the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Jan 2025
| 30 Jan 2025
Exploring a high-level programming model for the NWP domain using ECMWF microphysics schemes
Christian Kühnlein
Christoph Schär
Linda Schlemmer
Thomas C. Schulthess
Michael Staneker
Heini Wernli
We explore the domain-specific Python library GT4Py (GridTools for Python) for implementing a representative physical parametrization scheme and the related tangent-linear and adjoint algorithms from the Integrated Forecasting System (IFS) of ECMWF. GT4Py encodes stencil operators in an abstract and hardware-agnostic fashion, thus enabling more concise, readable, and maintainable scientific applications. The library achieves high performance by translating the application into targeted low-level coding implementations. Here, the main goal is to study the correctness and performance portability of the Python rewrites with GT4Py against the reference Fortran code and a number of automatically and manually ported variants created by ECMWF. The present work is part of a larger cross-institutional effort to port weather and climate models to Python with GT4Py. The focus of the current work is the IFS prognostic cloud microphysics scheme, a core physical parametrization represented by a comprehensive code that takes a significant share of the total forecast model execution time. In order to verify GT4Py for numerical weather prediction (NWP) systems, we put additional emphasis on the implementation and validation of the tangent-linear and adjoint model versions which are employed in data assimilation. We benchmark all prototype codes on three European supercomputers characterized by diverse graphics processing unit (GPU) and central processing unit (CPU) hardware, node designs, software stacks, and compiler suites. Once the application is ported to Python with GT4Py, we find excellent portability, competitive GPU performance, and robust execution in all tested scenarios including with single precision.
- Article
(2682 KB) - Full-text XML
- BibTeX
- EndNote





Soon after its first public release in 1957, Fortran became the language of choice for weather and climate models (Méndez et al., 2014). On the one hand, its procedural programming style and its built-in support for multi-dimensional arrays have granted Fortran large popularity in the whole scientific computing community. On the other, its low-level nature guarantees fast execution of intensive mathematical operations on vector machines and conventional central processing units (CPUs). In the last decades, these characteristics have permitted weather forecasts to be run several times per day under tight operational schedules on high-performance computing (HPC) systems (Neumann et al., 2019).
In recent years, in response to the simultaneous end of Moore's law and Dennard scaling, and due to the societal challenge to reduce energy consumption, the computer hardware landscape has been undergoing a rapid specialization to prevent unsustainable growth of the power envelope (Müller et al., 2019). As a result, most supercomputers nowadays have a heterogeneous node design, where energy-efficient accelerators such as graphics processing units (GPUs) co-exist with traditional CPUs. Because Fortran has been conceived with CPU-centric machines in mind, efficient programming of hybrid HPC platforms using the core Fortran language can be challenging (Méndez et al., 2014; Lawrence et al., 2018). Indeed, the sustained performance of legacy weather and climate model codes written in Fortran has decreased over the decades (Schulthess et al., 2018), revealing the urgency for algorithmic and software adaptations to remain competitive in the medium and long term (Bauer et al., 2021).
Compiler directives (or pragmas) are an attractive solution for parallelization, both to spread a workload across multiple CPU threads and to offload data and computations to GPU. The most famous incarnations of this programming paradigm are OpenMP (Dagum and Menon, 1998) and OpenACC (Chandrasekaran and Juckeland, 2017). Because compiler directives accommodate incremental porting and enable non-disruptive software development workflows, they are adopted by many weather and climate modeling groups, who are facing the grand challenge of accelerating large code bases with thousands of source files and millions of lines of code, which stem from decades of scientific discoveries and software developments (Lapillonne et al., 2017, 2020; Randall et al., 2022). In order not to threaten the overall readability of the code by exposing low-level instructions, the annotation of Fortran codes with compiler directives can be automated in the pre-processor step of the compilation process using tools such as the CLAW compiler (Clement et al., 2019) or the ECMWF source-to-source translation tool Loki (https://github.com/ecmwf-ifs/loki, last access: 23 September 2024). Although pragma-based programming models can support intrusive hardware-specific code transformations, additional specialized optimizations may still be required, which could finally lead to code duplication and worsen maintainability (Dahm et al., 2023). Moreover, performance and portability are much dependent on the level of support and optimization offered by the compiler stack.
On the contrary, domain-specific languages (DSLs) separate the code describing the science from the code actually executing on the target hardware, thus enabling performance portability, namely application codes that achieve near-optimal performance on a variety of computer architectures (Deakin et al., 2019). Large portions of many modeling systems are being rewritten using multiple and diverse DSLs, not necessarily embedded in Fortran. For instance, the dynamical core of the weather prediction model from the COnsortium for Small-scale MOdeling (COSMO; Baldauf et al., 2011) has been rewritten in C++ using the GridTools library (Afanasyev et al., 2021) to port stencil-based operators to GPUs (Fuhrer et al., 2014, 2018). Similarly, HOMMEXX-NH (Bertagna et al., 2020) is an architecture-portable C++ implementation of the non-hydrostatic dynamical core of the Energy Exascale Earth System model (E3SM; Taylor et al., 2020) harnessing the Kokkos library to express on-node parallelism (Edwards et al., 2014). The GungHo project for a new dynamical core at the UK Met Office (Melvin et al., 2019, 2024) blends the LFRic infrastructure with the PSyclone code generator (Adams et al., 2019). Pace (Ben-Nun et al., 2022; Dahm et al., 2023) is a Python rewrite of the Finite-Volume Cubed-Sphere Dynamical Core (FV3; Harris and Lin, 2013) using GT4Py (GridTools for Python) to accomplish performance portability and productivity. Similarly, various Swiss partners including the Swiss Federal Office of Meteorology and Climatology (MeteoSwiss), ETH Zurich, and the Swiss National Supercomputing Centre (CSCS) are porting the ICOsahedral Non-hydrostatic modeling framework (ICON; Zängl et al., 2015) to GT4Py (Luz et al., 2024). In another related project (Kühnlein et al., 2023), a next-generation model for the IFS at ECMWF is developed in Python with GT4Py building on the Finite Volume Module (FVM; Smolarkiewicz et al., 2016; Kühnlein et al., 2019).
The focus of the portability efforts mentioned above is the model dynamical core – the part of the model numerically solving the fundamental non-linear fluid-dynamics equations. In the present work, we turn the attention to physical parametrizations – which account for the representation of subgrid-scale processes – and additionally address the associated tangent-linear and adjoint algorithms. Parametrizations are being commonly ported to accelerators using OpenACC (e.g., Fuhrer et al., 2014; Yang et al., 2019; Kim et al., 2021). Wrappers around low-level legacy physics codes might then be designed to facilitate adoption within higher-level workflows (Monteiro et al., 2018; McGibbon et al., 2021). Lately, first attempts at refactoring physical parametrizations with respect to portability have been documented in the literature. For instance, Watkins et al. (2023) presented a rewrite of the MPAS-Albany Land Ice (MALI) ice-sheet model using Kokkos. Here, we present a Python implementation of the cloud microphysics schemes CLOUDSC (Ubbiali et al., 2024c) and CLOUDSC2 (Ubbiali et al., 2024d), which are part of the physics suite of the IFS at ECMWF.1 Details on the formulation and validation of the schemes are discussed in Sect. 2. The proposed Python implementations build upon the GT4Py toolchain, and in the remainder of the paper we use the term CLOUDSC-GT4Py to refer to the GT4Py rewrite of CLOUDSC, while the GT4Py ports of the non-linear, tangent-linear, and adjoint formulations of CLOUDSC2 are collectively referred to as CLOUDSC2-GT4Py. The working principles of the GT4Py framework are illustrated in Sect. 3, where we also advocate the advantages offered by domain-specific software approaches. Section 4 sheds some light on the infrastructure code (Ubbiali et al., 2024b) and how it can enable composable and reusable model components. In Sect. 5, we compare the performance of CLOUDSC-GT4Py and CLOUDSC2-GT4Py, as measured on three leadership-class GPU-equipped supercomputers, to established implementations in Fortran and C/C++. We conclude the paper with final remarks and future development paths.
Several physical and chemical mechanisms occurring in the atmosphere are active on spatial scales that are significantly smaller than the highest affordable model resolution. It follows that these mechanisms cannot be properly captured by the resolved model dynamics but need to be parametrized. Parametrizations express the bulk effect of subgrid-scale phenomena on the resolved flow in terms of the grid-scale variables. The equations underneath physical parametrizations are based on theoretical and semi-empirical arguments, and their numerical treatment commonly adheres to the single-column abstraction; therefore adjustments can only happen within individual columns, with no data dependencies between columns. The atmospheric module of the IFS includes parametrizations dealing with the radiative heat transfer, deep and shallow convection, clouds and stratiform precipitation, surface exchange, turbulent mixing in the planetary boundary layer, subgrid-scale orographic drag, non-orographic gravity wave drag, and methane oxidation (ECMWF, 2023).
The focus of this paper is on the cloud microphysics modules of the ECMWF: CLOUDSC – used in operational forecasting – and CLOUDSC2 – employed in the data assimilation. The motivation is threefold:
- i
Both schemes are among the most computationally expensive parametrizations, with CLOUDSC accounting for up to 10 % of the total execution time of the high-resolution operational forecasts at ECMWF.
- ii
They are representative of the computational patterns ubiquitous in physical parametrizations.
- iii
They already exist in the form of dwarfs. The weather and climate “computational dwarfs”, or simply “dwarfs”, are model components shaped into stand-alone software packages to serve as archetypes of relevant computational motifs (Müller et al., 2019) and provide a convenient platform for performance optimizations and portability studies (Bauer et al., 2020).
In recent years, the Performance and Portability team of ECMWF has created the CLOUDSC and CLOUDSC2 dwarfs. The original Fortran codes for both packages, corresponding respectively to the IFS Cycle 41r2 and 46r1, have been pulled out of the IFS code base, slightly polished2 and finally made available in public code repositories (https://github.com/ecmwf-ifs/dwarf-p-cloudsc and https://github.com/ecmwf-ifs/dwarf-p-cloudsc2-tl-ad, last access: 23 September 2024). Later, the repositories were enriched with alternative coding implementations, using different languages and programming paradigms; the most relevant implementations will be discussed in Sect. 5.
2.1 CLOUDSC: cloud microphysics of the forecast model
CLOUDSC is a single-moment cloud microphysics scheme that parametrizes stratiform clouds and their contribution to surface precipitation (ECMWF, 2023). It was implemented in the IFS Cycle 36r4 and has been operational at ECMWF since November 2010. Compared to the pre-existing scheme, it accounts for five prognostic variables (cloud fraction, cloud liquid water, cloud ice, rain, and snow) and brings substantial enhancements in different aspects, including treatment of mixed-phase clouds, advection of precipitating hydrometeors (rain and snow), physical realism, and numerical stability (Nogherotto et al., 2016). For a comprehensive description of the scheme, we refer the reader to Forbes et al. (2011) and the references therein. For all the coding versions considered in this paper, including the novel Python rewrite, the calculations are validated by direct comparison of the output against serialized language-agnostic reference data provided by ECMWF.
2.2 CLOUDSC2: cloud microphysics in the context of data assimilation
The CLOUDSC2 scheme represents a streamlined version of CLOUDSC, devised for use in the four-dimensional variational assimilation (4D-Var) at ECMWF (Courtier et al., 1994). The 4D-Var merges short-term model integrations with observations over a 12 h assimilation window to determine the best possible representation of the current state of the atmosphere. This then provides the initial conditions for longer-term forecasts (Janisková and Lopez, 2023). The optimal synthesis between model and observational data is found by minimizing a cost function, which is evaluated using the tangent-linear of the non-linear forecasting model, while the adjoint model is employed to compute the gradient of the cost function (Errico, 1997; Janisková et al., 1999). For the sake of computational economy, the tangent-linear and adjoint operators are derived from a simplified and regularized version of the full non-linear model. CLOUDSC2 is one of the physical parametrizations included in the ECMWF's simplified model, together with radiation, vertical diffusion, orographic wave drag, moist convection, and non-orographic gravity wave activity (Janisková and Lopez, 2023). In the following, we provide a mathematical and algorithmic representation of the tangent-linear and adjoint versions of CLOUDSC2. For the sake of brevity, in the rest of the paper we will refer to the non-linear, tangent-linear, and adjoint formulations of CLOUDSC2 using CLOUDSC2NL, CLOUDSC2TL, and CLOUDSC2AD, respectively.
Let be the functional description of CLOUDSC2, connecting the input fields x with the output variables y. The tangent-linear operator F′ of F is derived from the Taylor series expansion
where δx and δy are variations on x and y, and is a suitable norm. The formal correctness of the coding implementation of F′ can be assessed through the Taylor test (also called the “V-shape” test), which ensures that the following condition is satisfied up to machine precision:
The logical steps carried out in the actual implementation of the Taylor test are sketched in Algorithm A1 (Appendix A).
The adjoint operator F* of F′ is defined such that for the inner product :
In particular, Eq. (3) must hold for y=F(x) and :
The latter condition is at the heart of the so-called symmetry test for F* (see Algorithm A2 in Appendix A).
In scientific software development, it is common practice to conceive a first proof-of-concept implementation of a numerical algorithm in a high-level programming environment like MATLAB/Octave (Lindfield and Penny, 2018), or Python. Because these languages do not require compilation and support dynamic typing, they provide a breeding ground for fast prototyping. However, the direct adoption of interpreted languages in HPC has historically been hindered by their intrinsic slowness. To squeeze more performance out of the underlying silicon, the initial proof of concept is translated into either Fortran, C or C++. This leads to the so-called “two-language problem”, where the programming language used for the germinal prototyping is abandoned in favor of a faster language that might be more complicated to use. The lower-level code can be parallelized for shared memory platforms using OpenMP directives, while distributed memory machines can be targeted using Message Passing Interface (MPI) libraries. The resulting code can later be migrated to GPUs, offering outstanding compute throughput and memory bandwidth, especially for single instruction, multiple data (SIMD) applications. GPU porting is accomplished using either OpenACC or OpenMP directives or via a CUDA (https://docs.nvidia.com/cuda/, last access: 23 September 2024) or HIP (https://rocm.docs.amd.com/projects/HIP/en/latest/, last access: 23 September 2024) rewriting, amongst others. To efficiently run the model at scale on multiple GPUs, a GPU-aware MPI build should be chosen, so as to possibly avoid costly memory transfers between host and device and better overlap computations and communications.
The schematic visualization in Fig. 1a highlights how the above workflow leads to multiple implementations of the same scientific application utilizing different programming models and coding styles. This unavoidably complicates software maintainability: ideally, any modification in the numerical model should be encoded in all implementations, so as to preserve the coherency across the hierarchy. The maintainability problem is exacerbated as the number of lines of code, the pool of platforms to support, and the user base increase. This situation has been known as the “software productivity gap” (Lawrence et al., 2018), and we argue that it cannot be alleviated by relying on general-purpose programming paradigms and monolithic code designs. Instead, it calls for a more synergistic collaboration between domain scientists (which here include model developers, weather forecasters, and weather and climate scientists) and computer experts. A path forward is provided by DSLs through separation of concerns (Fig. 1b) so that domain scientists can express the science using syntactic constructs that are aligned with the semantics of the application domain and hide any architecture-specific detail. The resulting source code is thus hardware-agnostic, more concise, easier to read, and easier to manipulate. A toolchain developed by software engineers then employs automatic code generation techniques to synthesize optimized parallel code for the target computer architecture in a transparent fashion.
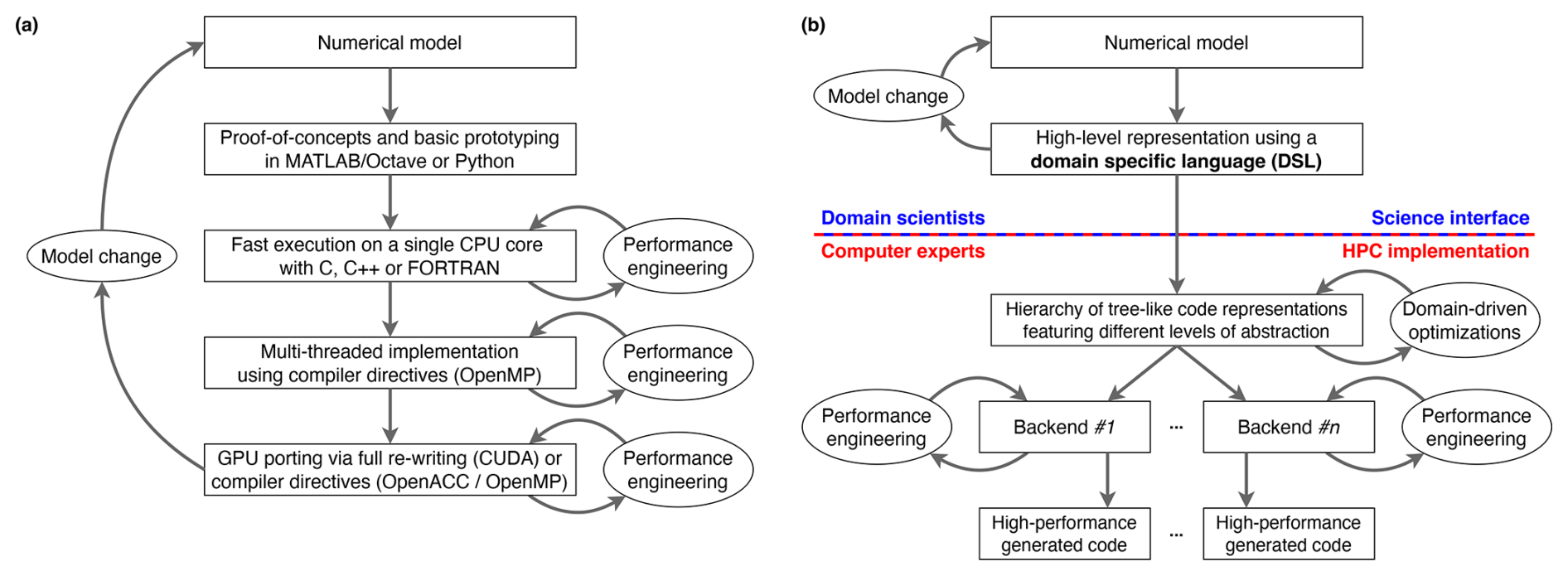
Figure 1Diagrams comparing (a) a well-established workflow in scientific software development and (b) a DSL-based approach resembling the software engineering strategy advocated in this paper. The dashed red-and-blue line in (b) marks the separation-of-concerns between the domain scientists and the computer experts.
3.1 The GT4Py framework
GT4Py (https://github.com/GridTools/gt4py, last access: 23 September 2024) is a Python library to generate high-performance implementations of stencil3 kernels as found in weather and climate applications. The library is developed and maintained by CSCS, ETH Zurich, and MeteoSwiss and benefits from important contributions by international partners such as the Paul Allen Institute for Artificial Intelligence (AI2). The choice of embedding the GT4Py framework in Python has been mainly dictated by the following factors:
- i.
Python is taught in many academic courses due its clean, intuitive, and expressive syntax; therefore a significant fraction of early-career domain scientists are exposed to the language.
- ii.
It admits a powerful ecosystem of open-source packages for building end-to-end applications.
- iii.
It is possible to seamlessly interface Python with lower-level languages with minimal overhead and virtually no memory copies.
- iv.
Under the thrust of the artificial intelligence and machine learning community (AI/ML), the popularity and adoption of Python across the whole scientific community is constantly growing, as opposed to Fortran (Shipman and Randles, 2023).
The proposed Python implementations of CLOUDSC and CLOUDSC2 are based on the first public release of GT4Py, which only supports Cartesian grids. The latest advancements to support unstructured meshes (contained in the sub-package gt4py.next) are not discussed in this study.
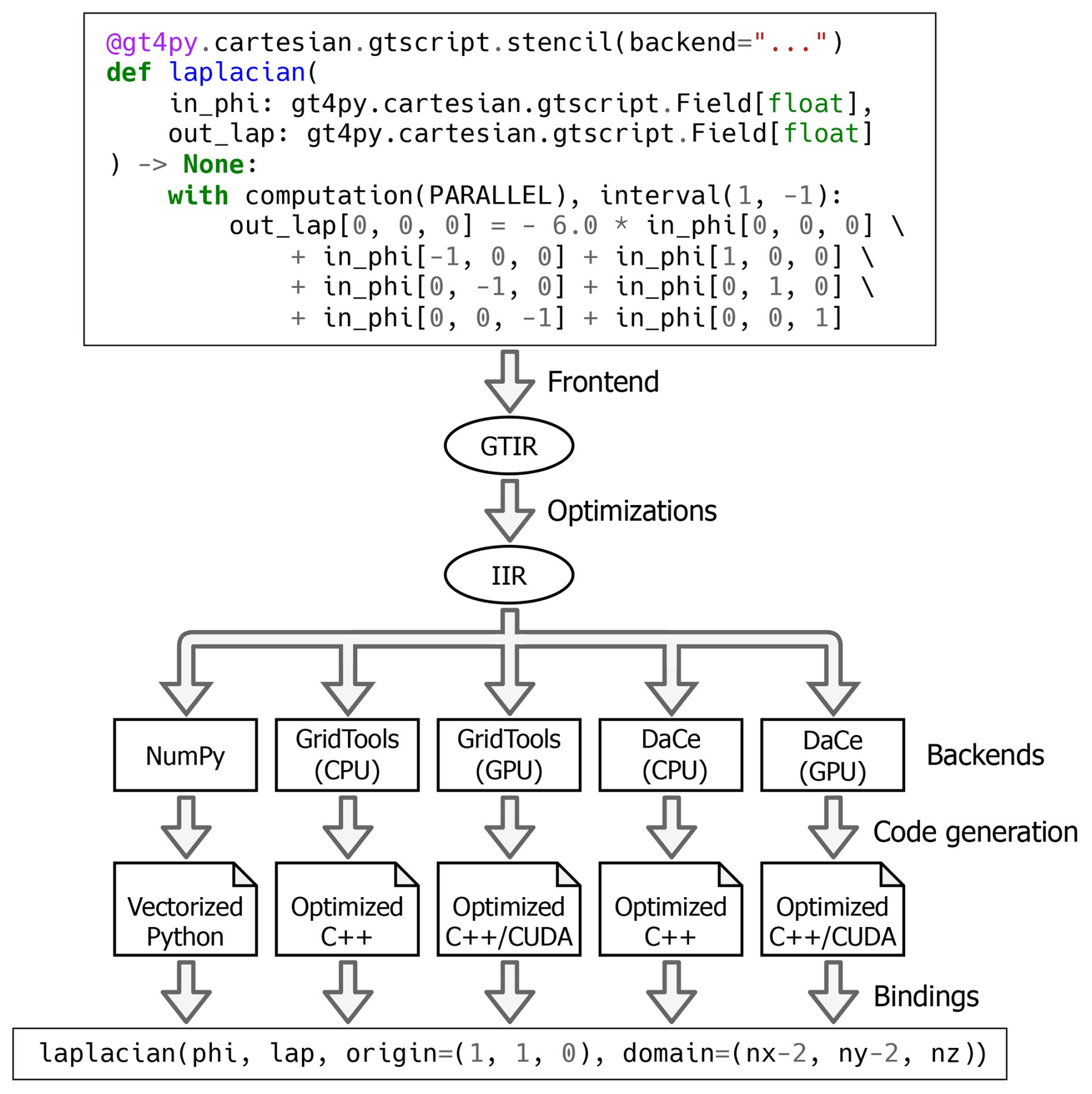
Figure 2Simplified view of the internal stages carried out by the GT4Py toolchain to generate a high-performance CPU or GPU implementation of the three-dimensional Laplacian stencil starting from its GTScript definition. For the sake of visualization, only two intermediate representations (IRs) are included: the GridTools IR (GTIR) and the implementation IR (IIR).
Figure 2 showcases the main steps undertaken by the GT4Py toolchain to translate the high-level definition of the three-dimensional Laplacian operator into optimized code, which can be directly called from within Python. The stencil definition is given as a regular Python function using the GTScript DSL. GTScript abstracts spatial for-loops away: computations are described for a single point of a three-dimensional Cartesian grid and can be controlled with respect to the vertical index bounds using the interval context manager. Vertical loops are replaced by computation contexts, which define the iteration order along the vertical axis: either PARALLEL (meaning no vertical data dependencies between horizontal planes), FORWARD, or BACKWARD. Each assignment statement within a computation block can be thought of as a loop over a horizontal plane; no horizontal data dependencies are allowed. Neighboring points are accessed through relative offsets, with the first two offsets being the horizontal offsets and the last offset being the vertical offset.
Any function marked with the gt4py.cartesian.gtscript.stencil decorator is translated by the GT4Py frontend into a hierarchy of tree-like intermediate representations (IRs), featuring different levels of abstractions to accommodate diverse optimizations and transformations (Gysi et al., 2021). The lowest-level IR (denoted as implementation IR, or IIR) is consumed by the backends to generate code that is either optimized for a given architecture or suited to a specific purpose. The following backends are currently available:
-
NumPy (Harris et al., 2020) is the de facto standard for array computing in Python and can be used for debugging and fast-prototyping.
-
GridTools (Afanasyev et al., 2021) is a set of libraries and utilities to write performance-portable applications in the area of weather and climate.
-
DaCe (Ben-Nun et al., 2019) is a parallel programming framework, which internally uses the Stateful DataFlow multiGraph (SDFG) data-centric intermediate representation to decouple domain science and performance engineering.
The generated code is compiled under the hood, and Python bindings for the resulting executable are automatically produced; therefore the stencil can finally be executed by passing the input and output fields and by specifying the origin and size of the computation domain. GT4Py provides convenient utilities to allocate arrays with an optimal memory layout for any given backend, relying on NumPy for CPU storages and CuPy (Okuta et al., 2017) for GPU storages. Concerning GPU computing, we highlight that GT4Py supports both NVIDIA and AMD GPUs.
A more realistic and pertinent code sample is provided in Listing 1. It is an abridged GT4Py implementation of the procedure computing the saturation water vapor pressure as a function of air pressure and temperature. The code is extracted from the CLOUDSC2-GT4Py dwarf and highlights two additional features of GTScript: functions and external symbols. Functions can be thought of as macros and can be used to improve composability, reusability, and readability. External symbols are used to encode those scalar parameters (e.g., physical constants) that are kept constant throughout a simulation and might only change between different model setups. External values must be provided at stencil compilation time. The functionalities provided by the package ifs_physics_common will be discussed in the following section.
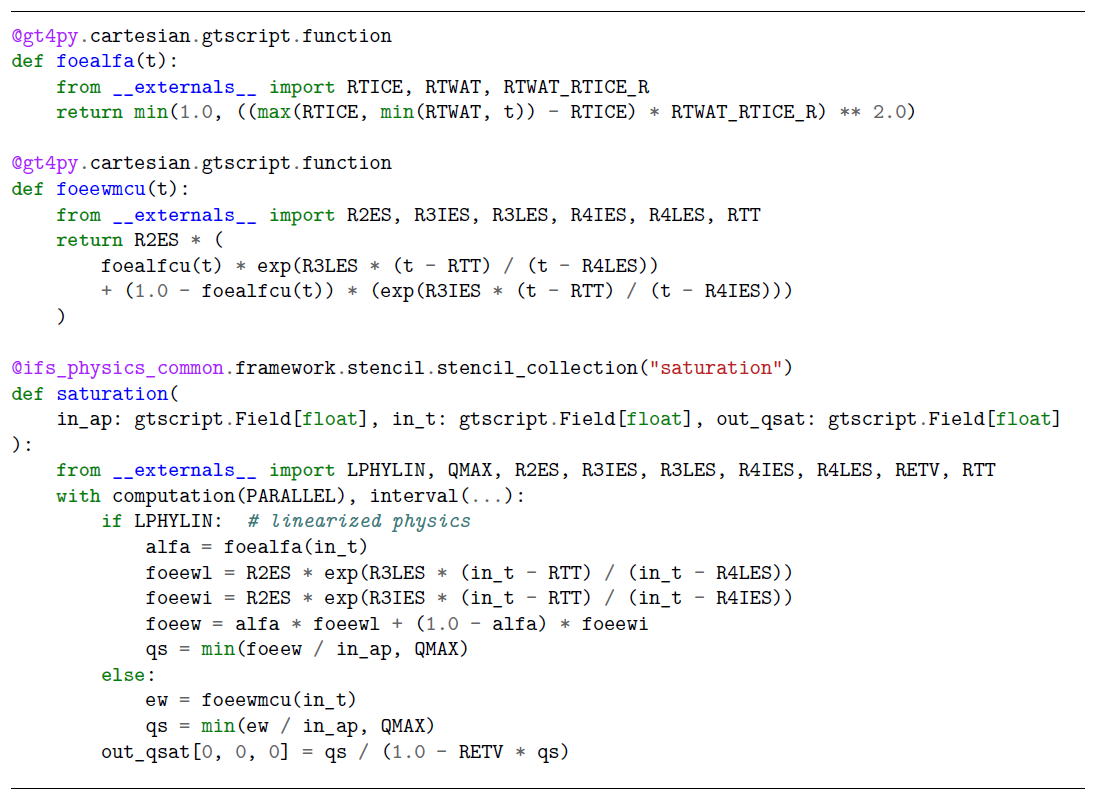
Listing 1GTScript (the Python-embedded DSL exposed by GT4Py) functions and stencil computing the saturation water vapor pressure given the air pressure and temperature. Abridged excerpt from the CLOUDSC2-GT4Py dwarf.
All stencils of CLOUDSC-GT4Py and CLOUDSC2-GT4Py are defined, compiled, and invoked within classes that leverage the functionalities provided by the Sympl package (Monteiro et al., 2018). Sympl is a toolset of Python utilities to write self-contained and self-documented model components. Because the components share a common application public interface (API), they favor modularity, composability, and inter-operability (Schär et al., 2019). These aspects are of utter importance, for instance, when it comes to assessing the impact of process coupling on weather forecasts and climate projections (Ubbiali et al., 2021).
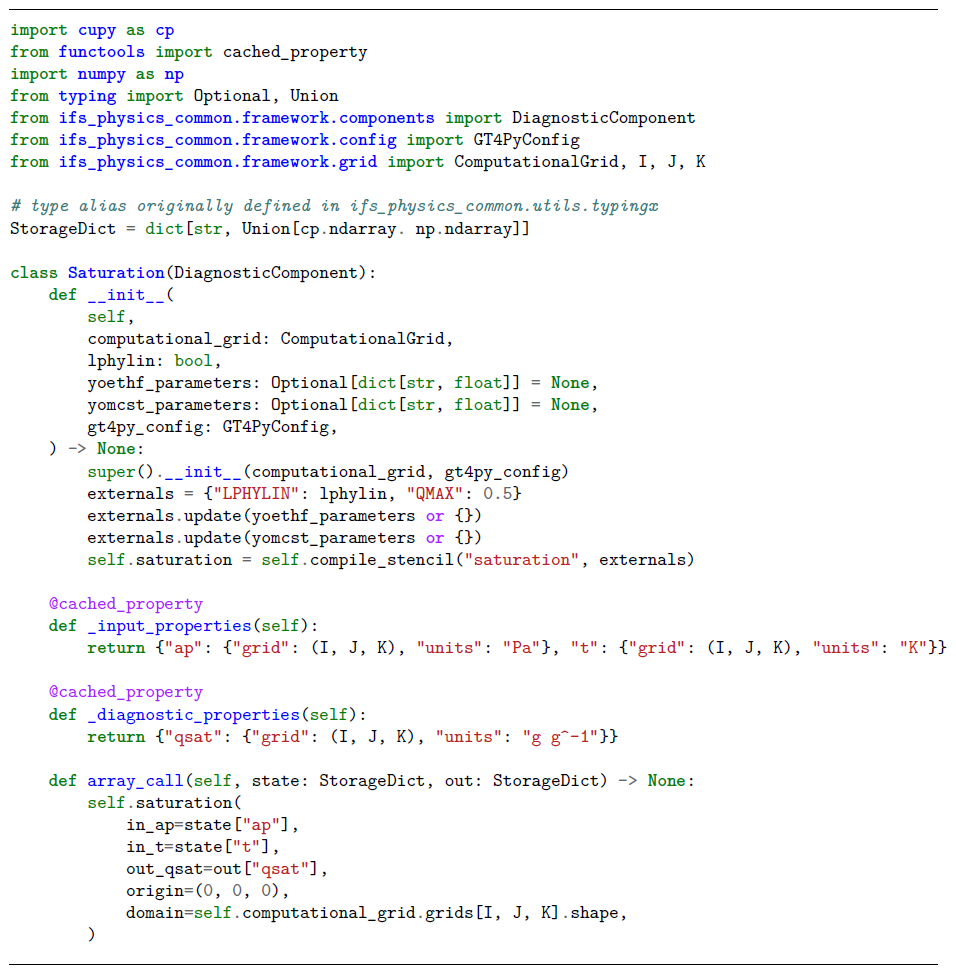
Listing 2A Python class to compute the saturation water vapor pressure given the air pressure and temperature. Abridged excerpt from the CLOUDSC2-GT4Py dwarf.
Sympl components interact through dictionaries whose keys are the names of the model variables (fields) and whose values are xarray's DataArrays (Hoyer and Hamman, 2017), collecting the grid point values, the labeled dimensions, the axis coordinates, and the units for those variables. The most relevant component exposed by Sympl is TendencyComponent, producing tendencies for prognostic variables and retrieving diagnostics. The class defines a minimal interface to declare the list of input and output fields and initialize and run an instance of the class. This imposes minor constraints on model developers when writing a new physics package.
The bespoke infrastructure code for CLOUDSC-GT4Py and CLOUDSC2-GT4Py is bundled as an installable Python package called ifs_physics_common. Not only does it build upon Sympl, but the package also provides grid-aware and stencil-oriented functionalities. Both the CLOUDSC cloud microphysics and the non-linear, tangent-linear, and adjoint formulations of CLOUDSC2 are encoded as stand-alone TendencyComponent classes settled over a ComputationalGrid. The latter is a collection of index spaces for different grid locations. For instance, (I, J, K) corresponds to cell centers, while (I, J, K-1/2) denotes vertically staggered grid points. For any input and output field, its name, units, and grid location are specified as class properties. When running the component via the dunder method __call__, Sympl transparently extracts the raw data from the input DataArrays according to the information provided in the class definition. This step may involve unit conversion and axis transposition. The resulting storages are forwarded to the method array_call, which carries out the actual computations, possibly by executing GT4Py stencil kernels.
Listing 2 brings a concrete example from CLOUDSC2-GT4Py: a model component leveraging the stencil defined in Listing 1 to compute the saturation water vapor pressure. The class inherits DiagnosticComponent, a stripped-down version of TendencyComponent, which only retrieves diagnostic quantities. Within the instance initializer __init__, the stencil from Listing 1, registered using the decorator ifs_physics_common.framework.stencil.stencil_collection, is compiled using the utility method compile_stencil. The options configuring the stencil compilation (e.g. the GT4Py backend) are fetched from the data class GT4PyConfig.
In this section, we highlight the results from comprehensive performance testing. We compare the developed CLOUDSC-GT4Py and CLOUDSC2-GT4Py codes against reference Fortran versions and various other programming prototypes. The simulations were performed on three different supercomputers:
- i.
Piz Daint (https://www.cscs.ch/computers/piz-daint, last access: 23 September 2024), an HPE Cray XC40/XC50 system installed at CSCS in Lugano, Switzerland;
- ii.
MeluXina (https://docs.lxp.lu/, last access: 23 September 2024), an ATOS BullSequana XH2000 machine hosted by LuxConnect in Bissen, Luxembourg, and procured by the EuroHPC Joint Undertaking (JU) initiative;
- iii.
the Cray HPE EX235a supercomputer LUMI (https://docs.lumi-supercomputer.eu/, last access: 23 September 2024), an EuroHPC pre-exascale machine at the Science Information Technology Center (CSC) in Kajaani, Finland.
On each machine, the CLOUDSC and CLOUDSC2 applications are executed on a single hybrid node that sports one or multiple GPU accelerators alongside the host CPU. An overview of the node architectures for the three considered supercomputers can be found in Table 1.
Table 1Overview of the node architecture for the hybrid partition of Piz Daint, MeluXina, and LUMI. Only the technical specifications which are most relevant for the purposes of this paper are reported.

Besides the GT4Py codes, we involve up to four alternative lower-level programming implementations, which will be documented in an upcoming publication:
- a.
The baseline is Fortran enriched with OpenMP directives for multi-threading execution on CPU.
- b.
An optimized GPU-enabled version based on OpenACC using the single-column coalesced (SCC) loop layout in combination with loop fusion and temporary local array demotion (so-called “k-caching”) is considered. While the SCC loop layout yields more efficient access to device memory and increased parallelism, the k-caching technique significantly reduces register pressure and memory traffic. This is achieved via loop fusion to eliminate most loop-carried dependencies and consequently allows temporaries to be demoted to scalars.
- c.
The currently best-performing Loki-generated and GPU-enabled variant is also taken into account.
- d.
Finally, an optimized GPU-enabled version of CLOUDSC including k-caching is used. The code is written in either CUDA or HIP, to target both NVIDIA GPUs (shipped with Piz Daint and MeluXina) and AMD GPUs (available on LUMI).
Table 2For each coding version of the CLOUDSC and CLOUDSC2 dwarfs considered in the performance analysis, the table reports the compiler suite used to compile the codes on Piz Daint, MeluXina, and LUMI. The codes are compiled with all major optimization options enabled. Those implementations which are either not available or not working are marked with a dash; more details, as well as a high-level description of each coding implementation, are provided in the text.

Table 2 documents the compiler specifications employed for each of the programming implementations, on Piz Daint, MeluXina, and LUMI. We consistently apply the most aggressive optimization, ensuring that the underlying code manipulations do not harm validation. For the different algorithms at consideration, validation is carried out as follows:
-
For CLOUDSC and CLOUDSC2NL, the results from each coding version are directly compared with serialized reference data produced on the CPU. For each output field, we perform an element-wise comparison using the NumPy function
allclose(https://numpy.org/devdocs/reference/generated/numpy.allclose.html, last access: 23 September 2024). Specifically, the GT4Py rewrites validate on both CPU and GPU, with an absolute and relative tolerance of 10−12 and 10−18 when employing double precision. When reducing the precision to 32 bits, the absolute and relative tolerance levels need to be increased to 10−4 and 10−7 on CPU and 10−2 and 10−7 on GPU. In the latter case, we observe that the field representing the enthalpy flux of ice still does not pass validation. We attribute the larger deviation from the baseline data on the device to the different instruction sets underneath CPUs and GPUs. -
All implementations of CLOUDSC2TL and CLOUDSC2AD are validated using the Taylor test (see Algorithm A1) and the symmetry test (see Algorithm A2), respectively. In this respect, we emphasize that the GT4Py implementations satisfy the conditions of both tests on all considered computing architectures, regardless of whether double or single precision is employed.
The source repositories for CLOUDSC and CLOUDSC2 dwarfs may include multiple variants of each reference implementation, varying for the optimization strategies. In our analysis, we always take into account the fastest variant of each alternative implementation; for the sake of reproducibility, Table 3 contains the strings identifying the coding versions at consideration and the corresponding NPROMA4 employed in the runs. Similarly, for all Python implementations we consider only the most performant backends of GT4Py: the GridTools C++ CPU backend with k-first memory layout, and the DaCe GPU backend.
Table 3For each reference implementation of the CLOUDSC and CLOUDSC2 dwarfs, the table reports the string identifying the specific variant considered in the performance analysis on Piz Daint, MeluXina, and LUMI. The corresponding NPROMA is provided within parentheses. Those implementations which are either not available or not working are marked with a dash.
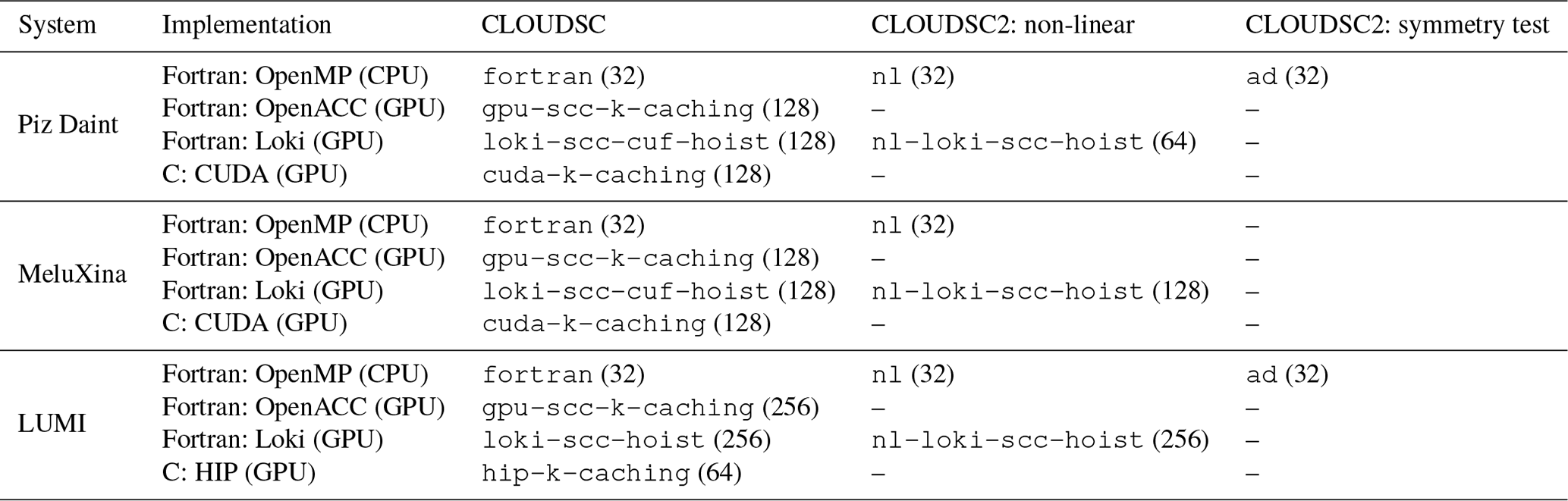
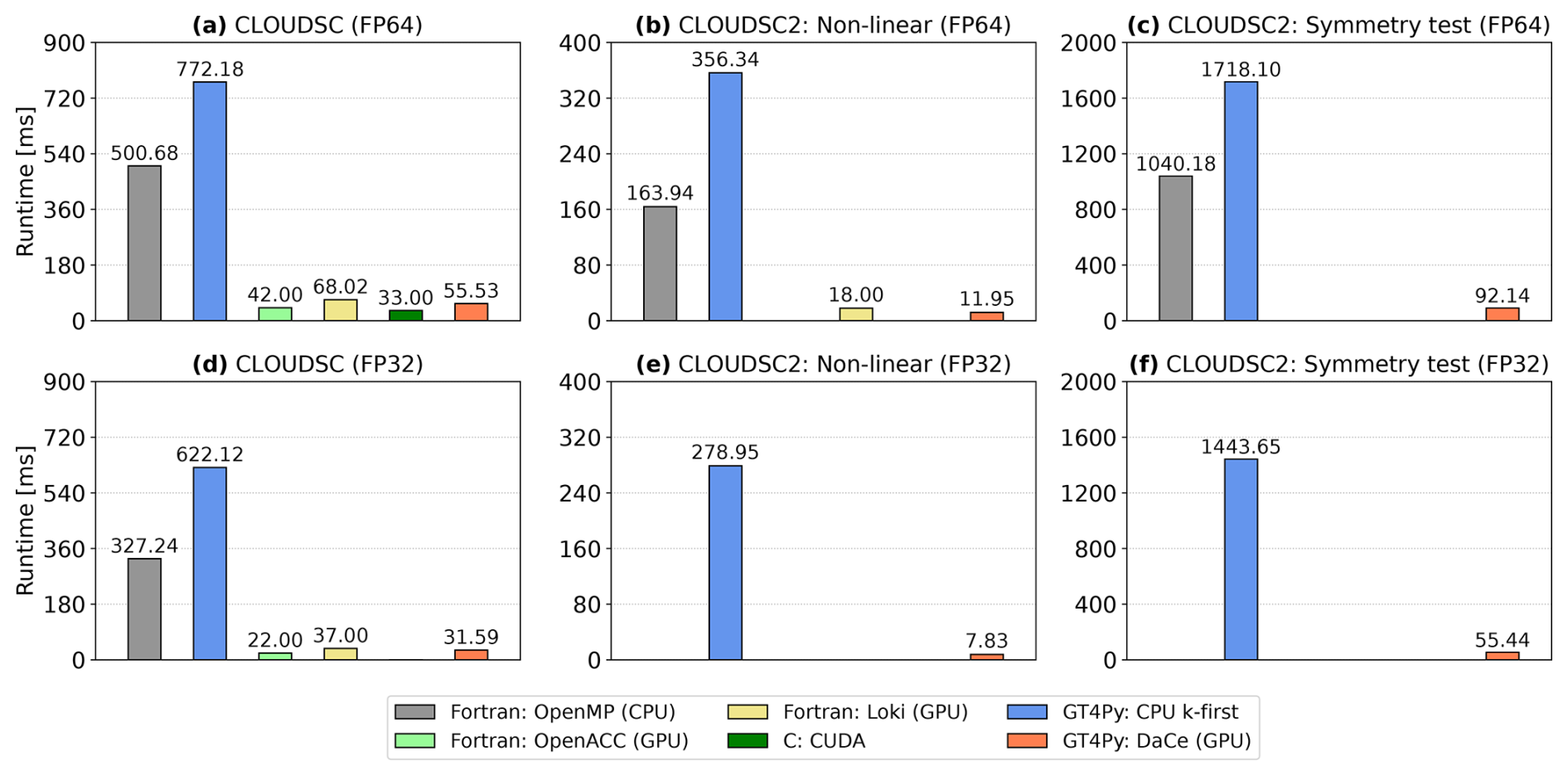
Figure 3Execution time on a single NUMA domain of a hybrid node of the Piz Daint supercomputer for CLOUDSC (a, d), CLOUDSC2NL (b, e), and the symmetry test for CLOUDSC2TL and CLOUDSC2AD (c, f) using either double-precision (a, b, c) or single-precision (d, e, f) floating point arithmetic. The computational domain consists of 65 536 columns and 137 vertical levels. Displayed are the multi-threaded Fortran baseline using OpenMP (grey); two GPU-accelerated Fortran implementations, using either OpenACC directives (lime) or the source-to-source translation tool Loki (yellow); an optimized CUDA C version (green); and the GT4Py rewrite, using either the GridTools C++ CPU backend with k-first data ordering (blue) or the DaCe GPU backend (orange). All numbers should be interpreted as an average over 50 realizations. The panels only show the code versions available and validating at the time of writing.
For the interpretation of the CPU-versus-GPU performance numbers, we note that host codes are executed on all the cores available on a single non-uniform memory access (NUMA) domain of a compute node, while device codes are launched on the GPU attached to that NUMA domain. In a distributed-memory context, this choice allows the same number of MPI ranks to be fit per node, on either CPU or GPU. Table 1 reports the number of NUMA partitions per node for Piz Daint, MeluXina, and LUMI, with the compute and memory resources being evenly distributed across the NUMA domains. Note that the compute nodes of the GPU partition of LUMI have the low-noise mode activated, which reserves one core per NUMA domain to the operating system; therefore only seven out of eight cores are available to the jobs. Moreover, we highlight that each MI250X GPU consists of two graphics compute dies (GCDs) connected via four AMD Infinity Fabric links but not sharing physical memory. From a software perspective, each compute node of LUMI is equipped with eight virtual GPUs (vGPUs), with each vGPU corresponding to a single GCD and assigned to a different NUMA domain.
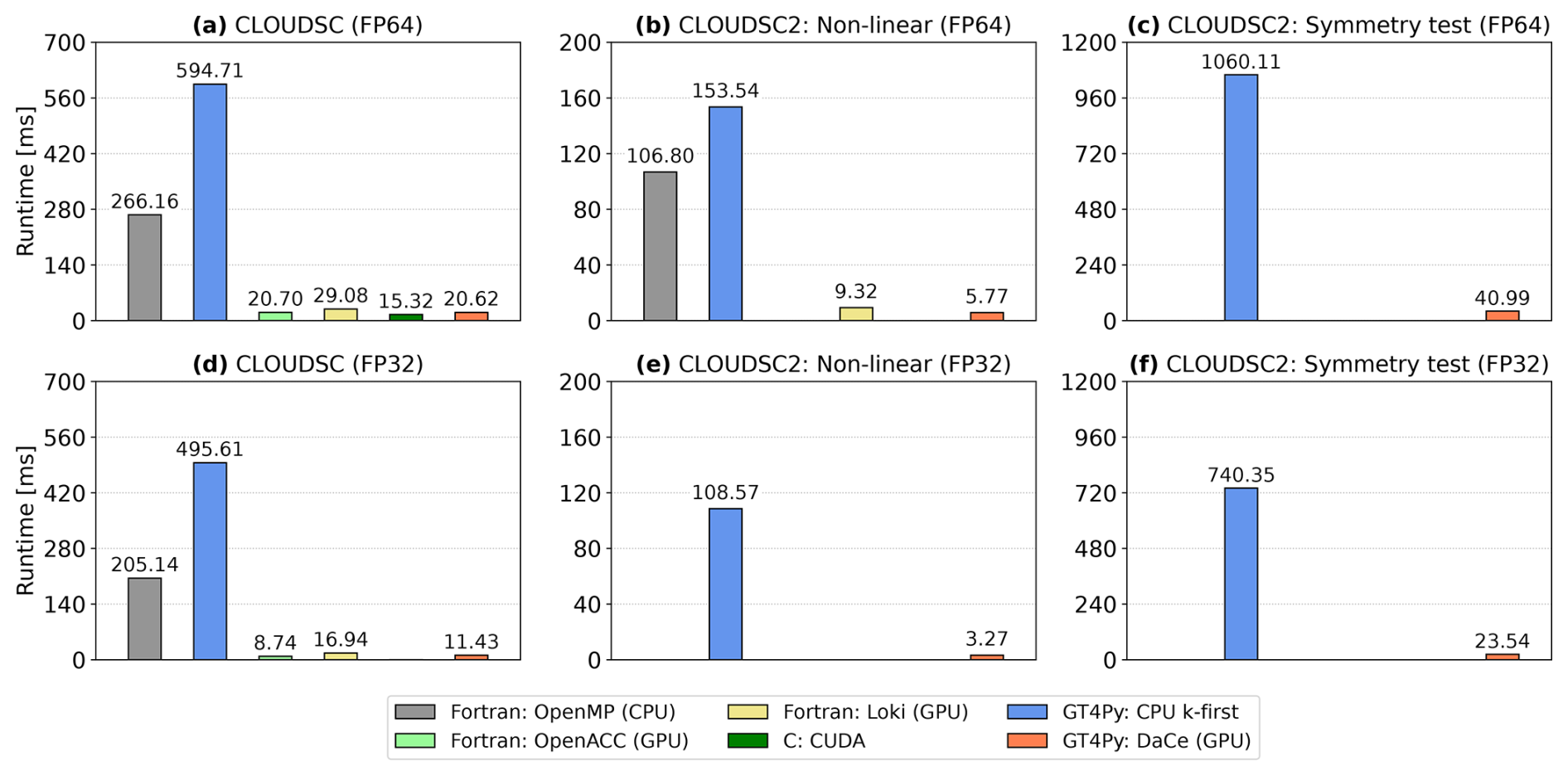
Figures 3–5 visualize the execution times for CLOUDSC (left column), CLOUDSC2NL (center column), and the symmetry test for CLOUDSC2TL and CLOUDSC2AD (right column) for Piz Daint, MeluXina, and LUMI, respectively.5 All performance numbers refer to a grid size of 65 536 columns, with each column featuring 137 vertical levels. In each figure, execution times are provided for simulations running either entirely in double precision (corresponding to the 64-bit IEEE format and denoted as FP64; top row) or in single precision (corresponding to the 32-bit IEEE format and denoted as FP32; bottom row). Within each panel, the plotted bars reflect the execution time of the various codes, with a missing bar indicating the corresponding code (non-GT4Py) is either not available or not working properly, specifically as follows:
-
The Fortran version of CLOUDSC2AD can only run on a single OpenMP thread on MeluXina (the issue is still under investigation).
-
A native GPU-enabled version of CLOUDSC using 32-bit floating point arithmetic does not exist at the time of writing, and no CUDA/HIP implementations are available for CLOUDSC2.
-
All Fortran-based implementations of the three formulations of CLOUDSC2 can only use double-precision computations.
-
A Loki version of CLOUDSC2TL and CLOUDSC2AD is not available at the time of writing.
Notably, we find the GT4Py rewrite of both CLOUDSC and CLOUDSC2 to be very robust, as the codes execute on every CPU and GPU architecture included in the study and can always employ either double- or single-precision floating point arithmetic. With GT4Py, changing the backend with the respective target architecture, or changing the precision of computations, is as easy as setting a namelist parameter. Moreover, at the time of writing, the GT4Py implementations of the more complex tangent-linear and adjoint formulations of CLOUDSC2 were the first codes enabling GPU execution, again both in double or single precision.
The performance of the high-level Python with GT4Py compares well against Fortran with OpenACC. The runtimes for GT4Py with its DaCe backend versus OpenACC are similar on Piz Daint, MeluXina, and LUMI. One outlier is the double-precision result on LUMI, for which the OpenACC code appears relatively slow. We suppose this behavior is associated with the insufficient OpenACC support for the HPE Cray compiler. Only the HPE Cray compiler implements GPU offloading capabilities for OpenACC directives on AMD GPUs, meaning that Fortran OpenACC codes require an HPE Cray platform to run on AMD GPUs. In contrast, GT4Py relies on the HIPCC compiler driver developed by AMD to compile device code for AMD accelerators, and this guarantees a proper functioning irrespective of the machine vendor. We further note that the DaCe backend of GT4Py executes roughly 2 times faster on MeluXina's NVIDIA A100 GPUs than on LUMI's AMD Instinct MI250X GPUs. As mentioned above, from a software perspective, each physical GPU module on LUMI is considered two virtual GPUs; therefore the code is actually executed on half of a physical GPU card. Hence we can speculate that using both dies of an AMD Instinct MI250X GPU, performance would be on a par with the NVIDIA A100 GPU.
Another interesting result is that both CLOUDSC-GT4Py and CLOUDSC2-GT4Py are consistently faster than the implementations generated with Loki. Loki allows bespoke transformation recipes to be built to apply changes to programming models and coding styles in an automated fashion. Therefore, GPU-enabled code can be produced starting from the original Fortran by, e.g., automatically adding OpenACC directives. However, because not all optimizations are encoded yet in the transformations, the Loki-generated device code cannot achieve optimal performance. Notwithstanding, source-to-source translators such as Loki are of high relevance for enabling GPU execution with large legacy Fortran code bases.
As used in this paper, GT4Py cannot yet attain the performance achieved by manually optimized native implementations with either Fortran on CPU or CUDA/HIP on GPU. Multi-threaded Fortran can be up to 3 times faster than the GridTools CPU backend of GT4Py using the k-first (C-like) memory layout, while the DaCe GPU backend of GT4Py can be up to a factor of 2 slower than CUDA/HIP. On the one hand, so far the development of GT4Py has been focused on GPU execution (see, e.g., Dahm et al., 2023) because this will be the dominant hardware for time-critical applications in the years to come. On the other hand, we stress that the k-caching CUDA and HIP variants of CLOUDSC were semi-automatically generated by performance engineering experts, starting from an automatic Fortran-to-C transpilation of the SCC variants and manually applying additional optimizations that require knowledge about the specific compute patterns in the application. This process is not scalable to the full weather model and not a sustainable code adaptation method. In contrast, no significant performance engineering (by, e.g., loop fusing and reducing the number of temporary fields) has been applied yet with CLOUDSC-GT4Py and CLOUDSC2-GT4Py.
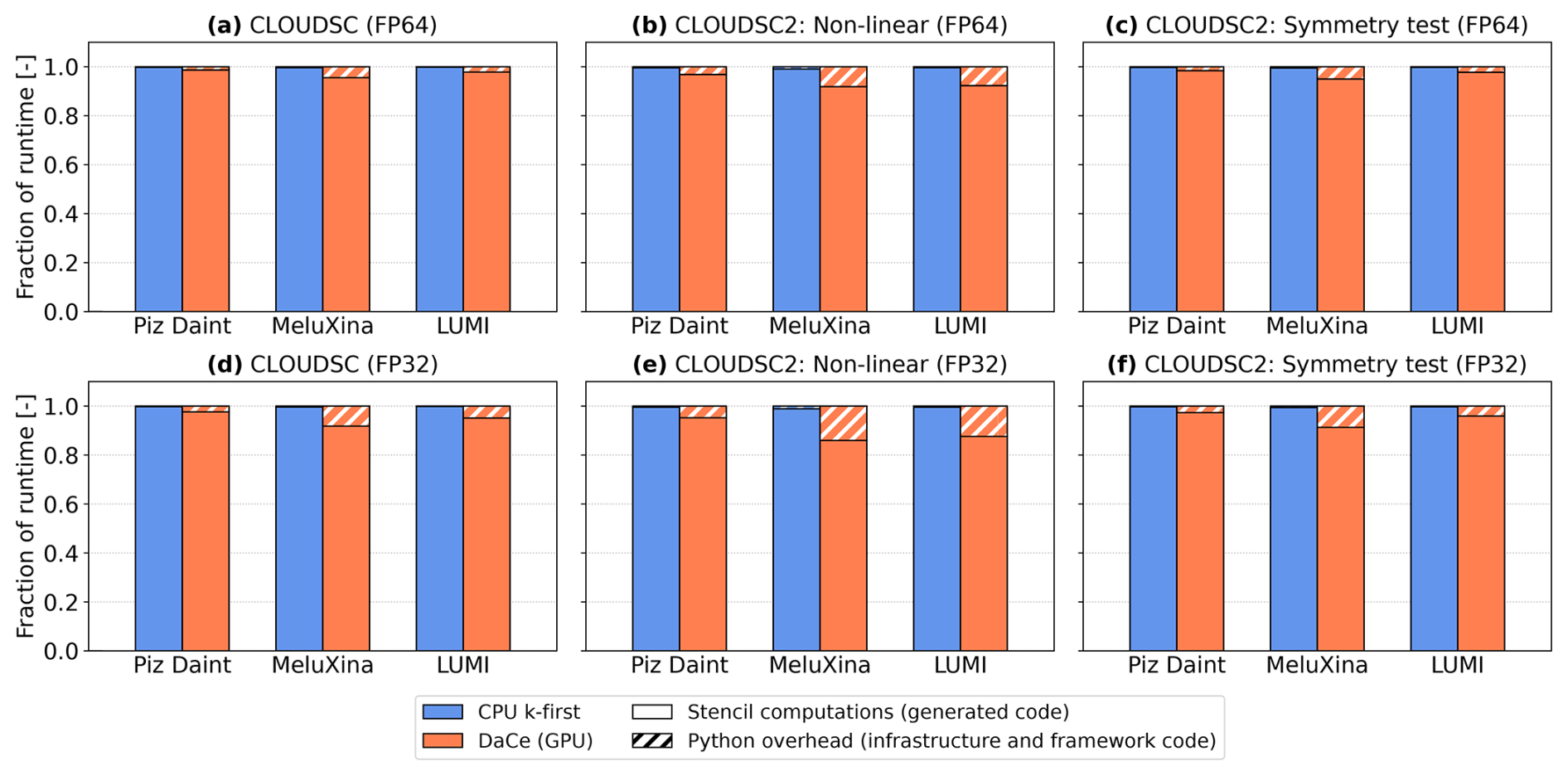
Figure 6For the GT4Py rewrites of CLOUDSC (a, d), CLOUDSC2NL (b, e), and the symmetry test for CLOUDSC2TL and CLOUDSC2AD (c, f), fraction of the total execution time spent within the stencil computations (full bars) and the Python side of the application (hatched bars) on Piz Daint, MeluXina, and LUMI. Results are shown for the GridTools C++ CPU backend with k-first data ordering (blue) and the DaCe GPU backend (orange), using either double-precision (a, b, c) or single-precision (d, e, f) floating point arithmetic.
To rule out the possibility that the performance gap between the Python DSL and lower-level codes is associated with overhead originating from Python, Fig. 6 displays the fraction of runtime spent within the stencil code generated by GT4Py and the high-level Python code of the application (infrastructure and framework code; see Sect. 4). Across the three supercomputers, the Python overhead decreases as (i) the complexity and length of computations increase, (ii) the peak throughput and bandwidth delivered by the hardware underneath decrease, and (iii) the floating point precision increases. On average, the Python overhead accounts for 5.4 % of the total runtime on GPU and 0.4 % on CPU; the latter corresponds to 0.7 % relative to the Fortran execution time.
Finally, we observe a significant sensitivity of the GPU performance with respect to the thread block size6: for values smaller than 128, performance is degraded across all implementations, with the gap between CUDA/HIP and GT4Py+DaCe being smaller. This shows that some tuning and toolchain optimizations can be performed to improve performance with the DSL approach.
The CLOUDSC and CLOUDSC2 cloud microphysics schemes of the IFS at ECMWF have served as demonstrators to show the benefits of a high-level domain-specific implementation approach to physical parametrizations. We presented two Python implementations based on the GT4Py framework, in which the scientific code is insulated from hardware-specific aspects. The resulting application provides a productive user interface with enhanced readability and maintainability and can run efficiently and in a very robust manner across a wide spectrum of compute architectures/systems. The approach can be powerful in the light of the increasingly complex HPC technology landscape, where general-purpose CPUs are increasingly complemented by domain-specific architectures (DSAs) such as GPUs, tensor processor units (TPUs), field-programmable gate arrays (FPGAs), and application-specific integrated circuits (ASICs). In addition to the CLOUDSC scheme used in the IFS forecast model, we have presented results with the GT4Py rewrites of the non-linear, tangent-linear, and adjoint formulations of CLOUDSC2 used in data assimilation. In both CLOUDSC-GT4Py and CLOUDSC2-GT4Py, the stencil kernels are encapsulated within model components sharing a minimal and clear interface. By avoiding any assumption on the host model, the interface aims to provide interoperable and plug-and-play physical packages, which can be transferred more easily between different modeling systems with virtually no performance penalty.
We carried out a comprehensive study to assess the portability of the Python codes across three major supercomputers, differing in terms of the vendor, the node architecture, the software stack, and the compiler suites. We showed that the GPU performance of GT4Py codes is competitive against optimized Fortran OpenACC implementations and performs particularly well when compared to the available codes generated with the Loki source-to-source translation tool. Low-level implementations written in either Fortran for CPUs or CUDA/HIP for GPUs, with additional optimizations that possibly require knowledge about the specific compute patterns, can provide better performance but are extremely challenging to create and maintain for entire models. The CPU performance of GT4Py is currently suboptimal, but this is an expected result given the focus on GPUs in the DSL development so far, and we clearly expect this to improve significantly with upcoming and future GT4Py versions. Indeed, since the DSL can accommodate any specific low-level optimization, attaining the same performance as native, expert-written Fortran and CUDA/HIP models is feasible and will be the target of our future efforts.
The presented results, based on a representative physical parametrization and considering tangent-linear and adjoint versions, add to the notion that weather and climate model codes can execute significantly faster on GPUs (Fuhrer et al., 2018), and the number of HPC systems with accelerators is steadily increasing7. Therefore, we envision that CPUs will be increasingly relegated to tasks that are not time-critical.
The current study supports our ongoing efforts and plans to port other physical parametrizations to Python with GT4Py. However, we note that GT4Py was originally devised to express the computational motifs of dynamical cores based on grid point methods, so not all patterns found in the parametrizations are natively supported by the DSL. In this respect, current limitations of the DSL exist for higher-dimensional fields (e.g., arrays storing a tensor at each grid point), but again we expect these to be fully supported for HPC with future extensions of GT4Py. In addition, Python offers a variety of alternative libraries that can be employed in conjunction with GT4Py to generate fast machine code.
In Sect. 2.2, we briefly described the aim and functioning of the Taylor test and the symmetry test for CLOUDSC2. Here, we detail the logical steps performed by the two tests with the help of pseudo-codes encapsulated in Algorithms A1 and A2.
Algorithm A1The Taylor test assessing the formal correctness of the coding implementation of the tangent-linear formulation of CLOUDSC2, denoted as CLOUDSC2TL. The three-dimensional arrays x and y collect the grid point values for all nin input fields and nout output fields of CLOUDSC2, respectively. The corresponding variations are δx and δy. The grid consists of ncol columns, each containing nlev vertical levels. Note that compared to its functional counterpart , CLOUDSC2TL(x, δx) returns both y and δy. The coding implementation of the non-linear CLOUDSC2 is indicated as CLOUDSC2NL.

Algorithm A2The symmetry test assessing the formal correctness of the coding implementation of the adjoint formulation of CLOUDSC2, denoted as CLOUDSC2AD. The machine epsilon is indicated as ε; all other symbols have the same meaning as in Algorithm A1. Note that compared to its functional counterpart , CLOUDSC2AD(x, δy) returns both y and δx*.

The source codes for ifs-physics-common (https://github.com/stubbiali/ifs-physics-common, last access: 23 September 2024, https://doi.org/10.5281/zenodo.11153742, Ubbiali et al., 2024b), CLOUDSC-GT4Py (https://github.com/stubbiali/gt4py-dwarf-p-cloudsc, last access: 23 September 2024, https://doi.org/10.5281/zenodo.11155002, Ubbiali et al., 2024c), and CLOUDSC2-GT4Py (https://github.com/stubbiali/gt4py-dwarf-p-cloudsc2-tl-ad, last access: 23 September 2024, https://doi.org/10.5281/zenodo.13239373, Ubbiali et al., 2024d), as well as the data and scripts to produce all the figures of the paper (https://github.com/stubbiali/cloudsc-paper, last access: 23 September 2024, https://doi.org/10.5281/zenodo.11155354, Ubbiali et al., 2024a), are available on GitHub and archived on Zenodo.
SU ported the CLOUDSC and CLOUDSC2 dwarfs to Python using GT4Py and ran all the numerical experiments presented in the paper, under the supervision of CK and HW. SU further contributed to the development of the infrastructure code illustrated in Sect. 4, under the supervision of CS, LS, and TCS. MS made relevant contributions to the Fortran and C reference implementations of the ECMWF microphysics schemes. SU and CK wrote the paper, with feedback from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
We would like to thank three anonymous referees for carefully reviewing the manuscript and providing many constructive comments. We acknowledge EuroHPC JU for awarding the project ID 200177 access to the MeluXina supercomputer at LuxConnect and the project ID 465000527 access to the LUMI system at CSC and thank Thomas Geenen and Nils Wedi from Destination Earth for their help. We are grateful to Michael Lange and Balthasar Reuter for discussions and support regarding IFS codes.
This study was conducted as part of the Platform for Advanced Scientific Computing (PASC)-funded project KILOS (“Kilometer-scale non-hydrostatic global weather forecasting with IFS-FVM”), which also provided us with computing resources on the Piz Daint supercomputer at CSCS. Christian Kühnlein was supported by the ESiWACE3 project funded by the European High Performance Computing Joint Undertaking (EuroHPC JU) and the European Union (EU) under grant agreement no. 101093054.
This paper was edited by Peter Caldwell and reviewed by three anonymous referees.
Adams, S. V., Ford, R. W., Hambley, M., Hobson, J., Kavčič, I., Maynard, C. M., Melvin, T., Müller, E. H., Mullerworth, S., Porter, A. R., Rezny, M., Shipway, B. J., and Wong, R.: LFRic: Meeting the challenges of scalability and performance portability in Weather and Climate models, J. Parallel Distr. Com., 132, 383–396, https://doi.org/10.1016/j.jpdc.2019.02.007, 2019. a
Afanasyev, A., Bianco, M., Mosimann, L., Osuna, C., Thaler, F., Vogt, H., Fuhrer, O., VandeVondele, J., and Schulthess, T. C.: GridTools: A framework for portable weather and climate applications, SoftwareX, 15, 100707, https://doi.org/10.1016/j.softx.2021.100707, 2021. a, b
Baldauf, M., Seifert, A., Förstner, J., Majewski, D., Raschendorfer, M., and Reinhardt, T.: Operational convective-scale numerical weather prediction with the COSMO model: Description and sensitivities, Mon. Weather Rev., 139, 3887–3905, https://doi.org/10.1175/mwr-d-10-05013.1, 2011. a
Bauer, P., Quintino, T., Wedi, N. P., Bonanni, A., Chrust, M., Deconinck, W., Diamantakis, M., Dueben, P. D., English, S., Flemming, J., Gillies, P., Hadade, I., Hawkes, J., Hawkins, M., Iffrig, O., Kühnlein, C., Lange, M., Lean, P., Maciel, P., Marsden, O., Müller, A., Saarinen, S., Sarmany, D., Sleigh, M., Smart, S., Smolarkiewicz, P. K., Thiemert, D., Tumolo, G., Weihrauch, C., and Zanna, C.: The ECMWF scalability programme: Progress and plans, ECMWF Technical Memo No. 857, https://doi.org/10.21957/gdit22ulm, 2020. a, b
Bauer, P., Dueben, P. D., Hoefler, T., Quintino, T., Schulthess, T. C., and Wedi, N. P.: The digital revolution of Earth-system science, Nature Comput. Sci., 1, 104–113, https://doi.org/10.1038/s43588-021-00023-0, 2021. a
Ben-Nun, T., de Fine Licht, J., Ziogas, A. N., Schneider, T., and Hoefler, T.: Stateful Dataflow Multigraphs: A Data-Centric Model for Performance Portability on Heterogeneous Architectures, in: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC '19, https://doi.org/10.1145/3295500.3356173, 2019. a
Ben-Nun, T., Groner, L., Deconinck, F., Wicky, T., Davis, E., Dahm, J., Elbert, O. D., George, R., McGibbon, J., Trümper, L., Wu, E., Führer, O., Schulthess, T. C., and Hoefler, T.: Productive performance engineering for weather and climate modeling with Python, in: SC22: International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE, 1–14, https://doi.org/10.1109/sc41404.2022.00078, 2022. a
Bertagna, L., Guba, O., Taylor, M. A., Foucar, J. G., Larkin, J., Bradley, A. M., Rajamanickam, S., and Salinger, A. G.: A performance-portable nonhydrostatic atmospheric dycore for the Energy Exascale Earth System Model running at cloud-resolving resolutions, in: SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE, 1–14, https://doi.org/10.2172/1830973, 2020. a
Chandrasekaran, S. and Juckeland, G.: OpenACC for Programmers: Concepts and Strategies, Addison-Wesley Professional, ISBN-10 0-13-469428-7, ISBN-13 978-0-13-469428-3, 2017. a
Clement, V., Marti, P., Lapillonne, X., Fuhrer, O., and Sawyer, W.: Automatic Port to OpenACC/OpenMP for Physical Parameterization in Climate and Weather Code Using the CLAW Compiler, Supercomputing Frontiers and Innovations, 6, 51–63, https://doi.org/10.14529/jsfi190303, 2019. a
Courtier, P., Thépaut, J.-N., and Hollingsworth, A.: A strategy for operational implementation of 4D-Var, using an incremental approach, Q. J. Roy. Meteor. Soc., 120, 1367–1387, https://doi.org/10.1256/smsqj.51911, 1994. a
Dagum, L. and Menon, R.: OpenMP: an industry standard API for shared-memory programming, IEEE Computional Science and Engineering, 5, 46–55, https://doi.org/10.1109/99.660313, 1998. a
Dahm, J., Davis, E., Deconinck, F., Elbert, O., George, R., McGibbon, J., Wicky, T., Wu, E., Kung, C., Ben-Nun, T., Harris, L., Groner, L., and Fuhrer, O.: Pace v0.2: a Python-based performance-portable atmospheric model, Geosci. Model Dev., 16, 2719–2736, https://doi.org/10.5194/gmd-16-2719-2023, 2023. a, b, c
Deakin, T., McIntosh-Smith, S., Price, J., Poenaru, A., Atkinson, P., Popa, C., and Salmon, J.: Performance portability across diverse computer architectures, in: 2019 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC), IEEE, 1–13, https://doi.org/10.1109/p3hpc49587.2019.00006, 2019. a
ECMWF: IFS Documentation CY48R1 – Part IV: Physical Processes, ECMWF, https://doi.org/10.21957/02054f0fbf, 2023. a, b
Edwards, H. C., Trott, C. R., and Sunderland, D.: Kokkos: Enabling manycore performance portability through polymorphic memory access patterns, J. Parallel Distr. Com., 74, 3202–3216, https://doi.org/10.1016/j.jpdc.2014.07.003, 2014. a
Errico, R. M.: What is an adjoint model?, B. Am. Meteorol. Soc., 78, 2577–2592, https://doi.org/10.1175/1520-0477(1997)078<2577:WIAAM>2.0.CO;2, 1997. a
Forbes, R. M., Tompkins, A. M., and Untch, A.: A new prognostic bulk microphysics scheme for the IFS, ECMWF Techical Memo. No. 649, https://doi.org/10.21957/bf6vjvxk, 2011. a
Fuhrer, O., Osuna, C., Lapillonne, X., Gysi, T., Cumming, B., Bianco, M., Arteaga, A., and Schulthess, T. C.: Towards a performance portable, architecture agnostic implementation strategy for weather and climate models, Supercomputing Frontiers and Innovations, 1, 45–62, https://doi.org/10.14529/jsfi140103, 2014. a, b
Fuhrer, O., Chadha, T., Hoefler, T., Kwasniewski, G., Lapillonne, X., Leutwyler, D., Lüthi, D., Osuna, C., Schär, C., Schulthess, T. C., and Vogt, H.: Near-global climate simulation at 1 km resolution: establishing a performance baseline on 4888 GPUs with COSMO 5.0, Geosci. Model Dev., 11, 1665–1681, https://doi.org/10.5194/gmd-11-1665-2018, 2018. a, b
Gysi, T., Müller, C., Zinenko, O., Herhut, S., Davis, E., Wicky, T., Fuhrer, O., Hoefler, T., and Grosser, T.: Domain-specific multi-level IR rewriting for GPU: The Open Earth compiler for GPU-accelerated climate simulation, ACM T. Archit. Code Op., 18, 1–23, https://doi.org/10.1145/3469030, 2021. a
Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M. H., Brett, M., Haldane, A., del Río, J. F., Wiebe, M., Peterson, P., Gérard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohlke, C., and Oliphant, T. E.: Array programming with NumPy, Nature, 585, 357–362, 2020. a
Harris, L. M. and Lin, S.-J.: A two-way nested global-regional dynamical core on the cubed-sphere grid, Mon. Weather Rev., 141, 283–306, https://doi.org/10.1175/mwr-d-11-00201.1, 2013. a
Hoyer, S. and Hamman, J.: xarray: ND labeled arrays and datasets in Python, J. Open Res. Softw., 5, 10, https://doi.org/10.5334/jors.148, 2017. a
Janisková, M. and Lopez, P.: Linearised physics: the heart of ECMWF’s 4D-Var, ECMWF Newsletter, 175, 20–26, 2023. a, b
Janisková, M., Thépaut, J.-N., and Geleyn, J.-F.: Simplified and regular physical parameterizations for incremental four-dimensional variational assimilation, Mon. Weather Rev., 127, 26–45, https://doi.org/10.1175/1520-0493(1999)127<0026:sarppf>2.0.co;2, 1999. a
Kim, J. Y., Kang, J.-S., and Joh, M.: GPU acceleration of MPAS microphysics WSM6 using OpenACC directives: Performance and verification, Comput. Geosci., 146, 104627, https://doi.org/10.1016/j.cageo.2020.104627, 2021. a
Kühnlein, C., Deconinck, W., Klein, R., Malardel, S., Piotrowski, Z. P., Smolarkiewicz, P. K., Szmelter, J., and Wedi, N. P.: FVM 1.0: a nonhydrostatic finite-volume dynamical core for the IFS, Geosci. Model Dev., 12, 651–676, https://doi.org/10.5194/gmd-12-651-2019, 2019. a
Kühnlein, C., Ehrengruber, T., Ubbiali, S., Krieger, N., Papritz, L., Calotoiu, A., and Wernli, H.: ECMWF collaborates with Swiss partners on GPU porting of FVM dynamical core, ECMWF Newsletter, 175, 11–12, 2023. a
Lapillonne, X., Osterried, K., and Fuhrer, O.: Using OpenACC to port large legacy climate and weather modeling code to GPUs, in: Parallel Programming with OpenACC, Elsevier, 267–290, https://doi.org/10.1016/b978-0-12-410397-9.00013-5, 2017. a
Lapillonne, X., Sawyer, W., Marti, P., Clement, V., Dietlicher, R., Kornblueh, L., Rast, S., Schnur, R., Esch, M., Giorgetta, M., Alexeev, D., and Pincus, R.: Global climate simulations at 2.8 km on GPU with the ICON model, EGU General Assembly 2020, Online, 4–8 May 2020, EGU2020-10306, https://doi.org/10.5194/egusphere-egu2020-10306, 2020 a
Lawrence, B. N., Rezny, M., Budich, R., Bauer, P., Behrens, J., Carter, M., Deconinck, W., Ford, R., Maynard, C., Mullerworth, S., Osuna, C., Porter, A., Serradell, K., Valcke, S., Wedi, N., and Wilson, S.: Crossing the chasm: how to develop weather and climate models for next generation computers?, Geosci. Model Dev., 11, 1799–1821, https://doi.org/10.5194/gmd-11-1799-2018, 2018. a, b
Lindfield, G. and Penny, J.: Numerical Methods: Using MATLAB, Academic Press, ISBN-10 0128122560, ISBN-13 978-0128122563, 2018. a
Luz, M., Gopal, A., Ong, C. R., Müller, C., Hupp, D., Burgdorfer, N., Farabullini, N., Bösch, F., Dipankar, A., Bianco, M., Sawyer, W., Kellerhals, S., Jucker, J., Ehrengruber, T., González Paredes, E., Vogt, H., Kardos, P., Häuselmann, R., and Lapillone, X.: A GT4Py-Based Multi-Node Standalone Python Implementation of the ICON Dynamical Core, Platform for Advanced Scientific Computing (PASC) Conference, Zurich, Switzerland, 3–5 June 2024. a
McGibbon, J., Brenowitz, N. D., Cheeseman, M., Clark, S. K., Dahm, J. P. S., Davis, E. C., Elbert, O. D., George, R. C., Harris, L. M., Henn, B., Kwa, A., Perkins, W. A., Watt-Meyer, O., Wicky, T. F., Bretherton, C. S., and Fuhrer, O.: fv3gfs-wrapper: a Python wrapper of the FV3GFS atmospheric model, Geosci. Model Dev., 14, 4401–4409, https://doi.org/10.5194/gmd-14-4401-2021, 2021. a
Melvin, T., Benacchio, T., Shipway, B., Wood, N., Thuburn, J., and Cotter, C.: A mixed finite-element, finite-volume, semi-implicit discretization for atmospheric dynamics: Cartesian geometry, Q. J. Roy. Meteor. Soc., 145, 2835–2853, 2019. a
Melvin, T., Shipway, B., Wood, N., Benacchio, T., Bendall, T., Boutle, I., Brown, A., Johnson, C., Kent, J., Pring, S., Smith, C., Zerroukat, M., Cotter, C., and Thuburn, J.: A mixed finite-element, finite-volume, semi-implicit discretisation for atmospheric dynamics: Spherical geometry, Q. J. Roy. Meteor. Soc., 150, 4252–4269, https://doi.org/10.1002/qj.4814, 2024. a
Méndez, M., Tinetti, F. G., and Overbey, J. L.: Climate models: challenges for Fortran development tools, in: 2014 Second International Workshop on Software Engineering for High Performance Computing in Computational Science and Engineering, IEEE, 6–12, https://doi.org/10.1109/se-hpccse.2014.7, 2014. a, b
Monteiro, J. M., McGibbon, J., and Caballero, R.: sympl (v. 0.4.0) and climt (v. 0.15.3) – towards a flexible framework for building model hierarchies in Python, Geosci. Model Dev., 11, 3781–3794, https://doi.org/10.5194/gmd-11-3781-2018, 2018. a, b
Müller, A., Deconinck, W., Kühnlein, C., Mengaldo, G., Lange, M., Wedi, N., Bauer, P., Smolarkiewicz, P. K., Diamantakis, M., Lock, S.-J., Hamrud, M., Saarinen, S., Mozdzynski, G., Thiemert, D., Glinton, M., Bénard, P., Voitus, F., Colavolpe, C., Marguinaud, P., Zheng, Y., Van Bever, J., Degrauwe, D., Smet, G., Termonia, P., Nielsen, K. P., Sass, B. H., Poulsen, J. W., Berg, P., Osuna, C., Fuhrer, O., Clement, V., Baldauf, M., Gillard, M., Szmelter, J., O'Brien, E., McKinstry, A., Robinson, O., Shukla, P., Lysaght, M., Kulczewski, M., Ciznicki, M., Piątek, W., Ciesielski, S., Błażewicz, M., Kurowski, K., Procyk, M., Spychala, P., Bosak, B., Piotrowski, Z. P., Wyszogrodzki, A., Raffin, E., Mazauric, C., Guibert, D., Douriez, L., Vigouroux, X., Gray, A., Messmer, P., Macfaden, A. J., and New, N.: The ESCAPE project: Energy-efficient Scalable Algorithms for Weather Prediction at Exascale, Geosci. Model Dev., 12, 4425–4441, https://doi.org/10.5194/gmd-12-4425-2019, 2019. a, b, c
Neumann, P., Dueben, P. D., Adamidis, P., Bauer, P., Brück, M., Kornblueh, L., Klocke, D., Stevens, B., Wedi, N. P., and Biercamp, J.: Assessing the scales in numerical weather and climate predictions: will exascale be the rescue?, Philos. T. Roy. Soc. A, 377, 20180148, https://doi.org/10.1098/rsta.2018.0148, 2019. a
Nogherotto, R., Tompkins, A. M., Giuliani, G., Coppola, E., and Giorgi, F.: Numerical framework and performance of the new multiple-phase cloud microphysics scheme in RegCM4.5: precipitation, cloud microphysics, and cloud radiative effects, Geosci. Model Dev., 9, 2533–2547, https://doi.org/10.5194/gmd-9-2533-2016, 2016. a
Okuta, R., Unno, Y., Nishino, D., Hido, S., and Loomis, C.: CuPy: A NumPy-Compatible Library for NVIDIA GPU Calculations, Proceedings of Workshop on Machine Learning Systems (LearningSys) in The Thirty-first Annual Conference on Neural Information Processing Systems (NIPS), http://learningsys.org/nips17/assets/papers/paper_16.pdf (last access: 25 September 2024), 2017. a
Randall, D. A., Hurrell, J. W., Gettelman, A., Loft, R., Skamarock, W. C., Hauser, T., Dazlich, D. A., and Sun, L.: Simulations With EarthWorks, in: AGU Fall Meeting Abstracts, vol. 2022, 2022AGUFM.A33E..02R, A33E–02, 2022. a
Schär, C., Fuhrer, O., Arteaga, A., Ban, N., Charpilloz, C., Di Girolamo, S., Hentgen, L., Hoefler, T., Lapillonne, X., Leutwyler, D., Osterried, K., Panosetti, D., Rüdisühli, S., Schlemmer, L., Schulthess, T. C., Sprenger, M., Ubbiali, S., and Wernli, H.: Kilometer-scale climate models: Prospects and challenges, B. Am. Meteorol. Soc., 101, E567–E587, https://doi.org/10.1175/bams-d-18-0167.1, 2019. a
Schulthess, T. C., Bauer, P., Wedi, N. P., Fuhrer, O., Hoefler, T., and Schär, C.: Reflecting on the goal and baseline for exascale computing: A roadmap based on weather and climate simulations, Comput. Sci. Eng., 21, 30–41, https://doi.org/10.1109/mcse.2018.2888788, 2018. a
Shipman, G. M. and Randles, T. C.: An evaluation of risks associated with relying on Fortran for mission critical codes for the next 15 years, https://doi.org/10.2172/1970284, 2023. a
Smolarkiewicz, P. K., Deconinck, W., Hamrud, M., Kühnlein, C., Mozdzynski, G., Szmelter, J., and Wedi, N. P.: A finite-volume module for simulating global all-scale atmospheric flows, J. Comput. Phys., 314, 287–304, https://doi.org/10.1016/j.jcp.2016.03.015, 2016. a
Taylor, M. A., Guba, O., Steyer, A., Ullrich, P. A., Hall, D. M., and Eldred, C.: An energy consistent discretization of the nonhydrostatic equations in primitive variables, J. Adv. Model. Earth Sy., 12, e2019MS001783, https://doi.org/10.1029/2019ms001783, 2020. a
Ubbiali, S., Schär, C., Schlemmer, L., and Schulthess, T. C.: A numerical analysis of six physics-dynamics coupling schemes for atmospheric models, J. Adv. Model. Earth Sy., 13, e2020MS002377, https://doi.org/10.1029/2020ms002377, 2021. a
Ubbiali, S., Kühnlein, C., Schär, C., Schlemmer, L., Schulthess, T. C., Staneker, M., and Wernli, H.: Data and scripts for the manuscript “Exploring a high-level programming model for the NWP domain using ECMWF microphysics schemes” (v0.1.0), Zenodo [code and data set], https://doi.org/10.5281/zenodo.11155354, 2024a. a
Ubbiali, S., Kühnlein, C., Schär, C., Schlemmer, L., Schulthess, T. C., and Wernli, H.: ifs-physics-common: v0.1.0, Zenodo [code], https://doi.org/10.5281/zenodo.11153742, 2024b. a, b
Ubbiali, S., Kühnlein, C., and Wernli, H.: gt4py-dwarf-p-cloudsc: v0.1.0, Zenodo [code], https://doi.org/10.5281/zenodo.11155002, 2024c. a, b
Ubbiali, S., Kühnlein, C., and Wernli, H.: gt4py-dwarf-p-cloudsc2-tl-ad: v0.3.0, Zenodo [code], https://doi.org/10.5281/zenodo.13239373, 2024d. a, b
Watkins, J., Carlson, M., Shan, K., Tezaur, I., Perego, M., Bertagna, L., Kao, C., Hoffman, M. J., and Price, S. F.: Performance portable ice-sheet modeling with MALI, Int. J. High Perform. C., 37, 600–625, https://doi.org/10.1177/10943420231183688, 2023. a
Yang, Z., Halem, M., Loft, R., and Suresh, S.: Accelerating MPAS-A model radiation schemes on GPUs using OpenACC, in: AGU Fall Meeting Abstracts, vol. 2019, 2019AGUFM.A11A..06Y, A11A–06, 2019. a
Zängl, G., Reinert, D., Rípodas, P., and Baldauf, M.: The ICON (ICOsahedral Non-hydrostatic) modelling framework of DWD and MPI-M: Description of the non-hydrostatic dynamical core, Q. J. Roy. Meteor. Soc., 141, 563–579, https://doi.org/10.1002/qj.2378, 2015. a
As we mention in Sect. 2, the versions of CLOUDSC and CLOUDSC2 considered in this study correspond to older release cycles of the IFS than the one currently used in production.
Compared to the original implementations run operationally at ECMWF, the CLOUDSC and CLOUDSC2 dwarf codes do not include (i) all the IFS-specific infrastructure code, (ii) the calculation of budget diagnostics, and (iii) dead code paths.
A stencil is an operator that computes array elements by accessing a fixed pattern of neighboring items.
NPROMA blocking is a cache optimization technique adopted in all Fortran codes considered in this paper. Given a two-dimensional array shaped , this is re-arranged as a three-dimensional array shaped . Commonly, the leading dimension of the three-dimensional array is called “NPROMA”, with K being the “NPROMA blocking factor”. Here, we indicate K simply as “NPROMA” for the sake of brevity. For further discussion of the NPROMA blocking, we refer the reader to Müller et al. (2019) and Bauer et al. (2020).
When measuring the performance of the symmetry test, the validation procedure – corresponding to lines 11–23 of Algorithm A2 – is switched off.
In the Fortran code, the thread block size corresponds to the NPROMA.
In the 63rd edition of the TOP500 list published in June 2024, 190 out of the 500 most powerful supercomputers in the world use graphics accelerator technology (https://www.top500.org/lists/top500/2024/06/highs/, last access: 23 September 2024).
- Abstract
- Introduction
- Defining the targeted scientific applications
- A domain-specific approach to scientific software development
- Infrastructure code
- Performance analysis
- Conclusions
- Appendix A: Algorithmic description of the Taylor test and symmetry test for CLOUDSC2
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Defining the targeted scientific applications
- A domain-specific approach to scientific software development
- Infrastructure code
- Performance analysis
- Conclusions
- Appendix A: Algorithmic description of the Taylor test and symmetry test for CLOUDSC2
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References