the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 21 Dec 2022
| 21 Dec 2022
The Multiple Snow Data Assimilation System (MuSA v1.0)
Esteban Alonso-González
Kristoffer Aalstad
Mohamed Wassim Baba
Jesús Revuelto
Juan Ignacio López-Moreno
Joel Fiddes
Richard Essery
Simon Gascoin
Accurate knowledge of the seasonal snow distribution is vital in several domains including ecology, water resources management, and tourism. Current spaceborne sensors provide a useful but incomplete description of the snowpack. Many studies suggest that the assimilation of remotely sensed products in physically based snowpack models is a promising path forward to estimate the spatial distribution of snow water equivalent (SWE). However, to date there is no standalone, open-source, community-driven project dedicated to snow data assimilation, which makes it difficult to compare existing algorithms and fragments development efforts. Here we introduce a new data assimilation toolbox, the Multiple Snow Data Assimilation System (MuSA), to help fill this gap. MuSA was developed to fuse remotely sensed information that is available at different timescales with the energy and mass balance Flexible Snow Model (FSM2). MuSA was designed to be user-friendly and scalable. It enables assimilation of different state variables such as the snow depth, SWE, snow surface temperature, binary or fractional snow-covered area, and snow albedo and could be easily upgraded to assimilate other variables such as liquid water content or snow density in the future. MuSA allows the joint assimilation of an arbitrary number of these variables, through the generation of an ensemble of FSM2 simulations. The characteristics of the ensemble (i.e., the number of particles and their prior covariance) may be controlled by the user, and it is generated by perturbing the meteorological forcing of FSM2. The observational variables may be assimilated using different algorithms including particle filters and smoothers as well as ensemble Kalman filters and smoothers along with their iterative variants. We demonstrate the wide capabilities of MuSA through two snow data assimilation experiments. First, 5 m resolution snow depth maps derived from drone surveys are assimilated in a distributed fashion in the Izas catchment (central Pyrenees). Furthermore, we conducted a joint-assimilation experiment, fusing MODIS land surface temperature and fractional snow-covered area with FSM2 in a single-cell experiment. In light of these experiments, we discuss the pros and cons of the assimilation algorithms, including their computational cost.
- Article
(4820 KB) - Full-text XML
- BibTeX
- EndNote





The snow cover has a profound effect on the water cycle (García-Ruiz et al., 2011) and ecosystems (Lin and West, 2022) of high-latitude and mountain regions. It represents a natural reservoir of freshwater resources, sustaining crop irrigation, hydropower generation, and drinking water supply to a fifth of humanity (Barnett et al., 2005). In addition, the ski industry is an important economic driver in many mountain areas. As a consequence, good knowledge of the snow cover properties has a strong scientific, societal, and economic value (Sturm et al., 2017).
Due to the harsh environmental conditions that often prevail in snow-dominated areas, in situ monitoring of the snowpack based on automatic devices and weather stations is both costly and logistically challenging. In addition, due to the spatiotemporal variability in the snowpack (López-Moreno et al., 2011), even dense monitoring networks may suffer from a lack of representativeness (Molotch and Bales, 2006; Cluzet et al., 2022). Yet, estimating SWE spatial distribution is important to make accurate predictions of snowmelt runoff in alpine catchments. Satellite remote sensing provides spatial information about snow-related variables including (i) snow cover spatial extent at various spatiotemporal scales (Aalstad et al., 2020; Gascoin et al., 2019; Hall et al., 2002; Hüsler et al., 2014), (ii) snow depth (Lievens et al., 2019; Marti et al., 2016), (iii) albedo (Kokhanovsky et al., 2020), and (iv) land surface temperature (Bhardwaj et al., 2017). However, the direct estimation of key variables such as the snow water equivalent (SWE) or density by means of remote sensing techniques remains challenging (Dozier et al., 2016). The only remote sensing tools that have shown some potential to retrieve SWE are passive microwave sensors. Unfortunately, their coarse resolution and the fact that they tend to saturate above a certain SWE threshold prevent their usage over mountainous regions or areas with a thick snowpack (Luojus et al., 2021).
Numerical models can estimate the distribution of SWE at different spatiotemporal scales using meteorological information derived from automatic weather stations (Essery, 2015; Liston and Elder, 2006a) or atmospheric models (Alonso-González et al., 2018; Wrzesien et al., 2018). Nonetheless, such snowpack models exhibit a number of limitations that may cause strong biases in the SWE simulations (Wrzesien et al., 2017). Snowpack model uncertainties originate partly from their simplified representation of physical processes (Günther et al., 2019; Fayad and Gascoin, 2020) but most importantly from errors in the meteorological forcing (Raleigh et al., 2015). In this context, the fusion of remote sensing products with snowpack models using data assimilation is key to improve snowpack simulations (Girotto et al., 2020; Largeron et al., 2020).
Several remotely sensed products may be used to update snowpack models. The fractional snow-covered area (FSCA) from optical sensors was the first product to be assimilated (Clark et al., 2006; Durand et al., 2008; Kolberg and Gottschalk, 2006). FSCA assimilation remains extensively used in both distributed (Margulis et al., 2016) and semi-distributed models (Thirel et al., 2013) due to the long time series of snow-covered area (SCA) observations and the development of new higher-resolution products (Baba et al., 2018). It is possible to further improve snowpack simulations by assimilating snow depths (Deschamps-Berger et al., 2022; Smyth et al., 2020). The assimilation of remotely sensed surface reflectances may also be beneficial (Charrois et al., 2016; Cluzet et al., 2020; Revuelto et al., 2021b), but further research is needed on this topic to demonstrate advantages over assimilating derived higher-level products such as FSCA and albedo.
Whereas snowpack models are increasingly available as open-source software and remote sensing products as open data, to our knowledge there is no standalone open-source application to develop multiple snow data assimilation experiments. This specific issue was highlighted by Fayad et al. (2017) as a strong limitation to advancing knowledge on the snow cover in regions which receive less attention from the mainstream research community. In addition, some data assimilation frameworks are based on highly specific implementations tied to operational constraints (Cluzet et al., 2021). This situation prevents the development of reproducible snow data assimilation studies and challenges the comparison of the performance of different snow data assimilation algorithms.
This is why we have developed a new open-source data assimilation toolbox, the Multiple Snow Data Assimilation System (MuSA). MuSA is an ensemble-based snow data assimilation tool. It enables the fusion of multiple observations with a physically based snowpack model while taking into account various sources of forcing and measurement uncertainty. It is an open-source collaborative project entirely written in the Python programming language. It should facilitate the development of snow data assimilation experiments, as well as the generation of snowpack reanalyses and near-real-time snowpack monitoring. It was designed with a modular structure to foster collaborative development, allowing advanced users to seamlessly implement new features with minimal effort. In the following sections, we describe the features of MuSA and show different examples of its usage, assimilating remote sensing products of different spatiotemporal resolutions.
The core of MuSA is an energy and mass balance of the snowpack model, Flexible Snow Model (FSM2; Essery, 2015). FSM2 has several options for the parameterizations of key processes related to the energy and mass balance of the snowpack. The most complex configuration is chosen by default in MuSA, leading to a more detailed simulation of the internal snowpack processes. Albedo is computed from the age of the snow, decreasing its value as snow ages and increasing it with fresh snowfalls. Thermal conductivity of the snowpack is computed as a function of the snow density. Snow density is computed considering overburden and thermal metamorphism. Turbulent energy fluxes are computed as a function of atmospheric stability. Meltwater percolation in the snowpack is computed using the gravitational drainage. Although this is the default configuration, it is possible to choose any other FSM2 setup, which may result in slight performance differences in terms of both the computational cost and the accuracy of the model (Günther et al., 2019). As envisaged in Westermann et al. (2022), the potential to run multiple model configurations leaves the door open for pursuing rigorous model comparison using the model evidence framework (MacKay, 2003) in the cryospheric sciences.
MuSA was designed as a Python program encapsulating the FSM2 Fortran code (Fig. 1). It handles the forcing and initial files, as well as the FSM2 runs and outputs, by internally generating the required ensemble of simulations from simple configuration (config.py) and constants (constants.py) files that should be filled by the user to both configure the MuSA environment and define the priors, respectively. Then, it solves most of the challenges of ensemble-based snow data assimilation frameworks for the user, as it internally handles the input/output (I/O) and parallelization while keeping track of the ensembles that should flow in different ways depending on the chosen data assimilation (DA) algorithm. The data assimilation algorithms are independently implemented on a grid cell basis, allowing both single-cell and parallel spatially distributed simulations. The outputs of MuSA consist of the posterior mean snow simulation from FSM2 (updated_idx_idy.csv), the posterior standard deviations of the FSM2 ensemble (sd_idx_idy.csv), information related to the posterior perturbation parameters and the observations (DA_idx_idy.csv), and the original simulation without perturbation (OL_idx_idy.csv). Additionally, it is possible to store the posterior ensemble of every cell.
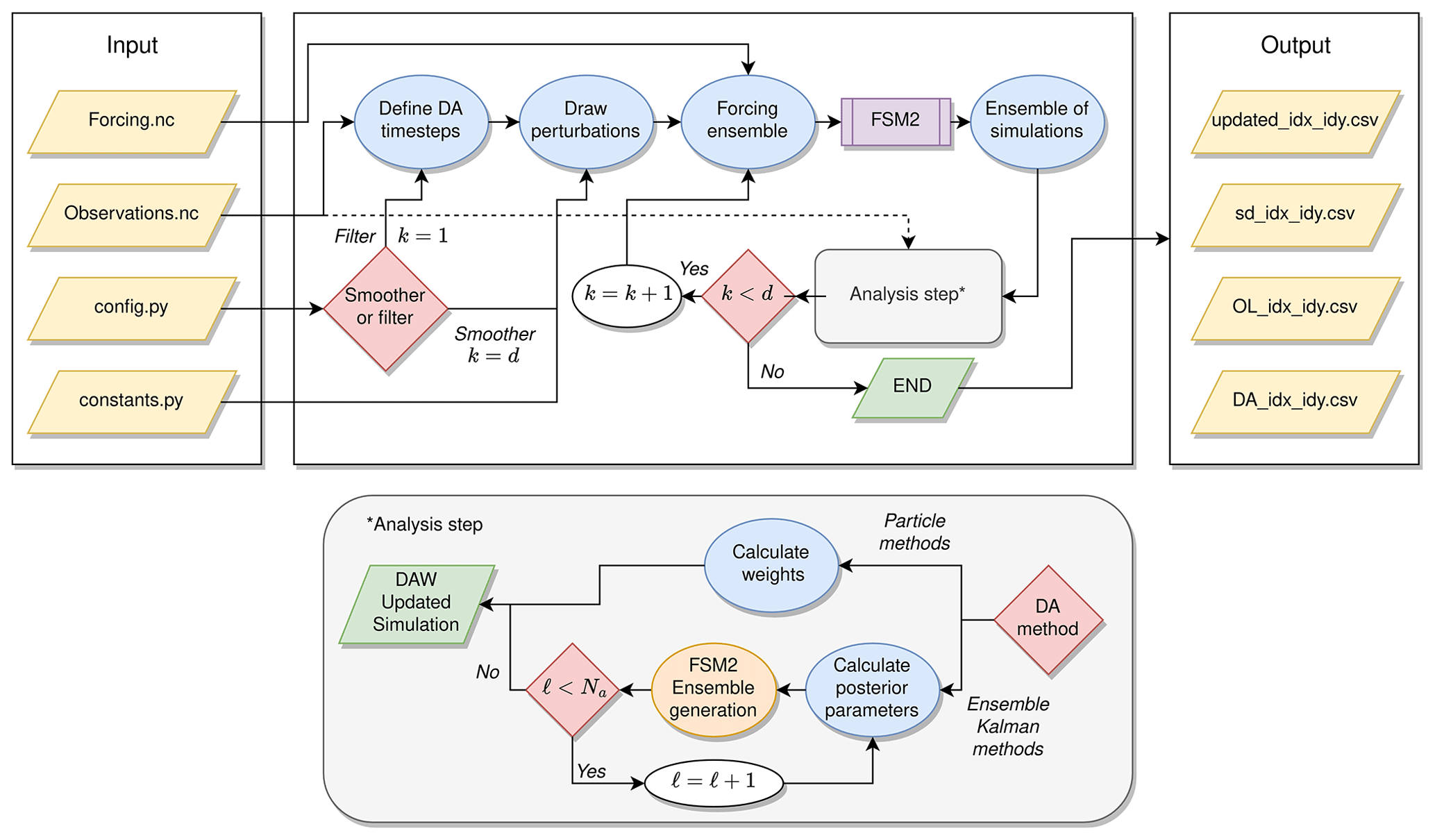
Figure 1MuSA internal workflow. k, d, ℓ, Na, DAW, idx, and idy refer to the timing of the analysis step, number of observation times, current assimilation cycle number, total number of assimilation cycles, data assimilation window, longitude cell index, and latitude cell index, respectively.
The following data assimilation algorithms are currently implemented in MuSA:
-
particle filter (PF; Gordon et al., 1993; van Leeuwen et al., 2019);
-
ensemble Kalman filter (EnKF; Evensen, 1994; van Leeuwen, 2020);
-
ensemble Kalman filter with multiple data assimilation (EnKF-MDA; Emerick and Reynolds, 2012);
-
particle batch smoother (PBS; Margulis et al., 2015), a batch smoother variant of the PF;
-
ensemble smoother (ES; van Leeuwen and Evensen, 1996), a batch smoother variant of the EnKF;
-
ensemble smoother with multiple data assimilation (ES-MDA; Emerick and Reynolds, 2013).
In its current version, MuSA is able to assimilate the following variables:
-
SWE [mm]
-
snow depth [m]
-
land surface temperature [K]
-
fractional snow-covered area [–]
-
albedo [–]
-
sensible heat flux to the atmosphere [W m−2]
-
latent heat flux to the atmosphere [W m−2].
We expect to provide support for even more variables in the future. Note that the ensemble Kalman schemes involving multiple data assimilation are iterative schemes (Stordal and Elsheikh, 2015; van Leeuwen et al., 2019). For the PF, several standard resampling algorithms (see Li et al., 2015, for a review) are available in MuSA, namely bootstrapping, residual resampling, stratified resampling, and systematic resampling. In addition to these standard resampling techniques, we have also implemented a heuristic approach based on redrawing from a normal approximation to the posterior, which is loosely inspired by more advanced particle methods (Särkkä, 2013; van Leeuwen et al., 2019). This redrawing from the approximate posterior generates new samples of perturbation parameters at each assimilation step. In the case of complete degeneracy, where all the weight is on one particle, this redrawing technique instead uses the prescribed prior standard deviations for generating perturbation parameters, corrected by a scaling factor (to be selected by the user, fixed to 0.3 by default) to avoid overdispersing the ensemble.
The inputs of MuSA are composed of (i) gridded meteorological forcing to generate the ensemble of FSM2 simulations and (ii) gridded observations which are assimilated. Optionally, it is possible to provide a mask, covering areas where simulations should not be implemented in order to save computational resources or restrict the runs to a specific area inside the provided domain. These inputs must be provided as files encoded in the Network Common Data Form (netCDF; Rew and Davis, 1990) format. MuSA is able to handle different observational products as long as the meteorological forcing and the observations share the same geometry (i.e., the same number of cells in the longitudinal and latitudinal dimensions). As in many other distributed snowpack models, there is currently no communication between grid cells in MuSA. This makes MuSA easily parallelizable as each cell is simulated and updated completely independently of the others (i.e., embarrassingly parallel). Different parallelization schemes are already implemented, including multiprocessing for single-node runs and message passing interface (MPI) and Portable Batch System job arrays, to provide support for computing clusters. Due to the embarrassingly parallel nature (no communication between tasks) of the MuSA computational problem, other parallelization schemes can easily be implemented. All the data processing is done by default in the temporary file system, but the user can choose any other location such as a specific temporary folder in a multi-node cluster or a random access memory drive in a local workstation to speed up the I/O processes.
2.1 Ensemble generation
The DA algorithms implemented in MuSA all require a prior ensemble of simulations to represent uncertainty. The number of ensemble members (or, equivalently, particles; van Leeuwen, 2009), which we denote by Ne, should be specified by the user, as this drastically affects both the computational cost of the experiments and the performance of the data assimilation algorithms. To generate an ensemble of snowpack state trajectories, MuSA perturbs the meteorological forcing to run an ensemble of FSM2 simulations. An arbitrary number of forcing variables can be perturbed. The perturbation of the forcing is performed by drawing spatially independent random perturbation parameters from a normal distribution or lognormal distribution. The prior standard deviation and mean of these distributions should be specified by the user. MuSA supports normal or lognormal probability functions to generate additive or multiplicative perturbations, respectively, depending on the physical bounds of the variable to be perturbed. Additive perturbations are typically used for air temperature. Multiplicative perturbations are recommended for precipitation to avoid negative values as well as for shortwave radiation to avoid negative values and positive nighttime values.
Once the forcing is perturbed, MuSA partitions the precipitation between the liquid and solid phase. To estimate the phase of the precipitation, two different approaches are implemented. The simpler approach is based on a logistic function of the 2 m air temperature (Kavetski and Kuczera, 2007). A more complex psychrometric energy balance method is also implemented in MuSA. This approach uses the relative humidity and 2 m air temperature to infer the surface temperature of the falling hydrometeors, from which the phase of the precipitation can be estimated (Harder and Pomeroy, 2013).
2.2 Meteorological forcing
The variables required as forcing to run MuSA include downwelling (i.e., incoming) shortwave and longwave radiation [W m−2], total (sum of liquid and solid) precipitation , surface atmospheric pressure [Pa], 2 m air temperature [K], relative humidity [%], and 10 m wind speed [m s−1]. In the current version of MuSA, the forcing must be provided in the netCDF format at an hourly time step in a grid-based geometry, without any specific requirement regarding the native spatial resolution. The most likely candidates to be used as meteorological forcing for MuSA will be the outputs of atmospheric simulations or automatic weather station data. These include atmospheric reanalyses, such as ERA5 (Hersbach et al., 2020) or MERRA-2 (Gelaro et al., 2017), and regional climate model outputs (Alonso-González et al., 2021) as well as the outputs of different downscaling approaches driven by the aforementioned datasets (e.g., Fiddes and Gruber, 2014; Gutmann et al., 2016; Havens et al., 2017; Fiddes et al., 2022; Liston and Elder, 2006b). Other sources of information include automatic weather stations or gridded products derived from the interpolation of point-scale meteorological information. The forcing variables should be provided in the International System of Units, but it is possible to perform simple unit transformations internally to facilitate the preprocessing of different forcing data sources, using the following affine transformation.
where ϕk (for ) is a forcing time series provided by the user with units Φ and ψk with converted units Ψ is the transformed forcing time series after scaling by a with units Ψ Φ−1 and translating by b with units Ψ.
Each grid cell is solved independently, which includes the reading of the forcing that occurs along the time dimension. Otherwise, each process would have to store considerably more data in memory, leading to more costly I/O operations that would slow down the run time. Even so, just reading along the time dimension can come with a considerable computational cost if the time dimension is large. To alleviate this, the time spent reading the forcing can be reduced by setting the chunk (a subset of the file to be read or written as a single I/O operation) of the netCDF forcing files along the time dimension. To speed up the subsequent relaunching of the simulations when smoothing and filtering, MuSA generates an intermediate binary file with the forcing information needed to run a complete simulation for each grid cell.
2.3 Observations and masked cells
MuSA is able to assimilate an arbitrary number of different observations that can be irregularly distributed in time and space. It is also possible to perform joint-assimilation experiments that assimilate more than one variable type at the same time. A temporally and spatially constant scalar corresponding to the assumed observation error variance must be provided for each type of observation that is to be assimilated. This assumption implies a diagonal observation error covariance matrix, R, which is tantamount to assuming that observation errors are uncorrelated in both time and space. Note that this formulation allows the user to account for differences in observation error that arise in the case when a variable is observed by multiple sensors with varying accuracy. By modifying the likelihood, it would also be possible to account for non-Gaussian observation errors (Fletcher and Zupanski, 2006; Fowler and van Leeuwen, 2013), but this is not yet supported in MuSA. The time step of the observations does not have to be the same as that of the forcing so that the observations can be irregularly spaced in time. Also, it is not necessary that the observations of the different variables occur at the same time step, allowing the assimilation of products from different satellite platforms with different orbits. Optionally, a binary mask can be provided in a separate file to delineate the basin of interest. If provided, MuSA will skip the cells that are not covered by the mask. Again, the mask must be provided on the same grid as the forcing and the observations. Many remotely sensed products exhibit gaps due to the presence of clouds or failures in the remote sensing devices. As a general rule we do not recommend filling the gaps of the observed series. These filled data would exhibit a different error variance than the direct estimations from the remote sensors, introducing uncertainties which are not compatible with the data assimilation process. MuSA will internally handle the gaps in the observations, provided that the netCDF files are generated using the aforementioned conventions, assimilating just the time steps where information is available.
Data assimilation (DA) is the exercise of fusing uncertain information from observations and (typically) geoscientific models (Evensen et al., 2022; Reich and Cotter, 2015). The DA schemes used in MuSA vary in their approach to state estimation as well as in the underlying assumptions and algorithms employed. In this section we provide an overview of these schemes as well as the underlying theory. Readers well versed in DA could consider skipping this entire section or at least skipping to Sect. 3.4 and 3.5 where the algorithms are presented.
3.1 Bayesian inference
In line with most modern approaches to DA (Wikle and Berliner, 2007; Carrassi et al., 2018; van Leeuwen et al., 2019), the assimilation schemes used in MuSA are built on the foundation of Bayesian inference (e.g., Lindley, 2000; MacKay, 2003; Särkkä, 2013; Nearing et al., 2016). In this approach, the target quantity is the posterior distribution p(x|y), the probability of the model state x∈ℝm given the observations y∈ℝd, which can be inferred using Bayes' rule:
in which p(y|x), the probability of the observed data given a model state, is called the likelihood and p(x), the probability of the state before considering the observations, is known as the prior. According to the likelihood principle, the likelihood should be seen as a function of the model state and not of the fixed observations. So it is implicitly understood that the state is as a vector of random variables, while the observation vector is deterministic. In this Bayesian interpretation, rather than being narrowly synonymous with frequency, probability is a broad measure of uncertainty. The evidence (or marginal likelihood) in the denominator of Eq. (2) is given by
where the range of integration is understood to be over all possible values of x, namely the support of the prior. This evidence is just a function of the observations, so it simply serves as a normalizing constant in this incarnation of Bayes' theorem, which we can rewrite as
to emphasize that the posterior is proportional to the product of the likelihood (what the data tell us) and the prior (what we believed before considering the data). These are usually probability density rather than mass functions as we tend to deal with continuous variables in DA. Since the posterior must integrate to 1, we can safely ignore the evidence term as long as we are just dealing with the usual first level of inference where we fit a specific model. The evidence is nonetheless vital in the second level of inference where we compare models (see MacKay, 2003), but we do not pursue that here. Thus, we will henceforth use the notation Z=p(y) to emphasize that the evidence simply serves as a normalizing constant in this overview.
To get the Bayesian engine to run and infer the posterior, we need to specify the two input distributions on the right-hand side of Eq. (2), namely the prior and the likelihood. To construct the likelihood, we specify an observation (or equivalently measurement, data-generating, forward) model of the form
where x⋆ contains the true values of the state variables, ℋ(⋅) is the observation operator which maps from state to observation space, and ϵ is the observation error. Often, as is the case in MuSA, the observation operator picks out predicted observations, i.e., the state variables that correspond to observations, from the full state vector. As is commonly done in DA (Carrassi et al., 2018), we assume that the observation errors are additive, are unbiased, and follow a Gaussian distribution; i.e., , where R is the observation error covariance matrix. Thereby the likelihood becomes
where is a normalizing constant, (⋅)T denotes the transpose, denotes the predicted observations, and we have used conditional on x being true. Roughly speaking, the likelihood can be seen as a model misfit term which quantifies how likely the actual observations are given a particular model state. The states with a higher likelihood will correspond to those with predicted observations closer to the actual observations. The next ingredient is the prior distribution over states, p(x), which can be specified based on initial beliefs, which may include physical bounds, expert opinion, “objective” defaults (using, e.g., maximum entropy), or knowledge from earlier analyses (Lindley, 2000; MacKay, 2003; Banner et al., 2020). For the latter, consider the case of assimilating two conditionally independent observations y1 and y2. Then the posterior can be obtained using either batch or recursive estimation (Särkkä, 2013). The batch approach involves solving directly for
while for the recursive approach we note that
so we can split up the batch solution by first conditioning on y1 to obtain an intermediate posterior; then we use this as a prior when updating with y2 to obtain the full posterior as follows:
This recursive approach will give the same answer as the batch approach, but it can often be helpful to split the inference into smaller chunks, especially for dynamic problems. We can extend recursive estimation to an arbitrary number of observations as long as they are conditionally independent.
In theory, evaluating the posterior simply involves taking the product of two terms. Naïvely, this suggests that we can estimate the posterior through a simple grid approximation (MacKay, 2003). Unfortunately, inferring the posterior is usually akin to looking for a needle in a haystack due to the curse of dimensionality (Snyder et al., 2008), which manifests itself when we have a high dimensional state space and/or highly informative data. As such, we need to adopt efficient algorithms when performing DA in practice. Roughly speaking, the most widely used Bayesian DA schemes can be split into two major computational approaches: variational techniques and Monte Carlo methods (Carrassi et al., 2018). Despite success in operational meteorology (Bannister, 2017), the variational approach has received less attention in cryospheric applications (Dumont et al., 2012), since it involves gradient terms that are difficult to implement and has not yet shown any clear gains in performance over Monte Carlo. As such, in MuSA we restrict ourselves to Monte Carlo methods where the naming reflects that these approaches rely on using (pseudo)random numbers to sample from probability distributions (MacKay, 2003).
3.2 Prediction, filtering, and smoothing
The subset of Monte Carlo methods used in MuSA can be split into two classes: those derived from the EnKF (Evensen, 1994) and those derived from the PF (Gordon et al., 1993). These can be further subdivided into filters and smoothers depending on how time dynamics are handled (Carrassi et al., 2018). As such, it is instructive to appreciate the differences between stochastic prediction, filtering, and smoothing (see Jazwinski, 1970; Särkkä, 2013) as well as how these are implemented in MuSA. To do so, we introduce the following notation: we consider discrete points in time for , where t0 is the initial time and Δt is the model time step and we let xk=x(tk) denote the state at a given time. We employ analogous notation for the observations yk, but (without loss of generality) we assume that the initial time is unobserved. Note that in practice we usually do not have observations at every model time step; we have just assumed this here to simplify notation. The extension of filters and smoothers to the more realistic case with sparse observations in time is straightforward and merely requires a slight change in indexing so that filtering and smoothing only take place using predicted observations at observation times.
In DA, prediction involves estimating the future state given past observations: , where and ℓ<k. The archetypal example of this is the familiar task of weather forecasting through ensemble-based numerical weather prediction (Bauer et al., 2015). In the context of prediction, the concepts of future and past are just relative to one another and not necessarily representative of real time. So one can also make predictions of the past, as long as any observations considered are from the even more distant past. Since prediction is a step in both filtering and smoothing, we explain how to implement it probabilistically. Prediction from k−1 to k can be formulated as follows:
where ℳ(⋅) is the dynamical model (FSM2 in MuSA) and is the additive model error term which we assume to be independent in time and follow a zero-mean Gaussian distribution with covariance matrix Q. These assumptions can be relaxed without loss of generality, but their convenience and broad justifiability mean that they are often employed (Carrassi et al., 2018). Crucially, the above prediction step produces Markovian (memoryless) dynamics where the current state depends only on the previous state and noise. The Markov property is crucial in making the filtering and smoothing problems tractable. It implies , which lets us factorize and simplify distributions such as the full prior as follows:
where the transition density is Gaussian of the form . Applying this recursively we obtain
Using this kind of factorization together with marginalization also helps us construct the marginal predictive distribution , where ℓ<k as follows:
This is the Chapman–Kolmogorov equation (Särkkä, 2013), which can be applied recursively to obtain the predictive distribution at the current time step using the transition density together with previous predictive distributions.
From prediction we move to filtering, which is the estimation of the current state given current and past observations: . This is the problem solved by sequential DA where an archetypal example is the initialization of numerical weather predictions as new observations become available to delay the effects of chaos (Bauer et al., 2015). To construct the filtering distribution we first re-introduce our Gaussian observation model into the dynamical context and make the usual assumption that the current observations are conditionally independent of both the observation and state histories (Särkkä, 2013), resulting in the dynamic likelihood
where denotes the predicted observations and we have added a time index to the normalizing constant (Ak) and the observation error covariance matrix (Rk) to emphasize that both the number and types of observations may vary in time. By combining Markovian state dynamics with a conditionally independent observation model, we end up with a state-space or hidden Markov model (Cappé et al., 2005) where the states at each time step are hidden (or latent) because they are not observable due to measurement error. The filtering distribution is obtained by combining the predictive distribution (which serves as the prior) and the dynamic likelihood through Bayes' theorem:
As such, prediction and filtering can be applied one after the other in time to sequentially obtain the filtering distributions of interest for all integration time steps . That is, starting from the initial prior p(x0), we run the dynamical model to k=1 to obtain the transition density in the product p(x1|x0)p(x0) and marginalize to obtain the predictive distribution p(x1), which we use as the prior when assimilating the observations y1 to estimate the filtering distribution p(x1|y1). We continue this cycle, running the dynamical model to k=2 to obtain and marginalizing to obtain p(x2|y1), which we use as the prior when assimilating y2 to arrive at . This filtering process of “online” assimilation as observations become available sequentially in time is appealing for operational forecasting, since it can continue indefinitely with low memory requirements while outputting the filtering and prediction distributions of interest. In practice when using Monte Carlo methods, we do not operate with the distributions themselves but rather with an ensemble of samples from these. Typically, due to the often prohibitively large size of a full spatiotemporal ensemble, one would only store summary statistics such as the posterior mean and standard deviation of the state for each point in space and time as the outputs of the analysis.
In addition to filtering, we are also able to solve some smoothing problems in MuSA. The key difference between filtering and smoothing is that the latter considers future observations; i.e., the (marginal) smoothing distribution is where ℓ>k. Several types of smoothing problems exist (Cosme et al., 2012; Särkkä, 2013), namely fixed-lag smoothing ( with l constant), which is equivalent to filtering but where the state is lagged relative to the observations; fixed-point smoothing (k is fixed) where the posterior at a fixed point in time (such as an initial condition) is conditioned on both past and future observations; and fixed-interval smoothing (ℓ is fixed) where we estimate the posterior for points in a time interval given all observations in that interval. In MuSA we focus on a form of the fixed-interval smoothing known as batch smoothing, in which the states within the time interval, henceforth called the data assimilation window (DAW), are updated in a single batch using all observations such that ℓ=n.
The batch-smoothing approach has been shown to be especially well suited for reanalysis-type problems in land and snow data assimilation, since it allows information from observations to propagate backward in time (Dunne and Entekhabi, 2005; Durand et al., 2008). We will restrict our attention to strong-constraint batch smoothing with indirect updates (Evensen, 2019; Evensen et al., 2022) where it is assumed that the dynamical model is perfect (i.e., no model error η) and that all uncertainty stems from parameters that are constant within the DAW. This approach is adopted for both simplicity and the fact that it ensures that the updated states are dynamically consistent with the physics in the model. It also has the advantage of implicitly ensuring that state variables such as snow depth or SWE remain within their physically non-negative bounds. In this approach, an ensemble of realizations of the model are run forward for an entire DAW during which all the observations and the corresponding predicted observations from the model are stored. At the end of the DAW, these observations are all assimilated simultaneously in a batch update to provide samples from the posterior parameter distribution. For seasonal snow the water year becomes a natural choice for the DAW. With this choice, potentially highly informative observations made during the ablation season are able to inform the preceding accumulation season (Margulis et al., 2015). This is crucial in peak SWE reconstruction, which is of great interest to snow hydrologists (Dozier et al., 2016).
3.3 Consistency
A potential problem in DA is that the stochastic perturbations and updates that are imposed on the model and the resulting dynamics may lead to inconsistent model states. We can define (at least) two different types of inconsistencies: (i) dynamical inconsistency and (ii) physical inconsistency where model states and/or parameters violate their physical bounds.
Dynamical inconsistency with respect to the underlying deterministic model can enter into the DA exercise either through stochastic model error terms in prediction steps or through the assimilation step itself. In the case of weak-constraint DA, where imperfections in the model are represented by stochastic model error terms, this kind of weak inconsistency exists by design and is a feature rather than a bug. In particular, the dynamical inconsistency created by the stochastic terms is meant to explicitly account for model uncertainty arising for example due to unresolved processes (Palmer, 2019). As such, the open-loop (no DA) stochastic model dynamics will be inconsistent with a deterministic version of the model. Arguably calling such a stochastic model dynamically inconsistent is somewhat of a misnomer, since it aspires to be more consistent with reality than a purely deterministic version of the same model.
The assimilation step itself can also introduce dynamical inconsistencies, particularly when applying filtering algorithms (Dunne and Entekhabi, 2005). For the EnKF these manifest as sawtooth-like patterns (jumps) in the dynamics at each assimilation step due to the fact that the Kalman-based analysis actually moves the ensemble from being samples of the prior to being (approximate) samples from the posterior. For the PF dynamical inconsistency also enters at the assimilation step whenever resampling is performed. The resampling step tends to kill off unpromising low-weight particles while reproducing more promising higher-weight particles. Since this evolutionary step is implemented sequentially in time when filtering, it will also introduce discontinuities into the dynamics of the model ensemble. In the case of both the EnKF and the PF, the discontinuity introduced at the assimilation step is an expected result of filtering. If one wishes to avoid this behavior, one should instead turn to smoothing algorithms.
Physical inconsistency can also enter through both stochastic perturbations and the assimilation step itself. Many snowpack state variables (and potential observables) have a relatively limited dynamic range and are either lower bounded, e.g., snow depth and SWE are non-negative, or double bounded, e.g., snow albedo and FSCA are physically confined to the range [0,1]. This means that directly applying assimilation routines which assume unbounded (e.g., Gaussian) distributions on the prior, likelihood, or model error can lead to physical inconsistencies in snow DA.
A simple but naïve solution is to just explicitly enforce state variables to lie within their physical bounds using minimum and/or maximum functions. Unfortunately, this is the same as truncating the underlying probability distributions and may degrade the performance of the assimilation scheme due to a strong violation of assumptions. Although this is a major concern for the EnKF-based schemes, which make explicit assumptions about Gaussianity, in practice it may also impact the PF where Gaussian distributions remain a convenient choice. A better way to deal with issues around physical inconsistency is to apply transformations to bounded random variables. Typically, these transformations will map such random variables from the bounded physical space to an unbounded space that can accommodate Gaussian distributions through Gaussian anamorphosis techniques (Bertino et al., 2003). This can be carried out using transforms that have been empirically constructed or using analytic functions. In MuSA, following Aalstad et al. (2018), we employ analytical Gaussian anamorphosis where we use a logarithm transform for variables that are physically lower bounded and a logit transform for variables that are physically double bounded. The corresponding inverse functions, i.e., the exponential and logistic transforms, can be used to map these unbounded variables back to the bounded physical space. For bounded variables we will often construct the prior distributions using these transforms. For example, assigning a lognormal prior can ensure that a variable never exceeds its lower bounds. In such a case the assimilation step takes place in the unbounded log-transformed space where this variable is normally (i.e., Gaussian) distributed, while the model integration takes place in the bounded physical space, which can be recovered using the exponential transform, where the variable is lognormally (i.e., log-Gaussian) distributed.
A key step taken in MuSA to reduce inconsistencies in snow data assimilation is to split the state vector in two: , where denotes parameters and denotes internal model states. Only the parameters, which can include both internal model parameters and forcing perturbation parameters, are assumed to be random variables in MuSA. This approach corresponds to the so-called forcing formulation (as opposed to the model-state formulation) of the DA problem (Evensen et al., 2022). The internal model states are taken to be deterministic given these parameters. Such a setup is tantamount to assuming that all the uncertainty in the model dynamics stems from the forcing data and internal parameters. This assumption is largely in line with previous findings (Raleigh et al., 2015), particularly for intermediate-complexity snow models such as FSM2 (Günther et al., 2019). This is gradually becoming a relatively standard setup in snow data assimilation experiments (Margulis et al., 2015; Magnusson et al., 2017; Aalstad et al., 2018; Alonso-González et al., 2021; Cluzet et al., 2020, 2022) although it has arguably not been as properly formalized as elsewhere in the DA literature (Evensen, 2019; Evensen et al., 2022). Through such a split we ensure that internal model states remain both dynamically and physically consistent given the parameters. The parameters, in turn, are made physically consistent by applying analytical Gaussian anamorphosis transforms in the DA scheme. As such, we will let u denote anamorphosed parameters that have undergone a forward transform to the unbounded space. It is implicitly assumed that these are inverse-transformed to the physical space before they are passed to FSM2 to help evolve the internal states forward in time.
In the filtering algorithms in MuSA, both the stochastic parameters and the conditionally deterministic internal states are dynamic. The parameter dynamics evolve according to simple jitter (Farchi and Bocquet, 2018) of the following form:
where we recall that and that the parameters are defined in the unbounded transformed space. Probabilistically, this corresponds to the Markovian transition density . The internal state variables, on the other hand, evolve according to the full dynamical model (FSM2), which also depends on the dynamic parameters uk through . These dynamics correspond to the transition density (e.g., Evensen, 2018)
where δ(⋅) is the Dirac delta function, which emphasizes that the internal state is not only Markovian but also conditionally deterministic given the parameters. This just formalizes that the only uncertainty in the internal state dynamics stems from the parameters to which we assign an initial prior p(u0). Without loss of generality and to simplify the presentation of the theory, we assume that we are dealing with seasonal snow, so the initial prior for the internal snow states, p(v0), is known: v0=ν0. Thus , since the annual integration period starts at the beginning of the water year where we assume that a snowpack has not yet formed, so internal snow state variables are either 0 (snow depth, SWE) or undefined (e.g., snow surface temperature). Together with the dynamic likelihood p(yk|uk), these distributions can be used to construct the target marginal filtering distribution , which we can estimate with ensemble Kalman or particle-filtering algorithms. By combining this marginal distribution with appropriate densities, we can also estimate the joint filtering distribution from which we can compute posterior expectations for the internal states of interest. The derivation of this distribution is relatively analogous to that for the smoother below but involves more steps and is thus not included herein. In practice, (approximate) samples from this joint filtering distribution are obtained from the posterior ensemble after each observation time and the subsequent assimilation step while running the filtering schemes in MuSA.
For the smoothing algorithms in MuSA, we instead assume that the dynamical model is perfect, so the components of u are constant (i.e., time-invariant) but uncertain parameters, which can be either internal parameters or related to the forcing, while still denotes the dynamic internal state variables with initial state v0 at t0 and final state vn at tn, which is the end of what is now an annual DAW. The prediction step with the assumed perfect dynamical model then becomes , which implies the following transition density:
This is just a formal way of denoting that the only uncertainty in the dynamics stems from time-invariant but uncertain parameters to which we assign a prior. As noted by Evensen (2019), when these perturbation parameters are interpreted as errors, this can be viewed as a limiting case of perfect time correlation where the errors become constant biases. The lack of dynamics in the perturbation parameters is thus akin to assuming that errors in the forcing are constant in time within a particular water year. This simplifying assumption imposes a longer memory in the system than with jitter and facilitates the propagation of information backward in time using smoothers. Given this transition density, the full prior for the entire DAW can be factorized as follows:
where as before is the prior for the initial condition of the state. The full posterior then becomes
which can be marginalized to obtain the marginal posterior for the parameters
where the batch likelihood is
in which contains the predicted observations for all observation time steps and , where is the batch observation error covariance matrix, which is a block diagonal matrix containing the observation error covariance matrices for all observation time steps. Note that since the state v0:n is conditionally deterministic given u, it is not included in the batch likelihood. By combining the batch likelihood with the prior for the parameters, we have all that we need to estimate the posterior for the parameters . The main difference from the filtering distribution is that all the data are assimilated in a single batch to update static parameters. Once we have obtained the posterior for the parameters, due to the strong constraint, we recall that we can easily recover the joint posterior for the states and parameters from which we can compute posterior expectations for the internal states of interest. In practice, the steps involved in estimating the posterior and subsequent expectations depend on which batch-smoothing algorithm is used.
3.4 Particle methods
Particle methods (van Leeuwen, 2009; Särkkä, 2013), also known as sequential Monte Carlo methods (Cappé et al., 2005; Chopin and Papaspiliopoulos, 2020), are appealing, since they impose few assumptions, can be relatively easy to derive, and are simple to implement in their basic form. In principle, they can be used to solve any Bayesian inference problem, including the aforementioned filtering and smoothing problems. The so-called bootstrap filter described by Gordon et al. (1993) arguably marks the introduction of particle filters to the wider scientific community. Nonetheless, the underlying idea of sequential importance resampling (SIR) was already well known in the statistics literature from which it emerged (see Smith and Gelfand, 1992, and references therein). For a more up-to-date perspective, van Leeuwen et al. (2019) provide a comprehensive review of particle methods for geoscientific data assimilation, including a discussion of the state of the art and promising avenues for further developments.
Particle methods have rapidly become the most widely adopted approach to data assimilation within the snow science community. The PF, in particular, has become increasingly popular in snow data assimilation studies. This began with the seminal work of Leisenring and Moradkhani (2011) and Dechant and Moradkhani (2011) showing how the PF can outperform the EnKF in snow data assimilation applications, assimilating SNOTEL SWE and passive microwave data, at least if relatively simple models and a large ensemble are used. Charrois et al. (2016) subsequently applied the PF in synthetic (twin) experiments that assimilated MODIS-like reflectance data into the Crocus snow model for a site in the French Alps. Magnusson et al. (2017) showed how snow depth assimilation using the PF improved the estimation of several variables, including SWE and snowmelt runoff, in an intermediate-complexity snow model for many sites across the Alps. The study of Baba et al. (2018) applied the PF to assimilate novel SCA satellite retrievals from Sentinel-2, demonstrating marked improvements in snowpack simulations across the sparsely instrumented High Atlas Mountains of Morocco. Piazzi et al. (2018) investigated the potential of performing a joint assimilation of several snowpack variables obtained from ground-based observations at three sites in the Alps using the PF, noting that degeneracy was more likely to occur for this setup than in more typical uni-variate snow data assimilation experiments. Smyth et al. (2019) assimilated monthly snow depth observations into an intermediate-complexity snow model with the PF at a well-instrumented site in the California Sierra Nevada, improving both snow density and SWE estimates with promising implications for the assimilation of snapshots of snow depth retrieved from airborne and spaceborne platforms. These results were confirmed by Deschamps-Berger et al. (2022), who showed that the assimilation of a single snow depth map per season is sufficient to improve the simulated spatial variability in the snowpack. Recent efforts (Cantet et al., 2019; Cluzet et al., 2021, 2022; Odry et al., 2022) have focused on the challenge of spatially propagating snowpack information from observed to unobserved locations when assimilating in situ snow depth and SWE data using the PF.
Another line of studies has adopted particle smoothing schemes, particularly the particle batch smoother (PBS; Margulis et al., 2015), for snow reanalysis. Here a batch of remotely sensed, typically FSCA, observations are assimilated simultaneously to weight (assign probability mass to) an ensemble of model trajectories for the entire water year. Margulis et al. (2016) used the PBS to perform a 90 m resolution snow reanalysis for the California Sierra Nevada covering the entire Landsat era from 1985 to 2015. Cortés and Margulis (2017) applied a similar setup to conduct a snow reanalysis for the extratropical Andes. Aalstad et al. (2018) compared the performance of the PBS with ensemble-Kalman-based smoothers when assimilating FSCA data from Sentinel-2 and MODIS for sites in the high Arctic and found that the PBS markedly outperformed non-iterative ensemble-Kalman-based smoothers in line with Margulis et al. (2015). Baldo and Margulis (2018) developed a multi-resolution snow reanalysis framework using the PBS and demonstrated, through tests in a basin in Colorado, that this could match the performance of the original single-resolution approach at a fraction of the computational cost. In DA experiments in the Swiss Alps, Fiddes et al. (2019) showed how clustering offers an alternative promising avenue for speeding up snow DA with the PBS, allowing for hyper-resolution reanalyses. Alonso-González et al. (2021) carried out a snow reanalysis over the sparsely instrumented Lebanese mountains by forcing FSM2 with quasi-dynamically downscaled meteorological reanalysis data and subsequently assimilating MODIS-based FSCA retrievals with the PBS. Liu et al. (2021) recently performed an 18-year 500 m resolution snow reanalysis for High Mountain Asia by using the PBS to jointly assimilate MODIS and Landsat FSCA data. Although all of these studies have focused on using FSCA data for snow reanalysis, other remotely sensed retrievals could also be considered. For example, the work of Margulis et al. (2019) has shown that the PBS can also be used to assimilate infrequent lidar-based snow depth retrievals with marked improvements in the estimation of snowpack-related variables.
Importance sampling is key to understanding these particle methods. Despite what the name may suggest, this is actually not an approach to directly generate samples from a target distribution of interest. Instead, it allows us to estimate expectations of functions with respect to a target distribution by drawing from another distribution that it is easier to sample from (MacKay, 2003). In DA, the posterior is the target distribution of interest, and the expectation of some function g(x) with respect to the posterior is defined as follows (Särkkä, 2013):
where the expectation E[⋅] of g(x)=x yields the posterior mean and the expectation of yields the posterior variance . If we could generate Ne independent samples from the posterior, , we could estimate the expectation in Eq. (23) numerically using direct Monte Carlo integration as follows:
where the x(i) with denotes Ne independent samples from the posterior. Thanks to the law of large numbers and the central limit theorem, we know that this approximation will converge almost surely to the true expectation as Ne→∞ with a standard error inversely proportional to (Chopin and Papaspiliopoulos, 2020). Unfortunately, we are rarely able to generate independent samples directly from the posterior.
In importance sampling, we instead use a proposal (or importance) distribution q(x) that we know how to sample from, which must have at least the same support as the posterior (i.e., q(x)>0 wherever ). Then, by multiplying the integrand with , we can solve Eq. (23) using importance-sampling-based Monte Carlo integration:
where x(i) now denotes samples from the proposal and we have defined the normalized weights . Following the nomenclature of Chopin and Papaspiliopoulos (2020), these weights are normalized in the sense that their expectation with respect to q(x) equals 1. A hurdle remains in that we only know the posterior up to an unknown normalizing constant (i.e., the evidence Z), so in practice we can only evaluate the un-normalized posterior. Recalling the definition of the evidence in Eq. (3), we can nonetheless use importance sampling to approximate it as follows:
where ) is the un-normalized posterior and we have defined the un-normalized weights , which no longer have an expectation of 1 with respect to q(x). Using the samples x(i)∼q(x), this evidence approximation, and that , we can now solve Eq. (23) as follows:
where, letting w(i)=w(x(i)) for economy, the auto-normalized weights are given by with the property that . Note that with these auto-normalized weights, q(x) also only needs to be known up to a normalizing constant Zq, since any such constants cancel out in the auto-normalization step. Furthermore, direct Monte Carlo integration can be seen as a special case of importance sampling where the proposal is the target distribution itself which leads to uniformly equal weights with a value of .
Mathematically, importance sampling is tantamount to a particle representation of the posterior through a sum of weighted Dirac delta functions centered on the sampled states x(i)∼q(x) of the form (Särkkä, 2013). We can see this by recalling that the Dirac delta has the properties that and , such that by inserting the particle representation in Eq. (23) we have
which is equal to the result in Eq. (27). This particle representation is helpful, since we can conceptualize distributions as consisting of a set of particles (or points) in state space whose probability masses are given by their weights.
The catch with importance sampling is that, unless the proposal is nearly identical to the target distribution, all the probability mass tends to collapse onto just a few particles as the dimensions of a problem increase (MacKay, 2003). This is the so-called degeneracy problem of particle methods, which is closely tied to the aforementioned curse of dimensionality (Farchi and Bocquet, 2018; Snyder et al., 2008). One way to partly circumvent degeneracy in a sequential setting is to employ resampling techniques (see Li et al., 2015) where a new set of equally weighted particles is drawn based on the weights (i.e., probability masses) of the existing particles. Effectively, resampling tends to reproduce particles with a higher weight while removing particles with a lower weight. Resampling thus provides obvious links between particle methods and more heuristic genetic algorithms, since the weights can be interpreted as a kind of “fitness” (Chopin and Papaspiliopoulos, 2020). The standard metric (e.g., Särkkä, 2013) for monitoring symptoms of degeneracy is the effective sample size
where a healthy ensemble of particles would have Neff=Ne, while a completely degenerated ensemble has Neff=1. This metric can be used to adaptively determine the need for resampling based on a requirement that the ratio stays above some “healthy” threshold. Although resampling ensures that weight is more evenly spread among the particles, the occurrence of several identical particles results in sample impoverishment, which can in the worst case also lead to a degenerate representation of the posterior. Particle diversity can nonetheless often be rejuvenated implicitly through stochastic terms (jitter) in the dynamical model or more explicitly with a few iterations of Markov chain Monte Carlo (MCMC; Gilks and Berzuini, 2001).
Having outlined importance sampling and resampling, the final step is to tie these steps together with the sequential aspect of particle methods. In the context of both particle filtering and smoothing, importance sampling can be applied sequentially in time as observations become available to the state-space model. For the particle filter, this occurs by first drawing particles from the initial prior and then for performing SIR:
-
Propagate the particles forward in time through the dynamical model from time k−1 to k where new observations are available.
-
Calculate the auto-normalized weights given the current observations.
-
Resample the particles, possibly only if the ratio is below some threshold.
The recipes for implementing most flavors of particle smoothers tend to be a little bit more involved (Särkkä, 2013). Fortunately, the particle batch smoother (PBS) in MuSA is relatively straightforward, since in practice it is equivalent to standard sequential importance sampling (SIS), which is just SIR without the resampling step. As such, SIS is quite prone to degeneracy. Nonetheless, an advantage with SIS is that, due to the absence of resampling, the dynamical state history of each particle will be completely consistent with the dynamical model. For the PBS we are only interested in the final (i.e., at time tn) weights , which, when attached to the full state histories, give us an approximation of the full posterior rather than the filtering distribution . This is advantageous in snow data assimilation, since it allows information from observations during the ablation season to propagate backward in time and influence states in the preceding accumulation season. The final weights can be computed either sequentially using SIS or in a batch update, since these are equivalent when the dynamics are Markovian and the observations are conditionally independent in time. The batch approach used in the PBS is appealing, since it can be wrapped around the model, allowing the dynamics to evolve freely for the whole data assimilation window from t0 to tn without the need for I/O interruptions in the time integration and typically resulting in marked run time acceleration compared to sequential approaches.
Now that we have introduced the particle methods, what remains is to describe their implementation in MuSA and in particular the choice of proposal distribution. For simplicity, we adopt the standard and simplest approach for particle methods, which is to use the prior as the proposal (van Leeuwen and Evensen, 1996). Note that this is analogous to what was done in the seminal bootstrap filter of Gordon et al. (1993) and is to our knowledge the only approach considered so far for snow data assimilation. Thereby, recalling that and inserting for q(x)=p(x), then , which gives us the following simple expression for the auto-normalized weights:
which is simply the normalized likelihood of the prior particles x(i)∼p(x). With the usual Gaussian likelihood employed in MuSA, these weights are given by
where denotes the predicted observations for the ith particle. In practice, to ensure numerical stability, we first compute the natural logarithm of the weights by using the log-sum-exp trick to avoid potential overflow and minimize the effects of underflow (Murphy, 2022; Chopin and Papaspiliopoulos, 2020). Subsequently, the weights can be diagnosed by taking the exponential of these stable logarithms.
In the current version of MuSA we apply resampling at each observation time step for the PF independently of what the effective sample size is. Furthermore the state x is split into parameters u and internal states v. The PF in MuSA is then implemented as described in the pseudocode in Algorithm 1. For clarity, this pseudocode omits details such as the log-sum-exp trick (Murphy, 2022) and the way that resampling is performed given that there are several options available (Li et al., 2015).
Algorithm 1Particle filter.
Note that the particles will all have a posterior weight equal to due to the resampling which happens at each observation time step. Combined with the transition density, these weights form the prior for the next observation time. This explains why no weights from the prior enter into the posterior weight calculation, since these are all equal and so cancel out in the auto-normalization. For the PF, the DAW can be understood to be the time interval between two neighboring observation times. The prior mean and variance of the internal states can be obtained by taking the (unweighted) ensemble means and variances of the particle trajectories in the DAW before the resampling step. The posterior means and variances of the internal states can be obtained by taking the (unweighted) ensemble mean and variance of the particle trajectories in the DAW after the resampling step.
In MuSA, the PBS is even more straightforward to implement than the PF. Pseudocode for the PBS algorithm as implemented in MuSA is outlined in Algorithm 2. Here too we have emphasized clarity in the pseudocode and omit details from the actual code such as the log-sum-exp trick.
Algorithm 2Particle batch smoother.
For the PBS, the DAW is the entire water year. The prior mean and variance of the internal states can be obtained by taking the (unweighted) ensemble means and variances of the particle trajectories in the DAW. The posterior means and variances of the internal states are obtained by taking the weighted ensemble mean and variance of the particle trajectories in the DAW.
3.5 Ensemble Kalman methods
The ensemble Kalman filter (EnKF) was originally proposed by Evensen (1994) as a Monte Carlo version of the original Kalman filter (KF; see Jazwinski, 1970; Särkkä, 2013). The original KF assumes that all distributions involved in filtering are Gaussian and that both the dynamical and the observation models are linear. These assumptions come on top of the usual filtering assumptions of Markovian state dynamics and conditionally independent observations. If all these assumptions are met, the exact filtering distribution turns out to be a Gaussian one of the form and there is a set of closed-form (i.e., analytical) equations for the mean mk and covariance Pk, which completely defines this Gaussian filtering distribution, known as the KF equations (Särkkä, 2013). Geoscientific models are almost never linear, so these equations can usually not be applied directly in practice. Even when they can, the need to explicitly store and update the state covariance matrix Pk with dimensions m×m can be computationally prohibitive in high dimensional problems typical in geoscience (Carrassi et al., 2018).
There exist several modified versions of the KF such as the extended KF (EKF) based on Taylor series approximations and the unscented KF (UKF) based on the unscented transform that can both partly circumvent the linearity assumption (Särkkä, 2013). Since both the EKF and the UKF also require an explicit covariance matrix update and are considerably more challenging to implement than the KF, they have only rarely been used for geoscientific DA. Instead, since its introduction by Evensen (1994), it is the EnKF that has become one of the methods of choice for DA. The reasons for this are that the EnKF is relatively straightforward to implement and understand (Katzfuss et al., 2016), it can handle non-linear models, the state covariance evolves implicitly with the ensemble, and it has proven to work well in very high dimensional operational applications in both meteorology and oceanography (see Carrassi et al., 2018, for a review). Although it makes the same Gaussian linear assumptions as the KF, in practice it can often still function well when these assumptions are strongly violated thanks to techniques such as Gaussian anamorphosis (Bertino et al., 2003) and iterations (Emerick and Reynolds, 2013). The ensemble Kalman approach can also be applied to solve smoothing problems as first shown by van Leeuwen and Evensen (1996). These smoothers, particularly the so-called ensemble smoother (ES), play an important role in solving reanalysis problems that arise in both land surface and snow data assimilation (Dunne and Entekhabi, 2005; Durand and Margulis, 2006).
The EnKF was one of the first schemes to be used for snow data assimilation. Slater and Clark (2006) used the EnKF to assimilate SWE data into a conceptual snow model at several sites in Colorado, leading to marked improvements in SWE estimates compared to both the control model runs and interpolated observations. Clark et al. (2006) used a snow depletion curve to assimilate synthetic satellite retrievals of FSCA into a conceptual snow hydrology model of a catchment in Colorado, leading to minor improvements in simulated streamflow. Durand and Margulis (2006) jointly assimilated synthetic satellite retrievals of brightness temperature and albedo into the SSiB3 model using the EnKF at a site in the California Sierra Nevada to yield marked improvements compared to the open loop. Andreadis and Lettenmaier (2006) used the EnKF to assimilate MODIS FSCA into the VIC model for the Snake River basin in the Pacific Northwest region of the USA, improving model estimates of both FSCA and SWE.
Following on from these initial studies there have been several more recent snow DA applications using the EnKF. In a synthetic experiment in northern Colorado, De Lannoy et al. (2010) showed how the EnKF can be used to assimilate coarse-scale passive microwave SWE observations into high-resolution runs of the Noah land surface model, leading to large reductions in error in SWE estimation compared to the open loop. In a follow-up study, De Lannoy et al. (2012) jointly assimilated real MODIS FSCA and AMSR-E SWE retrievals into the Noah model to demonstrate the complementary nature of these types of satellite observations for SWE estimation. Magnusson et al. (2014) used the EnKF to assimilate data from ground-based stations in the Swiss Alps and showed that assimilating fluxes (snowmelt and snowfall), rather than directly assimilating SWE data, improved the SWE estimation. The study of Huang et al. (2017) demonstrated that the assimilation of in situ SWE data into a hydrological model with the EnKF could improve streamflow simulations for several basins in the western USA. Stigter et al. (2017) performed a joint assimilation of in situ snow depth data and FSCA satellite retrievals with the EnKF to optimize parameters and subsequently estimate the climate sensitivity of SWE and snowmelt runoff for a Himalayan catchment. More recently, Hou et al. (2021) showed how machine learning techniques can be used to construct empirical observation operators to assimilate satellite-based FSCA with the EnKF.
The ensemble smoother (ES), the batch smoother version of the EnKF, has also been used extensively for snow DA, mainly for reanalysis. Durand et al. (2008) were the first to demonstrate the value of the ES for snow reanalysis by noting that it could be used as a new approach to solve the traditional problem of snow reconstruction. They showed substantial improvements in SWE estimation for the posterior compared to the prior after having assimilated synthetic FSCA observations into SSiB3. A key advantage of the ES over the EnKF is that it allows information to propagate backward in time, so observations made in the ablation season can update the preceding accumulation season. Following up this study with a real experiment assimilating Landsat FSCA retrievals into SSiB3 using the ES at a basin in the California Sierra Nevada, Girotto et al. (2014a) demonstrated explicitly how snow reanalysis using the ES is a more robust probabilistic generalization of the traditional deterministic approach to snow reconstruction. Subsequently, Girotto et al. (2014b) applied the same ES snow reanalysis framework to produce a multi-decadal high-resolution snow reanalysis for the Kern River watershed in the California Sierra Nevada. Oaida et al. (2019) used the ES to assimilate MODIS FSCA observations into the VIC model to produce a kilometer-scale snow reanalysis over the entire western USA. Aalstad et al. (2018) introduced an iterative version of the ES, the ensemble smoother with multiple data assimilation (ES-MDA; Emerick and Reynolds, 2013), for snow reanalysis and showed how this could outperform both the ES and the PBS when assimilating FSCA retrievals at sites on the high-Arctic Svalbard archipelago. In this iterative scheme the prior ensemble moves gradually to the posterior ensemble through a tempering procedure (see Stordal and Elsheikh, 2015, and references therein). The iterations thus mitigate the impact of the linearity assumption inherent in ensemble Kalman methods (Evensen, 2018), typically leading to marked improvements compared to the ES for non-linear models without the risk of degeneracy associated with particle methods as the curse of dimensionality rears its head (Snyder et al., 2008; Pirk et al., 2022).
A derivation of the KF equations, which the EnKF and ES are largely based on, is beyond the scope of this work. Full multivariate Bayesian derivations of these equations can be found on p. 197 of Jazwinski (1970) and in Sect. 4.3 of Särkkä (2013). The EnKF itself is thoroughly derived in Evensen (2009) and Evensen et al. (2022). There are actually several variants of the ensemble Kalman analysis step (see Carrassi et al., 2018). In MuSA we use the so-called stochastic rather than deterministic (or square-root) implementation. This stochastic formulation adds perturbations to the predicted observations to ensure adequate ensemble spread and consistency with the underlying Bayesian theory (Burgers et al., 1998; van Leeuwen, 2020).
Here we present the equations for both the stochastic EnKF (van Leeuwen, 2020) and the ES (van Leeuwen and Evensen, 1996), as well as their iterative versions based on the multiple data assimilation (MDA) scheme of Emerick and Reynolds (2012, 2013), in the form that they are used in MuSA. The iterative versions tend to perform better than their non-iterative counterparts for non-linear problems (Evensen, 2018). Let Na denote the number of assimilation cycles (iterations) performed in a pseudotime (rather than model) time. For the standard EnKF and ES we set Na=1, while with their iterative variants Na>1, typically Na=4 (Emerick and Reynolds, 2013; Aalstad et al., 2018). The superscript ℓ is used to index these iterations. Let denote the mp×Ne parameter matrix containing the ensemble () of parameter vectors u(i)(ℓ) for iteration ℓ. Recall that the subset of these parameters that are physically bounded have undergone the relevant analytic transformations for Gaussian anamorphosis, and the corresponding inverse transforms are applied back to physical space when these are passed through the dynamical model (see Aalstad et al., 2018). Similarly, let denote the predicted observation matrix containing the ensemble of predicted observations . Adopting this notation, the stochastic ensemble Kalman methods in MuSA are implemented as described in the pseudocode in Algorithm 3. For clarity, this pseudocode also omits details such as how the matrix inversion for the ensemble Kalman gain in Eq. (32) is carried out. For this we follow the pseudoinverse and rescaling approach outlined in Appendix A of Emerick and Reynolds (2012).
Algorithm 3Ensemble Kalman analysis with multiple data assimilation.
Recall that for Na=1 we recover the non-iterative stochastic EnKF and ES, while for Na>1 we are using iterative versions of these schemes that involve multiple data assimilation with inflated observation errors. The term “multiple data assimilation” refers to the assimilation of the same data multiple times rather than an assimilation of different types of data (joint assimilation). We speak of inflated observation errors, since the role of the coefficients α(ℓ) is to inflate the observation error covariance R in the Kalman gain Kℓ as well as the observation error term . This inflation is tantamount to tempering the likelihood as discussed by Stordal and Elsheikh (2015) and van Leeuwen et al. (2019), which explains why these iterative schemes perform better than their non-iterative counterparts for non-linear models in that they involve a more gradual transition from the prior to the posterior. Despite what the name might suggest, this multiple data assimilation approach does not actually violate the consistency of Bayesian inference by using the data more than once due to the way the observation error inflation is constructed, particularly due to the constraint that . Simply stated, this constraint ensures consistent results with a linear model, since by construction we obtain the same result by assimilating the data once with the original uninflated (α=1) observation errors as we do assimilating the same data multiple times with inflated (α>1) observation errors. With a non-linear model, practice has shown that these iterations of the ensemble Kalman analysis ensure that the approximate posterior is closer to the true posterior than if a more conventional single uninflated iteration is used (Evensen, 2018). It is possible to satisfy the constraint on the α(ℓ) with both uniform and non-uniform inflation coefficients (Evensen, 2019). For simplicity, following Emerick and Reynolds (2013), we currently opt for the former in MuSA by setting α(ℓ)=Na for all ℓ values by default while allowing for non-uniform coefficients as an option.
To keep the notation as simple as possible, we have not explicitly introduced time indices for these ensemble Kalman methods. Instead we can simply note that for the iterative and non-iterative EnKF, the loop above runs inside another outer loop that runs across all observation times. That is to say, the ℓ loop is run several times sequentially for multiple DAWs where each window is from one observation time to the next, such that the posterior parameters and internal states obtained at ℓ=Na for the current DAW that ran up to the current observation time become the initial prior at ℓ=0 for the next DAW that runs from the current observation time up to the next observation time. Recall that the parameters also undergo jitter dynamics when filtering.
For the non-iterative and iterative ensemble batch Kalman smoothers used in MuSA, namely the ES and the ES-MDA, there is no longer an outer time loop encapsulating the iterations. Instead, the DAW is the entire water year. In these smoother schemes, the parameters do not undergo any jitter. As such, the entire prior and posterior ensemble of state trajectories for a given water year will be consistent with the prior and posterior ensemble of static parameters for the entire water year. Recall that each water year is typically updated independently in MuSA, which currently focuses on seasonal snow.
In the following section, we illustrate the capabilities of MuSA using a case study and perform a benchmarking of the implemented data assimilation algorithms. We developed two data assimilation experiments in the 55 ha Izas experimental catchment (Revuelto et al., 2017) in the Spanish Pyrenees (see Fig. 2). The first experiment shows the capabilities of MuSA to assimilate hyper-resolution products in both a single-cell and distributed fashion, whereas the second demonstrates the capabilities to develop joint-assimilation experiments. Note that all the variables that we assimilate in these experiments are state variables in FSM2. We generated hourly meteorological forcing at 5 m resolution over the Izas catchment using the MicroMet meteorological distribution system (Liston and Elder, 2006b) to downscale the ERA5 atmospheric reanalysis (Hersbach et al., 2020).
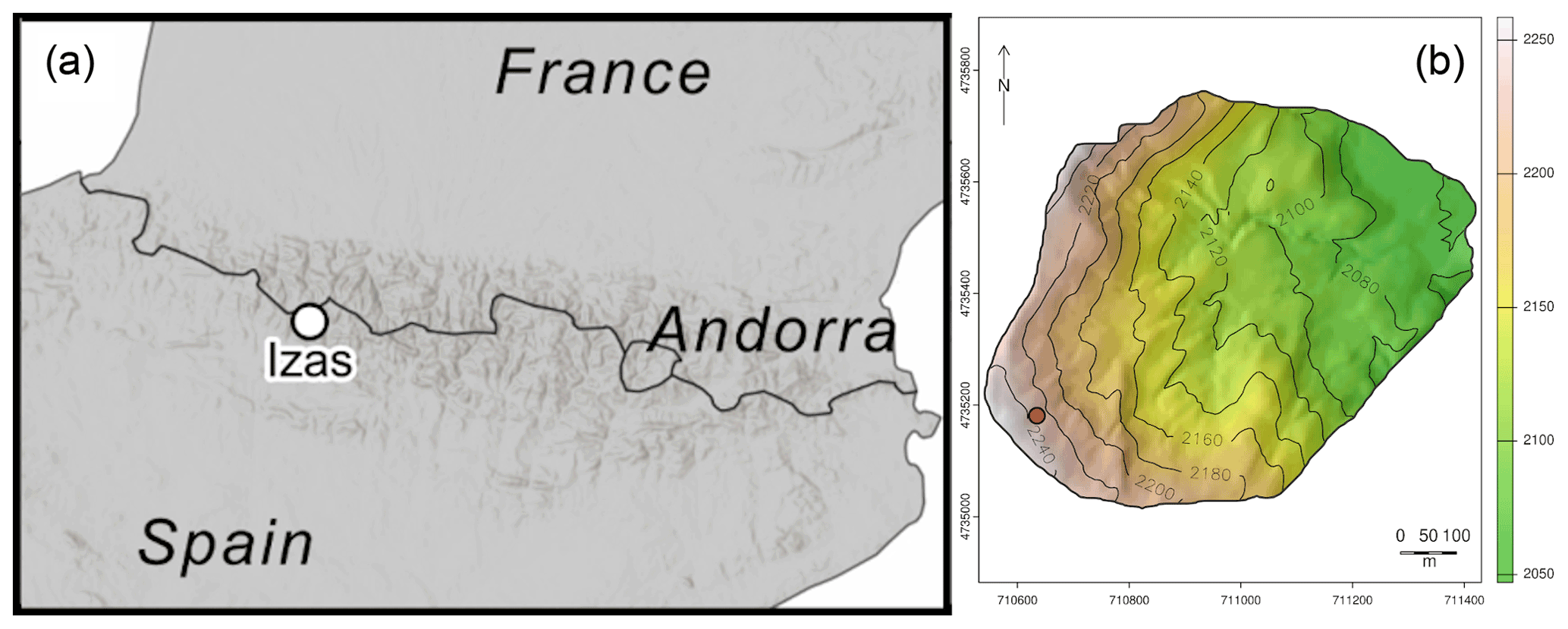
Figure 2Location of the Izas experimental basin in the Pyrenees (a) and topography (b). The red circle indicates the location of the cell used for the intercomparison of algorithms described below.
4.1 Single-cell and distributed assimilation of drone-based snow depth retrievals
For the first experiment, we ran MuSA to assimilate snow depth retrievals obtained from a fixed wing drone (Revuelto et al., 2021a, b), over two different snow seasons (2018/19 and 2019/20) in the Izas catchment using different data assimilation algorithms. The drone surveys were not equally distributed in time along the seasons, and the surveys present spatial gaps in some of the cells. The whole drone dataset is composed of 18 temporally distributed snow depth maps originally generated at 1 m but aggregated to 5 m spatial resolution so as to eliminate representativeness error (Janjić et al., 2018) by matching the model grid. Due to the high resolution of the observations, we expect MuSA to be able to implicitly reproduce the wind redistribution patterns by modifying the precipitation and temperature at the grid cell scale to compensate for the deposition and removal of wind-blown snow.
The simulation ensemble was composed of Ne=200 particles. The generation of the prior ensemble for both the single-cell and distributed simulation was developed by perturbing only the temperature and precipitation fields. The temperature was perturbed with a constant additive bias parameter, randomly drawn from a normal distribution defined by its mean (μ=0) and standard deviation (σ=2). Similarly, the precipitation was perturbed by a multiplicative fixed-in-time bias parameter, drawn from a lognormal distribution defined by the mean (μ=0) and standard deviation (σ=0.63) of the underlying normal distribution. These prior distributions were defined based on prior predictive testing (not shown here). As such, these are weakly informative priors (Banner et al., 2020) in that they produce predictions that we expect a priori (i.e., without looking at the data) to be of the right magnitude while obeying physical bounds. The variances of the observation errors were set to 0.04 m2 and were estimated from comparison with terrestrial-laser-scanning snow depth maps (Revuelto et al., 2021a, b). In the case of the single-cell comparison, we followed two different resampling strategies, the bootstrap and redraw from a normal approximation of the posterior (see Sect. 2). In the iterative versions of the ensemble-Kalman-based approaches, we fixed the number of assimilation cycles to Na=4 as a compromise between computational cost and performance. The former is directly proportional to Na, while the latter converges to an optimum as Na increases. This choice of Na is also in line with sensitivity analyses performed elsewhere (Emerick and Reynolds, 2013; Aalstad et al., 2018; Evensen, 2018).
The single-cell simulations were performed in a cell located in a topographic concavity within the catchment and therefore with exceptional accumulations and snow depth up to 6 m due to wind redistribution and preferential deposition (Comola et al., 2019). This is a challenge for the data assimilation process, as the observations fell very far from the central prior range of the ensemble of snow depths predicted by FSM2. The distributed simulation was developed in a supercomputing cluster using 20 nodes with 10 cores each. For this case study, we choose the most computationally efficient data assimilation algorithm, namely the PBS, to speed up the calculations. We subsequently compared the spatial distribution of the snowpack with one of the snow depth maps corresponding to a drone survey close to maximum snow accumulation (3 February 2020) that was not included in the assimilation.
4.2 Joint assimilation of satellite-based LST and FSCA retrievals
For the second experiment, we performed a coarser 1 km resolution experiment over the same area. We developed a single-cell joint-assimilation experiment, updating the FSM2 simulations with FSCA and land surface temperature (LST) retrievals from the MODIS sensor on board the Terra satellite, by using version 6 of the products MOD11A1 (Wan et al., 2015) and MOD10A1 (Hall and Riggs, 2016), respectively. The selected pixel for the MODIS retrievals was the one whose centroid fell closest to the Izas catchment centroid. While the FSCA retrievals from MODIS have a 500 m spatial resolution, the LST products have a resolution of 1000 m. To assimilate this information into FSM2 using the MuSA platform, we aggregated the FSCA products to match the 1 km LST grid. The forcing was generated by aggregating the 5 m forcing from the previous distributed data assimilation experiment. The variances of the observation errors were set to 0.15 and 10 [K2] for the FSCA and the LST, respectively. The data assimilation experiment was performed using the ES-MDA scheme. This data assimilation scheme was chosen because it performed better than the other algorithms (not shown here), which in some cases were not able to meaningfully update the simulations with the observations at all.
The number of iterations was again set to Na=4. The ensemble was composed of Ne=300 particles by perturbing all the forcing variables (temperature, precipitation, short and longwave radiation, wind speed, relative humidity, and surface air pressure) with normal additive or lognormal multiplicative random noise depending on whether or not the forcing variable had negative support so as to not generate physically impossible values.
4.3 Computational benchmarks
Finally, we developed a single-cell benchmark to measure the computational cost in terms of wall clock time for each algorithm. The benchmark was developed in a local machine with an Intel® Core™ i5-1145G7 processor and 32 GB of memory running an Ubuntu 20.04 system. The comparison was performed using 100, 200, and 300 particles and four iterations for the iterative ensemble Kalman approaches in a single cell, assimilating drone snow depth retrievals at a random location in the Izas catchment. The reported values of the benchmarks are the average of 10 MuSA runs and include the FSM2 compilation time (≃2 s using the GNU Fortran compiler 10.3.0 in the aforementioned local machine), which is negligible compared with the whole run.
5.1 Single-cell and distributed assimilation of drone-based snow depth retrievals
The results show how the performance of the different data assimilation algorithms differs, even with the same initial conditions and experimental setup, when the posterior ensembles are compared against the assimilated snow depth observations (Table 1, Figs. 3 and 4). The reference simulation exhibited a root mean square error (RMSE) compared with the observations of 3.18 m, higher than the posterior mean of any of the algorithms implemented in MuSA, except for the PF with bootstrap resampling, which collapses early in the simulation. The results are shown in Table 1.
Table 1RMSE for the reference run (Ref), particle filter with bootstrap resampling (PF-b), particle filter with redraw resampling (PF-r), ensemble Kalman filter (EnKF), ensemble Kalman filter with multiple data assimilation (EnKF-MDA), particle batch smoother (PBS), ensemble smoother (ES), and ensemble smoother with multiple data assimilation (ES-MDA). These errors were computed using the assimilated drone-based snow depth observations as the truth and using the posterior ensemble mean as the estimate from the respective DA schemes. All the schemes were run with Ne=200 particles, and the MDA schemes used Na=4 iterations.

The PF collapsed early in the single-cell simulation where all the weight is shared by just a few particles and eventually a single particle (see Fig. 3) due to the large difference between the observations and the ensemble of predictions at the first assimilation step. The particle filter with redraw-based resampling allowed the assimilation process to recover from the initial collapse through particle rejuvenation, leading to a more realistic non-degenerate ensemble simulation. Conversely, the ensemble-Kalman-based approaches were less prone to ensemble degeneracy. Here, the EnKF produced unsatisfactory results when the observations fell very far from the posterior ensemble in the first season and improved considerably in the second. Note, however, that we did not observe the same issue with the EnKF-MDA.
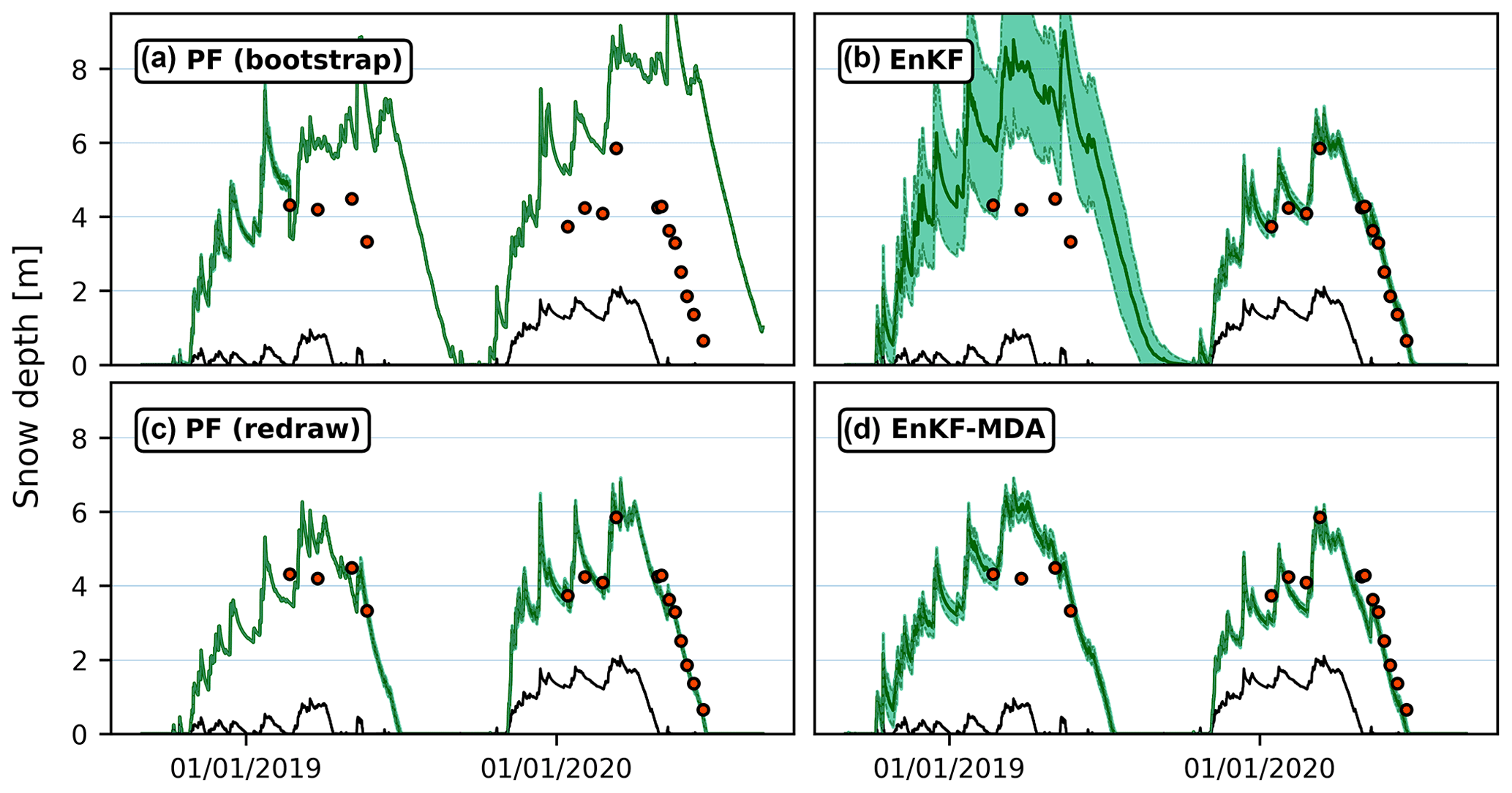
Figure 3Intercomparison of filter-based data assimilation experiments in the single cell of the Izas catchment highlighted in Fig. 2. The black line is a deterministic (no perturbations) open-loop simulation for reference, and the red dots are the observations; the dark green line (shading) shows the posterior mean (±1 standard deviation).
Figure 4 shows the results of the experiment using the smoother-based approaches. In this particular case, the posterior snow depth time series generated by using the PBS are much closer to the observations than when using particle filters with the bootstrap resampling (Fig. 3a). In addition, due to the absence of resampling, the PBS did not generate discontinuities in the series that can be observed in the particle filter posteriors (Fig. 3). The ensemble (Kalman) smoothers also outperformed their filter counterpart in this particular case. Moreover, the ES-MDA produced simulations closer to the observations compared to the other smoothers as confirmed in Table 1.
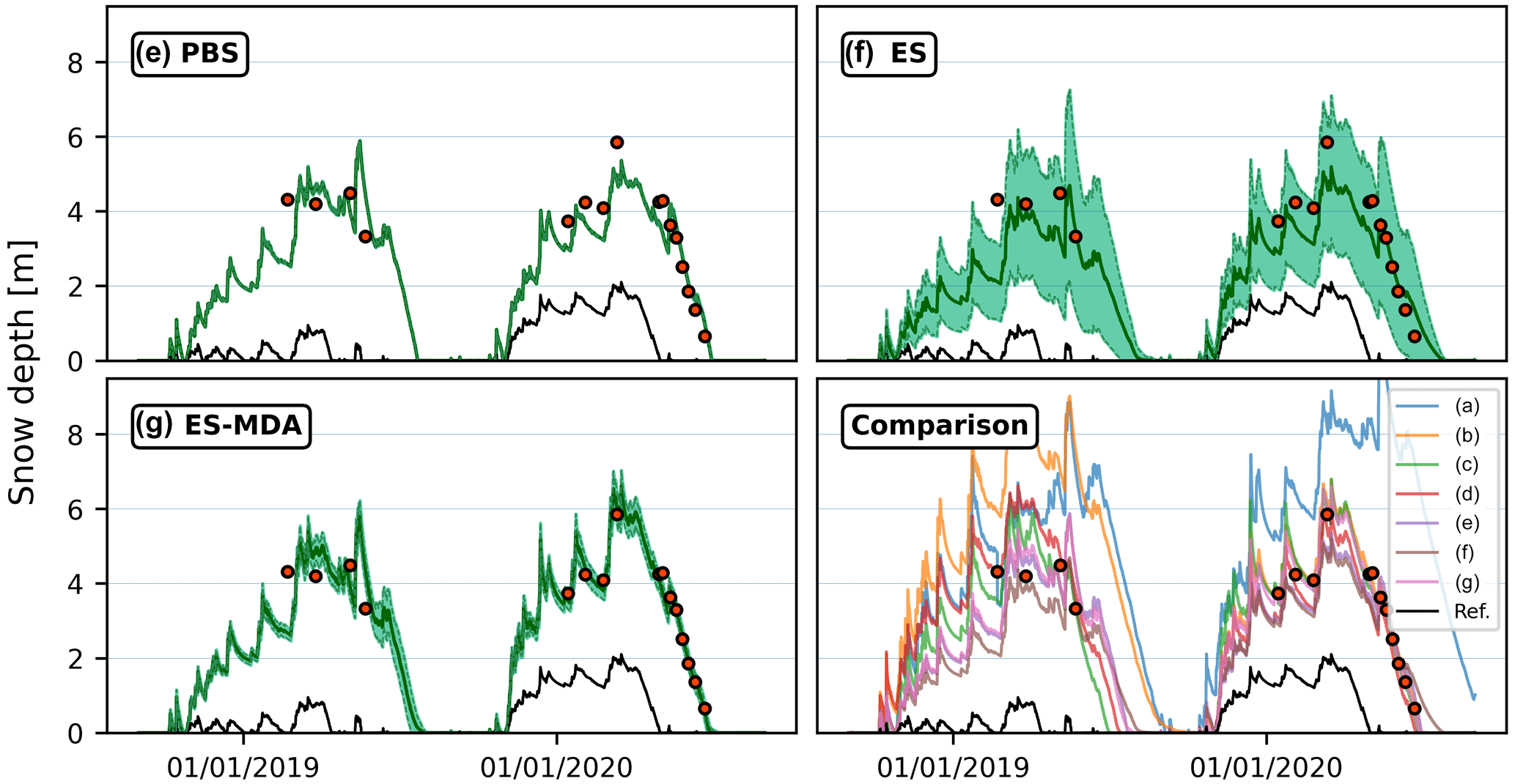
Figure 4Intercomparison of smoother-based data assimilation experiments and intercomparison of the posterior mean of all the data assimilation algorithms (letters a–g correspond to the panels in which the individual schemes are shown in Figs. 3 and 4) in the single cell of the Izas catchment highlighted in Fig. 2. The black line is a deterministic (no perturbations) open-loop simulation for reference, and the red dots are the observations; the dark green line (shading) shows the posterior mean (±1 standard deviation).
There is an obvious improvement in the snow depth spatial distribution patterns after running MuSA compared with the reference simulations for the hyper-resolution distributed simulation as shown in Fig. 5. The updated SWE products exhibited very consistent spatial patterns compared with the independent (i.e., non-assimilated) drone-based snow depth map, while the reference simulations exhibited a much lower and less realistic spatial variability. Similarly, the updated FSM2 snow depth simulations were very consistent with the non-assimilated snow depth maps with a coefficient of determination of R2=0.96, while the reference simulation exhibited R2=0.03.
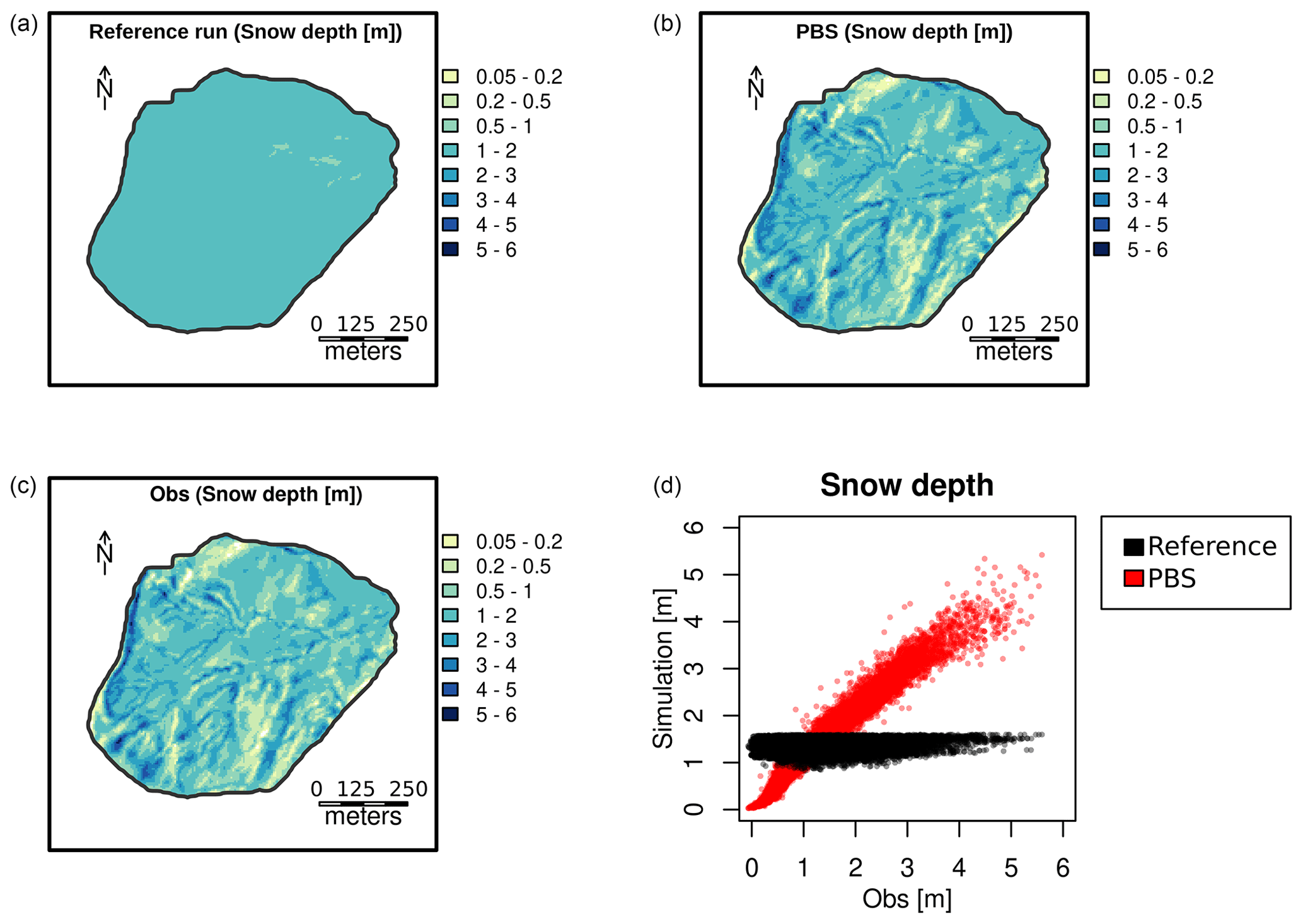
Figure 5Snow depth estimates for Izas on 3 February 2020: reference simulation (a), PBS posterior mean simulation (b), independent drone-based retrievals (c), and evaluation of the simulations (black: reference, red: PBS) relative to the drone-based retrievals (d).
Figure 6 shows the spatial distribution of the posterior mean temperature bias and precipitation multiplier over the Izas catchment after the assimilation of the drone-based snow depth retrievals. The distribution of the perturbation parameters showed spatial patterns consistent with the topography of Izas in both of the variables, ranging from −4 to 2 K in the case of the additive temperature bias and from 0.5 to 3 in the case of the precipitation multiplier.

Figure 6Posterior perturbation parameters for the precipitation [non-dimensional] (multiplicative) and temperature [K] (additive).
5.2 Joint assimilation of satellite-based LST and FSCA retrievals
The result of jointly assimilating LST and FSCA is shown in Fig. 7. As expected, the difference between the observations and the updated simulations was reduced, compared with the reference simulations. The root mean square error (RMSE) between the observations and the reference LST was 7.2 K compared to 5.1 K for the updated simulations. Similarly, the RMSE between the observations and the reference FSCA was 0.38, compared to 0.14 for the updated simulations. Such modifications of the FSCA and LST state variables resulted in a completely different SWE simulation that reached values of up to 900 mm of peak SWE compared to the 300 mm reached by the reference simulation.
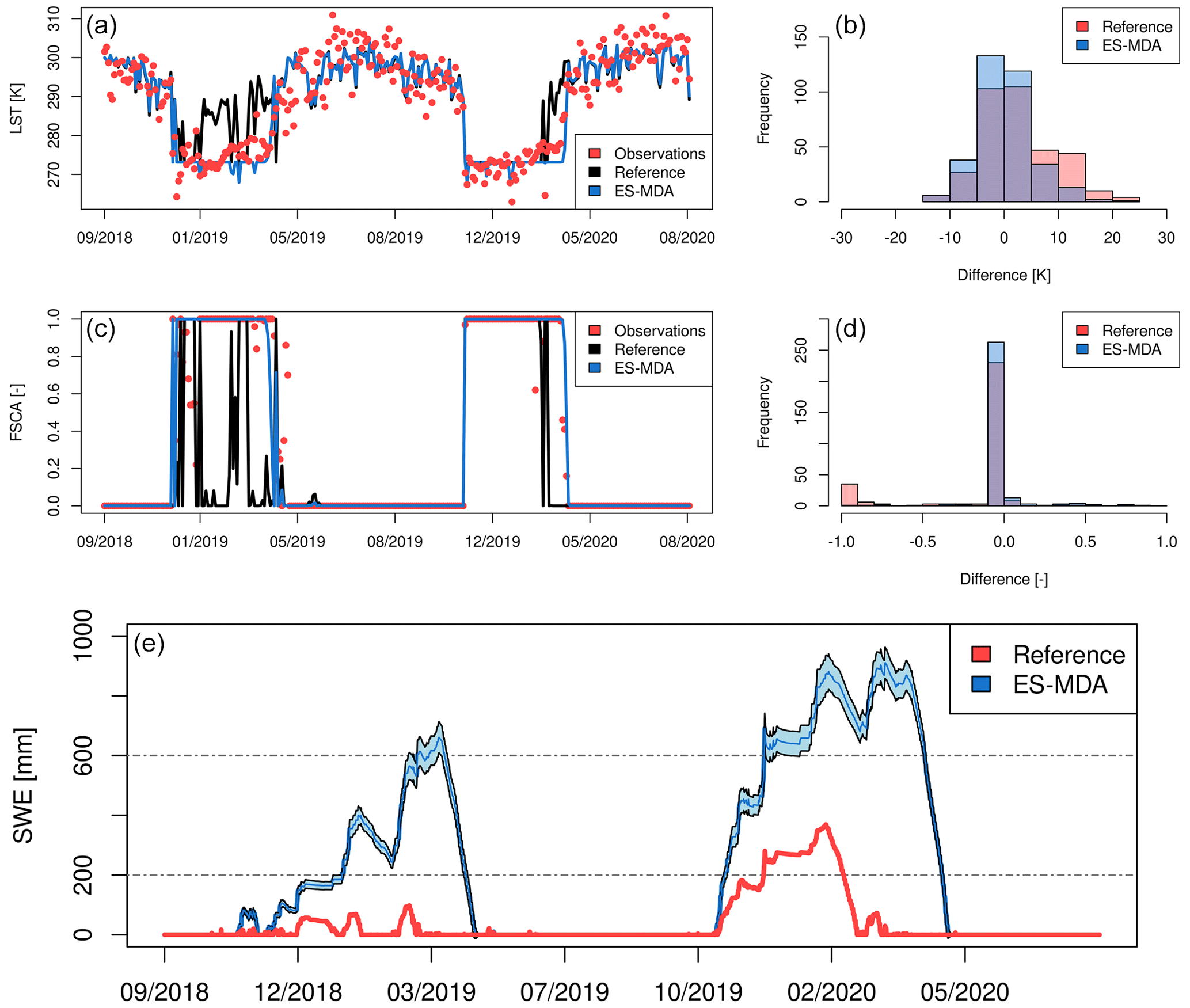
Figure 7Joint LST (a, b) and FSCA (c, d) data assimilation and its influence on the SWE simulations (e).
5.3 Computational benchmarks
In a single-cell benchmark experiment, the different data assimilation algorithms showed large variations in computational cost (Fig. 8). In this comparison with Ne=100 particles the computational cost measured in wall clock time ranged from 39 (PBS) to 270 s (EnKF-MDA, Na=4) per cell per year. These benchmarks showed that for all the cases the computational cost increased almost linearly with the number of particles. As expected, the iterative versions of the ensemble Kalman approaches are more demanding in terms of computational cost due to the larger number of FSM2 simulations required by the data assimilation algorithm. Filtering is also generally more expensive than (batch) smoothing, since it invokes more frequent calls to I/O operations. This is especially clear for the costly iterative ensemble Kalman methods, but note that the relative increase in wall clock time for filtering relative to smoothing is more or less the same across all methods and corresponds to a factor of roughly 1.5.

Figure 8Benchmarks for the computational cost, expressed in terms of wall clock time, of the different assimilation schemes implemented in MuSA.
The results from the intercomparison of different data assimilation experiments exhibited large variability in performance and computational cost across the schemes. This highlights the need for thorough testing, as the suitability of the assimilation algorithms will vary depending on the problem at hand. Despite the fact that most of the data assimilation algorithms improved the simulations compared with the reference simulations, their performance differed markedly. In fact, these differences tend not to be explored in the literature, where often the choice of one algorithm over others is not sufficiently justified empirically. The lack of tools to compare the performance of different data assimilation algorithms has probably contributed to this problem, since it requires substantial coding effort to implement all available options in each data assimilation experiment. As an example, a case could be made that ensemble-Kalman-based data assimilation approaches are often prematurely perceived as suboptimal for snow science applications due to the Gaussian linear assumption (Helmert et al., 2018; Largeron et al., 2020). In spite of this, our first experiment showed that the iterative version of ensemble-based Kalman smoothers outperformed the other smoother algorithms, as also found by Aalstad et al. (2018) and Pirk et al. (2022). These findings are consistent with the broader DA literature, where basic PFs (based on SIR) tend to suffer more from degeneracy due to the curse of dimensionality in high dimensional problems (Snyder et al., 2008). This degeneracy problem tends to be even worse with the PBS (based on SIS) due to the absence of resampling (van Leeuwen and Evensen, 1996; van Leeuwen, 2009; Särkkä, 2013; Pirk et al., 2022).
In their review, van Leeuwen et al. (2019) suggest promising remedies for this problem with more sophisticated particle methods that invoke innovations such as using better proposal distributions or iterations. The particle filter using redraws from a normal approximation of the posterior that we implemented in MuSA was loosely inspired by the use of proposal distributions and can overcome the degeneracy problems in the classic bootstrap particle filter (see Table 1). The use of iterations was pursued by Stordal and Elsheikh (2015), who recast the ES-MDA in the framework of iterative particle methods, leading to improved performance with subsurface flow problems. This suggests that a hybridization of ensemble Kalman and particle methods (Papadakis et al., 2010; Pirk et al., 2022) may also be a promising avenue for future work. We reiterate that we are not advocating for one class of DA methods over another; the point we are making is rather that to do so prematurely would be unwise. Common wisdom embodied in the “no free lunch” theorems for optimization (Wolpert and Macready, 1997) warns us not to expect one particular algorithm to always perform best but rather to expect that this will depend on the problem at hand. The power of MuSA is to provide a tool that simplifies the task of comparing different experimental setups by allowing the intercomparison of data assimilation algorithms as well as facilitating the implementation of new ones. In the future, more data assimilation algorithms could be implemented, including iterative versions of the PBS and particle filters as well as MCMC methods, which are the gold standard for Bayesian inference (Neal, 1993; Apte et al., 2007) but have received relatively less attention from the snow community (Kolberg and Gottschalk, 2006) due to their often prohibitive computational cost.
The selection of the data assimilation algorithm is not the only possible source of variability in the updated simulations. As an example, MuSA has two different precipitation partitioning methods implemented. In addition to the impact that the selection of the precipitation-phase partitioning method would have on the deterministic simulations, the perturbations in the forcing can also impact the precipitation phase in different ways depending on the selected partitioning method. For example, perturbing the relative humidity forcing would only impact the precipitation phase for one of the partitioning methods in FSM2. Different strategies to generate the prior ensemble of simulations may markedly impact the performance of the data assimilation algorithms, especially in the case of the PBS and particle filters, which are prone to degeneracy.
MuSA was also able to assimilate hyper-resolution snow depth maps in a distributed fashion. The assimilation of snow depth products has been shown to be a very robust approach to snow depth estimation. The posterior maps of the perturbation parameters showed intricately detailed spatial patterns, especially considering the fact that there is not any cell intercommunication in MuSA. The appearance of this spatial pattern in the perturbation parameters indicates that they are compensating for a missing processes in the model, which in this case is most likely to be the wind-driven ablation and accumulation processes, since most of the spatial variability in melt energy is provided by the MicroMet shortwave radiation routine (e.g., Baba et al., 2019). Thus, MuSA can be used to study the importance of missing snow processes in the FSM2 model. In the particular case of the assimilation of hyper-resolution snow depth maps, it may help to address the unresolved problem of wind redistribution in numerical snowpack modeling (Vionnet et al., 2021) by providing spatiotemporally continuous (i.e., gap-free) and physically consistent reconstructions of the snowpack dynamics that can be used as a target when designing and calibrating new process parameterizations in snow model development.
Despite the fact that there are some other examples of assimilating snow depth products, most of these have been carried out using in situ observations (Cantet et al., 2019; Cluzet et al., 2022; Odry et al., 2022) or were developed at coarser spatiotemporal resolutions (Deschamps-Berger et al., 2022). To our knowledge the assimilation experiment performed in Sect. 5.1 is the first test of assimilating drone retrievals in a numerical snow model. This approach should be useful for the monitoring of hydrological experimental catchments in snow-dominated areas, providing a cost-effective method to generate spatially and temporally continuous reconstruction of the SWE distribution. Using MuSA in combination with the ever-increasing capabilities of drones, it is possible to develop joint-assimilation experiments using snow depth and other variables such as LST or albedo at unprecedented resolutions. Furthermore, the assimilation of high-resolution snow depth maps may become a common practice in the future, even at wider scales, thanks to satellite-based snow depth retrievals (Marti et al., 2016; Treichler and Kääb, 2017; Lievens et al., 2019).
The joint assimilation of FSCA and LST retrievals from MODIS had a large impact in the updated SWE simulations. The assimilation of LST has the potential to provide additional information when FSCA saturates at 1, for example during most of the accumulation season and during the polar night in the absence of sunlight. This preliminary experiment suggests that the joint assimilation of LST and FSCA may be beneficial to improve distributed snow reanalyses at larger scales. There are several examples of assimilating SCA in both its binary and its fractional form (e.g., Margulis et al., 2016). However, the assimilation of LST in numerical snow models remains largely underexplored (Navari et al., 2016). This is probably due to the relative lack of accurate LST information at the desired scale for snow applications, especially over complex terrain, as the currently available satellite sensors that are able to provide LST information exhibit either a spatial resolution that can be too coarse or revisit times that are too infrequent (Largeron et al., 2020). Nonetheless, given the agenda of several space agencies, LST information will be readily available in the future at high spatiotemporal resolutions. This includes the Thermal infraRed Imaging Satellite for High-resolution Natural resource Assessment (TRISHNA; Lagouarde et al., 2018) and the Land Surface Temperature Monitoring (LSTM) missions. Another logical next step to explore in terms of joint assimilation would be to assimilate FSCA and LST together with the aforementioned satellite-based snow depth retrievals (Marti et al., 2016; Treichler and Kääb, 2017; Lievens et al., 2019).
The computational cost of each data assimilation algorithm and implementation depends on several factors. First, the computational cost of the particle filter and PBS approaches is different to the Kalman and the iterative Kalman approaches. This is due to the number of FSM2 runs required to run each algorithm. In the particle filter and PBS approaches, the number of FSM2 runs is Nr=Ne, where Nr denotes the number of runs (per grid cell) and Ne is the number of particles. On the other hand, the computational cost in terms of the number of FSM2 runs in the EnKF and ES will be Nr=2Ne. For the iterative versions of these ensemble-Kalman-based approaches, the number of runs will be , where Na is the number of assimilation cycles, i.e., the number of iterations in the ensemble Kalman update equations, selected by the user as explained in Sect. 3.5. In general, the ensemble Kalman techniques require more runs because they actually move (rather than just reweight) the parameter ensemble after assimilating the observations. To obtain the corresponding updated states (and predicted observations), FSM2 must be rerun with the updated parameters. In the non-iterative case this effectively requires a single rerun of the FSM2 ensemble, while for the iterative case it requires Na reruns of the FSM2 ensemble.
However, the number of FSM2 runs is not the only source of computational cost. The current version of MuSA is a wrapper around the FSM2 model. This simplifies the inclusion of other snow models if required by the user. It also means that MuSA can easily incorporate FSM2 upgrades. Nonetheless, this implementation comes with a computational cost due to the I/O operations and the system calls that are performed in the background when the MuSA system is running. The time expended on I/O operations and system calls will be higher in the parallel runs due to the use of disk space from different processes at the same time. This suggests that a more direct integration of FSM2 that avoids I/O operations and system calls could improve the overall performance of MuSA.
It is worth noting that MuSA may also be used to implement simpler and (therefore) faster snowpack models (e.g., Aalstad et al., 2018) if numerical efficiency is required. Conversely, more sophisticated multilayer models such as Crocus (Vionnet et al., 2012) and SNOWPACK (Bartelt and Lehning, 2002) could also be encapsulated in MuSA in the future. The implementation of more sophisticated models that include detailed radiative transfer schemes may provide MuSA with the capability of ingesting new remotely sensed information such as shortwave reflectances (Cluzet et al., 2020) or radar backscatter (Lievens et al., 2019). In addition, as FSM2 has support for different temporal resolutions, the future versions of MuSA will support different time steps, allowing us to reduce the computational cost in terms of both run time and data storage requirements. As such, there is room for reducing the computational cost of MuSA if necessary, which would open up the possibility of implementing it even at continental and hemispheric scales.
MuSA is a new snow data assimilation system that encapsulates the FSM2 snowpack model. There are six different ensemble-based data assimilation algorithms implemented in MuSA, as outlined in detail in Sect. 3, with several different resampling strategies in the case of particle filters. The data assimilation algorithms and the characteristics of the ensemble generation are provided by the user through simple configuration files. MuSA is able to assimilate different observational variables either independently or jointly (i.e., in the same assimilation step), even if these variables do not share the same time step or if they have gaps. The system is highly scalable such that it is possible to run it on both local machines and supercomputing infrastructures.
We used the MuSA system to assimilate snow depth maps derived from drone retrievals over the Izas experimental catchment for two different seasons at 5 m spatial resolution. The behavior of each data assimilation algorithm differed considerably, demonstrating that case-specific testing of algorithms rather than just relying on the literature can be very helpful for designing successful snow data assimilation experiments. In addition, we developed a single-cell data assimilation experiment, fusing LST and FSCA retrievals from MODIS with the FSM2 model. The results indicated a strong potential in the joint exploitation of these remotely sensed variables, suggesting that more research is needed in this regard. Finally, we presented a benchmark of the computing cost of the data assimilation algorithms. The choice of data assimilation algorithms had a considerable impact on the computational expense of the system and should be considered for high-resolution or large-scale runs.
The MuSA code is available at https://github.com/ealonsogzl/MuSA (last access: 16 December 2022); the version of MuSA used for this paper (with a subset of input data) can be found at https://doi.org/10.5281/zenodo.7014570 (Alonso González, 2022), and the complete input data for Izas used in the present study can be found at https://doi.org/10.5281/zenodo.7248635 (Alonso-González, 2022). The original FSM2 code is found at github.com/RichardEssery/FSM2 and in the MuSA repository with slight modifications from the original version. The MODIS data used herein, namely MOD10A1 (Hall et al., 2002) and MOD11A1 (Wan et al., 2015), are available for download from NSIDC and the NASA EOSDIS Land Processes DAAC, respectively. ERA5 data are available for download from the Copernicus Climate Data Store. MuSA can be launched on Linux/macOS or Windows platforms (via Windows Subsystem for Linux). MicroMet code is available upon request to Glen E. Liston (glen.liston@colostate.edu).
Conceptualization was by EAG and KA. Data were curated by EAG, MWB, and JR. Formal analysis was undertaken by EAG and KA. Funding was acquired by EAG, JILM, and SG. Investigation was undertaken by EAG and KA. Methodology was developed by EAG and KA. Project administration was the responsibility of EAG, JILM, and SG. Resources were the responsibility of EAG and JILM. Software was the responsibility of EAG and KA. Supervision was carried out by JILM and SG. Validation was performed by EAG and KA. Visualization was by EAG, KA, and SG. Writing – original draft preparation was by EAG and KA. Writing – review and editing was by EAG, KA, MWB, JR, JILM, JF, RE, and SG.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Esteban Alonso-González has been funded by the CNES postdoctoral fellowship. Data from the Izas experimental catchment were collected in the frame of HIDROIBERNIEVE – CGL2017-82216-R funded by a Spanish Ministry of Economy and Competitiveness project. Kristoffer Aalstad was funded by the Research Council of Norway through the Spot-On project (no. 301552) and acknowledges support from the LATICE strategic research area at the University of Oslo. Jesús Revuelto is supported by grant no. IJC2018-036260-I.
This research has been supported by the Centre National d'Études Spatiales (grant no. 0103207), the Ministerio de Economía y Competitividad (grant no. HIDROIBERNIEVE – CGL2017-82216-R), the Research Council of Norway (Spot-On (grant no. 301552)), and the Ministerio de Ciencia e Innovación (grant no. IJC2018-036260-I).
This paper was edited by Jeffrey Neal and reviewed by Bertrand Cluzet and one anonymous referee.
Aalstad, K., Westermann, S., Schuler, T. V., Boike, J., and Bertino, L.: Ensemble-based assimilation of fractional snow-covered area satellite retrievals to estimate the snow distribution at Arctic sites, The Cryosphere, 12, 247–270, https://doi.org/10.5194/tc-12-247-2018, 2018. a, b, c, d, e, f, g, h, i
Aalstad, K., Westermann, S., and Bertino, L.: Evaluating satellite retrieved fractional snow-covered area at a high-Arctic site using terrestrial photography, Remote Sens. Environ., 239, 111618, https://doi.org/10.1016/j.rse.2019.111618, 2020. a
Alonso González, E.: ealonsogzl/MuSA: v1.0 GMD submission (v1.0), Zenodo [code], https://doi.org/10.5281/zenodo.7014570, 2022. a
Alonso-González, E.: Inputs (forcing and observations) ready for use by “MuSA: The Multiscale Snow Data Assimilation System (v1.0)”, Zenodo [data set], https://doi.org/10.5281/zenodo.7248635, 2022. a
Alonso-González, E., López-Moreno, J. I., Gascoin, S., García-Valdecasas Ojeda, M., Sanmiguel-Vallelado, A., Navarro-Serrano, F., Revuelto, J., Ceballos, A., Esteban-Parra, M. J., and Essery, R.: Daily gridded datasets of snow depth and snow water equivalent for the Iberian Peninsula from 1980 to 2014, Earth Syst. Sci. Data, 10, 303–315, https://doi.org/10.5194/essd-10-303-2018, 2018. a
Alonso-González, E., Gutmann, E., Aalstad, K., Fayad, A., Bouchet, M., and Gascoin, S.: Snowpack dynamics in the Lebanese mountains from quasi-dynamically downscaled ERA5 reanalysis updated by assimilating remotely sensed fractional snow-covered area, Hydrol. Earth Syst. Sci., 25, 4455–4471, https://doi.org/10.5194/hess-25-4455-2021, 2021. a, b, c
Andreadis, K. M. and Lettenmaier, D. P.: Assimilating remotely sensed snow observations into a macroscale hydrology model, Adv. Water Resour., 29, 872–886, https://doi.org/10.1016/j.advwatres.2005.08.004, 2006. a
Apte, A., Hairer, M., Stuart, A. M., and Voss, J.: Sampling the posterior: An approach to non-Gaussian data assimilation, Physica D, 230, 50–64, https://doi.org/10.1016/j.physd.2006.06.009, 2007. a
Baba, M., Gascoin, S., Kinnard, C., Marchane, A., and Hanich, L.: Effect of Digital Elevation Model Resolution on the Simulation of the Snow Cover Evolution in the High Atlas, Water Resour. Res., 55, 5360–5378, https://doi.org/10.1029/2018WR023789, 2019. a
Baba, M. W., Gascoin, S., and Hanich, L.: Assimilation of Sentinel-2 data into a snowpack model in the High Atlas of Morocco, Remote Sens., 10, 1982, https://doi.org/10.3390/rs10121982, 2018. a, b
Baldo, E. and Margulis, S. A.: Assessment of a multiresolution snow reanalysis framework: a multidecadal reanalysis case over the upper Yampa River basin, Colorado, Hydrol. Earth Syst. Sci., 22, 3575–3587, https://doi.org/10.5194/hess-22-3575-2018, 2018. a
Banner, K. M., Irvine, K. M., and Rodhouse, T. J.: The Use of Bayesian Priors in Ecology: The Good, the Bad and the Not Great, Meth. Ecol. Evol., 11, 882–889, https://doi.org/10.1111/2041-210X.13407, 2020. a, b
Bannister, R. N.: A review of operational methods of variational and ensemble‐variational data assimilation, Q. J. Roy. Meteor. Soc., 143, 607–633, https://doi.org/10.1002/qj.2982, 2017. a
Barnett, T. P., Adam, J. C., and Lettenmaier, D. P.: Potential impacts of a warming climate on water availability in snow-dominated regions, Nature, 438, 303–309, https://doi.org/10.1038/nature04141, 2005. a
Bartelt, P. and Lehning, M.: A physical SNOWPACK model for the Swiss avalanche warning Part I: Numerical model, Cold Reg. Sci. Technol., 35, 123–145, https://doi.org/10.1016/S0165-232X(02)00074-5, 2002. a
Bauer, P., Thorpe, A., and Brunet, G.: The quiet revolution of numerical weather prediction, Nature, 525, 47–55, https://doi.org/10.1038/nature14956, 2015. a, b
Bertino, L., Evensen, G., and Wackernagel, H.: Sequential Data Assimilation Techniques in Oceanography, Int. Statist. Rev., 71, 223–241, https://doi.org/10.1111/j.1751-5823.2003.tb00194.x, 2003. a, b
Bhardwaj, A., Singh, S., Sam, L., Bhardwaj, A., Martín-Torres, F. J., Singh, A., and Kumar, R.: MODIS-based estimates of strong snow surface temperature anomaly related to high altitude earthquakes of 2015, Remote Sens. Environ., 188, 1–8, https://doi.org/10.1016/j.rse.2016.11.005, 2017. a
Burgers, G., Jan van Leeuwen, P., and Evensen, G.: Analysis Scheme in the Ensemble Kalman Filter, Mon. Weather Rev., 126, 1719–1724, https://doi.org/10.1175/1520-0493(1998)126<1719:ASITEK>2.0.CO;2, 1998. a
Cantet, P., Boucher, M. A., Lachance-Coutier, S., Turcotte, R., and Fortin, V.: Using a Particle Filter to Estimate the Spatial Distribution of the Snowpack Water Equivalent, J. Hydrometeorol., 20, 577–594, https://doi.org/10.1175/JHM-D-18-0140.1, 2019. a, b
Cappé, O., Moulines, E., and Rydén, T.: Inference in Hidden Markov Models, Springer, https://doi.org/10.1007/0-387-28982-8, 2005. a, b
Carrassi, A., Bocquet, M., Bertino, L., and Evensen, G.: Data assimilation in the geosciences: An overview of methods, issues, and perspectives, WIREs Clim. Change, 9, e535, https://doi.org/10.1002/wcc.535, 2018. a, b, c, d, e, f, g, h
Charrois, L., Cosme, E., Dumont, M., Lafaysse, M., Morin, S., Libois, Q., and Picard, G.: On the assimilation of optical reflectances and snow depth observations into a detailed snowpack model, The Cryosphere, 10, 1021–1038, https://doi.org/10.5194/tc-10-1021-2016, 2016. a, b
Chopin, N. and Papaspiliopoulos, O.: An Introduction to Sequential Monte Carlo, Springer, https://doi.org/10.1007/978-3-030-47845-2, 2020. a, b, c, d, e
Clark, M. P., Slater, A. G., Barrett, A. P., Hay, L. E., McCabe, G. J., Rajagopalan, B., and Leavesley, G. H.: Assimilation of snow covered area information into hydrologic and land-surface models, Adv. Water Resour., 29, 1209–1221, https://doi.org/10.1016/j.advwatres.2005.10.001, 2006. a, b
Cluzet, B., Revuelto, J., Lafaysse, M., Tuzet, F., Cosme, E., Picard, G., Arnaud, L., and Dumont, M.: Towards the assimilation of satellite reflectance into semi-distributed ensemble snowpack simulations, Cold Reg. Sci. Technol., 170, 102918, https://doi.org/10.1016/j.coldregions.2019.102918, 2020. a, b, c
Cluzet, B., Lafaysse, M., Cosme, E., Albergel, C., Meunier, L.-F., and Dumont, M.: CrocO_v1.0: a particle filter to assimilate snowpack observations in a spatialised framework, Geosci. Model Dev., 14, 1595–1614, https://doi.org/10.5194/gmd-14-1595-2021, 2021. a, b
Cluzet, B., Lafaysse, M., Deschamps-Berger, C., Vernay, M., and Dumont, M.: Propagating information from snow observations with CrocO ensemble data assimilation system: a 10-years case study over a snow depth observation network, The Cryosphere, 16, 1281–1298, https://doi.org/10.5194/tc-16-1281-2022, 2022. a, b, c, d
Comola, F., Giometto, M. G., Salesky, S. T., Parlange, M. B., and Lehning, M.: Preferential Deposition of Snow and Dust Over Hills: Governing Processes and Relevant Scales, J. Geophys. Res.-Atmos., 124, 7951–7974, https://doi.org/10.1029/2018JD029614, 2019. a
Cortés, G. and Margulis, S.: Impacts of El Niño and La Niña on interannual snow accumulation in the Andes: Results from a high-resolution 31 year reanalysis: El Niño Effects on Andes Snow, Geophys. Res. Lett., 44, 6859–6867, https://doi.org/10.1002/2017GL073826, 2017. a
Cosme, E., Verron, J., Brasseur, P., Blum, J., and Auroux, D.: Smoothing Problems in a Bayesian Framework and Their Linear Gaussian Solutions, Mon. Weather Rev., 140, 683–695, https://doi.org/10.1175/MWR-D-10-05025.1, 2012. a
Dechant, C. and Moradkhani, H.: Radiance data assimilation for operational snow and streamflow forecasting, Adv. Water Resour., 34, 351–364, https://doi.org/10.1016/j.advwatres.2010.12.009, 2011. a
De Lannoy, G. J. M., Reichle, R. H., Houser, P. R., Arsenault, K. R., Verhoest, N. E. C., and Pauwels, V. R. N.: Satellite-Scale Snow Water Equivalent Assimilation into a High-Resolution Land Surface Model, J. Hydrometeorol., 11, 352–369, https://doi.org/10.1175/2009JHM1192.1, 2010. a
De Lannoy, G. J. M., Reichle, R. H., Arsenault, K. R., Houser, P. R., Kumar, S., Verhoest, N. E. C., and Pauwels, V. R. N.: Multiscale assimilation of Advanced Microwave Scanning Radiometer-EOS snow water equivalent and Moderate Resolution Imaging Spectroradiometer snow cover fraction observations in northern Colorado, Water Resour. Res., 48, W01522, https://doi.org/10.1029/2011WR010588, 2012. a
Deschamps-Berger, C., Cluzet, B., Dumont, M., Lafaysse, M., Berthier, E., Fanise, P., and Gascoin, S.: Improving the Spatial Distribution of Snow Cover Simulations by Assimilation of Satellite Stereoscopic Imagery, Water Resour. Res., 58, e2021WR030271, https://doi.org/10.1029/2021WR030271, 2022. a, b, c
Dozier, J., Bair, E. H., and Davis, R. E.: Estimating the spatial distribution of snow water equivalent in the world’s mountains, Wiley Interdisciplinary Reviews: Water, 3, 461–474, https://doi.org/10.1002/wat2.1140, 2016. a, b
Dumont, M., Durand, Y., Arnaud, Y., and Six, D.: Variational assimilation of albedo in a snowpack model and reconstruction of the spatial mass-balance distribution of an alpine glacier, J. Glaciol., 58, 151–164, https://doi.org/10.3189/2012JoG11J163, 2012. a
Dunne, S. and Entekhabi, D.: An ensemble-based reanalysis approach to land data assimilation, Water Resour. Res., 41, W02013, https://doi.org/10.1029/2004WR003449, 2005. a, b, c
Durand, M. and Margulis, S. A.: Feasibility Test of Multifrequency Radiometric Data Assimilation to Estimate Snow Water Equivalent, J. Hydrometeorol., 7, 443–457, https://doi.org/10.1175/JHM502.1, 2006. a, b
Durand, M., Molotch, N. P., and Margulis, S. A.: Merging complementary remote sensing datasets in the context of snow water equivalent reconstruction, Remote Sens. Environ., 112, 1212–1225, https://doi.org/10.1016/j.rse.2007.08.010, 2008. a, b, c
Emerick, A. A. and Reynolds, A. C.: History matching time-lapse seismic data using the ensemble Kalman filter with multiple data assimilations, Comput. Geosci., 16, 639–539, https://doi.org/10.1007/s10596-012-9275-5, 2012. a, b, c
Emerick, A. A. and Reynolds, A. C.: Ensemble smoother with multiple data assimilation, Comput. Geosci., 55, 3–15, https://doi.org/10.1016/j.cageo.2012.03.011, 2013. a, b, c, d, e, f, g
Essery, R.: A factorial snowpack model (FSM 1.0), Geosci. Model Dev., 8, 3867–3876, https://doi.org/10.5194/gmd-8-3867-2015, 2015. a, b
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res., 99, 10143, https://doi.org/10.1029/94JC00572, 1994. a, b, c, d
Evensen, G.: Data Assimilation: The Ensemble Kalman Filter, Springer, https://doi.org/10.1007/978-3-642-03711-5, 2009. a
Evensen, G.: Analysis of iterative ensemble smoothers for solving inverse problems, Comput. Geosci., 22, 885–908, https://doi.org/10.1007/s10596-018-9731-y, 2018. a, b, c, d, e
Evensen, G.: Accounting for model errors in iterative ensemble smoothers, Comput. Geosci., 23, 761–775, https://doi.org/10.1007/s10596-019-9819-z, 2019. a, b, c, d
Evensen, G., Vossepoel, F. C., and van Leeuwen, P. J.: Data Assimilation Fundamentals, Springer, https://doi.org/10.1007/978-3-030-96709-3, 2022. a, b, c, d, e
Farchi, A. and Bocquet, M.: Review article: Comparison of local particle filters and new implementations, Nonlin. Processes Geophys., 25, 765–807, https://doi.org/10.5194/npg-25-765-2018, 2018. a, b
Fayad, A. and Gascoin, S.: The role of liquid water percolation representation in estimating snow water equivalent in a Mediterranean mountain region (Mount Lebanon), Hydrol. Earth Syst. Sci., 24, 1527–1542, https://doi.org/10.5194/hess-24-1527-2020, 2020. a
Fayad, A., Gascoin, S., Faour, G., López-Moreno, J. I., Drapeau, L., Page, M. L., and Escadafal, R.: Snow hydrology in Mediterranean mountain regions: A review, J. Hydrol., 551, 374–396, https://doi.org/10.1016/j.jhydrol.2017.05.063, 2017. a
Fiddes, J. and Gruber, S.: TopoSCALE v.1.0: downscaling gridded climate data in complex terrain, Geosci. Model Dev., 7, 387–405, https://doi.org/10.5194/gmd-7-387-2014, 2014. a
Fiddes, J., Aalstad, K., and Westermann, S.: Hyper-resolution ensemble-based snow reanalysis in mountain regions using clustering, Hydrol. Earth Syst. Sci., 23, 4717–4736, https://doi.org/10.5194/hess-23-4717-2019, 2019. a
Fiddes, J., Aalstad, K., and Lehning, M.: TopoCLIM: rapid topography-based downscaling of regional climate model output in complex terrain v1.1, Geosci. Model Dev., 15, 1753–1768, https://doi.org/10.5194/gmd-15-1753-2022, 2022. a
Fletcher, S. J. and Zupanski, M.: A hybrid multivariate Normal and lognormal distribution for data assimilation, Atmos. Sci. Lett., 7, 43–46, https://doi.org/10.1002/asl.128, 2006. a
Fowler, A. and van Leeuwen, P. J.: Observation impact in data assimilation: the effect of non-Gaussian observation error, Tellus A, 65, 20035, https://doi.org/10.3402/tellusa.v65i0.20035, 2013. a
García-Ruiz, J. M., López-Moreno, J. I., Vicente-Serrano, S. M., Lasanta-Martínez, T., and Beguería, S.: Mediterranean water resources in a global change scenario, Earth-Sci. Rev., 105, 121–139, https://doi.org/10.1016/j.earscirev.2011.01.006, 2011. a
Gascoin, S., Grizonnet, M., Bouchet, M., Salgues, G., and Hagolle, O.: Theia Snow collection: high-resolution operational snow cover maps from Sentinel-2 and Landsat-8 data, Earth Syst. Sci. Data, 11, 493–514, https://doi.org/10.5194/essd-11-493-2019, 2019. a
Gelaro, R., McCarty, W., Suárez, M. J., Todling, R., Molod, A., Takacs, L., Randles, C. A., Darmenov, A., Bosilovich, M. G., Reichle, R., Wargan, K., Coy, L., Cullather, R., Draper, C., Akella, S., Buchard, V., Conaty, A., da Silva, A. M., Gu, W., Kim, G., Koster, R., Lucchesi, R., Merkova, D., Nielsen, J. E., Partyka, G., Pawson, S., Putman, W., Rienecker, M., Schubert, S. D., Sienkiewicz, M., and Zhao, B.: The modern-era retrospective analysis for research and applications, version 2 (MERRA-2, J. Climate, 30, 5419–5454, https://doi.org/10.1175/JCLI-D-16-0758.1, 2017. a
Gilks, W. R. and Berzuini, C.: Following a moving target-Monte Carlo inference for dynamic Bayesian models, J. Roy. Stat. Soc. B, 63, 127–146, https://doi.org/10.1111/1467-9868.00280, 2001. a
Girotto, M., Cortés, G., Margulis, S. A., and Durand, M.: Examining spatial and temporal variability in snow water equivalent using a 27 year reanalysis: Kern River watershed, Sierra Nevada, Water Resour. Res., 50, 6713–6734, https://doi.org/10.1002/2014WR015346, 2014a. a
Girotto, M., Margulis, S. A., and Durand, M.: Probabilistic SWE reanalysis as a generalization of deterministic SWE reconstruction techniques, Hydrol. Process., 28, 3875–3895, https://doi.org/10.1002/hyp.9887, 2014b. a
Girotto, M., Musselman, K. N., and Essery, R. L. H.: Data Assimilation Improves Estimates of Climate-Sensitive Seasonal Snow, Current Climate Change Reports, 6, 81–94, https://doi.org/10.1007/s40641-020-00159-7, 2020. a
Gordon, N. J., Salmond, D. J., and Smith, A. F. M.: Novel approach to nonlinear/non-Gaussian Bayesian state estimation, IEE Proceedings F Radar and Signal Processing, 140, 107, https://doi.org/10.1049/ip-f-2.1993.0015, 1993. a, b, c, d
Günther, D., Marke, T., Essery, R., and Strasser, U.: Uncertainties in Snowpack Simulations – Assessing the Impact of Model Structure, Parameter Choice, and Forcing Data Error on Point-Scale Energy Balance Snow Model Performance, Water Resour. Res., 55, 2779–2800, https://doi.org/10.1029/2018WR023403, 2019. a, b, c
Gutmann, E., Barstad, I., Clark, M., Arnold, J., and Rasmussen, R.: The Intermediate Complexity Atmospheric Research model (ICAR, J. Hydrometeorol., 17, 957–973, https://doi.org/10.1175/JHM-D-15-0155.1, 2016. a
Hall, D. and Riggs, G.: MODIS/Terra Snow Cover Daily L3 Global 500m SIN Grid Version 6, NASA National Snow and Ice Data Center Distributed Active Archive Center [data set], https://doi.org/10.5067/MODIS/MOD10A1.006, 2016. a
Hall, D. K., Riggs, G. A., Salomonson, V. V., DiGirolamo, N. E., and Bayr, K. J.: MODIS snow-cover products, Remote Sens. Environ., 83, 181–194, https://doi.org/10.1016/S0034-4257(02)00095-0, 2002. a, b
Harder, P. and Pomeroy, J.: Estimating precipitation phase using a psychrometric energy balance method, Hydrol. Process., 27, 1901–1914, https://doi.org/10.1002/hyp.9799, 2013. a
Havens, S., Marks, D., Kormos, P., and Hedrick, A.: Spatial Modeling for Resources Framework (SMRF): A modular framework for developing spatial forcing data for snow modeling in mountain basins, Comput. Geosci., 109, 295–304, https://doi.org/10.1016/j.cageo.2017.08.016, 2017. a
Helmert, J., Şensoy Şorman, A., Alvarado Montero, R., De Michele, C., De Rosnay, P., Dumont, M., Finger, D. C., Lange, M., Picard, G., Potopová, V., Pullen, S., Vikhamar-Schuler, D., and Arslan, A. N.: Review of Snow Data Assimilation Methods for Hydrological, Land Surface, Meteorological and Climate Models: Results from a COST HarmoSnow Survey, Geosciences, 8, 489, https://doi.org/10.3390/geosciences8120489, 2018. a
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020. a, b
Hou, J., Huang, C., Chen, W., and Zhang, Y.: Improving Snow Estimates Through Assimilation of MODIS Fractional Snow Cover Data Using Machine Learning Algorithms and the Common Land Model, Water Resour. Res., 57, e2020WR029010, https://doi.org/10.1029/2020WR029010, 2021. a
Huang, C., Newman, A. J., Clark, M. P., Wood, A. W., and Zheng, X.: Evaluation of snow data assimilation using the ensemble Kalman filter for seasonal streamflow prediction in the western United States, Hydrol. Earth Syst. Sci., 21, 635–650, https://doi.org/10.5194/hess-21-635-2017, 2017. a
Hüsler, F., Jonas, T., Riffler, M., Musial, J. P., and Wunderle, S.: A satellite-based snow cover climatology (1985–2011) for the European Alps derived from AVHRR data, The Cryosphere, 8, 73–90, https://doi.org/10.5194/tc-8-73-2014, 2014. a
Janjić, T., Bormann, N., Bocquet, M., Carton, J. A., Cohn, S. E., Dance, S. L., Losa, S. N., Nichols, N. K., Potthast, R., Waller, J. A., and Weston, P.: On the representation error in data assimilation, Q. J. Roy. Meteor. Soc., 144, 1257–1278, https://doi.org/10.1002/qj.3130, 2018. a
Jazwinski, A.: Stochastic Processes and Filtering Theory, Academic Press, 1970. a, b, c
Katzfuss, M., Stroud, J. R., and Wikle, C. K.: Understanding the Ensemble Kalman Filter, The American Statistician, 70, 350–357, https://doi.org/10.1080/00031305.2016.1141709, 2016. a
Kavetski, D. and Kuczera, G.: Model smoothing strategies to remove microscale discontinuities and spurious secondary optima in objective functions in hydrological calibration, Water Resour. Res., 43, W03411, https://doi.org/10.1029/2006WR005195, 2007. a
Kokhanovsky, A., Box, J. E., Vandecrux, B., Mankoff, K. D., Lamare, M., Smirnov, A., and Kern, M.: The determination of snow albedo from satellite measurements using fast atmospheric correction technique, Remote Sens., 12, 234, https://doi.org/10.3390/rs12020234, 2020. a
Kolberg, S. A. and Gottschalk, L.: Updating of snow depletion curve with remote sensing data, Hydrol. Process., 20, 2363–2380, https://doi.org/10.1002/hyp.6060, 2006. a, b
Lagouarde, J.-P., Bhattacharya, B. K., Crébassol, P., Gamet, P., Babu, S. S., Boulet, G., Briottet, X., Buddhiraju, K. M., Cherchali, S., Dadou, I., Dedieu, G., Gouhier, M., Hagolle, O., Irvine, M., Jacob, F., Kumar, A., Kumar, K. K., Laignel, B., Mallick, K., Murthy, C. S., Olioso, A., Ottlé, C., Pandya, M. R., Raju, P. V., Roujean, J.-L., Sekhar, M., Shukla, M. V., Singh, S. K., Sobrino, J., and Ramakrishnan, R.: The Indian-French Trishna Mission: Earth Observation in the Thermal Infrared with High Spatio-Temporal Resolution, IGARSS 2018 – 2018 IEEE International Geoscience and Remote Sensing Symposium, 4078–4081, https://doi.org/10.1109/IGARSS.2018.8518720, 2018. a
Largeron, C., Dumont, M., Morin, S., Boone, A., Lafaysse, M., Metref, S., Cosme, E., Jonas, T., Wisntral, A., and Margulis, S.: Toward Snow Cover Estimation in Mountainous Areas Using Modern Data Assimilation Methods: A Review, Front. Earth Sci., 8, 325, https://doi.org/10.3389/feart.2020.00325, 2020. a, b
Leisenring, M. and Moradkhani, H.: Snow water equivalent prediction using Bayesian data assimilation methods, Stoch. Env. Res. Risk A., 25, 253–270, https://doi.org/10.1007/s00477-010-0445-5, 2011. a
Li, T., Bolic, M., and Djuric, P. M.: Resampling Methods for Particle Filtering: Classification, implementation, and strategies, IEEE Signal Processing Magazine, 32, 70–86, https://doi.org/10.1109/MSP.2014.2330626, 2015. a, b, c
Lievens, H., Demuzere, M., Marshall, H.-P., Reichle, R. H., Brucker, L., Brangers, I., de Rosnay, P., Dumont, M., Girotto, M., Immerzeel, W. W., Jonas, T., Kim, E. J., Koch, I., Marty, C., Saloranta, T., Schöber, J., and De Lannoy, G. J. M.: Snow depth variability in the Northern Hemisphere mountains observed from space, Nat. Commun., 10, 1–12, https://doi.org/10.1038/s41467-019-12566-y, 2019. a, b, c, d
Lin, Y. and West, G.: Periconnection: A novel macroecological effect in snow cover phenology modulating ecosystem productivity over upper Northern Hemisphere, Sci. Total Environ., 805, 150164, https://doi.org/10.1016/j.scitotenv.2021.150164, 2022. a
Lindley, D.: The Philosophy of Statistics, J. Roy. Stat. Soc. D, 49, 293–337, 2000. a, b
Liston, G. E. and Elder, K.: A Distributed Snow-Evolution Modeling System (SnowModel), J. Hydrometeorol., 7, 1259–1276, https://doi.org/10.1175/JHM548.1, 2006a. a
Liston, G. E. and Elder, K.: A Meteorological Distribution System for High-Resolution Terrestrial Modeling (MicroMet), J. Hydrometeorol., 7, 217–234, https://doi.org/10.1175/JHM486.1, 2006b. a, b
Liu, Y., Fang, Y., and Margulis, S. A.: Spatiotemporal distribution of seasonal snow water equivalent in High Mountain Asia from an 18-year Landsat–MODIS era snow reanalysis dataset, The Cryosphere, 15, 5261–5280, https://doi.org/10.5194/tc-15-5261-2021, 2021. a
López-Moreno, J. I., Fassnacht, S. R., Beguería, S., and Latron, J. B. P.: Variability of snow depth at the plot scale: implications for mean depth estimation and sampling strategies, The Cryosphere, 5, 617–629, https://doi.org/10.5194/tc-5-617-2011, 2011. a
Luojus, K., Pulliainen, J., Takala, M., Lemmetyinen, J., Mortimer, C., Derksen, C., Mudryk, L., Moisander, M., Hiltunen, M., Smolander, T., Ikonen, J., Cohen, J., Salminen, M., Norberg, J., Veijola, K., and Venäläinen, P.: GlobSnow v3.0 Northern Hemisphere snow water equivalent dataset, Sci. Data, 8, 163, https://doi.org/10.1038/s41597-021-00939-2, 2021. a
MacKay, D. J. C.: Information Theory, Inference, and Learning Algorithms, Cambridge University Press, ISBN 9780521642989, 2003. a, b, c, d, e, f, g, h
Magnusson, J., Gustafsson, D., Hüsler, F., and Jonas, T.: Assimilation of point SWE data into a distributed snow cover model comparing two contrasting methods, Water Resour. Res., 50, 7816–7835, https://doi.org/10.1002/2014WR015302, 2014. a
Magnusson, J., Winstral, A., Stordal, A. S., Essery, R., and Jonas, T.: Improving physically based snow simulations by assimilating snow depths using the particle filter, Water Resour. Res., 53, 1125–1143, https://doi.org/10.1002/2016WR019092, 2017. a, b
Margulis, S. A., Girotto, M., Cortés, G., and Durand, M.: A particle batch smoother approach to snow water equivalent estimation, J. Hydrometeorol., 16, 1752–1772, https://doi.org/10.1175/JHM-D-14-0177.1, 2015. a, b, c, d, e
Margulis, S. A., Cortés, G., Girotto, M., and Durand, M.: A landsat-era Sierra Nevada snow reanalysis (1985–2015, J. Hydrometeorol., 17, 1203–1221, https://doi.org/10.1175/JHM-D-15-0177.1, 2016. a, b, c
Margulis, S. A., Fang, Y., Li, D., Lettenmaier, D. P., and Andreadis, K.: The Utility of Infrequent Snow Depth Images for Deriving Continuous Space‐Time Estimates of Seasonal Snow Water Equivalent, Geophys. Res. Lett., 46, 5331–5340, https://doi.org/10.1029/2019GL082507, 2019. a
Marti, R., Gascoin, S., Berthier, E., de Pinel, M., Houet, T., and Laffly, D.: Mapping snow depth in open alpine terrain from stereo satellite imagery, The Cryosphere, 10, 1361–1380, https://doi.org/10.5194/tc-10-1361-2016, 2016. a, b, c
Molotch, N. P. and Bales, R. C.: SNOTEL representativeness in the Rio Grande headwaters on the basis of physiographics and remotely sensed snow cover persistence, Hydrol. Process., 20, 723–739, https://doi.org/10.1002/hyp.6128, 2006. a
Murphy, K. P.: Probabilistic Machine Learning: An Introduction, MIT Press, https://probml.github.io/pml-book/book1.html (last access: 16 December 2022), 2022. a, b
Navari, M., Margulis, S. A., Bateni, S. M., Tedesco, M., Alexander, P., and Fettweis, X.: Feasibility of improving a priori regional climate model estimates of Greenland ice sheet surface mass loss through assimilation of measured ice surface temperatures, The Cryosphere, 10, 103–120, https://doi.org/10.5194/tc-10-103-2016, 2016. a
Neal, R. M.: Probabilistic Inference Using Markov Chain Monte Carlo Methods, Technical Report CRG-TR-93-1, Department of Computer Science, University of Toronto, 1993. a
Nearing, G., Tian, Y., Gupta, H. V., Clark, M., Harrison, K., and Weijs, S.: A philosophical basis for hydrological uncertainty, Hydrol. Sci. J., 61, 1666–1678, https://doi.org/10.1080/02626667.2016.1183009, 2016. a
Oaida, C. M., Reager, J. T., Andreadis, K. M., David, C. H., Levoe, S. R., Painter, T. H., Bormann, K. J., Trangsrud, A. R., Girotto, M., and Famiglietti, J. S.: A High-Resolution Data Assimilation Framework for Snow Water Equivalent Estimation across the Western United States and Validation with the Airborne Snow Observatory, J. Hydrometeorol., 20, 357–378, https://doi.org/10.1175/JHM-D-18-0009.1, 2019. a
Odry, J., Boucher, M.-A., Lachance-Cloutier, S., Turcotte, R., and St-Louis, P.-Y.: Large-scale snow data assimilation using a spatialized particle filter: recovering the spatial structure of the particles, The Cryosphere, 16, 3489–3506, https://doi.org/10.5194/tc-16-3489-2022, 2022. a, b
Palmer, T. N.: Stochastic weather and climate models, Nat. Rev. Phys., 1, 463–471, https://doi.org/10.1038/s42254-019-0062-2, 2019. a
Papadakis, N., Mémin, E., Cuzol, A., and Gengembre, N.: Data Assimilation with the Weighted Ensemble Kalman Filter, Tellus A, 62, 673–697, https://doi.org/10.1111/j.1600-0870.2010.00461.x, 2010. a
Piazzi, G., Thirel, G., Campo, L., and Gabellani, S.: A particle filter scheme for multivariate data assimilation into a point-scale snowpack model in an Alpine environment, The Cryosphere, 12, 2287–2306, https://doi.org/10.5194/tc-12-2287-2018, 2018. a
Pirk, N., Aalstad, K., Westermann, S., Vatne, A., van Hove, A., Tallaksen, L. M., Cassiani, M., and Katul, G.: Inferring surface energy fluxes using drone data assimilation in large eddy simulations, Atmos. Meas. Tech., 15, 7293–7314, https://doi.org/10.5194/amt-15-7293-2022, 2022. a, b, c, d
Raleigh, M. S., Lundquist, J. D., and Clark, M. P.: Exploring the impact of forcing error characteristics on physically based snow simulations within a global sensitivity analysis framework, Hydrol. Earth Syst. Sci., 19, 3153–3179, https://doi.org/10.5194/hess-19-3153-2015, 2015. a, b
Reich, S. and Cotter, C.: Probabilistic Forecasting and Bayesian Data Assimilation, Cambridge University Press, https://doi.org/10.1017/CBO9781107706804, 2015. a
Revuelto, J., Azorin-Molina, C., Alonso-González, E., Sanmiguel-Vallelado, A., Navarro-Serrano, F., Rico, I., and López-Moreno, J. I.: Meteorological and snow distribution data in the Izas Experimental Catchment (Spanish Pyrenees) from 2011 to 2017, Earth Syst. Sci. Data, 9, 993–1005, https://doi.org/10.5194/essd-9-993-2017, 2017. a
Revuelto, J., Alonso-Gonzalez, E., Vidaller-Gayan, I., Lacroix, E., Izagirre, E., Rodríguez-López, G., and López-Moreno, J.: Intercomparison of UAV platforms for mapping snow depth distribution in complex alpine terrain, Cold Reg. Sci. Technol., 190, 103344, https://doi.org/10.1016/j.coldregions.2021.103344, 2021a. a, b
Revuelto, J., Cluzet, B., Duran, N., Fructus, M., Lafaysse, M., Cosme, E., and Dumont, M.: Assimilation of surface reflectance in snow simulations: Impact on bulk snow variables, J. Hydrol., 603, 126966, https://doi.org/10.1016/j.jhydrol.2021.126966, 2021b. a, b, c
Rew, R. and Davis, G.: NetCDF: an interface for scientific data access, IEEE Comput. Graph. Appl., 10, 76–82, https://doi.org/10.1109/38.56302, 1990. a
Särkkä, S.: Bayesian Filtering and Smoothing, Cambridge University Press, https://doi.org/10.1017/CBO9781139344203, 2013. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q
Slater, A. and Clark, M.: Snow Data Assimilation via an Ensemble Kalman Filter, J. Hydrometeorol., 7, 478–493, https://doi.org/10.1175/JHM505.1, 2006. a
Smith, A. F. M. and Gelfand, A. E.: Bayesian Statistics without Tears: A Sampling–Resampling Perspective, The American Statistician, 46, 84–88, https://doi.org/10.1080/00031305.1992.10475856, 1992. a
Smyth, E. J., Raleigh, M. S., and Small, E. E.: Particle Filter Data Assimilation of Monthly Snow Depth Observations Improves Estimation of Snow Density and SWE, Water Resour. Res., 55, 1296–1311, https://doi.org/10.1029/2018WR023400, 2019. a
Smyth, E. J., Raleigh, M. S., and Small, E. E.: Improving SWE Estimation With Data Assimilation: The Influence of Snow Depth Observation Timing and Uncertainty, Water Resour. Res., 56, e2019WR026853, https://doi.org/10.1029/2019WR026853, 2020. a
Snyder, C., Bengtsson, T., Bickel, P., and Anderson, J.: Obstacles to High-Dimensional Particle Filtering, Mon. Weather Rev., 136, 4629–4640, https://doi.org/10.1175/2008MWR2529.1, 2008. a, b, c, d
Stigter, E. E., Wanders, N., Saloranta, T. M., Shea, J. M., Bierkens, M. F. P., and Immerzeel, W. W.: Assimilation of snow cover and snow depth into a snow model to estimate snow water equivalent and snowmelt runoff in a Himalayan catchment, The Cryosphere, 11, 1647–1664, https://doi.org/10.5194/tc-11-1647-2017, 2017. a
Stordal, A. S. and Elsheikh, A. H.: Iterative ensemble smoothers in the annealed importance sampling framework, Adv. Water Resour., 86, 231–239, https://doi.org/10.1016/j.advwatres.2015.09.030, 2015. a, b, c, d
Sturm, M., Goldstein, M. A., and Parr, C.: Water and life from snow: A trillion dollar science question, Water Resour. Res., 53, 3534–3544, https://doi.org/10.1002/2017WR020840, 2017. a
Thirel, G., Salamon, P., Burek, P., and Kalas, M.: Assimilation of MODIS Snow Cover Area Data in a Distributed Hydrological Model Using the Particle Filter, Remote Sens., 5, 5825–5850, https://doi.org/10.3390/rs5115825, 2013. a
Treichler, D. and Kääb, A.: Snow depth from ICESat laser altimetry – A test study in southern Norway, Remote Sens. Environ., 191, 389–401, https://doi.org/10.1016/j.rse.2017.01.022, 2017. a, b
van Leeuwen, P. J.: Particle Filtering in Geophysical Systems, Mon. Weather Rev., 137, 4089–4114, https://doi.org/10.1175/2009MWR2835.1, 2009. a, b, c
van Leeuwen, P. J.: A consistent interpretation of the stochastic version of the Ensemble Kalman Filter, Q. J. Roy. Meteor. Soc., 146, 2815–2825, https://doi.org/10.1002/qj.3819, 2020. a, b, c
van Leeuwen, P. J. and Evensen, G.: Data Assimilation and Inverse Methods in Terms of a Probabilistic Formulation, Mon. Weather Rev., 124, 2898–2913, https://doi.org/10.1175/1520-0493(1996)124<2898:DAAIMI>2.0.CO;2, 1996. a, b, c, d, e
van Leeuwen, P. J., Künsch, H. R., Nerger, L., Potthast, R., and Reich, S.: Particle filters for high-dimensional geoscience applications: A review, Q. J. Roy. Meteor. Soc., 145, 2335–2365, https://doi.org/10.1002/qj.3551, 2019. a, b, c, d, e, f, g
Vionnet, V., Brun, E., Morin, S., Boone, A., Faroux, S., Le Moigne, P., Martin, E., and Willemet, J.-M.: The detailed snowpack scheme Crocus and its implementation in SURFEX v7.2, Geosci. Model Dev., 5, 773–791, https://doi.org/10.5194/gmd-5-773-2012, 2012. a
Vionnet, V., Marsh, C. B., Menounos, B., Gascoin, S., Wayand, N. E., Shea, J., Mukherjee, K., and Pomeroy, J. W.: Multi-scale snowdrift-permitting modelling of mountain snowpack, The Cryosphere, 15, 743–769, https://doi.org/10.5194/tc-15-743-2021, 2021. a
Wan, Z., Hook, S., and Hulley, G.: MOD11A1 MODIS/Terra Land Surface Temperature/Emissivity Daily L3 Global 1km SIN Grid V006, NASA EOSDIS Land Processes DAAC, https://doi.org/10.5067/MODIS/MOD11A1.006, 2015. a, b
Westermann, S., Ingeman-Nielsen, T., Scheer, J., Aalstad, K., Aga, J., Chaudhary, N., Etzelmüller, B., Filhol, S., Kääb, A., Renette, C., Schmidt, L. S., Schuler, T. V., Zweigel, R. B., Martin, L., Morard, S., Ben-Asher, M., Angelopoulos, M., Boike, J., Groenke, B., Miesner, F., Nitzbon, J., Overduin, P., Stuenzi, S. M., and Langer, M.: The CryoGrid community model (version 1.0) – a multi-physics toolbox for climate-driven simulations in the terrestrial cryosphere, Geosci. Model Dev. Discuss. [preprint], https://doi.org/10.5194/gmd-2022-127, in review, 2022. a
Wikle, C. K. and Berliner, L. M.: A Bayesian tutorial for data assimilation, Physica D, 230, 1–16, https://doi.org/10.1016/j.physd.2006.09.017, 2007. a
Wolpert, D. and Macready, W.: No free lunch theorems for optimization, IEEE T. Evolut. Comput., 1, 67–82, https://doi.org/10.1109/4235.585893, 1997. a
Wrzesien, M. L., Durand, M. T., Pavelsky, T. M., Howat, I. M., Margulis, S. A., and Huning, L. S.: Comparison of methods to estimate snow water equivalent at the mountain range scale: A case study of the California Sierra Nevada, J. Hydrometeorol., 18, 1101–1119, https://doi.org/10.1175/JHM-D-16-0246.1, 2017. a
Wrzesien, M. L., Durand, M. T., Pavelsky, T. M., Kapnick, S. B., Zhang, Y., Guo, J., and Shum, C. K.: A New Estimate of North American Mountain Snow Accumulation From Regional Climate Model Simulations, Geophys. Res. Lett., 45, 1423–1432, https://doi.org/10.1002/2017GL076664, 2018. a