the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 01 Jun 2022
| 01 Jun 2022
A comparative analysis for a deep learning model (hyDL-CO v1.0) and Kalman filter to predict CO concentrations in China
Weichao Han
Tai-Long He
Zhaojun Tang
Min Wang
Dylan Jones
The applications of novel deep learning (DL) techniques in atmospheric science are rising quickly. Here we build a hybrid DL model (hyDL-CO), based on convolutional neural networks (CNNs) and long short-term memory (LSTM) neural networks, to provide a comparative analysis between DL and Kalman filter (KF) to predict carbon monoxide (CO) concentrations in China in 2015–2020. We find the performance of DL model is better than KF in the training period (2015–2018): the mean bias and correlation coefficients are 9.6 ppb and 0.98 over eastern China and are −12.5 ppb and 0.96 over grids with independent observations (i.e., grids with CO observations that are not used in DL training and KF assimilation). By contrast, the assimilated CO concentrations by KF exhibit comparable correlation coefficients but larger negative biases. Furthermore, the DL model demonstrates good temporal extensibility in the test period (2019–2020): the mean bias and correlation coefficients are 95.7 ppb and 0.93 over eastern China and 81.0 ppb and 0.91 over grids with independent observations, while CO observations are not fed into the DL model as an input variable. Despite these advantages, we find a weaker prediction capability of the DL model than KF in the test period, and a noticeable underestimation of CO concentrations at extreme pollution events in the DL model. This work demonstrates the advantages and disadvantages of DL models to predict atmospheric compositions with respect to traditional data assimilation, which is helpful for better applications of this novel technique in future studies.
- Article
(11003 KB) - Full-text XML
- BibTeX
- EndNote





Accurate simulation and prediction of air pollutants are critical for making effective policies to improve air quality. Chemical transport models (CTMs), as powerful tools, have been widely used to simulate atmospheric compositions (Li et al., 2019; X. Chen et al., 2021; Lu et al., 2021). Despite the advances of CTMs, there are still noticeable discrepancies in the simulations due to uncertainties in the emission, physical and chemical processes (Quennehen et al., 2016; Kong et al., 2020). Tropospheric CO is one of the most important pollutants with significant sources from fossil fuel combustion. Atmospheric observations are thus used to evaluate the capacity of CTMs to capture the observed variabilities in atmospheric CO. For example, Kong et al. (2020) exhibited good consistency between modeled and observed CO variations in China but with significantly underpredicted CO concentrations. Tang et al. (2022) found the observed CO concentrations are noticeably higher than model simulations over low-pollution areas in China, but with a smaller difference over high-pollution areas.
Based on CTMs, data assimilation techniques integrate simulations and observations and thus can improve the modeled atmospheric compositions. For instance, Ma et al. (2019) found the assimilation of surface observations can effectively reduce the uncertainties in fine particulate matter (PM2.5), ozone (O3) and CO forecasts. Peng et al. (2018) assimilated surface observations and obtained near-perfect forecasts for PM2.5, O3 and CO on the first day, but the effects of the data assimilation decayed quickly with longer forecasts. The propagation of observational information in data assimilation depends on the modeled physical and chemical processes; i.e., the adjustment over grids lacking observations relies on regional transport of observational information from other grids. The assimilated results are thus still affected by potential model errors (e.g., the uncertainty in transport), which can lead to rapid decline of assimilation effects, if observations become unavailable.
Accompanied with recent advances in machine learning (ML) techniques, novel data-driven architectures and approaches have been extensively applied in the field of atmospheric science (R. Li et al., 2020; Zhang et al., 2020; Shi et al., 2021; Xing et al., 2021). Based on artificial neural networks, particularly convolutional neural networks (CNNs), deep learning (DL) uses multiple layers of computational kernels to extract and capture non-linear relationships between input and output variables. The predictions, provided by DL, are driven by observational or reanalysis data sets, which provides a new way of predicting atmospheric compositions without the influence of model errors. The non-linear relationships learned in the training data set can be extended spatially and temporally; for example, Kleinert et al. (2021) found the DL model can forecast surface O3 within a 4 d range. The application of long short-term memory (LSTM) networks further improves the ability of DL models in capturing temporal dynamics. For example, Y. Chen et al. (2021) found the LSTM-based approach can provide a good prediction for surface PM2.5 on the next day; He et al. (2022) exhibited the capability of a DL model to predict surface O3 in North America.
Despite the advantages of the DL approaches, the lack of parameterization of physical and chemical processes implies the predicted atmospheric compositions may deviate from the realistic atmospheric state, in contrast to conventional data assimilation approaches that are constrained by modeled processes. The lifetime of tropospheric CO is about 1–2 months, which makes it an ideal tracer for atmospheric transport. In this study, we present an application of a hybrid DL model (hyDL-CO) to the prediction of surface CO concentrations in China from 2015 to 2020, which utilizes both CNNs and LSTMs. We perform a comparative analysis between the DL model and a Kalman filter (KF) system in this work, to investigate the performances of the two approaches in predictions of atmospheric composition with a long lifetime and strong regional transport. Considering the lifetimes of O3 and PM2.5 are shorter than CO, we may assume comparable or better performances of DL in the predictions of O3 and PM2.5. The comparison in this work is helpful for understanding the advantages and disadvantages of the DL approach with respect to traditional data assimilation in the predictions of atmospheric compositions, which is critical for better applications of this novel technique in atmospheric environmental studies in the future.
This paper is organized as follows: in Sect. 2, we describe the CO observations, the KF approach and the hyDL-CO model used in this work. In Sect. 3, we assess the predicted CO by the DL model, the changes in CO emissions in China, the comparison between the DL model and KF, and the evaluation with independent observations. Our conclusions follow in Sect. 4.
2.1 MEE surface CO measurements
We use the China Ministry of Ecology and Environment (MEE) monitoring network surface in situ CO concentration data (https://quotsoft.net/air/, last access: 26 May 2022) for the period of 2015–2020. These real-time monitoring stations have the ability to report hourly concentrations of pollutants that fulfill the criteria from about 1700 sites in 2020. Concentrations were reported by the MEE in units of mg m−3 under standard temperature (273 K) until 31 August 2018. This reference state was changed on 1 September 2018 to 298 K. We converted CO concentrations to ppb and rescaled post-August 2018 concentrations to standard temperature (273 K) to keep the consistency in the trend analysis. The reported data with CO concentrations larger than 6000 ppb are removed in our analysis. The station-based observations are averaged and regridded to the 0.5∘ × 0.625∘ grid of the MERRA-2 reanalysis, with about 500 grids in total having observations. About 50 grids, or 10 % of grid-based observations, are randomly selected as independent observations, which are only used in the evaluation of the predicted CO from the DL model and the KF system. The training of the DL model and the assimilation using the KF are performed using the remaining 90 % observations.
2.2 KF approach
We employ the sequential KF based on the GEOS-Chem CTM to assimilate surface CO observations. This approach has been used in previous studies to optimize tropospheric CO concentrations (Jiang et al., 2017; Tang et al., 2022). The GEOS-Chem model (http://www.geos-chem.org, last access: 26 May 2022, version 12-8-1) is driven by assimilated meteorological data of MERRA-2. Our analysis is conducted at a horizontal resolution of nested 0.5∘ × 0.625∘ and employs the CO-only simulation in GEOS-Chem, which uses archived monthly OH fields from the full chemistry simulation (Fisher et al., 2017). The CO boundary conditions are updated every 3 h from a global simulation with 4∘ × 5∘ resolution. Emissions in GEOS-Chem are computed by the Harvard-NASA Emission Component (HEMCO). Global default anthropogenic emissions are from the Community Emissions Data System (CEDS) (Hoesly et al., 2018) and replaced by MEIC (Multiresolution Emission Inventory for China) in China and MIX (full name) in other regions of Asia (Li et al., 2017). The total anthropogenic CO emissions in the MEIC inventory are further scaled with linear projection. We refer the reader to X. Chen et al. (2021) for the details of model configurations.
In the assimilation algorithm, the forward model (M) predicts CO concentration (xat) at time t:
The optimized CO concentrations can be expressed as follows:
where yt is observation, and Kt represents the operation operator which projects CO concentrations from the model space to the observation space. Gt is the KF Gain matrix, which can be described as follows:
where Sat and Sϵ are model and observation covariance, respectively. Because the DL model is designed to reproduce observations without considering error covariance, here we assume fixed model error (50 %) and small observation error (1 %) to provide a fair comparison. The covariance matrix is diagonal without the consideration of off-diagonals.
2.3 hyDL-CO v1.0 model
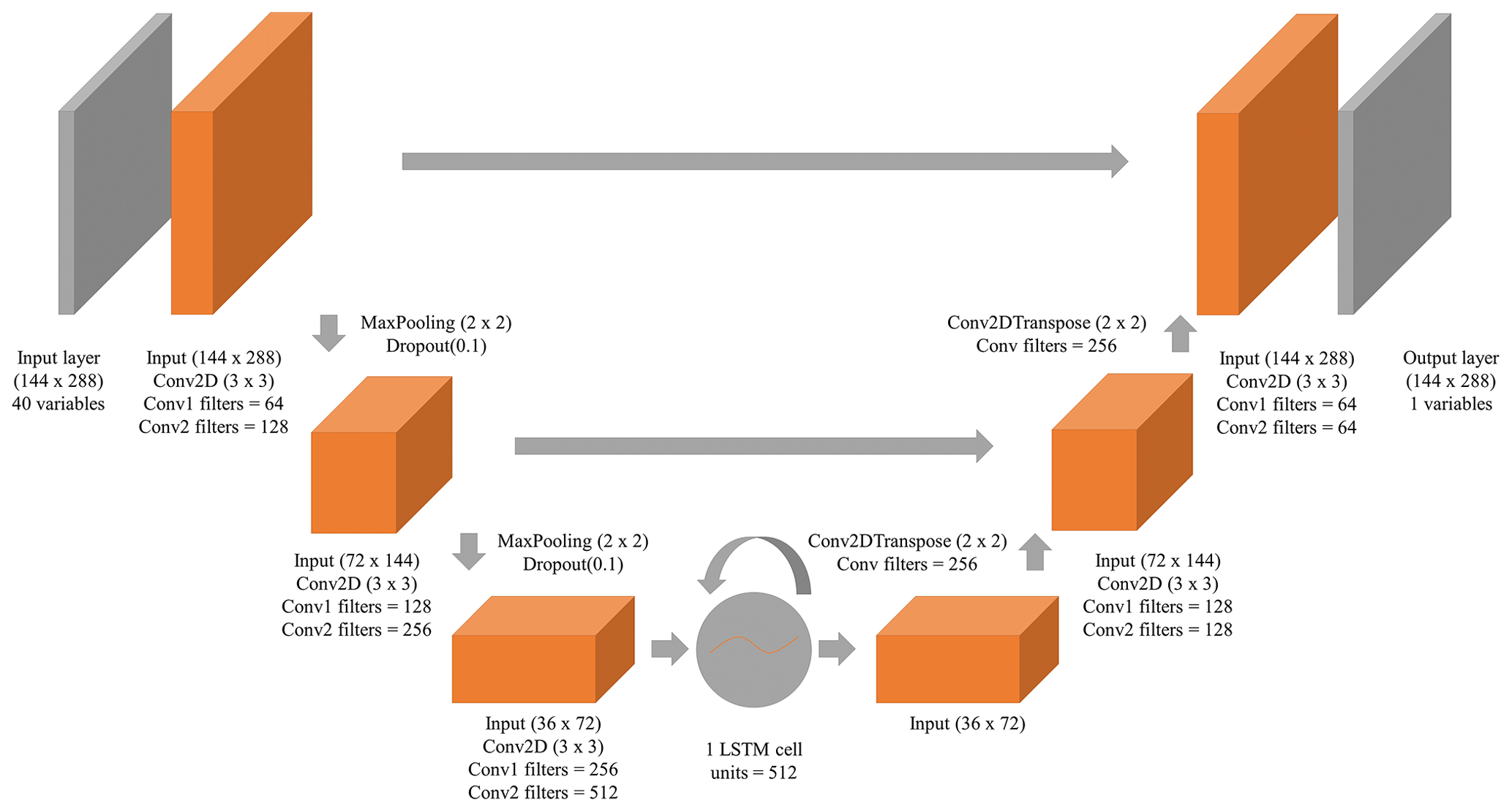
Our hyDL-CO model is a modified version of the U-net model used in He et al. (2022), where the model shows a superior capability in predicting surface summertime O3 in North America. The U-net architecture is a variant of autoencoder and was originally proposed for biomedical segmentation applications. In the first U-net paper, Ronneberger et al. (2015) conducted three experiments and showed that the U-net model outperforms other DL models. Since the proposal of U-net, it has become one of the most popular choices in the DL community and is compared with other ML models in many studies. For example, Korznikov et al. (2021) used several ML models for tree recognition using satellite images, and the U-net model shows the highest accuracy. Ravuri et al. (2021) used U-net as a baseline model and compared it with their generative adversarial network (GAN) in precipitation nowcasting. Andersson et al. (2021) showed that their IceNet, which is an ensemble of similar U-Net networks, has outstanding performance in seasonal forecasts of Arctic Sea ice.
As shown in Fig. 1, the first three blocks of neural layers behave as an encoder, which has six convolutional layers and two max pooling layers, to extract the features hidden in the input data. A dropout layer is added after each pooling layer to prevent data overfitting. The output from the encoder is highly compressed information that is not manipulated during the training process, which is also called the latent vector. We embed the LSTM model into the U-net architecture after the encoder, inspired by the idea of convolutional LSTM proposed in Shi et al. (2015), to capture short-term changes and long-term trends in the latent vectors. The output from the LSTM is then forwarded to a decoder with three blocks of layers, which has four convolutional layers and two transposed convolutional layers. The outputs from each convolutional layer in the model are passed through the rectified linear unit (ReLU) activation function to increase non-linearity. Residual learning connections (He et al., 2016) that forward the high-resolution features extracted by the encoder to the decoder are also added, which are shown to improve the performance of U-net (Ghorbanzadeh et al., 2021; Qi et al., 2020; Liu et al., 2020). These connections contain trainable weights that represent a more direct relationship between input and output variables.

The optimization of the model is supervised by the “ground truth”, which is the daily mean surface CO concentrations measured by the MEE network. The weights in the CNNs and transposed CNNs are optimized using the back-propagation algorithm (Rumelhart et al., 1986; LeCun et al., 1989), which employs the partial derivatives of the cost function with respect to the truth. Here cost function is defined as follows:
where yi and are the “true” and “predicted” values. This performance evaluation is calculated only in the grid with “true” values, so that the optimization of the model avoids the influence of regions without CO observations. The loss function to be optimized is the mean square error (MSE) between the “predicted” and “true” values. We use the Adam optimizer, which is a computationally efficient algorithm for gradient-based optimization of stochastic objective functions. For a faster convergence speed and the stability of the model performance, we rescale all the features to the nearly same scale. The processing method is multiplying the original variable by a constant 10n and adapting n for each variable according to the specified scale. For example, most of the values of sea level pressure (SLP) are distributed around 105, so we multiply SLP by 10−4 to make the value of the feature SLP distributed around 101. This processing prevents the DL model from being overfit by the features in input variables that have significantly larger scales than others. The hybrid model was built and implemented using Keras and Tensorflow, which are Python packages that are extensively used in DL studies. Table 1 shows some of the configuration hyperparameters of the training of our model.
The input variables include six meteorological variables: SLP, surface incoming shortwave flux (SWGDN), 2 m air temperature (T2M), 10 m eastward wind (U10M), 10 m northward wind (V10M), total precipitation (TP), and total anthropogenic CO and volatile organic compounds (VOC) emissions. The meteorology and emission data are extracted from the GEOS-Chem model with 0.5∘ × 0.625∘ horizontal resolution. Our focus area is 0–72∘ N, 0–180∘ E, and the output resolution is same as the 0.5∘ × 0.625∘ resolution of MERRA-2. The DL model grid thus has 288 grid boxes along the longitudinal direction and 144 for the latitude. Considering the long lifetime of CO, the concentration of surface CO is not only related to the emission and meteorological conditions at the current moment, but also at the previous moment. We trained the DL model using the information related to the “history” of CO, by adding the same set of input variables for the current day and previous 4 d as predictors. The information from the 5 d history has 40 predictors in total for the prediction of daily mean surface CO in each day. We use 2015–2018 as the training data set and 2019–2020 as the test set. The dimension of each input vector for the DL model is then (144, 288, 40), and the dimension of the output from the DL model is (144, 288, 1).
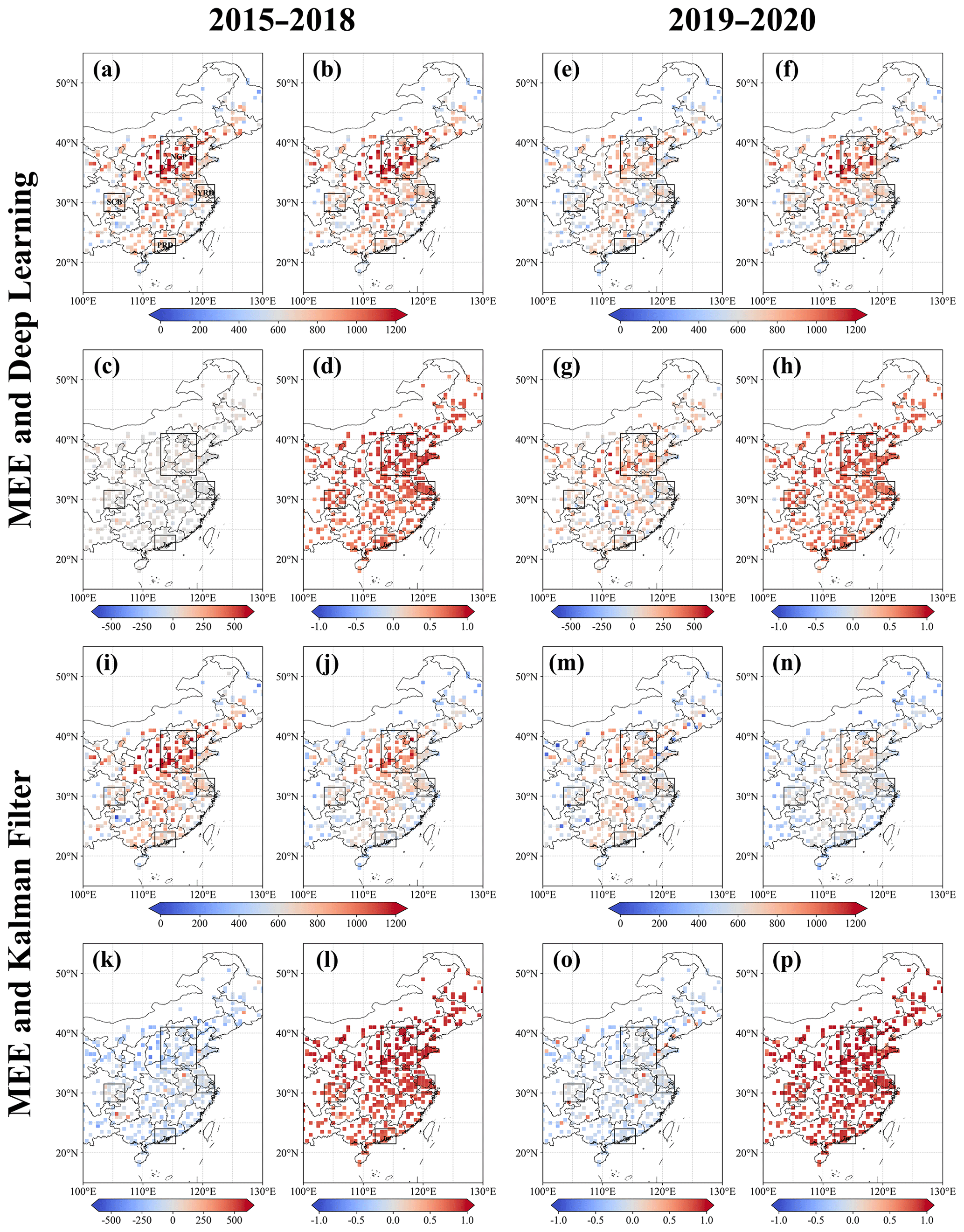
Figure 2(a) MEE CO observations (90 % stations) in 2015–2018. (b) Predicted CO concentrations by the DL model in 2015–2018. (c, d) Differences and Pearson correlation coefficients between predicted and observed CO in 2015–2018. (e–h) MEE CO observations (90 % stations), predicted CO concentrations by DL model and their differences, and Pearson correlation coefficients in 2019–2020. (i–p) Same as panels (a–h), but for KF. The unit is ppb.
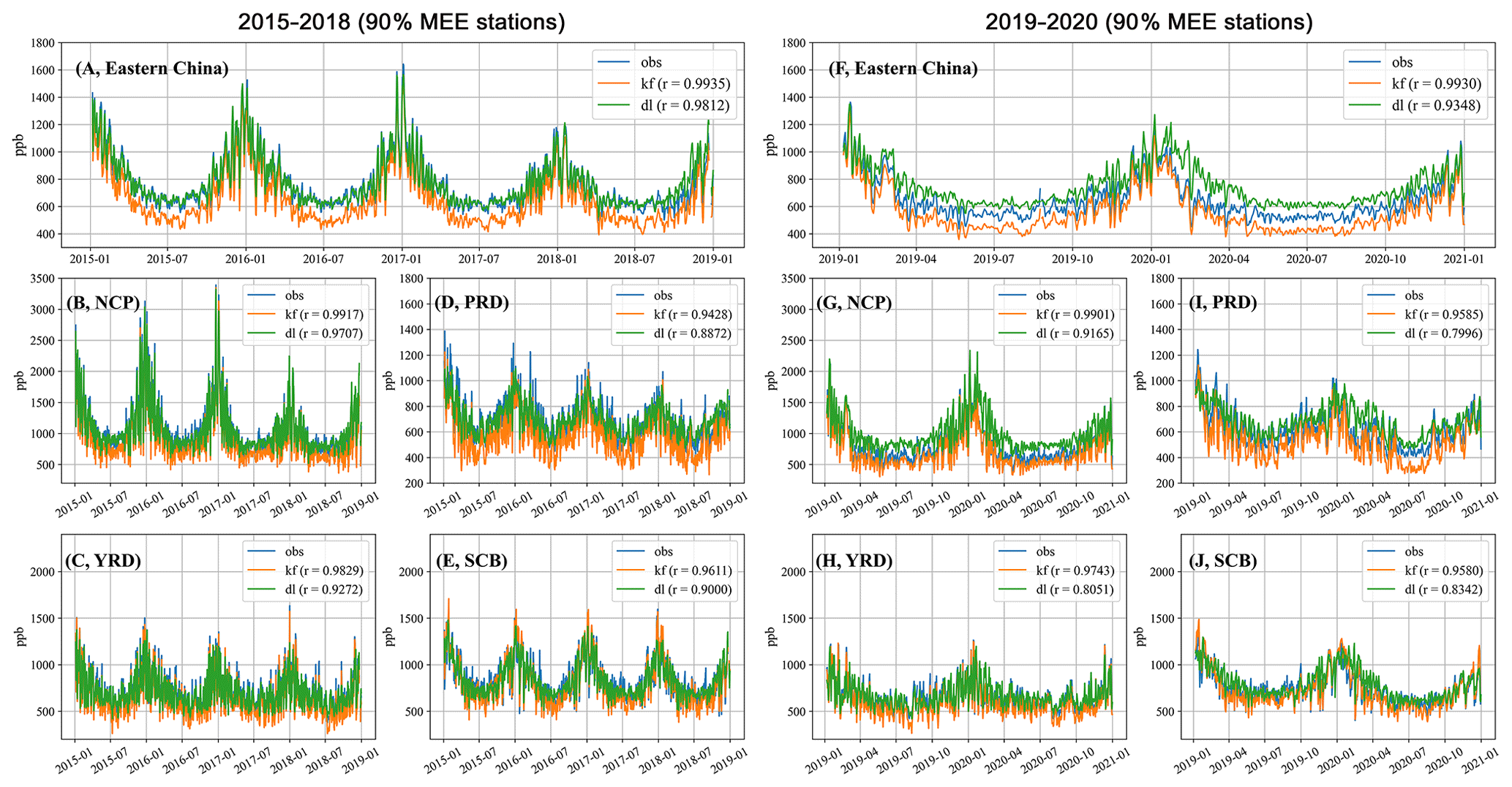
Figure 3Daily variabilities of CO concentrations from MEE (90 % stations), DL and KF in 2015–2018 and 2019–2020.
Table 2Deep learning (DL), Kalman filter (KF) and control run (CR) with respect to MEE CO observations in 2015–2018 and 2019–2020. The locations of independent MEE stations are shown in Fig. 6.

3.1 CO concentrations predicted by DL model
As shown in Fig. 2a, the annual averaged MEE CO observations are broadly higher than 400 ppb in eastern China in 2015–2018 and can reach 1000 ppb over the highly polluted North China Plain (NCP). The predicted CO concentrations by the DL model (Fig. 2b) match well with observations in 2015–2018. We find small differences between predictions and observations in Fig. 2c. The Pearson correlation coefficients are larger than 0.7 over eastern China and are as high as 0.9 over the highly polluted NCP (Fig. 2d). Figure 3a–e exhibit daily variabilities of CO concentrations over eastern China, as well as NCP, Yangtze River Delta (YRD), Pearl River Delta (PRD) and Sichuan Basin (SCB) domains. There is large seasonality in the observed CO concentrations: the wintertime CO concentrations can reach 1400 ppb over eastern China and 2500 ppb over the highly polluted NCP; the summertime CO concentrations are about 500 ppb over eastern China and 800 ppb over NCP. The predicted CO concentrations by the DL model demonstrate high consistency with observations. As shown in Table 2, the correlation coefficients between the DL model and MEE CO observations are 0.98, 0.97, 0.93, 0.89 and 0.90; the biases are 9.6, 18.2, −2.6, 12.7 and 17.6 ppb for eastern China, NCP, YRD, PRD and SCB, respectively.
The high consistency between observations and the DL model in the training period (2015–2018) is expected. Here we further evaluate the capability of the DL model to predict CO concentrations without the inputs of CO observations (i.e., in the test period). Figure 2e shows the MEE CO observations in 2019–2020. As shown in Fig. 2f, the DL model overestimated surface CO concentrations in 2019–2020, particularly, over the highly polluted NCP. The Pearson correlation coefficients in 2019–2020 (Fig. 2h) are slightly lower than those in the training period (Fig. 2d). As shown in Fig. 3f, the predicted CO concentrations exhibit larger deviations from observations in 2019–2020. The correlation coefficients (see Table 2) between observed and predicted CO in the test period are 0.93, 0.92, 0.81, 0.80 and 0.83; the biases are 95.7, 224.2, 22.0, 60.8 and 52.8 ppb for eastern China, NCP, YRD, PRD and SCB, respectively. Consequently, the lack of inputs of CO observations in the test period led to a decline of prediction capability, but it is still high enough to provide useful information to predict CO variabilities.
3.2 Changes of CO emissions inferred by DL model
Here we further explore the possible sources for the deviations of predicted CO concentrations from observations in 2019–2020. The observed CO concentrations are about 640 ppb in the summer of 2015 and decreased gradually to about 620 ppb by the summer of 2018. However, the observed CO concentrations dropped to about 550–530 ppb in the summer of 2019 and 2020. The rapid decrease in surface CO concentrations is dominated by the highly polluted NCP (Fig. 3g), whereas the differences between predicted and observed CO concentrations are limited over other domains. The rapid decrease in surface CO concentrations over NCP in 2019 could be associated with an unexpected drop in CO emissions, which is not considered in the linear projection of emission inventory, and led to overestimated CO concentrations in the DL model. In addition, recent studies (K. Li et al., 2020; X. Chen et al., 2021) indicated a dramatic increase in surface O3 concentration over NCP in 2019. The possible changes in atmospheric oxidation capability and sink of CO may not be sufficiently captured by the DL model, as the relevant information is not used as the input while training the model.
The unprecedented lockdowns across the world to contain the 2019 novel coronavirus (COVID-19) spread have led to a slowdown of economic activities, with pronounced declines in anthropogenic emissions. Shi and Brasseur (2020) found surface CO concentrations over northern China were 1.2–1.5 and 0.7–1.0 mg m−3 before and during the pandemic spread. Gaubert et al. (2021) suggested a reduction of about 15 % in CO emissions over northern China due to the COVID-19 controls. As shown in Fig. 3f, the MEE CO observations are about 10.2 % and 25.8 % lower than predicted CO by the DL model in Feb 2019 and 2020, respectively; the MEE CO observations are about 11.1 % and 14.2 % lower than predicted CO by the DL model in June–August 2019 and 2020, respectively. Assuming the difference in June–August (i.e., 11.1 % and 14.2 %) represents the annual CO emission trends, our analysis thus suggests a decline of about 12.5 % in CO emissions caused by COVID-19 controls, which is consistent with Gaubert et al. (2021).
3.3 Comparison between the DL model and KF assimilation
Figure 2i–p show the MEE CO observations and assimilated CO concentrations by KF in 2015–2018 and 2019–2020. In contrast to the DL approach, CO observations are assimilated in KF in both periods. While the spatial distributions of assimilated CO match well with observations, the CO concentrations in the assimilations are noticeably lower. As shown in Fig. 3a–e and Table 2, the differences between assimilated and observed CO are −114.9, −139.6, −58.0, −108.8 and −29.3 ppb for eastern China, NCP, YRD, PRD and SCB, respectively, which are larger than the differences in the DL model. Furthermore, the modeled CO concentrations in the control runs (CR, without assimilation of CO observations) are much lower: the differences are −409.6, −512.3, −246.0, −400.5 and −172.4 ppb for eastern China, NCP, YRD, PRD and SCB, respectively. The dramatic underestimations of CO concentrations in model simulations have been reported in recent studies (Feng et al., 2020; Kong et al., 2020; Peng et al., 2018), which could be associated with significant model representation error because most MEE stations are urban sites (Tang et al., 2022). It reveals the important discrepancy between DL and data assimilations: the analyzed concentrations in KF are based on the a priori and observed concentrations by considering the model and observation errors, which are not designed to reproduce the observations. In addition, the correlation coefficients are 0.99, 0.99, 0.98, 0.94 and 0.96 for eastern China, NCP, YRD, PRD and SCB in 2015–2018 in the KF, respectively, which are comparable with the DL model.
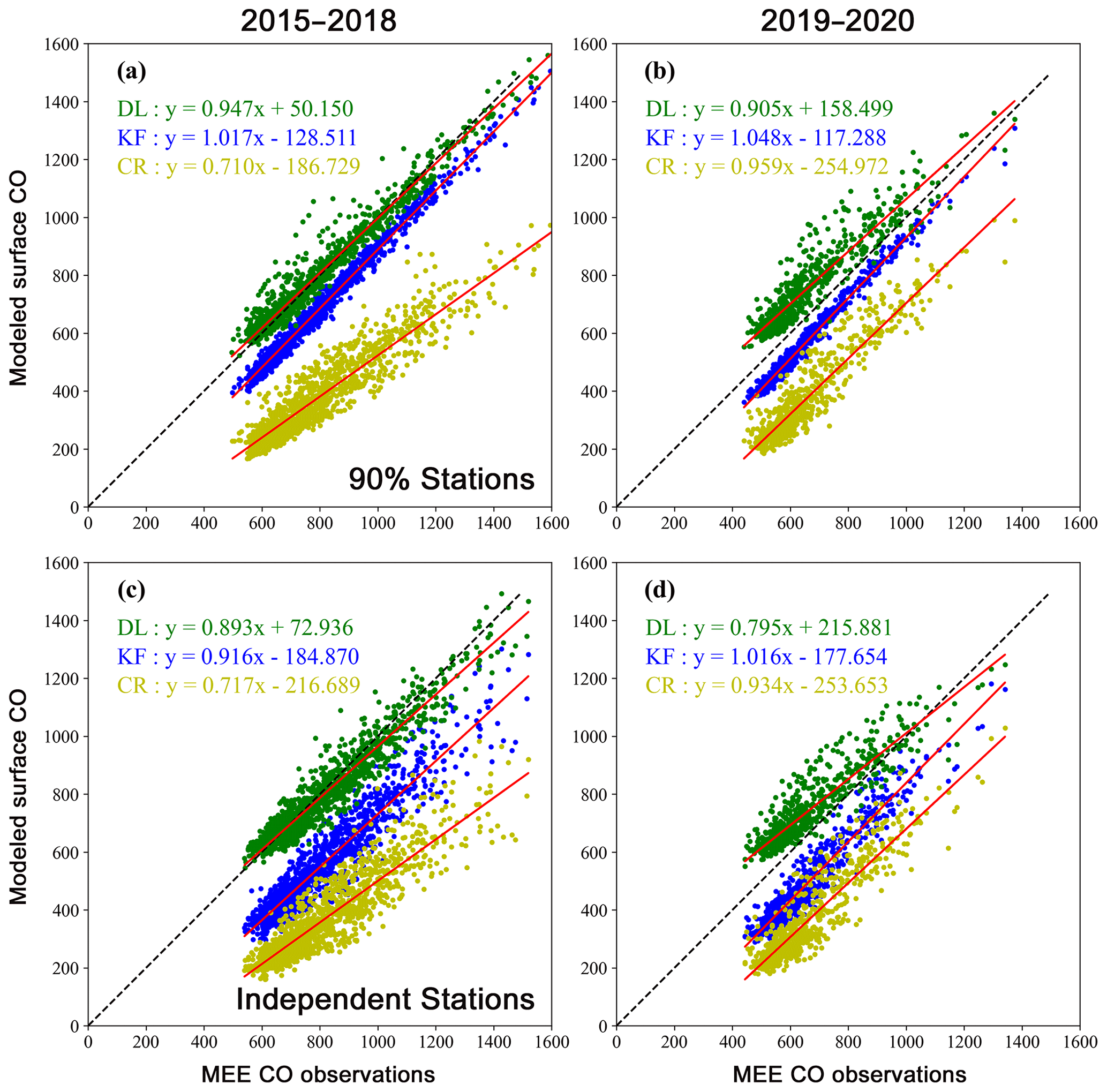
Figure 4(a, b) Relationships between CO concentrations provided by DL, KF, control run (CR) and MEE CO observations in 2015–2018 and 2019–2020. The dots represent daily average of CO concentrations over eastern China. The unit is ppb. (c, d) Same as panels (a, b), but with randomly selected independent MEE stations. The locations of independent MEE stations are shown in Fig. 6.
As shown in Fig. 3f–j and Table 2, the differences between assimilated and observed CO concentrations in 2019–2020 are −85.5, −66.3, −52.9, −89.3 and −18.7 ppb for eastern China, NCP, YRD, PRD and SCB, respectively, which are comparable with the differences in the DL model except for the highly polluted NCP; even the MEE CO observations are not inputted in the DL model in the test period. The correlation coefficients are 0.99, 0.99, 0.97, 0.96 and 0.96 for eastern China, NCP, YRD, PRD and SCB in 2019–2020 in the KF, respectively, which are higher than the DL model. In addition, Fig. 4a and b show the relationships between modeled CO and MEE CO observations. Both DL and KF show dramatic improvements with respect to the CR simulations in Fig. 4a and b, while the performance of the DL model is better than KF in the training period (Fig. 4a). In addition, the comparable performances between DL and KF in 2019–2020 (Fig. 4b) demonstrate the good temporal extensibility of DL model; i.e., skills learned in the training period can be extended to the following years with a limited decline in the prediction effects.

Figure 5(a, b) Predicted by DL (contour) and MEE (dotted) surface CO concentrations in 2015–2018 and 2019–2020. (c, d) Same as panels (a, b), but for KF.
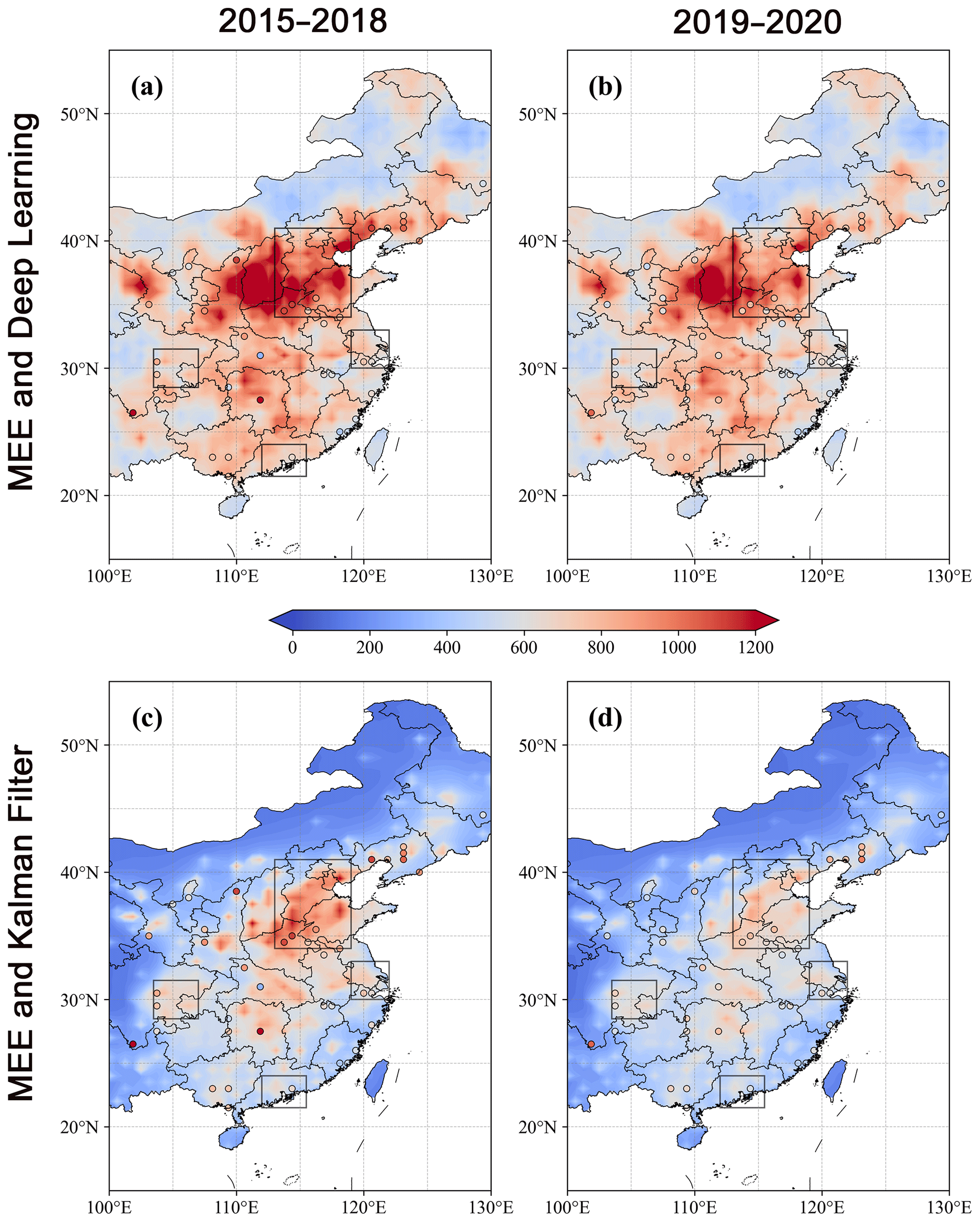
Figure 6(a, b) Predicted by DL (contour) and independent MEE (dotted) surface CO concentrations in 2015–2018 and 2019–2020. (c, d) Same as panels (a, b), but for KF. The randomly selected independent MEE stations (about 10 % of total stations) are not used in both DL and KF in 2015–2020.

Figure 7Daily variabilities of CO concentrations from independent MEE stations, DL and KF in 2015–2018 and 2019–2020. The locations of independent MEE stations are shown in Fig. 6.
3.4 Evaluation with independent MEE CO observations
Figure 5a and b show the spatial distributions of predicted CO concentrations by the DL model and MEE CO observations; Fig. 6a and b further exhibit the locations of randomly selected independent MEE stations (about 10 % of total stations). These independent stations are not used in either the DL model or KF in 2015–2020. Although we find broadly good agreements in the spatial distributions between predicted CO concentrations by DL and KF and MEE CO observations, there is still a noticeable discrepancy. The DL model suggests the highest CO concentrations are in the Shanxi province, by more than 1200 ppb, and background CO concentrations by about 400 ppb over remote areas. By contrast, the CO concentrations in the KF (Figs. 5c, d and 6c, d) are lower, and the highest CO concentrations are found in NCP rather than the Shanxi province. As shown in Fig. 7a–e, the DL model demonstrates a smaller bias with respect to independent MEE CO observations and higher correlation coefficients than KF in 2015–2018, suggesting better capability to predict CO concentrations. In 2019–2020 (Fig. 7f–j), the DL model exhibits a smaller bias over eastern China, but a larger bias than KF over the highly polluted NCP. The Pearson correlation coefficients are smaller in DL in 2019–2020 (see Table 2).
As shown in Fig. 4c and d, the assimilated CO concentrations by KF are closer to the control simulations with larger deviations from the MEE CO observations than those in Fig. 4a and b. It demonstrates the decline of assimilation effects when observations are unavailable. On the other hand, the slopes in the linear fits are 0.89 and 0.92 in DL and KF in 2015–2018 (Fig. 4c), respectively, and become 0.80 and 1.02 in 2019–2020 (Fig. 4d). The deviations in the slopes reflect an underestimation of CO concentrations in the DL model at grids with extremely high CO concentrations. The DL model predicts CO concentrations based on the skills learned in the training process. However, the training is dominated by the majority of CO observations with low and medium CO concentrations. As shown in Fig. 4a and b, extreme pollution events, with CO concentrations > 1200 ppb, account for only 3.4 % of the total number of observations. It cannot be learned sufficiently, because the DL model, as a data-driven approach, would require more observations about the extreme pollution events to improve the predictions. By contrast, KF is driven by observations directly so that both high and low CO concentrations can be simulated. In addition, because most MEE stations are urban sites, the good agreement between the DL model and MEE CO observations may not be able to ensure the accuracy of predicted CO concentrations over remote rural areas, as well as the high CO concentrations over mountain areas around urban basins in the Shanxi province. Integration of modeled CO concentrations in the DL model in future studies may improve predicted CO concentrations over remote areas without local observations.
A hybrid DL model (hyDL-CO), based on CNN and LSTM, was built in this work to provide a comparative analysis between DL and KF to predict CO concentrations in China in 2015–2020. We find the performance of the DL model is better than KF in the training period (2015–2018): the bias and correlation coefficients are 9.6 ppb and 0.98 over eastern China and −12.5 ppb and 0.96 over grids with independent observations. By contrast, the assimilated CO concentrations by KF demonstrate comparable correlation coefficients but larger negative biases: the bias and correlation coefficients are −114.9 ppb and 0.99 over eastern China and −252.5 ppb and 0.95 over grids with independent observations. The larger biases in the KF are caused by the discrepancy in the algorithm; i.e., the objective of data assimilation is to improve the simulated atmospheric compositions by considering the model and observation errors, which are not designed to reproduce the observations. Both DL and KF show better predictions than the control runs: the bias and correlation coefficients are −409.6 ppb and 0.94 over eastern China and −443.3 ppb and 0.91 over grids with independent observations.
Furthermore, we find good temporal extensibility of the DL model in the test period (2019–2020): the bias and correlation coefficients are 95.7 ppb and 0.93 over eastern China and 81.0 ppb and 0.91 over grids with independent observations. The correlation coefficients (0.91–0.93) show there is enough capability to provide useful information to predict CO variabilities without inputs of CO observations. In addition, we find an unexpected drop in CO emissions over the highly polluted NCP in 2019. Our analysis further exhibits a significant decline in CO emissions in early 2020 due to the COVID-19 controls. Despite these advantages, we find a noticeable underestimation of CO concentrations at grids with extremely high CO concentrations in the DL model, because the training is dominated by the majority of CO observations with low and medium CO concentrations, and thus the extreme pollution events cannot be learned sufficiently. This work demonstrates the advantages and disadvantages of DL models to predict atmospheric compositions with respect to traditional data assimilation. We assume comparable or better performances of DL in the predictions of O3 and PM2.5 than the CO analysis shown in this work, because of their shorter lifetimes, and advise more efforts to explore new applications of DL models in the predictions of other atmospheric compositions.
The MEE CO data can be downloaded from https://quotsoft.net/air/ (last access: 26 May 2022). The GEOS-Chem model (version 12.8.1) can be downloaded from http://wiki.seas.harvard.edu/geos-chem/index.php/GEOS-Chem_12#12.8.1 (last access: 26 May 2022). The code of the hyDL-CO model, sample data for the hyDL-CO model run and GEOS-Chem model output can be downloaded from https://doi.org/10.5281/zenodo.5913013 (Jiang, 2022).
ZJ designed the research. WH and TLH developed the model code and performed the research. ZJ wrote the article. All authors contributed to discussions and editing the article.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We thank the China Ministry of Ecology and Environment (MEE) for providing the surface CO measurements. The numerical calculations in this paper have been done on the supercomputing system in the Supercomputing Center of the University of Science and Technology of China.
This work was supported by the Hundred Talents Program of the Chinese Academy of Sciences and National Natural Science Foundation of China (grant no. 41721002).
This paper was edited by Volker Grewe and reviewed by two anonymous referees.
Andersson, T. R., Hosking, J. S., Perez-Ortiz, M., Paige, B., Elliott, A., Russell, C., Law, S., Jones, D. C., Wilkinson, J., Phillips, T., Byrne, J., Tietsche, S., Sarojini, B. B., Blanchard-Wrigglesworth, E., Aksenov, Y., Downie, R., and Shuckburgh, E.: Seasonal Arctic sea ice forecasting with probabilistic deep learning, Nat. Commun., 12, 5124, https://doi.org/10.1038/s41467-021-25257-4, 2021.
Chen, X., Jiang, Z., Shen, Y., Li, R., Fu, Y., Liu, J., Han, H., Liao, H., Cheng, X., Jones, D. B. A., Worden, H., and Abad, G. G.: Chinese regulations are working – why is surface ozone over industrialized areas still high? Applying lessons from Northeast US air quality evolution, Geophys. Res. Lett., 48, e2021GL092816, https://doi.org/10.1029/2021GL092816, 2021.
Chen, Y., Cui, S., Chen, P., Yuan, Q., Kang, P., and Zhu, L.: An LSTM-based neural network method of particulate pollution forecast in China, Environ. Res. Lett., 16, 044006, https://doi.org/10.1088/1748-9326/abe1f5, 2021.
Feng, S., Jiang, F., Wu, Z., Wang, H., Ju, W., and Wang, H.: CO Emissions Inferred From Surface CO Observations Over China in December 2013 and 2017, J. Geophys. Res.-Atmos., 125, 2019JD031808, https://doi.org/10.1029/2019jd031808, 2020.
Fisher, J. A., Murray, L. T., Jones, D. B. A., and Deutscher, N. M.: Improved method for linear carbon monoxide simulation and source attribution in atmospheric chemistry models illustrated using GEOS-Chem v9, Geosci. Model Dev., 10, 4129–4144, https://doi.org/10.5194/gmd-10-4129-2017, 2017.
Gaubert, B., Bouarar, I., Doumbia, T., Liu, Y., Stavrakou, T., Deroubaix, A., Darras, S., Elguindi, N., Granier, C., Lacey, F., Müller, J. F., Shi, X., Tilmes, S., Wang, T., and Brasseur, G. P.: Global Changes in Secondary Atmospheric Pollutants During the 2020 COVID-19 Pandemic, J. Geophys. Res.-Atmos., 126, 2020JD034213, https://doi.org/10.1029/2020jd034213, 2021.
Ghorbanzadeh, O., Crivellari, A., Ghamisi, P., Shahabi, H., and Blaschke, T.: A comprehensive transferability evaluation of U-Net and ResU-Net for landslide detection from Sentinel-2 data (case study areas from Taiwan, China, and Japan), Sci. Rep.-UK, 11, 14629, https://doi.org/10.1038/s41598-021-94190-9, 2021.
He, K., Zhang, X., Ren, S., and Sun, J.: Deep Residual Learning for Image Recognition, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 27–30 June 2016, Las Vegas, NV, USA, 770–778, 2016.
He, T. L., Jones, D. B. A., Miyazaki, K., Huang, B., Liu, Y., Jiang, Z., White, E. C., Worden, H. M., and Worden, J. R.: Deep learning to evaluate US NOx emissions using surface ozone predictions, J. Geophys. Res.-Atmos., 127, e2021JD035597, https://doi.org/10.1029/2021jd035597, 2022.
Hoesly, R. M., Smith, S. J., Feng, L., Klimont, Z., Janssens-Maenhout, G., Pitkanen, T., Seibert, J. J., Vu, L., Andres, R. J., Bolt, R. M., Bond, T. C., Dawidowski, L., Kholod, N., Kurokawa, J.-I., Li, M., Liu, L., Lu, Z., Moura, M. C. P., O'Rourke, P. R., and Zhang, Q.: Historical (1750–2014) anthropogenic emissions of reactive gases and aerosols from the Community Emissions Data System (CEDS), Geosci. Model Dev., 11, 369–408, https://doi.org/10.5194/gmd-11-369-2018, 2018.
Jiang, Z.: Deep learning model (hyDL-CO v1.0) to predict CO in China, https://doi.org/10.5281/zenodo.5913013 [code], 2022.
Jiang, Z., Worden, J. R., Worden, H., Deeter, M., Jones, D. B. A., Arellano, A. F., and Henze, D. K.: A 15-year record of CO emissions constrained by MOPITT CO observations, Atmos. Chem. Phys., 17, 4565–4583, https://doi.org/10.5194/acp-17-4565-2017, 2017.
Kleinert, F., Leufen, L. H., and Schultz, M. G.: IntelliO3-ts v1.0: a neural network approach to predict near-surface ozone concentrations in Germany, Geosci. Model Dev., 14, 1–25, https://doi.org/10.5194/gmd-14-1-2021, 2021.
Kong, L., Tang, X., Zhu, J., Wang, Z., Fu, J. S., Wang, X., Itahashi, S., Yamaji, K., Nagashima, T., Lee, H.-J., Kim, C.-H., Lin, C.-Y., Chen, L., Zhang, M., Tao, Z., Li, J., Kajino, M., Liao, H., Wang, Z., Sudo, K., Wang, Y., Pan, Y., Tang, G., Li, M., Wu, Q., Ge, B., and Carmichael, G. R.: Evaluation and uncertainty investigation of the NO2, CO and NH3 modeling over China under the framework of MICS-Asia III, Atmos. Chem. Phys., 20, 181–202, https://doi.org/10.5194/acp-20-181-2020, 2020.
Korznikov, K. A., Kislov, D. E., Altman, J., Doležal, J., Vozmishcheva, A. S., and Krestov, P. V.: Using U-Net-Like Deep Convolutional Neural Networks for Precise Tree Recognition in Very High Resolution RGB (Red, Green, Blue) Satellite Images, Forests, 12, f12010066, https://doi.org/10.3390/f12010066, 2021.
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., and Jackel, L. D.: Backpropagation applied to hand written zip code recognition, Neural Comput., 1, 541–551, https://doi.org/10.1162/neco.1989.1.4.541, 1989.
Li, K., Jacob, D. J., Liao, H., Shen, L., Zhang, Q., and Bates, K. H.: Anthropogenic drivers of 2013-2017 trends in summer surface ozone in China, P. Natl. Acad. Sci. USA, 116, 422–427, https://doi.org/10.1073/pnas.1812168116, 2019.
Li, K., Jacob, D. J., Shen, L., Lu, X., De Smedt, I., and Liao, H.: Increases in surface ozone pollution in China from 2013 to 2019: anthropogenic and meteorological influences, Atmos. Chem. Phys., 20, 11423–11433, https://doi.org/10.5194/acp-20-11423-2020, 2020.
Li, M., Zhang, Q., Kurokawa, J.-I., Woo, J.-H., He, K., Lu, Z., Ohara, T., Song, Y., Streets, D. G., Carmichael, G. R., Cheng, Y., Hong, C., Huo, H., Jiang, X., Kang, S., Liu, F., Su, H., and Zheng, B.: MIX: a mosaic Asian anthropogenic emission inventory under the international collaboration framework of the MICS-Asia and HTAP, Atmos. Chem. Phys., 17, 935–963, https://doi.org/10.5194/acp-17-935-2017, 2017.
Li, R., Zhao, Y., Zhou, W., Meng, Y., Zhang, Z., and Fu, H.: Developing a novel hybrid model for the estimation of surface 8 h ozone (O3) across the remote Tibetan Plateau during 2005–2018, Atmos. Chem. Phys., 20, 6159–6175, https://doi.org/10.5194/acp-20-6159-2020, 2020.
Liu, P., Wei, Y., Wang, Q., Chen, Y., and Xie, J.: Research on Post-Earthquake Landslide Extraction Algorithm Based on Improved U-Net Model, Remote Sens.-Basel, 12, rs12050894, https://doi.org/10.3390/rs12050894, 2020.
Lu, X., Ye, X., Zhou, M., Zhao, Y., Weng, H., Kong, H., Li, K., Gao, M., Zheng, B., Lin, J., Zhou, F., Zhang, Q., Wu, D., Zhang, L., and Zhang, Y.: The underappreciated role of agricultural soil nitrogen oxide emissions in ozone pollution regulation in North China, Nat. Commun., 12, 5021, https://doi.org/10.1038/s41467-021-25147-9, 2021.
Ma, C., Wang, T., Mizzi, A. P., Anderson, J. L., Zhuang, B., Xie, M., and Wu, R.: Multiconstituent Data Assimilation With WRF – Chem/DART: Potential for Adjusting Anthropogenic Emissions and Improving Air Quality Forecasts Over Eastern China, J. Geophys. Res.-Atmos., 124, 2019JD030421, https://doi.org/10.1029/2019jd030421, 2019.
Peng, Z., Lei, L., Liu, Z., Sun, J., Ding, A., Ban, J., Chen, D., Kou, X., and Chu, K.: The impact of multi-species surface chemical observation assimilation on air quality forecasts in China, Atmos. Chem. Phys., 18, 17387–17404, https://doi.org/10.5194/acp-18-17387-2018, 2018.
Qi, W., Wei, M., Yang, W., Xu, C., and Ma, C.: Automatic Mapping of Landslides by the ResU-Net, Remote Sens.-Basel, 12, rs12152487, https://doi.org/10.3390/rs12152487, 2020.
Quennehen, B., Raut, J.-C., Law, K. S., Daskalakis, N., Ancellet, G., Clerbaux, C., Kim, S.-W., Lund, M. T., Myhre, G., Olivié, D. J. L., Safieddine, S., Skeie, R. B., Thomas, J. L., Tsyro, S., Bazureau, A., Bellouin, N., Hu, M., Kanakidou, M., Klimont, Z., Kupiainen, K., Myriokefalitakis, S., Quaas, J., Rumbold, S. T., Schulz, M., Cherian, R., Shimizu, A., Wang, J., Yoon, S.-C., and Zhu, T.: Multi-model evaluation of short-lived pollutant distributions over east Asia during summer 2008, Atmos. Chem. Phys., 16, 10765–10792, https://doi.org/10.5194/acp-16-10765-2016, 2016.
Ravuri, S., Lenc, K., Willson, M., Kangin, D., Lam, R., Mirowski, P., Fitzsimons, M., Athanassiadou, M., Kashem, S., Madge, S., Prudden, R., Mandhane, A., Clark, A., Brock, A., Simonyan, K., Hadsell, R., Robinson, N., Clancy, E., Arribas, A., and Mohamed, S.: Skilful precipitation nowcasting using deep generative models of radar, Nature, 597, 672–677, https://doi.org/10.1038/s41586-021-03854-z, 2021.
Ronneberger, O., Fischer, P., and Brox, T.: U-Net: Convolutional Networks for Biomedical Image Segmentation, arXiv [preprint], arXiv:1505.04597, 2015.
Rumelhart, D. E., Hinton, G. E., and Williams, R. J.: Learning representations by back-propagating errors, Nature, 323, 533–536, https://doi.org/10.1038/323533a0, 1986.
Shi, X. and Brasseur, G. P.: The Response in Air Quality to the Reduction of Chinese Economic Activities during the COVID-19 Outbreak, Geophys. Res. Lett., 47, e2020GL088070, https://doi.org/10.1029/2020GL088070, 2020.
Shi, X., Chen, Z., Wang, H., Yeung, D.-Y., Wong, W.-K., and Woo, W.-C.: Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting, arXiv [preprint], arXiv:1506.04214, 2015.
Shi, Z., Song, C., Liu, B., Lu, G., Xu, J., Van Vu, T., Elliott, R. J. R., Li, W., Bloss, W. J., and Harrison, R. M.: Abrupt but smaller than expected changes in surface air quality attributable to COVID-19 lockdowns, Sci. Adv., 7, eabd6696, https://doi.org/10.1126/sciadv.abd6696, 2021.
Tang, Z., Chen, J., and Jiang, Z.: Effects of satellite and surface measurements on atmospheric CO assimilations over East Asia in 2015–2020, Atmos. Chem. Phys. Discuss. [preprint], https://doi.org/10.5194/acp-2021-1035, in review, 2022.
Xing, X., Xiong, Y., Yang, R., Wang, R., Wang, W., Kan, H., Lu, T., Li, D., Cao, J., Penuelas, J., Ciais, P., Bauer, N., Boucher, O., Balkanski, Y., Hauglustaine, D., Brasseur, G., Morawska, L., Janssens, I. A., Wang, X., Sardans, J., Wang, Y., Deng, Y., Wang, L., Chen, J., Tang, X., and Zhang, R.: Predicting the effect of confinement on the COVID-19 spread using machine learning enriched with satellite air pollution observations, P. Natl. Acad. Sci. USA, 118, e2109098118, https://doi.org/10.1073/pnas.2109098118, 2021.
Zhang, Y., Vu, T. V., Sun, J., He, J., Shen, X., Lin, W., Zhang, X., Zhong, J., Gao, W., Wang, Y., Fu, T. M., Ma, Y., Li, W., and Shi, Z.: Significant Changes in Chemistry of Fine Particles in Wintertime Beijing from 2007 to 2017: Impact of Clean Air Actions, Environ. Sci. Tech., 54, 1344–1352, https://doi.org/10.1021/acs.est.9b04678, 2020.