the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 12 Jul 2024
| 12 Jul 2024
STORM v.2: A simple, stochastic rainfall model for exploring the impacts of climate and climate change at and near the land surface in gauged watersheds
Manuel F. Rios Gaona
Katerina Michaelides
Michael Bliss Singer
Climate change is expected to have major impacts on land surface and subsurface processes through its expression in the hydrological cycle, but the impacts to any particular basin or region are highly uncertain. Non-stationarities in the frequency, magnitude, duration, and timing of rainfall events have important implications for human societies, water resources, and ecosystems. The conventional approach for assessing the impacts of climate change is to downscale global climate model output and use it to drive regional and local models that express the climate within hydrology near the land surface. While this approach may be useful for linking global general circulation models to the regional hydrological cycle, it is limited for examining the details of hydrological response to climate forcing for a specific location over timescales relevant to decision-makers. For example, the management of a flood or a drought hazard requires detailed information that includes uncertainty based on the variability in storm characteristics rather than on the differences between models within an ensemble. To fill this gap, we present the second version of our STOchastic Rainfall Model (STORM), an open-source and user-friendly modelling framework for simulating a climatic expression as rainfall fields over a basin. This work showcases the use of STORM in simulating ensembles of realistic sequences, and spatial patterns of rainstorms for current climate conditions, and bespoke climate change scenarios that are likely to affect the water balance near the Earth's surface. We outline and detail STORM's new approaches as follows: one copula for linking marginal distributions of storm intensity and duration; orographic stratification of rainfall using the copula approach; a radial decay rate for rainfall intensity which takes into consideration potential, but unrecorded, maximum storm intensities; an optional component to simulate storm start dates and times via circular/directional statistics; and a simple implementation for modelling future climate scenarios. We also introduce a new pre-processing module that facilitates the generation of model input in the form of probability density functions (PDFs) from historical data for subsequent stochastic sampling. Independent validation showed that the average performance of STORM falls within 5.5 % of the historical seasonal total rainfall in the Walnut Gulch Experimental Watershed (Arizona, USA) that occurred in the current century.
- Article
(9919 KB) - Full-text XML
- BibTeX
- EndNote





In earlier research (Singer et al., 2018; Singer and Michaelides, 2017), we introduced the STOchastic Rainstorm Model (STORM, https://github.com/blissville71/STORM, last access: 7 July 2024), presented the justification for its creation, and demonstrated its application to simulating spatial rainfall fields at Walnut Gulch Experimental Watershed (WGEW; Sect. 2.1), an intensely gauged semi-arid watershed in Arizona, USA. In this paper, we introduce STORM v.2 and highlight the novel aspects of the model that warrant a new version number. We made several changes to the model that make it more user-friendly and enhance its capability for simulating rainfall in a manner that supports computation of the water balance over gauged watersheds under historical climate or under various user-defined scenarios of climate change. Specifically, STORM v.2 (a) treats rainstorm intensity and duration as joint variables in a copula framework, rather than as independent variables, which overcomes a shortcoming in the previous version of the model; (b) offers an elevation stratification to account for orographic characteristics influencing precipitation, where the aforementioned copula framework can also be applied; (c) improves on the radial decay rate model for rainfall intensity to incorporate potential, but unrecorded, maximum storm intensities; (d) accounts for storm start dates and times from the perspective of circular/directional statistics, supporting a more realistic diurnal and seasonal timing of rainfall; and (e) contains a pre-processing module that automatically generates all the input probability density functions (PDFs) required for storm simulation. These advances, which will be discussed in detail below, were required to create a model that is faithful to the underlying rainfall processes (e.g. capturing relationships between rainstorm intensity, duration, and frequency) while also enabling broad uptake and easy use of the model for a range of purposes and for any small basin with available storm rainfall data.
An individual rainstorm (discrete in space and time) has an intensity that varies spatially from the centre of the storm to its margins and a duration over which an average intensity is expressed. Rainstorm intensity and duration are related in the sense that the highest-intensity storms are generally short-lived, while long rainstorms have a low average intensity. The functional form of the relationship between rainfall intensity and duration is typically characterized as a negative exponential, where intensity declines with duration (Nicholson, 2011). However, in rain gauge data, there can be dramatic scatter in this relationship, so a single-valued function cannot represent the phase space between intensity and duration. To overcome this limitation, the previous version of STORM fitted the relationship for the upper envelope of the intensity–duration phase space and then used the functional form of the fitted curve to fit additional curves that pass through the entire phase space (Singer et al., 2018). These empirical intensity–duration curves are then treated as a stochastic variable for random selection within the original STORM code. To further enable complete sampling of the entire phase space of intensity and duration, STORM 1.0 also includes a fuzzy tolerance such that storm intensity for the selected duration can vary up or down away from the selected curve.
This representation of intensity and duration is the crux of STORM 1.0, as it forms the basis for rainstorm characteristics that affect rainfall totals during a storm, over a season, and over the longer term. However, this approach has several weaknesses: (a) it is based on debatable, heuristic rules of probability designation; (b) it does not capture the inherent multi-valued relationship between rainfall intensity and duration; (c) the functional form of the relationship is assumed based on the upper envelope of the phase space; and (d) there is an arbitrary number of curves used to represent the phase space. Notably, we also use the curve number probabilities to represent orography in STORM 1.0. This means that the representation of orography in STORM 1.0 contains these same weaknesses.
The relationship between rainfall intensity and duration is a critical attribute of rainstorms that affects the characteristics of water delivery to the land surface, which affect the balance between infiltration and evapotranspiration and the corresponding antecedent moisture condition at any point in time and space. Thus, it is critical to characterize the distribution of storm intensity–duration from historical records, as well as the frequency of their occurrence. STORM v.2 now offers a better characterization of storm intensity–duration relationship by adopting a copula approach.
Copulas (or copulae), from the Latin word for “tie”, represent a way forward for characterizing the complex relationship between intensity and duration from the perspective of joint frequency of occurrence (Vandenberghe et al., 2011). A copula is a function that links/couples a multi-variate distribution function to its univariate marginals, regardless of any prior knowledge of such marginals (see Sect. 2.6). The copula approach obviates the need for fitting intensity–duration curves and for the arbitrary assignment of curve probabilities. Once the intensity–duration copula is fit, it can be sampled randomly to simulate the rainstorm characteristics.
Another shortcoming in STORM 1.0 was its reliance on user-developed PDFs as input to the model. We recognize that this requirement may be a major limitation which prevents some users from deciding to use STORM for rainstorm simulation. To make STORM more user-friendly, we added the pre-processing and visualization modules that, respectively, allow the automation in computing the best fit of PDFs on (input) gauge data and the visualization of the (output-modelled) storms (see Sect. 2.9).
We provide STORM v.2 (and its pre-processing and visualization modules, along with test/processed input data and parameters) as open-source code (https://github.com/feliperiosg/STORM2, last access: 7 July 2024). Unlike STORM 1.0, STORM v.2 is written only in Python 3 (Van Rossum and Drake, 2009). From here onwards, we will refer to STORM v.2 simply as STORM.
STORM is our contribution to the wealth of stochastic rainfall generators (SRGs) currently available. A state-of-the-art review of SRGs lies beyond the scope of this work. Nevertheless, here we briefly acknowledge some of the vast work carried out in this field during the last 2 decades. Stochastorm, developed by Wilcox et al. (2021), is a high spatiotemporal (of the order of kilometres and minutes) SRG for convective storms. It is event-based (like STORM), built upon a meta-Gaussian framework, and also able to generate rainfall fields. Vu et al. (2018) evaluated the performance of five stochastic weather generators (SWGs), namely CLIGEN, ClimGen, LARS-WG, RainSim, and WeatherMan. Nevertheless, Vu et al. (2018) focused their analyses, for the aforementioned five models, on characteristics of rainfall such as occurrence, intensity, and wet/dry spells over three climatic regions around the globe. Unlike STORM, which only focuses on rainfall, SWGs (e.g. Papalexiou et al., 2021; Peleg et al., 2017) are frameworks built to also model climatic variables other than rainfall, e.g. temperature and wind velocity/direction. Like STORM, another open-source framework is that of Benoit et al. (2018), which generates conditional or unconditional high-resolution (100 m; 2 min) continuous rain fields over small areas. Kleiber et al. (2012) developed a Gaussian-process framework that allows the generation of gridded rainfall fields (accounting for uncertainties in their estimates too). Similar to STORM, their model captures local and domain-aggregated rainfall from daily and seasonal to annually scales. Other open-source SRG frameworks, both based on the Neyman–Scott process, are STORAGE (STOchastic RAinfall GEnerator; De Luca and Petroselli, 2021), which generates long and high-resolution (1 or 5 min) time series, and NEOPRENE (Neyman-Scott Process Rainfall Emulator; Diez-Sierra et al., 2023), which simulates rainfall from the hourly to daily scale. Like STORM, NEOPRENE is also coded in Python. Other SRGs based on the Poisson process are RainSim V3 (Burton et al., 2008), designed for catchments up to 5000 km2 and timescales from hourly to yearly, and Let-It-Rain (Kim et al., 2017), which generates stochastic 1 h rainfall time series. AME (Advanced Meteorology Explorer) is a SRG for high spatial resolutions at daily temporal scales. Developed by Dawkins et al. (2022), AME is based on a hidden Markov model (HMM) that is able not only to capture observed rainfall but also meteorological drought behaviour. STREAP (Space–Time Realizations of Areal Precipitation; Paschalis et al., 2013) is also a high-resolution (10 min to daily in time; a few tens of kilometres in space) SRG. Both Dawkins et al. (2022) and Paschalis et al. (2013) provide a plethora of references to alternative stochastic frameworks in rainfall simulation. The latter also provides a detailed review of advances in stochastic spatiotemporal rainfall modelling, grouped into four categories, namely point process theory, random fields theory, multi-fractal processes, and “multi-site temporal simulation framework”.
Our model differs from the aforementioned ones in several ways. STORM is an open-source framework (accessible via it repositories) and built upon a free/open-source software platform (i.e. Python). This implies that anybody, from any computational platform, can modify and improve STORM according to their needs. Some of the SRGs cited here are not open-source, and some of the freely available SRGs (e.g. De Luca and Petroselli, 2021; Benoit et al., 2018; Kim et al., 2017) were built upon commercial applications (i.e. not open-source software). In our opinion, this is a key factor that plays against their widespread usability and/or deployability. Most of the SRGs parameterize the “inter-arrival” time (i.e. time between storms) via a PDF. STORM, via its circular framework, indirectly, and rather straightforwardly, characterizes this parameter by modelling instead the storm starting dates and times (see Sect. 2.7). Through a couple of scaling factors (see Sect. 2.8), STORM is able to simulate rainfall fields from potential climate change scenarios. This is a clever and modular functionality not present in many of the SRGs.
STORM is a stochastic model built upon continuous PDFs for seven variables, i.e. total seasonal rainfall (TOTALP), maximum storm radius/extent (RADIUS), rainfall decay rate from the storm centre outwards (BETPAR), maximum intensity (MAXINT), average duration (AVGDUR), storm start date (DOYEAR), and storm start time (DATIME). Here we model the relation between the storm's maximum intensity and its average duration via a copula approach (COPULA). STORM also allows the stratification of the copula approach based on the orography of the region, where one can specify maximum_intensity–average_duration copulas for every elevation band into which the catchment is split. This “elevation stratification”, along with the storm start time, is an optional feature in STORM. A digital elevation model (DEM) is required to model orographic effects, whereas a specific circular statistics library must be installed to model the starting times of rainstorms.
STORM also preserves the functionality of STORM 1.0 to simulate the impact of plausible climate change either on the total seasonal rainfall or the storm's maximum intensity. Such functionality is applied through two types of mutually exclusive factors: _SC (i.e. step change), which is constantly applied to every and each of the simulated years, and _SF (i.e. scaling factor), which is progressively applied to all of the simulated years. Hence, for potential/climate impacts on the total seasonal rainfall, these factors are dubbed PTOT_SC and PTOT_SF, whereas for potential/climate impacts on the maximum rainfall intensity, these factors are dubbed STORMINESS_SC and STORMINESS_SF (see Sect. 2.8).
2.1 Walnut Gulch Experimental Watershed
The Walnut Gulch Experimental Watershed1 is the catchment selected to calibrate and validate STORM. With an area of 147.75 km2, and managed by the USDA-ARS2 Southwest Watershed Research Center (SWRC), it is located near Tombstone, southwestern Arizona, USA. WGEW is situated at the transition between the Chihuahuan and Sonoran deserts and is located on a bajada sloping gently westwards from the Dragoon Mountains, reaching the San Pedro River at Fairbank, Arizona. The climate is semi-arid with a low average annual rainfall of ∼312 mm for the period 1956–2005 (Goodrich et al., 2008) (or 350 mm (Keefer et al., 2007) for an undisclosed period). Convective thunderstorms during the summer monsoon season (July–September) generate 60 % of the annual precipitation and are characterized by high spatial variability, limited areal extent, and high-intensity short-duration rainfall (Osborn, 1983; Osborn and Lane, 1969; Renard and Keppel, 1966). In this watershed, storm events have frequently been found to exceed intensities of 100 mm h−1 at the centre of the storm, lasting on the order of minutes (Nicholson, 2011; Renard and Laursen, 1975). Keefer et al. (2007) offer a detailed report on the physiography, instrumentation, and different applications on the WGEW.
Dating back from the early-/mid-1950s (Meles et al., 2022; Stillman et al., 2013), the WGEW is, according to Moran et al. (2008), “one of the most highly instrumented semi-arid experimental watersheds in the world”. Its rain gauge network is one the densest in the world for watersheds greater than 10 km2 (∼0.6 gauges km−2 (Goodrich et al., 2008); or one gauge per 1.7 km2 (Meles et al., 2022)). Storm rainfall data date back from 1953 (Moran et al., 2008), and up to 1999, the entire gauge network was analogue. From 2000 to the present, the gauge network was updated to a digital network (Meles et al., 2022; Goodrich et al., 2008). From the dataset used in this work, there were a total of 93 digital stations (as of 2022), averaging 84 stations per year since 2000. Figure B8 shows the gauge network used in this study.
We parameterize STORM using 37 years of analogue data (i.e. from 1963 through 1999). Even though there are gauge records for the WGEW from 1953, we use them starting from 1963 to account at least for 80 gauges per year. This analogue network amounts to 118 gauges sparsely deployed over the whole WGEW. We carried out simulations of 30 runs, with each run having 23 simulated years (i.e. 690 simulation years in total per simulation), in order to evaluate the performance of STORM on features such as seasonal total rainfall (over a small catchment), the number of storms generated, and the modelled climate impacts in rainfall intensity. The output of this evaluation exercise(s) was compared against 23 years of storm data from the aforementioned digital/automatic network, i.e. the one from 2000 onwards (see Sect. 3.1).
The richness and careful curation (for more than half a century) of this dataset, especially with regard to the high density of rain gauges and detailed and lengthy rainstorm records, was the main reason our model was designed and built with a focus on this particular catchment. Such data richness might not be the norm in other catchments around the globe. Nevertheless, nothing precludes the application of STORM to other (small) catchments in any climatic zone, as long as some detailed rainstorm records exist for the related area/catchment. The effect of the number and extension of rainstorm data on the performance of STORM is beyond the scope of the present work. Given the set-up of our model, it is expected that the richer the (rain gauge) records, the more robust the parameterization is, and therefore the better the performance of STORM will be.
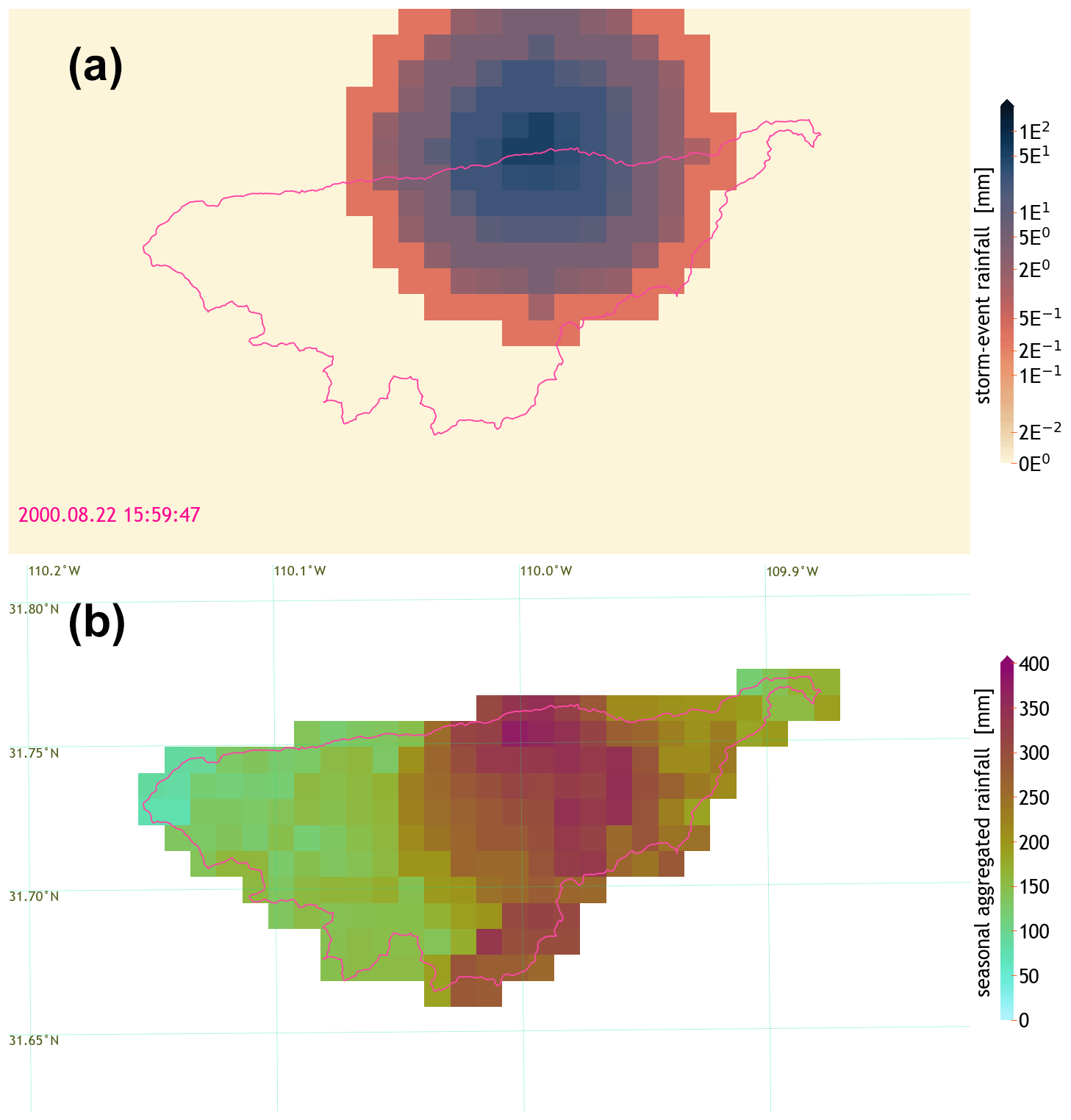
Figure 1Spatiotemporal distribution of simulated storm rainfall over the WGEW (see Sect. 2.1). Spatial resolution of 1×1 km. (a) One large simulated storm starting at ∼ 16:00 MST on 22 August, with a radius of ∼7 km, ∼4.5 h duration, and a maximum intensity of ∼51.3 mm (i.e. 11.37 mm h−1). Please note its logarithmic colour scale. (b) Cumulative seasonal distribution of 112 simulated storms for the wet season, i.e. from June through October. Even though the grid is presented in “lat–long” coordinates (i.e. CRS WGS-84), the actual projection (in both panels) is the 2D Cartesian coordinate system known as NAD83/UTM zone 12N (i.e. EPSG:26912; https://epsg.io/26912, last access: 7 July 2024).
2.2 Total seasonal rainfall (TOTALP)
In order to remain faithful to the total seasonal rainfall distribution across a basin of interest, STORM stops a given simulation season once the median of the cumulative rainfall over the catchment surpasses the sampled TOTALP value for the season under consideration. The TOTALP value is sampled from a PDF of historical medians of total seasonal storm rainfall. Each of these historical medians represents the spatial median of the cumulative seasonal rainfall recorded by the gauge network spread within the catchment. To avoid sampling negative values of rainfall, the fitting (and the sampling) of the PDF is done in (natural) logarithmic space, i.e. . Reaching the (catchment) median sampled from a distribution of historical medians offers a more accurate method for stochastic modelling of seasonal totals. Figure 1b shows the spatial distribution of rainfall at the end of one simulation run; i.e. once the median of the cumulative rainfall over the catchment is larger than the sampled value for TOTALP.
2.3 Maximum storm extent (RADIUS)
Storm radii are defined in STORM by grouping two or more gauges, computing the distance of each gauge to the centroid of the set/group of gauges, and selecting the maximum computed distance. Here, a “set/group of gauges” means all those gauges for which the time stamp of any storm start time is identically recorded among them in the historical database. A PDF of radii was generated from such groups with at least two rain gauges. We are aware that this assumption does not consider the extent, evolution, and/or trajectory of any storm in particular throughout the gauge data. Nevertheless, by assuming that identical time stamps in storm start times imply that the whole storm is being simultaneously captured by the gauge network, one can easily estimate an extension of the storm from gauge records. This premise also relies on the assumption of a circular-shaped model for storm cells and on a gauge network with consistent spatial density. Figure B1 shows the distribution of maximum storm (estimated) radii for the WGEW calibration dataset (i.e. storms recorded from August 1953 through October 1999; see Sect. 2.1). Figure 1a shows a simulated storm with a radius of ∼7 km. This approach is biased towards spatially large storms given that small-radii storms; i.e. storms not captured by a single gauge are disregarded in this methodology.
The minimum radius that can be sampled is restricted by the spatial resolution the user might set for the model output. For instance, for a model output resolution of 0.5×1.0 km, the minimum possible (sampled) radius would be 1 km. This is achieved by truncating the RADIUS PDF and then sampling from it. Instead of using a “maximum” criterion for the selection of storm radii, the user can also modify this criterion to be, e.g., the mean (or median or whatever) distance of a group of gauges and their centroid. This change can be implemented by the user via the pre_processing.py script. STORM 1.0 did not use a “radius” approach. Instead, storm area values were sampled from a pre-determined, fixed PDF.
2.4 Rainfall decay rate (BETPAR) and maximum storm intensity (MAXINT)
Following the approach of STORM 1.0, we model individual storms as isotropic circular cells, for which maximum intensities (Imax) are (always) located at their centres, with a quadratic exponential decay (β2) as the distance from such centres (r) increases:
where I(r) (in mm h−1) is the rainfall intensity at a distance r (in km) from the storm centre. β has units of km−1. We acknowledge that real storms may not be circular, but this assumption simplifies the mathematical representation of storms in the model.
In this new version, we use the quadratic exponential decay model to fit both the decay rate (β), and maximum intensity (Imax). This is done via scipy's module curve_fit; i.e. a non-linear least squares approach for which the trust region reflective method is applied, given the constraints we enforce to our minimization problem (Virtanen et al., 2020; Branch et al., 1999). Such constraints simply refer to the limits for which one intends β and Imax (in this case) to be within. For instance, and following Eagleson et al. (1987, Fig. 17), we bound β between zero and three, whereas we set Imax to be 3 times the highest intensity found in the gauge data as the upper limit and a value slightly above zero as the lower limit (0.07 mm h−1 in our case). Morin et al. (2005) and Eagleson et al. (1987) previously used the same model to fit rainfall decay rate from radar and gauge data, respectively, for the WGEW. Figure 1a shows a simulated storm with a steep β of and .
We fit the model for storms simultaneously registered by four or more gauges (i.e. with identical starting time stamps). Along with the optimal values for which the model is fitted, curve_fit also returns the estimated covariance of such optimal values. We only kept optimal values for which their covariance is equal or smaller than 5 and equal to or larger than 0. These “clean” optimal values are the ones over which the PDFs (BETPAR and MAXINT) are then constructed. We obtained similar results (not shown here) to Morin et al. (2005) and Eagleson et al. (1987) for the PDF of β. In our case, βmean≈0.1, compared to ∼0.4 for the Morin et al. (2005) and Eagleson et al. (1987) studies. This is mainly attributed to our methodology of simultaneously fitting both Imax and β. We also hit the μ≈0.4 when we only fit for β when using a larger number of storm records than they did in those previous studies.
We assume that in the vast majority of the cases, the rainfall recorded by the gauge network does not correspond to the maximum intensity of the storm event; thus, we required a method to model maximum storm intensity (MAXINT). Equation (1) is an adequate model that allows us to easily estimate the maximum rainfall intensity from gauge records (given the current computational tools and the extensive rainfall records). Figure B2 shows the difference between PDFs accounting (and not) for maximum intensity. Accounting for maximum storm rainfall intensity is a feature not present in STORM 1.0.
2.5 Storm average duration (AVGDUR)
The AVGDUR PDF is constructed from the corresponding optimal values for maximum intensity (MAXINT) (see Sect. 2.4). Once a “group of gauges” affected by a storm is established (see Sect. 2.3), storm duration is modelled as the average of all storm durations registered within this group. Nevertheless, the storm total duration registered by each gauge does differ from gauge to gauge, mainly due to the movement of the storm front over the gauge network. Thus, for every fit of Eq. (1) to a group of gauges (for which Imax and β are estimated), an average storm duration is also retrieved. And after selecting the best fits, with average storm durations included, we then proceed to fit the AVGDUR PDF.
2.6 Copula approach (MAXINT–AVGDUR COPULA)
The cornerstone of a copula framework is (set on) Sklar's theorem (e.g. Hofert et al., 2018, Chap. 1; Joe, 2014, Chap. 1; Nelsen, 2006, Chap. 2) which states that for any d-dimensional (joint) distribution function H with univariate marginals (margins) , there exists a d-dimensional copula C such that
If the univariate marginals are continuous, then C is uniquely defined on [0,1]d. In simpler terms, a copula is a function that links/couples (thus its etymology) a multi-variate (joint) distribution function to its univariate marginals with no prior knowledge of the actual shape (or type) of such marginals (e.g. Zhang and Singh, 2019; Hofert et al., 2018; Dai et al., 2014; Vandenberghe et al., 2011; Nelsen, 2006).
Elliptical copulas (which show elliptically contoured density level surfaces) refer to copulas from elliptical distributions (e.g. Tjøstheim et al., 2022, Chap. 5; Mai and Scherer, 2017, Chap. 4). An elliptical distribution represents a linear transformation of spherical distributions (Mai and Scherer, 2017, Chap. 4), with these being extensions of multi-normal distributions (Fang et al., 1990, Chap. 2). The vast majority of application from elliptical copulas are found in financial sciences (Genest et al., 2009; The Economist, 2009). Nonetheless, there are recent applications of elliptical copulas in hydrometeorology such as modelling radar rainfall uncertainty (Dai et al., 2014) and establishing the seasonal correlation between the El Niño–Southern Oscillation (ENSO), Pacific Decadal Oscillation (PDO), and precipitation (Khedun et al., 2014), for example. Chen and Guo (2019) and Zhang and Singh (2019) provide a thorough review of recent advances and applications of copulas (elliptical among others) in several areas of hydrology fields such as extreme analysis, drought(s), rainfall, flood (frequency, forecasting, and risk), streamflow, water quality, and suspended sediment transport. Elliptical copulas are very common and advantageous as they allow the specification of different levels of global correlation between marginals (Tjøstheim et al., 2022, Chap. 5). Nevertheless, they offer no simple closed-form expressions; that is, they have only implicit analytical expressions/solutions (Mai and Scherer, 2017, Chap. 4).
A (d-variate) Gaussian (i.e. standard normal) copula belongs to the parametric family of the elliptical copulas (e.g. Mai and Scherer, 2017, Fig. 4.1), and it is described by the functional form (e.g. Mai and Scherer, 2017, Chap. 4):
where ΦP is the joint cumulative distribution function (CDF) of a d-variate Gaussian distribution; Φ−1 is the univariate Gaussian inverse CDF (i.e. the quantile function); and P is the d×d correlation matrix of multi-variate normal random vector, with denoting that the copula is parameterized by the parameters of the correlation matrix (McNeil et al., 2015, Chap. 7).
STORM uses a bi-variate Gaussian copula to model the dependence between storm rainfall intensity and duration. In a d-variate Gaussian copula, the d×d correlation matrix could be replaced by a/the covariance matrix (Mai and Scherer, 2017, Chap. 4). For the bi-variate case, i.e. d=2, becomes , with ρ as the (scalar) Pearson correlation coefficient (e.g. Tjøstheim et al., 2022, Chap. 5; McNeil et al., 2015, Chap. 7; Joe, 2014, Chap. 4). In doing so, the parameterization is reduced to its minimum (only dependent on ρ), allowing its (relatively) easy implementation and therefore its popularity. Still, a bi-variate (or any d variate, for that matter) Gauss copula does not have a simple closed form but can be expressed as an integral over the density of a bi-variate normal random vector (e.g. McNeil et al., 2015, Chap. 7; Ross, 2013, Chap. 6):
STORM constructs the bi-variate Gaussian copula via the GaussianCopula module from the statsmodels package (Joe, 2014; Seabold and Perktold, 2010). First, during the pre-processing stage (Sect. 2.9), the Pearson correlation coefficient ρ is obtained through Greiner's equality (Berger, 2016):
where τ is Kendall's rank correlation (also known as Kendall's tau) (Virtanen et al., 2020; Kendall, 1945). A rank correlation is a copula-based measure of the (strength of the) dependence; i.e. it only depends on the copula (of a bi-variate distribution) and not on the marginals (McNeil et al., 2015, Chap. 7). It is computed from the ranks of the (empirical) data, which means one only needs the ordering of the random variables and not the actual values, i.e. storm intensity and duration in this case. Equation (5) generally holds for elliptical copulas (from which the bi-variate Gaussian is a member), offering a simple approach to compute ρ without the estimation of variances and covariances (Langworthy et al., 2021; McNeil et al., 2015, Chap. 6). Then, during a simulation (or validation) run, the bi-variate normal distribution is constructed from Eqs. (5) and (4) using the probability integral transform (Seabold and Perktold, 2010). Once the (bi-variate) Gaussian copula is built, n samples are randomly sampled from it. These samples are drawn from the CDF space; hence, each sample, i.e. (u,v) point, must be transformed (back) into the intensity–duration space. This transformation is done throughout the marginal PDFs (and their ppf objects from scipy's module stats). During the pre-processing stage, STORM builds the marginal PDFs for intensity and duration from the input gauge data.
Figure 2 shows a comparison between storm rainfall measured by rain gauges and simulated from a bi-variate Gaussian copula. From this figure, one can see that for the simulated exercise (Fig. 2b), STORM generates storms with higher (and lower) intensities than those actually observed by the gauge network (Fig. 2a), supporting a wider distribution of potential storm characteristics.
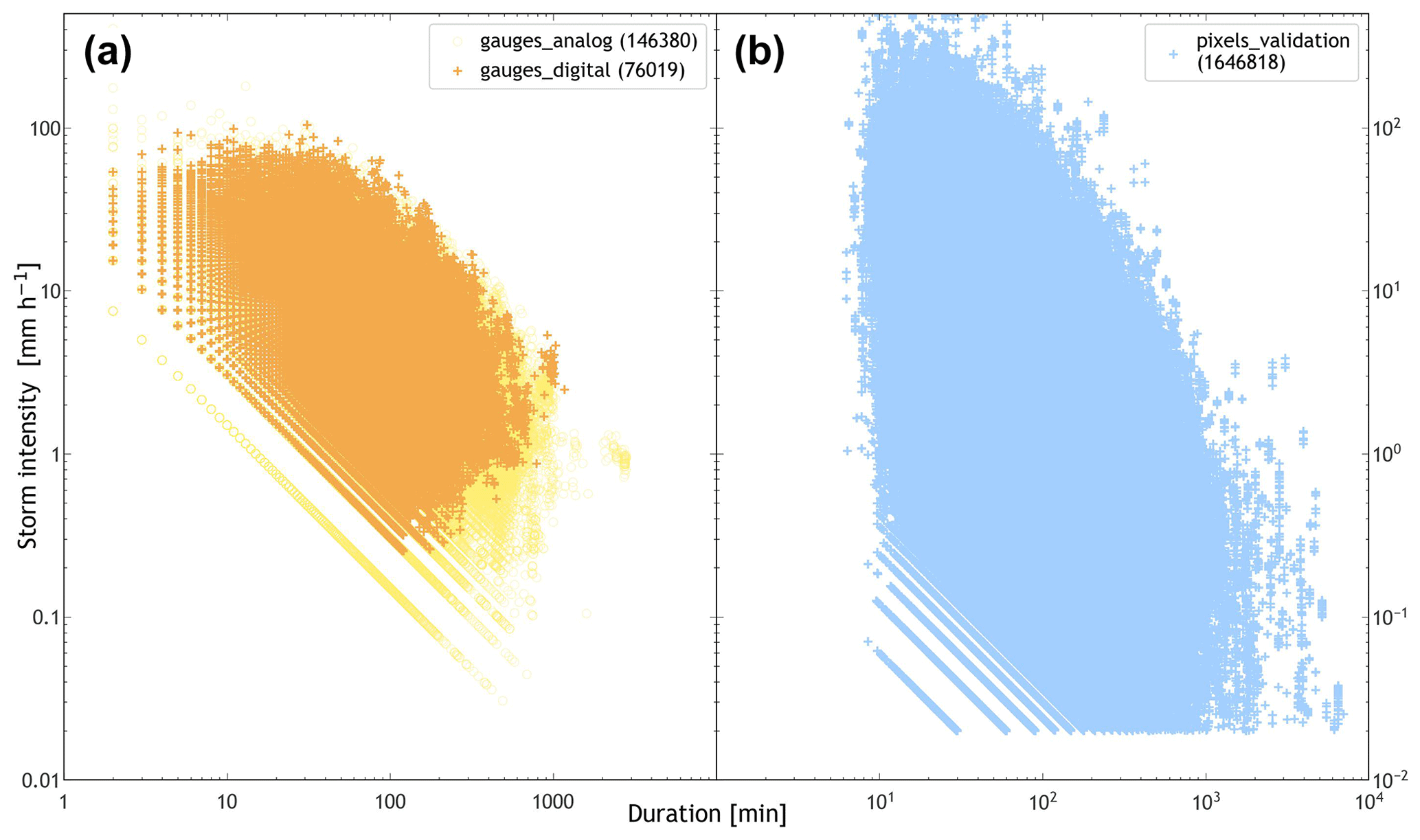
Figure 2Scatter plots of storm intensity (y axis; mm h−1) against storm duration (x axis; min) in log–log scale for gauge and validation datasets. (a) Recorded storms for the wet season (i.e. June through October) over the WGEW (see Sect. 2.1). The orange markers/crosses are records from the digital network, i.e. gauges from 2000 onwards (from June 2000 through October 2022; i.e. the validation dataset). The yellow markers/circles are records from the analogue network, i.e. gauges prior to 2000 (from August 1953 through October 1999; i.e. the calibration dataset). (b) The 23 years of simulated storms, with each year having 30 runs. These storm intensity–duration “pairs” are obtained from the marginal PDFs fitted in the pre-processing module (see Sect. 2.9) for storm maximum intensity (MAXINT) and average duration (AVGDUR), after being randomly sampled (in the CDF-space) from a bi-variate Gaussian copula (Eq. 4) with .
2.7 Day of year (DOYEAR) and time of day (DATIME)
Realistic storm start dates and times can now be sampled in STORM through a modular implementation of directional (or circular) statistics. Directional statistics take into consideration the periodicity of random variables that can be distributed in a closed space, e.g. torus, sphere, and circle (Breitenberger, 1963). The day of the year (DOY) and the time of the day (TOD) of an occurring storm belong to such a set of variables. This innovation supports the analysis of how rainfall accumulates throughout a season and how rainfall timing might be biased by the diurnal cycle (e.g. afternoon rainfall occurrence due to convective heating of the land surface).
STORM models storm start dates and times throughout a finite mixture of unimodal von Mises (vM) distributions. The vM distribution (also known as the Tikhonov distribution; e.g. Shmaliy, 2005) is a widely used PDF (in the circle space) given its simplistic parameterization and mathematical tractability (e.g. Pewsey et al., 2013; Mardia and Jupp, 1999). The vM distribution is a close approximation of distributions such as the cardioid, the wrapped Cauchy, and the wrapped normal. This latter distribution (as its name suggests) is the equivalent of wrapping the normal distribution (from the linear space) into the circular space (Mardia and Jupp, 1999, Chap. 3).
The model for a finite mixture of vM (MvM) PDFs (for a random variable θ) is given by (e.g. Jammalamadaka and SenGupta, 2001, Chap. 4.3)
with 0⩽θ, μi<2π, , and .
In Eq. (6), pi is the mixing proportion of the i unimodal vM distribution (i.e. everything to the right of pi), κ for κ⩾0} is the concentration parameter that quantifies the sparseness/spreading of the distribution around its mean direction μ and I0(κ) is the modified Bessel function of the first kind with order 0 and argument κ. Jammalamadaka and SenGupta (2001, Eq. 2.2.7) and/or Mardia and Jupp (1999, Eq. 3.5.19), for instance, define I0(κ) as
This latter, i.e. the rightmost term in Eq. (7), is the power series expansion (in infinite series form). Parameters μ and (Eq. 6) are analogous to the mean μ and variance σ2 of the normal distribution.
Equation (6) has no analytical solution. Hence, STORM uses the vonMisesMixtures (https://framagit.org/fraschelle/mixture-of-von-mises-distributions, last access: 7 July 2024) package, which computes the parameters (μ, κ, p) via maximum likelihood estimators within an expectation–maximization framework (e.g. Hornik and Grün, 2013; Dhillon and Sra, 2003). The description of such an algorithm is beyond the scope of this work. At its core, the vonMisesMixtures package uses the iv object from scipy's module special for the modified Bessel function (Virtanen et al., 2020; Temme, 1975) and the fsolve object from scipy's module optimize for the root finding (of non-linear functions). fsolve, ultimately, is a wrapper for a modified Powell's hybrid method (Moré et al., 1980, p. 57–64, 71–78); this latter method is an algorithm for non-linear optimization (Powell, 2009, 1970).
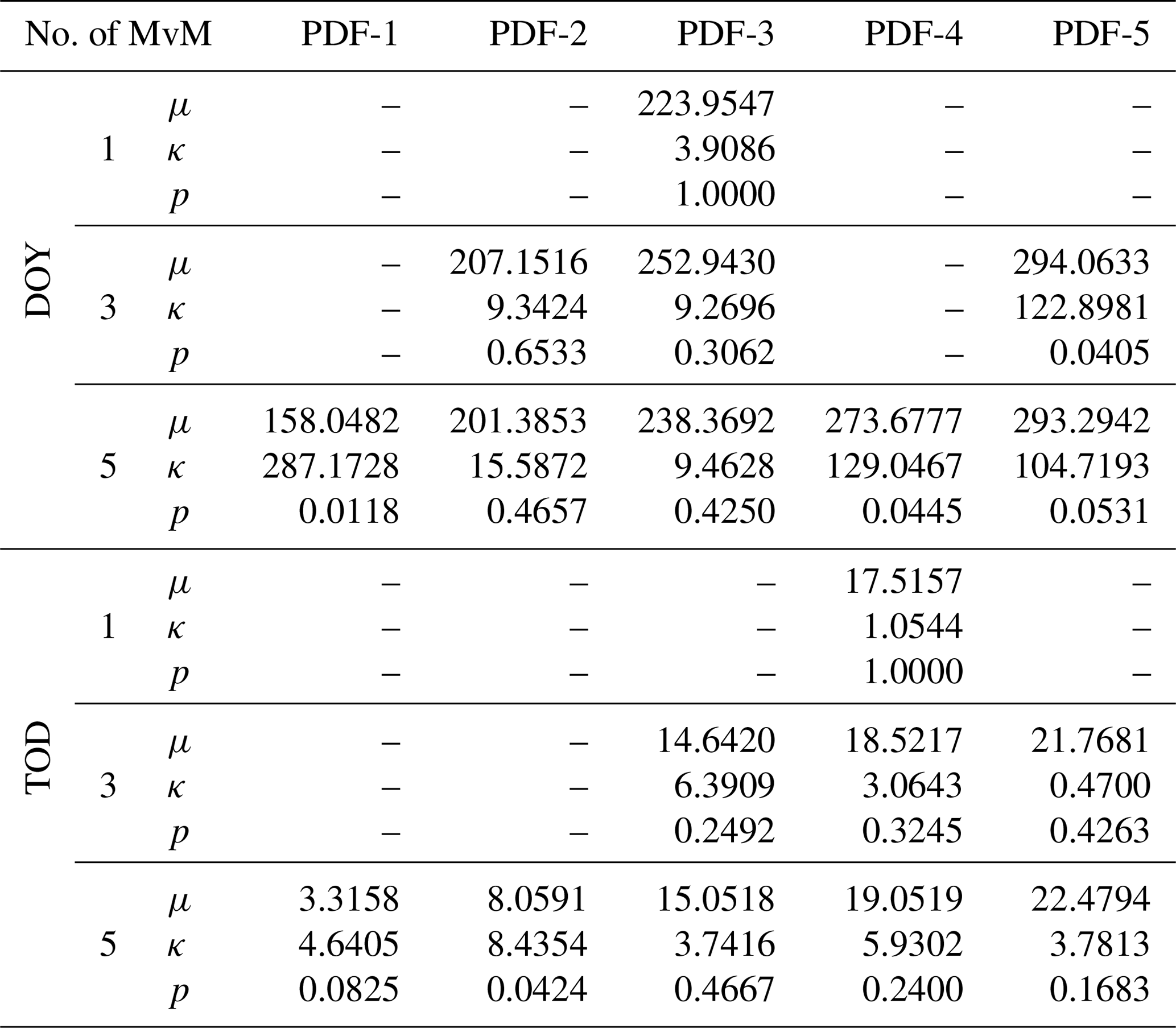
Table 1 presents the estimated parameters for mixtures of one, three, and five vM PDFs. Given the storm start DOY and TOD, STORM transforms those date and time stamps into radians and feeds them to the vonMisesMixtures package, along with the number of vM PDFs to compute the mixture. The conversion from decimal-based days (ddec) into radians (drad), follows: for , and . Similarly, the conversion from decimal-based hours (hdec) into radians (hrad), follows: for , and . Figure 3 shows the fitted mixtures reconstructed from the parameters in Table 1, along with the circular distribution of DOY and TOD. In Fig. 3b, the optimal (and more parsimonious) fit for TOD is given by three MvM PDFs. A fit for five MvM PDFs is also presented in Fig. 3b, even though it is overshadowed by the three MvM PDFs. This shows the preference (and optimality) of the latter model not only for capturing in detail the (potential) multi-modality of the TOD distribution (e.g. afternoon and nighttime storms being the most common between June and October) but also offering a less burdensome/intensive parameter estimation with regard to the former model (i.e. five MvM PDFs). Disregarding its circular framework, the TOD histogram presented in Fig. 3 is consistent with that of Eagleson et al. (1987, Fig. 5). Appendix A presents the rationale behind the optimum selection of five MvM PDFs for DOY, and three MvM PDFs for TOD, which are the default settings in STORM. Still, we encourage the user to assess the optimal number of vM PDFs on a case-by-case basis.

Figure 3(a) Circular distribution for 3 d binned data of (storm start) days of year (DOY; orange dots, with each dot representing 350 counts). The continuous black curve indicates the optimal mixture of von Mises (MvM) probability density functions (PDFs), which is a mixture of five vM PDFs, in this case (see Appendix A). The green curve represents a fit for three MvM PDFs. A 5 d bin circular histogram is also plotted on the inside. (b) Circular distribution for 12 min binned data of (storm start) times of day (TOD; blue dots, with each dot representing 150 counts). The continuous red curve indicates the optimal MvM PDFs, i.e. three MvM PDFs, in this case. The (almost imperceptible) green curve represents a fit for five MvM PDFs. A 1 h bin circular histogram is plotted on the inside. In both panels, the dashed black curves represent a fit of just one vM PDF. The size of the sample is ∼146k values for both DOY and TOD, encompassing the wet seasons (June through October) from 1953 through 1999, in the WGEW (see Sect. 2.1). Table 1 (Sect. 2.7) displays the parameters μ, κ, and p which the vM PDFs are constructed from.
The choice to implement an approach like the MvM PDFs allows the end-user to account for potential multi-modality (and asymmetry) in their storm start date and times. Nonetheless, in the eventuality that any user encounters some difficulties when installing or running the vonMisesMixtures package (as it is not shipped through the conda channels (Anaconda Software Distribution, 2023)), or that they simply do not want to follow such an approach, STORM can still run without this feature (once it is turned off). In that case, STORM finds the best fit throughout a set of discrete probability mass functions (PMFs) for the DOY and samples TOD from a uniform distribution (upscaled to the 00:00–24:00 h domain). Figure B3 shows the best fit of a PMF for DOY in the WGEW dataset. In Fig. B3, one can see the advantages of using a more elaborate model. i.e. MvM PDFs, with regard to a simple PMF model. Having a statistical model for the DOY is another improvement over STORM 1.0. Thus, we avoid modelling inter-arrival and do not contradict the notion of rainfall modelling from a (Poisson) point process perspective (e.g. Eagleson et al., 1987).
Both TOD and DOY sampling take place independently from one another. Then, they are glued together into full date and time stamps (i.e. DOYEAR and DATIME).Although theoretically possible, the probability of having two storms simulated at the same location with the very same date and time stamp is extremely low.
Table 1Mean dates and times μ (in decimal days of year for DOY and in decimal hours for TOD, respectively), concentration parameters κ, and mixing proportions p for one, three, and five mixtures of von Mises (MvM) probability density functions (PDFs). For instance, for the time of day (TOD) and for the three MvM PDFs, μ (in radians) are 0.691, 1.707, and 2.557, i.e. (in decimal hours), 14.64, 18.52, and 21.77 (where 0rad=12:00 and :00/24:00). The parameters for the five and three MvM PDFs are, respectively, the default for the DOY and TOD models in STORM. These defaults are defined in the pre_processing.py script/module (and in the input file ProbabilityDensityFunctions_ONE–ANALOG.csv). The fitted PDFs presented in Fig. 3 (and Fig. B3) can be reconstructed by plugging these parameters into Eqs. (7) and (6).
2.8 Scaling factors and orographic stratification
One key feature carried on from its predecessor is STORM's capability to model potential future climate change scenarios throughout two scaling factors (f1,f2) applied to TOTALP (total seasonal rainfall) and MAXINT (maximum storm intensity). Equation (8) is a generic equation in which U represents the variable to be scaled (i.e. TOTALP or MAXINT), U* is its new value after being modified by factors f1 or f2, and k is the iterator for the number of years per simulation, namely NUMSIMYRS.
Equation (8) implies that for every simulated year one can apply either a factor f1, which yields a constant increase (or decrease) for every year throughout the whole span of the simulation, or a factor f2 which progressively increases (or decreases) with regard to the previous simulated year. For instance, a factor will decrease by 10 % every sampled TOTALP in any given n-year simulation, indicating a progressively drying climate, whereas a factor will double the value of sampled TOTALP at the end of a 10-year simulation, characterizing a climate that is getting wetter, for instance. Both factors (f1,f2) are expressed as percentages and are mutually exclusive; i.e. STORM ensures they cannot be applied at the same time, even though Eq. (8) suggests the opposite (this constraint can easily be removed from the source code, though). Otherwise, the effect of each factor in the output becomes somewhat challenging to disentangle.
For TOTALP, f1=PTOT_SC, and f2=PTOT_SF, whereas for MAXINT, f1=STORMINESS_SC, and f2=STORMINESS_SF (i.e. variables used in the script rainfall.py). A legacy from STORM 1.0, PTOT_SC, is a factor that simulates (percentage) step changes in the catchment wetness (seasonal precipitation totals), whereas PTOT_SF is a fractional scaling factor (progressive percentage) that simulates temporal trends in seasonal totals. Similarly, STORMINESS_SC simulates step changes in storminess (increase/decrease in maximum storm intensities), whereas STORMINESS_SF is a fractional scaling trend in maximum intensities. Section 3.2 shows the results for one simulation where (Figs. 8 and B7b) and another where (Figs. 7 and B7a).
STORM now offers the possibility for the simulation of storm rainfall (e.g. intensity and duration) at different elevation bands, so orographic effects are taken into account. The basic (and simplest) set-up of STORM only requires the catchment shapefile (SHP) to determine the spatial domain over which the simulation(s) will take place. In this is scenario, it is not possible to determine any elevation bands from the SHP, and STORM reverts back to sampling storm intensity–duration pairs from the “global” copula; i.e. the copula model retrieved from all gauge data (see Sect. 2.6 and Fig. 2). On the other hand, if the user provides a SHP and its digital elevation model (DEM), then STORM can compute as many copulas as there are elevation bands into which the catchment is split (e.g. based on hypsometric analysis). To this end, and during the pre-processing stage (see Sect. 2.9.1), the user must define such elevation bands, and STORM will compute one copula per elevation band (as long as the storm/gauge dataset also provides the elevation of the gauge network, which is almost always the case). During the simulation/validation stage, the extent of the storm is defined and overlapped to the DEM, and then STORM calculates the median elevation, which is ultimately used to infer which copula (band) maximum rainfall intensity must be sampled from. By default, STORM calculates the median elevation of the storm extent over the DEM. Nevertheless, this metric can be changed to another statistic, for instance, the mean (see Sect. 2.9.1). Figure B5 shows the capability of STORM to account for orography, in this case, the simulation of different sets of storms at three elevation bands, e.g. up to 1350, between 1350 and 1500, and above 1500 m a.s.l. (metres above sea level). We found no significant differences in simulated or measured storms among any of these three bands, which can be attributed to the low orographic gradient within the WGEW.
2.9 Extras
2.9.1 Pre-processing module
This module is divided in two parts: (1) the actual module that processes all gauge data and generates the PDFs that STORM uses as input and (2) the file parameters.py in which all “soft-” and “hard-coded” parameters/variables are placed and can be read/ingested by STORM.
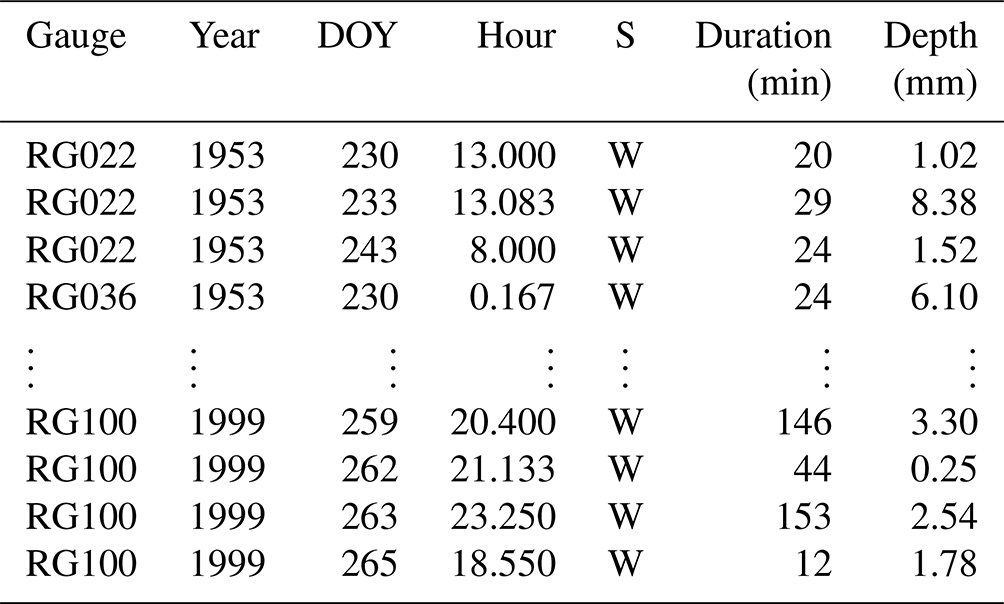
Table 2The first and last four rows of the (sorted) storm-event-based gauge data used by the script pre_processing.py to compute the best-fit parameters presented in Table 4. In the S column, W indicates a storm occurring within the established wet season. The complete table/data can be found in the file gage_data–1953Aug18-1999Dec29_eventh–ANALOG.csv that is located in the folder/path model_input/data_WG.
The standalone script pre_processing.py ingests event- and aggregate-based gauge data to best-fit PDFs for several variables (see Tables 2 and 3). These storm variables are as follows:
-
total seasonal rainfall – TOTALP,
-
maximum extent – RADIUS,
-
rainfall decay rate – BETPAR,
-
maximum intensity – MAXINT,
-
average duration – AVGDUR,
-
intensity–duration copula – COPULA,
-
starting date – DOYEAR, and
-
starting time – DATETIME.
The best-fitted PDFs are generated through Python's library fitter (Cokelaer et al., 2023). For a given variable/parameter, STORM's pre-processing module passes post-processed data to fitter, along with several families of probability distributions that might be adequate for its fitting. At its core, fitter uses scipy's object fit (from the stats module; see Sect. 2.6) “to extract the parameters of that distribution that best fit the data”. This is done via either the maximum likelihood estimation method or the method of moments (Virtanen et al., 2020). Because several probability distributions are passed to fitter (distributions which users can modify according to their needs), the latter finds the best-fitted parameters for such distributions and computes several assessment metrics, including the error sum of squares (SSE), AIC (Akaike's information criterion), and BIC (Bayesian information criterion; see Appendix A). The pre-processing module selects the fitted PDF with the lowest BIC (this assessment metric can be modified too by the user). The impact of parameter misspecification and estimation error and/or uncertainty in the performance of STORM is also beyond the scope of the present work. Tools like fitter are practical implementations that ultimately reduce to a minimum these sort of potential impacts in STORM's performance/outcomes.
Table 3Only 12 rows of the storm-aggregated gauge data used by the script pre_processing.py to compute the best fit for total seasonal rainfall (TOTALP in Table 4). In the S column, W indicates a month within the established wet season, whereas D is for months out of such a wet season. The complete table/data can be found in the file gage_data–1953Aug-1999Dec_aggregateh–ANALOG.csv that is located in the folder/path model_input/data_WG.
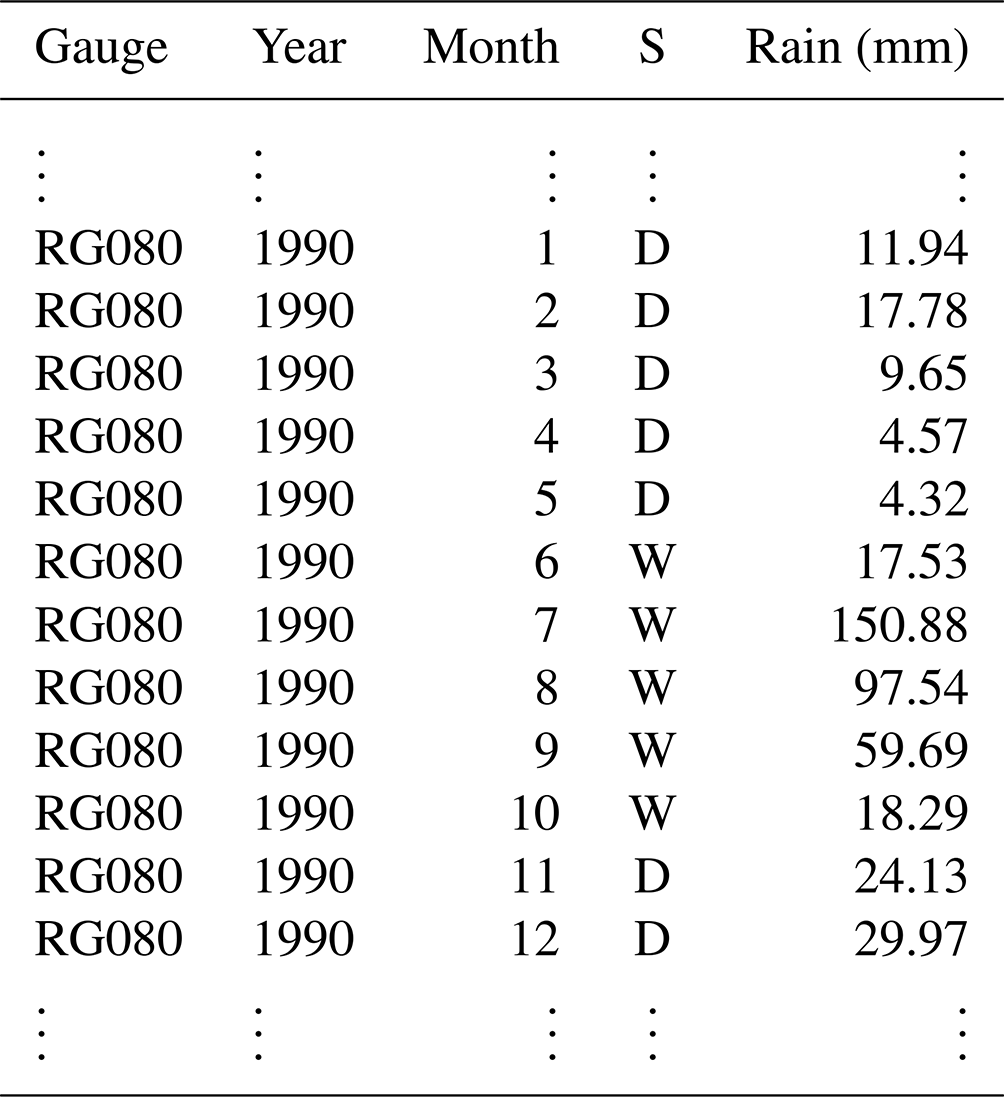
Table 4Parameters of PDFs that best fit the WGEW gauge data for a given random variable. _PDF indicates probability density functions, _RHO refers to the copula ρ parameter, and _VMF indicates a von Mises PDF. The number next to the aforementioned nomenclature refers to the wet season for which the variable is estimated/fit. In this case, there is only one wet season, thus the number 1. The “Z#” tag refers to the elevation band for which the parameters (of the random variable) are estimated. If the variable does not present such a tag (i.e. rows 1–5, 12, and 16–23), then that means that the parameters were estimated/fit regardless of elevation. Except for COPULA, DATIME, and DOYEAR, the end-string indicates the PDF family to which the parameters belong so that STORM (via scipy) can construct the adequate PDF. For variables built upon PDFs, i.e. rows 1–11, par-1 and par-2 columns are, respectively, for the mean and the variance. If the PDF presents more than two parameters (i.e. par-3 and/or par-4), then they are for location and scale. For COPULA, par-1 represents the correlation parameter ρ (see Sect. 2.6). For DOYEAR and DATIME, “m#” indicates the number of vM PDFs that make up the mixture, i.e. five vM for DOYEAR (see Sect. 2.7) and three vM for DATIME. Columns par-1, par-2, and par-3, respectively, represent their p, μ (in radians), κ parameters (see Table 1). This table is produced by the script pre_processing.py, exported as ProbabilityDensityFunctions_ONE–ANALOG.csv into the model_input folder/path, and later ingested by STORM.
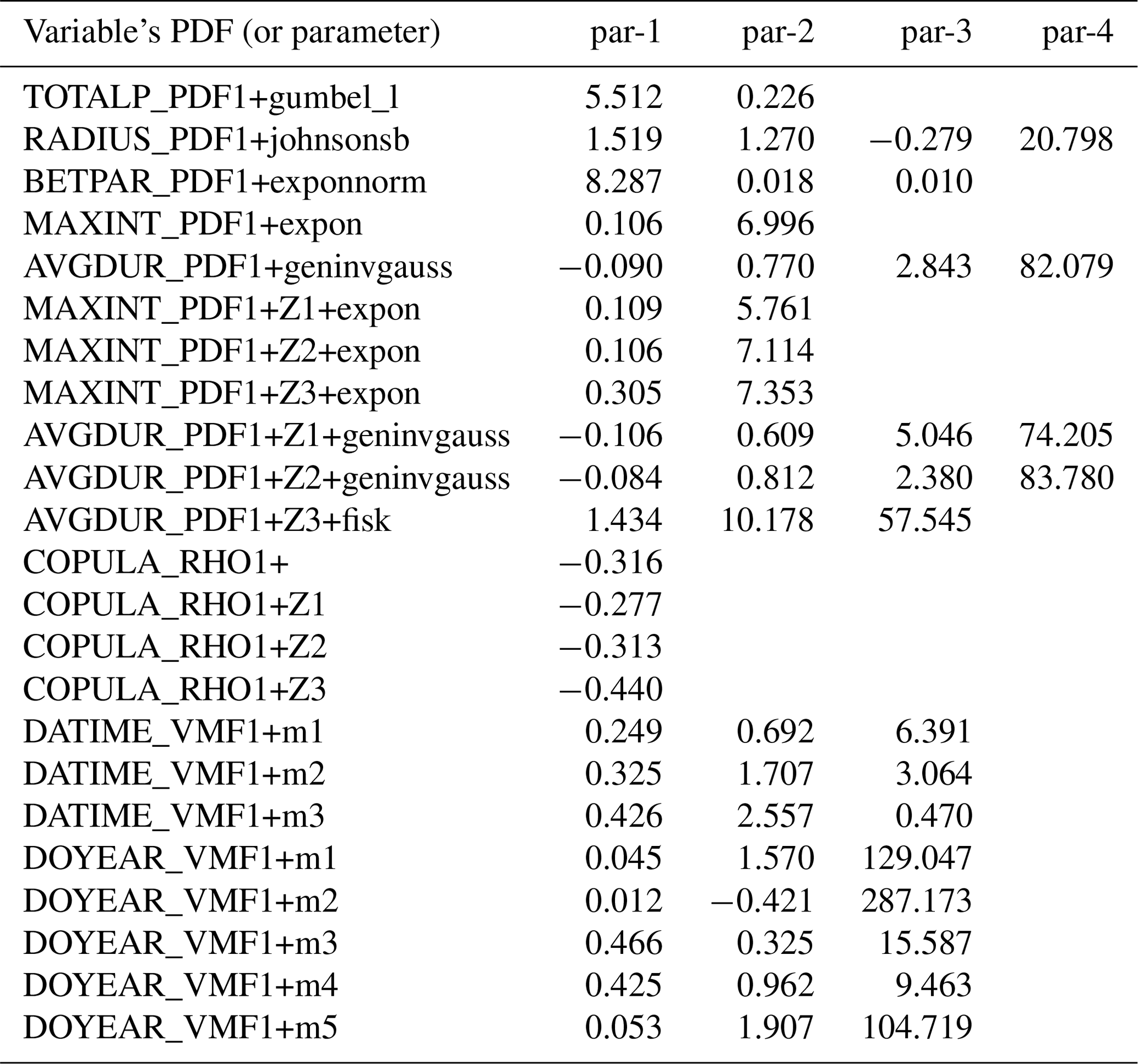
After the PDF fitting and selection is done, the best-fitted PDF parameters are then exported to a CSV (comma-separated value) file (stored in the model_input/data_WG folder) that is later read during the simulation/validation stage. Appending the tags “_PDF” (probability density function), “_RHO” (copula ρ parameter), and “_VMF” (von Mises PDF) allows STORM to read all the necessary statistical parameters stored in one single file (see Table 4). The number 1 appended to the PDF, RHO, and VMF tags indicates that the preprocessing was done for only one wet season. If analyses are carried out for more than one wet season, then STORM replicates the same analyses for every season, appending numerical tags accordingly (e.g. file ProbabilityDensityFunctions TWO-ANALOG-py.csv). If the analysis requires elevation stratification, STORM generates MAXINT and AVGDUR PDFs for each elevation band and appends a “Z#” tag to distinguish them from the all-gauge-based PDFs (see Table 4; rows 6–11 and 13–15). For the directional/circular variables DOYEAR and DATETIME, STORM appends as many “m#” tags as the number of vM PDFs required for the given mixture (see Table 4; last eight rows).
2.9.2 Visualization tool
GIF (graphics interchange format)3 animations of selected simulations are created via the script animation.py (located in STORM's xtras folder/path). STORM's simulations (or validations) are stored in NetCDF (Network Common Data Form)4 files; i.e. one file per each season containing m simulations for each 1 of n years. Once the NetCDF files are produced for a given simulation/validation, the user can easily create animations (and/or snapshots) depicting the evolution of storm events during the wet season, along with its seasonal aggregation within the defined catchment. An example of such an animation can be found in the README.md (page) of STORM's repository (https://github.com/feliperiosg/STORM2, last access: 7 July 2024). The snapshots from which the animation is built look like Fig. 1.
2.10 STORM's skeleton
Starting from the pre-processing module (see Algorithm 1), STORM ingests pre-preprocessed storm data in the format presented in Tables 2 and 3. The output of this pre-processing module is the file ProbabilityDensityFunctions_ONE–ANALOG.csv, which contains the parameters of several PDFs needed to stochastically model rainfall storms. Table 4 presents the aforementioned file in its entirety.
Algorithm 2 is the cornerstone of STORM. This algorithm shows the main steps required to simulate storm rainfall and relates all the stochastic variables previously described. Algorithm 3 (script storm.py) is the wrapper responsible for (1) gathering the input files/parameters (scripts parameters.py and parse_input.py), (2) verifying that all the necessary file/parameters and variables are correctly set and allocated (script check_input.py), and (3) ultimately calling Algorithm 2 (i.e. script rainfall.py).
Algorithm 1Pre-processing module.
Algorithm 2Computes and exports storm rainfall.
Algorithm 3STORM in a nutshell.
3.1 Evaluation of STORM
We carried out a validation run to evaluate the performance of STORM. In STORM, a “validation” run is equivalent to a “simulation” run (thus, we use these terms interchangeably). The difference is that for a simulation run the catchment mask is exported along with the output file, whereas for the validation run the mask of the gauge network (for which the validation exercise is carried out) is the one stored in the output. We ran 30 simulation runs, each comprising 23 years, through STORM. The above is equivalent to having storms, compared against the ∼76 000 storms (for the wet season) measured by the automatic network from 2000 through 2022, i.e. the validation dataset.
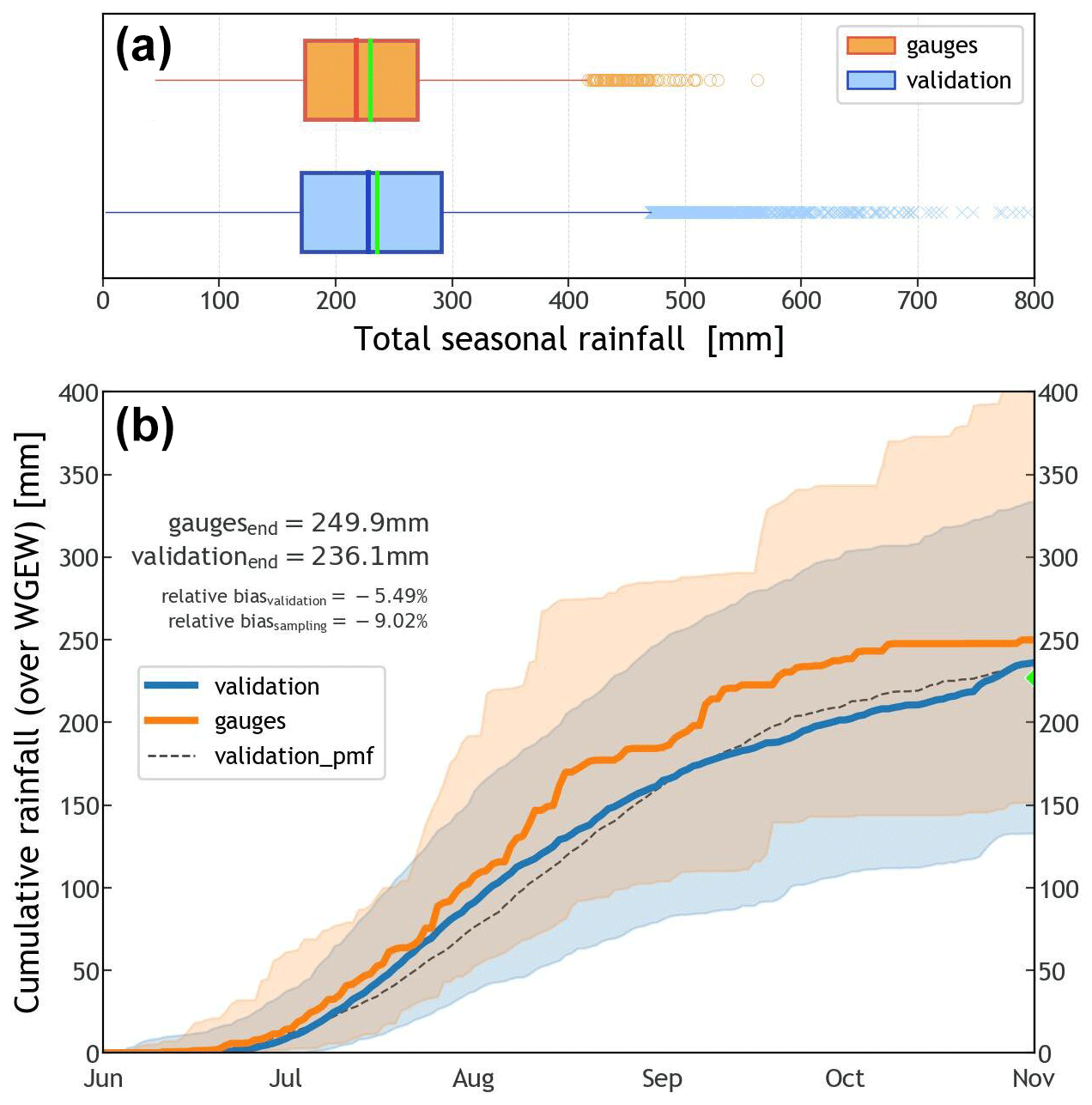
Figure 4(a) Distribution of storm rainfall totals (for the wet season) year-by-year and station/pixel-based, i.e. not spatially averaged, over the catchment. Blue represents the validation dataset (∼50.6k samples), whereas orange is for the gauge dataset (∼1.9k samples). The bright green line (inside the boxplots) represents the mean of the distribution, i.e. 229.2 mm and 235.4 mm, respectively, for gauge and validation sets. (b) Percentile time series for the 90th percentile of all time series from June through October (wet season) for the validation (blue) and gauge (orange) datasets. The solid lines represent the median(s) of each dataset (50th percentile). The dashed black line represents the median for a validation where DOY was modelled through a discrete PMF (see Fig. B3). The green marker at the end of the time series indicates the median of the sampled (simulated) values of total seasonal rainfall (TOTALP). Figure B4 shows percentile time series for the 100th percentile.
In general terms, STORM does well what it was set up to do, i.e. to reach the median precipitation over the entire catchment. This can be seen from the boxplots presented in Fig. 4a, where the (pixel/gauge aggregated) median for the validation dataset (228.3 mm) is just 5 % larger than the median for the gauge data (217.4 mm). This difference is mainly due to STORM always stopping after the (sampled) median seasonal total (TOTALP) is reached. Therefore, STORM seasonal aggregates (on average) will always be larger than the sampled value of reference. One advantage of such a stochastic approach is the ability to reach maxima (and minima) seasonal totals (per station/pixel) outside the inter-quartile range of the gauge dataset, thus accounting for unrecorded (but potential) extreme events.
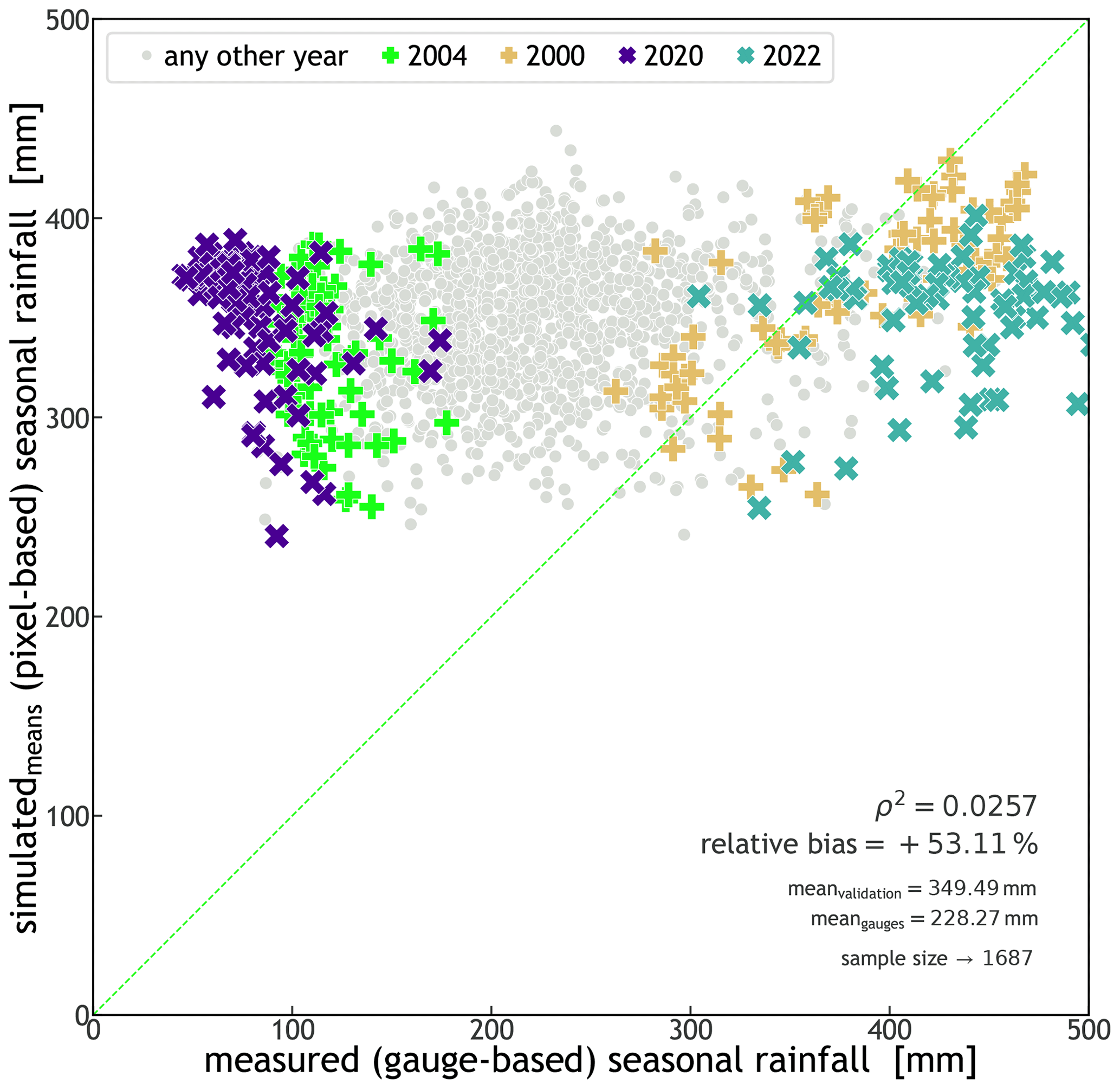
Due to the introduction of a new statistical characterization of the storm start date and time (DOY and TOD), STORM now captures some of the intra-seasonal variability in the rainfall. This can be seen in the percentile time series of cumulative seasonal rainfall presented in Fig. 4b. This latter plot shows how (on average) the cumulative rainfall, over the WGEW, slowly rises to a peak (inflexion point in the solid orange line) halfway through the wet season, from which then follows a slow and steady decline until November. Such a seasonal intra-variability is replicated by STORM (solid blue line) having a final underestimation of 5.5 % (i.e. 236.1 mm) with regard to the actual seasonal (cumulative) median of 249.9 mm. In the case that any user does not follow the circular statistics approach (see Sect. 2.7), STORM does also replicate rainfall intra-seasonal variability using a discrete PMF (dashed black line in Fig. 4b). However, it should be emphasized that STORM does not represent other local hydrometeorological patterns and global teleconnections (e.g. Sarachik and Cane, 2010; Diaz and Markgraf, 2000; Philander, 1990) that might contribute to intra- and inter-seasonal rainfall variability. The modelling of teleconnection phenomena/patterns in STORM was beyond the scope of this work. Nevertheless, such patterns could be empirically represented for particular seasons by altering either the rainfall total PDF (TOTALP) or maximum storm intensity (MAXINT), respectively, via the scaling factors PTOT_ or STORMINESS_ (see Sect. 2.8). For a control run, i.e. one without climate drivers (see Sect. 3.2), the scatter plot presented in Fig. 5 shows STORM's inability to depict extreme stormy seasons either wetter or drier than those in the historical distribution (i.e. a very low coefficient of determination; ρ2=0.0028). For instance, gauge data tell us that the years 2022 and 2020 had the wettest and driest seasons of the last 2 decades, respectively. The seasonal averages (for the whole gauge network) were 429.9 mm for 2022 and 82.5 mm for 2020. These seasonal (mean) extremes contrast with the systematic simulations (30 runs for each year) for which the validation dataset averages 237.0 mm for 2022 and 222.2 for 2020. Nonetheless, and regardless of the intra- and inter-annual rainfall variabilities, the seasonal average pixel total (235.4 mm) is just 3.2% larger than the seasonal average gauge total (228.1 mm). Having a low (auto-)correlation is not considered a bad feature in STORM and other stochastic models. As suggested and demonstrated by, e.g., Kim et al. (2017), a model performing better in metrics such as mean rainfall (and variance) rather than in auto-correlation (and probability of zero rainfall) is more suitable for practical applications because the watershed response variables like runoff volume and peak flow are much more sensitive to the former than to the latter. We emphasize again here that STORM is not designed to reproduce accurate time series of rainfall (compared to the historical data) but to produce multiple plausible rainstorms while remaining faithful to catchment-wide rainfall global statistics.
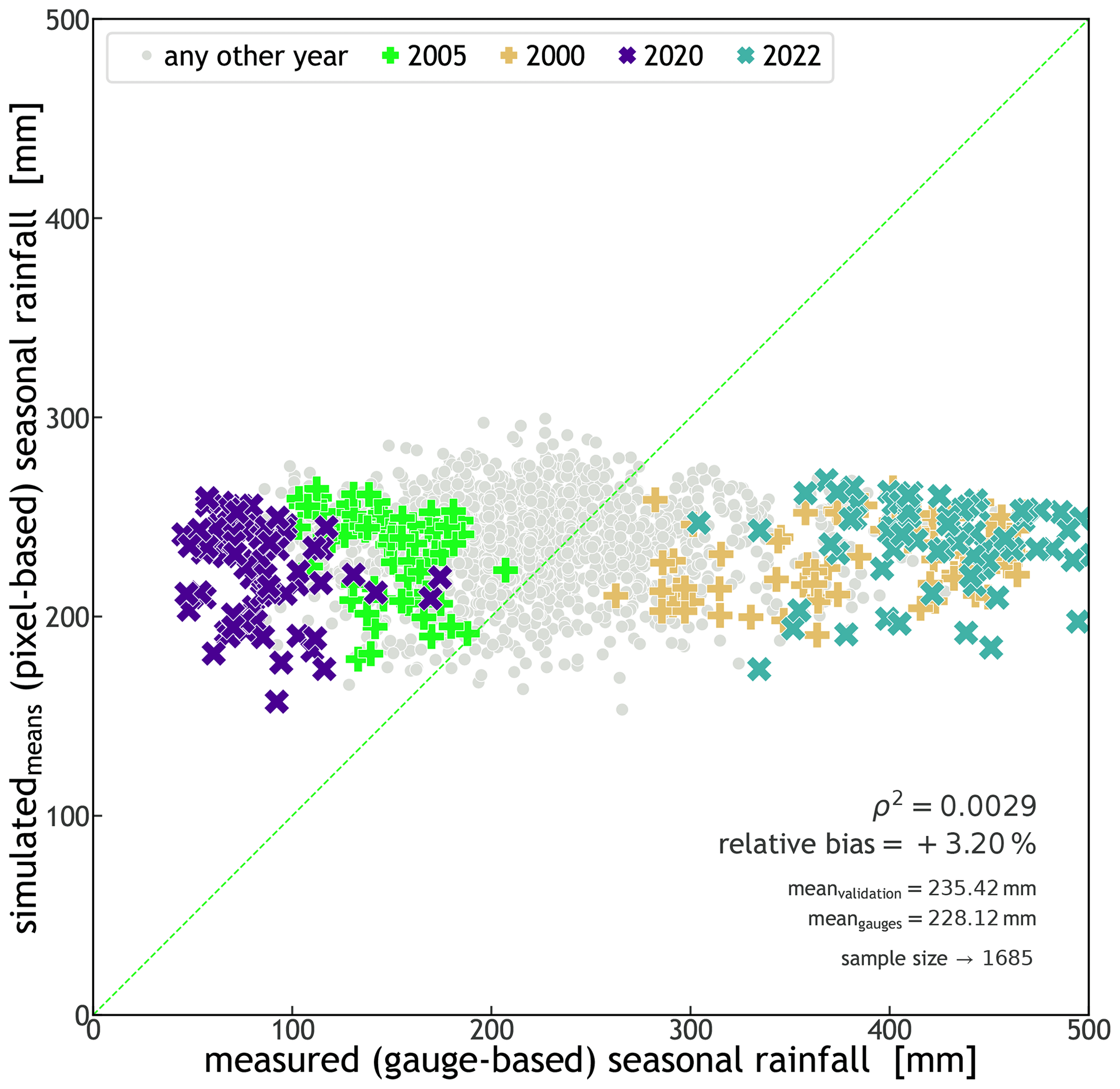
Figure 5Scatter plot of simulated (means) seasonal rainfall against measured seasonal rainfall. Each marker represents a pixel/station for which the seasonal totals of 30 simulations were averaged (y axis) and the actual seasonal total recorded for that location (x axis). The × markers indicate the wettest (2022) and driest seasons (2020) from 2000 through 2022. Within the plot, the coefficient of determination (ρ2, which is the square of the coefficient of correlation) is indicated. The medians of the datasets, the relative bias between them, and the size of the sample (an average of 73.3 gauges per year) are also shown. The green line indicates a 1:1 line. The very low coefficient of determination (ρ2=0.0028) indicates STORM's inability to explicitly simulate extreme rainfall seasons either wetter or drier than those present in the historical records.
The boxplots in Fig. 6a represent the distribution of the number of storms during the wet season for both validation (blue) and gauge (orange) datasets. Once again, one can see how STORM, despite being close to the average number of storms in a season (32), fails to account for the inter-annual variability in storm rainfall present in the gauge records. The average number of storms for the gauge data is (39). When disaggregated by year (see Fig. 6a), the maximum average number of storms (66.3) is found for the year 2022 (with a global maxima of 79 storms), whereas the minimum average (20.6) is for 2020 (13 storms for global minima). As illustrated in the scatter plot, 2022 and 2020 match the years for maximum and minimum (average) seasonal totals, respectively, indicating the direct relationship between the number of storms in a given season and its total precipitation.
We selected three gauges sparsely located throughout the WGEW and compared the temporal distribution of their median and mean storm intensities. The boxplots in Fig. 6b (all three rows) show that the median yearly storm intensities produced by STORM (blue boxes) are consistently lower than the median yearly intensities measured by the gauge network (orange boxes). On average, and throughout the whole validation exercise, the average median storm intensities from gauge data (4.0 mm h−1) is 48.8 % larger than the average from the medians of simulated storms (2.7 mm h−1). Nonetheless, and when accounting for the mean, recorded storm intensities (7.1 mm h−1) are 16.2 % lower than the mean of simulated storm intensities (8.5 mm h−1). This is mainly attributed to extremely large simulated storms (see Fig. B6a). In spite of its inability to model inter-annual storm variability, the stochasticity embedded in STORM allows plausible storm intensities larger and smaller than those (ever) recorded by the gauge network (see Fig. B6a, where the average maximum simulated intensities is 12.6 mm h−1, with maxima over 100 mm h−1; see Sect. 2.1).
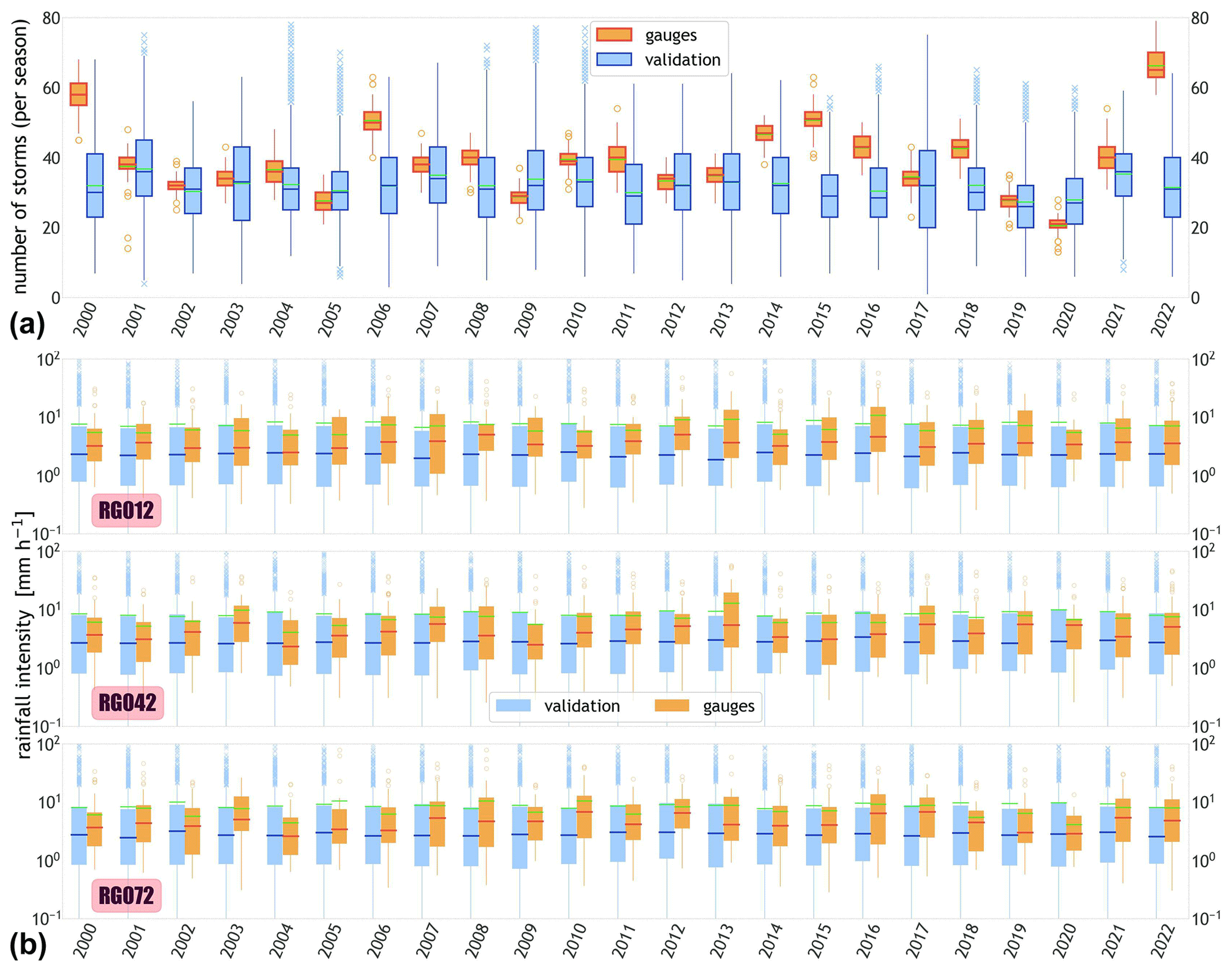
Figure 6Yearly boxplots for the validation (blue) and gauge (orange) datasets. (a) Distribution of the number of storms in a wet season. (b) Distribution of storm intensities of three stations, i.e. RG012, RG042, and RG072, inside the WGEW. In both panels, the green line within each boxplot represents the mean of the distribution. Please note the logarithmic scale of the y axes in panel (b) (i.e. rainfall intensity). Figure B8 shows the (sparse) location of the aforementioned gauges.
One final validation exercise was to compare the top 10th percentile of all storm intensities of both gauge and validation datasets (simulated maximum intensities also included). The storms' maxima (by design; see Sect. 2.4) are found in the centres of the storms and can only be retrieved for the simulation dataset. The boxplots presented in Fig. B6b show that, despite STORM's ability to simulate (on average) extreme rainfall intensities about twice as large/high as those recorded by the gauge network, the top 10th percentile of maxima simulated intensities are 44 % larger than the top 10th percentile of storm intensities in the gauge set. Figure B6a shows that, on average, mean maxima intensities (12.6 mm h−1) are 76.5 % larger than the mean of actual/recorded intensities (7.1 mm h−1) and 47.9 % larger than average simulated intensities. The above suggests the robustness of the methodology here developed to account for maximum intensities when simulating the storms. It also incorporates the theoretical understanding that individual gauges are unlikely to have recorded the maximum storm intensities.
3.2 Testing climate drivers
To evaluate the ability of STORM to account for potential future climate change scenarios, we carried out two additional validation exercises: one where TOTALP is increased by a fixed scalar throughout the whole period, i.e. , representing a wetter climate, and the other where MAXINT is reduced by a progressive scalar, i.e. , representing a decline in storm intensity. We are aware that these two scalars might not be realistic or even at all plausible. Still, we chose those numbers as they enable drastic changes in the final outputs, thus allowing straightforward comparisons between these “climate change” results and the ones presented for the default validation (i.e. where no climate controls are simulated).
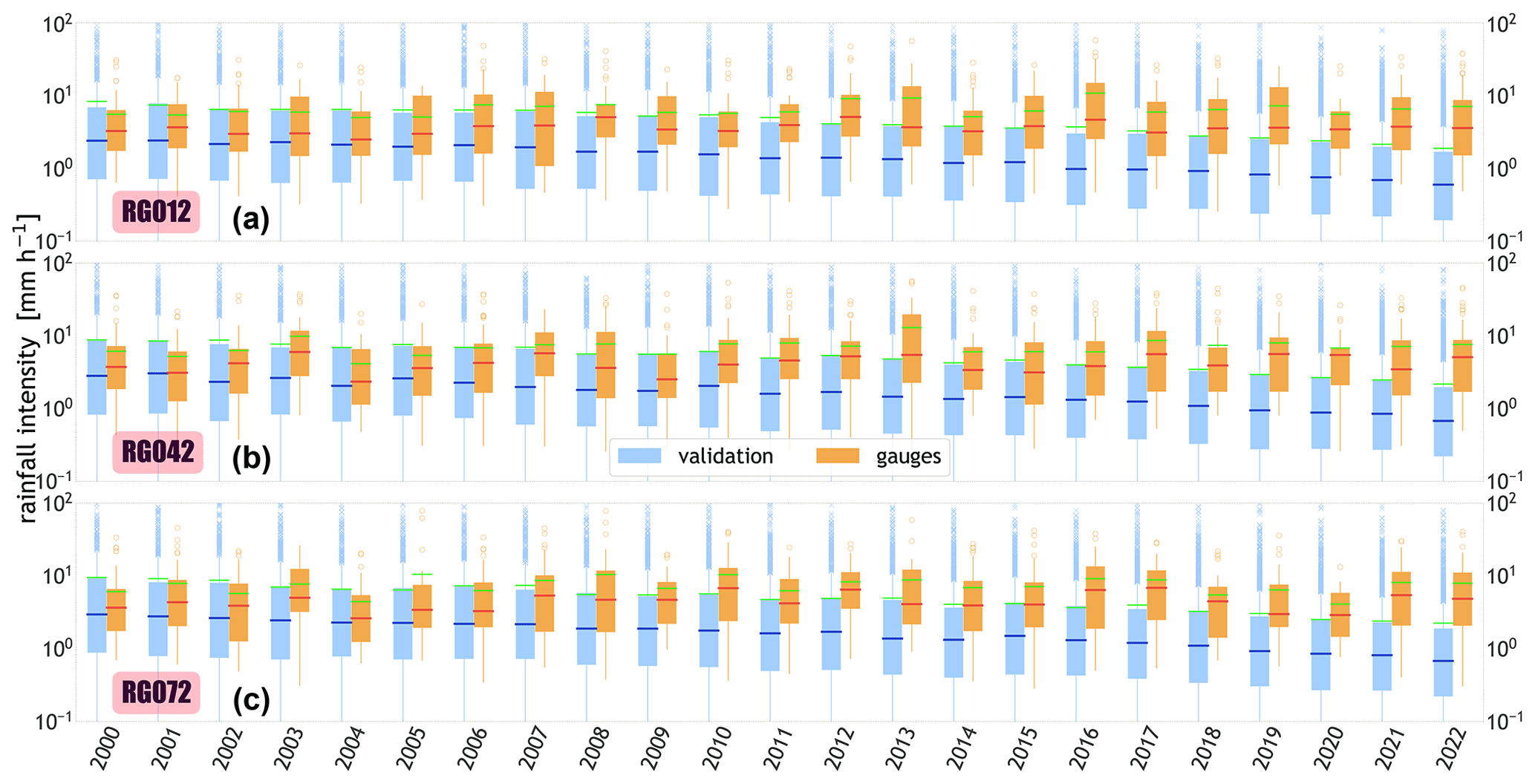
Figure 7Yearly boxplots for the validation (blue) and gauge (orange) datasets. The boxplots represent the distribution of storm intensities of three stations, i.e. RG012, RG042, and RG072, inside the WGEW (respectively, top, middle, and bottom rows). In all rows, the green line within each boxplot represents the mean of the distribution. Please note the logarithmic scale of the y axis (i.e. rainfall intensity). Figure B8 shows the (sparse) location of the aforementioned gauges. This plot is equivalent to Fig. 6b, except that here we force the sampled maximum storm intensity (MAXINT) to be 3.5 % lower than the previous year. Thus, and after 23 years of simulation, the (mean) decrease in maximum storm intensity is 77 % (less).
With a progressive factor, , applied to the MAXINT variable, we force the sampled maximum storm intensity of every simulated year to be 3.5 % less than the year before. Hence, for a validation run of 23 years, one can expect that in the last simulated year the (mean) decrease in maximum storm intensity would be 77 % (i.e. ) less than the first simulated year. The above can be seen in the yearly boxplots presented in Fig. 7. For any of the gauges presented in Fig. 7 (e.g. gauge RG042), one can see how the median rainfall intensity of the validation dataset, i.e. 0.68 mm h−1 at the end of the simulated period (2022), is 76 % less than the median at the starting of the simulation (2000), i.e. 2.82 mm h−1. The value is 86.7 % less when compared to the median at the end of the actual records (i.e. 5.08 mm h−1). In STORM 1.0, the progressive factor SF (over the MAXINT variable) is referred to as the “temporal trend in storminess” (Singer et al., 2018).
With a constant factor, , applied to the TOTALP variable, we force the sampled seasonal total rainfall of every simulated year to be 50 % higher than it normally would. Hence, no matter what year of a given validation one is running, the expected (mean) increase in seasonal total will be roughly constant. This effect can be seen in the scatter plot presented in Fig. 8. In this figure, the cloud of points (scatter) has shifted upwards 48.5 % of the mean value for simulated seasonal totals presented in Fig. 5, corresponding to a validation were no climate change scaling factor was applied. In STORM 1.0, the constant factor SC (over the TOTALP variable) is referred as “step change in wetness”.
Figure B7 shows how the number of storms (in a wet season) is modified due to the (two) aforementioned climate change factors. For the case in which TOTALP is increased by a fixed scalar (i.e. Fig. 8), STORM generates (on average) more storms per season in order to reach the increased total seasonal rainfall. For the case in which MAXINT is progressively reduced by a progressive scalar (i.e. Fig. 7), STORM is forced to continually increase the number of storms in order to reach the median (sampled) seasonal total.
3.3 STORM applications
These improvements to STORM 1.0 now make STORM suitable as a climate driver of other watershed response models that simulate hydrology (surface runoff, infiltration, and streamflow) (Michaelides and Wilson, 2007; Michaelides and Wainwright, 2002), groundwater recharge during and after rainfall events (Quichimbo et al., 2021), interactions between streamflow and alluvial aquifers (Evans et al., 2018), or even for representing ecohydrological responses of vegetation to climate forcing (e.g. Warter et al., 2023). It also enables STORM to be useful in water balance models (e.g. land surface models) to assess water availability to plants through dynamic ecohydrological simulation of plant–climate interactions and water utilization (Warter et al., 2021; D'Odorico et al., 2007; Caylor et al., 2006; Laio et al., 2006), as well as energy/carbon fluxes between the land surface and the atmosphere (Best et al., 2011; Bonan, 1996). Finally, STORM can also be used to drive geomorphic models that characterize erosion and deposition processes within drainage basins in response to sequences of rainfall and runoff (Michaelides and Singer, 2014; Michaelides and Martin, 2012) and even landscape evolution models that simulate landform development over longer timescales (Hobley et al., 2017; Tucker and Hancock, 2010). Coupling STORM to such models would enable a wide range of scientists to investigate key problems in the environment that have their origin in the climate system. These problems range from which water sources are used by plants (Sabathier et al., 2021; Sargeant and Singer, 2016; Singer et al., 2014; Dawson and Ehleringer, 1991) and what is the dominant source and timing of groundwater recharge (Quichimbo et al., 2020; Cuthbert et al., 2016; Wheater et al., 2010; Scanlon et al., 2006) to the role of climate in shaping landscape morphology (Michaelides et al., 2018; Singer and Michaelides, 2014; Tucker and Bras, 2000; Tucker and Slingerland, 1997). The new STORM could also be integrated with stochastic models characterizing atmospheric evaporative demand (e.g. Asfaw et al., 2023), which would allow for closure of the water balance.
Built upon STORM 1.0, STORM (https://github.com/feliperiosg/STORM2, last access: 7 July 2024) is an improved stochastic rainfall generator applicable to (small) gauged watersheds (with detailed rainstorm records) in any climatic zone. This stochastic framework heavily relies on PDFs of the total seasonal rainfall (TOTALP), maximum storm radius (RADIUS), decay rate of maximum rainfall from the storm's centre towards its maximum radius (BETPAR), maximum rainfall intensity (MAXINT), average storm duration (AVGDUR), copula's correlation parameter (COPULA), storm start date (DOYEAR), and (optional) storm start time (DATIME). The main modelling features of STORM with regard to its predecessor are storm intensity and duration represented via a (bi-variate) Gaussian copula framework, intensity–duration copulas at different elevation bands within the catchment, storm time occurrence via a circular statistics approach (i.e. mixture of von Mises PDF) or via discrete PMFs, storm start times via a circular statistics (optional), an alternative implementation of future climate scenarios, an output compressed into (georeferenced) NetCDF files and readily available for visualization, and a pre-processing module to construct all necessary PDFs from gauge data. Added to STORM, and with a future mindset of its applicability at larger scales, we implemented capabilities such as PDFs easily defined by the user (or retrieved from gauge data), storm simulation with regard to elevation (provided a digital elevation model – DEM), customizable spatial resolution (and coordinate reference system – CRS), spatial operations under a raster framework (thus adding speed, versatility, and scalability), and an optimal output storing in NetCDF format.
To develop the stochastic model, we derived and calibrated all PDFs to 37 years of storm data collected by an analogue network of 118 gauges sparsely deployed over the WGEW (148 km2). To test the performance of the model, we carried out one validation exercise consisting of 30 runs, with each one having 23 simulated years (i.e. 690 simulation years in total). The output of such a validation run was compared against 23 years of storm data collected by the digital network of 93 gauges located within the WGEW. To evaluate STORM's ability to model rainfall under potential future climate scenarios, we carried out two more validation runs, with each one comprising 690 simulation years too. These results were also compared against the digital/automatic gauge network.
Results showed that the seasonal total rainfall reached by STORM is 5.5 % lower than the actual records when accounted as the spatial median of all the stations/pixels within WGEW (see Fig. 4b). If accounted on a temporal basis, i.e. without any spatial averaging, then this relative difference amounts to +5 % (see Fig. 4a). On a seasonal basis, the storm mean rainfall intensity recorded by the gauge network is 16.2 % smaller than simulated storm intensities (see Fig. B6a). Nevertheless, the stochasticity embedded in our model allows for unrecorded but very plausible, either larger and/or smaller, storm intensities (see Figs. 6b and B6). Results obtained for the varying climate simulations showed that STORM is also able to imprint seasonal variability on rainfall (either in intensities or totals) in long-term analyses.
Future plans for the improvement of STORM will be focused on moving from drainage basins to regions, allowing for a wider range of applications such as land surface modelling. To achieve this, further improvements will be needed to characterize how rainstorm characteristics vary across a region so that they can be represented within STORM's PDFs. Finally, it will necessitate the use of gridded rainfall products for STORM to inform on the input PDFs.
The choice of a bi-variate Gaussian copula was mainly driven on its simplicity/easy configuration and applicability. Nevertheless, a further improvement (at least conceptually) might be the implementation of more elaborate copula models (and truly applicable to the intensity–duration case) like extreme values, Archimedean, etc. (e.g. Chen and Guo, 2019; Zhang and Singh, 2019; Salvadori and De Michele, 2006).
STORM's current weakness is its inability to account for other local hydrometeorological patterns and global teleconnections that may contribute to intra- and inter-seasonal rainfall variability (see Figs. 5 and 6a). This is something expected, as STORM (by design) does not incorporate any PDF that describes the behaviour of such inter-annual variability. Nevertheless, STORM's flexibility allows any user to roughly model the eventual impact of such teleconnections via the scaling factors PTOT_ or STORMINESS_ (see Sect. 2.8).
The Bayesian information criterion (BIC; also known as Schwarz's Bayesian criterion – SBC) is a metric used for the unbiased assessment of the optimal number of M-unimodal vM distributions (e.g. Rios Gaona and Villarini, 2018; Lark et al., 2014). Such a criterion allows the selection of the least complex of all the models in consideration, i.e. the one with the lowest BIC. From a mathematical point of view (Eq. A1), BIC (or similar models, i.e. AIC – Akaike's information criterion) combines the maximized log likelihood of the fitted model with a penalization term that is related to the number of estimated parameters (Pewsey et al., 2013, Eq. 6.3).
where ℓmax is the maximized (full) log-likelihood of a model with ν degrees of freedom and n the number of observations.

Figure A1Bayesian information criterion (BIC) for mixtures that go from one to nine von Mises (vM) probability density functions (PDFs). The blue line is for the BIC of day of year (DOY), whereas the red line is for the BIC of time of day (TOD). The colour of the y axes indicates the values of their respective BICs. The black circles indicate one of the lowest points of the related BIC curve. The lower the BIC, the more optimal the number of vM PDFs (in the mixture) that best describes the sample multi-modality. Thus, to avoid the selection of a model with too many vM PDFs, the black circles also indicate where the change in slope is more drastic, even if they are not global minima.
Unfortunately, the vonMisesMixtures package does not offer a way to retrieve the maximized log-likelihood from which to compute the BIC of the mixture of M-unimodal vM PDFs. Unlike Python's vonMisesMixtures package, R (R Core Team, 2023), jointly with the movMF package (Hornik and Grün, 2014), does offer the possibility for an easy retrieval of BIC estimates for fitted MvM PDFs (Fig. A1). The implementation of such a feature in STORM was beyond the scope of this work. Nevertheless, STORM does offer the script pre_processing_circular.R from which the entire circular analyses (BIC included) can be computed. Once this analysis is carried out, the user will have all the necessary elements to discern the optimal fit for their “circular” data.
Figure A1 shows the DOY, and TOD BICs for mixtures ranging from one to nine vM PDFs. Strictly speaking, and for the DOY case, the lowest BIC found in the figure is for a mixture of nine vM, i.e. −318370.54. One can argue that a nine MvM model certainly over-fits the multi-modality of DOY (see Fig. 3a) without even mentioning its computationally intensive parameter estimation. Nevertheless, if one looks at the five MvM model (BIC equals to −317840.12), one can see that the improvement of the BIC metric is increasingly very small beyond this point in comparison to the one to four MvM models. Therefore, we are confident that a five MvM model not only accurately describes the multi-modality of DOY (for the WGEW dataset) but also is faster in its parameter estimation with regard to any larger (i.e. more vM PDFs) model. Hence, a mixture of five vM PDFs is the default configuration for DOY in STORM. Following that train of thought, we found the three MvM model the optimal mixture for TOD and thus its default settings in STORM.

Figure B1Probability density functions (PDFs) for maximum storm extent (RADIUS; see Sect. 2.3). The cyan area represents the histogram of maxima radii estimated from three or more gauges, whereas the salmon area is for a maxima radii distribution (obtained) from two or more gauges. The solid blue line indicates the best fit for the cyan histogram, i.e. a Johnson's SB PDF (see Table 4; row 2). The dashed red line is also a Johnson's SB PDF (with parameters a=1.54, b=0.953, , and scale=18.289).

Figure B2Probability density functions (PDFs) for storm rainfall measured by gauge data (salmon histogram) and for estimated maxima (cyan histogram). The solid blue line indicates the best fit for the cyan histogram, i.e. an exponential PDF (see Table 4; row 4), whereas the dashed red line (also a best fit) is a Pareto PDF. Maximum intensities are retrieved by fitting an exponential (quadratic) model to measured storm rainfall (see Sect. 2.4). Note how the mean from estimated maximum intensities (μ=7.10) is larger than the mean of rainfall intensities measured by gauges (μ=4.98) prior to any model fitting.
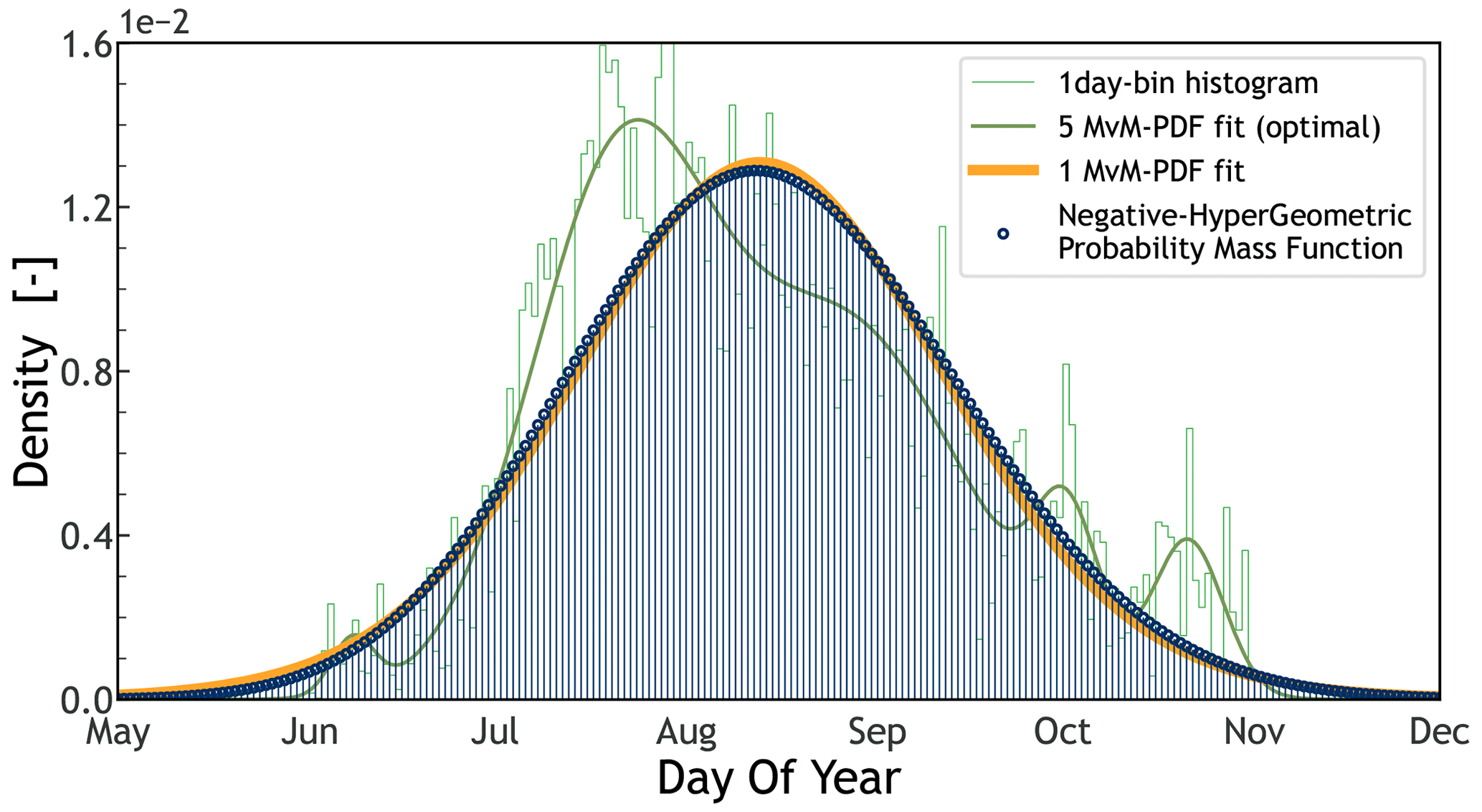
Figure B3Probability mass function (PMF – vertical lines ending in blue circles) of a negative hyper-geometric family fitted (best fit) to a distribution of storm start day of year (DOY – green histogram). The coarser green line represents the optimal fit of a mixture of five von Mises (MvM) PDFs for the aforementioned distribution, as presented also in Fig. 3 (over a “circular” space; see Sect. 2.7). The orange line is a one MvM PDF. Note its similarity with the PMF and its poor fit of the underlaying DOY distribution with regard to the five MvM PDF fit.
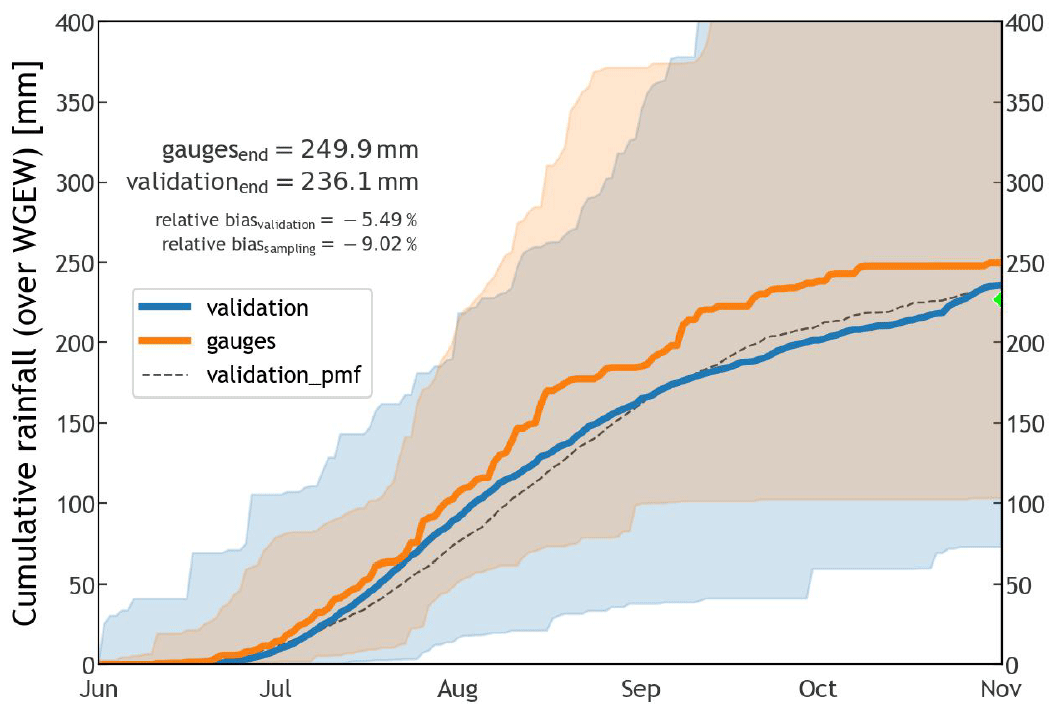
Figure B4Percentile time series for the 100th percentile of all time series from June through October (wet season) for the simulation/validation (blue) and gauge (orange) datasets. The solid lines represent the median(s) of each dataset (50th percentile). The dashed black line represents the median for a validation where DOY was modelled through a discrete PMF (see Fig. B3). The green marker at the end of the time series indicates the median of the sampled (simulated) values of total seasonal rainfall (TOTALP). By design, STORM stops once the sampled seasonal total is reached or surpassed (the probability of reaching exactly the sampled value is extremely low). Hence, the actual (median) simulated seasonal total will always be greater than the sampled TOTALP.

Figure B5Distribution of storm station/pixel-based intensities by elevation bands (i.e. orography). Blue is for the validation dataset, whereas orange is for gauge data. The green lines represent the mean of the distributions. Please note the logarithmic scale of the y axis. The x axis, from left to right, indicates three elevation bands for which analyses were carried out, i.e. up to 1350 m a.s.l., between 1350 and 1500 m.a.s.l., and above 1500 m a.s.l. Given the low gradient in relative orography within the WGEW, rainstorm variability with regard to orography is not a stark characteristic in this case.

Figure B6Distribution of storm station/pixel-based intensities (a) for all data, i.e. 100th-percentile and (b) for the top 10th percentile of all storm intensities. Blue is for the validation dataset, whereas orange is for gauge data. The green lines represent the mean of the distributions. Please note the logarithmic scale of the y axes in both panels. The rightmost column is for the maxima intensities found in the storm centres (see Sect. 2.4). Such storm centre maxima are only retrieved for the validation dataset (no way to account for them in the gauge set).
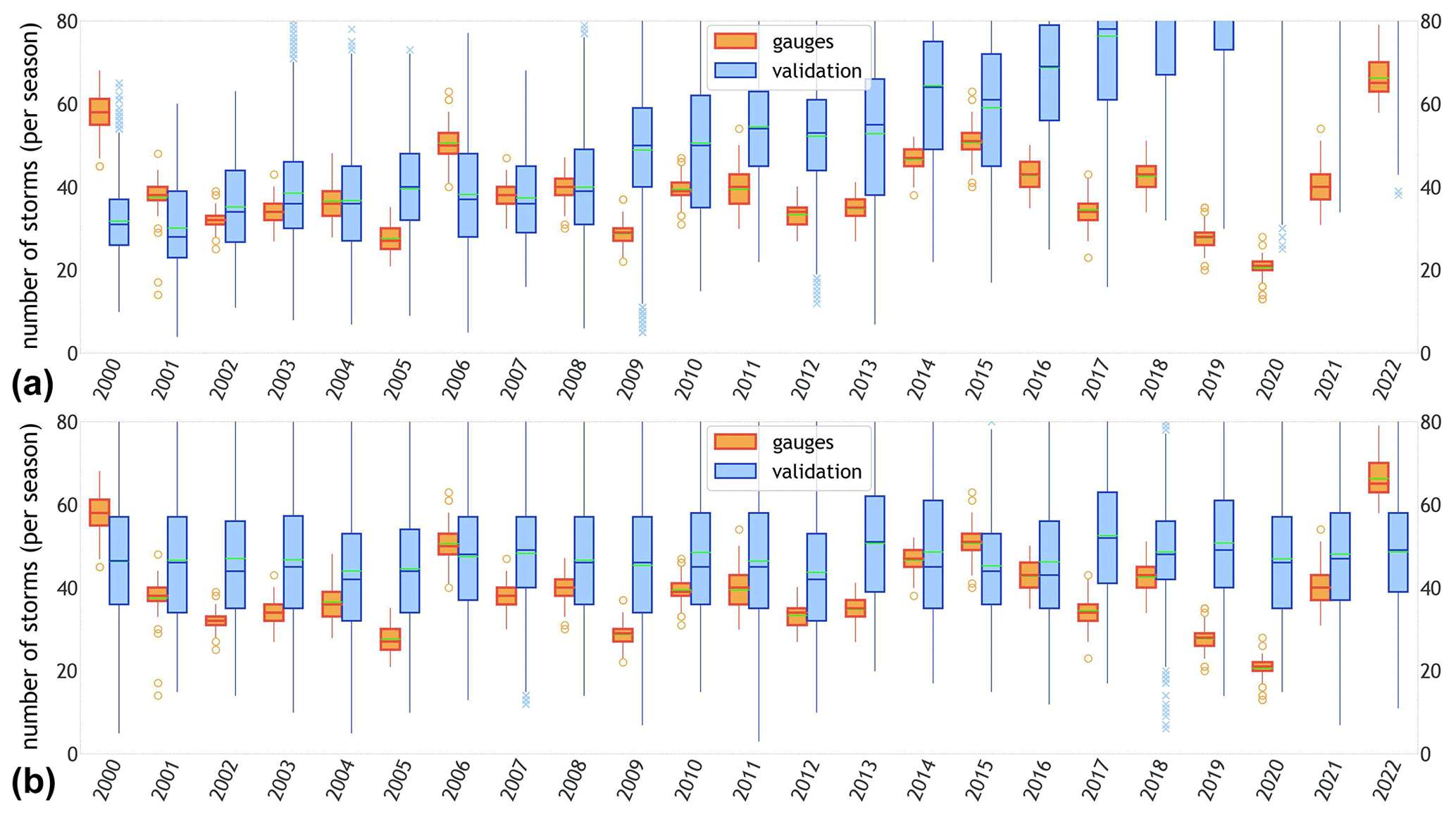
Figure B7Distribution of the number of storms in a wet season for the validation (blue) and gauge (orange) datasets. (a) Validation case for which MAXINT is reduced by a progressive scalar, i.e. (see Fig. 7). (b) Validation case for which TOTALP is increased by a fixed scalar throughout the whole period, i.e. (see Fig. 8). All y axes are consistent with Fig. 6a to allow (visually) equivalent comparisons. Note how, in panel (a), STORM generates more storms per season in order to reach the now increased total seasonal rainfall, whereas, in panel (b), the progressive decrease in storm intensity forces STORM to continually increase the number of storms in order to reach the median (sampled) seasonal total.

Figure B8Digital gauge network for the WGEW (from 2000 through 2022). The three bold markers, i.e. gauges/stations RG012, RG042, and RG072, indicate the geolocation of the gauges referred to in Figs. 6 and 7. Even though the grid is presented in lat–long coordinates (i.e. CRS WGS-84), the actual projection (in both panels) is the 2D Cartesian coordinate system known as NAD83/UTM zone 12N (i.e. EPSG:26912).
The current version of STORM v.2 is available from the project website at https://github.com/feliperiosg/STORM2 (last access: 7 July 2024) under the GPLv3 licence (https://www.gnu.org/licenses/gpl-3.0.en.html#license-text, last access: 7 July 2024). The exact version of the model used to produce the results used in this paper is archived on https://doi.org/10.5281/zenodo.8071820 (Rios Gaona, 2023), as are the pre- and post-processed data and scripts to run the model. Documentation to run the model and tools for its output visualization are also provided at the aforementioned links.
MFRG wrote and extensively tested the code, did the analyses and visualizations, and completed an early version of this work. MBS developed the idea, wrote an early version of this work, revised the finished version, and provided valuable feedback. KM revised the finished version of this work.
The contact author has declared that none of the authors has any competing interests.
The authors take no responsibility for the use or misuse of the provided code.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The authors thank Owen Jones and the referees for the constructive suggestions and comments that helped to improve this work.
This research has been supported by the European Union Horizon 2020 (programme DOWN2EARTH; grant no. 869550).
This paper was edited by Charles Onyutha and reviewed by Mouhamed Idrissou and three anonymous referees.
Anaconda Software Distribution: Conda, https://anaconda.com (last access: 7 July 2024), 2023. a
Asfaw, D. T., Singer, M. B., Rosolem, R., MacLeod, D., Cuthbert, M., Miguitama, E. Q., Rios Gaona, M. F., and Michaelides, K.: stoPET v1.0: a stochastic potential evapotranspiration generator for simulation of climate change impacts, Geosci. Model Dev., 16, 557–571, https://doi.org/10.5194/gmd-16-557-2023, 2023. a
Benoit, L., Allard, D., and Mariethoz, G.: Stochastic Rainfall Modeling at Sub-kilometer Scale, Water Resour. Res., 54, 4108–4130, https://doi.org/10.1029/2018WR022817, 2018. a, b
Berger, D.: Kendall's Rank Correlation vs Pearson's Linear Correlation: A Proof Of Greiner's Relation, SSRN, https://doi.org/10.2139/ssrn.2837712, 2016. a
Best, M. J., Pryor, M., Clark, D. B., Rooney, G. G., Essery, R. L. H., Ménard, C. B., Edwards, J. M., Hendry, M. A., Porson, A., Gedney, N., Mercado, L. M., Sitch, S., Blyth, E., Boucher, O., Cox, P. M., Grimmond, C. S. B., and Harding, R. J.: The Joint UK Land Environment Simulator (JULES), model description – Part 1: Energy and water fluxes, Geosci. Model Dev., 4, 677–699, https://doi.org/10.5194/gmd-4-677-2011, 2011. a
Bonan, G. B.: A Land Surface Model (LSM Version 1.0) for Ecological, Hydrological, and Atmospheric Studies: Technical Description and User's Guide (No. NCAR/TN-417+STR), Tech. Rep. NCAR/TN-417+STR, University Corporation for Atmospheric Research, https://doi.org/10.5065/D6DF6P5X, 1996. a
Branch, M. A., Coleman, T. F., and Li, Y.: A Subspace, Interior, and Conjugate Gradient Method for Large-Scale Bound-Constrained Minimization Problems, SIAM J. Sci. Comput., 21, 1–23, https://doi.org/10.1137/S1064827595289108, 1999. a
Breitenberger, E.: Analogues of the normal distribution on the circle and the sphere, Biometrika, 50, 81–88, https://doi.org/10.1093/biomet/50.1-2.81, 1963. a
Burton, A., Kilsby, C., Fowler, H., Cowpertwait, P., and O'Connell, P.: RainSim: A spatial-temporal stochastic rainfall modelling system, Environ. Modell. Softw., 23, 1356–1369, https://doi.org/10.1016/j.envsoft.2008.04.003, 2008. a
Caylor, K. K., D'Odorico, P., and Rodriguez-Iturbe, I.: On the ecohydrology of structurally heterogeneous semiarid landscapes, Water Resour. Res., 42, W07424, https://doi.org/10.1029/2005WR004683, 2006. a
Chen, L. and Guo, S.: Copulas and Its Application in Hydrology and Water Resources, no. 2364-8198 in Springer Water, Springer Singapore, 152 Beach Road, #21-01/04 Gateway East, Singapore 189721, Singapore, 1st edn., https://doi.org/10.1007/978-981-13-0574-0, 2019. a, b
Cokelaer, T., Kravchenko, A., lahdjirayhan, msat59, Varma, A., L, B., Stringari, C. E., Brueffer, C., Broda, E., Pruesse, E., Singaravelan, K., Li, Z., mark padgham, and negodfre: cokelaer/fitter: v1.6.0, Zenodo [code], https://doi.org/10.5281/zenodo.8226571, 2023. a
Cuthbert, M. O., Acworth, R. I., Andersen, M. S., Larsen, J. R., McCallum, A. M., Rau, G. C., and Tellam, J. H.: Understanding and quantifying focused, indirect groundwater recharge from ephemeral streams using water table fluctuations, Water Resour. Res., 52, 827–840, https://doi.org/10.1002/2015WR017503, 2016. a
Dai, Q., Han, D., Rico-Ramirez, M. A., and Islam, T.: Modelling radar-rainfall estimation uncertainties using elliptical and Archimedean copulas with different marginal distributions, Hydrol. Sci. J., 59, 1992–2008, https://doi.org/10.1080/02626667.2013.865841, 2014. a, b
Dawkins, L. C., Osborne, J. M., Economou, T., Darch, G. J., and Stoner, O. R.: The Advanced Meteorology Explorer: a novel stochastic, gridded daily rainfall generator, J. Hydrol., 607, 127478, https://doi.org/10.1016/j.jhydrol.2022.127478, 2022. a, b
Dawson, T. E. and Ehleringer, J. R.: Streamside trees that do not use stream water, Nature, 350, 335–337, https://doi.org/10.1038/350335a0, 1991. a
De Luca, D. L. and Petroselli, A.: STORAGE (STOchastic RAinfall GEnerator): A User-Friendly Software for Generating Long and High-Resolution Rainfall Time Series, Hydrology, 8, 76, https://doi.org/10.3390/hydrology8020076, 2021. a, b
Dhillon, I. and Sra, S.: Modeling Data using Directional Distributions, Tech. Rep. TR-03-06, University of Texas: Department of Computer Science, Austin, TX, USA, https://www.cs.utexas.edu/users/inderjit/public_papers/tr03-06.pdf (last access: 7 July 2024), 2003. a
Diaz, H. F. and Markgraf, V. (Eds.): El Niño and the Southern Oscillation: Multiscale Variability and Global and Regional Impacts, Cambridge University Press, https://doi.org/10.1017/CBO9780511573125, 2000. a
Diez-Sierra, J., Navas, S., and del Jesus, M.: NEOPRENE v1.0.1: a Python library for generating spatial rainfall based on the Neyman–Scott process, Geosci. Model Dev., 16, 5035–5048, https://doi.org/10.5194/gmd-16-5035-2023, 2023. a
D'Odorico, P., Caylor, K., Okin, G. S., and Scanlon, T. M.: On soil moisture-vegetation feedbacks and their possible effects on the dynamics of dryland ecosystems, J. Geophys. Res.-Biogeo., 112, G04010, https://doi.org/10.1029/2006JG000379, 2007. a
Eagleson, P. S., Fennessey, N. M., Qinliang, W., and Rodriguez-Iturbe, I.: Application of spatial Poisson models to air mass thunderstorm rainfall, J. Geophys. Res.-Atmos., 92, 9661–9678, https://doi.org/10.1029/JD092iD08p09661, 1987. a, b, c, d, e, f
Evans, C. M., Dritschel, D. G., and Singer, M. B.: Modeling Subsurface Hydrology in Floodplains, Water Resour. Res., 54, 1428–1459, https://doi.org/10.1002/2017WR020827, 2018. a
Fang, K.-T., Kotz, S., and Ng, K. W.: Symmetric Multivariate and Related Distributions, no. 36 in Monographs on Statistics and Applied Probability, Chapman & Hall/CRC, 6000 Broken Sound Parkway NW, Suite 300 Boca Raton, FL 33487-2742, 1st edn., https://doi.org/10.1201/9781351077040, 1990. a
Genest, C., Rémillard, B., and Beaudoin, D.: Goodness-of-fit tests for copulas: A review and a power study, Insurance Math. Econom., 44, 199–213, https://doi.org/10.1016/j.insmatheco.2007.10.005, 2009. a
Goodrich, D. C., Keefer, T. O., Unkrich, C. L., Nichols, M. H., Osborn, H. B., Stone, J. J., and Smith, J. R.: Long-term precipitation database, Walnut Gulch Experimental Watershed, Arizona, United States, Water Resour. Res., 44, W05S04, https://doi.org/10.1029/2006WR005782, 2008. a, b, c
Hobley, D. E. J., Adams, J. M., Nudurupati, S. S., Hutton, E. W. H., Gasparini, N. M., Istanbulluoglu, E., and Tucker, G. E.: Creative computing with Landlab: an open-source toolkit for building, coupling, and exploring two-dimensional numerical models of Earth-surface dynamics, Earth Surf. Dynam., 5, 21–46, https://doi.org/10.5194/esurf-5-21-2017, 2017. a
Hofert, M., Kojadinovic, I., Mächler, M., and Yan, J.: Elements of Copula Modeling with R, no. 2197-5744 in Use R!, Springer Cham, Gewerbestrasse 11, 6330 Cham, Switzerland, 1st edn., https://doi.org/10.1007/978-3-319-89635-9, 2018. a, b
Hornik, K. and Grün, B.: On maximum likelihood estimation of the concentration parameter of von Mises–Fisher distributions, Comput. Statist., 29, 945–957, https://doi.org/10.1007/s00180-013-0471-0, 2013. a
Hornik, K. and Grün, B.: movMF: An R Package for Fitting Mixtures of von Mises-Fisher Distributions, J. Stat. Softw., 58, 1–31, https://doi.org/10.18637/jss.v058.i10, 2014. a
Jammalamadaka, S. R. and SenGupta, A.: Topics in Circular Statistics, no. 5 in Series on Multivariate Analysis, World Scientific, P.O. Box 128, Farrer Road, Singapore 912805, https://doi.org/10.1142/4031, 2001. a, b
Joe, H.: Dependence Modeling with Copulas, no. 134 in Monographs on Statistics and Applied Probability, Chapman & Hall/CRC, 6000 Broken Sound Parkway NW, Suite 300 Boca Raton, FL 33487-2742, 1st edn., https://doi.org/10.1201/b17116, 2014. a, b, c
Keefer, T. O., et al.: Southwest Watershed Research Center and Walnut Gulch Experimental Watershed, Tech. Rep. SWRC Publ. Reference No. 1588, Southwest Watershed Research Center, 2000 East Allen Road, Tucson, AZ 85719, http://www.tucson.ars.ag.gov/unit/publications/PDFfiles/1588.pdf (last access: 7 July 2024), 2007. a, b
Kendall, M. G.: The Treatment of Ties in Ranking Problems, Biometrika, 33, 239–251, https://doi.org/10.1093/biomet/33.3.239, 1945. a
Khedun, C. P., Mishra, A. K., Singh, V. P., and Giardino, J. R.: A copula-based precipitation forecasting model: Investigating the interdecadal modulation of ENSO's impacts on monthly precipitation, Water Resour. Res., 50, 580–600, https://doi.org/10.1002/2013WR013763, 2014. a
Kim, D., Cho, H., Onof, C., and Choi, M.: Let-It-Rain: a web application for stochastic point rainfall generation at ungaged basins and its applicability in runoff and flood modeling, Stoch. Env. Res. Risk A., 31, 1023–1043, https://doi.org/10.1007/s00477-016-1234-6, 2017. a, b, c
Kleiber, W., Katz, R. W., and Rajagopalan, B.: Daily spatiotemporal precipitation simulation using latent and transformed Gaussian processes, Water Resour. Res., 48, W01523, https://doi.org/10.1029/2011WR011105, 2012. a
Laio, F., D'Odorico, P., and Ridolfi, L.: An analytical model to relate the vertical root distribution to climate and soil properties, Geophys. Res. Lett., 33, L18401, https://doi.org/10.1029/2006GL027331, 2006. a
Langworthy, B. W., Stephens, R. L., Gilmore, J. H., and Fine, J. P.: Canonical correlation analysis for elliptical copulas, J. Multivariate Anal., 183, 104715, https://doi.org/10.1016/j.jmva.2020.104715, 2021. a
Lark, R. M., Clifford, D., and Waters, C. N.: Modelling complex geological circular data with the projected normal distribution and mixtures of von Mises distributions, Solid Earth, 5, 631–639, https://doi.org/10.5194/se-5-631-2014, 2014. a
Mai, J.-F. and Scherer, M.: Simulating Copulas, no. Vol. 6 in Quantitative Finance, World Scientific, 5 Toh Tuck Link, Singapore 596224, 2nd edn., https://doi.org/10.1142/10265, 2017. a, b, c, d, e, f
Mardia, K. and Jupp, P.: Directional Statistics, Wiley Series in Probability and Statistics, John Wiley & Sons, Ltd., West Sussex, PO19 1UD England, https://doi.org/10.1002/9780470316979, 1999. a, b, c
McNeil, A. J., Frey, R., and Embrechts, P.: Quantitative Risk Management: Concepts, Techniques and Tools, Princeton Series in Finance, Princeton University Press, 41 William Street, Princeton, New Jersey 08540, revised edn., ISBN 978-0-691-16627-8, 2015. a, b, c, d, e
Meles, M. B., Demaria, E. M. C., Heilman, P., Goodrich, D. C., Kautz, M. A., Armendariz, G., Unkrich, C., Wei, H., and Perumal, A. T.: Curating 62 Years of Walnut Gulch Experimental Watershed Data: Improving the Quality of Long-Term Rainfall and Runoff Datasets, Water, 14, 2198, https://doi.org/10.3390/w14142198, 2022. a, b, c
Michaelides, K. and Martin, G. J.: Sediment transport by runoff on debris-mantled dryland hillslopes, J. Geophys. Res.-Earth Surf., 117, F03014, https://doi.org/10.1029/2012JF002415, 2012. a
Michaelides, K. and Singer, M. B.: Impact of coarse sediment supply from hillslopes to the channel in runoff-dominated, dryland fluvial systems, J. Geophys. Res.-Earth Surf., 119, 1205–1221, https://doi.org/10.1002/2013JF002959, 2014. a
Michaelides, K. and Wainwright, J.: Modelling the effects of hillslope-channel coupling on catchment hydrological response, Earth Surf. Proc. Land., 27, 1441–1457, https://doi.org/10.1002/esp.440, 2002. a
Michaelides, K. and Wilson, M. D.: Uncertainty in predicted runoff due to patterns of spatially variable infiltration, Water Resour. Res., 43, W02415, https://doi.org/10.1029/2006WR005039, 2007. a
Michaelides, K., Hollings, R., Singer, M. B., Nichols, M. H., and Nearing, M. A.: Spatial and temporal analysis of hillslope-channel coupling and implications for the longitudinal profile in a dryland basin, Earth Surf. Proc. Land., 43, 1608–1621, https://doi.org/10.1002/esp.4340, 2018. a
Moran, M. S., Holifield Collins, C. D., Goodrich, D. C., Qi, J., Shannon, D. T., and Olsson, A.: Long-term remote sensing database, Walnut Gulch Experimental Watershed, Arizona, United States, Water Resour. Res., 44, W05S10, https://doi.org/10.1029/2006WR005689, 2008. a, b
Moré, J. J., Garbow, B. S., and Hillstrom, K. E.: User Guide for MINPACK-1, Tech. Rep. ANL-80-74, Argonne National Laboratory, Argonne, IL, USA, https://www.math.utah.edu/software/minpack/ (last access: 7 July 2024), 1980. a
Morin, E., Goodrich, D. C., Maddox, R. A., Gao, X., Gupta, H. V., and Sorooshian, S.: Rainfall modeling for integrating radar information into hydrological model, Atmos. Sci. Lett., 6, 23–30, https://doi.org/10.1002/asl.86, 2005. a, b, c
Nelsen, R. B.: An Introduction to Copulas, no. 2197-568X in Springer Series in Statistics, Springer New York, New York, NY 10013, USA, 2nd edn., https://doi.org/10.1007/0-387-28678-0, 2006. a, b
Nicholson, S. E.: Dryland Climatology, Cambridge University Press, The Edinburgh Building, Cambridge CB2 8RU, UK, https://doi.org/10.1017/CBO9780511973840, 2011. a, b
Osborn, H. B.: Timing and duration of high rainfall rates in the southwestern United States, Water Resour. Res., 19, 1036–1042, https://doi.org/10.1029/WR019i004p01036, 1983. a
Osborn, H. B. and Lane, L.: Precipitation-runoff relations for very small semiarid rangeland watersheds, Water Resour. Res., 5, 419–425, https://doi.org/10.1029/WR005i002p00419, 1969. a
Papalexiou, S. M., Serinaldi, F., and Porcu, E.: Advancing Space-Time Simulation of Random Fields: From Storms to Cyclones and Beyond, Water Resour. Res., 57, e2020WR029466, https://doi.org/10.1029/2020WR029466, 2021. a
Paschalis, A., Molnar, P., Fatichi, S., and Burlando, P.: A stochastic model for high-resolution space-time precipitation simulation, Water Resour. Res., 49, 8400–8417, https://doi.org/10.1002/2013WR014437, 2013. a, b
Peleg, N., Fatichi, S., Paschalis, A., Molnar, P., and Burlando, P.: An advanced stochastic weather generator for simulating 2-D high-resolution climate variables, J. Adv. Model. Earth Syst., 9, 1595–1627, https://doi.org/10.1002/2016MS000854, 2017. a
Pewsey, A., Neuhäuser, M., and Ruxton, G. D.: Circular Statistics in R, Oxford University Press, Great Clarendon Street, Oxford, OX2 6DP, United Kingdom, 1st edn., 2013. a, b
Philander, S. G.: El Niño, La Niña, and the Southern Oscillation., no. 46 in International Geophysics Series, Academic Press, San Diego, California 92101, US, 1990. a
Powell, M. J. D.: A Hybrid Method for Nonlinear Equations, in: Numerical Methods for Nonlinear Algebraic Equations, edited by Rabinowitz, P., chap. 6, 87–114, Gordon and Breach Science Publishers, 150 Fifth Avenue, New York, N.Y. 10011, U.S., 1970. a
Powell, M. J. D.: On nonlinear optimization since 1959, in: The Birth of Numerical Analysis, edited by Bulthee, A. and Cools, R., 141–160, World Scientific, 5 Toh Tuck Link, Singapore 596224, https://doi.org/10.1142/9789812836267_0009, 2009. a
Quichimbo, E. A., Singer, M. B., and Cuthbert, M. O.: Characterising groundwater-surface water interactions in idealised ephemeral stream systems, Hydrol. Process., 34, 3792–3806, https://doi.org/10.1002/hyp.13847, 2020. a
Quichimbo, E. A., Singer, M. B., Michaelides, K., Hobley, D. E. J., Rosolem, R., and Cuthbert, M. O.: DRYP 1.0: a parsimonious hydrological model of DRYland Partitioning of the water balance, Geosci. Model Dev., 14, 6893–6917, https://doi.org/10.5194/gmd-14-6893-2021, 2021. a
R Core Team: R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/ (last access: 7 July 2024), 2023. a
Renard, K. G. and Keppel, R. V.: Hydrographs of Ephemeral Streams in the Southwest, J. Hydr. Eng. Div-asce., 92, 33–52, https://doi.org/10.1061/JYCEAJ.0001419, 1966. a
Renard, K. G. and Laursen, E. M.: Dynamic Behavior Model of Ephemeral Stream, J. Hydr. Eng. Div-asce., 101, 511–528, https://doi.org/10.1061/JYCEAJ.0004340, 1975. a
Rios Gaona, M. F.: feliperiosg/STORM2: v2.2.2, Zenodo [code and data set], https://doi.org/10.5281/zenodo.8071820, 2023. a
Rios Gaona, M. F. and Villarini, G.: Characterization of the diurnal cycle of maximum rainfall in tropical cyclones, J. Hydrol., 564, 997–1007, https://doi.org/10.1016/j.jhydrol.2018.07.062, 2018. a
Ross, S. M.: Simulation, Academic Press, Radarweg 29, PO Box 211, 1000 AE Amsterdam, The Netherlands, 5th edn., https://doi.org/10.1016/C2011-0-04574-X, 2013. a
Sabathier, R., Singer, M. B., Stella, J. C., Roberts, D. A., and Caylor, K. K.: Vegetation responses to climatic and geologic controls on water availability in southeastern Arizona, Environ. Res. Lett., 16, 064029, https://doi.org/10.1088/1748-9326/abfe8c, 2021. a
Salvadori, G. and De Michele, C.: Statistical characterization of temporal structure of storms, Adv. Water Resour., 29, 827–842, https://doi.org/10.1016/j.advwatres.2005.07.013, 2006. a
Sarachik, E. S. and Cane, M. A.: The El Niño-Southern Oscillation Phenomenon, Cambridge University Press, The Edinburgh Building, Cambridge CB2 8RU, UK, https://doi.org/10.1017/CBO9780511817496, 2010. a
Sargeant, C. I. and Singer, M. B.: Sub-annual variability in historical water source use by Mediterranean riparian trees, Ecohydrology, 9, 1328–1345, https://doi.org/10.1002/eco.1730, 2016. a
Scanlon, B. R., Keese, K. E., Flint, A. L., Flint, L. E., Gaye, C. B., Edmunds, W. M., and Simmers, I.: Global synthesis of groundwater recharge in semiarid and arid regions, Hydrol. Process., 20, 3335–3370, https://doi.org/10.1002/hyp.6335, 2006. a
Seabold, S. and Perktold, J.: Statsmodels: Econometric and Statistical Modeling with Python, in: Proceedings of the 9th Python in Science Conference, edited by: van der Walt, S. and Millman, J., 92–96, https://doi.org/10.25080/Majora-92bf1922-011, 2010. a, b
Shmaliy, Y. S.: Von Mises/Tikhonov-based distributions for systems with differential phase measurement, Signal Process., 85, 693–703, https://doi.org/10.1016/j.sigpro.2004.11.008, 2005. a
Singer, M. B. and Michaelides, K.: How is topographic simplicity maintained in ephemeral dryland channels?, Geology, 42, 1091–1094, https://doi.org/10.1130/G36267.1, 2014. a
Singer, M. B. and Michaelides, K.: Deciphering the expression of climate change within the Lower Colorado River basin by stochastic simulation of convective rainfall, Environ. Res. Lett., 12, 104011, https://doi.org/10.1088/1748-9326/aa8e50, 2017. a
Singer, M. B., Sargeant, C. I., Piégay, H., Riquier, J., Wilson, R. J. S., and Evans, C. M.: Floodplain ecohydrology: Climatic, anthropogenic, and local physical controls on partitioning of water sources to riparian trees, Water Resour. Res., 50, 4490–4513, https://doi.org/10.1002/2014WR015581, 2014. a
Singer, M. B., Michaelides, K., and Hobley, D. E. J.: STORM 1.0: a simple, flexible, and parsimonious stochastic rainfall generator for simulating climate and climate change, Geosci. Model Dev., 11, 3713–3726, https://doi.org/10.5194/gmd-11-3713-2018, 2018. a, b, c
Stillman, S., Zeng, X., Shuttleworth, W. J., Goodrich, D. C., Unkrich, C. L., and Zreda, M.: Spatiotemporal Variability of Summer Precipitation in Southeastern Arizona, J. Hydrometeorol., 14, 1944–1951, https://doi.org/10.1175/JHM-D-13-017.1, 2013. a
Temme, N.: On the numerical evaluation of the modified bessel function of the third kind, J. Comput. Phys., 19, 324–337, https://doi.org/10.1016/0021-9991(75)90082-0, 1975. a
The Economist: In defense of the Gaussian copula, electronic periodical, https://www.economist.com/free-exchange/2009/04/29/in-defense-of-the-gaussian-copula (last access: 5 October 2022), 2009. a
Tjøstheim, D., Otneim, H., and Støve, B.: Statistical Modeling Using Local Gaussian Approximation, Academic Press, 125 London Wall, London EC2Y 5AS, United Kingdom, https://doi.org/10.1016/C2017-0-02646-0, 2022. a, b, c
Tucker, G. E. and Bras, R. L.: A stochastic approach to modeling the role of rainfall variability in drainage basin evolution, Water Resour. Res., 36, 1953–1964, https://doi.org/10.1029/2000WR900065, 2000. a
Tucker, G. E. and Hancock, G. R.: Modelling landscape evolution, Earth Surf. Proc. Land., 35, 28–50, https://doi.org/10.1002/esp.1952, 2010. a
Tucker, G. E. and Slingerland, R.: Drainage basin responses to climate change, Water Resour. Res., 33, 2031–2047, https://doi.org/10.1029/97WR00409, 1997. a
UniData: Network Common Data Form (NetCDF), UniData [software], https://doi.org/10.5065/D6H70CW6, 2023. a
Vandenberghe, S., Verhoest, N. E. C., Onof, C., and De Baets, B.: A comparative copula-based bivariate frequency analysis of observed and simulated storm events: A case study on Bartlett-Lewis modeled rainfall, Water Resour. Res., 47, W07529, https://doi.org/10.1029/2009WR008388, 2011. a, b
Van Rossum, G. and Drake, F. L.: Python 3 Reference Manual, CreateSpace, Scotts Valley, CA, ISBN 978-1-4414-1269-0, 2009. a
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, İ., Feng, Y., Moore, E. W., VanderPlas, J., Laxalde, D., Perktold, J., Cimrman, R., Henriksen, I., Quintero, E. A., Harris, C. R., Archibald, A. M., Ribeiro, A. H., Pedregosa, F., van Mulbregt, P., and SciPy 1.0 Contributors: SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python, Nat. Methods, 17, 261–272, https://doi.org/10.1038/s41592-019-0686-2, 2020. a, b, c, d
Vu, T. M., Mishra, A. K., Konapala, G., and Liu, D.: Evaluation of multiple stochastic rainfall generators in diverse climatic regions, Stoch. Env. Res. Risk A., 32, 1337–1353, https://doi.org/10.1007/s00477-017-1458-0, 2018. a, b
Warter, M. M., Singer, M. B., Cuthbert, M. O., Roberts, D., Caylor, K. K., Sabathier, R., and Stella, J.: Drought onset and propagation into soil moisture and grassland vegetation responses during the 2012–2019 major drought in Southern California, Hydrol. Earth Syst. Sci., 25, 3713–3729, https://doi.org/10.5194/hess-25-3713-2021, 2021. a
Warter, M. M., Singer, M. B., Cuthbert, M. O., Roberts, D., Caylor, K. K., Sabathier, R., and Stella, J.: Modeling seasonal vegetation phenology from hydroclimatic drivers for contrasting plant functional groups within drylands of the Southwestern USA, Environ. Res.-Ecology, 2, 025001, https://doi.org/10.1088/2752-664X/acb9a0, 2023. a
Wheater, H. S., Mathias, S. A., and Li, X.: Groundwater Modelling in Arid and Semi-Arid Areas, Cambridge University Press, https://doi.org/10.1017/CBO9780511760280, 2010. a
Wilcox, C., Aly, C., Vischel, T., Panthou, G., Blanchet, J., Quantin, G., and Lebel, T.: Stochastorm: A Stochastic Rainfall Simulator for Convective Storms, J. Hydrometeorol., 22, 387–404, https://doi.org/10.1175/JHM-D-20-0017.1, 2021. a
Zhang, L. and Singh, V. P.: Copulas and their Applications in Water Resources Engineering, Cambridge University Press, University Printing House, Cambridge CB2 8BS, United Kingdom, https://doi.org/10.1017/9781108565103, 2019. a, b, c
Historical storm data (among many other hydrological and hydrometeorological data) from the WGEW are freely available at https://www.tucson.ars.ag.gov/dap/ (last access: 7 July 2024).
U.S. Department of Agriculture – Agricultural Research Service, https://www.ars.usda.gov/pacific-west-area/tucson-az/southwest-watershed-research-center/ (last access: 7 July 2024).
Software developed by CompuServe (https://www.w3.org/Graphics/GIF/spec-gif87.txt, last access: 7 July 2024).
Software developed by UCAR/Unidata (https://doi.org/10.5065/D6H70CW6, UniData, 2023).
- Abstract
- Introduction
- Data and methods
- Results and discussion
- Summary and conclusions
- Constraints and recommendations
- Appendix A: BIC estimation
- Appendix B: Additional figures
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Data and methods
- Results and discussion
- Summary and conclusions
- Constraints and recommendations
- Appendix A: BIC estimation
- Appendix B: Additional figures
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References