxide flux estimation, Geosci. Model Dev., 6, 583–590, https://doi.org/10.5194/gmd-6-583-2013, 2013. a
Zammit-Mangion, A., Cressie, N., Ganesan, A. L., O'Doherty, S., and Manning, A. J.: Spatio-temporal bivariate statistical models for atmospheric trace-gas inversion, Chemometr. Intell. Lab., 149, 227–241, https://doi.org/10.1016/j.chemolab.2015.09.006, 2015. a
Zammit-Mangion, A., Bertolacci, M., Fisher, J., Stavert, A., Rigby, M. L., Cao, Y., and Cressie, N.: WOMBAT: A fully Bayesian global flux-inversion framework, arXiv [preprint], arXiv:2102.04004, 2021. a
Zheng, T., French, N. H. F., and Baxter, M.: Development of the WRF-CO2 4D-Var assimilation system v1.0, Geosci. Model Dev., 11, 1725–1752, https://doi.org/10.5194/gmd-11-1725-2018, 2018. a, b
Zupanski, D., Denning, A. S., Uliasz, M., Zupanski, M., Schuh, A. E., Rayner, P. J., Peters, W., and Corbin, K. D.: Carbon flux bias estimation employing Maximum Likelihood Ensemble Filter (MLEF), J. Geophys. Res.-Atmos., 112, D17107, https://doi.org/10.1029/2006JD008371 2007. a, b
Zupanski, M.: Maximum Likelihood Ensemble Filter: Theoretical Aspects, Mon. Weather Rev., 133, 1710–1726, https://doi.org/10.1175/MWR2946.1, 2005. a