the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 10 Jul 2024
| 10 Jul 2024
Fluvial flood inundation and socio-economic impact model based on open data
Thomas Röösli
Thomas Vogt
David N. Bresch
Fluvial floods are destructive hazards that affect millions of people worldwide each year. Forecasting flood events and their potential impacts therefore is crucial for disaster preparation and mitigation. Modeling flood inundation based on extreme value analysis of river discharges is an alternative to physical models of flood dynamics, which are computationally expensive. We present the implementation of a globally applicable, open-source fluvial flood model within a state-of-the-art risk modeling framework. It uses openly available data to rapidly compute flood inundation footprints of historic and forecasted events for the estimation of associated impacts. For the example of Pakistan, we use this flood model to compute flood depths and extents and employ it to estimate population displacement due to floods. Comparing flood extents to satellite data reveals that incorporating estimated flood protection standards does not necessarily improve the flood footprint computed by the model. We further show that, after calibrating the vulnerability of the impact model to a single event, the estimated displacement caused by past floods is in good agreement with disaster reports. Finally, we demonstrate that this calibrated model is suited for probabilistic impact-based forecasting.
- Article
(7334 KB) - Full-text XML
- BibTeX
- EndNote





Floods are natural hydrological events with significant humanitarian impacts, causing devastation to communities and ecosystems worldwide. They affect millions of people annually, leading to loss of life, displacement, and extensive damage to infrastructure and livelihoods (CRED, 2023). Over the last few years, the number of people exposed to overlapping and compounding disasters has increased, thus intensifying crises worldwide (IDMC, 2023a, where IDMC is the International Displacement Monitoring Centre). Climate projections indicate that flood frequencies will increase in many regions of the world, as will the overall number of people exposed to floods, in a warming climate (Hirabayashi et al., 2013). The UN-adopted Sendai Framework for Disaster Risk Reduction argues for a better understanding of disaster risk to increase resilience and for employing adaptation and mitigation measures to reduce the humanitarian impacts of natural hazards (UNDRR, 2015). To that end, decision-makers and humanitarian actors require accurate risk assessments, early warning systems, and impact forecasts of imminent events.
Disaster displacement is the temporary or permanent relocation of people from their homes due to evacuation from, direct exposure to, or loss of livelihood from natural hazards (IFRC, 2020). Displacement further causes severe humanitarian impacts, with challenges in providing adequate shelter, food, clean water, health care, and long-term support to affected populations. Displaced children in particular are at risk of exploitation and abuse and being exposed to malnutrition and disease (UNICEF, 2023). The year 2022 saw a tragically high number of displacements, with more than 32 million internal (i.e., intranational) displacements due to natural hazards alone (IDMC, 2023a). A clear majority of them was caused by floods.
Fluvial floods, pluvial floods, and storm surges show complex interplay, and merging them into a single, comprehensive modeling approach is an ongoing effort (see Loveland et al., 2021; Eilander et al., 2023). Physical models for exclusively fluvial floods already require an elaborate model cascade (Winsemius et al., 2013). Global climate models (GCMs) provide the meteorological boundary conditions to run hydrological models like LISFLOOD (Van Der Knijff et al., 2010), CaMa-Flood (Yamazaki et al., 2011), or GLOFRIS (Ward et al., 2013). These simulate hydrological processes of catchments, including surface and subsurface runoff and river routing. For forecasts on shorter timescales and reanalyses, the forcing by GCMs can be replaced by forecasts and meteorological observations, respectively. The discharge computed by hydrological models serves as the input to high-resolution inundation models for flood dynamics. There are standalone models like CA2D (Dottori and Todini, 2011), but the aforementioned hydrological models all feature fluvial inundation model extensions. Alfieri et al. (2024) recently presented an operational flood forecasting and early warning system for the Greater Horn of Africa, demonstrating that flood forecasts based on a full hydrological modeling chain are feasible. However, these modeling chains are also computationally demanding and thus may not be suitable for every application. For instance, Sampson et al. (2015) reported that their model required a server cluster with 200 cores to compute flood maps for a 10° × 10° tile at 90 m resolution in under 24 h.
Extreme value analysis of river discharge is an established tool to relate predicted and past events. Hirabayashi et al. (2013) first associated return periods with retrospective land-surface model runs to estimate flooded areas and inundations from extreme river discharges predicted by GCMs. But the historical time series of GCMs and of river discharge reanalysis datasets are limited, and fitted extreme value distributions become uncertain for extreme events with large return periods. Willner et al. (2018) reduced this uncertainty by introducing another extreme value distribution fitted on a pre-industrial GCM run. Still, both studies applied downscaling to the resulting low-resolution flood depth to derive a high-resolution flood fraction. The flood depth information was omitted from the subsequent analyses of affected population. Sauer et al. (2021) and Kam et al. (2021) retained inundation information in the same approach and used it to estimate economic damage and population displacement, respectively, caused by floods in future climate projections.
In this paper, we present a globally applicable model for rapid mapping of flood inundation footprints and for computing associated impacts. Instead of employing our own hydrological model, we rely on river discharge data computed by the Global Flood Awareness System (GloFAS; Alfieri et al., 2013) and use global river flood hazard maps by Dottori et al. (2016b) to estimate flood depths based on local extreme value analysis. The flood model can be applied to river discharge (ensemble) forecasts and reanalysis alike and computes flood inundation maps for entire countries in a few minutes. It is implemented as a Python module of the risk model CLIMADA, which serves as platform for both climate risk assessment (Aznar-Siguan and Bresch, 2019) and impact-based forecasts (Röösli et al., 2021). We further employ the flood model in CLIMADA for estimating population displacement due to river floods in Pakistan. We demonstrate that it can be calibrated to reported displacement data and thus used in comparative event studies, event detection, and impact-based forecasting.
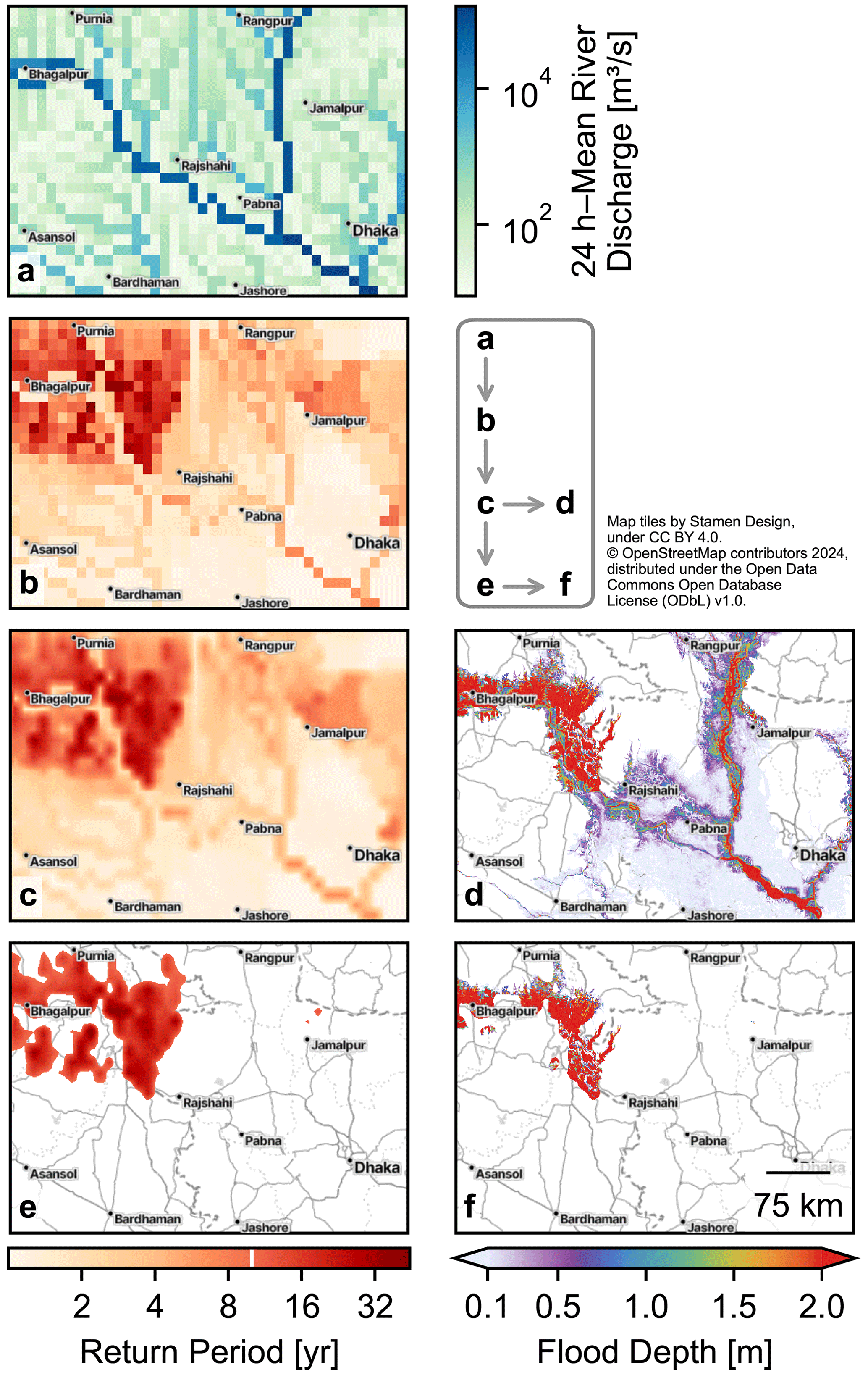
Figure 1Exemplary data transformation within the flood inundation model. The map covers the confluence of the rivers Ganges–Padma and Brahmaputra and its upstream area in Bangladesh and India. (a) The 24 h mean river discharge from the reanalysis dataset of GloFAS for 2 August 2007, during a period of floods along the Ganges–Padma river. (b) Return period computed from the river discharge data. (c) Return period regridded onto the flood hazard map grid using bilinear interpolation. (d) Inundation footprint resulting from the interpolation of flood hazard maps at each position based on the return period. (e) Return period after applying estimated flood protection standards, which ignores any return period below the protection threshold. For demonstration, we chose a threshold of r=10 years (indicated by the white line in the lower-left color bar) for the entire domain. (f) Inundation footprint from (e). Note the logarithmic scales for the discharge and return period.

Figure 2Visualization of interpolation for computing local flood depth in one spatial dimension (“Location”). (a) During regridding, return periods are interpolated linearly (solid line) from the coarser grid (blue markers) to the finer grid (red markers). For points outside the coarser grid, nearest-neighbor extrapolation is applied (dotted line). (b) At each location, the values of the flood maps for the given return periods (blue shades) are interpolated using the regridded return period values, yielding the output flood footprint (black line).
The proposed flood model computes a flood inundation footprint from gridded, geo-located river discharge via an extreme value analysis. In a pre-processing step, the historical time series of discharges is analyzed for each grid point by fitting a Gumbel distribution. Using this distribution, the model computes a return period to relate the discharge input to the historical time series, and it optionally applies information on flood protection standards. The return period, in turn, is used to look up flood depths in flood hazard maps.
2.1 Input data
The Global Flood Awareness System (GloFAS) provides global data on river discharge (Alfieri et al., 2013; Harrigan et al., 2023). Its hydrological modeling chain uses the LISFLOOD hydrological model developed at the Joint Research Centre (JRC) and meteorological forecast data from the European Centre for Medium-Range Weather Forecasts (ECMWF), among many other data sources. Version 3 of the GloFAS model has a time step of 24 h and outputs the 24 h mean river discharge on a 0.1° grid. The data provided are especially suitable for our task because a historical reanalysis dataset with discharge data starting from 1979 is published among daily ensemble forecasts (Harrigan et al., 2020). Since the same model is used to compute all GloFAS products, forecasted and historical time series can be compared without the need for model error or bias correction. Daily GloFAS forecast and reanalysis data are uploaded to the Copernicus Climate Data Store (C3S, 2023a, b) and can be downloaded via a web interface and a Python application programming interface (API).
Flood hazard maps display the flood inundation and extent for river systems assuming a flood with a specific return period. Dottori et al. (2016b) used GloFAS reanalysis data from 1979 to 2015 to develop global flood hazard maps of river systems with catchment areas greater than 5000 km2 for flood return periods of 10, 20, 50, 100, 200, and 500 years, at a resolution of 30′′ (arcsec). These maps are freely available from the JRC Data Catalogue (Dottori et al., 2016a). Notably, the models of Dottori et al. (2016b) do not include information on flood defenses and control mechanisms, apart from large-scale physical structures that are incorporated in the digital elevation model.
One particular effort to provide globally consistent flood protection information is the global database on flood protection standards (FLOPROS; Scussolini et al., 2016). This database merges empirical sources, policy specifications, and data from a model relating per capita wealth to flood protection on the sub-national level. However, information on control structures like dams and reservoirs – and especially their management – is not considered. Among the information layers provided by the database, we exclusively select the “merged layer” as the best guess for flood protection standards from the available information.
2.2 Overview
For any GloFAS discharge input data, the algorithm computes a flood footprint by
-
calculating the return period for the input data using the locally fitted Gumbel distributions,
-
regridding the return period data onto the grid of the flood hazard maps using bilinear interpolation,
-
optionally applying the FLOPROS protection standard, and
-
deriving a flood depth at every location by interpolating the respective depths in the flood hazard maps using the computed return period.
Figure 1 visualizes exemplary data at each step of the algorithm. In the following subsections, these steps are explained in detail.
2.3 Time series analysis
In this pre-processing step, an extreme value analysis is applied to the historical discharge data. To that end, a right-handed Gumbel distribution is fitted to the yearly maximum of the discharge time series at every location independently using the “SciPy” Python package (Virtanen et al., 2020).
The right-handed Gumbel distribution is defined by the probability density function (PDF)
where q is a realization of the random variable Q (here, the river discharge) and μ and β are location and scale parameters, respectively. Dankers and Feyen (2008) point out that for calculating return periods from river discharge, a three-parameter generalized extreme value distribution does not yield a clear improvement over the two-parameter Gumbel distribution if the time series is short.
For fitting the two parameters μ and β, we employ the “method of moments” (cf. Dottori et al., 2016b), which minimizes the L2 error between the first two moments (mean and variance) of the data distribution and the fitted Gumbel distribution,
where E is the expected value, Var is the variance, denotes the discharge data used for fitting, and Q∼pQ is the random variable defined by the fitted Gumbel distribution with the PDF given by Eq. (1).
This process yields a pair of parameters (μx,βx) for every location x on the grid covered by the GloFAS river discharge datasets. The number of samples for fitting each distribution is the number of years included in the reanalysis, up to the date of the publication by Dottori et al. (2016b), Nf=36. The fitted parameters are then stored to avoid repeating this procedure every time a flood footprint has to be computed.
2.4 Return period computation
After the previous pre-processing step, the model computes an equivalent return period for discharge input data qx at every location x. The cumulative distribution function of the fitted Gumbel distribution,
gives the probability of a discharge less than or equal to qx occurring at location x within a year. We interpret the complementary probability as the exceedance frequency
The inverse of that frequency is the return period of the event whereby the yearly maximum of discharges exceeds qx,
The return period computation transforms the data visualized in Fig. 1a into those in Fig. 1b.
The historical time series only spans 36 years, which results in strongly increasing uncertainty for discharges q with r(q)>36 years. We employ parametric bootstrap sampling to represent this uncertainty (Kyselý, 2008). In this approach, new extreme value distributions are created by drawing samples from the fitted one, and these new distributions are then used to compute a set of return periods using the aforementioned equations. More specifically, Nf samples are drawn from the Gumbel distribution, where Nf is the number of data points used to fit the original distribution as defined above. These samples are used as data points to fit a new Gumbel distribution, and that distribution is then inserted into Eqs. (3) to (5). The process is repeated Ns times, yielding an ensemble of return periods
which represents the uncertainty in the return period computation. The sampling density Ns can be chosen by the user. A higher density more accurately represents the uncertainty in the return period computation, but it also escalates the computational cost of the subsequent steps.
2.5 Geospatial regridding
The spatial resolution of the GloFAS discharge data (0.1° as of version 3) and the flood hazard maps (30′′) by Dottori et al. (2016b) differs significantly. We therefore regrid the return period data onto the grid of the flood hazard maps using the geospatial “xESMF” tool with bilinear interpolation (Zhuang et al., 2023). In the following, locations on the finer grid of the flood hazard maps will be denoted by x′ and the regridded return period data by .
Because the GloFAS data are coarser, there are locations near coastlines where flood hazard map data points lie “outside” the GloFAS data grid. To cover these locations, we employ a nearest-neighbor extrapolation of the return period data. The regridding is visualized in Fig. 2a and transforms the data displayed in Fig. 1b to those in Fig. 1c.
2.6 Flood protection standards
The FLOPROS database contains data on return periods associated with modeled flood protection standards (Scussolini et al., 2016). We consider the effect of protection measures by setting the return period to zero if it is lower than protection standard at the same location x′,
As zero is an invalid return period according to Eq. (5), the resulting values at the affected locations are effectively discarded. This step is optional, and users may choose between different FLOPROS information layers. The application of flood protection standards transforms the data visualized in Fig. 1c to those in Fig. 1e.
2.7 Flood footprint
Finally, the flood footprint related to the discharge input data is created by interpolating a flood depth value from the flood hazard maps. The flood hazard maps define a scalar field with three-dimensional coordinates: the location x′ and the return period r. The value of said field is the flood depth at the specified coordinates. To receive the flood depth for a particular return period at location x′, we interpolate the field at this location linearly in the return period dimension,
where r± indicates the lesser and greater return periods closest to and denotes the associated inundation values in the flood hazard maps. Additionally, we assume that, for the lowest return period r=1 year, the flood depth is always zero and that the maximum flood depth cannot exceed the inundation associated with the maximum return period for which hazard maps are available, rmax=500 years. With this, we define the flood depth as
The flood depth interpolation is visualized in Fig. 2b. The flood footprint computation transforms the data displayed in Fig. 1c to those in Fig. 1d and the data in Fig. 1e to those in Fig. 1f.
CLIMADA is an impact model that follows the definition by the Intergovernmental Panel on Climate Change (IPCC), whereupon risks emerge from the exposure of goods or people to weather- or climate-related hazards and their vulnerability towards these hazards (Aznar-Siguan and Bresch, 2019). CLIMADA represents hazards, exposure, and vulnerability in a spatially explicit manner and likewise computes impacts and risks. Within the framework, vulnerability is modeled as an impact function, which takes the local hazard intensity as an argument and yields a damage factor. Multiplying this factor with the local exposure returns the local impact.
The presented flood model is implemented as a Python module of CLIMADA (Aznar-Siguan et al., 2023). The code is included in the latest development version of the CLIMADA Petals module (CLIMADA Contributors, 2024). It produces one or multiple Hazard objects (the CLIMADA data structure of a geophysical hazard) from the discharge input data, which are downloaded automatically from the Copernicus Climate Data Store (CDS) by employing the “cdsapi” Python package (ECMWF, 2023a), which accesses the CDS API. For accessing, transforming, and storing the multi-dimensional data within our module, we use the “Xarray” Python package (Hoyer and Hamman, 2017).
Most of the module functionality is wrapped in the RiverFloodInundation class that performs these tasks with minimal user input. Users have to state which GloFAS discharge data to download and can then compute a CLIMADA hazard from these data using default settings. Alternatively, they can add custom settings (like bootstrap sampling) or adjust each step of the model pipeline (Sect. 2) individually. A setup function has to be executed once, which prepares the static data required for all computations. This function downloads the historical discharge data, performs the time series analysis, and stores the fitted Gumbel parameter distribution data on the user's device. It also downloads the flood hazard maps (given as GeoTIFF files) and merges them into a NetCDF file for easier access. Some of the tasks performed by the module benefit from parallel execution on multiple processors. Where applicable, users may add information on the number of processors a task should use and specify the amount of memory available. In all other cases, the computation pipeline uses the default Xarray multithreading to maximize performance.
Pakistan is a flood-prone country and is particularly vulnerable to the effects of climate change (Eckstein et al., 2021). In summer 2022, Pakistan experienced its arguably most devastating floods to date. They were caused by the compounding effects of a dry winter season, strong glacier melt and snowmelt due to unusually high temperatures, and a monsoon anomaly with heavy rainfall that lasted for weeks. The floods affected over 30 million people and left more than 20 million people in need of humanitarian assistance (OCHA, 2022b). Also due to its magnitude, the event gained much international interest and coverage in media and research alike. The variety of data available enables us to calibrate our model to this event. We then put the event in a historic perspective and demonstrate its capability for impact-based forecasting of a flood event in 2023.
This section describes the methodology of the model application and its results. The latter will be discussed in Sect. 5.
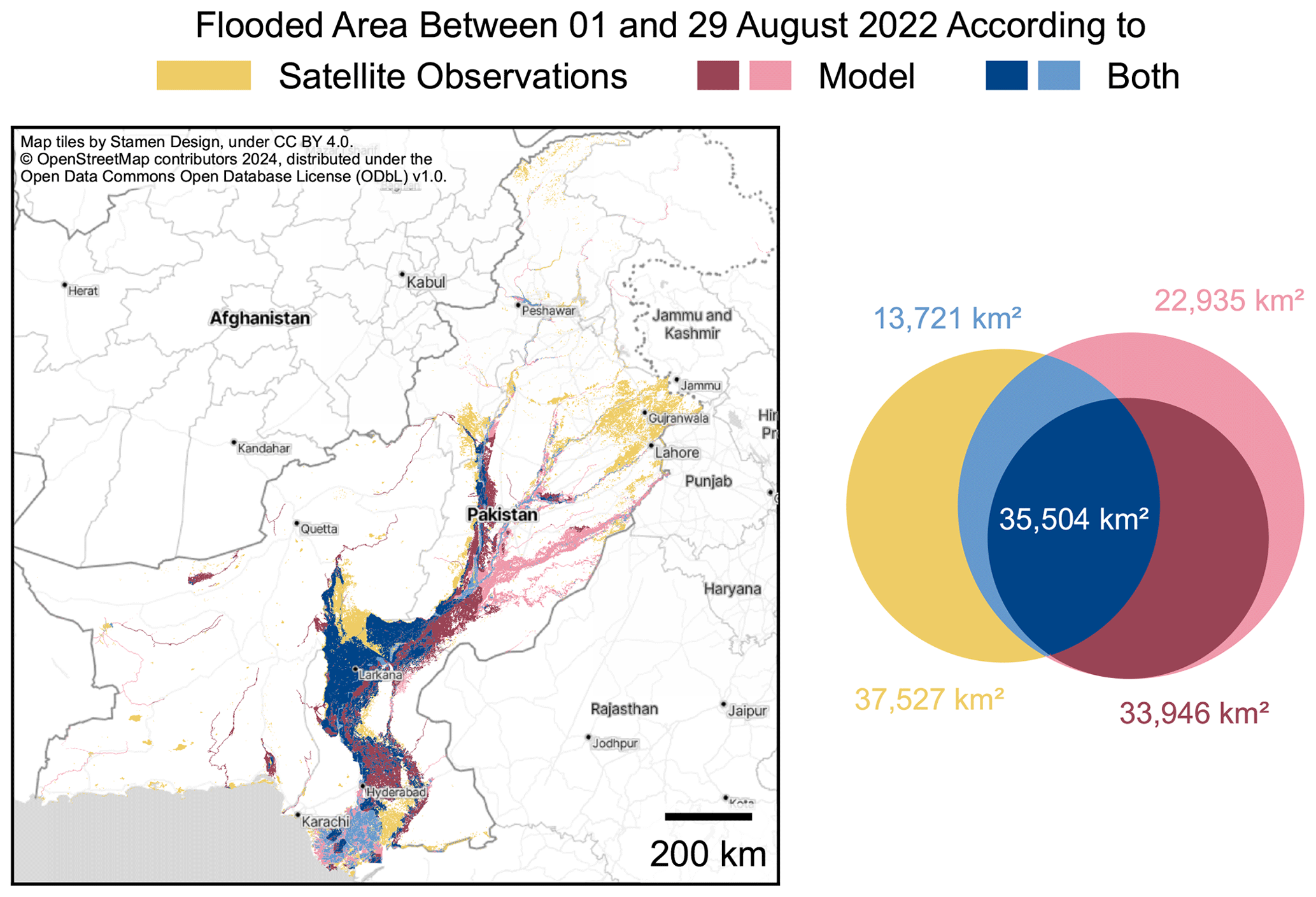
Figure 3Comparison between flood extents in Pakistan computed by the model and observed by Visible Infrared Imaging Radiometer Suite (VIIRS) instruments aboard the NOAA satellites (UNOSAT, 2022). Blue areas denote agreement between the observation and flood model. Red areas indicate where the model computed a flood, but no flood was observed. Yellow areas denote where the model did not compute a flood, but floods were observed. Darker and lighter hues of red and blue indicate the model output when considering flood protection standards according to the FLOPROS database and when not, respectively. Left: map of flood extents in Pakistan. Right: Venn diagram of the same data with respective total areas computed in a cylindrical equal-area projection (Esri:54034). Publisher's remark: please note that the above figure contains disputed territories.
Table 1Classification metrics for flood extents in Pakistan between 1 and 29 August 2022 computed with the model considering no flood protection (“No Protection”) and the FLOPROS protection standards (“FLOPROS”), respectively. Satellite data by UNOSAT (2022) are considered the ground truth against which the model data are compared. See Fig. 3 for a visualization. For each score, the value indicating better performance is highlighted. See Appendix A for the definition of these metrics.

4.1 Flood extent
In a first step, we computed a flood footprint with our model and compared its spatial extent with satellite observation data. The Humanitarian Data Exchange (HDX) hosts a dataset published by the United Nations Satellite Centre (UNOSAT), which is based on observations of the Visible Infrared Imaging Radiometer Suite (VIIRS) instruments aboard the NOAA-20 satellites (UNOSAT, 2022, glide number FL20220808PAK). This dataset contains satellite-detected water extents between 1 and 29 August 2022 in Pakistan, the time period of peak flood extents.
To derive an equivalent flood extent from our model, we downloaded the reanalysis river discharge for Pakistan between 1 and 29 August 2022 and selected the maximum discharge at each location. We then employed the flood model to compute a flood footprint. Since the satellite data do not estimate flood depth, we ignored the flood depth computed by the model and simply considered a location flooded if its flood inundation was greater than 10 cm. We considered two separate model runs: one which applied flood protection standards as listed in the FLOPROS database and one which did not account for any flood protection. To compare the model output and the satellite observation data, we coarsened the satellite data onto the 30′′ resolution of the model. This process omitted some small-scale features which could not be resolved by our model but changed the total flooded area of the VIIRS dataset only by about 1 %.
Figure 3 displays the flood extent as calculated by our model for Pakistan between 1 and 29 August 2022 and compares it to the satellite-based observations. Model agreement is good especially in the area around the city of Larkana. East of Hyderabad, the flood model predicts extensive flooded regions where the satellites only detected patchy flooding. The flood model fails to capture observed floods southeast of Hyderabad, north of Larkana, and around Gujranwala. Differences between the model without flood protection and with FLOPROS protection standards considered are pronounced near the Indus River delta southeast of Karachi, where the FLOPROS model fails to predict extensive flooded areas, and further upstream in eastern Pakistan, where the No Protection model predicts extensive flooding while little was observed.
To evaluate the accuracy of our model against the observed flood extent, we computed metrics for binary classification. Their definition can be found in Appendix A. The metrics for the Pakistan floods in August 2022 are displayed in Table 1. When applying FLOPROS flood protection standards to our model, the precision or positive predictive value P increases from 0.46 to 0.51 and the specificity or true negative rate S increases from 0.42 to 0.65 compared to the model without flood protection standards. However, the recall or true-positive rate R decreases from 0.57 to 0.41. This is reflected in the F1 score, which assesses the No Protection model performance slightly more highly than that of the FLOPROS model, with 0.51 compared to 0.45. Similarly, the critical success index scores 0.34 for the No Protection model against 0.29 for the FLOPROS model. The Matthews correlation coefficient (MCC) is 0.07 for the FLOPROS model, indicating only slightly better prediction than random values. Nonetheless, the MCC for the No Protection model is clearly worse with a value of −0.01.
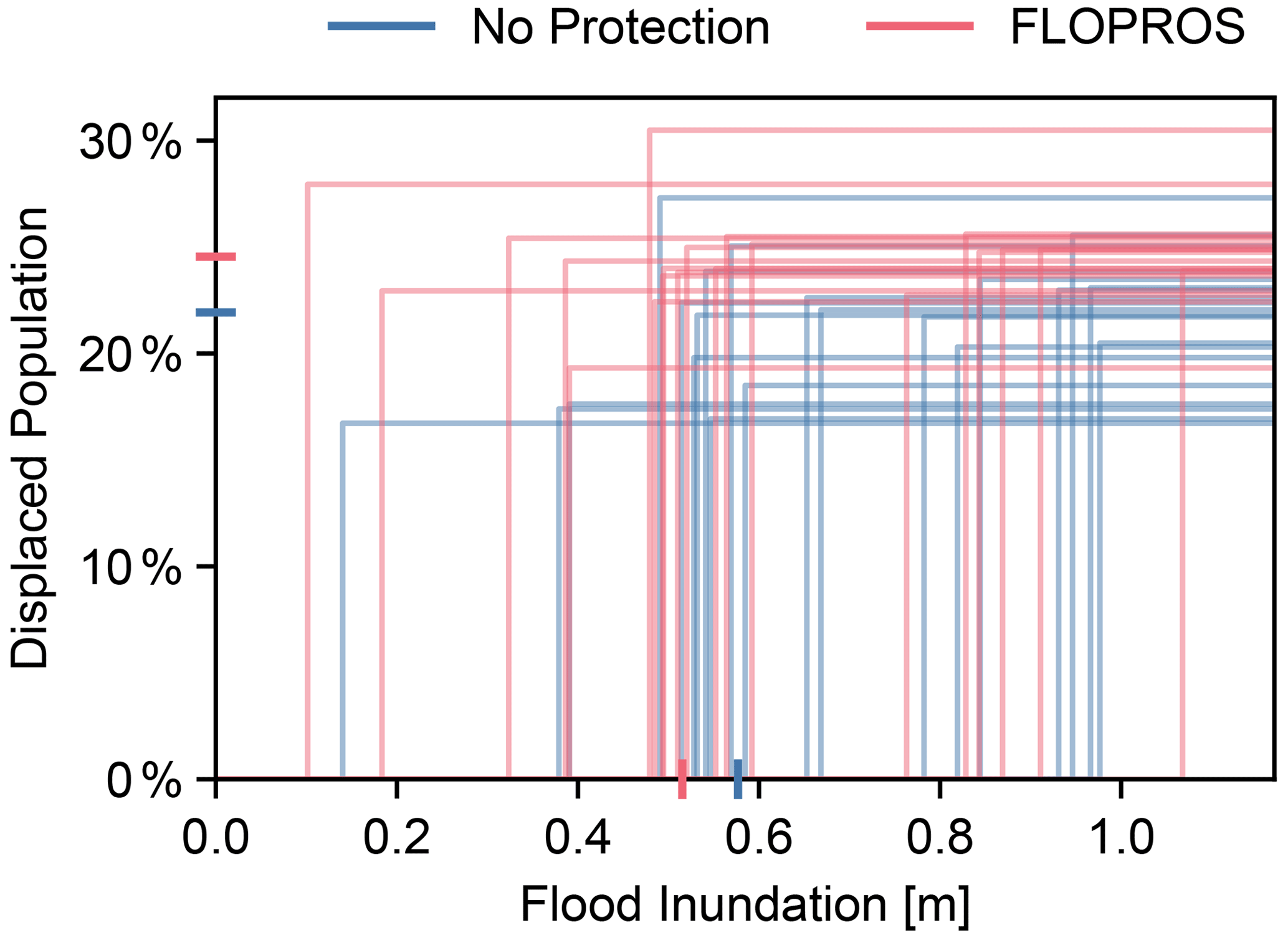
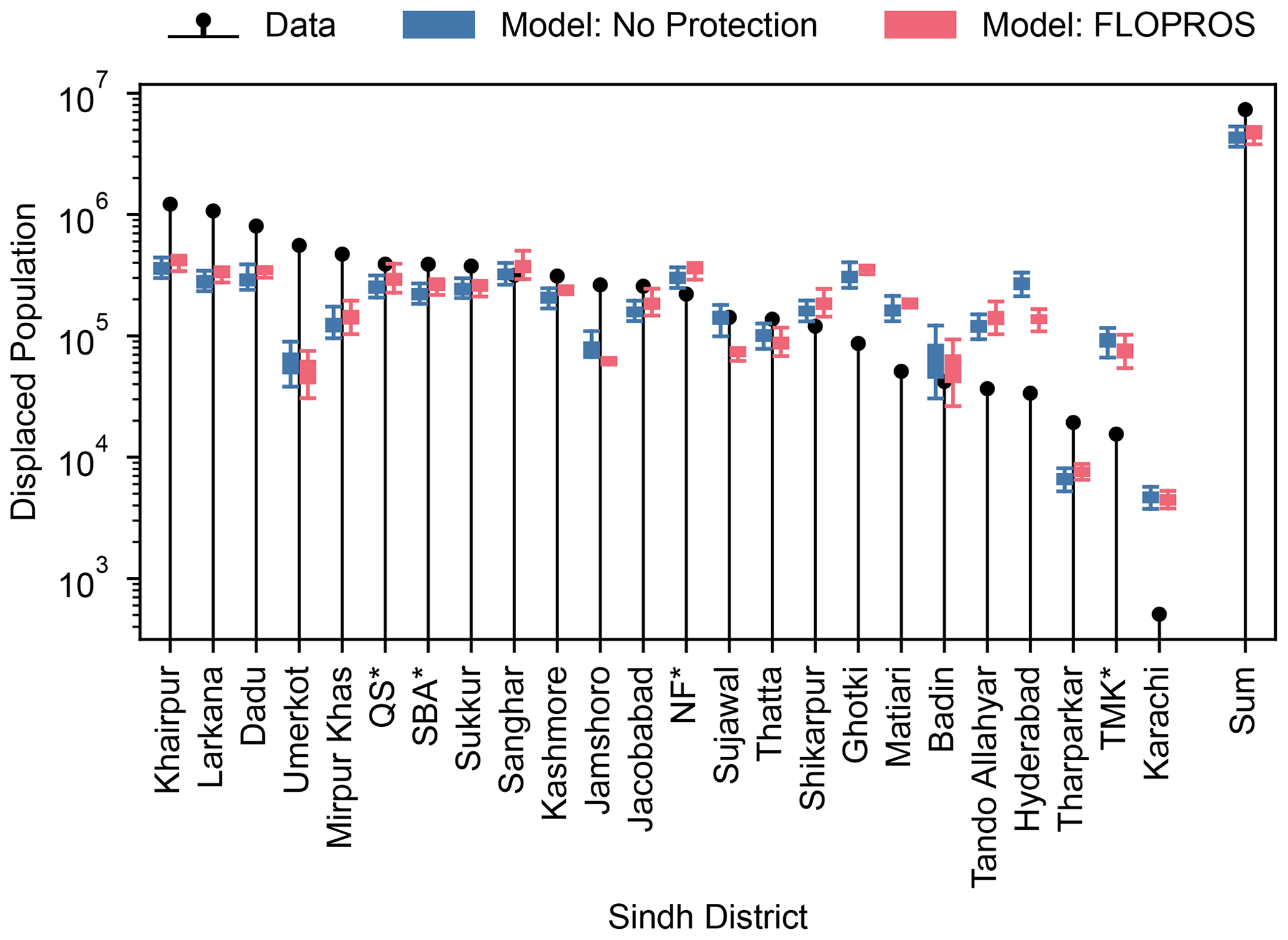
Figure 5Comparison between displacement data provided by PDMA (2022) and the calibrated impact model output for flood footprints without considering flood protection and with FLOPROS protection levels incorporated. The impact distribution for 20 cross-calibrated impact functions each is represented as a boxplot; boxes indicate the interquartile range, whiskers delimit the distribution confidence interval, and outliers are omitted. The vulnerability is the only source of uncertainty considered in the impact. “Sum” refers to the sum of all districts. “Karachi” refers to all districts within the Karachi division. * QS: Qambar Shahdadkot; SBA: Shaheed Benazirabad; TMK: Tando Muhammad Khan; NF: Naushahro Feroze.
4.2 Population displacement
In this section, we use data on displacement in Sindh Province during the 2022 floods to calibrate the impact functions in our model. The Provincial Disaster Management Authority (PDMA) releases regular situation reports on floods and other disasters and their impacts in Sindh. According to these reports, the maximum number of about 7.3 million displaced people was reached by 30 September 2022 (PDMA, 2022). The PDMA report of this day lists the displaced population per district of Sindh Province except Karachi, where a single number is reported for all six districts; see Appendix B for a listing of the data. We used these data to calibrate impact functions for our model, employing a “cross-calibration” method where we used multiple subsets of the data for calibrating an impact function ensemble. With this, we avoided overfitting and could investigate the uncertainty in the calibrated vulnerability.
4.2.1 Impact model and calibration setup
We developed a strongly simplified model for displacement because we intended this to serve mainly as a demonstrator for the capabilities of our flood model. As CLIMADA only considers immediate impacts due to a hazard footprint, we considered the reported displacement to be the impact of a single flood event. We used the flood inundation model to compute the hazard footprint of this event by inserting the maximum discharge from the GloFAS reanalysis data at every point within Sindh Province between 1 July and 30 September 2022. In doing so, we assumed that the reported displacements accumulated due to the floods during that period, and we neglected the fact that some people might have already returned to their homes. Again, we computed one footprint without flood protection and one where the FLOPROS protection level was considered. We used these two footprints in two separate calibration tasks, yielding two different impact models with one associated impact function ensemble each.
We selected the latest WorldPop population dataset from 2020 with a resolution of 30′′, or around 1 km at the Equator, as exposure (WorldPop, 2020). CLIMADA calculates impact as a ratio of local exposure affected by a local hazard. Therefore, this displacement model only considered displacement due to residential areas being flooded and rendered uninhabitable. Secondary reasons for displacement, like the loss of livelihoods or of access to critical infrastructure, were not explicitly resolved. Furthermore, impacts are instantaneous within CLIMADA, and time lags between a hazardous event and the related impact were therefore not considered in our model.
We chose a simple step function with two parameters as a generalized impact function,
where z is the inundation depth, T is the inundation threshold above which displacements occurs, and Π is the percentage of population displaced once displacement occurs. We chose this function due to its simplicity, as other functions might require more parameters to be calibrated or require more a priori assumptions. Furthermore, the two parameters of the step function are relatively easy to interpret.
We calibrated the impact function parameters with constrained Bayesian optimization by employing the “BayesianOptimization” Python package (Nogueira, 2014). This method uses Gaussian processes to iteratively sample a parameter space and find the optimal parameters within the space by means of Bayesian inference. In our context, the parameter space was sampled by selecting a pair of step function parameters through the Gaussian process; computing the impact with CLIMADA using the flood footprint, the WorldPop exposure, and the impact function defined by these parameters; and comparing the result with the PDMA data through a target function. The target function to be optimized (here, maximized) was the negative mean squared log error (MSLE) between the PDMA report data and the modeled impact,
where χi and are the modeled and the reported number, respectively, of displaced people for district i and ND is the number of districts. This error measure is suitable for data points with varying orders of magnitude and puts a larger penalty on underestimation than on overestimation. The modeled values χi were calculated by computing the impact for all exposure points in Sindh Province individually and then summing up the impacts for each district i. As parameter bounds we chose
We employed cross-calibration by calibrating the impact function multiple times on data subsets. The subsets were chosen to contain 20 randomly selected data points from the 24 available districts, ignoring the data and calculated impact for the remaining four districts. We repeated this process 20 times, resulting in a set of 20 calibrated impact functions both for the model without protection measures (No Protection model) and for the model with FLOPROS protection standards considered (FLOPROS model).
4.2.2 Calibration results
The calibrated impact functions are visualized in Fig. 4. For the No Protection model, the impact threshold ranges from 0.14 to 0.98 m, with a median of 0.58 m, and the percentage of displaced population ranges from 16.7 % to 27.3 %, with a median of 21.9 %. For the FLOPROS model, on the other hand, the threshold ranges from 0.10 to 1.07 m, with a median of 0.52 m, and the percentage of displaced population ranges from 19.3 % to 30.5 %, with a median of 24.5 %.
The impact estimation for all districts with the varying impact functions is visualized in Fig. 5. For the majority of districts, the difference between median estimated impact and the data is lower than 1 order of magnitude. However, in most cases, the variation in impact due to the different impact functions is lower than the deviation between the median impact estimate and data, meaning that the data are rarely covered by the range of model outputs. Also, the intra-model variance is typically higher than the variation between the No Protection and FLOPROS models.
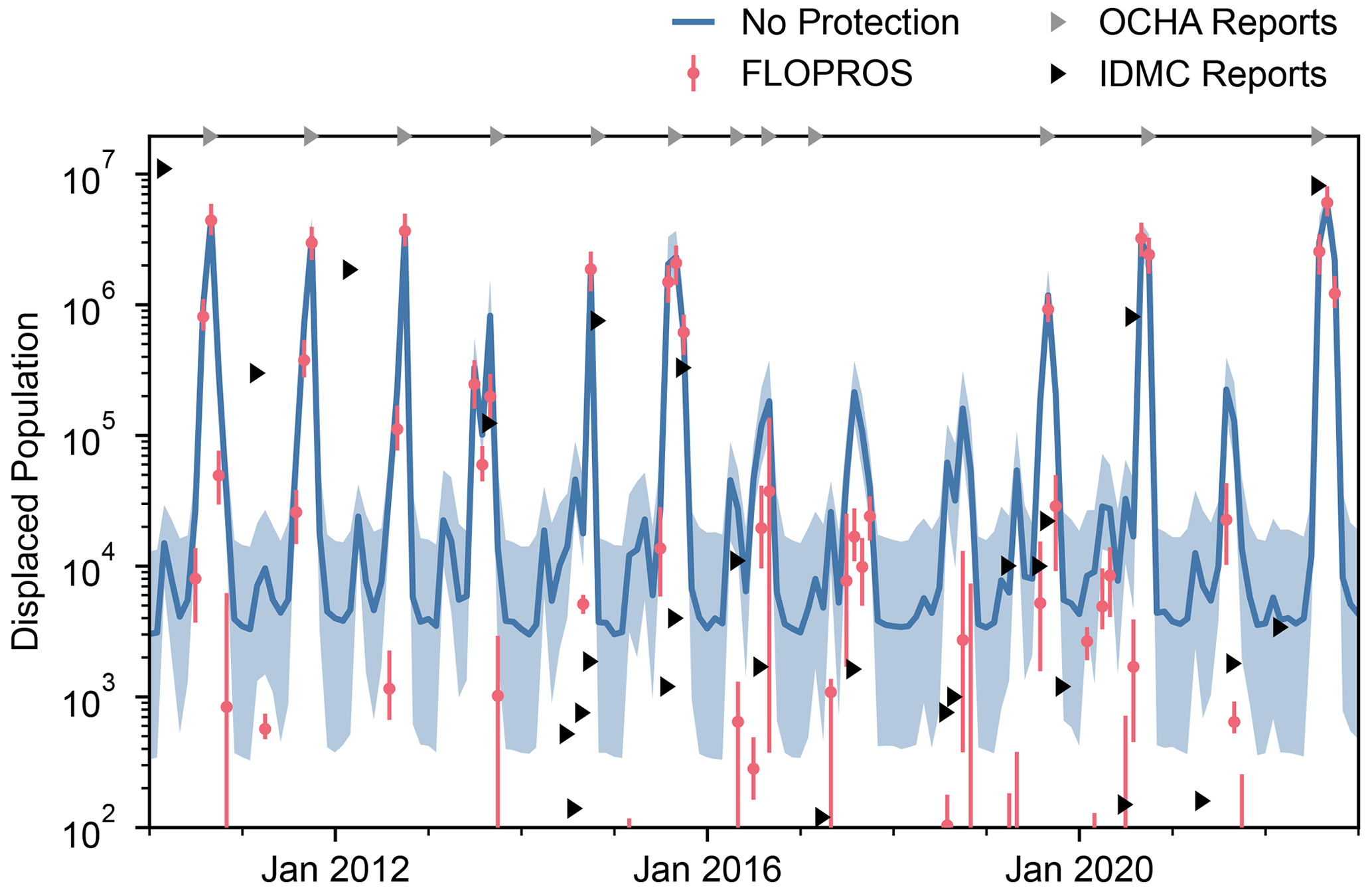
Figure 6Monthly displaced population estimated by the model considering no flood protection and by the model considering FLOPROS protection standards. Note that the models do not consider previous displacement and thus assume full recovery after 1 month; every data point must be interpreted as an independent displacement estimate due to river flooding occurring in that month. The solid line (“No Protection”) and the markers (“FLOPROS”) denote the median of a distribution sampled from 20 bootstrap-sampled flood footprints based on GloFAS river discharge reanalysis for each month and 20 cross-calibrated impact functions. The shaded areas (“No Protection”) and bars (“FLOPROS”) depict the range between the 5th and the 95th percentile of the respective distribution. Grey markers on the top axis indicate timings of flood disasters reported by OCHA (2023). Black markers indicate internal displacements due to flooding reported by IDMC (2023b). For both types of marker, their left border denotes the beginning of the event as defined by the respective organization.
4.3 Historical flood displacement
With the calibrated impact models, we set the flood event of 2022 into historical perspective by computing monthly flood impacts for recent years and comparing them to reports of flood disasters and associated displacement. For timings of flood disasters we consulted reports by the United Nations Office for the Coordination of Humanitarian Affairs (OCHA, 2023), and for associated figures of displaced population we consulted the Global Internal Displacement Database (IDMC, 2023b).
We used the daily GloFAS river discharge reanalysis from January 2010 through December 2022 and computed flood footprints from the monthly maximum of the datasets. Like before, model impacts were considered instantaneous, and the model did not retain an account of previously displaced people. We therefore effectively assumed full disaster recovery after 1 month. To represent the uncertainty in our flood model, we employed bootstrap sampling as described in Sect. 2.4 to compute an ensemble of 20 flood footprints for each month. Together with the 20 impact functions from the cross-calibration, we computed impacts for each month to sample the uncertainty in the impact estimation. Again, we distinguished between one model considering no flood protection and one model considering the FLOPROS protection standards. We chose the matching WorldPop dataset for each considered year as exposure (WorldPop, 2020). Because no WorldPop datasets exist for the years 2021 and 2022, for these years we selected the dataset of 2020, which was also used in the previous calibration step.
The displacement estimates for each model are visualized in Fig. 6, together with reported timings of and internal displacements due to flood disasters. For each month in the time frame considered, the No Protection model estimates a median of at least 3000 people displaced, with an uncertainty of about 1 order of magnitude. Contrarily, the FLOPROS model estimates a median of zero people displaced for most months. For high-impact events like in 2010, 2011, and 2012, the impact estimates of both models are nearly the same. For low-impact events like in 2016 and 2017, the displacement estimates by the FLOPROS model are about 1 order of magnitude lower than those by the No Protection model. The duration of high-impacts during the 2022 floods is similar to the floods of 2015. In terms of estimated displacement, the 2022 floods are comparable to the floods of 2010. For most high-impact events, both models estimate displacement on the same order of magnitude as reported by IDMC (2023b). Except for one instance in January 2017, each flood disaster reported by OCHA (2023) corresponds to a spike in estimated displacement with the same timing.
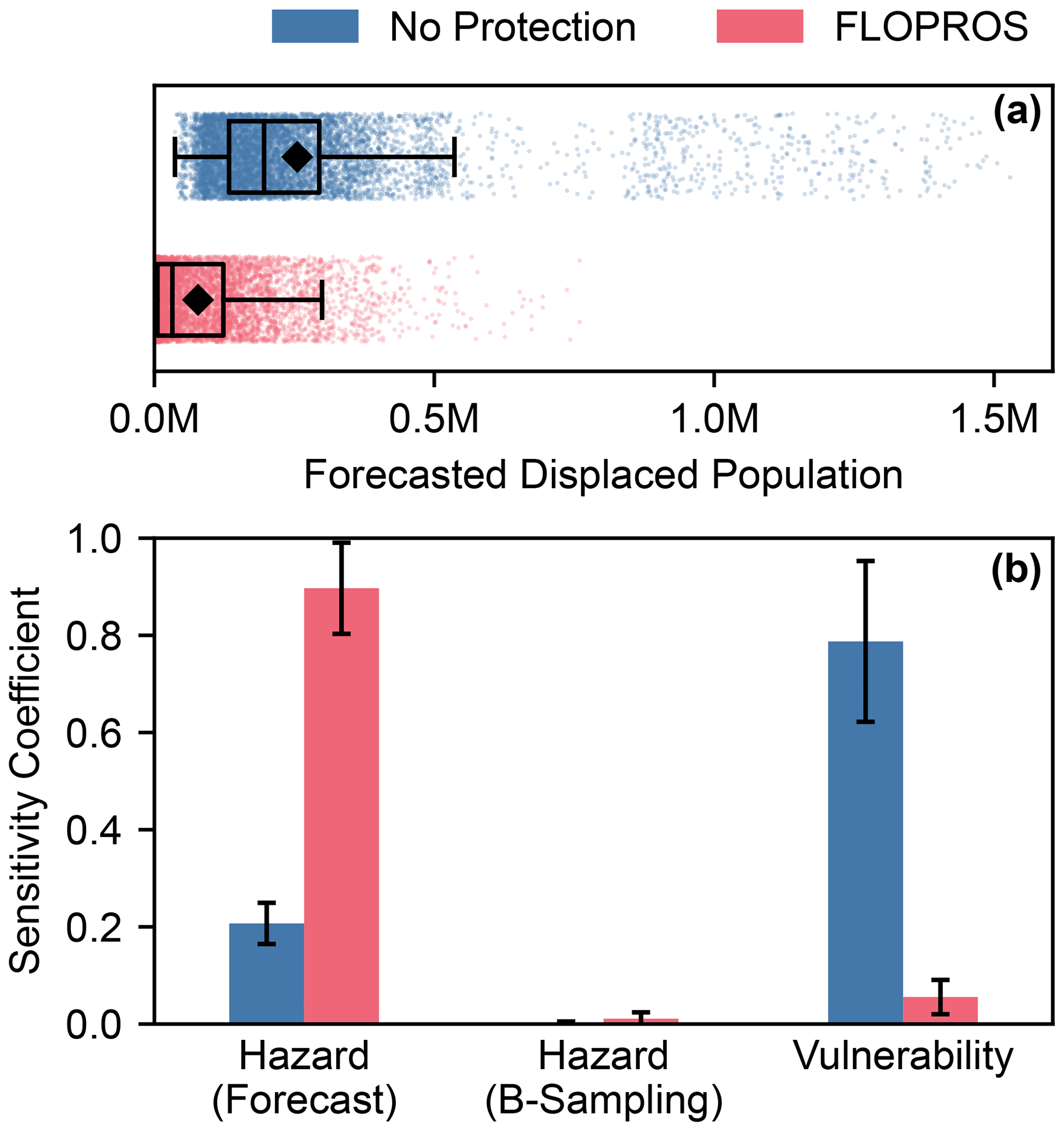
Figure 7Uncertainty in and sensitivity analysis of the forecasted displacement in Pakistan based on the GloFAS river discharge forecast from 8 July 2023, including a 5 d lead time, for the two models considering no flood protection and the FLOPROS flood protection standards, respectively. This considers uncertainty in the GloFAS forecast represented by the forecast ensemble (“Forecast”), the statistical flood model uncertainty represented by bootstrap sampling (“B-Sampling”), and the uncertainty in vulnerability represented by the ensemble of calibrated impact functions. (a) Sampled displacement in Pakistan for both model instances. Each point indicates the total impact of a sample. Boxes denote the lower quartile, median, and upper quartile, and squares denote the mean. Whiskers delimit the distribution confidence interval, outside which data points can be considered outliers. (b) First-order sensitivity coefficients with confidence intervals (error bars), indicating the fraction of model output variance that can be attributed to variations in the respective model input.
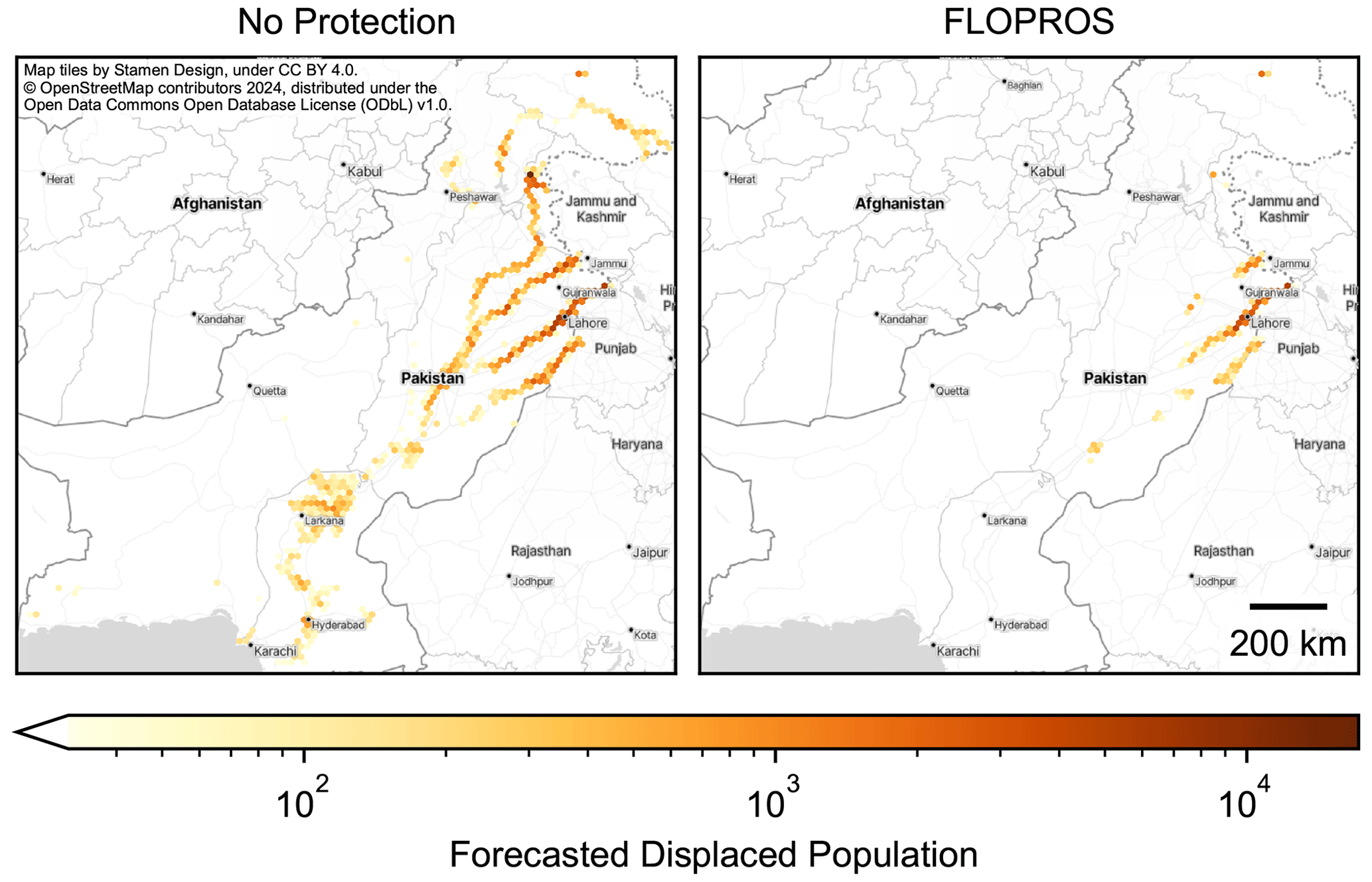
Figure 8Mean forecasted displacement based on the GloFAS river discharge forecast from 8 July 2023, including a 5 d lead time, for the two models considering no flood protection and the FLOPROS flood protection standards, respectively. The color of each hexagon represents the accumulated mean displacement within its area. The impact data themselves have the resolution of the WorldPop exposure layer (30′′). The total expected displacement is 255 211 for No Protection and 77 959 for FLOPROS; see Fig. 7a for the associated distribution. Publisher's remark: please note that the above figure contains disputed territories.
4.4 Impact-based forecasts
In this section, we apply the flood impact model to the GloFAS river discharge forecast, thus computing an impact-based forecast. The GloFAS river discharge forecast is produced in 24 h time intervals with a daily time step and a lead time of 30 d, matching the lead time of the ECMWF medium-range weather forecasts which serve as forcing for the GloFAS hydrological model. Like the ECMWF weather forecasts, the GloFAS river discharge forecasts represent model uncertainty by an ensemble of 50 members.
During the 2023 monsoon season, Pakistan was struck by several flood events, one of which occurred in early July (see ECHO, 2023). We investigated if such an event, and its magnitude with respect to humanitarian impacts, can be predicted by applying the calibrated displacement models to the GloFAS river discharge forecast issued on 8 July 2023. As weather forecasts are typically uncertain for lead times of more than a week, we restricted the forecast window to a lead time of 5 d. For each of the 50 forecast ensemble members, we computed the maximum discharge over the lead time at each location. Then we employed the flood model and generated 20 flood footprints from each member using bootstrap sampling. We repeated the impact calculation setup of the previous section, with the 20 calibrated impact functions supplying vulnerability information and the WorldPop dataset of 2020 serving as exposure without uncertainty. For both the model without flood protection and the model considering FLOPROS flood protection standards, this yielded impact model combinations. To analyze the uncertainty in the estimated impact and its sensitivity towards the input, we took 213=8192 samples from each of the two model distributions by employing the uncertainty and sensitivity quantification (“unsequa”) module in CLIMADA (Kropf et al., 2022).
The estimated displacements for these distributions are displayed in Fig. 7a. The No Protection model predicts higher impacts overall, with a median displacement of 195 957 people against the median value of 32 142 for the FLOPROS model. The associated means or expected values are 255 211 and 77 959. We find that the impact distributions of both models are long-tailed towards higher impacts. The upper limits of the confidence intervals (indicated by whiskers in Fig. 7a) are 536 049 (No Protection) and 299 525 (FLOPROS) displaced people, respectively, while outliers exceed 1 million (No Protection) and 500 000 (FLOPROS) displaced people. Both models thus significantly exceed historical displacement estimates for months without reported floods; compare Fig. 6.
The sensitivity of the total estimated displacement χ towards the input parameter πi can be expressed by the first-order sensitivity coefficient,
where the expectation value in the numerator is evaluated with a fixed parameter πi and the variance in the numerator is evaluated by only changing πi (Saltelli and Annoni, 2010). We interpret each of the input distributions (model forecast ensemble, bootstrap ensemble, impact function ensemble) as independent input parameters and evaluate their sensitivity coefficients using the aforementioned “unsequa” module. These coefficients for each model with respective confidence intervals are displayed in Fig. 7b. For the No Protection model, the sensitivity coefficient for the GloFAS forecast uncertainty is relatively low with 0.21±0.04, and the coefficient for the vulnerability is relatively high with 0.79±0.17. This is the opposite to the FLOPROS model, where the sensitivity coefficient for the forecast uncertainty is high with 0.90±0.09 and the coefficient for the vulnerability is low with 0.06±0.04. Both model estimates feature a negligible sensitivity towards the bootstrap sampling in the flood model, with sensitivity coefficients of 0.002±0.004 (No Protection model) and 0.011±0.013 (FLOPROS model). See Appendix C for the uncertainty in and sensitivity analysis of forecasts from 6, 7, and 8 July 2023.
Figure 8 displays the spatial distribution of forecasted population displacement. Both the No Protection and the FLOPROS model estimate high and localized displacement around Lahore in eastern Pakistan. The No Protection model additionally predicts high displacement near the border with Jammu and Kashmir. Further downstream along the Indus, around Larkana and Hyderabad, the same model indicates displacement for vast areas, but overall displacement here is lower than in the aforementioned regions. At each location where the FLOPROS model predicts displacement, the No Protection model does too. However, the FLOPROS model estimate is typically lower.
We present a globally consistent flood inundation model integrated and used in an impact model. In the following, we will discuss the results and the performance of the model, as presented in Sect. 4, and relate them to the current literature – first in terms of the flood inundation model itself and then in combination with the impact model.
5.1 Flood inundation model
The river flood inundation model presented in this paper combines river flood reanalysis and forecast data with river flood hazard maps, all based on the hydrological modeling system GloFAS. We took care to follow the same statistical approach as Dottori et al. (2016b) for calculating return periods to ensure that the return periods computed with our model and the return periods of the flood hazard maps are directly comparable. At the time of writing, GloFAS v4.0 had been operationalized in both the reanalysis and the forecast datasets, featuring major updates to the underlying models and data and a doubled resolution compared to previous versions (ECMWF, 2023b). The latter, however, implies that return periods of the flood hazard maps and those computed from GloFAS v4 data are not directly comparable. Switching to GloFAS v4 data in the presented model will therefore require some degree of downscaling and bias correction, akin to methods used in climate modeling. Ideally, GloFAS v4 data should be used together with flood hazard maps computed from the same model. The model could likewise be applied using river discharge data from the European Flood Awareness System (EFAS; Thielen et al., 2009) and flood hazard maps for Europe by Dottori et al. (2022) to achieve a higher accuracy and footprint resolution in Europe (only).
Contrary to Alfieri et al. (2015), who assigned areas of flood risk to the grid point of the corresponding hydrograph, the presented flood model operates on a local basis. For each location within a floodplain, the return period and flood inundation are computed separately, considering neither neighboring grid cells (except for the interpolation during regridding) nor the discharge inside the corresponding river. This has two major implications. On the one hand, neither Van Der Knijff et al. (2010) nor Alfieri et al. (2013) mention that the process of flooding, where water leaves the routing channel of the river, is explicitly considered in the hydrological LISFLOOD model used in GloFAS. We therefore have to assume that flooding in very large river plains might be underestimated in our model because local discharge might not adequately reflect that water is leaving the riverbed and spilling into the floodplain. However, this effect is slightly counteracted by the difference in resolution between the hazard maps and the discharge data, as the latter represent each river with a width of 0.1° latitude and longitude. On the other hand, the model is able to represent pluvial floods in river basins to some degree. In situations where discharge around a river is unusually high, but the river is able to take up that discharge without overflowing, the flood model will estimate a flooded area that would not have been predicted when only taking into account the return period at the location of the river. Such a situation is displayed in Fig. 1 towards the northwest, where the return periods around the river are much higher than for the discharge in the river itself. Nonetheless, fluvial and pluvial flood models are clearly distinct, and our model should not be considered the latter (cf. Eilander et al., 2023).
We compared the performance of the model with and without FLOPROS flood protection levels included through binary classification metrics displayed in Table 1. According to these metrics, and specifically for the case of the Pakistan 2022 floods, including FLOPROS protection levels does not clearly improve the estimated flood extent. With FLOPROS, the specificity of the model increases strongly and the precision increases slightly. However, the recall clearly decreases. While including FLOPROS thus avoids false positives considerably, it also reduced the true-positive rate of the model. This is in line with recent studies, which found that FLOPROS tends to overestimate flood protection levels, causing flood models to underestimate flood extents and severity (e.g., Mester et al., 2021). Furthermore, the classifiers should not be interpreted too thoroughly because the degree to which flood models can be verified is inherently limited, especially when relying on satellite observations (Bates, 2023).
5.2 Impact model
The impact model combines the flood inundation model with the CLIMADA impact framework. The inundation model there supplies the hazard component. The vulnerability is determined by calibrating impact functions to impact data of past events.
Although the flood model shows significant differences from the satellite-observed flood extent, the impact functions can be reasonably calibrated to replicate the number of displaced people in Sindh, Pakistan, during the 2022 floods. For nearly all districts, the number of displaced people estimated by the calibrated model deviates less than an order of magnitude from the reported number. We chose a step function as vulnerability for simplicity. The cross-calibrated parameters are spread considerably (see Fig. 4), but the effect of this spread on the estimated impact is surprisingly low (see Fig. 5). Likewise, although the distribution of parameters is different, the model with FLOPROS protection standards estimates impacts very similar to the model without flood protection measures. However, this might also be an effect of only slight differences between both footprints. We can therefore conclude that the deviation between estimated and reported impact is due to systematic model errors, like errors in the flood footprint or due to the particular choice of impact function.
Overall, the calibrated impact function parameters follow the expected behavior: to match the same calibration data, the model with the larger flood footprint (No Protection model) must estimate a lower impact per location; hence the median impact threshold is higher and the median percentage of displaced population is lower than for the model with the smaller flood footprint (FLOPROS model). Because of the highly simplified impact function, the calibrated displaced population ratio of around 25 % must be interpreted as the statistical mean over all occurrences of displacement, regardless of the local flood level. It is reasonable to assume that displacement increases with greater flood inundation. However, this cannot be covered by our choice of impact function. For estimating displacement risk due to river floods in a pessimistic scenario, Kam et al. (2021) assumed an inundation threshold of 0.5 m, which is close to the median values of our calibration results for both models.
Given our modeling choices, the impact model is only able to estimate displacement where residential areas are flooded. However, the PDMA data report the total displacement, irrespective of the individual reasons for displacement. By calibrating to these data, we implicitly incorporate indirect effects (socio-economic and political drivers) as well as direct effects (uninhabitable houses), which both lead to displacement, into the impact function. If there is little spatial disparity between both effects, the model is therefore able to report displacement numbers incorporating secondary reasons for displacement, but it cannot resolve the individual reasons for displacement. This is a source of model error, and the model will fail to incorporate correct numbers if the indirect flood effects are the major driver of displacement in a certain location. Figure 5 indicates that the flood impact model underestimates displacement in rural districts like Umerkot and Jacobabad and overestimates displacement in densely populated districts like Hyderabad and Karachi. In rural areas, people might be more likely to be displaced due to the lack of food, disruption of infrastructure, or destruction of farmland, even if their homes are technically unaffected by the flood. The densely populated larger cities, on the other hand, might have better flood protection and disaster mitigation measures. Indeed, large areas of farmland were destroyed and a considerable number of livestock perished as a result of the flood (OCHA, 2022a), and larger cities like Karachi received thousands of people from flood-affected rural areas (Tunio, 2022).
The historical displacement estimates in Pakistan displayed in Fig. 6 reveal that the No Protection model estimates a “baseline” of 1000 to 10 000 displaced people each month. While these figures are clearly exaggerated, they are an effect of the model assuming no flood protection at all. Nonetheless, high-impact flood events can be clearly distinguished from that baseline. The FLOPROS model predicts no displacement for most months. Therefore, any impact estimate above zero by this model is indicative of a flood event.
The timings of events estimated by the models match the reported data well. For high-impact events, the order of magnitude for displaced population matches the reported numbers for both models. However, since these events often span several months and because, in our particular model setup, we calculated impacts for each month separately, thus assuming full recovery after 1 month, the exact numbers are difficult to compare. Since 2014, IDMC reports have included many lower-impact flood events. While not all of them coincide with a peak in displacement estimated by the models, most of them range within or below the No Protection model baseline. The FLOPROS model therefore seems better suited for identifying flood disasters and estimating their severity.
With these results, we assume that the model can also be applied for identifying high-impact disasters if no data for calibration are available. If the parameters of the impact function are chosen such that the impact estimates become sensitive to the input, high-impact events will become evident by a peak in estimated displacement that can be clearly distinguished from the model baseline. For example, a flood inundation threshold of 0.2 m can be chosen to indicate the total population at risk of flooding. While the results may then differ from reports on affected or displaced population, the event severity can still be described relative to past events within the model.
As depicted in Fig. 8, both models can provide spatial information on flood impact hotspots. Comparing their output may provide information on worst-case scenarios, as the No Protection model effectively models the expected impact in case all protection measures fail. As we established that the FLOPROS model flood footprint is not necessarily a better estimate for the true flood extent, the No Protection model should therefore not be discarded.
Applying the impact model to a GloFAS river discharge forecast again revealed significant differences between the No Protection model and the FLOPROS model. The exact sensitivity of the impact estimate varies between forecasts. As shown in Fig. 7b, the FLOPROS model is more sensitive to the variation in the hazard forecast and less sensitive to the vulnerability than the No Protection model. However, these findings are unique to the forecast from 8 July 2023 and the particular model setup and need not follow a general trend. Nonetheless, there is evidence that the sensitivity towards input parameter uncertainty is stable, at least for a single flood event; see Appendix C. The differences in sensitivity between the two models can be explained with the application of the flood protection and the calibrated impact functions. For the FLOPROS model, the most important information is whether the protection level is exceeded or not. If it is, the flood depth is typically above the thresholds of the impact function ensemble. Therefore, sensitivity towards the hazard is higher than towards the vulnerability. The No Protection model is much more sensitive towards vulnerability because flooding occurs inevitably and the vulnerability therefore controls most of the impact magnitude. For both models, the sensitivity towards bootstrap sampling is negligible against the forecast uncertainty.
We presented a model for mapping river flood inundation footprints to GloFAS river discharge data. Its major advantage compared to physical river routing and flood dynamics models is the relatively low computational effort required to generate these footprints. The model is globally applicable, harnessing the high data quality of the GloFAS products. It is readily implemented in the risk modeling framework CLIMADA. We applied this model to estimate population displacement due to river floods in Pakistan, calibrating an ensemble of impact functions based on displacement data from 2022. We then applied the model to estimate historical displacement due to floods in Pakistan. The results matched OCHA and IDMC disaster reports well. We further demonstrated that this flood impact model can be applied to detect imminent events and estimate flood disaster severity through impact-based forecasts. While we showed that the model performs well in terms of countrywide numbers, we found significant differences on the district level between the calibrated model impact and reported displacements. We therefore conclude that the model's strengths lie in estimating overall event impacts and identifying spatial hotspots, rather than in small-scale flood dynamics analysis, e.g., on the city level. Although incorporating estimates of flood protection standards from the FLOPROS database changes flood footprints significantly, its effects on overall model performance remain inconclusive. As we cannot state a general range of risk associated with the two model versions, we suggest using both to estimate “worst-case” and “best-case” scenarios. However, a detailed comparison of the estimated impacts warrants further research. A sensitivity analysis revealed that the statistical uncertainty within our model is negligible compared to the uncertainty represented in the GloFAS river discharge forecast and the cross-calibrated impact functions. However, this analysis did not consider systematic model errors, such as uncertainty in the flood hazard maps or the exposure layer in the impact model. Still, dissecting the overall uncertainty in the estimated impact into sensitivity coefficients for each input parameter provides crucial information for decision-makers, as major sources of uncertainty can be identified. Further work on this flood model and its overall approach should focus on operationalizing early event detection and classification, thus supporting humanitarian organizations and stakeholders in anticipatory action and decision-making.
The metrics for binary classification, indicating the predictive performance of the flood extent estimated by the model against the flooded area observed by satellites, are computed as follows.
With true positive (TP) we denote the intersection of the flooded area estimated by the model Am with the flooded area observed by the satellite As:
Accordingly, a false positive (FP) is the set difference between Am and As and vice versa for a false negative (FN):
The classification measures precision P and recall R are calculated from these areas according to
where indicates the total area computed in a cylindrical equal-area projection (Esri:54034). We denote the set difference between the area of the most extensive river flood hazard map Ah (for a 500-year return period) and the union of observed and modeled flood areas as the true negative (TN):
We chose Ah instead of the whole area of Pakistan because the river flood model can only estimate flooding in the area of the floodplains represented in the hazard maps. Choosing the whole area of Pakistan that was not flooded would artificially improve the model classification score. With this, we can compute the specificity as
The critical success index (CSI) compares true positives with false negatives and false positives,
and the F1 score is given by the harmonic mean between precision and recall,
These measures take values between 0 and 1, with 1 indicating perfect prediction. Finally, the Matthews correlation coefficient (MCC) computes the correlation between predicted and measured values as
where 1 indicates perfect agreement, 0 indicates the predictive capability of random values, and −1 indicates complete disagreement.
The data on displaced population, as reported by PDMA (2022), are listed in Table B1. These data were used for calibrating impact functions by considering them to represent the impact of a single flood event. The event's hazard footprint was the maximum flood extent and inundation as calculated by the flood model from GloFAS data between 1 July and 30 September 2022. The data are visualized in Fig. 5 along with the estimated impacts after model calibration.

We expect that the results of the uncertainty in and sensitivity analysis of the forecast as given in Sect. 4.4 do not necessarily follow a general trend. It is conceivable that the sensitivity towards bootstrap sampling becomes larger when the uncertainty in the river discharge forecast is very low. Likewise, the interplay of FLOPROS protection standard and possible inundation depths might be different in other countries, increasing the sensitivity towards vulnerability even for the FLOPROS model. Additionally, the uncertainty in the river discharge forecast and hence the associated sensitivity strongly depend on the chosen lead time. Finally, the spread of estimated impacts can be much lower if the model does not predict a significant flood for a given river discharge forecast.
Table C1Forecasted displacement by the models including no protection standards (“No Protection”) and FLOPROS protection standards (“FLOPROS”) based on GloFAS river discharge forecasts issued on 6, 7, and 8 July 2023. The reported values are means and medians of the impact distributions yielded by both models, representing uncertainty from the discharge forecast, the bootstrap sampling within the flood model, and the ensemble of calibrated impact functions; see Sect. 4.4.

We display the model uncertainty in forecasted displacement based on GloFAS forecasts issued on 6, 7, and 8 July 2023, including a 5 d lead time each, in Fig. C1. The associated distribution means and medians are given in Table C1. While the mean and median for the No Protection model stay relatively stable and are on the same order of magnitude, the FLOPROS model exhibits a much more skewed distribution. For the days before 8 July 2023, the mean and median differ significantly, and the median increases from 6250 to 32 141 displaced people over 2 d. At the same time, the distribution spread of the No Protection model decreases from around 1 million to 500 000 displacements as the upper confidence interval limit.
The results of the sensitivity analysis of the same forecasts are displayed in Fig. C2. While the sensitivity coefficients for the FLOPROS model show the same pattern as in Fig. 7 for all forecasted days, the sensitivity of the No Protection model output shifts from forecast to vulnerability. We surmise that this is due to a nearing flood event for which the forecast uncertainty decreases the more imminent it becomes. This reduces the spread of the overall forecasted displacement. At the same time, it becomes more and more apparent within the forecast that protection levels as given in the FLOPROS database might be exceeded, demonstrated by a clear increase in median displacement in the FLOPROS model. This also contributes to the slightly increased sensitivity towards vulnerability in that model.

Figure C1Sampled displacement in Pakistan for the forecasts from the model considering no flood protection (“No Protection”) and the model considering FLOPROS flood protection standards (“FLOPROS”). Each point indicates the total impact of a sample. The sampling considers uncertainty represented by the GloFAS discharge forecast ensemble, by the bootstrapping when calculating the return periods within our model, and by the impact function ensemble calibrated with the respective model. Boxes denote the lower quartile, median, and upper quartile, and squares denote the mean. Whiskers delimit the distribution confidence interval, outside which data points can be considered outliers. The subplots display the exact same data on a linear (a) and a logarithmic (b) scale.

Figure C2First-order sensitivity coefficients with confidence intervals (error bars) for the impacts estimated by the model considering no flood protection (“No Protection”) and the model considering FLOPROS flood protection levels (“FLOPROS”), based on GloFAS forecasts issued on 6, 7, and 8 July 2023, including a 5 d lead time each. “Forecast” denotes the uncertainty represented by the GloFAS discharge forecast ensemble, “B-Sampling” the uncertainty from bootstrap sampling when computing the return period within our model, and “Vulnerability” the uncertainty represented by the impact function ensemble calibrated with the respective model. The sensitivity coefficients can be interpreted as indicating the fraction of impact variance that can be attributed to variations in the respective model input.
Software, data, and scripts for replicating the computations within this publication are available from https://doi.org/10.5281/zenodo.10518953 (Riedel, 2024).
LR and TR conceptualized the model and its application. LR developed the software, retrieved the data, conducted the research, created the visualizations, and wrote the manuscript draft. TV reviewed the software. All authors reviewed and edited the manuscript and participated in continual discussions.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The authors thank Chahan M. Kropf (ETH Zürich), Isabelle Bey (MeteoSwiss), and Pamela Probst (MeteoSwiss) for their valuable comments on the paper draft.
This paper was edited by Lele Shu and reviewed by Leonardo Milano and Sylvain Ponserre.
Alfieri, L., Burek, P., Dutra, E., Krzeminski, B., Muraro, D., Thielen, J., and Pappenberger, F.: GloFAS – global ensemble streamflow forecasting and flood early warning, Hydrol. Earth Syst. Sci., 17, 1161–1175, https://doi.org/10.5194/hess-17-1161-2013, 2013. a, b, c
Alfieri, L., Feyen, L., Dottori, F., and Bianchi, A.: Ensemble flood risk assessment in Europe under high end climate scenarios, Global Environ. Change, 35, 199–212, https://doi.org/10.1016/j.gloenvcha.2015.09.004, 2015. a
Alfieri, L., Libertino, A., Campo, L., Dottori, F., Gabellani, S., Ghizzoni, T., Masoero, A., Rossi, L., Rudari, R., Testa, N., Trasforini, E., Amdihun, A., Ouma, J., Rossi, L., Tramblay, Y., Wu, H., and Massabò, M.: Impact-based flood forecasting in the Greater Horn of Africa, Nat. Hazards Earth Syst. Sci., 24, 199–224, https://doi.org/10.5194/nhess-24-199-2024, 2024. a
Aznar-Siguan, G. and Bresch, D. N.: CLIMADA v1: a global weather and climate risk assessment platform, Geosci. Model Dev., 12, 3085–3097, https://doi.org/10.5194/gmd-12-3085-2019, 2019. a, b
Aznar-Siguan, G., Schmid, E., Vogt, T., Eberenz, S., Steinmann, C. B., Röösli, T., Yu, Y., Mühlhofer, E., Lüthi, S., Sauer, I. J., Hartman, J., Kropf, C. M., Guillod, B. P., Stalhandske, Z., Ciullo, A., Bresch, D. N., Riedel, L., Fairless, C., Schmid, T., Kam, P. M., Colombi, N., Meiler, S., Villiger, L., Rachel, B., Portmann, R., Bozzini, V., and Stocker, D.: CLIMADA v4.0.1, Zenodo [code], https://doi.org/10.5281/zenodo.8383171, 2023. a
Bates, P.: Fundamental limits to flood inundation modelling, Nature Water, 1, 566–567, https://doi.org/10.1038/s44221-023-00106-4, 2023. a
C3S: River discharge and related forecasted data from the Global Flood Awareness System, Copernicus Climate Change Service (C3S) Climate Data Store (CDS) [data set], https://doi.org/10.24381/cds.ff1aef77, 2023a. a
C3S: River discharge and related historical data from the Global Flood Awareness System, Copernicus Climate Change Service (C3S) Climate Data Store (CDS) [data set], https://doi.org/10.24381/cds.a4fdd6b9, 2023b. a
CLIMADA Contributors: CLIMADA Petals, GitHub [code], https://github.com/CLIMADA-project/climada_petals, last access: 1 July 2024. a
CRED: 2022 Disasters in Numbers, Emergency Events Database (EM-DAT) Annual Report, Centre for Research on the Epidemiology of Disasters (CRED), Brussels, https://cred.be/sites/default/files/2022_EMDAT_report.pdf (last access: 3 January 2024), 2023. a
Dankers, R. and Feyen, L.: Climate change impact on flood hazard in Europe: An assessment based on high-resolution climate simulations, J. Geophys. Res.-Atmos., 113, D19105, https://doi.org/10.1029/2007JD009719, 2008. a
Dottori, F. and Todini, E.: Developments of a flood inundation model based on the cellular automata approach: Testing different methods to improve model performance, Phys. Chem. Earth A/B/C, 36, 266–280, https://doi.org/10.1016/j.pce.2011.02.004, 2011. a
Dottori, F., Salamon, P., Alfieri, L., Bianchi, A., Feyen, L., Hirpa, F., and Lorini, V.: Flood Hazard Maps at European and Global Scale, European Commission [data set], JRC103765, https://data.jrc.ec.europa.eu/collection/id-0054 (last access: 16 January 2024), 2016a. a
Dottori, F., Salamon, P., Bianchi, A., Alfieri, L., Hirpa, F. A., and Feyen, L.: Development and evaluation of a framework for global flood hazard mapping, Adv. Water Resour., 94, 87–102, https://doi.org/10.1016/j.advwatres.2016.05.002, 2016b. a, b, c, d, e, f, g
Dottori, F., Alfieri, L., Bianchi, A., Skoien, J., and Salamon, P.: A new dataset of river flood hazard maps for Europe and the Mediterranean Basin, Earth Syst. Sci. Data, 14, 1549–1569, https://doi.org/10.5194/essd-14-1549-2022, 2022. a
ECHO: Pakistan – Severe weather, update, Situation Report, National Disaster Management Authority (NDMA), Pakistan Meteorological Department (PMD), European Civil Protection And Humanitarian Aid Operations (ECHO), Emergency Response Coordination Centre (ERCC), https://erccportal.jrc.ec.europa.eu/ECHO-Products/Echo-Flash#/echo-flash-items/25217 (last access: 11 October 2023), 2023. a
Eckstein, D., Künzel, V., and Schäfer, L.: Global Climate Risk Index 2021, Germanwatch e.V., https://reliefweb.int/report/world/global-climate-risk-index-2021 (last access: 5 January 2024), 2021. a
ECMWF: cdsapi, European Centre for Medium-Range Weather Forecasts (ECMWF), GitHub [code], https://github.com/ecmwf/cdsapi (last access: 11 October 2023), 2023a. a
ECMWF: GloFAS versioning system, European Centre for Medium-Range Weather Forecasts (ECMWF), Copernicus Emergency Management Service (CEMS), https://confluence.ecmwf.int/display/CEMS/GloFAS+versioning+system (last access: 3 January 2024), 2023b. a
Eilander, D., Couasnon, A., Leijnse, T., Ikeuchi, H., Yamazaki, D., Muis, S., Dullaart, J., Haag, A., Winsemius, H. C., and Ward, P. J.: A globally applicable framework for compound flood hazard modeling, Nat. Hazards Earth Syst. Sci., 23, 823–846, https://doi.org/10.5194/nhess-23-823-2023, 2023. a, b
Harrigan, S., Zsoter, E., Alfieri, L., Prudhomme, C., Salamon, P., Wetterhall, F., Barnard, C., Cloke, H., and Pappenberger, F.: GloFAS-ERA5 operational global river discharge reanalysis 1979–present, Earth Syst. Sci. Data, 12, 2043–2060, https://doi.org/10.5194/essd-12-2043-2020, 2020. a
Harrigan, S., Zsoter, E., Cloke, H., Salamon, P., and Prudhomme, C.: Daily ensemble river discharge reforecasts and real-time forecasts from the operational Global Flood Awareness System, Hydrol. Earth Syst. Sci., 27, 1–19, https://doi.org/10.5194/hess-27-1-2023, 2023. a
Hirabayashi, Y., Mahendran, R., Koirala, S., Konoshima, L., Yamazaki, D., Watanabe, S., Kim, H., and Kanae, S.: Global flood risk under climate change, Nat. Clim. Change, 3, 816–821, https://doi.org/10.1038/nclimate1911, 2013. a, b
Hoyer, S. and Hamman, J.: xarray: N-D labeled Arrays and Datasets in Python, J. Open Res. Softw., 5, 10, https://doi.org/10.5334/jors.148, 2017. a
IDMC: 2023 Global Report on Internal Displacement, Internal Displacement Monitoring Centre (IDMC), https://www.internal-displacement.org/publications/2023-global-report-on-internal-displacement (last access: 9 October 2023), 2023a. a, b
IDMC: Global Internal Displacement Database, Internal Displacement Monitoring Centre (IDMC), https://www.internal-displacement.org/database/ (last access: 20 October 2023), 2023b. a, b, c
IFRC: Forecast-based financing and disaster displacement: acting early to reduce the humanitarian impacts of displacement, International Federation of Red Cross and Red Crescent Societies (IFRC), https://www.forecast-based-financing.org/wp-content/uploads/2020/10/RCRC_IFRC-FbF-and-Displacement-Issue-Brief.pdf (last access: 2 April 2024), 2020. a
Kam, P. M., Aznar-Siguan, G., Schewe, J., Milano, L., Ginnetti, J., Willner, S., McCaughey, J. W., and Bresch, D. N.: Global warming and population change both heighten future risk of human displacement due to river floods, Environ. Res. Lett., 16, 044026, https://doi.org/10.1088/1748-9326/abd26c, 2021. a, b
Kropf, C. M., Ciullo, A., Otth, L., Meiler, S., Rana, A., Schmid, E., McCaughey, J. W., and Bresch, D. N.: Uncertainty and sensitivity analysis for probabilistic weather and climate-risk modelling: an implementation in CLIMADA v.3.1.0, Geosci. Model Dev., 15, 7177–7201, https://doi.org/10.5194/gmd-15-7177-2022, 2022. a
Kyselý, J.: A Cautionary Note on the Use of Nonparametric Bootstrap for Estimating Uncertainties in Extreme-Value Models, J. Appl. Meteorol. Climatol., 47, 3236–3251, https://doi.org/10.1175/2008JAMC1763.1, 2008. a
Loveland, M., Kiaghadi, A., Dawson, C. N., Rifai, H. S., Misra, S., Mosser, H., and Parola, A.: Developing a Modeling Framework to Simulate Compound Flooding: When Storm Surge Interacts With Riverine Flow, Front. Climate, 2, 609610, https://doi.org/10.3389/fclim.2020.609610, 2021. a
Mester, B., Willner, S. N., Frieler, K., and Schewe, J.: Evaluation of river flood extent simulated with multiple global hydrological models and climate forcings, Environ. Res. Lett., 16, 094010, https://doi.org/10.1088/1748-9326/ac188d, 2021. a
Nogueira, F.: Bayesian Optimization: Open source constrained global optimization tool for Python, GitHub [code], https://github.com/fmfn/BayesianOptimization (last access: 7 October 2023), 2014. a
OCHA: Pakistan: 2022 Monsoon Floods, Situation Report 10, United Nations Office for the Coordination of Humanitarian Affairs (OCHA), https://reliefweb.int/report/pakistan/pakistan-2022-monsoon-floods-situation-report-no-10-28-october-2022 (last access: 2 November 2023), 2022a. a
OCHA: Pakistan: 2022 Monsoon Floods, Situation Report 9, United Nations Office for the Coordination of Humanitarian Affairs (OCHA), https://reliefweb.int/report/pakistan/pakistan-2022-monsoon-floods-situation-report-no-9-14-october-2022 (last access: 16 October 2023), 2022b. a
OCHA: ReliefWeb advanced search for Disaster Type: Floods and Country: Pakistan, ReliefWeb, United Nations Office for the Coordination of Humanitarian Affairs (OCHA), https://reliefweb.int/disasters?advanced-search=% 28C182% 29_% 28TY4611% 29 (last access: 26 September 2023), 2023. a, b, c
PDMA: Daily Situation Report, PDMA (SINDH)/(SITREP)/2022/1239, Provincial Disaster Management Authority (PDMA), Rehabilitation Department, Government of Sindh, https://pdma.gos.pk/Documents/Flood/Flood_2022 (last access: 16 January 2024), 2022. a, b, c, d, e
Riedel, L.: Software, Data, and Scripts for “Fluvial Flood Inundation and Humanitarian Impact Model Based On Open Data”, Zenodo [code and data set], https://doi.org/10.5281/zenodo.10518953, 2024. a
Röösli, T., Appenzeller, C., and Bresch, D. N.: Towards operational impact forecasting of building damage from winter windstorms in Switzerland, Meteorol. Appl., 28, e2035, https://doi.org/10.1002/met.2035, 2021. a
Saltelli, A. and Annoni, P.: How to avoid a perfunctory sensitivity analysis, Environ. Model. Softw., 25, 1508–1517, https://doi.org/10.1016/j.envsoft.2010.04.012, 2010. a
Sampson, C. C., Smith, A. M., Bates, P. D., Neal, J. C., Alfieri, L., and Freer, J. E.: A high-resolution global flood hazard model, Water Resour. Res., 51, 7358–7381, https://doi.org/10.1002/2015WR016954, 2015. a
Sauer, I. J., Reese, R., Otto, C., Geiger, T., Willner, S. N., Guillod, B. P., Bresch, D. N., and Frieler, K.: Climate signals in river flood damages emerge under sound regional disaggregation, Nat. Commun., 12, 2128, https://doi.org/10.1038/s41467-021-22153-9, 2021. a
Scussolini, P., Aerts, J. C. J. H., Jongman, B., Bouwer, L. M., Winsemius, H. C., de Moel, H., and Ward, P. J.: FLOPROS: an evolving global database of flood protection standards, Nat. Hazards Earth Syst. Sci., 16, 1049–1061, https://doi.org/10.5194/nhess-16-1049-2016, 2016. a, b
Thielen, J., Bartholmes, J., Ramos, M.-H., and de Roo, A.: The European Flood Alert System – Part 1: Concept and development, Hydrol. Earth Syst. Sci., 13, 125–140, https://doi.org/10.5194/hess-13-125-2009, 2009. a
Tunio, Z.: In Pakistan, 33 Million People Have Been Displaced by Climate-Intensified Floods, Inside Climate News, https://insideclimatenews.org/news/16092022/pakistan-flood-displacement/ (last access: 10 October 2023), 2022. a
UNDRR: Sendai Framework for Disaster Risk Reduction 2015 - 2030, United Nations Office for Disaster Risk Reduction (UNDRR), https://www.undrr.org/quick/11409 (last access: 2 April 2024), 2015. a
UNICEF: Children displaced in a changing climate, United Nations Children's Fund (UNICEF), https://www.unicef.org/reports/children-displaced-changing-climate (last access: 17 October 2023), 2023. a
UNOSAT: Satellite detected water extents between 01 and 29 August 2022 over Pakistan, UN Operational Satellite Applications Programme (UNOSAT), The Humanitarian Data Exchange [data set], https://data.humdata.org/dataset/satellite-detected-water-extents-between-01-and-29-august-2022-over-pakistan (last access: 11 October 2023), 2022. a, b, c
Van Der Knijff, J. M., Younis, J., and De Roo, A. P. J.: LISFLOOD: a GIS-based distributed model for river basin scale water balance and flood simulation, Int. J. Geogr. Inform. Sci., 24, 189–212, https://doi.org/10.1080/13658810802549154, 2010. a, b
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, İ., Feng, Y., Moore, E. W., VanderPlas, J., Laxalde, D., Perktold, J., Cimrman, R., Henriksen, I., Quintero, E. A., Harris, C. R., Archibald, A. M., Ribeiro, A. H., Pedregosa, F., van Mulbregt, P., and SciPy 1.0 Contributors: SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python, Nature Methods, 17, 261–272, https://doi.org/10.1038/s41592-019-0686-2, 2020. a
Ward, P. J., Jongman, B., Weiland, F. S., Bouwman, A., Beek, R. v., Bierkens, M. F. P., Ligtvoet, W., and Winsemius, H. C.: Assessing flood risk at the global scale: model setup, results, and sensitivity, Environ. Res. Lett., 8, 044019, https://doi.org/10.1088/1748-9326/8/4/044019, 2013. a
Willner, S. N., Levermann, A., Zhao, F., and Frieler, K.: Adaptation required to preserve future high-end river flood risk at present levels, Sci. Adv., 4, eaao1914, https://doi.org/10.1126/sciadv.aao1914, 2018. a
Winsemius, H. C., Van Beek, L. P. H., Jongman, B., Ward, P. J., and Bouwman, A.: A framework for global river flood risk assessments, Hydrol. Earth Syst. Sci., 17, 1871–1892, https://doi.org/10.5194/hess-17-1871-2013, 2013. a
WorldPop: The spatial distribution of population in 2020 with country total adjusted to match the corresponding UNPD estimate, Pakistan (1 km resolution), WorldPop (School of Geography and Environmental Science, University of Southampton; Department of Geography and Geosciences, University of Louisville; Departement de Geographie, Universite de Namur) and Center for International Earth Science Information Network (CIESIN), Columbia University, Global High Resolution Population Denominators Project – Funded by The Bill and Melinda Gates Foundation (OPP1134076), WorldPop [data set], https://doi.org/10.5258/SOTON/WP00671, 2020. a, b
Yamazaki, D., Kanae, S., Kim, H., and Oki, T.: A physically based description of floodplain inundation dynamics in a global river routing model, Water Resour. Res., 47, W04501, https://doi.org/10.1029/2010WR009726, 2011. a
Zhuang, J., Dussin, R., Huard, D., Bourgault, P., Banihirwe, A., Raynaud, S., Malevich, B., Schupfner, M., Filipe, Levang, S., Jüling, A., Almansi, M., Scott, R., Rasp, S., Smith, T. J., Stachelek, J., Plough, M., Pierre, Bell, R., and Li, X.: pangeo-data/xESMF, Zenodo [code], https://doi.org/10.5281/zenodo.7800141, 2023. a
- Abstract
- Introduction
- Flood model
- Implementation
- Application to floods in Pakistan
- Discussion
- Conclusions
- Appendix A: Classification metrics for flood extent
- Appendix B: PDMA displacement data
- Appendix C: Uncertainty in and sensitivity analysis of multiple forecasts
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References
- Abstract
- Introduction
- Flood model
- Implementation
- Application to floods in Pakistan
- Discussion
- Conclusions
- Appendix A: Classification metrics for flood extent
- Appendix B: PDMA displacement data
- Appendix C: Uncertainty in and sensitivity analysis of multiple forecasts
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References