the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 13 Apr 2021
| 13 Apr 2021
SPEAD 1.0 – Simulating Plankton Evolution with Adaptive Dynamics in a two-trait continuous fitness landscape applied to the Sargasso Sea
Sergio M. Vallina
S. Lan Smith
Pedro Cermeño
Diversity plays a key role in the adaptive capacity of marine ecosystems to environmental changes. However, modelling the adaptive dynamics of phytoplankton traits remains challenging due to the competitive exclusion of sub-optimal phenotypes and the complexity of evolutionary processes leading to optimal phenotypes. Trait diffusion (TD) is a recently developed approach to sustain diversity in plankton models by introducing mutations, therefore allowing the adaptive evolution of functional traits to occur at ecological timescales. In this study, we present a model called Simulating Plankton Evolution with Adaptive Dynamics (SPEAD) that resolves the eco-evolutionary processes of a multi-trait plankton community. The SPEAD model can be used to evaluate plankton adaptation to environmental changes at different timescales or address ecological issues affected by adaptive evolution. Phytoplankton phenotypes in SPEAD are characterized by two traits, the nitrogen half-saturation constant and optimal temperature, which can mutate at each generation using the TD mechanism. SPEAD does not resolve the different phenotypes as discrete entities, instead computing six aggregate properties: total phytoplankton biomass, the mean value of each trait, trait variances, and the inter-trait covariance of a single population in a continuous trait space. Therefore, SPEAD resolves the dynamics of the population's continuous trait distribution by solving its statistical moments, wherein the variances of trait values represent the diversity of ecotypes. The ecological model is coupled to a vertically resolved (1D) physical environment, and therefore the adaptive dynamics of the simulated phytoplankton population are driven by seasonal variations in vertical mixing, nutrient concentration, water temperature, and solar irradiance. The simulated bulk properties are validated by observations from Bermuda Atlantic Time-series Studies (BATS) in the Sargasso Sea. We find that moderate mutation rates sustain trait diversity at decadal timescales and soften the almost total inter-trait correlation induced by the environment alone, without reducing the annual primary production or promoting permanently maladapted phenotypes, as occur with high mutation rates. As a way to evaluate the performance of the continuous trait approximation, we also compare the solutions of SPEAD to the solutions of a classical discrete entities approach, with both approaches including TD as a mechanism to sustain trait variance. We only find minor discrepancies between the continuous model SPEAD and the discrete model, with the computational cost of SPEAD being lower by 2 orders of magnitude. Therefore, SPEAD should be an ideal eco-evolutionary plankton model to be coupled to a general circulation model (GCM) of the global ocean.
- Article
(2006 KB) - Full-text XML
-
Supplement
(315 KB) - BibTeX
- EndNote





Phytoplankton are a polyphyletic group of microscopic primary producers widespread in aquatic environments. They are mainly single-celled, although colonial or multicellular species exist in most phytoplankton phyla (Beardall et al., 2009). Despite accounting for only 1 % of the global photosynthetic biomass, phytoplankton perform more than 45 % of Earth's net primary production (Field et al., 1998; Falkowski et al., 2004). They are the basis of all oceanic food webs and play key roles in biogeochemical cycles (Falkowski, 2012). In particular, they have a large impact on global climate through the export of detritic carbon from the surface to the ocean interior, sequestrating carbon in the deep ocean for timescales from a few years to more than a millennium depending on the depth they reach (DeVries and Primeau, 2011; DeVries et al., 2012). This process, called the “biological carbon pump”, regulates the concentration of carbon dioxide in the atmosphere (Volk and Hoffert, 1985; Falkowski et al., 1998).
Phytoplankton are highly diverse and live in many different environments. They differ in their ecological interactions and the processes through which they mediate biogeochemical cycles. For instance, some species can fix atmospheric nitrogen and enrich oligotrophic regions; some produce ballast minerals (mainly silica and calcium carbonate) and sink faster to the deep ocean, and others are mixotrophic, being able to both photosynthesize and feed on organic sources (Le Quéré et al., 2005). Most species are denser than seawater and eventually sink, but some are buoyant (Lännergren, 1979; Villareal, 1988). Phytoplankton size ranges from less than 1 µm for cyanobacteria like Prochlorococcus (Chisholm et al., 1988) to more than 1 mm for the giant diatom Ethmodiscus rex (Swift, 1973; Villareal and Carpenter, 1994). Their half-saturation constants for the main limiting nutrients range over 3 orders of magnitude (Edwards et al., 2012), reflecting adaptation to different nutrient supply levels. They are also adapted to very different temperatures: some diatoms can grow within sea ice (Ackley and Sullivan, 1994), whereas some hyperthermophilic cyanobacteria can grow at up to 75 ∘C in hot springs (Castenholz, 1969). Most oceanic species have an optimal temperature for growth between 0 and 35 ∘C (Thomas et al., 2012). Even within the same species or genus, wide variability has been observed for key traits such as iron requirements (Strzepek and Harrison, 2004), light requirements (Biller et al., 2015), and resistance to predation (Yoshida et al., 2004). Given that any change in the abundance and composition of phytoplankton has far-reaching consequences for other organisms and for the Earth's climate, it is important to understand the factors driving the dynamics of such communities.
Numerical modelling studies can address this issue by finding the mechanistic equations and parameters that most correctly account for the observations, and thereby provide invaluable insights into the general rules controlling ecosystems. Models can also be used to make predictions of how phytoplankton will impact or be impacted by future environmental changes (Norberg et al., 2012; Irwin et al., 2015). Mathematical models of phytoplankton growth as a function of nutrient concentration, temperature, and radiation have been developed since the 1940s (Riley, 1946; Steele, 1958; Riley, 1965), leading to the now common NPZD (nutrient, phytoplankton, zooplankton, detritus) models representing one or several compartments of nutrients, phytoplankton, zooplankton, and detritus (Fasham et al., 1990). Since the early 1990s (Maier-Reimer, 1993), the increase in computational power has allowed biogeochemical models to be fully coupled with ocean circulation (Aumont et al., 2003; Follows et al., 2007). However, representing all the phytoplankton diversity in models is neither feasible nor desirable. The computational cost would be high, and even if computationally feasible, the existing observations would not suffice to constrain the many free parameters.
Instead, ecological models account for biodiversity through a few key traits representing physiological characteristics or adaptation to different environments. The most widely investigated phytoplankton traits are cell size, nutrient niche, optimal temperature, optimal irradiance, and resistance to predation. Some trait-based models divide the phytoplankton community into discrete entities or “boxes” with different traits. The boxes can be as simple as diatoms and small phytoplankton groups (Aumont et al., 2015), with diatoms having higher nutrient concentration niches, or include more complex divisions into functional groups (Baretta et al., 1995; Le Quéré et al., 2005; Follows et al., 2007). In this article, we will call these models “discrete” or “multi-phenotype”. The other approach, which further reduces the number of equations while still allowing communities to adapt to changes in their environments, is to consider one or several continuously distributed traits and to compute only the dynamics of aggregate properties, such as community biomass, mean trait values, and trait variances (Wirtz and Eckhardt, 1996; Norberg et al., 2001; Bruggeman and Kooijman, 2007; Merico et al., 2009; Acevedo-Trejos et al., 2016; Smith et al., 2016; Chen and Smith, 2018). In this method trait variance can be used as a quantitative index of biodiversity. A community with a higher trait variance is considered to be more diverse because it has a wider spread and more even distribution of trait values (Li, 1997), although it does not necessarily have a higher number of taxonomic species (richness) (Vallina et al., 2017). This second type of model will be called “aggregate” or “continuous trait”.
One weakness induced by the simplification of phytoplankton communities in both aggregate and discrete models, however, is that competitive exclusion (Hardin, 1960; Hutchinson, 1961) often leads to a collapse of the modelled diversity (Merico et al., 2009), making adaptation impossible unless trait variance is artificially imposed (Norberg et al., 2012; Wirtz, 2013) or a mechanism is explicitly added to sustain it. One way to sustain biodiversity is through immigration from a distant community (Norberg et al., 2001; Savage et al., 2007). Yet, immigration does not explain the diversity observed in closed laboratory experiments, including continuous cultures (Fussmann et al., 2007; Kinnison and Hairston, 2007; Beardmore et al., 2011). Biodiversity can also be sustained by viruses (Thingstad and Lignell, 1997) or predators (Murdoch, 1969; Kiørboe et al., 1996) if they specialize in a narrow range of prey or switch their preference to the most common phytoplankton species. This is the idea behind the “kill the winner” theory (Thingstad, 2000; Vallina et al., 2014b), whereby predation concentrating more on the most dominant species maintains diversity because then each prey species persists at the abundance at which the predation rate equals its growth rate.
An alternative approach recently introduced to sustain diversity in models is to allow the simulated phytoplankton to mutate their functional traits (Kremer and Klausmeier, 2013; Merico et al., 2014), as mutations are the ultimate cause of all diversity and adaptation. Due to their short generation times of around 1 d (Marañon et al., 2013), phytoplankton are known to evolve at the timescale of a few years (Schlüter et al., 2016). For phytoplankton, ecological timescales featuring successions of dominant species in reaction to changes in the environment and selection of the fittest overlap evolutionary timescales on which species can also evolve genetically to adapt to their new environment (Irwin et al., 2015). As far as we know, the first aggregate phytoplankton model allowing a phytoplankton trait to randomly mutate through subsequent generations, before being selected by the environment, was developed by Merico et al. (2014). They called their scheme trait diffusion (TD), where “diffusion” is a mathematical term referring to the spreading of a property, in this case the trait value, not to physical transport. Trait diffusion of a single physiological trait was recently introduced in a model coupled with oceanic circulation (Chen and Smith, 2018). Upgrading the trait diffusion framework to several traits requires more complex equations and the introduction of a new class of state variables: the covariances between traits. However, multi-trait models are more realistic, and conceptual modelling studies have shown that the dynamics of correlated traits sometimes differ from those of single-trait models (Savage et al., 2007).
There are several other types of plankton ecological (without mutations) or eco-evolutionary (with mutations) models, such as individual-based models, resident–mutant models, and models with stochastic mutations. Each represents and sustains diversity in its own unique way. All the modelling approaches mentioned in this paper and others are reviewed with their assumptions, costs, and benefits by Ward et al. (2019). For instance, the aggregate approach corresponds to the parametric trait distribution model in their Fig. 3 (eco-v), and the multi-phenotype approach encompasses the “everything is everywhere” (eco-iii), functional groups (eco-iv), and deterministic mutations (evo-iii) cases depending on the number of phenotypes and the presence or absence of mutations. What makes aggregate models particularly advantageous is their cost efficiency and their applicability to a spatial context. Adding adaptive evolution to models has been identified as a key challenge for the near future, as it will allow researchers to answer several unresolved ecological questions more fundamental than sustaining variance that cannot be answered by purely ecological models. For instance, eco-evolutionary models can be used to assess the relative roles of natural selection and neutral evolution in explaining the observed diversity patterns. They could also serve to explore hypotheses on the emergence of new species and new environments after a mass extinction. Finally, representing evolution is necessary to estimate the prevalence of extinction, adaptation, and migration in response to future environmental changes.
Here we present a new aggregate phytoplankton model called SPEAD (Simulating Plankton Evolution with Adaptive Dynamics), an eco-evolutionary model using the trait diffusion framework for two key phytoplankton traits: the nitrogen half-saturation constant and optimal temperature for growth. The SPEAD model is based on an NPZD model (Vallina et al., 2014a, 2017), wherein the phytoplankton compartment is represented by the community biomass, mean trait values, trait variances, and covariance. SPEAD is embedded in a 1D (water column) physical setting simulating the Sargasso Sea using data from the Bermuda Atlantic Time-series Studies (BATS). We chose the 1D rather than a simpler 0D setting because vertical turbulent diffusion (not to be confused with trait diffusion) is the main source of covariance by mixing communities from different depths. Since the trait diffusion equations can easily be adapted to a discrete model, we have also built a discrete version of SPEAD wherein the phytoplankton community consists of 625 different phenotypes (i.e. 25 half-saturation constants and 25 optimal temperatures), each characterized by its own fixed set of trait values. The discrete version is more intuitive and easier to programme, and it provides a useful control experiment.
In the following sections, we first describe our ecological model, the differential equations controlling the growth of phytoplankton, and the adaptive evolution of their trait distribution, as well as the physical model setting. Then, we present the model outputs. In order to validate SPEAD and to highlight its novelties, we will focus on answering the following four questions.
-
How well does SPEAD represent the bulk properties of phytoplankton communities observed in the Sargasso Sea?
-
Do the aggregate and discrete approaches agree?
-
How are phytoplankton dynamics changed by the value of the mutation rates?
-
Can the mean value and variance of each trait be represented independently by a one-trait model wherein only nitrogen half-saturation or optimal temperature varies between phenotypes?
Finally, we discuss the reach of our modelling framework, focusing on three aspects: the performance of aggregate models, the choice of phytoplankton traits, and the relationship between trait diffusion and evolution.
2.1 A phytoplankton community model with two traits
Our phytoplankton community model SPEAD extends an existing nitrogen-based NPZD model (Vallina et al., 2017). Nitrogen is partitioned into four pools, all expressed in millimoles of nitrogen per cubic metre (mmol N m−3): phytoplankton (P in the equations), zooplankton (Z), dissolved inorganic nitrogen or DIN (N), and particulate organic nitrogen or PON (D as in “detritus”). Phytoplankton increase biomass by taking up DIN (Vp). Zooplankton increase biomass by grazing phytoplankton (Gz). The non-predation mortalities of phytoplankton (Mp) and zooplankton (Mz) and the nitrogen exudation by zooplankton (Ez) are divided between DIN and PON. Given that nitrogen is the limiting nutrient for phytoplankton growth, we do not consider nitrogen exudation by phytoplankton. ωp, ωz, and ϵz are constants representing the respective proportions of Mp, Mz, and Ez going to DIN. PON is remineralized to DIN (Md). The fluxes from one pool to another are controlled by the pool concentrations and by two environmental forcings: temperature (T; ∘C) and photosynthetically active radiation or PAR (I; W m−2). The main state variables of the model and their relationships are shown in Table 1 and Fig. 1a, and the expressions of the biogeochemical fluxes between the pools (mmol N m−3 d−1) are given by the following equations, with their dependencies.
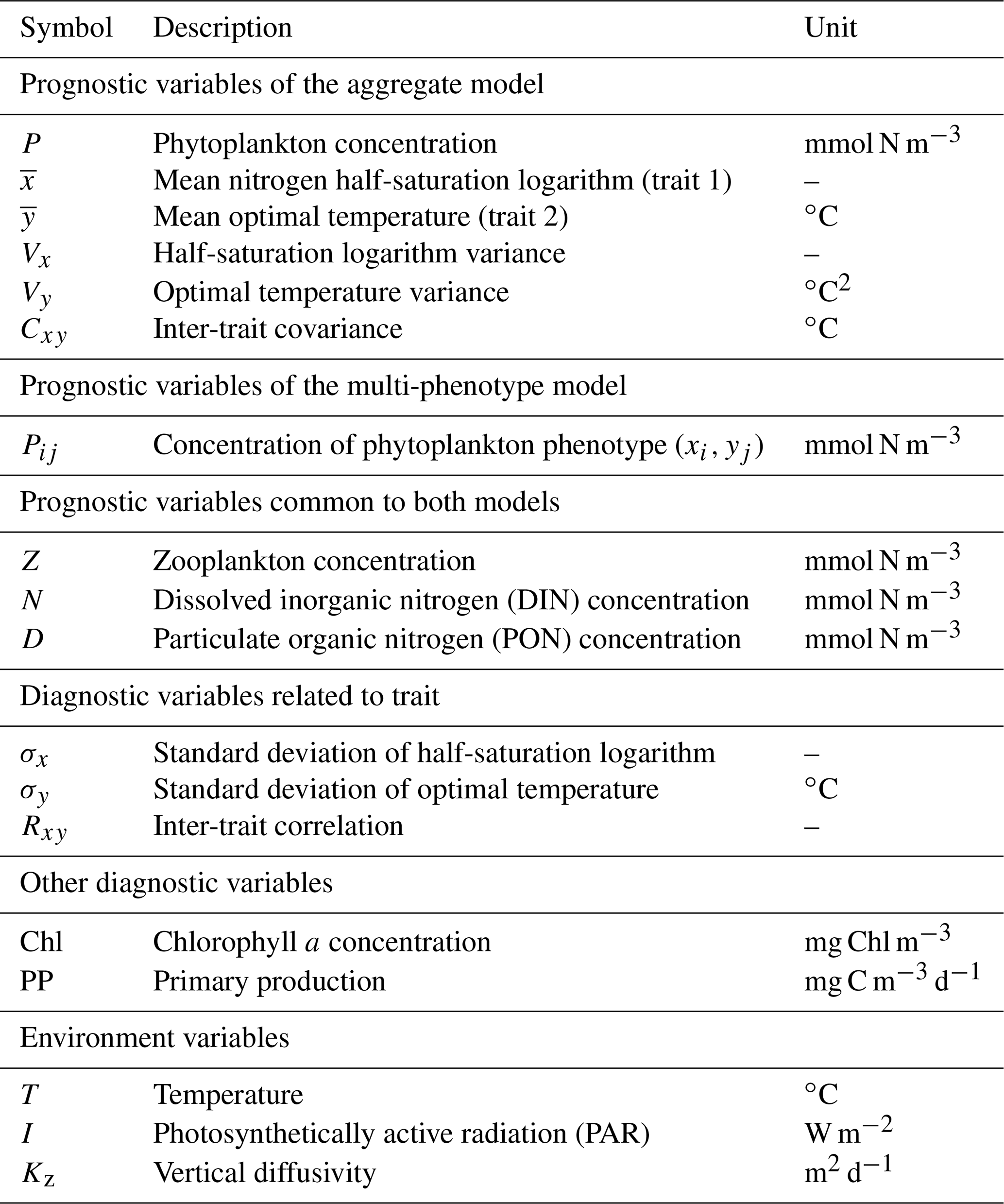
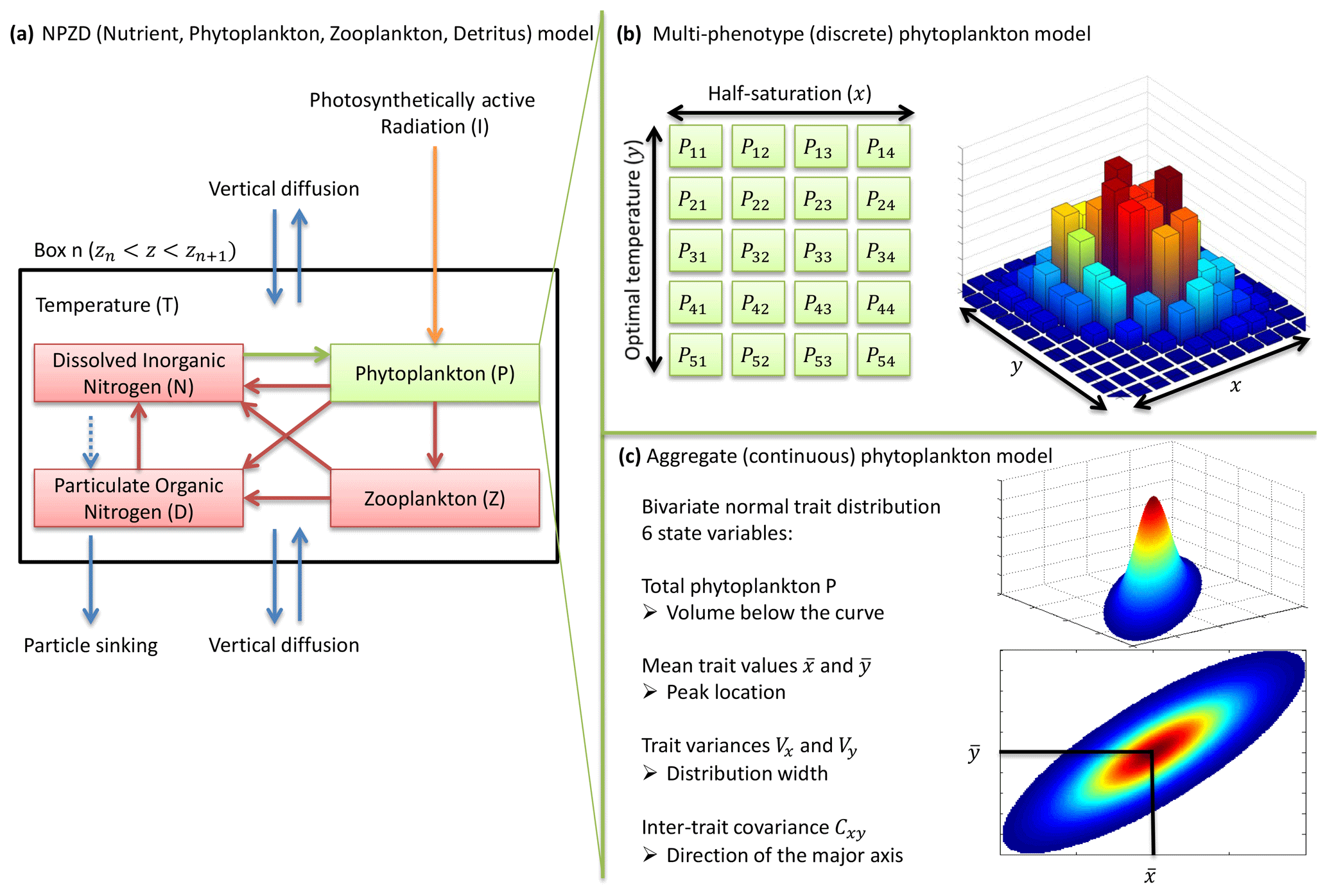
Figure 1NPZD (nutrient, phytoplankton, zooplankton, detritus) model within its physical setting (a). The phytoplankton pool is represented by a discrete set of species with different traits (b) or by moments of the trait distributions, assuming a bivariate normal distribution (c). Colours in (b) and (c) represent phytoplankton concentration.
Zooplankton, DIN, and PON are generic pools characterized by a single variable: their concentration. Phytoplankton and zooplankton mortality, zooplankton exudation, grazing, and the particle remineralization rate have simple expressions as a function of the nitrogen pool concentrations and temperature.
The constants appearing in this equation (αh, T0, Kp, βz, ψz, ψp, and ψd) are described in Table 2. Zooplankton mortality depends on the square of zooplankton concentration in order to prevent an explosion of zooplankton concentration. This stabilizing quadratic mortality term represents consumption by animals higher on the trophic chain, which is expected to increase faster than a linear function of Z biomass. Grazing is formulated as a Holling type III function (Holling, 1959) of phytoplankton concentration, with a niche at low concentrations to prevent the whole phytoplankton community from going extinct, even when they have very low growth rates. Grazing, mortality, and remineralization are considered heterotrophic processes and as such increase exponentially with temperature. The exponential factor is αh = 0.092 ∘C−1. This is equivalent to multiplying the speed of all these processes by 2.5 when the temperature increases by 10 ∘C, as in a Q10=2.5 formulation. This value of Q10 is close to measured values for zooplankton grazing (Hansen et al., 1997) and to the theoretical predictions of the metabolic theory of ecology for respiration (Gillooly et al., 2001; Allen et al., 2005).
In contrast, the phytoplankton pool is composed of diverse organisms responding to environmental conditions in different ways. The diversity of phytoplankton is represented by variations in the values of two traits: the logarithm of the half-saturation constant for nitrogen uptake (x) and the optimal temperature for growth (y). From now on, we will refer to each set (x,y) of trait values as a “phenotype”. Nutrient uptake by phytoplankton depends on the trait distribution. The bivariate trait distribution is represented by a density p(x,y) (mmol N m−3 ∘C−1) so that the biomass of phytoplankton (mmol N m−3) with trait values between x1 and x2 and between y1 and y2 is equal to , and by extension the total phytoplankton biomass P is equal to the density integrated over the whole trait domain. Any phenotype has its own uptake rate up(x,y) (d−1). The uptake rate is the product of a constant () and three dimensionless growth factors: a nutrient factor (γn(N,x)), a temperature factor (γT(T,y)), and an irradiance factor (γI(I)). Two of these factors, γn(N,x) and γI(I), represent limitations by resources. The third factor, γT(T,y), represents the kinetic effect of temperature on growth. In this study, we use the Monod approach (Monod, 1949) so that cells do not store nutrients and the uptake rate is equal to the reproduction or growth rate. We assume that all phytoplankton are unicellular and we do not consider changes in their cell volumes, which allows us to use the words “growth” and “reproduction” interchangeably. All phenotypes share the same rates of mortality and grazing.
The last term in the equation of trait density (Eq. 10) is trait diffusion (TD), as defined by Merico et al. (2014). Trait diffusion represents the fact that offspring can exhibit different trait values than their parents due to mutations or otherwise heritable plasticity. In our numerical model, we assume only that these mutations are heritable and random. They can represent genetic mutations and other, e.g. epigenetic, phenotypic plasticity. We assume that mutations on x and y are independent of each other. In the limit of small but frequent mutations, stochasticity can be neglected (Dieckmann and Law, 1996; Champagnat et al., 2006), and this process can be represented as a deterministic diffusion depending on diffusivity parameters νx and νy and on the second derivatives of the growth rate (up(x,y)) relative to each trait. Note that in TD, diffusion is a mathematical term referring to the spreading of a property, in our case trait values, not to a physical mixing process. It should therefore not be confused with vertical turbulent diffusion, which is also present in our model (see Sect. 2.3). To avoid ambiguity, from now on, we will refer to the trait diffusivity parameters as “mutation rates”. νx and νy are mutation rates per generation, not per unit of time; therefore, time does not appear in their units. They have the same units as trait variances. The derivation of the trait diffusion term is explained in Appendix A. The differential equations followed by a given phenotype (x,y) are as follows.
Like all biodiversity models, SPEAD must not allow a phenotype to outcompete all other phenotypes in all environments because any such Darwinian demon would drive all its sub-optimal competitors to extinction and trait variance would collapse to zero. In order to make competition for nutrients possible, we have defined two uptake traits so that either low or high values are advantageous in certain environments and disadvantageous in others. The shape of the two trade-offs and the three growth factors are presented in Fig. 2.

Figure 2Phytoplankton growth factors γn (nutrient-dependent), γT (temperature-dependent), and γI (PAR-dependent). Panels (a) and (b) represent the growth factor as a function of nutrient concentration and temperature, respectively, for different phenotypes. Panels (c) and (d) represent the growth factor as a function of the corresponding trait for different values of the environmental parameter. The maximum of each curve corresponds to the phenotype most adapted to a given environment. Panels (e) and (f) are normalized versions of (c) and (d), respectively, so that their maximum is always 1. Panel (g) is the PAR-dependent growth factor, which is common to all phenotypes in this version of SPEAD.
The first trait allowed to mutate in SPEAD, x, is the logarithm of the half-saturation constant that controls the nutrient limitation factor γn(N,x). The half-saturation constant Kn(x) is the DIN concentration at which the nitrogen uptake rate is equal to one-half of the maximum uptake rate for the same temperature and solar irradiance. As the concentrations are always positive and span several orders of magnitude, we use a natural logarithmic scale and define as our first trait axis, with mmol N m−3 as a reference value for Kn. The half-saturation constant can be linked to the well-known trade-off between the affinity for a nutrient and the maximum uptake rate, also known as the gleaner–opportunist trade-off (Frederickson and Stephanopoulos, 1981). For a given phenotype, γn(N,x) follows a Michaelis–Menten function of nutrient concentration.
The nutrient limitation factor at a high nitrogen concentration, , is set so that each phenotype has an ecological niche wherein it grows faster than its competitors. To obtain the expression of , we first introduce two variables that represent the competitive ability of phytoplankton in two types of environments: the growth rate in the limit of a high nitrogen concentration (; d−1) and the affinity for nitrogen (; d−1 mmol−1 m3). These two variables fully define the Michaelis–Menten function for nutrient uptake. The affinity represents the initial slope of the curve at zero resource concentration, while the maximum growth rate represents the horizontal asymptote of the curve that is reached at an infinite resource concentration (see Fig. 2 in Vallina et al., 2019). The affinity is closely related to the growth rate at a low nitrogen concentration, which is equal to . The maximum growth rate is related to the biomass-specific handling rate of nutrient ions at high nitrogen concentrations. The values of and are given by introducing Eq. (12) into Eq. (11) and taking the limit of high or low concentrations.
In order to prevent phenotypes from dominating all nutrient niches (i.e. from being Darwinian demons), we assume that the product of maximum growth and affinity is constant with (independent of) x (Meyer et al., 2015). Therefore, is proportional to the square root of Kn and to a factor independent of x, yielding the following expression for :
With this “maximum growth rate–nutrient affinity” trade-off, phenotypes that grow faster than their competitors at high nutrient concentrations (high ), called opportunists, are disadvantaged at low concentrations (low fp) by the same factor, and those which grow comparatively fast at low nutrient concentrations (high fp), called gleaners, are at a disadvantage under high concentrations (low ). This constraint has been observed in bacteria and phytoplankton (Healey and Hendzel, 1980; Button et al., 2004; Elbing et al., 2004; Cermeño et al., 2011; Vallina et al., 2019), has been used in models (Dutkiewicz et al., 2009; Vallina et al., 2014b; Smith et al., 2016; Vallina et al., 2017), and is the simplest way to discriminate the bloom-forming opportunist phytoplankton (such as diatoms) from the ubiquitous gleaners (such as Prochlorococcus) without explicitly representing the complex effects of cell size or the way uptake sites are packed at the cell surface. However, the thermodynamic bases of the trade-off are still unclear (Wirtz, 2002). For any nutrient concentration N, we note that the phenotype corresponding to the largest growth rates is . This is why, under the assumption of the gleaner–opportunist trade-off defined above, Kn defines the optimal nutrient concentration of each x phenotype at which they are competitively superior (Vallina et al., 2017). This result, however, is dependent on the specific model assumption that is a constant.
The second phytoplankton trait that is allowed to mutate in SPEAD is the optimal temperature. Temperature affects microbes in two ways. One is generic and applies to the whole plankton community. An increase in temperature increases the speed of both primary production and heterotrophic processes for thermodynamic reasons. This effect is often assumed to be exponential. In our model, the exponential factor for autotrophic primary production is αa=0.056 ∘C−1, which corresponds to a Q10 of 1.75, slightly lower than the classical value of 1.88 from Eppley (1972) but higher than the values based on the metabolic theory of ecology for photosynthesis (López-Urrutia et al., 2006). The second effect of temperature is phenotype-specific. Each phenotype has an optimal temperature for growth, which is the second trait axis and is denoted by y. The effect of temperature on a given phenotype (x,y) is asymmetric: at temperatures more than 5 ∘C above y growth ceases, but temperatures below y merely slow growth. We defined our temperature multiplicative growth factor to be as close as possible to the species-specific curves of Eppley (1972):
The temperature tolerance ΔT is set to 5 ∘C. T0 is a reference temperature with no ecological meaning. For a fixed value of y, γT(T,y) has a maximum at T=y with a value of . At and warmer, growth is impossible. For a given value of the environment temperature T, the phenotypes with the largest growth rates have an optimal temperature y around 2 ∘C larger than T. This apparent mismatch, whereby the dominant phenotype at temperature T can grow even faster at temperatures a few degrees warmer, is both coherent with other models (Beckmann et al., 2019) and observed in nature (Thomas et al., 2012; Irwin et al., 2012).
In this study, the PAR limitation factor γI(I) is the same for all phenotypes. It includes an optimal PAR (Iopt) of 25 W m−2 and photoinhibition above this level. Our value for Iopt is in the middle of the range considered by Follows et al. (2007), and our expression for γI(I) is equivalent to theirs.
In the above equation, is a normalization factor (to ensure that γI(I) cannot exceed 1) and χ is an inhibition factor. The higher the inhibition factor, the less photoinhibition there is at irradiances larger than Iopt. In this study, we use χ=12, which is the average value in Follows et al. (2007) for large phytoplankton and corresponds well to published photoinhibition curves (Platt et al., 1980; Whitelam and Codd, 1983; Walsh et al., 2001).
For comparison with data, two additional variables can be estimated from the model: primary production and chlorophyll a concentration. Primary production (PP) is expressed in milligrams of carbon per cubic metre per day (mg C m−3 d−1). Our model-based estimate is calculated by multiplying the phytoplankton concentration and the uptake rate, normalizing from nitrogen to carbon with the 106:16 Redfield molar ratio (Redfield, 1934) and then converting from the amount of substance to mass using the molar mass of carbon (12 g mol−1). The chlorophyll a concentration (Chl; mg Chl m−3) is obtained by dividing the phytoplankton concentration in mass of carbon by a variable carbon to chlorophyll mass ratio (C : Chl). The C : Chl ratio is estimated as in Vallina et al. (2008) using a function of depth and time developed by Lefèvre et al. (2002), with parameter values calibrated with the observations of Goericke and Welschmeyer (1998). At the surface, C : Chl is a sinusoidal function of the day of year, varying between a maximum of 160 mg C mg Chl−1 at the summer solstice and a minimum of 80 mg C mg Chl−1 at the winter solstice. From the depth at which W m−2 to the bottom, C : Chl decreases linearly with I(z,t) down to a value of 40 mg C mg Chl−1 when light is absent.
2.2 Aggregate and multi-phenotype models
Traits x and y have an infinity of possible values. In order to solve the equations numerically, the problem needs to be simplified. Two approaches are considered here. In the multi-phenotype or discrete model approach (Fig. 1b), the trait space is discretized, and only a finite number of phenotypes with fixed trait values are simulated. Phenotypes with intermediate trait values are neglected. In the aggregate or continuous model approach (Fig. 1c), the state variables are total phytoplankton concentration, the mean trait values, the trait variances, and the inter-trait covariance. In the continuous trait model, a specific shape of the trait distribution must be assumed a priori (Wirtz and Eckhardt, 1996; Bruggeman and Kooijman, 2007). In the discrete trait model, the trait distribution is an emergent property, and thus it does not need to be assumed beforehand.
In the multi-phenotype model, only nx values of x and ny values of y are allowed. The phytoplankton community is divided into nx×ny phenotypes. The values of both traits are explicitly bounded by xmin, xmax, ymin, and ymax. Each phenotype is separated from its immediate neighbours by a trait interval on x or a trait interval on y. Mutation fluxes at the boundaries (i.e. mutations of the phenotypes with the highest or lowest trait values leading out of the domain) are set to zero. In the interior of our trait domain, the concentration of the phenotype with the jth value of x and the kth value of y, noted Pjk, is controlled by the following equation, where , called the net growth rate, is the sum of all growth and death terms affecting phytoplankton concentration.
In all our discrete simulations, we impose (Kn=0.082 mmol N m−3), (Kn=4.48 mmol N m−3), ∘C, and ∘C. All model values of temperature and DIN concentrations are within these boundaries. We set nx=25 and ny=25 in order to ensure that in most cases Δx and Δy are less than the standard deviations of x and y, respectively. Thus, the total number of discrete phenotypes (x,y) is .
In the aggregate model, the trait distribution is assumed to be continuous. In this case, and contrary to the multi-phenotype case, the trait axes are formally unbounded, although phenotypes with extreme trait values always have low net growth rates, making them extremely rare. The prognostic variables are six statistical moments of the trait distribution: the total phytoplankton concentration P(t), the mean trait values and , the trait variances Vx(t) and Vy(t), and the inter-trait covariance Cxy(t). They are defined as follows.
The second-order moments (Vx, Vy and Cxy) are difficult to interpret directly due to their dimensions. In the analyses, we thus transform variances into standard deviations (σx and σy) and covariance into correlation (Rxy) as follows:
These three diagnostic variables, along with P, , and , are also computed for the multi-phenotype model for comparison. The standard deviations have the same dimensions as the mean traits and can thus be compared to them. Ecologically, they represent trait diversity. Inter-trait correlation is a dimensionless number between −1 and +1, which is easier to interpret than the covariance. A correlation of −1 means above-average values of x always coincide with below-average values of y and vice versa. A correlation of +1 means above-average values of x always coincide with above-average values of y. A correlation of 0 means all combinations are equally possible (i.e. the two traits are independent).
We follow the method developed by Norberg et al. (2001), based on Taylor expansions of the uptake and net growth rates to derive the differential equations for the moments of the trait distribution. We assume a bivariate normal distribution of traits, which is a generalization of the 1D Gaussian function. Normal distributions are observed in nature for the logarithm of size (Cermeño and Figueiras, 2008; Quintana et al., 2008; Downing et al., 2014) and are convenient assumptions for models because they produce the simplest forms for the equations (Wirtz and Eckhardt, 1996; Merico et al., 2009). The derivation is explained in detail in Appendix B. In the absence of trait diffusion, our equations are a particular case of the general equations derived by Bruggeman (2009) for multivariate normal trait distributions. In the single-trait case, they are simpler than the original equations of Merico et al. (2014) and identical to the more recent formulation of Coutinho et al. (2016). In the absence of physical transport, the differential equations followed by the prognostic variables are as follows.
The net growth rate and its derivatives with respect to traits are in all cases taken near the mean trait values ( and ) and for the values of N, T, and I at time t. The growth rate of the whole phytoplankton community depends first on the net growth rate of the most abundant phenotype (the “winner” of the competition), , with correction terms for the less abundant and generally less fit phenotypes (“losers”). Mean traits increase when larger trait values are associated with larger net growth rates and decrease in the opposite case . The change is faster when trait variances (Vx and Vy) are high. As a consequence, the overall effect of trait diversity on primary production depends on the environmental conditions. In a stable environment, high trait variances diminish the primary production because phenotypes with low growth rates are present. Under frequent disturbances, however, high trait variances increase the short-term adaptive capacity, allowing the community to maintain mean traits close to the optimum and thereby increasing primary production (Smith et al., 2016). We note that when traits covary (Cxy≠0), the change in each trait depends on both nutrient concentration N and water temperature T . Variances decrease due to competition when mean trait values are close to the values that maximize the net growth rate . This is most often the case, since phenotypes that are not optimal tend to be outcompeted. Trait diversity must therefore be maintained by some other process: this is the role of trait diffusion. In these equations, trait diffusion is a (positive) source of variance equal to but does not affect the equations for phytoplankton concentration, mean traits, or covariance. This is coherent with the fact that mutations are symmetrical (no effect on and ) and neither create nor remove biomass (no effect on P). Trait diffusion does not affect covariance because mutations of the two traits are independent of each other. There is no mechanistic relationship between optimal temperature and half-saturation. Mutations can create all combinations: cold-water gleaners, warm-water gleaners, cold-water opportunists, and warm-water opportunists. However, by increasing variances, trait diffusion decreases the absolute value of correlation. Only the environment can correlate the traits by favouring some combinations over others. Although correlation is defined as a local quantity, for a given depth and time, it is expected to be influenced by the spatio-temporal patterns of environment variations because local communities always contain remnants of past communities and migrants from other locations.
2.3 Physical setting
SPEAD 1.0 has one spatial dimension: the vertical. A depth-resolved simulation is the minimum physical setting in the ocean to resolve the different temperature and nutrient niches and the decisive effect of the vertical mixing on the variances and the covariance. The model is divided into 20 vertical levels from the surface to 200 m deep, with a uniform vertical step of 10 m.
Two processes can transport matter from one vertical level to another and thus need to be added to the differential equations of the 0D model presented in Sect. 2.1 and 2.2. First, PON sinks at a speed of w=1.2 m d−1. Sinking is represented by an extra term in the PON equation (Eq. 4) equal to , where z is depth and is always positive. The vertical derivative is solved by a first-order upwind scheme. Second, tracers are vertically mixed by turbulent diffusion. Vertical turbulent diffusion (called vertical diffusion from now on, which is unrelated to trait diffusion) tends to homogenize the spatial distribution of each tracer. It is controlled by the vertical diffusivity parameter κz, expressed in square metres per day (m2 d−1). The vertical diffusion of a conserved tracer A is . This expression applies to all concentrations of the discrete model and to concentrations N, P, Z, and D of the continuous trait model. As a consequence, their full local (Eulerian) time derivatives at a given depth z are as follows.
In contrast, the vertical turbulent diffusions of the statistical moments , , Vx, Vy, and Cxy do not follow a simple analytical expression because they are not material quantities and thus are not conserved during mixing. For instance, the mixing of two phytoplankton communities with different mean traits creates additional trait variance. Fortunately, vertical mixing conserves the sums of phytoplankton trait values and the sum of squared trait values . Following the method of Bruggeman (2009), we therefore use these conserved moments as tracers involved in physical transport. Their full Eulerian derivatives are computed as follows using the product rule.
The above Eulerian derivatives are the derivatives used in SPEAD to proceed from one time step to the next. Then, at each time step, we recover the necessary statistical moments by back-computing them.
The derivatives with respect to z used in the vertical diffusion terms are estimated by an implicit scheme in order to avoid numerical instability. The depth-resolved model is solved in time with a fourth-order Runge–Kutta numerical scheme.
Three environmental forcings are necessary to run the model: temperature, PAR, and vertical diffusivity. All three depend on depth and time and have been set to values from the Sargasso Sea. The forcings are seasonal. Inter-annual variations and the day–night cycle are neglected. Temperature and surface PAR (I0(t)) directly affect the rates of plankton growth and death. They are set for each day using observations collected during the Bermuda Atlantic Time-series Study (BATS) (Steinberg et al., 2001). PAR availability is assumed to decrease exponentially with depth , with a PAR vertical attenuation coefficient (kw) of 0.04 m−1. Self-shading by phytoplankton is neglected. The vertical diffusivity κz is the third forcing. Contrary to temperature and PAR, it has not been directly observed. Therefore, the turbulent diffusivity comes from the physical model GOTM for the Sargasso Sea (Bruggeman and Bolding, 2014). All three forcings as functions of time and depth are shown in Fig. 3.
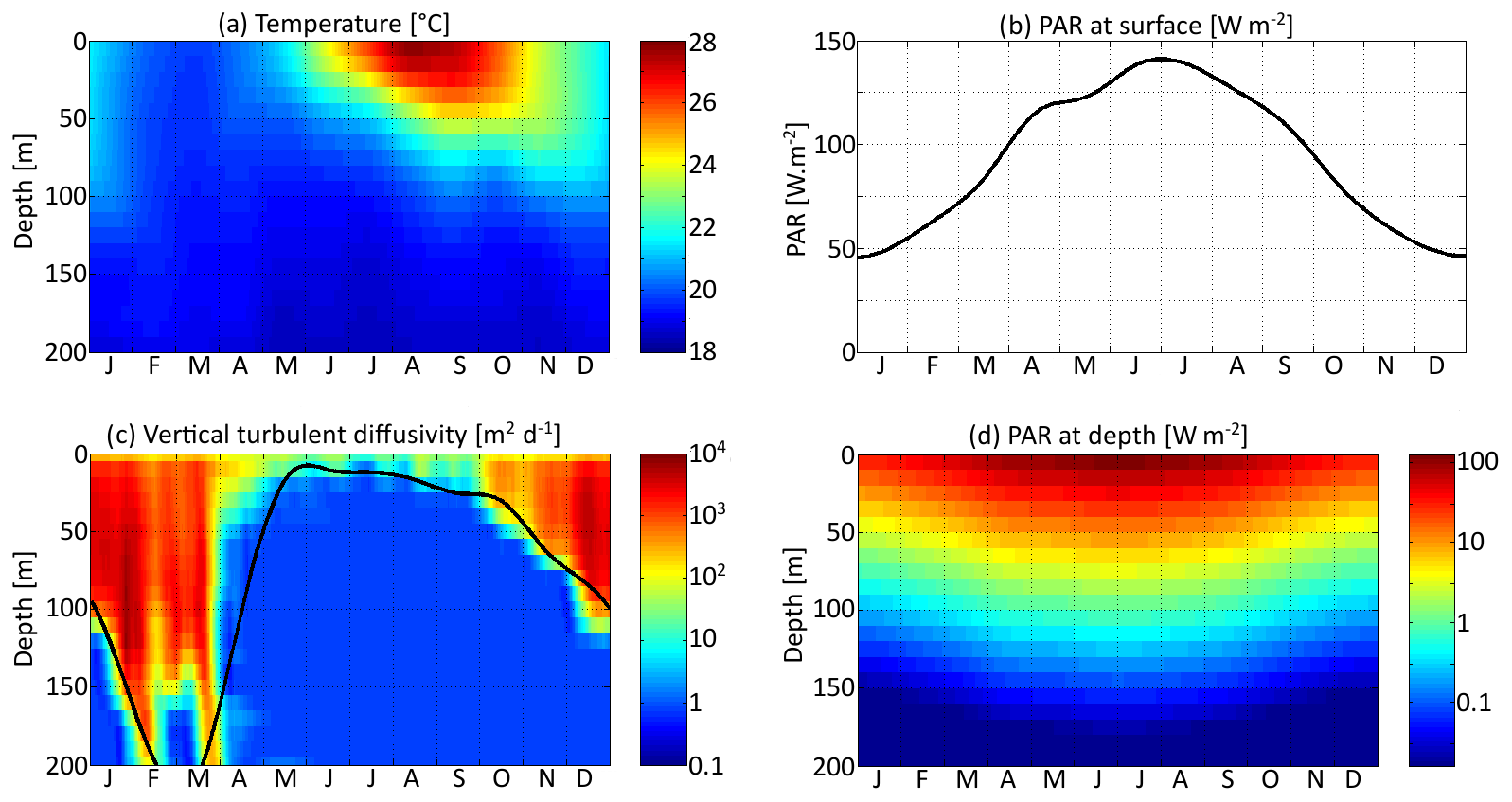
Figure 3Distribution in depth and time of three environmental variables: (a) temperature, (b, d) photosynthetically active radiation (PAR), and (c) vertical turbulent diffusivity. The black curve in (d) represents the lower limit of the mixed layer.
2.4 List of simulations
The simulation of the aggregate two-trait model with mutation rates νx=0.001 and νy=0.01 ∘C2 is our standard simulation for this study. νx is expressed without a unit because the trait axis x is in logarithmic scale, but like νy it is a variance increase per generation. Most of the results presented in Figs. 4, 5, 6, 7, and 9 come from this standard simulation. The bulk properties of SPEAD 1.0 (total primary production, total phytoplankton biomass, nutrient and detritus concentrations) are validated using observations from the BATS station in the Sargasso Sea (Steinberg et al., 2001; Vallina et al., 2008; Vallina, 2008). The multi-phenotype discrete version of SPEAD is used to validate (i) the assumption made in the aggregate continuous model that traits are normally distributed and (ii) the simulated values and tendencies of the moments of the continuous trait distribution. In order to better understand the behaviour of the model, the standard simulation is also compared to simulations with different mutation rates and to simulations with adaptive dynamics for only one trait, keeping the other trait unable to mutate but at its optimal value.
Trait diffusion is a relatively recent concept, and the values of the mutation rates are not yet well calibrated by observations. To obtain a qualitative idea of the ecosystem model behaviour, we tried a wide range of values for νx (from 0.00001 to 0.1). The largest value was chosen for its similarity to the trait diffusivity parameter used by Merico et al. (2014) and Chen and Smith (2018) to account for the observed trait variance. However, νx=0.1 allows the phytoplankton to reach a variance of Vx=4 in only 20 generations, since 2νx is added to the phytoplankton population variance at each generation. This variance is the maximum allowed in the discrete model and corresponds to having half the community at each extreme of the trait axis ( and ). However, laboratory experiments based on single clones show significant evolution only on timescales of hundreds to thousands of generations (Schlüter et al., 2016). For this reason we also conducted simulations with mutation rates as low as 0.00001 and a control simulation without trait diffusion at all (νx=0). As the mutation rate has the dimension of trait squared and as the range of temperature is around 3 times larger than the range of nutrient concentration logarithms, we fixed the same ratio of mutation rates, ∘C2, for all simulations. We checked that departing from this ratio did not qualitatively affect our results. In total, we conducted simulations for 10 sets of mutation rates, including the control case.
A two-trait model is not simply the superposition of two one-trait models for at least two reasons. First, when two environmental factors limit biomass growth but only one is included in the model, the simulation is likely to overestimate the phytoplankton growth rate. Second, when there is a strong inter-trait correlation, each environmental factor impacts both traits. For instance, if the ambient DIN concentration (N) is below the (geometric) mean half-saturation constant (), the competition for nutrients will select for phenotypes with a lower half-saturation constant. If at the same time the half-saturation is negatively correlated with optimal temperature (i.e. if phenotypes with low half-saturation constants also tend to have high optimal temperatures), the competition for nutrients will also increase the concentrations of phenotypes with high optimal temperatures, in addition to the effect of environment temperature. In the conceptual model of Savage et al. (2007), the inter-trait correlation in a two-trait model led to higher variances and to a considerable improvement in the ability of the mean phytoplankton traits to track optimal values controlled by environmental conditions compared with one-trait models. In order to know whether these results also apply to our model, we compare the dynamics of traits x and y in SPEAD to the dynamics of simplified one-trait models wherein either x or y varies between phenotypes and the other trait is optimized instantaneously (i.e. set to the optimal value at each location and time given the environmental conditions).
The time step for our simulations is 6 h. At the first time step and at all vertical levels, the DIN concentration is initialized to 1.8 mmol N m−3, phytoplankton and zooplankton concentrations to 0.1 mmol N m−3, and the PON concentration to 0.0 mmol N m−3. The total amount of nitrogen in the water column is conserved, and every loss below 200 m due to PON sinking is compensated for by an equivalent gain of DIN, also at 200 m. Mean logarithm of half-saturation and mean optimal temperature are initialized at −0.5 (corresponding to Kn=0.61 mmol N m−3) and 24 ∘C, respectively, with initial standard deviations of 0.1 and 0.3 ∘C. Each simulation is run for at least 3 years and until convergence is reached. Our convergence criterion is that, for every day of year and every depth level, the difference between the last 2 years should be less than 0.1 % for P, Vx, and Vy, less than 0.1 % of the modelled range for and , and less than 0.001 for Rxy. In other words, convergence is achieved when the seasonal cycle of the model state variables is repeated from year to year. The results shown are in all cases from the last simulated year. We checked that total nitrogen was the only feature in the initial conditions that affected the results.
3.1 Bulk modelled properties and comparison with observations
The first step to validate the SPEAD model is to compare some bulk properties with observations from the Sargasso Sea in order to assess the realism of the trait-independent biogeochemical parameters (Table 2). In Fig. 4, the primary production, chlorophyll, and DIN and PON concentrations of the aggregate model are compared to a 10-year climatology of monthly observations of primary production, chlorophyll, nitrate, and PON concentrations (Vallina et al., 2008). The distribution pattern of bulk properties in SPEAD does not depend much on the mutation rates and is very similar to those of 0-trait simulations without trait diversity (see the Supplement). Differences between these simulations are small compared with the differences between the model and observations. With carefully chosen values for the parameters of the ecosystem model, the model and observations agree well, although some minor discrepancies exist due to the simplicity of our parameterizations.
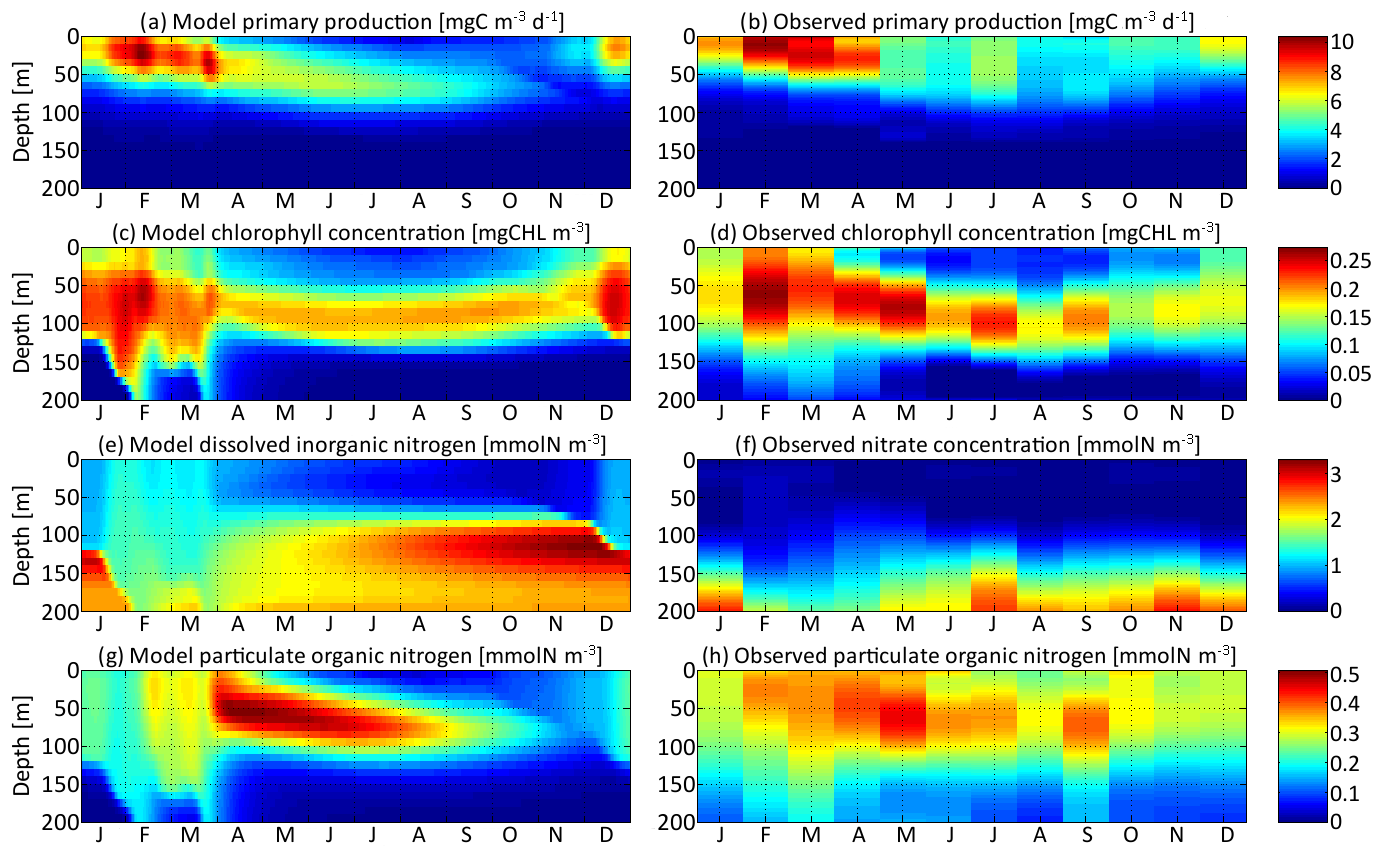
Figure 4Distribution in depth and time of (a) model primary production, (c) chlorophyll concentration, (e) dissolved inorganic nitrogen concentration, and (g) particulate organic nitrogen concentration for νx=0.001 and νy=0.01 ∘C2. Each variable is compared with equivalent observations in the Sargasso Sea (b, d, f, h).
Primary production is the state variable best reproduced by the model, with a maximum around 10 mg C m−3 d−1 in the first 50 m in February and March in both the model and the observations. From May to September, primary production spreads slightly more in depth but is overall around half its maximum value. Primary production is negligible deeper than 80 m. The chlorophyll concentration is reproduced with the right order of magnitude, an absolute maximum correctly located in February between 50 and 80 m deep at about 0.25 mg Chl m−3, and a deep chlorophyll maximum around 100 m in summer. However, the model chlorophyll concentration is lower than the observations in spring and higher in late autumn. The chlorophyll concentration begins to increase in December in the model but only in February in the observations. Both the chlorophyll concentration and primary production are proportional to the phytoplankton concentration. The reason for the temporal mismatch between SPEAD and the observations for the chlorophyll concentration, but not in primary production, must then be related to the temporal variability of the other factors affecting these two quantities: the nitrogen uptake rate and the C : Chl ratio. The relatively high primary production and very low chlorophyll concentration observed in December might be better accounted for if the uptake rate were faster in December than in February, despite the lower availability of nutrients and light, or if turbulence were included in the estimation of the C : Chl ratio so that it reaches its lowest value in February, when the waters are best mixed and phytoplankton cannot stay close to the surface (Taylor et al., 1997), rather than in December, when the surface light intensity is minimal (Lefèvre et al., 2002; Jakobsen and Markager, 2016).
Dissolved inorganic nitrogen is compared to the observed nitrate concentration, knowing that this form of DIN dominates at depth but co-occurs with nitrite and ammonium, which are also components of DIN. The modelled DIN and the observed nitrate concentrations share the same range, with a maximum of 2.8 mmol m−3 in the observations and 3.3 mmol m−3 in the model. Another common point between the model and the observations is that both reach a maximum at the bottom of our setting at 200 m, with concentrations between 2.1 and 2.8 mmol m−3 during most of the year. Because of the strong vertical mixing, from February to April, the concentrations are lower, between 1.5 and 2.0 mmol m−3, but still maximal. However, from June to January, the modelled DIN concentration exhibits a second maximum that is absent from the observations. This second maximum is located just below the euphotic layer between 100 m and 150 m deep, with values as high as 3.3 mmol m−3 in late November. Both modelled and observed concentrations are minimal at the surface due to the nitrogen uptake by phytoplankton. However, their values diverge by more than 1 order of magnitude. Modelled DIN concentrations at the surface vary between 0.18 and 1.34 mmol m−3, with a mean of 0.67 mmol m−3, whereas observed nitrate concentrations vary between 0 and 0.11 mmol m−3, with a mean of 0.03 mmol m−3. We assume that these discrepancies are due to the contribution of ammonium and possibly nitrite, since the few studies reporting measured concentrations of ammonium in the Sargasso Sea (Menzel and Spaeth, 1962; Brzezinski, 1988) have shown that ammonium was more homogeneously distributed in the upper 200 m than nitrate and was the dominant form of dissolved nitrogen from the surface to 100 m deep.
Particulate organic nitrogen distributions from the model and observations are relatively similar, with a maximum around 0.5 mmol m−3 (0.45 mmol m−3 in the observations, 0.51 mmol m−3 in the model) in April and May at depths between 30 m and 80 m. However, the seasonality and vertical gradients are much larger in the model, wherein particles are very rare in autumn and nearly absent at depths greater than 100 m, whereas observed PON concentrations are never below 0.08 mmol m−3. The observations might be better explained if a minority of particle production went to a slowly remineralizing refractory pool, enabling them to stay during the whole year and to reach greater depths (Aumont et al., 2017), but we did not increase the complexity of the particle parameterization because this is not the focus of our study.
3.2 Trait distribution of SPEAD and comparison with a multi-phenotype model
The second step to validate the aggregate SPEAD model and the only validation of its bivariate trait distribution is comparing it to the multi-phenotype model. Although both are models and thus simplify reality in similar ways, the multi-phenotype model is used as a reference for two reasons. First, it is more intuitive than the aggregate model, with birth and death processes and mutations to the nearest neighbours as the only terms in the equations. Therefore, the moments of the trait distribution in the multi-phenotype model can be used as a control to confirm that the equations of the aggregate model are correct. Second, the multi-phenotype model does not assume any particular trait distribution shape and can be used to validate the a priori assumption of the aggregate model that the trait distribution is a bivariate normal distribution.
The spatial and temporal patterns of the phytoplankton concentration, mean traits, trait standard deviations, and inter-trait correlation for the standard simulation with mutations rates of νx=0.001 and νy=0.01 ∘C2 are shown in Fig. 5. The value of varies between −0.83 (Kn=0.44 mmol N m−3) and +0.6 (Kn=1.82 mmol N m−3), with standard deviations between 0.31 and 0.77. The value of varies between 22.0 and 26.1 ∘C, with standard deviations between 0.81 and 1.92 ∘C. By comparison, the modelled DIN concentration varies between 0.18 and 3.31 mmol N m−3, and the water temperature varies between 18.5 and 27.8 ∘C. As expected, the mean trait values remain consistently within the range of the environmental drivers to which they adapt. Because the best competitor at a given time and depth needs tens of generations to become dominant after having been a rare phenotype, the mean traits react with a delay of 1 to 2 months and with a lower amplitude than their drivers. Cold-water opportunists (high x trait, low y trait) dominate in winter and spring throughout the water column. In summer, they are slowly replaced by warm-water gleaners (low x trait, high y trait) in the upper 70 m but retain dominance at greater depths at which their half-saturation constants continue increasing and their optimal temperatures continue decreasing. The coexistence of two very distinct communities in summer and early autumn is made possible by the intense stratification, which creates a physical barrier between the different depth levels. In late autumn, the two communities are rapidly mixed by vertical turbulent diffusion, producing a peak in the standard deviation of each trait: in other words, a peak in the local (alpha) diversity. Then, as the water column becomes more homogeneous, competition selects for a single dominant phenotype, reducing the trait diversity until the next autumn. Inter-trait correlation is negative at all times and depths due to the negative correlation of the environmental drivers. High DIN concentrations generally coincide with low temperatures, favouring cold-water opportunists. This happens during winter because turbulent mixing brings nutrient-rich cold waters from the deep layers up to the surface. During summer, the consumption of nutrients by primary producers leads to a coincidence of warm temperatures with low DIN concentrations at the surface. In late autumn, the negative correlation reaches its maximum absolute value when the two main communities are suddenly mixed. During the rest of the year, trait diffusion progressively reduces the inter-trait correlation.
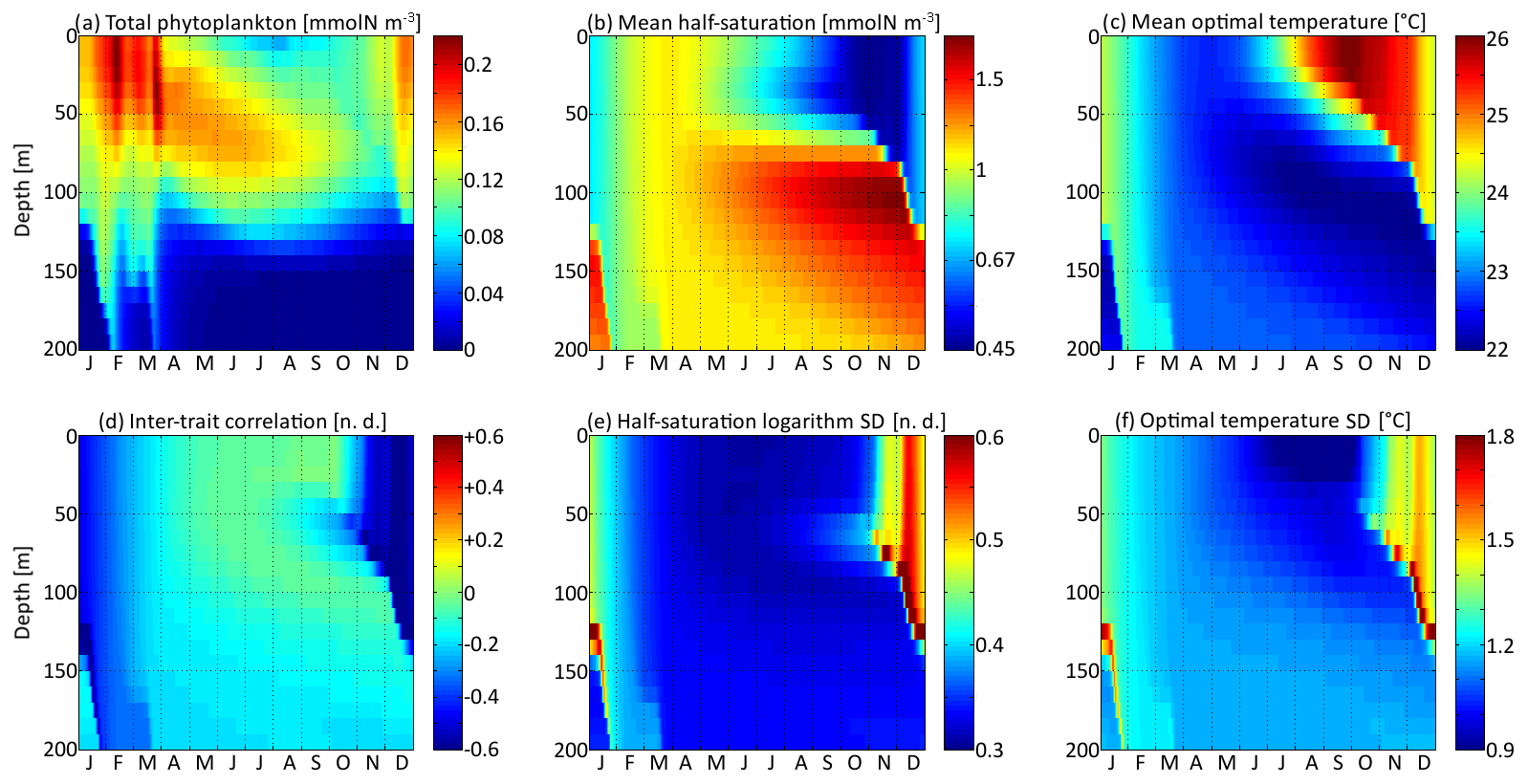
Figure 5Distribution in depth and time of trait distribution moments for νx=0.001 and νy=0.01 ∘C2: (a) phytoplankton concentration, (b) (geometric) mean half-saturation, (c) optimal temperature, (d) inter-trait correlation, (e) half-saturation logarithm standard deviation, and (f) optimal temperature standard deviation. For readability, the mean value of trait x is transformed into a nitrogen concentration in (b). To speak properly and in contrast to other means present in this study, the mean half-saturation is a geometric mean, not an arithmetic mean.
In Fig. 6, the state variables of the aggregate model are compared to the trait distribution moments of the discrete model. The discrete model is considered as a “truth” and the difference between the two models as an “error”, which is positive if the value is higher in the aggregate model. The aggregate model reproduces P and very precisely, with linear determination coefficients (R2) of 0.998 and 0.988, respectively. The biases (mean errors) are very low: +0.0005 mmol N m−3 on P and −0.04 on . The bias of is larger at −0.50 ∘C, but the coefficient of determination is still very high at R2=0.862. The error is largest in the deep community in summer and early autumn, reaching a maximum of −1.51 ∘C in early September around 100 m. The most likely reason why the aggregate model underestimates , but not , is that the response of phytoplankton to temperature is asymmetrical. Increases in the environment temperature put more selective pressure on the phytoplankton community than decreases. This feature is poorly taken into account by the aggregate SPEAD model because of its assumption that traits are normally distributed. There is a mismatch between the asymmetrical shape of temperature niches and the imposed symmetrical shape of the distribution of optimal temperatures (y trait) in the aggregate model. This mismatch does not happen for the x trait. As is typically the case in aggregate models, there are more errors in the higher-order moments, in our case the standard deviations and the inter-trait correlation. The coefficients of determination for σx, σy, and Rxy are R2=0.813, R2=0.462, and R2=0.896, respectively. Their biases are −0.04, +0.09 ∘C, and −0.001, respectively, which is around 10 % of the mean value for σy and σx and negligible for Rxy. All three variables decrease much faster in early winter in the aggregate model than in the multi-phenotype model. Additionally, in summer, there is a strong discrepancy for σy. In the discrete model, σy can reach as low as 0.57 ∘C, but in the aggregate model it is never less than 0.81 ∘C and very rarely less than 1.0 ∘C.
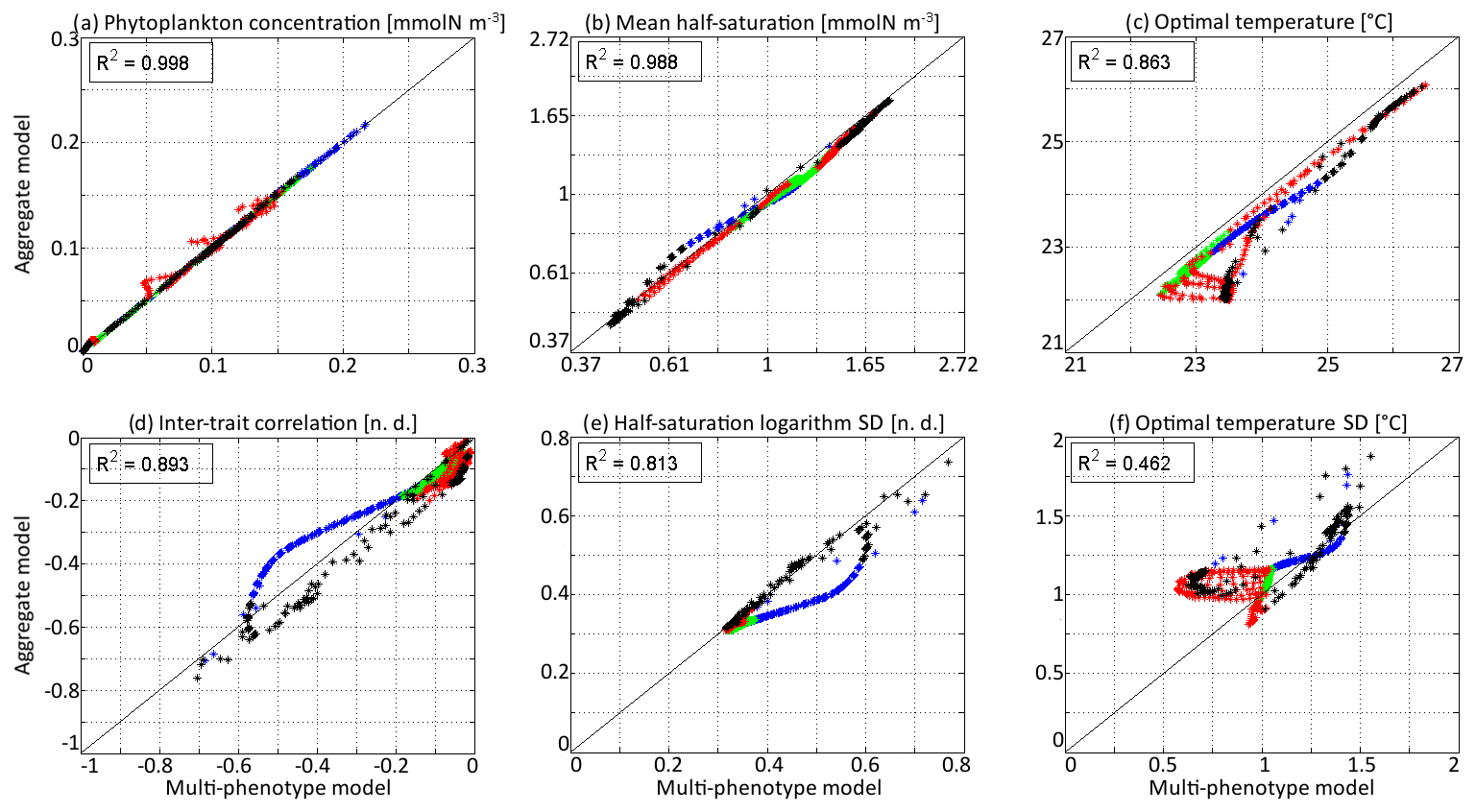
Figure 6Comparison at all depths and times of the aggregate and multi-phenotype model state variables for νx=0.001 and νy=0.01 ∘C2: (a) total phytoplankton concentration, (b) (geometric) mean half-saturation, (c) mean optimal temperature, (d) inter-trait correlation, (e) half-saturation logarithm standard deviation, and (f) optimal temperature standard deviation. Blue is winter, green is spring, red is summer, and black is autumn.
The main errors on σx, σy, and Rxy are caused by the aggregate model's assumption of a multivariate normal distribution, which is not strictly correct based on the results of the discretely resolved model. In Fig. 7, we show in a 2D colour plot how the two traits are distributed in the discrete model at three different depths (surface, 50 m, and 100 m) at the end of each season (March, June, September, December). This distribution is compared with the bivariate normal distribution of the aggregate model, represented by ellipses. In March, when the waters are well mixed, and in June, when the stratification has just begun, the traits are normally distributed and the two models agree. There is only a small error on the distribution of optimal temperature. In March at all depths and in June at 100 m, the normal distribution of the aggregate model contains more phenotypes with low optimal temperatures than the distribution of the discrete model. In summer, the traits are also normally distributed near the surface. However, the distribution of optimal temperature is markedly right-skewed deeper in the water column. Optimal temperatures below that of the most common phenotypes are extremely rare, whereas those larger than this level are more common. The aggregate model has its below the peak of the multi-phenotype model and has a much larger σy. This is the largest error for both a mean trait value and a trait standard deviation in this study. Since nothing similar occurs with half-saturation, this error must be linked to the right skew in the temperature-dependent growth factor when expressed as a function of optimal temperature (Fig. 2d). In stable environments with little change in temperature with time and little vertical mixing, the distribution of optimal temperature tends to become naturally right-skewed. However, our results show that re-mixing (in late autumn), fast environmental change (near the surface), and trait diffusion can reduce or eliminate this skew so that the trait distribution is often close to normality. In December during the re-mixing phase, the trait distribution completely deviates from normality and becomes bimodal, with a community of warm-water gleaners and a community of cold-water opportunists co-occurring throughout the water column. At this time the standard deviations and the inter-trait correlation are at their annual maxima. The moments of the trait distribution at that time are very well captured by the aggregate model. However, assuming a normal trait distribution is not only wrong in terms of ecological description but also leads to incorrect dynamics during winter. In winter, the ecological selection in the now mixed waters reduces trait diversity, and trait diffusion reduces the inter-trait correlation. These processes occur faster in the aggregate model than in the multi-phenotype model (see Fig. 6) because the selective pressure is larger for a normal distribution than for a bimodal one. From a mathematical point of view, this can be shown in a simplified one-trait model. Selection through competition reduces the trait variance at a speed equal to (this is a one-trait unskewed version of Eq. B7), where M4 is the fourth-order moment or “kurtosis”. In a Gaussian distribution, . Bimodal distributions have a lower kurtosis; therefore, they are affected more slowly by ecological selection. By design, the aggregate model cannot account for this effect because it assumes a unimodal Gaussian distribution. From a more ecological point of view, it can be noted that in order to replace a bimodal distribution by a unimodal one with a smaller variance, a previously rare intermediate phenotype must rise to prominence and previously dominant phenotypes must become rare, which is a dramatic change. By comparison, in an already unimodal Gaussian distribution, reducing the variance only means making rare and extreme phenotypes even rarer.
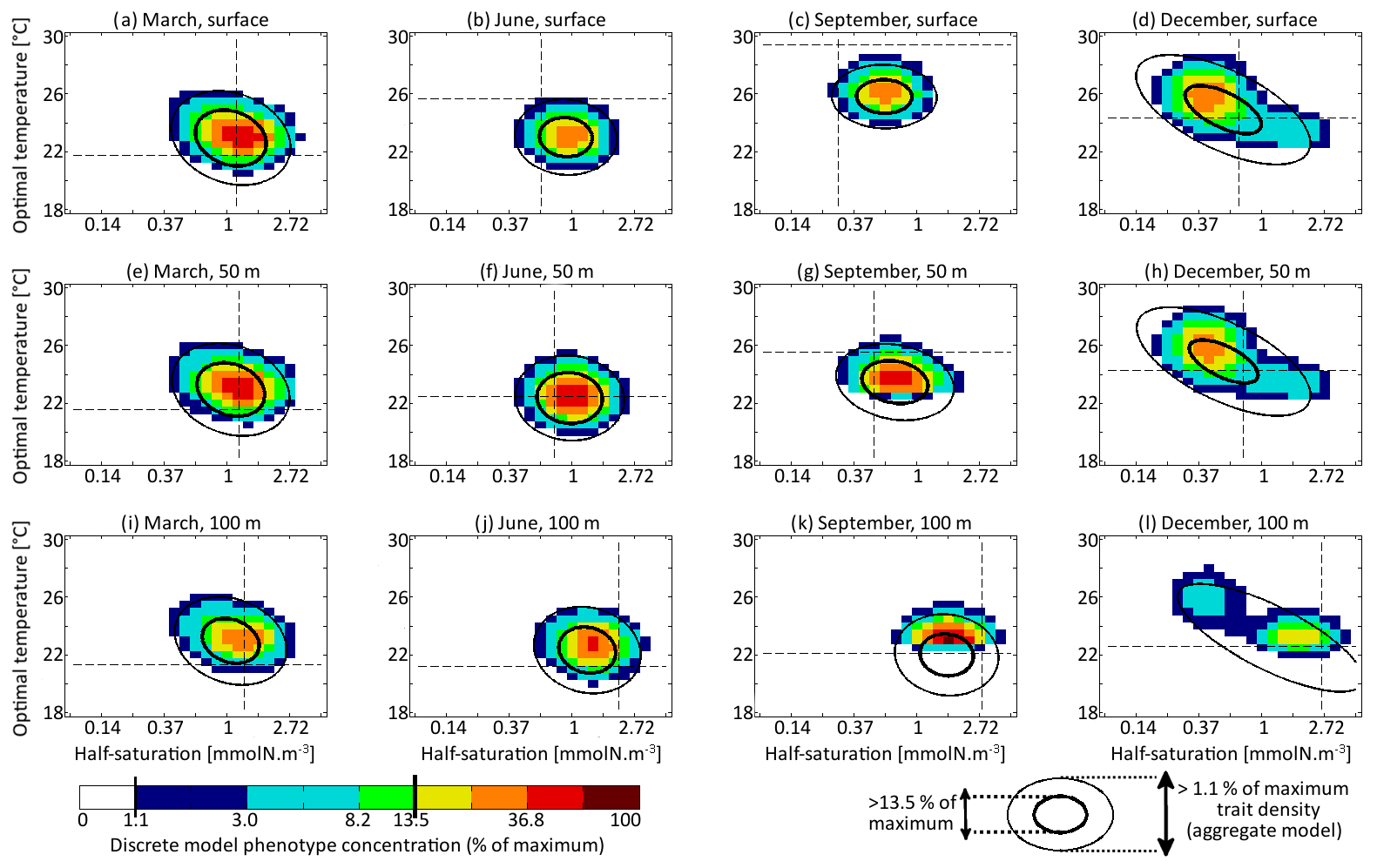
Figure 7Concentrations of each phenotype of the multi-phenotype model (colour) compared with lines of equal density of the aggregate model (νx=0.001 and νy=0.01 ∘C2). Subplots correspond to days 71, 161, 251, and 341 and depths of 0, 50, and 100 m. Dashed lines indicate the optimal competitor.
3.3 Trait dynamics with different mutation rates
In this section, we compare the results of simulations conducted with nine different sets of mutation rates, from νx=0.00001 and νy=0.0001 ∘C2 to νx=0.1 and νy=1.0 ∘C2. A control simulation with no trait diffusion is also included. That amounts to a total of 10 simulations. This comparison highlights the unique role played by trait diffusion in SPEAD, even at very low mutation rates. The ratio of mutation rates, 10 ∘C2, is the same in all simulations presented in this study. We do not assume that this ratio always has this value in nature. Simulations with other values were also performed, and the ratio was found to have little effect on the results. The mean value and variance of each trait are very similar in all simulations in which they have the same mutation rate, whereas primary production and correlation are impacted in similar proportions by both mutation rates. Therefore, the variability in was overlooked for simplicity.
For each simulation, Fig. 8 shows the values of depth-integrated primary production per year and the yearly averaged values and ranges of , , σx, σy, and Rxy. Additional diagnostics are presented in Table 3. The number of years to converge to a steady state, beyond being just a numerical issue, can also serve as an ecological indicator of the time needed to damp a perturbation or to adapt to a new physical setting, although, by design, our convergence times cannot be less than 3 years. For either trait, the maximum value of is the number of generations required to reach the highest trait variances of the simulation in the absence of ecological selection and with trait diffusion as the only source of variance. Although highly idealized, this number is a proxy for the timescale of evolutionary processes. Table 3 also assesses whether bimodality is present in the discrete model and whether the mean traits come within 1 standard deviation of the discrete model boundaries at some point in the year. Bimodality was assessed visually based on the trait distributions of the discrete model during the December mixing event.
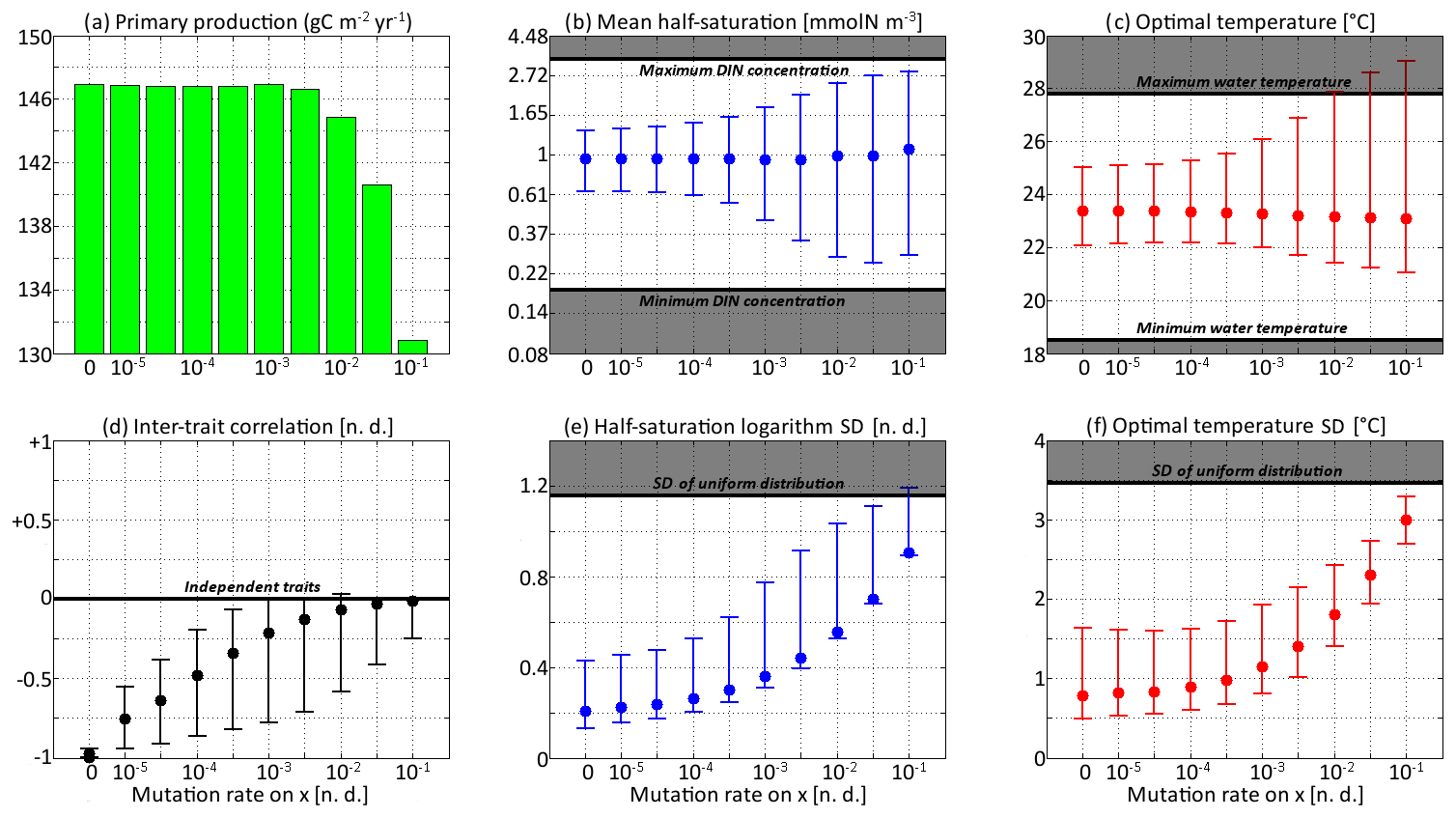
Figure 8Primary production and trait distribution moments for different mutation rates. The ratio is kept constant and equal to 10 ∘C2. Moment ranges are represented by error bars and their mean by dots. The mean traits are compared to the extreme values of their environmental drivers (dissolved inorganic nitrogen concentration and temperature). The trait standard deviations are compared to their values in a uniform distribution within the boundaries of the discrete model.
Table 3Convergence time and various properties of SPEAD 1.0 simulations with different mutation rates.
Primary production lies between 146.8 and 147.0 g C m−2 yr−1 for all mutation rates between νx=0 (control) and νx=0.001, then decreases at higher trait diffusivities to finally reach 130.8 g C m−2 yr−1 for νx=0.1. This result agrees with the model of Chen et al. (2019) as applied to the North Pacific. Their phytoplankton community was characterized by one trait, cell size, which is somehow related to our half-saturation trait x. They found that primary production was diminished when νx increased, but they only considered relatively high mutation rates between 0.01 and 0.1, as well as a control simulation. Under relatively stable conditions, we find that fast mutation rates (νx>0.01) are a drawback for primary production because they promote large trait variances, allowing non-competitive phenotypes (i.e. under-performers) to proliferate. However, phytoplankton mutating very fast could be invaded by phenotypes mutating more slowly. Therefore, we do not expect them to be common in nature.
In the simulations with νx=0.01, νx=0.03, and νx=0.1, the mean trait values remain close to their environmental drivers, and their range over the year is as wide as that of the DIN concentration and temperature, respectively. On average, the community adapts nearly instantaneously to its environment. However, the cost for this apparent success in fast-tracking the environmental conditions is that the standard deviations of the trait distribution are very high and close to that of a uniform distribution between the trait boundaries of the discrete model. Given that the trait domain of the discrete model is already wider than the ranges of DIN concentration and in situ temperature, this result suggests that either (1) phenotypes that are maladapted at all depths and throughout the year are common (explaining the low primary production) or (2) that we have reached the limit of validity of the aggregate approach. In these simulations, skewed or bimodal distributions are extremely rare and smoothed out in a few days, and correlations are negligible, even in December when the stratification is broken, because trait diffusion is a symmetrical process that constantly replenishes all rare phenotypes, including warm-water opportunists and cold-water gleaners that are maladapted at all depths and during the entire year. The simulations with large mutation rates converge in 3 or 4 years and can sustain their variances in fewer than 60 generations, which is in less than a year. They use mutations to follow the seasonal cycle of their environment faster than the usual timescales of evolution, even for phytoplankton (Schlüter et al., 2016).
When the mutation rates are lower, the mean traits still vary during the year but not as much or as fast as the physical environment, and no phenotypes are found outside the trait domain of the discrete model. With νx at 0.001 or lower, several years are required to sustain the variance and to converge to a seasonally stable state. In this case, the mutations create variance over the long term, facilitating the ecological successions of phenotypes seasonally and adaptive evolution inter-annually. However, low mutation rates do not allow the community to evolve seasonally. Bimodality is present in the discrete version, at least during the late autumn mixing, and lasts longer as the mutation rates decrease. The variances increase when the trait diffusivity parameters increase, which is what trait diffusion was designed for. We note that, contrary to chemostat models (Merico et al., 2009), SPEAD 1.0 does not require trait diffusion to sustain a positive trait diversity: the trait variances do not collapse to zero even in the absence of trait diffusion. The late autumn mixing is a source of variance in its own right, avoiding the collapse of trait diversity even in the control simulation. However, the trait standard deviations in the control case are very low, between 0.13 and 0.43 for x and between 0.49 and 1.64 ∘C for y. Trait diversity appears even lower when accounting for the fact that correlation between x and y is blocked at −1. The x and the y traits totally determine each other, as if there were only one trait and no extra degree of freedom. The only active phenotypes are located on a straight line. Trait diffusion is not necessary to sustain variance, but it is necessary to allow the model to explore the entire trait space and to adapt to entirely new sets of environmental conditions.
Increasing trait diffusivity to νx=0.00001, νx=0.00003, or νx=0.0001 does not produce a large increase in trait variance, which keeps being extremely low and mainly controlled by the December mixing, but it reduces the inter-trait correlation to moderate values, mainly between −0.75 and −0.5. Simulations with the above mutation rates also share high primary production and timescales of a few years (approximately hundreds to thousands of generations) to adapt to their environments, which are features coherent with our expectations of the effect of inter-generational mutations.
3.4 Trait dynamics compared with one-trait models
In Figs. 9 and 10, the trait distribution moments of SPEAD at the surface are compared with the environmental drivers (DIN concentration and water temperature) and with the outputs of two single-trait aggregate models, wherein only the half-saturation constant or only optimal temperature is allowed to vary between phenotypes, subject to trait diffusion. Figure 9 shows the comparison for the standard values of the mutation rates: νx=0.001 and νy=0.01 ∘C2. However, the differences between two-trait and one-trait models are likely to be larger when correlations between x and y are large. Therefore, in Fig. 10, we compare the two-trait and one-trait model distributions obtained with the lowest non-zero mutation rates of νx=0.00001 and νy=0.0001 ∘C2, which lead to inter-trait correlations between −0.8 and −1 in the two-trait model.
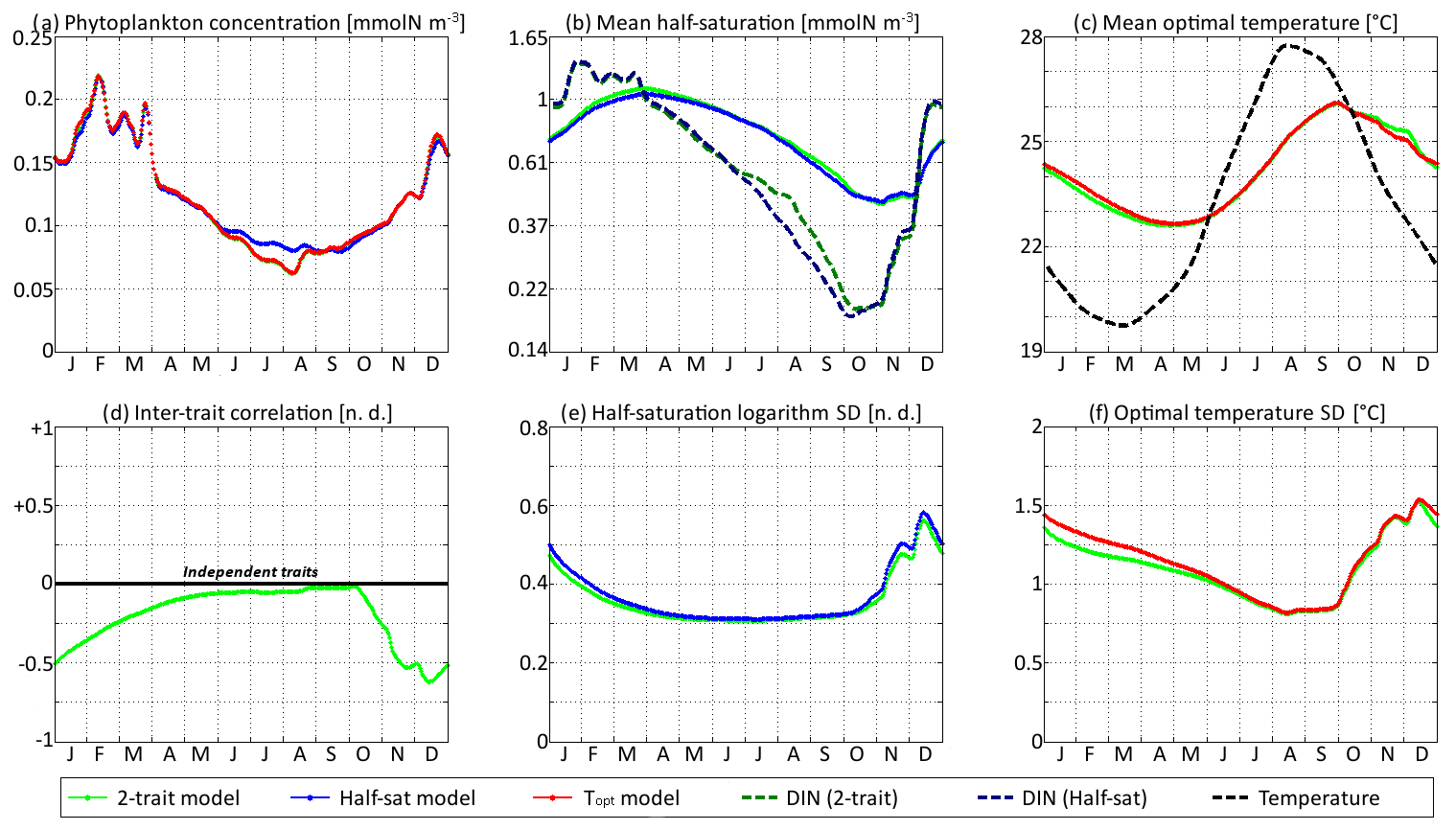
Figure 9SPEAD state variables at the surface for νx = 0.001 and νy=0.01 ∘C2 (standard) compared with the state variables of one-trait models: (a) total phytoplankton concentration, (b) (geometric) mean half-saturation, (c) mean optimal temperature, (d) inter-trait correlation, (e) half-saturation logarithm standard deviation, and (f) optimal temperature standard deviation. The dashed lines represent the environmental drivers.
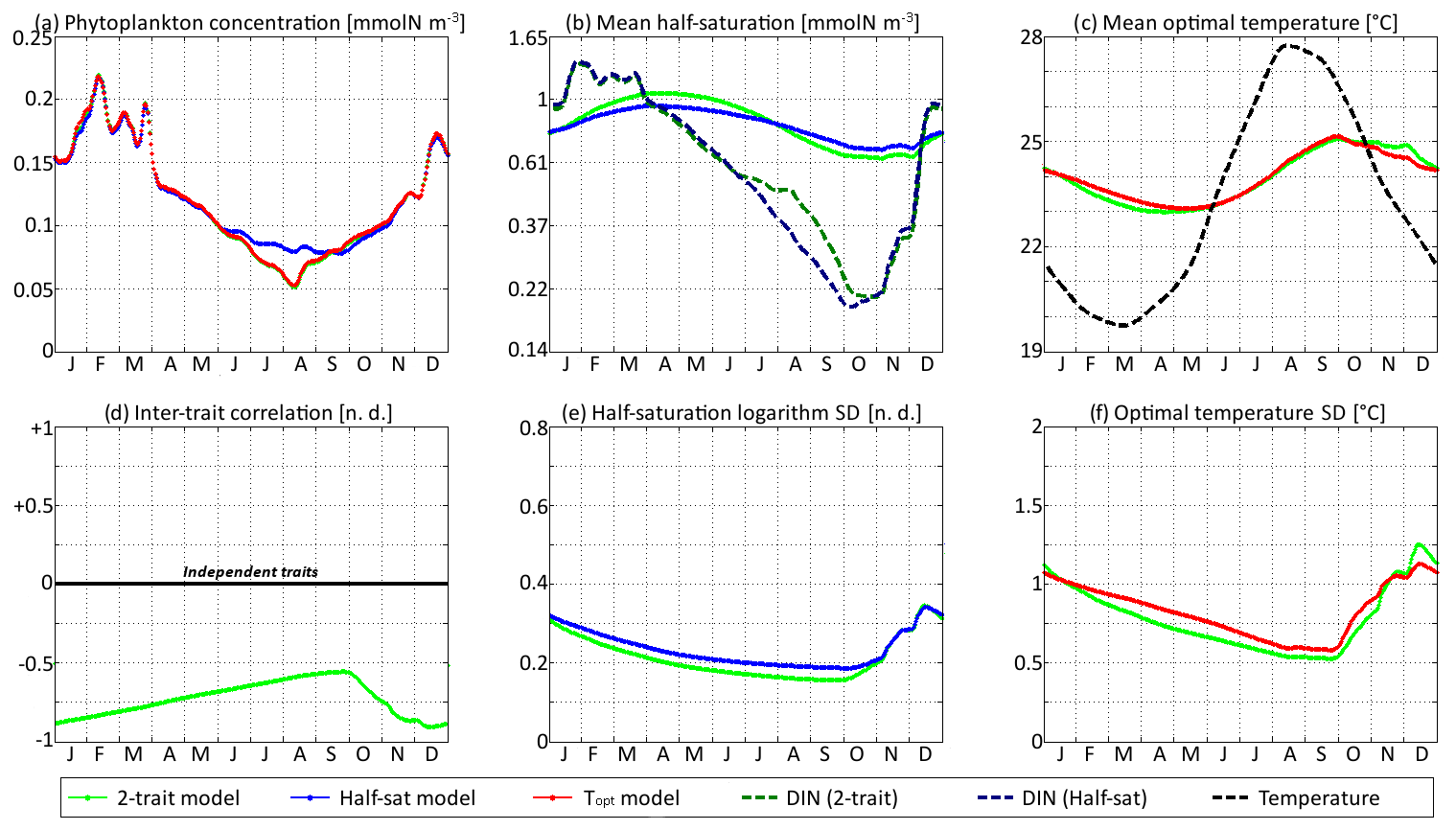
Figure 10SPEAD state variables at the surface for νx=0.00001 and νy=0.0001 ∘C2 (low mutation rates) compared with the state variables of one-trait models: (a) total phytoplankton concentration, (b) (geometric) mean half-saturation, (c) mean optimal temperature, (d) inter-trait correlation, (e) half-saturation logarithm standard deviation, and (f) optimal temperature standard deviation. The dashed lines represent the environmental drivers.
With standard mutation rates, the trait dynamics are very similar in all three models. The two-trait model has slightly lower standard deviations than the one-trait models during some parts of the year, but the difference is always within 10 %. The seasonal patterns are very similar in both timing and amplitude. The greatest differences are found in summer from mid-June to mid-August, when the one-trait model with adaptive dynamics for half-saturation has a greater phytoplankton concentration by as much as 29 % and a lower nutrient concentration by as much as 24 % compared to the other two models, with concentrations that are very similar to each other. This result means that at the onset of summer, the most important factor decreasing the ability of phytoplankton to grow is not the lack of nutrients, but temperature itself. In other words, the phenotypes that dominated in spring decline, not because they are not adapted to oligotrophic conditions, but because they are not adapted to the high temperatures of summer and the growth rate of a phenotype declines sharply when temperature exceeds its optimal value. This effect is negligible at the highest mutation rates because in this case the community is able to evolve and adapt very quickly to the summer warming, but ti becomes more important as the mutation rates and hence the optimal temperature variances decrease.
The differences between models are larger at low mutation rates. With the smallest non-zero mutation rates, the summer difference in phytoplankton biomass increases. The one-trait half-saturation model has a phytoplankton biomass as much as 57 % greater and a DIN concentration as much as 30 % smaller than in the other models. Trait variances are again lower in the two-trait model during most of the year but sometimes exceed the one-trait variances during the autumn mixing. However, the most notable change is that the seasonal amplitude of mean half-saturation () is 56 % higher in the two-trait model than in the one-trait half-saturation model. Having a second trait allows the ecosystem to adapt faster to environmental changes. This effect is even more notable when considering that both the half-saturation variance and the nutrient-mediated selective pressure are lower in the two-trait model. This effect does not extend to the other trait, although the mean optimal temperature of the two-trait model and that of the one-trait optimal temperature model sometimes show a slight departure from each other in a seasonally dependent way.
The effects described above are related to inter-trait correlation, which is driven by correlated environmental conditions and becomes very large in the case of low mutation rates. Equations (29) to (34) can help us understand the effect of trait correlation on the seasonality of mean traits and trait variances. In the mean trait equations (30 and 31), correlation implies that both temperature and the DIN concentration drive changes in both mean trait values. The covariance term can either accelerate or slow down the response of each mean trait, but generally the sign of covariance is such that the change is accelerated. This is what occurs from December to March, when the environment selects for higher half-saturation constants and lower optimal temperatures, and the environmentally induced negative correlation between traits further accelerates this adaptation. From June to October, the same effect occurs but is significant only for half-saturation. During these months, the two-trait model actually experiences a slower increase in optimal temperature than the one-trait model because it has a smaller variance and because the selective pressure of high temperatures is much sharper than the nutrient-mediated pressure conveyed by the correlative term. In November, correlation has the opposite effect: as the temperature decreases while the DIN concentration remains low, the environment at that time selects for both low optimal temperature and low half-saturation, and the negative correlation prevents the optimal temperature from decreasing.
The effect of correlation on variance is even more convoluted. In Eqs. (32) and (33), inter-trait correlation adds a second variance-reducing competition term ( and , respectively, both very likely to be negative). This is why variances are smaller in the two-trait model during most of the year. However, one source of variance is not accounted for in these equations: vertical mixing. Trait variance is not a conservative tracer. Indeed, mixing two communities with different mean trait values “creates” additional variance. As phytoplankton adapt better to their environment in the two-trait model than in the one-trait models, the difference between surface and subsurface communities when the water column is stratified is larger in the two-trait model, and therefore the late autumn mixing event adds more trait variance in the two-trait model. This is why the variances are higher in the two-trait model than in the one-trait models in December.
4.1 Strengths and weaknesses of aggregate models
SPEAD is an aggregate phytoplankton model. Aggregate models, used as far as we know since Wirtz and Eckhardt (1996), do not compute the abundance of each phytoplankton species as discrete entities, but represent the phytoplankton community by its total biomass together with the mean values, variances, and covariances of a few key traits controlling its competitive ability along different environmental gradients. Aggregate models are known to reduce the computational cost of ecosystem models by at least 1 order of magnitude. In a 0D physical setting (i.e. not spatially resolved), the single-trait aggregate model of Acevedo-Trejos et al. (2016) was found to be 18 times faster to run than its alternative discrete model with as few as 10 phenotypes. SPEAD 1.0 is 70 times faster in its aggregate version than in its alternative discrete version with phenotypes, despite the two model versions having to compute the same number of non-phytoplankton variables. The exact factor of cost reduction depends on the number of phenotypes used in the discrete model, and it is likely to be even larger if the number of traits increases. The computational cost of a multi-phenotype model with phenotypes covering the entire trait domain is an exponential function of the number of traits. For instance, allowing 25 values of optimal irradiance would multiply the cost of our discrete model by 25. By contrast, the cost of an aggregate model is a quadratic function of the number of traits. In our case, adding a third trait would simply increase the number of phytoplankton state variables from 6 to 10 (total phytoplankton concentration, three mean traits, three trait variances, three inter-trait covariances) and add a few new terms in each equation, which is far less computationally demanding. This makes aggregate models promising tools to explore high-dimensional trait spaces of the ecology and evolution of microbial ecotypes (Vallina et al., 2019). We note that some discrete models use an approach different from the one described in our study: they run several simulations with a relatively low number of randomly sampled phenotypes and then make an ensemble mean of all their simulations. For instance, in Follows et al. (2007), each member of the ensemble contains 78 random phenotypes, which is not a particularly large number given that they have four functional types and that their traits include half-saturation constants for several nutrients, optimal temperature, and optimal irradiance. Still, running 10 such simulations to compute an ensemble mean is computationally expensive. Aggregate models do not need ensemble means for sampling the trait space since they are continuous by design: their phytoplankton communities fill the trait space completely without the need for any arbitrary sampling.
Aggregate models are very efficient because their state variables are the quantities that make the most ecological sense. In thermodynamics, computing the trajectory of each atom or molecule is not only infeasible, but also of little use. The collection of trajectories does not provide more information on the macroscopic behaviour of a thermodynamic system than aggregate properties such as temperature, pressure, and density. Equally, modelling the dynamics of thousands of species would be incredibly costly, and sufficient observational data would not be available to validate the models. Furthermore, the results would also be extremely difficult to interpret (Levins, 1966). Given that the most important quantities for understanding a community of species with similar niches are biomass, mean trait values, and trait diversity, the aggregate model focuses computational power where it is most needed without much loss of information. Aggregate models also explicitly quantify the factors controlling biodiversity, such as the second derivatives of the net growth rate and the trait diffusivity parameters (Chen et al., 2019).
However, the aggregate approach has one major weakness: a specific shape for the trait distribution must be assumed a priori, with only as many degrees of freedom as there are free parameters (Wirtz and Eckhardt, 1996; Bruggeman and Kooijman, 2007). There is no universal distribution shape for phytoplankton traits, which is why the equations describing their dynamics are not as precise as the equations of thermodynamics. In this study, we assumed that the optimal temperature was normally distributed and that the half-saturation constant was lognormally distributed. This Gaussian closure was chosen because of its simple moment equations and low number of free or arbitrary parameters. Normally distributed temperature and irradiance niches have been observed by Irwin et al. (2015). The half-saturation constant is strongly correlated with cell size (Litchman et al., 2007; Edwards et al., 2012), and lognormal distributions have been observed in nature for size (Cermeño and Figueiras, 2008; Quintana et al., 2008; Schartau et al., 2010; Downing et al., 2014; Marañon, 2015), although not in all cases. Another very common distribution is the power (or log-linear) law (Rodríguez, 1994; Cermeño and Figueiras, 2008; Huete-Ortega et al., 2012), although the power law must be truncated on at least one side. We note that a power-law distribution with a cutoff on the left might be better able to represent the right-skewed size distribution (even in logarithmic scale) of oligotrophic environments wherein Prochlorococcus, the smallest known phytoplankton, dominates and coexists only with larger species (Marañon, 2015). What neither a unimodal nor a power-law distribution can capture is bimodality, which is known to occur at least in lakes due to common herbivores, in particular daphnids, feeding optimally on prey of intermediate size (Gaedke and Klauschies, 2017).
Normal distributions are symmetrical, unimodal, and unbounded. If the real trait distribution deviates from these three properties, errors will arise in aggregate models based on a normal distribution. Not only is information lacking by not including higher-order moments such as skewness and kurtosis, but the dynamics of mean traits and trait variances could be significantly altered. If the trait distribution is skewed, the community will respond faster to a certain type of perturbation than to the opposite perturbation. For instance, if optimal temperature is right-skewed, the phytoplankton community will adapt faster to warming than to cooling environmental conditions. Phytoplankton with larger optimal temperature will need less time to become dominant in the case of warming than cold-water phenotypes in the case of cooling because they will start from a higher concentration. To express the above in terms of moment equations, the variance of a right-skewed distribution increases when the environment favours larger trait values, thus facilitating the adaptation, but it decreases when the environment favours smaller trait values (see Appendix B and the neglected term M30 in Eq. B7). If the trait distribution is multimodal, the reduction in trait diversity induced by competitive exclusion (Hardin, 1960) will be slower. This is because replacing all pre-existing communities by intermediate and previously rare phenotypes takes more time than making the most abundant phenotype even more abundant and the rarest even rarer, as in a unimodal distribution (see Appendix B and the neglected kurtosis term M40 in Eq. B7, knowing that multimodal distributions have low kurtosis).
Normal distributions are unbounded, with the assumption that extreme values are rare and ecologically meaningless. The consequence of this apparently reasonable assumption is that model phytoplankton can adapt to any environmental change if they are given enough time, irrespective of the intensity of that change. This contrasts with expectations of the behaviour of real phytoplankton communities, as explained in the following example. If a closed (i.e. without immigration) phytoplankton community experiences temperatures between 15 and 25 ∘C, the local phenotypes should be adapted to temperatures between 15 and 25 ∘C, and no single individual should be optimized for temperatures out of the boundaries, since it would be outcompeted at all places and times. If the environment suddenly warms, the phenotypes with an optimal temperature closer to 25 ∘C should come to dominate. However, if the temperature reaches 30 ∘C, no phenotype with an optimal temperature of 30 ∘C can rapidly come to dominate, since no such phenotype pre-exists in the system. Adaptation to temperatures higher than 25 ∘C can only occur through mutations or immigration. In an aggregate model, however, none of these processes are required. Phytoplankton will be able to adapt to any warming because an extremely small but non-zero biomass of phenotypes adapted to very high temperatures is always present by model design and can become dominant if the environment selects them.
In the present study, the aggregate (continuous trait) model agrees very well with a multi-phenotype (discrete trait) model, wherein no distribution shape is imposed but the trait distribution is spontaneously close to normality during most of the year. Skewness and kurtosis occur during some times of the year, only to be removed later, and do not strongly impact our estimates of the lower-order moments. The assumed normal trait distribution is symmetrical and unimodal; therefore, some errors occur when the trait distribution is skewed or bimodal. The mean optimal temperature is slightly underestimated and its variance is overestimated because SPEAD does not account for the slight right skew of optimal temperatures distributions. The other main error is that variance tends to decrease too fast in winter, after the re-mixing of the previously stratified water column, because SPEAD cannot account for bimodality. The seasonal cycle and the orders of magnitude, however, are accurate. Our results are similar to that of Acevedo-Trejos et al. (2016). However, other studies show much larger errors (Coutinho et al., 2016; Klauschies et al., 2018) and consider Gaussian-based aggregate models to be inaccurate.
Whether the trait distribution of a model ecosystem is normal or not depends on the ecological processes included by the modeller. At least two factors in SPEAD play in favour of a normal distribution. The first factor is trait diffusion. In a fluid, the diffusive movement of a tracer follows a Gaussian law provided that the diffusivity coefficient is constant (Einstein, 1905). Trait diffusion plays the same role here for traits and tends to erase skewness and bimodality. The second factor is the simplicity of our ecological model. All our phytoplankton phenotypes compete for the same resource. In a given environment defined by nutrient concentration and temperature, there is a single most competitive phenotype, and the phytoplankton net growth rate decreases continuously when moving away from this optimum. Grazing and mortality rates do not act against this trend because we impose them to be identical for all phenotypes. Conversely, two factors in SPEAD play against normality, but their reach is relatively minor. The asymmetry of the temperature response curve promotes right-skewed distributions of optimal temperature. However, and despite the naive expectation, this right skew is generally not large in the discrete model because the standard deviation of optimal temperature is always smaller than the temperature tolerance (ΔT=5 ∘C). The second effect is the alternation of stratification and mixing during the year. In summer, stratification leads to the formation of two distinct communities in the surface and subsurface. When the vertical mixing strengthens again in late autumn, the two communities mix into a temporary bimodal distribution.
Other ecological settings yield more widespread multimodality. Multimodality can be induced by immigration (Norberg et al., 2001), resting stages (Beckmann et al., 2019), fast environmental oscillations (Beckmann et al., 2019), spatially heterogeneous environments (Wickman et al., 2019), “convex” trade-offs favouring extreme phenotypes (Coutinho et al., 2016), and zooplankton prey selectivity (Wirtz, 2013; Klauschies et al., 2018). In particular, evolutionary branching of both phytoplankton and zooplankton into tens of size clusters can occur when each zooplankton grazes only on a small size range (Sauterey et al., 2017). However, it is important to point out that only fixed zooplankton preferences cause disruptive selection. By contrast, active switching by grazers (“kill the winner”) is insufficient to promote evolutionary branching as by design it promotes uniform distributions, flattening the peaks and filling the gaps in trait distributions. Using a Gaussian-based aggregate model in a setting promoting branching would of course be inappropriate: SPEAD would be unable to simulate evolutionary branching of phenotypes in these kinds of ecological scenarios
Alternatives to Gaussian closures have been proposed since early in the development of aggregate models. Norberg et al. (2001) and Norberg (2004) used more complex closures to estimate skewness and kurtosis. However, these closures had free parameters varying from ecosystem to ecosystem, and a discrete model was required to compute them, cancelling the advantage of aggregate models in terms of computational cost. Klauschies et al. (2018) replaced the normal distribution by a beta distribution. The beta distribution is bounded, allows bimodality, and was proven to increase the realism of trait-based aggregate models in a bounded trait scenario. However, applying this method requires defining fixed boundaries for phytoplankton traits. Phytoplankton have a minimum cell size (and half-saturation) at 0.5 µm, which is the size of Prochlorococcus, but they do not have a well-defined maximum cell size. Also, optimal temperature at local scales does not have clear boundaries. Therefore, any set of boundaries would be arbitrary and might prevent further adaptation to changing environments beyond those limits.
A more practical approach to account for non-Gaussian distributions would be to divide the community into several functional groups, each one having a normal trait distribution of its own (Terseleer et al., 2014; Chen and Laws, 2017). The sum of these communities can have a skewed or multimodal trait distribution. Trait variances (in particular size variance) could be high within phytoplankton as a whole, without bolstering the adaptive capacity of each functional group (see Sect. 4.3). All phenotypes within a given functional group must feed on the same nutrients, be subject to the same trade-offs, and should not be subject to processes promoting evolutionary branching. Ideally, and in order to prevent the convergence of all functional groups on the same trait values, each group should have distinct qualitative properties or trade-offs. Functional groups could include diatoms, mixotrophs, diazotrophs, or Prochlorococcus, among others. Two communities defined by the same parameters could coexist and avoid merging if an intermediate trait range is permanently disadvantageous due, for instance, to a convex trade-off or to a size-specific grazer. The multi-Gaussian approach would combine the moderate computational cost of Gaussian aggregate models with the more thorough description of planktonic ecosystems allowed by discrete models.
4.2 Traits in phytoplankton community models
In nature, many different traits define phytoplankton niches: nitrogen, phosphorus or iron uptake abilities, requirements for other nutrients (for instance, silica or calcite), stoichiometry, optimal temperature, optimal irradiance, mixotrophy, diazotrophy, motility, buoyancy, resistance to predation, toxicity, and many others. In many trait-based models, this complexity is reduced to one trait. The most common trait is cell size (Terseleer et al., 2014; Acevedo-Trejos et al., 2016; Smith et al., 2016; Chen and Smith, 2018). Cell size is used as a master trait because it is the most observable trait and correlates strongly with many other phytoplankton traits, such as light requirements (Taguchi, 1976; Edwards et al., 2015; Álvarez et al., 2017) and resistance to predation (Kiørboe, 1993; Thingstad et al., 2005). Some other commonly modelled traits include resistance to predation (Norberg et al., 2001; Merico et al., 2009), optimal temperature (Norberg et al., 2012; Beckmann et al., 2019), and optimal irradiance (Follows and Dutkiewicz, 2011).
The first trait included in SPEAD, half-saturation for nutrients, is known to be strongly correlated with cell size (Litchman et al., 2007; Edwards et al., 2012). Small species, such as cyanobacteria, have low half-saturation constants and can thrive in oligotrophic waters. They correspond to the gleaners of our model. Large species are more likely to be involved in blooms but require more nutrients. They correspond to the opportunists of our model. In this study, we chose not to use size but to impose only a simple gleaner–opportunist trade-off. This choice was made for two reasons: to maintain compatibility with the Darwin model (Follows et al., 2007; Vallina et al., 2014a) and to facilitate the analysis of the outputs of our otherwise complex model, as in our setting the best competitors in a given environment have a half-saturation equal to the dissolved inorganic nitrogen concentration. Our modelling framework can, however, be easily adapted to use size instead of half-saturation as the first trait (Smith et al., 2016).
The trait dynamics of models with two traits differ from those of simpler and less realistic single-trait models. Savage et al. (2007) obtain larger trait variances and much larger adaptive capacities when two traits are modelled together rather than in separate models. In our study, we also find a larger adaptive capacity, although it is conveyed by inter-trait correlation only. We actually find decreased variances caused by stronger competition during most of the year, except during the late autumn re-mixing of the water column following the summer stratification. This discrepancy might have been caused by the presence of an immigration term to sustain variance in Savage et al. (2007) but not in SPEAD, since our re-mixing of the water column is most analogous to a dispersal or migration process and we simulate it explicitly. SPEAD simulations coupled with a realistic 3D circulation model wherein phytoplankton are explicitly allowed to migrate in all directions (ideally in a patchy environment) would finally tell us if variance is increased or decreased by including more traits.
The low computational cost of aggregate models allows increasing the number of modelled traits, provided that sufficient observational data are available to constrain the corresponding trade-offs. Since the environmental drivers, such as nutrient concentrations, temperature, and light, are correlated with each other, the traits are likely to be correlated unless some processes erasing the correlations are introduced. Regardless of the effect of interactions between traits on variance, multi-trait models will be able to adapt to their environments faster without the need for large and unrealistic mutation rates or other terms sustaining large variances, such as immigration or “kill the winner” grazing.
4.3 Trait diffusion, variance, and evolution
Trait diffusion is a key process in SPEAD. Indeed, SPEAD is the first model to include diffusion of multiple traits, providing insights into how both mutations and selection can impact phytoplankton communities. For each modelled trait, a diffusivity parameter, or mutation rate, has to be set. The chosen values of these parameters decisively affect trait dynamics. However, the mutation rates remain poorly constrained. The most appropriate rate depends on what the modeller intends to represent by trait diffusion. To understand why, we will need to discuss the notions of ecological and evolutionary timescales, as well as the notions of adaptation and species.
A first interpretation of trait diffusion is that it is the most conservative way to add variance when the exact processes sustaining trait variance are unknown or too complex to be implemented in models. Indeed, trait diffusion simply adds new variance (aggregate approach) or disperses phytoplankton in a trait space (discrete approach), leaving little room to arbitrary parameters. By contrast, immigration (Norberg et al., 2001) requires assumptions about both immigration rates and the composition of immigrant communities. Likewise, “kill the winner” (Vallina et al., 2014b) requires assumption about whether it is mediated by viruses or zooplankton, whether consumers are specialized or can actively switch their preference between prey, and whether or not there is a time lag in their response.
This interpretation of trait diffusion as a generic source of variance is implicitly followed when the diffusivity parameter is set by an optimization algorithm in order to account for the observed trait variance and no other mechanism sustaining variance is included. This way, Chen and Smith (2018) found a diffusivity for the logarithm of size of 0.1, equal to our largest diffusivity for the logarithm of half-saturation. Even in the homogeneous environments of mesocosms, Wirtz (2013) reports a logarithmic size variance of 0.2 to 0.5, which corresponds to standard deviations between 0.45 and 0.7. In SPEAD, reaching these high values of trait variance is only possible with diffusivities higher than or equal to 0.003, despite the fact that our physical setting creates its own variance by mixing phenotypes adapted to the environmental conditions of different depths. This interpretation of trait diffusion is also coherent with the use of trait diffusion as a variance treatment (Chen et al., 2019) to study the effect of diversity on primary production and with the original goal of trait diffusion, which was to sustain trait variance in 0D settings (Merico et al., 2014; Acevedo-Trejos et al., 2016). In these models, trait diffusion is never run combined with other variance-sustaining mechanisms. In real ecosystems, however, mutations are expected to occur at the same time as migration, “kill the winner” grazing, and many other mechanisms that may promote diversity, including multiple convex trade-offs (Beardmore et al., 2011) and mixotrophy (Ward and Follows, 2016). The way trait diffusion is derived opens a second interpretation of what it represents. Trait diffusion is symmetrical: mutations occur at the same rate towards higher and lower trait values. Trait diffusion is also heritable: mutants transfer their mutations to their offspring. These properties correspond to the evolutionary process of random mutations and selection of the fittest by the environment. They do not correspond to environmentally induced non-heritable variations such as phenotypic plasticity (Ghalambor et al., 2007) or to any selective ecological process driven by the environment, even if some promote variance.
According to Fussmann et al. (2007), “Evolution is the change of genotype frequencies within populations or species, whereas community dynamics represent the change of abundances of different species”. This definition depends on the notion of species. Like many phytoplankton models, SPEAD lacks the notion of species and does not distinguish between intraspecific and interspecific trait variance. Our trait space is continuous by design. By mutating, phytoplankton can cross the boundaries between phenotypes as if they were all of the same species. The only distinction in SPEAD is between mutations and selection. Mutations are a strictly evolutionary process represented in SPEAD by trait diffusion through subsequent generations. Selection encompasses both intraspecific selection, which is a second evolutionary process, and interspecific selection, which is an ecological process. In SPEAD, selection has two effects: it drives the mean traits towards their optimum values (see Eqs. 30–31) and decreases trait variances by eliminating the rarest and least fit phenotypes (see Eqs. 32–34). Some cases of adaptive evolution to environmental changes in only a few generations have been reported (Fussmann et al., 2007; Kinnison and Hairston, 2007) but are not necessarily caused by mutations occurring at these timescales. They can also be driven by ecological selection from previously existing intraspecific diversity. In order to choose correct mutation rates these two evolutionary processes must be distinguished.
An alternative interpretation is that ecological processes are particular cases of eco-evolutionary processes whereby the phenotypes of the offspring are identical to those of their parents (Doebeli et al., 2017). This definition emphasizes the lack of a fundamental difference between the two types of processes from a mechanistic point of view, since both are rooted in the same birth–death dynamics. Under this alternative interpretation, ecological timescales are simply the timescales at which the effect of mutations is small, and evolutionary timescales are those at which the effect of mutations is large. Therefore, the ecological selection timescales overlap the adaptive evolution timescales, and the difference between the two is diffuse at intermediate timescales. Schlüter et al. (2016) showed that an algal culture starting with a single clone of the abundant coccolithophore Emiliania huxleyi could evolve new traits in response to ocean acidification in a time measurable in the laboratory. Their experiment lasted for 2100 generations, and the changes after only 100 generations were small. These numbers agree with seminal studies on Escherichia coli wherein bacteria were shown to adapt to temperature increases or to changes in nutrient availability in 100 to a few thousand generations (Bennett et al., 1990; Lenski et al., 1991; Travisano et al., 1995). These are the timescales a mutation rate should reflect. In the case of phytoplankton this means a few years, which falls under the category of “contemporary evolution” but does not allow each species to adapt easily to a seasonal cycle or to faster perturbations. The corresponding trait diffusivity parameters in our study are in the middle of our range, between and 10−3 for half-saturation and between and 10−2 ∘C2 for optimal temperature (see Table 3).
The trait distributions in SPEAD provide additional insights. In the absence of trait diffusion, the two traits become almost totally correlated: one cannot vary without the other. This is a soft version of the diversity collapse observed in 0D models of a one-trait fitness landscape. In our 1D model of a two-trait fitness landscape, trait variances do not collapse to zero, but a bi-dimensional trait space becomes unidimensional and phytoplankton lose their ability to adapt in other directions. Nutrient and temperature niches are known to be correlated in nature, but their correlation is never perfect (Irwin et al., 2012). A small trait diffusivity is sufficient to avoid the collapse of the dimensional trait space into a unidimensional one and likely limits such trait correlations in natural ecosystems, given that mutations affecting half-saturation and optimal temperature are likely independent and hence able to freely fill the full trait space. With very fast trait diffusion, the mean phenotypes adapt instantaneously to their environment but at the cost of keeping a large pool of maladapted phenotypes, which regularly represent more than 15 % of the community even if they have very low fitness because mutations are continuously creating them. These maladapted phenotypes explain the decrease by up to 10 % of the modelled annual primary production. In nature, the optimal niches of species do not cover all the variability of nutrient concentration and water temperature (Irwin et al., 2012). Furthermore, most real mutations having an effect on the phenotype are deleterious (Timofeeff-Ressovsky, 1940). A mutation rate able to permanently sustain maladapted phenotypes despite strong selection against them would imply a large number of deleterious mutations not represented in our model and hence massive mortality. Moderate mutation rates are therefore more likely.
Modelling several communities with their own trait distributions and their own mutations might relax the contradiction between the use of trait diffusion to explain trait variance and the use of trait diffusion to represent evolutionary processes. The variance within a species or a group is lower than the total community variance and can be sustained with lower mutation rates. This approach can also be used to separate the adaptive evolution of each species from the ecological successions (i.e. inter-group competition) in response to environmental change (Norberg et al., 2012), finally disentangling all components of eco-evolutionary processes.
4.4 Future directions
SPEAD 1.0 is the first step of the SPEAD project, whose aim is to simulate plankton evolution with adaptive dynamics in the ocean. In this first version of the model, we kept the complexity manageable, with only one spatial dimension (the vertical) and two functional traits, in order to facilitate the validation of our aggregate approach and to diagnose the effects of trait diffusion. The equations of SPEAD 1.0 for the mean trait, trait variance, and covariance resolving two functional traits can be used as a starting point to build more comprehensive trait-based models in multi-dimensional continuous trait spaces, with or without mutations. Three axes of potential future improvement have already been identified: (1) coupling SPEAD with a general circulation model, (2) increasing the number of traits, and (3) dividing the community into several functional groups, which implies combining the continuous trait distribution approach with the discrete ecotype approach.
More concretely, our goal for the near future is to include optimal solar irradiance as a third functional trait and implement the aggregate approach with trait diffusion in a 3D trait space into the Darwin model (Follows et al., 2007; Dutkiewicz et al., 2009; Barton et al., 2010; Follows and Dutkiewicz, 2011; Ward et al., 2012; Dutkiewicz et al., 2013). Darwin is a versatile model that allows many discrete ecotypes to be resolved along several environmental gradients and can be coupled with the MIT general circulation model (Marshall et al., 1997). Optimal irradiance has been present as a trait in the Darwin model since its origin. Indeed, light can be a limiting resource for phytoplankton in the ocean in mixed water columns, where plankton cannot stay close to the surface, and near the deep chlorophyll maximum of stratified water columns. Optimal irradiances are known to cover more than 2 orders of magnitude (Edwards et al., 2015) and to determine the niches of many ecotypes, even within the same species (Biller et al., 2015). The inclusion of optimal solar irradiance as a mutating trait in SPEAD will be a key step to better capture ecological successions. One challenge will be to allow phenotypes to adapt to their environment while at the same time accounting for the mechanistic correlation between nutrient and irradiance niches, since both are related to cell size. The phytoplankton in Darwin were originally divided into four functional groups: Prochlorococcus analogues, other small phytoplankton, diatoms, and other large phytoplankton. Representing each functional group by its own normal distribution is a possible starting point to develop the multi-Gaussian approach.
Improved versions of SPEAD should be able to address various ecological issues related to community assembly and responses to climate change that current models cannot address. The response of the phytoplankton community to environmental changes in a simple NPZD model can only be an increase or a decrease in primary production. Estimates of changes in primary production from NPZD models are likely to be inaccurate because the parameters of NPZD models are validated against observations of present environments. Under environmental changes, the composition of the plankton community is likely to change and the model parameters have no reason to remain valid. Models based on plankton functional types are more accurate, as they can account for ecological selection: a plankton type (e.g. diatoms) can be replaced by another type (e.g. cyanobacteria) in response to a perturbation (e.g. increased stratification). However, they do not represent adaptive evolution through which groups or species can change their traits and maintain local dominance. Therefore, they might overestimate the extinction rate and the shift in community composition. Eco-evolutionary models like SPEAD do not explain why groups that diverged millions of years ago exist, but a multi-Gaussian version of SPEAD, wherein each group follows its own adaptive dynamics, could account for their contemporary evolution in new environments. By including both trait diffusion and ecological selection of the fittest phenotypes competing in a given environment, SPEAD can potentially be used to disentangle the role of ecological and evolutionary processes in shaping diversity patterns in phytoplankton. In particular, it can be used to determine the conditions under which species or functional groups may survive climate change by evolving new traits or may be replaced by other species or functional groups from other regions. Predicting changes in phytoplankton composition is particularly important as species perform different functions and have different impacts on their environment. For instance, they contribute differently to the carbon pump (e.g. by sinking more or less fast) and to the nitrogen cycle (e.g. by fixing atmospheric nitrogen or not). Therefore, changes in community composition might dramatically impact global climate and should be included in climate prediction models. The effect of environmental changes, such as warming and increased stratification, on plankton size structure and the effect of biodiversity – controlled by trait diffusion among other processes – on primary production and ecosystem functioning are other examples of contemporary ecological issues that SPEAD might contribute to addressing.
In this article, we present a new aggregate model of a phytoplankton community called SPEAD (Simulating Plankton Evolution with Adaptive Dynamics), wherein different phenotypes competing for dissolved inorganic nitrogen are characterized by two traits: their half-saturation constants for nitrogen uptake (in logarithmic scale) and their optimal temperature for growth. The phytoplankton community is represented by the six lowest-order moments of its trait distribution: total concentration, the mean value of each trait, the variance of each trait, and the inter-trait covariance. The dynamics of these state variables are driven by three environmental factors: nutrient concentration, temperature, and solar irradiance. The physical setting represents a water column down to 200 m. The seasonal alternation of stratification and vertical mixing also has a strong effect on the trait distribution. Trait diffusion through subsequent generations is included to represent heritable mutations and hence sustain trait diversity. To our knowledge, SPEAD is the first aggregate model to simultaneously include two traits (with a proper representation of inter-trait correlation) and trait diffusion.
The ecological parameters of SPEAD were set to reproduce the observed primary production as well as the chlorophyll, nitrate, and particulate organic nitrogen concentrations observed by BATS in the Sargasso Sea. Despite its strong assumption that traits are normally distributed, SPEAD was shown to agree precisely with a discrete model explicitly representing all phenotypes, with only minor deviations at depth in summer when optimal temperature is underestimated and in early winter when trait variances decrease too fast. This good agreement is made possible by trait diffusion and by the simplicity of our ecological setting, and it might not be extendable to all ecosystem models. The trait dynamics depend strongly on the imposed trait diffusivity parameters. With very high diffusivities, primary production is low, variances are high, and the two traits are independent, filling the entire trait space. With very low diffusivities, variances are low (albeit non-zero) and the two traits are very strictly correlated: only warm-water gleaners and cold-water opportunists can survive. We think that intermediate values of mutation rates are more realistic, but the precise value depends on whether trait diffusion is meant to sustain the trait diversity of a whole community or to represent the mutations occurring within a given species.
SPEAD has a computational cost 2 orders of magnitudes lower than a full discrete model, and its variables are readily interpretable in ecological terms. This effectiveness makes it possible to increase the number of traits. As optimal irradiance is key to explaining phytoplankton distribution in the water column and is already present in the Darwin model, the next step of the SPEAD project will be to include it as a third dynamic trait. In agreement with Savage et al. (2007), we showed that adding traits accelerated the response of pre-existing traits to environmental changes. Other avenues of future improvement include representing various functional groups, each with their own distinct normal distributions, and coupling SPEAD with a general circulation model. Future versions of our multi-trait framework may address ecological questions related to the impact of selection, mutations, and biodiversity on community dynamics and to the response of phytoplankton to climate change.
In this study, we represented phytoplankton mutations as a trait diffusion term, following the work of Merico et al. (2014). In this Appendix we show how the expression for trait diffusion is derived and discuss its conditions of validity.
Let us consider the dynamics of an isolated phytoplankton community wherein each individual is characterized by the values of two traits: x (in trait unit x or tux) and y (in tuy). Phytoplankton are distributed in the trait space with a density (mmol N m−3 tux−1 tuy−1). The mass concentration of phytoplankton cells with values of the first trait between x and x+dx and values of the second trait between y and y+dy is if dx and dy are small.
If traits are strictly inherited, the equation governing for a given phenotype (x,y) depends on the reproduction (; d−1) and death (; d−1) rates.
In the above equation, is the net growth rate. In our model, the reproduction rate is identical to the nitrogen uptake rate because nitrogen, the limiting nutrient, is not exuded, cells do not modify their nitrogen content, and all nitrogen taken up is used for reproduction. However, genetic mutations or phenotypic plasticity can produce offspring with trait values different from that of their parents. For simplicity, we will consider mutations increasing or decreasing the traits to be equally probable. We assume that the offspring of a parent with trait value x will have trait value x−δx with a probability and trait value x+δx with the same probability, where νx is a diffusivity parameter expressed in tux2 that is considered independent of trait value, mutation step (δx), and time. Mutations also occur on trait y, with a mutation step δy and a y-diffusivity parameter νy. Mutations on both traits are assumed independent. The probability of having a mutation on both x and y is just the product of the probabilities of each mutation. Hence, the time derivative of with mutations is as follows.
In the limit of small but frequent mutations, this equation can be simplified by making a second-order approximation of u⋅p.
The sum of terms in , , and is zero, and the sum of factors before u⋅p is 1. Hence, the above equation simplifies to the following.
This second-order approximation is valid in the limit as mutations become small (δx and δy tend to zero) and frequent ( and tend to infinity) so that higher-order terms can be neglected. The mathematical expression of the mutation term is somewhat analogous to that representing the diffusion of a tracer in physical space. In this analogy, the trait space replaces the physical space, νx⋅u and νy⋅u replace the diffusivity, and the density is the diffused tracer. This analogy is the origin of the phrase “trait diffusion”. We note that in a multi-trait space, whatever the number of traits, the diffusion of each trait has the same expression as in the one-trait space.
Phytoplankton community models can be discrete or aggregate. In a discrete model, the phytoplankton community is divided into a finite number of phenotypes, each characterized by a different set of trait values. Mutations are discrete with steps equal to the difference between a phenotype and its nearest neighbours. The differential equation for a discrete phenotype is intuitive and depends only on its net growth rate and a trait diffusion term.
The variables of aggregate models and the differential equations they follow are less intuitive. In an aggregate model, a general shape must be assumed for the trait distribution with some degrees of freedom, and the prognostic variables are the moments of the trait distribution that are free to vary. In a single-trait model, the most commonly assumed shape is the normal (or Gaussian) distribution (Wirtz and Eckhardt, 1996; Bruggeman and Kooijman, 2007), wherein the phytoplankton density p(x,t) (mmol N m−3 tux−1, with tux or the trait unit x) is equal to
In this distribution, the three free parameters are the phytoplankton concentration P(t), the mean trait value , and the trait variance Vx(t). They are respectively equal to , , and . In a multi-trait space, we will assume that the traits follow a multivariate normal distribution, which is a generalization of a normal distribution. If N is the number of dimensions, then
In this case, x is the vector containing all traits, is the vector of mean trait values, and Σ(t) is the matrix of variances and covariances. There are free parameters in total: one phytoplankton concentration, N mean trait values, N trait variances, and covariances. In the following, we will show how to derive the differential equations for each type of variable. To this end, we use the method developed by Norberg et al. (2001) based on Taylor expansions of the rates of reproduction and net growth. The assumption of a normal trait distribution is only required to compute the time derivatives of variance and covariance, but not for the equations of total biomass and mean trait values.
The trait space is considered to be unbounded, with the implicit assumption that extreme values are extremely rare and ecologically meaningless. This is expressed in the fact that p and all products including p or any of its derivatives tend to 0 when a trait tends to (plus or minus) infinity. For simplicity, in the following part of this section, we will not show the dependencies on the environmental factors and will limit ourselves to two traits, but our method can be extended to derive the equations for any given number of traits. The reproduction and net growth rates of the phenotype defined by trait values (x,y) are denoted u(x,y) and a(x,y), respectively. Integrals are over the whole bi-dimensional domain. We will first derive the equations in the absence of trait diffusion and then discuss what terms are added by the trait diffusion scheme. The net growth of a given phenotype is
As a consequence, the equation controlling P(t) is
We will use the notation ajk (d−1 tux−j tuy−k) for derived j times with respect to x and k times with respect to y, normalized by the factorials of j and k, and the notation Mjk (tuxj tuyk) for the central moment of order j with respect to x and k with respect to y.
We note that M00=1 (by definition of the total concentration), M10=0, M01=0 (by definition of the mean traits), M20(t)=Vx(t), M02(t)=Vy(t) (by definition of the variance), and M11(t)=Cxy(t).
A Taylor expansion of the net growth rate on x and y around yields
The time derivative of P(t) depends on the time derivative of p(x,t). Unless explicitly indicated otherwise, all derivatives with respect to traits are taken at the current mean trait values.
The first and largest term of this sum is the net growth rate at the mean trait values, denoted . This is the expected growth rate of a community without trait variance. Since M10=0 and M01=0, there is no term depending on or . As we want to estimate the effect of trait diversity on the community, we consider the second-order terms proportional to Vx(t), Vy(t), or Cxy(t). Higher-order terms, which vanish when variance is small, are neglected so that
Second-order derivatives are expected to be negative if is in the neighbourhood of the optimal trait value, and Vx(t) and Vy(t) are always positive. Therefore, the second-order terms are generally negative. This means that having large trait variances, or in other words having a large proportion of cells with non-optimal trait values, has a negative effect on the net community growth.
In the equation for the mean trait, however, having a large variance is an advantage. Let us define an intermediate variable Sx(t) (mmol N m−3 tux) as or, equivalently, as . The time derivative of Sx(t) is as follows.
As Sx(t) is a product, its derivative can also be written as
By equating the two previous expressions, we get
In this equation, we only consider the highest-order terms:
This equation represents the adaptation of the community to its environment. If the mean trait is not optimal, it will increase or decrease in order to maximize the net specific growth rate. The speed of this selection process is proportional to variance: biodiversity is required to track the environmental conditions. The covariance term means that if traits are correlated, the optimization of trait y will also affect trait x.
The mean value of trait y follows a similar equation:
The equations describing time changes in variances and covariance require more assumptions. As previously, we define an intermediate variable Zx(t) (mmol N m−3 tux2) as P(t)Vx(t) or, equivalently, as . In this integral, two terms depend on time: and . Hence, the time derivative of Zx(t) is as follows.
By definition of , we have . Thus,
As Zx(t) is a product, its derivative can also be written as
By equating the two previous expressions, we get
In this equation, the two terms proportional to compensate, and it is no longer possible to neglect the third and fourth orders of the trait distribution. With only the two lowest-order non-zero terms retained, the time derivative of variance is
The moments M30(t) and M40(t) are called the skewness and kurtosis of x, respectively. They represent the shape of the trait distribution. These moments could be described by their own equations, but their time derivatives depend on moments of even higher orders, and so on. In order to limit mathematical complexity and computation time, we do not explicitly compute moments of higher order than variance. Instead, we close our system by giving these moments the same value as in a bivariate normal distribution. In a bivariate normal distribution, odd-order moments (where j+k is odd) are zero (for reasons of symmetry) and even-order moments can be expressed as a function of variances (Isserlis, 1916).
The equation for Vx(t) then simplifies to
The equation for Vy(t) is obtained by swapping the x and y indices:
These expressions represent the effect of competition on trait variance. If the mean trait is near an optimum, then and are negative and trait diversity tends to collapse due to competitive exclusion.
The equation for covariance is derived in a similar way. We define Zxy(t) as P(t)Cxy(t). The time derivative of Zxy(t) is as follows.
The last two terms are zero since M10=0 and M01=0. Thus,
Since Zxy is a product, its derivative can also be written as
By equating the two previous expressions, we get
In the case of a bivariate normal distribution, the only terms remaining produce the following equation.
Replacing M31(t), M22(t), and M13(t) by their expressions as a function of lower-order moments yields
Competition tends to reduce variance, which must therefore be sustained by another process. In our model, this is the role of trait diffusion, as described in Appendix A and originally derived by Merico et al. (2014). Trait diffusion represents the effect of heritable mutations on the trait distribution and adds two new terms to the net growth in Eq. (B3) that are mathematically very similar to tracer diffusion.
The additional term for the total biomass time derivative due to the diffusion of x is
This result comes from the fact that u⋅p and its derivatives tend towards zero when any trait tends towards infinity. The effect of the diffusion of y would equally be zero. This means trait diffusion is not a source of biomass. The additional term for due to the diffusion of x is as follows.
The effects of y diffusion on and of both x and y diffusion on are equally zero. Trait diffusion has no effect on the mean trait equations. It does not favour any direction of change. However, trait diffusion is a source of variance. Indeed, a similar integration by parts adds a new non-zero term to .
This integral is similar to (replacing a by u) and can be Taylor-expanded in the same way. The contribution of y diffusion on Vx is a different case. The extra term on is zero.
Thus, the new equations of Vx(t) and Vy(t) accounting for trait diffusion are as follows.
Because is positive for every value of x and y, the trait diffusion term is positive. Trait diffusion is able to counter the effect of competitive exclusion and sustain variance.
The effect on Zxy(t) is
Thus, trait diffusion does not add nor remove covariance to the phytoplankton community. However, by increasing the variances, trait diffusion decreases the correlation. In other words, trait diffusion decorrelates the traits by making rare trait combinations more likely.
We note that, in the absence of trait diffusion, our equations are a particular case of the general equations derived by Bruggeman (2009) for multivariate normal trait distributions. In a single-trait case, they are simpler than the original equations (Merico et al., 2014) but identical to the more recent formulation of Coutinho et al. (2016) and derived using the same method.
The code and data for SPEAD 1.0 are freely available on GitHub (https://github.com/GuillaumeLeGland/SPEAD, last access: 31 March 2021) and Zenodo (and https://doi.org/10.5281/zenodo.4673500, Le Gland and Vallina, 2021) under the MIT license. The code for SPEAD 1.0 is written in MATLAB (version R2010b) and is fully compatible with open-source GNU-Octave (version 4.4.1). The execution has been tested on Windows with a 2.5 GHz Intel i5-3210M processor, on Linux Ubuntu with a 2.4 GHz Intel Xeon E5645 processor, and on Linux Debian with a 2.6 GHz Intel Xeon E5-2640 processor. The main code modules are as follows.
-
SPEAD_1D is the main script to launch SPEAD, calling all functions.
-
SPEAD_1D_keys is the function with which the different options are declared.
-
SPEAD_1D_parameters assigns the values of the model parameters.
-
SPEAD_gaussecomodel1D_ode45eqs is a function called at each time step to solve the ordinary differential equations of the aggregate (continuous) model.
-
SPEAD_discretemodel1D_ode45eqs is a function called at each time step to solve the ordinary differential equations of the multi-phenotype (discrete) model.
SPEAD 1.0 also contains numerous other functions to plot figures and to represent each physical or ecological process (vertical mixing, aggregate trait diffusion, discrete trait diffusion). The four observation files (for primary production, chlorophyll concentration, nitrate concentration, and particulate organic nitrogen concentration) and the four external forcing files (for water temperature, surface PAR, vertical mixing, and mixed layer depth) are located in the INPUTS folder. Once all files are loaded, SPEAD is run simply by calling SPEAD_1D.
The supplement related to this article is available online at: https://doi.org/10.5194/gmd-14-1949-2021-supplement.
GLG, SMV, SLS, and PC conceived and designed the study. SMV wrote the initial code for the one-trait model and acquired the observational data. GLG derived the equations for the two-trait model and the trait diffusion scheme, built the final code, and wrote the first draft. All authors contributed to and reviewed the paper.
The authors declare that they have no conflict of interest.
The authors thank all the scientists who produced the data and developed all the concepts used in this article. In particular, we thank Agostino Merico, Esteban Acevedo-Trejos, and Marcel Oliver for the discussions we had on trait diffusion. The Institute of Marine Sciences (ICM – CSIC) is supported by a “Severo Ochoa” Centre of Excellence grant (CEX2019-000928-S) from the Spanish government.
This work was funded by national research grant CTM2017-87227-P (SPEAD) from the Spanish government. We acknowledge support for the publication fee by the CSIC Open Access Publication Support Initiative through its Unit of Information Resources for Research (URICI).
This paper was edited by Andrew Yool and reviewed by Fanny Monteiro and one anonymous referee.
Acevedo-Trejos, E., Brandt, G., Smith, S. L., and Merico, A.: PhytoSFDM version 1.0.0: Phytoplankton Size and Functional Diversity Model, Geosci. Model Dev., 9, 4071–4085, https://doi.org/10.5194/gmd-9-4071-2016, 2016. a, b, c, d, e
Ackley, S. F. and Sullivan, C. W.: Physical controls on the development and characteristics of Antarctic sea ice biological communities: a review and synthesis, Deep-Sea Res. Pt. I, 41, 1583–1604, https://doi.org/10.1016/0967-0637(94)90062-0, 1994. a
Allen, A. P., Gillooly, J. F., and Brown, J. H.: Linking the global carbon cycle to individual metabolism, Funct. Ecol., 19, 202–213, https://doi.org/10.1111/j.1365-2435.2005.00952.x, 2005. a
Álvarez, E., Nogueira, E., and López-Urrutia, Á.: In-vivo single-cell fluorescence and the size-scaling of phytoplankton chlorophyll content, Appl. Environ. Microb., 83, e03317-16, https://doi.org/10.1128/AEM.03317-16, 2017. a
Aumont, O., Maier-Reimer, E., Blain, S., and Monfray, P.: An ecosystem model of the global ocean including Fe, Si, P colimitations, Global Biogeochem. Cy., 17, 1060, https://doi.org/10.1029/2001GB001745, 2003. a
Aumont, O., Ethé, C., Tagliabue, A., Bopp, L., and Gehlen, M.: PISCES-v2: an ocean biogeochemical model for carbon and ecosystem studies, Geosci. Model Dev., 8, 2465–2513, https://doi.org/10.5194/gmd-8-2465-2015, 2015. a
Aumont, O., van Hulten, M., Roy-Barman, M., Dutay, J.-C., Éthé, C., and Gehlen, M.: Variable reactivity of particulate organic matter in a global ocean biogeochemical model, Biogeosciences, 14, 2321–2341, https://doi.org/10.5194/bg-14-2321-2017, 2017. a
Baretta, J. W., Ebenhöh, W., and Ruardij, P.: The European Regional Seas Ecosystem Model, a complex marine ecosystem model, Neth. J. Sea Res., 33, 233–246, https://doi.org/10.1016/0077-7579(95)90047-0, 1995. a
Barton, A. D., Dutkiewicz, S., Flierl, G., Bragg, J., and Follows, M. J.: Patterns of diversity in marine phytoplankton, Science, 327, 1509–1511, https://doi.org/10.1126/science.1184961, 2010. a
Beardall, J., Allen, D., Bragg, J., Finkel, Z. V., Flynn, K. J., Quigg, A., Rees, T. A. V., Richardson, A., and Raven, J. A.: Allometry and stoichiometry of unicellular, colonial and multicellular phytoplankton, New Phytol., 181, 295–309, https://doi.org/10.1111/j.1469-8137.2008.02660.x, 2009. a
Beardmore, R., Gudelj, I., Lipson, D. A., and Hurst, L. D.: Metabolic trade-offs and the maintenance of the fittest and the flattest, Nature, 472, 342–346, https://doi.org/10.1038/nature09905, 2011. a, b
Beckmann, A., Schaum, C.-E., and Hense, I.: Phytoplankton adaptation in ecosystem models, J. Theor. Biol., 468, 60–71, https://doi.org/10.1016/j.jtbi.2019.01.041, 2019. a, b, c, d
Bennett, A. F., Dao, K. M., and Lenski, R. E.: Rapid evolution in response to high-temperature selection, Nature, 346, 79–81, https://doi.org/10.1038/346079a0, 1990. a
Biller, S. J., Berube, P. M., Lindell, D., and Chisholm, S. W.: Prochlorococcus: the structure and function of collective diversity, Nat. Rev. Microbiol., 13, 13–27, https://doi.org/10.1038/nrmicro3378, 2015. a, b
Bruggeman, J.: Succession in plankton communities: A trait-based perspective, PhD thesis, Vrije Universiteit Amsterdam, The Netherlands, 2009. a, b, c
Bruggeman, J. and Bolding, K.: A general framework for aquatic biogeochemical models, Environ. Modell. Softw., 61, 249–265, https://doi.org/10.1016/j.envsoft.2014.04.002, 2014. a
Bruggeman, J. and Kooijman, A. L. M.: A biodiversity-inspired approach to aquatic ecosystem modeling, Limnol. Oceanogr., 52, 1533–1544, https://doi.org/10.4319/lo.2007.52.4.1533, 2007. a, b, c, d
Brzezinski, M. A.: Vertical distribution of ammonium in stratified oligotrophic waters, Limnol. Oceanogr., 33, 1176–1182, 1988. a
Button, D. K., Robertson, B., Gustafson, E., and Zhao, X.: Experimental and theoretical bases of specific affinity, a cytoarchitecture-based formulation of nutrient collection proposed to supercede the Michaelis-Menten paradigm of microbial kinetics, Appl. Environ. Microb., 70, 5511–5521, https://doi.org/10.1128/AEM.70.9.5511-5521.2004, 2004. a
Castenholz, R. W.: Thermophilic blue-green algae and the thermal environment, Bacteriol. Rev., 33, 476–504, https://doi.org/10.1128/MMBR.33.4.476-504.1969, 1969. a
Cermeño, P. and Figueiras, F. G.: Species richness and cell-size distribution: size structure of phytoplankton communities, Mar. Ecol. Prog. Ser., 357, 75–85, https://doi.org/10.3354/meps07293, 2008. a, b, c
Cermeño, P., Lee, J.-B., Wyman, K., Schofield, O., and Falkowski, P. G.: Competitive dynamics in two species of marine phytoplankton under non-equilibrium conditions, Mar. Ecol. Prog. Ser., 429, 19–28, https://doi.org/10.3354/meps09088, 2011. a
Champagnat, N., Ferrière, R., and Méléard, S.: Unifying evolutionary dynamics: From individual stochastic processes to macroscopic models, Theor. Popul. Biol., 69, 297–321, https://doi.org/10.1016/j.tpb.2005.10.004, 2006. a
Chen, B. and Laws, E. A.: Is there a difference of temperature sensitivity between marine phytoplankton and heterotrophs, Limnol. Oceanogr., 62, 806–817, https://doi.org/10.1002/lno.10462, 2017. a
Chen, B. and Smith, S. L.: CITRATE 1.0: Phytoplankton continuous trait-distribution model with one-dimensional physical transport applied to the North Pacific, Geosci. Model Dev., 11, 467–495, https://doi.org/10.5194/gmd-11-467-2018, 2018. a, b, c, d, e
Chen, B., Smith, S. L., and Wirtz, K. W.: Effect of phytoplankton size diversity on primary productivity in the North Pacific: trait distributions under environment variability, Ecol. Lett., 22, 56–66, https://doi.org/10.1111/ele.13167, 2019. a, b, c
Chisholm, S. W., Olson, R. J., Zettler, E. R., Goericke, R., Waterbury, J. B., and Welschmeyer, N. A.: A novel free-living prochlorophyte abundant in the oceanic euphotic zone, Nature, 334, 340–343, https://doi.org/10.1038/334340a0, 1988. a
Coutinho, R. M., Klauschies, T., and Gaedke, U.: Bimodal trait distributions with large variances question the reliability of trait-based aggregate models, Theor. Ecol., 9, 389–408, https://doi.org/10.1007/s12080-016-0297-9, 2016. a, b, c, d
DeVries, T. and Primeau, F.: Dynamically and Observationally Constrained Estimates of Water-Mass Distributions and Ages in the Global Ocean, J. Phys. Oceanogr., 41, 2381–2401, https://doi.org/10.1175/jpo-d-10-05011.1, 2011. a
DeVries, T., Primeau, F., and Deutsch, C.: The sequestration efficiency of the biological pump, Geophys. Res. Lett., 39, L13601, https://doi.org/10.1029/2012GL051963, 2012. a
Dieckmann, U. and Law, R.: The dynamical theory of coevolution: a derivation from stochastic ecological processes, J. Math. Biol., 34, 579–612, https://doi.org/10.1007/bf02409751, 1996. a
Doebeli, M., Ispolatov, Y., and Simon, B.: Towards a mechanistic foundation of evolutionary Theory, Elife, 6, e23804, https://doi.org/10.7554/eLife.23804.001, 2017. a
Downing, A. S., Hajdu, S., Hjerne, O., Otto, S. A., Blenckner, T., Larsson, U., and Winder, M.: Zooming in on size distribution pattern under species coexistence in Baltic Sea phytoplankton, Ecol. Lett., 17, 1219–1227, https://doi.org/10.1111/ele.12327, 2014. a, b
Dutkiewicz, S., Follows, M. J., and Bragg, J. G.: Modeling the coupling of ocean ecology and biogeochemistry, Global Biogeochem. Cy., 23, GB4017, https://doi.org/10.1029/2008GB003405, 2009. a, b
Dutkiewicz, S., Scott, J. R., and Follows, M. J.: Winners and losers: Ecological and biogeochemical changes in a warming ocean, Global Biogeochem. Cy., 27, 463–477, https://doi.org/10.1002/gbc.20042, 2013. a
Edwards, K. F., Thomas, M. K., Klausmeier, C. A., and Litchman, E.: Allometric scaling and taxonomic variation in nutrient utilization traits and maximum growth rate of phytoplankton, Limnol. Oceanogr., 57, 554–566, https://doi.org/10.4319/lo.2012.57.2.0554, 2012. a, b, c
Edwards, K. F., Thomas, M. K., Klausmeier, C. A., and Litchman, E.: Light and growth in marine phytoplankton: allometric, taxonomic, and environmental variation, Limnol. Oceanogr., 60, 540–552, https://doi.org/10.1002/lno.10033, 2015. a, b
Einstein, A.: On the Movement of Small Particles Suspended in Stationary Liquids Required by the Molecular-Kinetic Theory of Heat, Ann. Phys., 322, 549–560, https://doi.org/10.1002/andp.19053220806, 1905. a
Elbing, K., Larsson, C., Bill, R. M., Albers, E., Snoep, J. L., Boles, E., Hohmann, S., and Gustafson, L.: Role of hexose transport in control of glycolytic flux in Saccharomyces cerevisiae, Appl. Environ. Microb., 70, 5323–5330, https://doi.org/10.1128/AEM.70.9.5323-5330.2004, 2004. a
Eppley, R. W.: Temperature and phytoplankton growth in the sea, Fish. B.-NOAA, 70, 1063–1085, 1972. a, b
Falkowski, P.: The power of plankton, Nature, 483, 17–20, https://doi.org/10.1038/483S17a, 2012. a
Falkowski, P. G., Barber, R. T., and Smetacek, V.: Biogeochemical Controls and Feedbacks on Ocean Primary Production, Science, 281, 200–206, https://doi.org/10.1126/science.281.5374.200, 1998. a
Falkowski, P. G., Katz, M. E., Knoll, A. H., Quigg, A., Raven, J. A., Schofield, O., and Taylor, F. J. R.: The Evolution of Modern Eukaryotic Phytoplankton, Science, 305, 354–360, https://doi.org/10.1126/science.1095964, 2004. a
Fasham, M. J. R., Ducklow, H. W., and McKelvie, S. M.: A nitrogen-based model of plankton dynamics in the oceanic mixed layer, J. Mar. Res., 48, 591–639, https://doi.org/10.1357/002224090784984678, 1990. a
Field, C. B., Behrenfield, M. J., Randerson, J. T., and Falkowski, P.: Primary production of the biosphere: integrating terrestrial and oceanic components, Science, 281, 237–240, https://doi.org/10.1126/science.281.5374.237, 1998. a
Follows, M. J. and Dutkiewicz, S.: Modeling diverse communities in marine microbes, Annu. Rev. Mar. Sci., 3, 427–451, https://doi.org/10.1146/annurev-marine-120709-142848, 2011. a, b
Follows, M. J., Dutkiewicz, S., Grant, S., and Chisholm, S. W.: Emergent biogeography of microbial communities in a model ocean, Science, 315, 1843–1846, https://doi.org/10.1126/science.1138544, 2007. a, b, c, d, e, f, g
Frederickson, A. G. and Stephanopoulos, G.: Microbial competition, Science, 213, 972–979, https://doi.org/10.1126/science.7268409, 1981. a
Fussmann, G. F., Loreau, M., and Abrams, P. A.: Eco-evolutionary dynamics of communities and ecosystems, Funct. Ecol., 21, 465–477, https://doi.org/10.1111/j.1365-2435.2007.01275.x, 2007. a, b, c
Gaedke, U. and Klauschies, T.: Analyzing the shape of observed trait distributions enables a data-based moment closure of aggregate models, Limnol. Oceanogr.-Meth., 15, 979–994, https://doi.org/10.1002/lom3.10218, 2017. a
Ghalambor, C. K., McKay, J. K., Carroll, S. P., and Reznick, D. N.: Adaptive versus non-adaptive phenotypic plasticity and the potential for contemporary adaptation in new environments, Funct. Ecol., 21, 394–407, https://doi.org/10.1111/j.1365-2435.2007.01283.x, 2007. a
Gillooly, J., Brown, J., West, G., Savage, V., and Charnov, E.: Effects of size and temperature on metabolic rate, Science, 293, 2248–2251, https://doi.org/10.1126/science.1061967, 2001. a
Goericke, R. and Welschmeyer, N. A.: Response of Sargasso Sea phytoplankton biomass, growth rrate and primary production to seasonally varying physical forcing, J. Plankton Res., 20, 2223–2249, https://doi.org/10.1093/plankt/20.12.2223, 1998. a
Hansen, P. J., Bjørnsen, P. K., and Hansen, B. W.: Zooplankton grazing and growth: Scaling with the 2–2000-µm body size range, Limnol. Oceanogr., 42, 687–704, https://doi.org/10.1016/0077-7579(95)90047-0, 1997. a
Hardin, G.: The competitive exclusion principle, Science, 131, 1292–1297, https://doi.org/10.1126/science.131.3409.1292, 1960. a, b
Healey, F. P. and Hendzel, L. L.: Physiological indicators of nutrient deficiency in lake phytoplankton, Can. J. Fish. Aquat. Sci., 37, 442–453, https://doi.org/10.1139/f80-058, 1980. a
Holling, C. S.: The components of predation as revealed by a study of small mammal predation of the European pine sawfly, Can. Entomol., 91, 293–320, https://doi.org/10.4039/Ent91293-5, 1959. a
Huete-Ortega, M., Cermeño, P., Calvo-Díaz, A., and Marañon, E.: Isometric size-scaling of metabolic rate and the size abundance distribution of phytoplankton, P. Roy. Soc. B-Biol. Sci., 279, 1815–1823, https://doi.org/10.1098/rspb.2011.2257, 2012. a
Hutchinson, G. E.: The paradox of the plankton, Am. Nat., 95, 137–145, https://doi.org/10.1086/282171, 1961. a
Irwin, A. J., Nelles, A. M., and Finkel, Z. V.: Phytoplankton niches estimated from field data, Limnol. Oceanogr., 57, 787–797, https://doi.org/10.4319/lo.2012.57.3.0787, 2012. a, b, c
Irwin, A. J., Finkel, Z. V., Müller-Karger, F. E., and Ghinaglia, L. T.: Phytoplankton adapt to changing ocean environments, P. Natl. Acad. Sci. USA, 112, 5762–5766, https://doi.org/10.1073/pnas.1414752112, 2015. a, b, c
Isserlis, L.: On certain probable errors and correlation coefficients of multiple frequency distributions with skew regression, Biometrika, 11, 185–190, https://doi.org/10.1093/biomet/11.3.185, 1916. a
Jakobsen, H. H. and Markager, S.: Carbon-to-chlorophyll ratio for phytoplanktoon in temperate coastal waters: Seasonal pattern and relationship to nutrients, Limnol. Oceanogr., 61, 1853–1868, https://doi.org/10.1002/lno.10338, 2016. a
Kinnison, M. T. and Hairston, N. G.: Eco-evolutionary conservation biology: contemporary evolution and the dynamics of persistence, Funct. Ecol., 21, 444–454, https://doi.org/10.1111/j.1365-2435.2007.01278.x, 2007. a, b
Kiørboe, T.: Turbulence, phytoplankton cell size, and the structure of pelagic food webs, Adv. Mar. Biol., 29, 1–72, https://doi.org/10.1016/S0065-2881(08)60129-7, 1993. a
Kiørboe, T., Saiz, E., and Viitasalo, M.: Prey switching behaviour in the planktonic copepod Acartia tonsa, Mar. Ecol. Prog. Ser., 143, 65–75, https://doi.org/10.3354/meps143065, 1996. a
Klauschies, T., Coutinho, R. M., and Gaedke, U.: A beta distribution-based moment closure enhances the reliability of trait-based aggregate models for natural populations and communities, Ecol. Model., 381, 46–77, https://doi.org/10.1016/j.ecolmodel.2018.02.001, 2018. a, b, c
Kremer, C. T. and Klausmeier, C. A.: Coexistence in a variable environment: Eco-evolutionary perspectives, J. Theor. Biol., 339, 14–25, https://doi.org/10.1016/j.jtbi.2013.05.005, 2013. a
Lännergren, C.: Buoyancy of natural populations of marine phytoplankton, Mar. Biol., 54, 1–10, https://doi.org/10.1007/BF00387045, 1979. a
Le Gland, G. and Vallina, S. M.: SPEAD v1.1 (Version v1.1), Zenodo, https://doi.org/10.5281/zenodo.4673500, 2021. a
Le Quéré, C., Harrison, S. P., Prentice, I. C., Buitenhuis, E. T., Aumont, O., Bopp, L., Claustre, H., Cotrim Da Cunha, L., Geider, R., Giraud, X., Klaas, C., Kohfeld, K. E., Legendre, L., Manizza, M., Platt, T., Rivkin, R. B., Sathyendranath, S., Uitz, J., Watson, A. J., and Wolf-Gradow, D.: Ecosystem dynamics based on plankton functional types and for global ocean biogeochemistry models, Global Change Biol., 11, 2016–2040, https://doi.org/10.1111/j.1365-2486.2005.1004.x, 2005. a, b
Lefèvre, M., Vézina, A., Levasseur, M., and Dacey, J. W. H.: A model of dimethylsulfide dynamics for the subtropical North Atlantic, Deep-Sea Res. Pt. I, 49, 2221–2239, https://doi.org/10.1016/S0967-0637(02)00121-8, 2002. a, b
Lenski, R. E., Rose, M. R., Simpson, S. C., and Tadler, S. C.: Long-term experimental evolution in Escherichia coli, I. Adaptation and divergence during 2000 generations, Am. Nat., 138, 1315–1341, https://doi.org/10.1086/285289, 1991. a
Levins, R.: The strategy of model building in population biology, Am. Sci., 54, 421–431, 1966. a
Li, W. K. W.: Cytometric diversity in marine ultraphytoplankton, Limnol. Oceanogr., 42, 874–880, https://doi.org/10.4319/lo.1997.42.5.0874, 1997. a
Litchman, E., Klausmeier, C. A., Schofield, O. M., and Falkowski, P. G.: The role of functional traits and trade-offs in structuring phytoplankton communities: scaling from cellular to ecosystem level, Ecol. Lett., 10, 1170–1181, https://doi.org/10.1111/j.1461-0248.2007.01117.x, 2007. a, b
López-Urrutia, A., San Martin, E., Harris, R. P., and Irigoien, X.: Scaling the metabolic balance of the oceans, P. Natl. Acad. Sci. USA, 103, 8739–8744, https://doi.org/10.1073/pnas.0601137103, 2006. a
Maier-Reimer, E.: Geochemical cycles in an ocean general circulation model, Preindustrial tracer distributions, Global Biogeochem. Cy., 7, 645–677, https://doi.org/10.1029/93GB01355, 1993. a
Marañon, E.: Cell size as a key determinant of phytoplankton metabolism and community structure, Annu. Rev. Mar. Sci., 7, 241–264, https://doi.org/10.1146/annurev-marine-010814-015955, 2015. a, b
Marañon, E., Cermeño, P., López-Sandoval, D. C., Rodríguez-Ramos, T., Sobrino, C., Huete-Ortega, M., Blanco, J. M., and Rodríguez, J.: Unimodal size scaling of phytoplankton growth and the size dependence of nutrient uptake and use, Ecol. Lett., 16, 371–379, https://doi.org/10.1111/ele.12052, 2013. a
Marshall, J., Hill, C., Perelman, L., and Adcroft, A.: Hydrostatic, quasi-hydrostatic, and nonhydrostatic ocean modeling, J. Geophys. Res., 102, 5733–5752, https://doi.org/10.1029/96JC02776, 1997. a
Menzel, D. W. and Spaeth, J. P.: Occurrence of ammonia in Sargasso Sea waters and in rain water at Bermuda, Limnol. Oceanogr., 7, 159–162, https://doi.org/10.4319/lo.1962.7.2.0159, 1962. a
Merico, A., Bruggeman, J., and Wirtz, K.: A trait-based approach for downscaling complexity in plankton ecosystem models, Ecol. Model., 220, 3001–3010, https://doi.org/10.1016/j.ecolmodel.2009.05.005, 2009. a, b, c, d, e
Merico, A., Brandt, G., Smith, S. L., and Oliver, M.: Sustaining diversity in trait-based models of phytoplankton communities, Front. Ecol. Evol., 2, 59, https://doi.org/10.3389/fevo.2014.00059, 2014. a, b, c, d, e, f, g, h, i
Meyer, J. R., Gudelj, I., and Beardmore, R.: Biophysical mechanisms that maintain biodiversity through trade-offs, Nat. Commun., 6, 6278, https://doi.org/10.1038/ncomms7278, 2015. a
Monod, J.: The growth of bacterial cultures, Annu. Rev. Microbiol., 3, 371–395, https://doi.org/10.1146/annurev.mi.03.100149.002103, 1949. a
Murdoch, W. W.: Switching in general predators: experiments on predator specificity and stability of prey populations, Ecol. Monogr., 39, 335–354, https://doi.org/10.2307/1942352, 1969. a
Norberg, J.: Biodiversity and ecosystem functioning: A complex adaptive systems approach, Limnol. Oceanogr., 49, 1269–1277, https://doi.org/10.4319/lo.2004.49.4_part_2.1269, 2004. a
Norberg, J., Swaney, D. P., Dushoff, J., Lin, J., Casagrandi, R., and Levin, S. A.: Phenotypic diversity and ecosystem functioning in changing environments: A theoretical framework, P. Natl. Acad. Sci. USA, 98, 11376–11381, https://doi.org/10.1073/pnas.171315998, 2001. a, b, c, d, e, f, g, h
Norberg, J., Urban, M. C., Vellend, M., Klausmeier, C. A., and Loeuille, N.: Eco-evolutionary responses of biodiversity to climate change, Nat. Clim. Change, 2, 747–751, https://doi.org/10.1038/NCLIMATE1588, 2012. a, b, c, d
Platt, T., Gallegos, C. L., and Harrison, W. G.: Photoinhibition of photosynthesis in natural assemblages of marine phytoplankton, J. Mar. Res., 38, 687–701, 1980. a
Quintana, X. D., Brucet, S., Boix, D., López-Flores, R., Gascón, S., Badosa, A., Sala, J., Moreno-Amich, R., and Egozcue, J. J.: A nonparametric method for the measurement of size diversity with emphasis on data standardization, Limnol. Oceanogr.-Meth., 6, 75–86, https://doi.org/10.4319/lom.2008.6.75, 2008. a, b
Redfield, A. C.: On the proportions of organic derivatives in sea water and their relation to the composition of plankton, in: James Johnstone memorial volume, University Press of Liverpool, 176–192, 1934. a
Riley, G.: Factors controlling phytoplankton populations on Georges Bank, J. Mar. Res., 6, 54–73, 1946. a
Riley, G.: A mathematical model of regional variations in plankton, Limnol. Oceanogr., 10, 202–215, https://doi.org/10.4319/lo.1965.10.suppl2.r202, 1965. a
Rodríguez, J.: Some comments on the size-based structural analysis of the pelagic ecosystem, Sci. Mar., 58, 1–10, 1994. a
Sauterey, B., Ward, B., Rault, J., Bowler, C., and Claessen, D.: The implications of eco-evolutionary processes for the emergence of marine plankton community biogeography, Am. Nat., 190, 116–130, https://doi.org/10.1086/692067, 2017. a
Savage, V. M., Webb, C. T., and Norberg, J.: A general multi-trait-based framework for studying the effects of biodiversity on ecosystem functioning, J. Theor. Biol., 247, 213–229, https://doi.org/10.1016/j.jtbi.2007.03.007, 2007. a, b, c, d, e, f
Schartau, M., Landry, M. R., and Armstrong, R. A.: Density estimation of plankton size spectra: a reanalysis of IronEx II data, J. Plankton Res., 32, 1167–1184, https://doi.org/10.1093/plankt/fbq072, 2010. a
Schlüter, L., Lohbeck, K. T., Gröger, J. P., Riebesell, U., and Reusch, T. B. H.: Long-term dynamics of adaptive evolution in a global important phytoplankton species to ocean acidification, Science Advances, 2, e1501660, https://doi.org/10.1126/sciadv.1501660, 2016. a, b, c, d
Smith, S. L., Vallina, S. M., and Merico, A.: Phytoplankton size-diversity mediates an emergent trade-off in ecosystem functioning for rare versus frequent distrubances, Sci. Rep.-UK, 6, 34170, https://doi.org/10.1038/srep34170, 2016. a, b, c, d, e
Steele, J. H.: Plant production in the northern North Sea, H. M. Stationery Office, Marine Res., Scot. Home Dept., 1958, 1–36, 1958. a
Steinberg, D. K., Carlson, C. A., Bates, N. R., Johnson, R. J., Michaels, A. F., and Knap, A. H.: Overview of the US JGOFS Bermuda Atlantic Time-series Study (BATS): a decade-scale look at ocean biology and biogeochemistry, Deep-Sea Res. Pt. II, 48, 1405–1447, https://doi.org/10.1016/S0967-0645(00)00148-X, 2001. a, b
Strzepek, R. F. and Harrison, P. J.: Photosynthetic architecture differs in coastal and oceanic diatoms, Nature, 431, 689–692, https://doi.org/10.1038/nature02954, 2004. a
Swift, E.: The marine diatom Ethmodiscus rex: Its morphology and occurrence in the plankton of the Sargasso Sea, J. Phycol., 9, 456–460, https://doi.org/10.1111/j.1529-8817.1973.tb04121.x, 1973. a
Taguchi, S.: Relationship between photosynthesis and cell size of marine diatoms, J. Phycol., 12, 185–189, https://doi.org/10.1111/j.1529-8817.1976.tb00499.x, 1976. a
Taylor, A. H., Geider, R., and Gilbert, F. J. H.: Seasonal and latitudinal dependencies of phytoplankton carbon-to-chlorophyll a ratio: results of a modeling study, Mar. Ecol. Prog. Ser., 152, 51–66, https://doi.org/10.3354/meps152051, 1997. a
Terseleer, N., Bruggeman, J., Lancelot, C., and Gypens, N.: Trait-based representation of diatom functional diversity in a plankton functional type model of the eutrophied southern North Sea, Limnol. Oceanogr., 59, 1958–1972, https://doi.org/10.4319/lo.2014.59.6.1958, 2014. a, b
Thingstad, T. F.: Elements of a theory for the mechanisms controlling abundance, diversity, and biogeochemical role of lytic bacterial viruses in aquatic systems, Limnol. Oceanogr., 45, 1320–1328, https://doi.org/10.4319/lo.2000.45.6.1320, 2000. a
Thingstad, T. F. and Lignell, R.: Theoretical models for the control of bacterial growth rate, abundance, diversity and carbon demand, Aquat. Microb. Ecol., 13, 19–27, https://doi.org/10.3354/ame013019, 1997. a
Thingstad, T. F., Øvreås, L., Egge, J. K., Løvdal, T., and Heldal, M.: Use of non-limiting substrates to increase size, a genereic strategy to simultaneously optimize uptake and minimize predation in pelagic osmotrophs?, Ecol. Lett., 8, 675–682, https://doi.org/10.1111/j.1461-0248.2005.00768.x, 2005. a
Thomas, M. K., Kremer, C. T., Klausmeier, C. A., and Litchman, E.: A global pattern of thermal adaptation in marine phytoplankton, Science, 338, 1085–1088, https://doi.org/10.1126/science.1224836, 2012. a, b
Timofeeff-Ressovsky, N. W.: Mutations and geographical variation, in: The new systematics, Clarendon Press Oxford, 73–136, 1940. a
Travisano, M., Mongold, J. A., Bennett, A. F., and Lenski, R. E.: Experimental tests of the role of adaptation, chance, and history in evolution, Science, 267, 87–90, https://doi.org/10.1126/science.7809610, 1995. a
Vallina, S. M.: Reply to a comment by Larsen, S. H. on “Analysis of a potential “solar radiation dose-dimethylsulfide-cloud condensation nuclei” link from global mapped seasonal correlations”, Global Biogeochem. Cy., 22, GB3006, https://doi.org/10.1029/2007GB003099, 2008. a
Vallina, S. M., Sim'o, R., Anderson, T. R., Gabric, A., and Cropp, R.: A dynamic model of oceanic sulfure (DMOS) applied to the Sargasso Sea: Simulating the dimethylsulfide (DMS) summer paradox, J. Geophys. Res., 113, G01009, https://doi.org/10.1029/2007JG000415, 2008. a, b, c
Vallina, S. M., Follows, M. J., Dutkiewicz, S., Montoya, J. M., Cermeño, P., and Loreau, M.: Global relationship between phytoplankton diversity and productivity in the ocean, Nat. Commun., 5, 4299, https://doi.org/10.1038/ncomms5299, 2014a. a, b
Vallina, S. M., Ward, B. A., Dutkiewicz, S., and Follows, M. J.: Maximum feeding with active prey-switching: A kill-the-winner functional response ad its effect on global diversity and biogeography, Prog. Oceanogr., 120, 93–109, https://doi.org/10.1016/j.pocean.2013.08.001, 2014b. a, b, c
Vallina, S. M., Cermeño, P., Dutkiewicz, S., Loreau, M., and Montoya, J. M.: Phytoplankton functional diversity increases ecosystem productivity and stability, Ecol. Model., 361, 184–196, https://doi.org/10.1016/j.ecolmodel.2017.06.020, 2017. a, b, c, d, e
Vallina, S. M., Martinez-Garcia, R., Smith, S. L., and Bonachela, J. A.: Models in microbial ecology, in: Encyclopedia of microbiology, Elsevier, Amsterdam, Netherlands, 211–246, https://doi.org/10.1016/B978-0-12-809633-8.20789-9, 2019. a, b, c
Villareal, T. A.: Positive buoyancy in the oceanic diatom Rhizosolenia debyana H. Peragallo, Deep-Sea Res. Pt. I, 35, 1037–1045, https://doi.org/10.1016/0198-0149(88)90075-1, 1988. a
Villareal, T. A. and Carpenter, E. J.: Chemical composition and photosynthetic characteristics of Ethmodiscus rex (Bacillariophyceae): Evidence for vertical migration, J. Phycol., 30, 1–8, https://doi.org/10.1111/j.0022-3646.1994.00001.x, 1994. a
Volk, T. and Hoffert, M. I.: Ocean Carbon Pumps: Analysis of Relative Strengths and Efficiencies in Ocean-Driven Atmospheric CO2 Changes, in: The Carbon Cycle and Atmospheric CO2: Natural Variations Archean to Present, edited by: Sundquist, E. and Broecker, W., American Geophysical Union, Washington, D.C., United States, 99–110, https://doi.org/10.1029/GM032p0099, 1985. a
Walsh, J. J., Dieterle, D. A., and Lenes, J.: A numerical analysis of carbon dynamics of the Southern Ocean phytoplankton community: the role of light and grazing in effecting both sequestration of atmospheric CO2 and food availability to larval krill, Deep-Sea Res. Pt. I, 48, 1–48, https://doi.org/10.1016/S0967-0637(00)00032-7, 2001. a
Ward, B. A. and Follows, M. J.: Marine mixotrophy increases trophic transfer efficiency, mean organism size, and vertical carbon flux, P. Natl. Acad. Sci. USA, 113, 2958–2963, https://doi.org/10.1073/pnas.1517118113, 2016. a
Ward, B. A., Dutkiewicz, S., Jahn, O., and Follows, M. J.: A size-structured food-web model for the global ocean, Limnol. Oceanogr., 57, 1877–1891, https://doi.org/10.4319/lo.2012.57.6.1877, 2012. a
Ward, B. A., Collins, S., Dutkiewicz, S., Gibbs, S., Bown, P., Ridgwell, A., Sauterey, B., Wilson, J. D., and Oschlies, A.: Considering the role of adaptive evolution in models of the ocean and climate system, J. Adv. Model. Earth Sy., 11, 3343–3361, 2019. a
Whitelam, G. C. and Codd, G. A.: Photoinhibition of photosynthesis in the cyanobacterium Microcystis areruginosa, Planta, 157, 561–566, https://doi.org/10.1007/BF00396889, 1983. a
Wickman, J., Diehl, S., and Bränström, Â.: Evolution of resource specialisation in competitive metacommunities, Ecol. Lett., 22, 1746–1756, https://doi.org/10.1111/ele.13338, 2019. a
Wirtz, K. W.: A generic model for changes in microbial kinetic coefficients, J. Biotechnol., 97, 147–162, https://doi.org/10.1016/S0168-1656(02)00064-0, 2002. a
Wirtz, K. W.: Mechanistic origins of variability in phytoplankton dynamics: Part I: niche formation revealed by a size-based model, Mar. Biol., 160, 2319–2335, https://doi.org/10.1007/s00227-012-2163-7, 2013. a, b, c
Wirtz, K. W. and Eckhardt, B.: Effective variables in ecosystem models with an appliation to phytoplankton succession, Ecol. Model., 92, 33–53, https://doi.org/10.1016/0304-3800(95)00196-4, 1996. a, b, c, d, e, f
Yoshida, T., Hairston, N. G., and Ellner, S. P.: Evolutionary trade-off between defence against grazing and competitive ability in a simple unicellular alga, Chlorella vulgaris, P. Roy. Soc. B-Biol. Sci., 271, 1947–1953, https://doi.org/10.1098/rspb.2004.2818, 2004. a
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Why mutations can be represented as trait diffusion
- Appendix B: Differential equations of a multi-trait aggregate model with trait diffusion
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Why mutations can be represented as trait diffusion
- Appendix B: Differential equations of a multi-trait aggregate model with trait diffusion
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement