the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 22 Aug 2019
| 22 Aug 2019
An optimization for reducing the size of an existing urban-like monitoring network for retrieving an unknown point source emission
Hamza Kouichi
Pierre Ngae
Amir-Ali Feiz
Nadir Bekka
This study presents an optimization methodology for reducing the size of an existing monitoring network of the sensors measuring polluting substances in an urban-like environment in order to estimate an unknown emission source. The methodology is presented by coupling the simulated annealing (SA) algorithm with the renormalization inversion technique and the computational fluid dynamics (CFD) modeling approach. This study presents an application of the renormalization data-assimilation theory for optimally reducing the size of an existing monitoring network in an urban-like environment. The performance of the obtained reduced optimal sensor networks is analyzed by reconstructing the unknown continuous point emission using the concentration measurements from the sensors in that optimized network. This approach is successfully applied and validated with 20 trials of the Mock Urban Setting Test (MUST) tracer field experiment in an urban-like environment. The main results consist of reducing the size of a fixed network of 40 sensors deployed in the MUST experiment. The optimal networks in the MUST urban region are determined, which makes it possible to reduce the size of the original network (40 sensors) to (13 sensors) and 1∕4 (10 sensors). Using measurements from the reduced optimal networks of 10 and 13 sensors, the averaged location errors are obtained as 19.20 and 17.42 m, respectively, which are comparable to the 14.62 m obtained from the original 40-sensor network. In 80 % of the trials with networks of 10 and 13 sensors, the emission rates are estimated within a factor of 2 of the actual release rates. These are also comparable to the performance of the original network, whereby in 75 % of the trials the releases were estimated within a factor of 2 of the actual emission rates.
- Article
(2039 KB) - Full-text XML
-
Supplement
(6292 KB) - BibTeX
- EndNote





In the case of an accidental or deliberate release of a hazardous contaminant in densely populated urban or industrial regions, it is important to accurately retrieve the location and the intensity of that unknown emission source for risk assessment, emergency response, and mitigation strategies by the concerned authorities. This retrieval of an unknown source in various source reconstruction methodologies is completely dependent on the contaminant's concentrations detected by some pre-deployed sensors in the affected area or a nearby region. However, the pre-deployment of a limited number of sensors in that region required an optimal strategy for the establishment of an optimized monitoring network to achieve maximum a priori information regarding the state of emission. It is also required to correctly capture the data while extracting and utilizing information from a limited and noisy set of concentration measurements. Establishing optimal monitoring networks for the characterization of unknown emission sources in complex urban or industrial regions is a challenging problem.
The problem of monitoring network optimization is complex and may consist of a first deployment of the sensors, updating an existing network, reducing the size of an existing network, or increasing the size of an existing network. These problems are independent and each one has its own requirements. The degree of complexity also depends on (i) the network type (mobile network deployed only in an emergency, permanent mobile network, permanent static network), (ii) the scale (local, regional, etc.), and (iii) the topography of the area of interest (flat terrain without obstacles, complex terrain, cities, urban, industrial regions, etc.). It is important to note that the optimization also depends on the objective of a network design, such as the reconstruction of an emitting source, analysis of the air quality, and/or the triggering of an alert. This study is focused on reducing the size of an existing network at a local scale in an urban-like terrain for source reconstruction.
This study presents an optimization methodology for reducing the size of an existing monitoring network in a geometrically complex urban environment. The measurements from a reduced optimal network can be used for the source term estimation (STE) of an unknown source in an urban region with almost the same level of source detection ability as the original network of a larger number of samplers. The establishment of an optimal network required sensor concentration measurements, along with the availability of meteorological data, an atmospheric dispersion model, the choice of an STE procedure, and an optimization algorithm. These types of networks can have great applications in the oil and gas industries for the estimation of emissions of greenhouse gases (GHGs) like methane. In order to utilize an inversion method to estimate methane emissions, accurate measurements of methane in a network of high-precision sensors downwind of a possible source are a prerequisite. However, these sensors may not be deployed in large numbers due to their high cost. Alternatively, low-cost sensors (which may not be as high precision) can rapidly be deployed specifically for collecting the initial measurements. Using these less accurate measurements and the proposed optimization methodology, a reduced optimal network can quickly be designed to provide the “best” positions for the deployment of high-precision sensors to obtain accurate methane measurements. These high-precision measurements can be utilized in an inversion method to estimate accurate methane emissions. A similar and very useful application of the method proposed here can be applied for the estimation of methane emissions from landfills.
Ko et al. (1995) showed that the optimization of sensor networks is an NP-hard (i.e., nondeterministic polynomial time hardness) problem, which means that it is difficult for an exhaustive search algorithm to solve all instances of the problem because it requires considerable time. Various optimization algorithms have been proposed to find the best solution, but these methods are not applicable to all cases, especially for large problems. To solve such problems, metaheuristic algorithms are efficient. Some studies have discussed the optimization of sensor distribution and number for gas emission monitoring; e.g., Ma et al. (2013), Ngae et al. (2019). Ma et al. (2013) used a direct approach with a Gaussian dispersion model to optimize sensor networks in homogeneous terrains. However, the present study utilizes an inverse approach by solving the adjoint transport–diffusion equation with a building-resolving computational fluid dynamics (CFD) model for an urban environment. This methodological approach for an optimal monitoring network (i.e., coupling of the optimization algorithm, inverse tracers transport modeling, and CFD) includes the geometric and flow complexity inherent in an urban region for the optimization process. Recently, for a different application point of view, Ngae et al. (2019) also described an optimization methodology for determining an optimal sensor network in an urban-like environment using the available meteorological conditions only. The CFD computations also required a considerable amount of time to compute the flow and dispersion in an urban environment. However, in order to apply the proposed methodology in an emergency situation for an area of interest in a complex urban or industrial environment, an archive database of CFD calculations can be established for a wide range of meteorological and turbulence conditions and can be utilized in the optimization process.
In this study, a simulated annealing (SA) stochastic optimization algorithm (Jiang et al., 2007; Abida et al., 2008; Abida and Bocquet, 2009; Saunier et al., 2009; Kouichi et al., 2016; Kouichi, 2017; Ngae et al., 2019) is utilized. The SA algorithm was designed in the context of statistical physics. It incorporates a probabilistic approach to explore the search space and converges iteratively to the solution. This algorithm is often used and recommended to solve the problems of sensor network optimization (Abida, 2010). The network optimization process consists of finding the best set of sensors that leads to the minimum of a defined cost function. A cost function can be defined as a regularized norm square of the distance between the measurements and forecasts, which is also used for the STE (Sharan et al., 2012). In this study, two canonical problems are considered independently. (i) The first is the optimization of the measuring network. Optimization consists of selecting the best positions of the sensors among a set of potential locations. This choice is operated in a search space constituted by all the possible networks (of a specific size) and based on a cost function that quantitatively describes the quality of the networks. (ii) The second is the identification of the unknown source. The STE is studied in the framework of a parametric approach. Here the challenge is to determine the parameters of the source (intensity and position) using measurements from the sensors of an optimally designed network.
The reduced optimal networks are validated using an STE technique to estimate the unknown parameters of a continuous point source. The STE problem for atmospheric dispersion events has been an important topic of much consideration as reviewed in Rao (2007) and Hutchinson et al. (2017). Often, the source term is estimated using a network of static sensors deployed in a region. In an inverse process for the STE, the adjoint source–receptor relationship, concentrations, and meteorological measurements are required. The adjoint source–receptor relationship is defined by an inverse computation of the atmospheric transport–dispersion model (Pudykiewicz, 1998). This relationship is often affected by nonlinearities in the flow field by building effects in complex scenarios arising in urban environments, where the backward and forward dispersion concentrations will not match. Various inversion methods can be classified in two major categories: probabilistic and deterministic. The probabilistic category treats source parameters as random variables associated with the probability distribution. This includes the Bayesian estimation theory (Bocquet, 2005; Monache et al., 2008; Yee et al., 2014), Monte Carlo algorithms using Markov chains (MCMC) (Gamerman and Lopes, 2006; Keats, 2009), and various stochastic sampling algorithms (Zhang et al., 2014, 2015). Deterministic methods use cost functions to assess the difference between observed and modeled concentrations and are based on an iterative process to minimize this difference (Seibert, 2001; Penenko et al., 2002; Sharan et al., 2012). Among the other approaches, advanced search algorithms like the genetic algorithm (Haupt et al., 2006), the neural network algorithm (Wang et al., 2015), and other regularization methods (Ma et al., 2017; Zhang et al., 2017) have been used for the STE. In this study, we utilized the renormalization inversion method (Issartel, 2005) for the STE using measurements from the optimal networks, which is deterministic in nature and does not require any prior information on the source parameters. The renormalization inversion approach was successfully applied and validated for the retrieval of an unknown continuous point source in flat terrain (Sharan et al., 2009) and also in an urban-like environment (Kumar et al., 2015b). Initially, the renormalization inversion method was proposed to estimate emissions from the distributed sources (Issartel, 2005). Sharan et al. (2009) and other studies have shown that this technique is also effective for estimating continuous point sources. For these applications, the hypothesis of a linear relationship between the receptor and the source was assumed. For homogeneous terrains, the adjoint functions can analytically be computed based on the Gaussian solution of the diffusion–transport equation to estimate a continuous point release. However, the flow field in urban or industrial environments is quite complex, and the asymmetry of the flow and the dispersed plume in urban regions is generated mainly by the presence of buildings and other structures. In general, Gaussian models are unable to capture the effects of complex urban geometries on adjoint sensitivities between sources and receptors, and if dense gases are involved, the Gaussian distribution hypothesis fails. Recently, Kumar et al. (2015b, 2016) have extended the applications of the renormalization inversion technique to retrieve an unknown emission source in urban environments, whereby a CFD approach was used to generate the adjoint receptor–source relationship. In this process, a coupled CFD–renormalization source reconstruction approach was described for the identification of an unknown continuous point source located at the ground surface or at a horizontal plane corresponding to a known or predefined altitude above the ground surface or an elevated release in an urban area.
This study deals with a case of optimally reducing the size of an existing monitoring network. For this purpose, a predefined network of sensors deployed in an area of interest is considered to determine an optimized network with a smaller number of sensors but with comparable information. This work explores two requirements of the optimal networks that modify the spatial configuration of an existing network by moving the sensors and also reducing the number of sensors of an existing large network. In real situations, this methodology can be applied for the optimization of mobile networks deployed in an emergency situation. The methodological approach to optimally reduce the size of an existing monitoring network in an urban environment is presented by coupling the SA stochastic algorithm with the renormalization inversion technique and the CFD modeling approach. The concentration measurements obtained from the optimally reduced sensor networks in 20 trials of the Mock Urban Setting Test (MUST) field tracer experiment are utilized to validate the methodology by estimating an unknown continuous point source in an urban-like environment.
In the context of an inversion approach, source parameters are often determined using concentration measurements at the sensor locations and a source–receptor relationship. The release is considered continuous from a point source located at the ground or at a horizontal plane corresponding to an altitude of a known source height. Since the optimization methodology presented in the next section utilizes some concepts from the renormalization inversion methodology (Sharan et al., 2009), the renormalization theory to estimate a continuous point release is briefly presented in the following subsections.
2.1 Source–receptor relationship
A source–receptor relationship is an important concept in the source reconstruction process and it can be linear or nonlinear. This study deals with the linear relationship because except for nonlinear chemical reactions, most of the other processes occurring during the atmospheric transport of trace substances are linear: advection, diffusion, convective mixing, dry and wet deposition, and radioactive decay (Seibert and Frank, 2004). A source–receptor relationship between the measurements and the source function is defined based on a solution of the adjoint transport–diffusion equation that exploits the adjoint functions (retroplumes) corresponding to each receptor (Pudykiewicz, 1998; Issartel et al., 2007). These retroplumes provide sensitivity information between the source position and the sensor locations. Let us consider a discretized domain of N grid cells in a two-dimensional space , a vector of M concentration measurements , and an unknown source vector s(x)∈ℝN to estimate. The measurements μ are related to the source vector s by the use of sensitivity coefficients (also referred to as adjoint functions) (Hourdin and Talagrand, 2006). The sensitivity coefficients describe the backward propagation of information from the receptors toward the unknown source. These vectors are related by the following linear relationship:
where ϵ∈ℝM is the total measurement error and is the sensitivity matrix with . Here, each column vector a(xi)∈ℝM of the matrix A represents the potential sensitivity of a grid cell with respect to all M concentration measurements.
For a given set of concentration measurements μ, the source estimate function s(x) in Eq. (1) can easily be estimated by formulating a constrained optimization problem. This optimization problem minimizes a cost function J(s)=sTs, subjected to a constraint . Using the method of Lagrangian multipliers, s(x) can be estimated as a least-norm solution:
where H−1 is the inverse of the Gram matrix H=AAT. This estimate (Eq. 2) is not satisfactory because it generates artifacts at the grid cells corresponding to the measurement points. Adjoint functions become singular at these points and have very large values. These large values do not represent a physical reality but rather artificial information. This was highlighted by Issartel et al. (2007), who reduced this artificial information by a process of renormalization.
2.2 Renormalization process
This process involves a weight function in space, which is purely a diagonal matrix with the diagonal elements wjj>0 such that . The introduction of W transforms the source–receptor relationship in Eq. (1) to
where the modified sensitivity matrix Aw is defined as in which the column vector of Aw is the weighted sensitivity vector at xi. Considering a similar approach as outlined in the previous subsection, a new constrained optimization problem can be formulated for Eq. (3) to estimate s(x). This optimization problem minimizes a cost function J(s)=sTWs, subjected to a constraint , and deduces the following expression sw of s (Appendix A in Kumar et al., 2016):
where is the inverse of .
The weight function in the above-discussed renormalization process is computed by using an iterative algorithm proposed by Issartel et al. (2007) (Appendix A). A brief derivation for the estimation of an unknown point source (i.e., location and intensity) from the renormalization inversion is described in Appendix B.
A predefined large network of n sensors deployed in an area of interest is considered to determine an optimized network with a smaller number of sensors but with comparable information. For a given number of p sensors such that p<n, one determines an array of p sensors among n, which delivers a maximum of information. It is a combinatorial optimization problem that consists of choosing p sensors among n, thus constituting an optimal network. The optimal network will consist of p sensors for which a defined cost function is minimum. The number of possible choices nCp (number of combinations of p among n) is very high when an initial network is sufficiently instrumented (n large) and p is small with respect to n. As the number of combinations to be tested is very large, the minimum of a cost function will be evaluated by a stochastic algorithm, viz. simulated annealing (SA).
3.1 Cost function
A cost function is defined (based on renormalization theory) as a function that minimizes the quadratic distance between the observed and simulated measurements according to the Hw norm (Issartel et al., 2012), where Hw is the Gram matrix defined in Sect. 2.2. A cost function (say Js(x)) to minimize is defined (Appendix C) as follows:
where sw is given by Eq. (4). A global minimum of the cost function Js(x) is evaluated by the SA algorithm.
3.2 Simulated annealing (SA) algorithm for the sensor's network optimization
The problem of optimization of a network is solved using a simulated annealing algorithm. The SA optimization algorithm is utilized here for the determination of the optimal networks by comparing its performance with the genetic algorithm (GA) (Kouichi, 2017). These algorithms of different search techniques (SA probabilistic and GA evolutionary) are evaluated based on the same cost function. The results showed that the optimal networks retained by the GA and the SA are quantitatively and qualitatively comparable (Kouichi, 2017). SA is advantageous because it is relatively easy to implement and takes smaller computational time in comparison to GA. Both the SA and GA optimization algorithms in the framework of this approach (based on renormalization theory) have little influence on the estimation of the parameters of a source (Kouichi, 2017).
SA is a random optimization technique based on an analogy with thermodynamics. The technique was introduced to computational physics over 60 years ago in the classic paper by Metropolis et al. (1953). The algorithm of simulated annealing is initiated by starting from an admissible network. At the subsequent steps, the system moves to another feasible network, according to a prescribed probability, or it remains in the current state. However, it is crucial to explain how this probability is calculated. The mobility of the random walk depends on a global parameter T, which is interpreted as “temperature”. The initial values of T are large, allowing for the free exploration of large extents of the state space (this corresponds to the “melted state” in terms of the kinetic theory of matter). In the subsequent steps, the temperature is lowered, allowing the algorithm to reach a local minimum.
For SA, each network is considered as a state of a virtual physical system, and the objective function is interpreted as the internal energy of this system in a given state. According to statistical thermodynamics, the probability of a physical system to be in the same state follows the Boltzmann distribution and depends on its internal energy and the temperature level. By analogy, the physical quantities (temperature, energy, etc.) become pseudo-quantities. And during the minimization process, the probabilistic treatment consists of accepting a new network selected in the neighborhood of the current network following the same Boltzmann distribution and depending on both the cost difference between the new and current networks and on the pseudo-temperature (simply called temperature). To find the solution, SA incorporates the temperature into a minimization procedure. So at high temperature (i.e., starting temperature), the space of solution is widely explored, while at lower temperature the exploration is restricted. The algorithm is stopped when the cold temperature is reached. It is necessary to choose the law of decreasing temperature, called the cooling schedule. Different approaches to parameterize SA are explored in Siarry (2016). Kirkpatrick et al. (1983) proposed an average probability to determine the initial (starting) temperature. Nourani and Andresen (1998) compared the widely used cooling schedules (exponential, logarithmic, and linear). The SA algorithm starts the minimization of an objective function at annealing temperature from a single stochastic point, and then it searches for the minimal solutions by attempting all the points in the search domain with respect to their temperature value. The algorithm is depicted in a flow diagram in Fig. 2, and a step-by-step implementation of the SA procedure for an optimized monitoring network in an urban environment is described as follows.
Step 1. Parameter setting and initialization
Network parameters (n and p). The variable n is the number of possible locations of the sensors and p is the optimal network number of sensors.
Starting temperature (T0). T0 is also called the highest temperature. It was determined from the Metropolis law: , where is an average of the difference of cost functions calculated for a large number of cases. P0 is an acceptance probability and following the recommendations of Kirkpatrick et al. (1983), it was set to 0.8. Start iterations (Itt=0).
Length of the bearing (Lmax). The length of the bearing is the number of iterations to be performed at each temperature level. An equilibrium is reached for this number of iterations and any significant improvement of the cost function can be expected. No general rule is proposed to determine a suitable length. This number is often constant and proportional to the size of the problem.
The temperature decay factor (θ). The temperature remains constant for Lmax iterations corresponding to each bearing. We used the exponential schedule due to its efficiency as denoted by Nourani and Andresen (1998). Then, as the temperature decreases the law between two bearings varies as , with , where b represents a bearing. So, a decay pattern was retained by the bearings.
The cold temperature (Tcold). Tcold is often called the stopping temperature. There is no clear rule to set this parameter. It is possible to stop calculations when no improvement in the cost function is observed during a large number of combinations. One can estimate this number and take into account the maximum length Lmax of each bearing; thus, the cold temperature can be expressed as a fraction of the starting temperature T0.
Assigning the first best set of sensors, . The variable xrand(p,n) corresponds to a vector of p sensor locations randomly chosen among the n possible locations. A new solution is randomly explored. This vector is assigned to the first best set of sensors.
Step 2. Assigning a new set of sensors
This step involves , where xrand(p,n) corresponds to a vector of p sensors locations randomly chosen among the n possible locations. This vector is assigned to a new set (xnew) of sensors.
Step 3. Cost difference
Given a sensor location xnew, the cost function Js(xnew) is computed as follows:
-
set the μ vector by using the measurements at the xnew locations;
-
set rows of matrix A using the sensitivity at the xnew locations;
-
determine w(x), Hw, and aw iteratively using the algorithm in Eq. (A2);
-
compute the source term sw(x) using Eq. (4) and
-
compute the cost function Js(xnew) using Eq. (5).
Js(xbest) is computed like Js(xnew) using the same precedent steps. A cost difference is then calculated using . Increment the iterations .
Step 4. Test of sign of ΔJs
If ΔJs<0, the error associated with xnew is less than that with xbest, and thus xnew will become the next “best network” (step 6). If this condition is not satisfied, the algorithm can jump out of a local minimum (step 5).
Step 5. Conditional jump
When ΔJs>0, the algorithm has the ability to jump out of any local minima if the condition is satisfied, where P01 is the acceptance probability (a random number between 0 and 1), and T is the current annealing temperature. It means that xnew will be the next best network even if the associated error is greater than that of xbest. If , go to step 7.
Step 6. Update xbest
In this step, xbest is updated by xnew.
Step 7. Maximum iteration check
If the maximum number of iterations of a bearing (Lmax) is reached, a state of equilibrium is then achieved for this temperature and one can cool the actual temperature (step 8). If not, continue iterations (step 2).
Step 8. Temperature cooling
Temperature is cooled using the cooling schedule and the iteration variable is reset to zero.
Step 9. Cold temperature test
The cold temperature (Tcold) is also known as the stopping temperature. If this temperature is reached, the algorithm is stopped. When Tcold is not reached, other temperature bearings are performed using the cooling schedule.
Step 10. Optimal network
At this step, the last best network xbest is the optimal network. Source parameters are then estimated using the concentration measurements and retroplumes only for sensors from the obtained optimal network as follows: (i) x0 is estimated at the position of the maximum of the source estimate function sw(x), and (ii) the intensity q0 is given by .
In stochastic optimization algorithms, especially in SA, it was observed that there is no guarantee for the convergence of the algorithm with such a strong cooling (Cohn and Fielding, 1999; Abida et al., 2008). However, chances are that a near-optimal network configuration can be reached. Due to this, one or more near-optimal networks can be obtained from this methodology that satisfy the conditions of a nearly overall optimum condition.
The MUST field experiment was conducted by the Defense Threat Reduction Agency (DTRA) in 2001. It aimed to help develop and validate numerical models for flow and dispersion in an idealized urban environment. The experimental design and observations are described in detail in Biltoft (2001) and Yee and Biltoft (2004). In this experiment, an urban canopy was represented by a grid of 120 containers. These containers were arranged along 12 rows and 10 columns on the army ground in the Utah desert, USA. Each container has dimensions of 2.54 m high, 12.2 m long, and 2.42 m wide. The spacing between the horizontal lines is 12.9 m, while the columns are separated by a distance of 7.9 m. The total area thus formed is approximately 200×200 m2. The experiment consists of 63 releases of a flammable gas (propylene C3H6) that is not dangerous or harmful in quantities and could be released through the dissemination system into the open atmosphere (Biltoft, 2001). Different wind conditions (direction, speed, atmospheric stability) as well as different positions for gas emissions (inside or outside the MUST urban canopy at different heights) were considered. These gas emissions were carried out under stable, very stable, and neutral stability conditions. In this study, 20 trials in various atmospheric stability conditions are selected and the meteorological variables are taken from an analysis of meteorological and micro-meteorological observations in Yee and Biltoft (2004) (Table 1). It is noted that the errors related to meteorological data can affect the accuracy of the source term estimation (Zhang et al., 2014, 2015), although this error is not considered in this study. In each trial, the gas was continuously released for ≈15 min, during which concentration measurements were made. These concentration measurements were carried out by 48 photoionization detectors (PIDs); 40 sensors were positioned on four horizontal lines at 1.6 m of height (Fig. 1), and 8 sensors were deployed in the vertical direction at a tower located approximately in the center of the MUST array.
Table 1The meteorological values (wind speed (S04), wind direction (α04) at 4 m level of mast S), turbulence (the Obukhov length (L), friction velocity (u*), turbulent kinetic energy (k) at 4 m level of tower T), and source parameters (source height (zs), release duration (ts), release rate (qs)) in 20 selected trials of the MUST field experiment (Biltoft, 2001; Yee and Biltoft, 2004). Here, trial nos. 1–20 are assigned for continuation and simplicity, but these do not correspond to the same assigned trial number for a given trial name in the MUST experiment.
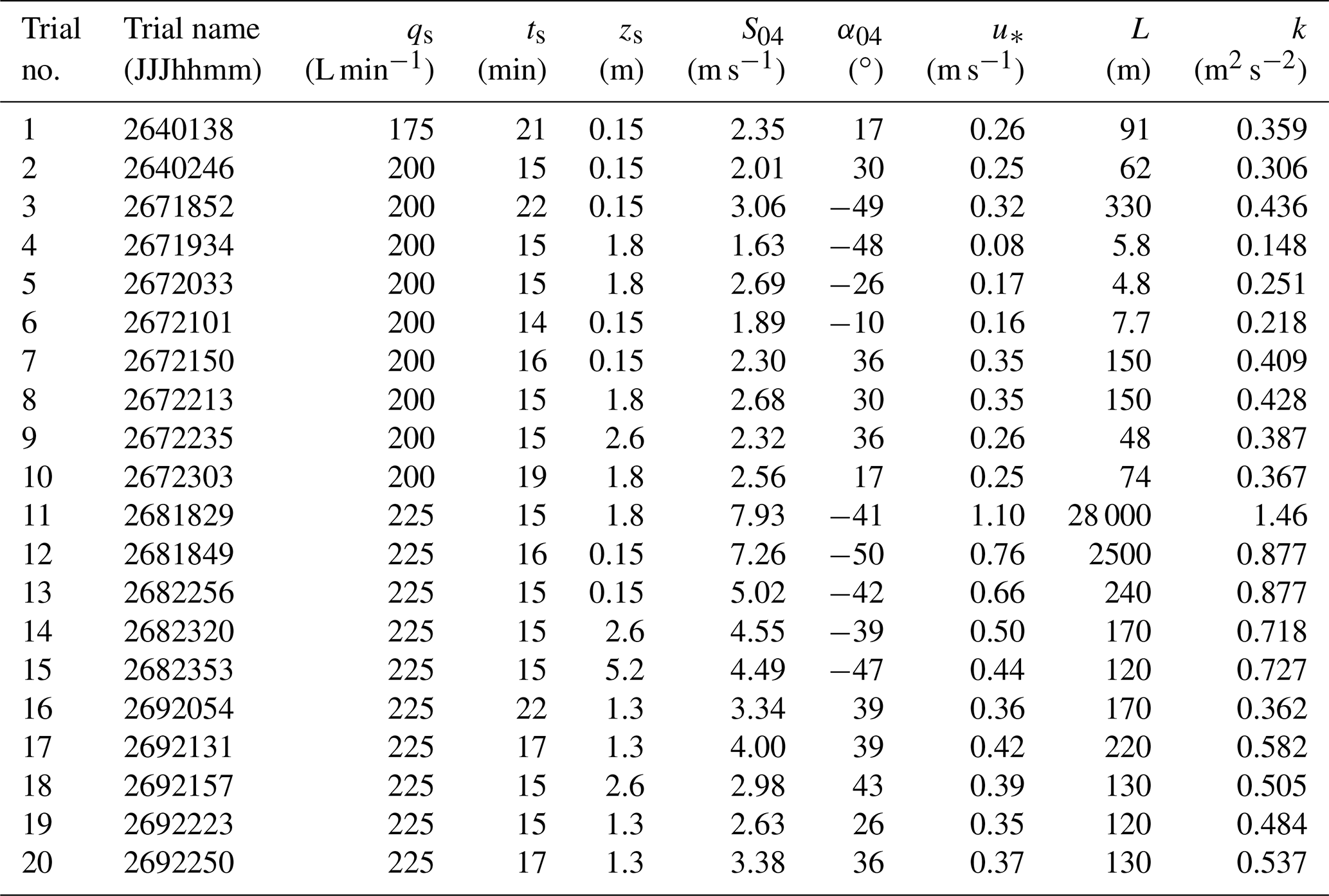
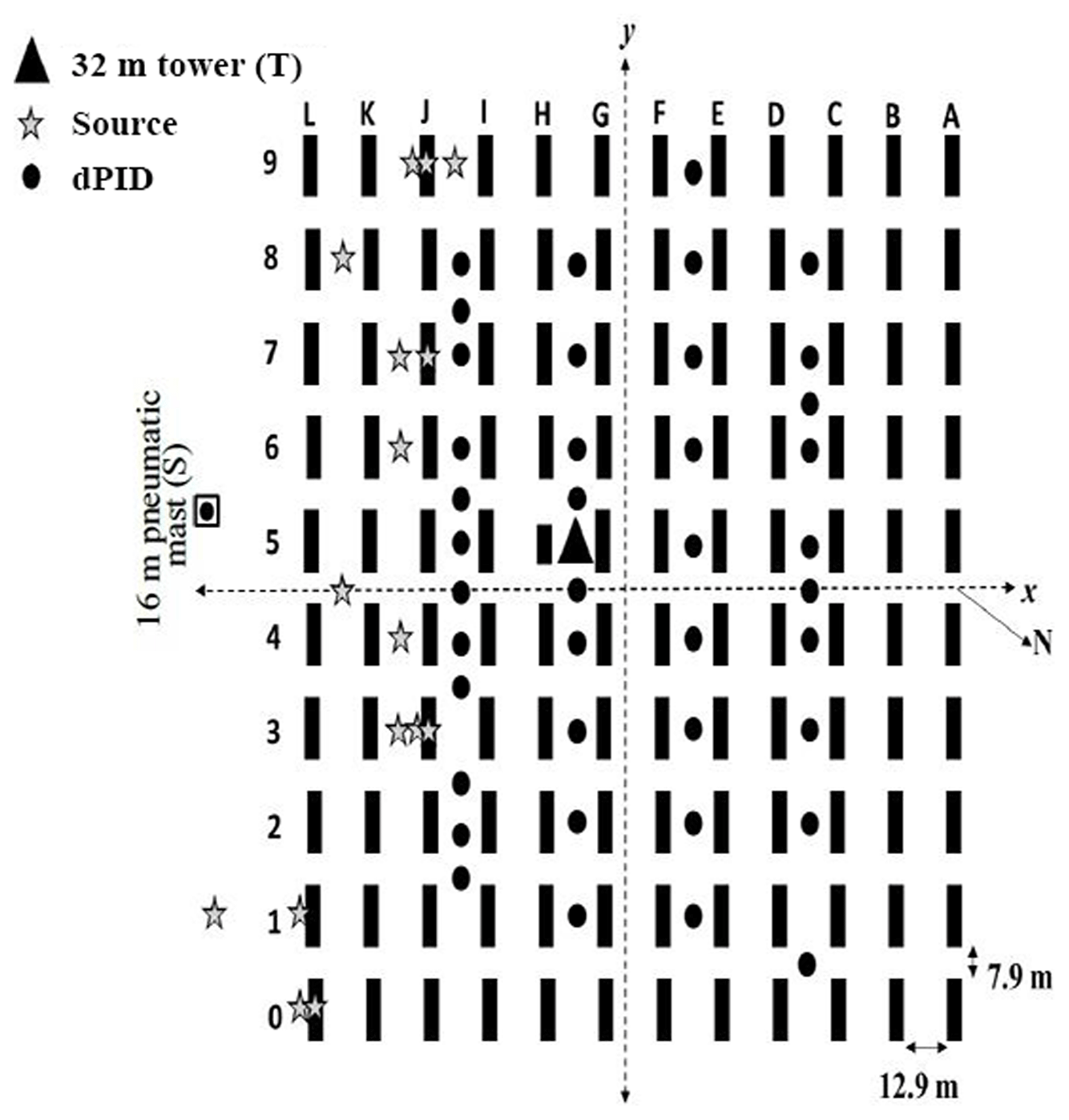
Figure 1A schematic diagram of the MUST geometry showing 120 containers and source (stars) and receptor (black filled circles) locations. In a given trial only one source was operational.
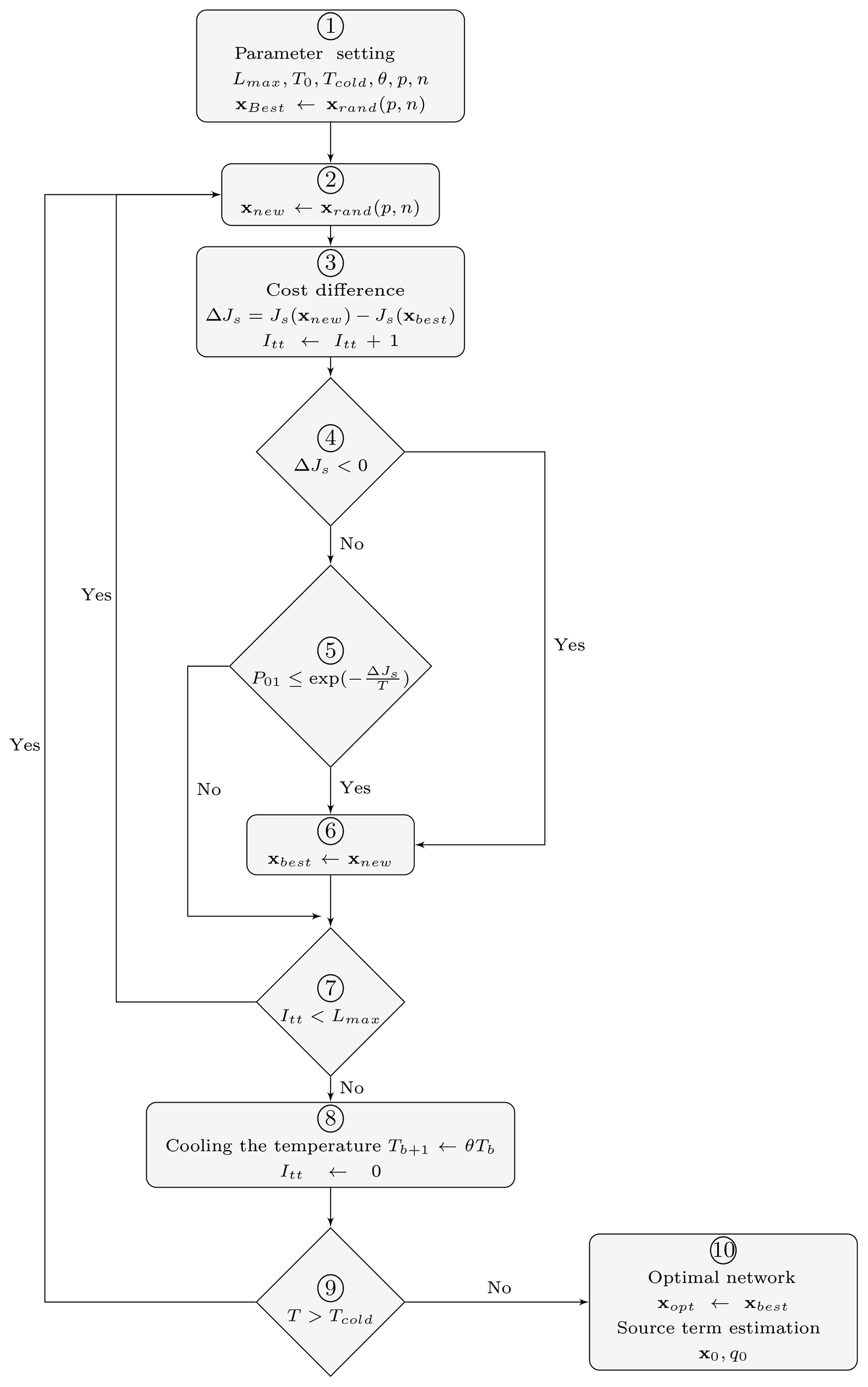
Figure 2Flow diagram of the simulated annealing procedures to determine an optimized monitoring network.
The flow field in atmospheric dispersion models in geometrically complex urban or industrial environments cannot be considered homogeneous throughout the computational domain. This is because the buildings and other structures in that region influence and divert the flow into unexpected directions. Consequently, the dispersion of a pollutant and computations of the adjoint functions (retroplumes) are affected by the flow field induced by these structures in an urban region. Recently, Kumar et al. (2015a) utilized a CFD model to compute the flow field and forward dispersion in 20 trials of the MUST field experiment. In order to reconstruct an unknown continuous point source, the computed flow field is then used to compute the retroplumes for all selected trials (Kumar et al., 2015b). The CFD computations of the flow field presented in Kumar et al. (2015a) and retroplumes computed in Kumar et al. (2015b) are utilized in the proposed optimization methodology described in this study to obtain optimal monitoring networks. In these studies, the CFD model fluidyn-PANACHE was utilized to calculate the flow field, considering a subdomain of calculation (whose dimensions are 250×225 m2 with a height of 100 m) that consists of the MUST urban array created by the containers, sources, receptors, and other instruments in this experiment. This subdomain is embedded in a larger computational domain (dimensions of 800×800 m2 with a height of 200 m) to ensure a smooth transition of the flow between the edges of the domain and the obstacle zone. This extension of the outer domain far from the main experimental site is essential to reduce effects of the inflow boundary conditions imposed at the inlet of the outer domain. A more detailed description of the CFD model and its simulations for the MUST field experiment, e.g., boundary conditions and the turbulence model, is presented in Kumar et al. (2015a) and briefly discussed in the Supplement. An unstructured mesh was generated in both domains with more refinement in the urbanized area in the inner subdomain and at the positions of the receptors, thus generating 2 849 276 meshes.
The simulation results with fluidyn-PANACHE in each MUST trial were obtained with inflow boundary conditions from vertical profiles of the wind (U), the turbulent kinetic energy (k), and its dissipation rate (ϵ). These inflow profiles include the following: (i) a wind profile as in Gryning et al. (2007), which includes profiles in stable and neutral conditions and a profile based on the stability function by Beljaars and Holtslag (1991) in very stable conditions; (ii) a temperature profile, which includes logarithmic profiles based on Monin–Obukhov similarity theory; and (iii) turbulence profiles, in which k and ϵ profiles are based on an approximate analytical solution of one-dimensional k−ϵ prognostic equations (Yang et al., 2009). The atmospheric stability effects in the CFD model fluidyn-PANACHE are included through the inflow boundary condition (via advection). The fluidyn-PANACHE model includes a planetary boundary layer (PBL) model that serves as an interface between the meteorological observations and the boundary conditions required by the CFD solver. The observed turbulence parameters, e.g., (i) sensible heat flux (Qh), the Obukhov length (L), (iii) surface friction velocity (u*), and the temperature scale (θ*), were used to derive the vertical profiles of mean velocity and potential temperature. As an example, the wind velocity vectors around some containers for trial 11 are shown in Fig. S1.1 in the Supplement. This figure shows the deviations in the wind speed and its direction due to the obstacles in an urban-like environment. It should be noted that the MUST experiment took place under neutral to stable and strongly stable conditions. However, the only atmospheric stability effects included in the CFD model are through the specification of inflow boundary conditions. Atmospheric stability has a profound impact on dispersion and would thus influence the adjoint functions. However, as presented and discussed in our previous study (Kumar et al., 2015a), even with specification of the stability-dependent inflow boundary conditions only, the predicted forward concentrations from the CFD model are in good agreement with the measured concentrations for all 20 trials in different atmospheric stability conditions. However, at microscales, small irregularities can also break the repeated flow patterns found in a regular array of containers with an identical shape (Qu et al., 2011). In addition, uncertainties associated with the thickness and the properties of the material of the container wall also affect flow pattern and the resulting concentrations and adjoint functions (Qu et al., 2011). Accordingly, the atmospheric stratification and stability effects should also be included through surface cooling or heating in the CFD model as well as stability effects from inflow boundary conditions. Since the released gas propylene is heavier than air and behaves as a dense gas, a buoyancy model was used to model the body force term in the Navier–Stokes equations. The buoyancy model is suitable for the dispersion of heavy gases for which a density difference in the vertical direction drives the body force.
In order to compute the retroplumes in each MUST trial, first the CFD simulations were performed to compute the converged flow field in the computational domain. Second, the flow field is reversed and used in the standard advection–diffusion equation to compute the adjoint functions ai(x). In this computation of the retroplumes corresponding to each receptor in a selected trial, the advection–diffusion equation is solved by considering a receptor as a virtual point source with a unit release rate at the height of that receptor. Also, the meteorological conditions remained invariant during the whole experimental period in a trial. Details about the retroplumes and the correlated theory of duality verification (i.e., comparison of the concentrations predicted with the forward (direct) model and the adjoint model) for all 20 trials of the MUST field experiment are given in Kumar et al. (2015b), and we have utilized the same retroplumes in this study for the optimization process. Since we are concerned with establishing an optimized monitoring network in a domain that contains the MUST urban array, the retroplumes are computed in the inner subdomain only. Consequently, all the computations for an optimized monitoring network were carried out in the inner subdomain only. The sensors in the optimized monitoring network are intended to deploy at a fixed vertical height above the ground surface. Accordingly, the retroplumes corresponding to only 40 receptors at 1.6 m of height were utilized in computations for the optimized monitoring networks in the MUST urban environment.
The calculations were performed by coupling the SA algorithm to a deterministic renormalization inversion algorithm and the CFD adjoint fields to optimally reduce the size of an existing monitoring network in an urban-like environment of the MUST field experiment. The network optimization process consists of finding the best set of sensors that leads to the lowest cost function. In this study, the validation is realized following two separate steps. The first step consists of forming two optimal monitoring networks by using the presented optimization methodology, which makes it possible to reduce the size of an original network of 40 sensors to approximately one-third (13 sensors) and one-fourth (10 sensors). The second step consists of comparing the a posteriori performance of the obtained reduced-size optimal networks with the MUST original network of 40 sensors at 1.6 m above the ground surface. In first step, a comparison (based on a cost function) with networks of the same size (e.g., 10 sensors) was implicitly performed during the optimization process. As the SA is an iterative algorithm, during the optimization process networks of the same size are compared at each iteration and the best one is retained. The networks have also been generated randomly like in Efthimiou et al. (2017); however, the search space of the problem is very large. In our case, the number of compared networks is equivalent to the number of iterations (as an example for an optimal network of 10 sensors, configurations are compared). Here, the comparison is based on a cost function and inspired by the renormalized data-assimilation method. The cost function quantifies the quadratic distance between the observed and the simulated measurements. The “optimal network” produces the best description of the observations (i.e., corresponds to the minimal quadratic distance) and permits the a posteriori estimation of the location and emission rate of an unknown continuous point source in an urban-like environment.
The size of the MUST predefined (original) network is 40 sensors, and the sizes of the optimized networks are fixed after performing a first optimization with the number of sensors from 4 to 16 (Kouichi, 2017). This first evaluation showed that for some trials, a small number of sensors could not allow for the correct reconstruction of the source, and divergences in the calculations have been noted. Accordingly, the source estimation obtained for different trials and network sizes shows that, very often, networks of fewer than eight sensors may not characterize the source correctly. On the other hand, beyond 13 sensors, the source estimation is not significantly improved, and the associated errors were roughly constant (Kouichi, 2017). Therefore, in order to ensure an acceptable estimate of the source for all the trials, the sizes of the optimized network are fixed as 10 and 13 sensors (1∕4 and , respectively, of the original network of 40 sensors).
The optimization calculations were performed using MATLAB on a computer with the configuration Intel® Core™ i7-4790 CPU @ 3.60 GHz and 16 GB of RAM. The averaged computational time for the optimization of one 10-sensor network was ≈2.5, and it was ≈8.5 h for the 13-sensor network. In computations, a value of parameter T0=10 was fixed according to the scale of the cost function and using the methodology described in step 1, and was used for both optimal sensor networks; θ is a decay factor of the temperature for an exponential cooling schedule that describes a procedure of the temperature decrease. The best cooling schedule is the exponential decay as demonstrated by Nourani and Andresen (1998) and Cohn and Fielding (1999); θ was fixed as 0.9 following the recommendation in the literature (Siarry, 2014). This value allows for sufficiently slow cooling in order to give more chances for the algorithm to explore a large search space and to avoid the local minima. Lmax is taken as 100 and 200 for the 10- and 13-sensor networks, respectively, following the recommendation in Siarry (2014) and according to the number of possible combinations that increases with the number of sensors (8.5×108 for 10 sensors and 1.2×1010 for 13 sensors).

Figure 3The optimal networks of 10 (a–c) and 13 sensors (d–f), respectively, for trials 5 (very stable), 11 (neutral), and 19 (stable). Blank and filled black circles respectively represent all (40) potential positions and the optimal positions of sensors.
Figure 3 shows the optimal networks of 10 and 13 sensors, respectively, for three representative trials in the MUST urban array: trials 5 (very stable), 11 (neutral), and 19 (stable). These three trials correspond to one trial each in neutral, stable, and very stable atmospheric conditions during the release. The optimal monitoring networks of 10 and 13 sensors for all 20 selected MUST trials are shown in Figs. S2.1 and S2.2.
In order to analyze the performance of the optimal monitoring configurations of smaller sizes, source reconstructions were performed to estimate the unknown location and the intensity of a continuous point release. These source reconstruction results were obtained using the information from the optimal monitoring networks formed by 10 and 13 sensors in each MUST trial. In this performance evaluation process, the retroplumes and the concentration measurements were utilized from the sensors corresponding to these optimal networks. The retroplumes were computed using CFD simulations, considering the dispersion in a complex terrain. The source reconstruction results from both the optimal monitoring networks were also compared with results computed from the initial MUST network formed by 40 sensors (Kumar et al., 2015b). As in practice, the number of measurements is limited, but this comparison allowed for the conclusion that in urban areas, the optimal reduction of a network size is possible without significantly degrading its efficiency for source estimation.
Table 2Source estimation results from the different monitoring networks for each selected trial of the MUST field experiment. and respectively denote the location error (m) and ratio of the estimated to true source intensity with the corresponding monitoring network. Here, the superscript p on and represents the number of sensors in an optimal network. “Skeleton” refers to the number of sensors common to the optimal networks of 10 and 13 sensors for a given MUST trial.
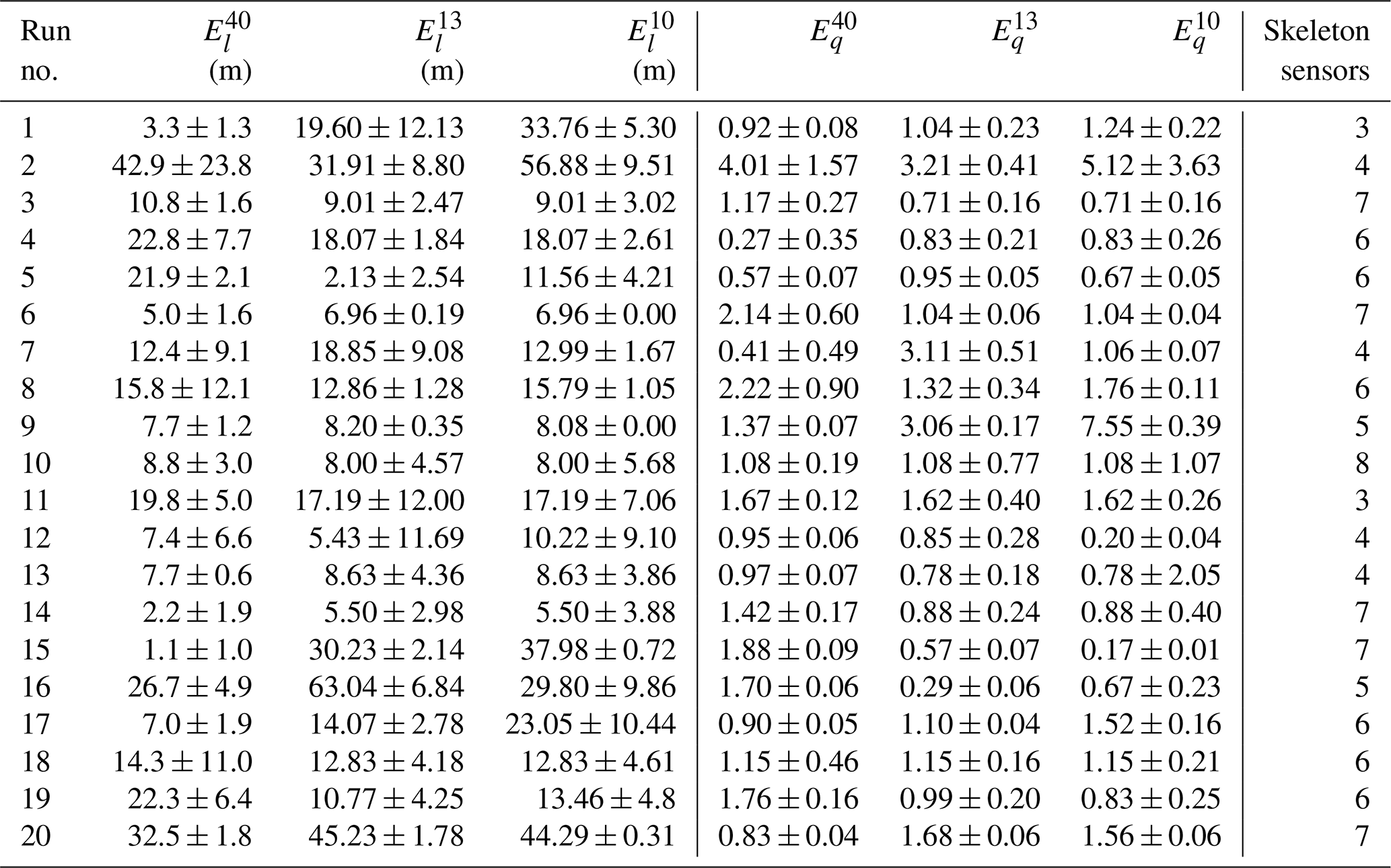
Source estimation results from the different monitoring networks are shown in Table 2 for all 20 selected trials of the MUST experiment. These results are presented in terms of the location error , which is an Euclidean distance between the estimated and the true source location, and is a ratio of the estimated to the true source intensity. The corresponding monitoring network is represented by a superscript p (representing the number of sensors in an optimal network) on and . In order to quantify the uncertainty, 10 % Gaussian noise was added at each measurement. Accordingly, 50 simulations for the source reconstruction were performed with these noise measurements using the optimal networks for each trial. The average and the standard deviation of and are calculated, and the results are also presented in Table 2.
For a given trial, the skeleton parameter represents the common sensors between two optimal networks of different sizes (with 10 and 13 sensors). These results show that the SA algorithm coupled with renormalization inversion theory and the CFD modeling approach succeeded in reducing the size of an existing larger network to estimate unknown emissions with similar accuracy in an urban environment.

Figure 4Isopleths of the renormalized weight function (w(x)) (gray in first and third columns) and the normalized source estimate function (colored in second and fourth columns) for both optimal networks of 10 and 13 sensors, respectively, for trials 5 (very stable), 11 (neutral), and 19 (stable). The black and white filled circles respectively represent the true and estimated source locations.
Figure 4 shows isopleths of the renormalized weight function (also called the visibility function) and the normalized source estimate function corresponding to both optimal monitoring networks for three representative trials (e.g., 5, 11, and 19) of the MUST experiment. These isopleths for all 20 selected MUST trials are shown in Fig. S3. As already discussed in the literature, the visibility function includes the natural information associated with a monitoring network for source retrieval in a domain and physically interprets the extent of regions seen by the network (Issartel, 2005; Sharan et al., 2009). This function is independent of the effective values of the concentration measurements and depends only on the geometry of the monitoring network. Hence, this leads to a priori information about the unknown source apparent to the monitoring network. A statistical parameter, a factor of g (FAg), for the source reconstruction results from each monitoring network is presented in Table 3, where FAg represents the percentage of trials in which the source intensity is estimated within a factor of g of the actual emission rates. The statistics calculated with the original 40-sensor network show that the average location error for all 20 trials is 14.62 m, and in 75 % of the trials, the intensity of the source is estimated within a factor of 2 of the actual emission rates. In 90 % of the trials, intensity was estimated within a factor of 3, and it was estimated within a factor of 4 in 95 % of the trials (Table 3). If trial 2 is considered, large location errors (greater than 30 m) and intensity values ranging between a factor of 3 and 5 were observed (Table 2) independently of the number of sensors in the networks. If we consider trials 15, 16, and 20, it was noted from the numerical results that larger location errors do not necessarily correspond to high intensity errors (Table 2).
Table 3Statistics for the source reconstruction results from each monitoring network. Here, is the averaged location error for all 20 trials corresponding to each network. FAg represents the percentage of trials in which the source intensity is estimated within a factor of g.

From the distribution of the optimized sensors in the networks in Fig. 3 for trials 5, 11, and 19 as well as in Figs. S2.1 and S2.2 for all selected trials, it was noted that a larger number of sensors are close to the source position in the optimal networks in most of the trials. The source reconstruction results from the optimal monitoring networks formed by 10 sensors have an averaged location error of 19.20 m for all 20 trials in the MUST experiment (Tables 2 and 3). In most of the trials, the location and the intensity of a continuous point emission are estimated accurately and close to the true source parameters. The location error is minimum in trial 14 ( m) and maximum in trial 2 ( m) (Table 2). For this configuration of the optimal sensor network, the source intensity in 80 % of the trials is estimated within a factor of 2 of the true release rates (Tables 2 and 3).
For all 20 trials, the averaged location error is 17.42 m for the optimal networks formed by 13 sensors, which is smaller than the averaged m obtained with 10 sensors (Tables 2 and 3). The location error is observed as a minimum in trial 5 ( m) and as a maximum in trial 16 ( m) (Table 2). For this optimal network, in 80 % of the trials, the source intensity is estimated within a factor of 2 of the actual emission rates. It was noted from the evaluation results that the increase in the number of sensors in a network has little influence on the accuracy of the estimated intensity (Tables 2 and 3).
In some trials, it was also noted that the distance of an estimated source to a real source decreases with a decrease in sensor number and also increases with the number of sensors in some other cases. It may be because the information added by a new sensor was not necessarily beneficial. It is noticeable that in a particular meteorological condition (i.e., wind direction, wind speed, and atmospheric stability), some of the sensors in a network may have little contribution to the STE. So, increasing the number of sensors may not always provide the best estimation because with the addition of more sensors, we also add more model and measurement errors in the estimation process. These errors can affect the source estimation results in some trials. In some cases, it may also depend on the sensitiveness of the added sensor's position in an extended optimal network to the source estimation. It is also noted that for a monitoring network, not only the number of sensors but also the sensor distribution (or sensor position) affects the information captured from the network.
In fact, both optimal networks for each trial show a diversity of structures independently of the number of sensors considered. For this, the skeleton was used to analyze the heterogeneity of the structures of different optimal networks. A skeleton with seven sensors is considered a strong common base for the networks. This is the case for trials 3, 6, 14, 15, and 20 (Table 2). It is noted that the overall results obtained are comparable (few differences between the results obtained by the networks). For these networks, a strong common base leads to a near-global optimum. If we consider networks with a weak common base, the skeleton was formed by up to three sensors, particularly in trials 1 and 11. The performances do not systematically converge independently of the size of the networks. Thus, for trial 1, better results were obtained with a network formed by 13 sensors compared to that by 10 sensors. This result reflects the fact that the algorithm with the network formed by 13 sensors probably converges toward a near-global optimum. For trial 11, it was also noted that the performances obtained by the two networks are identical. This shows that the networks with different sensor configurations may lead to a nearly overall optimum. This result is in coherence with Kovalets et al. (2011) and Efthimiou et al. (2017). Considering a network of 10 sensors, they show for the same experimental data that the best source reconstruction is possible with only 5 % or 10 % of the randomly selected total network combinations.
Considering the networks of intermediate structures with skeletons varying from four to six sensors, for trials 2, 4, 5, 7, 8, 9, 12, 13, 16, 17, 18, and 19, no obvious trend is noticed. These results tend to show that for a given trial, one or more optimal networks can satisfy the conditions of a nearly overall optimum (to be minimized). The obtained optimal networks may have a more or less common structure (having a greater or lesser number of skeletons).
Moreover, uncertainties calculated for different network sizes do not show an obvious trend. Indeed, a general relationship between the number of samplers and the uncertainties is not obvious. One may notice that changing the size of the network (increasing or decreasing the number of sensors) can lead to the growth or diminution of the uncertainties in the source parameter estimations. As an example, for trial 7 uncertainties grow, while for trial 17 uncertainties diminish (Table 2).
It should be noted that this study deals with the case of reducing the number of sensors in order to obtain an optimal network from an existing large network. This optimization was carried out under the constraints of an existing network of the original 40 sensors in the MUST field experiment. If one compares the performances of the obtained optimal monitoring networks of smaller sizes with the initial (original) network of 40 sensors in the MUST environment, both optimal networks provide satisfactory estimations of unknown source parameters. The 40-sensor network gives an averaged location error of 14.62 m for all trials, and the release rate was estimated within a factor of 2 in 75 % of the trials. However, reducing the number of sensors to of the original 40 sensors, the 13-sensor optimal networks also give comparable source estimation performances with an averaged location error of 17.42 m. Even with the 13-sensor optimal networks, source intensities in 80 % of the trials were accurately estimated within a factor of 2. Similarly for the 10-sensor optimal networks, the averaged location error (19.20 m) is slightly larger than that obtained from the 13- and 40-sensor networks. However, reducing the number of sensors to 1∕4 gives extra advantages in the case of limited sensor availability for a network in emergency scenarios, such as accidental or deliberate releases, in complex urban environments.
It should also be noted that the optimization evaluation in this study is performed using the MUST set of measurements, and this makes it more likely that the resulting sensor configuration performs well in reconstructing the source (in other words, the same measurements should not be used for the optimization and for the reconstructions). However, this does not limit the application of the proposed methodology for some important practical applications like accurate emission estimations. In fact, this can be considered a limitation of the data used for this application because for a complete process of optimization and then evaluation one requires a sufficiently long set of measurements so that all the data can be divided into two parts, (i) one part for designing an optimal sensor network and (ii) another part for the evaluation of the designed optimal network. However, the durations of the releases in the MUST field experiment were not sufficiently long to divide all the data from a test release separately into two parts for designing the optimal sensor network and then its evaluation. In further evaluations of the resulting optimal sensor configuration, a different set of concentration measurements can be constructed by adding some noise to the measurements. For a continuous release in steady atmospheric conditions, the average value of the steady concentration in a test release is not expected to deviate drastically from the mean values in each segment of the complete data. So this new set of concentration measurements with added noise can partially fulfill the purpose of evaluating a designed optimal network. As shown in Table 2, the errors in the estimated source parameters are small even with the new sets of concentration measurements constructed by adding 10 % Gaussian noise. This exercise shows that even if we have utilized a partially different set of the measurements for the evaluation of the optimal networks, the optimal networks have almost the same level of source detection ability in an urban-like environment. However, realistic data are required for further evaluation of the optimization methodology.
Although the MUST field experiment has been widely utilized for the validation of atmospheric dispersion models and inversion methodologies for unknown source reconstruction in an urban-like environment, its experimental domain was only approximately 200 m × 200 m (with buildings represented by a grid of containers) and can be considered small for a real urban environment. Thus, it may not quite represent a real urban region in terms of scale, meteorological variability, and nonuniform terrain or roughness–canopy structure. However, the methodology presented here is general in nature to apply to a real urban environment. The methodology involves the utilization of a CFD model, which can generally include the effects of urban geometry, meteorological variability, and nonuniform terrain or roughness–canopy structure in a real urban environment. It is also noted that the optimal network design would depend on diurnal and spatial variability in meteorological conditions, which may increase or decrease the optimum number of sensors and may also change the “best positions” to be instrumented by sensors.
This study describes an approach for optimally reducing the size of an existing monitoring network of sensors in a geometrically complex urban environment. It is a matter of reducing the size of networks while retaining the capabilities of estimating an unknown source in an urban region. Given an urban-like environment of the MUST field experiment, the renormalization inversion method was chosen for the source term estimation. It was coupled with the CFD model fluidyn-PANACHE for the generation of the adjoint fields. Combinatorial optimization by simulated annealing consisted of choosing a set of sensors that leads to an optimal monitoring network and allows for an accurate unknown source estimation. This study demonstrates how the renormalization inversion technique can be applied to optimally reducing the size of an existing large network of concentration samplers for quantifying a continuous point source in an urban-like environment with almost the same level of source detection ability as the original network with a larger number of samplers.
The numerical calculations were performed by coupling the simulated annealing stochastic algorithm to the renormalization inversion technique and the CFD modeling approach to optimally reduce the size of an existing monitoring network in urban-like environment of the MUST field experiment. The optimal networks were constructed to reduce the size of the original networks (40 sensors) to approximately one-third (13 sensors) and one-fourth (10 sensors). The 10- and 13-sensor optimal networks have estimated average location errors of 19.20 and 17.43 m, respectively, and have comparable source estimation performances with an averaged location error of 14.62 m from the original 40-sensor network. In 80 % of trials with optimal networks of 10 and 13 sensors, the emission rates are estimated within a factor of 2 of the actual release rates. These are also comparable to the performance of the original 40-sensor network, whereby in 75 % of the trials the releases were estimated within a factor of 2 of the actual release.
It was shown that in most of the MUST trials, the number of sensors in optimal networks slightly influences the location error of an estimated source, and this error tends to increase as the number of sensors decreases. In 20 MUST trials, an analysis of the networks formed by 10 and 13 sensors revealed the heterogeneity of their structures in an urban domain. It was observed that for some trials, optimal networks had a strong common structure. This tends to prove that a certain number of sensors have a primordial role in reconstructing an unknown source. It would reflect the fact that disjoint sets of sensors can lead to the best estimate of an unknown source in an urban region. This opens enormous prospects for assessing the relative importance of each sensor in a source reconstruction process in an urban environment. Defining a global optimal network for all meteorological conditions is a complex problem, but it is of greater importance that one may realize. This challenge consists of defining an optimal static network able to reconstruct the sources in all varied meteorological conditions. This information can be of great importance to determine an optimal monitoring network by reducing the number of sensors for the characterization of unknown emissions in complex urban or industrial environments.
The authors received access to the MUST field experiment dataset from Marcel König of the Leibniz Institute for Tropospheric Research. The MUST database was officially available from the Defense Threat Reduction Agency (DTRA). Code developed and utilized for this work is accessible from https://doi.org/10.5281/zenodo.3269751 (Kouichi et al., 2019).
Issartel et al. (2007) demonstrated that a weight function, which reduces the artifacts of the adjoint functions at the measurement points, must verify the following renormalization criterion:
From an iterative algorithm by Issartel et al. (2007), w(x) is determined as
and
Following Sharan et al. (2009), consider a point source of continuous release at a position and with the intensity qo. The point source is thus expressed as a function of the preceding parameters: . The relationship between the source and the measurements (Eq. 3) becomes . By replacing the measurement term in Eq. (4), one obtains
sw reaches its maximum at position xo as the renormalization criterion (Eq. A1) is satisfied only at this position. Thus, sw(x) at xo becomes
which estimates the source intensity .
A cost function is defined (based on the renormalization theory) as a function that minimizes the quadratic distance between the observed and the simulated measurements according to the Hw norm (Issartel et al., 2012). Hw is the Gram matrix defined in Sect. 2.2. The quadratic distance between the real and the simulated concentration measurements according to the Hw norm is given by
When considering a point source, is written by , where qo and x are respectively the intensity and the position of a point source. By replacing in Eq. (C1), one obtains (Sharan et al., 2012; Issartel et al., 2012)
For a fixed x in Eq. (C2), J reaches a strict local minimum if the following two conditions are satisfied.
For each fixed x, the first condition (Eq. C3) gives an estimate () of q0 as . The second condition (Eq. C4) is always satisfied as , ∀x (Sharan et al., 2012). Corresponding to the estimate from the first condition (Eq. C3), the cost function J from Eq. (C2) leads to the following expression (Issartel et al., 2012):
where sw is the same as given in Eq. (4) and is a positive constant. Considering Eq. (C5), it is obvious that the minimization of J also corresponds to the maximization of the term or minimization of the term . Accordingly, the minimum value of the cost function J in Eq. (C5) leads to the following expression of the cost function (say Js(x)) to minimize:
A global minimum of the cost function Js(x) is evaluated by the SA algorithm.
The supplement related to this article is available online at: https://doi.org/10.5194/gmd-12-3687-2019-supplement.
HK and PN conceived the idea of the optimization of the sensor networks and developed the algorithm. PK conducted the CFD calculations for the MUST field experiment and analyzed the results to utilize in the optimization algorithm. HK, PN, PK, and AAF analyzed the results and prepared the paper with contributions from NB. All authors reviewed the paper.
The authors declare that they have no conflict of interest.
The authors would like to thank Marcel König of the Leibniz Institute for Tropospheric Research and the Defense Threat Reduction Agency (DTRA) for providing access to the MUST field experiment dataset. The authors gratefully acknowledge Fluidyn France for use of the CFD model fluidyn-PANACHE. We also thank Claude Souprayen from Fluidyn France for useful discussions. Finally, we thank the reviewers Janusz Pudykiewicz, George Efthimiou, two anonymous reviewer, and the topical editor Ignacio Pisso for their detailed and technical comments that helped to improve this study.
This paper was edited by Ignacio Pisso and reviewed by George Efthimiou, Janusz Pudykiewicz, and two anonymous referees.
Abida, R.: Static and mobile networks design for atmospheric accidental releases monitoring, Theses, Ecole des Ponts ParisTech, available at: https://pastel.archives-ouvertes.fr/pastel-00638050 (last access: July 2016), 2010. a
Abida, R. and Bocquet, M.: Targeting of observations for accidental atmospheric release monitoring, Atmos. Environ., 43, 6312–6327, https://doi.org/10.1016/j.atmosenv.2009.09.029, 2009. a
Abida, R., Bocquet, M., Vercauteren, N., and Isnard, O.: Design of a monitoring network over France in case of a radiological accidental release, Atmos. Environ., 42, 5205–5219, https://doi.org/10.1016/j.atmosenv.2008.02.065, 2008. a, b
Beljaars, A. and Holtslag, A.: Flux parameterization over land surfaces for atmospheric models, J. Appl. Meteorol., 30, 327–341, https://doi.org/10.1175/1520-0450(1991)030<0327:FPOLSF>2.0.CO;2, 1991. a
Biltoft, C. A.: Customer Report for Mock Urban Setting Test, Tech. rep., West Desert Test Center, U.S. Army Dugway Proving Ground, Dugway, Utah, USA, 2001. a, b, c
Bocquet, M.: Reconstruction of an atmospheric tracer source using the principle of maximum entropy. I: Theory, Q. J. Roy. Meteor. Soc., 131, 2191–2208, https://doi.org/10.1256/qj.04.67, 2005. a
Cohn, H. and Fielding, M.: Simulated Annealing: Searching for an Optimal Temperature Schedule, SIAM J. Optimiz., 9, 779–802, https://doi.org/10.1137/S1052623497329683, 1999. a, b
Efthimiou, G. C., Kovalets, I. V., Venetsanos, A., Andronopoulos, S., Argyropoulos, C. D., and Kakosimos, K.: An optimized inverse modelling method for determining the location and strength of a point source releasing airborne material in urban environment, Atmos. Environ., 170, 118–129, https://doi.org/10.1016/j.atmosenv.2017.09.034, 2017. a, b
Gamerman, D. and Lopes, H. F.: Markov chain Monte Carlo: stochastic simulation for Bayesian inference, CRC Press, New York, USA, 2006. a
Gryning, S.-E., Batchvarova, E., Brummer, B., Jorgensen, H., and Larsen, S.: On the extension of the wind profile over homogeneous terrain beyond the surface boundary layer, Bound.-Lay. Meteorol., 124, 251–268, https://doi.org/10.1007/s10546-007-9166-9, 2007. a
Haupt, S. E., Young, G. S., and Allen, C. T.: Validation of a receptor-dispersion model coupled with a genetic algorithm using synthetic data, J. Appl. Meteorol. Clim., 45, 476–490, https://doi.org/10.1175/JAM2359.1, 2006. a
Hourdin, F. and Talagrand, O.: Eulerian backtracking of atmospheric tracers. I: Adjoint derivation and parametrization of subgrid-scale transport, Q. J. Roy. Meteor. Soc., 132, 567–583, https://doi.org/10.1256/qj.03.198.A, 2006. a
Hutchinson, M., Oh, H., and Chen, W.-H.: A review of source term estimation methods for atmospheric dispersion events using static or mobile sensors, Inform. Fusion, 36, 130–148, https://doi.org/10.1016/j.inffus.2016.11.010, 2017. a
Issartel, J.-P.: Emergence of a tracer source from air concentration measurements, a new strategy for linear assimilation, Atmos. Chem. Phys., 5, 249–273, https://doi.org/10.5194/acp-5-249-2005, 2005. a, b, c
Issartel, J.-P., Sharan, M., and Modani, M.: An inversion technique to retrieve the source of a tracer with an application to synthetic satellite measurements, P. Roy. Soc. Lond. A Mat., 463, 2863–2886, https://doi.org/10.1098/rspa.2007.1877, 2007. a, b, c, d, e
Issartel, J.-P., Sharan, M., and Singh, S. K.: Identification of a Point of Release by Use of Optimally Weighted Least Squares, Pure Appl. Geophys., 169, 467–482, https://doi.org/10.1007/s00024-011-0381-4, 2012. a, b, c, d
Jiang, Z., de Bruin, S., Heuvelink, G., and Twenhöfel, C.: Optimization of mobile radioactivity monitoring networks, Fifth International Symposium on Spatial Data Quality, 13–15 June 2007, Enschede, the Netherlands, available at: http://edepot.wur.nl/24174 (last access: March 2015), 2007. a
Keats, W. A.: Bayesian inference for source determination in the atmospheric environment, PhD thesis, http://hdl.handle.net/10012/4317 (last access: July 2016), 2009. a
Kirkpatrick, S., Gelatt, C. D., and Vecchi, M. P.: Optimization by Simulated Annealing, Science, 220, 671–680, https://doi.org/10.1126/science.220.4598.671, 1983. a, b
Ko, C.-W., Lee, J., and Queyranne, M.: An Exact Algorithm for Maximum Entropy Sampling, Oper. Res., 43, 684–691, https://doi.org/10.1287/opre.43.4.684, 1995. a
Kouichi, H.: Sensors networks optimization for the characterization of atmospheric releases source, Theses, Université Paris Saclay, France, available at: https://hal.archives-ouvertes.fr/tel-01593834 (last access: January 2018), 2017. a, b, c, d, e, f
Kouichi, H., Turbelin, G., Ngae, P., Feiz, A., Barbosa, E., and Chpoun, A.: Optimization of sensor networks for the estimation of atmospheric pollutants sources, WIT Trans. Ecol. Envir., 207, 11–21, 2016. a
Kouichi, H., Ngae, P., Kumar, P., Feiz, A.-A., and Bekka, N.: Matlab code for an optimization for reducing the size of an existing urban-like monitoring network for retrieving an unknown point source emission, Zenodo, https://doi.org/10.5281/zenodo.3269751, 2019. a
Kovalets, I. V., Andronopoulos, S., Venetsanos, A. G., and Bartzis, J. G.: Identification of strength and location of stationary point source of atmospheric pollutant in urban conditions using computational fluid dynamics model, Math. Comput. Simulat., 82, 244–257, https://doi.org/10.1016/j.matcom.2011.07.002, 2011. a
Kumar, P., Feiz, A.-A., Ngae, P., Singh, S. K., and Issartel, J.-P.: CFD simulation of short-range plume dispersion from a point release in an urban like environment, Atmos. Environ., 122, 645–656, https://doi.org/10.1016/j.atmosenv.2015.10.027, 2015a. a, b, c, d
Kumar, P., Feiz, A.-A., Singh, S. K., Ngae, P., and Turbelin, G.: Reconstruction of an atmospheric tracer source in an urban-like environment, J. Geophys. Res.-Atmos., 120, 12589–12604, https://doi.org/10.1002/2015JD024110, 2015b. a, b, c, d, e, f
Kumar, P., Singh, S. K., Feiz, A.-A., and Ngae, P.: An urban scale inverse modelling for retrieving unknown elevated emissions with building-resolving simulations, Atmos. Environ., 140, 135–146, https://doi.org/10.1016/j.atmosenv.2016.05.050, 2016. a, b
Ma, D., Deng, J., and Zhang, Z.: Comparison and improvements of optimization methods for gas emission source identification, Atmos. Environ., 81, 188–198, https://doi.org/10.1016/j.atmosenv.2013.09.012, 2013. a, b
Ma, D., Tan, W., Zhang, Z., and Hu, J.: Parameter identification for continuous point emission source based on Tikhonov regularization method coupled with particle swarm optimization algorithm, J. Hazard. Mater., 325, 239–250, https://doi.org/10.1016/j.jhazmat.2016.11.071, 2017. a
Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., and Teller, E.: Equation of State Calculations by Fast Computing Machines, J. Chem. Phys., 21, 1087–1092, https://doi.org/10.1063/1.1699114, 1953. a
Monache, L. D., Lundquist, J. K., Kosović, B., Johannesson, G., Dyer, K. M., Aines, R. D., Chow, F. K., Belles, R. D., Hanley, W. G., Larsen, S. C., Loosmore, G. A., Nitao, J. J., Sugiyama, G. A., and Vogt, P. J.: Bayesian Inference and Markov Chain Monte Carlo Sampling to Reconstruct a Contaminant Source on a Continental Scale, J. Appl. Meteorol. Clim., 47, 2600–2613, https://doi.org/10.1175/2008JAMC1766.1, 2008. a
Ngae, P., Kouichi, H., Kumar, P., Feiz, A.-A., and Chpoun, A.: Optimization of an urban monitoring network for emergency response applications: An approach for characterizing the source of hazardous releases, Q. J. Roy. Meteor. Soc., 145, 967–981, 2019. a, b, c
Nourani, Y. and Andresen, B.: A comparison of simulated annealing cooling strategies, J. Phys. A-Math. Gen., 31, 8373, https://doi.org/10.1088/0305-4470/31/41/011, 1998. a, b, c
Penenko, V., Baklanov, A., and Tsvetova, E.: Methods of sensitivity theory and inverse modeling for estimation of source parameters, Future Gener. Comp. Sy., 18, 661–671, https://doi.org/10.1016/S0167-739X(02)00031-6, 2002. a
Pudykiewicz, J. A.: Application of adjoint tracer transport equations for evaluating source parameters, Atmos. Environ., 32, 3039–3050, https://doi.org/10.1016/S1352-2310(97)00480-9, 1998. a, b
Qu, Y., Milliez, M., Musson-Genon, L., and Carissimo, B.: Micrometeorological Modeling of Radiative and Convective Effects with a Building-Resolving Code, J. Appl. Meteorol. Clim., 50, 1713–1724, https://doi.org/10.1175/2011JAMC2620.1, 2011. a, b
Rao, K. S.: Source estimation methods for atmospheric dispersion, Atmos. Environ., 41, 6964–6973, https://doi.org/10.1016/j.atmosenv.2007.04.064, 2007. a
Saunier, O., Bocquet, M., Mathieu, A., and Isnard, O.: Model reduction via principal component truncation for the optimal design of atmospheric monitoring networks, Atmos. Environ., 43, 4940–4950, https://doi.org/10.1016/j.atmosenv.2009.07.011, 2009. a
Seibert, P.: Inverse Modelling with a Lagrangian Particle Disperion Model: Application to Point Releases Over Limited Time Intervals, Springer US, Boston, MA, USA, 381–389, https://doi.org/10.1007/0-306-47460-3_38, 2001. a
Seibert, P. and Frank, A.: Source-receptor matrix calculation with a Lagrangian particle dispersion model in backward mode, Atmos. Chem. Phys., 4, 51–63, https://doi.org/10.5194/acp-4-51-2004, 2004. a
Sharan, M., Issartel, J.-P., Singh, S. K., and Kumar, P.: An inversion technique for the retrieval of single-point emissions from atmospheric concentration measurements, P. Roy. Soc. Lond. A Mat., 465, 2069–2088, https://doi.org/10.1098/rspa.2008.0402, 2009. a, b, c, d, e
Sharan, M., Singh, S. K., and Issartel, J.-P.: Least Square Data Assimilation for Identification of the Point Source Emissions, Pure Appl. Geophys., 169, 483–497, https://doi.org/10.1007/s00024-011-0382-3, 2012. a, b, c, d
Siarry, P.: Métaheuristiques: Recuits simulé, recherche avec tabous, recherche à voisinages variables, méthodes GRASP, algorithmes évolutionnaires, fourmis artificielles, essaims particulaires et autres méthodes d'optimisation, Editions Eyrolles, Paris, France, 2014. a, b
Siarry, P.: Simulated Annealing, Springer International Publishing, Cham, 19–50, https://doi.org/10.1007/978-3-319-45403-0_2, 2016. a
Wang, B., Chen, B., and Zhao, J.: The real-time estimation of hazardous gas dispersion by the integration of gas detectors, neural network and gas dispersion models, J. Hazard. Mater., 300, 433–442, https://doi.org/10.1016/j.jhazmat.2015.07.028, 2015. a
Yang, Y., Gu, M., Chen, S., and Jin, X.: New inflow boundary conditions for modelling the neutral equilibrium atmospheric boundary layer in computational wind engineering, J. Wind Eng. Ind. Aerod., 97, 88–95, https://doi.org/10.1016/j.jweia.2008.12.001, 2009. a
Yee, E. and Biltoft, C.: Concentration Fluctuation Measurements in a Plume Dispersing Through a Regular Array of Obstacles, Bound.-Lay. Meteorol., 111, 363–415, https://doi.org/10.1023/B:BOUN.0000016496.83909.ee, 2004. a, b, c
Yee, E., Hoffman, I., and Ungar, K.: Bayesian Inference for Source Reconstruction: A Real-World Application, International Scholarly Research Notices, 2014, 1–12, https://doi.org/10.1155/2014/507634, 2014. a
Zhang, X., Raskob, W., Landman, C., Trybushnyi, D., and Li, Y.: Sequential multi-nuclide emission rate estimation method based on gamma dose rate measurement for nuclear emergency management, J. Hazard. Mater., 325, 288–300, https://doi.org/10.1016/j.jhazmat.2016.10.072, 2017. a
Zhang, X. L., Su, G. F., Yuan, H. Y., Chen, J. G., and Huang, Q. Y.: Modified ensemble Kalman filter for nuclear accident atmospheric dispersion: Prediction improved and source estimated, J. Hazard. Mater., 280, 143–155, https://doi.org/10.1016/j.jhazmat.2014.07.064, 2014. a, b
Zhang, X. L., Su, G. F., Chen, J. G., Raskob, W., Yuan, H. Y., and Huang, Q. Y.: Iterative ensemble Kalman filter for atmospheric dispersion in nuclear accidents: An application to Kincaid tracer experiment, J. Hazard. Mater., 297, 329–339, https://doi.org/10.1016/j.jhazmat.2015.05.035, 2015. a, b
- Abstract
- Introduction
- Source term estimation method: the renormalization
- The combinatorial optimization of a monitoring network
- The Mock Urban Setting Test (MUST) tracer field experiment
- CFD modeling for retroplumes in an urban environment
- Results and discussion
- Conclusions
- Code and data availability
- Appendix A: Weight function
- Appendix B: Identification of point source
- Appendix C: Derivation of the cost function
- Author contributions
- Competing interests
- Acknowledgements
- Review statement
- References
- Supplement
- Abstract
- Introduction
- Source term estimation method: the renormalization
- The combinatorial optimization of a monitoring network
- The Mock Urban Setting Test (MUST) tracer field experiment
- CFD modeling for retroplumes in an urban environment
- Results and discussion
- Conclusions
- Code and data availability
- Appendix A: Weight function
- Appendix B: Identification of point source
- Appendix C: Derivation of the cost function
- Author contributions
- Competing interests
- Acknowledgements
- Review statement
- References
- Supplement